算法·搜索与图论
搜索与图论
DFS与BFS
- DFS用的是stack堆,BFS用的是queue队列,dfs往下搜的时候只需要记录路径上的所有点,因此空间和高度成正比,BFS会把每一层都存下来,所需要的空间是指数级别
- 当所有边的权重相同的时候BFS第一次搜索到的点一定是最近的一个点,DFS不具有最短路性质
- 涉及到最小步数,最短距离,最少操作几次基本都是bfs
- 算法思路奇怪的一般都是dfs,或者对空间要求比较高的

DFS深度优先搜索
- 最重要的就是顺序,一般是树的形式
- 回溯一定要注意恢复现场
- 剪枝:提前判断当前方案是不是合法的,如果不合法可以不用往下走直接回溯
- 最优解剪枝
- 可行性剪枝
1 | |
1 | |
BFS宽度优先搜索

1 | |
1 | |
1 | |
1 | |
1 | |
树和图的存储
-
树是无环连通图
-
有向图
- 边有方向
-
无向图
- 边没有方向
有向图
邻接矩阵
1 | |
邻接表
每个节点上开一个表,存一个点可以走到哪个点,插入即找到点对应的单链表然后头插
1 | |
树与图的遍历
时间复杂度O(n+m),n表示点数,m表示边数
深度优先遍历
1 | |
宽度优先遍历
1 | |
1 | |
树与图的遍历:拓扑排序
时间复杂度O(n+m),n表示点数,m表示边数
有向图才有拓扑序列,如果有环没有拓扑序,有向无环图一定有拓扑序列,也被称为拓扑图
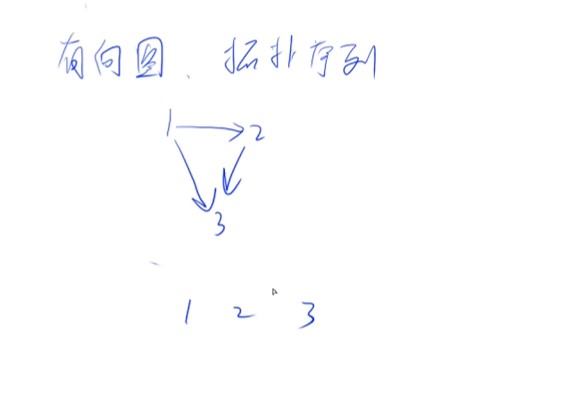
入度是指有多少条边指向自己,因此所有入度为0的点都可以作为起点
出度是指有多少条边出去
- 把所有入度为0的点入队
- 一个有向无环图至少存在一个入度为0的点
- 有向无环图的拓扑序不一定是唯一的
1 | |
最短路
- 源点起点,汇点终点
- n是点的数量,m是边的数量
- m和n^n一个级别的叫稠密图
- m和n一个级别的叫稀疏图
- 考察的难点在于如何把问题抽象成一个图,如何定义点和边,使得问题能够套入最短路模板
- 图论侧重于实现
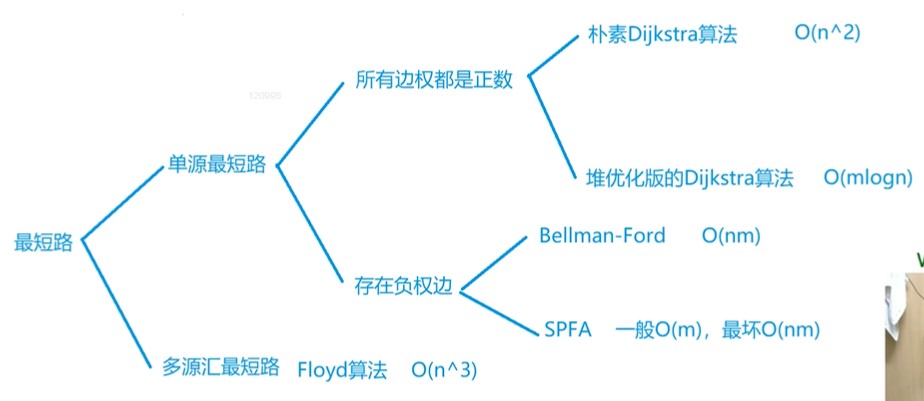
单源最短路
- 求一个点到其他所有点的最短距离
- 所有边权都是正数
- 朴素dijkstra
- O(n²),适合稠密图,即边数比较多的时候,如当边数和n²是一个级别的时候
- 堆优化版dijkstra
- O(mlogn),适合稀疏图,如n和m是一个级别的时候
- 朴素dijkstra
- 存在负权边
- bellman-ford O(nm)(存在负环 )
- spfa算法 一般:O(m),最坏O(nm)(不存在负环)
- 如果限制经过的边数,只能用bellman-ford算法
- 所有边权都是正数
朴素dijkstra算法
1 | |
- 时间复杂度是O(n²+m),n表示点数,m表示边数
- 初始化距离
1 | |
堆优化版的dijkstra算法
- 手写堆
- 优先队列(不支持修改任意一个元素,里面的元素可能是m个,时间复杂度变为mlogm,但由于是稀疏图,所以和mlogn差不多
1 | |
bellman-ford算法
时间复杂度O(mn),n表示点数,m表示边数
dist[b]<=dist[a]+w 三角不等式
有边数限制的最短路只能用bellman-ford算法







1 | |
1 | |
1 | |
spfa算法
图中一定不能有负环
1 | |
spfa判断途中是否存在负环
1 | |
多源汇最短路
-
很多不同起点到其他点的最短路
-
Floyd算法O(n^3)
Floyd算法
1 | |
最小生成树
最小生成树没有环,正边和负边都没有问题
普利姆算法Prim
朴素版prim
时间复杂度O(n²),n表示点数,m表示边数,稠密图
1 | |
堆优化版
时间复杂度O(mlogn),稀疏图
克鲁斯卡尔算法Kruskal
时间复杂度O(mlogn),n表示点数,m表示边数
- 将所有边按照权重从小到大排序
- 枚举每条边a,b,权重c
- 如果a,b不连通,将这条边加入集合中来。
1 | |
二分图:染色法、匈牙利算法
染色法
判断一个图是不是二分图
- 当且仅当图中不含奇数环,奇数环是指边的数量是奇数,二分图是指可以把所有点划分到两边去,使得所有的边都是在集合之间的,集合内部没有边
- 一条边的旁边两个点颜色一定不同
O(n+m)
1 | |
匈牙利算法
O(mn),实际运行时间一般远小于O(mn)
1 | |
树上启发式合并(DSU on tree)
时间复杂度O(nlogn)
思路:树上启发式合并(DSU on tree)
- 1.先处理子树大小,类似树链剖分分一下重儿子和轻儿子,为了后续操作降低复杂度
2.遍历树,对于任何一棵树,先遍历轻儿子,如果有重儿子最后遍历,数据返回的时候只保留重儿子信息,更新颜色出现次数
3.如果子树颜色出现的最大数 * 最大数次数 = 子树的大小,那么这颗子树就是颜色平衡树,ans ++即可
概念:
- 重儿子:子树的节点最多的儿子,其中如果两个儿子的子树都相同,那么其中任意个。
轻儿子:其余的儿子。
重边:父亲到重儿子的边。
轻边:其余的边。
重链:节点到重儿子的路径。
1 | |
算法·搜索与图论
http://example.com/2024/03/26/算法·搜索与图论/