算法·基础算法与数据结构
1 | |
时间复杂度

基础算法
排序
快速排序——分治 O(nlogn)-O(n²)
- 确定分界点:q[l],q[(l+r)/2],q[r];随机
- 调整区间:第一个区间所有的数都小于等于x,第二个区间所有的数都大于等于x
- 递归处理左右两端
快排非稳定,归并稳定(位置不发生变化)
暴力做法
-
a[],b[]
-
q[l-r] q[i]<=x x->a[]
q[i]>=x x->b[]
-
a[]->q[] b[]->q[]
1 | |
归并排序——分治 O(nlogn)
- 确定分界点:mid=(l+r)/2
- 递归排序left,right
- 归并——合二为一O(n)
1 | |
二分
二分不用考虑有没有解

整数二分
- 有单调性的题目可以二分,但可以二分不一定有单调性,二分的本质不是单调性
- 二分的本质是性质,使得一部分满足红色性质,一部分满足绿色性质,整个区间可以一分为二,二分可以寻找性质的边界

①红点
-
mid=l+r+1>>1;
if(check(mid)) true ->[mid,r] l = mid;//mid满足红色性质
false->[l,mid-1] r = mid-1;//mid不满足红色性质,在绿色性质区域
②绿点
-
mid = l+r>>1;
if(check(mid)) true->[l,mid] r = mid;//mid满足绿色性质
false->[mid+1,r] l = mid+1;//mid满足红色性质,不满足绿色性质
1 | |
1 | |
浮点数二分
注:判断是否满足绿色性质
1 | |
高精度
大整数存法
一般从个位开始存,即a[0]为个位数字,最高位在最后
1 | |
取位运算
1 | |
字符串转化为数字
1 | |
高精度加法
A、B位数都是10^6
1 | |
高精度减法
A、B位数都是10^6
1 | |
高精度乘法
一般为大整数x小整数,大整数的位数一般是小于10^6,小整数的数值一般小于10^9
1 | |
高精度*低精度
1 | |
高精度除法
高精度/低精度
1 | |
1 | |
前缀和与差分
数组a1,a2,a3,a4…an
前缀和
前缀和数组Si=a1+a2+…+ai 下标一定从1开始
-
Si求法
- for(i = 1;i<=n;i++) s[i]=s[i-1]+a[i];S0=0
-
前缀和的作用
-
能快速求出来原数组里一段数的和
例如计算[l,r]这段的距离,如果没有前缀和数组,时间复杂度为O(n),如果有前缀和,时间复杂度为O(1)
[l,r]=s[r]-s[l-1];
-
一维前缀和
1 | |
二维前缀和

1 | |
1 | |
差分
-
a1,a2,a3…an
-
构造b1,b2,b3…bn
-
使得 ai=b1+b2+…bi;
-
即Sbi=ai;
-
即b1=a1;
b2=a2-a1;
b3=a3-a2;
…
bn=an-an-1;
-
a是b的前缀和,b是a的差分
-
作用:
-
对b数组求一遍前缀和即可求得原数组,时间复杂度为O(n)
-
如果想要原数组的每一个数都加上一个值,通过差分和前缀和的时间复杂度为O(1)
-
Bi=Bi+c(C会一直带到后面),后面的Al-An全部都会加上C ,如果想要只发生在l-r,则Br+1=Br+1 - C(C抵消掉了)
-
eg:b1+c=a1+c
b2=a2-a1
b3=a3-a2
- a1=b1+c
- a2=b1+b2=a2-a1+a1+c=a2+c
- 依此类推,后面的a1~an都会+c,相当于对原数组的每一个数都加上一个值
-
-
-
一维差分
1 | |
1 | |
二维差分

- 核心思想:
- 二维差分的核心思想是通过记录二维数组中相邻元素的差值,将对原数组的子矩阵操作转化为对差分数组中对应元素的操作,以达到高效处理区间修改问题的目的。
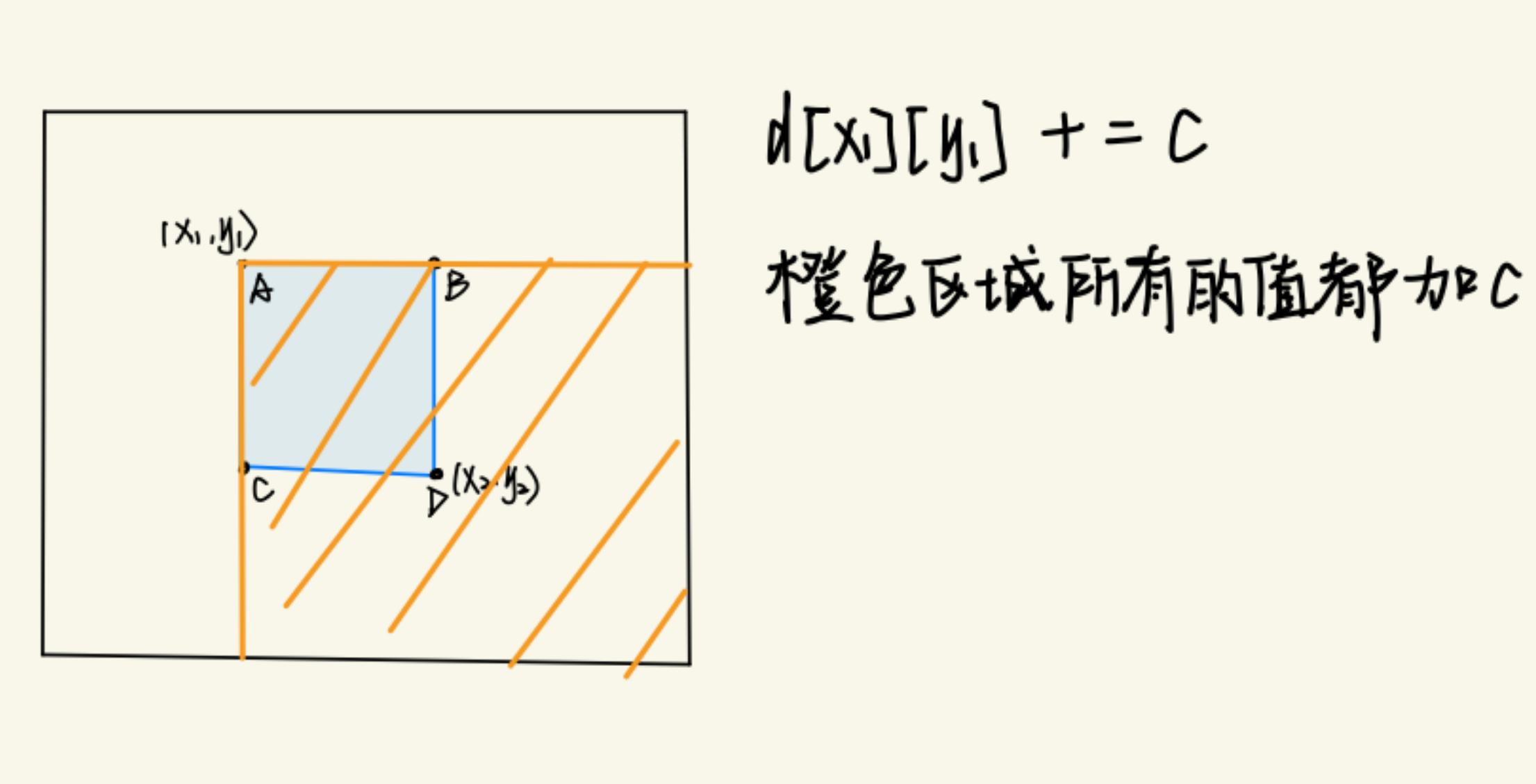
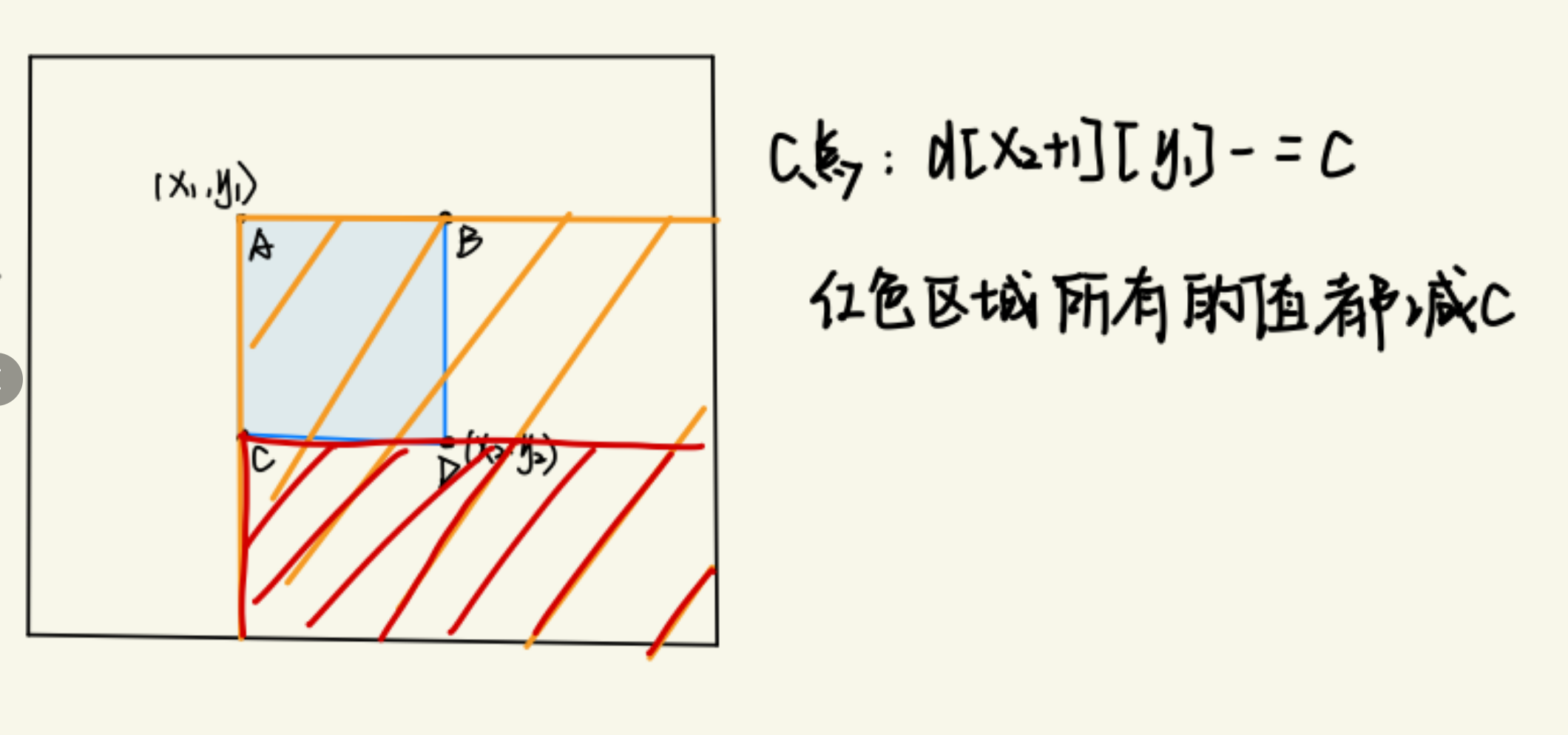
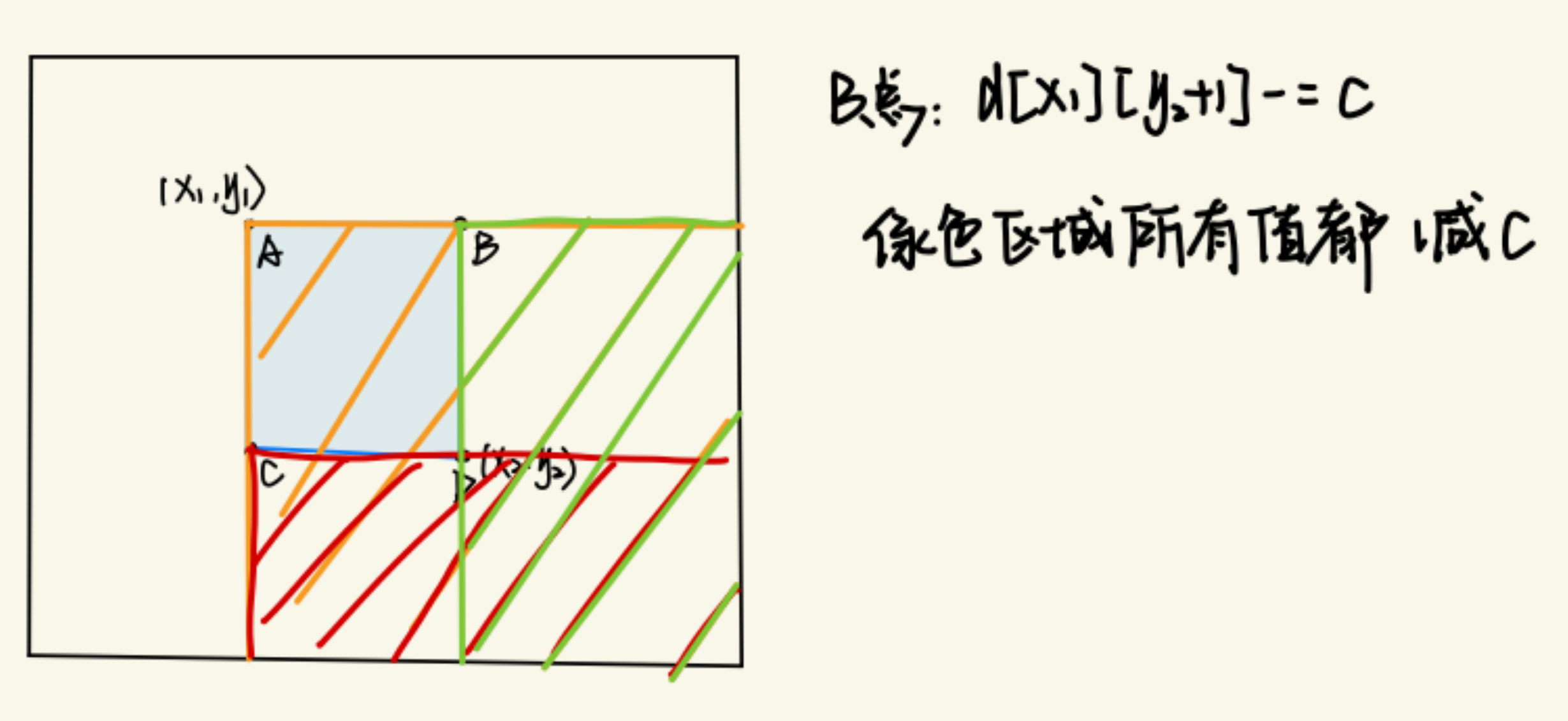
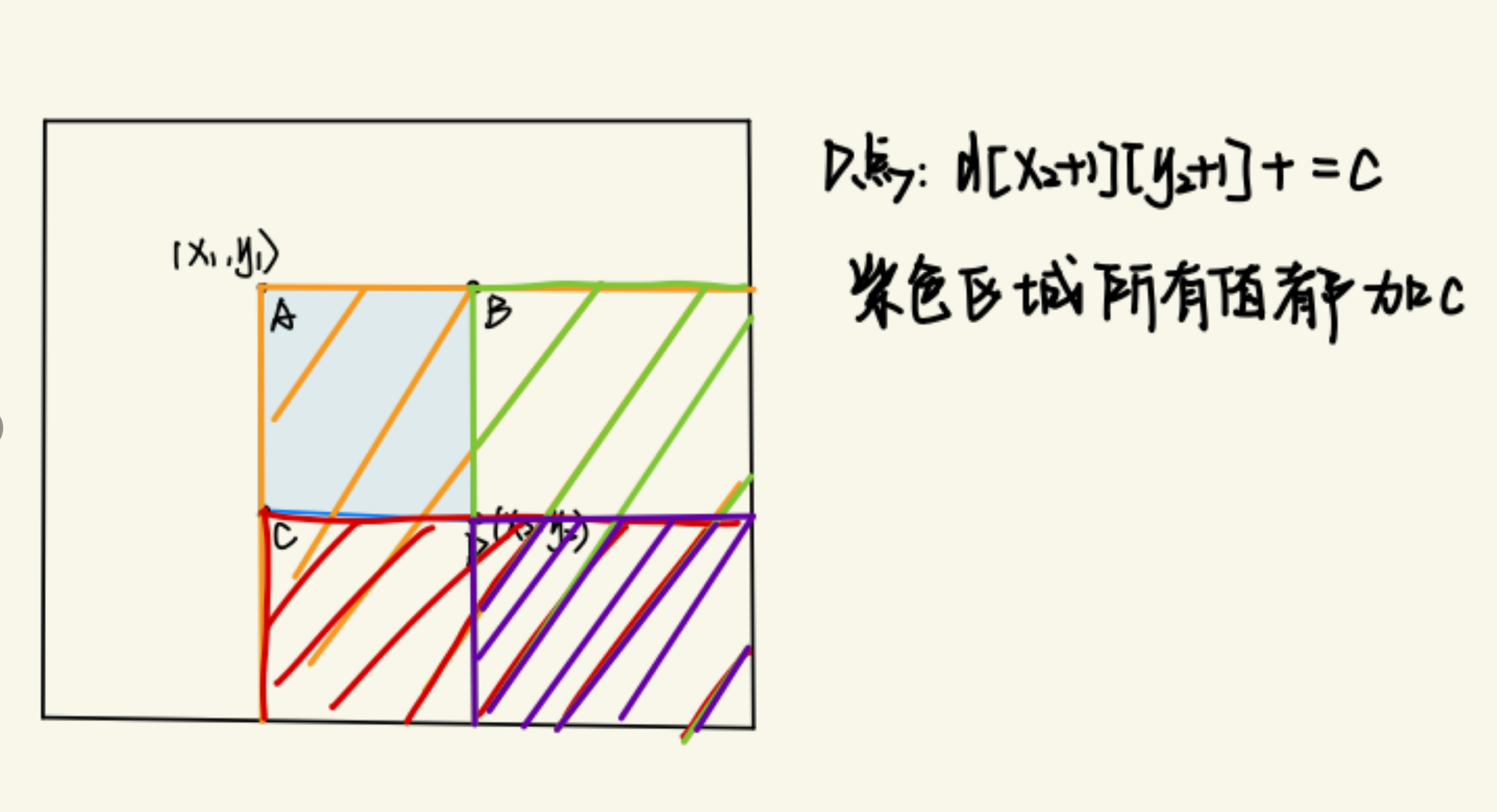

1 | |
1 | |
-
我们可以通过数学推导来证明你提到的
insert操作和b[i][j] = a[i][j] - a[i-1][j] - a[i][j-1] + a[i-1][j-1]这种定义是等效的。1)二维差分数组的定义
给定一个原数组
a[i][j],我们要构造一个二维差分数组b[i][j],其中:b[i][j]=a[i][j]−a[i−1][j]−a[i][j−1]+a[i−1][j−1]b[i][j] = a[i][j] - a[i-1][j] - a[i][j-1] + a[i-1][j-1]b[i][j]=a[i][j]−a[i−1][j]−a[i][j−1]+a[i−1][j−1]2)解释
insert操作你提供的
insert函数操作是针对差分数组b[i][j]进行的,它会对子矩阵[x1..x2] × [y1..y2]做一个加法操作。这个加法的过程是在四个角点上进行调整:1
2
3
4b[x1][y1] += c;
b[x2+1][y1] -= c;
b[x1][y2+1] -= c;
b[x2+1][y2+1] += c;这个操作的含义是:
- 在差分数组的
(x1, y1)处加上c(表示从这个点开始加c) - 在
(x2+1, y1)和(x1, y2+1)处分别减去c(这表示影响区域结束的地方) - 最后在
(x2+1, y2+1)处再加上c,以抵消重复的减去部分。
3)数学证明
insert和b[i][j] = a[i][j] - a[i-1][j] - a[i][j-1] + a[i-1][j-1]等效我们要证明的是,
insert操作最终会使差分数组b等于你提供的定义:b[i][j]=a[i][j]−a[i−1][j]−a[i][j−1]+a[i−1][j−1]b[i][j] = a[i][j] - a[i-1][j] - a[i][j-1] + a[i-1][j-1]b[i][j]=a[i][j]−a[i−1][j]−a[i][j−1]+a[i−1][j−1]首先,我们回顾一下二维差分的定义:
- 当我们在
b[i][j]上加上某个值c时,这实际上会影响到该位置(b[i][j])及其“右下角”范围内的区域。 - 每次
insert(x1, y1, x2, y2, c),我们将对指定的子矩阵(从(x1, y1)到(x2, y2))的区域进行更新。
为了能证明它的等效性,我们需要查看
insert操作在累加前缀和时的效果:4)通过
insert更新推导-
差分数组的更新
-
假设我们调用了
insert(x1, y1, x2, y2, c),它会在差分数组b中标记四个角点:b[x1][y1]+=c,b[x2+1][y1]−=c,b[x1][y2+1]−=c,b[x2+1][y2+1]+=cb[x1][y1] += c, \quad b[x2+1][y1] -= c, \quad b[x1][y2+1] -= c, \quad b[x2+1][y2+1] += cb[x1][y1]+=c,b[x2+1][y1]−=c,b[x1][y2+1]−=c,b[x2+1][y2+1]+=c
-
-
还原前缀和
当你对b进行二维前缀和操作时(如你代码中的这行):1
b[i][j] += b[i-1][j] + b[i][j-1] - b[i-1][j-1];这一过程相当于在
b[i][j]上累积所有之前的更新。我们可以从b的定义出发,看看这个过程会如何让b[i][j]变成我们期望的a[i][j] - a[i-1][j] - a[i][j-1] + a[i-1][j-1]。
5)最终结果的推导
通过二维前缀和更新后的
b[i][j]会包含所有被更新的差分信息。推导出来的公式是:b[i][j]=a[i][j]−a[i−1][j]−a[i][j−1]+a[i−1][j−1]b[i][j] = a[i][j] - a[i-1][j] - a[i][j-1] + a[i-1][j-1]b[i][j]=a[i][j]−a[i−1][j]−a[i][j−1]+a[i−1][j−1]这正是二维差分数组的定义。
6)总结
insert操作通过在差分数组b中的四个角点做加减操作,实现了矩形区间加法操作。- 在更新
b后,你对b执行前缀和计算(加上b[i-1][j]、b[i][j-1],减去重复加的部分b[i-1][j-1]),最终得到了原数组a的每个元素。
这样,通过
insert操作对差分数组的更新和前缀和的计算,我们证明了insert操作和b[i][j] = a[i][j] - a[i-1][j] - a[i][j-1] + a[i-1][j-1]的等效性。 - 在差分数组的
双指针算法
- 两个序列,一个指针指向第一个序列,另一个指针指向第二个序列
- 一个序列,一个指针指向开头,一个指针指向结尾
- 所有的双指针算法时间复杂度都是O(n)
1 | |
-
核心思想:
-
for(int i = 0;i<n;i++)
for(int j =0;i<n;j++)
O(n^2)
将上面的朴素算法优化到O(n)
-
-
一般先思考暴力做法,然后看i和j之间有没有单调关系,利用单调关系改变时间复杂度
1 | |
位运算
- 求n的二进制表示中第k位数字是几,个位是第0位,从右往左算
- 先把第k位移到最后一位
- n>>k;
- 看一下个位是几
- x&1;
- 先把第k位移到最后一位
1 | |
lowbit(x):返回x的最后一位1
1 | |
- 原码 1010
- 反码 取反
- 补码 取反加一(计算机里的负数用补码来表示)
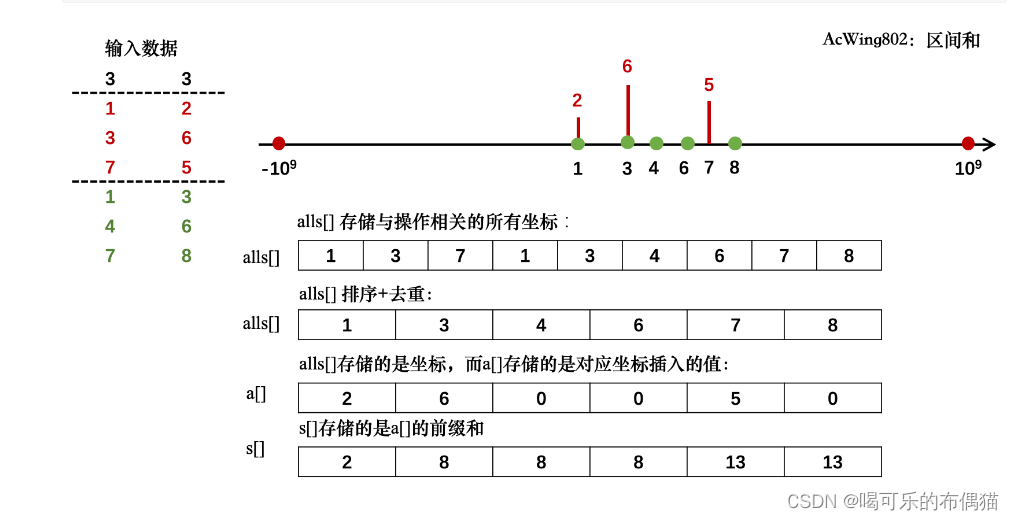
离散化
值域大,个数少

问题:
- a中可能有重复元素,需要去重
- 如何算出ai离散化后的值
- 二分
- 保序离散化,小的在前面大的在后面
1 | |
1 | |
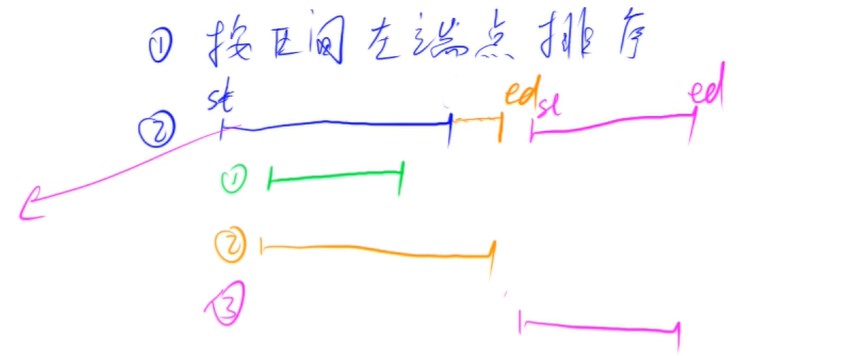
区间合并
- 按区间左端点排序
- 扫描整个区间,把所有可能有交集的区间合并
1 | |
数据结构
链表与邻接表:树与图的存储
单链表(数组模拟)(静态链表)
常用邻接表,存储树和图

1 | |
struct版在408(1),struct创建新链表比较慢
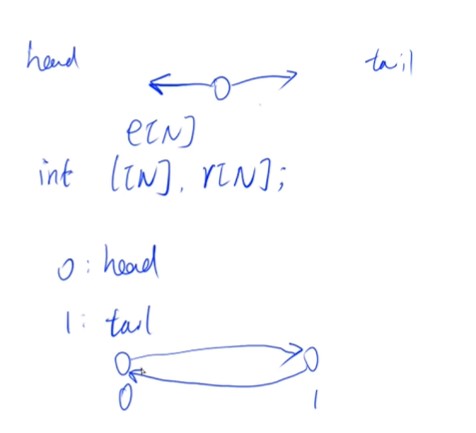
双链表(数组模拟)(静态链表)
常用于优化某些问题
双链表即一个节点指向左右
初始化
右插
1 | |
栈与队列:单调队列、单调栈
栈(先进后出)
1 | |
中缀表达式
1 | |
单调栈
- 单调栈和单调队列都是用栈和队列暴力模拟问题,即找出朴素算法,再看一下没用的元素,删掉元素看是否有单调性,有单调性可以用单调队列或者单调栈优化问题,取极值直接找两个端点,找一个点可以用二分
1 | |
队列(先进先出)
普通队列
1 | |
循环队列
1 | |
单调队列
- 队列里面存的是下标
1 | |
kmp
思路:
-
暴力算法怎么做
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16s[N],p[M];//s是主串,p是模板串
for(int i = 1;i<=n;i++){
//
bool flag = true;
for(int j = 1;j<=m;j++)
if(s[i+j-1]!=p[j]){//因为匹配的时候指向s的也要往后挪动,所以这里的[]内是指s的本轮循环的位置还要往后挪多少位置,最开始的时候是初始位置对比字串,所以挪动的位置为0,此后要-1来保持对准
flag = false;
break;
}
} -
如何去优化
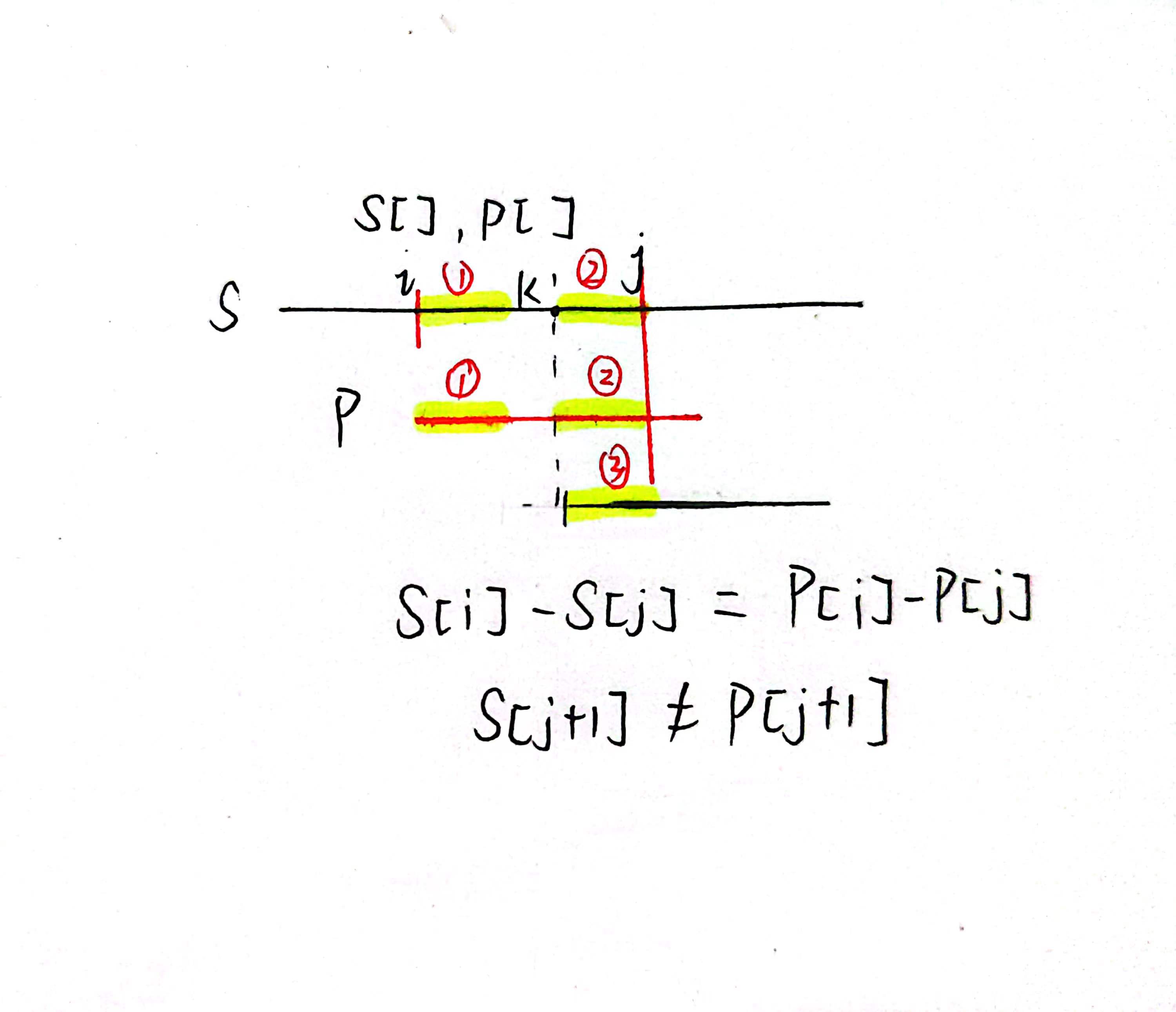
存在五个相等的轴,其中:
- 由于第一段第二段在i-j都相等,所以P①=S①,P②=S②
- 由于J+1匹配失败,P字串向后移动直到再次匹配,此时P③=S②,由于S②=P②,所以P②=P③
- 由于P实际上为字串位移,所以P③=P①
- 综上,存在五段相等的轴
- 因此,只需要求子串P中,P①=P②的最大区域,当该区域越大, P再次匹配往后移动的距离越短
因此,对于字串P:
-
需要预处理出以某个点为终点的后缀与前缀相等,相等的长度最大为多少

1
Next[i]=j//即从i开始的后缀与从1开始的前缀相等,而且后缀的长度最长
1 | |
1 | |
kmp匹配过程

求next数组的过程

完整过程

Trie
支持两个操作:
- 高效地存储和查找字符串集合的数据结构
- 字符类型和个数不会很多,要么都是大写要么都是小写要么都是数字
- trie树的存储

1 | |
并查集
-
快速处理
-
将两个集合合并
-
询问两个元素是否在一个集合当中
-
近乎O(1)
-
用树的形式维护所有集合,根节点的编号就是集合的编号,每个节点都存储一个父节点p[x],当要查找元素属于哪个集合,只要找到根节点的编号即可。
-
如何判断是否是树根:if(p[x]==x)
-
如何求x的集合编号:while(p[x]!=x)x=p[x];//只要不是树根就一直往上走,直到走到树根为止
-
优化:路径压缩

-
-
如何合并两个集合
px是x的集合编号,py是y的集合编号。p[x]=y;

-
-
-
读入操作
char op[2];
scanf(“%s”,op) 用字符串不会读入空格和回车
1 | |
堆
-
功能
- 插入一个数
- 求集合当中的最小值
- 删除最小值
- 删除任意一个元素
- 修改任意一个元素
-
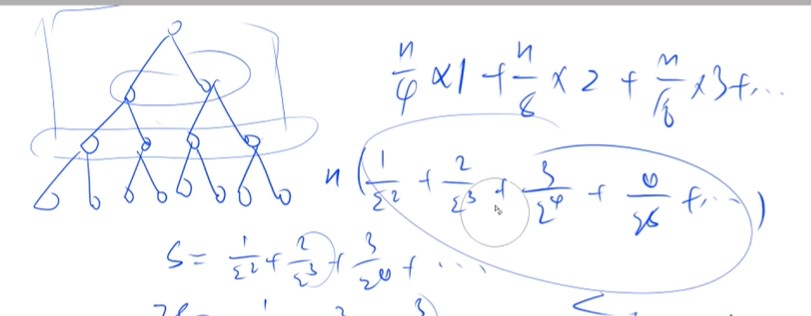
堆是一颗完全二叉树,除了最后一层节点外,上面的节点都是满的,最后一层从左到右排列
建堆:
1 | |

建堆时间复杂度解释
堆的高度最高是logn层
- heap_swap示意图
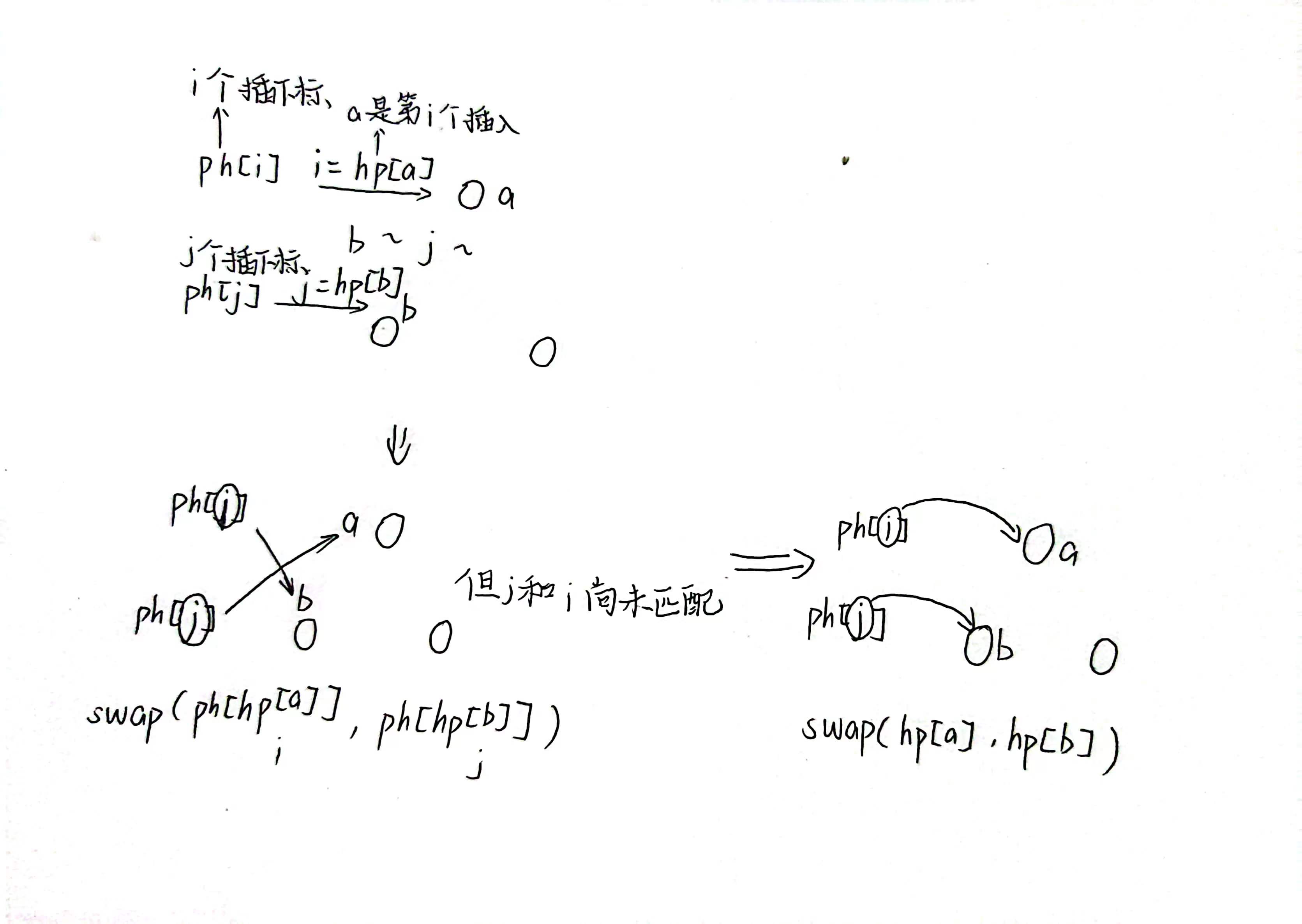
1 | |
Hash表
-
存储结构
-
开放寻址法
-
拉链法
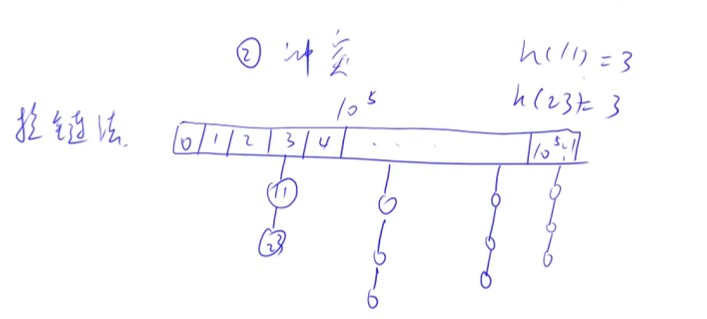
-
-
字符串哈希
-
作用:把一个比较庞大的空间(值域)映射到比较小的空间,映射后的函数叫做哈希函数
- x %10^5 ∈(0,10^5)
- 模的数一般要取成质数,所以一般要遍历寻找最小的质数
- 冲突:两个不一样的数映射成了同一个数,处理冲突的方式可以分为开放寻址法和拉链法
- x %10^5 ∈(0,10^5)
拉链法
1 | |
1 | |
开放寻址法
- 只开一个数组,但是开的长度一般是输入数据的2-3倍
1 | |
字符串哈希
字符串前缀哈希法
-
先预处理出所有前缀的哈希

把字符串看成是p进制的数字,每一位上的字母就表示p进制上的每一位数字,然后再取模,就可以把字符串映射到从0到Q-1
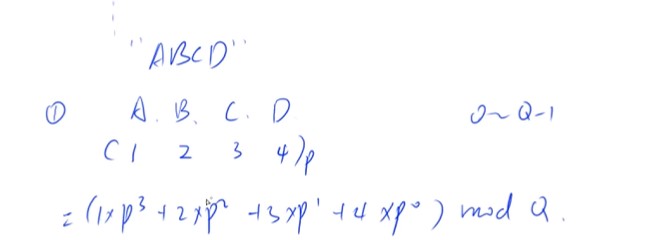
-
A-Z不能映射成0,一般从1开始
-
字符串哈希假定不存在冲突,因此不考虑冲突
-
好处是可以利用前缀哈希算出来任意一个子串的哈希值
-
作用:
快速判断两个字符串是否相同,哈希值相同,两个字符串相同,如果哈希值不同,则两个字符串不同
1 | |
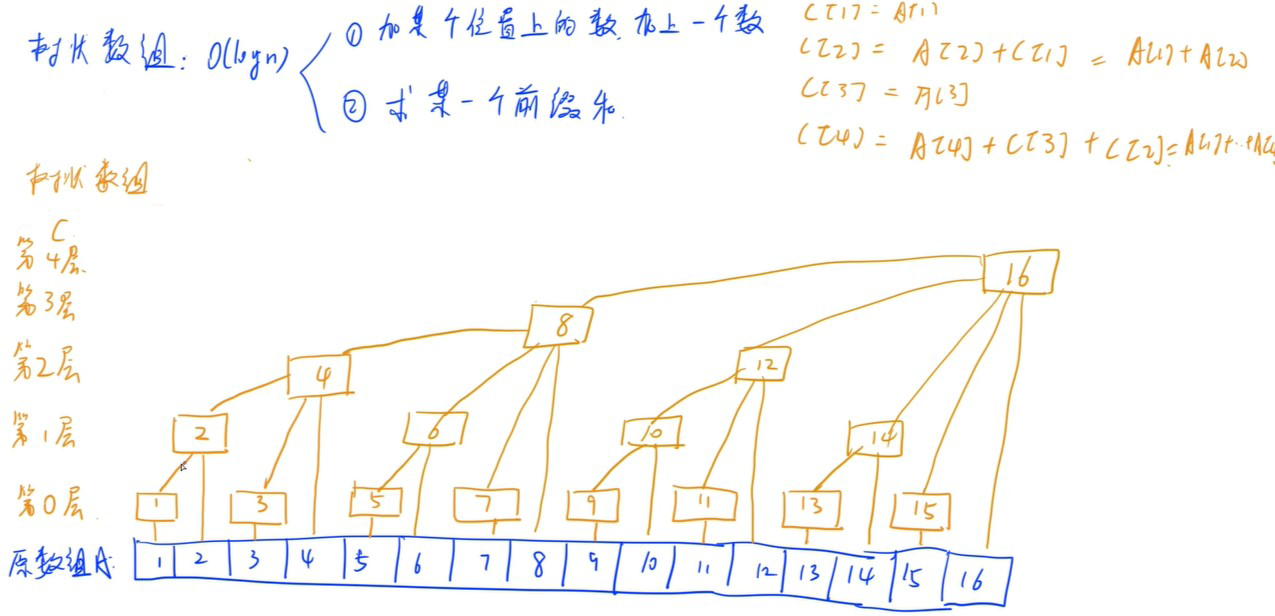
树状数组
- O(logn)
- 可以动态地给某个位置上的数加上一个数(单点修改)
- 求某一个前缀和(区间查询)
- 奇数位置存的都是原数组(第0层)
1 | |
线段树
- 单点修改(Ologn)
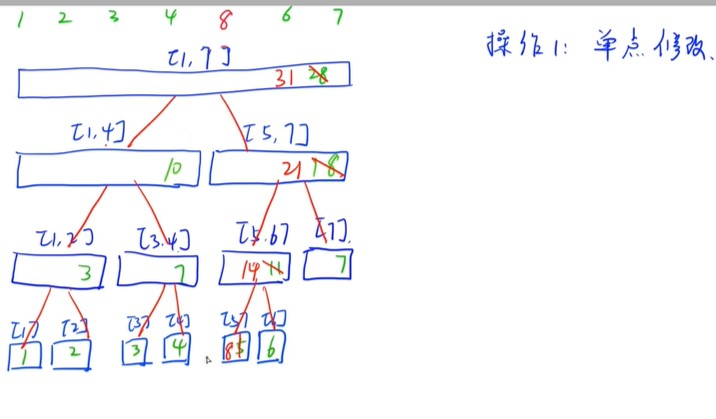
- 区间查询(Ologn)
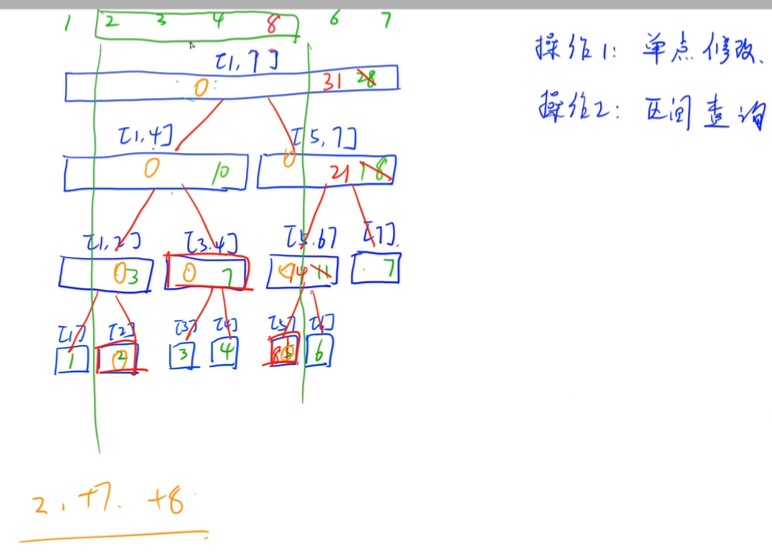
- 染色求面积求长度

- pushup:用子节点信息更新当前节点信息
- build:在一段区间上初始化线段树
- modify:修改
- query:查询

1 | |
STL简介
详情看备战408(1)
当系统为某一个程序分配空间的时候,所需的时间基本上与空间大小无关,与申请次数有关,比如申请一个长度为1000的数组和申请1000个长度为1的数组,因此vector的思路是可以浪费空间但要减少申请次数,如先申请32,再申请64,不够的时候将长度*2,因此要申请一个长度为n的数组,申请空间次数是logn,额外copy的次数大概是O1
vector
1 | |
pair
1 | |
string
1 | |
queue
1 | |
priority_queue
1 | |
stack
1 | |
deque
1 | |
set,map,multiset,multimap
1 | |
bitset
1 | |