深度学习
线性模型
深度学习引言
概述
- 深度学习(deep learning)是机器学习的分支,是以神经网络为架构,对资料进行表征学习的算法
- (深度)神经网络
- 表征学习:通过学习提取到特征,不需要手工提取特征
- eg:让机器去认识一只猫,手工提取特征就是人工描述特征,去编程规则,表征学习就是告诉机器某个训练集里面有/没有猫,为什么,特征就是机器运用算法自动提取特征。
- 深度学习与机器学习
- 深度学习是机器学习的一部分
深度学习的应用
CV(计算机视觉)
- 图像分类

- 目标检测
.PNG)
- 图像分割

- 单目深度估计

- 自动驾驶感知
.png)
- 自动驾驶决策
.png)
NLP及其他序列数据
- 机器翻译
.png)
- 语音识别
.png)
生成式AI
- ChatGPT
.png)
- 图片生成
.png)
- 视频生成
.png)
- AI游戏引擎

深度学习的主要组件
- 数据:用于训练模型
- 模型:转换数据,即输入数据,输出预测值
- 目标函数:量化模型的准确度
- 优化算法:调整模型参数,使得模型对目标函数的表现更好
线性回归
- 回归:一类任务的统称,叫做回归任务,回归任务的目的就是想去预测一个连续函数,比如说股票价格,通过一些信息来输入给一个函数,让这个函数去预测未来的股票价格。去找到这个函数的过程,就叫做回归。
- 线性就是用一个线性模型去做后边任务的
房价预测问题

- 线性模型
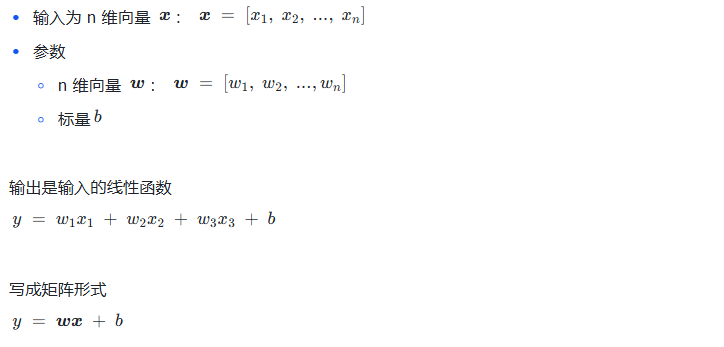
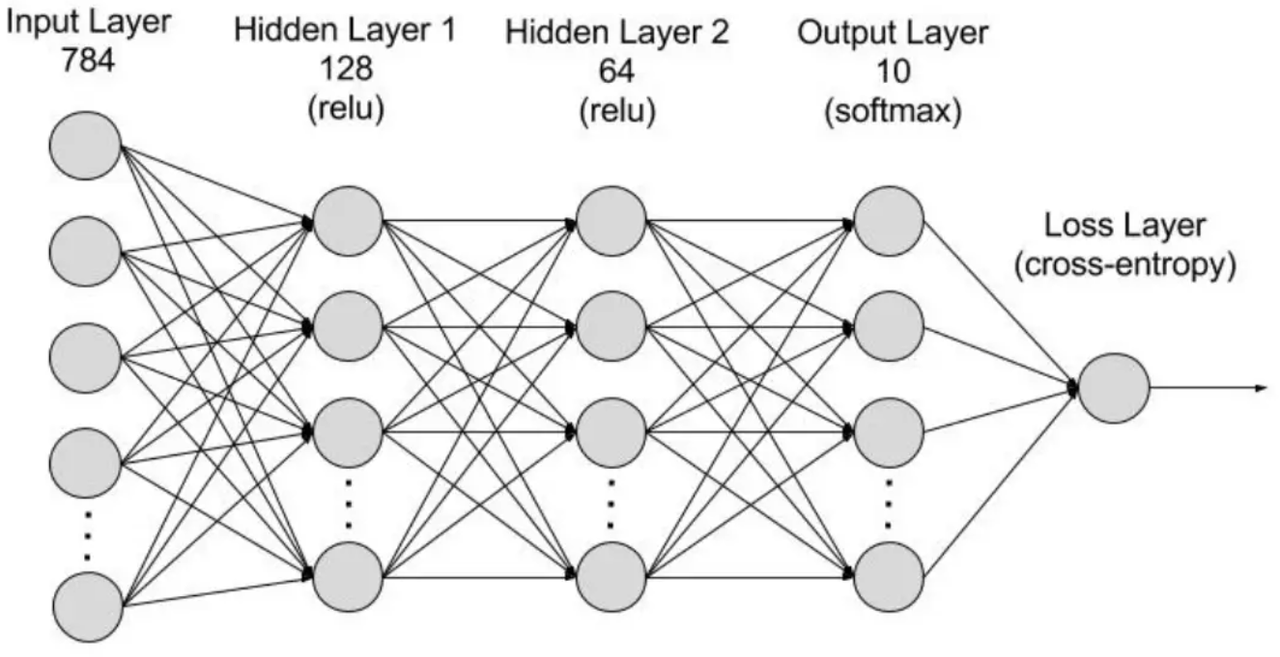
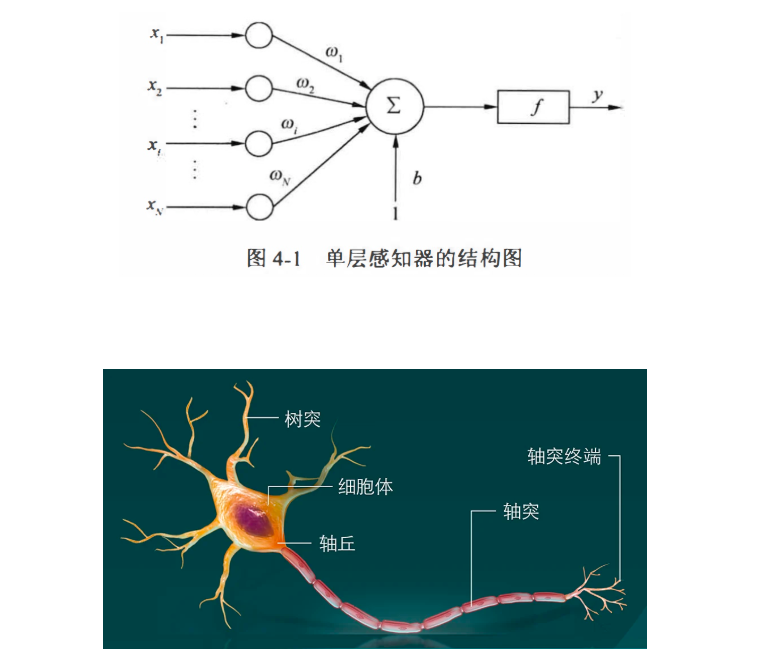
- 单层感知器
- 神经元有n个输入,对应x1、x2…xn,对于每一个输入,做一个乘法,有一个权重Wi与之相乘,每个边对应一个权重
损失函数
- 我们希望预测结果尽量准确, 那首先要定义如何评判预测的准确程度
- 损失函数:比较预测值和真实值,从而评判预测的准确程度(损失)
- 所有的深度学习任务,都要定义损失函数
- 预测值越不准确,损失越大
- 绝大部分的深度学习算法,都是使用梯度下降的原理来做这个参数优化的
- 定义符号:

- 单样本均方误差损失函数(L2损失)
- 常用于线性回归或者所有回归问题中
- 最终,我们将希望找到使代价函数变小的W和B的值

-
全样本的均方误差损失函数

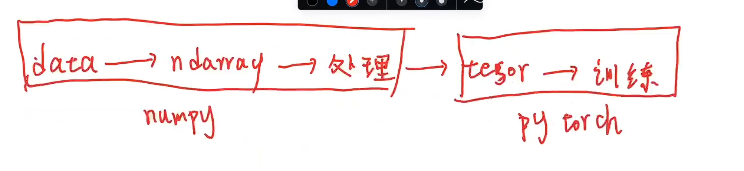
数据处理
numpy与pytorch
-
NumPy 是 Python 的一个开源科学计算库
- NumPy 的核心是 ndarray,支持快速的多维数组和矩阵操作
- 丰富的数学函数:NumPy提供了许多数学运算函数,如加减乘除、矩阵运算、统计函数等
- 数据分析和科学计算的基础库,许多数据分析、机器学习库(如 Pandas、Scikit-Learn)都依赖于它
-
PyTorch 是一个深度学习框架,用于构建和训练神经网络模型,广泛应用于研究和工业界
- 提供各种神经网络组件,方便的构建神经网络
- PyTorch 中的数据使用 tensor (张量)表示,与 ndarray 比较相似,可以互相转换
- tensor支持一些ndarray不支持的特性,这些特性对于深度学习非常重要
- GPU加速:PyTorch 支持将数据和模型放到 GPU 上运行
- 内置自动微分功能,可以自动计算梯度,在训练深度学习模型时十分便捷
-
numpy和pytorch关系
- 数据最开始是杂乱的, 需要先进行预处理才能训练网络,用numpy把数据转化为ndarray进行处理,所以数据处理阶段会用到numpy多一点,之后转化为tensor放到模型里面去进行训练
numpy基础
创建
1 | |
基本属性
1 | |
索引与切片
1 | |
基本运算
1 | |
改变形状
1 | |
统计
1 | |
与python列表对比
- numpy 支持向量化运算,速度更快
- python是遍历求和
1 | |
Tensor基础操作
- tensor是pytorch中的主要结构
- tensor 与 ndarray 的很多逻辑是相同的,主要增加了一些深度学习需要的功能:
- 自动微分,计算梯度
- 支持 GPU 运算
创建
1 | |
基本属性
1 | |
基本运算
1 | |
改变形状
1 | |
自动微分
1 | |
与ndarray转化
1 | |
梯度下降
- 梯度下降算法的作用,是寻找给定函数的极小值点
- 一般来说这个给定函数就是我们的损失函数
- 只能找到一个极小值点,不能保证找到全局的极小值点,绝大部分的时候找不到最小值
- 最后能落到哪一个极小值点和初值有关系
- 一般来说找不到全局最优解
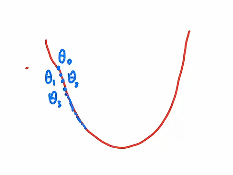
一维梯度下降
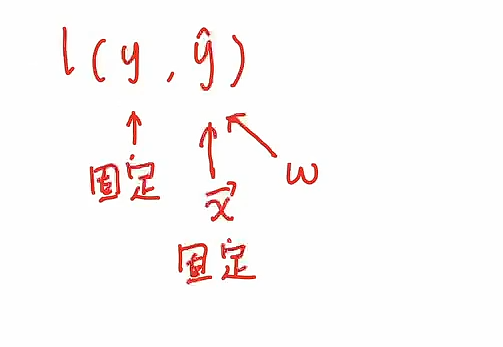
假设要优化的参数是 $$\theta$$(比如房价预测里面y=wx+b,这个w就是θ)
损失函数是 $$\theta$$的函数:$$J = \ell(\theta)$$
- 注:对于一个模型而言,训练集是固定的,即真值对于训练集而言是固定的,所以自变量是模型的参数,我们要调整的也是模型的参数,通过调整模型的参数,让损失函数减小,从而让这个模型在数据集上去拟合的更好一些
算法步骤:
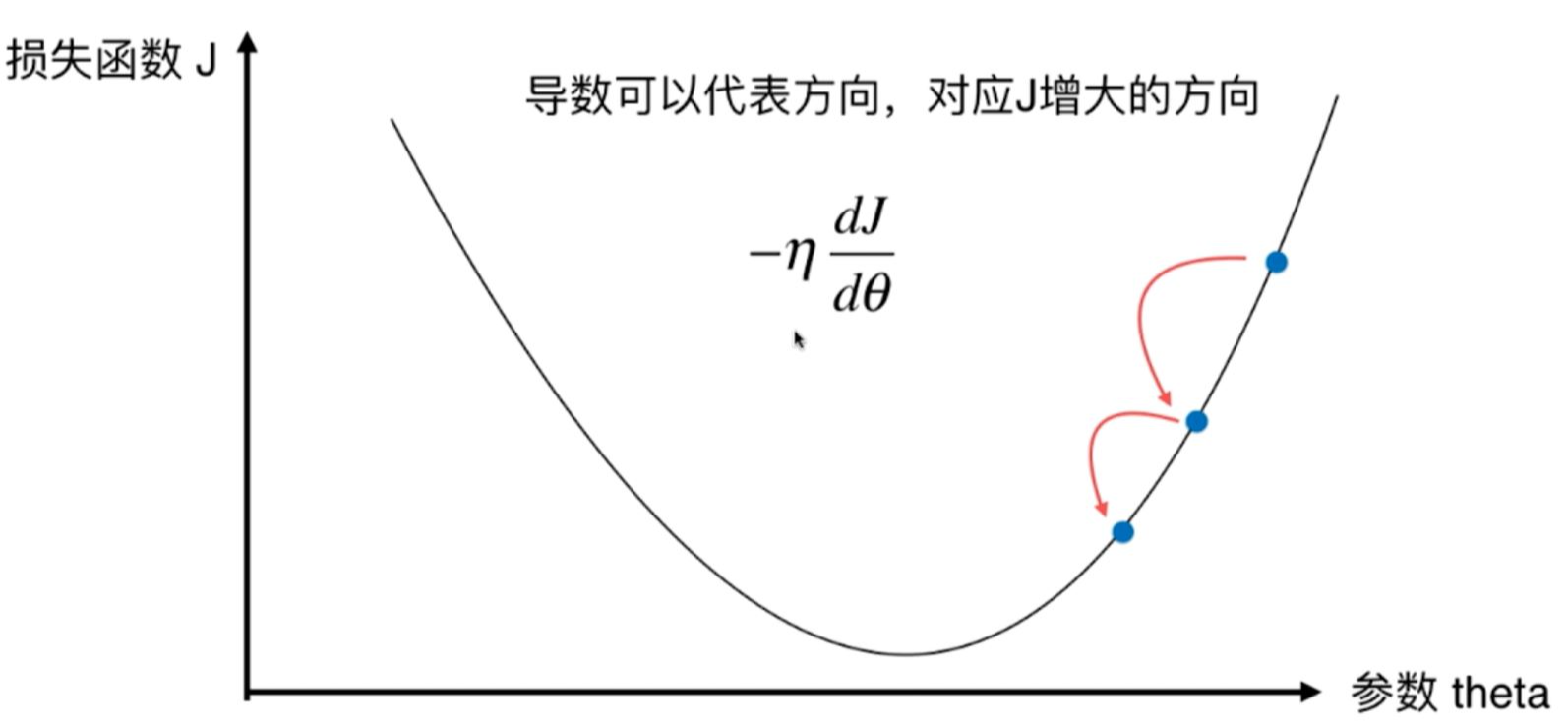
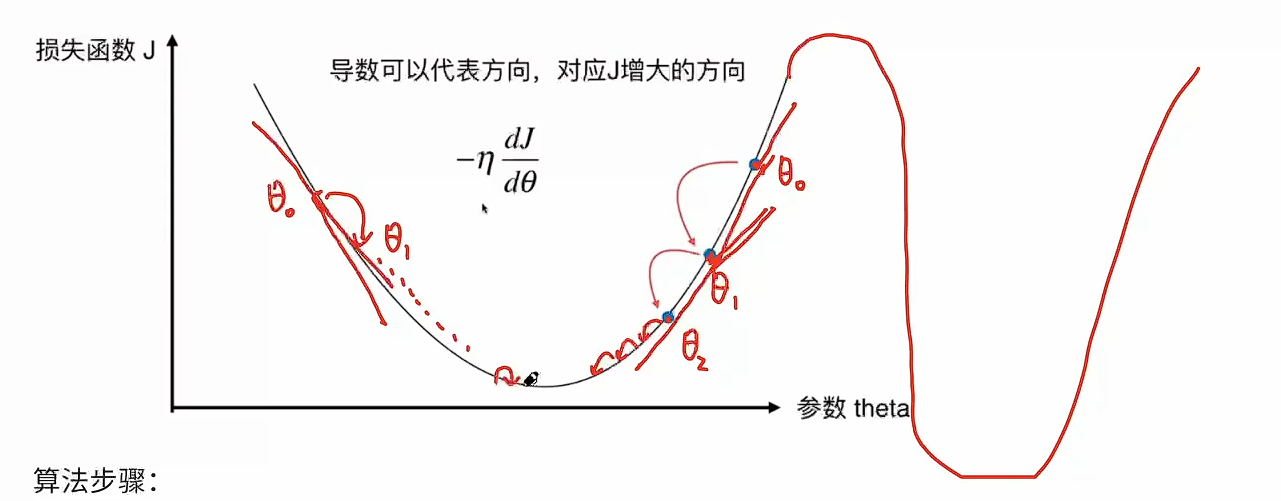
- 选择一个起点 $$\theta_0$$
- 比如图中最右边的蓝点
- 选择一个步长(学习率) $$\eta$$
- 每一次要走多远,梯度下降就是一步步在往下坡的方向走
- 确定:往哪个方向走,走多远
- 每一次要走多远,梯度下降就是一步步在往下坡的方向走
- 更新参数: $$\theta_t = \theta_{t-1} - \eta \cdot \frac{dJ}{d\theta}$$
- 通过求导来得到我们这个损失函数在当前θ这一点上的导数
- 微分:△y=f(x+△x)一f(x)=f’(x)·△x+o(△x)
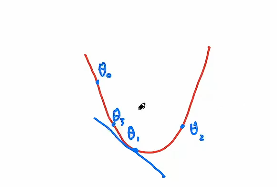
多维的梯度下降
将 $$b$$添加到 $${w}$$中
预测方程简化为 $$y = {wx}$$
.png)
-
找到损失函数在当前参数的梯度,即增长的方向,然后调个头乘以-1往下走
-
对于一个给定的输入输出,损失函数的自变量为 $${w}$$
- 要优化的是参数 $${w}$$,更新参数
-
-
梯度就是求偏导数:$$\nabla E_p = \frac{\partial E_p}{\partial x}\mathbf{i} + \frac{\partial E_p}{\partial y}\mathbf{j} + \frac{\partial E_p}{\partial z}\mathbf{k}$$
- 梯度是向量,是方向,梯度的大小表示某一方向增长速度
学习率的选择
- 学习率太小,会导致学习速度过慢
- 学习率太大,会导致震荡
代码实现:线性回归
- 线性回归是最简单的一种神经网络
- 训练神经网络的步骤
- 构建、处理训练数据(数据清洗)
- 定义模型结构
- 定义损失函数、优化器(优化器用于做梯度下降)
- 训练
- 查看、分析结果
- 代码
1 | |
- 首先是用模型现在的这个权重,先去做一遍预测,得到预测值
- 用预测值和真值算一遍这一轮的损失
- 把上一轮计算梯度的那些梯度清零
- 计算本轮的梯度,把本轮的loss的梯度都存储到前面相应的变量里面
- 更新参数,每个参数我去用梯度乘以学习率去更新,得到新的参数,应用到神经网络里面
- 这些参数其实都没有暴露出来参数存在哪里,都是存在前面定义的这些网络内部的模块里面,存在定义好的组件里,或者叫层里面。更新参数的时候也是这个变量内保存的参数发生了变化
softmax回归
回归与分类
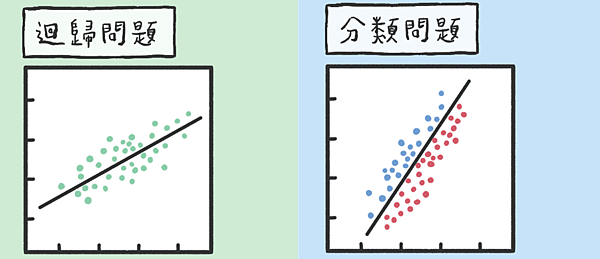
- 回归:输出连续的值,要寻找的是对分布的最优拟合
- 分类:预测离散的值(类别),要寻找的是决策边界
- 对于回归问题,我们只有一个输出。假如我们预测的是一个标量,我们只有一个输出,如果我们要预测的值有几个维度,我们的输出就会有几个值。
- 分类也是这样子,有n个类,最后就会有n个值
One-hot编码
假设要将图片分为:猫、狗、人
如何定义这三个离散类别?
直接用数值代表类别:猫=10,狗=20,人=30
这样定义的问题:
- 相对大小顺序的意义?
- 会引入一些不存在的需要先验的问题,可能有一种误导性
- 数值关系的意义?
- 神经网络输出是一个实数,是一个负无穷到正无穷的一个范围。加入神经网络输出了一个实数值,怎么判断这个实数值属于哪种类别?
one-hot 编码:
各个类别需要互相独立,因此放在不同的维度里
有 n 个类别,每个类别都用一个 n 维向量表示:
- 猫 = [1, 0, 0]
- 狗 = [0, 1, 0]
- 人 = [0, 0, 1]
- 只有0和1,没有数值大小的问题,在不同的维度去编码,也没有一个相对大小的问题了
- 常用于离散值或者分类值的编码
举例:识别手写数字的任务

softmax函数
.png)
.png)
假设类别有三种,则输出层有三个神经元,分别输出每种类型的分数
这样做的问题:
- 输出的值域是实数集
- 想得到的是概率,即所有类别分数求和 = 1
直接进行归一化是不行的, 因为可能会有负数
- 所以要引入softmax函数
softmax函数
- softmax函数把每一个值都变成了一个正数
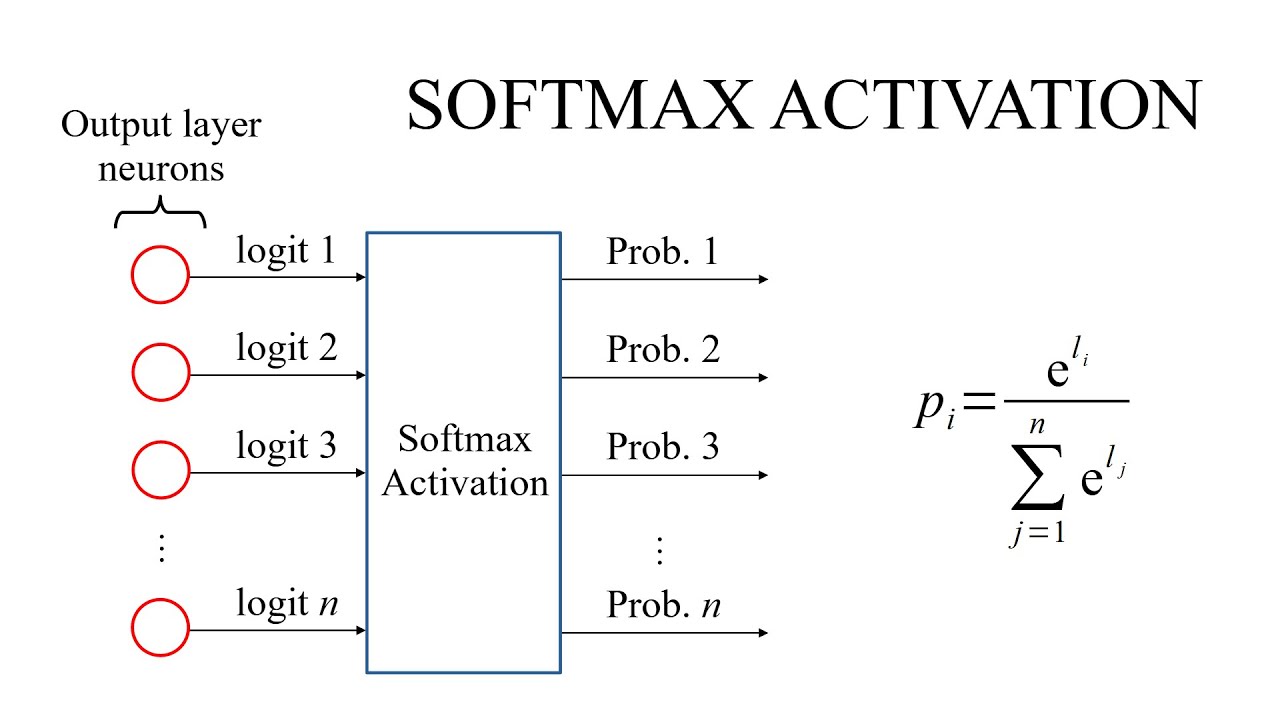
- n个输入,要预测的n个类别,有多少输入就有多少输出,输入是正无穷和负无穷之间的值,输出的值每一个都是正数,并且和为1
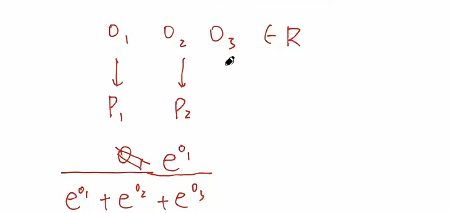
举例:
[1, -1, 2]$$经过 Softmax 函数后得到 $$[0.26, 0.04, 0.7]
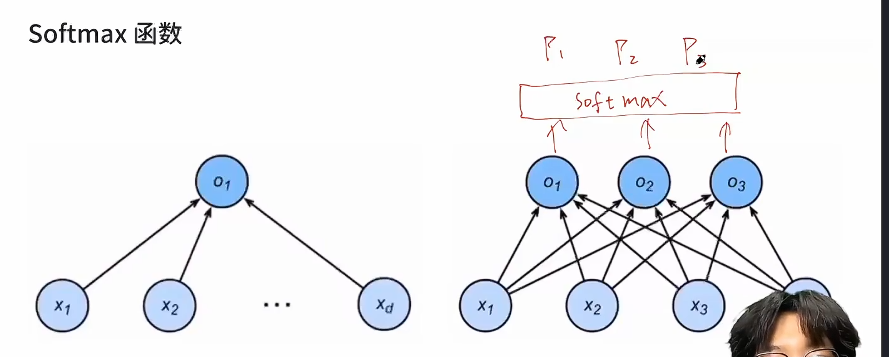
交叉熵(损失函数)
对于连续值,可以用平方误差损失函数
对于 one-hot 编码,还可以用平方误差吗?
举例:
损失:0.18
损失:0.173
- 对于分类问题,我们希望神经网络它判断我这个类别的概率是多少,希望这个概率越大越好,也就是说如果这个类别是人的话,我希望人对应的这个维度的概率越大越好,但是上述举例可以看出,概率越大但是反而损失变大了,已经违背了我们损失函数的定义了,所以会受到其他项的概率的影响,但我们只想要正确的项的概率越大越好
目的:让 one-hot 中为 1 的维度,对应的 Softmax 输出值最大
平方误差损失函数不能达到目的!
交叉熵损失函数
- yi是真值,后面是预测值
- 实际上就是把杂项筛去
通常与 one-hot 搭配使用
\hat{y}_i$$是 Softmax 输出的概率在对应的类别维度上的值(对应正确类别)
* 越接近于1,损失函数就越小
* y本身小于1,小于1log是负数,负数取负是个正数,离1越近越接近于0
.png)
## 手推softmax回归
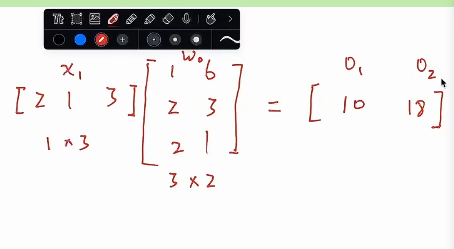
* 假设我们现在要根据测量出的长宽高来预测一个物体是苹果还是香蕉,对这个问题进行建模
* 测量的是长宽高,所以输入是x1,x2,x3,最后预测是苹果或者香蕉,有两个类别,我们构建一个单层的模型,有两个输出O1,O2,他们之间是一个全连接的状态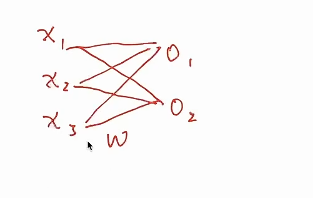
* 这个全连接表示一个w矩阵,输入是3,输出是2,所以是一个3*2的矩阵,还要加一个偏置进去
* x*w得到了o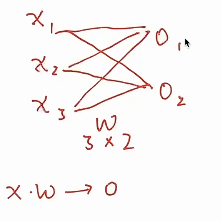
* 网络结构上要做分类,希望网络能给到我每一个类别的概率,所以我在得到网络的输出之后,希望它会有一个softmax函数,最后得到我属于两个类别的概率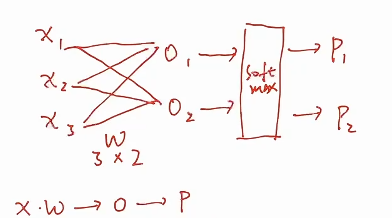
* 通过一些假设的数据来手动推导一下这个网络的运行
* 实际做训练的时候,权重是有一个初值的,会做一个随机初值化,所以W0随便给一些值的3*2矩阵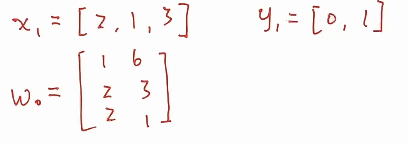
* 1、训练第一步,数据如何处理
* 首先,要得到预测值是什么
* 预测值就是x和权重矩阵相乘,这个时候O1和O2是实数域上的,没有经过softmax的函数,我们希望通过得到对两个类别的概率的预测
* 经过一个softmax计算获得p1和p2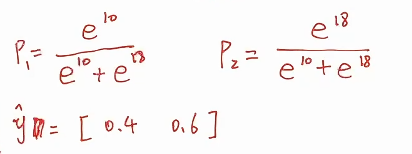
* 计算loss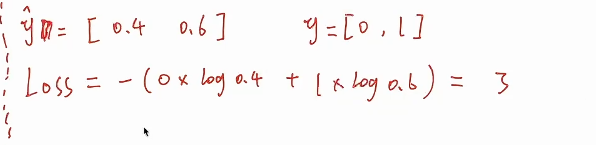
* 通过loss求梯度,梯度算出来以后是一个和w尺寸相同的张量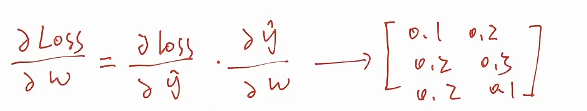
* 梯度相加算法 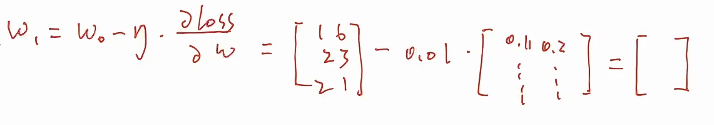
* 用新的参数去更新替换神经网络里面的参数
* 下一次把x2,y2拿出来,用更新的参数拿过来再做一轮这样的更新,这样一轮一轮更新下去,网络参数就会收敛到一个比较好的情况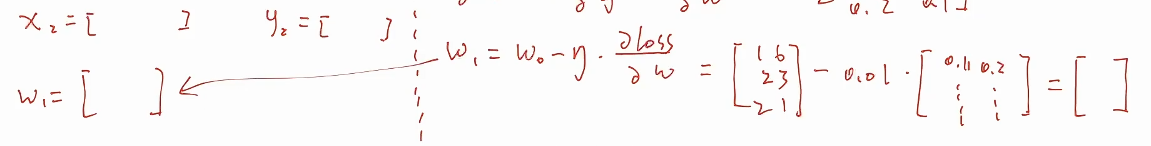
## 代码实现:softmax回归
* pytorch中交叉熵损失函数内置了softmax,不需要手动再加一层softmax进去了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.nn.functional as F
# ===================== 1. 构建人工数据集 =====================
# 创建两个类别的数据集,使用正态分布生成两组数据
# 类别 0 的数据,均值为 (2, 2)
x0 = torch.randn(50, 2) + torch.tensor([2, 2])#前面randn生成一个标准正态分布,50*2的尺寸,后面直接传入一个python列表,生成了一个1*2这样的尺寸,加起来利用了张量的广播机制,所以这里只有一行,前面有50行,会复制成50*2的尺寸然后进行相加,也就是50行每一行都加了一个(2,2),所以均值为2,2
# x0.shape = (50, 2)
#每个样本是一个维度为2的一个向量,构建了50个这样的向量,每个向量的维度是2,后面加了一个(2,2)
# 类别 1 的数据,均值为 (7, 7)
x1 = torch.randn(50, 2) + torch.tensor([7, 7])
#构建了两个类别,一个类别1一个类别2,二者特征不一样,类别1服从均值为2的正态分布,类别2服从均值为7的正态分布
# 标签为 0、1
#训练数据有标签,标签就是真值
y0 = torch.zeros(50, dtype=torch.long)
y1 = torch.ones(50, dtype=torch.long)
# y0.shape = (50,)
#因为有50个样本,所以标签的长度或者它的形状一共有50个
# 合并数据
X = torch.cat([x0, x1], dim=0)
# X.shape = (100, 2)
#前50行x0后50行x1
y = torch.cat([y0, y1], dim=0)
# y.shape = (100,)
#x和y就是我们整个的训练数据了,一共有100个样本,表现也是100个,每个样本有两个特征,到此数据集构造完成
# 可视化数据
plt.scatter(X[:, 0].numpy(), X[:, 1].numpy(), c=y.numpy())
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Training Data')
plt.show()
#画出一个散点图
# ===================== 2. 定义Softmax分类模型 =====================
#和线性回归模型很像,但是因为我们的输入维度和输出维度变了,我们的输入和输出都是二维的
class SoftmaxClassifier(nn.Module):
def __init__(self):
super(SoftmaxClassifier, self).__init__()
# 两个特征输入,两个类别输出
self.linear = nn.Linear(2, 2) # 输入2维,输出2维
def forward(self, x):
return self.linear(x)
#在forward里面我们直接把这个线性层输出了,没有经过softmax,所以这里输出的实际上是实数集上的一个东西,从负无穷到正无穷,还不能表示最后的概率
#但我们不需要手动加softmax,因为说pytorch它会自动在交叉熵损失函数里面实现softmax,所以我们正常输出就可以
# 实例化模型
model = SoftmaxClassifier()
# ===================== 3. 定义损失函数和优化器 =====================
# 交叉熵损失,内部包含了 softmax
criterion = nn.CrossEntropyLoss()
#也就是说虽然forward里面输出的是两个实数集的内容,但是送到交叉熵损失函数里面的时候,pytorch框架会先把我输入的数据做一层softmax,变成概率,然后再通过交叉熵损失函数
# 随机梯度下降 (SGD) 作为优化器
optimizer = optim.SGD(model.parameters(), lr=0.01) # 学习率 0.01
# ===================== 4. 训练模型 =====================
epochs = 1000 # 训练回合数
for epoch in range(epochs):
# 使用模型预测输出
predictions = model(X)
# predictions.shape = (100, 2),输入样本得到预测值,预测值的规模是100*2,100是因为有100个样本,2是因为上面定义输出是2维的
# 计算损失
loss = criterion(predictions, y)#得到预测值函数以后塞到损失函数里面计算损失,predictions是预测值,y是真值,送进去的y实际上不是一个one-hot编码,是一个拼接而成的矩阵。但是在pytorch里面我们就是把类别的索引直接给交叉熵损失函数,他在内部会自动计算这个交叉熵
#y是一个100*1的,y拔是一个100*2的,O1和O2是神经网络直接的输出,都是属于实数集R的
#在交叉熵损失函数的内部,会首先把prediction过一遍softmax得到属于每一个类别的概率P1P2
#再结合这个索引去做一个交叉熵。比如说第一个类别是0,这个数据属于第0个类别,那么我在交叉熵的时候,只需要考虑-log(P1),如果算到第51个也就是类别1,变成对应-log(P2)
# 梯度清零,防止累积
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 打印训练过程中的损失值
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')
# ===================== 5. 可视化结果 =====================
# 使用训练好的模型在同一数据上进行预测
with torch.no_grad():
predicted_labels = torch.argmax(model(X), dim=1) # 取出每个样本的最高分对应的类别,dim=1意思是聚集到列上,即每一行取这个最大值的索引作为这一行的值
# predicted_labels.shape = (100,)
#如何拿到预测的类别的:因为我们知道model x出来的东西是O1和O2,是一个实数集上的东西,但是我想拿到的是它预测的类别,那么我该怎么判断类别?
#其实就是哪个最大,就属于哪一类,虽然O1和O2还没有过softmax不代表概率,但是因为softmax是一个单调函数,所以O1越大,概率就越大,所以说O1O2的相对大小就已经可以确定模型最后概率预测的相对大小,所以这里直接比较模型输出的O1O2的相对大小即可,选取最大的索引作为预测的类别
#最后会得到一个100*1的矩阵,里面的每一个值都是这一行的最大的元素对应的索引
# 可视化真值与预测结果对比
plt.scatter(X[:, 0].numpy(), X[:, 1].numpy(), c=y.numpy(), marker='o', label='True Labels')#取第一个特征作为横轴的坐标,取第二个特征作为纵轴的坐标,y作为类别
plt.scatter(X[:, 0].numpy(), X[:, 1].numpy(), c=predicted_labels.numpy(), marker='x', label='Predicted Labels')#取predicted_labels作为预测值y拔
#两个画在一个图上,一个用圆圈表示,一个用叉来表示
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('True Labels vs Predicted Labels')
plt.legend(['True Labels (circles)', 'Predicted Labels (crosses)'])
plt.show()
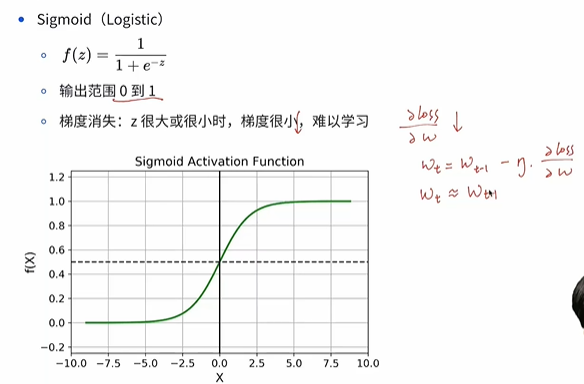
- 输出范围 0 到 1
- 梯度消失:z 很大或很小时,梯度很小,梯度很小的时候神经网络难以学习参数,因为梯度下降算法是上一个参数-学习率*梯度,梯度小后面的乘积结果也会很小,最后变化很小。
- 这个就叫做梯度消失,网络训练不动了,每一次更新我只能找到一个非常小的更新,这个时候可能会让我们的训练变得很慢或者消耗很多的算力,所以梯度消失是一个训练网络时需要解决的问题
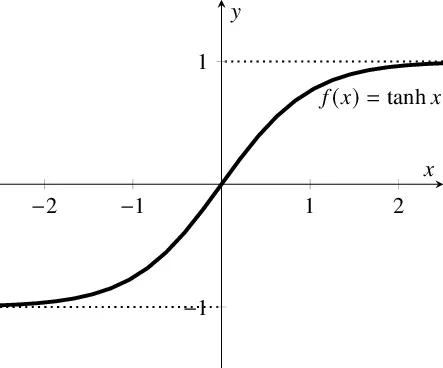
Tanh
- Tanh
-
- 输出范围 -1 到 1
- 同样存在梯度消失问题,值很大的时候非常平坦
-
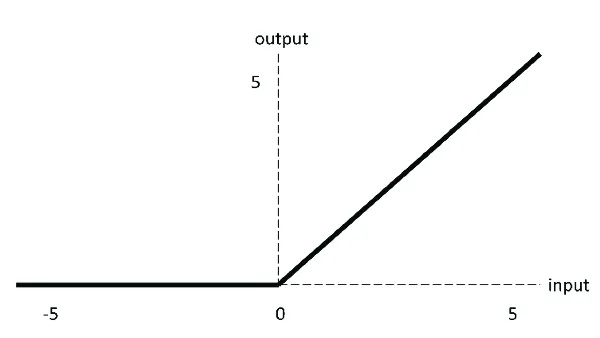
ReLU
- ReLU(Rectified Linear Unit,修正线性单元)
-
- 输出范围 0 到正无穷
- 计算速度快
- 正数部分导数为 1,有利于梯度下降
- 负数部分梯度消失,如果输出的是负数,相当于这个神经元没有起作用
- 用的多
-
Leaky ReLU
- Leaky ReLU
- 负数部分也具有斜率,消除了梯度消失问题
- 实践中和ReLU差别不大,所以在实践中现在ReLU用的比较多
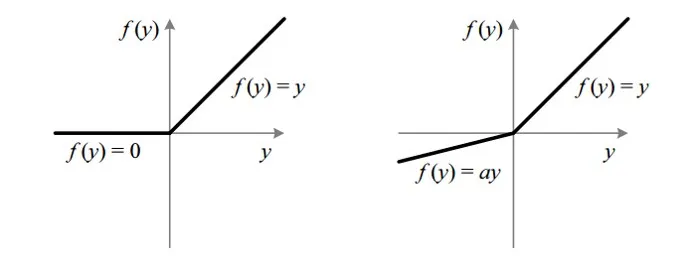
softmax函数
- softmax
- 输出限制在0和1之间
- 输出做归一化,和为1
.png)
损失函数、激活函数、梯度下降之间的关系
损失函数不是“可视化模型”的。它的首要身份是:训练要最小化的目标(objective)。
可视化只是它的“副产品”(我们把 loss 画出来看训练好不好)。
1)它们三者的真正链条
更精确地说是:
激活函数把网络的“线性输出 变成可用的输出 (尤其是输出层需要符合概率/范围)。
损失函数 把“预测和真值的差距”变成一个标量,作为要优化的目标。
梯度下降/优化器 用去更新参数 ,让 loss 下降。
所以关系是:
这是一条闭环。
2)损失函数的“最重要作用”是什么?
不是可视化,而是这两点:
A. 定义“什么叫错、错得多严重”
同样的预测误差,不同损失函数会给不同惩罚。
- 回归:MSE 会对大误差惩罚更重(平方),MAE 更“线性”、更抗离群点。
- 分类:交叉熵会强烈惩罚“自信但错”的预测。
这会直接改变模型学出来的东西。
B. 给优化器提供“方向”(梯度信号)
优化器更新用的梯度来自损失函数:
所以损失函数不仅仅“量化差距”,更是训练的驱动信号来源。
如果损失函数选得不合适(或数值不稳定),梯度可能太小/太大/抖动,训练就会很难。
3)“优化器只是公式吗?”——更准确的说法
优化器不是“顺带用到 loss 的公式”,而是:
- loss 定义了目标
- 优化器只是用一种策略去最小化这个目标
同一个 loss,可以用不同优化器(SGD / Momentum / Adam),效果、速度、稳定性都可能不同。
4)你说的“计算机不知道我们给的是什么东西”这点,补一句关键的
计算机确实“语义上不知道”,但训练并不是靠“知道意思”,而是靠:
- 你给了输入 xxx
- 你给了标签 yyy
- 你定义了“预测怎么产生”(网络 + 激活)
- 你定义了“错了怎么算”(loss)
- 你用梯度下降去调参数
最后模型就学到一种从 x→yx\rightarrow yx→y 的映射。
5)一句话把你最后一句改得更准
你原句:“损失函数最重要的是可视化模型,顺带用于优化器的一个公式?”
更准确版本是:
损失函数最重要的是定义训练目标并产生梯度信号,帮助优化器更新参数;可视化只是我们观察训练过程的一种方式。
多层感知机(MLP)
- 可以被理解为是一种网络模型的结构,简单来讲,它其实就是把我们之前学过的多个线性层加起来,把上一层的输出当作下一层的输入再传过去,把多个线性层摞起来就形成了一个MLP
- MLP(Multilayer Perceptron)是一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题
- 因为有很多个层,层数越多,理论上它的表达能力就越强,它就能越能拟合更复杂的函数
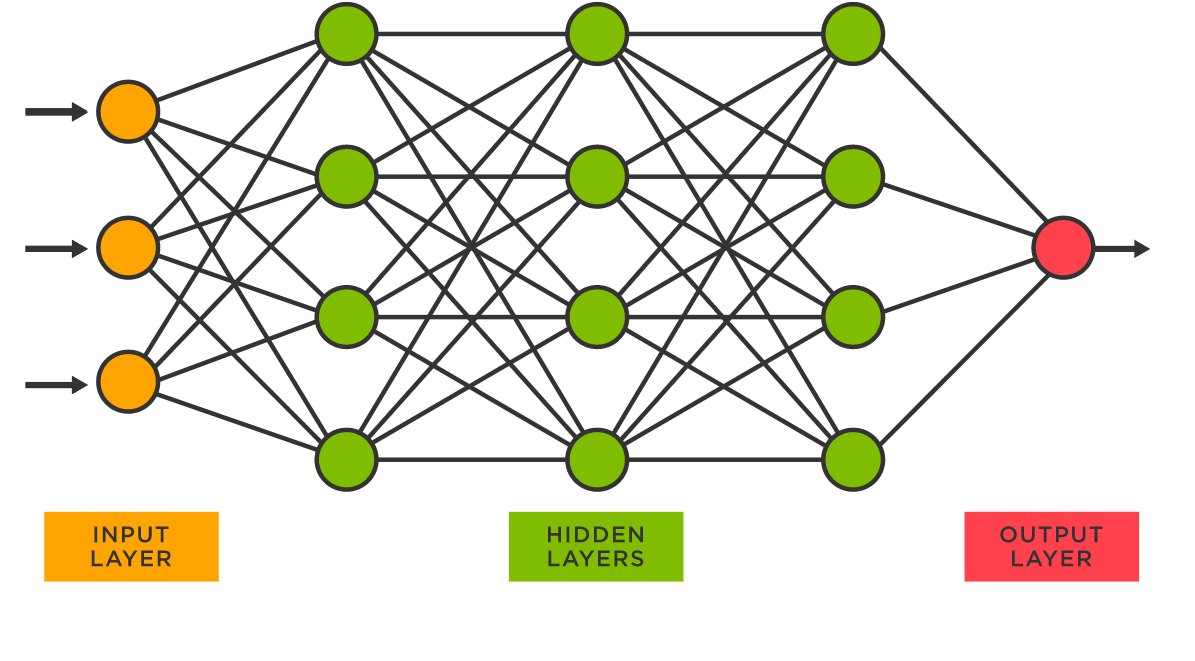
全连接层
-
深度神经网络:每一层获取上一层的输出作为这一层的输入,这层的输出再作为下一层的输入,一层层传递,这就是深度神经网络的工作原理
-
全连接层就是深度神经网络里面最基础的一种层
-
全连接的核心操作是矩阵乘法,本质上是把一个特征空间线性变换到另一个特征空间,然后再过一个激活函数,就到下一个全连接层
-
超参数
-
超参数一般决定了这个神经网络的一些结构上的东西,比如说网络有多少层,网络的激活函数是什么,这些都是超参数,它不会跟随着网络的训练而改变,它是我们人自己去涉及的
-
参数以外的东西
-
输入特征数 (输入维度)M:输入样本的特征数量,决定了权重矩阵的行数
-
输出特征数(输出维度) N:输出样本的特征数量,决定了权重矩阵的列数
- 该图L1层(第一个全连接层)3个输入特征,4个输出特征
- x是一个1*3的矩阵,权重矩阵是一个3 *4的矩阵,相乘生成一个1 *4的矩阵,再经过激活函数得到y1,激活函数不会改变维度,所以输入特征和输出特征直接决定了我的权重矩阵的形状,3是输入特征数,4是输出特征数
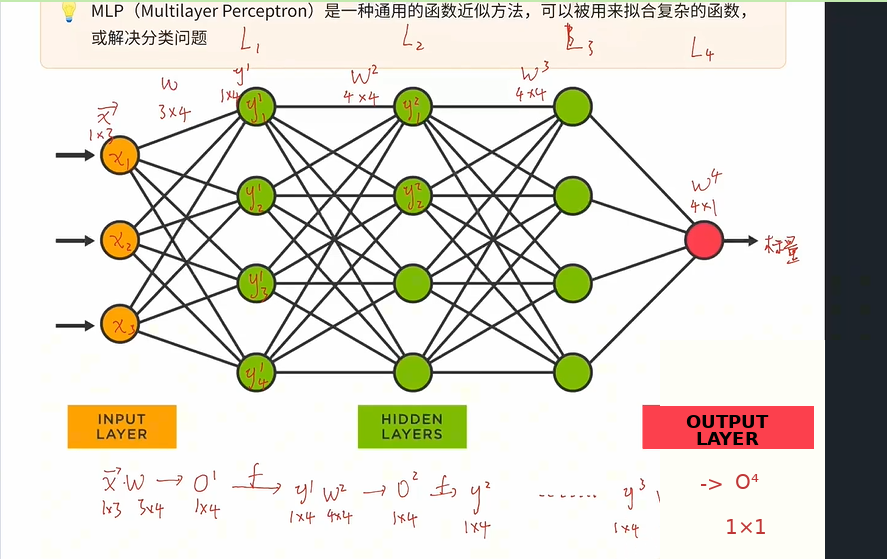
- 该图L1层(第一个全连接层)3个输入特征,4个输出特征
-
激活函数 $$\sigma(x)$$
-
-
参数(神经网络通过梯度下降自己学习和更新的东西)
- 权重矩阵$${w}$$:M*N 的矩阵,对输入特征做线性变换
- 偏置项 $$b$$:N 维的向量
-

-
超参数(整个MLP)
- 层数:包括输入层、隐藏层和输出层,直接影响模型的深度和复杂性
- 每层的神经元数量(维度):每个层次的宽度,决定了该层能够捕获的信息量
- 每层的神经元数量越多,能存储的这个权重信息就越多
- 学习率:过大导致震荡,过小学习缓慢
- 激活函数:用于添加非线性,使得网络能够学习复杂的函数
- 每层的激活函数可以不一样
- 优化器:更新参数的方法
- 梯度下降/梯度下降算法的变种
- Batch size:每次训练的样本数量
- 迭代次数:影响训练时长,以及网络的过拟合与欠拟合
- 定义了我们整个网络的结构、训练等方面,不随着训练而更新
激活函数的作用
- 如果没有非线性激活函数,神经网络的深度将没有意义,最终都可以被简化为一个单层网络(矩阵连乘)。
- 因为线性变换的叠加,还是一个线性变换。
-

手推正向、反向传播
正向传播
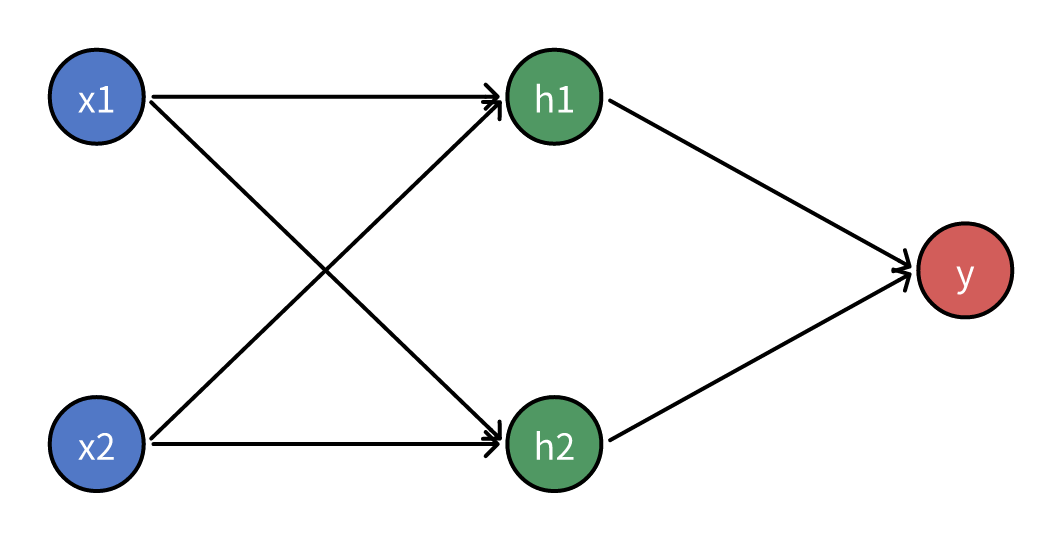
- 把数据输入神经网络,得到输出值的过程
- 计算方向是从我的输入数据到输出数据
- 每一条边都表明我是一个加权和过来,每一条边就对应着第一层权重矩阵里的一个元素,一个标量
- 完成一次正向传播,算出来一个预测值
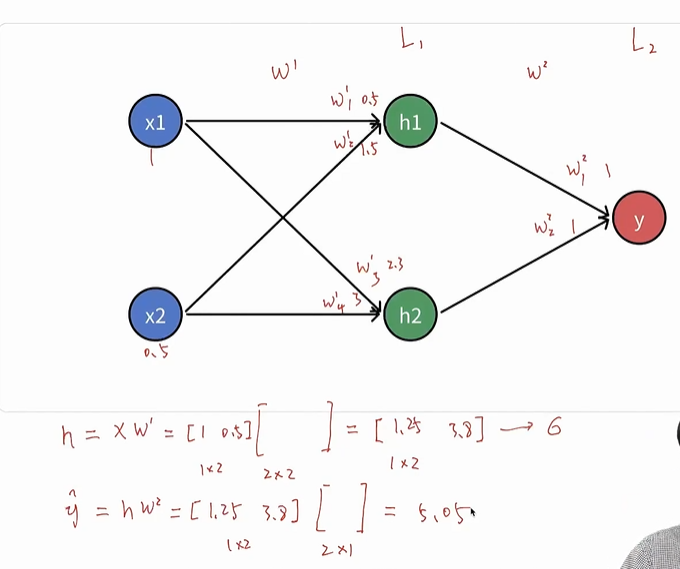
- 然后再算出损失函数。通过输入拿到输出,并且算出来输出和损失,这就是正向传播的一个过程。
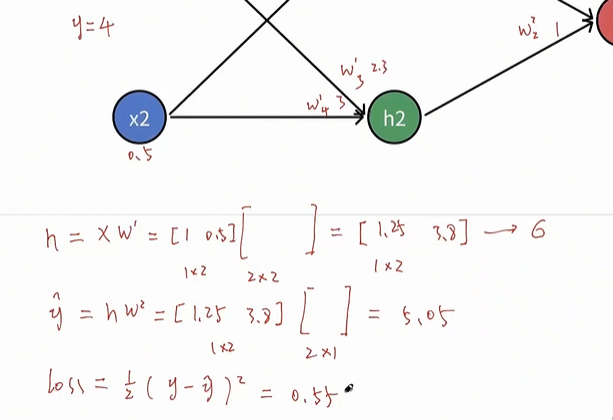
- 然后再算出损失函数。通过输入拿到输出,并且算出来输出和损失,这就是正向传播的一个过程。
反向传播
-
在训练阶段,正向传播得到 loss 后,通过梯度更新网络参数的过程(本质是求导的链式法则)
-
优化目标
- 希望调整我的权重来最小化我的损失函数
优化方法
.png)
-
从后往前依次根据链式法则把loss对y拔的梯度一个一个这样往前计算
- 之所以从后往前计算,是因为计算前面的导数的时候需要用到后面的结果,如果没有反向传播,直接算,那么每次都要重新算一遍
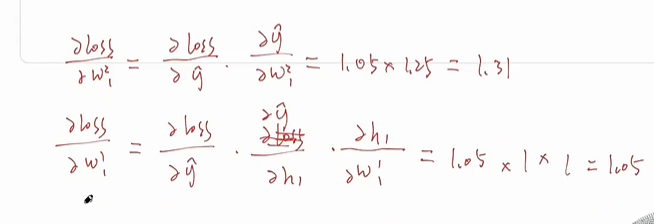
计算图
- 在深度学习框架中,我们使用更加模块化的方式来表示模型的正向传播和反向传播过程,这就使用了计算图
- 计算图:通过定义一些基础的运算,比如说加法和乘法,以及这些运算的前向传播和反向传播的过程,这样我们把各种运算组合起来的时候,根据求导的链式法则,我们就可以自动地通过计算图里面的计算顺序来求出我们想要的梯度
- 图中每一个黄框都是一个计算过程,都是最简单的计算过程,比如加法或者乘法
.png)
-
求导:
- 有了这样的表达过程,我们在进行反向传播的时候,就可以直接获取到我想要的梯度它的各个组成部分了
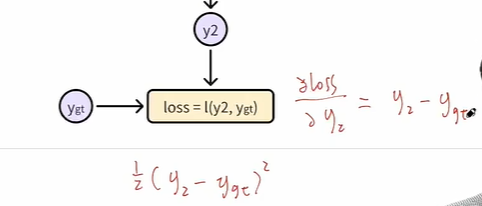
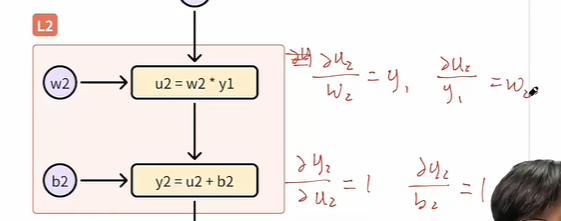
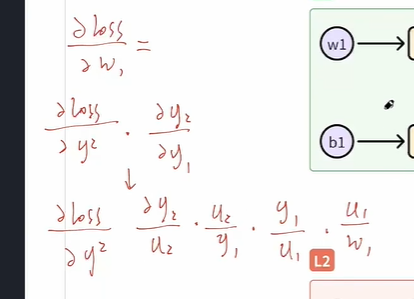
- 比如要计算w1的梯度,我们应该通过链式法则来进行拆解,根据计算图一路往回进行拆解,我们通过计算图可以很清晰地往回来追溯得到对应的导数,而链式求导中的每一项也都是这一个最基础的单元运算,已经预先定义好的,比如说loss对于Y2的导数
-
有了计算图来把计算流程确定下来,可以很轻松地把链式求导链找出来,并且这链上的每一个元素也都是每个单元运算里面都定义好的
-
深度学习框架它的自动求导的实现方法就是通过这种计算图的方法来追踪对于每一个张量进行的运算,每对一个张量进行运算,框架就都会在计算图里面进行一个结点的添加,就可以来追踪对它的运算
代码示例
1 | |
批量操作
批量的引入
- 批量(Batch)指神经网络一次处理多个样本,批量大小就是一次处理的样本数量
- 为什么要引入批量
- 如果每次只处理一个样本,并行度低,无法完全利用 GPU
- GPU计算能力强是因为它的并行度很高,有很多核在里面,所以想要用GPU,一般要用更大的批量
- 单个样本无法代表所有训练数据,导致梯度更新不稳定
- 更新参数的时候要计算loss对于这个参数的梯度,但是算梯度的时候,我们的输入数据在里面,需要用到输入数据。因此,更新参数的过程就可以理解为网络在不断地去学习输入样本的特征的一个过程
- 加入每次是一个样本的一个神经网络,它计算出来的梯度只是这一个样本产生的梯度,但是样本之间,即使是可能属于同一个类别,也是有一些可能是随机性的差异在里面,这种随机差异,如果每次只传一个样本,它就可能会被网络学到,干扰梯度,因为网络其实分不清样本的哪些特征是真正让它有效的
- 更新参数的时候要计算loss对于这个参数的梯度,但是算梯度的时候,我们的输入数据在里面,需要用到输入数据。因此,更新参数的过程就可以理解为网络在不断地去学习输入样本的特征的一个过程
- 如果每次只处理一个样本,并行度低,无法完全利用 GPU
- 批量大小
- 使用全部训练数据作为批量大小
- 这些数据都是要被加载到内存和加载到缓存里面的
- 使用小批量(mini batch),如 16、32、64,在训练集上多次迭代
- 取决于显存和数据规模
- Batch size 是超参数
批量预测
-
假设 batch_size = n
-
每个样本的特征长度为 m
-
-
- w是全连接层的权重矩阵,全连接层就是一个矩阵乘法,假设输出维度是k,w就是一个m*k的矩阵
- z就是这一层的输出
- 对z来说,每一行也是一个样本,跟x里面的每个样本是对应的
-
- 经过一个激活函数得到预测值
- 预测值也有n行,跟输入数据的n行每一行都是对应的
-
- 因为loss是一个标量不是一个向量,loss取平均数
-
-
在深度学习里面,我们一般用行来表示样本,所以Batch size=n代表我们输入进去的数据一共有n行,用列表示特征
小批量随机梯度下降(SGD)
-
- 公式还是一样的
| 单样本梯度下降 | 小批量梯度下降 |
|---|---|
| 每次只能处理一个样本,计算效率低 | 一次加载随机 n 个样本,更好的利用资源 |
| 根据单个样本计算梯度,导致参数更新的高方差,下降路径崎岖不平,相对容易陷入局部最优解 | 根据一批样本计算均值,梯度更稳定,泛化性更好 |
| 只需要调整学习率 | batch_size 和学习率往往相关,更大的batch_size一般意味着更稳定和准确的梯度,需要更大的学习率 |
- 很多时候只要不爆显存,就把Batchsize调大,因为越大并行度越高,算的越快,再去调学习率
Pytorch中的Dataset和DataLoader
- Dataset 用于定义数据集
- 数据集有哪些,以及如何从数据集里面取数据,把数据返回
- DataLoader 通过迭代从数据集中加载数据(需要将 Dataset 传入 DataLoader)
- 定义好dataset之后传给dataloader,dataloader帮助加载数据,通过迭代循环的方式来加载数据
1 | |
总结
- 为了计算资源、梯度更新的稳定性,引入批量
- 引入超参数:批量大小(batch_size)
- 批量大小与学习率相关,一般更大的批量要用更大的学习率
训练、验证、测试集
概念
- 在深度学习中,数据集通常分为 训练集(Training Set)、验证集(Validation Set) 和 测试集(Test Set),三者不能重叠
| 训练集 | 验证集 | 测试集 |
|---|---|---|
| 训练模型 | 评估模型在训练过程中的表现,根据表现来调参 | 评估最终模型的表现 |
| 占总数据的 60%-80% | 占总数据的 10%-20% | 占总数据的 10%-20% |
| 大量数据,有代表性 | 必须是模型从未见过的数据,才能客观评价模型表现 |
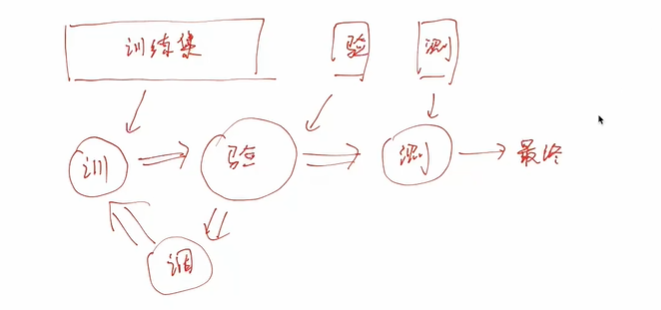
代码
1 | |
过拟合、欠拟合
定义
.png)
- 第一行是分类问题,第二行是回归问题
- 欠拟合
- 模型没有捕捉到数据中的模式
- 在训练集和测试集表现都不好
- 过拟合
- 模型过度捕捉了数据规律,“记住”了数据
- 把噪音也当作特征了
- 在训练集表现很好,在测试集表现不好
- 模型过度捕捉了数据规律,“记住”了数据
- 过拟合与泛化性
- 泛化性是指模型对未见过的数据的表现能力
- 过拟合是导致泛化性不足的原因之一
- 泛化性,是深度学习界、工业界最关注的问题之一
- 数据量和模型容量不匹配,比较小的数据用太大的模型去训练,容易导致过拟合,如果是很大很复杂的数据,用一个小的网络去训练,容易导致欠拟合
影响因素
- 网络的复杂程度(模型容量)
- 模型能学到的最复杂的特征能有多复杂
- 整个表达能力的上限
- 如果网络模型很复杂,容易导致过拟合
- 训练的数据量
- 训练的数据量比较小,容易导致过拟合
- 训练时间(epoch)
- 训练轮次过多容易过拟合
- 训练轮次少容易欠拟合
.png)
- 训练数据的噪声(数据增强)
- 训练数据的多样性也会影响过拟合或者欠拟合
- eg:假如我有一些猫的图片,可能这个图片没有很多,直接给网络学习,可能因为数据小,容易过拟合
- 如果增加一些旋转,增加一些噪声,泛化性就会增强,就不容易那么过拟合了
- 所以噪声不能太小
.png)
- 正则化方法
L1、L2正则化
- 正则化的方法用来应对模型的过拟合问题的
模型容量
- 模型容量过大,是导致过拟合的原因之一
- 影响模型容量
- 模型结构大小(参数量)
- 模型的层数越多,容量越大
- 每层的维度越大,容量也越大
- 模型的参数量也能看出来容量的大小
- 权重的取值范围
- 如果每层的权重都很小,模型的复杂度就会下降
- 模型结构大小(参数量)
L2权重衰退
-
权重衰退通过限制权重的取值范围,来限制模型容量,进而缓解过拟合问题
- 之前优化过程是修改w,从而让损失函数最小化
-
将优化目标改为:
- 左半部分是损失函数,右边是引入的二范数,欧几里得距离,没有给权重的平方和
- 不仅想降低loss,还希望我所有的权重的平方和要尽量的小,相当于希望权重的取值范围也要小一点,起到限制模型容量的作用
- 既想要loss小,也想让权重的这个取值比较小,向0靠近,不要太大
引入超参数 $$\lambda$$,控制正则化的强度
- λ越大,正则化越强,λ非常大的时候,实际上就是要让权重非常小,λ很小或者等于0,那这个就没有什么正则化的强度在了
.png)
- 权重矩阵这里的二范数,其实就是其到原点的距离
-
单纯loss的表现或者说在训练集上的精度,可能会下降一点的,但是我们会期望它用更小的这个权重的取值,让他的泛化性得到增强
-
引入正则化后的参数更新:
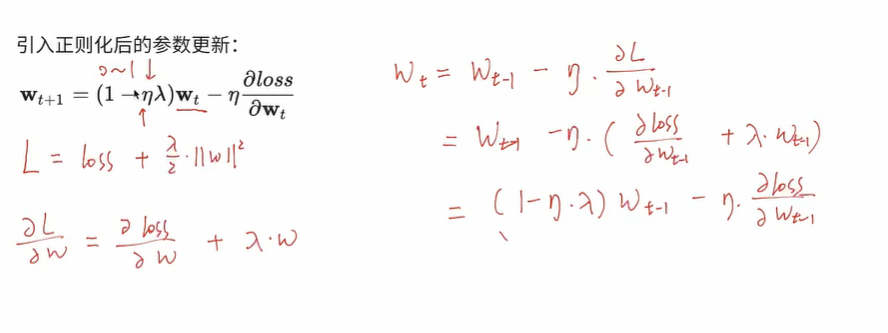
- 每次都是先把当前的权重缩小一点,然后进行更新
- λ越大,权重越小,对权重的限制就越严格,衰退更明显
代码
- 权重衰退只影响了模型参数更新的阶段,模型结构没有变
1 | |
总结
- 正则化是深度学习中缓解过拟合的方法
- 权重衰退(L2 正则化)通过控制权重的取值范围,来降低模型容量
- L2正则化的意思是W用二范数
- 引入超参数 $$\lambda$$,控制权重衰退的程度
Dropout
- dropout也是一种正则化方法,为了减小模型的过拟合问题,提高模型的泛化性,相比于权重衰退,有的时候丢弃法效果会更好
概念
-
泛化性好的模型,要能抵抗数据的噪音
- 可以在数据中加噪音,也可以在层与层之间添加噪音
- 丢弃法就是在层与层之间加入噪音的一种方法
.png)
-
噪音不应改变数据的期望(无偏噪音)
- 现实中的噪音,包括我们希望模型应对的噪音都属于无偏噪音。也就是加入噪音之后不改变数据分布的期望,数据大一点或者小一点,但总体而言不会让数据整体发生偏移,可能会改变其方差
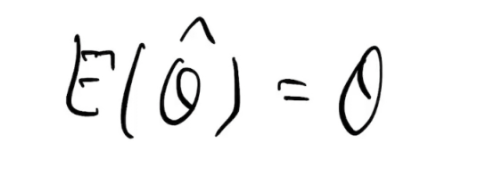
-
对全连接层的输出数据,加入如下噪音:
- 有p的概率让全连接层的输出变成0,剩下的元素按比例放大

- 作用体现在对网络结构的更改上,随机地去掉一些神经元
.png)
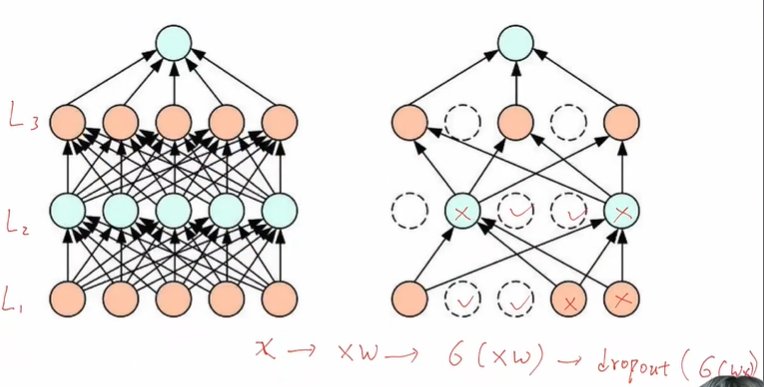
- 在训练阶段,Dropout 生效
- 在推理阶段,Dropout 不生效
- 因为正则化是为了减少模型的过拟合,这个过拟合或者权重的更新只在训练阶段有,在推理阶段模型已经更新完毕,为了最后推理阶段的稳定性,dropout不生效
代码
1 | |
1 | |
代码实现:MLP
1 | |
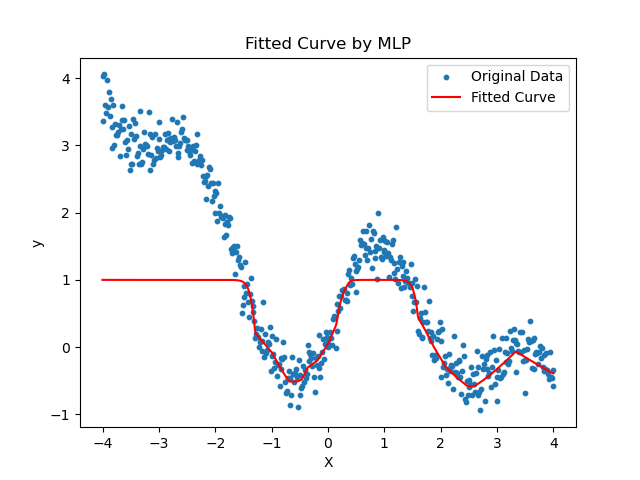
-
加入噪声之后的人工数据集
-
红线是神经网络的输出值
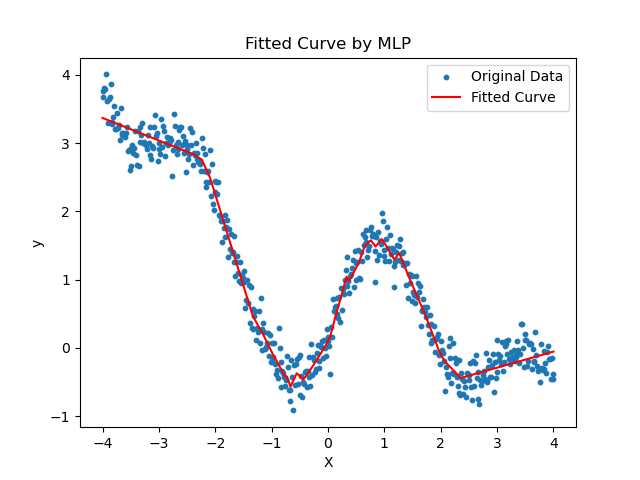
-
如果没有加激活函数
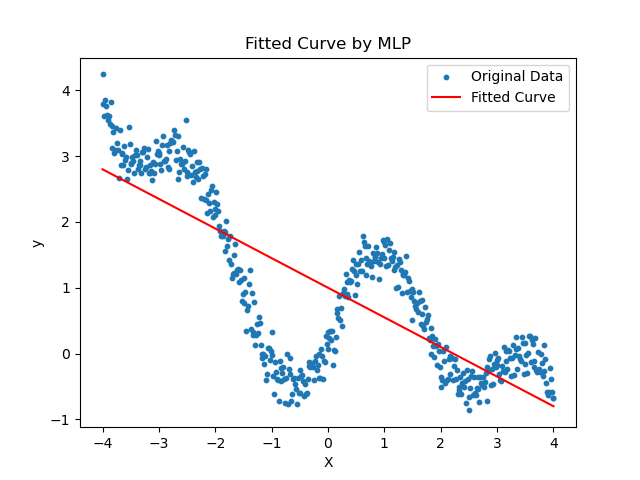
-
如果输出层加了激活函数
Kaggle实战:泰坦尼克号太空飞船
竞赛信息
-
通过乘客信息,预测该乘客是否被传送
-
train.csv - 大约三分之二(约8700)乘客的个人记录,用作训练数据
- PassengerId - 每位乘客的唯一标识符。每个标识符的形式为gggg_pp,其中gggg表示乘客所旅行的组别,pp是他们在组内的编号。组内的人通常是家庭成员,但不一定总是。
- HomePlanet - 乘客出发的星球,通常是他们的永久居住星球。
- CryoSleep - 表示乘客是否选择在航行期间被置于休眠状态。
- Cabin - 乘客居住的船舱编号。形式为deck/num/side,其中side可以是P(左舷)或S(右舷)。
- 可能拆解成三个特征,作为三列传送到网络里面去
- Destination - 乘客将下船的星球。
- Age - 乘客的年龄。
- VIP - 乘客在航行期间是否支付了特殊VIP服务费。
- RoomService, FoodCourt, ShoppingMall, Spa, VRDeck - 乘客在泰坦尼克号飞船设施中的账单金额。
- Name - 乘客的姓名和姓氏。
- Transported - 乘客是否被传送到另一个维度。这是目标,需要预测的列。
- 在分析数据的时候,我们也会去考虑我们有的这些数据哪一个是有用的,哪一个是没有用的,实际训练的时候就可以不用该数据
- 数字比较好处理,可以直接输入到网络里面去,字符串得考虑怎么做一个编码
-
test.csv - 剩余三分之一(约4300)乘客的个人记录,用作测试数据。我们的任务是预测这些乘客是否被传送。
-
csv是一个文本文件表示的表格文件,处理csv文件常用的一个库叫pandas
代码
- preprocess.py - 数据预处理
1 | |
- mlp.py - 网络结构
1 | |
训练代码
1 | |
NLP自然语言处理
- 自然语言处理NLP的概念是和CV计算机视觉相对的,本质上是深度学习在不同情况下的应用。自然语言处理关注的是人类的文本,CV关注的是图像,自然语言处理比CV难一些,难在自然语言处理的特征处理和CV不同,因为CV里面它的像一张图,天然就是这种像素属性,一种数值,自然语言处理是一段文本,并没有相应的数值表示,需要考虑怎样去把一段文本转化为一串数字,这样才能塞进神经网络里面。
- 对文本的预处理就是CV和NLP不同的地方。
- CV不太需要预处理,它可以直接把一张图,就是一个像素的矩阵,一个数值的矩阵丢进去
- 有了处理和输入以后,对于模型相关的,只需要对于模型的架构,一些激活函数,内部的超参数进行修改和设定,这样的话,注意力转移到了模型上面
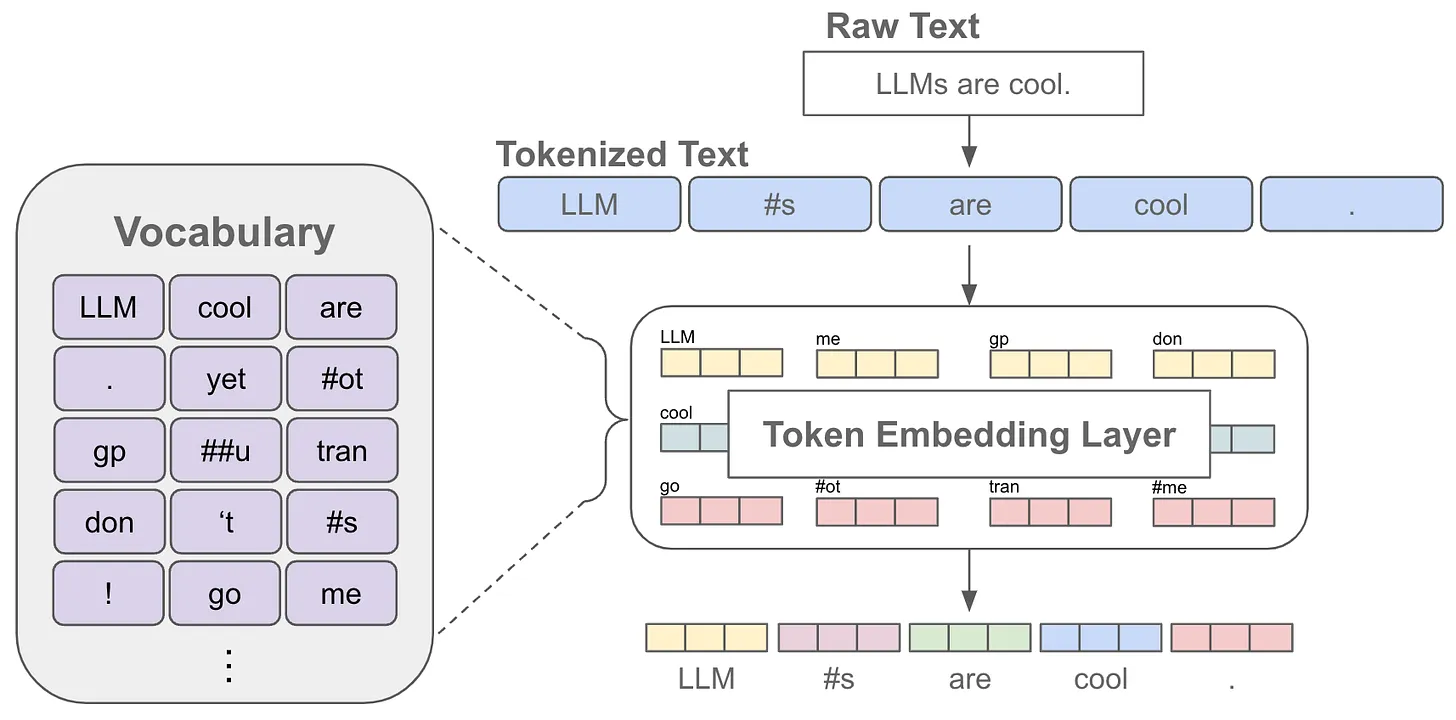
Tokenization-文本的数字化
Token
Token释义
-
在自然语言处理(NLP)中,“token”是指文本中的一个基本单元或组成部分。Token化(Tokenization)是将文本分割成这些单元的过程,这些单元可以是单词、数字、符号或者它们的组合。Token化的目的是为了更容易地处理文本数据,因为大多数NLP任务都需要以某种方式分析文本中的词汇和结构。
- 例如,考虑句子:“我今天去了图书馆。”在这个例子中,通过token化,这句话可以被分解为以下tokens:
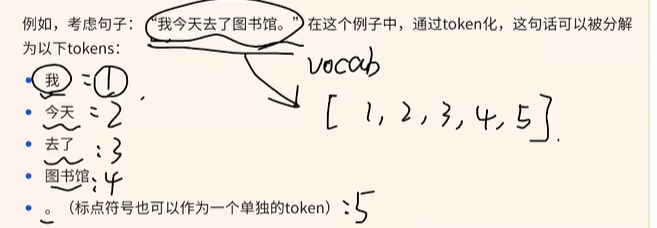
- 我
- 今天
- 去了
- 图书馆
- 。(标点符号也可以作为一个单独的token)
- 维护一个字典vocab,这个字典里面就是token分配一个ID数字,然后就能把所给句子表示成数字组成的串
- 例如,考虑句子:“我今天去了图书馆。”在这个例子中,通过token化,这句话可以被分解为以下tokens:
-
不同的NLP任务可能需要不同粒度的token化。例如,在一些情况下,你可能希望保留标点符号作为单独的tokens,而在其他情况下,则可能希望将其与相邻的单词合并。此外,对于像中文这样的语言,由于单词之间没有明显的空格分隔,token化可能会更加复杂,需要依赖于专门的算法来正确识别词语边界。
-
Token化是许多NLP流程的第一步。
为什么需要token
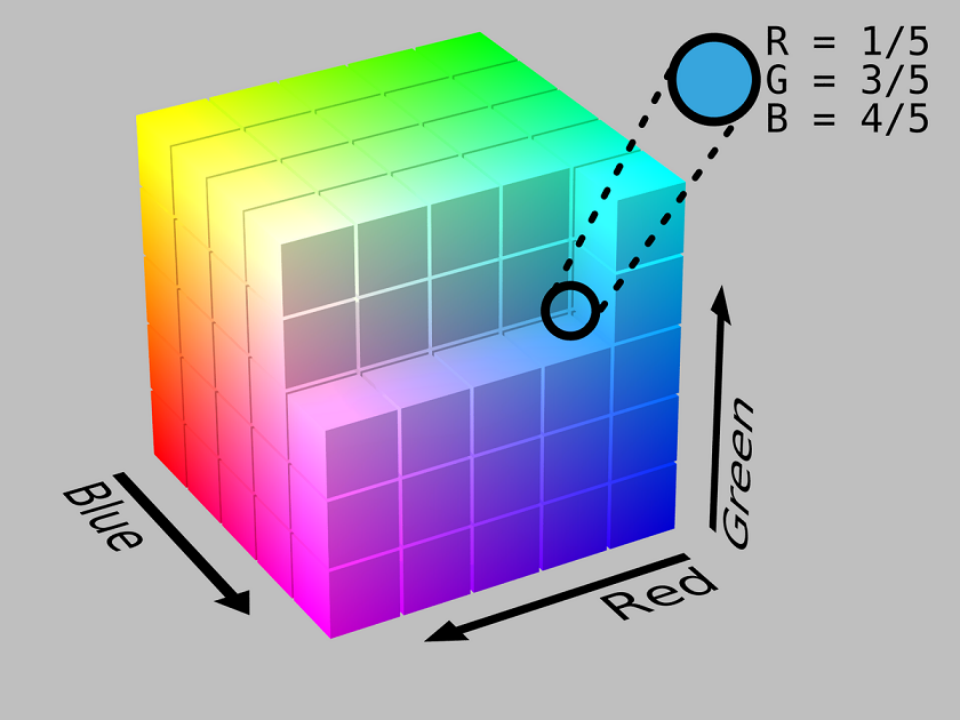
- CV中的像素值都是连续的,可以直接拿去训模型
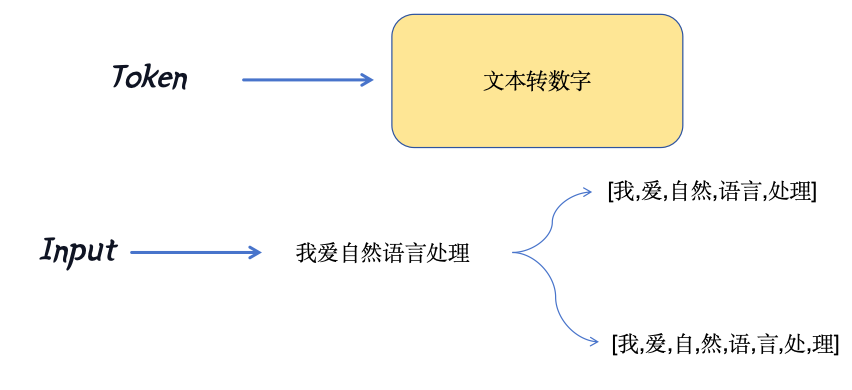
- NLP中的文本是离散的,如何转换成计算机能够拿去运算的连续值,这是一个问题
Tokenization
- Tokenization就是将一段文本切分为若干个token的过程。这也是我们将文本这种人类语言转化为机器能够看懂的机器语言的第一步,先切分。

- NLP的前处理就是在完成这样的事情
Tokenization不同的切分策略
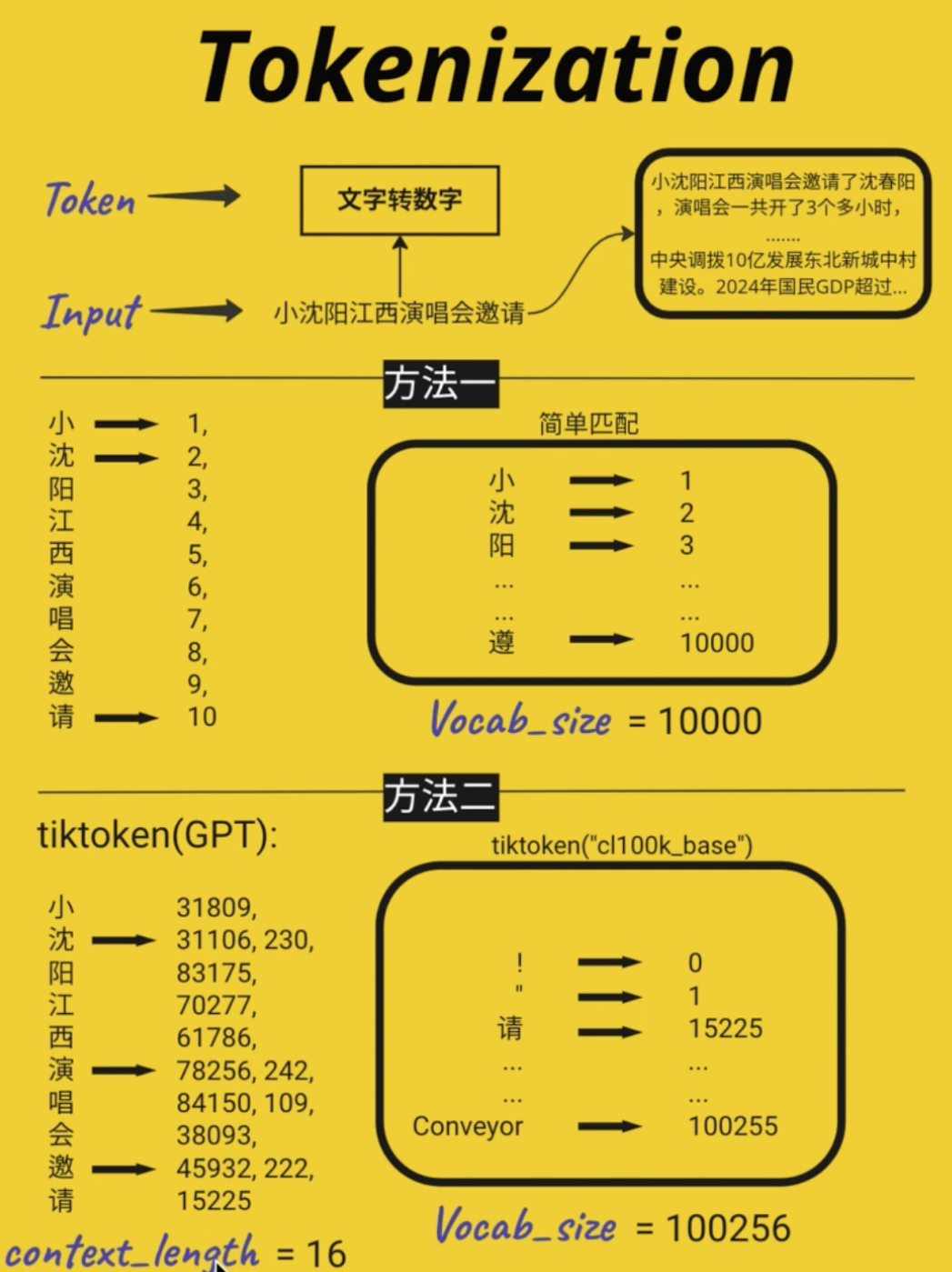
- 方法一:一个字一个字划分
- 方法二:目前GPT和工业界常用的方法:tiktoken
- 这里沈有两个ID是因为这个沈它没有办法用一个token表示出来,在BPE的时候没有把这两个token合在一起,只能用两个token来表示
朴素方法
word-based tokenization
- 这是最常见的方式,即把文本按照空格和标点符号分割成单词序列。例如,句子 “Hello, world!” 可以被 tokenization 成 [“Hello”, “,”, “world”, “!”]。
- 缺点
- 词汇表庞大:对于大规模语料库,词汇表可能非常大,导致内存消耗增加。
- OOV(Out-of-Vocabulary)问题:未见过的单词无法被正确处理,特别是在处理专有名词、新词或拼写错误时。
- 语言依赖:对于没有明显单词边界的语言(如中文),这种方法效果不佳。
Char-based tokenization

-
Char-based Tokenization将每个 unicode 和 ascii 字符表示为一个token,可以解决缺失词的问题
- 把26个英文字母视为token,只维护26个字母作为最基本的token,所有的英文都可以用26个字母表示
-
缺点
- 计算量大,每个单词需要标识为更长的token序列
- 词汇表减少了,但是模型可能要识别半天,才能识别一个单词,更不用说去读一个文章
- 字符本身缺乏语义,丢失了word本身的语义信息,模型学起来会很困难,很难收敛到局部最优解,缺乏泛化能力。
- 计算量大,每个单词需要标识为更长的token序列
最佳实践🌟 subword tokenization
- 最具代表性的算法:BPE算法,字节对编码(BPE, Byte Pair Encoder)。
- 大家都在用且最常用的一种分词思想
BEP分词算法
BEP算法原理

构建词表
- 确定词表大小,即subword的最大个数V;
- 最终结束需要这个条件,当此表的词汇量达到这个数的时候,模型就终止了
- 在每个单词最后添加一个,并且统计每个单词出现的频率;
- 将所有单词拆分为单个字符,构建出初始的词表,此时词表的subword其实就是字符;
- 挑出频次最高的字符对,比如说
t和h组成的th,将新字符加入词表,然后将语料中所有该字符对融合(merge),即所有t和h都变为th。新字符依然可以参与后续的 merge,有点类似哈夫曼树,BPE 实际上就是一种贪心算法;
1 | |
- 对于很短的文本,我们没有办法在很短的训练里面找出这种规律,但是假设我们在特别大规模的文本上,在人类所有的语言的英文的语料库上去训练,就很容易能够刟est,er这种组合,识别token
- /w用来标注这个单词是否到此结束了
编码
词表构建完成后,需要对训练语料进行编码,编码流程如下:
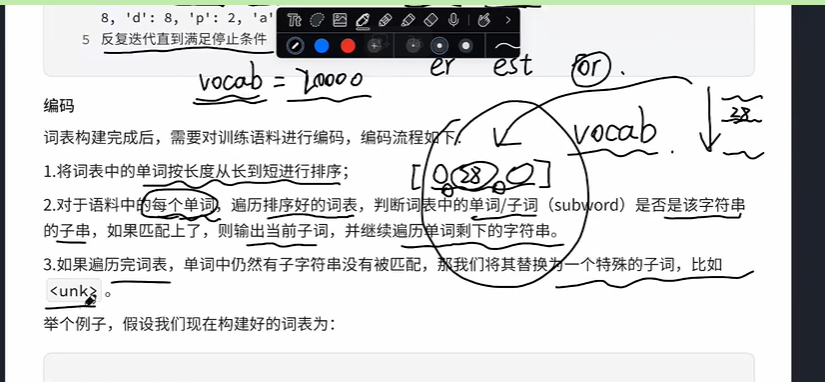
- 1.将词表中的单词按长度从长到短进行排序;
-
2.对于语料中的每个单词,遍历排序好的词表,判断词表中的单词/子词(subword)是否是该字符串的子串,如果匹配上了,则输出当前子词,并继续遍历单词剩下的字符串。
-
3.如果遍历完词表,单词中仍然有子字符串没有被匹配,那我们将其替换为一个特殊的子词,比如
<unk>。 -
举个例子,假设我们现在构建好的词表为:
1 | |
- 对于给定的单词
mountain</w>,其分词结果为:[moun,tain</w>],最终结果为[3,2]- 先切分,再映射
- 编码:文本👉数字
- 把人类的语言翻译成机器能懂的编号
解码(翻译)
- 数字👉文本
- 机器再昨晚一系列处理之后,机器给出的也是这样的编号,拿到这样的编号之后,怎样把它翻译成人能看懂的语言
- 语料解码就是将所有的输出子词拼在一起,直到碰到结尾为
<\w>。举个例子,假设模型输出为:
1 | |
- 那么其解码的结果为
1 | |
BEP思想下的改良-BBEP

- 在字节的层面上做出进一步的改进
-
BBPE(Byte-Level BPE):Byte-level BPE 迈向更通用的Tokenizer
- 也就是利用UTF-8进行token化,然后对token化后的数字进行BPE的操作
-
对于英文、拉美体系的语言来说使用BPE分词足以在可接受的词表大小下解决OOV的问题,但面对中文、日文等语言时,其稀有的字符可能会不必要的占用词汇表,因此考虑使用字节级别byte-level解决不同语言进行分词时OOV的问题。
-
具体的,BBPE考虑将一段文本的UTF-8编码(UTF-8保证任何语言都可以通用)中的一个字节256位不同的编码作为词表的初始化基础Subword。
- Vocab_size=256
- 也就是粒度更加细化以适用世界的通用语言
-
相比ASCII只能覆盖英文中字符,UTF-8编码创建的本身就是为了通用的将世界上不同的语言字符尽可能全部用一套编码进行编号,同时相比UTF-32对于每个字符都采用4位字节(byte)过于冗长。改进的UTF-8编码是一个变长的编码,有1~4个范围的字节(bytes)长度。对于不同语言中字符采用不同长度的字节编码,例如英文字符基本都是1个字节(byte),中文汉字通常需要2~3个字节。
-
补充知识点:
在计算机中,每个字节(Bype) 有8位的2进制编码,在电脑显示时全部用2进制太冗长,因此每个字节(bytes) 通常使用2个16进制编码(0~F) 进行表示。
- 例如: 字母 'A’的unicode-8 用十进制表示的值是:65,两位16进制表示就是 : 41
1 | |
Tokenizer
- Tokenizer就是我们用来分词的工具,是一种分词思想的工程化具体实现
常用的Tokenizer
- SentencePiece: LLama\baichuan
- Tiktoken:GPT
为什么要用?
- 需要海量文本训练,且重复性劳动大,并且可复用程度很高
- 难度在于训练而不在于使用
注意
- 每个模型都要用自己对应的tokenzier!
- a模型用了b模型的tokenizer就会出现货不对板的情况
如何使用
- Hugging Face 的
transformers库是一个非常流行和强大的工具,支持多种预训练模型和相应的 tokenizer。以下是使用transformers库中的 tokenizer 的基本步骤:- 使用 GPT 的 tokenizer 可以通过 Hugging Face 的
transformers库来实现。GPT 模型(如 GPT-2 和 GPT-3)的 tokenizer 提供了方便的接口来处理文本数据。以下是详细的步骤:
- 使用 GPT 的 tokenizer 可以通过 Hugging Face 的
安装 transformers 库
- 首先,确保你已经安装了
transformers库。如果还没有安装,可以使用以下命令进行安装:
1 | |
导入所需的模块
1 | |
加载预训练的 tokenizer
1 | |
对文本进行 tokenization
1. 分词(Tokenize)
将文本字符串转换为 tokens 列表:
1 | |
注意:GPT-2 的 tokenizer 使用了一个特殊的前缀 Ġ 来表示单词的开头。
2. 将 tokens 转换为 IDs
将 tokens 转换为对应的 token IDs:
1 | |
3. 直接编码文本为 IDs
可以直接将文本编码为 token IDs,包括添加特殊 token(如 [CLS] 和 [SEP]):
1 | |
4. 解码 IDs 回文本
将 token IDs 解码回原始文本:
1 | |
批量处理文本
如果你有一批文本需要处理,可以使用 batch_encode_plus 方法:
1 | |
处理特殊 token
GPT 模型通常使用 EOS 作为特殊 token。你可以通过 tokenizer.eos_token 获取这个特殊 token:
1 | |
- 在每一段文本的结束后面,都会跟一个
token,在后面生成式模型的时候会有用处 - 即生成模型的时候,到哪一句话结束,当模型预测出下一个token是eos的概率最大的时候,就作为一个结束符号
- 当模型检测到生成的eos之后,模型就不再进行下一步的生成了
可视化token分享
- 输入汉字,展示token,点击token IDS变成数字,同一个颜色的会划分为同一个token
-1770293256224.png)
-1770293256224.png)
- 魑魅魍魉划分为四个就是因为BPE的时候没有形成一个很好的字节对,还是单一的字节对
Word Embedding
- 当前,我们已经完成了分词任务,即将一段文本划分成了若干个最小的单元组成的序列,也就是token,并且每个token我们都给了一个ID(通过维护了一个vocab完成token到ID之间的相互映射)
- 文本→id序列以后,就能把它放到神经网络中去了吗?
- 不行,因为这种ID数字实际上是没有任何科学依据的,谁排在前面或者后面完全取决于整个vocab的策略,想把某个数字排在前面或者后面完全是随机的,或者说是依据某一个特定的规则。
- 数值是单一维度的,之间有一个大小关系,这种大小关系显然不能表示每一个token的独立性了,而模型天然都是对数字敏感的,如果直接赋值,模型会认为这些token之间存在大小关系,这样显然不合理
- 因此要将他们用one-hot编码来表示
- 比如如果我有一个1万个vocab_size的词表,可以用一个1w维的向量来表示里面的每一个token,每个token的向量相互正交,能够保证相互之间的独立性
- 但也存在问题,比如虽然香蕉和苹果之间独立了,但他们都是水果,希望他们的意思能够更近一点,这样可以降低维度,还可以让他们有一定的相似性,这就是做wordbedding的一个原因,以及如何做wordembedding,即将one-hot编码压缩到一个固定维度的大小。
- 把一个非常高维的一个空间压缩到一个低维的空间,拿到低维向量表示,一旦低维,某一些向量就会产生一些空间上的交集,那么他们就会有一定的相似性
- 这样压缩以后他们不再正交,这样就有了一个相似性,当去做这种cos相似度的时候,日股香蕉和苹果,相似性得分就会比较高,香蕉和你做cos相似度的时候,相似性得分就会比较低,因为方向不一致。
- 但也存在问题,比如虽然香蕉和苹果之间独立了,但他们都是水果,希望他们的意思能够更近一点,这样可以降低维度,还可以让他们有一定的相似性,这就是做wordbedding的一个原因,以及如何做wordembedding,即将one-hot编码压缩到一个固定维度的大小。
- 比如如果我有一个1万个vocab_size的词表,可以用一个1w维的向量来表示里面的每一个token,每个token的向量相互正交,能够保证相互之间的独立性

什么是 Word Embedding?
Word Embedding 就是把文字转换成数字的形式,这样计算机就能更容易地理解和处理这些文字。我们要在得到每个token ID的情况下,进一步得到能输入神经网络的数字表示。
举个例子
假设我们有两个词:“猫”和“狗”。通过某种算法,我们得到了它们的词向量:
-
ID→向量,因为这个向量才使我们能够输入进模型的东西
- 直接输入数字不行,直接输入one-hot编码维度过大,而且每个token与token之间完全没有任何交集完全独立不符合一些预设的逻辑
-
“猫” ->
[0.1, 0.8, 0.5, ...] -
“狗” ->
[0.2, 0.7, 0.4, ...]
你会发现这两个词的数字序列很接近,这反映了“猫”和“狗”在很多情况下是类似的。
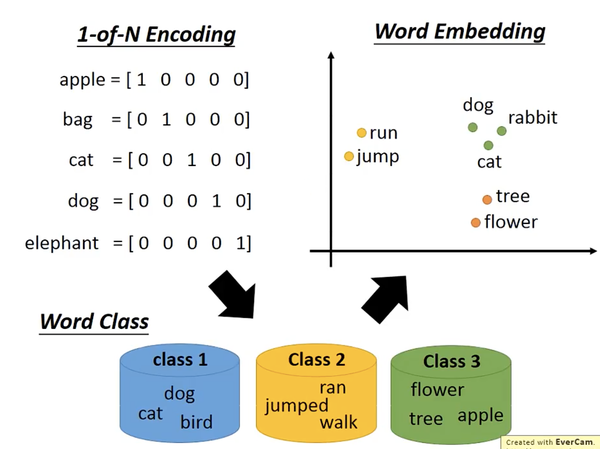
词向量
-
词向量就是某一个多维向量能唯一代表某一个词。
- 举个例子:假设中文只有4个词【你、我、他、它】,如果用0或1去表示他们,【你】可以表示为(1,0,0,0),【我】可以表示为(0,1,0,0),以此类推。 这些0或1组成的向量就可以称之为词向量,但是这种模式的词向量并不好,主要原因有两点:第一中文中有非常多的词,如果每一个词就占一位,那么这样的词向量就会非常长, 同时如果添加了新的词汇,向量的维度就需要增加。第二这些词向量永远都是有一个唯一的1,其余都是0,这样的词向量只能代表这个词,但是不能代表这个词的意思,每个向量之间都是正交。 所以以上述onehot方式编码的向量,并没有什么意义。
-
为了解决上述这个问题呢,Mikolov就提出了一种模型叫Word Embeddings,这种模型可以把词投射到一个固定的多维空间, 每个词的词向量都是同样的长度且相近语义的词会聚集在一起。
- 固定多维空间的大小是认为决定的,工业界常用300-400
-
一句话总结Embedding:
Embedding就是把token转换为向量的过程
如何实现-高维one-hot编码压缩到低维
实现这种模型,又分两种主流的方法,一个叫Continuous Bag-of-Words model(CBOW),一个叫skip-gram(跳远模型)。
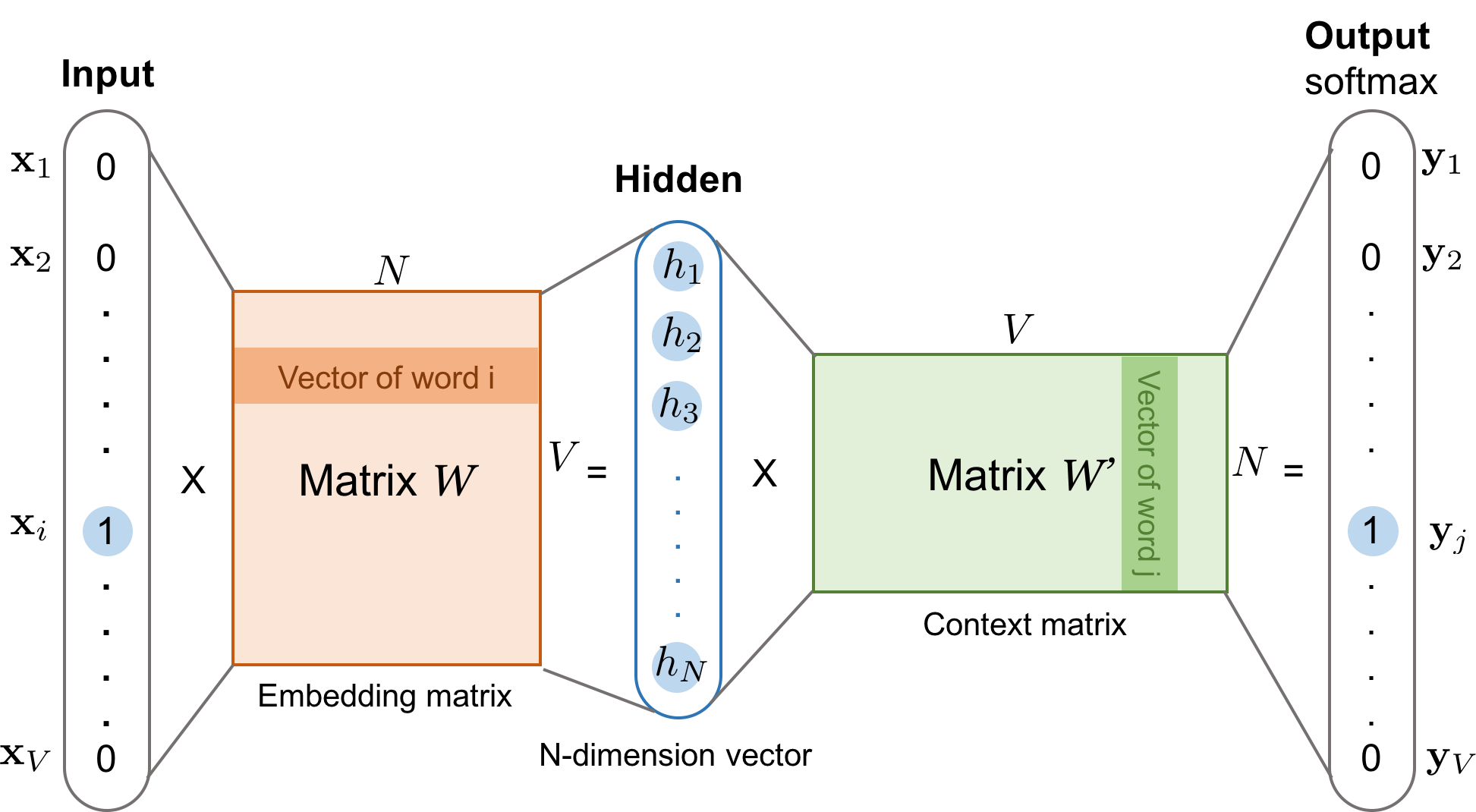
CBOW
CBOW认为一个词的语义可以通过其周边的词来表示,所以通过周边的词来预测被选词。
- 独热编码首先都可以放入神经网络中
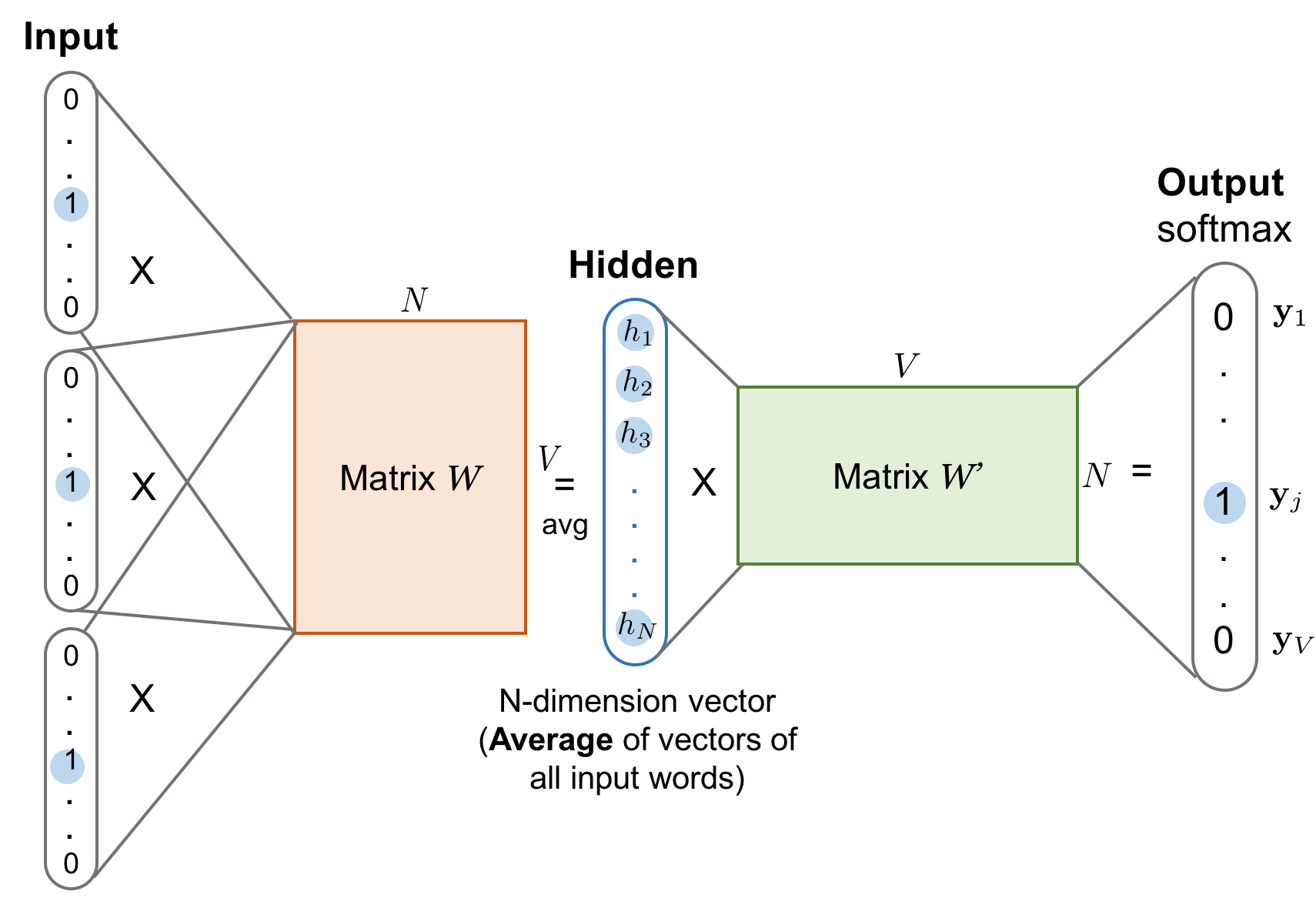
这张图其实完整的描述了cbow的全部过程,但是并不好理解,所以我用一个例子一步一步解释这张图
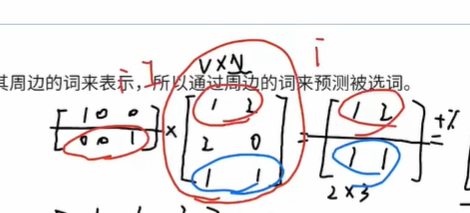
假设在世界上只有一个句子I love you, 也就是说只有三个单词(用大写的V表示,V=3),通过onehot编码的方式,I可以表示为(1,0,0), love可以表示为(0,1,0),you可以表示为(0,0,1)。
cbow用周边n(超参数)个词预测中间的词,假设n=1,我们的模型要通过(I,you)预测出love。
- 注:窗口大小 n 表示:左边取 n 个词 + 右边取 n 个词,所以上下文词总数 = 2n
-
将
I(1,0,0)和you(0,0,1)输入输入层,由于n=1,所以输入层由两个神经元组成。-
当 n=1:
- 左边 1 个词:
I - 右边 1 个词:
you - 总共 2 个上下文词 → 输入就是两份 one-hot:
x_left和x_right
因此说“输入层由两个神经元组成”,指的是两个输入向量(两个上下文词)。
- 左边 1 个词:
-
-
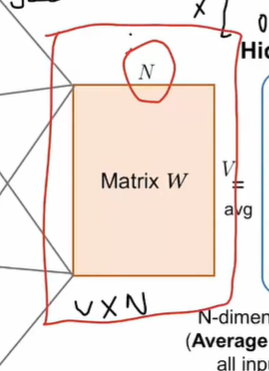
每个输入向量乘以一个V*N的矩阵,V是上面说的词库的大小,在这里就是3,N则是隐藏层神经元的个数。
-
因为输入向量是一个1* V的矩阵,所以相乘后的结果是一个1*N的矩阵。
- NLP推导默认one-hot用行向量表示,因此输入x的形状是1xV,而词向量矩阵W是VxN
-
把所有的输入向量产生的乘积累加之后取平均值得到一个新的1*N的矩阵就是我们在隐藏层的输出。
-
把这个输出的向量再乘以一个NxV的矩阵(与上述VxN的矩阵没有任何关系),又会得到一个1*V的矩阵,可以把这一层叫做投影层,这层的作用就是把隐藏层的结果再映射到词库里。
-
我们把最终得到的1*V的矩阵通过softmax得到矩阵中最大概率的那个列,而这一列就应该对应love这个单词,如果不是,说明我们的隐藏层和投影层的矩阵并不符合要求。
-
我们通过loss function(损失函数)以及反向传播算法去不断调整这两个矩阵的参数,直到其到达一个我们相对满意的程度。这就是训练模型的过程。
-
当这个模型达到一定的准确率后,我们通过每个词的onehot编码乘以隐藏层的矩阵得到的1*N矩阵,就是我们要得到的这个词的词向量了,所以隐藏层神经元的个数就决定了词向量的维度。
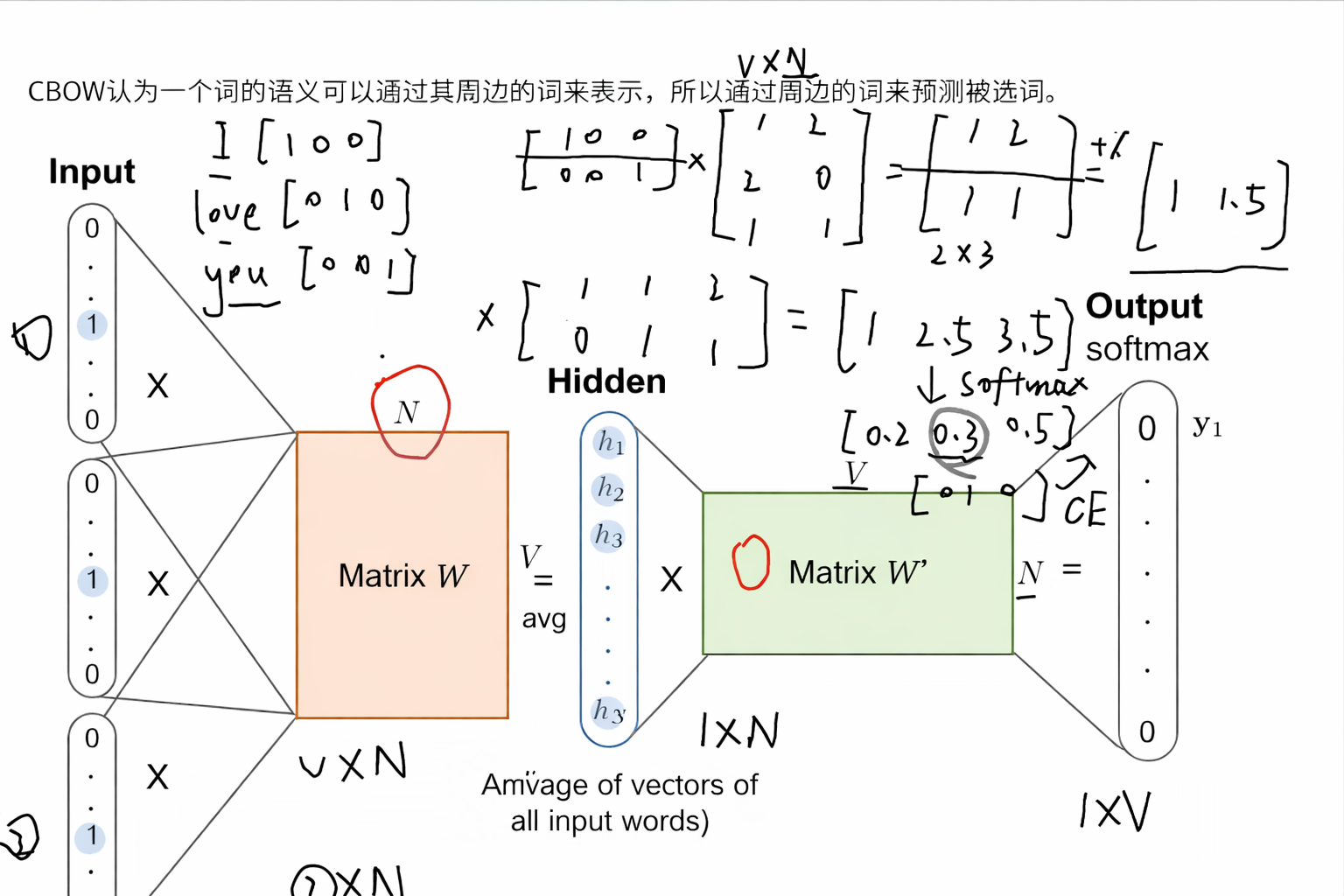
-
用I和you去预测love
- I和you组成一个2x3的输入矩阵
- 和一个VxN的矩阵相乘,得到一个2x2的矩阵
- 这个N通常比V要小一点
- 对隐藏层输出矩阵进行加权平均
- 因为按理来说是一个个丢进去累加以后取平均得到一个1xN的矩阵,但是这里是合成一个矩阵丢进去,所以结果要进行加权平均得到一个1xN的矩阵
- 乘以一个NxV的矩阵,最后得到一个1xV的输出结果矩阵
- 结果矩阵过一个softmax函数得到最后的预测概率矩阵
- 预测值和真实值计算交叉熵损失函数,进行反向传播优化更新参数(前后两个矩阵),让模型预测的准确度更高
-
实际会在大量的文本上去做,有非常多的训练数据,可以把非常多这样的文本,然后以这样的形式去做训练,我任取一段文本出来,我把中间那个词挖掉,然后我都用周围的词去预测我中间这个词去做训练,我就可以把这两个矩阵训练地越来越好,训练好之后我们就可以把前面这部分的矩阵给它取出来,也就是说我在预测中间这个单词做的越来越好的情况下,我假设说能够真的把中间这个单词预测的越来越好,那么我对它原本的意思就能够理解的非常透彻。
-
因此我把中间这个产物提取出来,作为我的词向量。这个天然就是一个词表,因为任何一个独热编码进来,都可以去这个表里面查,第i位是1,第i行就是其所对应的词向量(因为矩阵乘法的取1),同时由于n<v,所以完成了降维的操作
-
Skip-gram
不同于CBOW,Skip-Gram模型通过选中词预测周围n个词。
- CBOW有2n个输入,去预测中间的一个词,Skip-gram是用中间的一个词去预测周围的n个词,然后去算softmax,就变成了一个多目标的输入
还是按照CBOW的例子,在Skip-Gram模型下,当n=1时,我们的模型需要通过love预测出I和you。
Skip-Gram的训练过程基本与CBOW相同,唯一的区别就是CBOW需要输入向量是多个,需要把隐藏层的结果累加取平均值, 而Skip-Gram则不需要,直接计算就好。
Word2Vec
Word2Vec是一个由 Google 在 2013 年推出。Word2Vec 的核心思想是通过上下文来预测单词,或者通过单词来预测上下文,从而生成词向量。这些词向量能够捕捉词与词之间的语义和语法关系。
其技术原理就是在上述两种模型的模式下,进行大量的文本得到的预训练好的模型矩阵
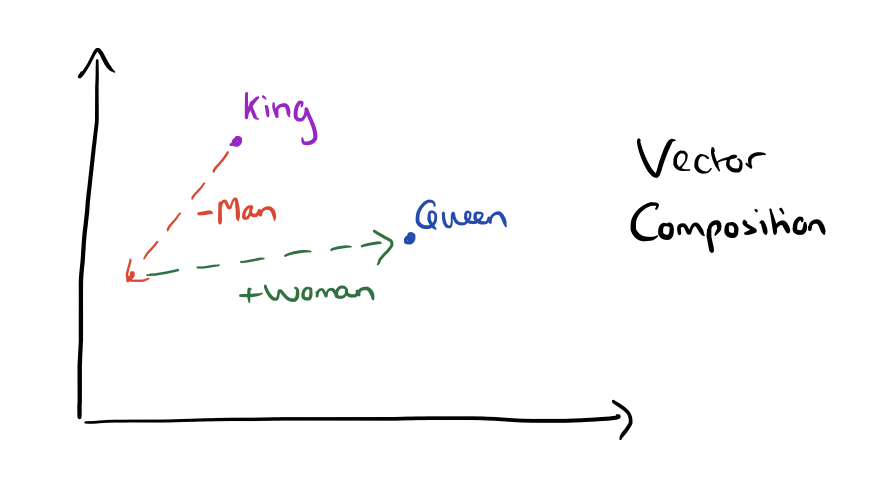
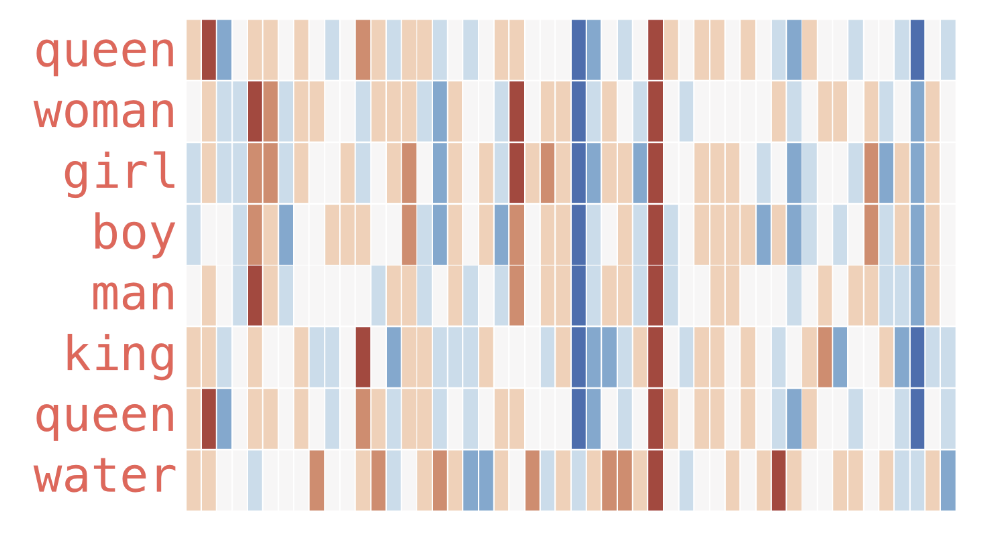
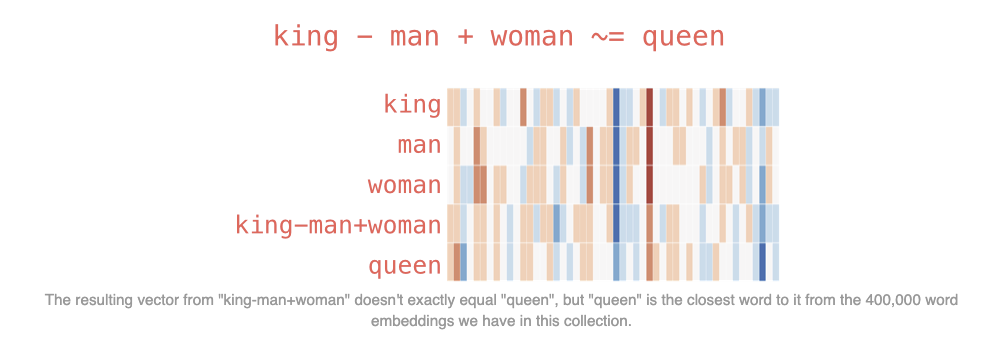
思考一个问题
word2vec这种预训练的词向量表示有什么缺点呢?
参考资料
https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
https://medium.com/@fraidoonomarzai99/word2vec-cbow-skip-gram-in-depth-88d9cc340a50
https://jalammar.github.io/illustrated-word2vec/🌟🌟🌟推荐阅读
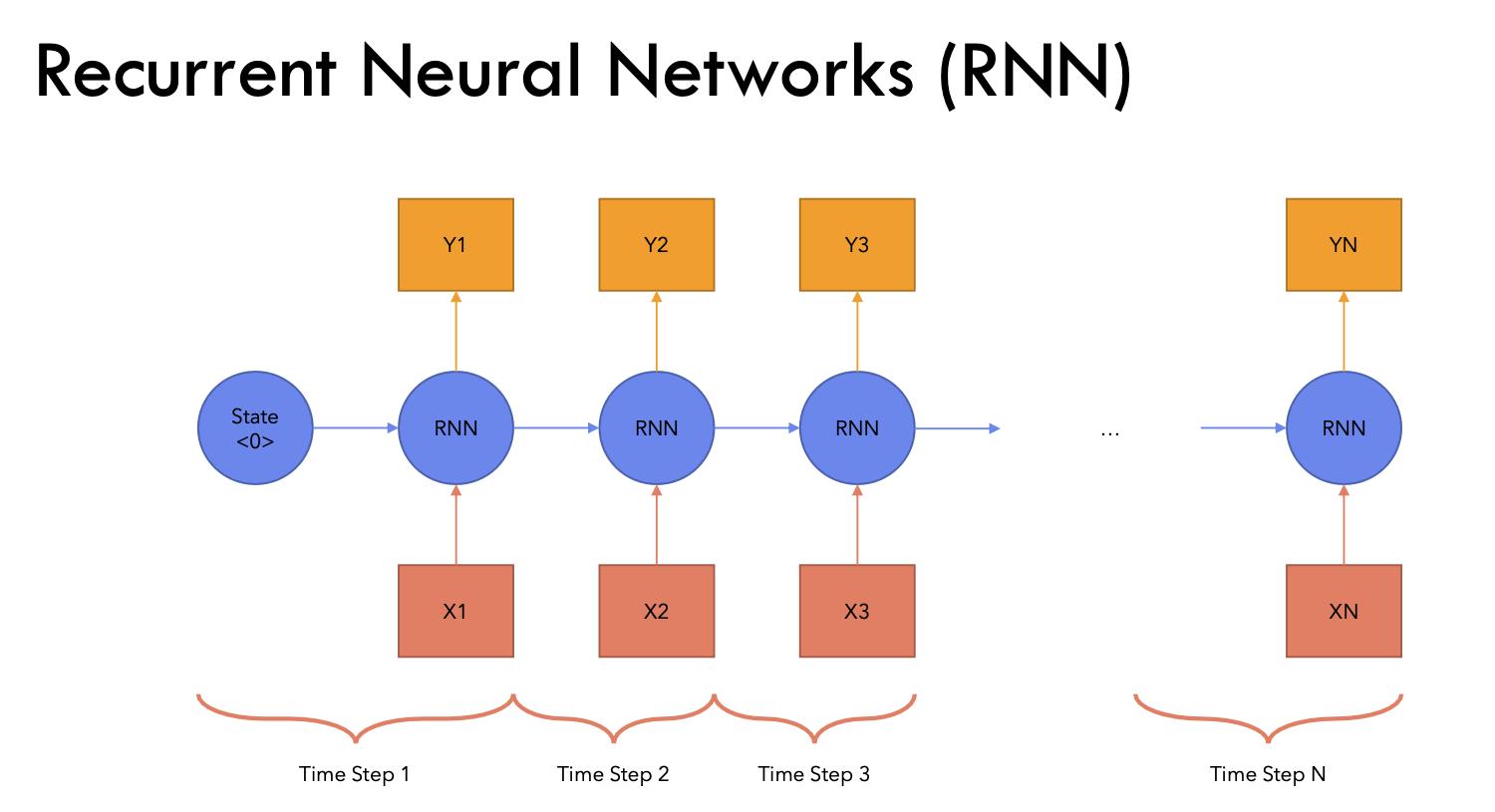
循环神经网络RNN
- Recurrent Neural Network
RNN架构
时序序列
-
时序序列其实就是一组按时间顺序记录的数值,它描述的是某个东西在不同时间的变化过程。比如每天的气温、股票的价格、一个店铺每天的客流量等。这些数据按照时间先后排列,显示了它们随着时间的变化趋势。
简单来说,时序序列就是:一串按时间排好顺序的数字,告诉我们某件事在时间上的变化规律。通过分析这些数字,我们能发现它是否有上升、下降的趋势,或者有规律的波动,甚至是一些意料之外的异常变化。
- 其实语言也是一种时序序列,人们渴望对语言模型进行建模完成翻译、分类等任务,于是RNN应运而生
RNN-最初的循环神经网络
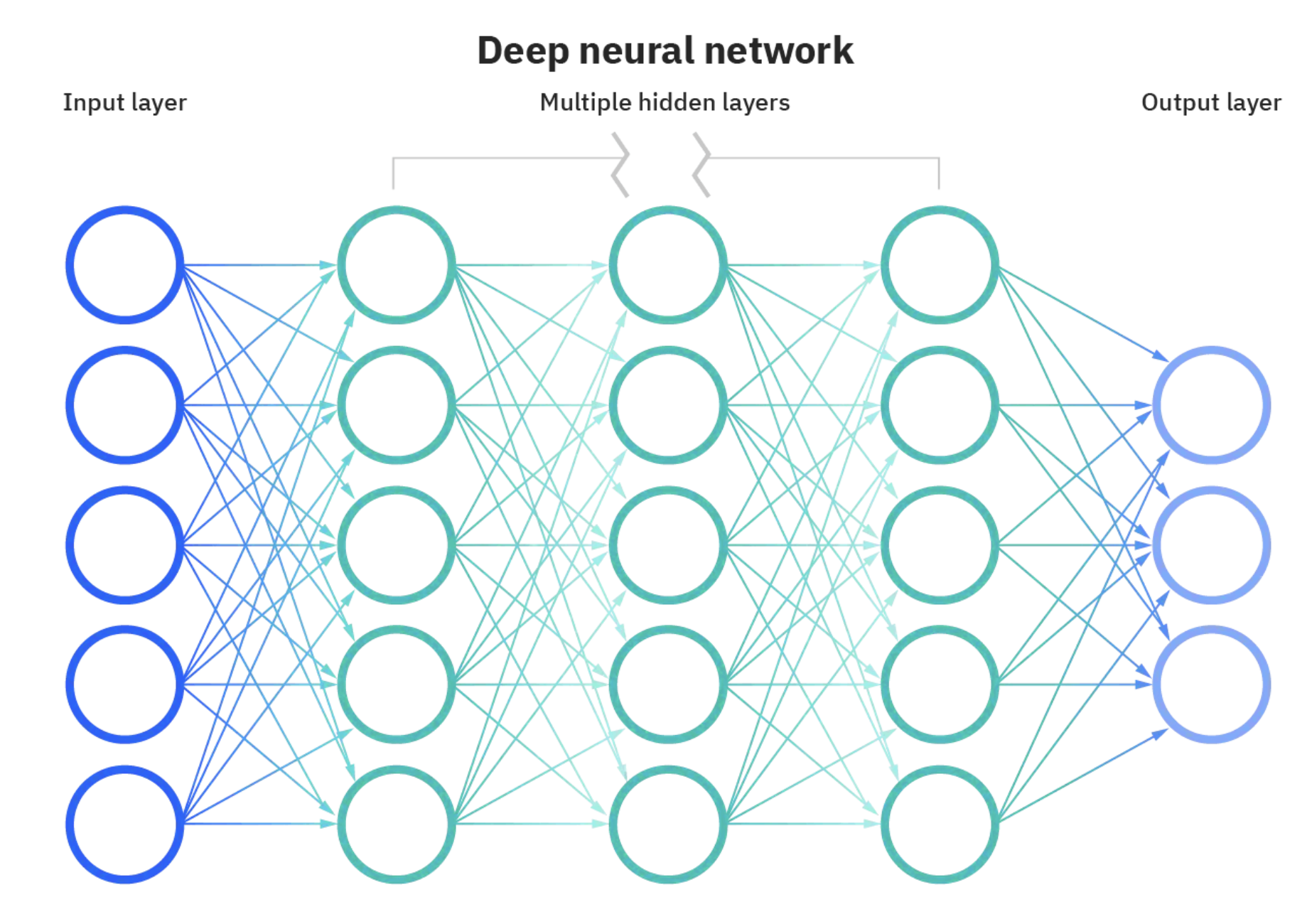
- 常规神经网络接收不到这种时序信息,结果与位置无关,因为每一个都会乘以权重矩阵得到相应的结果,本质上对位置是完全不敏感的,即使调换了位置模型也感知不出来,因此常规神经网络无法处理时序序列
模型架构
- 传统的循环神经网络(Recurrent Neural Networks,简称 RNN)是一类允许将前一个输出作为输入并保留隐藏状态的神经网络。它们的典型结构如下:
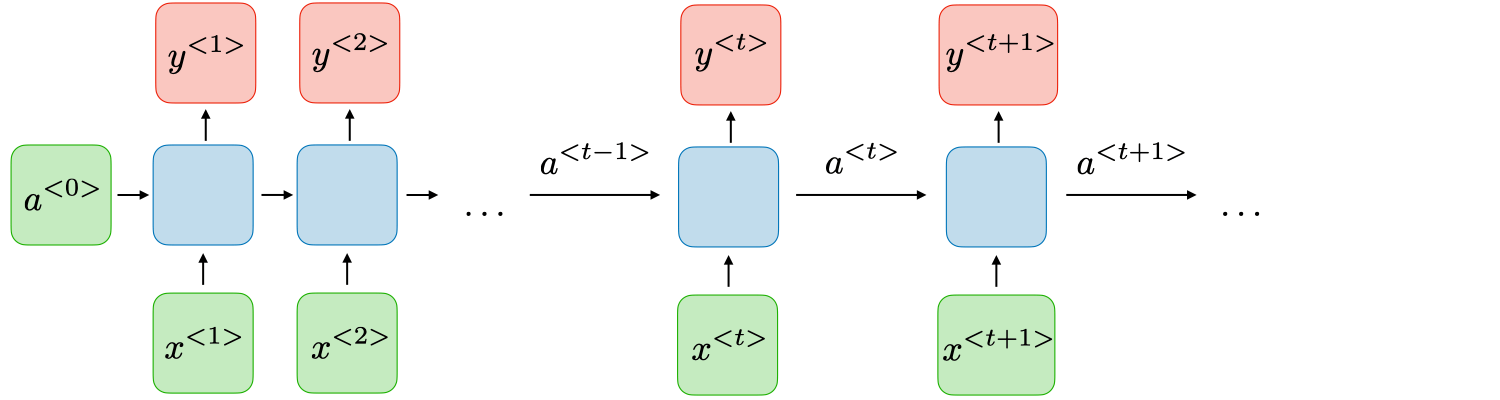
对于每个**时间步t,**激活值 $$a^{}$$(hidden隐藏值/激活值)和输出 $$y^{}$$(output)的表达式如下:
- 上一个时可的激活值,每一个时可都会产生一个激活值。上一个时刻的激活值乘上我的Waa矩阵。hidden可以通过aa矩阵映射到另一个a上,x通过ax矩阵也可以映射到a上,然后加上一个偏置,过一个激活函数。
- 很类似最原始的神经网络
- at经过Wya矩阵映射到y上,加个偏置,过一个激活函数,得到y
W_{ax},W_{aa},W_{ya},b_a,b_y$$是共享的参数矩阵,而 $$g_1,g_2$$是激活函数 - 蓝色方框里的东西就是一整个公式里面写的内容,每个蓝色里面两个输入(a和x)两个输出(下一个at和y),隐藏值是传递的,因此隐藏值会包含前面的所有信息 - 现在这一时刻的隐藏状态,是由上一个状态的隐藏状态和当前的输入一起来贡献的,Waa和Wax矩阵控制了两个状态的比例 - 比如更注重历史信息,Waa的值就会偏大一些,Wax的值就会偏小一些;如果更注重但钱的输入,Wax的值就会偏大,Waa的值就会偏小,弱化之前的隐藏状态 - 每个蓝色方框里面的内容都是一样的 - 可以保证泛化性,因为任何的时间来到都按照这样的方式处理 - 如果不一样的话就会退化成多层的神经网络,如果有10步就是一个10层的神经网络,就是每一个步骤它的参数都是独立的,都会在梯度回传的时候,容易过拟合,因为参数量太大了 - 所以为了保证每个始终到来能够捕捉这种上一个时间步和下一个时间步的统用规律,所以它的参数必须共享 - 多少步才能完结? - 马尔可夫假设/定律 - 对于一个序列数据而言,进行了若干步以后,我的第N步内容已经在前N步无关了,假设前N步还有的话,我和他们之间已经是独立的了。 - 一般会指定一个序列,比如一个10步的时间步,当我们运行到11步的时候,和第1步没关系了,只看到2-10步去预测11步,所以只是保存了一个窗口 - 过一层加入一个新的状态,并且用hidden来存储之前的状态 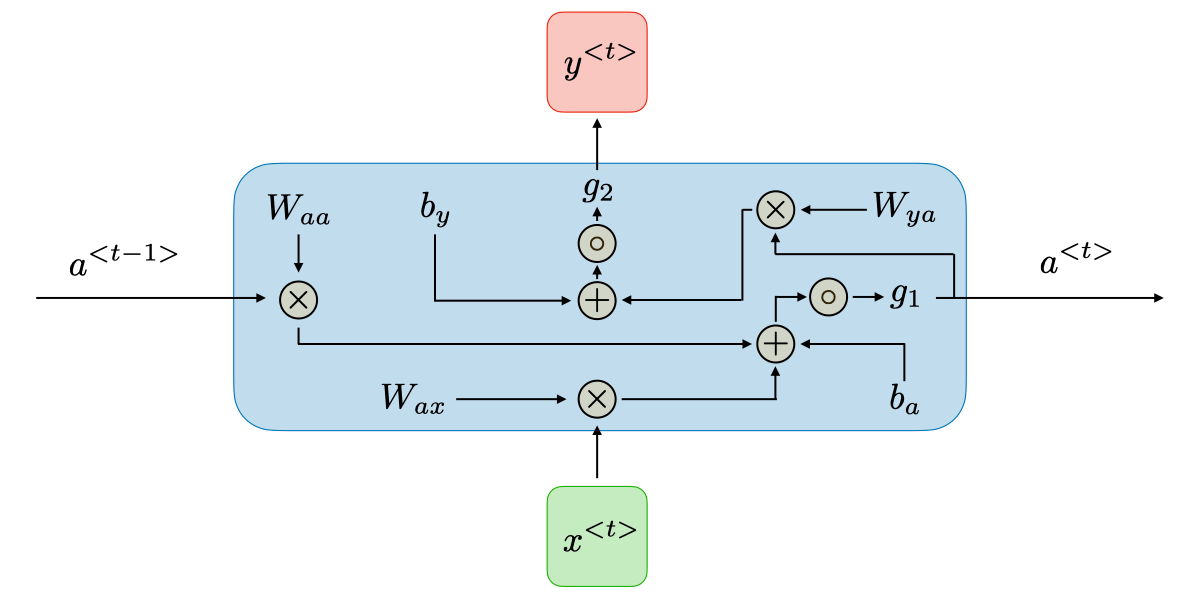 ## RNN微观运行模拟 ### 微观运算流程 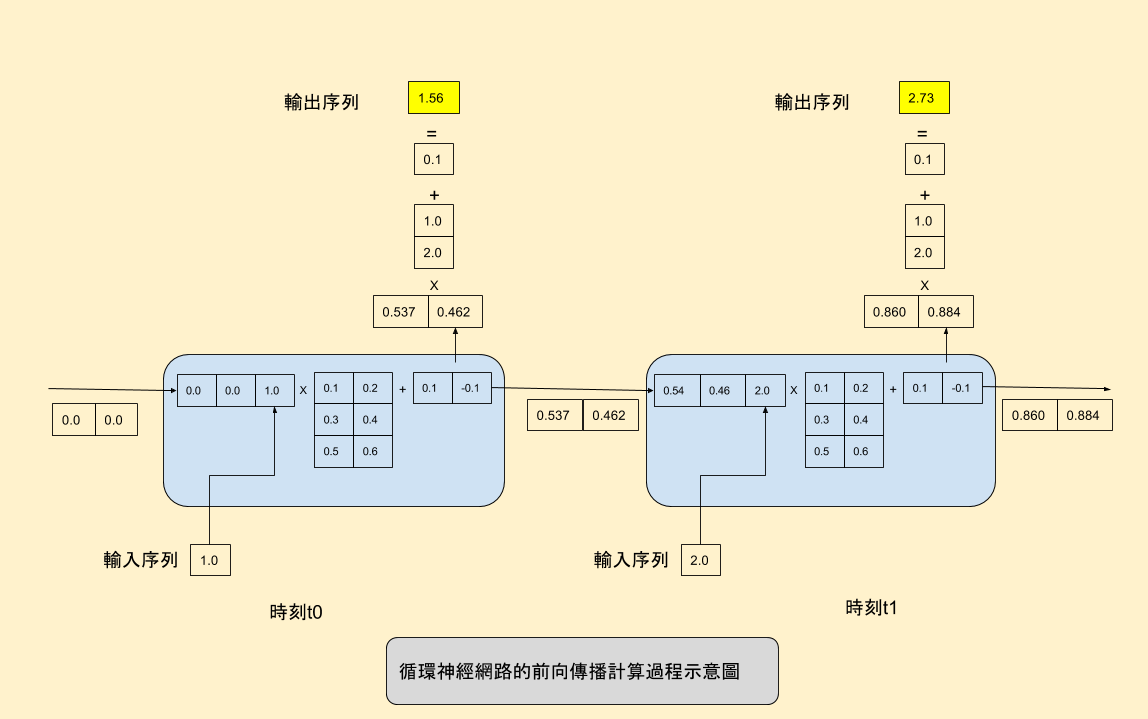 - $$a^{t}=g_1(W_{aa}a^{t-1}+W_{ax}x^{}+b_a)
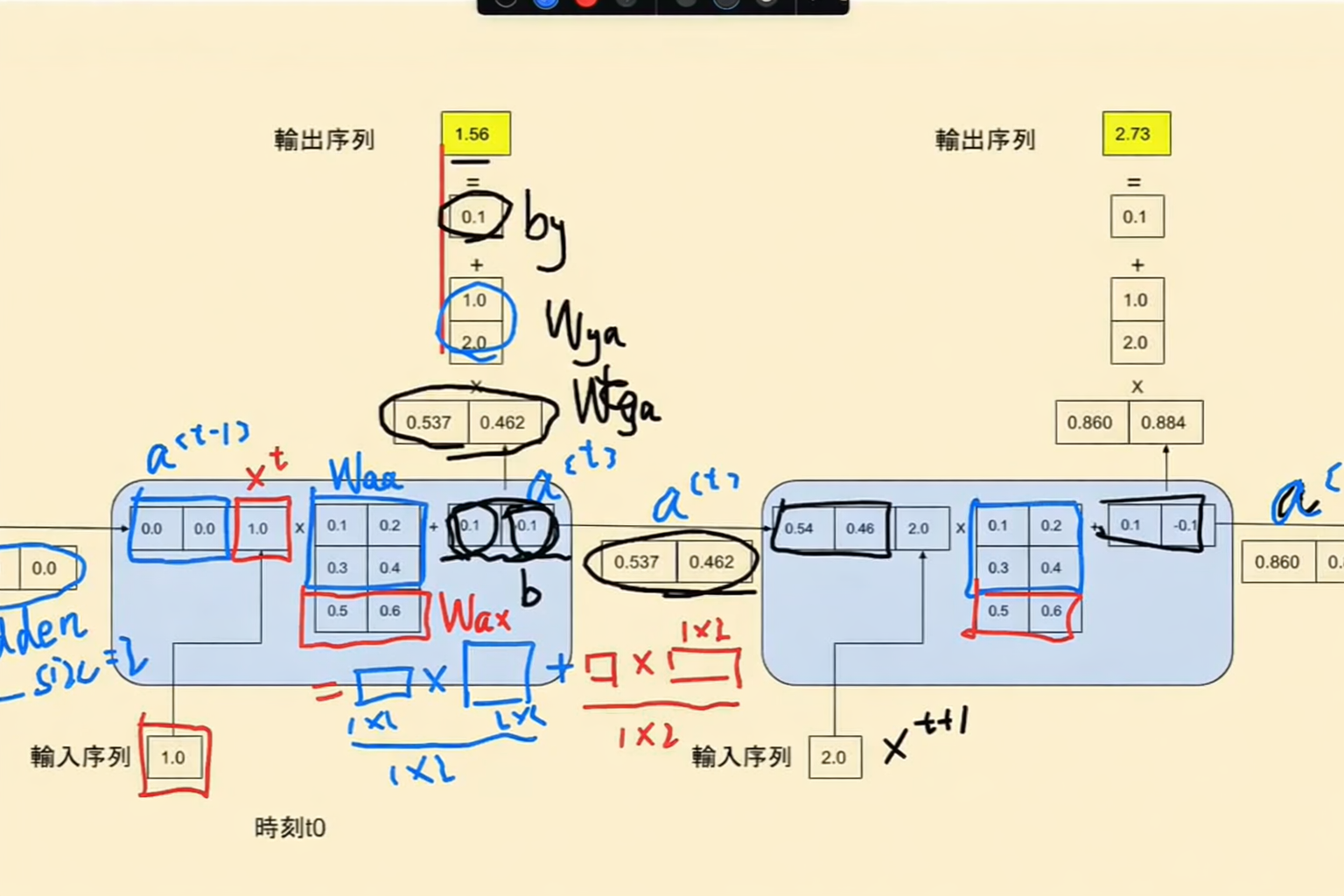
- 这个指的是蓝色方框里面的所有内容
RNN种类
| RNN种类 | 架构图 | 例子 | |
|---|---|---|---|
| One-to-one |  |
传统神经网络 | hidden默认=0 |
| One-to-many | 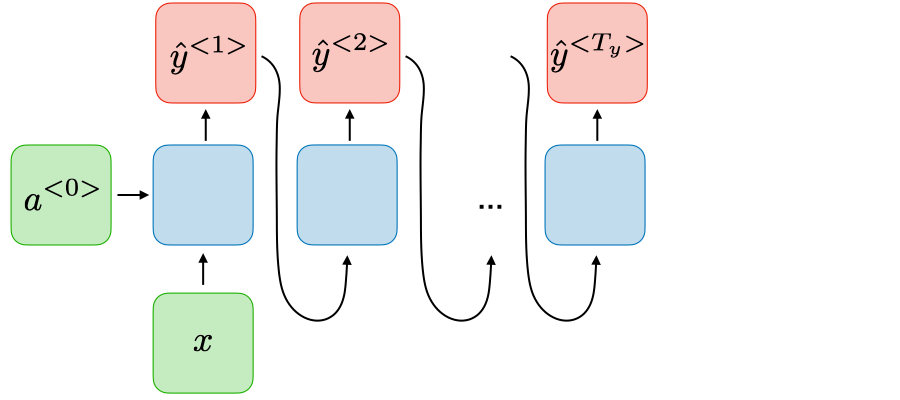 |
生成模型 | 给一个字,让它一个字一个字生成 |
| Many-to-one | 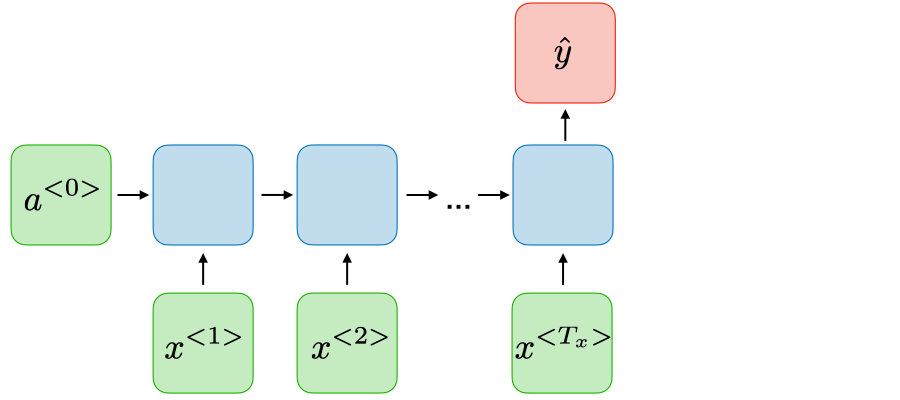 |
分类模型 | 最终取最后一个时间步的输出作为模型输出结果 |
| Many-to-many | 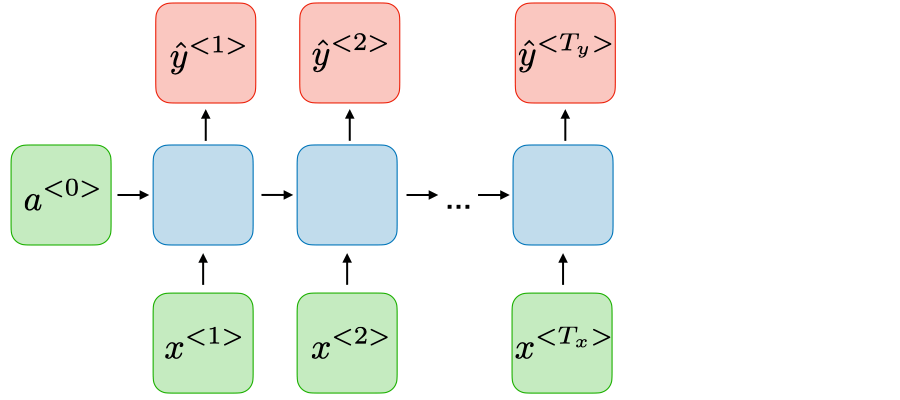 |
NER命名实体识别 | 对于一句话,识别某一个token是动词还是形容词,对每一个token进行分类,不需要用到后面的信息,只需要用到前面的信息。更加注重当前信息而非历史信息 |
| Many-to-many | 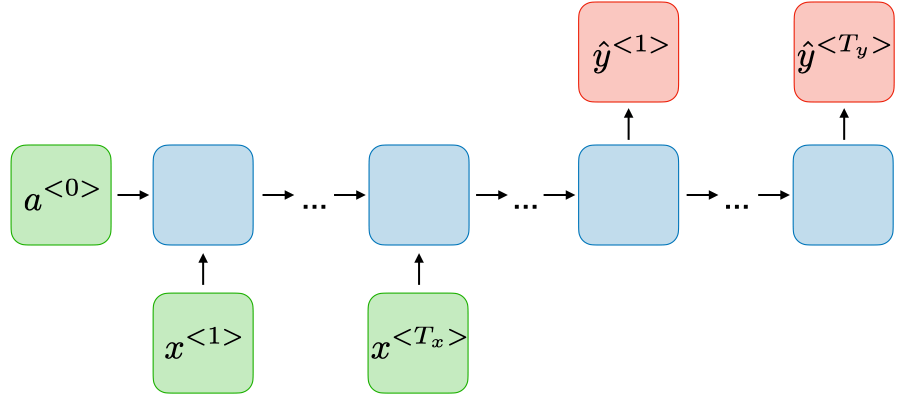 |
机器翻译 |
RNN的优缺点
| 优点 | 缺点 |
|---|---|
| 可以处理任意长度的输入 模型大小不随输入大小而增加 计算过程会考虑历史信息 权重在时间步长上共享 (针对之前的神经网络而言) |
计算速度较慢,参考串行进位加法器的缺点,时间效率低,无法串行计算 难以获取较长时间前的信息 当前状态无法考虑任何未来的输入 |
-
RNN最大问题:难以解决长距离依赖
为何会导致这一问题?
常用激活函数
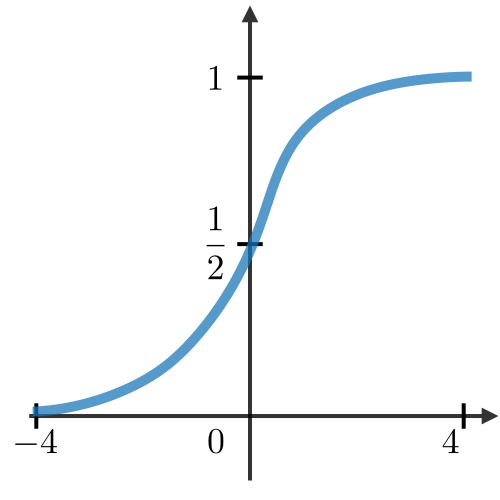
| sigmoid | Tanh | ReLU |
|---|---|---|
| 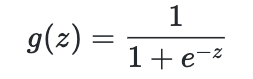 | 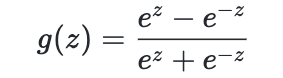 | 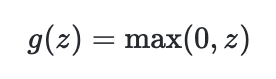 |
 |
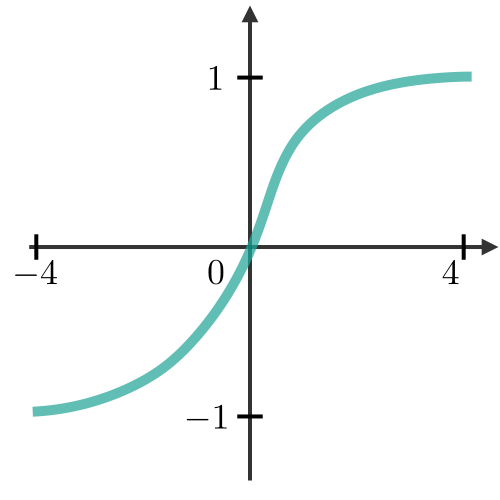 |
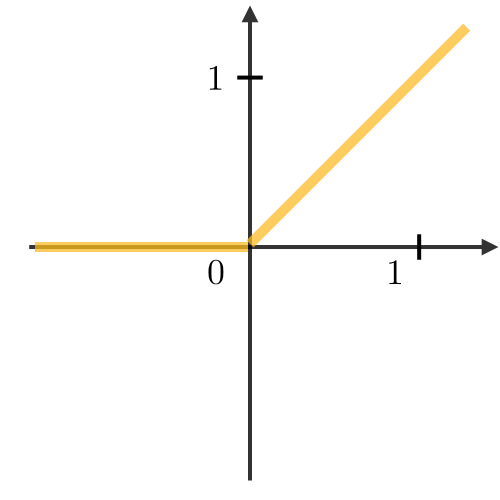 |
- 在 RNN 中经常会遇到梯度消失和梯度爆炸现象。产生这些现象的原因是,由于梯度的乘法效应,随着层数的增加,梯度可能会呈指数级衰减或增长,因此很难捕捉到长期依赖关系。
RNN实践
利用pytorch从零实现RNN模型
步骤1:导入必要的库
1 | |
步骤 2:定义 RNN 类
创建一个 RNN 类,并定义它的初始化方法、前向传播方法等。
1 | |
步骤 3:创建数据和超参数
设定 RNN 的输入、隐藏层大小、输出大小等超参数。这里用简单的随机数据进行演示。
1 | |
步骤 4:定义损失函数和优化器
使用交叉熵损失函数以及 SGD 优化器。
1 | |
步骤 5:训练循环
定义一个简单的训练循环。
1 | |
解释说明
- 数据输入:在训练过程中,模型接收一个序列,每一个时间步的数据经过前向传播,将输出与更新后的隐藏状态返回。
- 损失计算:只在序列的最后一个时间步计算损失。对于“许多对一”模型,通常选择最后一个时间步的输出与真实标签进行对比。
- 梯度更新:反向传播的梯度计算和参数更新,通过
loss.backward()和optimizer.step()完成。
直接使用RNN模型
导入必要的库
1 | |
定义RNN结构
RNN模型由输入层、隐藏层和输出层组成。以下是构建RNN的代码示例:
1 | |
这里,input_size表示输入特征的数量,hidden_size表示隐藏层神经元的数量,output_size表示输出层神经元的数量。
初始化模型参数
1 | |
实例化模型
1 | |
使用模型进行前向传播
假设输入x是一个张量,形状为(batch_size, sequence_length, input_size),例如:
1 | |
解释各部分含义
input_size:每个时间步输入的特征维度。hidden_size:隐藏层的维度,决定了隐藏状态的大小。num_layers:RNN的层数。output_size:模型输出的维度,常用于映射为实际需要的输出格式。
在这个例子中,模型先将输入传入RNN层得到时间序列的输出,然后选取最后一个时间步的输出,经过全连接层后输出最终结果。
常见操作和技巧
- 初始化隐藏状态:通常在每次前向传播中都需要初始化隐藏状态
h0,尤其是在处理独立的数据批次时。 - 选择时间步的输出:在很多任务中,我们只关心最后一个时间步的输出(例如句子分类任务),但也可以取所有时间步的输出用于不同任务(如机器翻译)。
- 多层RNN:增加
num_layers可以创建深层RNN,捕捉更复杂的模式。
循环神经网络-LSTM架构
RNN有什么样的问题
.png)
- 中间省略了两个线性层,还有一个激活函数得到Ot
梯度消失和梯度爆炸问题
- 梯度消失问题:在RNN中,由于每个时间步的梯度反向传播都会被相乘,当时间步较多时,反向传播到前面的梯度会逐渐减小,最终变得非常小,导致模型无法有效更新权重。这使得RNN难以捕捉到远距离的信息,只能学习短时间的依赖关系。
- 梯度爆炸问题:在反向传播中,梯度在多次相乘后也可能变得非常大,导致模型的权重更新过大,引发数值不稳定。RNN在训练长序列时容易出现梯度爆炸问题,需要额外的梯度裁剪(gradient clipping)等技巧来缓解。
难以捕捉长时间依赖
- RNN缺乏有效的机制来记住序列中的长时间依赖信息。它的结构决定了模型只能依赖当前时间步的状态来更新,较难处理需要长时间记忆的任务(例如在语言建模中,早期提到的主题或主语信息在较长序列后续还需要用到)。
无选择性的记忆方式
- 在RNN中,所有输入信息都在序列中传播,没有控制信息传递的机制。这种无选择性的记忆方式意味着网络无法主动“记住”或“遗忘”某些信息,这会导致重要信息和无用信息被一视同仁地处理。
- 并不能特异化地去记住一些特定的信息
- 普通的RNN没有专门的短期和长期记忆结构,所有的历史信息都通过一个单一的隐藏状态来传递,这导致短期信息与长期信息混在一起,容易相互干扰。
LSTM-长短期记忆网络(Long Short-Term Memory)
模型架构
.png)
.png)
- f遗忘门,i输入门,o输出门,通过三个门决定上一个步骤的信息,有多少能够进入下一个步骤中。
- 黄色部分可以第一步同时生成,红色部分第二步同时生成
- f=1代表之前的信息是无损通过的,f开始减少,说明只有部分信息能够通过,信息被弱化,被缩放,比如f=0.3,则有0.7的信息特征没有办法通过,=0全部拒绝不予通过
- 三个门可以同时生成,这三个门全都依赖于ht-1和xt的共同作用,上一个步骤的隐藏状态和这个步骤的xt输入,如果不重要,遗忘门就会偏小,不让它进来,有了三个门之后,就可以控制Ct和Ht的更i性能
- 分类任务就是把最后的h提取出来,因为它里面包含了全部的信息,接一个全连接层,过一个softmax就可以去做这种分类任务
- 不仅有hidden作为隐藏状态,引入了记忆单元/记忆细胞C,相当于引入了一条支线
- 主线记录一些相对来说重要的信息比如输出,支线记录一些可能会重要的信息
.png)
- 遗忘门机制,过一个权重矩阵,加一个偏置值(一个隐藏层),再过一个激活函数
.png)
- 输出门机制,过一个权重矩阵,加一个偏置值(一个隐藏层),再过一个激活函数
- 和遗忘门的区别在于权重矩阵不同
- Ct是候选记忆单元,用来生成下一个步骤的Ct
.png)
- f决定对上个Ct遗忘多少,假如f趋近于1,说明Ct-1无损地进入到后续的这个信息传输里面,而it就是我的输入门,假如趋近于1,说明它也是无损的。
- 如果ft趋近于0,那么Ct-1就是忘掉,所以说是遗忘门,能够决定是否忘掉之前按的内容
- 输入门也决定候选记忆元到底保留还是以往
.png)
- 这个Ot决定了我有多少Ct能够进入到ht,趋近于0不做更新,趋近于1更新回来
- 总结:三个矩阵在控制三个不同的输出
激活函数
.png)
- 为什么用sigmoid做激活函数
- 因为sigmoid值域在0-1之间,天然像一个门,如果全0,则不通过信息,如果全1,则保留完整的信息
- 通过全连接层以后结果是一个实数,通过sigmoid函数能够使结果具有非常可解释性
.png)
- 为什么候选记忆元和ht用tanh函数呢
- 因为tanh的值域在(-1,1)之间,Ht由Ct和Ot计算得到,Ot要经过tanh,Ct也要经过tanh,两个(-1,1)之间的数相乘,最后结果仍然在(-1,1)之间,这样无论过多少层,无论序列有多长,无论经过多少个这样的单元,h都是在(-1,1)之间,有很强的稳定性,不会进行累加
Ct和Ht的作用
记忆单元 (Cell State)
记忆单元 $$C _t$$ 是LSTM中的长期记忆部分,负责在序列的长时间跨度内存储重要信息。
- 作用:记忆单元 $$C _t$$用于存储贯穿整个序列的关键信息,允许LSTM保留长期依赖(long-term dependencies)。通过遗忘门和输入门的调控, $$C _t$$中的信息能够长期保留,也可以在适当时候被更新或遗忘。这样可以有效缓解梯度消失问题,使得LSTM可以更好地学习到长时间跨度的依赖关系。
- 特点:记忆单元 $$C _t$$是一个累积的状态,不直接暴露给输出层。它通过在每个时间步的更新,保留了来自序列初期甚至更早信息的长期记忆。
- 在不同步骤中传递信息,Ct反而有点像hidden,Ht有点像out
- 公式:$$Ct=f_t⋅C_{t-1} + i_t \cdot \tilde{C}_t$$
- 其中 $$f_t$$ 是遗忘门, $$i_t$$是输入门, $$\tilde{C}_t$$ 是候选记忆单元。
隐藏状态 (Hidden State)
隐藏状态 $$h_t$$ 是LSTM的短期记忆和当前时间步的输出,它包含了时间步 t 时刻的即时信息。
- 作用:隐藏状态$$h_t$$ 作为 LSTM 的输出,被传递给下一层或下一时间步。在实际应用中,$$h_t$$包含了LSTM当前时刻的状态信息,适合用于短期依赖任务。例如,语言生成任务中,每个时间步的输出 hth_tht 能够捕获当前词或片段的信息,以便生成下一步的输出。
- 特点:隐藏状态是经过输出门和 tanh激活函数的调控结果,具有即时性和短期性。因为每个时间步都会生成新的 $$h_t$$,它不会像 CCC 那样在时序中累积长久的信息,而是更反映当前时刻的上下文。
- 公式: $$h_t=o_t \cdot \tanh(C_t)$$
- 其中,ot是输出门,Ct 是当前时间步的记忆单元。
总结区别
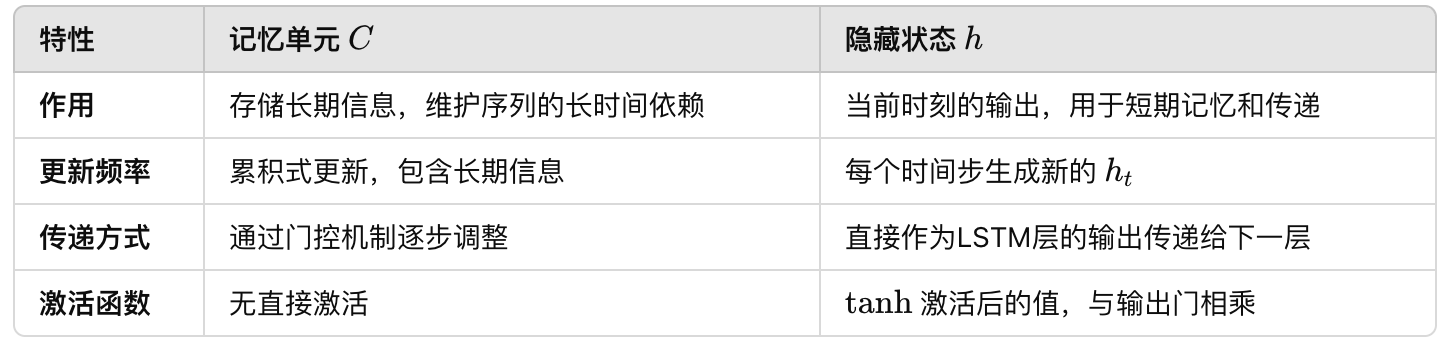
在实际应用中,记忆单元 扮演了长期信息存储的角色,而 隐藏状态 负责在每个时间步中输出即时信息。这种分工让LSTM可以同时捕捉长、短期的依赖关系,并有效解决传统RNN在处理长序列时遇到的梯度消失问题。
LSTM实践
1 | |
简洁使用
1 | |
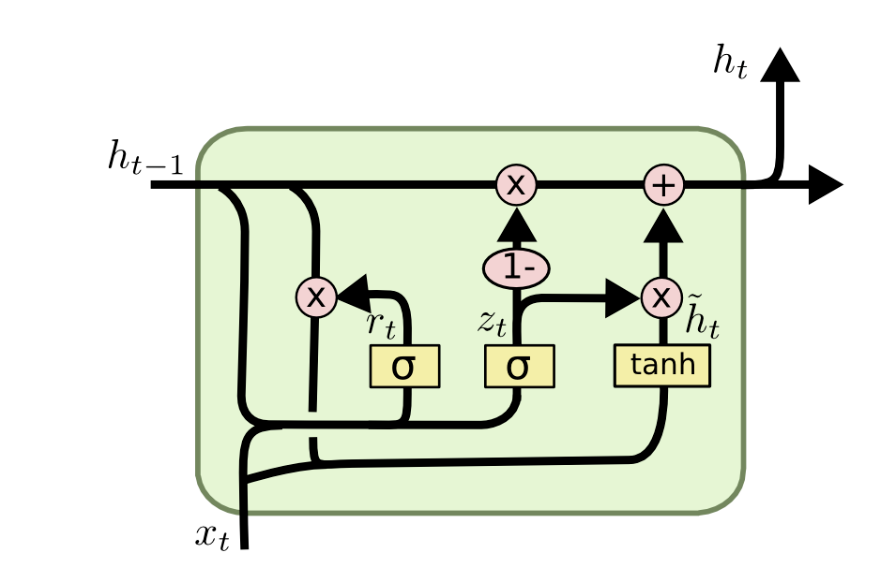
GRU结构
GRU是在2014年提出来的,而LSTM是1997年。
GRU类似LSTM,也是为了解决RNN长期记忆的梯度消失问题
LSTM有三个不同的门,参数较多,训练困难。GRU只含有两个门控结构,调优后相比LSTM效果相差无几,且结构简单,更容易训练,所以很多时候会更倾向于使用GRU。
.png)
.png)
-
GRU在LSTM的基础上主要做出了两点改变 :
(1)GRU只有两个门。GRU将LSTM中的输入门和遗忘门合二为一,称为更新门(update gate),控制前边记忆信息能够继续保留到当前时刻的数据量;另一个门称为重置门(reset gate),控制要遗忘多少过去的信息。
(2)取消进行线性自更新的记忆单元(memory cell),而是直接在隐藏单元中利用门控直接进行线性自更新。GRU的逻辑图如图所示:
.png)
-
Zt更新门,门要经过sigmoid激活函数,通过Wz权重,过Ht-1和Xt,决定更新多少。
- Rt重置门,区别在于权重矩阵不一样
- 省略了记忆细胞Ct,重新转移到了Hinderstate,得到了一个候选记忆状态。
- H帽用到重置门,Rt=1相当于说把之前的隐藏状态都用上,Rt=0相当于把之前的隐藏状态都抛弃,Xt是全部用进来
- H是候选隐藏状态xZt和之前的状态做一个平均,Zt就是更新门,决定了控制前面多少信息能够保留到当前时刻的数据。
- Zt=1,基本全用Ht hat,Zt=0,对当前时刻不进行更新,沿用以前的状态,把以前的信息保留住了
- 作用就是在候选的隐藏状态和上一个隐藏状态之间的比例,来组成当前的一个隐藏状态
- Zt=1,基本全用Ht hat,Zt=0,对当前时刻不进行更新,沿用以前的状态,把以前的信息保留住了
-
我们先通过上一个传输,下来的状态 $$h^{t-1} $$和当前节点的输入 $$x_t$$ 来获取两个门控状态。如下图2-2所示,其中 r 控制重置的门控(reset gate), z 为控制更新的门控(update gate)。
-
\sigma$$ 为*[sigmoid](https://link.zhihu.com/?target=https%3A//en.wikipedia.org/wiki/Sigmoid_function)*函数,通过这个函数可以将数据变换为0-1范围内的数值,从而来充当门控信号。
GRU与LSTM的异同
1. 共同点
- 克服长程依赖问题:通过引入门控机制来控制信息流动。
- 适用于序列数据:如时间序列、自然语言处理、音频数据等。
- 网络结构:都包含隐藏状态,能够将序列信息编码并传递到后续时间步。
2. 不同点
特性LSTMGRU门的数量3个门(输入门、遗忘门、输出门)2个门(重置门、更新门)单元状态包含隐藏状态和单元状态(cell state),双状态结构只有隐藏状态,单状态结构参数量参数较多,计算开销较大参数较少,计算开销较小记忆能力能够更精细地控制信息的遗忘和记忆结构较简单,可能会表现出较快的训练和预测表达能力更灵活,能处理更复杂的序列模式在某些情况下,效果接近甚至优于LSTM,但计算效率更高
在不同场景的选择
1. LSTM适用场景
- 需要捕获复杂长程依赖的任务:如机器翻译、长时间依赖的时间序列预测。
- 比如文章很长,但即使我运行到了文章的结尾,但是我对于文章中的某一个字或者某一个词细节很看重,找出某个人干了什么事之类的细节的东西
- 对模型表现要求较高:特别是在小数据集上训练时,LSTM的复杂性可能有助于更好地拟合数据。
- 需要更精确的记忆控制:如医疗时间序列分析(复杂的动态模式)。
2. GRU适用场景
- 计算资源有限:由于GRU参数较少,训练和推理速度更快,适合资源受限的场景。
- 数据集规模较大:大数据集上,GRU的简单结构能更快地收敛,且性能与LSTM相当。
- 应用场景对长期依赖的要求不太苛刻:如简单的时间序列预测、情感分析等。
- GRU上限比LSTM更高,更能捕捉一般的情况,上限高下限也低
3. 实验驱动的选择
对于具体问题,通常可以尝试以下步骤:
- 从GRU开始:由于其计算效率高,适合快速迭代。
- 尝试LSTM:如果GRU表现不佳,可以尝试LSTM,特别是在需要更强记忆能力时。
- 性能对比:根据模型在验证集或测试集上的表现(如损失、准确率、F1分数等)来决定最终使用哪种模型。
GRU代码的从0实现
从0实现
1 | |
- 输出示例
1 | |
简易实现(直接使用torch内部GRU)
1 | |
- 输出示例
1 | |
kaggle竞赛:情感分类
项目地址
https://www.kaggle.com/competitions/dsaa-6100-movie-review-sentiment-classification/data
https://chatgpt.com/share/67431be2-17c0-800a-9e1e-ac7650effadc
完整版:
1 | |
卷积神经网络CNN
认识图片数据
- 这里的图片是指位图图片,由一个个像素构成
图片的数据格式
- 在深度学习中,将图片转换为矩阵,再输入到神经网络
.png)
-
图片像素和矩阵元素,在位置上一一对应
- 一张分辨率为 1024*768 的图片,就是一个 1024行,768列的矩阵
- 每个像素对应着矩阵里面的一个数值
-
矩阵元素的数值,表示像素的亮度
-
一般用 8 位无符号整数(uint8),即每个像素取值是 0 - 255
-
除了灰度图,也有“二值图”,用 0 和 1 表示黑白
.png)
-
-
图片可能有多个通道,每个通道都是尺寸相同的矩阵
-
常见的如:RGB 彩色图、带深度通道的深度图
- RGB彩色图有三个矩阵,每个矩阵表示一个通道
-
深度图的意思是还有距离矩阵,做立体视觉的时候可能会有深度通道
-
-
通道本质是不同的特征,一个 n 通道的图片,可以理解为每个像素都用一个长为 n 的特征向量来表示
.png)
代码示例
1 | |
用MLP处理图片
原理
.png)
.png)
- MLP 的输入是一个向量,图片是一个矩阵
- 矩阵的每一行是一个样本,有多行是因为用了batch
- 输入层里面的每一个神经元是和我样本的特征向量里的每一个维度相对应的
- 输入的特征向量,每一个向量有多少个元素,输入层就有多少个神经元
- 当我图片是一个二维的矩阵,我要把它变成一个一维的向量,我才能输送到这样的一个MLP里去
- 直接将图片展平为一个向量,就可以输入到 MLP 中
- 把下面的放到第一行后面
MNIST数据集
.png)
- 0 - 9 的手写阿拉伯数字
- 包含 60,000 个图片的训练集, 10,000 个测试集
- 28*28 的灰度图
- 单通道
- 经过了平移、缩放、归一化等预处理,可直接使用
代码
1 | |
图像的卷积运算
全连接层处理图片的问题
.png)
- MLP处理图像的问题
- 全连接层参数过大
- 全连接层的神经元数量可能很大很大
- 冗余的连接
- 比如第一个像素和最后一个像素没什么关系,但是隐藏层的每一个神经元在提取特征的时候,既连到了第一个像素,又连接到了最后一个像素,所有的像素都是一样的,没有考虑到任何局部性的信息,导致了很多的冗余
- 参数与坐标位置相关
- 不满足平移不变性
- 全连接层参数过大
- 图像特征的性质
- 局部性:单个特征存在于图像的局部区域,因此不用过度在意图像中较远区域的关系
- 平移不变性:检测对象可能出现在图像中的任何位置
- 不应该因为位置的不同而出现差异
- 引入卷积
- 参数不用太多,主要关注局部区域
- 参数不依赖于像素的坐标
卷积
-
两个函数的卷积,本质上就是先将一个函数翻转,然后进行滑动叠加。
-
在连续情况下,叠加指的是对两个函数的乘积求积分。
-
在离散情况下,就是加权求和。
-
-
连续卷积
-
-
离散卷积
-
- f可以看作一个函数,可以理解为加权求和
-
图像处理中的卷积
.png)
-
输入图像 X:$$n_{h}\times n_{w}$$
-
卷积核 W:给定数值的一个小矩阵,用于提取特定的特征,$$k_{h}\times k_{w}$$
- 权重,其实对应着MLP里面w矩阵
-
计算过程
-
卷积核从图像左上方开始以一定步长进行移动
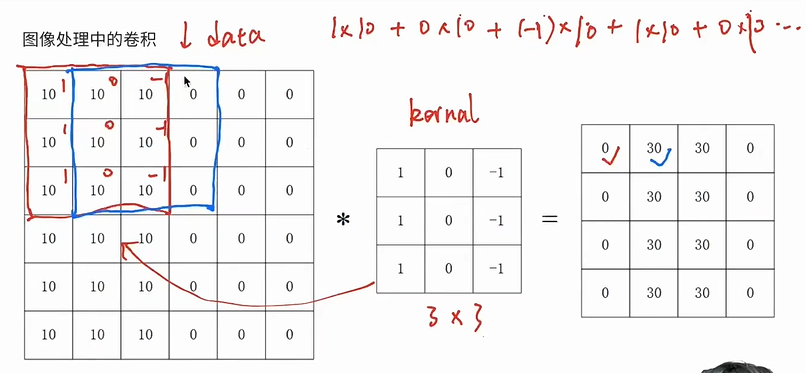
-
每次移动,使用卷积核的参数与当前图像对应位置的像素相乘求和,作为当前位置的输出
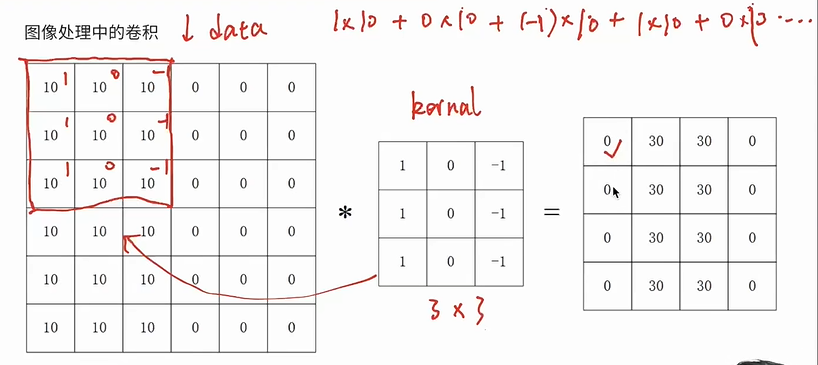
-
输出图像形状:$$(n_{h}-k_{h}+1)\times (n_{w}-k_{w}+1)$$
-
.png)
.png)
- 不同的卷积核(滤波器)可以实现不同功能,比如平滑、模糊、边缘检测、增加锐度等
.png)
- 变成领域里面像素的平均值,相当于对图像里面的每一个像素,对其周围的像素求平均值,作为这个像素的值,最后就是一个模糊的效果
.png)
.png)
- 当最左边和最右边的值差别比较大的时候,出来的结果就会比较大,本质上是边缘检测,检测数值的边缘。如果左右数值差异大,说明这里有边缘
.png)
- 上下边缘检测
扩展内容👇
https://blog.csdn.net/jackzhang11/article/details/103802502
一个可视化卷积(滤波器)的网站👇
https://setosa.io/ev/image-kernels/
卷积层
- 卷积层是神经网络中的一种层,基于图像卷积运算
- 与全连接层类似,卷积层也通过一系列超参数定义,且具有可学习的参数
- 参数
- 卷积核:W,多通道的二维矩阵
- 偏置:$$b\in R$$
- 计算过程
- 卷积:$$Z=X*W+b$$
- xw是卷积操作,不是乘法,最后加上偏置
- 应用激活函数:$$Y=\sigma (Z)$$
- 卷积:$$Z=X*W+b$$
.png)
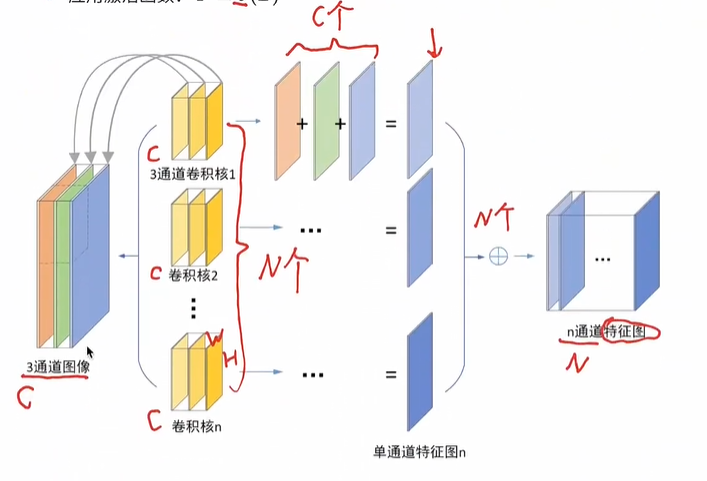
-
超参数
- 输入通道数:C
- 类似于全连接层输入数据有多少个特征数量一样
- 卷积核的数量(输出通道数):N
- 类似于全连接层的输出维度
- 有n个卷积核会有n个结果,把n个结果重新拼成一个n通道的图片,最后得到一个输出n个通道的特征图
- 类似于全连接层有n个神经元,输出维度就是n
- 卷积核的尺寸:H*W(卷积核通道数为 C ,与输入通道数相同)
- 每一个输入通道都有一个对应的这个卷积核的通道跟他去做卷积
- 填充(padding):在输入图像的边界填充若干行、若干列元素(通常是 0),以保持卷积前后的形状
- 因为做完卷积之后图片会变小,有时候为了神经网络简洁,希望它卷积前后尺寸不要改变
- 步长(stride):卷积核从输入图像的左上角开始滑动,上述例子每次滑动一个元素。有时为了高效计算或缩减采样次数,可以每次滑动多个元素
- 激活函数
- 输入通道数:C
-
添加2行填充、2列填充,垂直步长为3、水平步长为3的卷积示意图:
.png)
-
关于填充大小的定义有两种:
- 第一种
-
p_{h}$$:上下一共填充$$p_{h}$$行
- 输出的形状:$$[(n_{h}-k_{h}+p_{h}+s_{h})/s_{h}]\times[ (n_{w}-k_{w}+p_{w}+s_{w})/s_{w}]$$
-
- 第二种
-
p_{h}$$:上下各填充$$p_{h}$$行
- 输出的形状:$$[(n_{h}-k_{h}+2p_{h}+s_{h})/s_{h}]\times[ (n_{w}-k_{w}+2p_{w}+s_{w})/s_{w}]$$
- pytorch 中的 padding 使用的就是这种定义,padding=1表示上下各加一行的填充,左右各加一列的填充
-
-
1*1卷积
-
卷积核尺寸为 1*1 的卷积层
- 每一个像素都自己跟自己算,只对单个像素的通道进行变换,进行一个特征向量的转化,通道数量变化。
-
作用:降维、升维
-
本质是一种全连接层
-
对于每一个像素的所有通道数或者说特征向量做了一个全连接
-
和用MLP处理图片的全连接不太一样,MLP是每一个神经元对于所有位置的像素做了一个全连接,参数和位置相关,这个全连接对于一个像素的所有特征做了一个全连接,对每一个像素的所有通道做了一个这种变化
-
**卷积神经网络(CNN)**使用卷积核(比如1×1)逐个像素处理图像,每次处理一个局部信息,保留了图像中的空间关系。每个像素都会影响到结果,这样有助于提取空间特征,比如边缘或颜色的变化。
MLP处理图像时,会把所有像素的信息都拉平到一个一维的向量,然后进行计算,这样丧失了像素之间的空间关系,更多的是对图像的整体特征进行处理。
-
-
.png)
-
- 第一种
池化层
池化层(汇聚层)
.png)
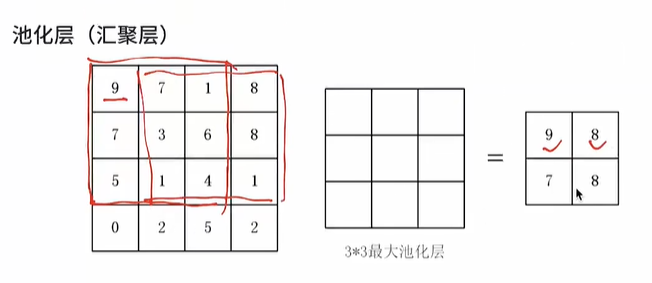
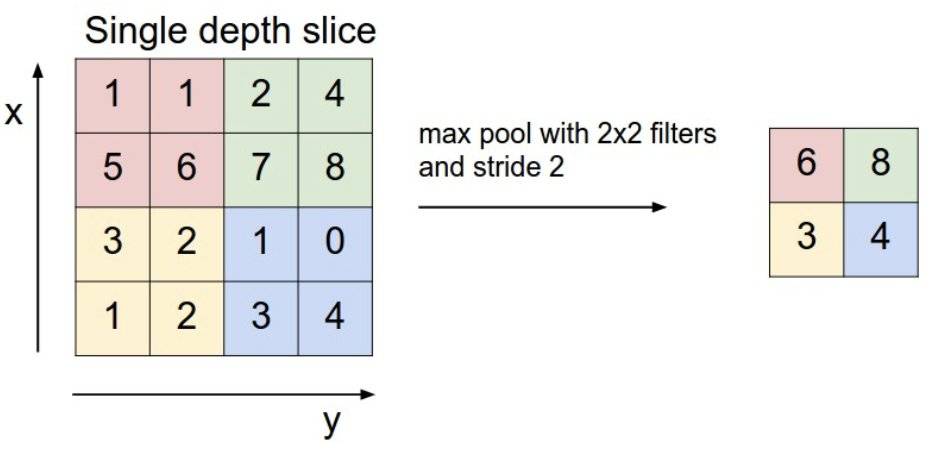
- 参数:无
- 池化层本身不学习任何的参数,没有需要更新学习的参数,只有超参数
- 超参数
- 池化种类
- 最大池化层:取窗口的最大值
- 定义一个窗口的大小,然后——
- 和卷积一样盖在图片的某一个位置
- 保留最明显的特征,比较小的特征就不要浪费数据计算,只需要提取最大的特征
- 平均池化层:取窗口的平均值
- 最大池化层:取窗口的最大值
- 步长
- 池化种类
- 作用:在尽可能有效提取特征的情况下,减少数据量
- eg:把前面卷积层输出的图片,再缩小汇聚一下
卷积神经网络CNN
- Convolutional Neural Network
卷积神经网络(CNN)
卷积神经网络一般由卷积层、池化层、全连接层组成
.png)
-
Alexnet本身是做图像分类任务的
- 卷积神经网络常见设计范式
- 尺寸越来越小,通道数量越来越多
- 进来的图片经过一层卷积得到的数据叫做特征图
- 首先卷积是在提取特征,特征图存储了提取到的特征,并且随着一层层卷积和池化,提取到的特征是越来越高级的特征,所以通道数会增加,这就认为网络需要更高的通道数来存储它提取到的更丰富的特征
- 尺寸缩小可能是更高级的特征没有那么多的数量
- 为什么最后能够放入MLP
- 因为最后尺寸非常小,本身不包含太多位置信息,抓哟的信息都存在不同的通道里面去了,这时候拉直,不会有太大问题
- 因为向量里面的每一个元素,表示的已经是比较高姐的特征了,不是简单的边缘,用MLP在一个高级的特征上做一个分类
-
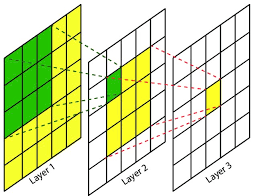
感受野
- 前向传播时,可能影响该元素的所有之前层的元素
- 即该元素能感受到的特征范围
- 单次卷积后,每个元素的感受野等于卷积核尺寸
- 经过多次卷积,元素的感受野不断增大,每个元素能表示范围更广的特征
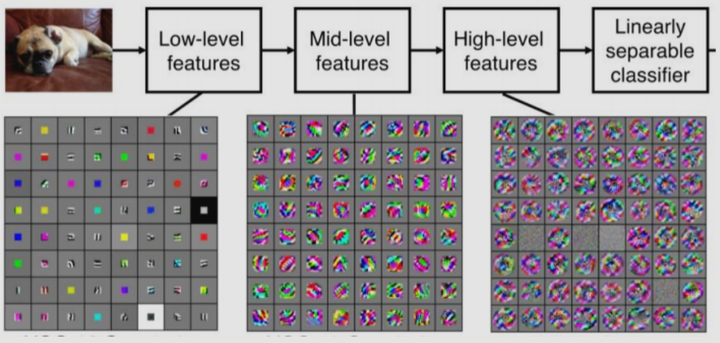
- 特征提取:开始只提取到局部、简单的特征(如边缘),经过层层的卷积和汇聚,提取到范围更广、更高层次的特征
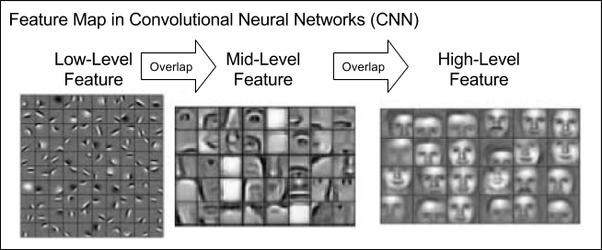
代码实现CNN
- SimpleCNN.py:适配 MNIST 数据集的 CNN
1 | |
- train.py:训练和测试代码
1 | |
准确率、精确率、召回率、F1值
- loss的绝对大小实际上没有物理含义
- 上述指标用来评估分类问题的模型的性能
混淆矩阵
- 每一列表示一个类的预测
- 每一行表示一个类的实际值
.png)
- 二分类问题的混淆矩阵,所以有两个类
- 前一个字母代表预测正确与否,后一个字母代表预测的是正还是负
.png)
- 多分类的混淆矩阵
.png)
- 混淆矩阵本质上是一种可视化的工具,让哦我们比较直观地看到分类问题这些结果有哪些是对的,哪些是错的,错在哪
准确率、精确率、召回率
-
准确率(正确率):所有分类(无论是正类还是负类)正确分类的比例
-
-
精确率(查准率):预测值为正分类中,正确分类的比例
-
-
召回率(查全率):实际正例中,被正确分类为正例的比例
-
-
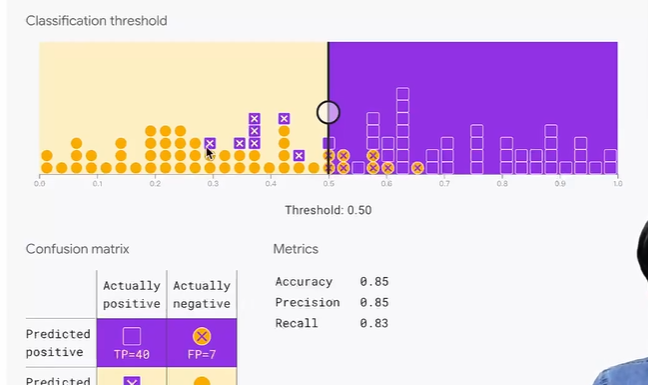
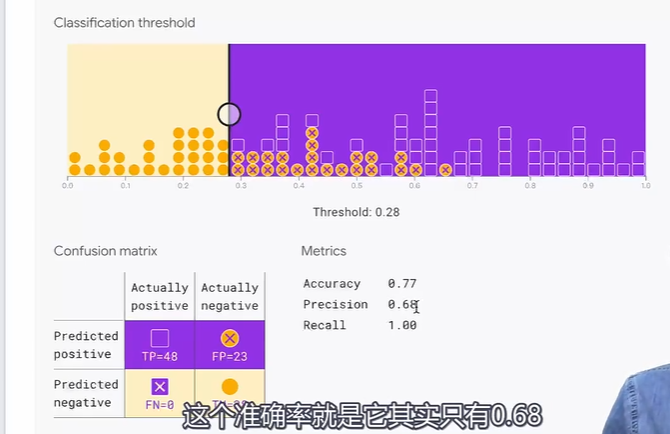
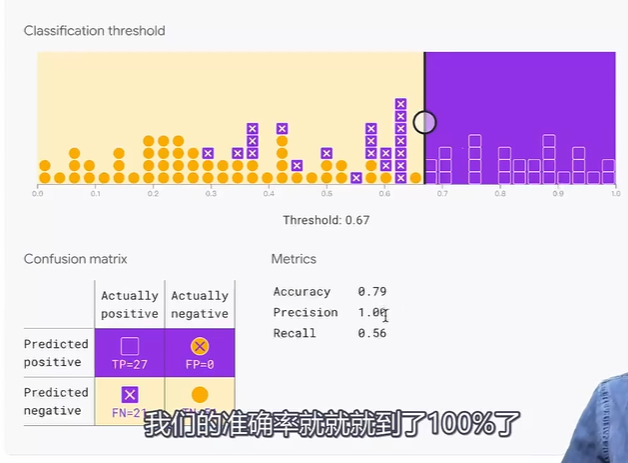
分类阈值会影响精确率和召回率,网页 Demo:https://developers.google.com/machine-learning/crash-course/classification/accuracy-precision-recall?hl=zh-cn#precision
-
精确率和召回率通常呈反函数关系,不同的应用场景会看重不同的指标
- 垃圾邮件分类
- 更关注查准率
- 自动驾驶刹车
- 更关注查全率
- 垃圾邮件分类
F-Score
-
同时考虑召回率和精确率
-
F1 分数,召回率和精确率同等重要
-
-
F1=1是最好的情况,如果查全率和查准率都很小,F1回趋近于0,很差的情况
-
-
F_{\beta}$$分数:$$\beta$$越大,召回率(查全率)的权重越大,精确率(查准率)权重越小 - $F_{\beta} = \frac{(1 + \beta^2) \cdot \text{precision} \cdot \text{recall}}{(\beta^2 \cdot \text{precision}) + \text{recall}}$
使用 sklearn 库计算各个指标
1 | |
经典模型:AlexNet
- 引发深度学习热潮的源头,在2012年 ImageNet 竞赛中以超过第二名 10.9 个百分点的绝对优势一举夺冠
.png)
- 网络结构
AlexNet 共包含5个卷积层(包含3个池化)和3个全连接层。其中,每个卷积层都包含卷积核、偏置项、ReLU激活函数。第1、2、5个卷积层后面都跟着一个最大池化层,后三个层为全连接层。最终输出层为softmax,将网络输出转化为概率值,用于预测图像的类别。
- 主要贡献
- 其提出了ReLu激活函数,加快了网络收敛速度。
- 提出了Dropout,缓解网络的过拟合。
- 提出重叠的最大池化,池化步长小于核尺寸,输出存在重叠和覆盖,提升了特征丰富性。
经典模型:VGG
- VGG 的特点是使用“块”结构,将神经网络简化
- 更规范化,用一种更简单的这种结构化的参数,描述一整个网络结构
.png)
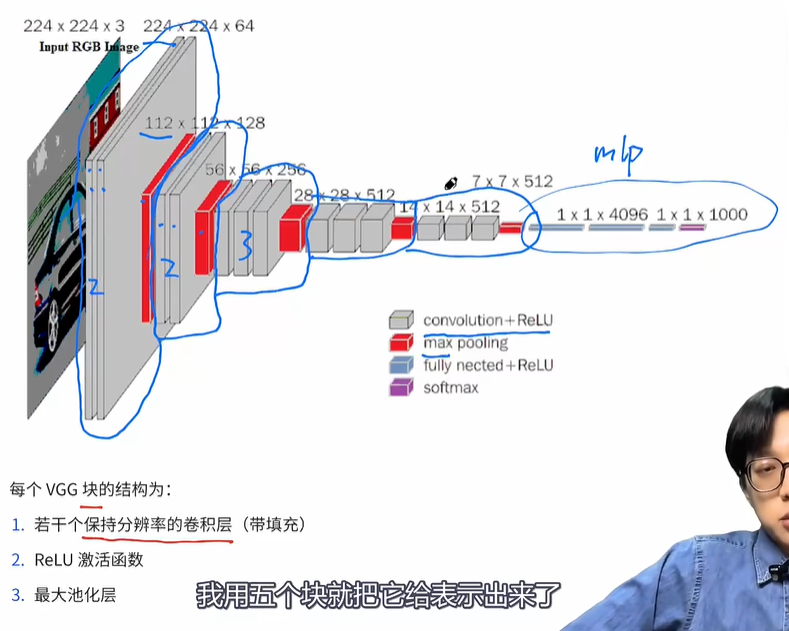
- 每个 VGG 块的结构为:
- 若干个保持分辨率的卷积层(带填充)
- 通过控制步长和填充,让卷积之后的分辨率不会缩小
- ReLU 激活函数
- 最大池化层
- 每个块都是以一个最大池化层结束
.png)
代码示例
1 | |
批量归一化(BatchNorm)
Batch Normalization
- BN 也是神经网络的一种层结构,类似于卷积层和全连接层,用于将数据规范化
- 规范化:希望数据能在一个范围内稳定分布
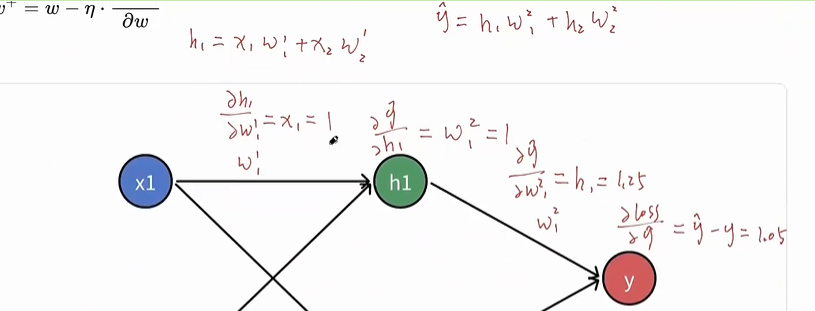
-
思想:随着网络加深,数据分布可能变得不稳定,通过添加BN层来规范化数据,让网络更稳定
-
作用:加速收敛、便于训练,缓解过拟合(类似正则化方法),但是BN层有参数可以学习
-
让进入后续层/激活函数的数值尺度更稳定,训练更顺滑。
-
把输入拉回到更“适合激活函数工作”的范围,减少饱和,让梯度保持活跃。梯度更稳定,不容易爆/不容易消失。
-
对初始化不那么敏感
-
可以用更大的学习率、更快收敛
-
先变成EX=0,DX=1的标准正态分布,变成标准正态分布之后,但是网络不一定都是想要均值为0,方差为1的数据,他可能想要其他分布的数据,所以给了网络自己选择的权利,假如了拉伸参数γ和偏移参数,相当于说自己创建了一个分布函数
-
-
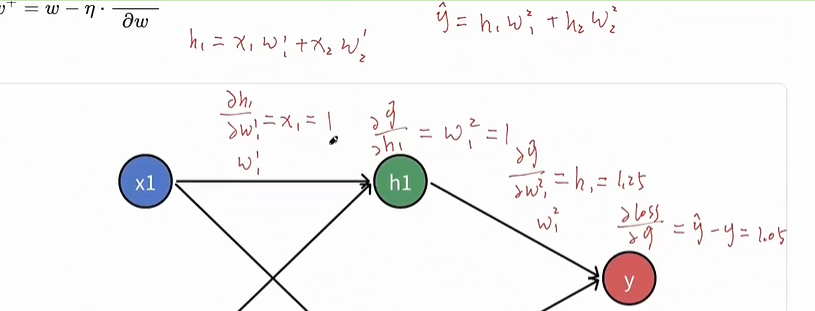
参数
- 拉伸参数(scale): $$\gamma$$
- 偏移参数(shift): $$\beta$$
-
直观理解:将数据主动居中,并将它们重新调整为神经网络需要的平均值和大小
-
batch_size 不能为 1,batch_size 足够大时,BN 的效果才好
- 如果batch_size=1,分子相减=0,整个神经网络失效了
不同模式下的表现
-
训练模式
- 用两个变量保存均值和方差
- 对于每个batch,都计算均值和方差,并不断更新变量
- 更新方法:移动平均 $$\mu = \alpha * \mu + (1 - \alpha) * \mu_t$$
- 好处是不用保留历史数据记录的每个数据的均值,不用求和除以样本总数,每次滚动计算平均值
- 训练完成后,BN层自己要把计算的均值和方差保存,用于预测使用
-
预测模式
- 不再更新均值和方差变量
- 直接用训练时保存的均值和方差变量
不同的层上的表现
-
全连接层
- 将BN放在与权重相乘之后,激活函数之前
- 每个特征维度,对应一组 BN 参数
- 每个维度单独计算均值和方差,对于每个维度都有拉伸参数和偏移参数,不同维度之间独立
-
卷积层:每个输出通道后一个BN,然后是激活函数

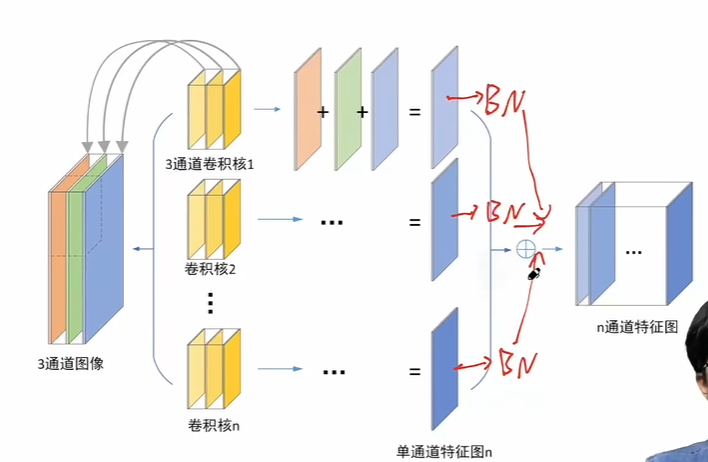
代码
1 | |
梯度爆炸与梯度消失
梯度不稳定
- 训练网络时,梯度是从后向前传播的,靠近输入的层会面临梯度不稳定(因为反向传播链更长了),即梯度消失或梯度爆炸
.png)
- 梯度消失:参数的梯度值趋近于 0,导致几乎无法更新
- 梯度爆炸:参数的梯度值很大,导致无法收敛
.png)
影响因素
- 层数,即网络深度
- 激活函数
- 所以在隐藏层里面这两个激活函数用的不多
.png)
.png)
- 参数初始值,参数值的大小会影响梯度大小
- 参数初始化成一个标准正态分布的情况能够缓解这个问题
- 数据规范化,如 BatchNorm
- 缓解梯度爆炸或者梯度消失
- 残差连接
- 对于网络结构的一种修改,初衷很大一部分就是缓解深度的网络的难以训练的问题
经典模型:ResNet
思想
-
ResNet 的主要作用,是让网络加深后能取得更好的效果,从此能够训练更深的网络
-
两个角度:
- 缓解梯度消失和梯度爆炸,让训练更加稳定
- 让不同的深度的网络成为“嵌套函数类”
- 非嵌套函数类下,每个f都是一个函数类,可以理解为这些层的神经网络它能够表达的函数的范围,所以网络越深,拟合的函数肯定是越复杂,越多,面积越来越大,但是面积越来越大,拟合函数越来越多,但是可能出现偏移,也就是离得越来越远,即更复杂的模型不一定效果更好
- 嵌套函数类可以保证加深网络深度以后,性能不会下降,F1能到的点F4也能到
.png)
残差块
- 引入残差连接,使其可以学习成恒等映射
- 左边是没有加入残差连接的时候
- 假如Fx没有学到任何东西,至少之前的x可以保留下来,不会让网络变得更差,也就是F2仍可以保留F1可以拟合的那些函数,变成一个嵌套函数类
- 如果Fx能学习到东西,下一层面积扩大,学不到东西至少不会丢掉前面能够学习到的东西
.png)
.png)
- 如果卷积层改变了分辨率或通道数,则通过 1*1 卷积层来匹配数据尺寸
- 匹配通道数:控制 1*1 卷积层的输出通道数
- 匹配分辨率:控制 1*1 卷积层的步长
.png)
ResNet
- 与 VGG 类似,ResNet 也是用块的形式定义网络结构,即残差块,有两种残差块,一种是没有改变特征图的尺寸的,一种是改变尺寸的
.png)
.png)
- 虚线表示使用 1*1 卷积的残差连接,改变了通道数和分辨率
示例代码
1 | |
Transformer
- 2017年Google团队在论文《Attention is All You Need》中提出Transformer,其不仅重新定义了自然语言处理的边界,还在计算机视觉、语音处理等领域产生了深远影响。它以全新的注意力机制替代了传统的递归结构和卷积结构,彻底改变了模型捕捉长距离依赖的方式。
- Transformer论文本身是旨在解决翻译任务的,但其模型架构的创新让其在所有NLP、CV任务上大放异彩,广泛使用,现在火爆的大模型也是以Transformer为模型架构的。
![]()
![]()
输入嵌入和位置编码
为什么RNN不行?
- 串行计算,对于长序列计算速度太慢了
- 梯度消失和梯度爆炸问题
- 很难解决长距离依赖,序列跨度长了之后,就难以获得信息
Transformer-架构解析
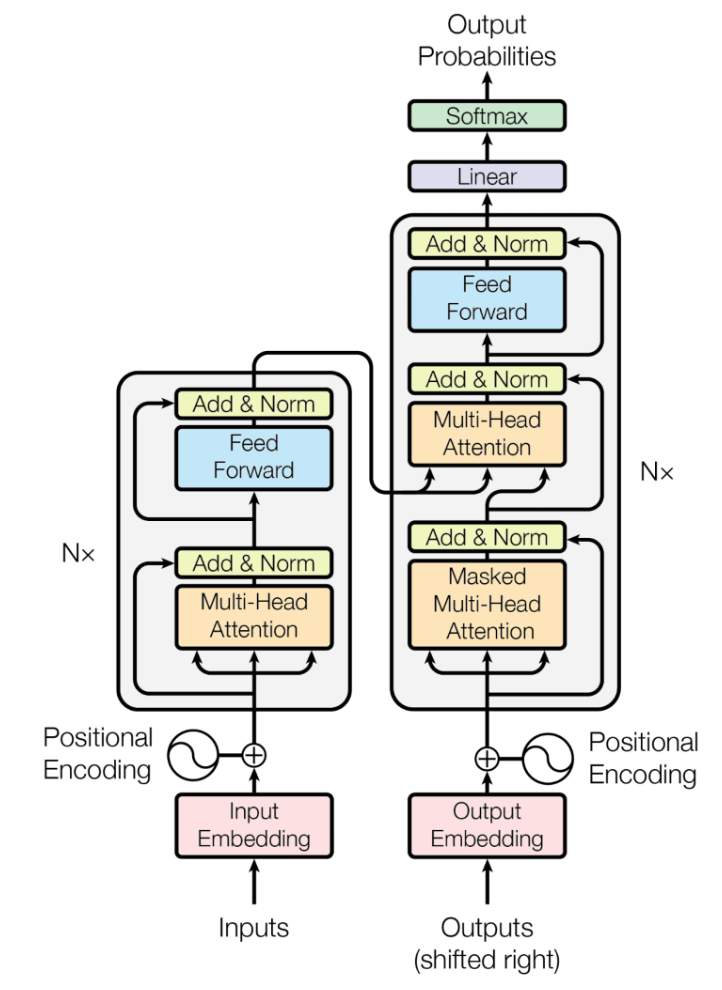
Encoder:编码器
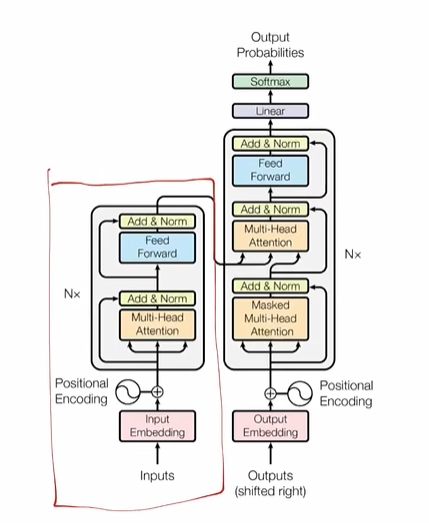
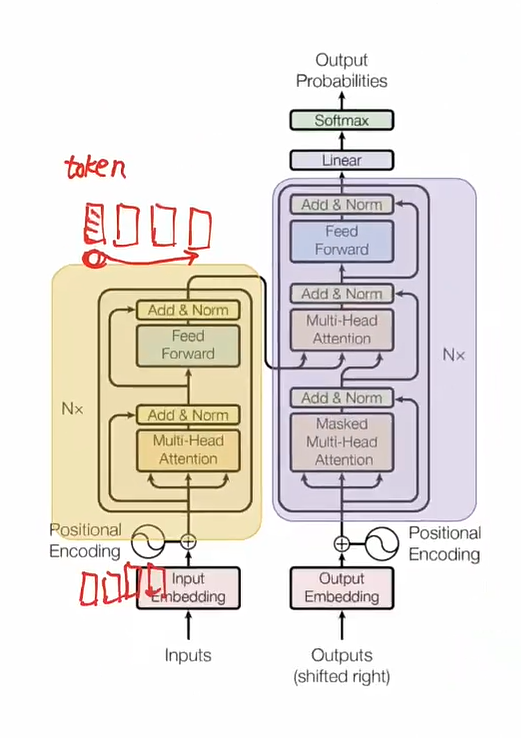
输入Embedding
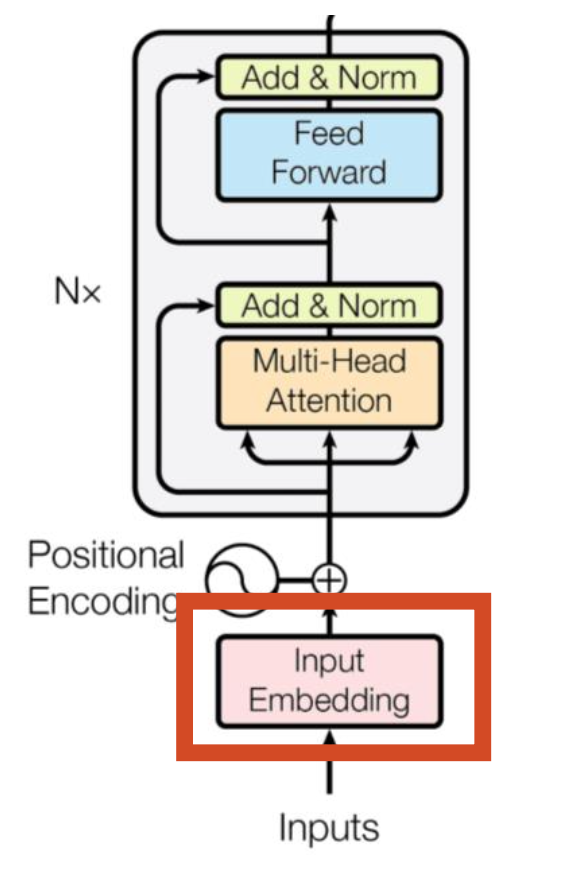
- input就是一句话,一个sequence,由若干个token组成
- 什么是input embedding?
- 对原始的句子进行分词,分成每个token
- 把每个token embedding成一个固定维度的向量
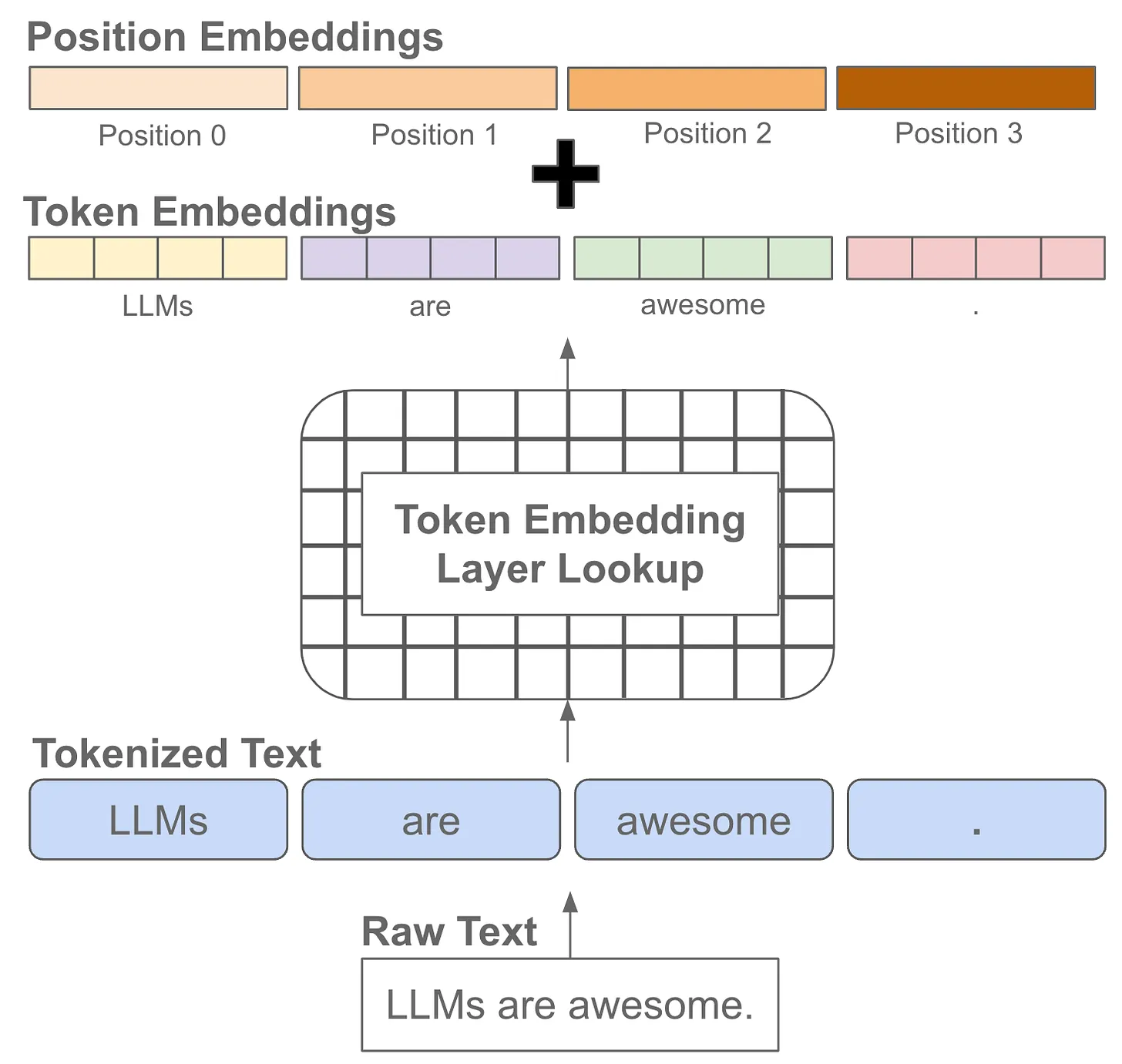
Positional-Encoding:位置编码
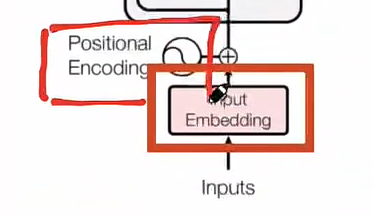
- 什么是位置编码?
- 我们希望每个词都能够携带关于其在句子中位置的信息。
- 我们希望模型能够将出现在彼此靠近的词视为“接近”,将距离较远的词视为“远离”。
- 我们希望位置编码能够表示一种模式,便于模型学习。
- 非常简单粗暴直接开加,embedding+数值positional encoding,就得到了encoder input
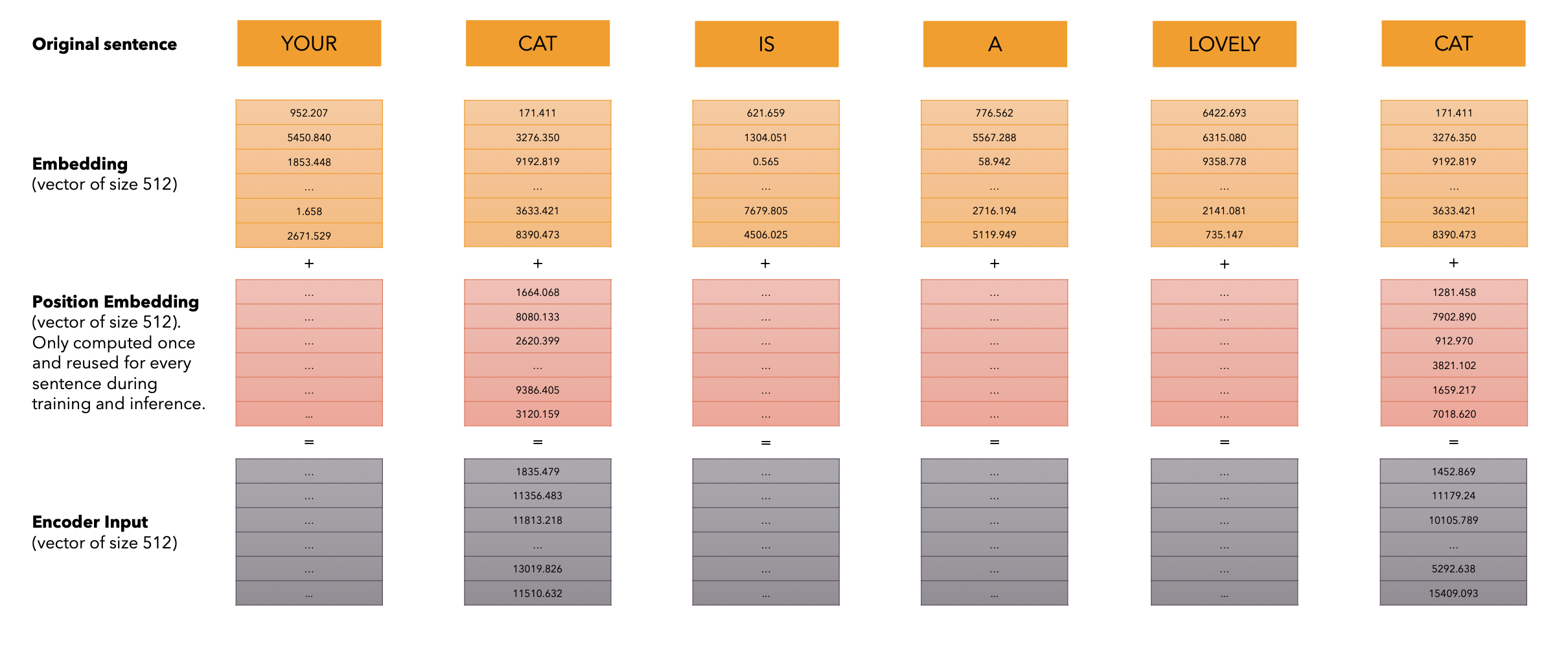
position-embedding的计算方式
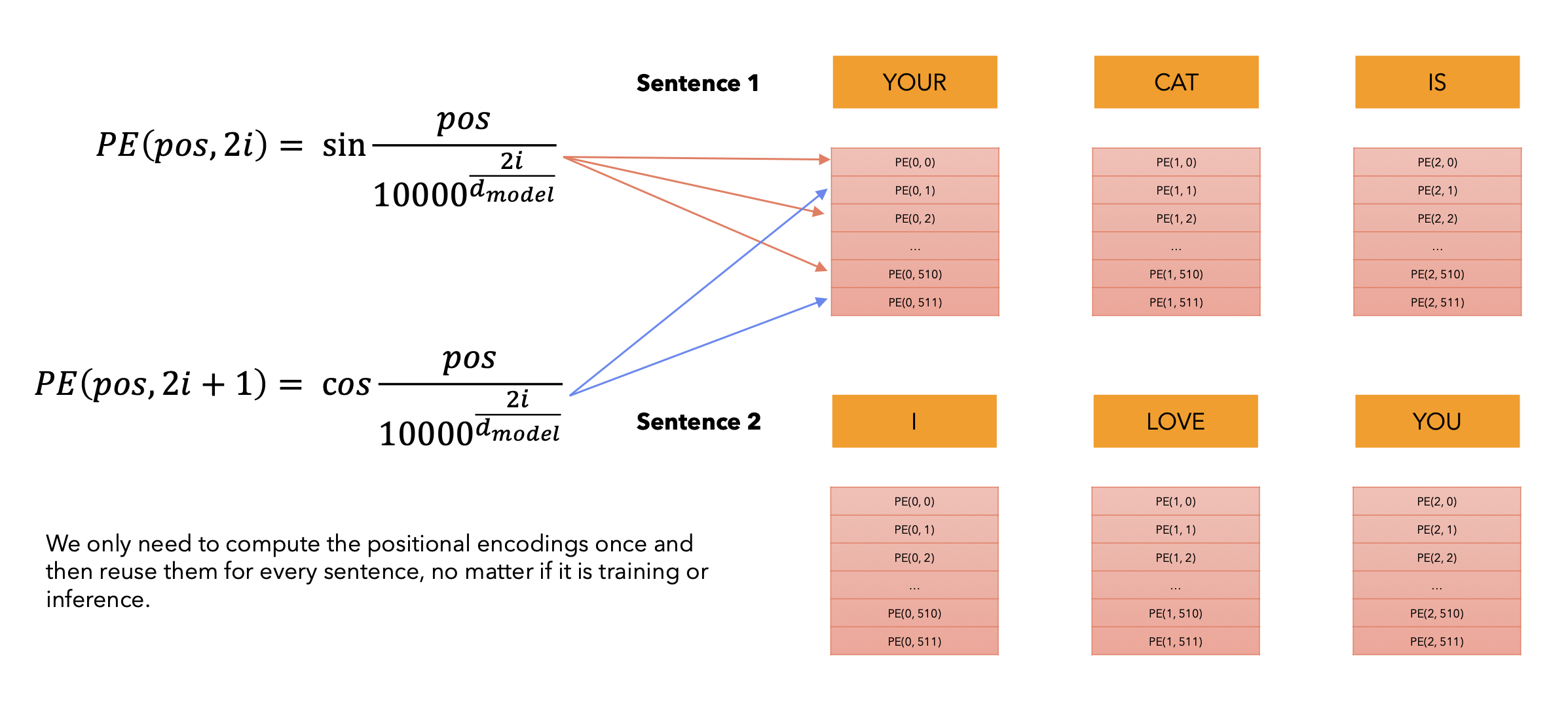
-
仔细去看就是和它的绝对位置有关
- 绝对位置编码的值只和我当前向量所处的一个绝对位置有关,然后就能计算出positional embedding的值
- 奇数用cos计算,偶数用sin计算
- pos是x值坐标,i是y的坐标(在这个词向量中的深度)
- 宏观理解:这个值和这个向量的某个数在整个的sequence和我的向量深度中具体处在某一个位置上,只和这样的一个位置有关
-
为什么是三角函数来作为计算的函数呢?
- 三角函数(如cos和sin)自然地表示出一种连续的模式,模型可以识别这种模式,因此相对位置对模型而言更容易被捕捉。通过观察这些函数的图像,我们也可以看到一种规律性的模式,因此我们可以假设模型也能够识别出这种规律。
- 三角函数是一种计算机非常容易识别的模型,对计算机来说,很容易读懂这种三角函数的语言,这块就涉及到数字信号处理的知识,对于计算机来说它天生就容易读懂这种信号。
- 它是一种规律性的模式,很容易能够让计算机意识到这是当前会处在哪个位置得到的数字,就加上了这种带有位置的信息
- 直接这样暴力相加,会不会把原来的embedding的信息给覆盖掉?
- 不会,对于模型来说很容易识别这种加减学习。
注意力机制
自注意力机制-Self Attention
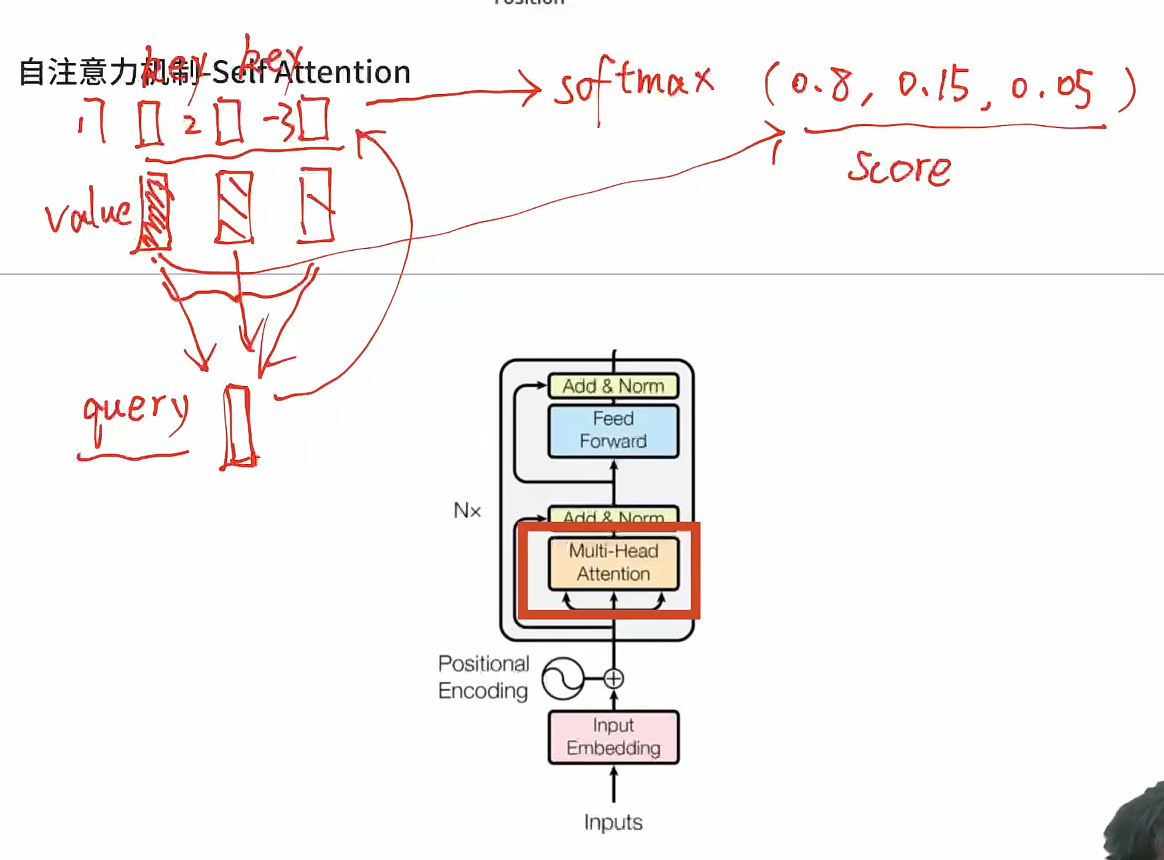
- 注意力机制本身是一种融合技术
- eg:假设现在有三个向量,让这三个向量去做一个融合,注意力会有一个query查询向量,这三个向量分别有三个指标key,然后query和key会分别去计算他们的分数,算他们的相似分数,直接做点积相乘,然后去算它的相似度。根据相似性标量过一个softmax得出了重要性分数。依据这个去乘它的value,相加得到Output
- 数学的点积相乘其实就描述了它的方向相似性
- 是一种信息的多采样,把重要的部分多多地去采样进来,少的部分采样的比较少
- eg:假设现在有三个向量,让这三个向量去做一个融合,注意力会有一个query查询向量,这三个向量分别有三个指标key,然后query和key会分别去计算他们的分数,算他们的相似分数,直接做点积相乘,然后去算它的相似度。根据相似性标量过一个softmax得出了重要性分数。依据这个去乘它的value,相加得到Output
什么是注意力机制?
注意力机制(Attention Mechanism)是一种在深度学习中广泛应用的技术,其核心思想是模拟人类注意力集中于关键信息的能力,从而在处理数据时提升模型的效率和性能。
-
核心思想:注意力机制通过赋予输入的不同部分不同的权重,允许模型动态地聚焦于输入中更重要的信息。与传统的平均处理或简单加权方式不同,注意力机制可以根据上下文动态调整这些权重。
-
主要步骤:
-
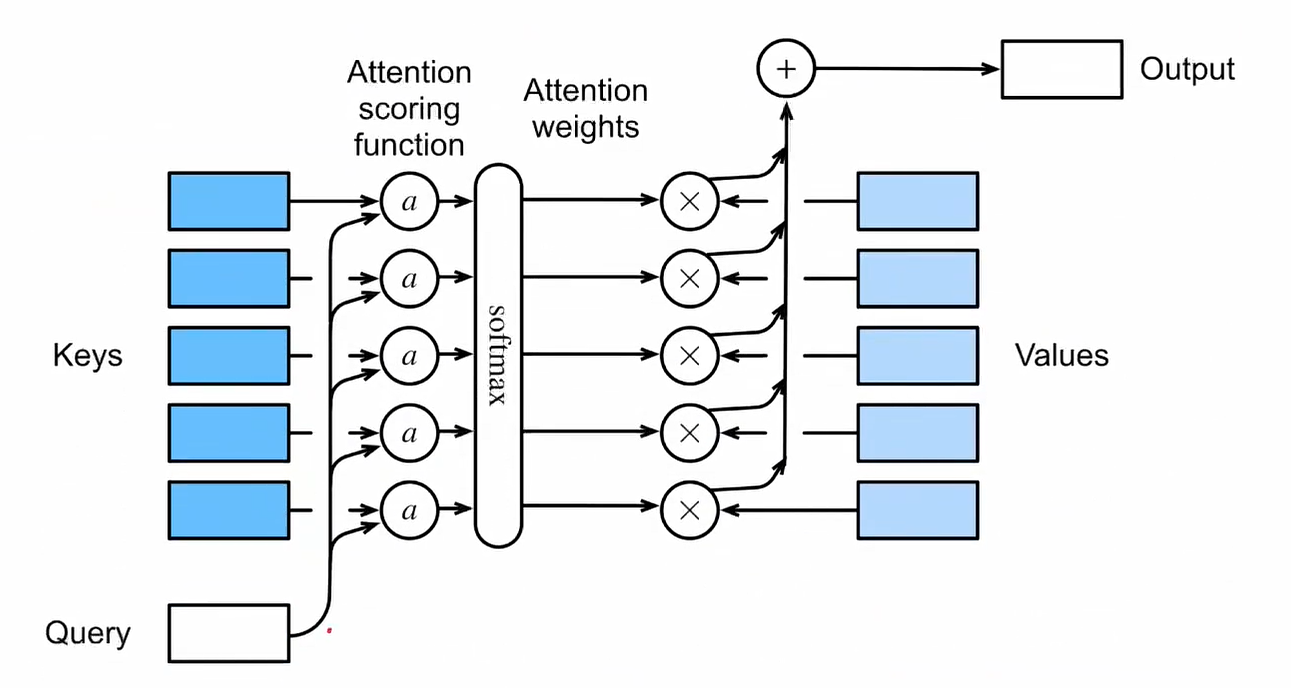
权重计算: 输入数据的各部分被映射到查询向量(Query)、键向量(Key)和值向量(Value)。通过计算查询和键之间的相关性,生成注意力权重,通常使用点积、加性方法或其他相似度计算。
-
- 根据查询向量来生成每一个值向量对应的分数,查询向量和键向量会做点积来得到这样的分数,得到这个分数之后,把值向量加权平均到一起,加在一起就是attention计算
- 本质上就是把值向量以一个合理的方式运送到一起
-
-
- key和value一一对应,query和key去算score得到分数a(相关性),分数a经过softmax以后变成权重(概率分布),拿到分数a之后,把分数a和Values相乘(用权重去加权Values),之后把所有加权后的Value相加得到输出Output,这就是注意力的最终输出,一个融合后的向量(相乘的都是矩阵)
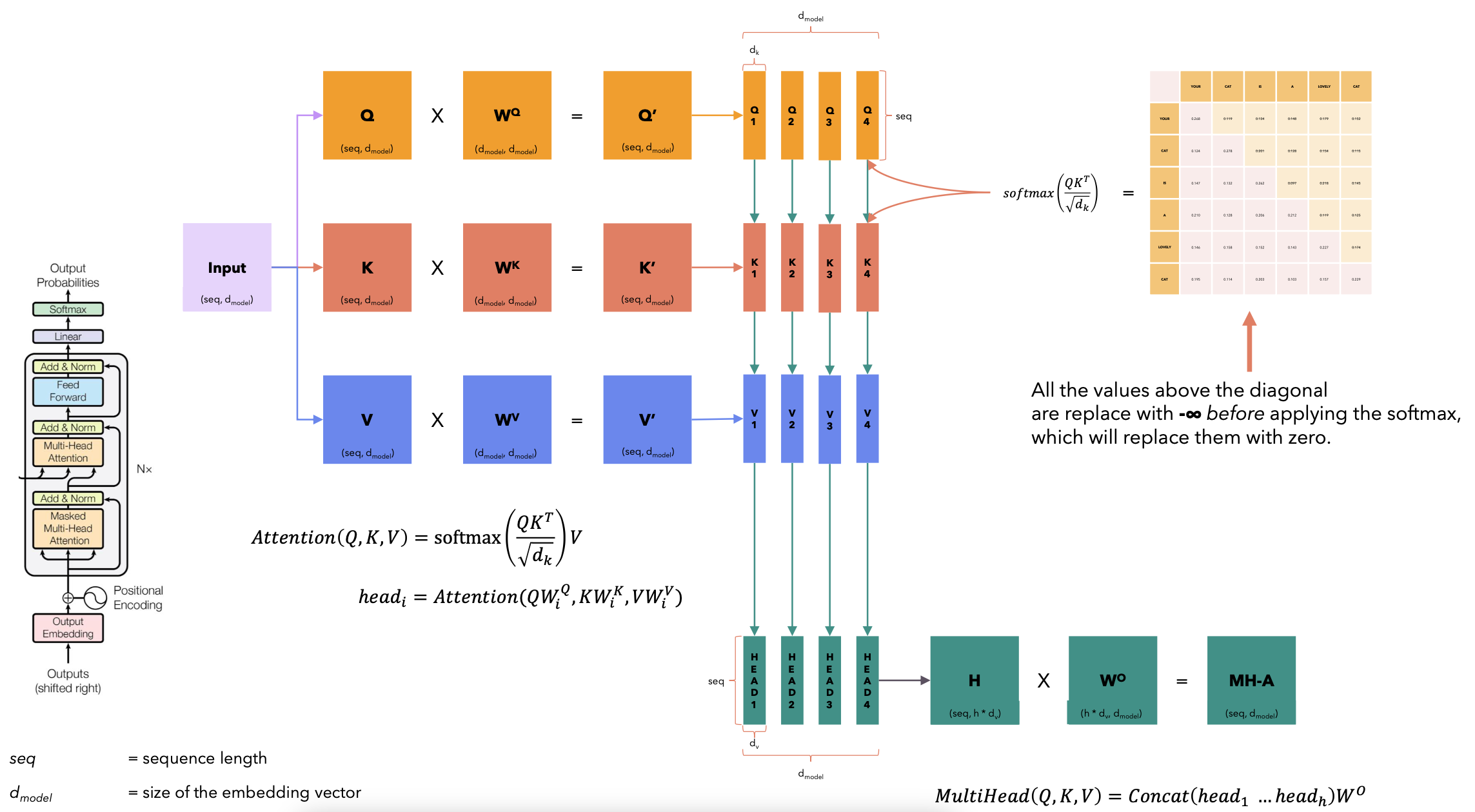
- 权重归一化: 使用Softmax函数将注意力权重归一化,确保权重值落在0到1之间,并且总和为1。
- 加权求和: 将归一化后的权重应用到值向量上,得到最终的注意力输出。
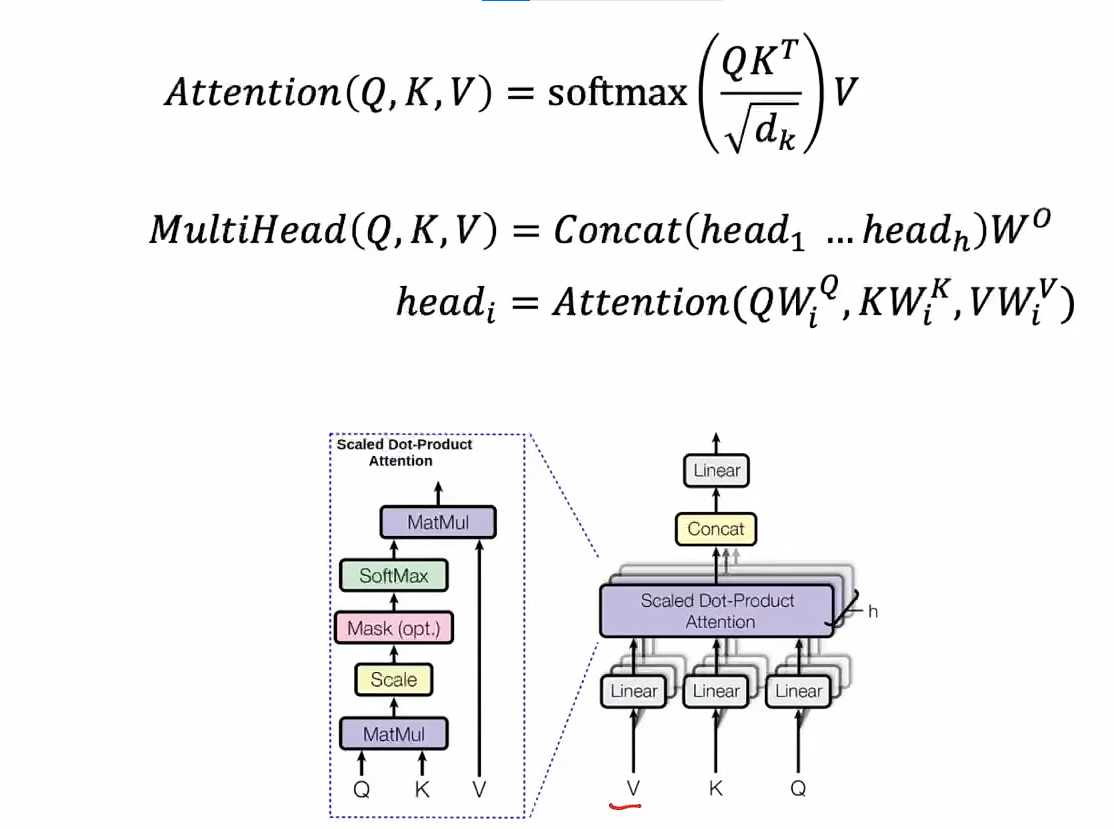
- :query/key 的维度(每个头里 q/k 向量的长度)
- :缩放因子,消除因为向量长度过大而导致的问题,防止点积太大导致 softmax 饱和、训练不稳
什么是自注意力机制?
-
self-attention的目的是学习输入句子中每个词的重要程度(注意力权重分布),然后将其与每个词的value相乘,得到attention的输出。 之所以称之为self,是因为query和key-value均来自同一个输入(在transformer decoder阶段attention输入可以看到query来自上游decoder的输出,key-value来自encoder的输出。)
-
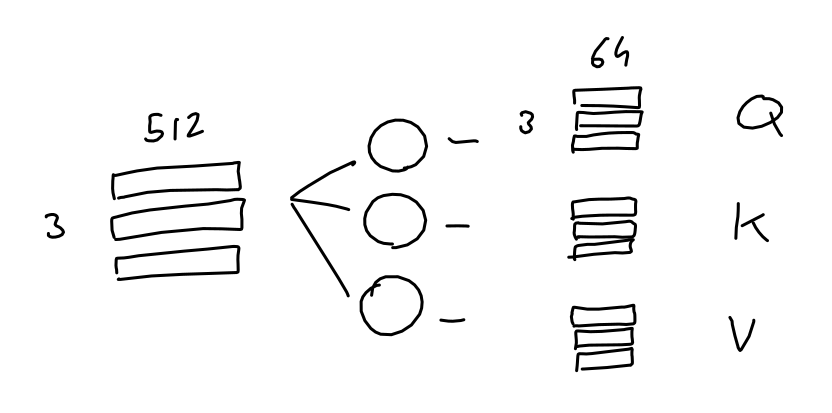
自注意力(Self-Attention) 使模型能够将词与其他词关联起来。 在这个简单的例子中,我们考虑序列长度 seq=6, 。 矩阵 Q(查询)、K(键)和 V(值)直接来自输入句子。(6个token,每个token的长度是512
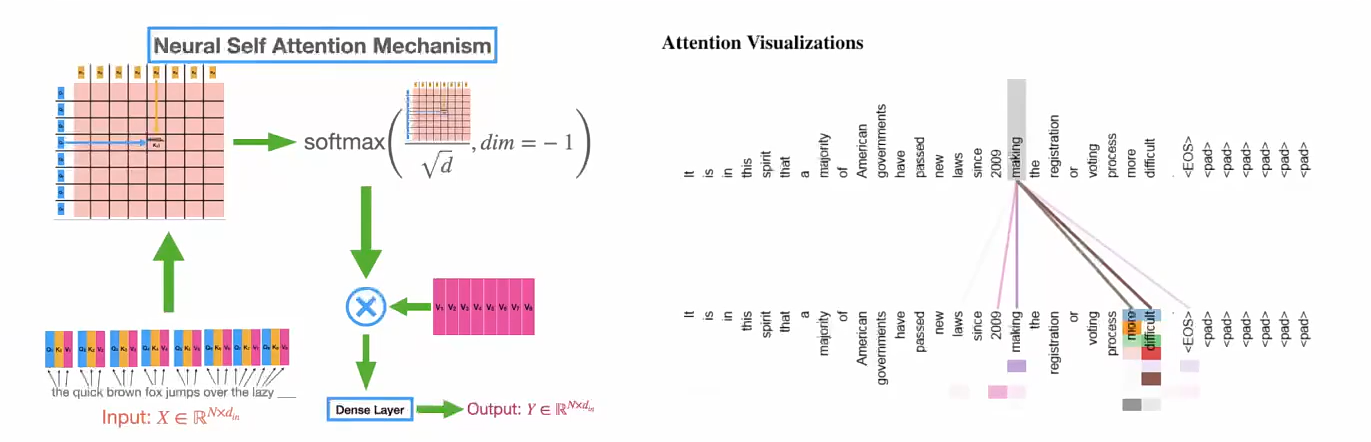
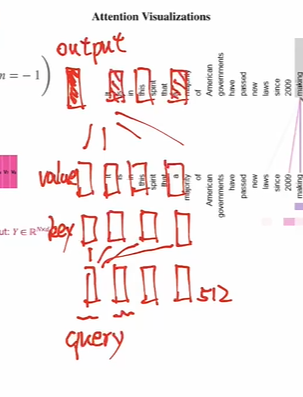
- 注意力分数计算:矩阵运算
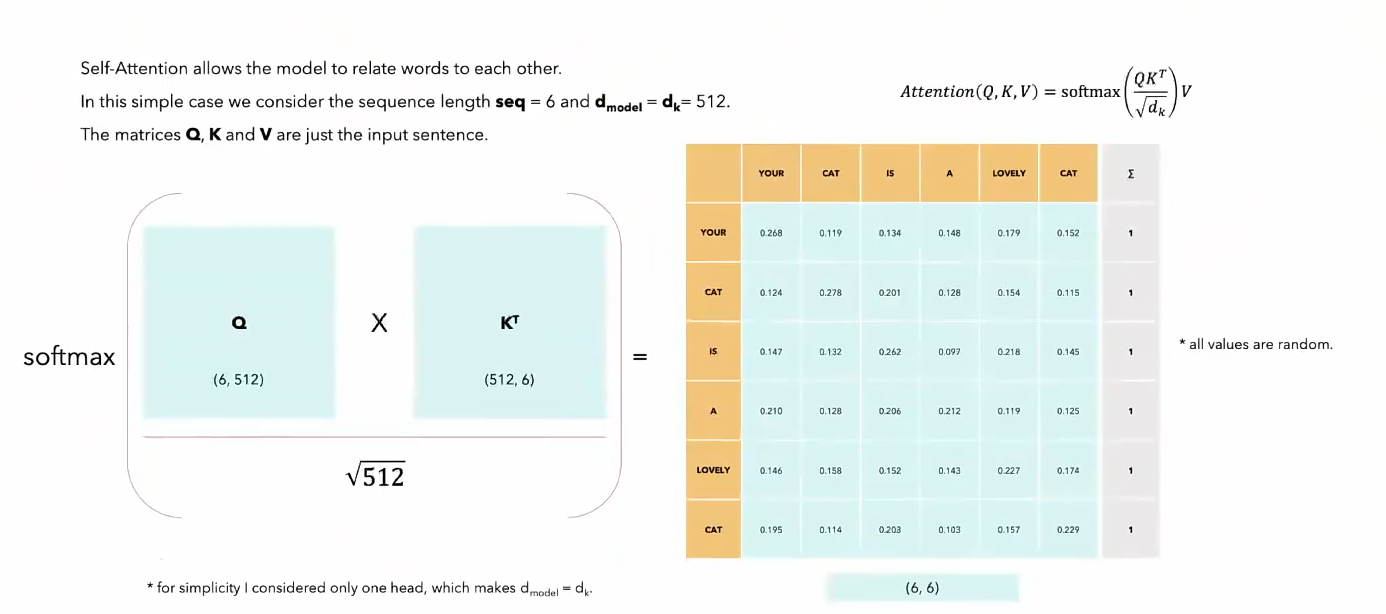
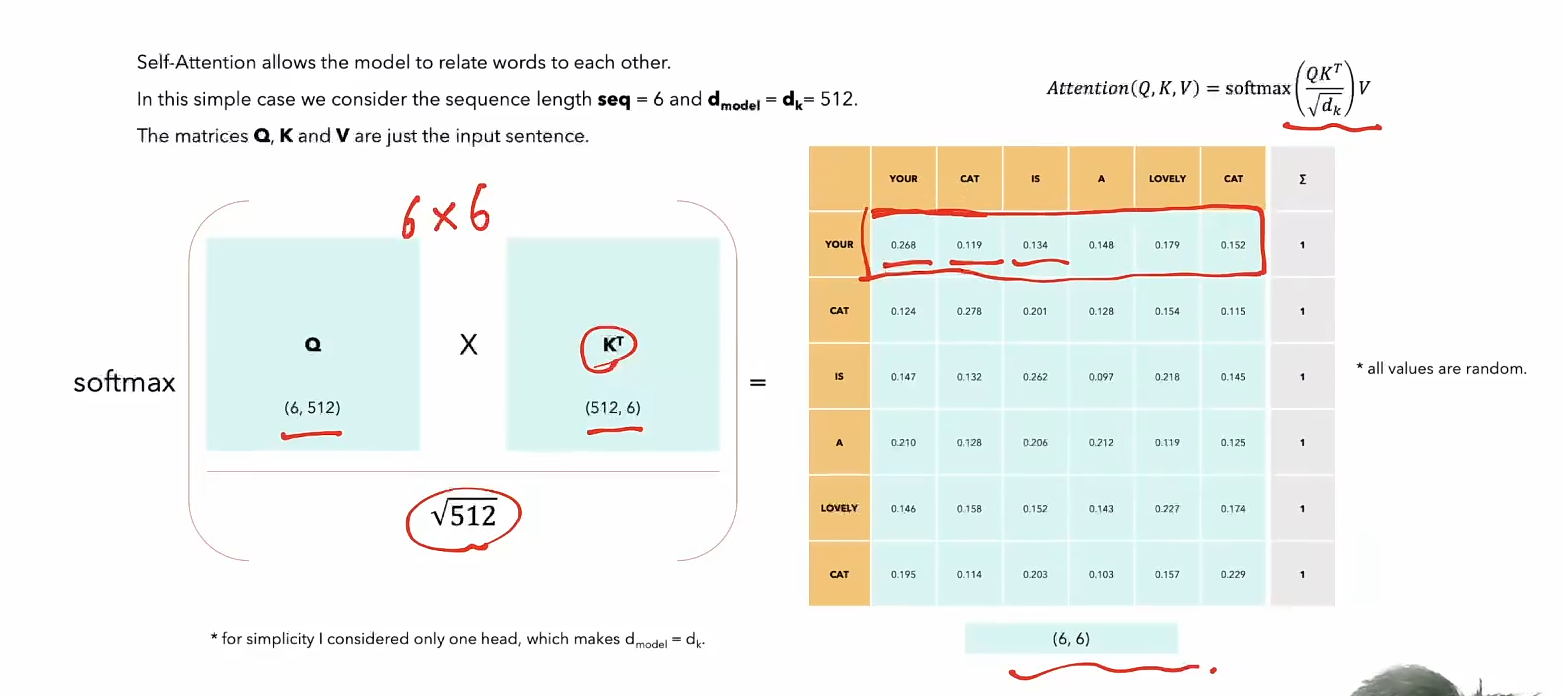
- softmax是每一行单独去做的
- 往往对角线上有罪罚的值,因为自己和自己最相似
- 拿到一个词向量之后,我把这个词的每一个token既当作value又当作query,又当作key去计算,复制三份,然后以每一个token作为query进行计算,最后形成n个output
注意力分数与向量V加权
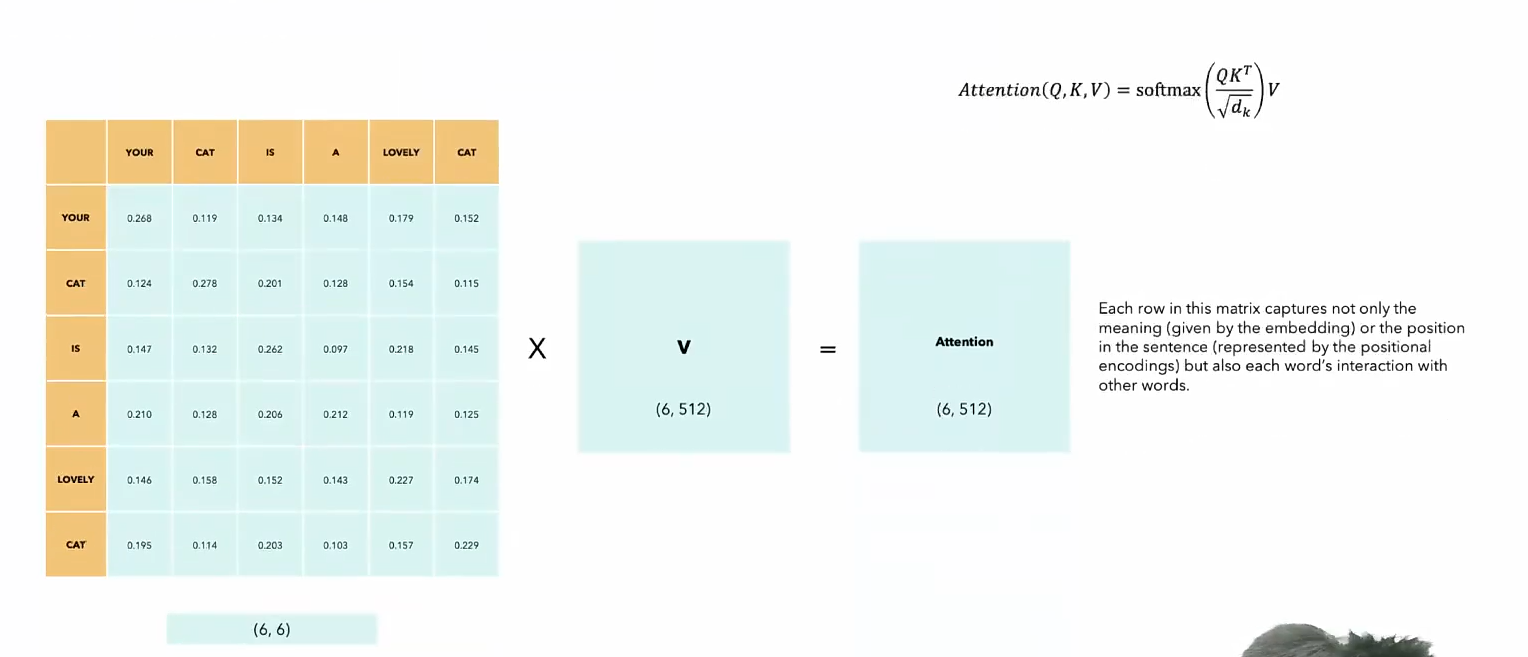
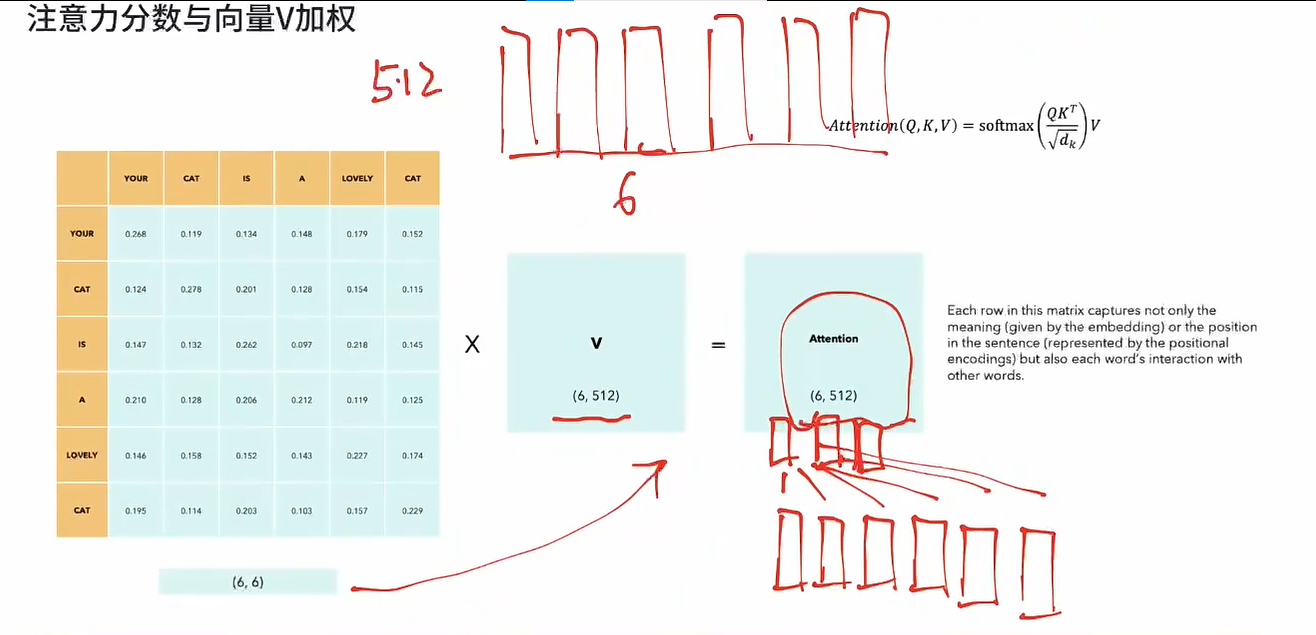
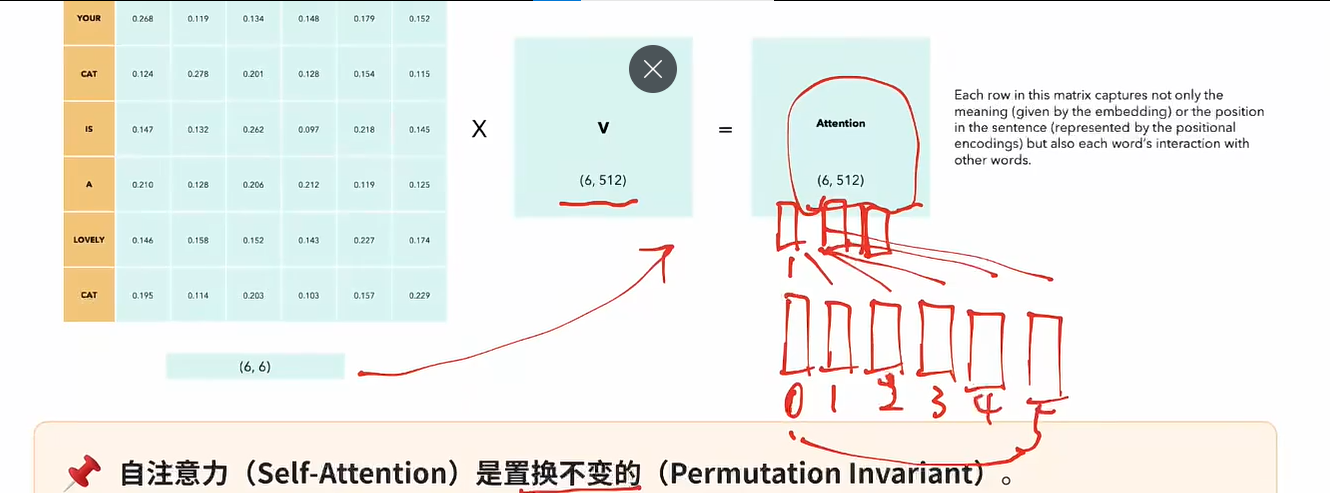
-
相当于我们token在进行一通计算之后,分别得到了和自己原来一样形状,但是包含了来自其他token的信息,存在信息交互
-
自注意力(Self-Attention)是置换不变的(Permutation Invariant)。 (自注意力机制对输入序列的顺序不敏感,输入的排列不会影响结果。)
-
自注意力不需要额外的参数。 (到目前为止,词与词之间的交互仅由其嵌入表示(embedding)和位置编码(positional encoding)驱动。稍后,这一特性将会发生变化。)
- 没有需要学习的参数/权重矩阵,一旦query、key、value确定下来,生成出来的output也是唯一确定了
-
我们认为对角线上的值最高。 (自注意力机制中,元素与自身的关联性通常最强,因此注意力矩阵的对角线位置的权重值一般最高。)
-
如果我们不希望某些位置之间发生交互,可以在 softmax 之前将这些位置的值设置为 -∞。 (通过这样操作,可以在计算注意力矩阵时排除这些位置的交互。我们将在解码器中使用这种方法。)
- -∞做完softmax之后,基本上变成0,代表我对他的关注度是无限趋近于0
多头注意力机制:Multi-Head Attention
多头注意力机制(Multi-Head Attention)
- 多头注意力机制是Transformer模型中的核心组件,它在单一注意力机制的基础上,通过并行化的方式提升了模型的表达能力,能够更好地捕获输入数据中不同的特征和关系。
核心思想

- 多头注意力通过将**输入数据(每一个token的embedding)**映射到多个不同的“头”(Head),让每个头在不同的子空间中独立地学习和处理信息。然后将所有头的输出进行合并,从而得到更丰富的上下文表示。
- 映射到不同的头:因为需要去抽取不同的语义空间,类似于卷积神经网络中通道的做法
- 比如有的头负责捕捉语义,有的头负责去捕捉情感色彩,有的头负责捕捉重要信息,我们可以主观或者直观上地给他赋予一些意义。
- 头越多能够抽取到不同的语义特征,模型效果越好
- 映射到不同的头:因为需要去抽取不同的语义空间,类似于卷积神经网络中通道的做法
具体步骤

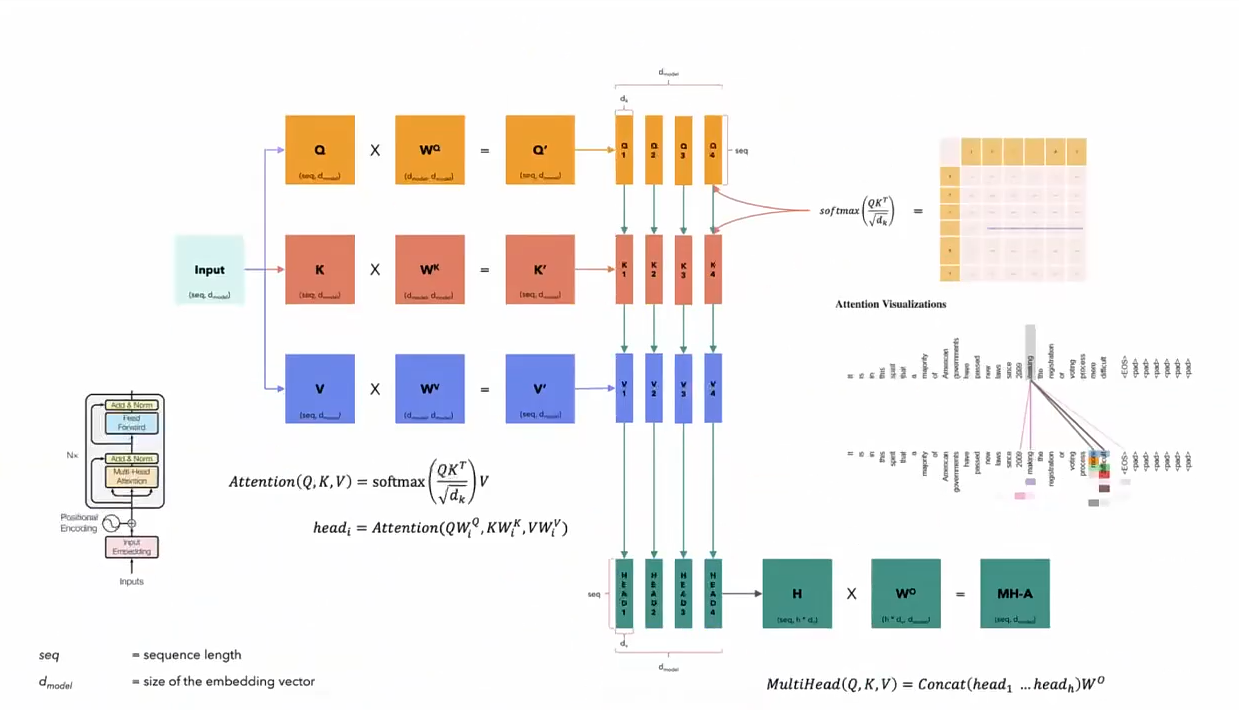
-
线性变换: 输入的每个位置的嵌入(Embedding)通过独立的线性变换映射成查询向量(Query)、键向量(Key)和值向量(Value)。 如果有 h 个头,每个头会有独立的投影矩阵 $$W_Q^{(i)}$$, $$W_K^{(i)}$$, $$W_V^{(i)}$$,用于生成这些向量。
- 有了线性变化,模型就有了可学习的参数,所以模型就会先验地主动地改变这个映射方式,让embedding变到一个合适的value/query/key值,去得到更合理的向量融合
-
计算注意力: 对每个头独立地计算注意力值,具体公式为:
-
-
这里, 是查询和键的向量维度,用于缩放点积,防止数值过大导致梯度消失。
-

-
- token长度是4,有4个头的话,每个头对应4个token的四个向量,4个头有4组这样的向量,也就是16个
-
-
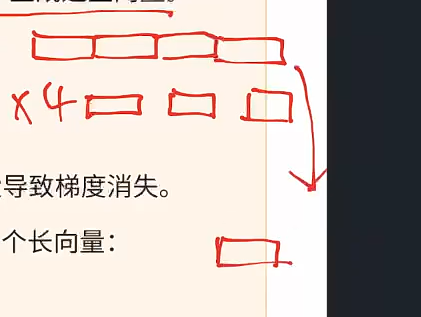
合并头输出: 每个头的输出被拼接(Concatenate)在一起,形成一个长向量:
-
-
然后再通过一个线性变换 $$W_O$$将其映射回原始的嵌入维度。

特点与优势
- 捕获多样化信息: 每个头可以关注输入的不同部分,学习到更加多样化的语义关系和特征。
- 增强模型表达能力: 通过多个注意力机制并行处理,模型能够同时关注局部和全局信息。
- 降低维度处理限制: 每个头的注意力计算是在较低维度的子空间中完成的,减少了计算复杂度。
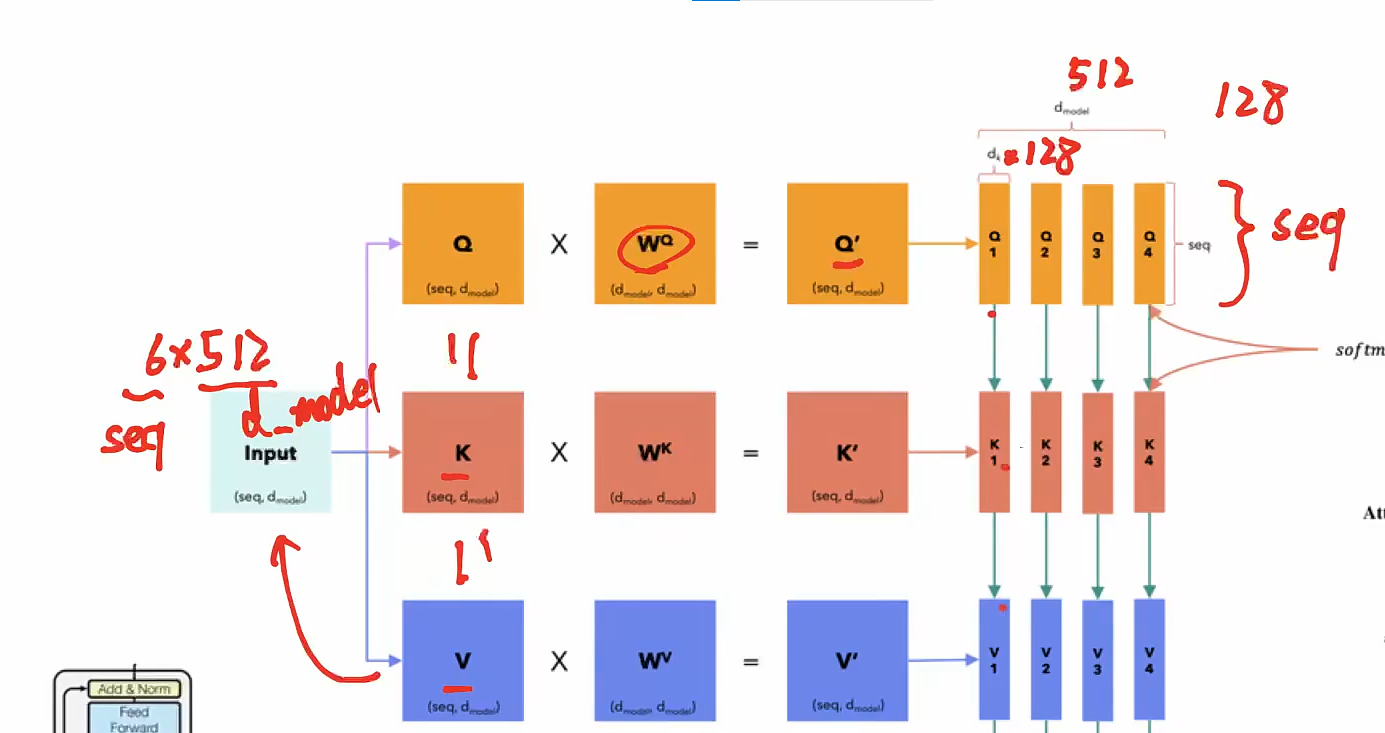
- 多头注意力对向量维度进行n等均分,分别去做attention
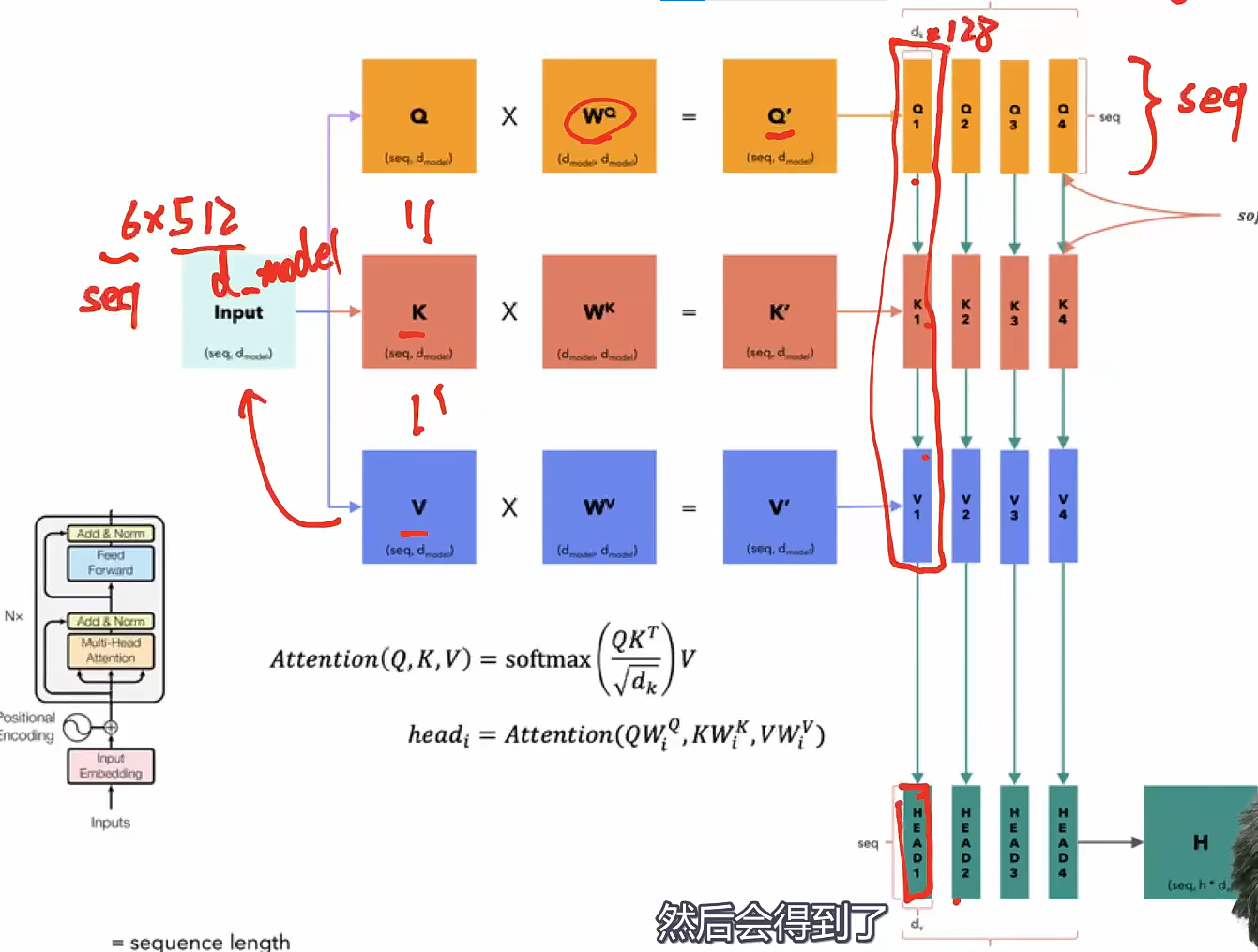
- 头与头之间独立计算,不进行信息交互
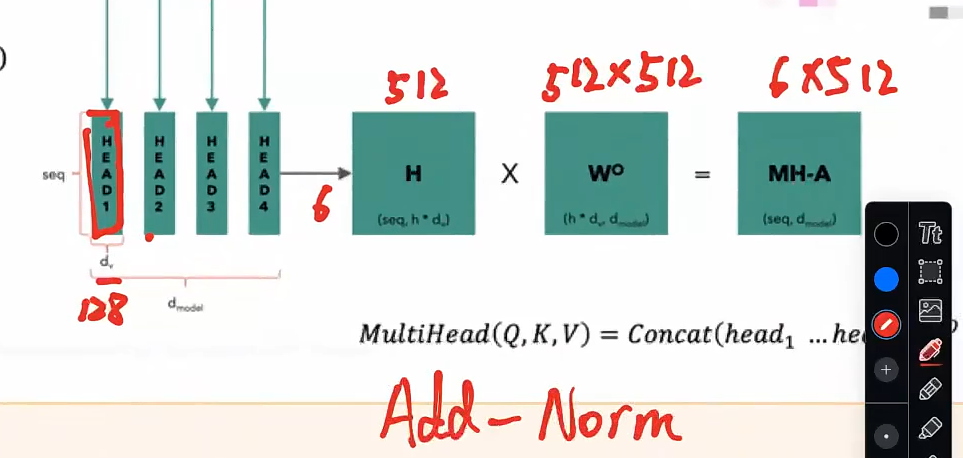
- head拼接形成head矩阵,然后过一个权重矩阵形成输出
为什么把他们称为querys,keys,values?
- 网上说,这些术语来源于数据库术语或类似 Python 的字典结构。
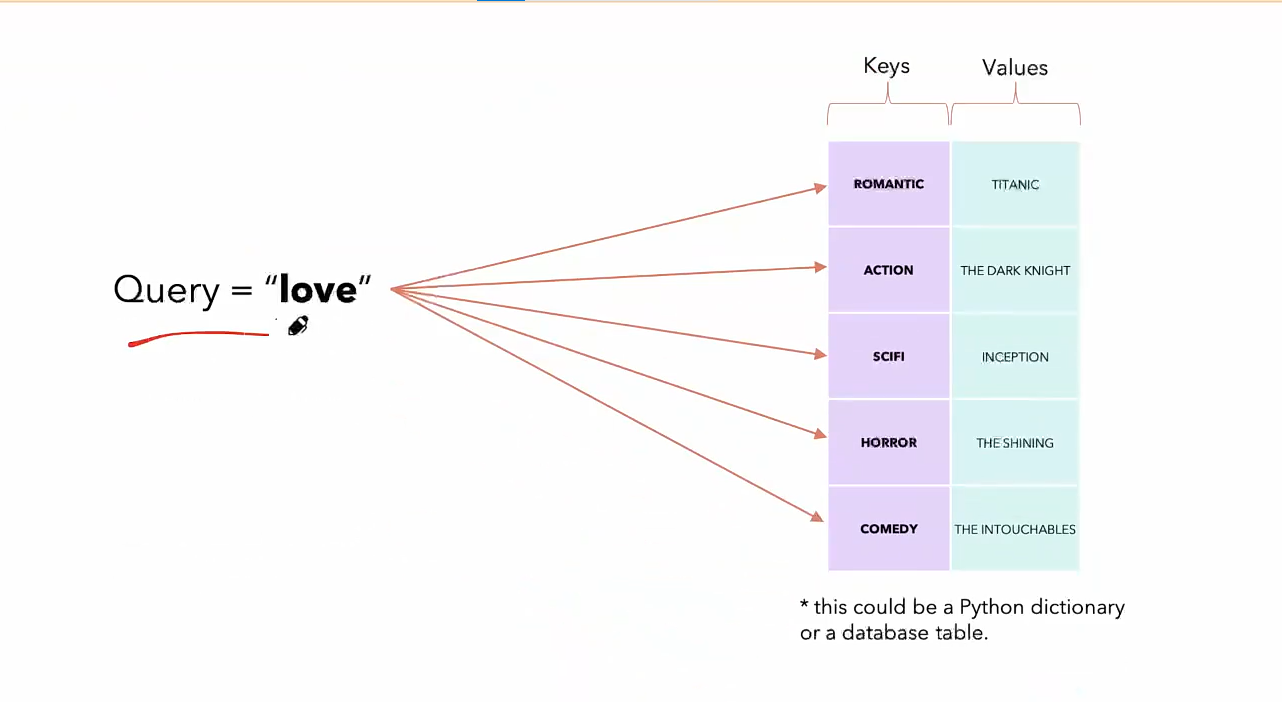
Add&Norm
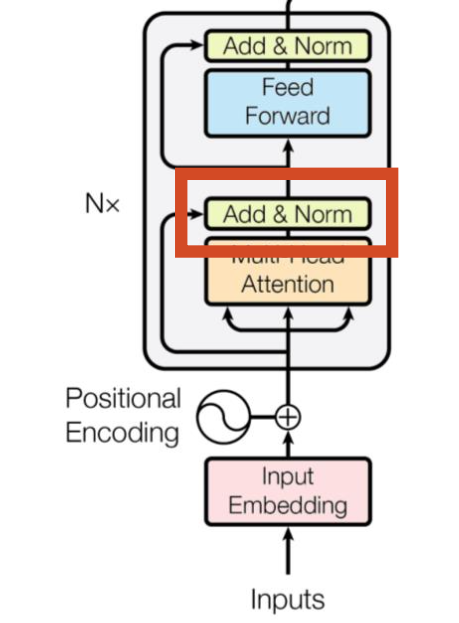
层归一化:Layer Normalization
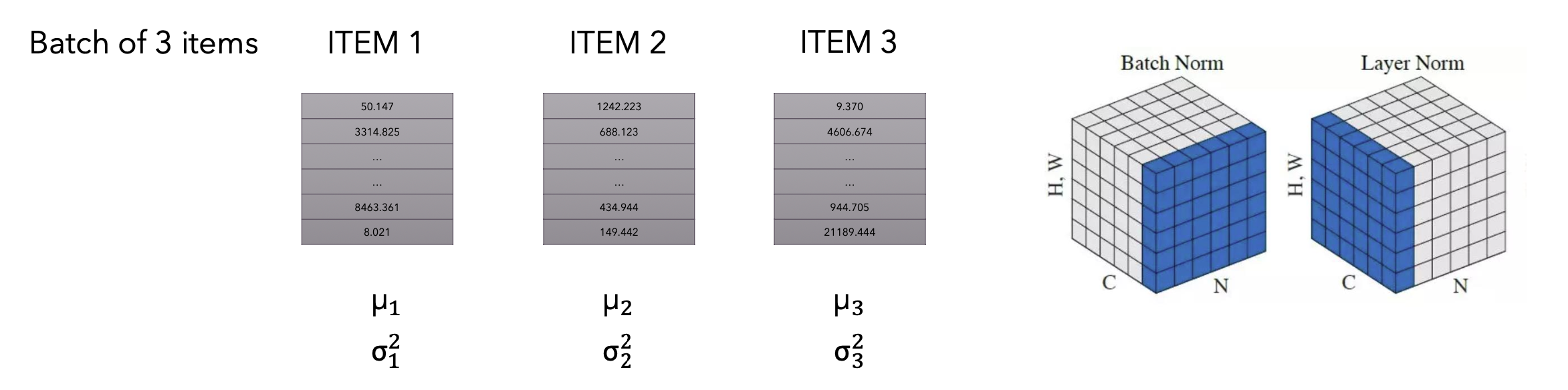
- Layer Normalization 是一种正则化技术,用于稳定神经网络的训练,特别是在深度学习中,它能够加速训练并提高模型的鲁棒性。与 Batch Normalization 不同,Layer Normalization 不依赖于批量大小,对单个样本的特征进行归一化,特别适合于循环神经网络(RNN)等对时间步敏感的结构。
- BN是对同一个feature内的不同样本进行归一化,而LN就是对样本内的不同feature进行归一化。
核心思想
- Layer Normalization 的目标是对神经网络的每一层输入进行归一化,使其具有零均值和单位方差。这有助于减少输入分布的变化(即内在协变量偏移,Internal Covariate Shift),从而加速网络收敛。
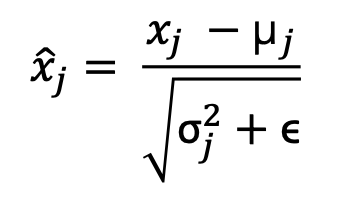
-
对于每一个token,分别计算其均值和方差,然后对里面的每一项进行归一化操作,每个token是单独进行标准化的
-
为什么不用BN:
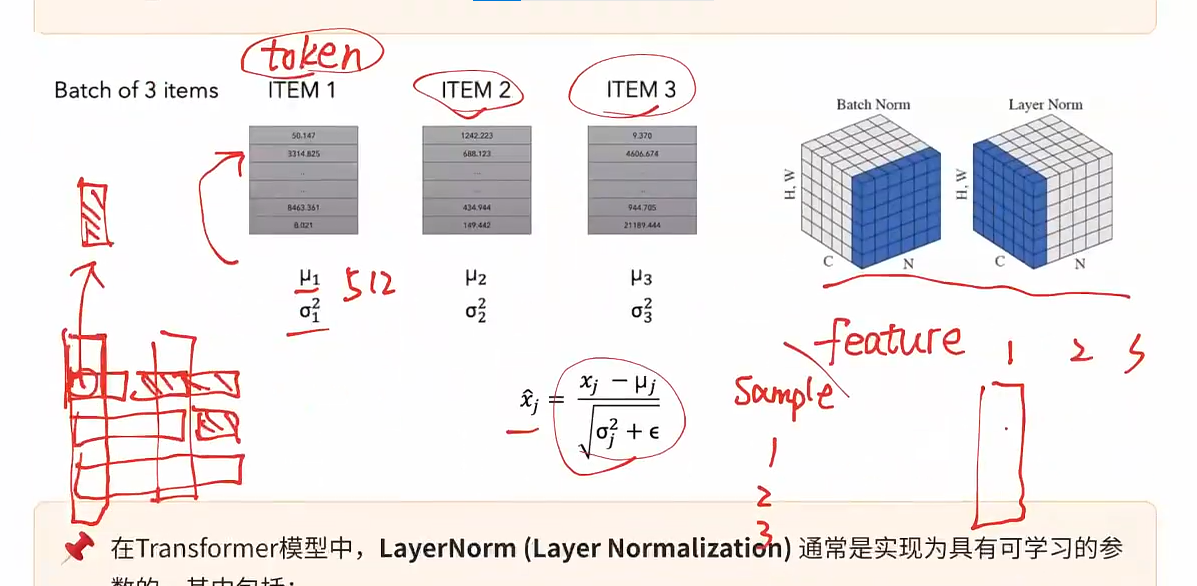
- 因为BN实对同一个feature内的不同sample进行归一化,自然语言处理中,sequence和sequence之间往往是不相同的,因此后续可能没法进行对齐,这种缺少token的情况会导致数值的极大不稳定性,因此只能对于每一个token内部进行归一化
-
-
在Transformer模型中,LayerNorm (Layer Normalization) 通常是实现为具有可学习的参数的,其中包括:
- 缩放参数(scale/gamma):用于调整标准化后的输出的尺度。
- 偏移参数(bias/beta):用于调整标准化后的输出的偏移。
-
这两个参数在大多数框架(如PyTorch、TensorFlow)中都是默认可学习的,也就是说,模型可以在训练过程中自动调整这些参数以适应任务需求。
-
具体实现上,LayerNorm的公式为:
-
其中:
- x是输入向量。
- μ 是输入的均值。
-
\sigma^2$$是输入的方差。
- γ是可学习的缩放参数。
- β是可学习的偏移参数。
前馈神经网络:FFN
- 本质就是过一个全连接层
.png)
![]()
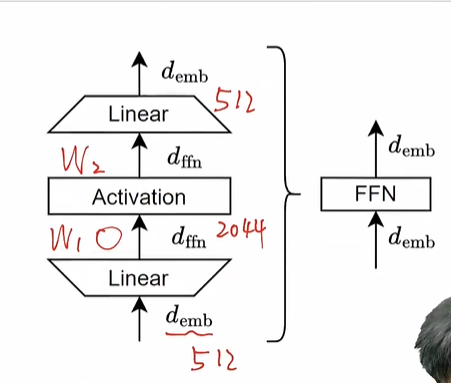
- 先升维后降维来获得这种复杂的计算,神经元数量一下子上去了,去学习这种复杂的行为,升维是一个全连接层W1,降维又是一个全连接层W2
Encoder块*n得到最终Encoder输出向量
-
Encoder块:
-
多头注意力机制
-
Add&Norm
-
前馈神经网络
-
Add&Norm
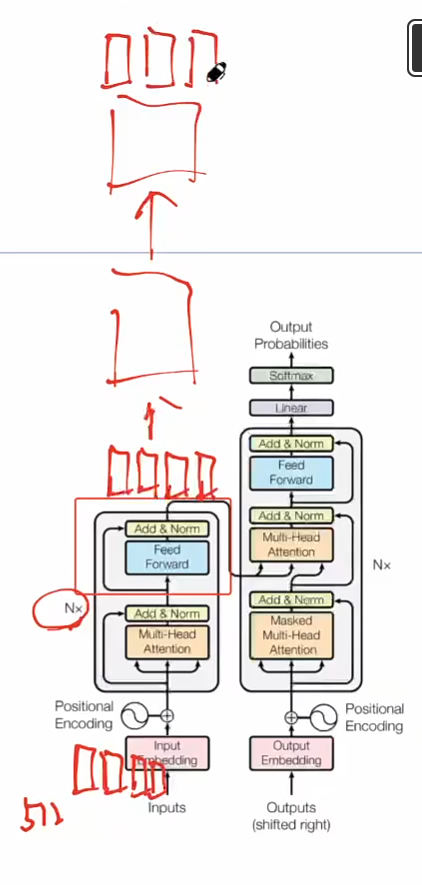
-
-
*n是因为4个向量进去还得是4个向量出来,输入输出维度一样,就可以叠加n次,把上一层的输出继续作为下一层的输入,层数一步步上升,语义的抽取,它能学习到的越来越高级,最终我们还会得到四个向量作为encoder的输出
.png)
掩码注意力和交叉注意力
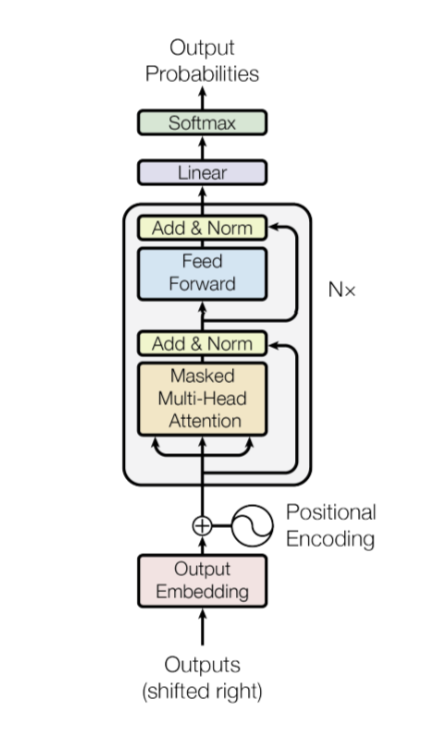
Decoder:解码器
- 和encoder的区别:
- masked multi-head attention
- cross-attention
掩码多头注意力机制:Masked Multi-Head Attention
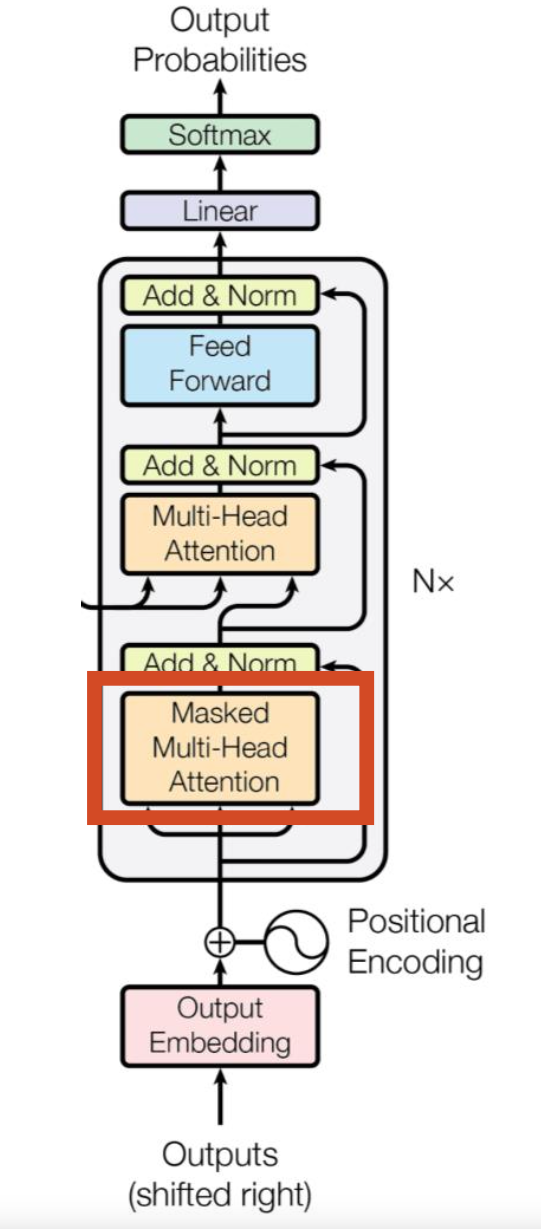
-
我们的目标是使模型具有因果性:这意味着某个位置的输出只能依赖于之前位置的词汇。模型不能看到未来的词汇。
-
也就是:生成式模型在生成第 t 个词时,只能用已经出现过的词(1~t-1),不能用未来的词(t+1…)。
-
1)为什么要这样做?
因为 Transformer 的 decoder 是用来“一个词一个词往后生成”的。
比如你要生成句子:
我 / 爱 / 你
当模型在生成“爱”(第2个词)时,现实世界里它不可能提前知道第3个词是“你”。
所以它只能根据“我”来预测“爱”。这就是“因果性”:
- 预测当前位置 ttt 的输出,只能依赖 <t<t<t 的信息
- 不能依赖 >t>t>t 的信息
2)那训练时不是整句话都给模型了吗?怎么防止“偷看答案”?
训练时确实把整句都喂进去(为了并行加速),但为了不让模型作弊,要加 Mask(遮罩):
- 在 self-attention 里,每个位置本来可以看全句所有位置
- Masked Self-Attention 会强制:
- 位置 ttt 只能看 1…t(或 1…t-1,取决于实现)
- 看不到 t 右边的“未来词”
实现上就是把注意力矩阵的“右上三角”(未来位置)打成 −∞-\infty−∞,softmax 后权重变成 0。
-
-
-
掩码自注意力机制是一种改进的自注意力机制,通常用于生成式任务中(例如语言模型、序列生成)。它的核心目的是通过掩盖(Masking)某些位置的注意力权重,确保模型在计算某个时间步的输出时,只能依赖于当前或之前的输入信息,避免使用未来的信息,从而实现因果性(Causality)。
核心思想
- 在标准的自注意力机制中,每个词(或时间步)都可以与序列中其他所有词交互(包括当前词和未来词)。然而,在因果生成任务中,例如机器翻译或文本生成,模型在预测下一个词时不能访问未来的词。为了实现这一点,引入了掩码自注意力机制。
实现方法
-
掩码矩阵:
-
构造一个掩码矩阵,大小为 (L,L),其中 L是输入序列的长度。
-
对于位置 i和 j:
-
如果j>i(即未来位置),将注意力分数设置为 −∞,表示这些位置不参与计算。
-
如果 j≤i(即当前或过去位置),保留原始分数。
-
下三角部分是0,这样相加后下三角部分不受影响,上三角部分变成0
-
变成一个下三角矩阵
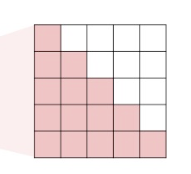
- 我在通过第一个词去预测第二个词的时候,看不到后面四个词,只能看到前面的词
-
-
-
点积注意力的修改:
- 在计算注意力权重之前,将掩码矩阵加到注意力分数中:
-
-
其中:
-
Q, K, V是查询、键和值。
-
M 是掩码矩阵,其值为 −∞或0。
-
- 在计算注意力权重之前,将掩码矩阵加到注意力分数中:
-
Softmax作用:
- Softmax 会将 −∞的分数转化为 0,从而有效地掩盖未来位置的影响。
特点
- 因果性:
- 掩码自注意力保证了每个时间步的计算仅依赖于当前和过去的信息,不会泄露未来信息。
- 动态性:
- 掩码矩阵可以动态生成,适用于不同长度的输入序列。
- 高效生成:
- 在生成任务(如文本生成)中,掩码机制帮助模型逐步生成每个词。
-
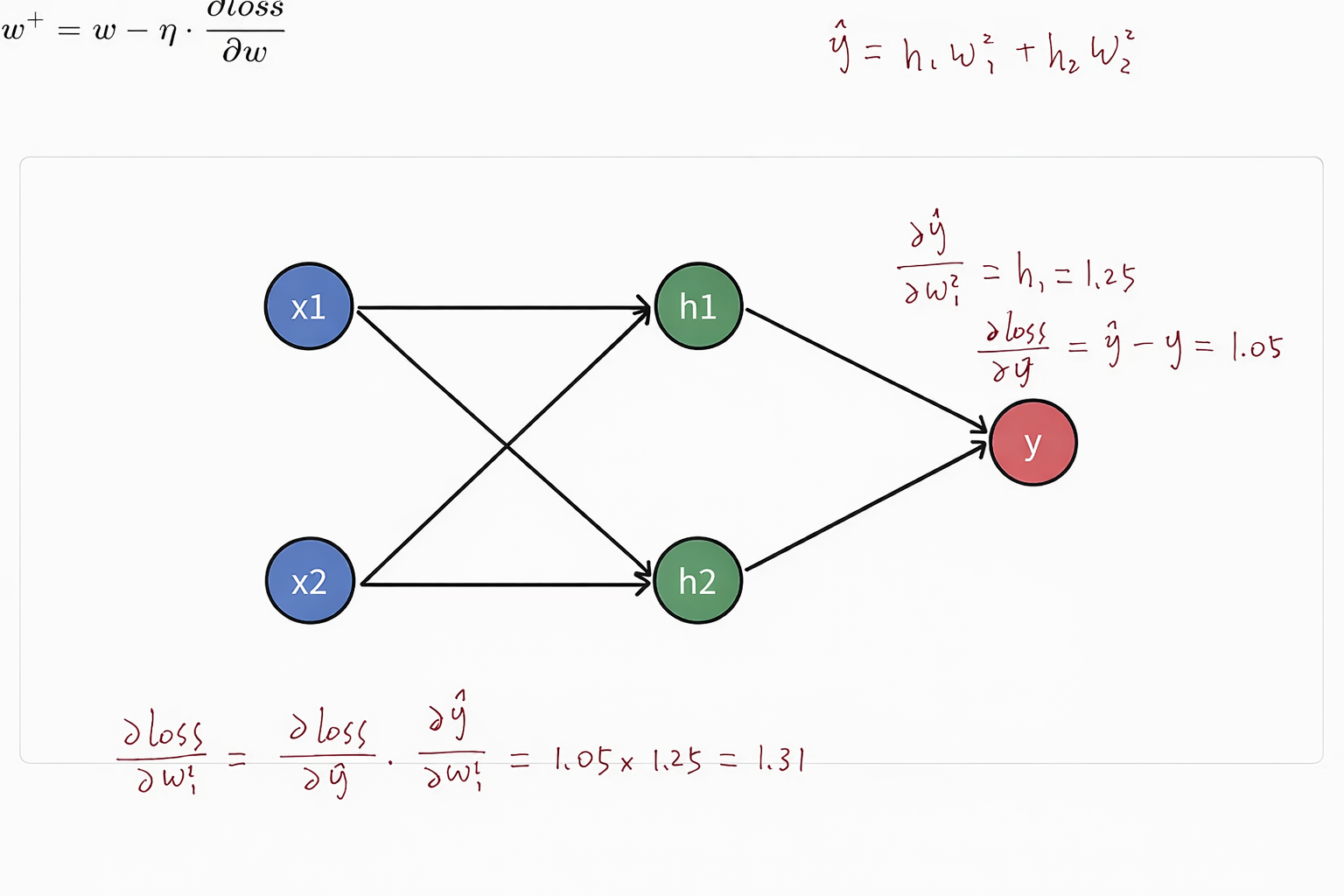
多头注意力算完之后橙色部分变成-∞,这样每次在算token的时候,第一行代表的是根据前面生成后面。同时并行计算
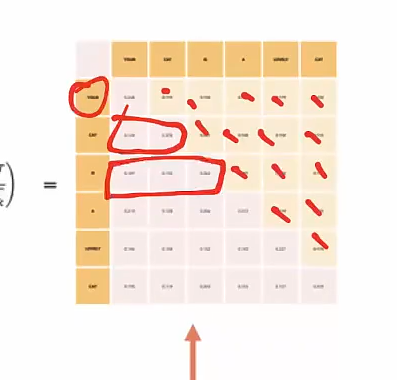
交叉注意力:Cross Attention
.png)
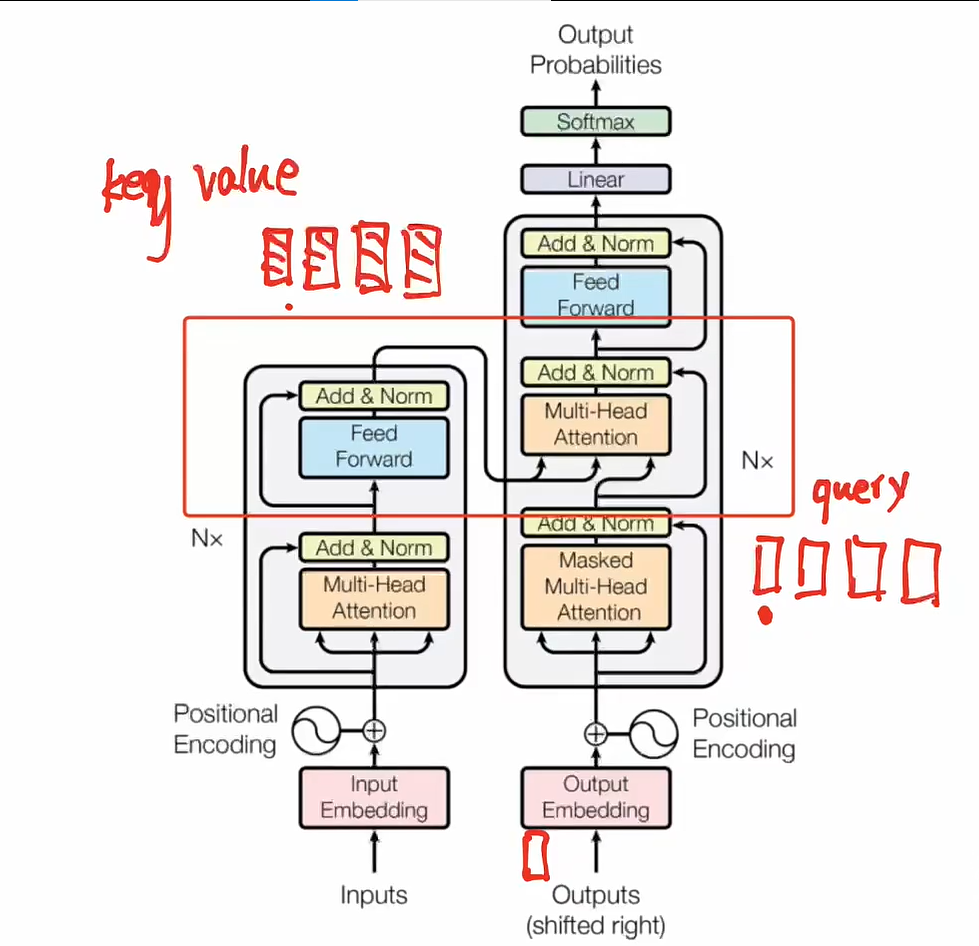
- encoder部分的输出作为key/value,生成的输入先embedding,position-encoding,然后作为query去计算,然后检索到它的key和value,然后把encoder的部分(value)去进行加权,得到最终的每一个token对应的向量,然后在上面进行计算
Transformer中的Cross Attention(交,叉注意力)
- 在 Transformer 模型中,交叉注意力(Cross-Attention)是解码器中的关键机制,它用于让解码器在生成目标序列时,关注编码器的输出序列信息,从而实现输入与输出之间的交互建模。交叉注意力是 Encoder-Decoder Attention 的具体实现,用于在源序列和目标序列之间建立联系。
- 把encoder和decoder联系起来的枢纽
核心功能
- 建立输入与输出的联系:
- 交叉注意力机制让解码器能够根据编码器的输出动态选择相关信息,为生成目标序列提供上下文。
- 信息交互:
- 解码器的查询(Query)来自目标序列(解码器隐藏状态),键(Key)和值(Value)来自源序列(编码器输出)。
Cross-Attention 与 Self-Attention 的区别
| 对比维度 | Cross-Attention | Self-Attention |
|---|---|---|
| 输入来源 | 查询来自解码器,键和值来自编码器 | 查询、键和值都来自同一序列 |
| 功能 | 连接编码器和解码器,建立输入与输出的关联 | 在单个序列中建立元素间的全局依赖 |
| 应用位置 | Transformer 解码器的 Encoder-Decoder Attention | Transformer 编码器和解码器的自注意力层 |
Transformer训练与推理通路
训练
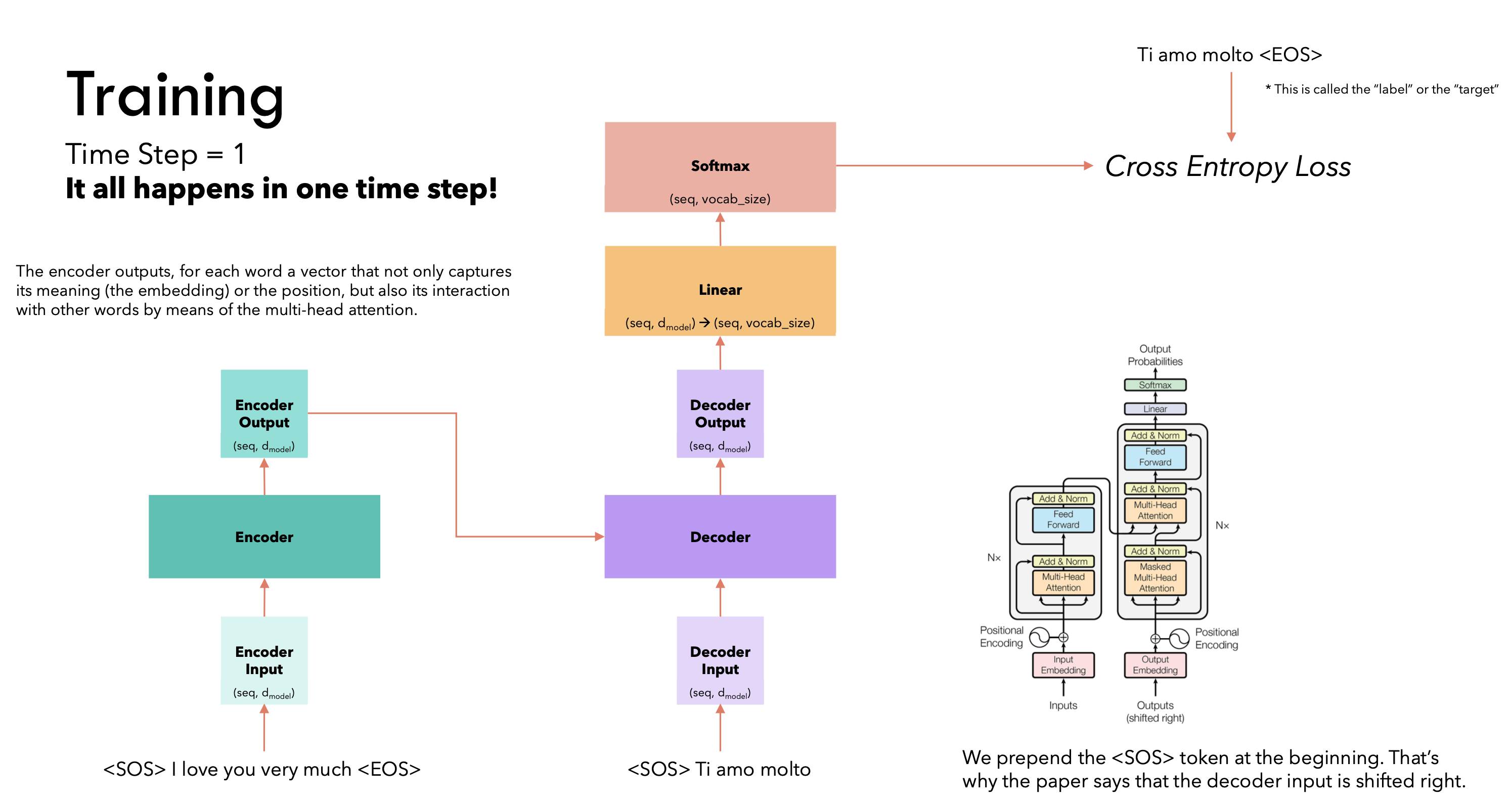
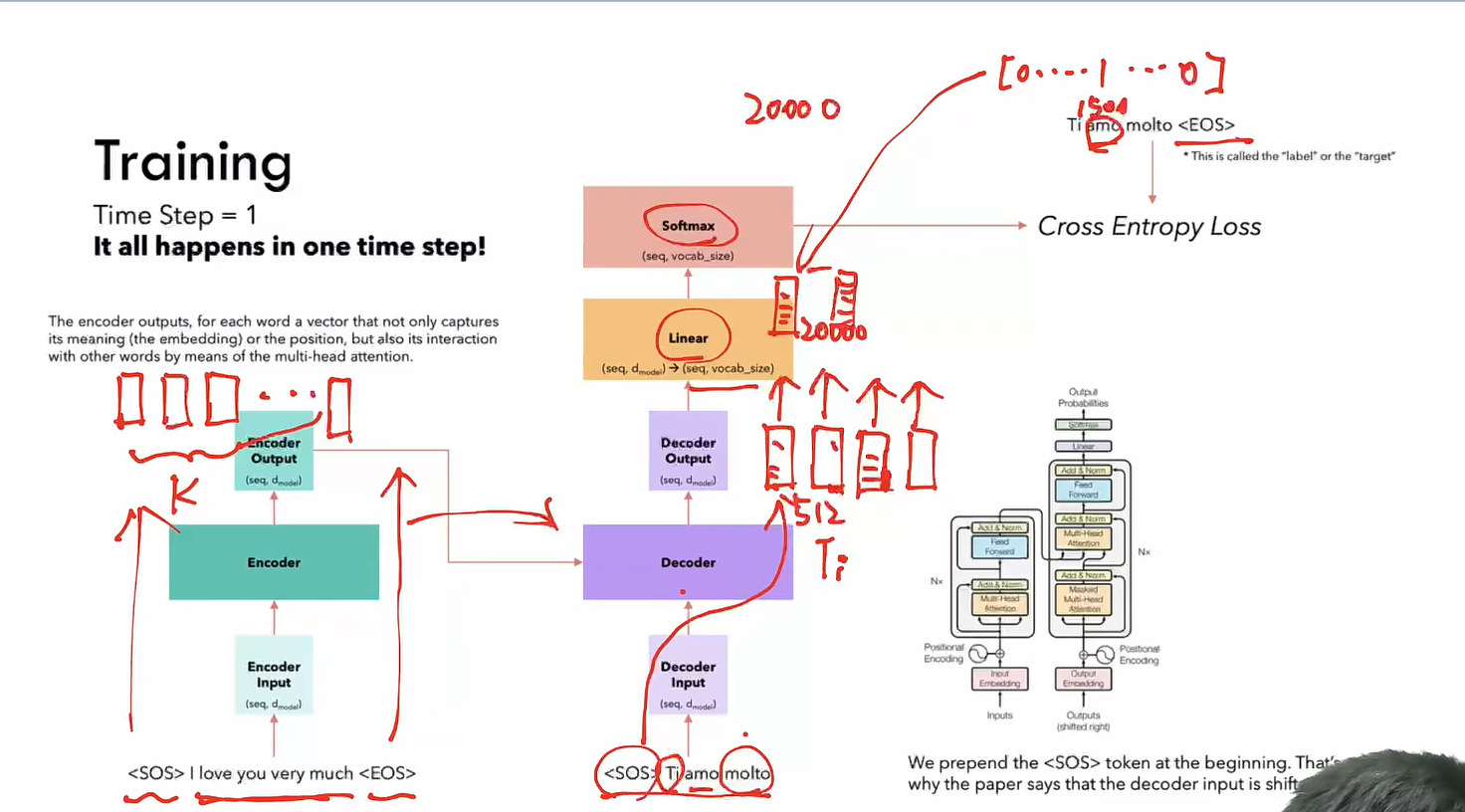
- Input放到encoder里面,会有对应的k个向量的输出,output放到Decoder里面,也会有对应的n个向量的输出
- 对于Decoder输出,映射后过一个线性层,映射到vocab_size长度的向量上,并且去取它做一个softmax,变成了一个长度为vocab_size,概率和为1的概率分布,这样就可以得出它对于每一个token的概率。
- 假如我们通过SOS预测Ti,会把Ti视为一个独热编码,如果Ti的标签是1500,最终和预测的概率分布进行交叉熵损失函数计算,通过sos就能最大化ti的概率,让它去通过sos把Ti的概率变大
- 每个token虽然我拿到的是对应的token,但是我这个token对应的向量的作用是用来预测下一个单词的,会和下一个单词做交叉熵,所以每一个token的信息是尽力去贴合下一个token的,这就是自回归任务
- 最后一个单词和EOS这个token做交叉熵,代表如果有最后一个单词,最后预测出EOS,这就是结束符。当我的模型预测出结束符之后,代表这句话结束了,代表一个终止
- 这是一个并行的过程,在一个时间步内完成
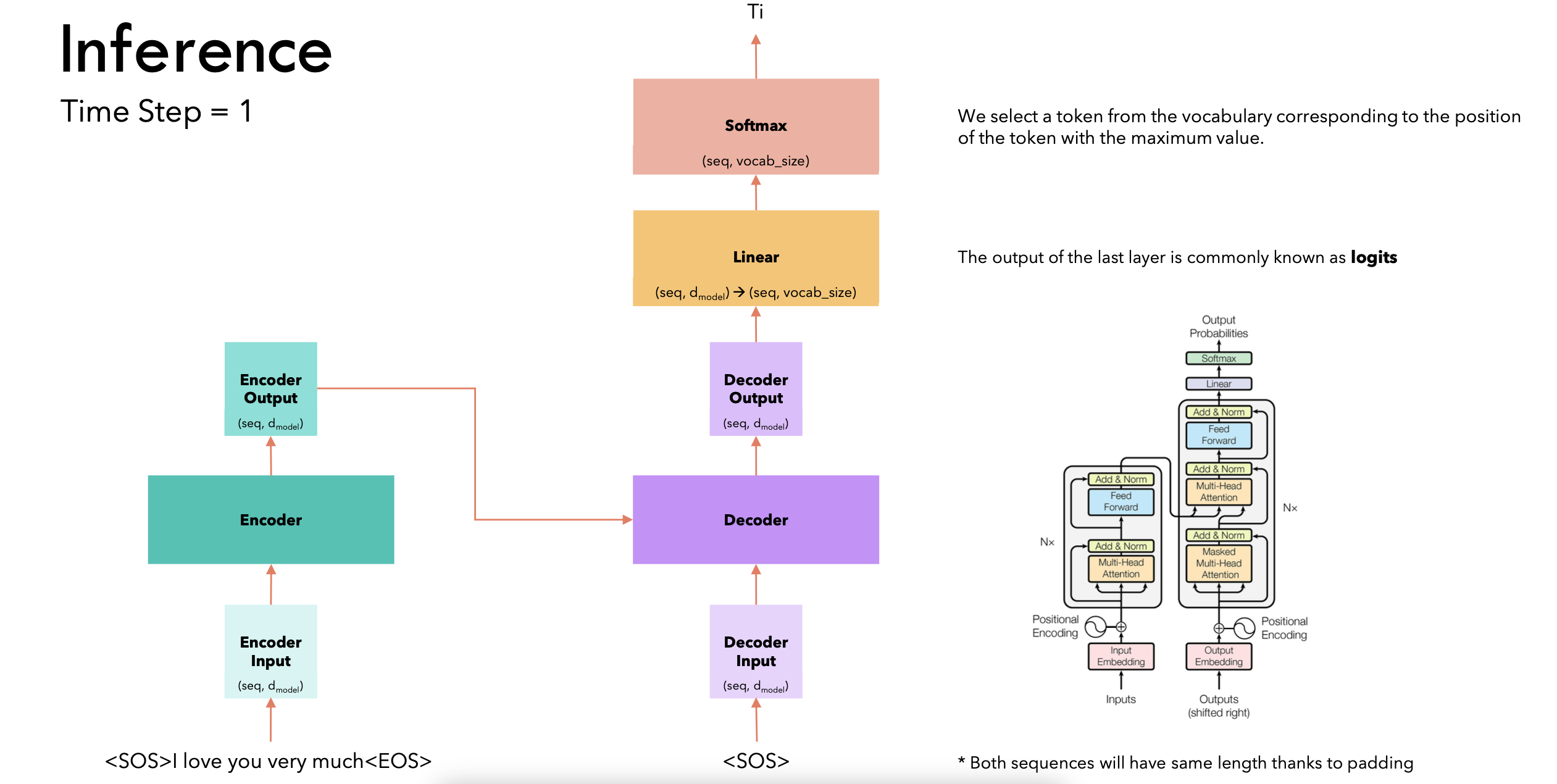
推理
-
训练是一个并行执行的过程,而推理是一个一步步的过程
- 因为训练是知道label的,我知道前面的词是什么,即使预测错了也会拿正确的前面的label去预测后面的此
- 对于推理来说,我是不知道实际真实的标签,只能一步步预测,把第一步的预测结果放到下一个时间步,只有知道前一个token才能预测下一个token,是一个串行执行的过程
- 因此这里可能导致误差累积,前一个错了下一个可能更错
-
时间步1
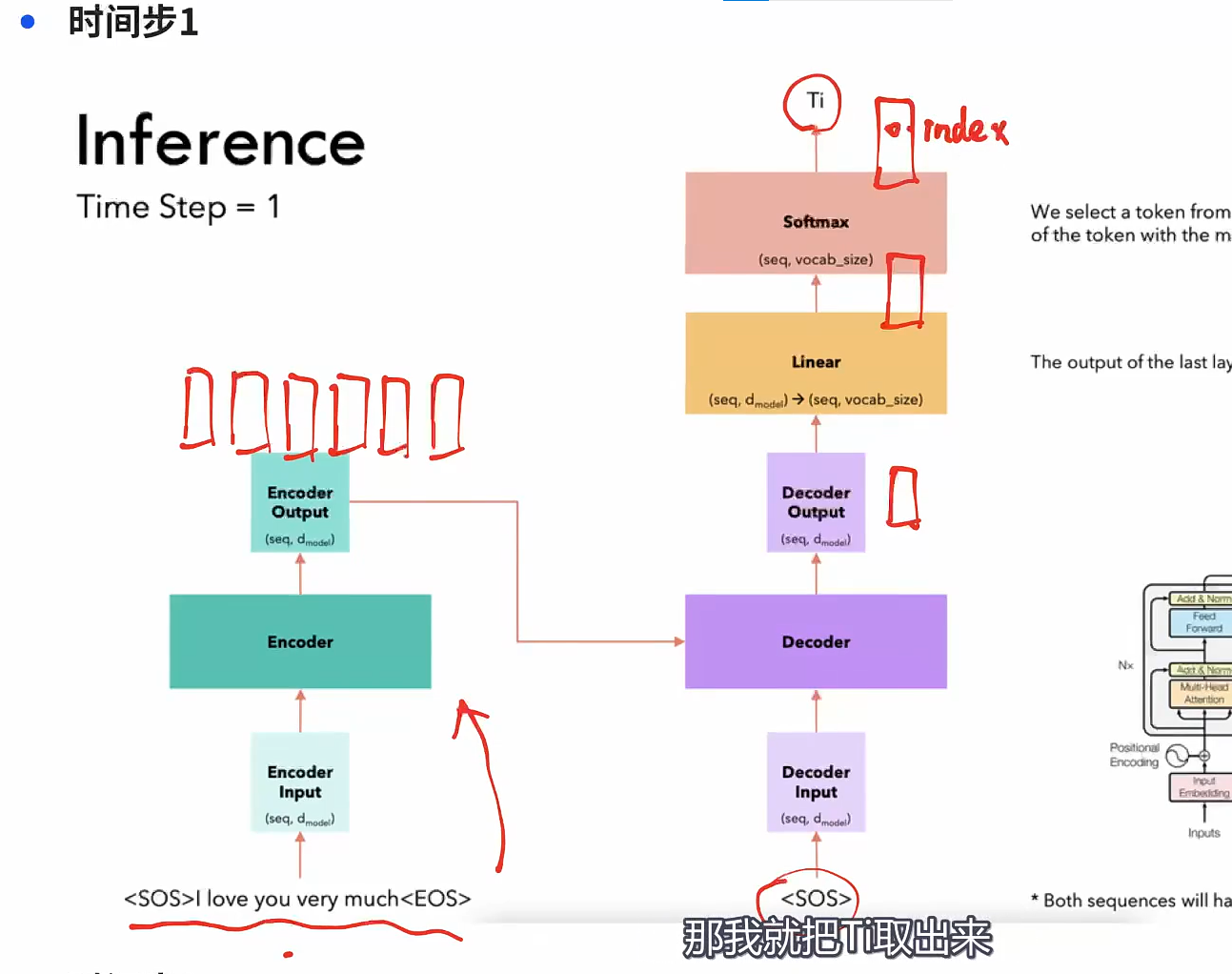
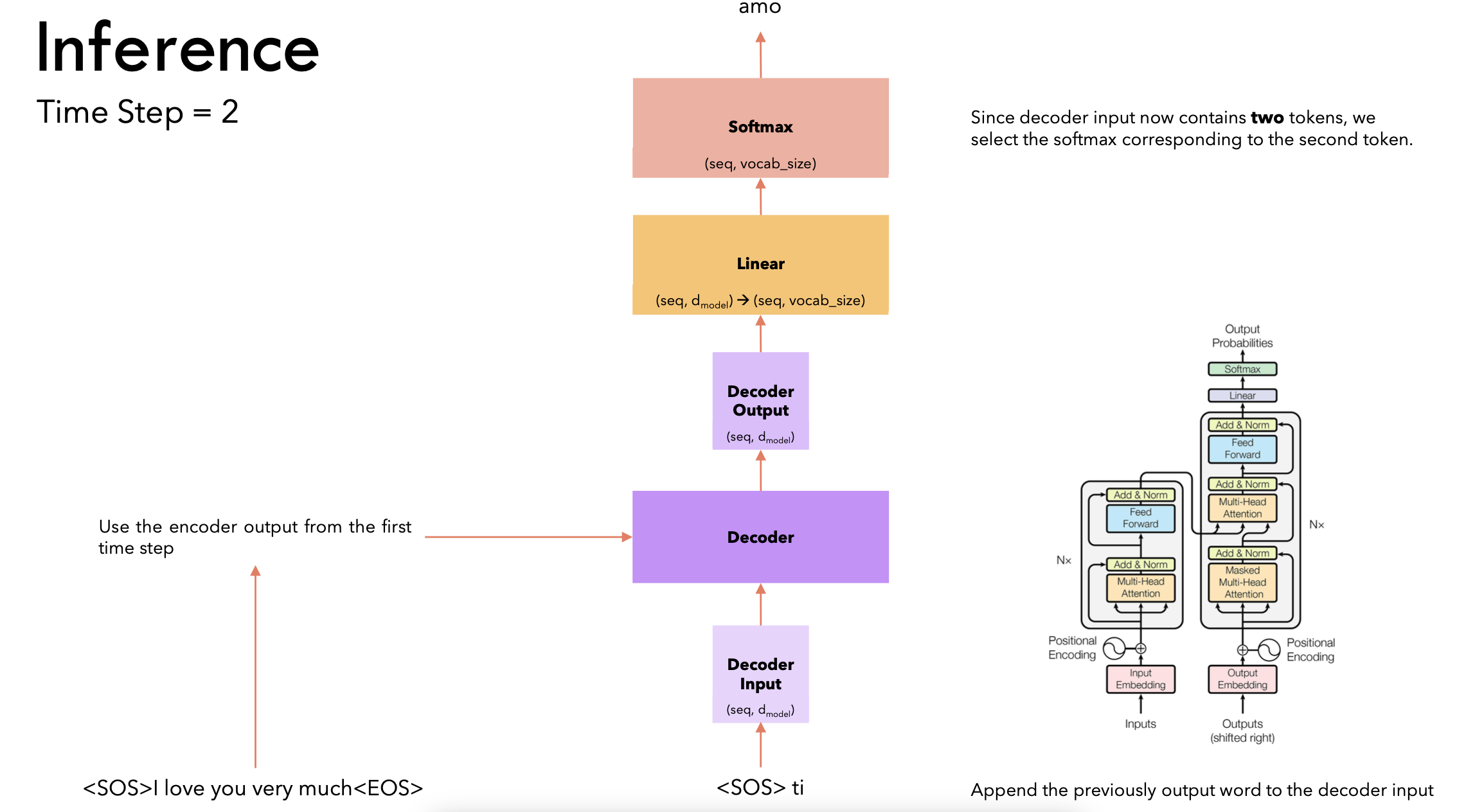
- 时间步2
- 时间步3
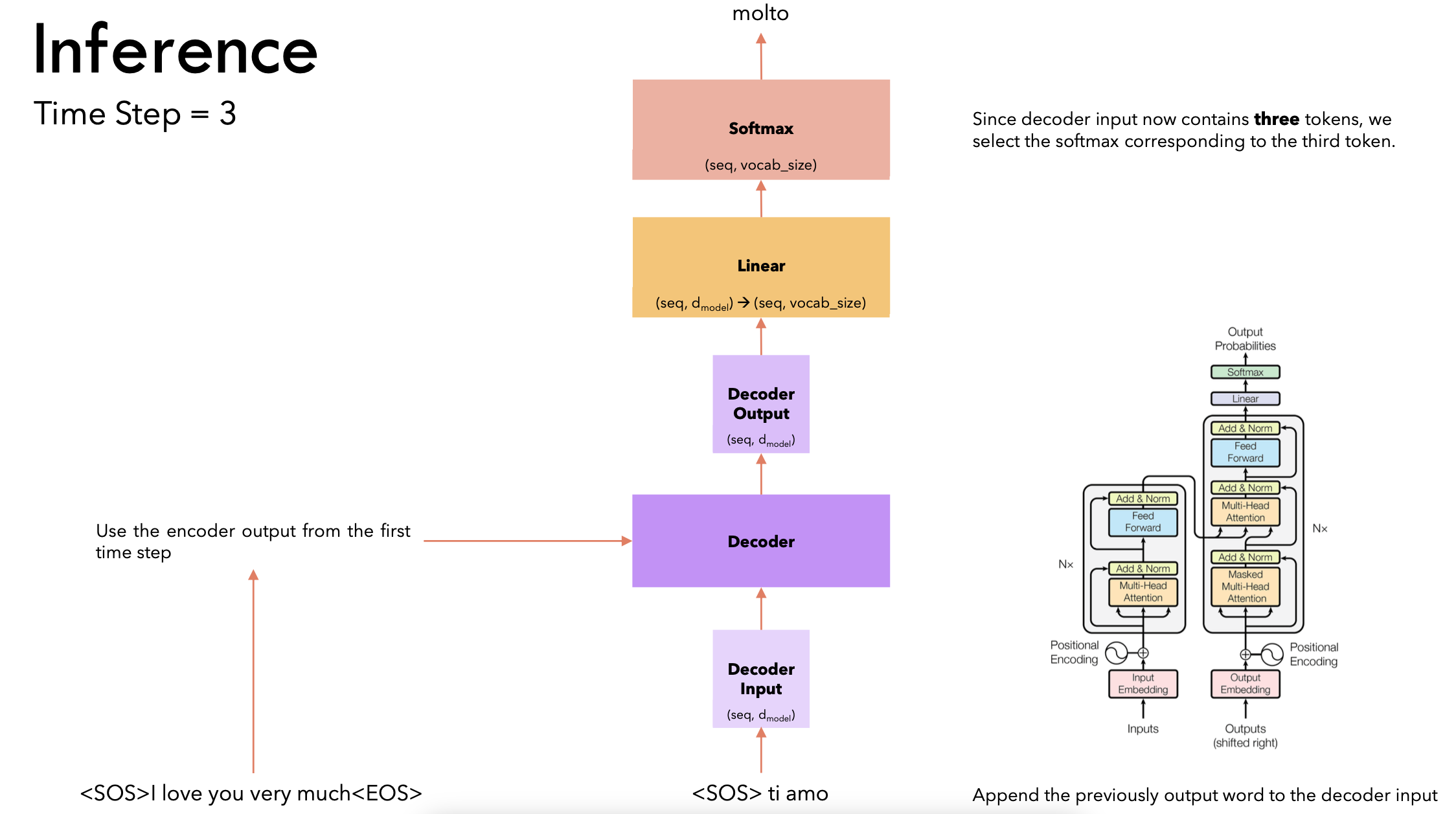
- 时间步4
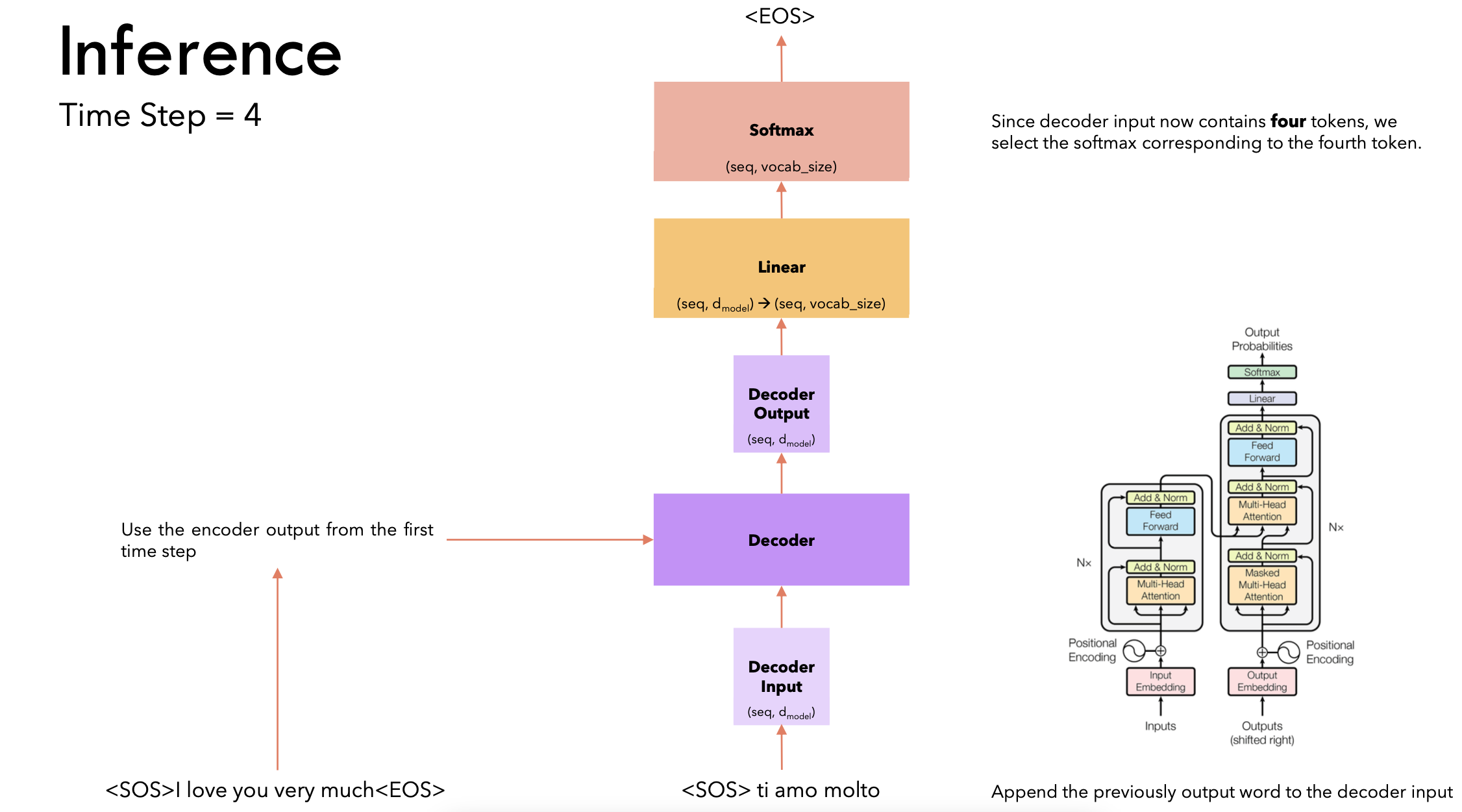
Transformer从0到1
- 组件:
- Feed Forward
- Add&Norm
- Multi-Head Attention
- Self Multi-Head Attention
- Mask-Self Attention
- Cross Attention
1 | |
大语言模型
BERT结构

-
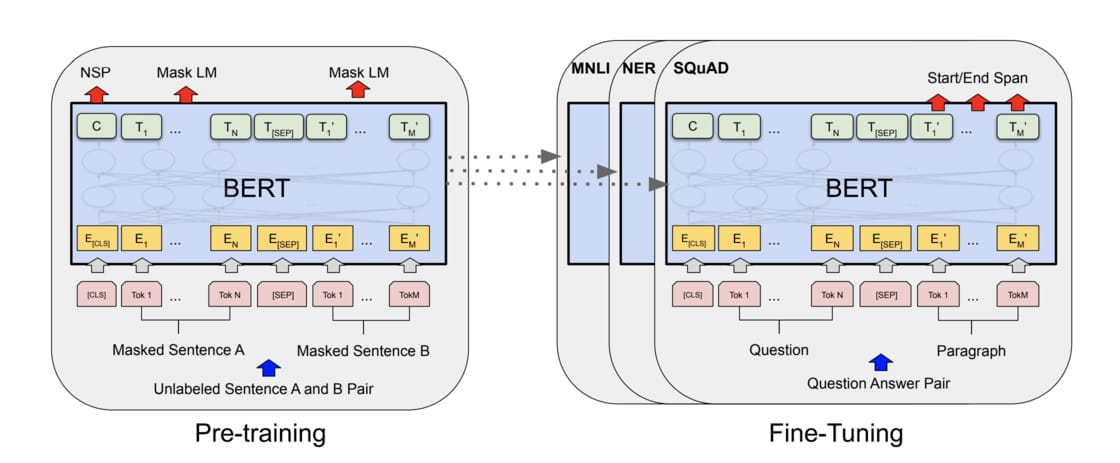
NLP在BERT之前,一直没有一个深的神经网络,使得我训练好之后能够帮助一大片的NLP的任务,导致在NLP里面,很多时候还是对每个人构造自己的神经网络,然后在自己上面做训练。BERT的出现使得我们终于可以在一个大的数据集上,训练好一个比较深的神经网络,然后应用在很多NLP的任务上面,既简化了这些NLP任务的训练,又提升了它的性能
-
Pre-training:在一个训练集上训练好一个模型,这个模型主要的目的是用在一个别的任务上面
-
BERT:深的双向的transformer,用来做预训练的,针对的是一般的语言的理解任务
-
Bert是用来设计去训练深的双向表示,然后使用没有标号的数据,然后再联合左右的上下文信息
- GPT:单向,用左边的上下文信息去预测未来,而BERT用了左边和右边的信息,所以是一个双向的
- ELMo用的是一个RNN架构,而BERT用的是Transformer,所以ELMo在用到一些下游的任务的时候下,需要对架构进行调整,而BERT的地方相对比较简单,只需要改最上层
-
使用非监督的预训练是非常好的,这样使得训练资源(训练样本)比较少的任务,也能够享受深度神经网络,主要的工序就是把前任的结果拓展到深的双向的架构上面,使得同样的一个预训练的模型,能够处理大量的不一样的自然语言的任务
-
ELMo用了双向的信息,但是网络架构用的是比较老的RNN,GPT用了新一点的transformer,但只能处理一些单向的信息,BERT就是把ELMo双向的想法和GPT使用transformer的东西合起来,具体改动就是在做语言模型的时候不是预测未来,而是变成完形填空
-
BERT和它之后的一系列工作,证明了在NLP上面使用没有标号的大量的训练集训练成的模型,效果比在有标号的相对说小一点的数据上训练模型效果更好
-
BERT有两个步骤:
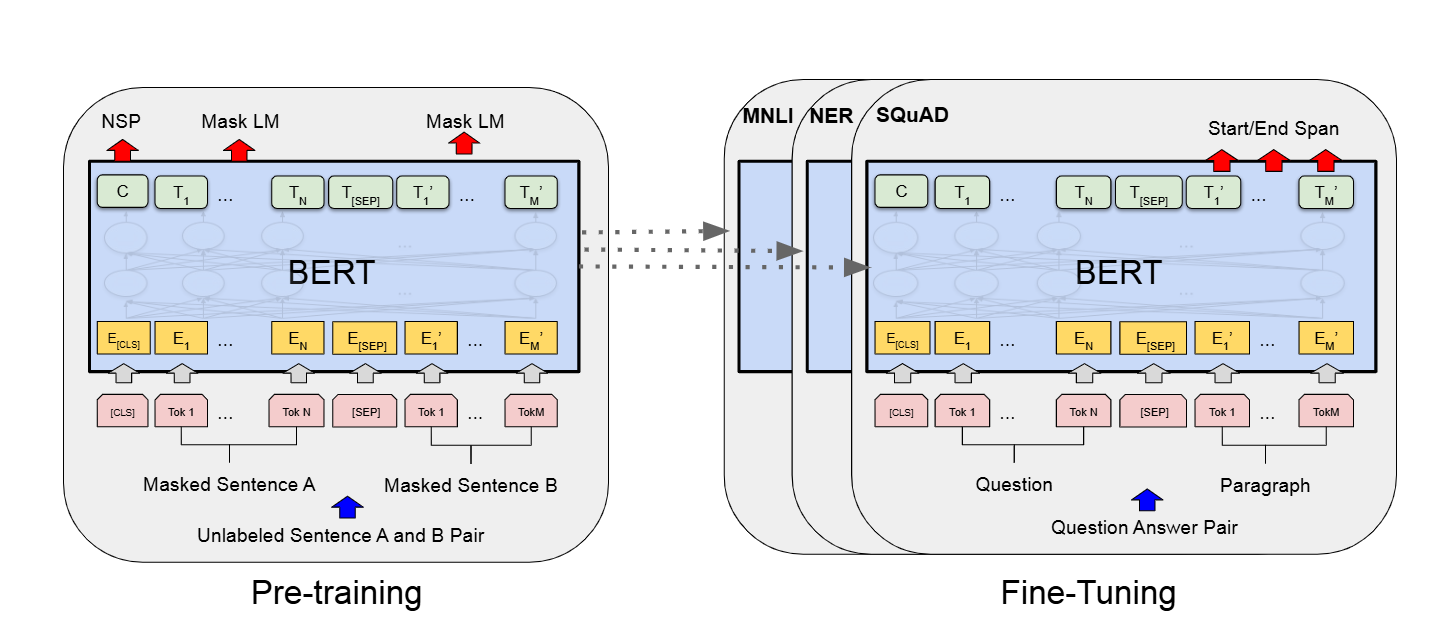
- 预训练
- 模型是在一个没有标号的数据上训练,把它的权重训练好
- 微调
- 同样适用一个BERT的模型,但是它的权重被初始化成我们在预训练中间得到的那个权重,所有的权重在微调的时候都会被参与训练,用的是有标号的数据。
- 每一个下游的任务都会创建一个新的BERT模型,其权重的初始化值来自于前面训练好的权重,虽然他们都是用最早那个预训练好的BERT模型作为初始化,但是对每一个下游任务,都会根据自己的有标号的数据对BERT继续进行训练,这样子得到对这个任务而言我BERT的版本
- 调了三个参数:
- L:transformer块的个数,H隐藏层的大小,A是自注意力机制里面多头的头的个数。
- 两个模型
- BERT_BASE
- BERT_LARGE
- BERT模型的复杂度跟层数是一个线性的关系,跟宽度是一个平方的关系,深度变成了两倍,宽度也选择了一个值使得这个增加的平方大概是之前的两倍
- 预训练
-
怎么把超参数换算成可学习参数的大小?
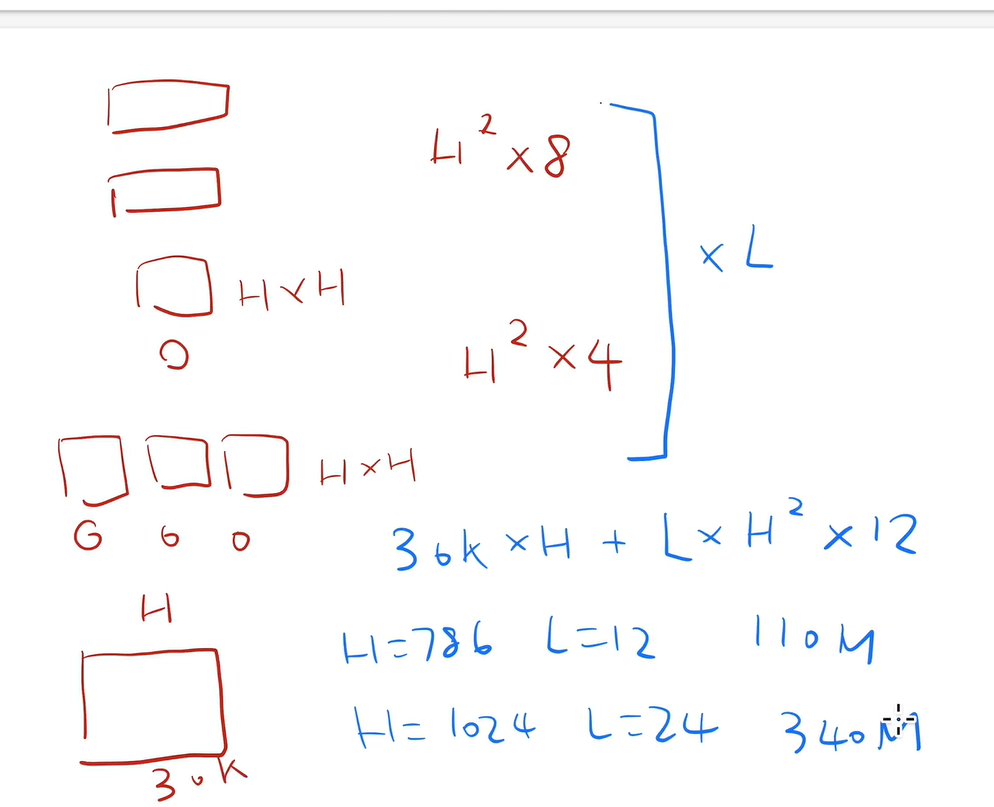
- 模型里可学习的参数主要来自于两块
- 嵌入层
- 矩阵,输入是字典的大小,输出是隐藏单元的个数h
- 嵌入层输出会进入transformer块
- transformer块
- 有两个东西
- 自注意力机制
- 自注意力机制本身没有可学习的参数,但是对多头注意力的话,它会把所有进入的KVQ分别做一次投影,这个投影矩阵就是可学习的参数,之后结果还有一个投影映射到目标,所以还有一个投影矩阵参数学习。
- MLP多层感知机
- 两个全连接层,两个需要学习的矩阵参数
- 自注意力机制
- 有两个东西
- 嵌入层
- 模型里可学习的参数主要来自于两块
-
输入和输出
-
输入:既可以是一个句子,也可以是一个句子对
-
句子是一段连续的文字,不一定是语义善过的句子
-
输入是一个序列,可一个句子也可以两个句子
- 和transformer不一样,transfomer训练的时候输入是一个序列对,编码器和解码器会分别输入一个序列,但是BERT这里只有一个编码器,为了处理两个句子的情况,需要把两个句子变成一个序列
-
WordPiece:如果一个词在整个里面出现的概率不大的话,应该切开看子序列如果某一个子序列是一个词根,那么只保留这个子序列就行了,这样就可以把一个很长的词切成一个个片段,而且这些片段是经常出现的。这样的话我可以用一个相对来说比较小的,3w的一个词典就能表示一个比较大的文本
-
嵌入层
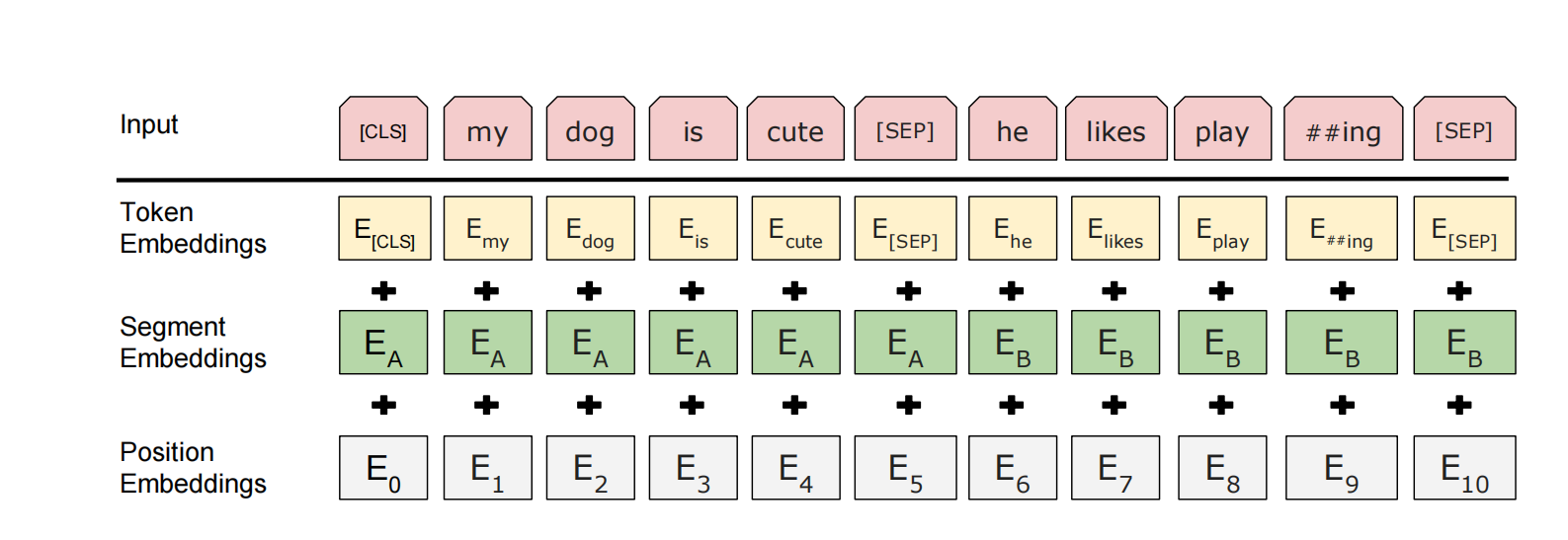
- 输入就是每一个token本身的嵌入,加上句子位置的嵌入,加上序列位置的嵌入
- BERT里面对应的向量都是通过学习得来的
-
对于一个输入的token,如果是wordpiece生成的,有15%的概率会随即替换成一个掩码MASK,对于特殊的token如CLS和SEP,不做替换。训练的时候大概看到15%的MASK,微调的时候没有MASK,因为微调不用这个函数,所以没有mask的东西,二者看到的数据不一样,可能有一定的问题
- 解决方法:对于15%选中的去mask的词,有80%真的替换,10%的概率替换成随机的token,10%的概率什么都不干,就存在那里,但是用它做预测,相当于加了一些噪音
-
-
-
BERT和编码器解码器的不同
- BERT把整个句子对都放在一起进去了,所以self-attention能够在两端互相看,在编码器解码器架构里面,编码器看不到解码器的东西。
- 代价:不能像TRANSFOMER一样机器翻译
-
BERT原论文超参数做微调结果非常不稳定
- 方差很大
- 3epoch太少
- BERT用的是Adam不完全版,需要换回正常版
-
BERT双向带来的坏处
- 机器翻译不好做
- 文本摘要/生成类不好做
- 更适合NLP分类问题
-
BERT符合大家对于一个深度学习模型的期望,训练一个很深很宽的模型,在一个很大的训练集上训练好,这个模型拿出来以后,可以用在很多小的问题上,能够通过微调来全面提升这些小数据上的性能。
BERT:NLP领域的巨人
-
在BERT出现之前,很多NLP任务(如情感分析、问答系统等)需要分别设计任务特定的模型,导致开发成本高、迁移能力差。下图是一些例子
-
如果能有一个模型在大规模的无监督语料上做预训练,先捕获通用的语言知识(听懂人话),再通过微调适具体任务,从而显著降低开发的复杂性就好了。
-
人类在理解语言时是双向的,会结合前后文语义来理解当前词的含义。BERT的核心创新是采用了双向编码器,通过Transformer架构实现了对上下文的双向理解,因此人们就想将文本理解和表征工作大一统于BERT。
BERT介绍
-
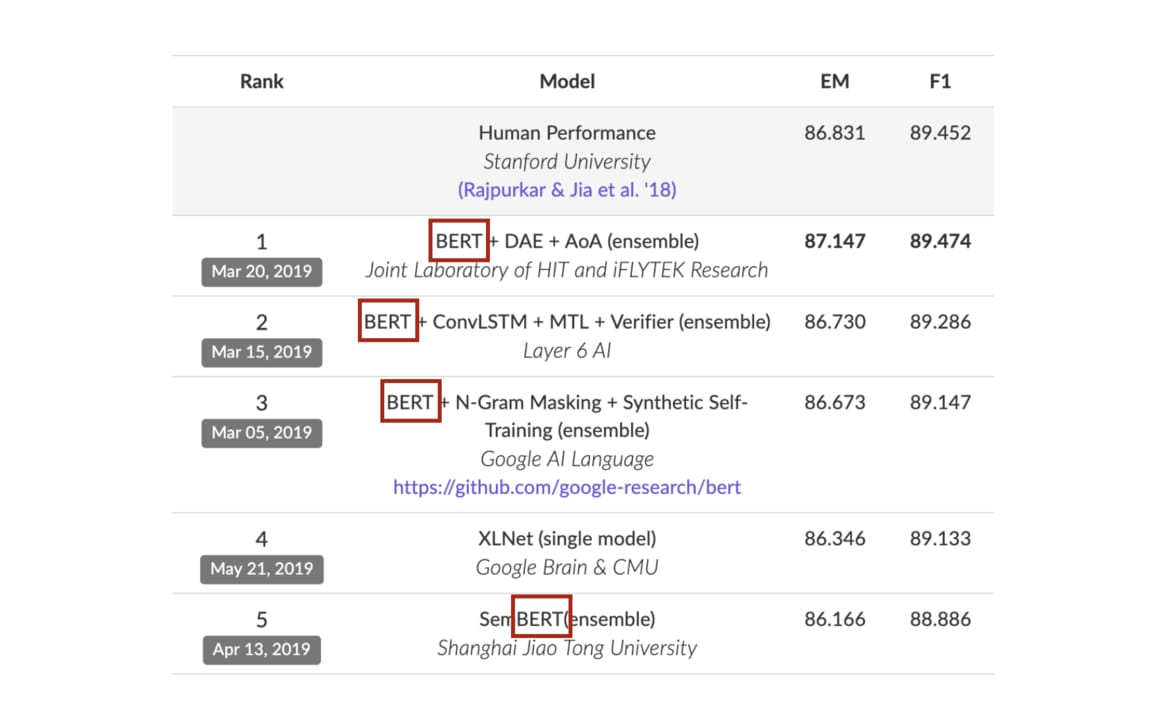
BERT(Bidirectional Encoder Representation from Transformers)是2018年10月由Google AI研究院提出的一种预训练模型,该模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
-
BERT的网络架构使用的是《Attention is all you need》中提出的多层Transformer结构。其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。Transformer的结构在NLP领域中已经得到了广泛应用。
-
“长期依赖问题”说白了就是:
一句话里,决定当前这个词/这个判断的关键信息,可能在很远很远之前出现,模型需要“记住并用上”那条远处的信息。
-
1)一个最直观的例子(语法一致)
- The book that I borrowed from the library last week *is* interesting.
主语是 book(单数),动词应该用 is。
但 book 和 is 中间隔了很长一段修饰成分。模型必须跨越这段距离,依然把 book 当作主语。
如果模型“记不住开头的 book”,就可能误用 are。
2)语义上的长期依赖(指代、上下文)
- 小王把小李的手机捡到了。后来他还给了失主。
“他”指的是谁?答案依赖前文人物关系和事件链,有时跨好几句。
3)为什么说这在 NLP 里“棘手”?
因为传统 RNN/LSTM 是按顺序一步步处理的:
- 信息要从句子开头传到很后面,得经过很多步传播
- 传播越久,信息越容易“衰减/被覆盖”(训练时还会出现梯度消失/爆炸)
- 结果就是:离得越远,模型越难把前面关键信息用到后面
这就是“长期依赖难学”。
4)Transformer 为什么缓解它?
Transformer 用 attention:当前词可以直接“去看”任意位置的词(计算相关性),不需要像 RNN 那样一步步传递。
所以课里常说“把任意两词的距离变成 1”,意思是:
- 在计算上,从 A 用 attention 关注 B,不管 B 在多远,都可以“一步到位”建立联系。
一句话总结:
长期依赖问题 = 需要跨很长文本距离,把早先的信息正确地用于后面的理解/预测;传统序列模型传得远就容易丢,Transformer 用 attention 让远处信息能直接被用到。 - The book that I borrowed from the library last week *is* interesting.
-

BERT框架
-
一个(巨大的)变换器模型编码器(没有解码器)
-
两种模型大小:
- 基础版:#blocks = 12,隐含大小= 768,#heads = 12,#参数 = 110M
- 增强版:#blocks = 24,隐含大小= 1024,#heads = 16,#参数= 340M
-
使用超过30亿单词的大型语料库(书籍和维基百科)训练
-
模型输入
Embedding
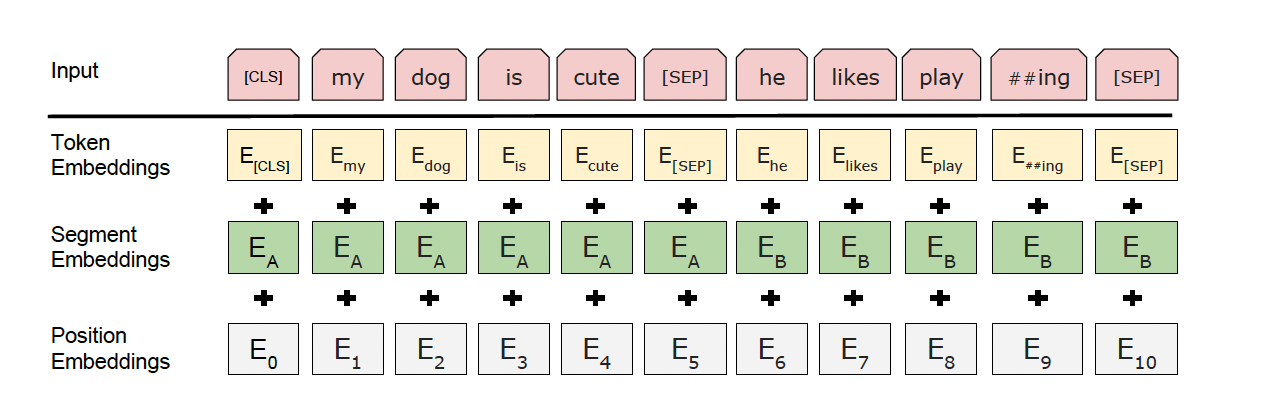
-
Embedding由三种Embedding求和而成:
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
-
其中
[CLS]表示该特征用于分类模型,对非分类模型,该符号可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。 -
BERT在第一句前会加一个
[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。 具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层(BERT-base为例),每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。而[CLS]位本身没有语义,经过12层,句子级别的向量,相比其他正常词,可以更好的表征句子语义。
Transformer Encoder¶
-
BERT是用了Transformer的encoder侧的网络。
-
在Transformer中,模型的输入会被转换成512维的向量,然后分为8个head,每个head的维度是64维,但是BERT的维度是768维度,然后分成12个head,每个head的维度是64维,这是一个微小的差别。Transformer中position Embedding是用的三角函数,BERT中也有一个Postion Embedding是随机初始化,然后从数据中学出来的。
-
BERT模型分为24层和12层两种,其差别就是使用transformer encoder的层数的差异,BERT-base使用的是12层的Transformer Encoder结构,BERT-Large使用的是24层的Transformer Encoder结构。
BERT分词
句子A:I went to the store.句子B:At the store, I bought fresh strawberries.
BERT 用 WordPiece工具来进行分词,并插入特殊的分离符([CLS],用来分隔样本)和分隔符([SEP],用来分隔样本内的不同句子)。
因此实际输入序列为:
[CLS] i went to the store . [SEP] at the store , i bought fresh straw ##berries . [SEP]
GELU作为激活函数替代ReLU
ReLU 的优点是简单、高效,但存在一些问题:
- 导数为 0 的负值区域会导致神经元死亡(Dead Neurons)。
- 在一些任务中,可能不如更复杂的非线性函数表现好。
GELU 的公式
GELU 激活函数的原始定义为:
其中 $$\Phi(x)$$是标准正态分布的累积分布函数,公式为
为了提升计算效率,《A logistic approximation to the cumulative normal distribution》论文中提出了一个近似公式:
- 近似公式与精确公式的曲线非常接近,大多数情况下近似公式已经足够。
这是一种更平滑的激活函数,相较于 ReLU,其优点在于:
- 平滑非线性:GELU 平滑地将输入值映射到 0 和非线性激活区域,更接近自然的神经元激活方式。
- 对负值的容忍性:不像 ReLU 会将负值直接截断,GELU 在负值区域也有一定的激活作用。
BERT 论文中提到选择 GELU 是因为在预训练语言模型中表现优于 ReLU 和其他常用激活函数(如 Swish 和 ELU)。
GELU 在处理小输入值时更加灵活,可以更有效地捕获语言数据中复杂的特征关系。
1 | |
BERT预训练和微调
BERT的预训练任务
- BERT是一个多任务模型,它的预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP,如 下图 所示。
- 自监督:不需要人工进行一些标注,直接就把海量的文本拿过来,然后让其预测中间的一些词,不需要人工打标,自动形成这样的标签
- MLM:把中间的一些词mask掉,让你去预测mask掉的单词
- NSP:给你两个句子,让你去判断这两个句子是否连贯
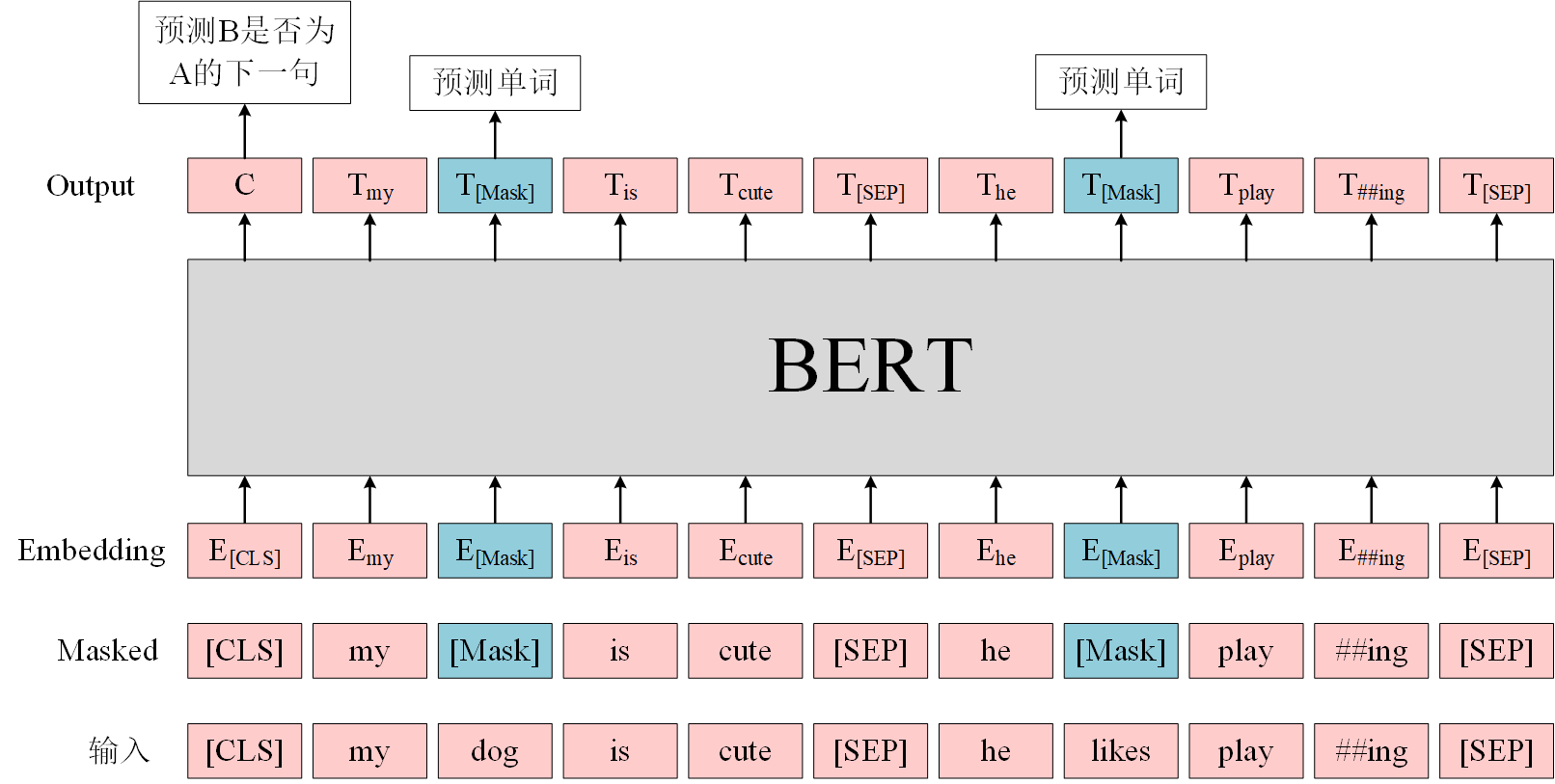
MLM¶
- **MLM是指在训练的时候随即从输入语料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。**正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。在BERT的实验中,**15%**的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
- 80%的时候会直接替换为
[Mask],将句子my dog is cute转换为句子my dog is [Mask]。 - 10%的时候将其替换为其它任意单词,将单词
cute替换成另一个随机词,例如apple。将句子my dog is cute转换为句子my dog is apple。 - 10%的时候会保留原始Token,例如保持句子为
my dog is cute不变。
- 80%的时候会直接替换为
- 不是100%Mask掉的原因
这么做的原因是如果句子中的某个Token 100%都会被mask掉,在实际的下游任务中(如问答、分类等),输入数据通常不会包含[Mask]。如果模型没有在非[Mask]的上下文中学会预测单词,就可能表现不佳。
- 加入随机token得原因
- 随机替换会将目标词替换为一个与上下文语义可能完全无关的词。例如,将句子
My dog is cute替换为My dog is apple。 - 这会让模型面对矛盾或异常的信息,迫使它更加依赖上下文中的其他线索(而不是简单模式匹配)来预测被遮蔽的词汇。
- 这样增强了模型对上下文的整体理解能力,有助于其在复杂语境中进行语义推理。
- 随机替换会将目标词替换为一个与上下文语义可能完全无关的词。例如,将句子
- 保持不变token的原因
- 在预训练阶段,如果目标词总是被遮蔽或替换,而下游任务中目标词通常是完整的(没有
[Mask]标记),会导致模型在迁移到下游任务时表现不佳。 - 通过保持10%的目标词不变,模型能够在预训练时学会直接从上下文中预测单词(即使没有显式的
[Mask]标记),从而更贴合微调阶段的分布。
- 在预训练阶段,如果目标词总是被遮蔽或替换,而下游任务中目标词通常是完整的(没有
优点
- 1)被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;
- 2)被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
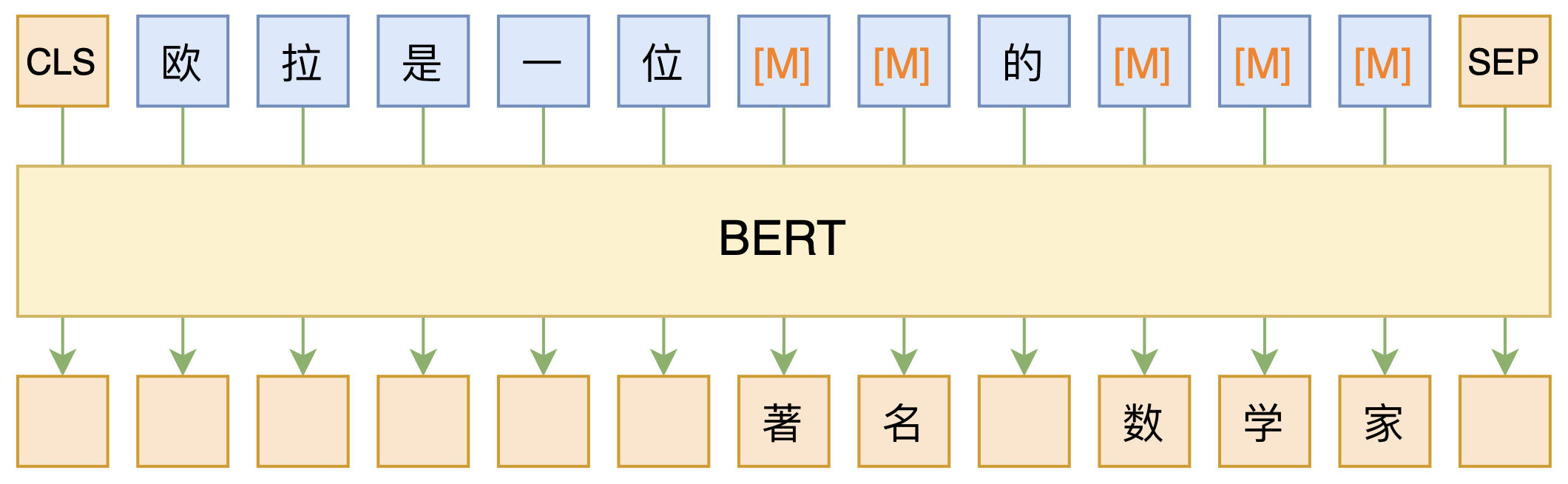
NSP
- Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出
IsNext,否则输出NotNext。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在图4中的[CLS]符号中。。

在此后的研究(论文《Crosslingual language model pretraining》等)中发现,NSP任务可能并不是必要的,消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高。这可能是由于Bert以单句子为单位输入,模型无法学习到词之间的远程依赖关系。针对这一点,后续的RoBERTa、ALBERT、spanBERT都移去了NSP任务。
BERT预训练模型最多只能输入512个词,这是因为在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的。在直接使用Google 的BERT预训练模型时,输入最多512个词(还要除掉[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的embedding。
如果有足够的硬件资源自己重新训练BERT,可以更改 BERT config,设置更大max_position_embeddings 和 type_vocab_size值去满足自己的需求
BERT微调
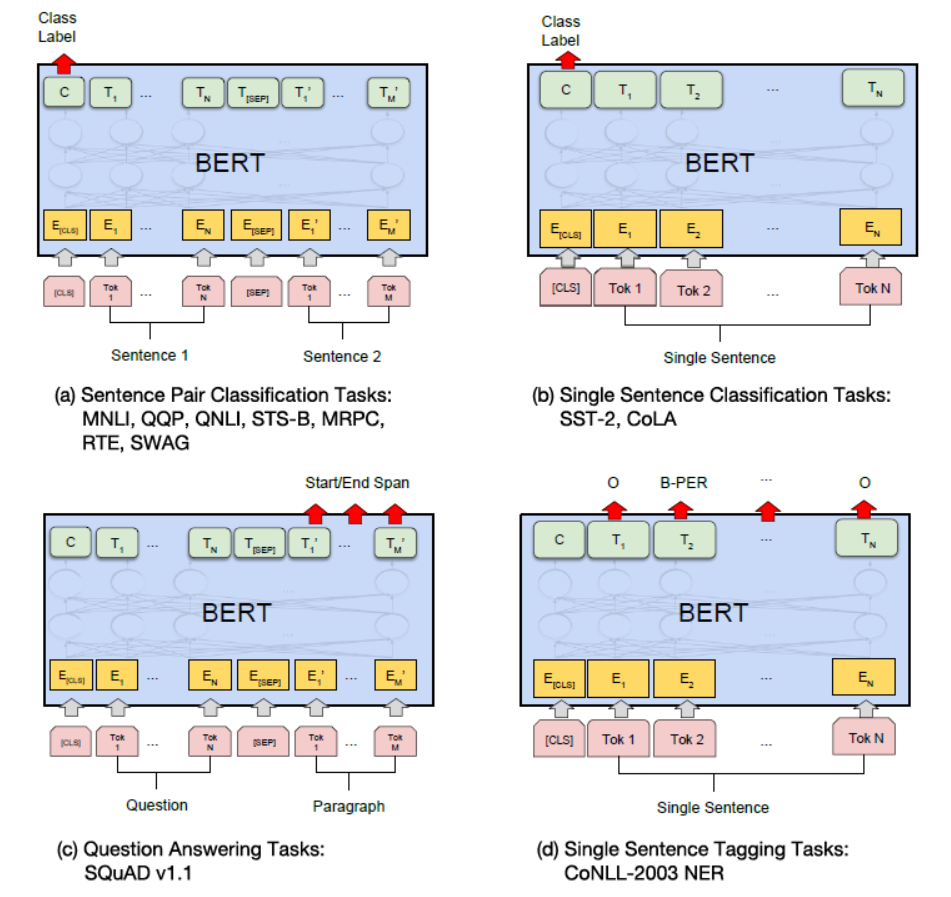
在海量的语料上训练完BERT之后,便可以将其应用到NLP的各个任务中了。 微调(Fine-Tuning)的任务包括:基于句子对的分类任务,基于单个句子的分类任务,问答任务,命名实体识别等。
- 基于句子对的分类任务:
- MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,我们需要做的是去发掘前提和假设这两个句子对之间的交互信息。
- QQP:基于Quora,判断 Quora 上的两个问题句是否表示的是一样的意思。
- QNLI:用于判断文本是否包含问题的答案,类似于我们做阅读理解定位问题所在的段落。
- STS-B:预测两个句子的相似性,包括5个级别。
- MRPC:也是判断两个句子是否是等价的。
- RTE:类似于MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。
- SWAG:从四个句子中选择为可能为前句下文的那个。
- 基于单个句子的分类任务
- SST-2:电影评价的情感分析。
- CoLA:句子语义判断,是否是可接受的(Acceptable)。
- 问答任务
- SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。
- 命名实体识别
- CoNLL-2003 NER:判断一个句子中的单词是不是Person,Organization,Location,Miscellaneous或者other(无命名实体)。
BERT代码从0到1
从0到1
1 | |
对于一般模型,都可以在Huggingface找到,关于模型参数,可以看conifg.json文件
1 | |
BERT-Kaggle实战
使用预训练BERT完成Kaggle任务:
- 完成相应包的导入
1 | |
1 | |
1 | |
.png)
1 | |
1 | |
.png)
1 | |
.png)
1 | |
.png)
1 | |
.png)
1 | |
1 | |
1 | |
1 | |
.png)
1 | |
1 | |
1 | |
1 | |
.png)
- 目录
.png)
1 | |
.png)
1 | |
.png)
1 | |
.png)
.png)
- 在Kaggle竞赛页面中提交

- 相比于GRU,获得了显著的性能提升,公榜和私榜分数都在0.94左右。
- 虽然竞赛已经结束,但我们在未经细致超参数调整和特征工程的情况下就能取得接近SoTA的分数,可见BERT模型预训练—微调模式的卓越能力。
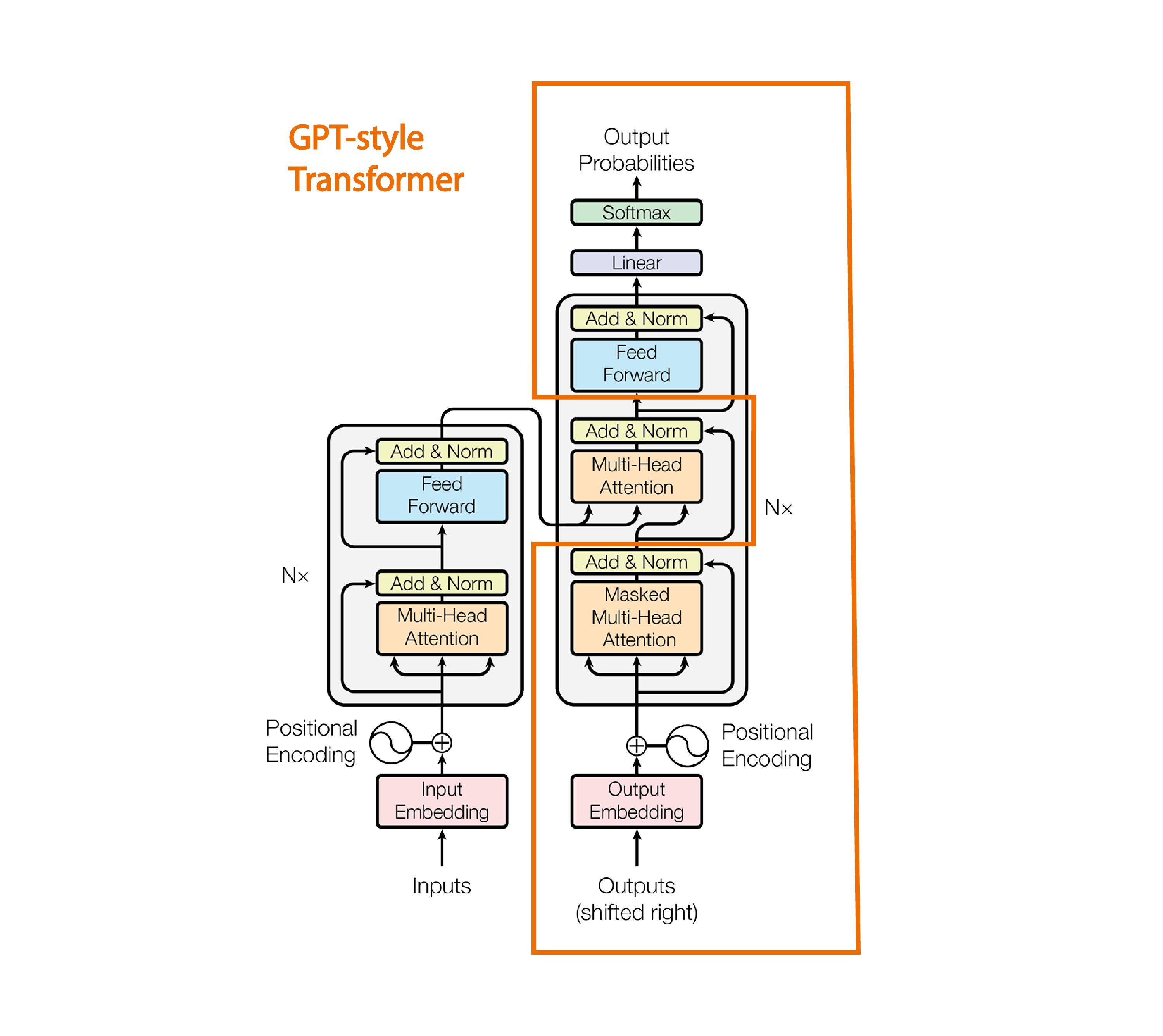
GPT结构
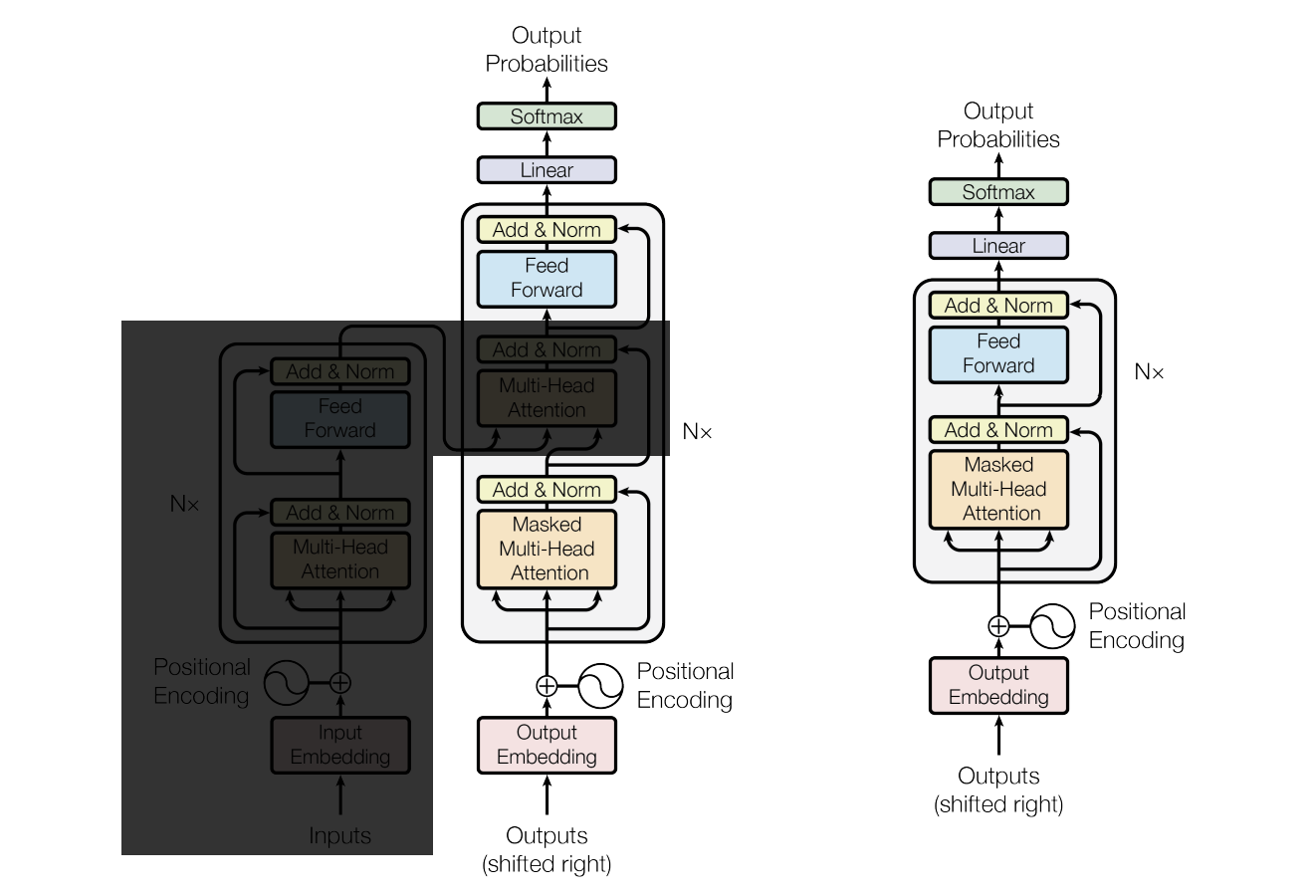
-
GPT(Generative Pretrained Transformer)采用的是Decoder-Only架构。简单来说,它基于Transformer模型,但仅使用Transformer的解码器部分,而不包含编码器。下面是这一结构的主要特点和工作原理:
- Transformer架构概述
- Transformer模型由两部分组成:编码器(Encoder)和解码器(Decoder)。
- 编码器主要用于处理输入序列,将其转换为上下文表示,而解码器则生成输出序列。
- GPT只使用了Transformer的解码器部分。encoder以及decoder和encoder做交互的这一部分去掉了。
- 解码器(Decoder)结构
GPT的解码器结构由多个相同的层(Layer)堆叠而成,每一层都包含以下几个关键组件:
- 自注意力机制(Self-Attention):通过自注意力机制,模型能够根据输入序列中的各个位置的上下文信息来调整对不同位置的关注权重。
- 前馈神经网络(Feedforward Network):通常由两个全连接层组成,用于进一步处理自注意力层的输出。
- 层归一化(Layer Normalization):用于对每一层的输出进行标准化,改善训练的稳定性。
-
GPT当时效果不太好是因为它整个的模型尺寸和训练数据的量级还没有推上去
GPT微观流程
输入和输出
-
BERT是上下文理解,通篇理解,生成的话需要GPT这种结构
- Transformer当时就是一个翻译任务,encoder拿来做原来的sequence的理解,decoder拿来做输出的,GPT就是删掉encoder,纯拿来做输出,直接在大规模的语料上学习分布,直接输出。
- 大道至简,简单的模型复杂多样的语料,最后生成的模型很符合人类的逻辑
- Transformer当时就是一个翻译任务,encoder拿来做原来的sequence的理解,decoder拿来做输出的,GPT就是删掉encoder,纯拿来做输出,直接在大规模的语料上学习分布,直接输出。
-
在我们了解其他内容之前,我们需要知道:GPT 的输入和输出是什么?
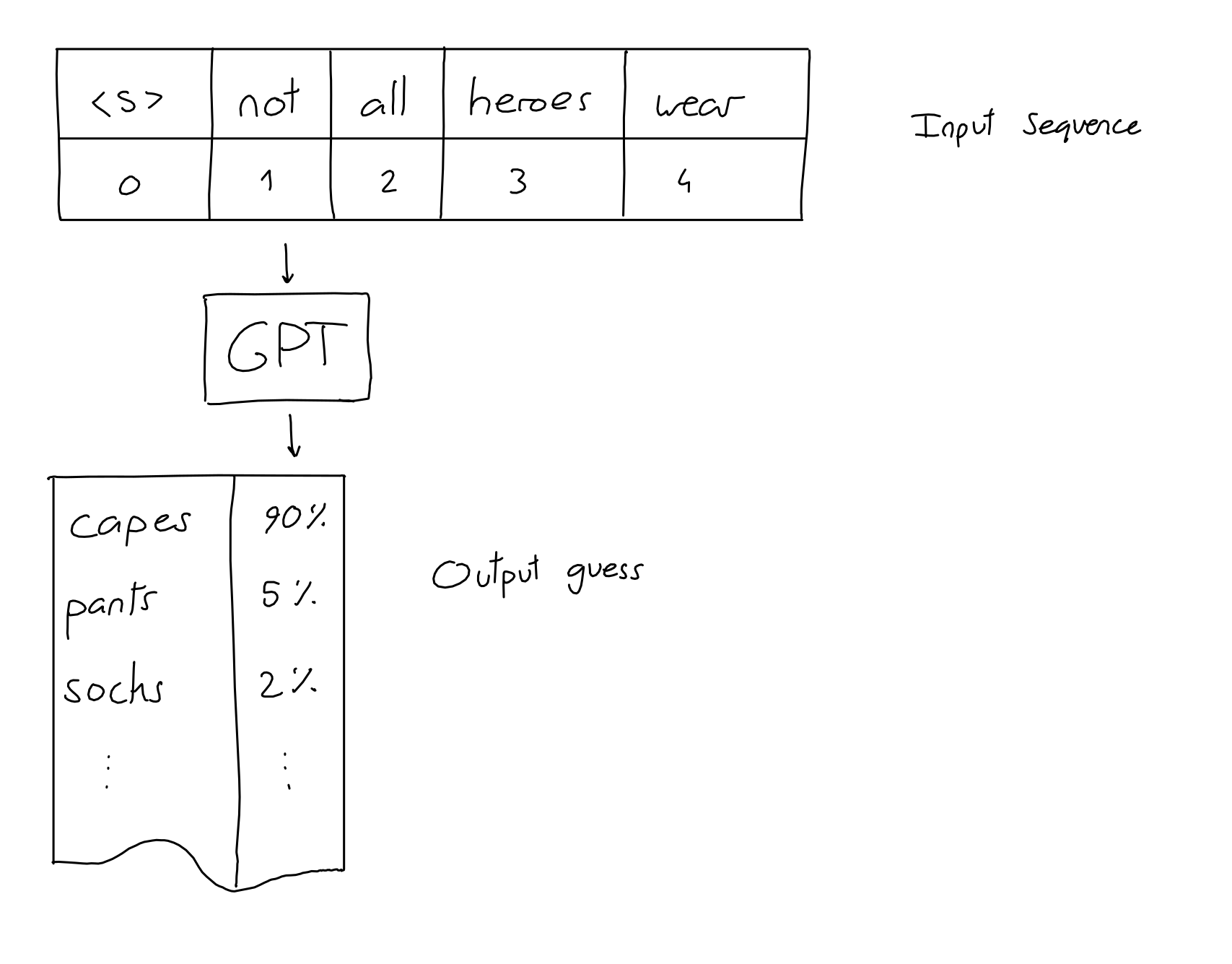
-
输入是 N 个单词(又称 token)的序列。输出是对最有可能放在输入序列末尾的单词的猜测。(词语接龙)
-
就是这样!你看到的所有令人印象深刻的 GPT 对话、故事和示例都是用这个简单的输入输出方案制作的:给它一个输入序列 - 获取下一个单词。
- Not all heroes wear -> capes
-
当然,我们经常想得到多个单词,但这不是问题:得到下一个单词后,我们将其添加到序列中,并得到下一个单词。
- Not all heroes wear capes ->
but - Not all heroes wear capes but ->
all - Not all heroes wear capes but all ->
villans - Not all heroes wear capes but all villans ->
do
- Not all heroes wear capes ->
-
根据需要重复,最终你会得到生成的长文本。
-
其实准确地说,我们需要从两个方面去纠正上述内容。
- 1、输入序列实际上固定为 2048 个字(对于 GPT-3)。我们仍然可以传递短序列作为输入:我们只需用“空”值填充所有额外的位置。
- 固定长度:矩阵运算,(batchsize,seqlen,embeddinglen)保证矩阵方方正正便于运算
- 不足padding补全,补全的部分mask掉
- 2、GPT 输出不只是一个猜测,而是一个猜测序列(长度为 2048)(每个可能单词的概率)。序列中的每个“下一个”位置都有一个猜测。但在生成文本时,我们通常只查看序列中最后一个单词的猜测。
- 预测值和真值做交叉熵损失函数,但是预测下一个的时候还是用真值的token(teach forcing)
- 不需要人为标注,一个sequence天生就是一个标注数据
- 在推理的时候,我们不知道整个序列,所以我们是一个token一token去生成,如果下一个token生成错了,它会把错误累积在后续输出,但如果训练数据足够广阔,它会把整个分布学习得非常正确,也就无所谓对错了,因为一句话可能有多种说话方式,不一定要按照特定的一个顺序来说
- 1、输入序列实际上固定为 2048 个字(对于 GPT-3)。我们仍然可以传递短序列作为输入:我们只需用“空”值填充所有额外的位置。
-
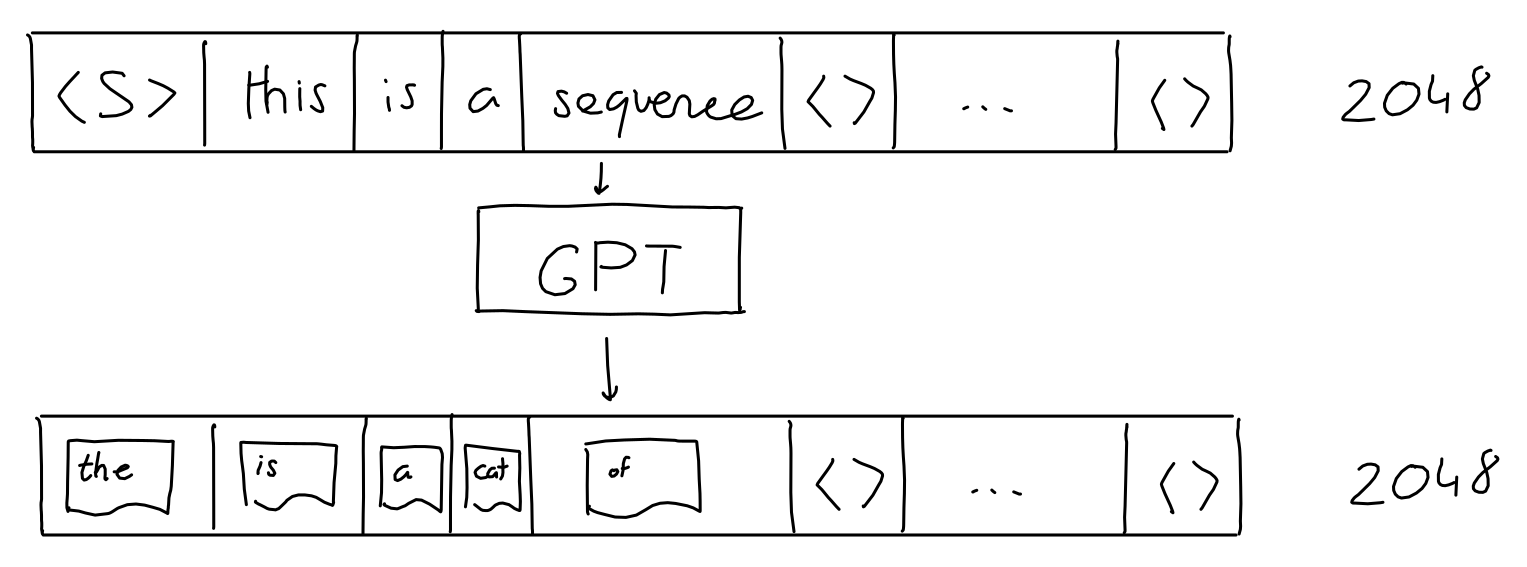
编码
-
但GPT 实际上无法理解单词。作为一种深度学习算法,它对数字向量进行操作。那么我们如何将单词转换成向量呢?
-
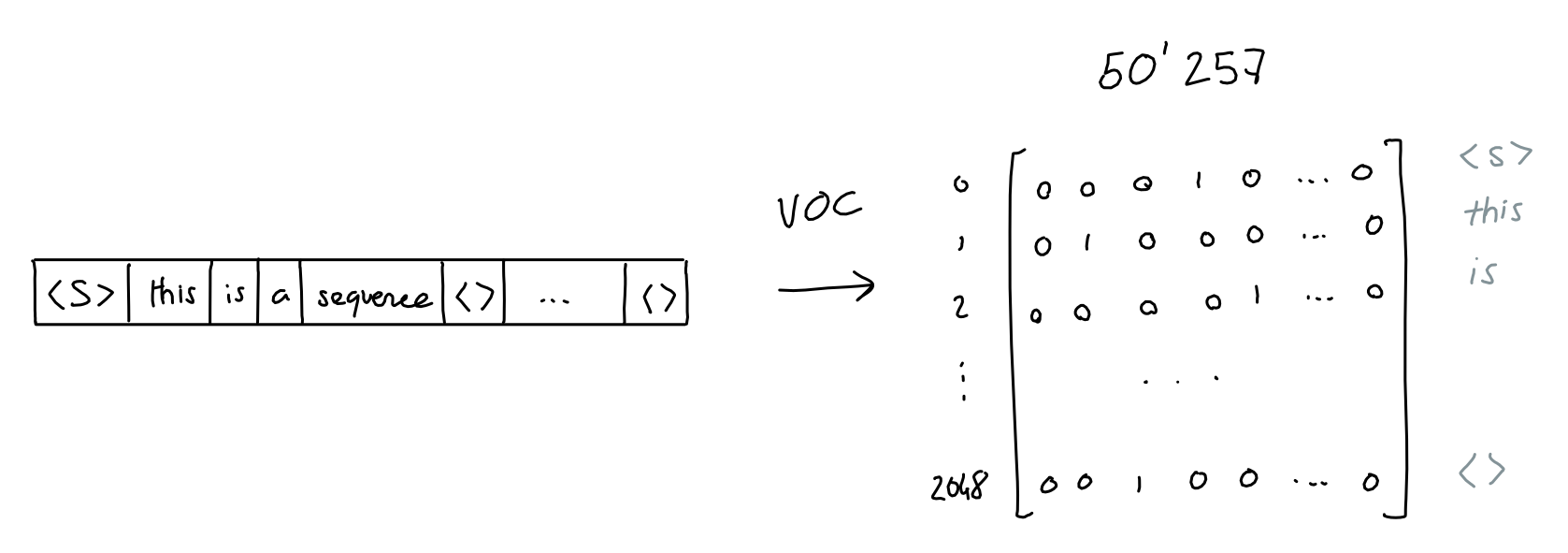
第一步是保留所有单词的词汇表,这样我们就可以为每个单词赋予一个值。Aardvark 为 0,aaron 为 1,依此类推。(GPT 的词汇表有 50257 个单词)。
-
注意:为了提高效率,GPT-3 实际上使用了字节级字节对编码 (BPE) 标记化。这意味着词汇表中的“单词”不是完整的单词,而是文本中经常出现的字符组(对于字节级 BPE,为字节)。
- 使用 GPT-3 字节级 BPE 标记器,“Not all heroes wear capes”被拆分为标记"Not" “all” “heroes” “wear” “cap” “es”,词汇表中的 ID 为 3673、477、10281、5806、1451、274。
-
因此,我们可以将每个单词变成一个大小为 50257 的独热编码向量,其中只有索引 i(单词的值)处的维度为 1,其他所有维度均为 0。
-

- 当然,我们对序列中的每个单词都这样做,
嵌入
- 50257 作为one-hot向量来说相当大,而且其中大部分都是零,且token与token之间彼此正交。这浪费了很多空间。
- 为了解决这个问题,我们学习了一个嵌入函数:一个神经网络,它接受一个长度为 50257 的 1 和 0 向量,并输出一个长度为 n 的数字向量。在这里,我们试图将单词含义的信息存储(或投影)到更小的维度空间。
- 例如,如果嵌入维度为 2,则就像将每个单词存储在 2D 空间中的特定坐标处。
- 为了解决这个问题,我们学习了一个嵌入函数:一个神经网络,它接受一个长度为 50257 的 1 和 0 向量,并输出一个长度为 n 的数字向量。在这里,我们试图将单词含义的信息存储(或投影)到更小的维度空间。
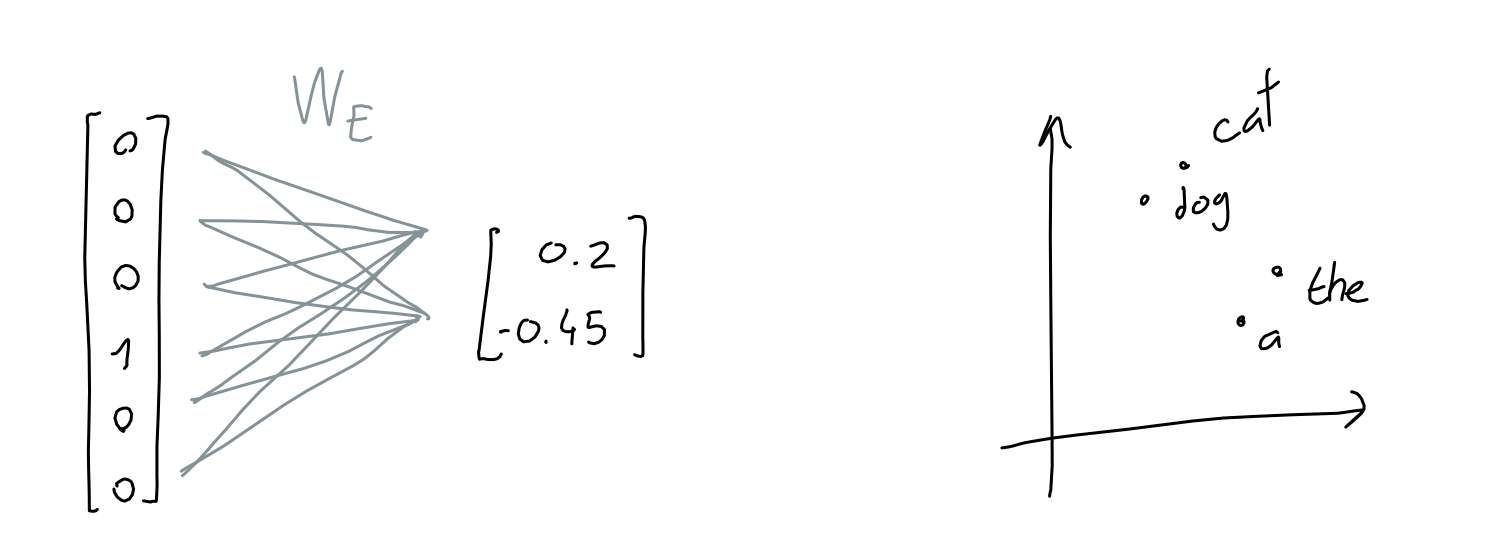
- 当然,嵌入维度通常大于 2:GPT 使用 12288 维度。
- 实际上,每个单词的独热向量都会与学习到的嵌入网络权重相乘,最终得到一个 12288 维的嵌入向量。
- 从算术角度来说,我们将 2048 x 50257 序列编码矩阵与 50257 x 12288 嵌入权重矩阵(学习到)相乘,最终得到 2048 x 12288 序列嵌入矩阵。
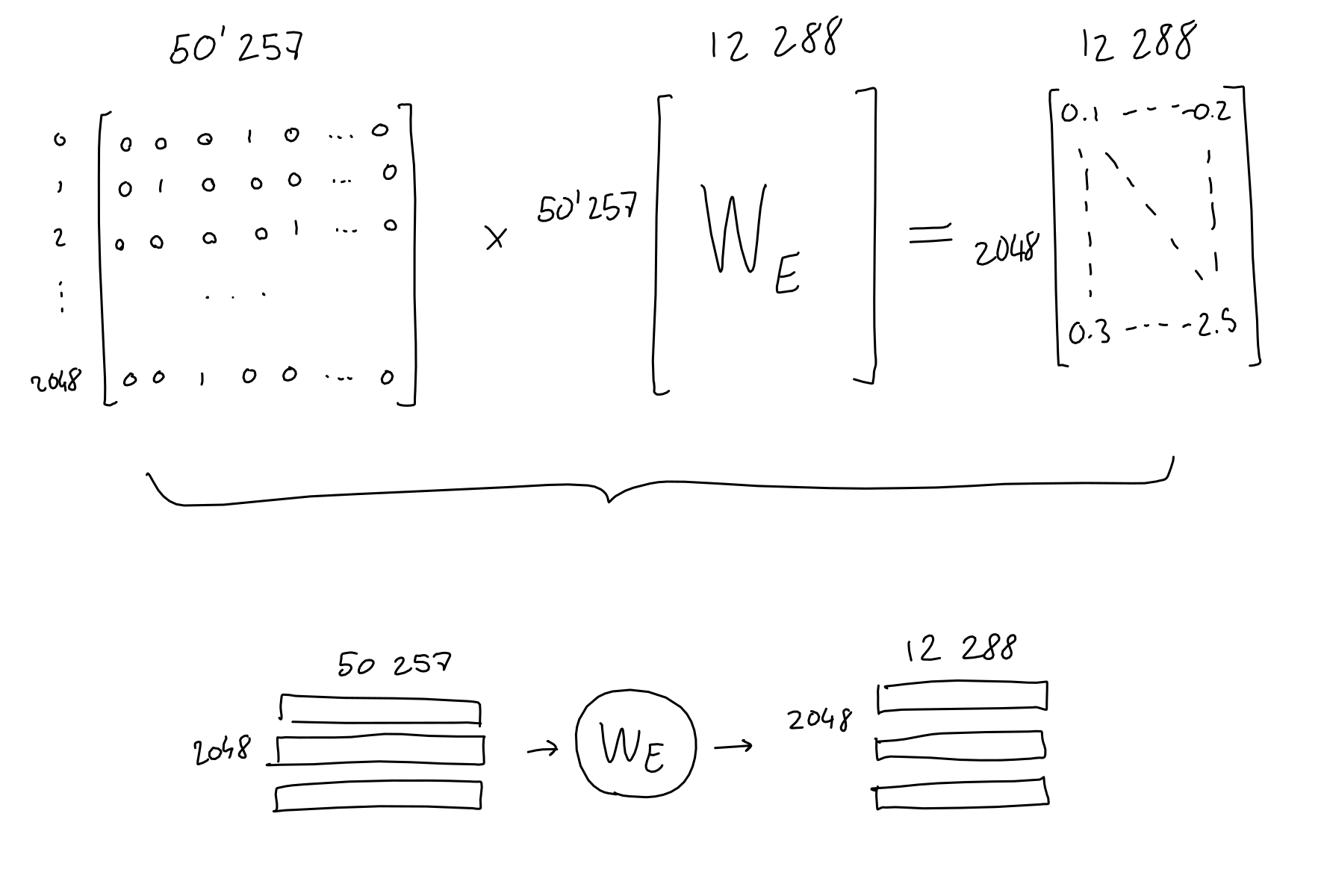
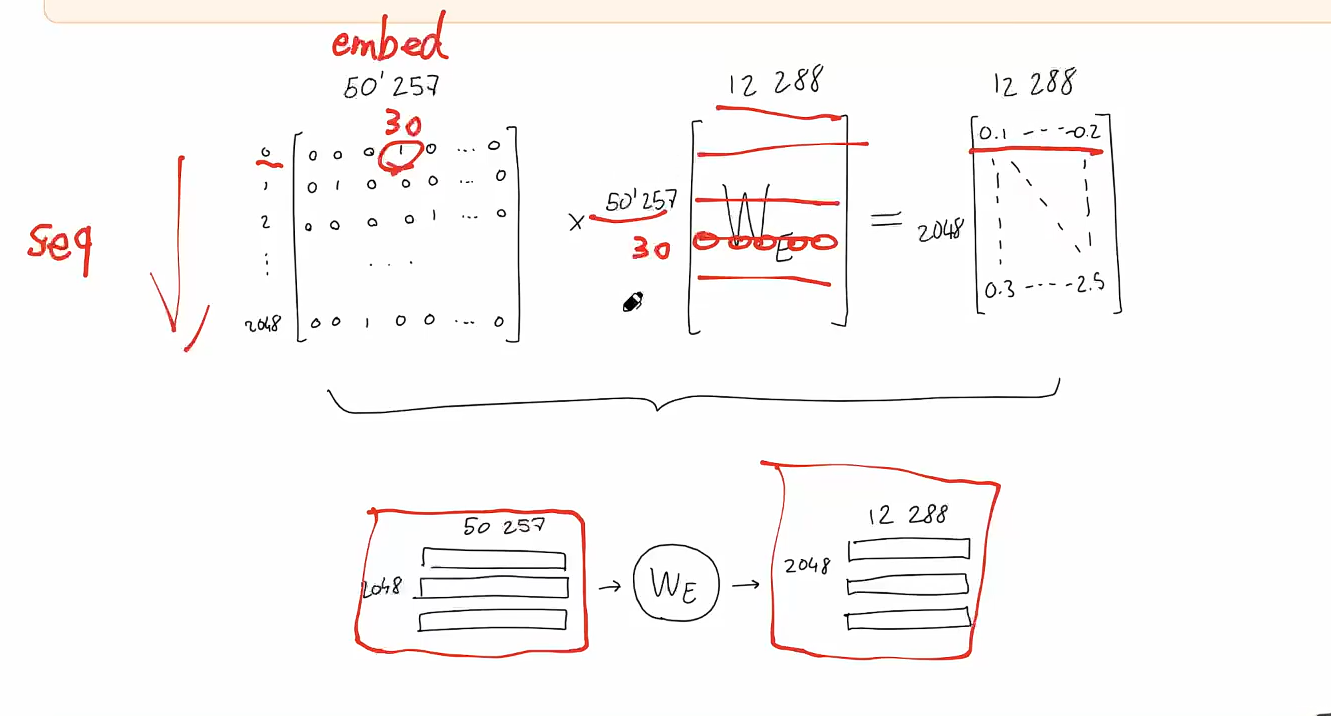
- 其结果等价于直接将token_id{x}告诉嵌入权重矩阵,然后从权重矩阵的第{x}行取出向量,并将2048行向量直接相拼接。
- 这意味着:到目前为止,序列中的token**没有信息交互。**只和自己有关系
位置编码
- 为了对序列中当前标记的位置进行编码,作者获取标记的位置(标量 i,在 [0-2047] 中)并将其传递给 12288 个正弦函数,每个函数都有不同的频率。
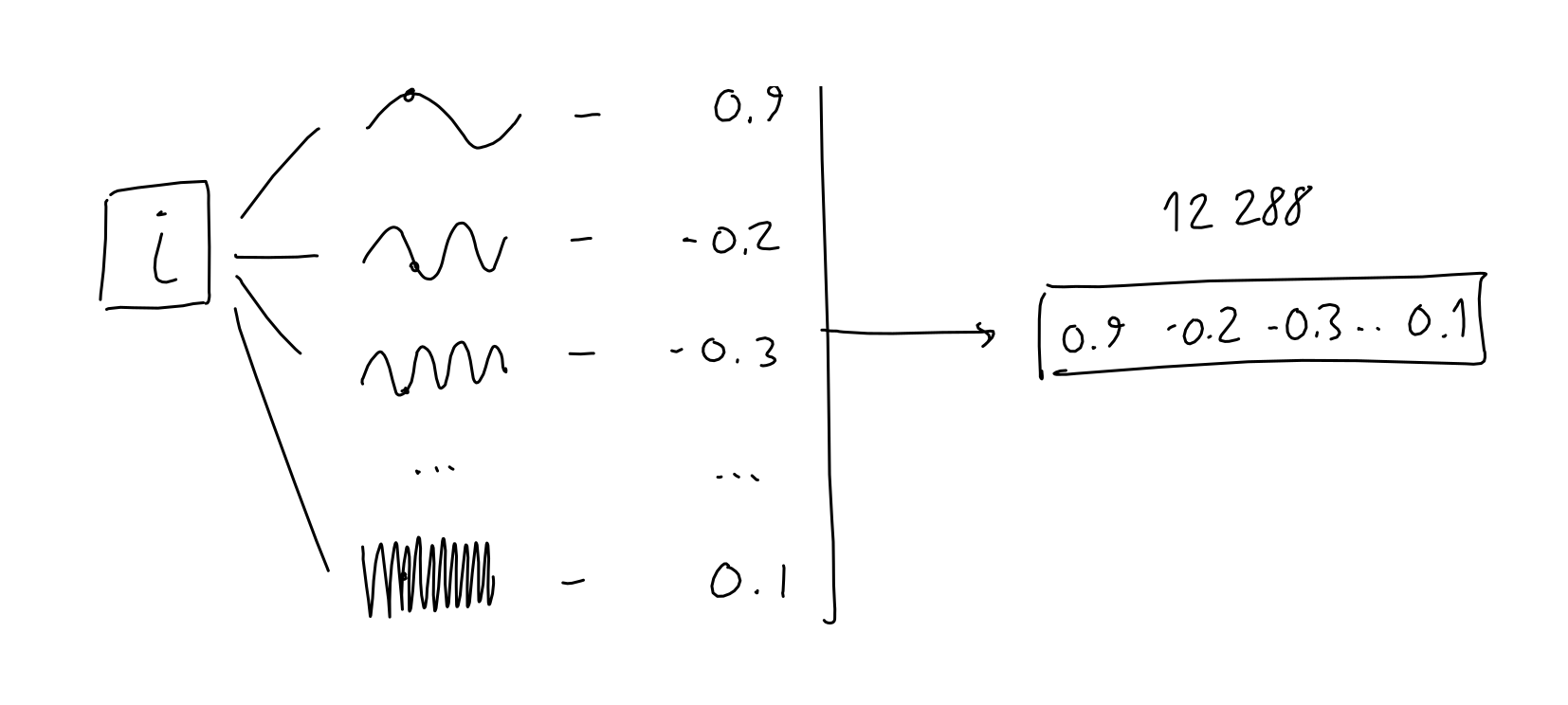
- 对于每个标记,结果是 12288 个数字向量。与嵌入一样,我们将这些向量组合成一个具有 2048 行的矩阵,其中每行是序列中标记的 12288 列位置编码。
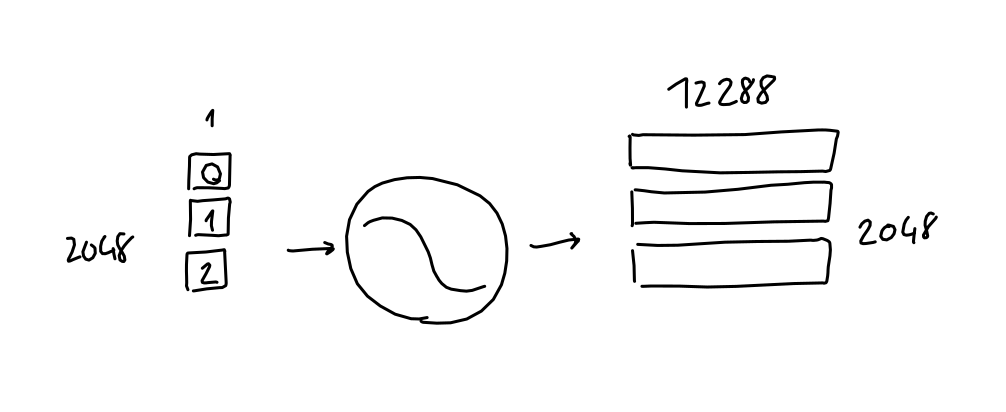
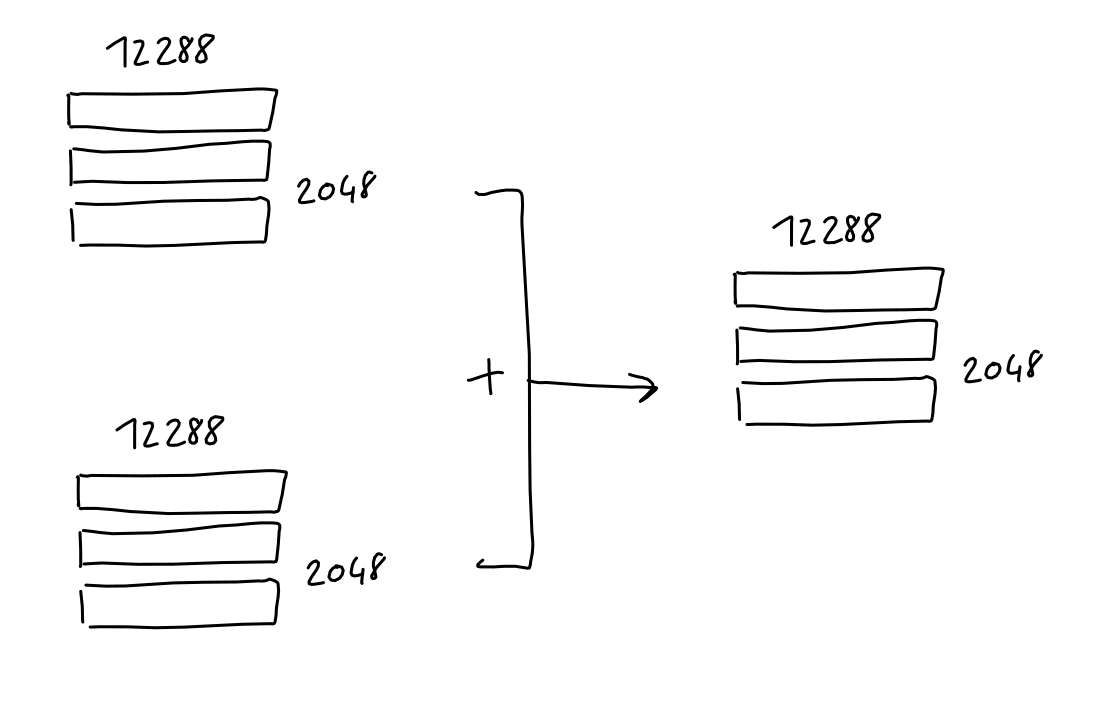
- 最后,这个序列位置编码矩阵具有与序列嵌入矩阵相同的形状,可以简单地添加到其中。
Attention(简化版)
- 简单来说,注意力机制的目的在于:对于序列中的每个输出,预测需要关注哪些输入token以及关注程度。这里,想象一个由 3 个token组成的序列,每个token都用 512 个值的嵌入表示。
- 该模型学习了 3 个线性投影,它们都应用于序列嵌入。换句话说,我们学习了 3 个权重矩阵,它们将我们的序列嵌入转换为三个独立的 3x64 矩阵,每个矩阵用于不同的任务。
- 前两个矩阵(“查询”和“键”)相乘(QK (T)),得到一个 3x3 矩阵。该矩阵(通过 softmax 归一化)表示每个token对其他token的重要性。
- 注意:此(QK (T )是 GPT 中唯一一个跨序列单词进行操作的运算。它是唯一一个矩阵行交互的运算。
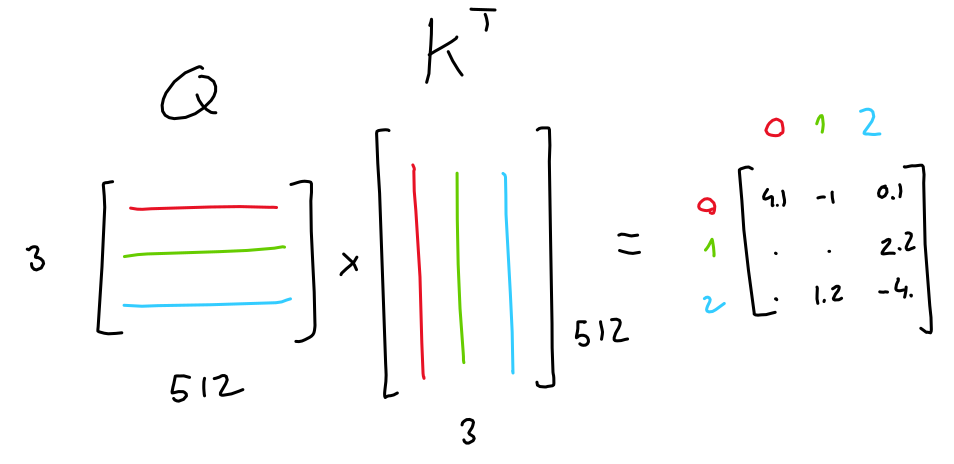
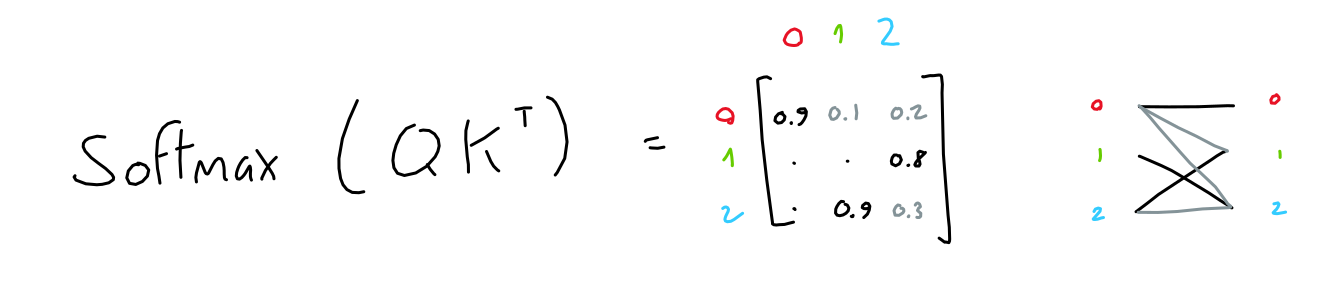
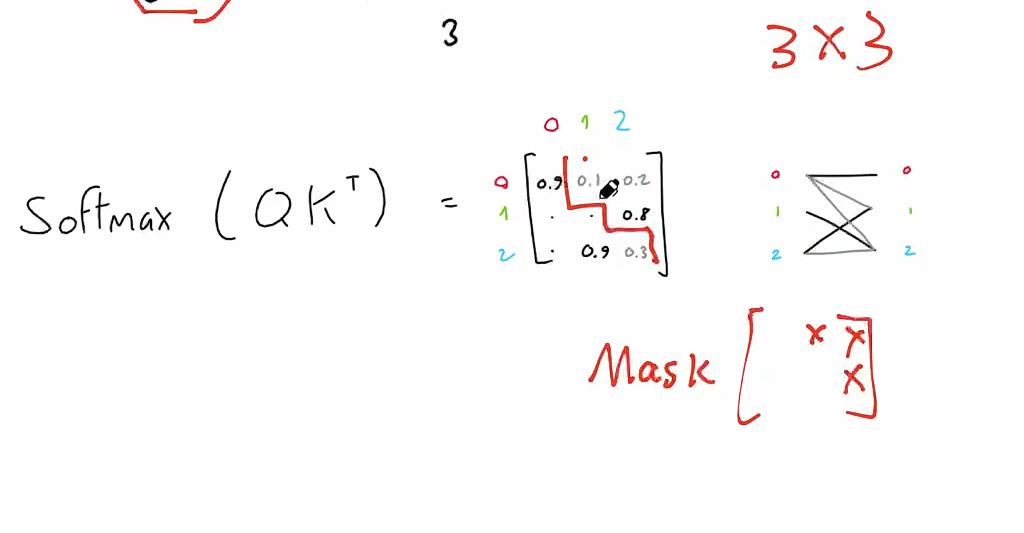
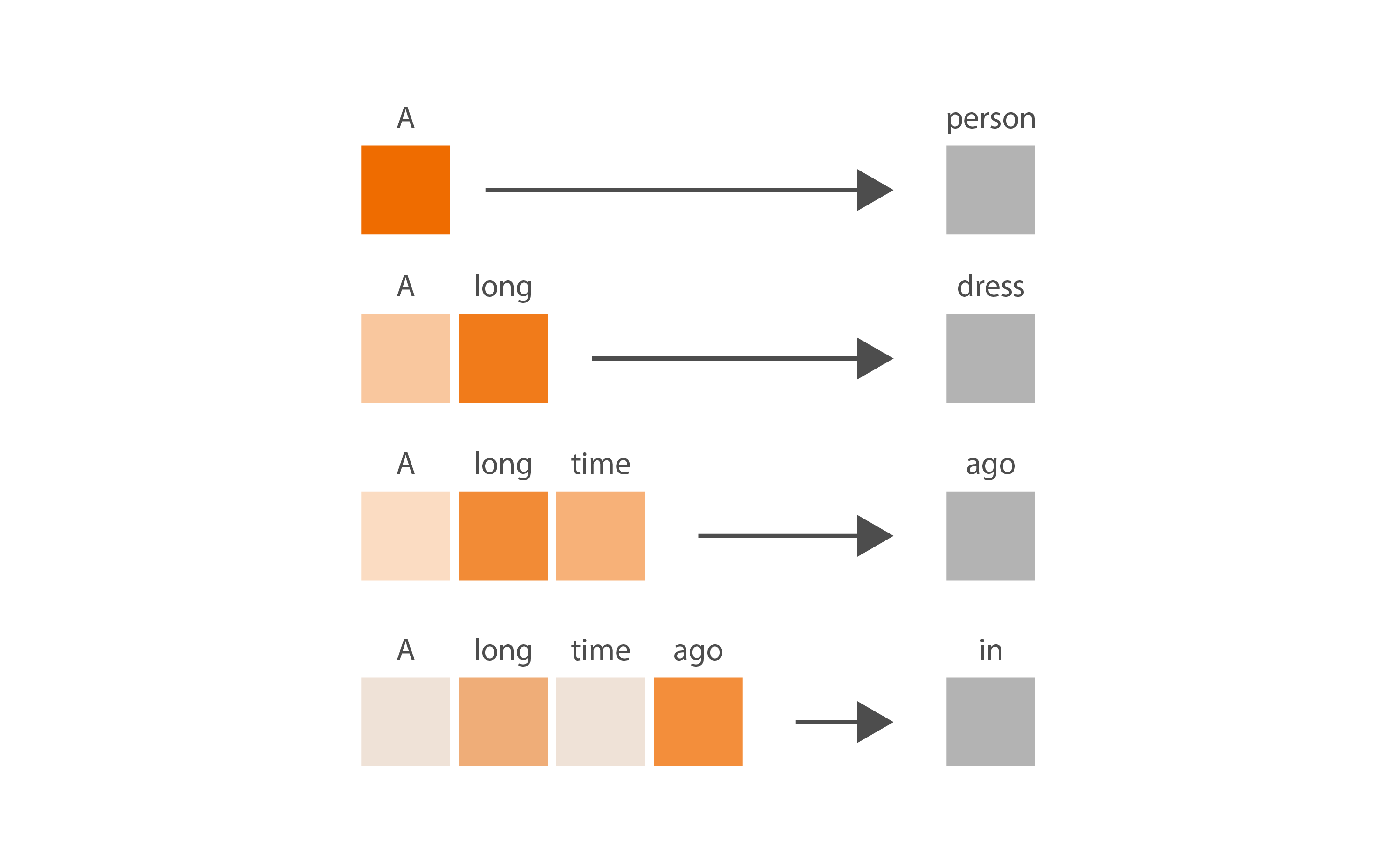
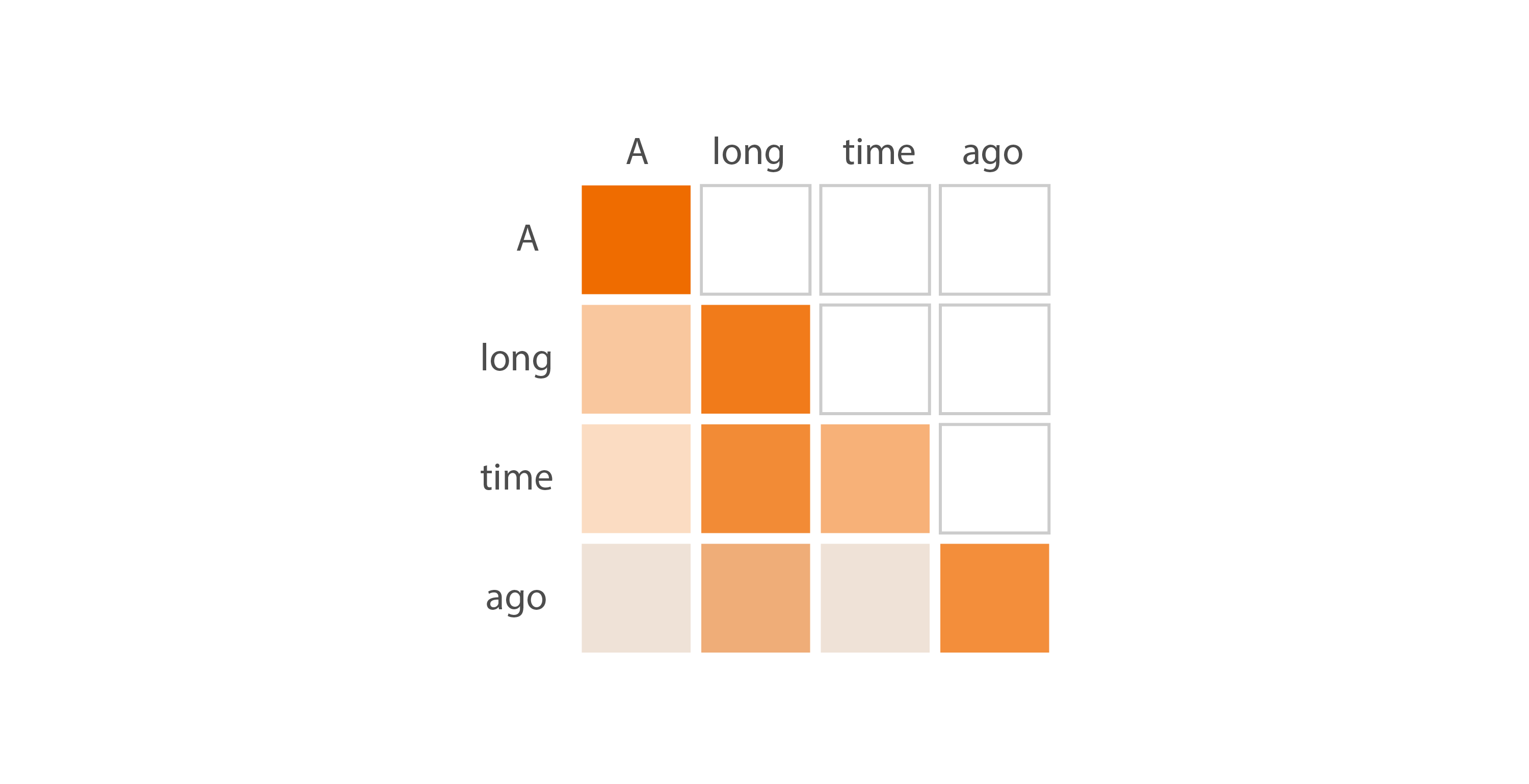
- 第三个矩阵(“值”)与这个重要性矩阵相乘,结果是,对于每个token,都混合了所有其他token的值,并根据其各自token的重要性进行加权。
- 掩码注意力会形成一个上三角矩阵,保证根据当前序列预测下一个token时,不会与后续token产生信息交互
.png)
多头注意力机制
- 现在,在作者提出的 GPT 模型中,他们使用了多头注意力机制。这意味着上述过程会重复多次(在 GPT-3 中为 96 次),每次都使用不同的学习查询、键、值投影权重。
- 每个注意力头(单个 2048 x 128 矩阵)的结果被连接在一起,得到一个 2048 x 12288 矩阵,然后将其与线性投影(不会改变矩阵形状)相乘,以获得良好的测量效果。
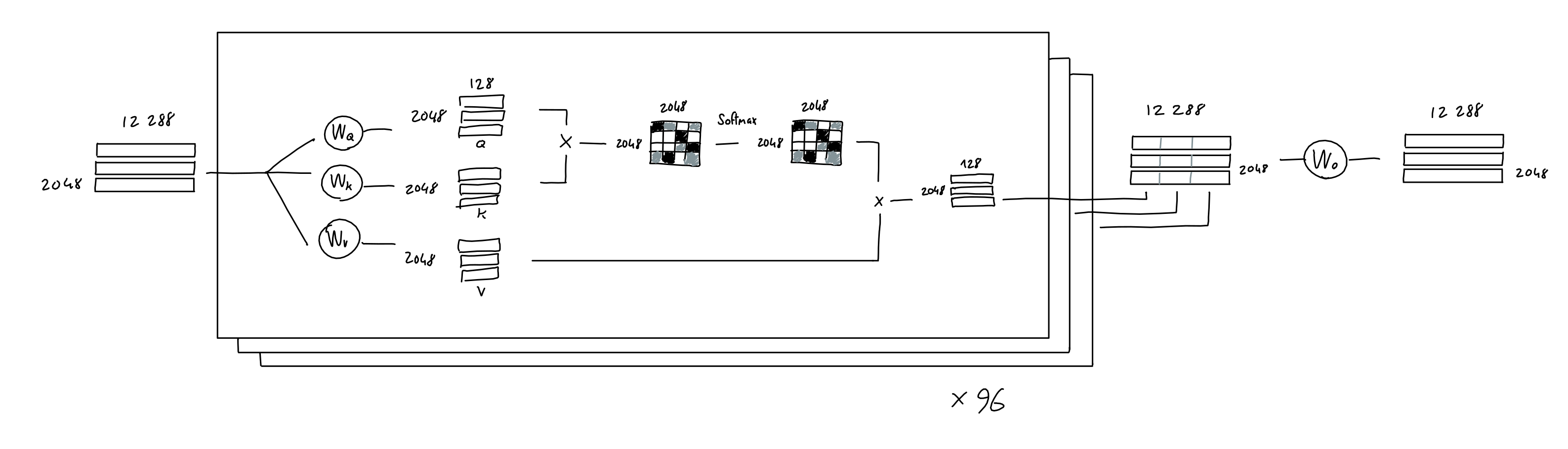
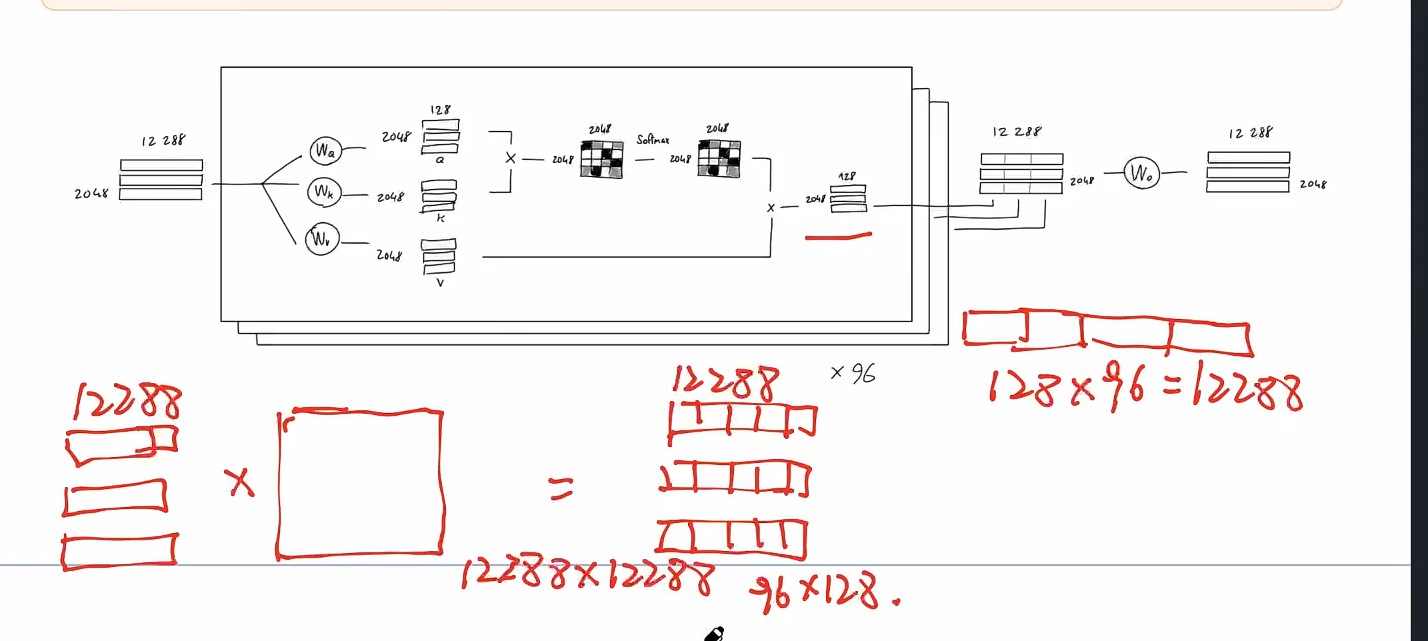
- “吹毛求疵”:上图表示每个头部都有单独的权重矩阵。然而,在实践中,注意力模型实现可能会对所有头部使用一个大的组合权重张量,进行一次矩阵乘法,然后将其拆分成每个头部的 a、k、v 矩阵。不用担心:理论上,它也不会影响模型输出,因为代数运算是相同的。
前馈
- 前馈模块是一个老式的多层感知器,具有 1 个隐藏层。获取输入,乘以学习到的权重,添加学习到的偏差,重复此操作,即可获得结果。
- 这里,输入和输出形状相同(2048 x 12288),但隐藏层的大小为 4*12288。
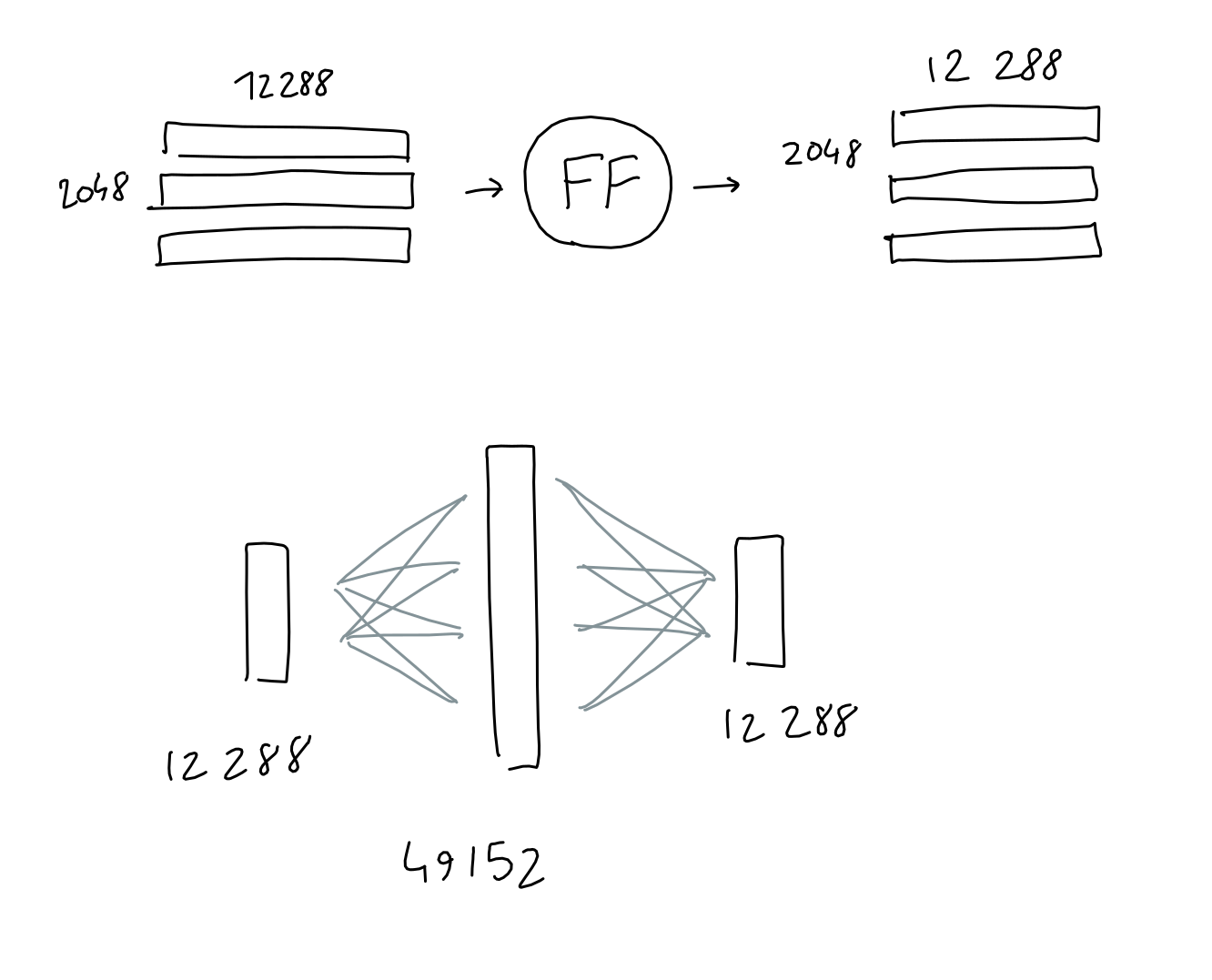
- 需要明确的是:我将此操作画成一个圆圈,但与架构中的其他学习投影(嵌入、查询/键/值投影)不同,这个“圆圈”实际上由两个连续的投影(学习权重矩阵与输入相乘)组成,每个投影之后都添加了学习偏差,最后添加一个 ReLU。
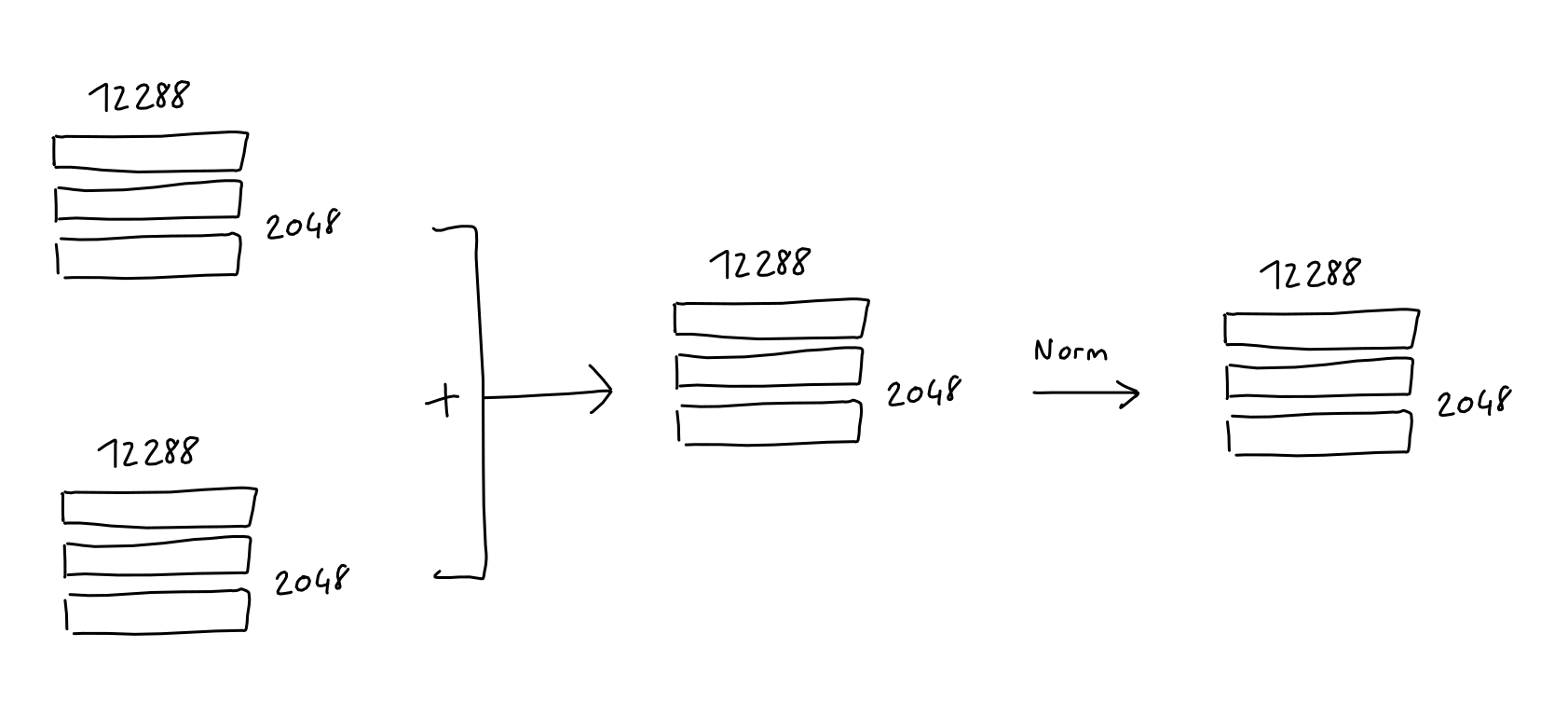
Add&Norm
- 在多头注意力和前馈块之后,块的输入被添加到其输出,结果被归一化。这在深度学习模型中很常见(自 ResNet 以来)
解码
- 经过 GPT-3 注意力/神经网络机制的所有 96 层后,输入被处理成一个 2048 x 12288 的矩阵。对于序列中 2048 个输出位置中的每一个,这个矩阵应该包含一个 12288 向量,其中包含有关应该出现哪个单词的信息。但我们如何提取这些信息呢?
- 如果您还记得在“嵌入”部分中,我们学习了一种映射,它将给定的单词(一个单词的独热编码)转换为 12288 个向量嵌入。事实证明,我们可以反转此映射,将输出的 12288 个向量嵌入转换回 50257 个单词编码。这个想法是,如果我们花费所有这些精力来学习从单词到数字的良好映射,我们不妨重复使用它!
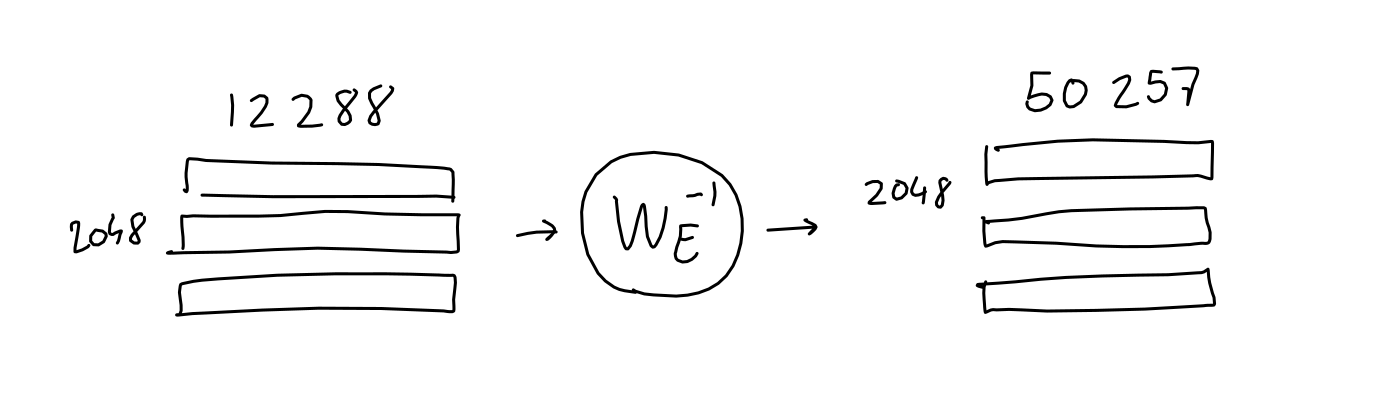
- 当然,这样做不会像开始时那样给我们 1 和 0,但这是一件好事:经过快速的 softmax,我们可以将结果值视为每个单词的概率。
- 此外,GPT 论文中提到了参数 top-k,它将输出中可能采样的单词数量限制为 k 个最有可能的预测单词。例如,如果 top-k 参数为 1,我们总是选择最有可能的单词。


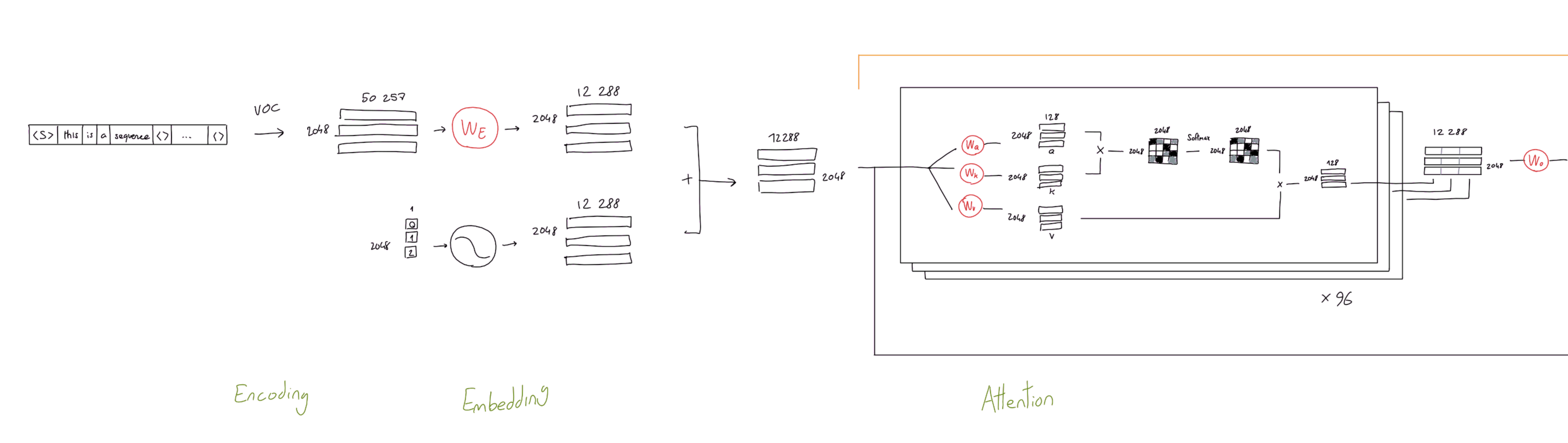
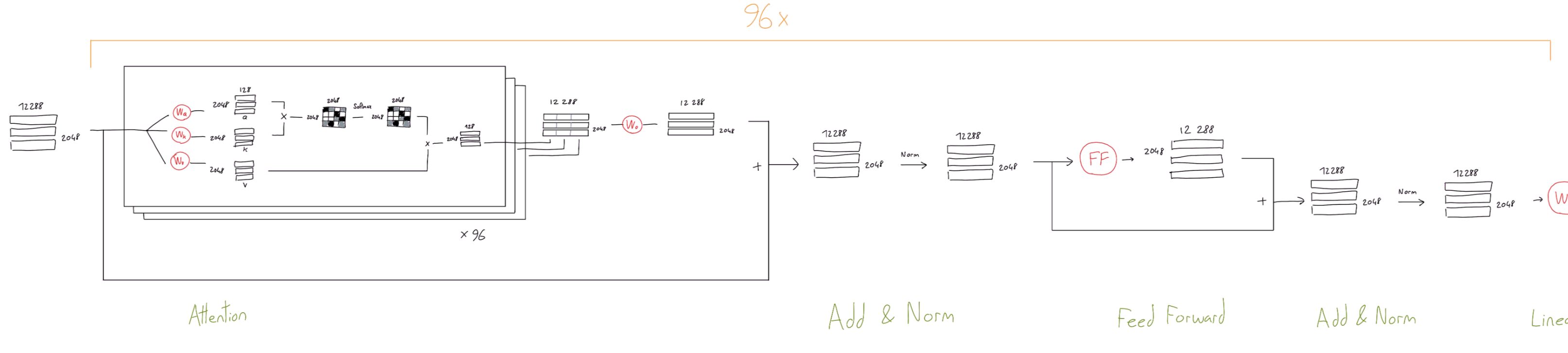
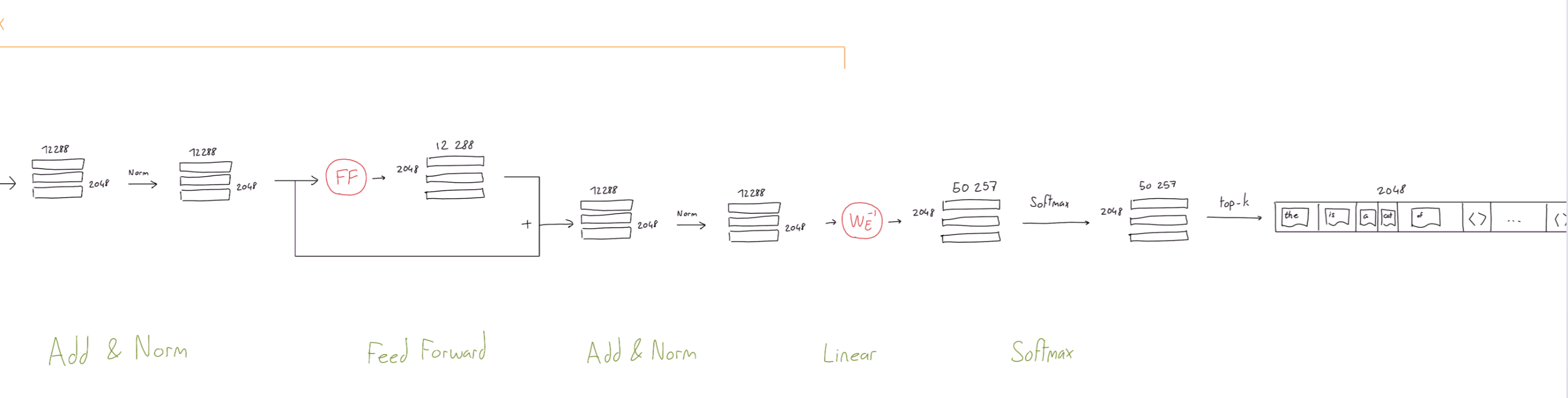
GPT预训练
大语言模型预训练
- 大语言模型的训练分为几个步骤:
- 预训练(Pre-train)
- 有监督对齐(SFT)
- 强化学习对齐(RLHF)
- 对人类的一些偏好、安全问题进行对齐
- 下游微调(Fine-tune)
- 对于某些具体的任务进行对齐
- 第一步(也是计算成本最高的一步)是预训练,我们将在本概述中重点介绍这一步骤。
- 在预训练期间,我们会获得大量未标记的文本语料库,并通过以下方式训练模型:
- i)从数据集中抽取一些文本;
- ii)训练模型预测下一个单词。
- 这是一个自监督目标,因为不需要任何标签。相反,下一个标记的基本事实已经存在于语料库本身中——监督来源是隐式的。这样的训练目标称为下一个标记预测,或标准语言建模目标。
- 在预训练期间,我们会获得大量未标记的文本语料库,并通过以下方式训练模型:

- **上下文窗口。**语言模型使用特定大小的标记序列进行预训练,该大小称为上下文窗口的大小或上下文长度。此大小(通常在 1K 到 8K 个标记范围内(尽管某些模型要大得多!))通常根据硬件和内存限制进行选择(3)。鉴于我们只学习此长度输入的位置嵌入,上下文窗口限制了 LLM 可以处理的输入数据量。然而,后续训练的长文本外推技术(如PI插值、NTK-Aware)可以推断出比训练期间看到的输入更长的输入。
- 长文本能力:长文本外推技术,在预训练完之后,通过PI插值和NTK-Aware的方式,让大模型拥有长文本的能力,但是在预训练阶段都会把长度固定在一个
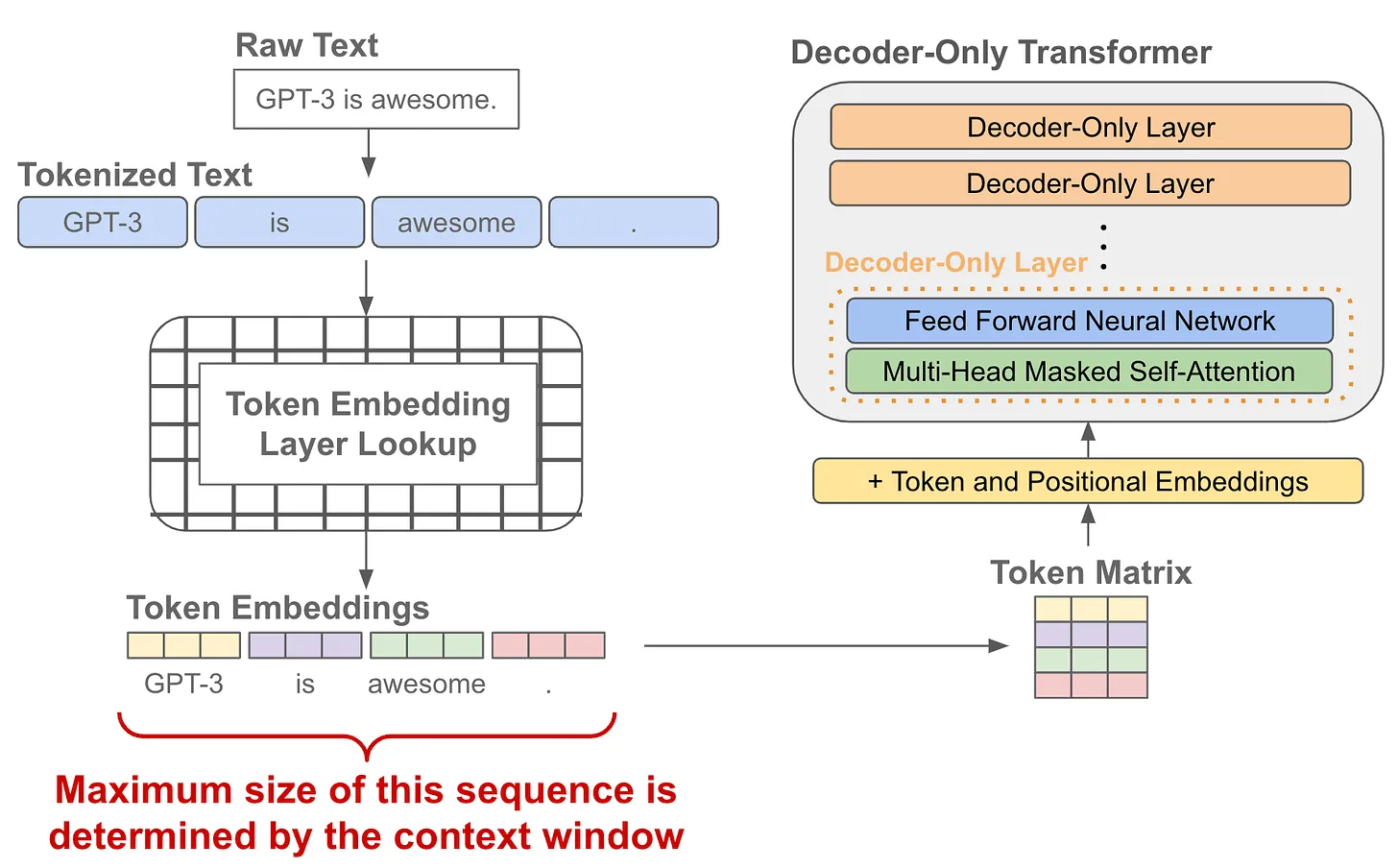
预训练过程
- **预测下一个 token。**有了 token 嵌入(带有位置嵌入)之后,我们将这些向量传递到仅解码器转换器中,该转换器为每个 token 嵌入生成相应的输出向量
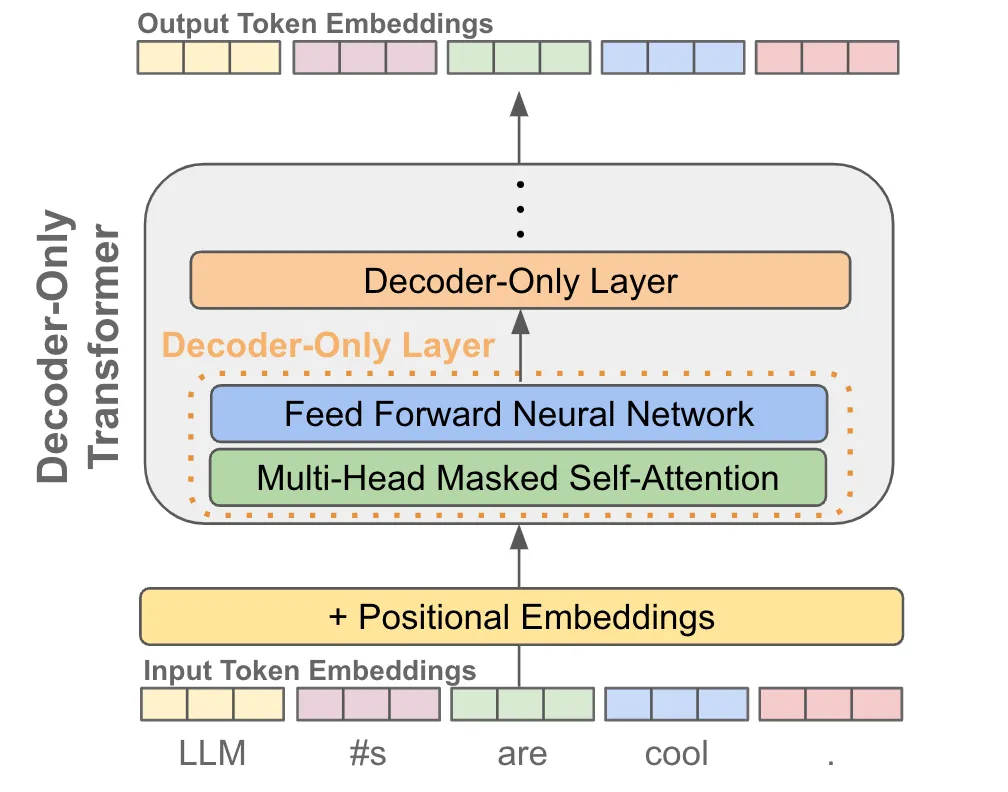
- 给定每个token的输出向量,我们可以通过以下方式执行下一个token预测:
- i)获取token的输出向量;
- ii)使用此向量预测序列中的下一个token。
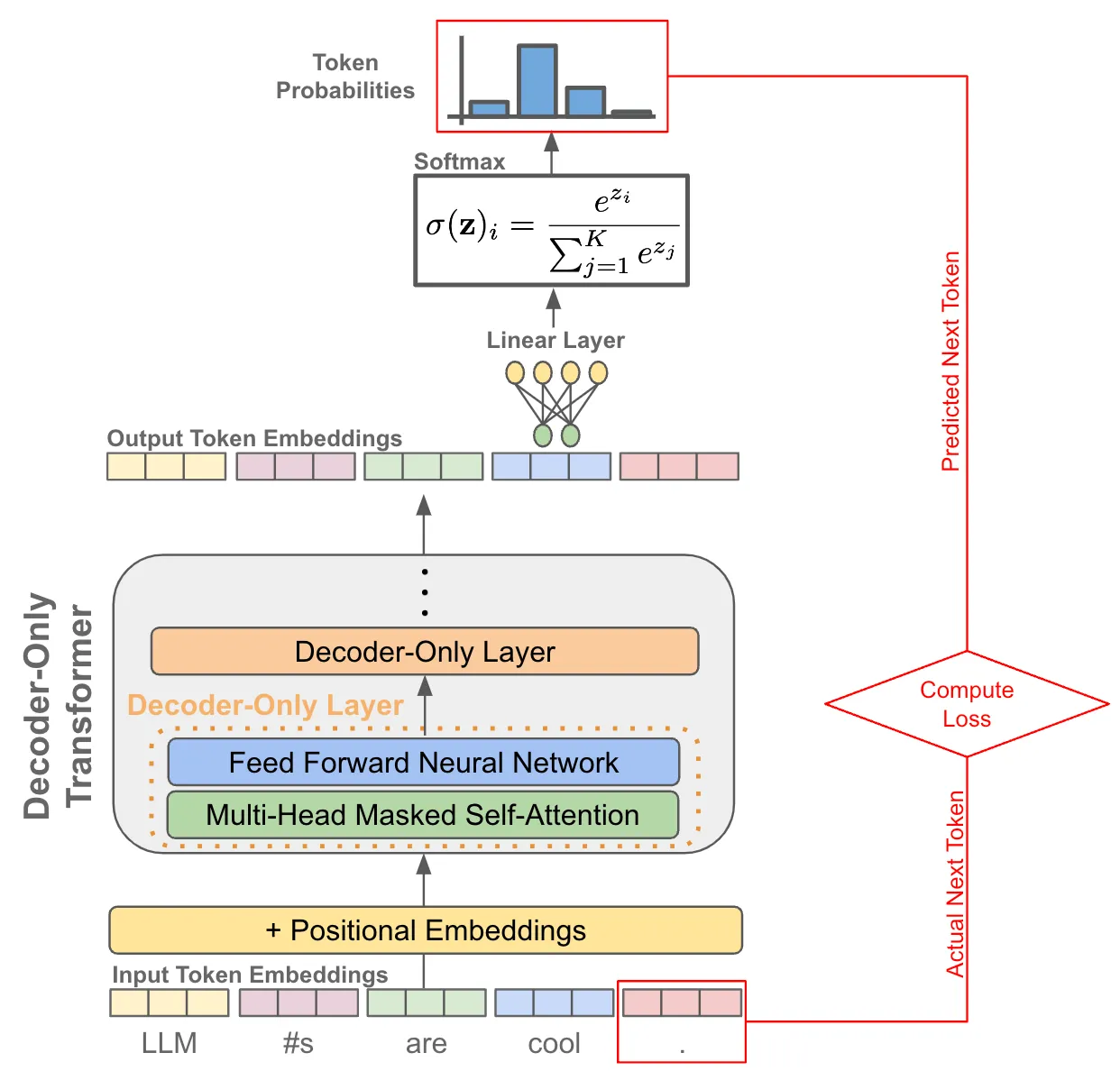
- 如上所示,通过将token的输出向量作为输入传递到线性层来预测下一个token,该线性层输出与词汇表大小相同的向量。应用 softmax 变换后,会形成token词汇表的概率分布,我们可以
- i)在推理期间从该分布中抽取下一个token,或者
- ii)在预训练期间训练模型以最大化下一个token正确的概率。
- 预测整个序列中的token。在预训练期间,我们不会只预测单个下一个标记。相反,我们会对序列中的每个token执行下一个标记预测,并汇总所有token的损失,除以它们的平均长度,得到平均损失。由于使用了因果自注意力,每个输出标记向量仅考虑当前token和序列中位于其之前的token。因此,可以使用仅解码器转换器的单次前向传递对整个序列执行下一个token预测,因为每个标记都不了解位于其之后的token。
GPT推理
大语言模型推理
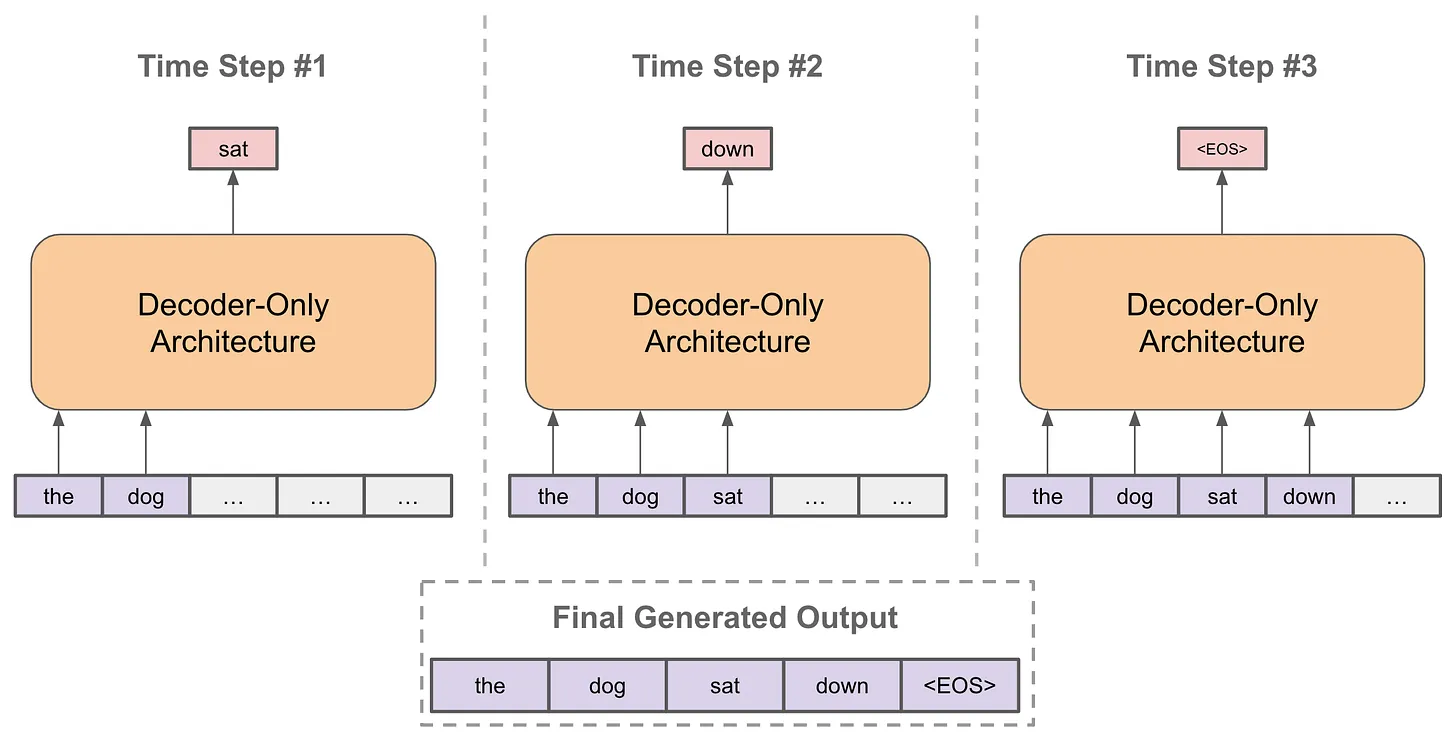
- 现在,我们了解了如何预训练语言模型,但在进行推理时也会使用下一个标记预测!*下一个标记预测是训练和使用 LLM 的所有方面的基础。*从初始(可能为空)输入序列或前缀开始,语言模型通过遵循自回归下一个标记预测过程(参见上文)生成文本,步骤如下:
- 预测下一个 token
- 将预测的 token 添加到当前输入序列中
- 重复
采样策略
- 对于垃圾邮件分类任务,输出概率最高的值是可以的。如果电子邮件有 90% 的概率是垃圾邮件,则将其归类为垃圾邮件。但是,对于语言模型,总是选择最有可能的token(贪婪采样)会产生无聊的输出。想象一下,无论你问什么问题,模型总是用最常见的单词来回答。
- **选择下一个标记。**在上一节中,我们已经了解了如何创建标记的概率分布。但是,*我们实际上如何从该分布中选择下一个token?*通常,我们只是从该分布中抽样下一个token。但是,存在许多采样策略,这些策略通过修改标记的概率分布来对这种方法进行细微的改变。常见的采样策略如下:
- 贪婪搜索(每次只采样概率最高的token)
- 语言模型是一个开放性的问题,并不是一个很封闭,很绝对的分类问题,所以不适合采用这种策略
- 随机搜索
- 温度
- 核采样(top-p)采样
- Top-K 采样
- 贪婪搜索(每次只采样概率最高的token)
温度
- 温度是微调 GPT-3 等大型语言模型 (LLM) 输出的关键超参数。它在控制生成文本的随机性和创造性方面起着至关重要的作用。这些大型语言模型的输出是单词出现概率的函数。换句话说,要生成一个单词,词典中的每个单词都与一个概率相关联,并在此基础上确定如何进行。这个超参数的主要思想是 调整这些概率以强制随机性或确定性。
- 字典中每个单词的概率生成是在最后一层通过应用softmax作为激活函数完成的。回想一下,softmax作用于 logits 以将它们转换为概率。这正是温度发挥作用的地方。
- 温度在结果过softmax之前做一个缩放
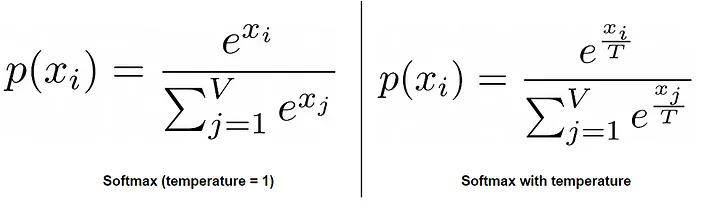
-
从上面的公式可以看出,softmax对每个 logit (x)求幂,然后将每个求幂的值除以所有求幂的值之和。此步骤确保输出是概率分布,这意味着值介于 0 和 1 之间,并且总和为 1。温度超参数是定义为“T”**的值,应用于每个 logit,使低温使概率更加偏向极端。
- T变大,那么缓和差距,T变小,放大差距,不改变顺序
-
假设有以下句子:
- Yesterday I went to the cinema to see a ___
这个想法是预测下一个单词。神经网络将确定字典中每个单词的概率,在本例中,我们将仅使用 5 个token分布来简化流程。
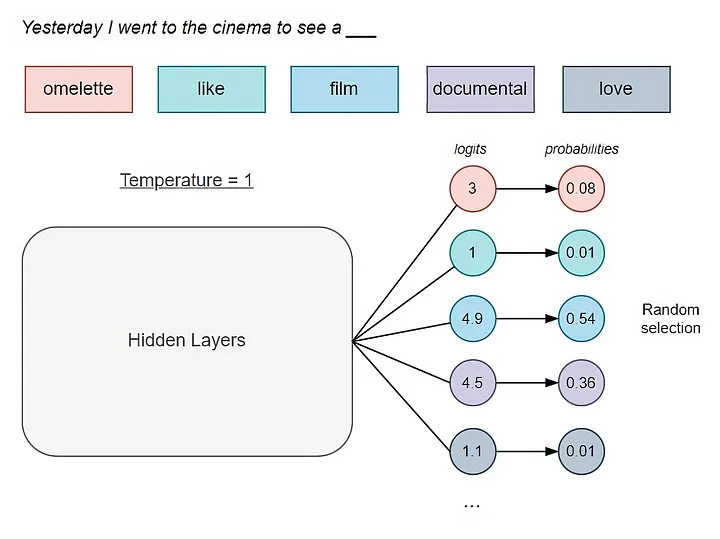
- 从生成的概率来看,随机性将负责确定后面的单词。如上所示,在上面的示例中,应用了普通softmax(温度 = 1)。下面,我们将看到温度值为0.3、10和0时的结果。

- 随着温度值接近 0,概率会进一步增加,从而使得选择的可能性更大。相反,当温度变得更高时,概率会降低,从而使得更多意想不到的单词更有可能被选中。
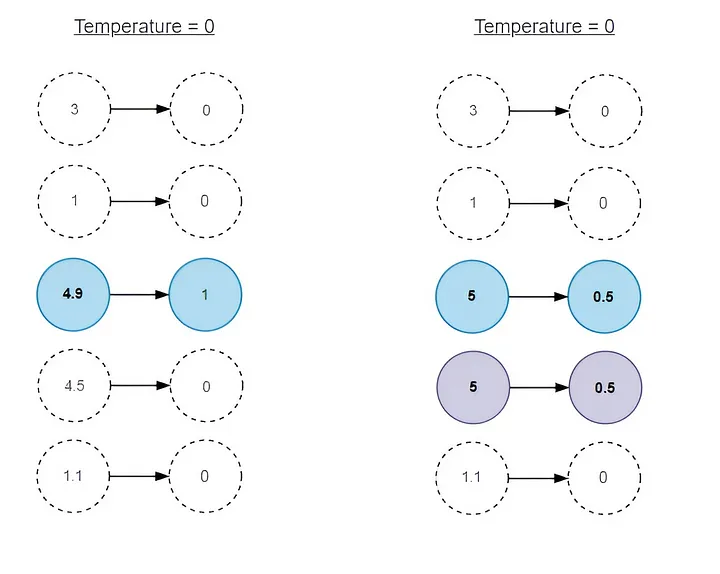
- 因此,当温度值等于 0 时,它就变成一个确定性解。但是,如果有两个词具有相同的 logit 值,因此概率也相同,则温度为 0 将使这两个词被选中的可能性相等,并且加起来为 1。
Top_p和Top_k
- Top_p(核采样):它从概率分布中选择最可能的token,考虑**累积概率,直到达到预定义的阈值“p”。**这限制了选择的数量,并有助于避免过于多样化或无意义的输出。
- Top_k (Top-k 采样) :它根据概率将 token 的选择限制为**“** ***k”***个最可能的选项。这可以防止模型考虑概率非常低的 token,从而使输出更加集中和连贯。
- Top_p和Top_k的核心思想是缩小采样空间,避免采样到过于多样化和无意义的token
- 一般来说top-p效果更好,top-p考虑概率分布,top-k考虑排名
- 在缩小的集合里面去做一些随机采样,这样可以让大模型具有随机性
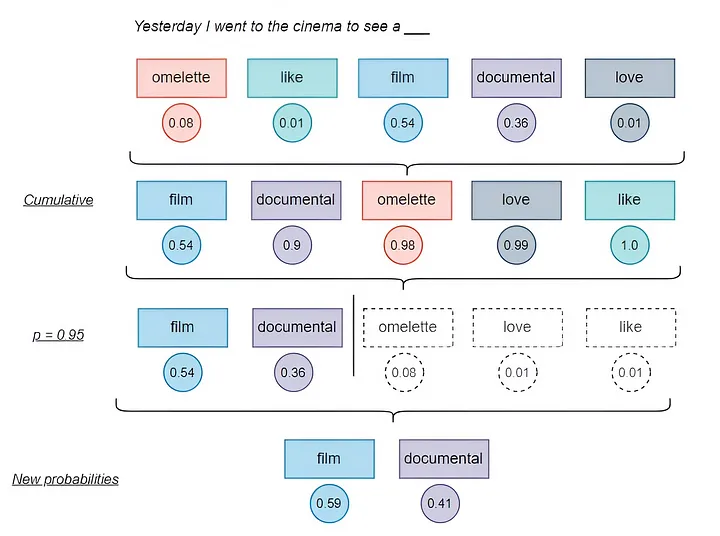
- 在上图中,我们可以看到top_p 的工作原理。您可以看到它如何经历排序过程,然后是概率的累积。利用这些,建立一个阈值并选择这些单词。最后,重新计算概率。假设“p”值小于最大概率,则选择最可能的单词。
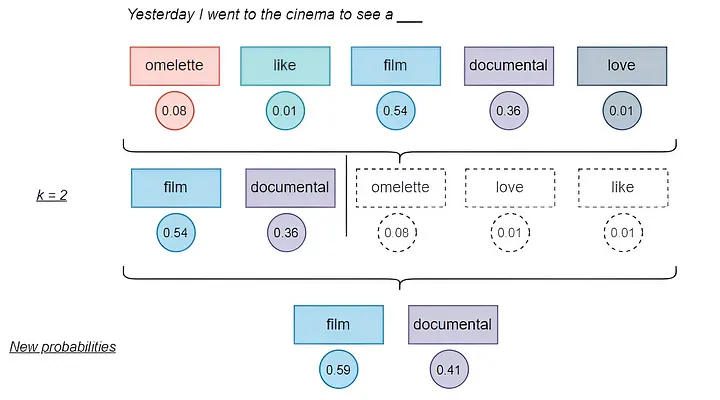
-
Top_k 的工作原理相同,但仅将参数“k”视为最可能的单词。与top_p过程一样,对概率进行排序,但在这种情况下,无需累积。排序后,设置“k”的阈值,最后重新计算概率。
-
现代大模型常用采样组合是Temperature+Top_p采样
LLaMA3解析
- 本节课旨在以LLaMA3为案例,讲解现代大语言模型通用最佳实践,截止2024年12月11日,市场上主流的开源大语言模型都采用类似架构,非常具有代表性。
基于Transformer-Decoder的改进
RMS-Norm
- LLaMA3采用RMS-Norm来进行归一化,从而取代了Layer-Norm
- RMS-Norm相较于Layer-Norm大大节省了计算开销,并且经过试验验证,与Layer-Norm取得相似的效果
- 现在的大语言模型参数量非常大,训练数据非常多,对整个计算能力和计算效率要求高
- RMS少了计算均值和方差的步骤,保留了缩放,没有了偏移
- 每一个token内部做RMSnorm

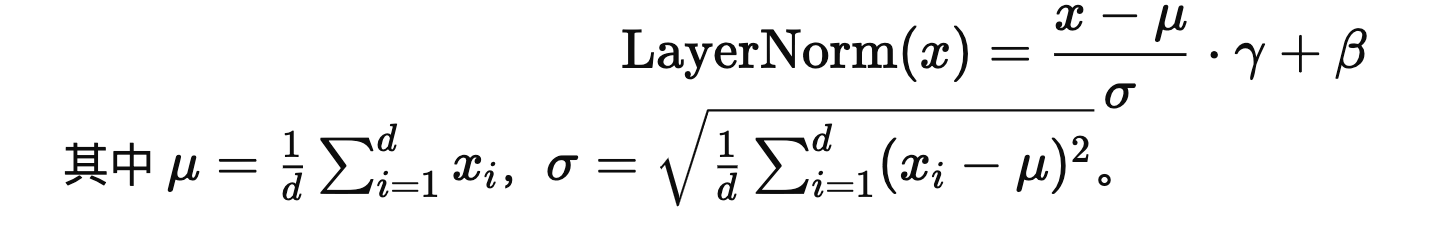
RoPE位置编码(Rotary Positional Encoding)
- RoPE位置编码取代了绝对位置编码(Transformer)/可学习的位置编码(BERT)
- 后两者都是token embedding计算position encoding,然后再用token embedding+position encoding得到
- RoPE先用token embedding过了权重矩阵,拿到query和key,再对query和key旋转,以保证value的一个正确性或者说不受位置干扰的一个性质
- 当前的token会和其他token产生注意力,注意力分数根据距离决定,距离远一点,注意力分数可能会很小
核心思想
- RoPE 将位置编码直接应用于自注意力机制中的查询向量(query)和键向量(key),通过旋转变换的方式为它们引入相对位置信息。这种方法基于以下核心步骤:
- 输入向量分解为二维空间:
- 假设输入向量 $$x \in \mathbb{R}^d$$ 的维度为 d,我们将它的每两个连续维度配对,形成 $$\frac{d}{2} $$个二维向量。
- 例如, $$x = [x_1, x_2, x_3, x_4]$$ 会被分为两对: $$(x_1, x_2)$$ 和 $$(x_3, x_4)$$。
- 假设输入向量 $$x \in \mathbb{R}^d$$ 的维度为 d,我们将它的每两个连续维度配对,形成 $$\frac{d}{2} $$个二维向量。
- 为每个二维向量引入旋转变换:
- 对于每对维度,定义一个旋转角度 θ 来编码位置信息。
- 具体旋转公式为:
-
- 对应到所有向量维度,利用每个位置的特定角度 θ 完成变换。
-
- 与位置相关的旋转角度:
- 旋转角度基于位置索引 p 和频率分量 ω来定义: $$ \theta_{p, k} = p \cdot \omega_k$$
- p是位置信息。
-
\omega_k$$ 是与维度 k相关的频率分量。 - $$\omega_k=10000^{-\frac{2k}{d}}
- 一个进度,(0,1)之间的值
- 旋转角度基于位置索引 p 和频率分量 ω来定义: $$ \theta_{p, k} = p \cdot \omega_k$$
- 将旋转编码引入自注意力机制:
- 对查询 q 和键 k应用旋转编码,使得点积 $$q \cdot k$$自然包含相对位置信息:
-
- 对查询 q 和键 k应用旋转编码,使得点积 $$q \cdot k$$自然包含相对位置信息:
- 输入向量分解为二维空间:
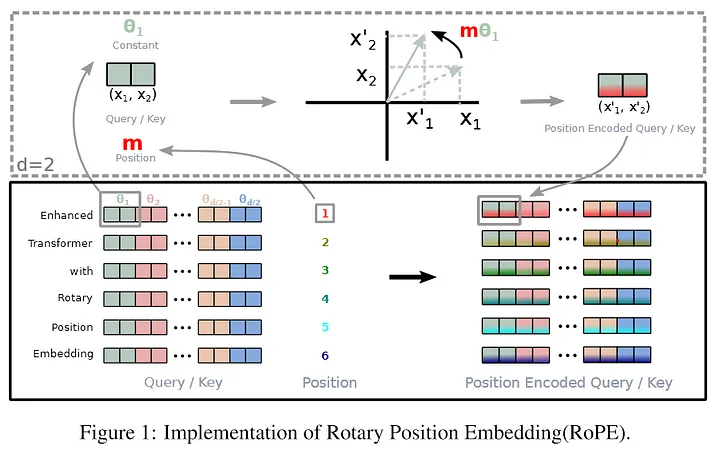
-
偏移后的向量拼接在一起,里面蕴含了位置信息,里面没有需要学习的参数。
-
具体计算示例:



为什么用RoPE替换绝对位置编码?
- 绝对位置编码的局限性:
- 位置依赖性:绝对位置编码(如 sinusoidal 编码或 learnable 编码)将固定的位置索引编码到每个词的位置上,这使得模型对序列长度非常敏感,无法很好地推广到未见过的长序列。
- 缺乏相对位置信息:绝对位置编码不能捕捉词之间的相对位置信息,而相对位置通常更重要(例如,在长序列中,关键关系常表现为词之间的相对距离)。
- RoPE 的相对性:
- RoPE 的旋转编码使得位置信息直接内嵌到查询和键的点积中,并且自然而然地包含了相对位置关系。
- RoPE作用后的q与k在做点积时,其结果会包含一项:
-
-
f(q,k):与原始查询和键相关的内容。
-
g(p_1-p_2)$$:与位置差值相关的因子。 - 关注相对距离而不是绝对的信息 - 原有的只是绝对的信息
-
- RoPE作用后的q与k在做点积时,其结果会包含一项:
- ROPE的长度外推性非常好
- 通过缩放基底,能够扩大模型的外推性,改变基底之后再训练一定步骤,能够拥有对于新位置的感知能力,在模型超过4k的困惑度上,不会显著增加,即使模型生成很长,困惑度也会维持在一个比较低的水平。
- 模型不会因为长度显著增长而导致模型不会生成
- RoPE 的旋转编码使得位置信息直接内嵌到查询和键的点积中,并且自然而然地包含了相对位置关系。
- RoPE 的高效性:
- RoPE 计算简单,只需要在查询和键上进行矩阵变换,计算开销比大多数复杂的相对位置编码方法(如 Transformer-XL 的相对位置编码)要低,一般通过复数乘法来做。
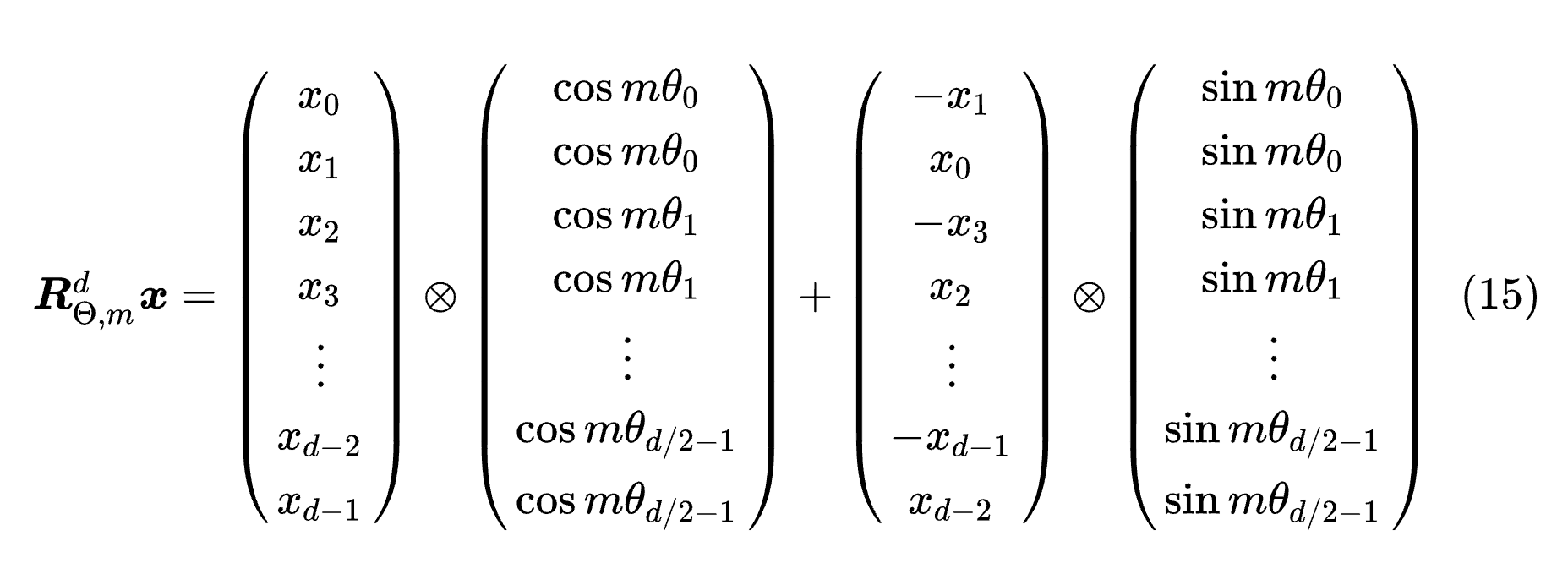
SwiGLU
- 用SwiGLU替换掉了FFN
- SwiGLU 的公式如下:
- 激活函数全连接层,乘上对于x的一个映射(相当于过了一个全连接层)
Swish激活函数
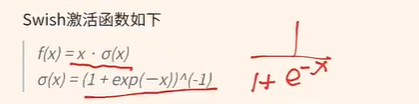
-
Swish激活函数如下
f(x) = x · σ(x)
σ(x) = (1 + exp(−x))^(-1)
SWISH激活函数是光滑且非单调,在x大于0时f(x)无上限,在x小于0时f(x)有下限,图如下
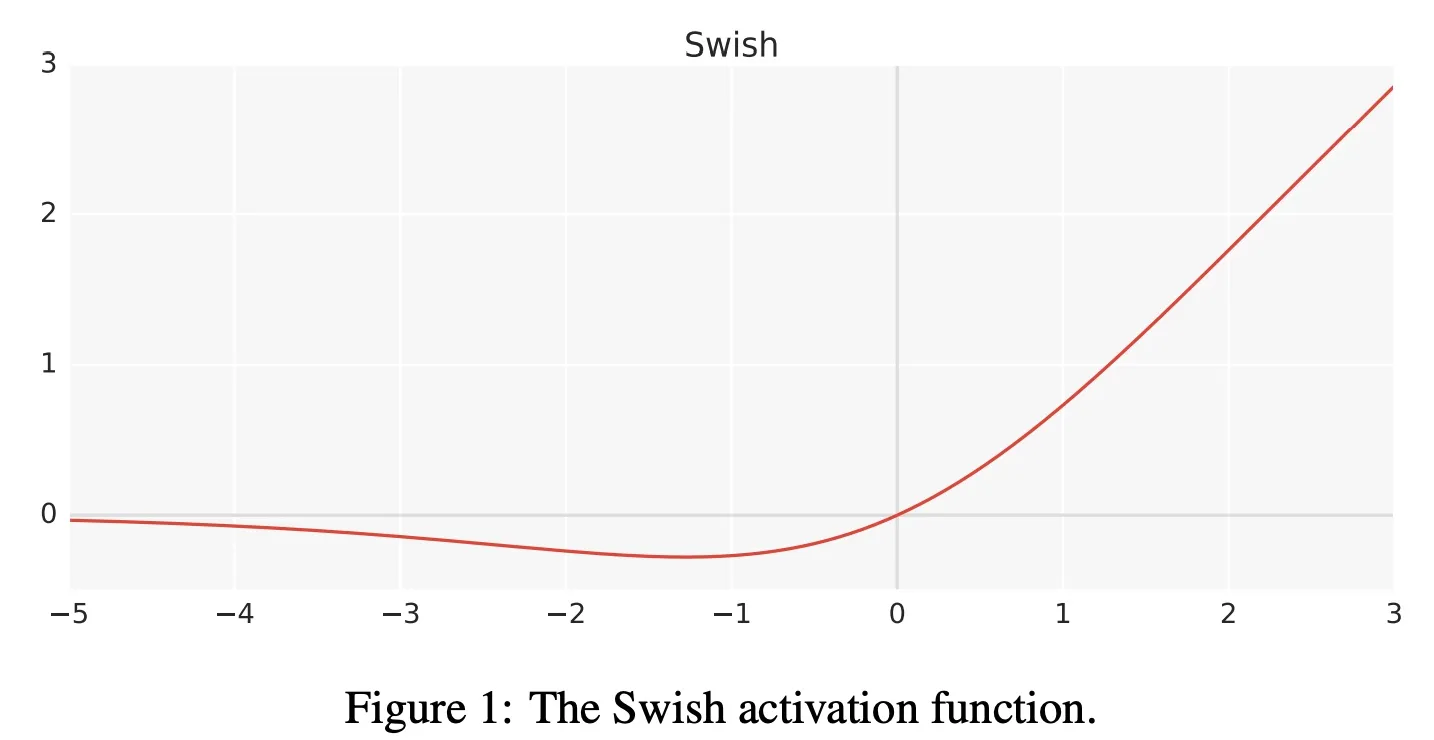
- 比ReLU的好处在于底下有了负值,不会对于小于0的值直接杀死,对负值有一定的敏感性
-
f’(x) = σ(x) + x · σ(x)(1 − σ(x))
= σ(x) + x · σ(x) − x · σ^2(x)
= x · σ(x) + σ(x)(1 − x · σ(x))
= f(x) + σ(x)(1 − f(x))
- 反向传播效率高,会比GELU计算效率高,而且效果逼近GELU
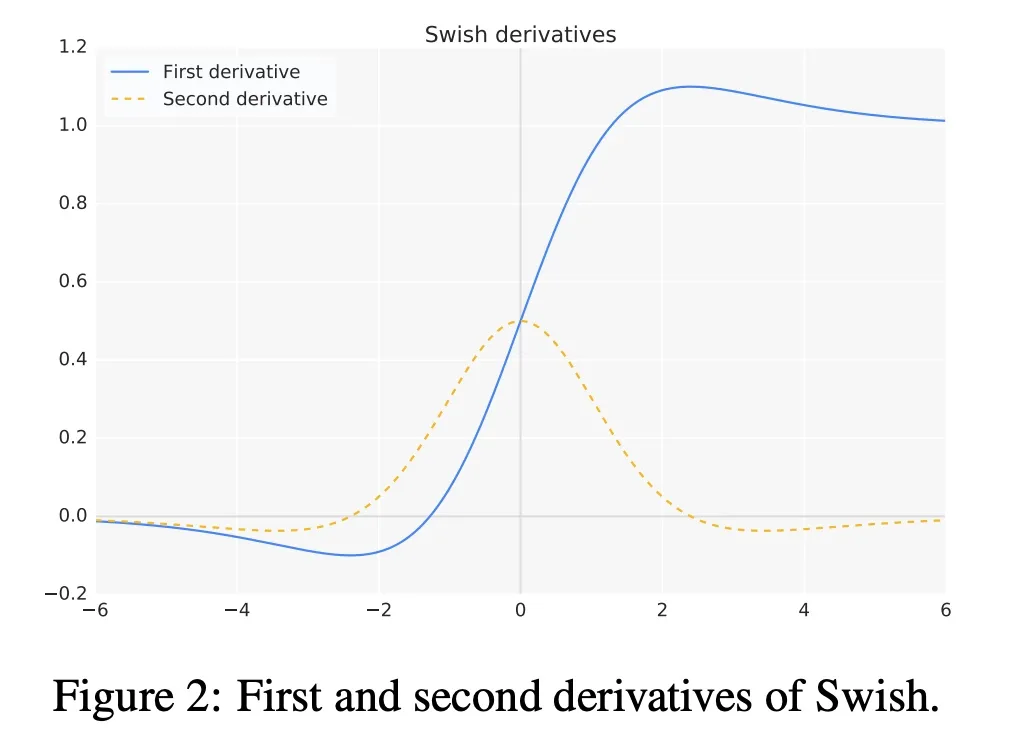
GLU门控单元(Gated Linear Unit)

-
GLU 的公式为:
- GLU 使用 Sigmoid 作为激活函数。
- SwiGLU 使用 Swish 替代 Sigmoid,提供更平滑的梯度和增强的表达能力。
- SwiGLU在性能上优于ReLU和GELU
KV缓存
- 什么是 KV-Cache?
- 在 Llama 3 架构中,在推理时引入了 KV-Cache 的概念,以 Key 和 Value 缓存的形式存储先前生成的 token。这些缓存将用于计算自注意力以生成下一个 token。只有 key 和 value token 会被缓存,而查询 token 不会被缓存,因此称为 KV Cache。
- 为什么我们需要KV Cache?
- 让我们看下面的图来阐明。
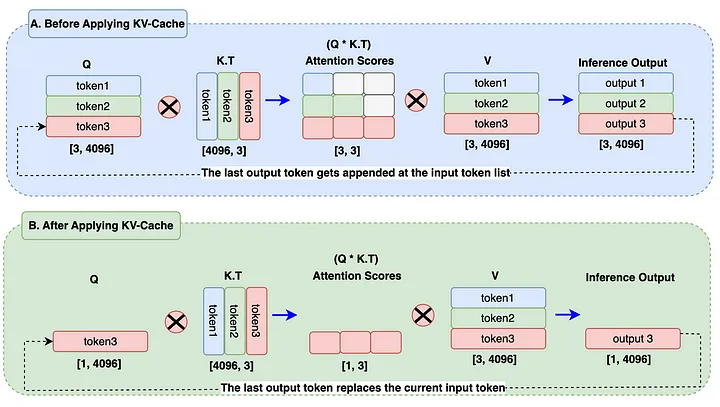
- 在图中的 A 块中,在生成 output3 token 时,之前的输出 token(output1,output2)还在计算,而且这两个token的值不会因为后面的output3而改变,因此这是完全没有必要的。这导致在计算注意力时需要进行额外的矩阵乘法,因此计算资源增加了很多。
- 在图中的块 B 中,输出标记替换了查询嵌入中的输入标记。KV Cache存储了先前生成的标记。在注意力得分计算期间,我们只需使用查询中的 1 个标记并使用键和值缓存中的先前标记。它将从块 A 到块 B 的矩阵乘法从 3x3 减少到 1x3,减少了近 66%。在现实世界中,由于序列长度和批量大小巨大,这将有助于显著降低计算能力。最后,将始终只生成一个最新的输出标记。这是引入 KV-Cache 的主要原因。
分组注意力查询
- 组查询注意力机制与之前的模型(例如 Llama 1)中使用的多头注意力机制相同,唯一的区别在于查询使用单独的头,键/值使用单独的头,但是由多个query共享。通常,分配给查询的头的数量是键和值头数量的 n 倍。让我们看一下图表以进一步加深理解。
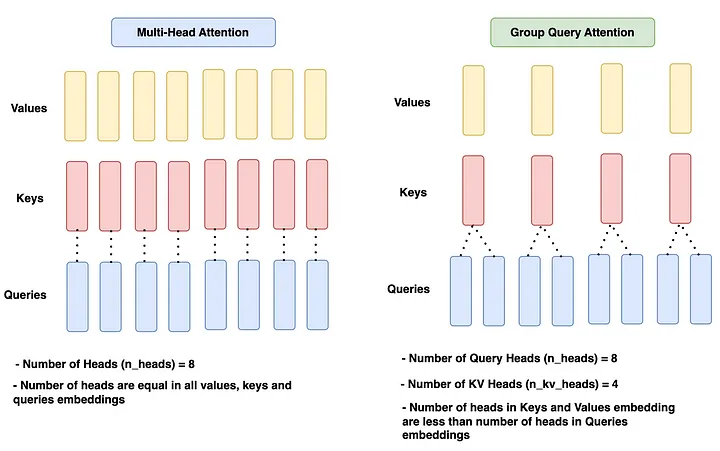
- 在给定的图表中,多头注意力在所有查询、键和值中具有相同数量的头,即 n_heads = 8。
- 组查询注意块有 8 个用于查询的头 (n_heads) 和 4 个用于键和值的头 (n_kv_heads),比查询头少 2 倍。
- 既然 MultiHead Attention 已经这么好了,为什么还需要 Group query Attention?
- 要回答这个问题,我们需要先回顾一下 KV Cache。KV Cache 有助于大大减少计算资源。然而,随着 KV Cache 存储越来越多的先前 token,内存资源将显著增加。无论从模型性能角度还是从财务角度来看,这都不是一件好事。
- 因此需要减少key和value,最好是大家能够共用一些头
- **因此,引入了 Group query Attention。**减少 K 和 V 的 head 数量会减少要存储的参数数量,因此使用的内存更少。各种测试结果证明,采用这种方法,模型准确率仍保持在同一范围内。
- 要回答这个问题,我们需要先回顾一下 KV Cache。KV Cache 有助于大大减少计算资源。然而,随着 KV Cache 存储越来越多的先前 token,内存资源将显著增加。无论从模型性能角度还是从财务角度来看,这都不是一件好事。
全貌
.webp)
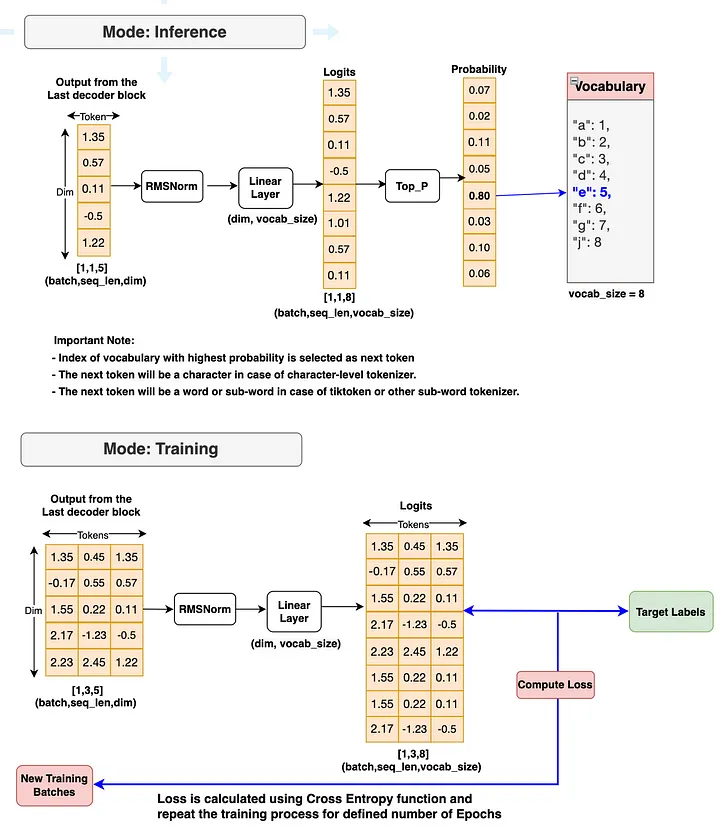
从0实现LLaMA3
- 我们从0实现一个LLaMA3的模型结构并且加载LLaMA3-8B-Instruct的参数,当然,tokenizer会使用预训练好的,这是基于BBPE训练出来的。
1 | |
-
输出:
hello world!
读取模型文件
-
通常,读取模型文件,往往取决于模型类的编写方式以及其中的变量名。
但由于要从零实现 Llama3,直接将模型全重加载到model变量
1 | |
[
“tok_embeddings.weight”,
“layers.0.attention.wq.weight”,
“layers.0.attention.wk.weight”,
“layers.0.attention.wv.weight”,
“layers.0.attention.wo.weight”,
“layers.0.feed_forward.w1.weight”,
“layers.0.feed_forward.w3.weight”,
“layers.0.feed_forward.w2.weight”,
“layers.0.attention_norm.weight”,
“layers.0.ffn_norm.weight”,
“layers.1.attention.wq.weight”,
“layers.1.attention.wk.weight”,
“layers.1.attention.wv.weight”,
“layers.1.attention.wo.weight”,
“layers.1.feed_forward.w1.weight”,
“layers.1.feed_forward.w3.weight”,
“layers.1.feed_forward.w2.weight”,
“layers.1.attention_norm.weight”,
“layers.1.ffn_norm.weight”,
“layers.2.attention.wq.weight”
]
1 | |
{
“dim”: 4096,#每一个token的向量对应的输入输出,4096的维度
“n_layers”: 32,
“n_heads”: 32,#query头
“n_kv_heads”: 8,#多个query头共享的kv头
“vocab_size”: 128256,
“multiple_of”: 1024,
“ffn_dim_multiplier”: 1.3,#升维因子
“norm_eps”: 1e-05,#防止分母为0
“rope_theta”: 500000.0#基底
}
使用这些配置推理模型的细节
- 模型有 32 个 Transformer 层
- 每个多头注意力块有 32 个头
- 词汇表大小等
1 | |
- 这里使用 tiktoken(OpenAI 的库)作为分词器
1 | |
[128000, 1820, 4320, 311, 279, 17139, 3488, 315, 2324, 11, 279, 15861, 11, 323, 4395, 374, 220]
[‘<|begin_of_text|>’, ‘the’, ’ answer’, ’ to’, ’ the’, ’ ultimate’, ’ question’, ’ of’, ’ life’, ‘,’, ’ the’, ’ universe’, ‘,’, ’ and’, ’ everything’, ’ is’, ’ ']
将 token 转换为 embedding
-
这里使用内置的神经网络模块
-
无论如何,
[17x1]token 现在是[17x4096],即每个 token 的长度为 4096 的 embeddings

-
注意:跟踪 shapes,这样一切将变得理解更容易
1 | |
torch.Size([17, 4096])
接下来使用 RMS 归一化嵌入
-
请注意,经过此步骤后 shapes 不变, 只是值被归一化
- 这17个token,每个token内部都会去进行RMS
-
需要注意的是,需要一个 norm_eps(来自配置)以避免不小心将 RMS 设置为 0 并导致除以 0 的情况
.webp)
1 | |
构建第一个 Transformer 层
归一化
-
从模型字典中访问
layer.0(这是第一层) -
归一化后 shapes 仍然是
[17x4096], 与嵌入相同但已归一化
1 | |
torch.Size([17, 4096])
从头实现注意力机制
- 加载第一个 Transformer 层的注意力头
- 当我们从模型中加载
query,key,value和output权重矩阵时,注意到 shapes 分别为[4096x4096],[1024x4096],[1024x4096],[4096x4096] - 乍一看这有些奇怪,因为在理想情况下我们希望每个头单独拥有各自的 q,k,v 和 o
- 这里作者将其捆绑在一起,为什么会这样呢? 因为这样有助于并行化注意力头的计算
- 当我们从模型中加载
1 | |
torch.Size([4096, 4096])
torch.Size([1024, 4096])
torch.Size([1024, 4096]) #kv和q/o相差四倍的原因:四个一分组,每组有4个,4个q共享一个key和value,所以这里右边是输入,左边是输出
torch.Size([4096, 4096])
展开 query
-
在下一步中,将展开多个注意力头的 query,得到的 shapes 为
[32x128x4096] -
这里的 32 是 Llama3 的注意力头数量,128 是 query 向量的大小,4096 是 token 嵌入的大小
-
这里的 **query 向量大小(128)**指的是:每一个注意力头里,单个 token 的 Query 表示向量的维度(head_dim)。
用 Llama3 这组数来理解最直观:
- 隐藏状态/词向量(token embedding / hidden state)维度:4096(也叫
- 注意力头数:32
- 所以每个头分到的维度:
它“代表什么”?
对每个 token 的隐藏向量 $$x\in \mathbb{R}^{4096}$$,每个头都会用自己的线性映射生成 query:
所以:
- 128 = 这个头拿来和 Key 做点积算注意力分数的“特征空间维度”
- 4096 = 输入的 token 隐藏表示维度
- 32 = 有 32 个不同的头,各自学不同“关注模式”
把 32 个头的 query 拼回去,整体仍然是 $$32\times128=4096$$维——只是被拆成了 32 份,每份 128 维分别去算注意力。
顺带一提:如果你看到的 shape 是 [32×128×4096],它很像是在描述 每个头的 (每头一个 128×4096 的投影矩阵),而不是单个 token 的 q 本身。
-
1 | |
torch.Size([32, 128, 4096])
实现第一层的第一个头
- 这里查询了第一个层的第一个头的
query权重矩阵,其大小为[128x4096]
1 | |
torch.Size([128, 4096])
现在将 query 权重与 token 嵌入相乘,以获得每个 token 的 query
- 这里可以看到得到的 shape 是
[17x128], 这是因为有 17 个 token,每个 token 有一个长度为 128 的 query
1 | |
torch.Size([17, 128])
位置编码
- 当前,每个 token 都有一个 query 向量,但如果你想一想 – 其实各个 query 向量并不知道它们在 prompt 中的位置。
1 | |
- 在我示例 prompt 中,使用了三次
"the",需要根据它们在 prompt 中的位置为每个"the"token 生成不同的query向量(每个长度为128)。可以使用 RoPE(旋转位置编码)来实现这一点。
1 | |
torch.Size([17, 64, 2])
- 这里为 prompt 中每个位置生成了旋转位置编码。可以看到,这些编码是正弦和余弦函数的组合。
- 在上的步骤里, 将
query向量分成对, 并对每对应用旋转角度移位! - 现在有一个大小为
[17x64x2]的向量,这是针对 prompt 中的每个 token 将 128 个长度的 query 分为 64 对! 这 64 对中的每一对都将旋转m*$$\theta$$,其中m是旋转查询的 token 的位置!
为每个二维向量引入旋转变换:
- 对于每对维度,定义一个旋转角度 θ 来编码位置信息。
- 具体旋转公式为:
- 对应到所有向量维度,利用每个位置的特定角度 θ 完成变换。
与位置相关的旋转角度:
- 旋转角度基于位置索引 p 和频率分量 ω来定义: $$ \theta_{p, k} = p \cdot \omega_k$$
- p是位置信息。
\omega_k$$ 是与维度 k相关的频率分量。 - $$\omega_k=10000^{-\frac{2k}{d}}
1 | |
tensor([0.0000, 0.0156, 0.0312, 0.0469, 0.0625, 0.0781, 0.0938, 0.1094, 0.1250,
0.1406, 0.1562, 0.1719, 0.1875, 0.2031, 0.2188, 0.2344, 0.2500, 0.2656,
0.2812, 0.2969, 0.3125, 0.3281, 0.3438, 0.3594, 0.3750, 0.3906, 0.4062,
0.4219, 0.4375, 0.4531, 0.4688, 0.4844, 0.5000, 0.5156, 0.5312, 0.5469,
0.5625, 0.5781, 0.5938, 0.6094, 0.6250, 0.6406, 0.6562, 0.6719, 0.6875,
0.7031, 0.7188, 0.7344, 0.7500, 0.7656, 0.7812, 0.7969, 0.8125, 0.8281,
0.8438, 0.8594, 0.8750, 0.8906, 0.9062, 0.9219, 0.9375, 0.9531, 0.9688,
0.9844])
1 | |
tensor([1.0000e+00, 8.1462e-01, 6.6360e-01, 5.4058e-01, 4.4037e-01, 3.5873e-01,
2.9223e-01, 2.3805e-01, 1.9392e-01, 1.5797e-01, 1.2869e-01, 1.0483e-01,
8.5397e-02, 6.9566e-02, 5.6670e-02, 4.6164e-02, 3.7606e-02, 3.0635e-02,
2.4955e-02, 2.0329e-02, 1.6560e-02, 1.3490e-02, 1.0990e-02, 8.9523e-03,
7.2927e-03, 5.9407e-03, 4.8394e-03, 3.9423e-03, 3.2114e-03, 2.6161e-03,
2.1311e-03, 1.7360e-03, 1.4142e-03, 1.1520e-03, 9.3847e-04, 7.6450e-04,
6.2277e-04, 5.0732e-04, 4.1327e-04, 3.3666e-04, 2.7425e-04, 2.2341e-04,
1.8199e-04, 1.4825e-04, 1.2077e-04, 9.8381e-05, 8.0143e-05, 6.5286e-05,
5.3183e-05, 4.3324e-05, 3.5292e-05, 2.8750e-05, 2.3420e-05, 1.9078e-05,
1.5542e-05, 1.2660e-05, 1.0313e-05, 8.4015e-06, 6.8440e-06, 5.5752e-06,
4.5417e-06, 3.6997e-06, 3.0139e-06, 2.4551e-06])
1 | |
torch.Size([17, 64])
1 | |
torch.Size([17, 64])
得到旋转向量后
- 可以通过再次将复数看作实数来返回成对的 query
1 | |
torch.Size([17, 64, 2])
- 旋转对现在已合并,现在有了一个新的 query 向量(旋转 query 向量),其 shape 为
[17x128],其中 17 是 token 的数量,128 是 query 向量的维度
1 | |
torch.Size([17, 128])
keys(几乎与 query 一模一样)
- keys 生成的 key 向量的维度也是 128
- keys 的权重只有 query 的 1/4,因为 keys 的权重在 4 个头之间共享,以减少计算量
- keys 也像 query 一样被旋转以添加位置信息,其原因相同
1 | |
torch.Size([8, 128, 4096])
1 | |
torch.Size([128, 4096])
1 | |
torch.Size([17, 128])
1 | |
torch.Size([17, 64, 2])
1 | |
torch.Size([17, 64])
1 | |
torch.Size([17, 64, 2])
1 | |
torch.Size([17, 128])
现在,已经有了每个 token 的旋转后的 query 和 key
-
每个 query 和 key 的 shape 都是
[17x128] -
接下来,将 query 和 key 的矩阵相乘
-
这样做会得到每一个 token 相互映射的分数
-
这个分数描述了每个 token 的 query 与每个 token 的 key 的相关度。这就是自注意力 :)
-
注意力得分矩阵(qk_per_token)的 shape 是
[17x17],其中 17 是 prompt 中的 token 数量
- 相当于每个token和每个token之间的注意力分数
-
1 | |
torch.Size([17, 17])
现在必须屏蔽 QK 分数
-
在 llama3 的训练过程中,未来的 token qk 分数被屏蔽。
-
为什么?因为在训练过程中,只学习使用过去的 token 来预测 token 。
-
因此,在推理过程中,将未来的 token 设置为零。
1 | |
-1770300245827.png)
1 | |
tensor([[0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
1 | |
.png)
1 | |
.png)
这些分数(0-1)用于确定每个 token 中融合 value 矩阵的比例
-
和 key 一样,value 权重也在每 4 个注意力头之间进行共享(以节省计算量)
-
因此,下面的 value 权重矩阵的 shape 为
[8x128x4096]
1 | |
torch.Size([8, 128, 4096])
llama3的第一层,第一个头的权值矩阵如下所示:
1 | |
torch.Size([128, 4096])
value 向量
- 现在使用 value 权重来获取每个 token 的注意力值,其大小为
[17x128],其中 17 是 prompt 中的 token 数,128 是每个 tokene 的 value 向量的维度
1 | |
torch.Size([17, 128])
注意力(attention)
- 和每个 token 的 value 相乘后得到的注意力向量的 shape 为
[17*128]
1 | |
torch.Size([17, 128])
多头注意力 (multi head attention)
-
现在已经有了第一层和第一个头的注意力值
-
现在将运行一个循环,并执行与上面单元格中相同的数学运算,但只针对第一层中的每个头
1 | |
32
- 现在有了第一个层的 32 个头的 qkv_attention 矩阵,接下来将把所有注意力分数合并成一个大矩阵,大小为
[17x4096]
1 | |
torch.Size([17, 4096])
权重矩阵,最后几步之一
- 对于第0层,最后要做的一件事是,将权重矩阵相乘
1 | |
torch.Size([4096, 4096])
这是一个简单的线性层,所以只需要进行乘法运算
1 | |
torch.Size([17, 4096])
- 注意之后,现在有了嵌入值的变化,应该将其添加到原始的 token embeddings 中(残差)
1 | |
torch.Size([17, 4096])
将其归一化
1 | |
torch.Size([17, 4096])
加载 FFN 权重并实现前馈网络
-
在 llama3 中,使用了
SwiGLU前馈网络,这种网络架构非常擅长非线性计算。 -
如今,在 LLMS 中使用这种前馈网络架构是相当常见的
1 | |
torch.Size([17, 4096])
在第一层之后,终于为每个 token 生成了新的 EMBEDDINGS(残差)
-
离结束还剩 31 层(一层 for 循环)
-
可以将经过编辑的 embedding 想象为包含有关第一层上提出的所有 query 的信息
-
现在,每一层都会对 query 进行越来越复杂的编码,直到得到一个 embedding,其中包含了需要的下一个 token 的所有信息。
1 | |
torch.Size([17, 4096])
整合
1 | |
得到最终 Embedding,对下一个 token 做预测
- embedding 的 shape 与常规 token embedding shape
[17x4096]相同,其中 17 是 token 数量,4096 是 embedding 维度
1 | |
torch.Size([17, 4096])
最后,将 embedding 解码为 token value
将使用输出解码器将最终 embedding 转换为 token。
1 | |
torch.Size([128256, 4096])
使用最后一个 token 的 embedding 来预测下一个值
希望在我们预料之内, 42 :)
注意:根据《银河系漫游指南》书中提到,“生命、宇宙和一切的终极问题的答案是 42 ” 。大多数现代语言模型在这里应该会回答 42,这应该能验证我们的整个代码!祝我好运 :)
1 | |
torch.Size([128256])
模型预测的 token 编号是 2983,这是否代表 42 的 token 编号?
1 | |
tensor(2983)
1 | |
42
参考资料
- RoPE
https://www.zhihu.com/tardis/zm/art/647109286?source_id=1003
现代计算机视觉
回看卷积神经网络CNN
CNN的运算方式
-
相信大家已经对基础的深度学习和经典的计算机视觉技术有了一定了解。
-
从这个章节开始,我们会一起学习现代计算机视觉的许多知识。
-
这节课里,我们首先来复习一下cv的经典算子:卷积神经网络CNN。
.png)
- 搜索cnn,大家通常看到的简图长这个样子:
- 一个图像分类任务,输入一张图片,由模型判断图像中的物体的种类。
- 比如这里是一个三分类任务,判断是dog bird 还是cat。
.png)
- input layer就是**将输入图像预处理然后转为张量(向量)**的过程
- 对于rgb图像而言,一个常见的预处理后尺寸是224x224x3
- 预处理方式通常有resize、crop、旋转,或者添加一些遮挡和模糊等等,这些预处理方式都是为了增加数据的多样性和鲁棒性,减少偏置。
.png)
- hidden layer就是cnn的主要计算环节
- 每一个hidden layer由cnn卷积、激活函数构成
- 每一层的特征图大小是可变的,通常随着层数加深,h和w越来越小,通道数越来越大
- 第i层的feature map的通道数是由第i-1层的卷积核数量决定的。
.png)
- output layer通常是一个全联接层,
- 它将卷积得到的图像特征转换为一个向量,向量的长度就是分类类别的数目
- 然后再过一个sofrmax函数,将向量转换为概率分布。
- 上述介绍的是cnn的最基本知识,如果大家有遗忘的地方,可以回看第二章进行复习。
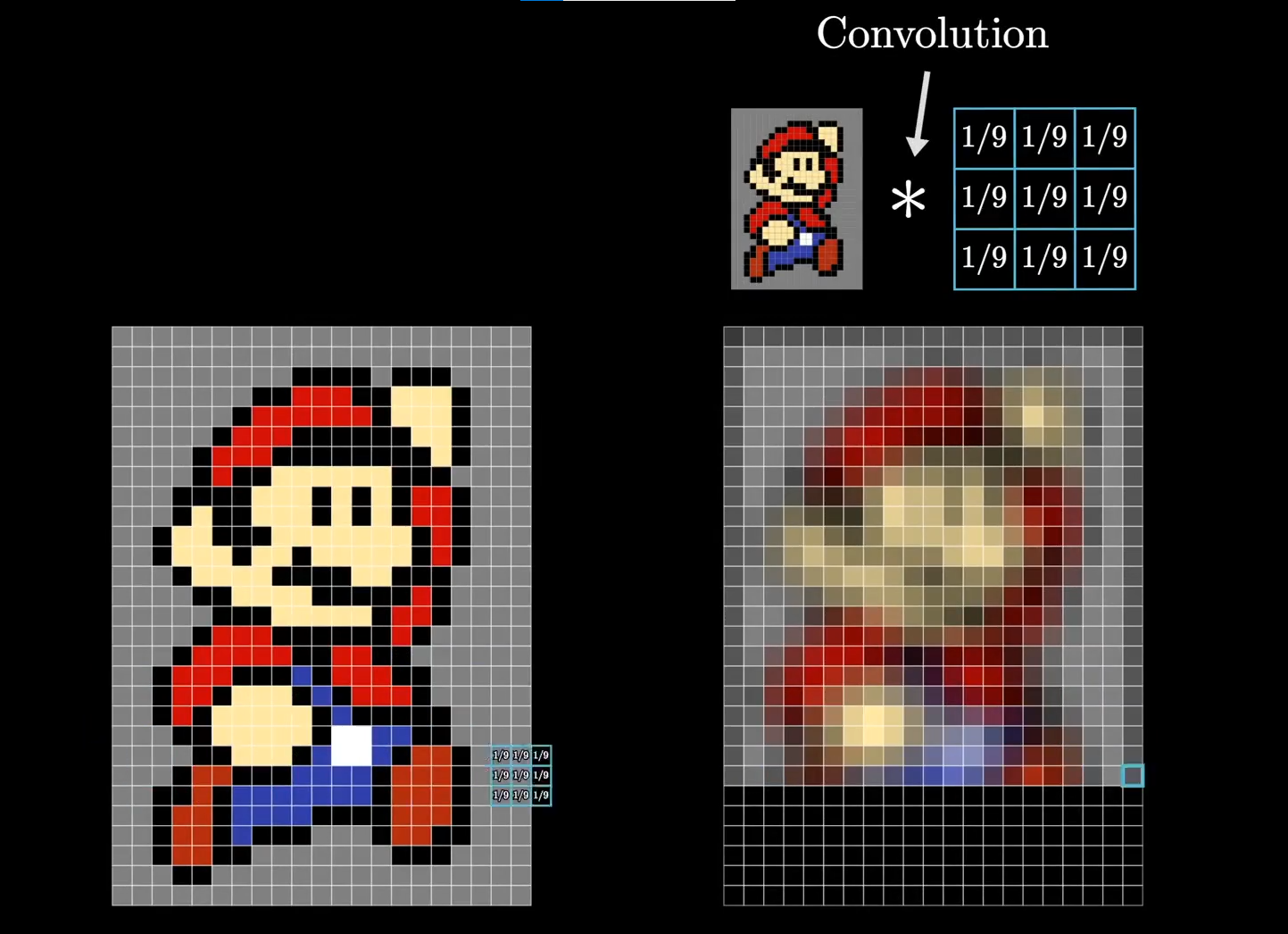
- 采用一个3*3的卷积核,在这个卷积核中每个位置都是1/9,实际的卷积操作就是每一个位置的像素x1/9然后相加。
- 每一个像素实际上是一个长度为3的向量(列向量),因为输入的是一个RBG图,有三个通道(每个通道的数值占1行)
- 这些像素的值都是0-1之间的小数,正常应该是0-255之间的值,变成0-1之间是因为CNN在预处理的时候会把这个图像去做一个归一化,把每个像素值从0-255之间归一化到0-1之间。
- 所以每一个像素所对应的是一个长度为3,值在0-1之间的向量
卷积核与感受野

- 原图到layer1的特征图用了20个卷积核,这里厚度就是20
- 从layer1到layer2的特征图采用了20个卷积核,所以layer2的特征图深度就是20
卷积核学到了什么
.png)
- 那么,每个卷积核到底学到了什么呢?
- 这里我们直接来看一篇论文:Visualizing and Understanding Convolutional Networks(点击超链接可以查看原论文哦!)。
- 它们将卷积层的输出重新映射回rgb空间,来对cnn学习到的内容进行可视化。
- 在早期的卷积层,卷积核学到的主要是一些细节的纹理信息;
- 但随着深度增加,卷积核逐渐学到了更多的全局的语义信息。
- resnet将局部的纹理信息和全图的语义信息结合起来,就模仿了人类去认识视觉内容的过程
.png)
- 这是为什么呢?
- 大家可以看到,越是深层的卷积核,它在原图上的感受野是越大的。
- 所以我们可以得到一个结论:早期的卷积核学习到的主要是局部的纹理信息与细节,而深层的卷积核则学习到更多的全图语义信息。
CNN的缺陷
- 上节课大家回顾了CNN,这节课我们就来探讨,CNN在处理图像时的一些固有缺陷。

卷积操作
.png)
- 通过上次对卷积核的剖析,相信大家也发现了:
- 卷积操作:擅长在局部邻域内提取特征。这种特性使得 CNN 非常适合捕捉图像中的局部模式(例如边缘、纹理等),但在捕捉全局特征方面可能相对不足。
- 虽然深层的卷积核的感受野逐渐扩大,但是它毕竟不是全图,而且已经经过了几层的信息折损。
感受野
.png)
- 第二个问题在于感受野。
- 感受野:在 CNN 中,感受野的大小是固定的,取决于卷积核的尺寸和网络的层数。无法自适应地聚焦于图像中的重要区域,很难同时处理局部和全局信息。
- 但在人脑中,观察重点是一个自适应的、动态变化的过程。
- 但是在人脑认识一个视觉信息的时候,在处理局部信息和全局信息是非常自然且自适应的,不是像我们的卷积神经网络一样,强行地去把深层和浅层的这种特征加在一起
结构化
.png)
- 我们提到,浅层的卷积核学习纹理信息,通过不断提取信息和扩大感受野,卷积核逐渐学习到了全图信息。
- 这就意味着:CNN的结构设计导致其天然适应具有空间结构的信息,但这种设计在面对缺乏显式空间结构的数据时表现较差:无法学习到更加具有泛化性的特征。
- 比如说我们在面对这种有非常明显的纹理结构的花纹的时候,CNN提取出来的特征就非常清楚,但是在面对一些比较圆润的,比较模糊的图片,比如水面、大面积白色的过度地带,提取出来的特征就不是很清楚,肉眼无法识别它本身面对的对象是什么了
强归纳偏置
.png)
- 依赖于提前人工预先去给他的一些设置,因此很大程度上取决于事先人为设计的这个模式是好还是坏
- 具有很强的人工先验的设计出来的结构,没办法自适应地区学习图像中的视觉焦点该放在哪里
回看Transformer
- 这节课我们一起回顾一下Transformer的一些基本情况。
.png)
-
我们来回顾一下经典的transformer结构;
-
经典的transoformer结构是由encoder和decoder组成的,这个图为了简化,只画了一个transformer block在这里。
- 在视觉信息学习过程中,通常只用到transformer中的encoder部分
- GPT用到decoder部分,BERT用到encoder
-
它的最终输出形式是predict next token,是由decoder输出的;
- 根据前i-1个token来预测第i个token可能会输出什么
-
输入的词汇经过tokenize后,再打成embedding;
-
将这个词进行分词转换成一定的词缀,去找每一个词缀在词汇表中对应的索引,找到索引之后得到这个词汇的编码表示
-
得到编码表示去过一个embedding层,得到每一个token的embedding表示

-
把它的这个位置编码加进去,结合这个位置编码后的embedding,就可以输入到transformer block去了

-
-
embedding输入再输入transformer block;
-
transformer block通常由这几个部分组成:首先是layer norm,层归一化,对每一层的输入进行归一化处理,使其有相同的均值和方差。层归一化可以提高模型的训练稳定性和收敛速度。
-
然后就是transformer的核心部分,也就是self-attention的运算;
- encoder里面计算的是self-attention
- decoder里面计算的是cross-attention
-
最后是一个feed forward模块,它通常由两个MLP加一个激活函数构成(给特征做一个非线性转换)。当然了,就像所有cnn一样,transformer中也有一个参差连接的结构。
- 把早期的局部信息和后续高级的抽象信息结合起来
-
.png)
- 我们再来看看transformer中最核心的环节,也就是自注意力机制。
- embedding在输入之后,首先被转为了QKV三个矩阵。
- query、key和value来自于谷歌搜索引擎,用户输入的是query,用来匹配的标签就叫做key,query和key会有一种算法来计算每一个页面的重要性,这个重要性就是页面的value,最终的搜索结果会根据value的降序排序来排列,value越高的页面排的越前。
- 自注意力的公式就是:Q乘以K再除以根号dk。dk就是transformer中所有embedding的长度。起一个放缩的作用。
- 自注意力的计算本质上是算不同token之间的相关程度
- Q乘以K的结算结果其实是一个权重矩阵。它衡量的是,一个句子里每个词和其它词的相关程度
- 每一个词首先会变成embedding(长度为dk的向量),自注意力机制计算的是不同embedding之间的相关性大小
- embedding在输入之后,首先被转为了QKV三个矩阵。

- 前面我们说到,Q乘以K的结算结果其实是一个权重矩阵。它衡量的是,一个句子里每个词和其它词的相关程度。
- 除以一个根号dk,起一个放缩作用。这个整体还是一个矩阵,再过一个softmax将数值转换为概率,这块儿就变成什么了呢,它是一个每一个值都为概率的矩阵。在(i,j)位置上的值,就是第i个token和第j个token的相关度。
- 再用这个亲密度矩阵去乘value,得到最终的自注意力的计算结果,最终的这个计算结果还是一个矩阵,这个矩阵衡量第i个token和第j个token之间的相关性的大小程度,也就是最终的矩阵中(i,j)位置上的值
ViT:Vision Transformer
.png)
- Transformer本身是一个处理文本序列信息的,而文本序列信息是一个一维的信息,而图像天生是一种二维的信息,由许多平面上的像素组成。因此,想要将图像信息变成类似于文本token一样的一维序列信息,来利用transformer这种良好的结构。
1️⃣ Patch Token(图像块嵌入)
-
含义: Vision Transformer 不像 CNN 一样直接处理整个图像,而是先把输入图像切分成固定大小的小块(patch)。 例如,一张$$224×224$$ 的图像可以切分成 的 patch,每边有 个,因此共有 个 patch。。
-
处理方式: 每个 patch 被展平成一个向量,然后通过一个线性投影(Linear Projection)(将其特征取出来)映射到固定长度的向量空间,这个过程相当于把每个 patch 看作一个“单词”,相当于一个文本token所变换成的一个embedding。
- 结构上实现了把一个大图首先变成了一字排开的一些小的token序列,对每个token再提一个它单独的这个特征出来
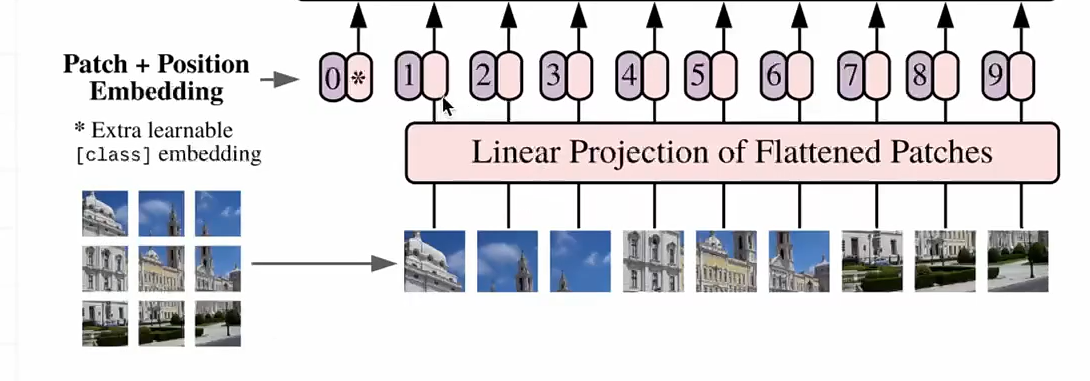
-
用途: 所有 patch token 加上位置信息(position embedding)后,一起输入到 Transformer Encoder 进行后续的自注意力计算。
- classtoken带有分类信息,position-embedding有位置编码,放到transformer encoder去提取特征,提取出来的特征过一个MLP,最后再去做类别分类
2️⃣ Class Token(类别标识向量)
- 含义: Class token 是 ViT 特有的设计,类似于 BERT 中的
[CLS]token。 它是一个可学习的向量,初始值随机,通过训练逐渐学习成为整个图像信息的全局摘要。 - 作用: Class token 在每个 Transformer 层里都会和所有 patch token 交互,吸收全局上下文信息。 最终,Transformer Encoder 的输出中,这个 token 就是图像的“代表”,后续通过 MLP Head 用于分类预测(鸟、球、车等)。
- classtoken所蕴含的信息就是这个图像包含的到底是一个什么类别的物体
全局建模
.png)
-
在 Vision Transformer (ViT) 中,输入图像首先被切分为若干个固定大小的 patch,每个 patch 通过线性映射得到一个 patch token。同时,ViT 在所有 patch token 前加入一个额外可学习的 class token,用来聚合全局信息用于分类。
-
ViT 的核心思想是:所有 token(包括 patch token 和 class token)都可以在 Transformer Encoder 中彼此交互,每一层的自注意力机制都允许每个 token 与序列中的任意其他 token 计算注意力权重,从而实现信息的全局整合(全局建模)。换句话说,注意力窗口是覆盖整张图像的,不存在局部感受野的限制。
-
相比之下,卷积神经网络(CNN)在低层主要通过局部卷积核提取局部特征,只有在网络加深、或通过堆叠卷积与池化层后,才能间接获得较大的感受野。因此,ViT 在原理上允许直接利用长距离依赖,更适合捕获全局上下文信息。
感受野
.png)
-
在 Vision Transformer (ViT) 中,输入图像被分割成若干 patch,并经过线性映射和位置编码后,形成 patch token。ViT 还引入了一个可学习的 class token,与所有 patch token 一起输入 Transformer 编码器。
-
ViT 的核心特征是:自注意力机制可以让序列中的每个 token 与所有其他 token 计算注意力权重。(每一个patch都会和其他的patch进行信息交互) 因此,每个 patch token 可以直接访问整张图像的上下文信息,class token 也可以从所有 patch 中聚合信息(每个patch还要跟class token即图像最抽象的语义来做一次建模)。换句话说,ViT 的“注意力窗口”覆盖了整个图像,全局信息交互是一次完成的,而不需要多层叠加。
-
相比之下,传统 CNN(右图所示)通过局部卷积核提取局部特征,低层只能感知很小的区域,只有在堆叠多层卷积和池化后,单个神经元的感受野才逐渐扩大。因此,CNN 的信息传递受限于有限的感受野,远距离依赖需要经过多层传播才能捕获。
结构化
.png)
-
注意力机制的本质是计算每个区域和其它区域的关联性,在理解视觉内容时是自适应的。
-
自适应:因为我们把每一个patch都考虑到了,还把这个图象的整体的语义信息通过class token考虑到了,所以说我们最后建模出来的这个效果就是我们在理解图片的时候会自适应的去观察到这个图像中的重点。
- 比如下图CNN可能看到的是小狗和环境之间的分界线,绳子和北京,草地和天空之间的分界线,但在VIT里面,我们会自适应地把这个注意力放在图像当中最关键的信息,也就是和classtoken最相关的信息那里。这样的话我们在理解图像的时候,不再拘泥于图像有没有纹理,阴影之类的,我们是自适应地根据它的语义来理解这张图像

-
-
在 Vision Transformer (ViT) 中,输入图像首先被切分为多个 patch,并通过线性映射和位置编码得到 patch token,同时引入一个可学习的 class token。所有这些 token 一起输入到 Transformer Encoder 中进行多层的自注意力计算。
-
自注意力机制的本质是:计算任意两个区域(token)之间的相关性,并根据这种相关性自适应地分配权重,决定信息如何流动。这意味着每个 token 可以从所有其他 token 中选择性地聚合有用的信息,从而形成对图像内容的全局理解。
-
右边的示例展示了 ViT 在处理不同图像时,学到的注意力分布:
- 对于狗的图片,ViT 自动关注到狗的主体区域;
- 对于飞机,模型的注意力集中在机体部分;
- 对于蛇,注意力聚焦在蛇的纹理与轮廓。
-
这说明 ViT 的自注意力机制能够根据输入内容,自适应地决定“看哪里、忽略哪里”,而不像卷积那样固定感受野和权重。这种自适应全局建模能力是 ViT 在复杂视觉任务中优于传统 CNN 的核心优势之一。
-
核心点:
- 自注意力 = 计算所有区域两两之间的相关性
- 注意力模式是输入依赖的、动态的
- 全局信息交互,一层即可建立长距离依赖
弱归纳偏置
.png)
-
CNN 的卷积操作带有一种强烈的归纳偏置,即假设图像中的局部像素相关性更高。
-
这种归纳偏置在许多视觉任务中是有效的,而且它在一个比较小的数据值上,因为有这种先验知识在,它也可以更好地收敛,用一个很小的数据就能训练出来效果。
- 但也会限制模型的表现。
-
ViT 的自注意力机制没有这种归纳偏置,因为我们是每一个patch之间都去信息建模的,它能自由地学习不同特征之间的关系,因此在大量数据的支持下,ViT 有能力从数据中学习更复杂更鲁棒的特征表示。
- 但是相应的收敛起来比较慢,需要的数据量比cnn大得多
ViT结构&位置编码
.png)
- VIT核心思想:
- 把一张完整的二维大图裁剪成多个patch,
- 然后把这些patch依次排开,再把每个patch依次去过一个linear projection,把它的这个小的特征提取出来,这些小的特征依次排开,模仿了文本序列里面过了tokenization之后形成的一系列token。
- 再把这个一系列token之前加上一个classtoken,用来表征这张图片的全局的语义信息,
- 再把这个整体的token序列再加上一个位置编码,
- 所形成的这个最终的token序列过一个transformer encoder去做它这个特征建模,
- 再把提取出来的特征做一个MLP,然后去做一个分类任务
Patch Token
- ViT 将输入图像切分成固定大小的 patch(小块),例如 $16 \times16 $像素一个 patch。每个 patch 被展平成向量后,通过线性投影映射到固定维度,形成 patch token。每个 patch token 表示局部区域的特征。
Class Token
- 除了 patch token,ViT 还引入一个额外的 class token,它是一个可学习的向量,初始随机,训练过程中会学习到如何聚合全局信息。经过多层 Transformer 编码后,这个 token 用作整张图像的语义表示,输入到 MLP Head 用于分类。
位置编码(Position Embedding)
-
由于 Transformer 自注意力机制本身对输入顺序不敏感,ViT 必须通过位置编码引入 patch 的位置信息。具体做法是给每个 token(包括 class token 和所有 patch token)加上一个可学习的位置向量,告诉模型这个 token 对应图像的哪个位置。
-
有了位置编码后,模型才能同时利用局部区域的内容信息和其空间分布信息,保证空间结构不会丢失。
固定位置编码
.png)
-
ViT 通常使用固定位置编码(fixed positional encoding),这种编码方式与传统的 Transformer 中使用的编码类似。
-
pos:序列位置(ViT 把 patch 线性展开后按顺序编号)。
-
i:位置向量中的维度索引。
-
d:通道维度(embedding 维度)。

- 每一个小的patch提的特征长度。过了linear projection变成特征向量
-
维度 2i 用正弦,2i + 1 用余弦,频率按 递减,覆盖从高频到低频的信息。
-
10000是一个频率缩放因子
- 低维度对应短周期(高频):当 i 较小(靠近 0)时,分母中的指数较小,导致 pos/较小的值 较大,使得正弦和余弦函数变化较快,周期较短,表示细粒度的位置信息。
- 高维度对应长周期(低频):当 i 增大时,指数增大,分母变大,导致 pos/较大的值 较小,正弦和余弦函数变化较慢,周期较长,表示粗粒度的位置信息。
-
为什么 ViT 适用这套 1-D 编码?
- 展平处理 ViT 先把图像分割为 patch,再按扫描顺序(如行优先)展平成一维序列;因此直接沿用 1-D 正余弦编码即可为每个 patch 赋予唯一位置。
- 可外推性 固定正余弦编码不依赖训练参数,同一频率模式在更长序列上仍然有效,有利于在测试时处理更大分辨率或更多 patch 的输入。
- 无额外参数 与可学习位置向量相比,固定编码不增加参数,也不会产生随训练而“漂移”的位置信息,对小数据集或低参数预算场景更友好。
可学习位置编码
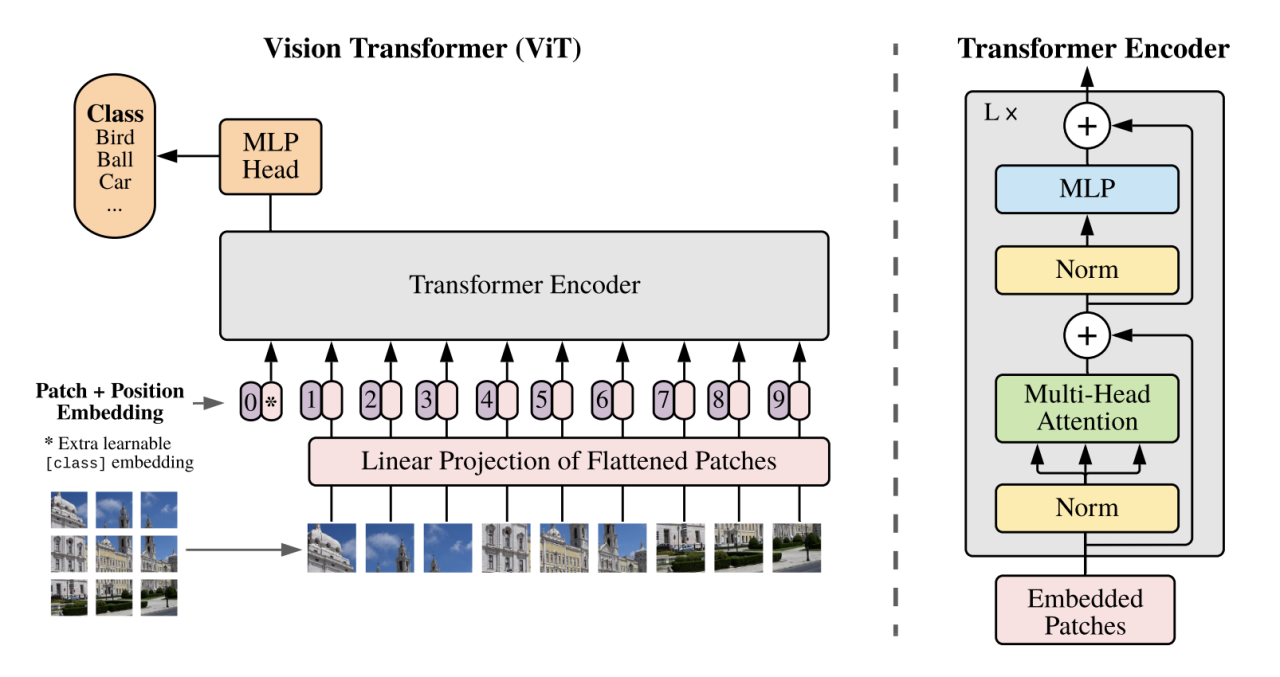
-
与固定编码不同,可学习位置编码不依赖任何固定的数学函数,而是直接把每个位置的编码看作一组可训练的参数。它在训练开始时随机初始化,随后与模型的其他参数一起通过反向传播自动学习得到最优的空间位置信息表达。
-
这种做法的好处是更灵活:模型可以根据实际的数据分布,自动调整每个位置向量的数值,而不受正余弦频率模式的限制。因此,尤其在大规模数据集上,可学习的位置编码往往可以提升 ViT 的分类性能。
-
在实现时,PyTorch 中通常直接定义一个形状为
(N + 1, D)的可训练矩阵(N 个 patch token,加 1 个 class token),在前向传播时把它加到 token 序列上即可。这个方法简单、参数量小(相对于整个模型),但对模型的效果往往有实用的增益。-
CLS token 的确是在 patch 经过线性投影(linear/patch embedding)之后,加到序列最前面。
但这里的max_len说“patch 数量 + 1”并不矛盾,因为它指的是——位置编码需要覆盖整个 token 序列长度,而这个序列长度在加了 CLS 以后就是 N_patches + 1。把流程按形状捋一遍你就清楚了(以 ViT 为例):
1) patch → linear 投影(patch embedding)
- 图像切成 N个 patch
- 每个 patch 展平后过线性层,变成 维
- 得到:
2) 准备 CLS token(它本身也是 d_modeld_modeld_model 维可学习向量)
cls是一个参数向量,形状通常是:
3) 拼接成 Transformer 的输入序列
重点:Transformer 看到的序列长度就是 N+1。
-
-
位置编码的方式更加灵活和鲁棒,灵活适应不同的数据分布。收敛比较慢但是鲁棒性和泛化性比较好。
位置编码的重要性

ViT代码实现
- 实现任何一个深度学习项目,一定要新建一个专属的python环境,在干净的环境里面从头开始配包配依赖项目。千万不要在自己默认的系统环境里面去随便改配置文件
1 | |

1 | |
现代目标检测
传统目标检测的缺点
目标检测
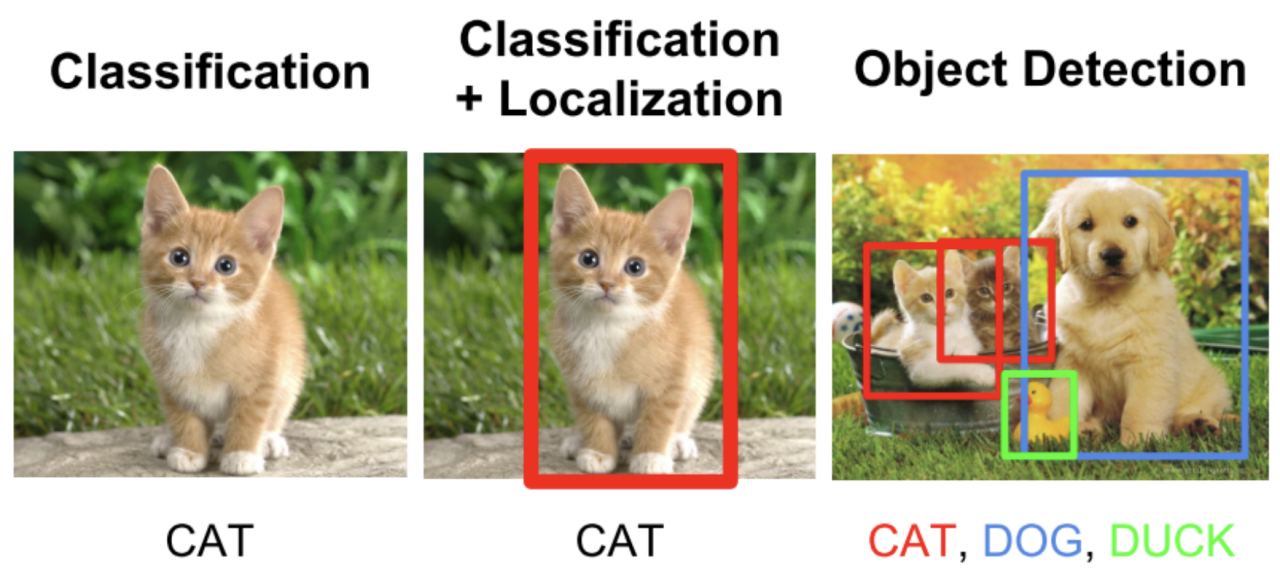
-
目标检测(Object Detection)是计算机视觉中的一个核心任务,旨在在一张输入图像中同时识别出所有感兴趣的物体,并准确预测它们的位置(通常用边界框表示)及对应的类别标签。
-
如图所示:
- 分类(Classification):只判断图像中存在哪个类别(如 CAT)。
- 分类 + 定位(Classification + Localization):不仅判断类别,还预测目标的大致位置,用一个框标出单个物体。
- 目标检测(Object Detection):可以识别图像中的多个物体,每个物体都要单独标注类别和位置。因此它是分类和定位的组合且是多实例的扩展。
-
目标检测输出的是一个包含若干个三元组的结果: (类别,位置框,置信度) 每个物体都有独立的框和标签,且通常需要覆盖不同尺度、不同位置的目标。
传统检测的流程

1️⃣ Two-Stage 检测方法
核心思想:分两步进行
- 第一步:先生成可能包含物体的候选区域(Region Proposal)
- 第二步:对每个候选区域进行分类和精确定位回归
代表性方法:
- RCNN (2014) 首个开创性方法。使用 Selective Search 生成候选区域(~2000个),然后对每个区域裁剪后送入 CNN 做分类,最后用 SVM 分类器和回归器做后处理。缺点是速度慢、重复计算多。
- Fast RCNN (2015) 改进了 RCNN 的重复特征提取问题。整张图先经过一次 CNN,生成 feature map,然后用候选框(RoI)在 feature map 上进行 RoI Pooling,再送入后续分类和回归分支。显著提升了效率。
- Faster RCNN (2015) 在 Fast RCNN 基础上进一步改进,提出了 Region Proposal Network (RPN),用可学习的网络代替手工设计的 Selective Search。RPN 和检测网络共享卷积特征,实现端到端训练和更快的候选框生成。
2️⃣ One-Stage 检测方法
核心思想:直接在整张图像上做密集预测,跳过候选区域生成,单阶段完成定位与分类,速度更快。
代表性方法:
- YOLO (You Only Look Once) 直接将图像分成网格,每个网格预测若干边界框及类别概率。实现了实时检测,推理速度极快。后续演化出 YOLOv2、YOLOv3、YOLOv4、YOLOv5、YOLOv7 等多代版本。
Two-Stage

-
输入一张图像,提取一些潜在的proposal(候选),即有可能是前景物体的一些区域,把这些区域对应的像素拿出来,再去过一个CNN,把它的feature提出来,feature拿出来之后再过一个MLP,得到这个区域特征之后,再和事先预定的类别逐个比对yes or no,总有一个label和提取出来的proposal的特征相似度或者匹配度最高,就把它作为我们这个proposal最终分类的结果,那么就完成了目标检测这个任务
-
核心思想是:先生成候选区域,再用 CNN 提取特征,最后分类和回归。
-
具体步骤如下:
- 输入图像(Input image)
- 直接输入一张自然图像。
- 候选区域生成(Extract region proposals)
- 使用 Selective Search 算法在图像上生成约 2000 个可能包含物体的候选框(region proposals)。这些框尽可能覆盖所有可能的目标位置。
- 特征提取(Compute CNN features)
- 对每个候选区域进行裁剪(warp),然后单独送入一个预训练的 CNN(如 AlexNet)提取固定长度的特征向量。由于对每个候选框都要单独跑一次 CNN,这个过程非常耗时。
- 分类与回归(Classify regions)
- 对每个候选框的 CNN 特征向量,使用独立训练的 SVM 分类器判断属于哪一类(如人、猫、狗等),同时用线性回归器对候选框位置进行微调(bounding box regression),以提高定位精度。
- two stage:
- stage1:拿proposal,提取proposal特征
- 最关键的一步
- stage2:二分类任务,把特征和每个label做对比,找到相似度最高的label作为检测结果
- stage1:拿proposal,提取proposal特征
Region Proposal 候选区域生成
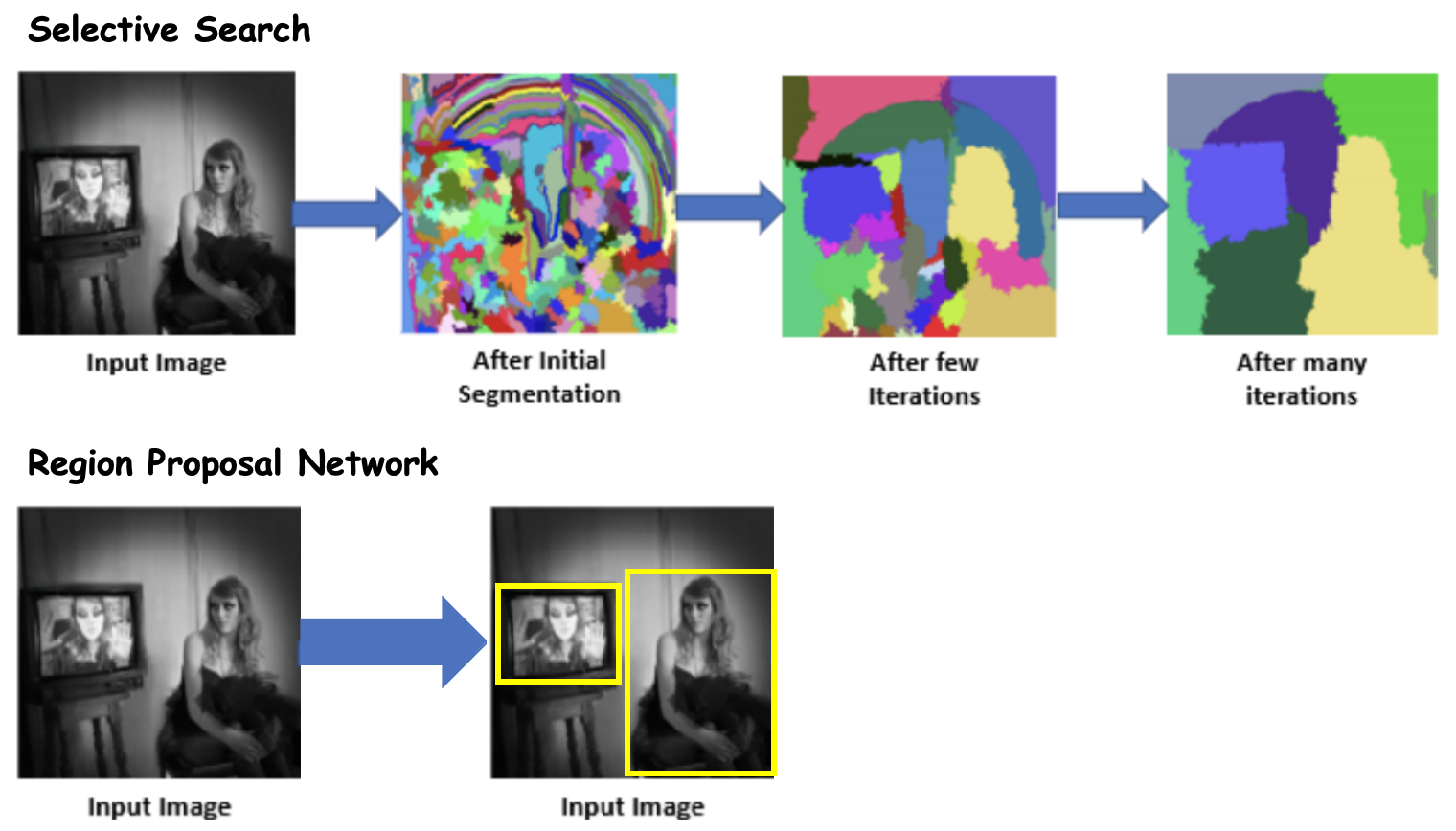
- 有两种方法:
1️⃣ 选择性搜索(Selective Search)
- 原理:先对输入图像进行初始的多尺度分割(如图上方所示),把相邻的像素组合成小的区域块(superpixels),然后基于颜色、纹理、大小等手工设计的相似性度量,逐步迭代合并相似区域,形成不同尺度的候选区域。
- 手工做一个粗略的segmentation
- 需要定义不同区域的合并原则和合并阈值
- 特点:
- 完全基于启发式算法,无需学习。
- 参数(如初始分割的尺度、区域合并阈值)需要手动调节以适应不同场景。
- 生成候选框数量可控(通常 ~2000 个),但计算速度较慢。
- 局限:无法自适应学习最优区域,且不同场景下可能需要重新调参。
- 非常依赖于人工设计的特征,以及区域合并的方法
2️⃣ 区域建议网络(Region Proposal Network, RPN)
- 原理:RPN 是 Faster R-CNN 中提出的可学习候选区域生成方法。它在 feature map 上滑动小卷积窗口,对每个位置预测一组预定义的**锚框(Anchor Boxes,初步检测框)**的前景/背景概率以及边界框的回归偏移量,从而生成最终的候选区域。
- 在图片的每个像素逐一去遍历,找到最有可能把锚框固定下来的像素,然后把锚框框出来就可以了。
- 锚框设计:
- 需要预先定义不同尺度(如小、中、大)和长宽比(如 1:1、1:2、2:1)的锚框,用以覆盖不同形状和大小的目标。
- 这些锚框的尺寸、比例是超参数,通常基于数据集统计或者经验设置,不同任务可能需要调整。
- 锚框的设计很大程度上决定了目标检测的效果好不好
- 不同的数据集得设计不同的锚框,设计工作繁杂
- 特点:
- 与主检测网络共享特征,训练端到端。
- 不需要额外的手工特征设计,相比选择性搜索速度更快,且可自适应学习候选框。
非极大值抑制 NMS
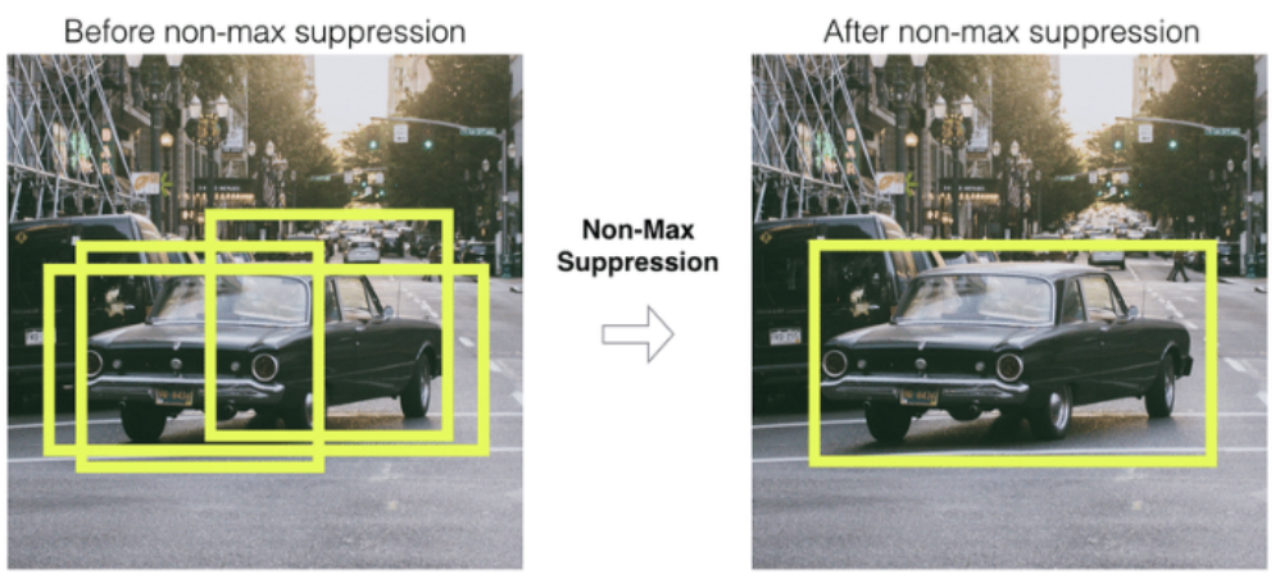
-
在目标检测中,模型通常会对同一个物体预测出多个重叠的候选框(如图左所示)。
-
NMS 的目的是从这些冗余框中,保留一个最优的框,并去除其余重叠度高的重复框,从而得到更简洁、准确的检测结果(如图右)。
工作原理
- 按置信度(confidence score)对所有候选框排序
- 从最高置信度的框开始,依次选择,并删除与其 IOU(交并比)大于设定阈值的其他框
- 重复该过程,直到所有框都处理完
阈值设定要点
-
IOU 阈值:这是控制去重严格程度的关键参数,通常设置在 0.5 到 0.7 之间。
- IOU,全称 Intersection over Union,中文通常称为交并比,是衡量两个区域重叠程度的一个常用指标,广泛用于目标检测、分割等任务中。
- 交集面积/并集面积
-
影响:
- 阈值较高 → 更宽松 → 保留更多重叠框 → 召回率高但可能重复检测
- 阈值较低 → 更严格 → 删除更多框 → 重复少但可能漏检目标
-
因此,需要在 精度(Precision) 和 召回率(Recall) 之间做权衡,通常通过验证集调优。
-
NMS 是目标检测必不可少的后处理步骤,用于合并冗余候选框,IOU 阈值的合理设定直接影响检测效果。
One-Stage
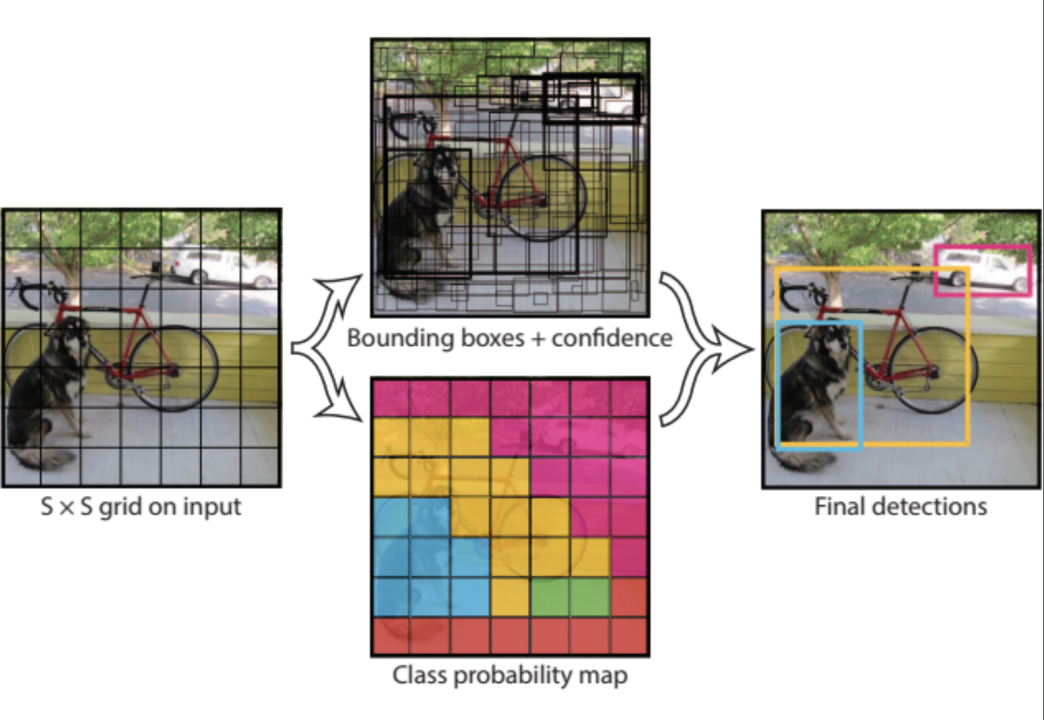
-
One-Stage 检测(如 YOLO、SSD)与 Two-Stage 的最大区别在于:它们不先生成候选区域(proposal),而是直接对输入图像进行密集的端到端预测,输出即为最终检测结果。
- 找锚框的同时对这个图片做类别的probability map,即每个区域大概是哪个类别的概率,用一个先验的概率来表示一下。
- 找锚框的时候结合种类可能性地图,如果框完整地在某个区域内,那么可能就是一个检测完成的框
-
具体来说:
-
1️⃣ 输入图像会先被划分成一个固定的网格(如图左,S × S)。
-
2️⃣ 对于每个网格单元,网络直接输出:
- 一组 Anchor Boxes(预定义的边界框模板)
- 每个 Anchor 的位置偏移(回归值)
- 每个 Anchor 的类别概率分布(Class Probability Map)
- 每个 Anchor 的置信度分数(Bounding Boxes + Confidence)
-
3️⃣ 这些信息通过一个单一的网络前向过程一次性得到,不经过额外的 Region Proposal Network,也不需要后续 RoI Pooling。
-
4️⃣ 最终,网络直接根据预测出的 Anchor + 类别概率,经过非极大值抑制(NMS),得到最后的检测结果(如图右)。
关键点:
- Anchor 和 Class Map 直接用来计算损失: 网络的训练目标是让输出的 Anchor 偏移值与真实框尽可能接近,同时让 Class Map 的类别概率与真实标签匹配,这样可以在单阶段内完成位置与类别的联合学习。
- 没有 proposal 阶段: Unlike Two-Stage 方法(如 Faster R-CNN)先生成 proposal、再分类,One-Stage 检测器直接输出最终的检测结果,简化了流程,提高了速度。
传统检测的缺陷:性能和初始的人工干预非常相关!
- 泛化性很差
DETR
-
上节课呢,我们介绍了cv领域中一个非常经典且在现实场景中应用很频繁的任务,目标分类。
-
传统的目标检测方法非常复杂且依赖于人工的假设。
-
transformer出现后,目标检测领域出现了一个里程碑式的工作:DETR。
传统目标检测

-
非常依赖于事先的人工假设,比如预定proposal、预定anchor,检测器的性能受这些预先假设影响很大;
-
同时检测器的性能,还很大程度上依赖于后处理nms;
-
这些因素的影响下,目标检测过程变得非常的复杂,这使得训练过程很难收敛、调参也变得很困难。
DETR的核心思想

DETR Architecture
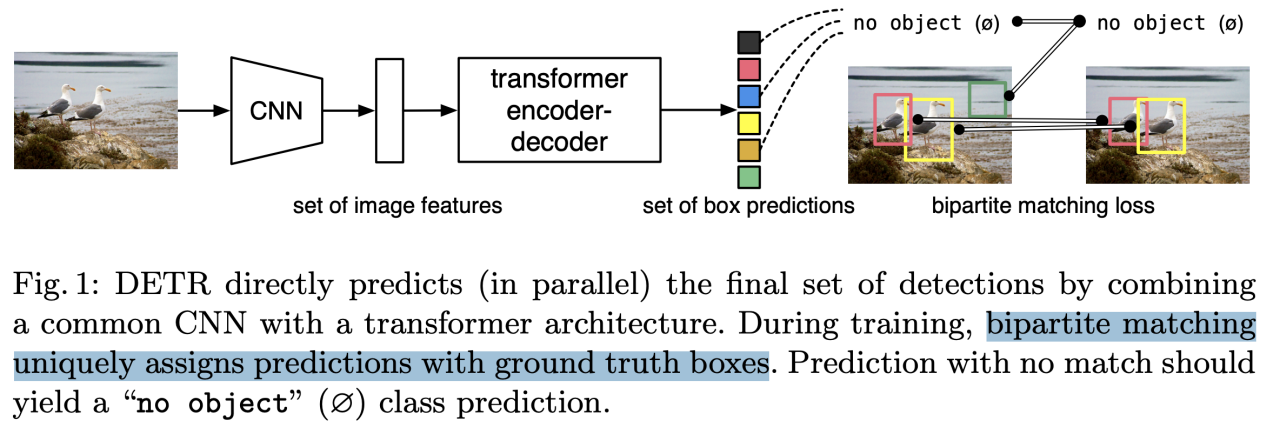
左半部分:特征提取 + Transformer Encoder
-
CNN提取特征,transformer encoder-decoder进行特征加强
-
我们先来看模型的左半部分使用了transformer encoder之后呢,正如我们在之前的课程里说的,图像里的每个patch之间都会有交互;
-
这样一来呢,模型就知道哪个patch是哪个物体、哪个patch是另外一个物体了。
-
这时候去预测检测框,对于同一个物体呢,就不会有那种上上下下左左右右很多重复的框了。
-
也就是说,全局特征建模天然很适合去掉冗余的检测框。
Object Query
-
decoder做的事交叉注意力,图像的特征通过CNN提取之后,需要有另外的一些query来跟这个图像的query去做交互(cross attention),这些另外的query是人为设定的
- 每一个object query蕴含了一个检测框的信息
-
DETR 在 Transformer 里使用了专门设计的 object query,图中没有显式画出来。
- 定义: 在 DETR 中,object query 是一组可学习的、固定长度的向量,随机初始化后,和图像特征通过 Transformer 交互,用来捕获和解码目标信息。
- 作用: 每个 object query 可以被视作“查询一个可能存在的物体”,因此 object query 的个数直接决定了 DETR 输出检测框的最大数量。
- 默认设置: 原论文里,DETR 默认设置 object query 的个数为 100。 不论输入图片中实际有几个物体,模型都会输出 100 个候选框(包括预测为“没有物体”的那些)。
输出后怎么处理?
-
1️⃣ 有了 100 个候选框和分类结果后,接下来要把它们和真实标注(ground truth boxes)一一匹配,才能计算损失。
-
2️⃣ 传统方法(如 Faster R-CNN)使用锚框或候选区域和 NMS,DETR 不需要,而是把 目标检测视作一个集合预测问题。
-
3️⃣ 为此,DETR 用了**匈牙利算法(Hungarian Algorithm)**来做 二分图匹配(bipartite matching):
- 目标是找到一种匹配方式,使得所有预测框与真实框的总体匹配成本最小(综合了分类误差和位置误差)。
- 匹配不上真实目标的候选框则被标记为 “no object”。
二分图匹配
-
二分图匹配是图论中的一个经典问题,指的是在一个**二分图(Bipartite Graph)**中,找到一个最大匹配,使得每条边都连接两个不同集合中的顶点,且没有两个边共享同一个顶点。
-
一个图称为二分图,如果其顶点集可以分成两个不相交的子集 U和V,并且图中的所有边都连接 U 和 V 中的顶点,而不存在任何一条边连接同一子集中的两个顶点。简
-
单来说,二分图的顶点分成两类,图中的边只会连接这两类中的顶点,而不会连接同类顶点。
-
二分图匹配的目标是在二分图中找到一个最大的边集,使得每个边集中的边都只连接 U 中的一个顶点和 V 中的一个顶点,且所有边都不共享同一个顶点。
-
我们预测出这100个框之后呢,去和gt框去做二分图匹配,最后和gt可以匹配的框,就是我们最终预测出来的物体框;
- gt视为一个子集,预测框视为一个子集
-
匹配到的作为label
-
那些和gt没有匹配的框,就会被标记为no-object,也就是背景框。
什么是二分图匹配?
- 二分图: 一个图的顶点可以被划分为两个不相交的子集 UUU 和 VVV,图中的每条边只连接来自不同子集的顶点,不存在连接同一子集顶点的边。 简单来说,就是“左右两组点,边只跨组相连”。
- 二分图匹配的目标: 在二分图中找到最大的边集,使得:
- 每条边连接一对不同子集中的顶点。
- 没有两条边共享同一个顶点。 这在图论中叫做最大匹配问题。
DETR 中怎么用?
- 在 DETR 里:
- 左边的顶点:固定数量的预测框(如 100 个 object query 的输出)。
- 右边的顶点:图片中真实存在的目标(ground truth boxes)。
- 任务:
- 对于每个真实目标,只分配一个预测框与之匹配。
- 预测框与真实目标的匹配成本由分类误差、框位置误差(如 IOU)共同决定。
- 用匈牙利算法(Hungarian Algorithm)求解最优匹配,保证匹配总成本最小。
- 匹配结果:
- 成功匹配上的预测框,就是模型最终预测出来的目标框。
- 无法匹配到真实目标的预测框,会被标记为 “no object”(背景),对应背景类。
关键点总结
✅ 为什么用二分图匹配? 因为 DETR 把目标检测视为集合预测问题,不需要手动生成候选区域,也不需要后期 NMS,而是直接用一组 learnable query 生成固定数量的候选框,通过二分图匹配来唯一确定哪些是有效目标、哪些是背景。
✅ 效果:
- 每个真实物体最多只对应一个预测框,天然去重。
- 匹配无歧义,损失计算简单明了,端到端优化。
实验结果
-
这张表展示了 DETR 与多种 Faster R-CNN 变体在 COCO 验证集上的检测指标对比,最后一列 APL(AP_L) 就是用于衡量对大目标(Large objects)的检测准确度。
-
从表中可以看到:
-
尤其是 DETR-DC5-R101,APL 达到 62.3,相比最好的 Faster R-CNN-R101-FPN+ 的 56.0,提升非常明显。
解释:为什么 DETR 对大目标表现更好?
- 传统 CNN 检测器(如 Faster R-CNN): 依赖局部卷积特征和锚框(anchor)的预定义形状与尺度。感受野和锚框共同限制了它对大物体的捕获能力,往往需要额外设计多尺度 FPN 来弥补。
- DETR(基于 Transformer): 没有锚框,完全基于自注意力(self-attention)机制,对图像进行 全局建模。无论目标大小,都可以通过长距离依赖捕获完整的目标边界和上下文信息。
- 这验证了一个核心观点: Vision Transformer 擅长建立全局依赖,天然适合检测大目标,不需要人为假设 anchor 尺寸或额外的金字塔结构。
DETR详解
细说二分图匹配
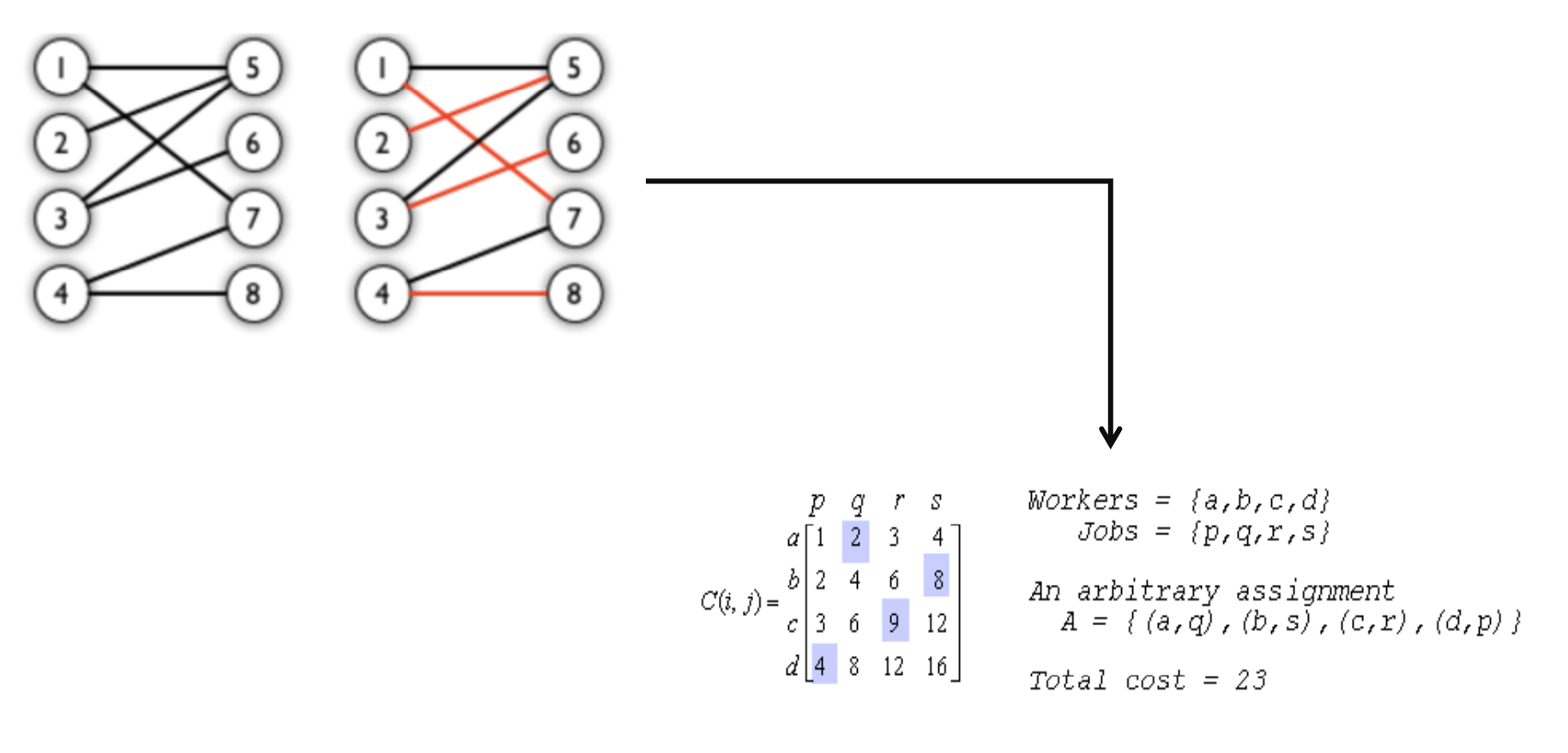
1️⃣ 普通二分图匹配(不带权重)
-
在之前讲过的基础二分图匹配里,所有边是没有权重的,只需要找到一个满足条件(匹配边数最大且互不冲突)的边集即可。但如果没有权重,往往会有多个可能的匹配解。
-
例如左上图所示,左边 4 个顶点和右边 4 个顶点之间有多种合法的匹配方式。
2️⃣ 带权二分图匹配
-
如果我们给每条边赋予一个权重(表示匹配这两个顶点的“代价”或“成本”),那么问题就不再是简单找一个最大匹配,而是要找一个:
- 边数最大(覆盖所有工人和岗位)
- 且总权重最小(总成本最低)
-
这样的问题在图论里叫做带权二分图匹配,也是匈牙利算法(Hungarian Algorithm)的典型应用场景。
3️⃣ 工人分配工作示例
- 右下角表格展示了一个具体例子:
- 4 个工人:a, b, c, d
- 4 个工作:p, q, r, s
- 每个工人分配到每个工作会产生一个对应的成本 C(i, j)
- 例如:
- 工人 a 做工作 p 的成本是 1,做工作 q 的成本是 2,依此类推。
- 例如:
4️⃣ 目标
-
在所有可能的分配方案中,找到一个方案使得每个工人分配到恰好一个工作,同时所有工人的总成本最小。
-
示例中:
- 一个可能的分配是 A = {(a,q), (b,s), (c,r), (d,p)}
- 这四对分配的总成本是 23
-
通过算法(如匈牙利算法)可以求得最优匹配,即在所有可能的分配中,总成本最低。
匈牙利算法
- 准备工作
- 每一行减去最小的数
- 每一列减去最小的数
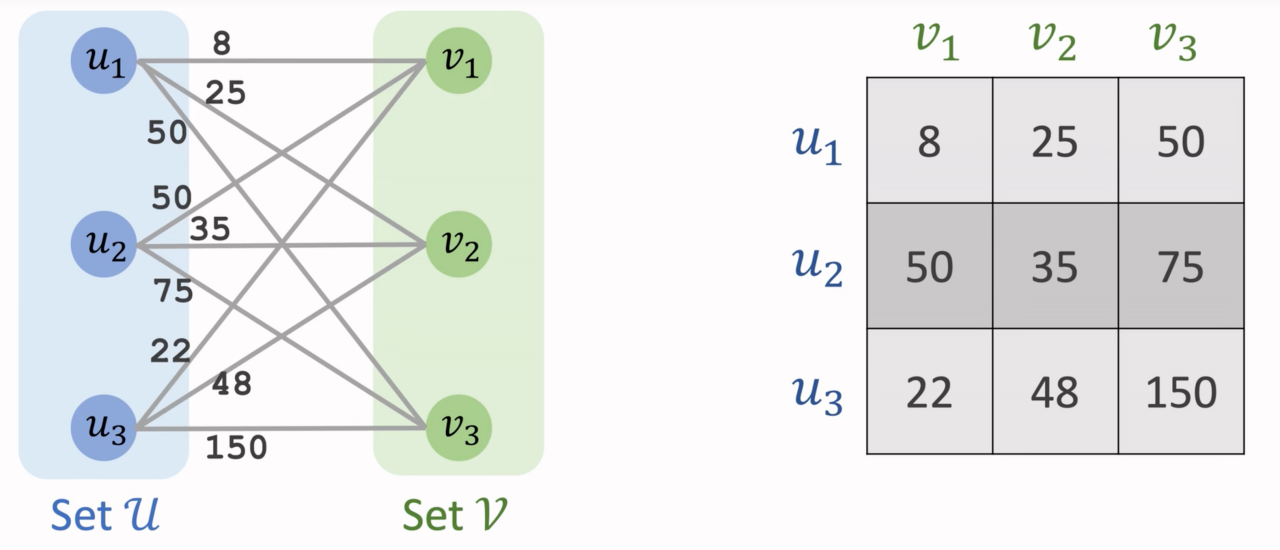
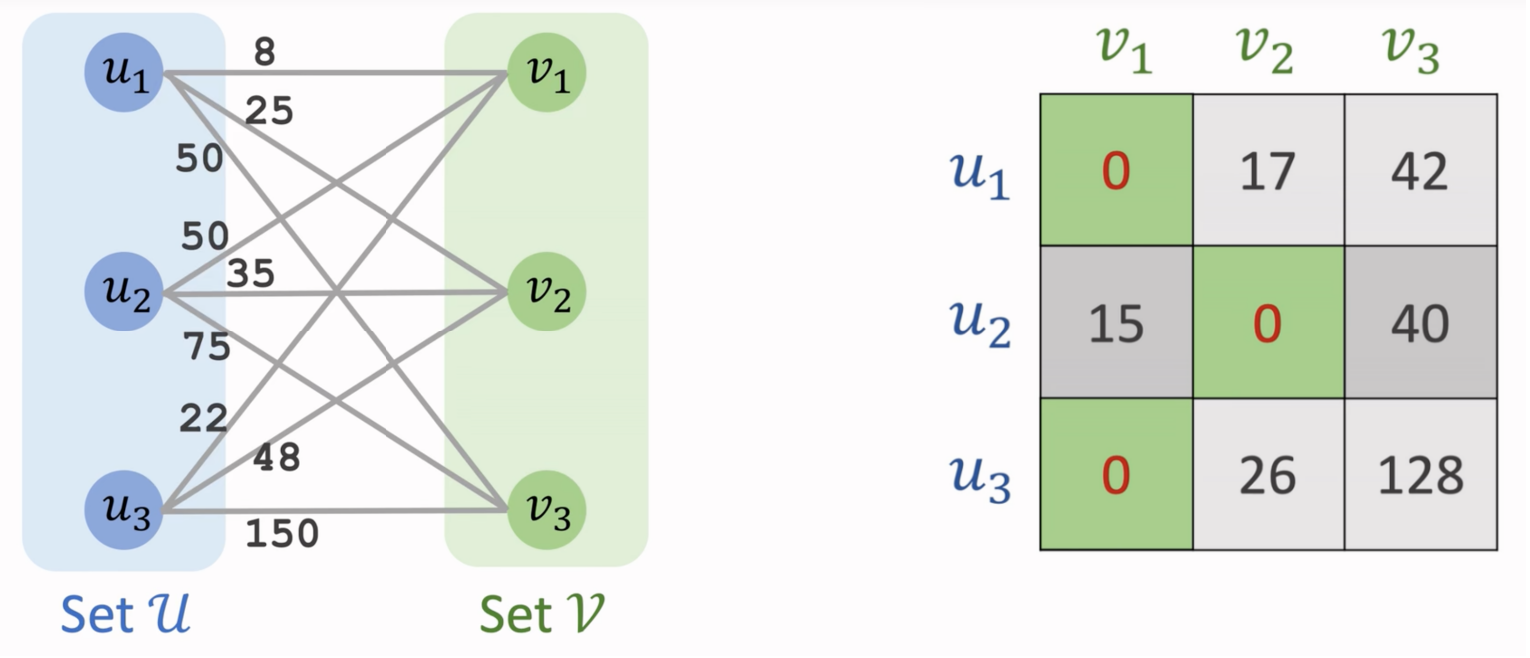
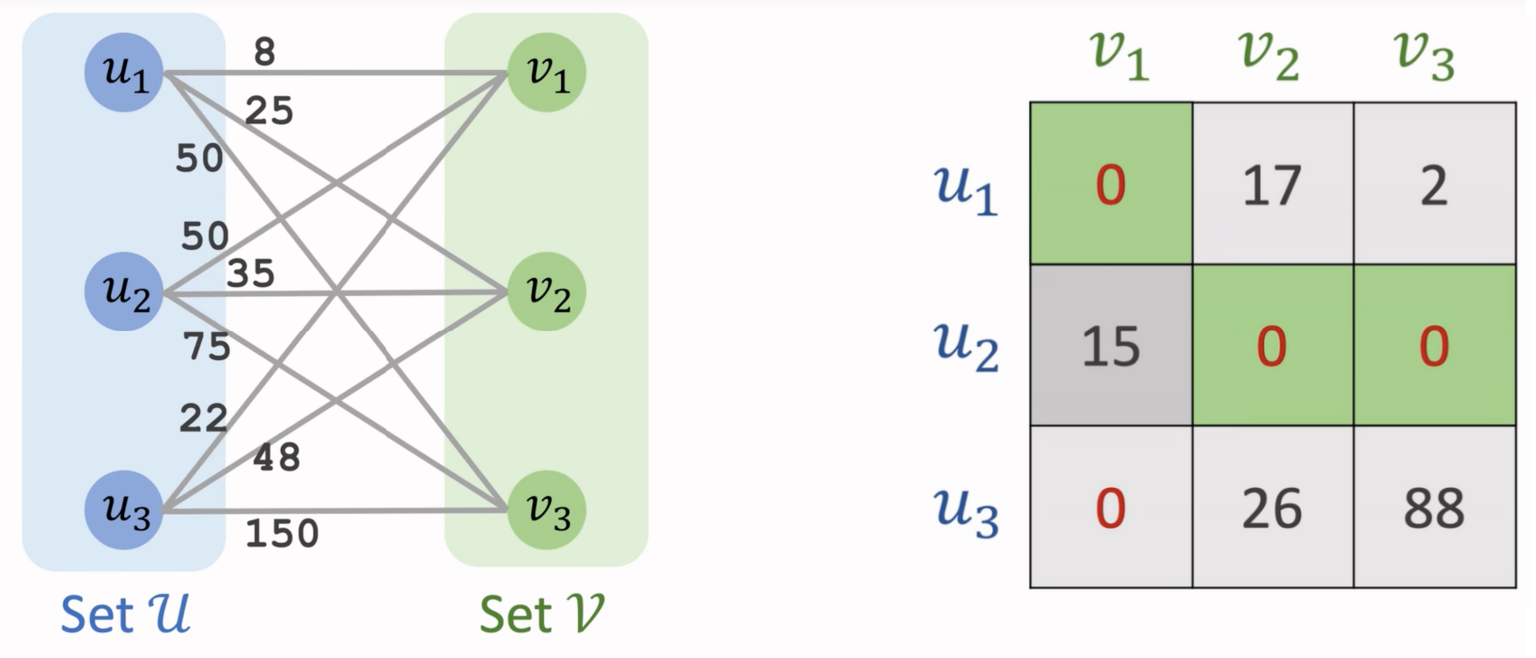

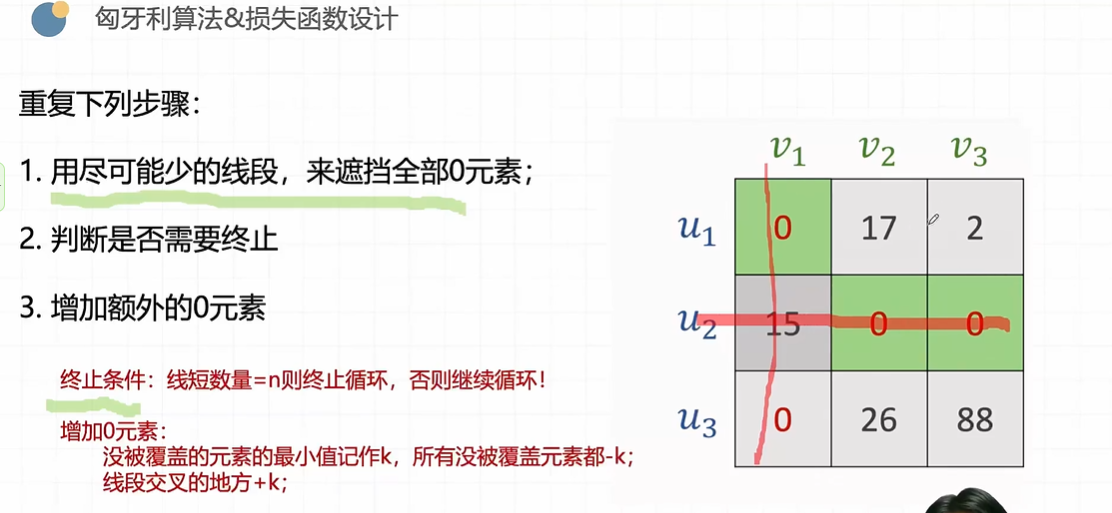
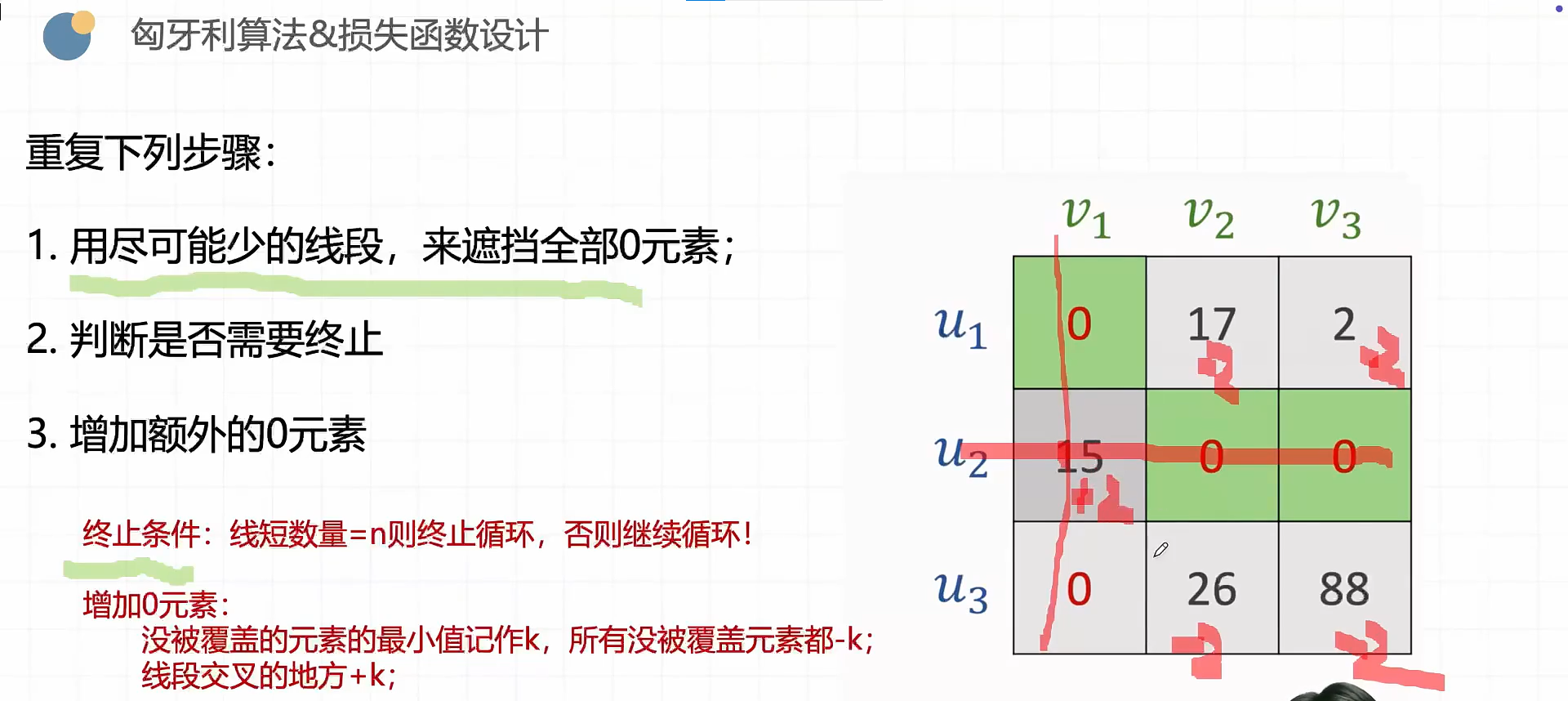


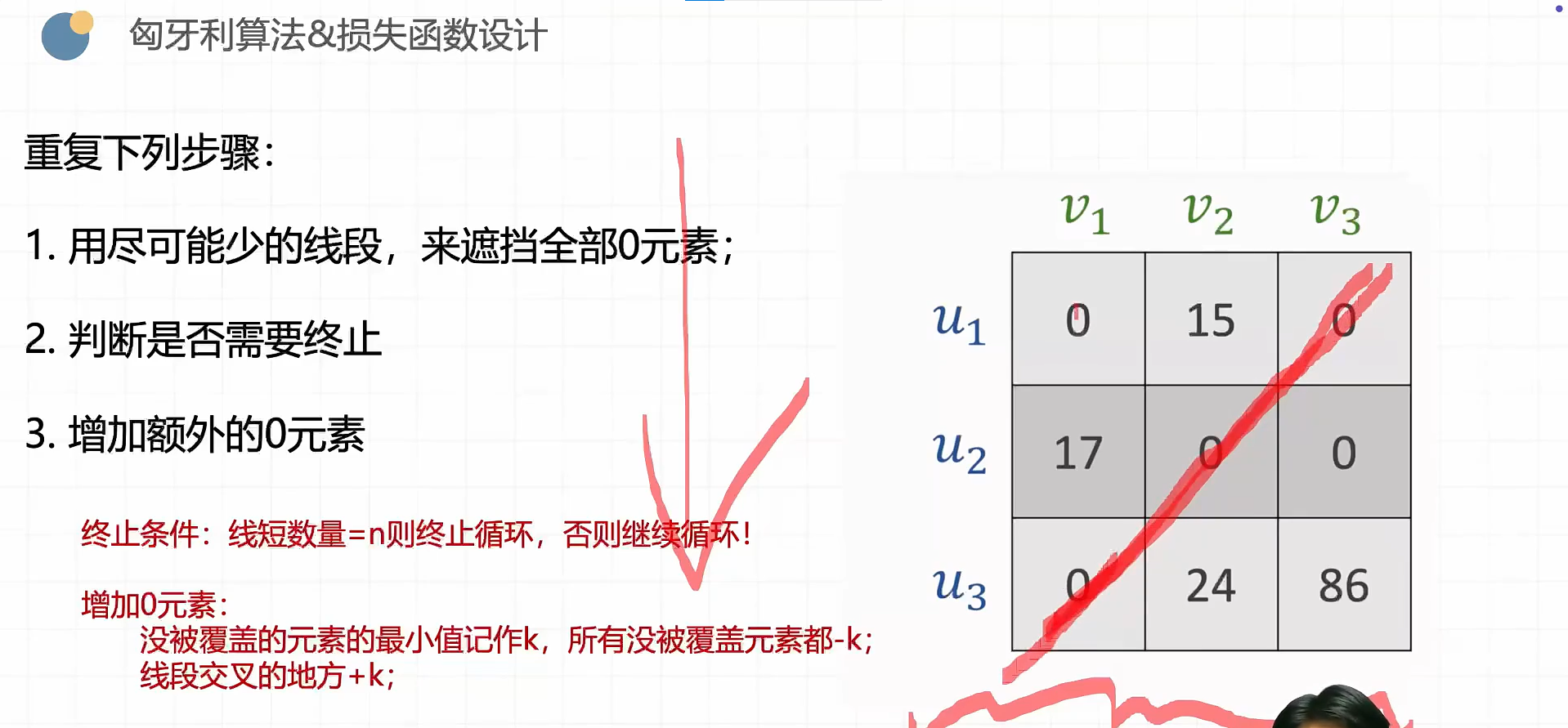
- 所有的0元素里面找3个0,这三个0不能在同一行同一列
DETR Loss
为什么先讲损失函数?
-
在 DETR 中,虽然整体模型结构(CNN + Transformer + MLP Head)比较简单直观,但它之所以能实现不需要候选框和 NMS 就直接输出去重的检测结果,核心关键在于设计了一个全新的损失函数和匹配机制。
-
也就是说:
- ✅ 模型框架本身是标准 Transformer
- ✅ 真正保证一对一预测、无冗余、端到端检测的,是这个损失函数
DETR 的 Hungarian Loss(匈牙利匹配损失)
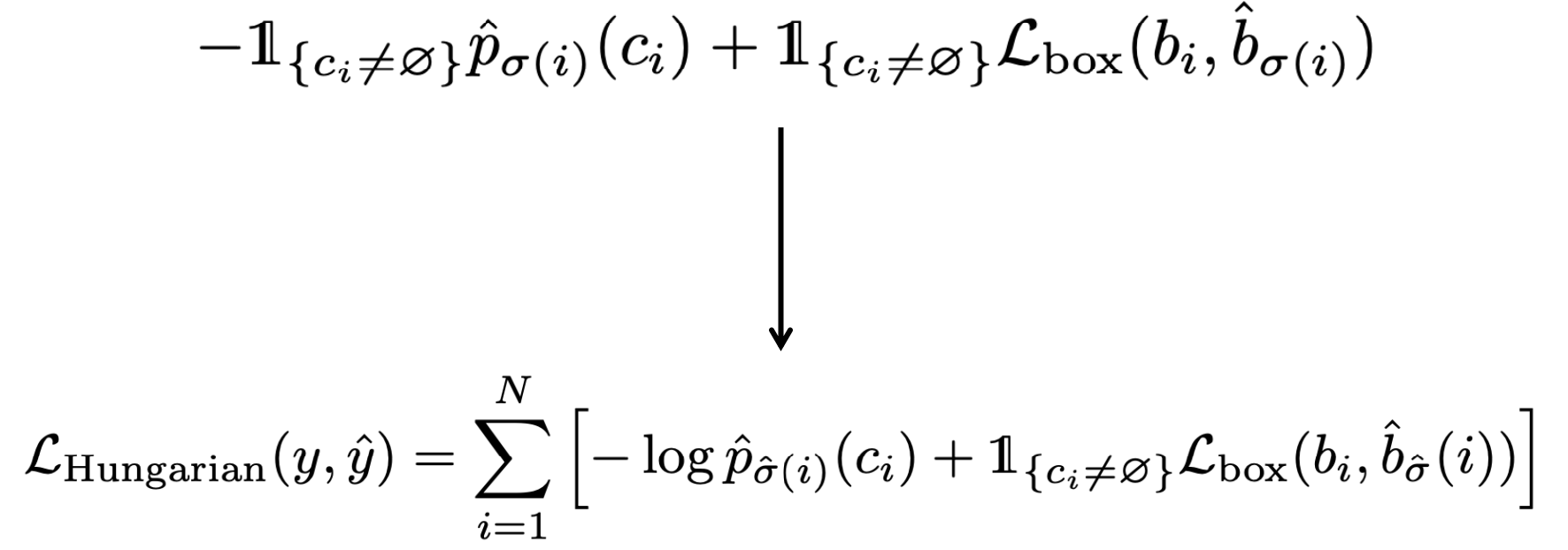
- 上面是每一个位置的损失函数,这个损失函数衡量的是单个框和单个GT框之间的损失,左半部分衡量类别预测准度,右半部分衡量框的位置准不准
- 下面是累加和,用匈牙利算法找一种匹配,根据这种匹配去把它们加起来
1️⃣ 预测阶段
- DETR 会输出一个固定数量N的候选框(由 object query 决定),不论图像中有多少目标。
2️⃣ 匹配阶段
- 每个预测框都可以和每个真实框比较,计算一个匹配代价,代价由:
- 分类误差(预测类别与真值的交叉熵)
- 框位置误差(边界框的 L1 损失 + GIoU 损失)组成,如公式所示:
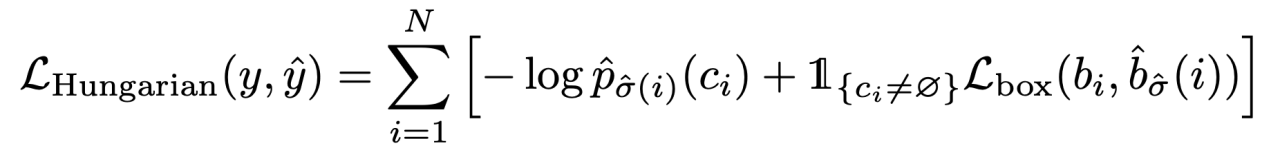
- 对于未匹配到目标的预测框,会被分配为“no object”类别(背景)。
3️⃣ 目标
- 将所有预测与真实标签的匹配组合放入 Cost Matrix,通过匈牙利算法找到总代价(loss)最小的匹配方式,然后只对匹配好的对计算监督损失。
总结
- DETR 通过这套 Hungarian Loss + 匹配,把检测问题转化为集合预测问题。
- 匹配后的监督使得每个真实目标只对应一个预测框,其余预测自动被学成背景类。
- 正因为有了这种“全局最优的一对一匹配”,我们不需要候选框生成器(如 RPN)也不需要后期的 NMS 去重 —— 预测即是最终结果。
DETR Architecture
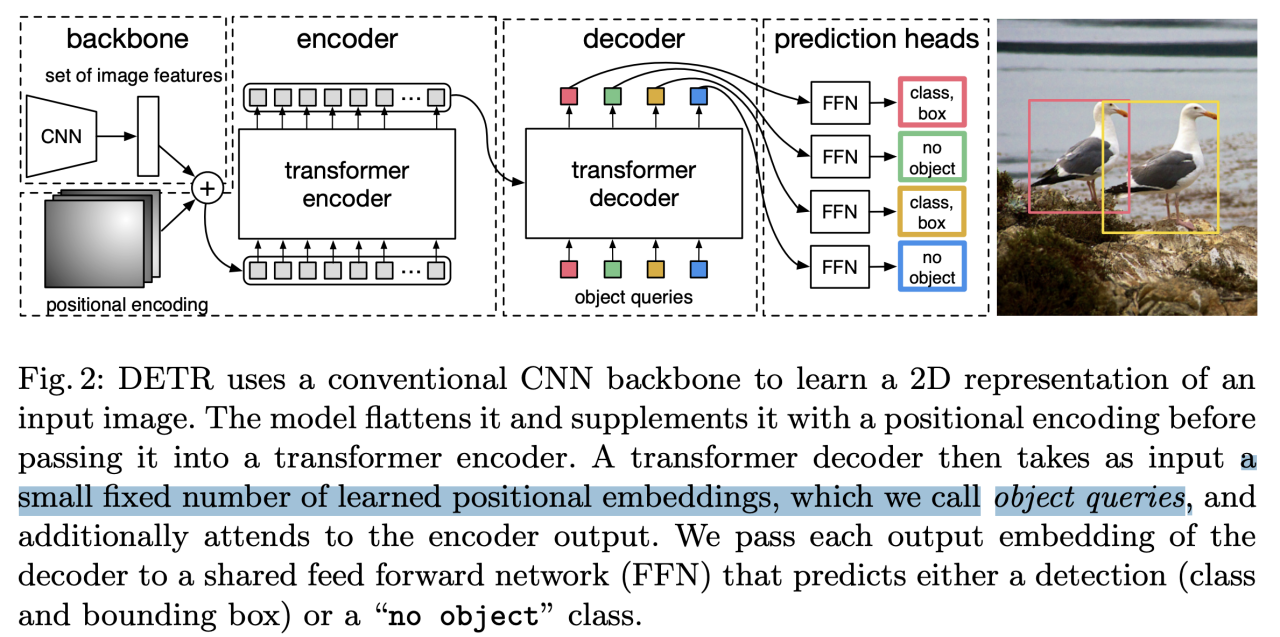
1️⃣ Decoder 的输入:object queries
- 在 DETR 中,Transformer 的 Decoder 接收一组固定数量的 object queries 作为输入。
- 这些 queries 是可学习的位置嵌入(learned positional embeddings),初始随机,训练时自动学会代表不同的目标区域。
- 一张图无论有多少目标,Decoder 的 object queries 个数都是固定的(论文里通常设为 100)。
2️⃣ Decoder 的输出:每个 query 预测一个目标
-
Decoder 对每个 object query 输出一个向量,表示对某个物体的“猜测”。
-
Decoder 的每个输出都接了一个 共享参数的 FFN(前馈神经网络),用于做目标检测的具体预测:
- 类别 + 置信度:是哪个类别,是否是“no object”
- 边界框(bbox):预测该物体的框位置
-
如图右所示:
- 有些 query 学到的是实际目标(红框、黄框)
- 有些 query 学到的是“背景”,预测为 “no object” 类别(绿色)
3️⃣ 每个 Decoder 层都计算监督 Loss
- DETR 的 Decoder 通常有多层(例如 6 层)。
- 每一层输出的 100 个 query 都接同一个 FFN(参数共享),并且每层都参与计算监督损失(类别损失 + 框回归损失)。
- 这样可以让模型在 Decoder 的不同层逐步 refine(细化)预测结果。
4️⃣ 关键点
- ✅ Object queries:决定了输出框的数量;每个 query 会学到关注某个物体(或背景)。 ✅ 共享 FFN:对每个 query 的输出向量做具体检测预测。 ✅ 多层监督:保证模型从 coarse 到 fine 逐步学到更准确的检测结果。
DETR代码
- 上节课呢,我们一起学习了DETR的设计细节,尤其是DETR如何利用匈牙利算法,来对预测框和gt框进行多对多的匹配。
- 这节课,我们再来详细看一下它的代码是如何实现的,同时编写代码来查看DETR的注意力机制到底学到了什么。

1 | |
- DETR得以爆火的一大原因呢,就是它非常非常简单:简单到只需要几十行代码就可以。
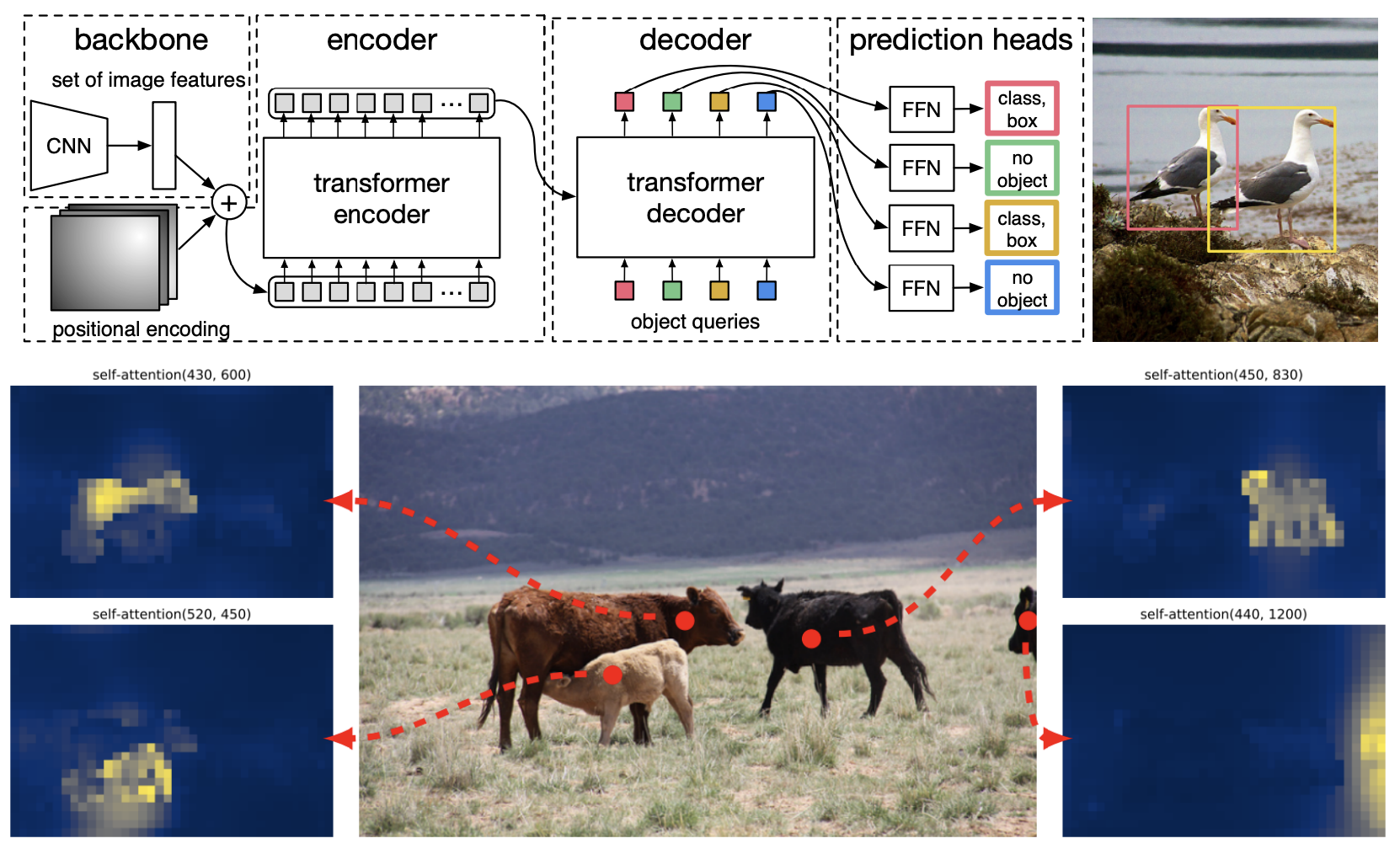
- encoder:不同图片分片之间的相关度计算,归一化。学到的就是每个patch属于哪一个物体。encoder会聚类,之间的亲和度比较高
- decoder:交叉注意力,学到了encoder输出的patch所代表的前景物体的边缘。找到同一个物体的基础之上,这个物体的边缘在哪里,再过一个MLP得到bounding box
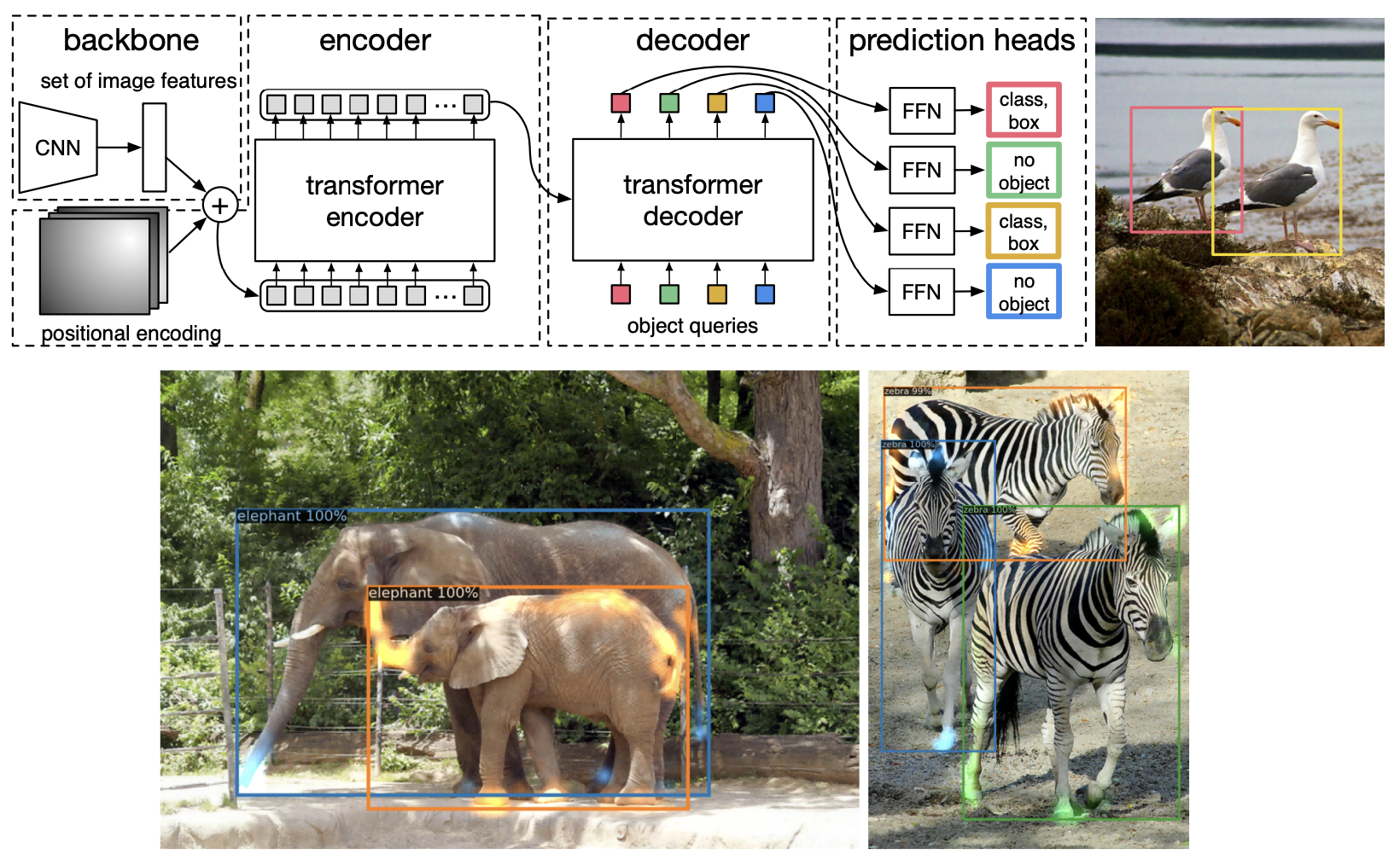
1 | |
现代图像分割
图像分割任务定义与分类
- 在之前几节课里,我们一起学习了基于transformer的目标检测框架DETR。
- 目标检测是一个比较基础的任务,它给每个物体都用一个框框出来;
- 目标检测更进一步,就是分割。
- 对精度和准确度要求更嘎
- 这节课,我们就来一起看看分割是做一个什么任务、大模型是如何做分割的。

- mask的预测结果是一个二维的图片,一堆像素,一个二维矩阵,矩阵和原图大小一样,没有mask都是0,有mask的地方都是1
1️⃣ 语义分割(Semantic Segmentation)
- 定义:语义分割的目标是将图像中的每个像素分类为一个特定的类别(如“人”、“车”、“道路”等)。
- 前景和背景都要出一个mask分割出来,同一种东西出同一种mask,一种颜色代表一种语义的label
- 特点:
- 每个像素仅关心它属于哪个类别,但不区分同一类别的不同实例(例如,所有“人”都用同一种颜色表示)。
- 适用于需要了解图像中各个区域属于什么类别的场景。
- 示例:图中上方的示意图,所有的人和车被标记为同一个类别(无论这些物体是哪个具体的“人”或“车”)。
2️⃣ 实例分割(Instance Segmentation)
- 定义:实例分割不仅需要对图像中的每个像素进行分类,还需要区分同一类别中的不同实例(即“分割每个独立物体”)。
- 同一个类别的东西,每个个体也要用不同的颜色框出来
- 实例分割一般只关注前景物体
- 特点:
- 每个物体都被单独标记,允许同一类别中的不同物体有不同的标签(如不同的“人”或“车”)。
- 适用于需要细分每个物体的场景,如目标检测。
- 示例:图中下方的示意图,多个狗被区分成不同的实例(每只狗使用不同颜色表示)。
3️⃣ 全景分割(Panoptic Segmentation)
- 定义:全景分割结合了语义分割和实例分割的优点。它不仅为每个像素分配类别标签,还能区分同一类别的不同实例,同时为背景区域提供标签。
- 前景后景都得找到,而且前景的每一个个体都得分割
- 特点:
- 每个像素都被分配一个类别标签,并且对于实例类别中的每个物体都有单独的标识。
- 适用于需要全面、细致地了解图像内容的任务。
- 示例:图中右下角的示意图,包含了每个实例(如行人、车)以及背景(如天空、道路)的完整标注。
SAM核心思想
- SAM 在线demo:https://segment-anything.com/
- SAM 论文:https://arxiv.org/pdf/2304.02643


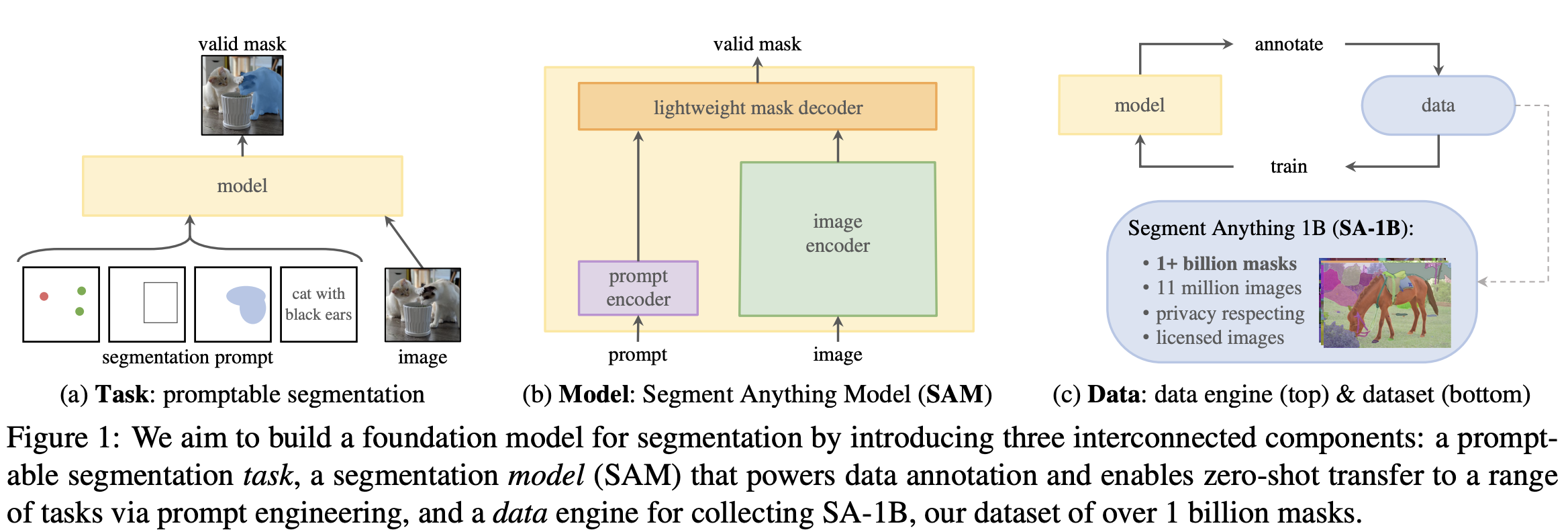
- data engine:数据引擎,可以不断地去生成训练数据,不用人工标注,data engine可以自己去标注
- 参数不大,训练数据很大
- Zero-shot performance:
- One-shot
- 教某个知识点,只有一个例题
- few-shot
- 教某个知识点,只有多个例题
- Zero-shot
- 碰到一个新任务,不用讲,只学过基础知识点但就会做这种新的知识的题目
- 从来没见过的事情,直接就会
- One-shot
1️⃣ SAM 是什么?
Meta 的 SAM(Segment Anything Model)是一个“大模型”,专门用来做图像分割。
它和传统分割模型最大的不一样就是:
SAM 是可提示(promptable)的,用一句话比喻,就是: SAM 对分割的灵活性,就像 GPT 对语言任务的灵活性一样!
2️⃣ 什么叫 promptable?
- prompt engineering:
- 大模型的反应取决于用户输入的提示,根据提示完成用户提示所规定的任务
你可以把 SAM 理解成 “图像分割界的 GPT”:
- 对 GPT 来说:
- 它先预训练(pretrain)好了语言能力;
- 之后你想写邮件、写论文、写小说,只要换一个提示(prompt),它就能干不同的活。
- 对 SAM 来说:
- 它先在超大数据集上预训练了通用的分割能力;
- 之后你想要分哪块区域,只需要给一个提示(prompt),它就能分出来。
3️⃣ 可以用哪些提示?
SAM 接受的提示非常多样(见图左下角):
- 用点点一下(点提示)
- 用框圈一下(框提示)
- 用粗略的形状涂一下(蒙版提示)
- 用文字描述(如 “黑耳朵的猫”)
- 甚至完全不提示,直接自动分割整张图
4️⃣ 怎么做到的?
看图:
- 图片先由 image encoder 编码。
- 提取图像特征
- 提示由 prompt encoder 编码。
- 提取用户输入的特征
- 两者信息结合,由 mask decoder 输出最终的精确分割区域(mask)。
这就像 GPT 先理解上下文,再用 decoder 生成文字一样。
5️⃣ 为什么厉害?
- 传统分割模型,换一个需求就要重新训练或调参;
- SAM 只需换一个 prompt 就行,分割完全可控;
- 这样不但方便各种场景下使用,还能帮助标注大规模数据(图右的 data engine),就像 GPT 可以帮人快速写稿。
✅ 一句话总结
Meta 的 SAM = 图像分割界的 GPT:预训练好通用分割能力,后期只需简单提示(prompt)就能快速适配任何分割需求,一切“按需分割”,零样本也能搞定!
SAM的训练数据构建
构建流程
1️⃣ 第一阶段:模型辅助的人工标注
- 目标:通过人工标注加速初期数据集的构建。
- 流程:在这一阶段,专业标注员使用 SAM 提供的 浏览器交互式工具,点击前景/背景点来标注分割掩码。标注员可以用“画笔”和“橡皮擦”工具精细调整掩码。
- 关键点:
- 标注员无需限制只标注语义类别,可以自由标注“东西”和“物体”。
- 标注员通过正向的promt和负向的promt来引导它去把那个正确的mask给它分割出来
- SAM 模型在这个阶段使用公共数据集进行训练,并随着数据收集不断更新。
- 随着训练的不断迭代,每个掩码的平均标注时间从 34秒 减少到 14秒,速度是 COCO 数据集标注的 6.5 倍。
- 成果:该阶段标注了 4.3M 个掩码,来自 120k 张图片。
2️⃣ 第二阶段:半自动化标注
- 目标:增加掩码的多样性,从而增强 SAM 模型的分割能力。
- 流程:
- 先通过模型 自动检测自信的掩码。
- 标注员在这些预填充的图像上继续标注 未标记的物体。
- 自信掩码是通过训练一个 边界框检测器,对第一阶段的掩码进行进一步检测得来的。
- 关键点:
- 标注员被要求标注 不那么显眼的物体,因此标注难度提升,每个掩码的平均标注时间回升到 34 秒。
- 该阶段共标注了 5.9M 个掩码,覆盖 180k 张图像。
- 掩码数量从每张图像的 44 个增加到 72 个。
- 成果:总计收集了 10.2M 个掩码,为模型提供了更多样化的训练数据。
3️⃣ 第三阶段:完全自动化标注
- 目标:使标注过程完全自动化,利用强大的模型进一步提升数据质量。
- 流程:
- 在这一阶段,SAM 的模型已经收集了大量的数据,并进行了足够的训练。
- 模糊感知模型的引入,使得 SAM 在标注具有不确定性的情况下,能够准确预测出有效的掩码。
- 歧义性识别
- 模型通过 32×32 的规则网格对每个点进行预测,能够返回对应的 部分、子部分和整体物体的掩码。
- 对于每个点,模型还会输出 IoU(交并比)预测,并选择 自信的、稳定的掩码。
- 在选择掩码后,模型使用 非极大值抑制(NMS) 来过滤重复的掩码,进一步优化结果。
- 关键点:
- 处理多个 重叠的放大图像裁剪,以提高小物体掩码的质量。
- 最终,自动生成掩码的模型应用于数据集中的所有 11M 张图像。
- 成果:成功生成 1.1B 个高质量掩码,完成了数据集的构建。
构建成果:SA-1B数据集
✅ 数据规模与来源
- 图像(Images)
- 总计 1100 万(11M) 张多样化、高分辨率、合法授权并且注重隐私保护的图像。
- 原始图像分辨率平均约 3300×4950 像素;公开版本为了存储和下载便利,将图像的短边下采样至 1500 像素,即使如此,分辨率依然远高于典型数据集(如 COCO 的约 480×640 像素)。
- 所有公开图像已对人脸和车牌进行了模糊处理以保护隐私。
✅ 分割掩码(Masks)
- 总计生成了 11 亿(1.1B)个高质量分割掩码。
- 其中 99.1% 由数据引擎完全自动生成,只有极少部分依赖模型辅助或人工标注。
- 为验证自动掩码质量,官方对 500 张图(约 50K 个掩码)进行专业修正后比对,结果显示:
- 94% 的自动掩码与人工修正掩码 IoU 大于 90%
- 97% 的掩码 IoU 大于 75%
- 这一一致性与公开文献中标注者之间的一致性(85–91% IoU)相当,且实验结果表明,使用自动掩码训练模型效果接近使用完整数据引擎标注结果。
✅ 掩码属性与分布
- 空间分布:
- 与同类分割数据集相比(如 LVIS、ADE20K),SA-1B 在图像四角的覆盖更充分,中心偏置较低,相比 COCO 和 Open Images V5 覆盖更广。
- 掩码数量:
- 与第二大同类数据集 Open Images 相比:
- 图像数量多 11 倍
- 掩码数量多 400 倍
- 平均单图掩码数量多 36 倍
- ADE20K 作为单图掩码数最多的公开数据集,也比 SA-1B 少 3.5 倍。
- 与第二大同类数据集 Open Images 相比:
- 掩码大小与形状复杂度:
- SA-1B 每张图含更多小型和中型掩码,形状复杂度(凹度)与其他公开数据集相当。
SA-1B 是目前规模最大、最多样化、最高分辨率、且自动化标注质量极高的大规模分割数据集,为训练通用的可提示(promptable)视觉基础模型奠定了关键数据基础。
SAM的image encoder和prompt encoder
- 视觉模型的套路:
- 过一个encoder做自身建模
- 输入到decoder里面和其他的一些特征做交叉注意力计算
- 加一个不同的loss去实现对应的下游任务
Image Encoder
✅ 核心思想
- 可扩展性 与 强大的预训练能力 是设计的首要动机。
- 选用的是 MAE(Masked Autoencoder)预训练的 Vision Transformer (ViT),并对 ViT 结构做了最小化的适配以支持高分辨率输入。
- MAE是一种训练方式,用这种训练方式训出来的模型对于图像的这种结构和纹理特征更加敏感,更加鲁棒,因而很适合做分割任务
✅ 具体实现
1️⃣ 主干网络
- 使用 ViT-H/16(H 表示大模型规模,16 表示 patch size)。
- 结合了 14×14 窗口注意力(windowed attention),并在网络中穿插 4 个均匀分布的全局注意力块,参考了 Swin Transformer 的设计思想 [62]。
2️⃣ 输入处理
- 将输入图像 重新缩放并填充,得到标准输入分辨率 1024×1024。
- ViT encoder 输出的是输入图像的 1/16 下采样 embedding,即 embedding 尺寸为 64×64。
3️⃣ 降维与归一化
- ViT 输出后,先用一个 1×1 卷积 将 channel 数降至 256。
- 再用一个 3×3 卷积 继续提炼特征,输出同样为 256 channel。
- 每个卷积后接 Layer Normalization 以稳定训练。
✅ 效率与交互性
- 关键点:整个 image encoder 只需对每张图片执行一次,与具体的分割 prompt 无关。
- 因此,虽然 ViT-H 的计算量大,但可以分摊到后续对不同 prompts 的交互中,实现 实时提示分割 时只需重复使用同一个图像 embedding。
Prompt Encoder
✅ 核心任务
Prompt Encoder 的作用是把用户输入的各种提示(prompts)转换成与图像特征对齐的向量表示,以便模型解码器基于这些提示生成对应的分割结果。
✅ 支持两类提示
1️⃣ 稀疏提示(Sparse Prompts)
-
特征比较少,可能几个向量就搞定了
-
包括:点(points)、框(boxes)和文本(text)
-
点(point):
- 用点的 位置编码 + 一个可学习的“前景点”或“背景点”类型向量。
-
框(box):
- 用 左上角位置编码 + learned embedding(表示“左上角”)
- 加上 右下角位置编码 + learned embedding(表示“右下角”)
-
文本(text):
- 直接使用 CLIP 的文本编码器输出作为文本向量表示(也可替换为其他文本编码器)。
→ 这类提示最终都会被映射成 256 维向量。
2️⃣ 密集提示(Dense Prompts)
-
相当于直接输入了一个图片进去
-
主要指 用户输入的掩码(masks)
-
需要用一个卷积的操作把输入的mask特征提取出来,再通过逐一对比加到提取出来的image embedding上面
-
掩码有空间对齐性质,处理流程:
- 首先将输入掩码下采样至原图分辨率的 1/4。
- 再通过两次 2×2、stride=2 的卷积继续降采样,输出 channel 分别为 4 和 16。
- 最后用 1×1 卷积把 channel 调整到 256,确保与图像 embedding 对齐。
- 只改变图片的厚度不改变图片的尺寸,信道数改变
- 每个卷积层后接 GELU 激活 和 Layer Norm。
-
得到的掩码 embedding 会与图像 embedding 做逐元素相加。
👉 若没有输入 mask,则对每个 embedding 位置加一个可学习的 “no mask” embedding 以显式表示。
✅ 总结一句话
SAM 的 Prompt Encoder 设计非常灵活:
- 稀疏提示 用位置编码+类型向量或外部文本编码,转换成紧凑的 256 维向量
- 密集提示(掩码) 用可卷积网络做空间下采样,生成与图像 embedding 同尺寸的特征,方便逐像素对齐。
这种设计保证了无论用户输入点、框、文本还是初步掩码,模型都能用统一的方式高效理解和利用提示,完成灵活的交互式分割。
SAM的mask decoder
✅ 核心目标
Mask Decoder 的任务是:
高效地把图像 embedding、用户输入的 prompt embedding,以及一个 output token,整合起来,输出最终的分割掩码(mask)。
它借鉴了 Transformer 分割模型(如 [14, 20])的思路,但做了轻量化设计,保证推理实时、交互流畅。
✅ 输入组成
- 图像image embedding:来自 ViT 的下采样特征,空间维度 64×64,通道数 256。
- image encoder对于我们的这个原图做了特征提取之后,提取出来的图像特征,特征图的尺寸为64x64
- Prompt Embeddings:点、框、文本、掩码等提示信息的编码。
- 用户输入的prompt提了特征输出的prompt token,即prompt encoder的输出
- Output Token:类似于 ViT 的 [CLS] token,用来聚合全局信息,驱动最后的掩码生成。
- 一个可学习的向量
✅ Decoder 结构
1️⃣ Transformer 核心
Mask Decoder 是一个 改造版的 Transformer Decoder,共包含 两层,每层包含以下 4 步操作:
| 步骤 | 说明 |
|---|---|
| (1) Token(output +prompt) 自注意力 | Prompt Embedding + Output Token 内部相互交流信息 |
| (2) Token → 图像 embedding 的 Cross Attention | Token 查询图像 embedding,提取与提示相关的局部图像特征 |
| (3) Token 内部 MLP 更新 | 用点式 MLP (全连接层)更新每个 Token 的表征 |
| (4) 图像 embedding → Token 的 Cross Attention | 反向交互:图像 embedding 作为查询,Token 作为 Key/Value,让图像 embedding 也能吸收 Prompt 约束 |
- 每一步都有残差连接(Residual)、Layer Norm 和 Dropout(0.1)。
- 本质就是把用户prompt提取出来的特征到image的特征空间里面去找,看用户prompt对应的物体是什么
- 相当于把这个prompt作为一个query去图像空间里面找
2️⃣ 位置编码补充
- 在所有 Attention 操作中:
- 图像 embedding 加入位置信息(Positional Encoding),保持空间结构。
- Prompt Embedding 也重新加回其原始位置编码,保持几何信息的准确性。
3️⃣ 输出生成
- Decoder 迭代两层后:
- 将更新后的图像 embedding 用 两层转置卷积 上采样 4×(从 64×64 变为 256×256,和输入图像下采样 4×一致)。
- 恢复一些图像的细节
- 这里得出来的东西经过和prompt的token的建模关系之后,得出来的东西差不多相当于一个mask
- Token 再对交叉建模后的 embedding 做一次 Attention。
- 把token作为query又查了一次,查完的结果就已经是token的一些特征信息了
- 第一个输出token 的IoU,过了一个MLP之后可以直接算这个IoUscore了,de到各GT mask的IoU分数了
- 第二个输出output token per mask,每一个输出token代表一个mask的特征信息,经过3个MLP(因为输出三种mask)做不同的映射,分成三份不同的mask和GT label做运算。这样3个MLP头就学到了对同一个mask token映射到不同大小scale mask上的映射关系
- Output Token(mask token) 送入一个小的 3 层 MLP,输出与上采样 embedding 的 channel 匹配的向量。
- 用 逐点相乘(point-wise product) 将 MLP 的输出与上采样 embedding 融合,得到最终的前景概率图,即分割掩码。
- 将更新后的图像 embedding 用 两层转置卷积 上采样 4×(从 64×64 变为 256×256,和输入图像下采样 4×一致)。
✅ 效率设计
- Transformer 的内部维度为 256,MLP 内部维度较大(2048),但 MLP 只处理 Prompt Tokens,数量很少(通常 <20)。
- Cross Attention 时,图像 embedding 的 Query/Key/Value 通道会降到 128(即 256 的一半),以减少计算量。
- 所有 Attention 层使用 8 个头。
- 上采样的转置卷积参数:2×2,stride=2,输出 channel 依次是 64 和 32,带 GELU 激活。
SAM-代码架构
直接使用代码
1 | |
- 端到端 forward(image encoder → prompt encoder → mask decoder → 后处理)
1 | |
SAM-image encoder代码实现
- predictor
1 | |
- image encoder
1 | |
SAM-prompt encode 代码实现
1 | |
SAM-mask decoder代码实现
1 | |