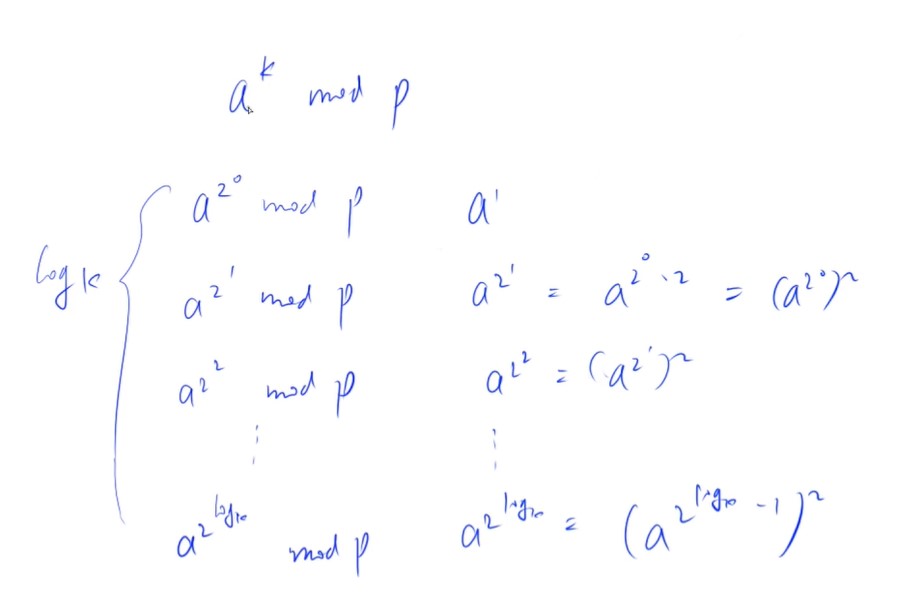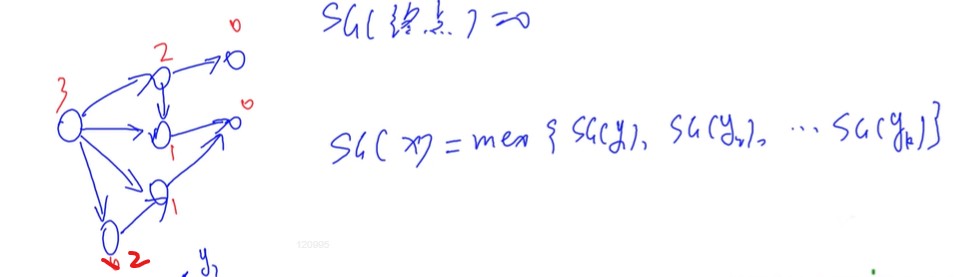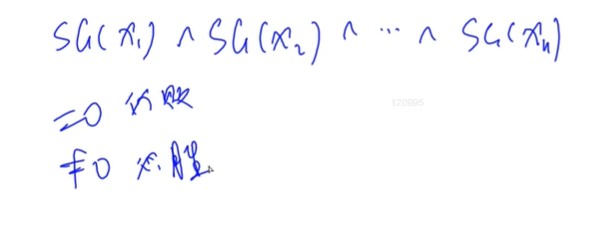boolis_prime(int x) { if (x < 2) returnfalse; for (int i = 2; i <= x / i; i ++ )//防溢出 if (x % i == 0) returnfalse; returntrue; }
试除法分解质因数
从小到大枚举所有约数
底数是指指数,指数是指每个底数出现的次数
n中最多只包含一个大于sqrt(n)的质因子
时间复杂度
O(x)−O(logn)
1 2 3 4 5 6 7 8 9 10 11 12
voiddivide(int x) { for (int i = 2; i <= x / i; i ++ ) if (x % i == 0)//i一定是质数 { int s = 0; while (x % i == 0) x /= i, s ++ ; cout << i << ' ' << s << endl; } if (x > 1) cout << x << ' ' << 1 << endl; cout << endl; }
朴素筛法求素数(埃筛)
时间复杂度是nlogn
1 2 3 4 5 6 7 8 9 10 11 12 13 14
int primes[N], cnt; // primes[]存储所有素数 bool st[N]; // st[x]存储x是否被筛掉
voidget_primes(int n) { for (int i = 2; i <= n; i ++ ) { if (st[i]) continue;//如果被筛过,继续找质数 //没有被筛过,是质数 primes[cnt ++ ] = i;//把质数i加入质数数组里面并且指向下个位置 for (int j = i + i; j <= n; j += i)//把i的倍数删掉 st[j] = true; } }
线性筛法求素数
质数定理:1-n中有n/lnn个质数
时间复杂度是O(nloglogn)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
int primes[N], cnt; // primes[]存储所有素数 bool st[N]; // st[x]存储x是否被筛掉
voidget_primes(int n) { for (int i = 2; i <= n; i ++ ) { if (!st[i]) primes[cnt ++ ] = i;//是质数加入数组 for (int j = 0; primes[j] <= n / i; j ++ ) {//从小到大枚举所有质数 st[primes[j] * i] = true;//只用筛质数的倍数,当一个数不是质数的时候就不需要筛掉他的所有倍数(因为质数会筛掉),这样可以避免重复。每次把质数和i的乘积筛掉 if (i % primes[j] == 0) break;//意味着primes[j]一定是i的最小质因子,因为是从小到大枚举的质因子,pj也已i当时pj*i的最小质因子 //如果i%pj!=0,说明pj一定小于i的所有质因子。pj也一定是pj*i的最小质因子 } } }
vector<int> get_divisors(int x) { vector<int> res; for (int i = 1; i <= x / i; i ++ ) if (x % i == 0) { res.push_back(i); if (i != x / i) res.push_back(x / i);//防止重复输入 } sort(res.begin(), res.end()); return res; } intmain(){ int n; cin >> n; while(n--){ int x; cin>>x; auto res= get_divisors(x); for(auto t :res)cout<<t<<' '; cout<<endl; } return0; }
//求约数之和 //约数个数 //先把乘积因式分解求出来 #include<iostream> #include<algorithm> #include<unordered_map> usingnamespace std; typedeflonglong LL; constint mod=1e9+7; intmain(){ int n; cin>> n; unordered_map<int,int>primes; while(n--) { int x; cin >> x; for(int i =2;i<=x/i;i++) while(x%i==0){ x/=i; primes[i]++; } if(x>1)primes[x]++; } LL res =1; for(auto prime:primes) { int p = prime.first,a=prime.second; LL t = 1; while(a--) t=(t*p+1)%mod; res=res*t%mod; } cout<<res<<endl; return0; }
欧几里得算法(辗转相除法)
d能整除a,d能整除b,d能整除a+b
gcd(a,b)=gcd(b,a mod b)
1 2 3 4 5 6
intgcd(int a, int b) { return b ? gcd(b, a % b) : a; //三目运算符 表达式1?表达式2:表达式3; 1条件,2if 3else //b不是0,返回b和a%b,是的话返回a }
欧拉函数
互质是公约数只有1的两个整数,叫做互质整数
1-N中与N互质的数的个数被称为欧拉函数,记为Φ(N)。若在算术基本定理中:
N=p1α1∗p2α2∗...∗pmαm
则:
Φ(N)=N∗p1p1−1∗p2p2−1∗...∗pmpm−1
Φ(N)=N∗(1−p11)∗(1−p21)∗...∗(1−pm1)
从1-N中去掉p1,p2…pk的所有倍数(都含有公约数质数本身)
加上所有pi*pj的倍数(所有两个质数的组合)
减去所有pi *pj *pk的倍数
加上pi * pj * pk * pl的倍数
依此类推
欧拉函数
时间复杂度是
O(n)
1 2 3 4 5 6 7 8 9 10 11 12 13
intphi(int x) { int res = x; for (int i = 2; i <= x / i; i ++ ) if (x % i == 0) { res = res / i * (i - 1); while (x % i == 0) x /= i;//分解约数 } if (x > 1) res = res / x * (x - 1);//最后一个带2/x的约数
#include<iostream> usingnamespace std; constint N =1000010; int primes[N],cnt; typedeflonglong LL; bool st[N]; int phi[N]; LL get_eluers(int n){ phi[1]=1; for(int i = 2;i<=n;i++){ if(!st[i]){//是质数 primes[cnt++]=i; phi[i]=i-1; } for(int j = 0;primes[j]<=n/i;j++){ st[primes[j]*i=true; if(i%primes[j]==0){ phi[primes[j]*i]=phi[i]*primes[j]; break; } phi[primes[j]*i]=phi[i]*(primes[j]-1); } } LL res=0; for(int i = 1;i<=n;i++) res+=phi[i]; return res; } intmain(){ int n; cin >> n; cout<<get_eluers(n);<<endl; return0; }
欧拉定理
≡同余,两个整数除以同一个整数,若得相同余数,则二整数同余。
若a与n互质,则有
aφ(n)≡1(modn)
当n是质数的时候,有:
an−1≡1(modn)
快速幂
1 2 3 4 5 6 7 8 9 10 11 12
求 m^k mod p,时间复杂度 O(logk)。 intqmi(int m, int k, int p) { int res = 1 % p, t = m; while (k) { if (k&1) res = res * t % p; t = t * t % p; k >>= 1; } return res; }
// 求x, y,使得ax + by = gcd(a, b) intexgcd(int a, int b, int &x, int &y) { if (!b) { x = 1; y = 0;/*如果b=0,则gcd(a, b) = 1 * a + 0 * b*/ return a; } int d = exgcd(b, a % b, y, x); /*此时我们假设已经求出来了x, y,ax + by = d,根据辗转相除法(欧几里得算法)分析: 此时为gcd(a, b), 则下一循环为gcd(b, a % b),此时我们求它的x1, y1可得 b * x1 + (a % b) * y1 = b * x1 + (a - (a / b) * b) * y1 = b * x1 + a * y1 – (a / b) * b * y1 = a * y1 + b * (x1 – a / b * y1) 我们发现: x = y1, y = x1 - a / b * y1因此我们根据这个规律可以推导出x和y*/
y -= (a/b) * x; return d;//d是最大公约数 } intmain(){ int n; cin >> n; while(n--) { int a,b,x,y; cin>> a >> b; exgcd(a,b,x,y); cout<<x<y;
// 求x, y,使得ax + by = gcd(a, b) intexgcd(int a, int b, int &x, int &y) { if (!b) { x = 1; y = 0; return a; } int d = exgcd(b, a % b, y, x); y -= (a/b) * x; return d;//d是最大公约数 } intmain(){ int n; cin >> n; while(n--) { int a,b,m; cin>> a >> b>>m; int x,y; int d =exgcd(a,m,x,y); if(b%d) puts("impossible"); else cout<<(LL)x*(b/d)%m; } return0; }
中国剩余定理
假设整数m1,m2,…,mn两两互质,则对任意的整数a1,a2,…,an,方程组(S)有解
M=m1∗m2∗m3∗...∗mk
Mi=miM
Mi−1表示Mimodmi
x=a1∗M1∗M1−1+a2∗M2∗M2−1+...+aK∗MK∗MK−1
也被称为中国剩余定理
求逆即Mi^-1相当于解ax≡1(mod m),用扩展欧几里得算法可以求
a mod b = c 等价于 (a + nb) mod b = c;
a mod b = c 等价于 2a mod 2b = 2c;
// a[N][N]是增广矩阵 intgauss() { int c, r; for (c = 0, r = 0; c < n; c ++ ) { int t = r; for (int i = r; i < n; i ++ ) // 找到绝对值最大的行 if (fabs(a[i][c]) > fabs(a[t][c])) t = i;
if (fabs(a[t][c]) < eps) continue;
for (int i = c; i <= n; i ++ ) swap(a[t][i], a[r][i]); // 将绝对值最大的行换到最顶端 for (int i = n; i >= c; i -- ) a[r][i] /= a[r][c]; // 将当前行的首位变成1 for (int i = r + 1; i < n; i ++ ) // 用当前行将下面所有的列消成0 if (fabs(a[i][c]) > eps) for (int j = n; j >= c; j -- ) a[i][j] -= a[r][j] * a[i][c];
r ++ ; }
if (r < n) { for (int i = r; i < n; i ++ ) if (fabs(a[i][n]) > eps) return2; // 无解 return1; // 有无穷多组解 }
for (int i = n - 1; i >= 0; i -- ) for (int j = i + 1; j < n; j ++ ) a[i][n] -= a[i][j] * a[j][n];
首先预处理出所有阶乘取模的余数fact[N],以及所有阶乘取模的逆元infact[N] 如果取模的数是质数,可以用费马小定理求逆元 intqmi(int a, int k, int p)// 快速幂模板 { int res = 1; while (k) { if (k & 1) res = (LL)res * a % p; a = (LL)a * a % p; k >>= 1; } return res; }
// 预处理阶乘的余数和阶乘逆元的余数 fact[0] = infact[0] = 1; for (int i = 1; i < N; i ++ ) { fact[i] = (LL)fact[i - 1] * i % mod; infact[i] = (LL)infact[i - 1] * qmi(i, mod - 2, mod) % mod; }
#include<iostream> #include<algorithm> usingnamespace std; typedeflonglong LL; constint N =100010,mod = 1e9+7; int fact[N],infact[N]; intqmi(int a, int k, int p)// 快速幂模板 { int res = 1; while (k) { if (k & 1) res = (LL)res * a % p; a = (LL)a * a % p; k >>= 1; } return res; } intmain(){ fact[0]=infact[0]=1; for(int i = 1;i<N;i++){ fact[i]=(LL)fact[i-1]*i%mod; infact[i]=(LL)infact[i-1]*qmi(i,mod-2,mod)%mod; } int n; cin >> n; while(n--){ int a,b; cin >> a >> b; cout<<(LL)fact[a]*infact[b]%mod*infact[a-b]%mod; } return0; }
当我们需要求出组合数的真实值,而非对某个数的余数时,分解质因数的方式比较好用: 1. 筛法求出范围内的所有质数 2. 通过 C(a, b) = a! / b! / (a - b)! 这个公式求出每个质因子的次数。 n! 中p的次数是 n / p + n / p^2 + n / p^3 + ... 3. 用高精度乘法将所有质因子相乘 #include<iostream> #include<algorithm> usingnamespace std; constint N =5010; int primes[N], cnt; // 存储所有质数 int sum[N]; // 存储每个质数的次数 bool st[N]; // 存储每个数是否已被筛掉
voidget_primes(int n)// 线性筛法求素数 { for (int i = 2; i <= n; i ++ ) { if (!st[i]) primes[cnt ++ ] = i; for (int j = 0; primes[j] <= n / i; j ++ ) { st[primes[j] * i] = true; if (i % primes[j] == 0) break; } } }
intget(int n, int p)// 求n!中的质数的指数 { int res = 0; while (n) { res += n / p; n /= p; } return res; }
vector<int> mul(vector<int> a, int b)// 高精度乘低精度模板 { vector<int> c; int t = 0; for (int i = 0; i < a.size(); i ++ ) { t += a[i] * b; c.push_back(t % 10); t /= 10; }
while (t) { c.push_back(t % 10); t /= 10; }
return c; }
get_primes(a); // 预处理范围内的所有质数
for (int i = 0; i < cnt; i ++ ) // 求每个质因数的次数 { int p = primes[i]; sum[i] = get(a, p) - get(b, p) - get(a - b, p); }
intmain(){ int a,b; cin>>a>>b; get_primes(a); for(int i = 0;i<cnt;i++)//遍历质数 { int p =primes[i]; sum[i]=get(a)-get(b)-get(a-b);//求出质数的指数 } vector<int> res; res.push_back(1); for(int i = 0;i<cnt;i++)// 用高精度乘法将所有质因子相乘,先遍历质数 for(int j =0;j<sum[i];j++)//遍历该质数的指数 res = mul(res,primes[i]); for(int i = res.size()-1;i>=0;i--) cout<<res[i];//高精度乘法的输出,倒着存正着输出 puts(""); return0; }
#include<iostream> #include<algorithm> usingnamespace std; constint mod =1e9+7; typedeflonglong LL; intqmi(int a ,int b,int p){ int res= 1; while(k){ if(k&1) res = (LL) res*a %p; a= (LL)a* a %p; k>>=1; } return res;
} intmain(){ int n; cin>>n; int a = 2*n,b=n; int res=1; for(int i =a;i>a-b;i--)res = (LL)res*i%mod; for(int i = 1;i<=b;i++) res= (LL) res*qmi(i,mod-2,mod)%mod; res = (LL)res*qmi(n+1,mod-2,mod)%mod; cout<<res<<endl; return0; }
#include<iostream> #include<algorithm> usingnamespace std; constint N =20; int n,m; int p[N]; typedeflonglong LL; intmain(){ cin >> n>>m; for(int i =0;i<m;i++) cin>>p[i]; int res = 0; // 利用位运算来统计所有集合被选的状态 将i用二进制表示 其中1为当前位集合被选 0为没有选
//集合-nim #include<iostream> #include<algorithm> #include<cstring> #include<unordered_set> usingnamespace std; constint N=110,M=10010; int n,m; int s[N],f[N];//s存储操作数量,f存储sg函数 intsg(int x){ if(f[x]!=-1) return f[x];//说明已经找出该点的sg函数,不重复计算
unordered_set<int> S;//用来存储所有能够到的局面 for(int i = 0;i<m;i++){ int sum=s[i];//从中取出s[i]个石子 if(x>=sum)S.insert(sg(x-sum));//如果取走石子的个数没有超过剩余石子的个数,说明可以取走,往记录图中加入该局面
} //mex操作 for(int i = 0;;i++) if(!S.count(i))//如果该局面没有出现过 return f[x]=i;//说明该点的sg就是它本身
} intmain(){ cin >>m; for(int i =0;i<m;i++) cin >>s[i];//读入每次可取操作数 cin>>n; memset(f,-1,sizeof f);//初始化 int res =0; for(int i = 0;i<n;i++){ int x; cin>>x;//读入石子数量 res^=sg(x);//有向图往下一个节点走 } if(res) puts("Yes"); elseputs("No"); return0; }