408错漏知识
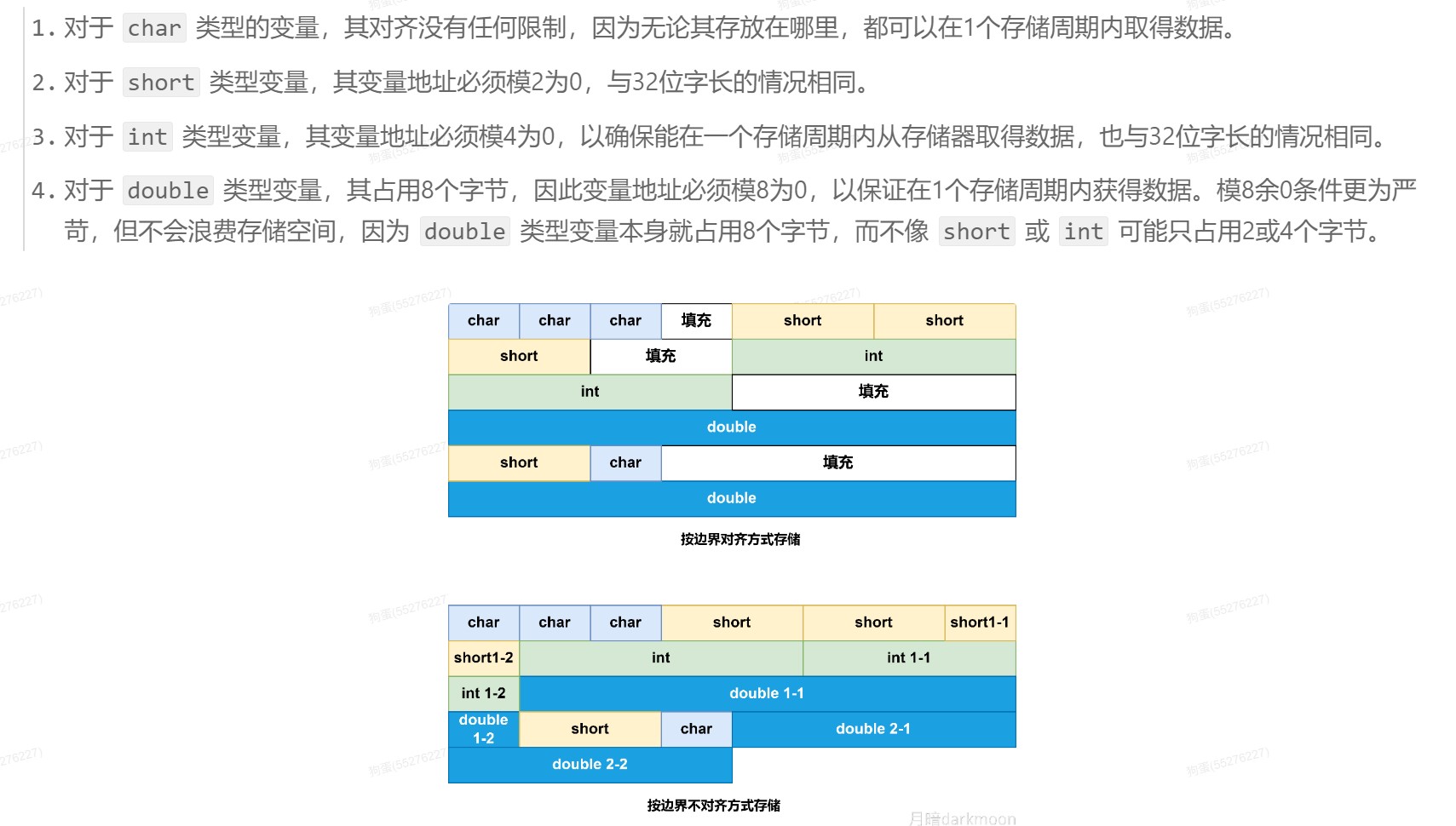
DS(数据结构)
数据结构的基本概念
- 数据元素是数据的基本单位。
- 数据项是构成数据元素的不可分割的最小单位
- 循环队列和线索二叉树都属于物理结构
- 抽象数据结构包含数据对象、数据关系、基本操作
- 算法的设计依赖于逻辑结构
- 算法的实现依赖于物理结构
- 数据结构是具有特定关系的数据元素的集合
时间复杂度
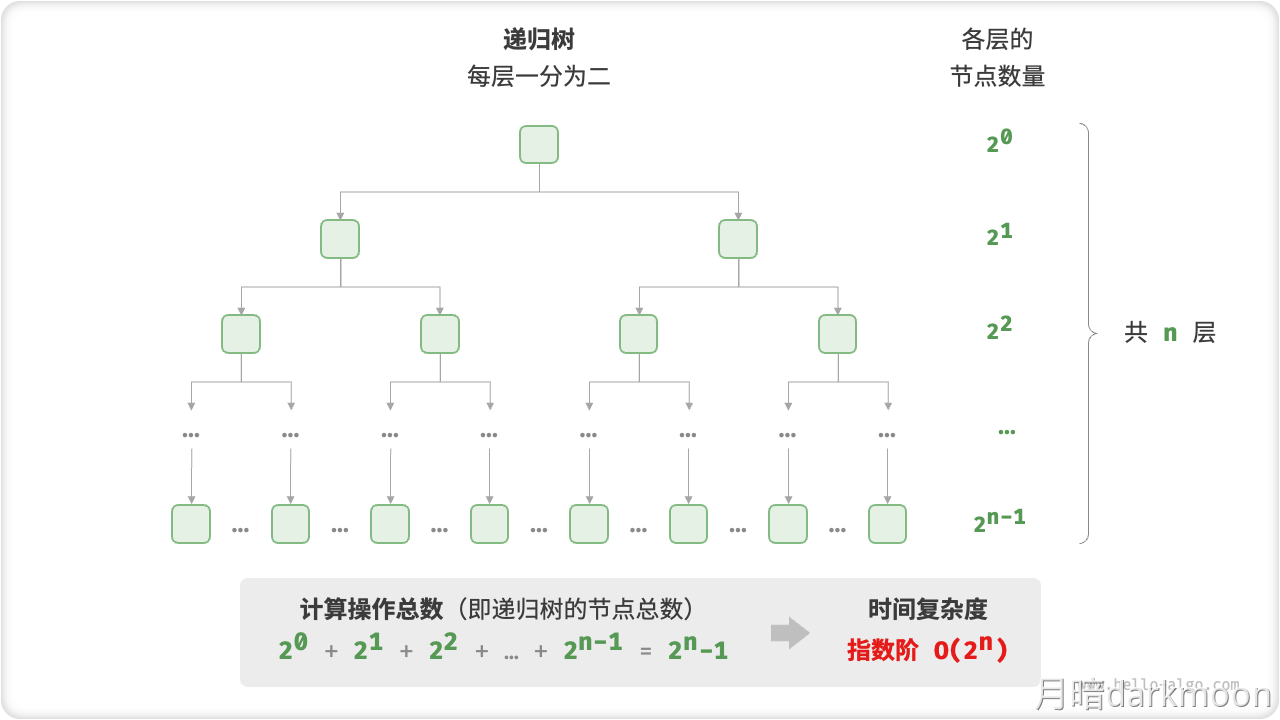
外部排序
- I/O次数的计算:初始归并段生成的I/O次数+归并时的I/O次数
- 初始归并段生成的I/O次数=磁盘块数*2(读写各I/O一次)
- 归并时的I/O次数=磁盘块数* 2 *归并趟数
- 败者树中非叶子节点存储的是失败者的标记(归并段下标),而叶子节点存储的是各个路当前记录的索引值
- 败者树的空间复杂度是O(n),时间复杂度是O(nlogn)
- 败者树为k路归并段内部排序所使用的,用于提高内部排序效率,与I/O次数无关

链表
- 从长度为n的顺序表中删除任一各元素,平均时间复杂度是O(n)
单链表
- 单链表中删除一个节点有两种方法
- 1、将该点直接删除,让该点的上一个节点直接指向该点的下一个节点
- 2、将该点变成该点的下一个点
- 要保证插入的先后顺序与对应节点在链中的顺序相反,必须使用头插法
- 要保证插入的先后顺序与对应节点在链中的顺序相同,必须使用尾插法
静态链表
-
静态链表删除或插入不需要移动元素
-
静态链表的存储空间虽然是顺序分配的,但元素的存储不是顺序的,查找时仍然要按照链依次进行,而插入、删除都不需要移动元素。静态链表的存储空间是一次性申请的,能容纳的最大元素个数在定义时就已经确定。由于并非每个空间都存储了元素,因此会导致存储空间的浪费
-
数组一旦确定,数据元素的容量和位置关系就是固定的,因此不能进行插入和删除等操作
-
稀疏矩阵压缩存储后,不能直接根据元素所在数组中的位置在内存中定址,也就意味着失去了随机存取的功能
-
广义表:



栈和队列和数组
- 最适合用作链队的链表就是带有队首指针和队尾指针的非循环单链表
- 循环队列的三种判满方式都需要额外的开销,需要牺牲一个队列空间
- 三元组的内容为(行,列,值),其次还要存储稀疏矩阵和行列总数(否则无法分辨矩阵规模)和非零元素个数(三元组表的大小)。交换每个三元组的行列以外,还要交换总行和总列才可以实现转置
- 十字链表法适合频繁插入删除和快速定位行列元素,三元组的存储效率一般低于十字链表
卡特兰数的应用


- n个不同元素进栈,出栈元素不同排列的个数N可由卡特兰数确定
- 先序序列为入栈次序,中序序列为出栈序列,因为前序序列和中序序列可以唯一确定一棵二叉树,因此问先序序列为xxxx的不同二叉树的个数是?相当于问以xxxx为入栈次序,出栈序列的个数是?
- 进栈出栈操作与二叉树中序遍历的关系
- 一个节点进栈后有两种处理方式:
- 要么立即出栈(此时该入栈结点没有左孩子),要么下一个结点进栈(有左孩子)
- 一个结点出栈后有两种处理方式
- 继续出栈(该结点无右孩子)
- 要么下一个结点进栈(有右孩子)
- 一个节点进栈后有两种处理方式:
矩阵压缩存储计算
- 算该点前面有多少个数,多少个数*每个数的大小,这就是该元素的起始位置,如果是结构体,再根据结构体的结构进行计算
串
- 普通匹配算法的时间复杂度为O(mn),kmp算法时间复杂度为O(m+n),如果每次匹配部分匹配都接近模式串长度n,那么普通匹配算法达到最坏时间复杂度O(mn),相反普通匹配算法和kmp算法接近
kmp算法小总结
- 代码
1 | |
-
next数组手算过程:
- next[1]都无脑写0,next[2]都无脑写1
- 其他next:比较前缀后缀相同的最长长度,然后+1(因为是下一个位置)
- next数组采用求匹配失败的元素的左边起子串的前缀后缀相同的下一个位置

-
nextval数组手算过程
- 先求next数组
- nextval数组j=1的位置无脑写0,然后后面的进行回溯,如果回溯到不一样的就保持不变,一样的就继续回溯
- 如果回溯到的点一样,就可以用它的next数组

栈
- 上溢是指存储器满,还往里写,下溢是指存储器空,还往外读。
树

-
只要按照前序序列的顺序入栈,那么无论怎么出栈,肯定是符合中序序列的
-
原森林中每一个分支节点产生唯一一个对应二叉树中没有右孩子的结点,森林中最右边子树的根节点在二叉树中也没有右孩子,所以原森林中分支节点个数+1=二叉树中没有右孩子的结点数量
- 在树到二叉树的转换过程中,右孩子的数量=分支节点个数+1,这个+1是因为最后一个分支节点的右孩子指向空(
NULL),这个空的右孩子也被算作一个额外的右孩子。
- 在树到二叉树的转换过程中,右孩子的数量=分支节点个数+1,这个+1是因为最后一个分支节点的右孩子指向空(
-
树转换为二叉树后,没有右孩子的节点个数=分支节点个数+1
-
任一二叉树的叶节点在先序、中序、后序遍历序列中相对位置一定是相同的。
-
要交换二叉树的所有分支节点的左右子树的位置,利用前序或后序遍历框架解决最合适
-
森林中树的个数=结点数-边数
-
有n个结点的二叉树,最小高度是log2(n+1)上取整,最高高度是n,因此n个结点的二叉树有n-log2(n+1)+1种可能的层高
-
哈夫曼树的加权平均长度=(结点的路径数*权值的总和)/(结点权值总和)
-
m叉哈夫曼树

树的结点关系总结
- 树的

- 二叉树的

- B树的
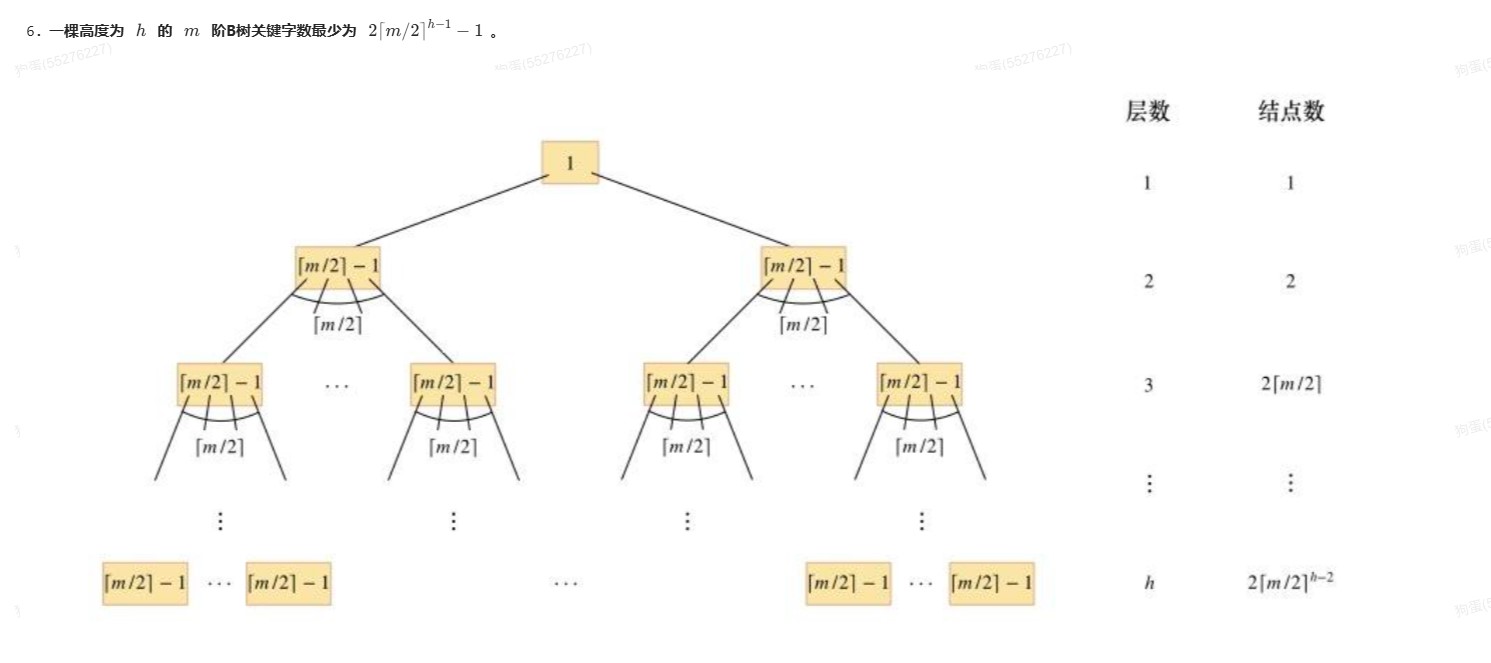

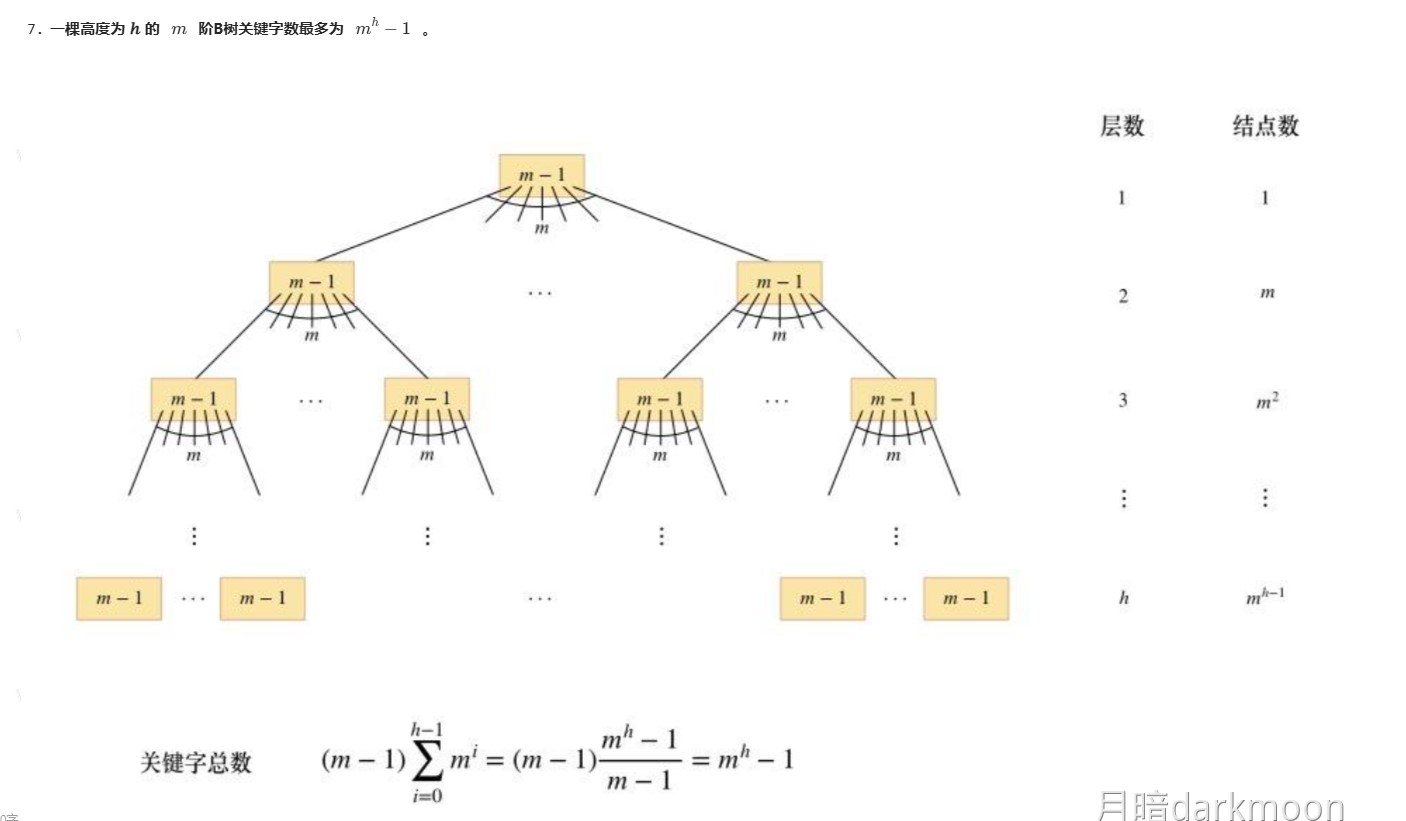


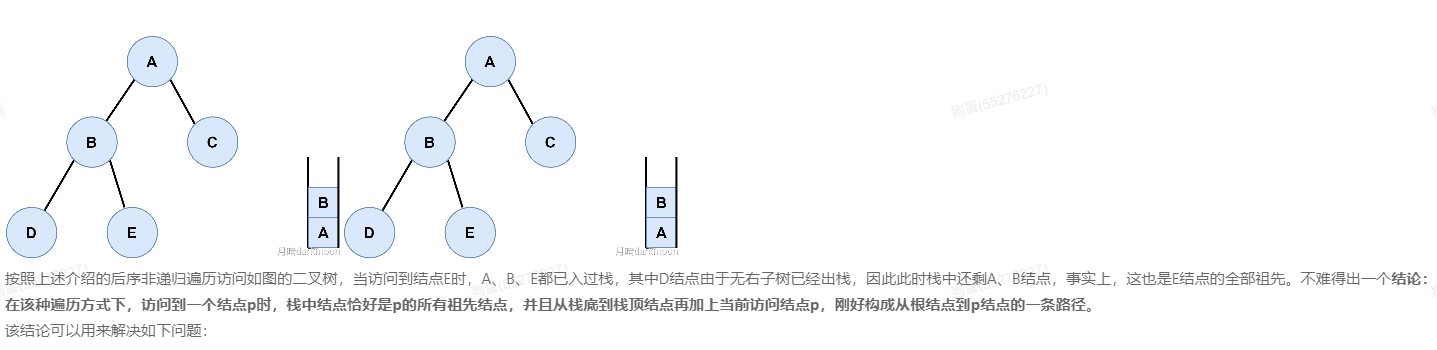
- 败者树高度

二叉树的迭代遍历




根据遍历序列确定二叉树的形态

并查集三个阶段的时间复杂度

图
- 只有在无向图中,DFS的调用次数=连通分量的个数
- 有向图中因为强连通分量要求互相之间都有去往边,而DFS只保证有从一个顶点向另一个顶点的边,不保证有反向的边
- 无向图判环
- DFS或BFS或并查集或拓扑排序
- 有向图判环
- DFS和拓扑排序或并查集
- 使用邻接矩阵表示图的时候,可以直接访问矩阵元素获取边,因此增删查的时间复杂度为O(1)
- prim算法中,当同时有两个代价相同的顶点时,优先将编号更小的顶点加入MST
- kruskal算法中,当多边权值相同时,起点编号更小的边排在前面
- 有向无环图仅仅在存在一条路径可以包含其所有顶点的情况下,有唯一的拓扑排序方式,这时,拓扑排序与他们在这条路径中出现的顺序相同
图的顶点和边的关系

408图论算法复杂度+适用场景(含负权边/负环)
| 算法 / 存储结构 | 时间复杂度 | 空间复杂度 | 适用场景 | 说明 |
|---|---|---|---|---|
| 邻接矩阵 | —— | O(V²) | 稠密图 | 查询边是否存在快 O(1),遍历慢 O(V) |
| 邻接表 | —— | O(V+E) | 稀疏图 | 遍历快 O(V+E),查询边是否存在慢 O(deg(v)) |
| 十字链表(有向图) | —— | O(V+E) | 需要同时高效处理出度和入度的有向图 | 每条边存两次引用 |
| 邻接多重表(无向图) | —— | O(V+E) | 需要避免无向边重复存储 | 每条边只存一次结点 |
| DFS(邻接表) | O(V+E) | O(V+E) | 遍历所有顶点与边;拓扑排序;连通分量;检测环 | 深度优先搜索 |
| DFS(邻接矩阵) | O(V²) | O(V²) | 小规模稠密图遍历 | 遍历邻接点需扫一行 |
| BFS(邻接表) | O(V+E) | O(V+E) | 无权图最短路径;分层遍历;连通分量 | 队列实现、广度优先搜索 |
| BFS(邻接矩阵) | O(V²) | O(V²) | 小规模稠密图遍历 | |
| 拓扑排序(邻接表) | O(V+E) | O(V+E) | DAG 的线性序;任务调度;编译依赖 | 常用 Kahn 算法(队列)或 DFS |
| 拓扑排序(邻接矩阵) | O(V²) | O(V²) | 小规模稠密图 | 每次找入度=0 需扫一列 |
| Prim 算法(朴素版,邻接矩阵) | O(V²) | O(V²) | 稠密图最小生成树 | 每次扫描所有顶点选最小边 |
| Prim 算法(堆优化版,邻接表) | O(E log V) | O(V+E) | 稀疏图最小生成树 | 用优先队列维护候选边 |
| Kruskal 算法 | O(E log E)≈O(E log V) | O(V+E) | 稀疏图最小生成树 | 边排序 + 并查集 |
| Dijkstra(朴素版,邻接矩阵) | O(V²) | O(V²) | 稠密图,单源最短路径(不允许负权边) | 每次找最近点 O(V) |
| Dijkstra(堆优化,邻接表) | O(E log V) | O(V+E) | 稀疏图,单源最短路径(不允许负权边) | 用堆维护最短距离 |
| Floyd 算法 | O(V³) | O(V²) | 多源最短路径,小规模稠密图,允许负权边;可检测负环(dist[i][i]<0) |
若有负环则无解 |
| Bellman-Ford 算法 | O(VE) | O(V+E) | 单源最短路径,允许负权边;可检测负环(松弛 V 次后仍变化) | 若有负环则无解 |
| SPFA 算法 | 平均 O(E),最坏 O(VE) | O(V+E) | 单源最短路径,允许负权边;可检测负环(某点入队 ≥ V 次) | 若有负环则无解 |
| 三元组表(边集数组) | —— | O(E) | 适合稀疏图;常用于 Bellman-Ford、Kruskal、SPFA | 每条边存 (i,j,w),遍历邻接点效率低 |
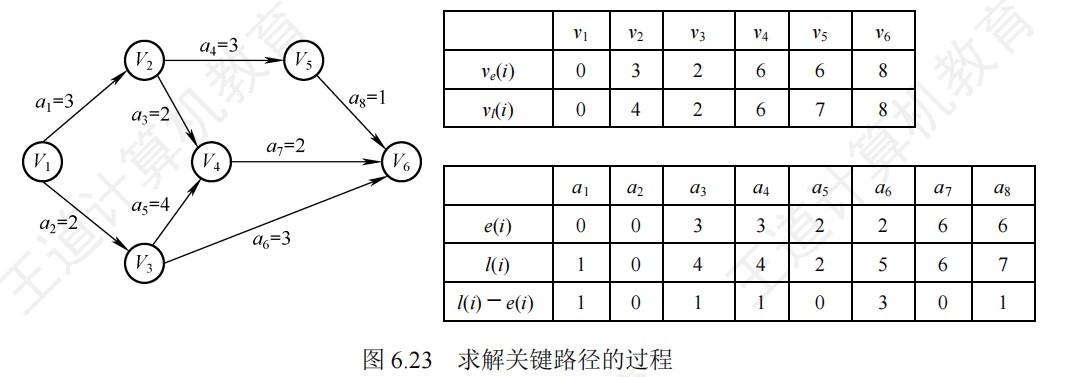
关键路径的相关计算
- 事件Vk的最早发生时间Ve(k)
- 即max{以k结点为弧头的所有边 的弧尾事件 的最早发生时间+该边权值}
- 计算该值时,可以从前往后,从源点出发,每输出一个入度为0的顶点时,计算它所有直接后继顶点的最早发生时间,如果大于则更新
- 源点到Vk的最长路径长度
- 事件Vk的最迟发生时间Vl(k)
- 即min{以k为弧尾的所有边 的弧头事件 的最迟发生时间-该边权值}
- 计算该值时,可以从后往前,从汇点(终点)出发,利用记录拓扑序列的栈,从栈顶出发,以此计算所有直接前驱节点k的最迟发生时间,小于则更新
- 总长度-这个点到终点最长路径的时间
- 活动Ai的最早开始时间E(i)
- E(i)=Ve(k),Vk是弧尾事件,因为只有事件Vk能开始做,活动Ai才能开始做
- 活动Ai的最迟开始时间L(i)
- L(i)=Vl(j)-Weight(Vk,Vj)
- 即该边弧头事件的最迟发生时间-该边的权值
- 总长度-这个边的弧头到终点的最长路径-这个边的权值
- 活动Ai完成的时间余量D(i)
- D(i)=l(i)-e(i)
- 活动余量为0/最迟开始时间=最早开始时间的活动是关键活动
- 顺序
- 从源点出发,先求Ve()
- 再从汇点出发,求Vl()
- 根据Ve()求E()
- 根据Vl求L()
- 求AOE网中所有活动的差额D,并找出D为0的活动构成关键路径
- 只有加快包括在所有关键路径上的关键活动才能达到缩短工期的目的
查找
折半查找
- 有序线性表的顺序查找中,实际上失败节点是不存在的,所以到达失败节点时所查找的长度=它上面的圆形结点的所在层数
- 折半查找在查找不成功时和给定值进行关键字比较次数最多为树的高度,即(Log2n)下取整+1或(log2n+1)上取整
- 折半查找的判定树有n个非叶结点(元素节点)和n+1个方形叶节点(失败结点)
- 折半查找的成功ASL=(层数*点数和)/有序表元素数
- 折半查找的失败ASL=(方形结点上面的圆形节点所在层数*点数和)/方形结点个数
- 二分查找的判定树唯一,而二叉排序树的查找不唯一,相同的关键字其插入顺序不同可能生成不同的二叉排序树
- 二叉排序树的插入和删除平均时间复杂度是O(logn),二分查找的插入和删除时间复杂度为O(n)
- 折半查找树基本都是偏向一边的,也就是说左右子树高度要么相等,要么每个左右子树的高度差都是固定值
- 折半查找判定树是一棵二叉排序树。
- 小数据量下,线性查找性能更佳

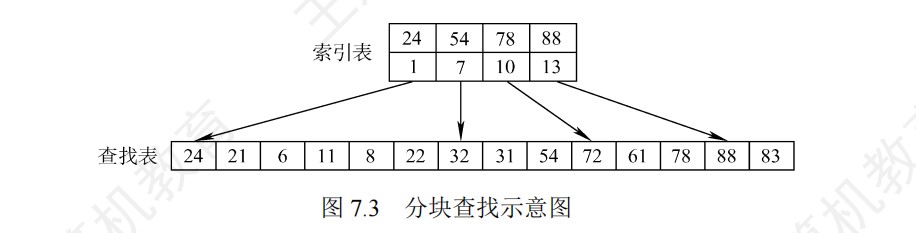
分块查找
- 分块查找分为索引表和查找表,索引表中每个元素含有各块的最大关键字和各块中第一个元素的地址
- 即使在索引表上直接找到了元素,也仍然要进入块内查找,只有在块内找到才是真的找到
- 分块查找既有动态结构又适于快速查找
二叉排序树(BST)
- 二叉排序树新插入的结点一定是一个叶节点
- 删除的是有两个孩子的节点:用直接前驱(左子树最右下)或者直接后继(右子树最左下)来替代原节点,然后进行调整
- 如果删除的结点是叶节点,那么删除后再插入,树的形态与原来保持不变,如果删除的结点不是叶子节点,那么删除再插入其形态就会变化了。
平衡二叉树(AVL)
-
平衡二叉树是对失衡的最小子树的根结点进行调整,每次调整的都是以插入路径上离插入节点最近的平衡因子的绝对值大于1的结点作为根的子树
-
LL和RR的单旋操作发生在最小不平衡子树的根节点和其两个子树构成的三角中
-
LR和RL的双旋操作,先发生在孩子的子树的根节点构成的三角,再发生在最小不平衡子树的根节点构成的三角
-
平衡二叉树的删除
- 删除的是叶子节点:直接删除
- 删除的是只有左子树或者右子树的节点:删除后用子树替代原节点
- 删除的是有两个孩子的节点:用直接前驱(左子树最右下)或者直接后继(右子树最左下)来替代原节点,然后进行调整
-
平衡二叉树的结点数计算

-
求解给定结点数的平衡二叉树的查找所需的最多比较次数(或树的最大高度)
- n0=0,n1=1,n2=2,nh=nh-1+nh-2+1
-
平衡二叉树的叶节点删除后再插入,形态也可能发生变化
-
所有非叶节点的平衡因子均为1,即平衡二叉树结点数最少的情况
-
AVL的树型个数判断
- ①确定最高高度和最低高度
- ②确定不同层高的树型数量
- ③乘法原理

红黑树
- 十二字真言
- 根叶黑,左根右,黑路同,不红红
- n个结点的红黑树有n+1个空黑叶节点

- 对于一颗动态查找树,若插入和删除操作比较少,查找操作比较多,则采用AVL树比较合适,否则采用红黑树更合适
- 不过广义上来讲,二者的插入、删除、查找的时间复杂度均为O(logn)
- AVL的查找效率往往优于红黑树
- 一颗含有n个结点的红黑树的高度至多为2log_2(n+1)
B树
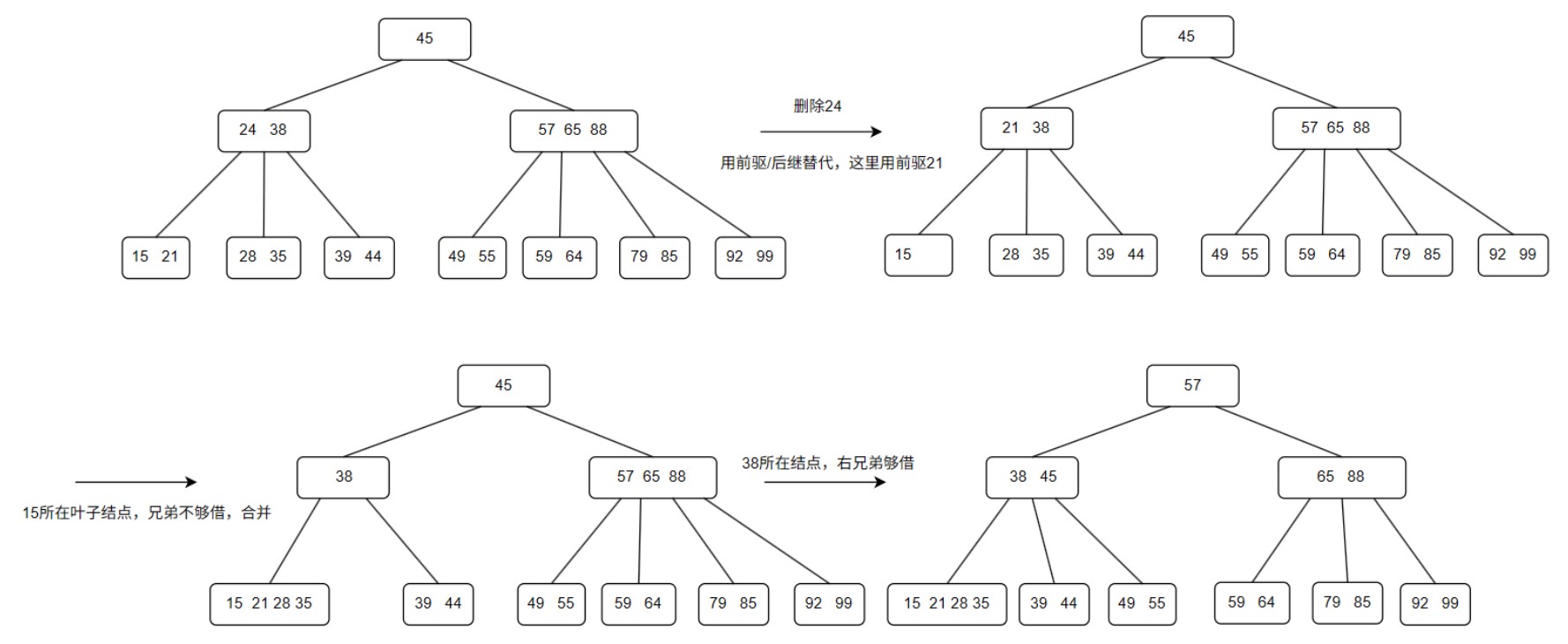
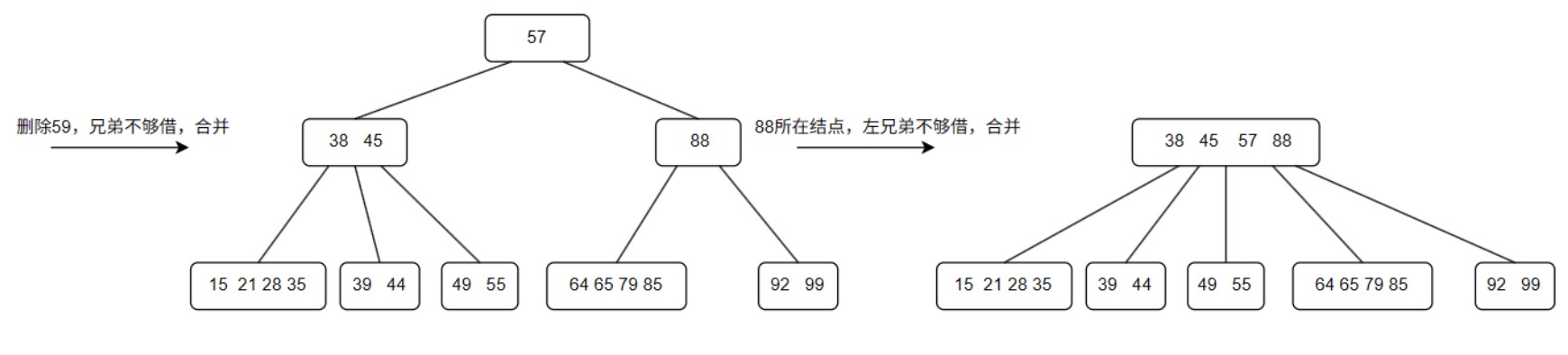
- B树的删除
- 叶子节点:直接删除
- 符合规则无需改动
- 不满足最低叶子节点:
- 兄弟够借借兄弟
- 兄弟不够借,合并兄弟节点和自己以及夹在中间的双亲结点
- 非叶子节点:删除后用直接前驱或者直接后继替代,相当于在叶子节点删除直接前驱或者直接后继
- 叶子节点:直接删除
- B树的插入
- 在一棵高度为h的B树中插入一个新关键码可能导致节点分裂,这种分裂过程可能从下向上一直到根节点,使得树的高度+1,假设内存足够大,在插入过程中为查找插入位置读入的结点一直在内存中,假设根节点高度为1,且根节点初始未读入内存,则最坏情况下可能需要读/写磁盘次数为3h+1
- 首先,从根节点找到插入位置需要进行h次读磁盘操作
- 在最坏情况下,在待插入结点中插入一个关键码后,导致节点分裂,在该层分裂成2个结点,因此需要2次读磁盘操作,分裂操作逐层向上传导,导致每一层都有节点分裂,因为节点分裂而导致的写磁盘操作总共有2h次
- 再加上最后一次节点分裂形成新根结点需要额外的一次写磁盘操作,写磁盘的总次数为2h+1
- 因此,整个过程中读写磁盘的总次数为3h+1
- 在一棵高度为h的B树中插入一个新关键码可能导致节点分裂,这种分裂过程可能从下向上一直到根节点,使得树的高度+1,假设内存足够大,在插入过程中为查找插入位置读入的结点一直在内存中,假设根节点高度为1,且根节点初始未读入内存,则最坏情况下可能需要读/写磁盘次数为3h+1
- 408真题将B树的叶节点定义为最底层的终端节点
- B树的查找包括①在B树中找节点;②在节点内找关键字。
- 由于B树经常存储在磁盘上,因此
- ①操作(在B树中找节点)在磁盘上进行
- ②操作(在节点内找关键字)在内存中进行
- 在磁盘上找到目标节点后,先将节点信息读入内存,然后再采用顺序查找法或折半查找法
- 在磁盘上进行查找的次数即目标节点在B树上的层次数,决定了B树的查找效率
- 由于B树经常存储在磁盘上,因此
- B树的查找时间复杂度为O(logn)
| B树应用 | B+树应用 |
|---|---|
| 数据库索引 | 数据库索引 |
| 文件系统的目录管理 | 文件系统 |
| 内存管理 | 内存数据库 |
| 搜索引擎的倒排索引 | 外部排序 |
B树的应用场景:
- 适合一般的索引结构,用于数据库索引和文件系统目录管理等。
- 支持插入和删除操作,但在范围查询时,相比B+树效率较低。
- 插入、删除操作的效率较好,因为所有节点都包含数据,因此能较为直接地查找到所需信息。
B+树的应用场景:
- 数据库和文件系统中更常用,因为B+树在范围查询方面性能更优。
- 所有数据存储在叶子节点中,叶子节点之间通过链表连接,可以快速进行范围查询。
- 高效的顺序访问和磁盘优化,特别适合处理大量数据时提高访问速度。
具体差异:
- 范围查询:
- B树:由于数据存储在所有节点中,进行范围查询时需要遍历整个树,效率较低。
- B+树:所有数据存储在叶子节点,且叶子节点通过链表连接,范围查询可以一次性访问所有相关数据,效率更高。
- 空间效率:
- B树:每个节点都存储数据,因此对于存储空间的需求相对较高。
- B+树:内部节点仅存储索引,节省了空间,且可以存储更多的索引信息,适合大规模数据存储。
哈希表
-
开放定址法中的平方探测法,要求k<=m/2,散列表长度m必须是一个可以表示为4k+3的素数
-
直接定址法不会产生冲突
-
失败时,分母是散列函数中的模的值(或者说初次探测可能会落在的区间,即min{散列表长度,散列函数中的模的值});成功时,分母是元素个数
-
数字分析法

-
平方取中法

-
线性探测法很容易造成同义词、非同义词的聚集“堆积”现象,严重影响查找效率
- 只有同义词的不叫聚集,只能叫冲突
-
平方探测法先正再负
-
双散列法只能缓解聚集现象,而不能避免
-
所有的开放定址法都无法避免聚集现象。
-
开放定址法四种方法的探测覆盖率问题

查找算法时间复杂度表

排序
-
从五个方面考察排序算法
- 时间复杂度
- 空间复杂度
- 常数辅助空间的算法
- 简单选择排序
- 插入排序
- 冒泡排序
- 希尔排序
- 堆排序
- 常数辅助空间的算法
- 稳定性
- 稳定的算法只有
- 插入排序
- 冒泡排序
- 归并排序
- 基数排序
- 计数排序
- 稳定的算法只有
- 适用性
- 顺序存储
- 折半插入排序
- 希尔排序
- 快排
- 堆排序
- 顺序存储和链式存储
- 冒泡排序
- 简单选择排序
- 归并排序
- 基数排序
- 顺序存储
- 过程特征
-
快速排序的枢轴值将序列划分的越平均排序速度越快
-
快速排序越有序,递归深度越深
-
直接插入排序与简单选择排序相比
- 直接插入排序元素比较次数少
- 简单选择排序移动的元素少
- 均为就地排序,空间复杂度均为O(1)
-
是否具有稳定性不能衡量一个算法的优劣
-
基数排序不基于比较操作
排序算法时间复杂度表
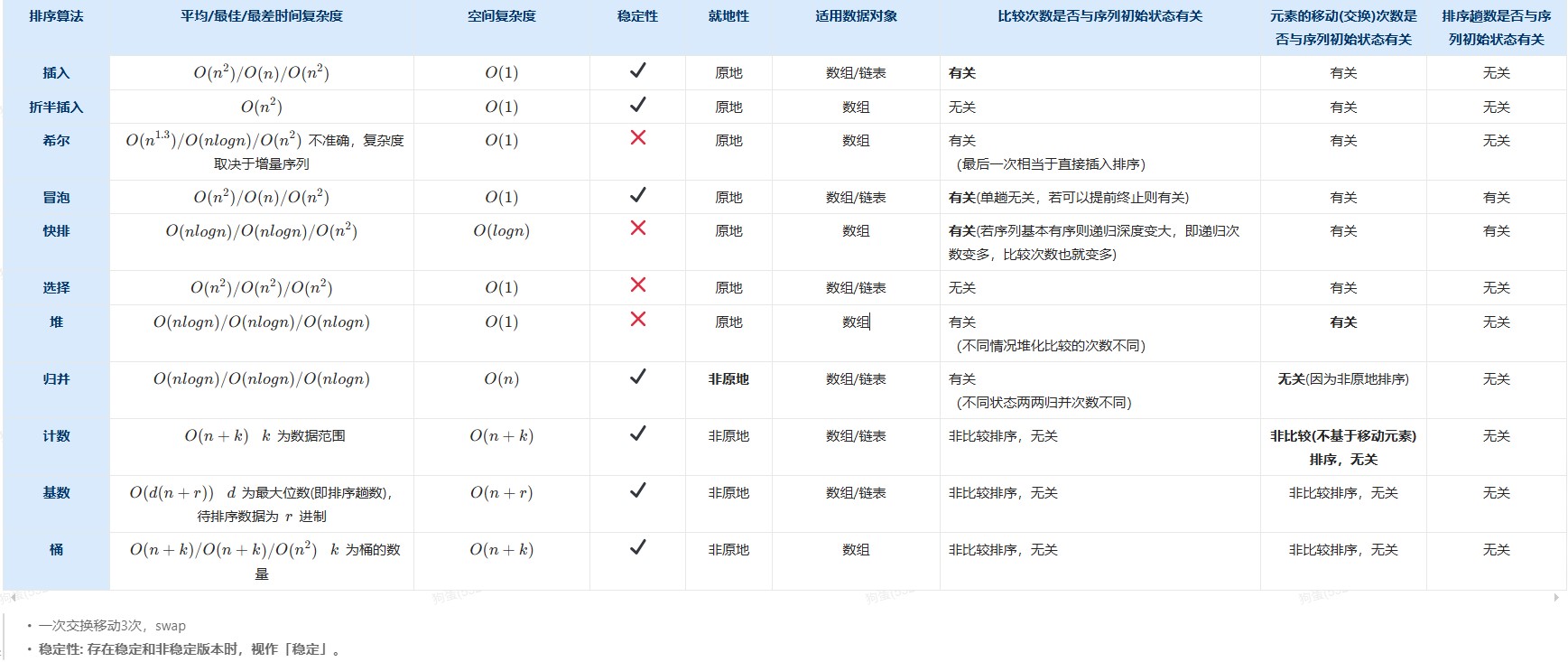
| 排序算法 | 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 就地性 | 适用数据对象 | 比较次数与初始状态关系 | 移动次数与初始状态关系 | 排序趟数与初始状态关系 |
|---|---|---|---|---|---|---|---|---|---|---|
| 插入排序 | O(n²) | O(n) | O(n²) | O(1) | ✔ 稳定 | 原地 | 数组/链表 | 有关 | 有关 | 无关 |
| 折半插入 | O(n²) | O(nlogn) | O(n²) | O(1) | ✔ 稳定 | 原地 | 数组 | 无关 | 有关 | 无关 |
| 希尔排序 | O(n^1.3) | O(n log n) | O(n²) | O(1) | ✘ 不稳定 | 原地 | 数组 | 有关 | 有关 | 无关 |
| 冒泡排序 | O(n²) | O(n) | O(n²) | O(1) | ✔ 稳定 | 原地 | 数组/链表 | 有关 | 有关 | 有关 |
| 快速排序 | O(n log n) | O(n log n) | O(n²) | O(log n) | ✘ 不稳定 | 原地 | 数组 | 有关 | 有关 | 有关 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | ✘ 不稳定 | 原地 | 数组/链表 | 无关 | 有关 | 无关 |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | ✘ 不稳定 | 原地 | 数组 | 有关 | 有关 | 无关 |
| 归并排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | ✔ 稳定 | 非原地 | 数组/链表 | 有关 | 无关 | 无关 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(n+k) | ✔ 稳定 | 非原地 | 数组 | 无关 | 无关 | 无关 |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r))顺序基数排序O(n + r) 链式基数排序O® |
✔ 稳定 | 非原地 | 数组 | 无关 | 无关 | 无关 | |
| 桶排序 | O(n+k) | O(n+k) | O(n²) | O(n+k) | ✔ 稳定 | 非原地 | 数组 | 无关 | 无关 | 无关 |
各个排序的操作顺序
插入排序
- 含义:找到插入位置,将后面的数据后移,空出位置后插入
直接插入排序
- ①找到插入位置k(涉及比较次数)
- ②k后面的所有元素依次向后移一个位置(涉及移动次数)
- ③插入
- L1视为固定,只需要进行n-1次插入操作
- 最多比较次数为n(n-1)/2
- 直接插入排序和自己之前的开始,依次往前比较,查到即停止
- 只有在线性表的初始状态为反序的情况下,直接插入排序过程中元素的移动次数才会达到最大值
折半插入排序
- ①二分找到插入位置k(涉及比较次数)
- ②k后面的所有元素依次向后移一个位置(涉及移动次数)
- ③插入
- 折半插入排序的比较次数与待排序表的初始状态无关,仅取决于表中的元素个数n;而移动次数并未改变,依赖于带排序表的初始状态
- 折半插入排序相对于直接插入优化的是比较次数
希尔排序
- ①根据增量分组
- ②在个组内进行直接插入排序(逐渐获得较好的局部有序性)
- ③重复上述过程
- 希尔排序的d是指从每组第一个数开始,从后数d个数加入同一组
- 组内直接插入排序的比较次数:和前面一个开始比,比到小的就停止
交换排序
- 根据序列中两个元素关键字的比较结果来对换这两个记录在序列中的位置
冒泡排序
- ①从后往前(或者从前往后)两两比较相邻元素的值,如果为逆序,则交换他们,直到序列比较完毕。(从前往后或者从后往前走一遍叫做一趟冒泡
- 冒泡排序在排序好以后还要再走一遍确认没有发生交换,表命已经有序,冒泡排序结束
- 每趟都有一个元素被放到最终的位置上

- 序列的逆序数不变,交换次数不变,移动次数=交换次数*3
- 只有在线性表的初始状态为反序的情况下,冒泡排序过程中元素的移动次数才会达到最大值
快速排序
- 注:此处所写过程为笔试考试过程,不同于yxc写的上机代码
- ①取首元素作为枢轴
- ②两个指针分别指向表头表尾
- ③表尾指针先动,找到第一个小于枢轴的元素,交换到i所指的位置
- ④表头指针往后走,找到第一个大于枢轴的元素,交换到j所指位置
- ⑤重复上述过程,直到i、j相遇
- ⑥将枢轴元素放到i==j的位置
- ⑦上述过程叫做一趟排序,重复上述过程,直到序列全局有序
- 快排是所有内部排序算法中平均性能最优的排序算法
- 快排不产生有序子序列,但每一趟排序后会将上一趟划分的各个无序子表的枢轴(基准)元素放到其最终的位置上。
- 快排比较次数的计算
- 长度为n的子表,比较n-1次,当子表长度为1的时候不进行比较。
- 快排序列的确定
- 第一层分界点不是端点,第二层必然存在左右半边,因此必然至少有三个点在正确的位置上
- 第一层分界点是端点,第二层只有一个区间,因此该区间内只有一个分界点,因此至少有两个点在正确的位置上,且其中一个点为端点
选择排序
- 基本思想:每一趟在后面n-i+1个待排序元素中选取关键字最小的元素,作为有序子序列的第i个元素,直到第n-1趟做完,待排序元素只剩下一个
简单选择排序
- ①找到待排序元素中的最小元素
- ②第i趟就同第i个数进行交换
- 简单选择排序的比较次数与序列初始状态无关,始终是n(n-1)/2次
堆排序
- 可以将堆视为一颗完全二叉树
- 不是二叉排序树
- 不是平衡二叉树
- ①将n个元素建成初始堆
- ②输出堆顶元素,重新调整维持堆的性质
- 根节点的关键字小于左右孩子中关键字较大者,则交换
- 建堆时间复杂度O(n),建堆比较次数O(n),空间复杂度O(1),调整堆O(logn)
- 堆排序是所有时间复杂度为O(logn)的排序算法中空间复杂度最小的
- 在向n个元素的堆中插入一个元素的时候,比较次数最多等于树的高度-1,即log2n下取整
- 初始堆进行调整的时候,调节某一个分支节点子树的时候,一定要保证这个子树是大根堆后再调整下一个分支节点
- 堆排序的删除调整中,两个孩子先进行比较,然后孩子的最大值和根节点进行比较,两次比较都是单独算次数,并且只有变动的点经过的路径要进行比较
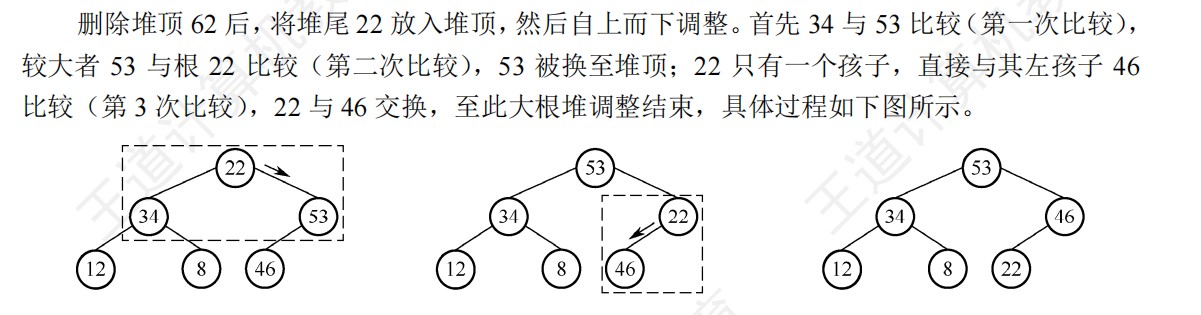
- 堆的插入调整中,只和根节点进行比较
- 注意初始堆是插入完毕后进行调整,而依次插入初始为空的大根堆是每次插入都要调整
- 由于堆是用于排序的,在查找的时候它是无序的,所以效率没有其他查找结构高
- 堆排序可以并行执行,因为根节点的左右子树构成的子堆在执行过程中是互不影响的
- 堆排序中,第二次调整堆的意思是,建堆以后进行的第二次调整
归并排序
- 奇数个归并段,最后一个段单独空出来,下一轮再参与归并
- 整个归并排序需要log2n上取整趟
- 对n个元素进行k路归并排序的时候,需要logkn上取整趟
- 每趟归并的时间复杂度为O(n)
基数排序
- 不基于比较和移动进行排序,基于关键字各位的大小进行排序
- 最高位优先MSD,最低位优先LSD
- 使用的是r个队列
- ①分配,根据关键字放入对应的队列
- ②收集,把各个队列的结点首尾相接,得到新的节点序列,从而组成新的线性表
- 求升序序列的情况下,从左到右收集,分配的时候也是从左到右分配
- 时间复杂度与初始序列状态无关
计数排序
- 思路:对每个待排序元素x,统计小于x的元素个数,利用该信息就可以确定x的最终位置。
- 当数组的值域过大,效率反而不如一些基于比较的排序
外部排序
-
败者树的作用
- 增大归并路数,减少关键字对比次数
-
置换-选择排序的作用
- 增大归并段长度来减少归并段数量
-
最佳归并树(哈夫曼树)的作用
- 用于长度不等的归并段进行多路平衡归并
-
外部排序过程中的时间代价主要考虑I/O次数
-
若要进行k路归并排序,则需要在内存中分配k个输入缓冲区和1个输出缓冲区
-
如何进行k路归并
- ①把k个归并段的块读入k个输入缓冲区
- ②用“归并排序”的方法从k个归并段中选出几个最小记录暂存到输出缓冲区中
- ③当输出缓冲区满时,写出外存
- 第一次生成的是初始归并段
-
外部排序时间开销=读写外存的时间+内部排序的时间+内部归并的时间
-
外部排序做题需要有全局思维,即有两块空间,一个是磁盘一个是内存,而这两大空间又能划分为n个子空间,也就是磁盘中的磁盘块,和内存中的输入缓冲区和输出缓冲区
- 一个归并段可能包含多个磁盘块,而读写次数以磁盘块为单位计算
- 由于归并段是内部有序的,所以在给多个归并段进行归并的时候,一般优先读取每个归并段最前面的磁盘块,而输出缓冲区满后写入磁盘的,也是写入最前面的磁盘块
-
外部排序的读写磁盘次数=文件总块数x2+文件总块数x归并趟数x2
-
k路归并≠k路平衡归并,k路平衡归并要求m个归并段参与归并,经过该趟处理得到m/k上取整个新的归并段
-
外部排序的优化流程
- 初始状态
- ①二路归并→多路归并→败者树
- 优化方向:
- ①多路归并
- 原理:减少归并趟数,从而减少I/O读写次数
- 归并趟数=logkr上取整
- k越大,r越小,归并趟数越少,读写磁盘次数越少
- 归并趟数=logkr上取整
- 缺点:
- k路归并需要k个输入缓冲区,内存开销增加
- 每挑选一个关键字需要对比关键字k-1次,内部归并所需时间增加
- 优化方向:
- ①败者树
- 第一次构造k路归并败者树需要比较k-1次,有了败者树之后,关键字对比次数减少到log2k上取整
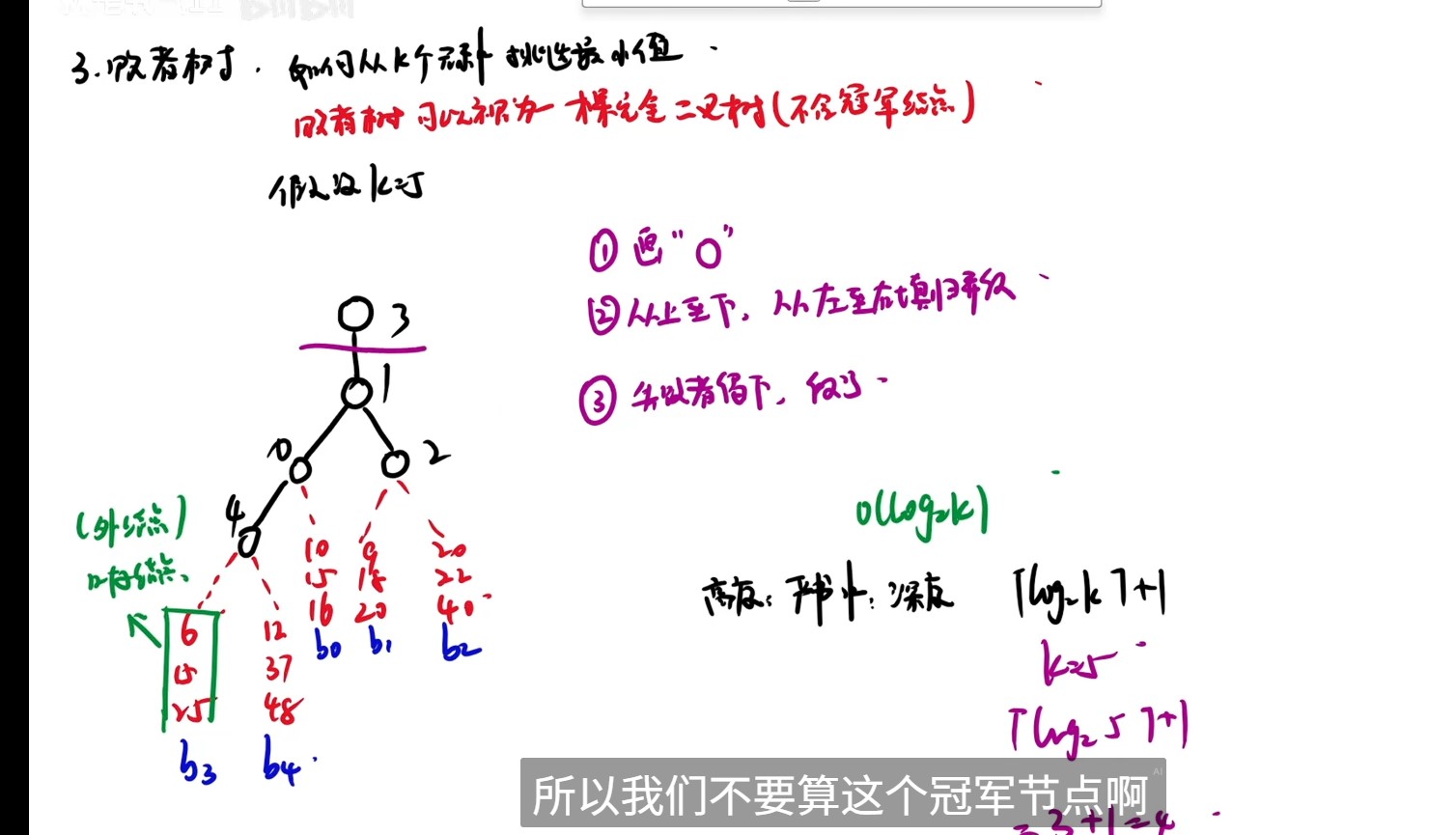
- k个叶节点分别对应k个归并段中当前参加比较的元素,非叶子节点用来记忆左右子树中的失败者,而让胜者一直往上比较,一直到根节点
- 叶子节点是虚拟的
- 根节点记录冠军来自哪个归并段,分支节点记录失败者来自哪个归并段
- 败者树的每次维护必定要从叶节点一直走到根节点,不可能从中间停止
- 使用败者树后,内部归并的比较次数与归并路数无关,总的比较次数=(n-1)(log2r上取整)
- n是归并的元素个数,r是初始归并段的数量
- k路归并败者树的建树时间复杂度为O(klog2k),空间复杂度O(n),调整一次的时间复杂度O(logn)
- 败者树是一颗完全二叉树,初始归并段的个数就是叶子节点个数,因此计算高度时要把初始归并段算作叶子节点
- 败者树胜者胜出输出后,胜者所在的那个归并段的下一个元素上位,然后败者树重新调整,从这个上位元素所在的子树开始调整,一直维护到根节点即新胜利者出现
- ①败者树
- 优化方向:
- ②形成N/L个初始归并段(N为记录总数,L为内存工作区可以容纳L个记录)→置换-选择排序→最佳归并书
- 优化方向:
- ①置换选择排序
- 可以让每个初始归并段的长度超越内存工作区大小的限制
- 问题:长度不同的情况下如何决定哪几个归并段进行归并
- 优化方向:
-
①最佳归并树
- 归并过程中的磁盘I/O次数=归并树的WPL*2=非叶节点的权值之和x2
- 注意总体I/O次数还要加入构造初始归并段的I/O次数,即磁盘块块数*2
- 归并过程中的磁盘I/O次数=归并树的WPL*2=非叶节点的权值之和x2
-
②败者树优化置换选择排序比较次数(注意k路归并最先放在A[k-1],从后往前放


-
- 优化方向:
- ①置换选择排序
- 优化方向:
- ①二路归并→多路归并→败者树
- 初始状态
-
最佳归并树和败者树的区别
- 最佳归并树用于决定哪几个归并段进行归并,而败者树用于在这几个归并段进行归并的时候,减少关键字比较次数,形成新的归并段
-
败者树补充


-
外部排序的归并趟数不算生成初始归并段的那趟,只算生成初始归并段以后的排序趟数
CO(计组)
计算机系统概述
- 编译程序产生的目标代码执行效率高,但是可移植性较差;解释程序具有较好可移植性,但执行效率较低
- 向后兼容是指时间上向后兼容,即新机器兼容使用以前机器的指令系统。
- 全面代表计算机性能的是实际软件的运行情况
冯诺依曼计算机的特点

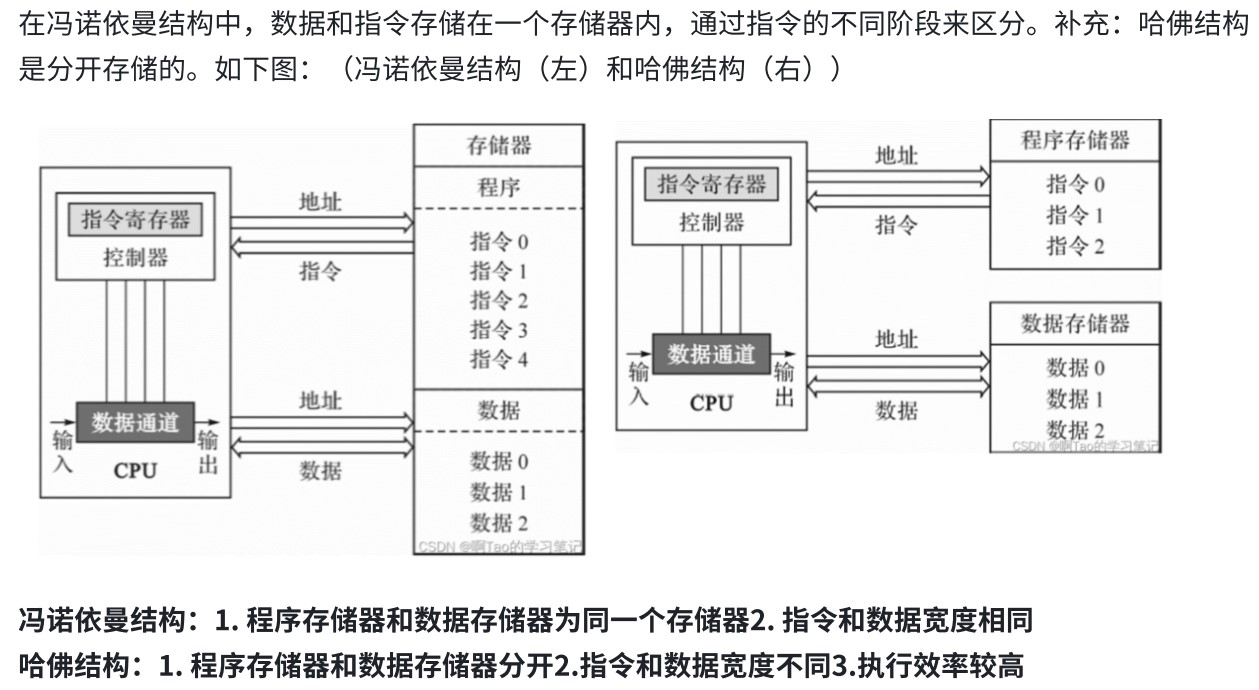
- 输入设备都必须有离散化和编码两方面的功能
计算机分层系统

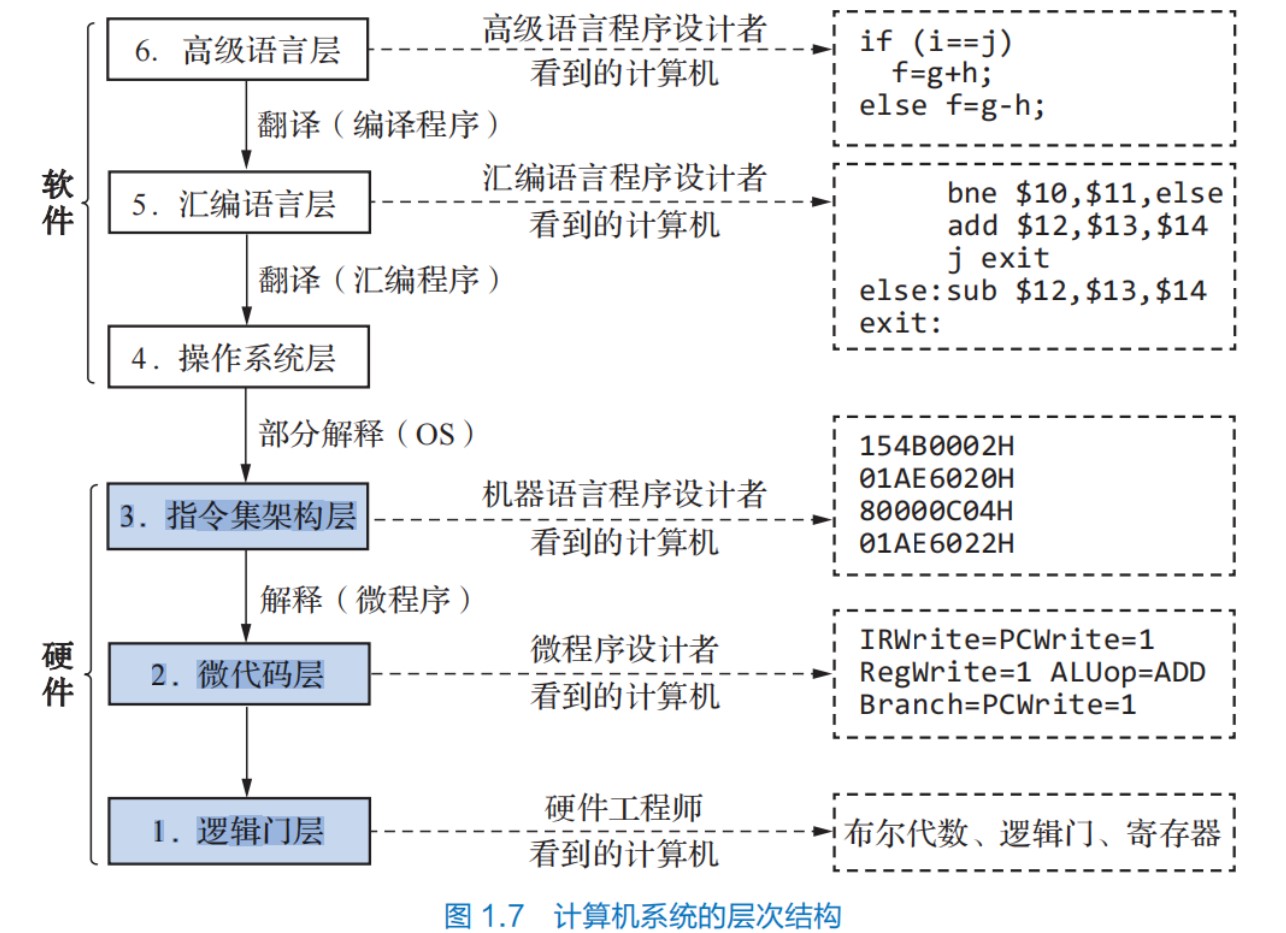
计算机性能指标
- MIPS=(主频/CPI)/10^6
- 时间=CPI*指令总数/主频
- 影响平均CPI的因素
- 微体系结构决定硬件执行指令的效率
- 如流水线、超标量、分支预测等
- 指令调度策略用于优化指令执行顺序,减少数据依赖或者控制依赖导致的冒险
- 如编译器静态调度或硬件动态调度
- 指令系统结构直接决定指令的复杂度和执行效率
- 如RISC或CISC
- 微体系结构决定硬件执行指令的效率
- 系统的吞吐量主要取决于主存储器的存取周期
各种字长的总结
- 机器字长
- CPU在同一时间内一次能够处理的二进制的位数,相当于CPU中定点运算数据通路的位数
- 一个字的宽度并不等于机器字长
- 通常与CPU的寄存器位数、加法器有关
- 一般等于通用寄存器的大小
- 字长越长,数的表示范围越大,计算精度越高
- 编址单位
- 存储单元的宽度,也就是按多少位存储
- 存取宽度
- 一次从由多个DRAM芯片构成的存储模块(即主存)中同时读写的信息的宽度
- eg:假定某个存储模块由8个4096*4096 * 8位的DRAM芯片按交叉编址方式构成,则该存储模块的存取宽度是64位,也即,8个芯片可同时读写,每个芯片同时读8位,因而最多可以同时存取64位信息
- 传输宽度
- 总线宽度,一次最多能在总线上传输的数据位数,对于存储器总线来说,总线上传输的信息宽度应该等于存储器的存取宽度,因此在设计系统时,应该考虑传输宽度和存取宽度的匹配,并且每个设备中的总线接口部件也要与这些宽度匹配。
- 指令字长
- 指令的位数,有定长指令字机器和不定长指令字机器。定长指令字机器中所有指令的位数是相同的,因此定长指令字大多是32位。不定长指令字机器的指令有长有短,但每条指令的长度一般都是8的位数。因此,一个指令字在存储器中存放时,可能占用多个存储单元;从存储器读出并通过总线传输时,可能分多次进行,也可能一次读多条指令
- 指令字长决定了IR寄存器的位数
- 存储字长
- 一个存储单元的位数,也就是CPU向内存某个地址取数据时一次性取走的数据量
- MDR位数与总线中的数据线宽度相等, 与存储字长不一定相等,与ALU的位数也不一定相等,也就是说MDR只对数据通路负责
- 因为数据可以多次存取,但是数据的输入接口必须能够对接
- 机器字长、存储字长、指令字长之间的长度关系
- 存储字长和机器字长的关系
- 机器字长>=存储字长,通常是存储字长的整数倍,相等的时候方便一次性存取计算
- 存储字长和指令字长的关系
- 半存储字长指令、单存储字长指令、双存储字长指令
- 机器字长和指令字长之间没有约束关系,机器字长强调操作数长度,指令字长强调指令长度
- 存储字长和机器字长的关系
数据的表示和运算
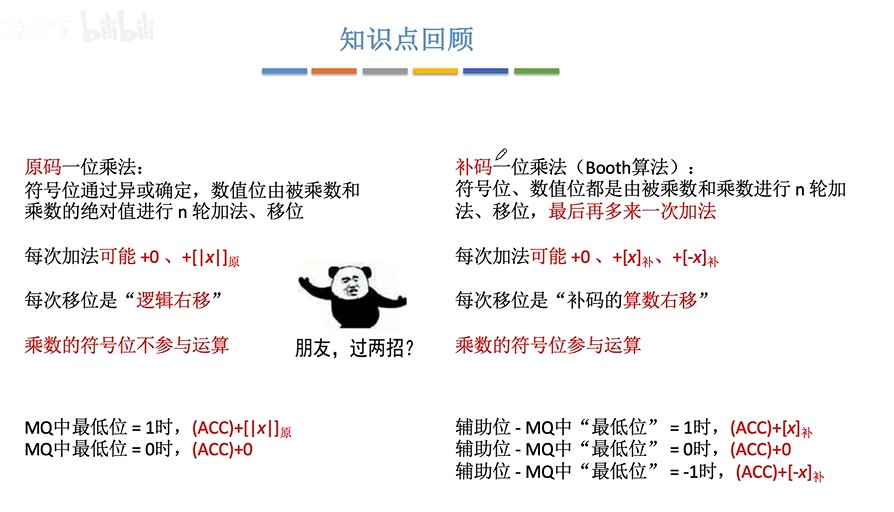
- 原码一位乘共进行n次加法和n次逻辑右移
- 补码booth乘法共进行n+1次加法和n次算术右移
- 补码的本质是取模,对于补码表示的定点小数,模数是2,对于补码表示的定点整数,模数是2^(n+1)(n+1位补码)
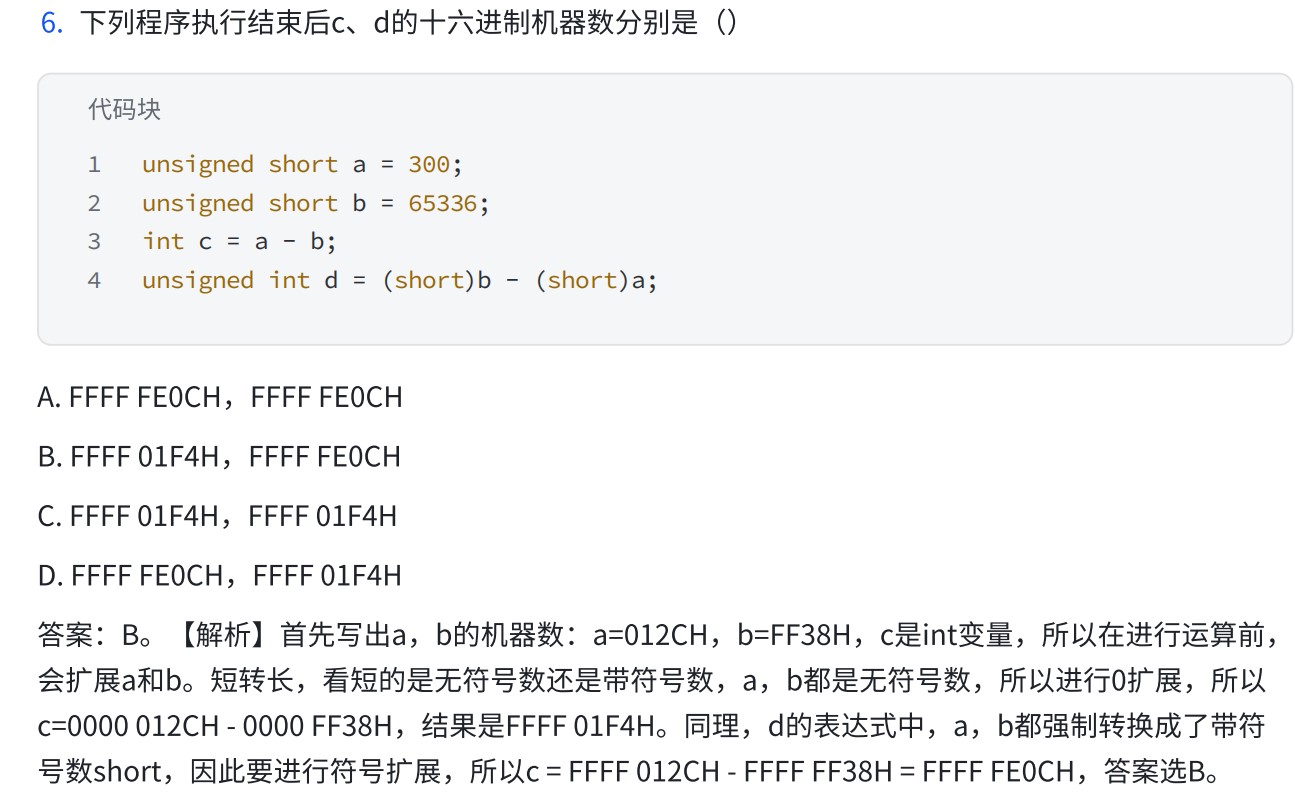
- 两个短相加变长,会先对两短进行扩展,扩展的时候按照短自己的类型进行扩展(短的是无符号数就0扩展,是有符号数就符号扩展)。
-
加减法电路
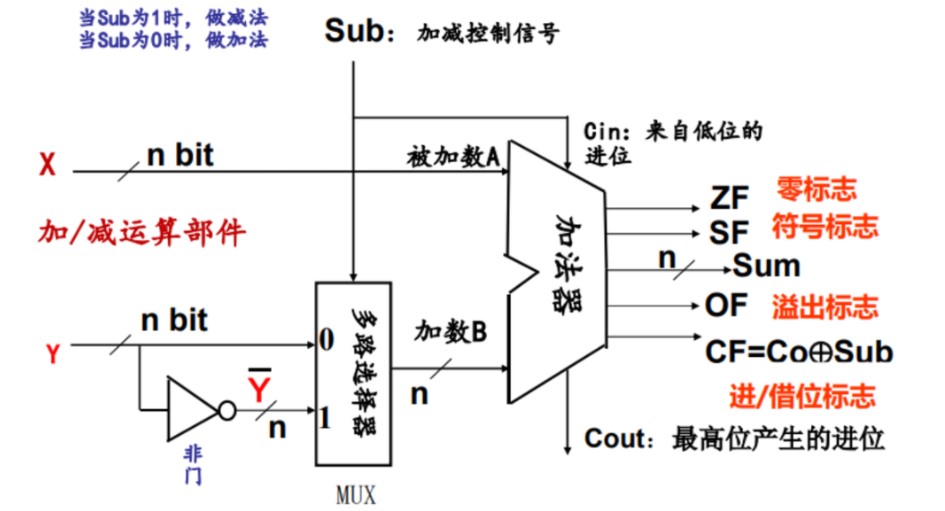
sub=1,一个作为控制信号传到多路选择器控制取反后的Y进入加法器,而另一个作为cin也就是低位的进位加到加法器
最好会画
-
并不是每个十进制小数都可以准确地用二进制小数表示,但是任意一个二进制小数都可以用十进制小数表示
-
定点小数是纯小数,没有整数部分,约定小数点的位置在符号位后,有效数值部分最高位之前
-
定点整数是纯整数,没有小数部分
-
负数补码大小的快速判断
- 数值位部分越小,其绝对值越大,即负得越多,即越小
-
无符号整数主要用于表示指针、进行地址运算
-
char在C语言中是有符号的
-
C语言常见的类型都是用补码形式存储的
-
ALUop的位数决定了ALU操作的种类
-
对于有符号数来说,加法器两端分别是他们的补码表示,对于无符号数来说,加法器两端是他们的二进制表示
-
无论是无符号数减法还是补码减法,都是用被减数加上减数的负数的补码来实现的,运算器本身无法识别所处理的二进制串是有符号数还是无符号数
-
OF快速判断
.png)
- 大小端判断:从左往右地址从低往高,如果顺序符合人类阅读,那就是大端,逆序则是小端
原码、补码、移码的定义(重点)




- 补码符号位不变时,其真值随着数值位的增大而增大
类型转换集合(重点)
同字长有符号数和无符号数之间
- 有符号数和无符号数的强制转换,保持二进制各位的值不变,仅改变解释这些位的方式
- 有符号数转化为无符号数的时候,符号位解释为数值的一部分
- 无符号数转化为有符号数的时候,最高位解释为符号位
- 可能改变数值的情况
- 负数有符号数转化为无符号数
- 无符号数转化为有符号数
- 有符号数和无符号数参与运算,按无符号数进行运算,运算与结果类型都是无符号

不同字长整数之间
- 大转小,高位直接截断,低位直接赋值
- 小转大,无符号整数0扩展,有符号整数符号扩展
- char型为8位有符号整数,转换int时高位补符
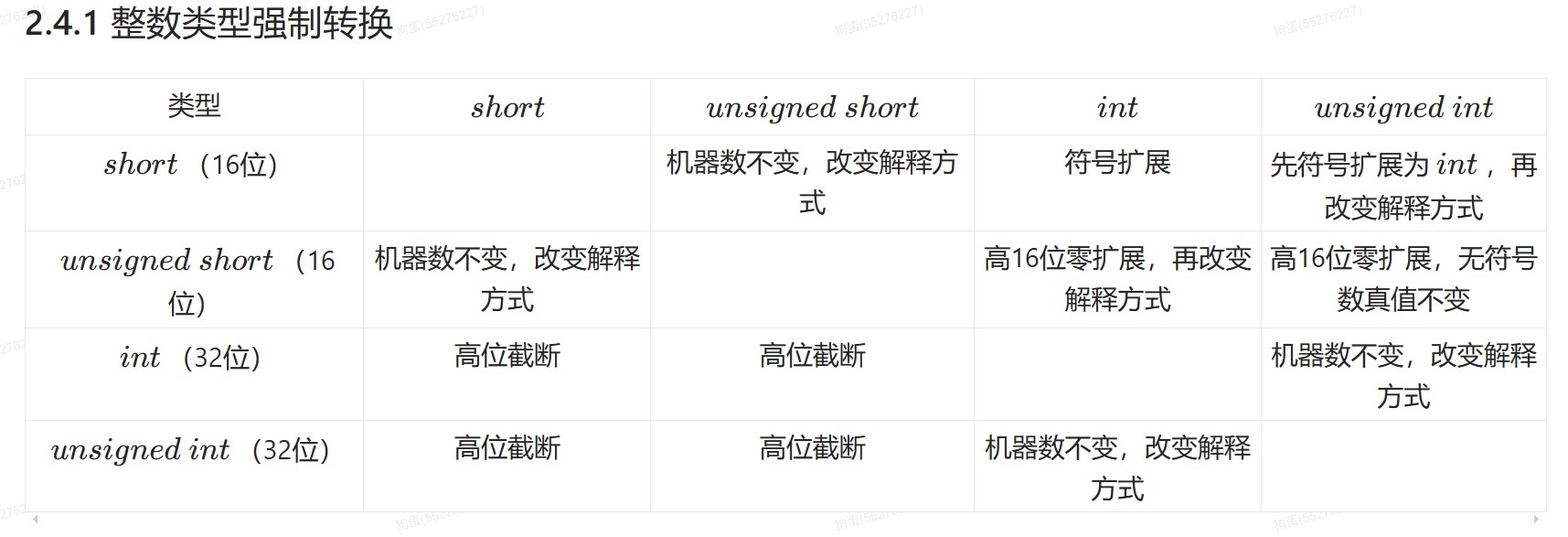
不同字长无符号数和有符号数之间
- 小转大,先扩展,再换解释
- 原数字是无符号整数,进行0扩展,然后将扩展后的数按照有符号数进行解释
- 原数字是有符号整数,进行符号扩展,然后将扩展后的数按照无符号数进行解释
- 大转小,先截低位,再改变解释方式
- 总的来说,转换的时候,先进行字长转换,再改变解释方式
- 不同字长的无符号数和有符号数进行运算,结果为字长更长的类型,因为字长更长,能表示的范围更大
- 隐式类型转换:不同类型数混合运算的时候,遵循的原则是类型提升,即较低类型转换为较高类型,运算中和结果都是更高的类型
浮点数和整数之间
- int转float,int是补码,由于float尾数是原码表示,所以先要将int转为原码表示。


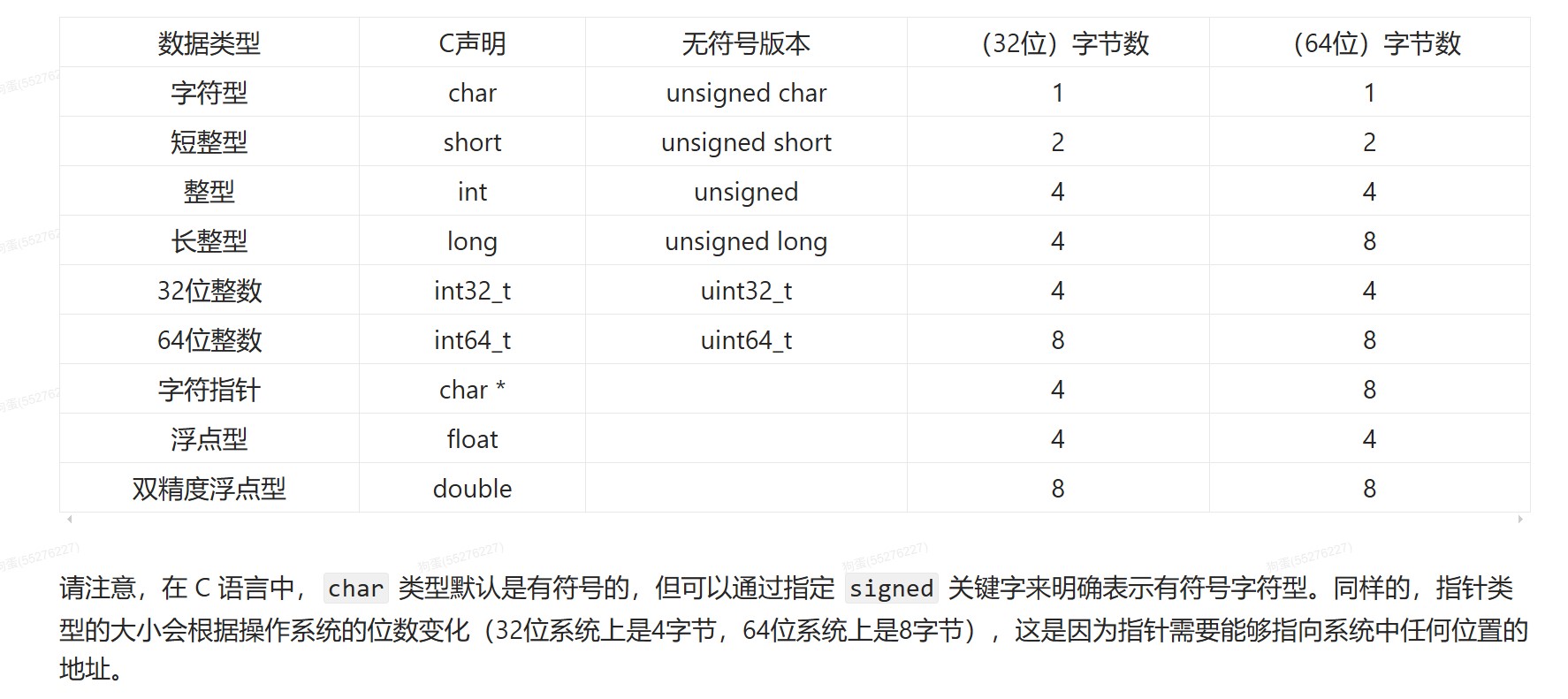
- float的有效位数是24位,相当于十进制7位,double的有效位数是53位,相当于十进制17位,int的有效位是31位,相当于十进制10位
定点整数的运算(重点)
溢出判断
- 逻辑位移,左移出1,溢出
- 算术位移,左移前后符号位不同,溢出
- 这里的左移前后符号位不同,移出的每一位都要判断,只要有一位不同就是溢出
- 补码定点数加减法
- 同号相加,异号相减,符号位改变,溢出
- ①一位符号位
- 操作数符号相同,结果与源操作数的符号不同,结果溢出
- ②双符号位(模4补码)
- 运算结果的两个符号位相同,表示未溢出,不同表示溢出
- 最高位符号代表真正的符号
- 模4补码存储仅需一个符号位,只有在ALU中采用双符号位
- ③OF判断
- 最高位进位异或次高位进位
- 模4补码更容易检查加减运算中的溢出问题而非乘除运算中的溢出问题
- 原码定点乘法
- 在字长为32位的计算机中,对于两个int型有符号数的乘积,若乘积高32位的每一位都相同,且都等于乘积低32位的符号,则表示不溢出,否则表示溢出
- 在字长为32位的计算机中,对于两个unsigned int型无符号数的乘积,若乘积高32位全位0,则表示不溢出,否则表示溢出
- 原码的除法运算
- 第一次商1,溢出
- 浮点数尾数原码小数相除,第一次试商为1,虽然溢出但可以通过右规消除
- 两种快速判断方法


无符号数和有符号数大小的比较
- 无符号数大小的比较

- 有符号数大小的比较

原码的加法运算
- ①规则:符号位和数值位分开处理
- ②加法规则:
- 符号位相同,数值位相加,结果符号位不变,最高位相加产生进位则溢出
- 符号不同,做减法,绝对值大的数减去绝对值小的数,结果符号位与绝对值大的数相同
- ③减法规则:
- 减数符号取反,按照加法规则运算
定点乘法运算
-
①规则:数值位和符号位分开求
- 乘积的符号位由两个乘数的符号位异或得到
- 乘积的数值位是两个乘数的绝对值之积
-
②两个n位无符号数相乘共需进行n次加法和n次逻辑右移运算
-
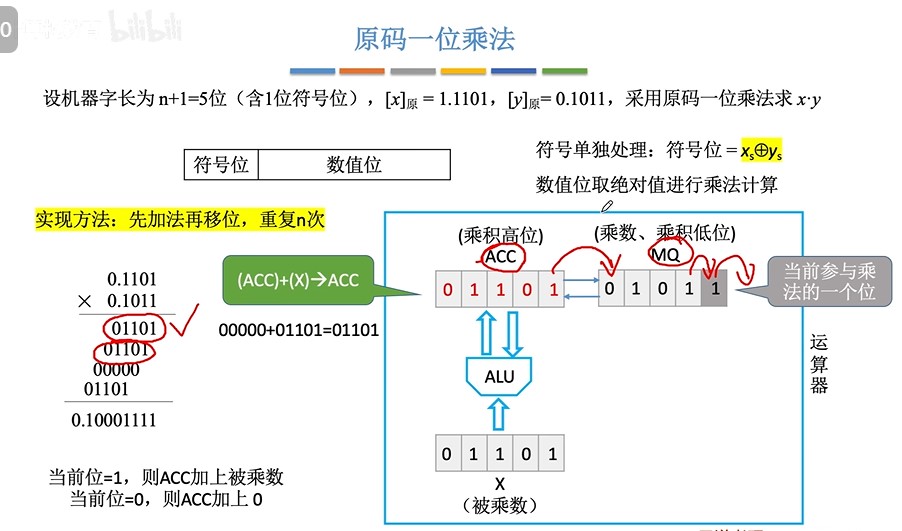
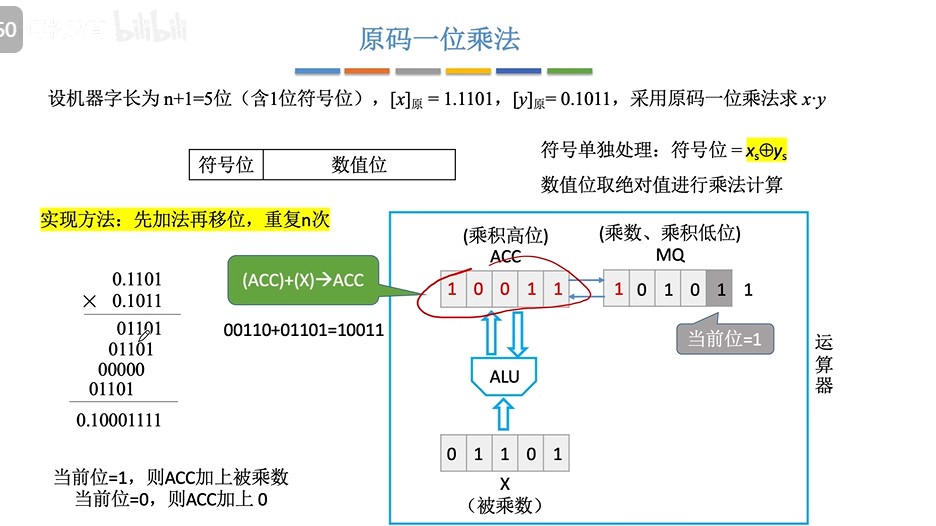
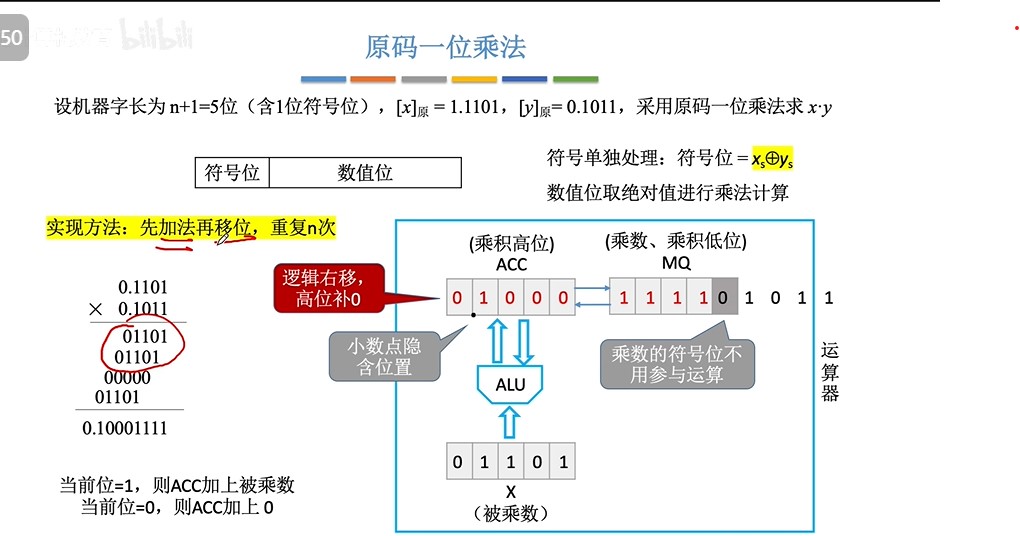
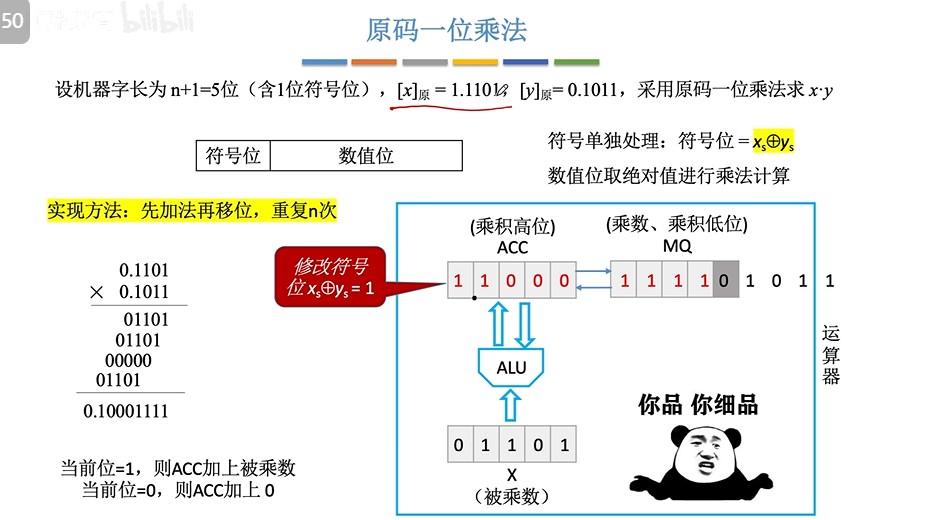
③手算方式

④机算方式(乘法运算电路)
- 书上图(假设一次循环在一个时钟周期内完成,则n位乘法需要n个时钟周期来完成)
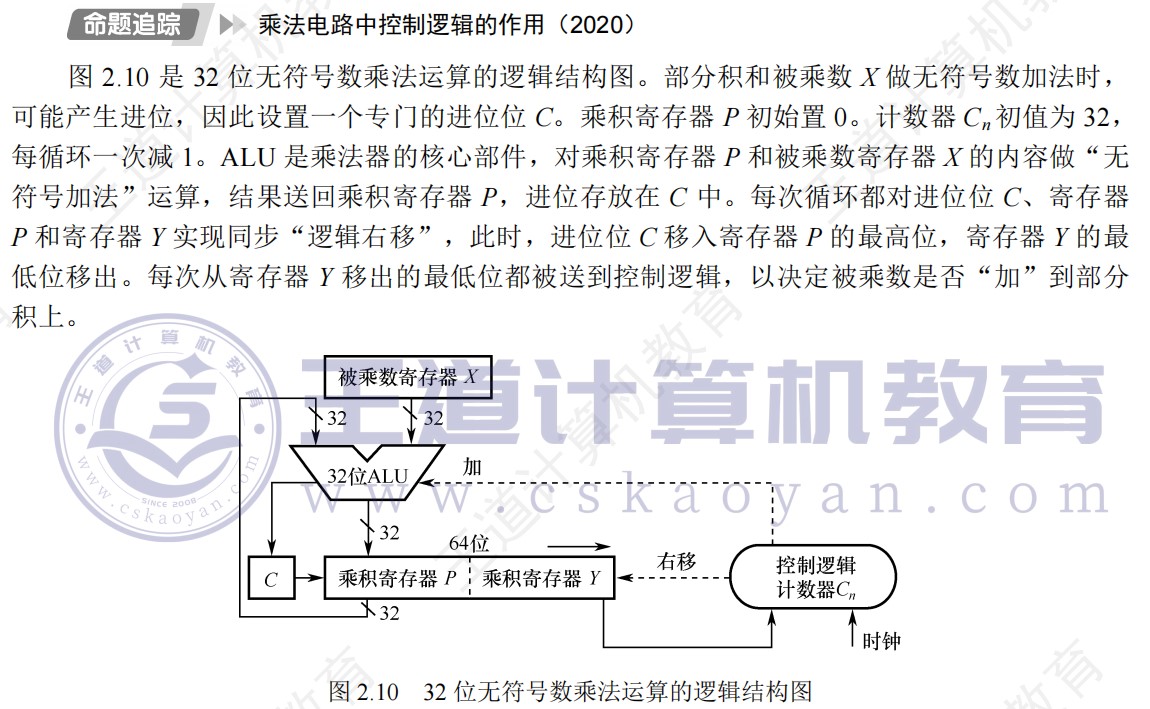
- 完整过程演示(5位机器字长,1位符号位,4位数值位)



-
⑤溢出判断
- 在字长为32位的计算机中,对于两个int型有符号数的乘积,若乘积高32位的每一位都相同,且都等于乘积低32位的符号,则表示不溢出,否则表示溢出
- 在字长为32位的计算机中,对于两个unsigned int型无符号数的乘积,若乘积高32位全位0,则表示不溢出,否则表示溢出
-
⑥手算模拟机算过程

定点除法运算
-
n位定点数的除法运算,统一为一个2n位的数除以一个n位的数,得到一个n位的商
-
因此需要对被除数进行扩展:
- 定点正小数(原码),低位添n个0
- 定点正整数(无符号数),高位添n个0
-
①除法运算的过程:
- ①够减则商1,不够减商0
- 注意与CRC冗余验证码区分,CRC首位1则商1,首位0商0
- ②每次得到的差为中间余数,将除数逻辑右移后与上次的中间余数比较,够减商1,不够减商0,重复直到商的位数满足要求为止(机器字长位数)
- ①够减则商1,不够减商0
-
2n位/n位,商的位数为n+1位(因为进行了扩展,注意和乘法位数区分)
-
②溢出判断
- 第一次商1,代表结果溢出(无法用n位表示商)
- 对于浮点数尾数的原码小数相除,第一次试商位1,说明尾数部分有溢出,可以通过右规消除
-
③原码除法运算同样要将符号位和数值位分开处理,商的符号位是两个数符号位的异或结果,数值位是两个数的绝对值之商
-
在定点小数的除法运算中,被除数一定小于除数,因为如果大于,则商会>1,而定点小数无法表示>1的范围,因此当第一步的商是1,说明被除数比除数更大,硬件电路检测出以后会直接停止这些除法的运算
-
④除法运算电路
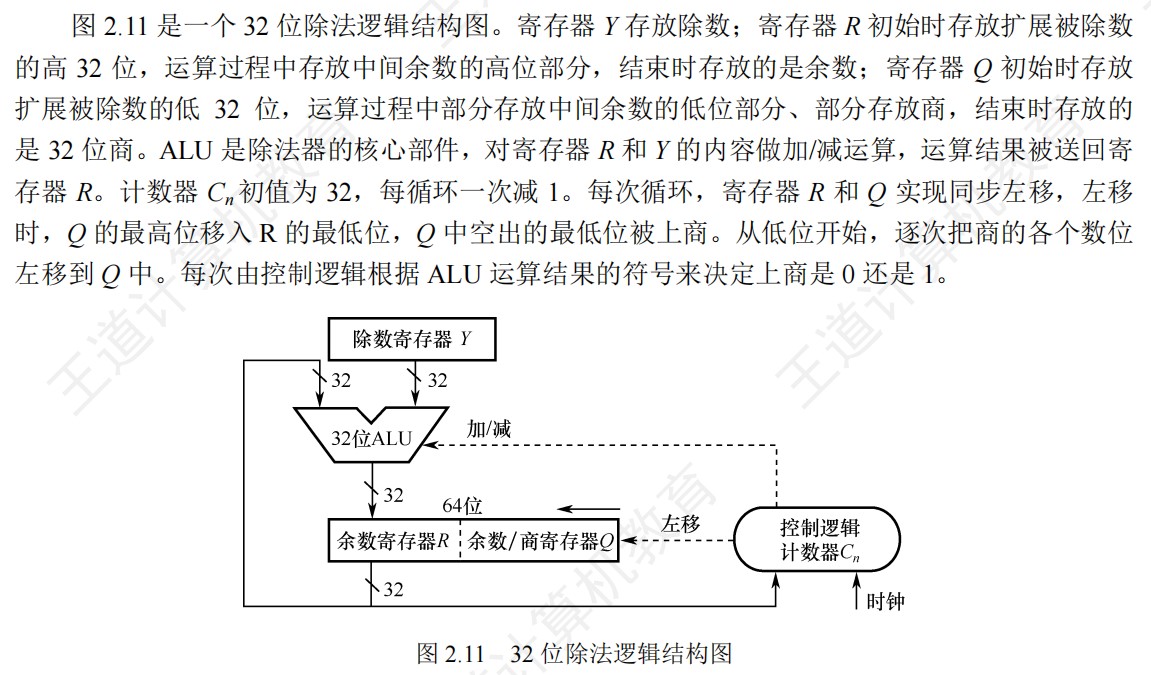
-
32位int型整数相除,则除了-2^31/-1会溢出,其余情况都不会溢出
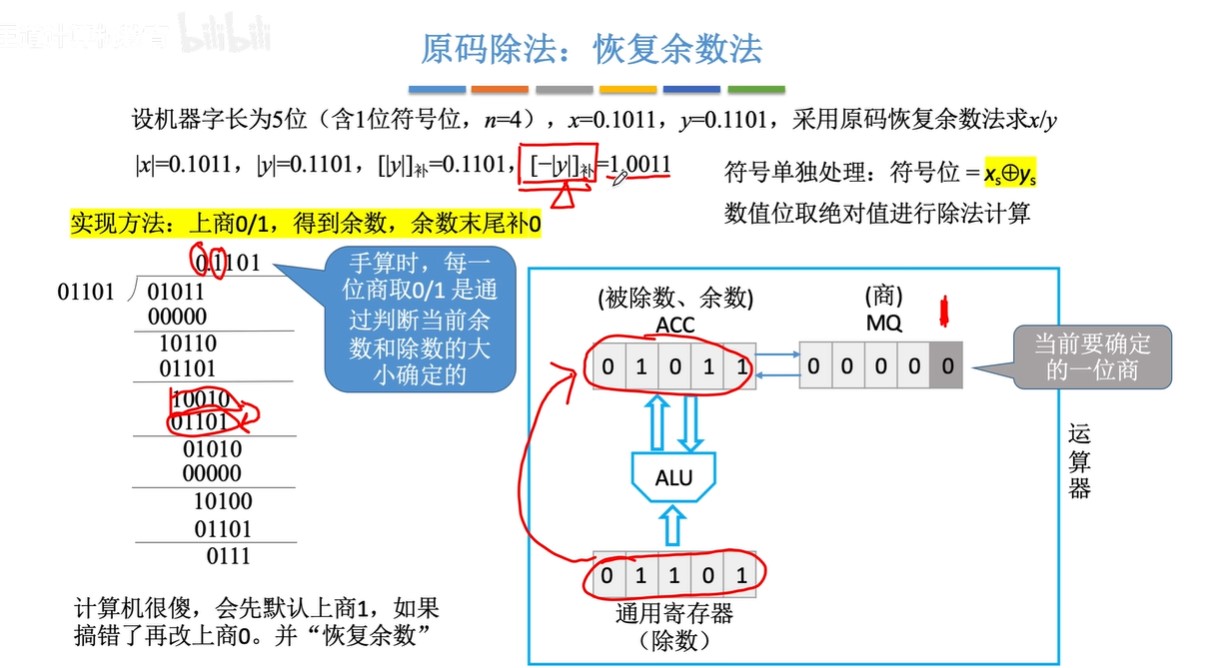
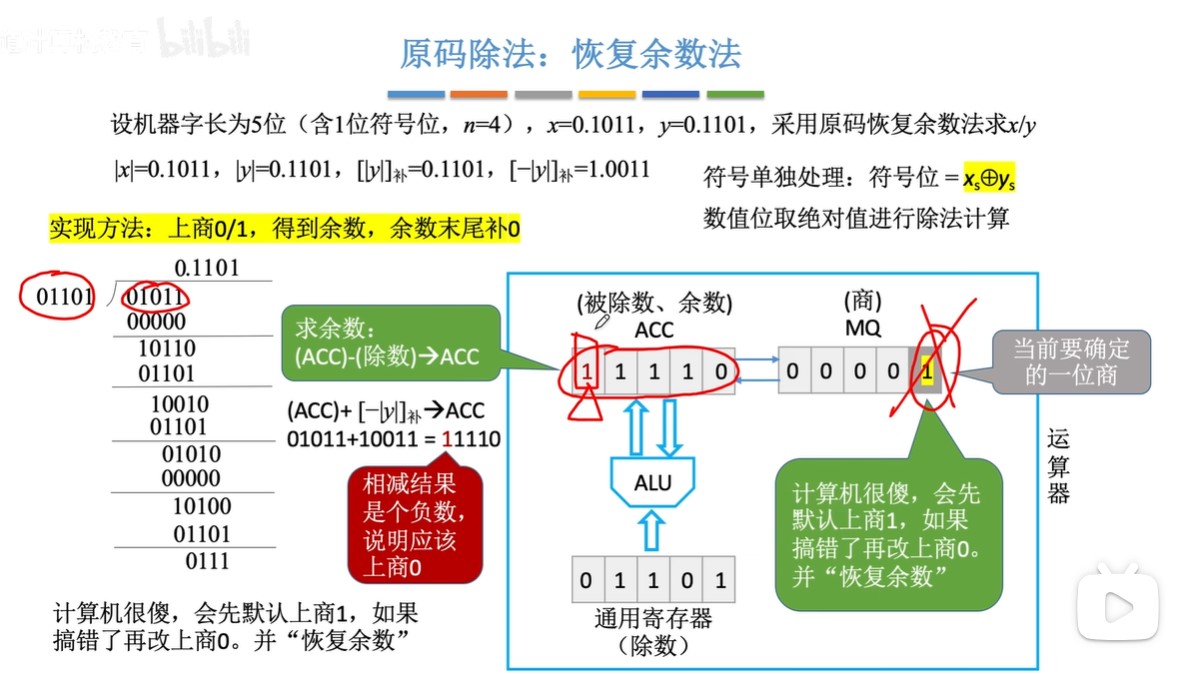
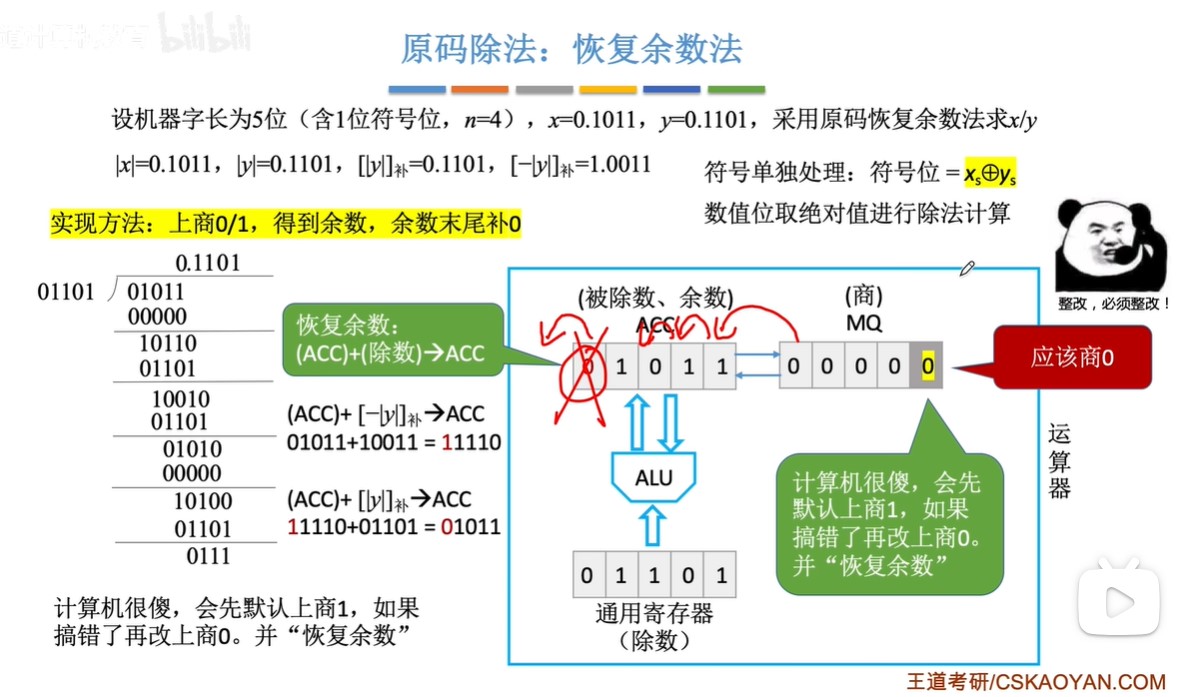
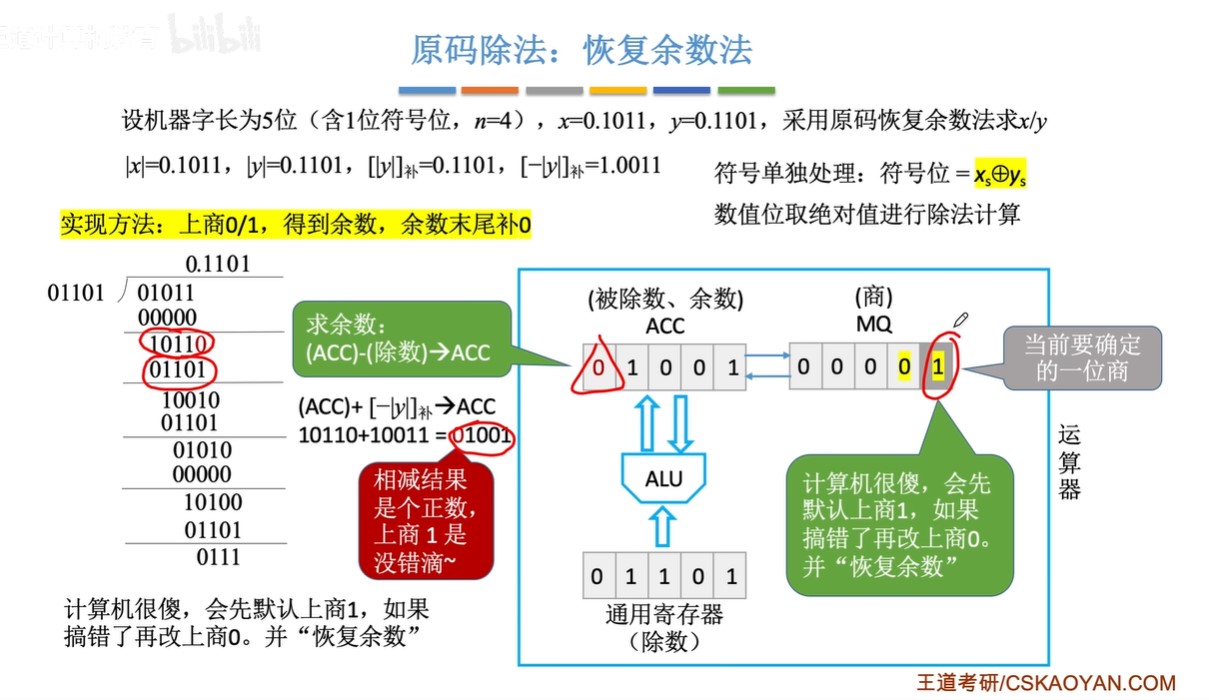
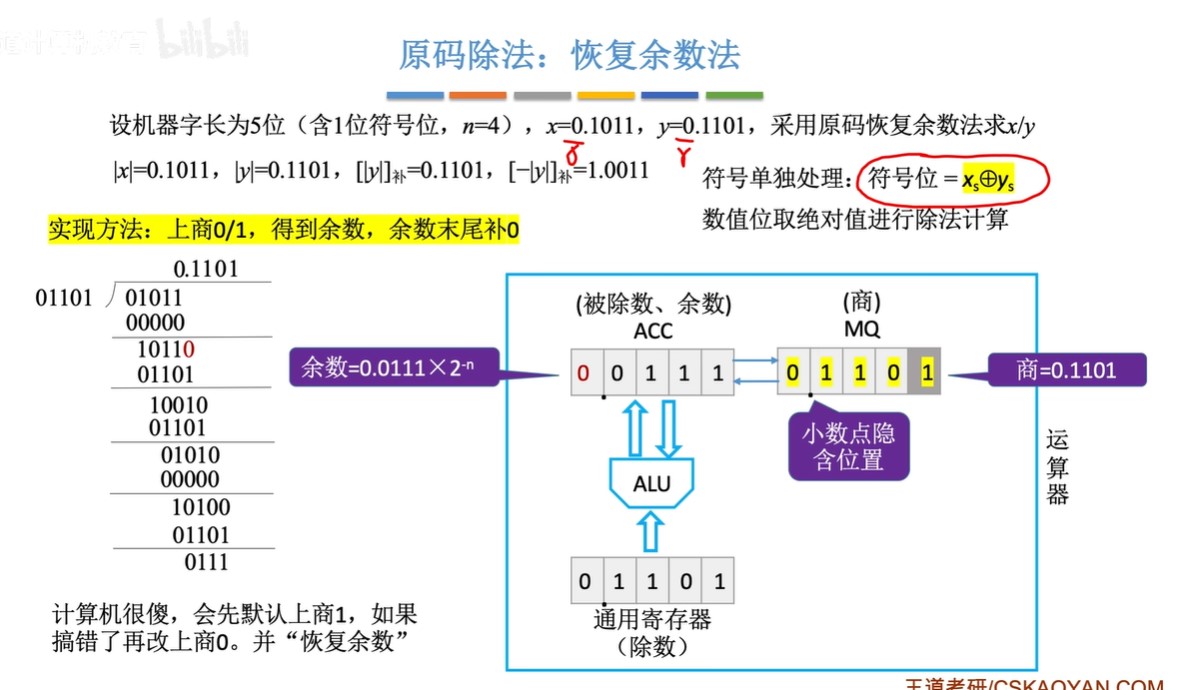
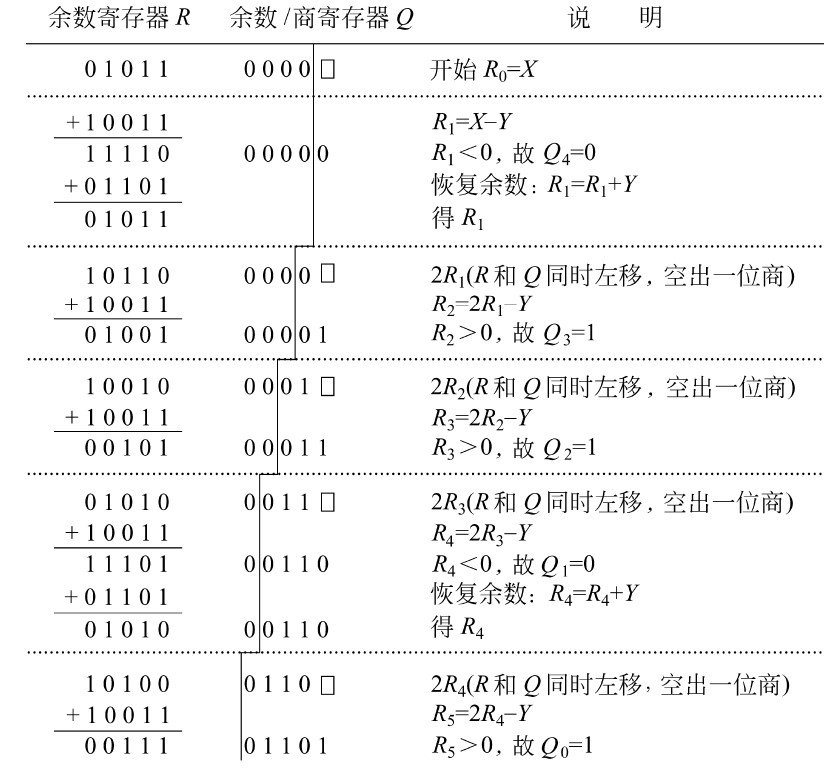
原码除法:恢复余数法(机算)
-
步骤:
- ①默认商1
- ②求余数,结果为负,改商0,余数+除数;结果为正,跳③
- ③ACC(累加寄存器)和MQ(乘商寄存器)同时逻辑左移,余数末尾补0
- 由于第②步的恢复余数,余数一定是个正数也就是开头为0,所以左移不会发生溢出
- 由于MQ最开始全位0,所以左移相当于余数末尾补0
- ④重复上述过程直到商的位数达到机器字长(1位符号位+(n-1)位数值位)
- ⑤符号位单独处理
-
恢复余数法中,一共左移n次,上商n+1次,最后一次上商余数不逻辑左移
- 因为要有符号位,所以上商n+1次,而左移的次数是因为要有n位数值位
- 原码的符号位也是参与运算了的,只不过是绝对值除法,所以符号位均为0
-
图示

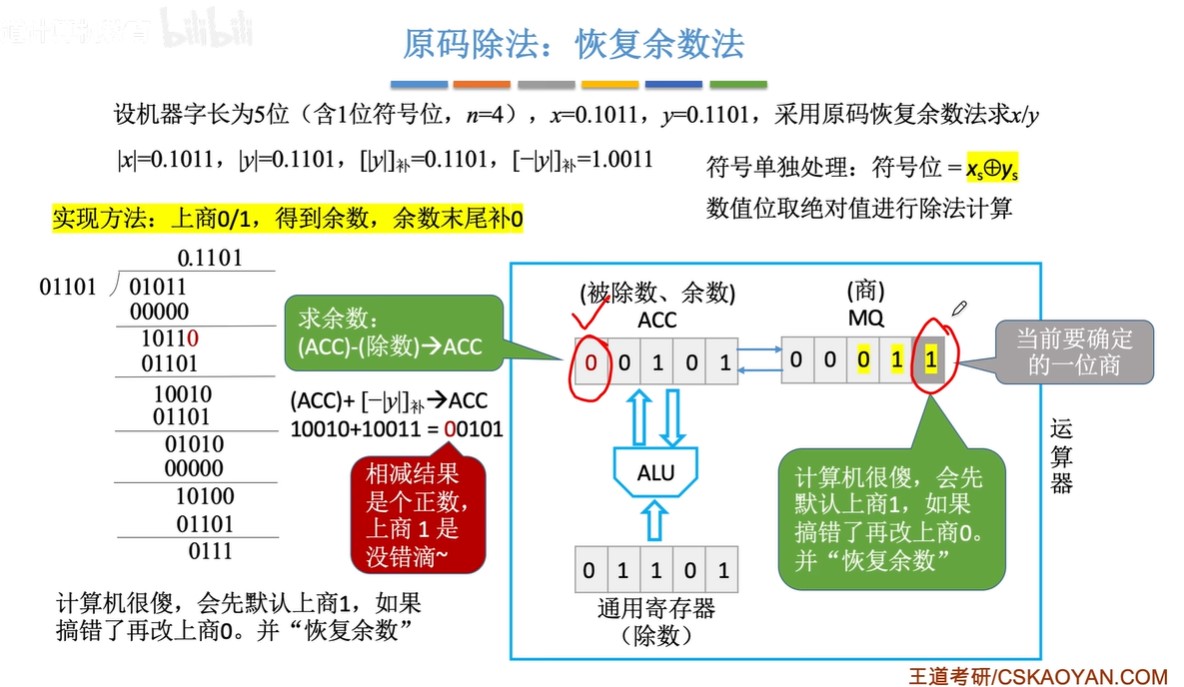

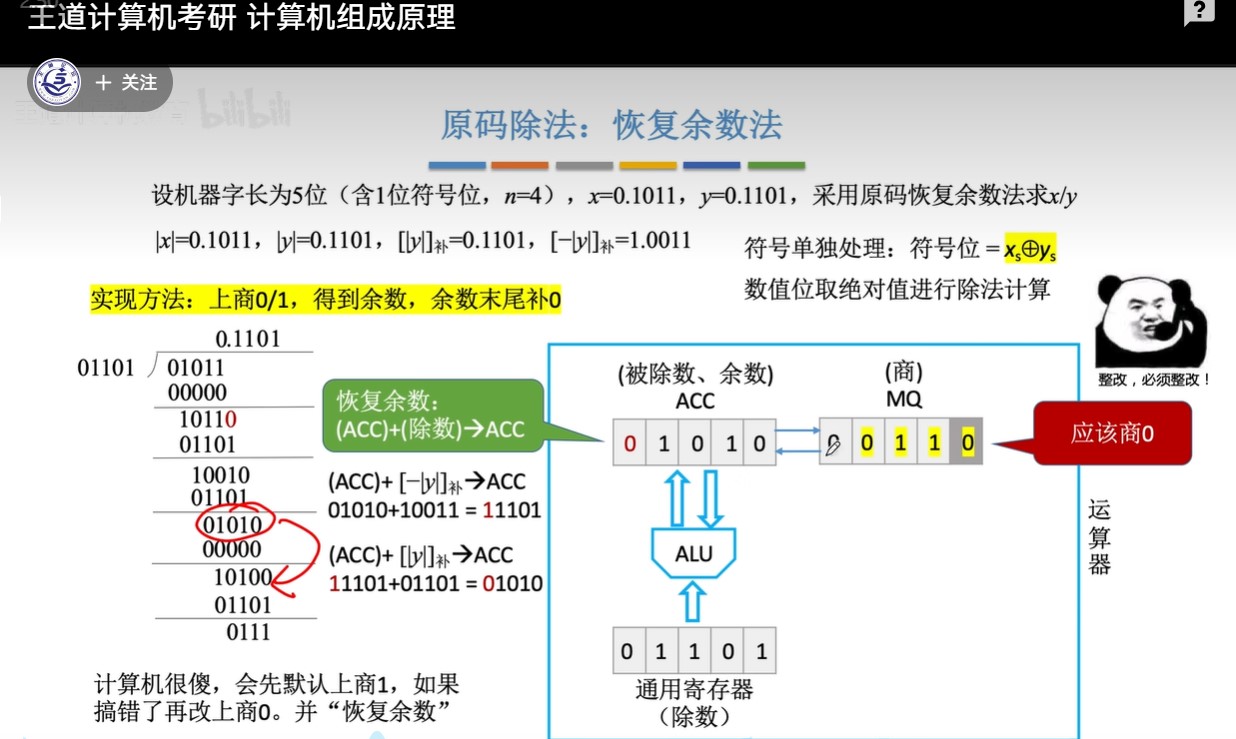
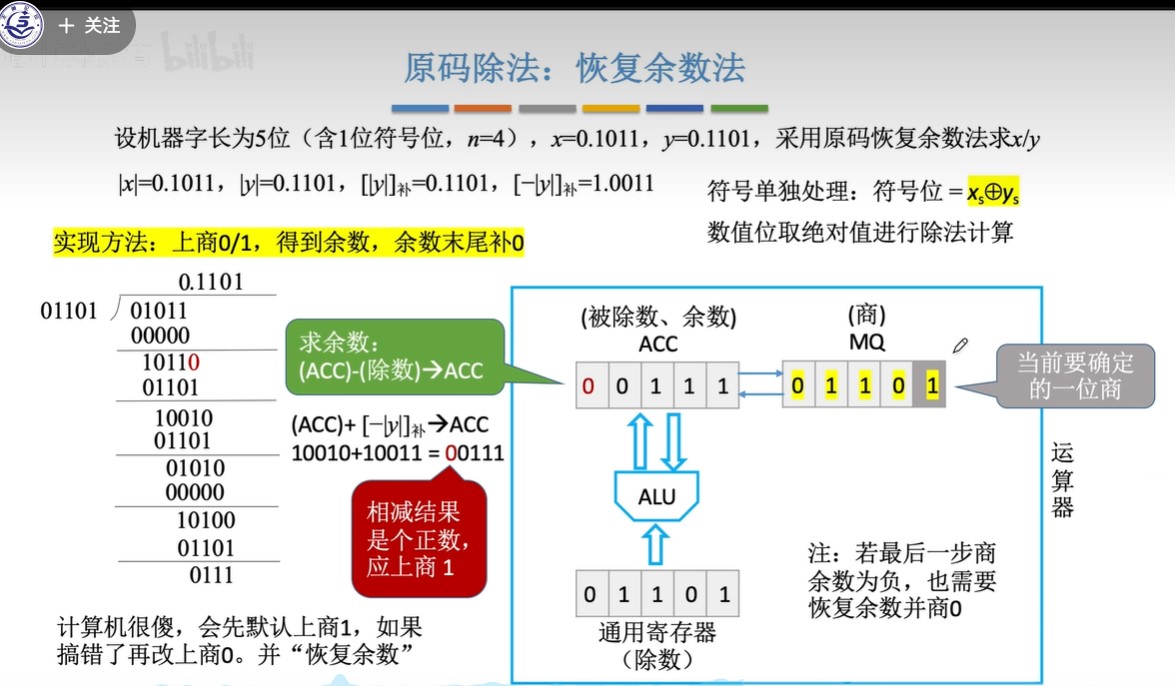
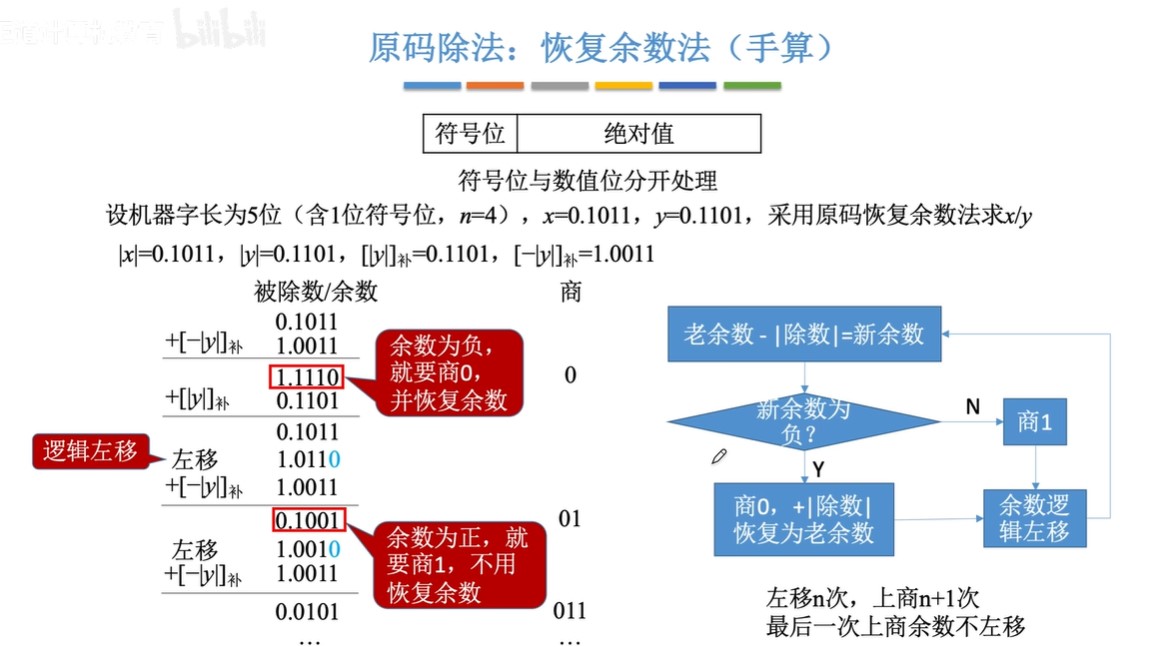
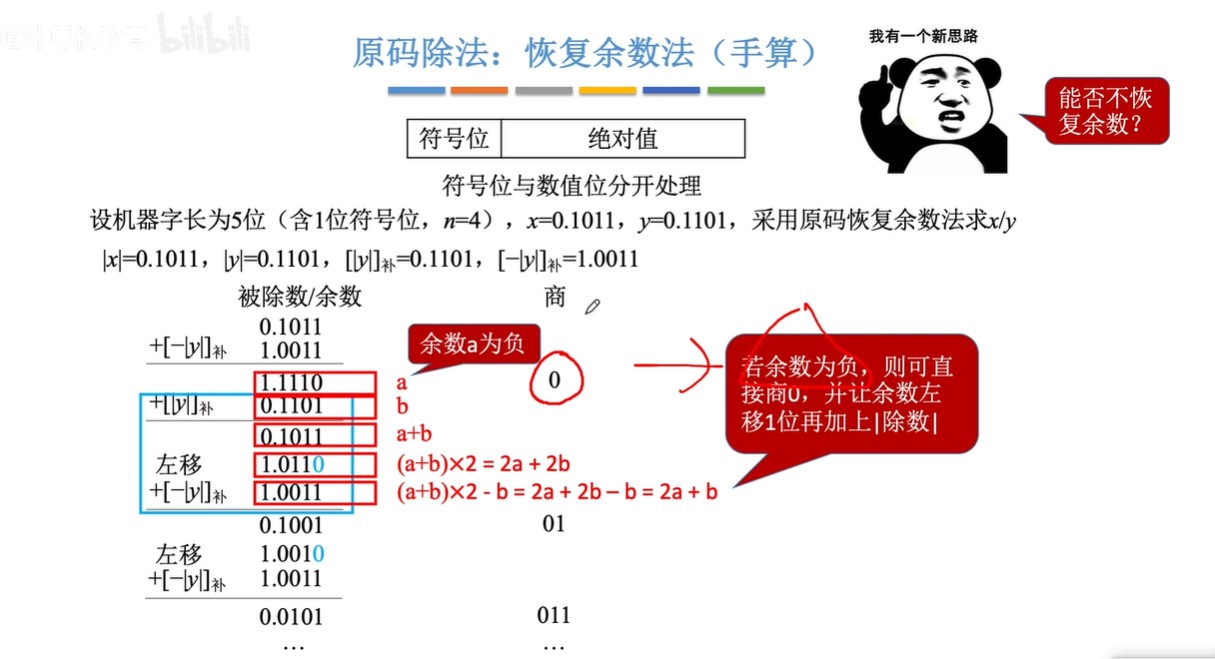
原码除法:恢复余数法(手算)
-
步骤:
- ①预处理:写出“除数的绝对值“”被除数的绝对值““除数绝对值的补码”“绝对值负数的补码”
- 因为数值位单独运算,数值位当作无符号整数进行运算
- ②每次都先试商1,相减(加上负减数的补码)得到余数
- ③余数为负,加回减数补码,恢复余数;余数为正,跳到④
- ④逻辑左移,余数末尾补0
- ⑤重复上述过程直到商的位数达到机器字长的位数
- ①预处理:写出“除数的绝对值“”被除数的绝对值““除数绝对值的补码”“绝对值负数的补码”
-
图示:
原码除法:加减交替法(不恢复余数法)
- 步骤:
- ①预处理:写出“除数的绝对值“”被除数的绝对值““除数绝对值的补码”“绝对值负数的补码”
- ②每次都先试商1,相减(加上负减数的补码)得到余数
- ③当余数为负,改商0,逻辑左移后再加除数,得到新余数;余数为正,逻辑左移再减去除数,得到下一个新余数
- ④重复上述过程直到商位数达到机器字长
- 如果最后一步上商为0,则必须恢复余数,把试商时减掉的除数加回去
- 口诀:正、1、、左移、减、负、0、左移、加
- 加减交替法和恢复余数法的区别
- 加减交替法先逻辑位移再加减
- 恢复余数法先加减再逻辑位移
补码一位乘法(Booth算法)(机算)
-
步骤
- ①预处理:写出被乘数的双符号位补码,负被乘数的双符号位补码,乘数的补码
- ②对ACC和X左扩充一位,MQ右括充一位初始为0的辅助位,所有寄存器统一用n+2位(n是数值位位数)
- ③先计算辅助位-MQ中最低位,然后根据结果进行加法运算
- 辅助位-MQ最低位=1,ACC+[X]补
- 辅助位-MQ最低位=0,ACC+0
- 辅助位-MQ最低位=-1,ACC+[-X]补
- ④对ACC和MQ内容同时进行算术右移
- ⑤重复n次
- ⑥最后多一次加法,使得原符号位在辅助线左边
-
图示
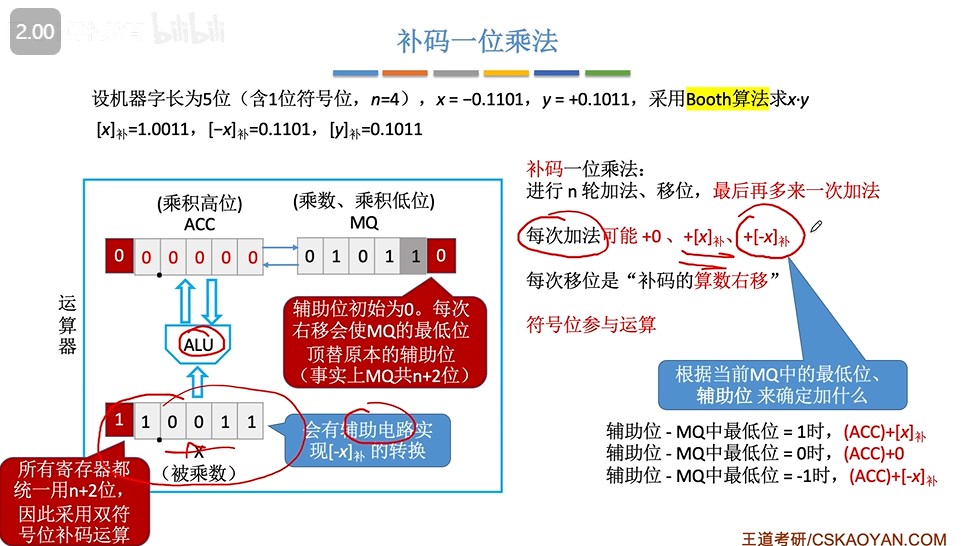
补码一位乘法(Booth算法)(手算模拟)
- 步骤:
- ①预处理:写出被乘数的补码,负被乘数的补码,乘数的补码
- ②等式分为高位部分积和低位部分积(乘数),模拟ACC和MQ,在乘数末尾画一条线,线右边加0(辅助位)
- ③先计算辅助位-MQ中最低位,然后根据结果进行加法运算
- 辅助位-MQ最低位=1,ACC+[X]补
- 辅助位-MQ最低位=0,ACC+0
- 辅助位-MQ最低位=-1,ACC+[-X]补
- ④积整体算术右移
- ⑤重复n次
补码一位乘法和原码一位乘法的区别
- 补码一位乘的逻辑结构不需要进位位C,补码一位乘需要进位位C
补码的除法运算(加减交替法)
-
步骤:
-
①预处理:写出被除数补码、除数补码、负除数补码
-
②因为符号位参与运算,所以第一步被除数和除数单独处理:
被除数和除数同号,则被除数减去除数;被除数和除数异号,则被除数加上除数
-
③余数和除数同号,商1,余数逻辑左移一位减去除数;余数和除数异号,商0,余数逻辑左移一位加上除数
-
④重复n次直到商为n+1位,末尾恒置1
-
-
口诀:同、1、减,异、0、加
补码加减交替法和原码加减交替法的对比
- 原码比较余数正负,补码比较余数和除数符号
- 原码余数为负,商0左移再加除数;余数为正,商1左移再减除数
- 补码余数和除数同号,商1,余数左移一位减去除数;余数和除数异号,商0,余数左移一位加上除数
- 共同点:
- 都重复n次
- 商1先逻辑左移再减除数,商0先逻辑右移再加除数
逻辑电路与或非积累(重点)
一位全加器的和和进位表达式

一位符号位的溢出逻辑判断表达式

双符号位的溢出逻辑判断表达式

CF的逻辑表达式

SF和OF的逻辑表达式

浮点数
- 浮点数的舍入

- 基数不同,浮点数的规格化形式也不同。当浮点数尾数的基数为2时,原码规格化数的尾数最高位一定是1。基数为4,原码规格化数的尾数最高两位不全为0
- 23位尾数实际上表示了24位有效数字
- 一般n位移码时2^(n-1),但是IEEE7的移码是2^(n-1)-1
- 长度相同、格式相同的两种浮点数,基数大的表示的范围更大,精度更低
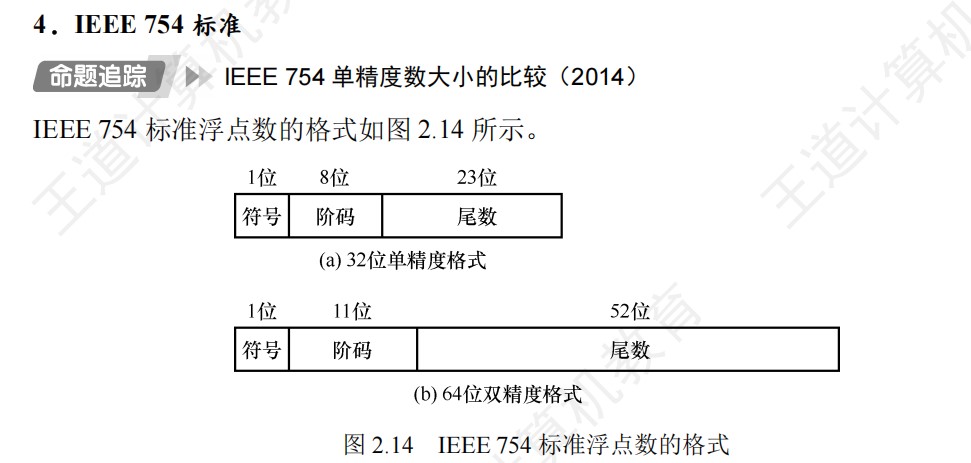
IEEE754汇总
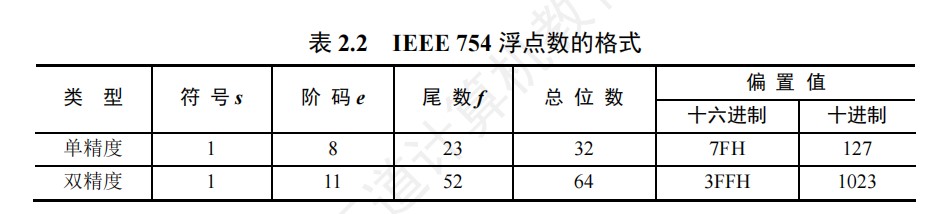

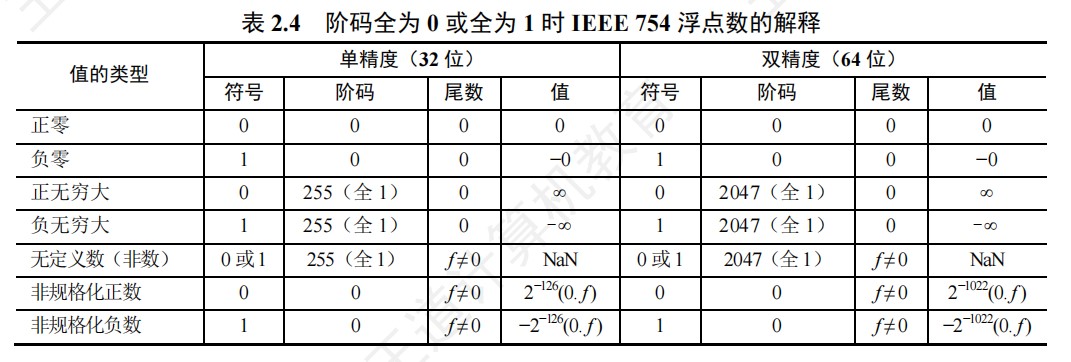
实数和IEEE754单精度数的相互转换
- 实数转化为float步骤:
- ①将实数转化为二进制数,符号独立,只转换数值部分
- ②将实数转化为1.xxxx * 2^n的格式
- ③计算阶码E=n+127,再将E转化为二进制数
- ④按照IEEE754单精度浮点数格式进行表示

- float转化为实数步骤:
- ①将float按二进制展开
- ②根据IEEE754单精度浮点数的格式进行划分
- 注:注意隐藏位
浮点数和定点数的区别和比较
- 字长相同,浮点数的表示范围更大,定点数的精度更高
- 定点运算中,当运算结果超出数的表示范围时,发生溢出;在浮点运算中,运算结果超出尾数表示范围却不一定溢出,只有规格化后的阶码超出所能表示的范围时,才会发生溢出
浮点数的加减运算
- 步骤:
- ①对阶
- 小阶码向大阶码看齐,尾数右移时,若舍弃有效位会产生误差,影响精度。为了保证运算的精度,尾数右移时,低位移出的位不要丢掉,应保留并参加尾数部分的运算,最后再将运算结果进行舍入,还原成IEEE754格式
- ②尾数加减
- 对接后的尾数按定点原码小数的加减运算规则进行运算
- 因为IEEE754浮点数尾数还有一个隐藏位,因此在进行尾数加减时,必须将隐藏位还原到尾数部分
- ③尾数规格化
- 变成1.xxxx的形式
- ④舍入
- 在对阶和尾数右规时,可能发生舍入,定点数没有舍入
- (1)就近舍入
- 当运算结果是两个可表示数的非中间值时,实际上是0舍1入方式
- 里哪个近就变哪个
- 当运算结果正好在两个可表示数的中间时,选择结果为偶数
- 就近舍入中间值向两边舍入取决于尾数最后一位,若是0,则直接截断尾数,若是1,则要把尾数最后一位变成0,所以采取进1的方式)
- 当运算结果是两个可表示数的非中间值时,实际上是0舍1入方式
- (2)正向舍入
- 取数轴右边最近的可表示数
- (3)负向舍入
- 取数轴左边最近的可表示数
- (4)截断法
- 直接截取所需位数,丢弃后面的所有位,相当于向原点舍入
- ⑤溢出判断
- 尾数规格化和尾数舍入的时候,可能出现阶码溢出的问题
- **右规和尾数舍入。**数值很大的尾数舍入时,可能因为末位+1而发生尾数溢出,此时需要通过右规来调整尾数和阶码。右规时阶码+1,导致阶码加大,因此需要判断是否发生了指数上溢
- 左规。左规时阶码-1,导致阶码减小,因此需要判断是否发生了指数下溢。左规一次,阶码-1,然后判断阶码是否全0来确定指数是否下溢
- 正指数超过127或1023,指数上溢,产生异常;负指数小于-149或-1074,指数下溢,按照机器0处理
- 注:某些题目中可能指定尾数或阶码采用补码表示。通常可以采用双符号位,当尾数求和结果溢出(入尾数变为10.xxxxx或01.xxxx)时,需要右规一次;当结果出现00.0xxx或11.1xxxx时,需要左规,直到尾数变为00.1xxx或11.0xxxx(符号位和最高位异号)
- 尾数规格化和尾数舍入的时候,可能出现阶码溢出的问题
- ①对阶
- float类型中,当两个数的阶码相差超过24时(>=25),较小的数在加法中就会被完全忽略。这是由float的24位尾数精度决定的。
舍入和溢出的场景
- 舍入
- 对阶和尾数右规
- 溢出
- 上溢
- 右规
- 尾数舍入
- 下溢
- 左规
- 上溢
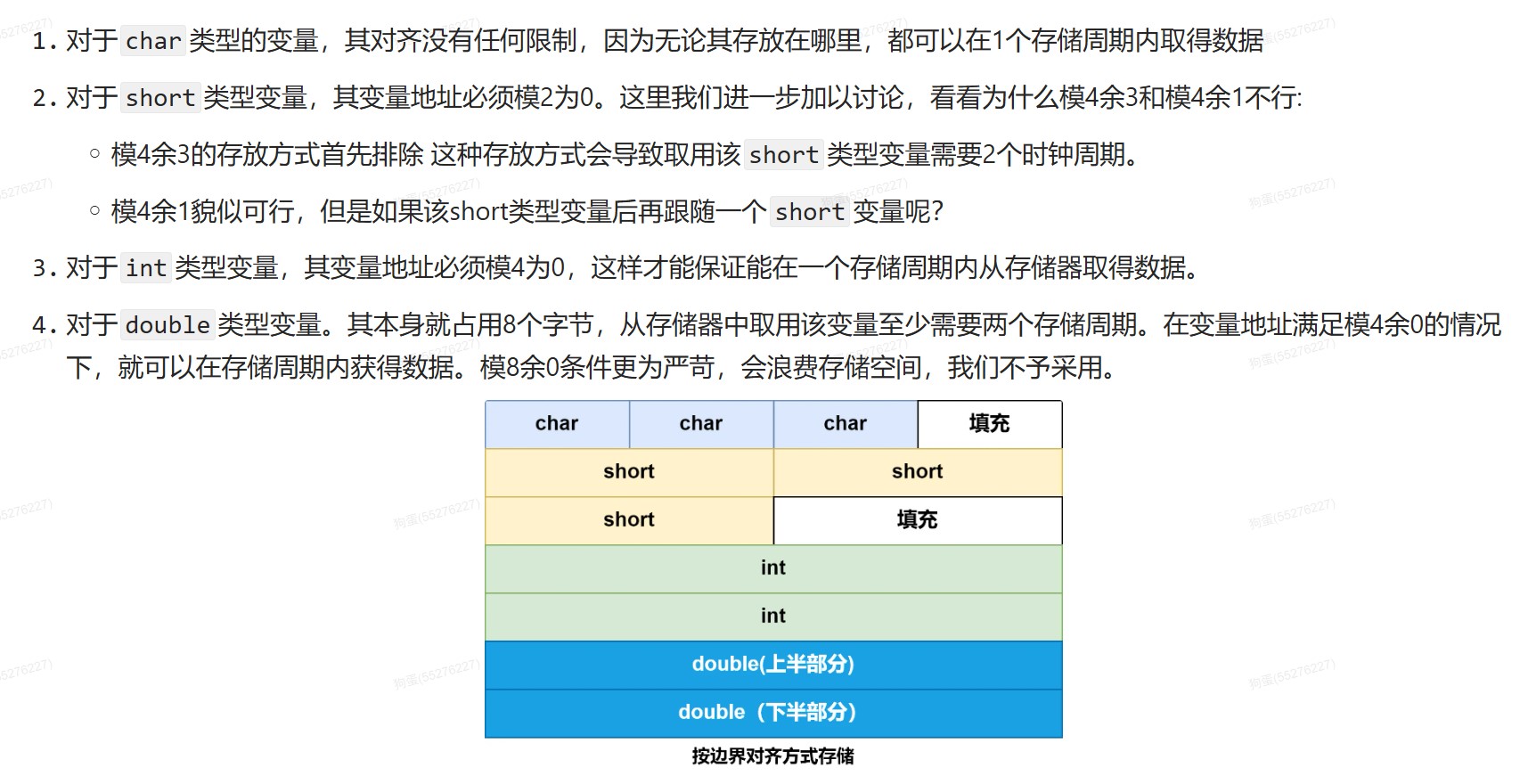
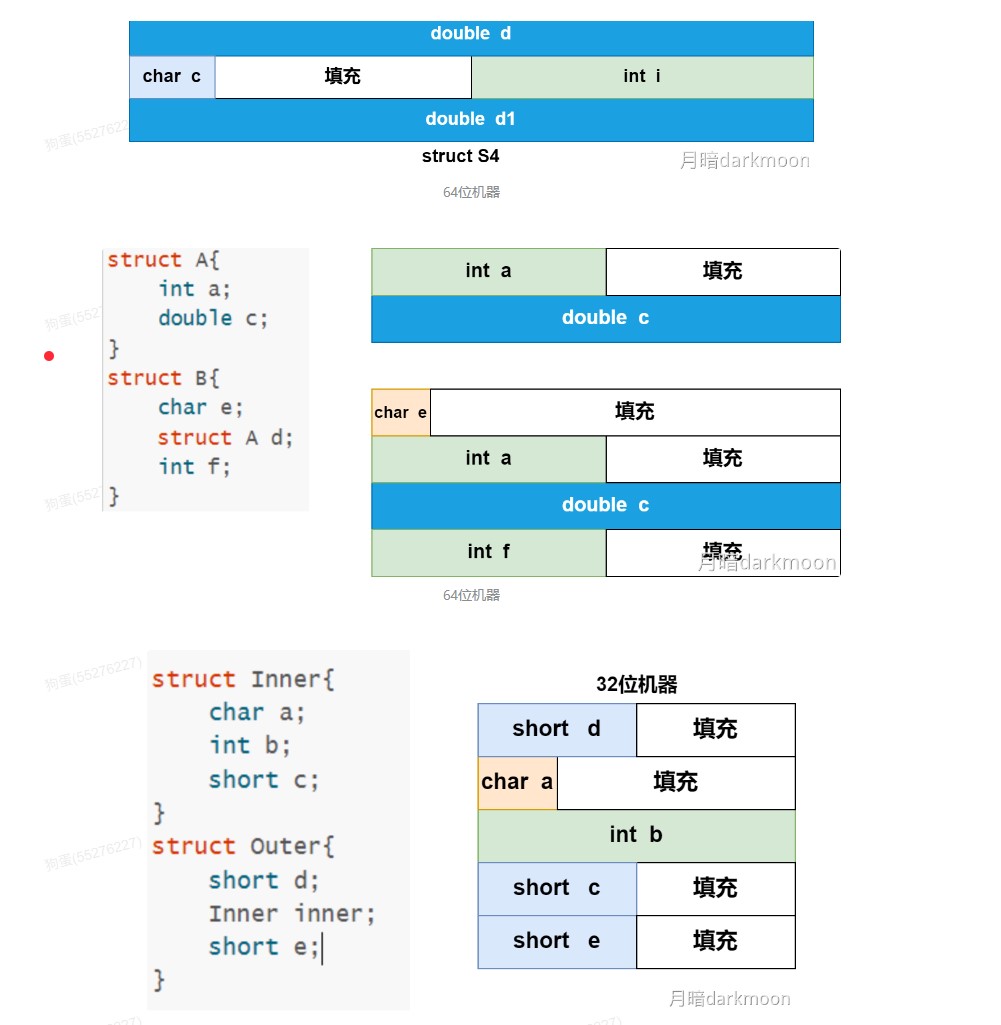
边界对齐
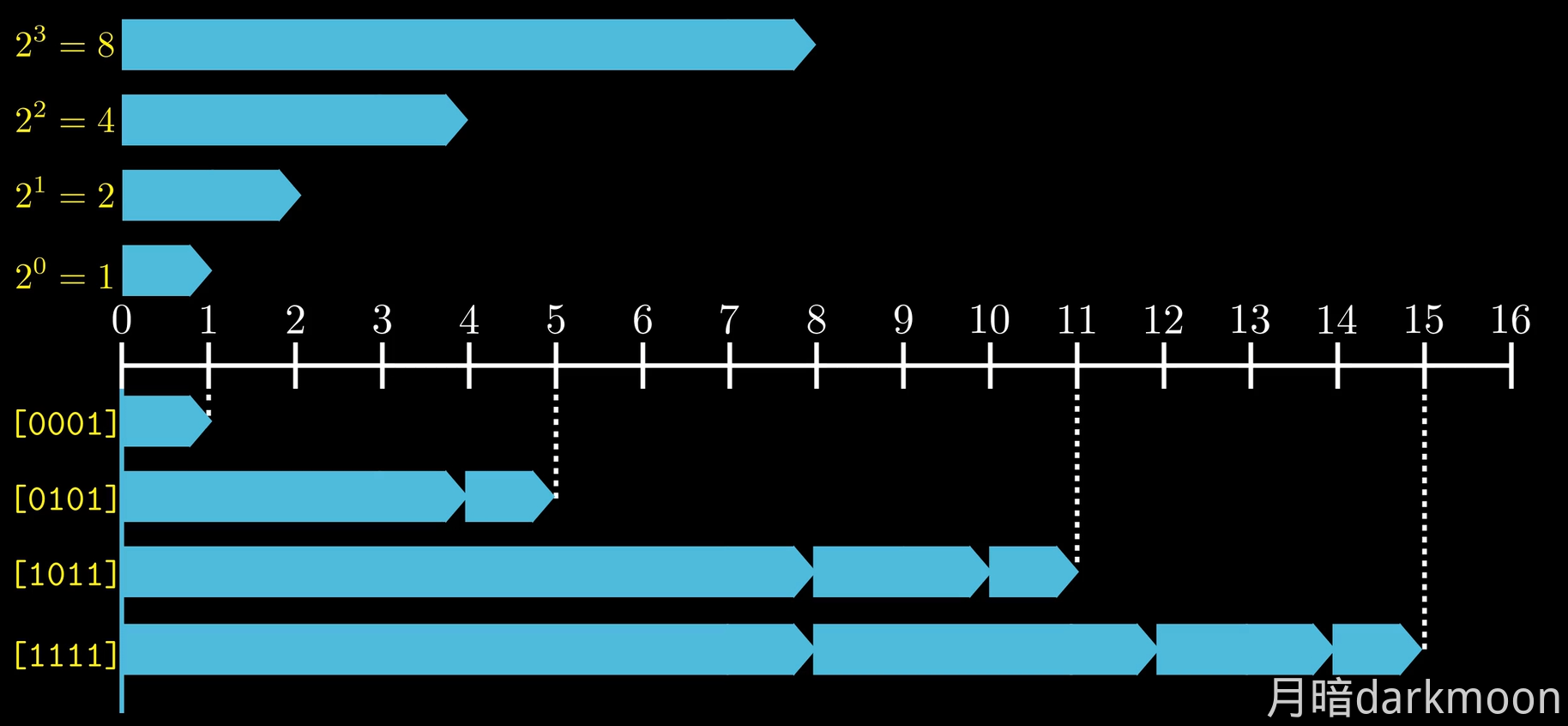
位权
- 无符号整数的位权
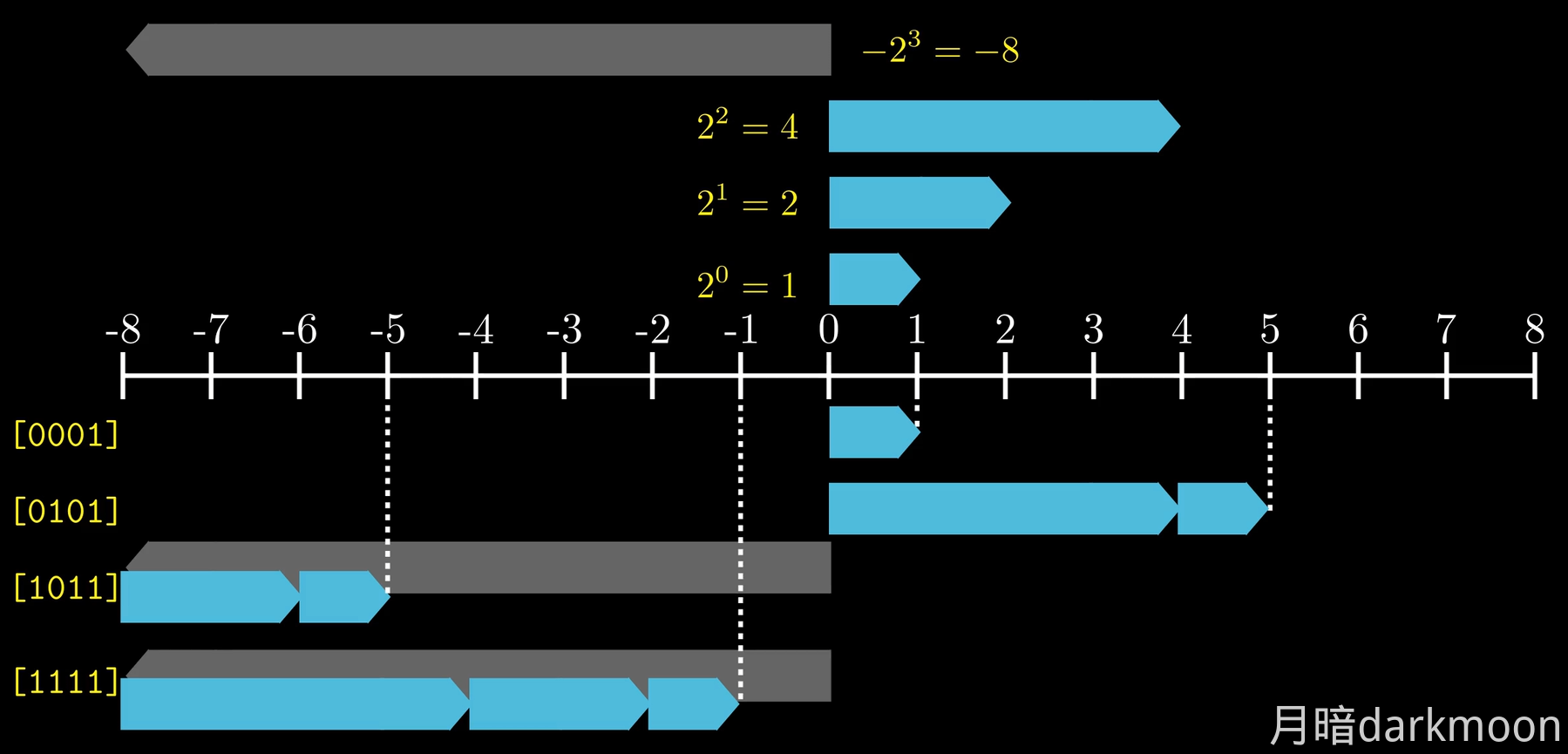
- 有符号整数补码的位权
除法汇总
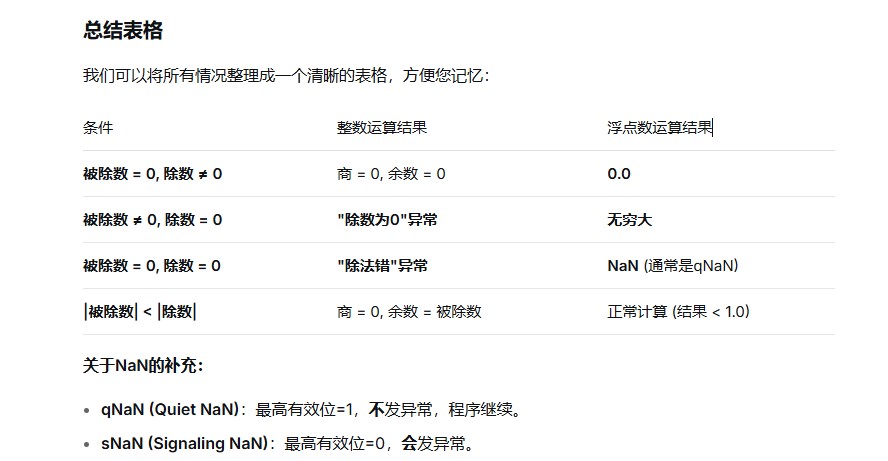
-
对于除数为0的情况,根据是定点除法指令还是浮点除法指令有不同的处理方式
- 对于浮点数除0,异常处理程序可以选择将指令执行结果用特殊的值(NaN或∞)表示,然后返回到用户进程继续执行除法指令后面的一条指令
- 对于整数除0,则会发生整除0故障,通常调用abort例程来终止当前用户进程
-
①若被除数为0,除数不为0,或者定点整数除法时|被除数|<|除数|,则说明商为0,余数为被除数,不再继续执行
- ②若被除数不为0,除数为0,对于整数,则发生“除数为0”异常;对于浮点数,则结果等于无穷大
- ③若被除数和除数都为0,对于整数,则发生除法错异常;对于浮点数,则有些机器产生一个不发信号的NaN,或者产生NaN信号,取决于最高有效位
-
当结果出现尾数为0的时候,不管阶码是什么,都将阶码取为0
-
当操作数为无穷大时,系统可以有两种处理方式
- 产生不发信号的非数NaN
- 产生明确的结果
-
NaN
- 当最高有效位为1的时候,为不发信号NaN,当结果产生这种非数时,不发异常通知,即不进行异常处理;当最高有效位为0时为发信号NaN,当结果产生这种非数时,则发一个异常操作通知,表示要进行异常处理
- 除了第一位有定义外其余的位没有定义,所以可用其余位来指定具体的异常条件
- 一些没有数学解释的计算,会产生一个NaN
关于除法运算逻辑结构到底扩展什么
-
原码除法
-
因为原码除法符号位不参与运算,所以原码除法中,被除数和除数都当作无符号整数,进行0扩展
- 如果是定点整数,高位扩0
- 如果是定点小数,低位扩0
-
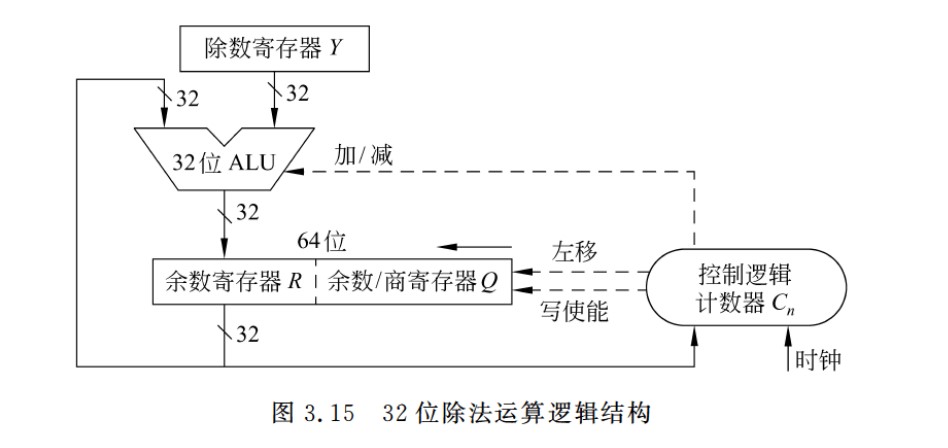
除法运算逻辑,除数寄存器Y存放除数,余数寄存器R开始时置被除数的高32位,作为初始中间余数R0的高位部分,结束时存放的是余数;余数/商寄存器Q开始时置被除数的低32位,作为初始中间余数R0的低位部分,结束时存放的是32位商
-
定点整数和定点整小数都可以用该除法逻辑实现,只是被除数扩展的方法不太一样,导致溢出的情况也有所不同

-
-
补码除法运算
- 对于两个n位补码除法,被除数需要进行符号扩展,若被除数为2n位,除数为n位,则被除数无需扩展。除数无需扩展,只需要直接放入寄存器中。
存储系统
概述
- 主存和Cache之间的数据调动是由硬件自动完成的,对所有程序员均是透明的。主存和辅存之间的数据调动是由硬件和操作系统共同完成的,对应用程序员是透明的
- 主存主要是由DRAM实现,Cache则由SRAM实现
主存储器
-
固态硬盘属于半导体存储器,其核心存储介质为闪存,不同于机械硬盘
-
寄存器属于半导体存储器
-
主存和外存之间的交换通常采用DMA方式
-
ROM通常存放系统程序、标准子程序和各类常数,RAM则是为用户编程而设置的
-
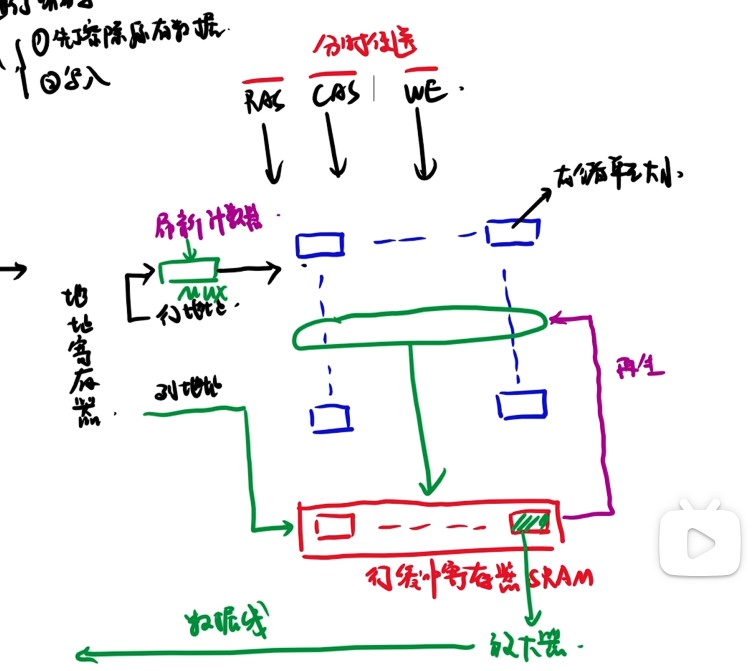
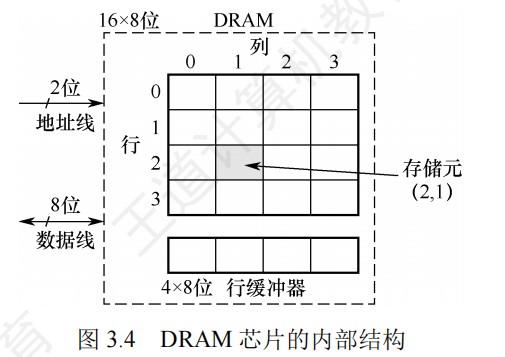
行列地址线复用的情况下,由于DRAM按行刷新,因此行地址位数要小于等于列位地址数,而地址线条数=max(列地址位数,行地址位数)
-
地址线和译码器输出的选择线的关系:n条地址线,译码输出的选择线是2^n条
-
DRAM按行刷新,刷新计数器和行地址一样,送往行译码器再进行行选,所以刷新计数器即地址线根数=log行数bit
-
行缓冲为一行的数据大小=列数*数据位数
-
多路选择器是一种能够从多个输入信号中选择一个输出的信号转换设备。译码器是一种将二进制编码转换为一组特定输出信号的设备。在寄存器堆中,译码器常常用于地址译码,从而控制对特定寄存器的访问。
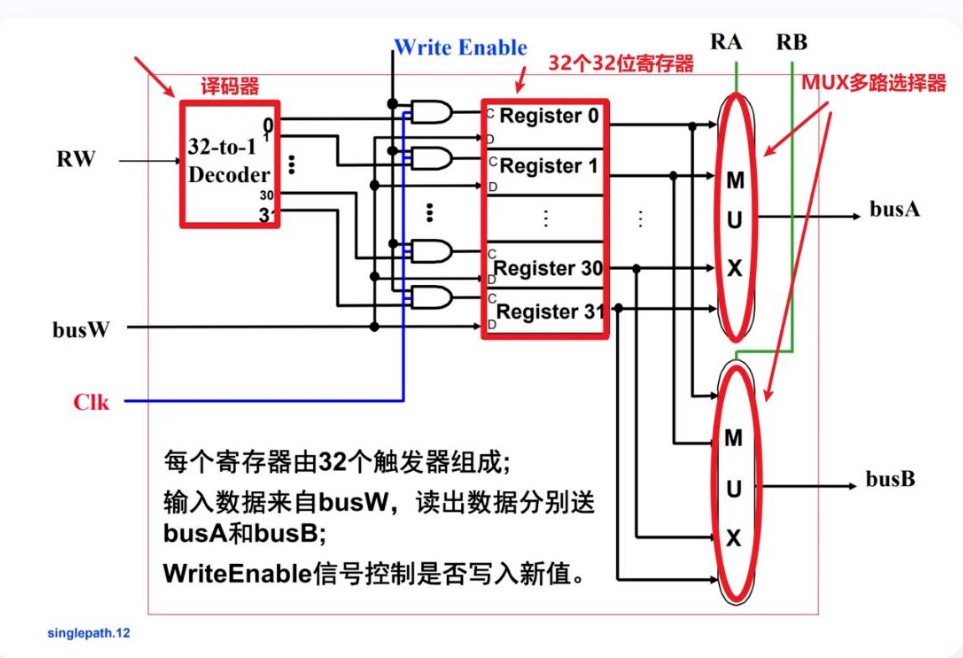
- 执行寄存器写相关指令时(将结果保存在寄存器中),指令中的寄存器编号被送到一个地址译码器进行译码,选中某个寄存器进行写入,读出时(从寄存器中获得计算数据)寄存器编号作为一个控制信号来控制一个多路选择器,选择相应的寄存器读出。
- 读口(组合逻辑操作):无需时钟控制,busA和busB分别由RA和RB给出地址。地址RA或RB有效后,经一个“取数时间(AccessTime)”,busA和busB有效
- 写口(时序逻辑操作):需要时钟控制。写使能为1的情况下,时钟边沿到来时,busW传来的值开始被写入RW指定的寄存器中。
- 写是需要改变寄存器的值的,需要等到数据的信号稳定后写入,防止出错。而读只需要和寄存器里的值相等就行
-
SRAM不地址复用,DRAM地址复用
-
SRAM的静态是指即使信息被读出后,它仍保持其原状态不需要再生(非破坏性读出)
-
刷新对CPU透明,即不依赖于外部的访问,芯片内部自行生成刷新的行的地址
-
DRAM按行刷新,所有芯片同时刷新某一行,时间间隔是刷新周期/行数
-
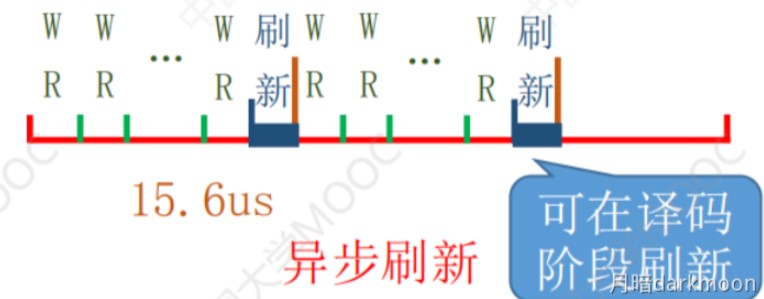
-
异步刷新的死时间率=读写周期/(刷新周期/行数)*100%
-
刷新和再生的区别
- 刷新以行为单位逐行恢复数据,而再生仅需要恢复被读出的那些单元的数据
- 刷新每隔一段时间固定发生,而再生是发生在有人对数据进行了读取之后
-
行缓冲器的大小=列数 * 存储元的位数,用SRAM实现,选中某行后,该行的所有数据都被送到行缓冲器,以后每个时钟都可以连续地从DRAM中输出一个数据,因此可以支持突发传输(在寻址阶段给出数据的首地址,在传输阶段可传送多个连续存储单元的数据)
-
SDRAM(同步DRAM芯片),与CPU的数据交换同步于系统的时钟信号,并且以CPU-主存总线的最高速度运行,不需要插入等待状态,在时钟的控制下进行数据的读写,将CPU发出的地址和控制信号所存起来,经过指定的时钟周期数后再响应,此时CPU可以执行其他操作
- 在传统DRAM中,CPU将地址和控制信号送至存储器后,需要经过一段延迟时间,数据才读出或写入,在此期间,CPU不断采样DRAM的 完成信号,在读写完成之前,CPU不能做其他工作,降低了CPU的执行速度
- SDRAM支持突发传送,只要在第一次存取时给出首地址,以后按地址顺序读写即可,不再需要地址建立时间和行、列预充电时间,就能快速连续地从行缓冲器中输出一连串数据。
- 行缓冲器用来缓存指定行中每一行的数据,通常用SRAM实现,内部的工作方式寄存器(也称模式寄存器)可用来设置传送数据的长度以及从收到读命令(与CAS信号同时发出)到开始传送数据的延迟时间等,前者称为突发长度(BL),后者称为CAS潜伏期(CL),根据BL和CL,CPU可以确定何时开始从总线上取数以及连续取多少个数据
- 在开始的第一个数据读出后,同一行的所有数据都被送到行缓冲器中,以后每个时钟可从SDRAM读取一个数据,并在下一个时钟内通过总线传送到CPU
-
采用n位预取技术,存储器总线每秒传送数据的次数为芯片频率 n,带宽为每秒传送数据的次数*存储器总线每次传输的数据大小,总线时钟频率=每秒传送数据的次数/2(/2是因为一个时钟上升沿和下降沿都在传送,传送两次)*
-
突发传送下带宽的计算:突发传送是在完整的存储周期之后才传输数据,也就是说,第一个存储周期负责传送发送信息和数据,之后的时间负责传输剩余n-1个数据,带宽=一次突发传送的数据大小/一次突发传送的时间
-
存储器相同行、列上的多位(位平面数)同时被读出或写入
-
DRAM芯片目前普遍采用双译码结构
-
寄存器用触发器实现
-
SRAM和DRAM都是MOS管型半导体存储器,而ROM是双极型半导体存储器
-
现在的DRAM芯片采用行缓冲,可能因为位置不同而使访问时间有所差别,当访问的数据所在行已经被加载到行缓冲中时,访问时间较短(行命中),但如果访问的数据不在行缓冲中,则需要先选中对应的行,再从该行中读取数据
-
有些芯片的存储阵列采用三维结构,用多个位平面构成存储阵列(即后面所说的位扩展),不同位平面在同一行和列交叉点上的多位构成一个存储字,被同时读出或写入
-
行列译码器的方案下,高位是行地址,低位是列地址,每个存储单元只有行选通线和列选通线同时被选中时才能被选中
-
刷新放大器是集成在RAM上的,因此,刷新只进行了一次访存,也就是占用一个存取周期
-
如果将刷新安排在不需要访问存储器的译码阶段,既不会加长存取周期,又不会产生死时间,这是分散刷新的方式的发展,也称之为透明刷新
- 为什么每出现新一代DRAM芯片,容量至少提高到4倍?
- 行地址和列地址分时复用,每出现新一代DRAM芯片,至少要增加一根地址线,则行地址和列地址各增加一位,所以行数和列数各增加一倍,因而容量至少提高到4倍
- MAR的位数决定了主存地址空间的大小,MAR应保证访问到整个主存地址空间
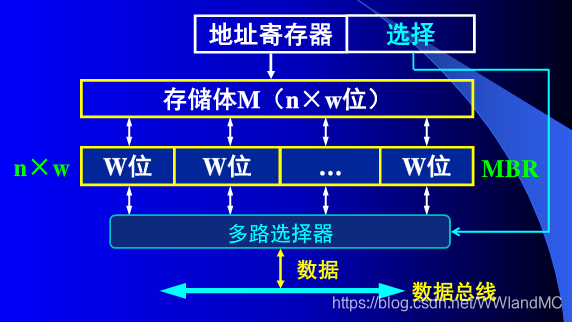
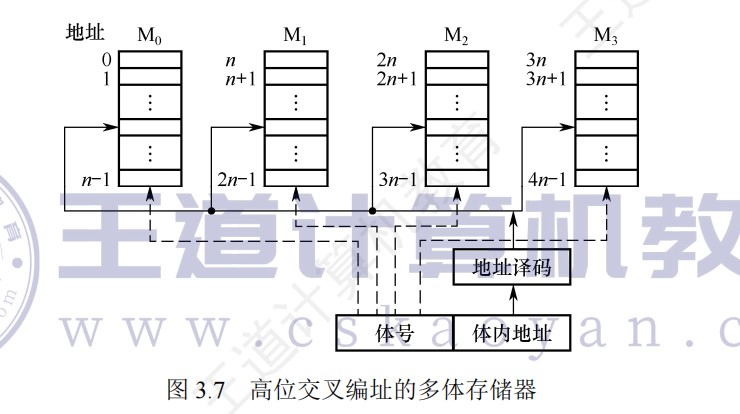
多模块存储器
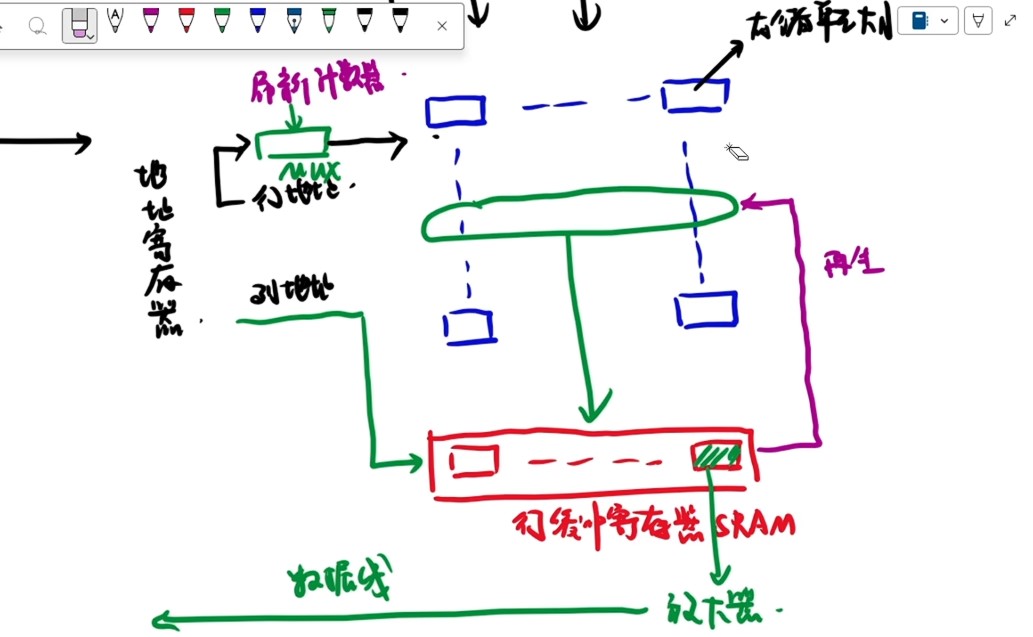
单体多字存储器
-
相当于把n个内存条的存储单元看作一个整体的存储单元,只有一套读写电路、地址寄存器和数据寄存器,当我们想要读取某个信息都是一排一排地读取的
-
如果我们想要的信息是存储在连续一排的空间时:
假设存取周期T=存取时间r+恢复时间3r,这种情况下我们在一个时间T内可以读取①②③④的信息,然后⑤所在的内存条的恢复时间刚过完,我们继续读取即可,而不采用并行设计时需要的时间为4T
-
如果我们想要的信息是③④⑤⑥这样不在一排的信息时,我们就需要读取两排的信息,这时还会读入不需要的信息①②

多体并行存储器
-
各模块都有独立的读/写控制电路、地址寄存器和数据寄存器、地址译码器,既能并行工作,又能交叉工作。
-
多模块的模块数m,应该是和存储周期T和总线传输周期r有关,与存取时间无关
-
交叉编址一般就是指低位交叉编址,连续编址在一般指的是高位交叉编址
-
轮流启动:一个块的长度=数据通路的长度(总线一次性可以传输的位数),因此只能一块块取
-
①给出首地址
-
②启动第一个存储单元所在的存储体(准备数据)
-
③传输数据
-
-
同时启动:所有块的长度=数据通路的长度,因此可以同时一把抓
- 类似广播机制:将不同体内相同体内地址共同送入地址线中
-
高位交叉编址的存取方式仍然是串行存取,这种存储器仍然是顺序存储器
-
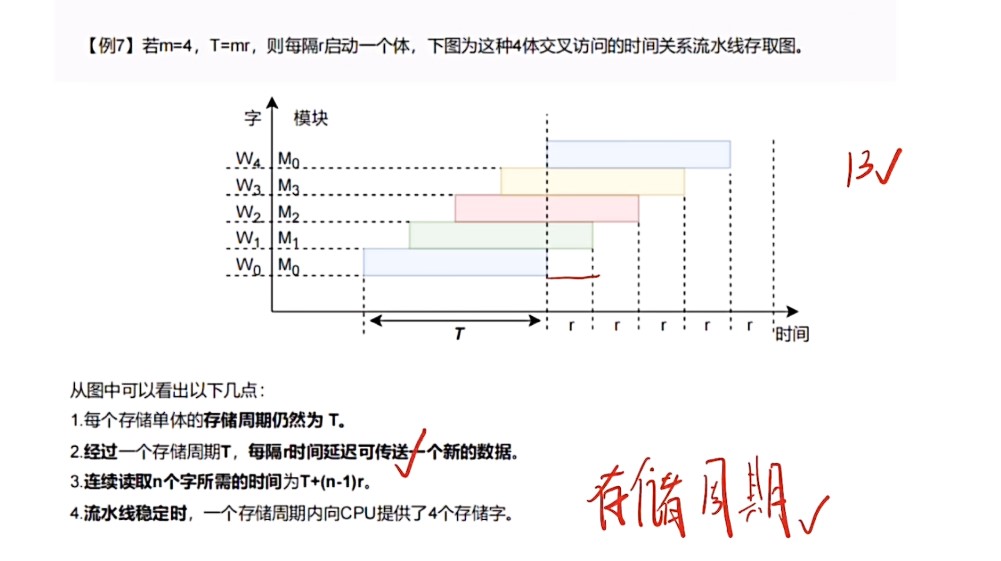
CPU一次读取操作实际上分成三个步骤:①地址和命令的传输时间②主存准备数据的时间③传输时间,而存取时间只是主存接收到读写命令开始到信息被送入数据线上的时间,或者说准备数据的时间,即②的时间
-
因此,标准的流水存取示意图中,第一个模块在T(存储周期)之后还要经过一次r(总线传输周期),才能够完成第一个模块的传输,读取到数据,而T+r的时候第二个存储字才准备好,然后接下来经过一个r的时间去进行一个传送
-
存取周期用来准备数据,准备好之后才是传输
-
-
经典计算题
- 类似的题目先计算前面的轮数,最后一轮单独计算



- t=T+(m-1)r,其中T是存取周期,r是总线周期,m是读取的块数
-
一段访存的过程中某两次访存会发生冲突的条件是:这两次访存过程将访问相同的模块并且两次访问间进行了不到【T/r-1】个访存过程
-
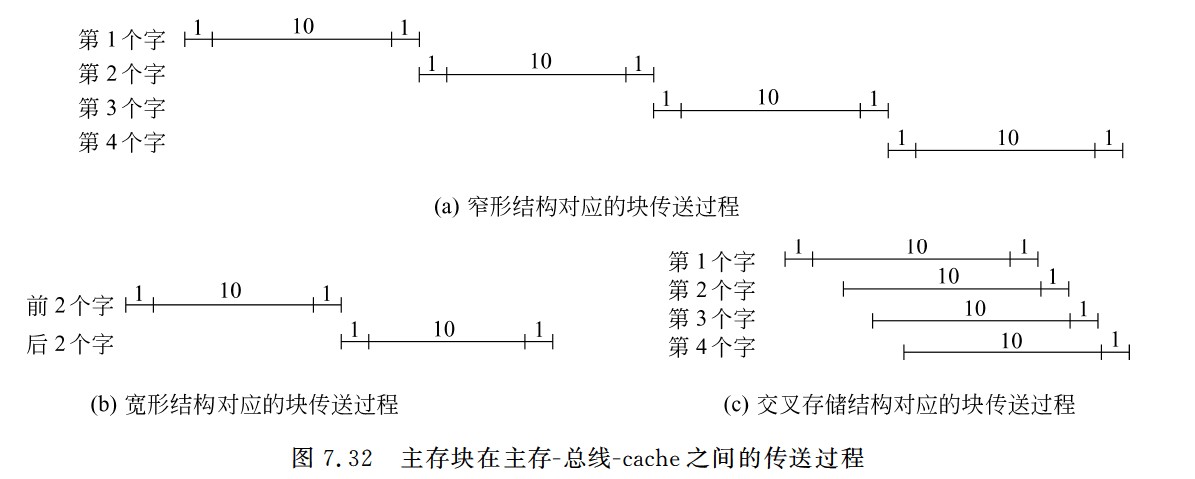
突发传送和Cache和交叉存储器的计算

关于交叉存储器(低位交叉编址)检测访问冲突的一种算法
【组成原理-存储】关于交叉存储器检测访问冲突的一种算法_访存冲突-CSDN博客
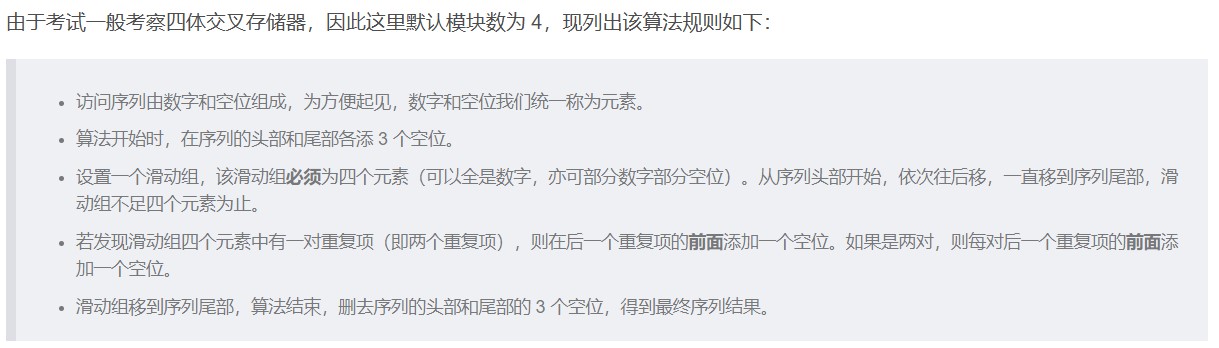
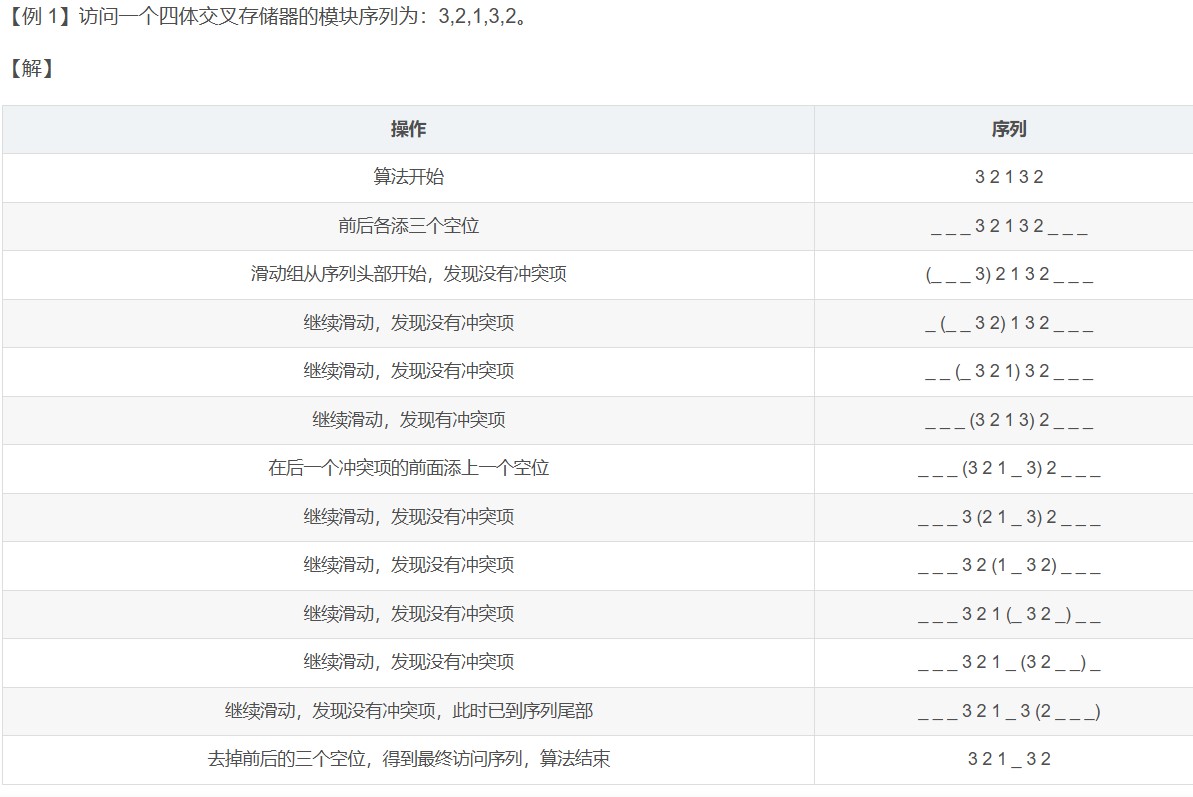
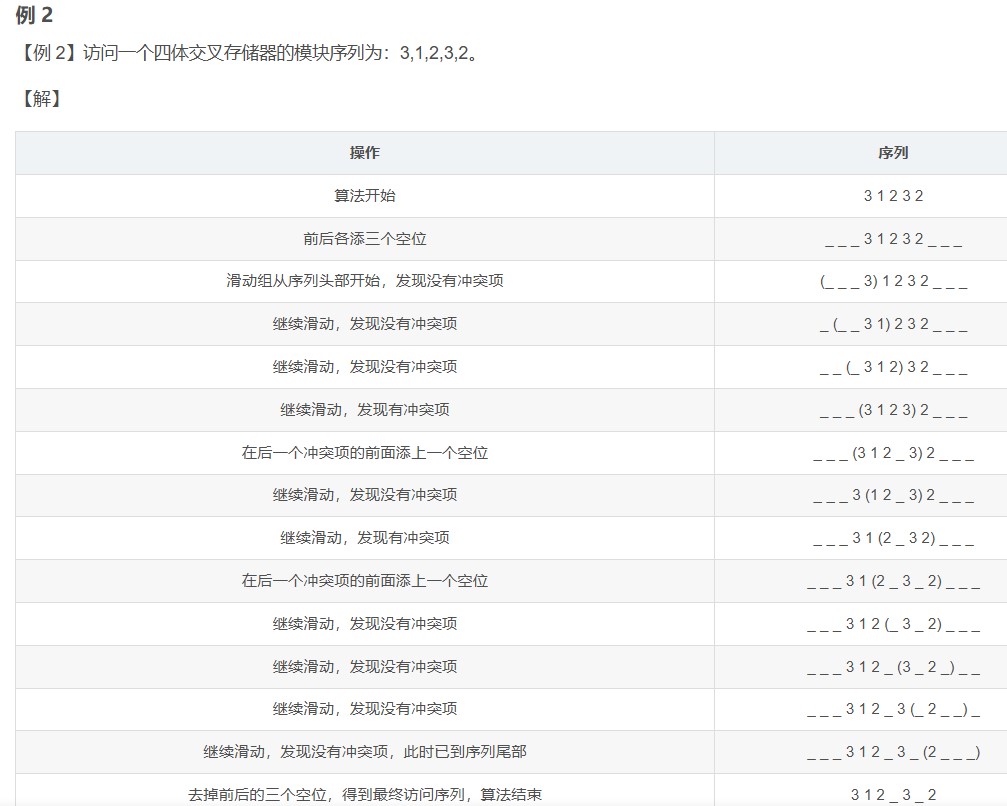
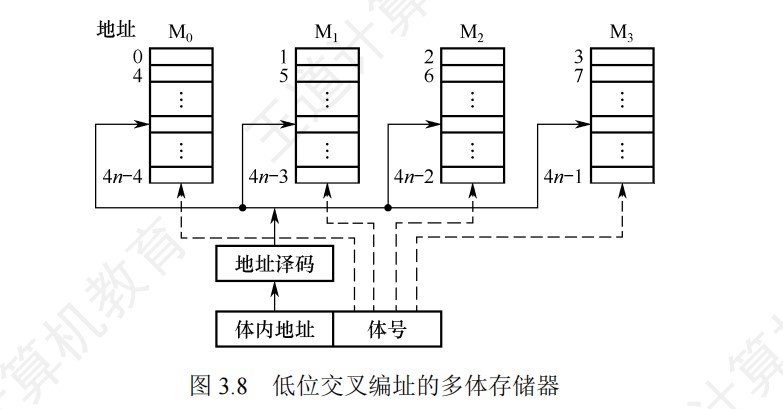
主存容量的扩展
- 字扩展的情况下,各芯片分时工作
- 高位片选信号
- 片内地址线由低到高,片选信号线范围内也是由低到高
- 位扩展的情况下,各芯片同时工作
- 字位同时扩展:先位扩展再字扩展
- 将进行位扩展的芯片作为一组,各组的连接方式与位扩展的相同;由系统地址线高位译码产生若干片选信号,分别接到各组芯片的片选控制线
- 地址计算:
- 以芯片组为单位,看前面的字不看位,字有2^n位,那么片内地址就是n位,前面的根据有2^n组,那么就有n位片选信号,拼在一起构成地址,每组最低位就是片内地址全0,最高就是片内地址全1
- **地址主要用来确定访问哪个存储模块(组),而同一模块内的多个芯片共享相同的地址,通过数据总线的不同位来区分。**因为是先位扩展再字扩展,实际上同一个芯片组共享同样的行数,地址相同,区别在于数据引脚连接的是哪几根数据线
片选和线选
- 线选法,当某位地址线信息为0的时候,就选中与之对应的存储芯片,每次只能一位有效
- 字选的译码是由芯片的片内逻辑完成的,片选的译码由外接译码器逻辑完成
- 片选情况下,地址总位数=片选地址位数+字选地址位数
外存
磁盘
-
磁盘对工作环境要求较高
-
磁盘控制器负责接收并解释CPU发来的命令,然后再根据命令向磁盘驱动器发出各种控制信号,并检测磁盘驱动器的状态
-
扇区是磁盘读写的最小单位,即磁盘按块存取
-
磁盘的存储能力受限于最内道的最大记录密度
-
磁盘高速缓存:在内存中开辟一部分区域,用于缓冲将被送到磁盘上的数据。
- 优点:写磁盘时按簇进行,可以避免频繁地用小块数据写盘;有些中间结果数据在写回磁盘之前可被快速地再次使用
-
磁盘容量有非格式化容量和格式化容量之分。
- 非格式化容量是指磁记录表面可利用的磁化单元总数,非格式化容量=记录面数×柱面数×每条磁道的磁化单元数。
- 格式化容量是指按照某种特定的记录格式所能存储信息的总量。格式化容量=记录面数×柱面数×每道扇区数×每个扇区的容量。
- 格式化后的容量比非格式化容量要小。
-
存取时间
- 存取时间由**寻道时间(磁头移动到目的磁道的时间)、旋转延迟时间(磁头定位到要读/写扇区的时间)和传输时间(传输数据所花费的时间)**三部分构成。
- 寻道时间和旋转延迟时间通常取平均值(平均寻道时间取从最外道移动到最内道时间的一半,平均旋转延迟时间取旋转半周的时间)。

-
磁盘读/写操作是串行的,不可能同时读写,也不可能同时读两组数据或者写两组数据
-
磁盘阵列

-
读取一个磁道数据的时间=磁盘旋转一周的时间-通过扇区间隙的总时间
-
一个扇区的传输时间=(分/转数)/扇区数量
-
序号/一个柱面上的扇区数=柱面号余X
- 磁道号为X/每条磁道上的扇区数
- 扇区号为Xmod每条磁道上的扇区数
-
沿磁盘半径方向单位长度的磁道数称为道密度,道密度是相邻磁道间距的倒数
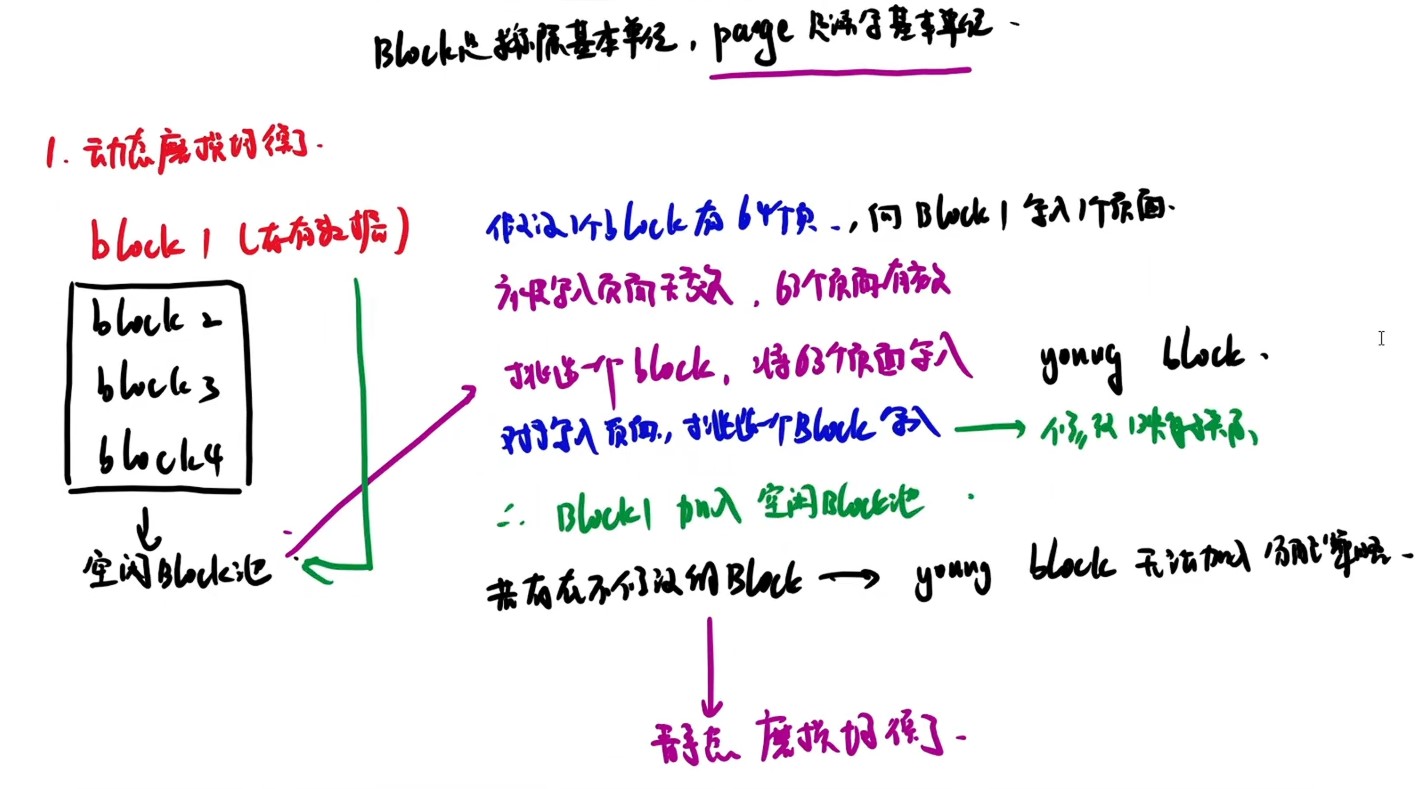
固态硬盘
- 以页为单位进行读写,以块为单位进行擦除,只有在一页所属的块整个被擦除后,才能写这一页。
- 写操作中试图修改一个包含已有数据的页,则这个块中所有含有用数据的页都必须被复制到一个新(擦除过的)块中,然后才能对页进行写操作。
- 固态硬盘比机械硬盘能耗更低、抗震性更好、安全性更高
- 所有存储元最初都是“1"状态,需要改写0的时候才进行改动
- 动态算法每次都挑最年轻的内存块来用,老的内存块尽量不用;静态算法把长期没有修改的老数据从一个年轻内存块里面搬出来,重新找个最老的内存块放着,这样年轻的内存块就能再度进入经常使用区。
- 将磁盘替换位随机访问的Flash半导体存储器后,FCFS调度策略效率最高
Cache
- cache比较器个数

-
Cache的替换由硬件实现
-
CPU和Cache的数据交换以字为单位,而Cache和主存之间的数据交换则以块为单位
-
未命中时,CPU从主存中读出地址所在的一块信息送到Cache行中,将有效位置1,并在标记设置为地址中的高t位,同时将该地址中的内容送CPU
-
指令Cache与数据Cache分离通常在L1级,此时通常为写分配法和回写法合用
-
标量没有空间局部性
-
评价一段程序的局部性特征时可以参考下列原则:
- 对相同变量有重复访问的程序有良好的时间局部性
- **对于具有步长为k且有引用模式的程序,步长越小,程序具有越好的空间局部性。**具有步长为1的引用模式的程序具有很好的空间局部性,在内存中以大步长跳来跳去的程序空间局部性会很差
- 对于取指令来说,循环体一般具有良好的时间局部性和空间局部性,循环体越小,循环迭代次数越多,局部性越好
-
一次Cache访问缺失的时间为一次主存访问的时间和一次Cache访问的时间之和,而不是调入Cache之后再从Cache读
-
cache存取周期=cache-主存系统效率x平均访问时间
-
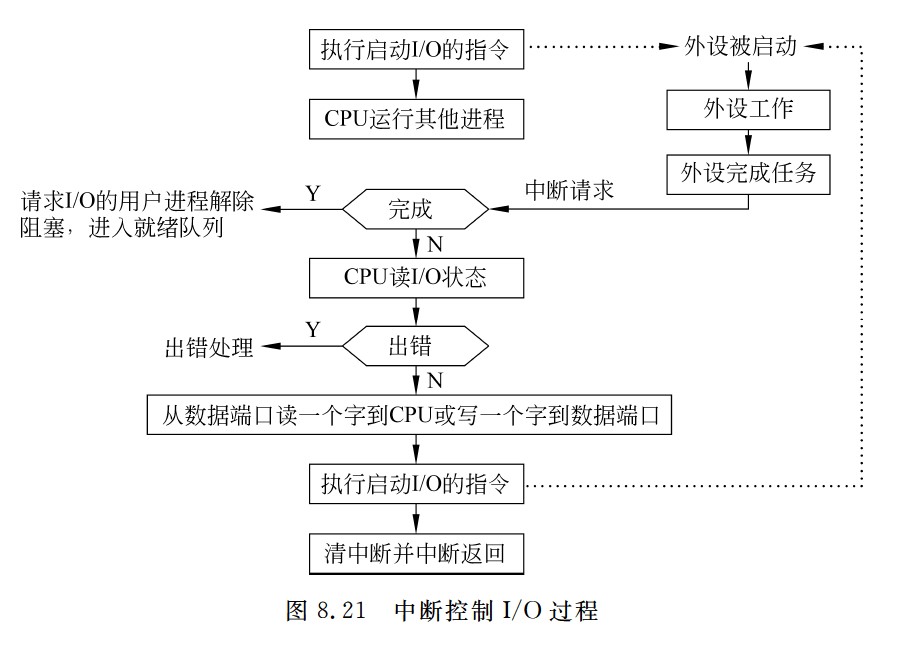
取指令 Cache 缺失的处理过程:若在 cache 中取当前指令时发⽣缺失,则处理器必须按如下步骤完成:
① 把程序计数器的值恢复到当前指令的地址,然后通过总线中的地址线送到存储器中的地址缓冲器中,以便存储器对地址译码。
② 控制存储器执⾏⼀次读操作(若⼀个主存块只有⼀条指令,则⼀次读操作读⼀条指令即可;若⼀个主存块占⽤多条指令,则控制⼀次读出多条指令或若干次),对主存的访问要通过总线完成,⼀次总线事务完成⼀次读操作。
③ 读出的指令写到 cache 中,并把主存地址的⾼位写⼊到标记字段,最后设置有效位。
④ 重新执⾏当前指令的第⼀步操作,即取指令,这次在 cache 中取指令时便能命中。显然,cache 缺失不是内部异常,更不是外部中断,不会引起对当前正在执⾏程序的“中断”,因⽽不会调出操作系统内核程序来处理 cache 缺失,即上述处理过程不是由软件完成的,⽽是由 CPU 这个硬件完成的。
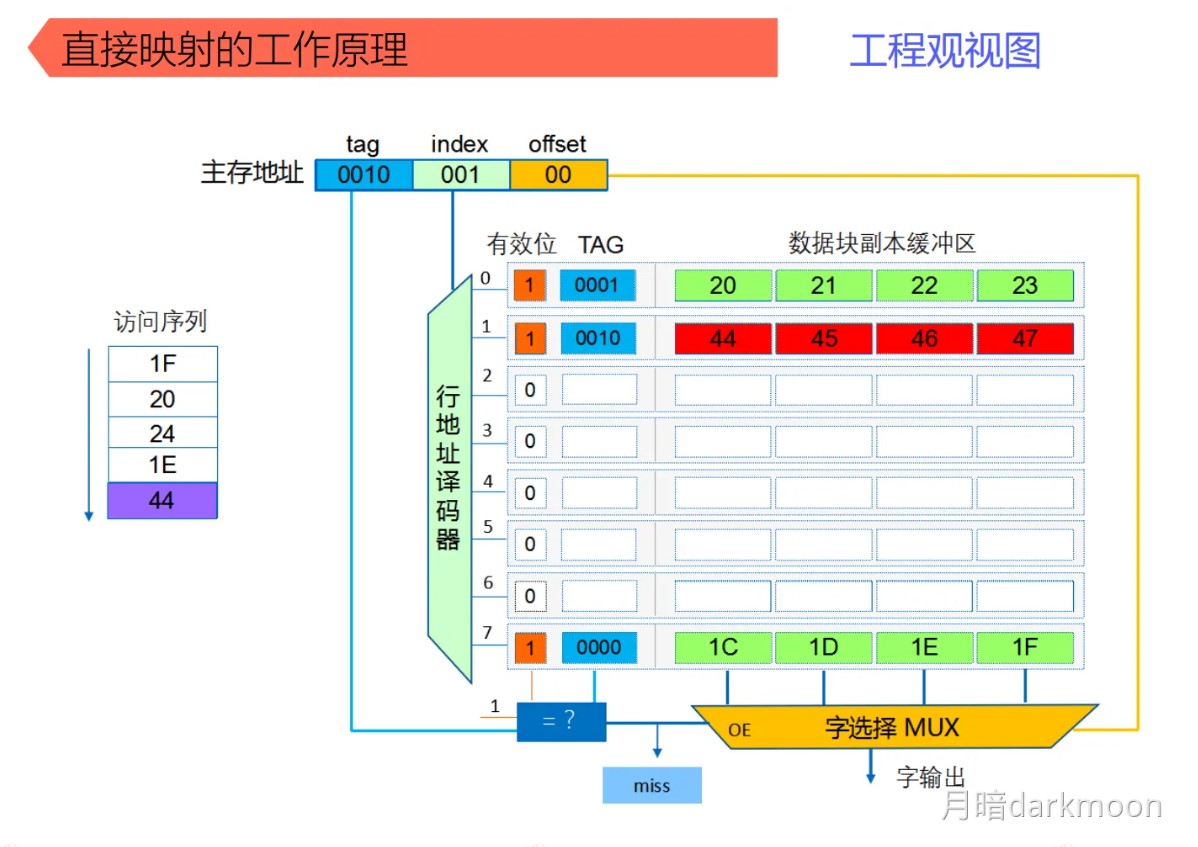
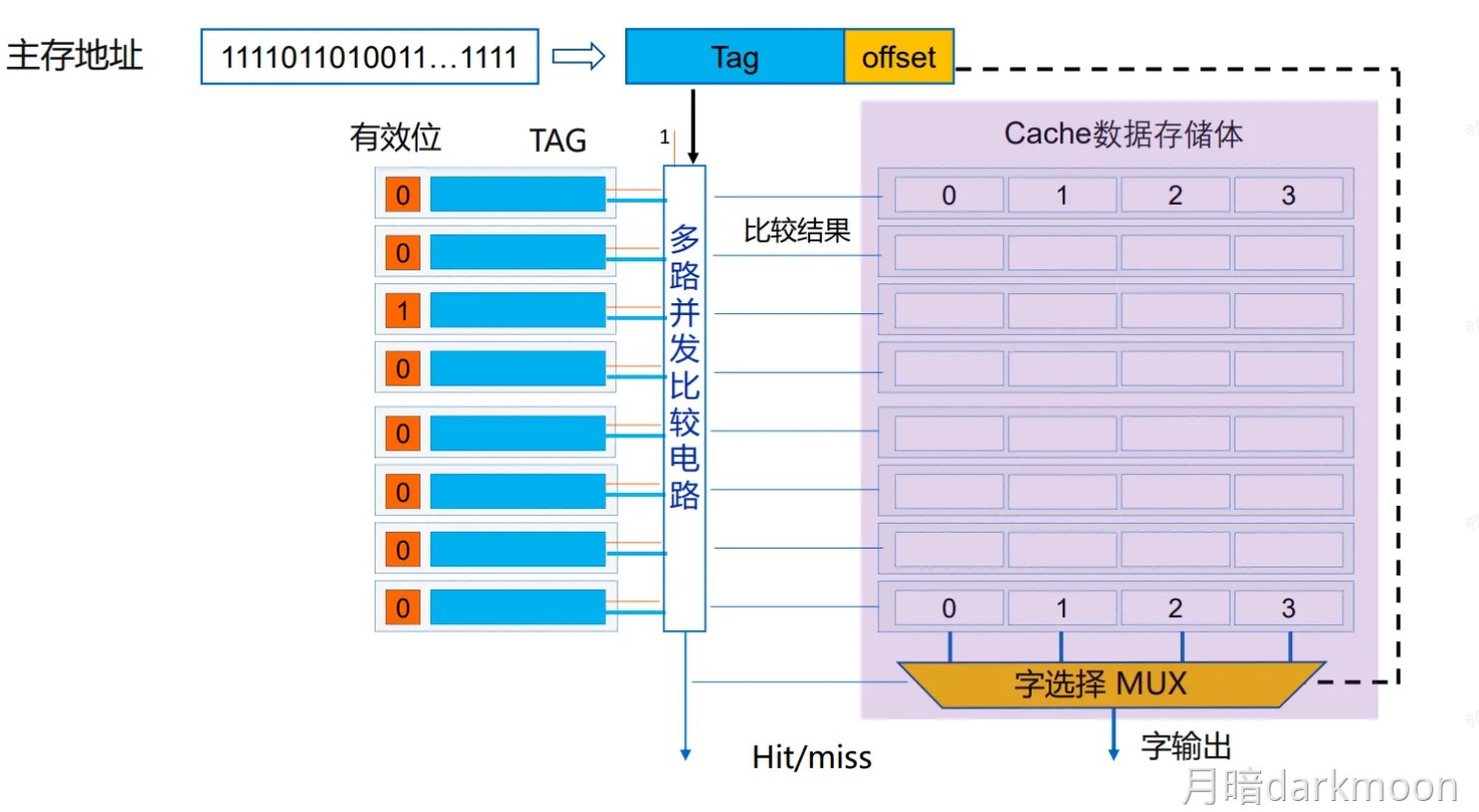
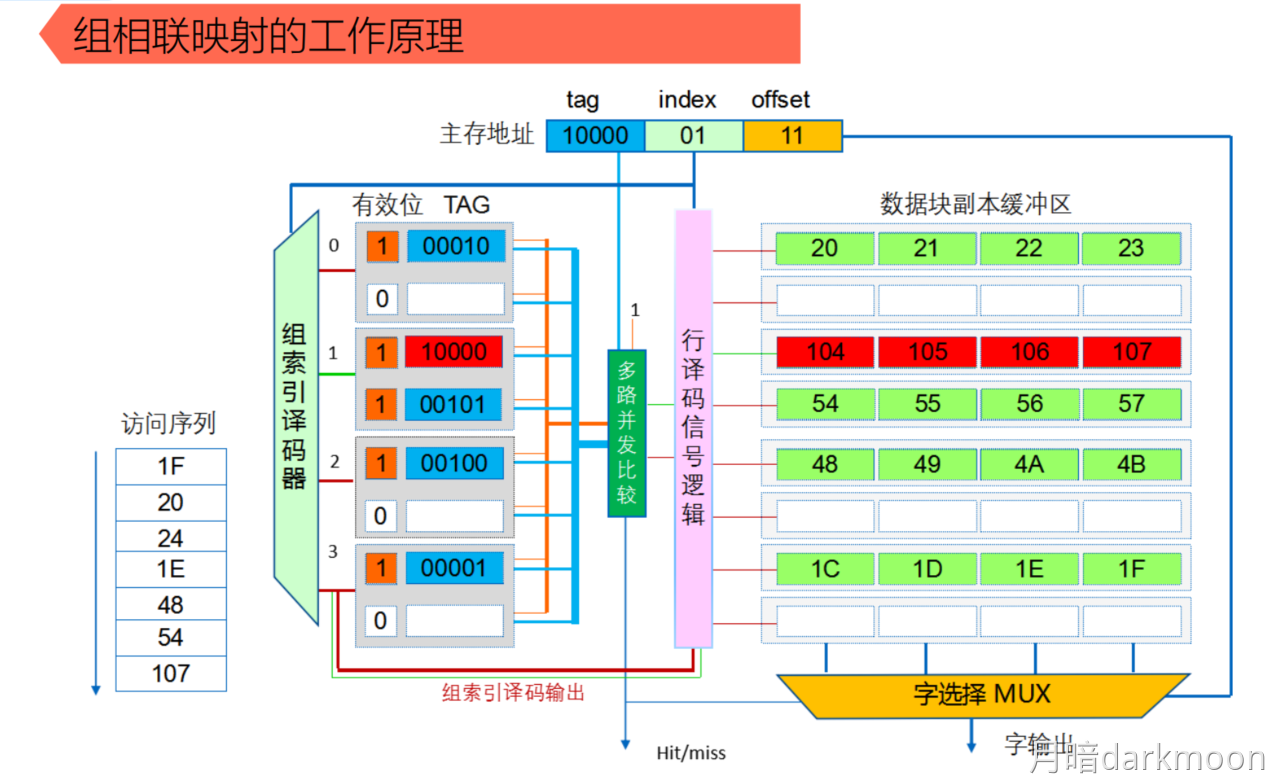
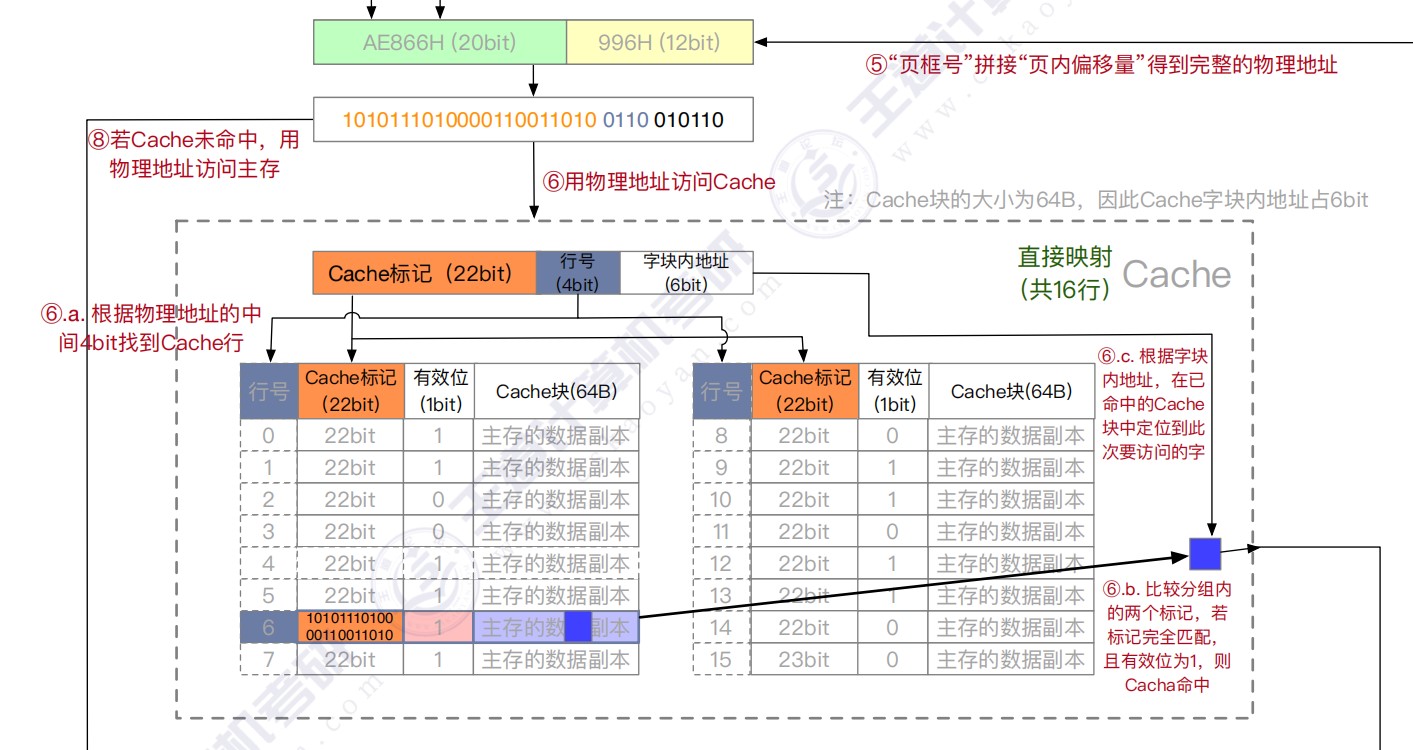
三种映射方式
- 直接映射标记所占的额外空间开销最少,全相联映射标记所占的额外空间最大

直接映射
-
直接映射无须使用替换算法,发生冲突时,原来的块将无条件被替换出去,冲突概率最高,空间利用率最低
-
容易实现,命中时间短
-
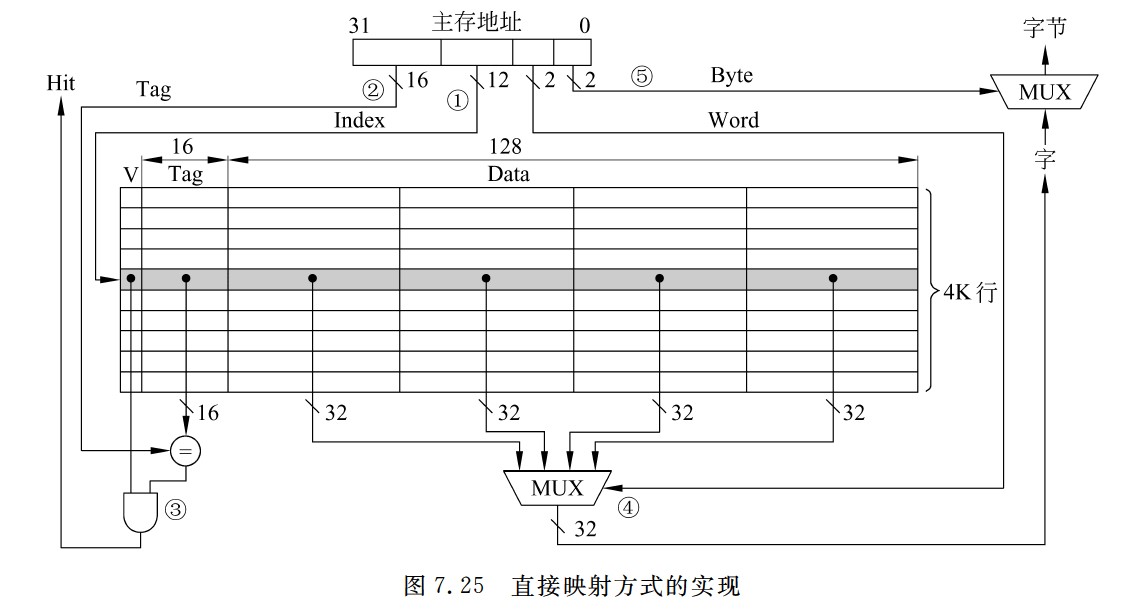
Cache行号=主存块号%Cache总行数
-
地址映射表的大小=Cache行数 * tag标记阵列bit数
- 主存容量是Cache容量的2^n倍,说明tag+行号=n位
-
直接映射给一个地址,硬件就可以直接得出它在Cache中所对应的行号,因为每个地址只可能映射到Cache中的一个地方(要么是它,要么不是它), 因此这里面比较器只要有一个就够用了,比较器两端的输入分别是地址块里的前n位标记和对应Cache行的地址
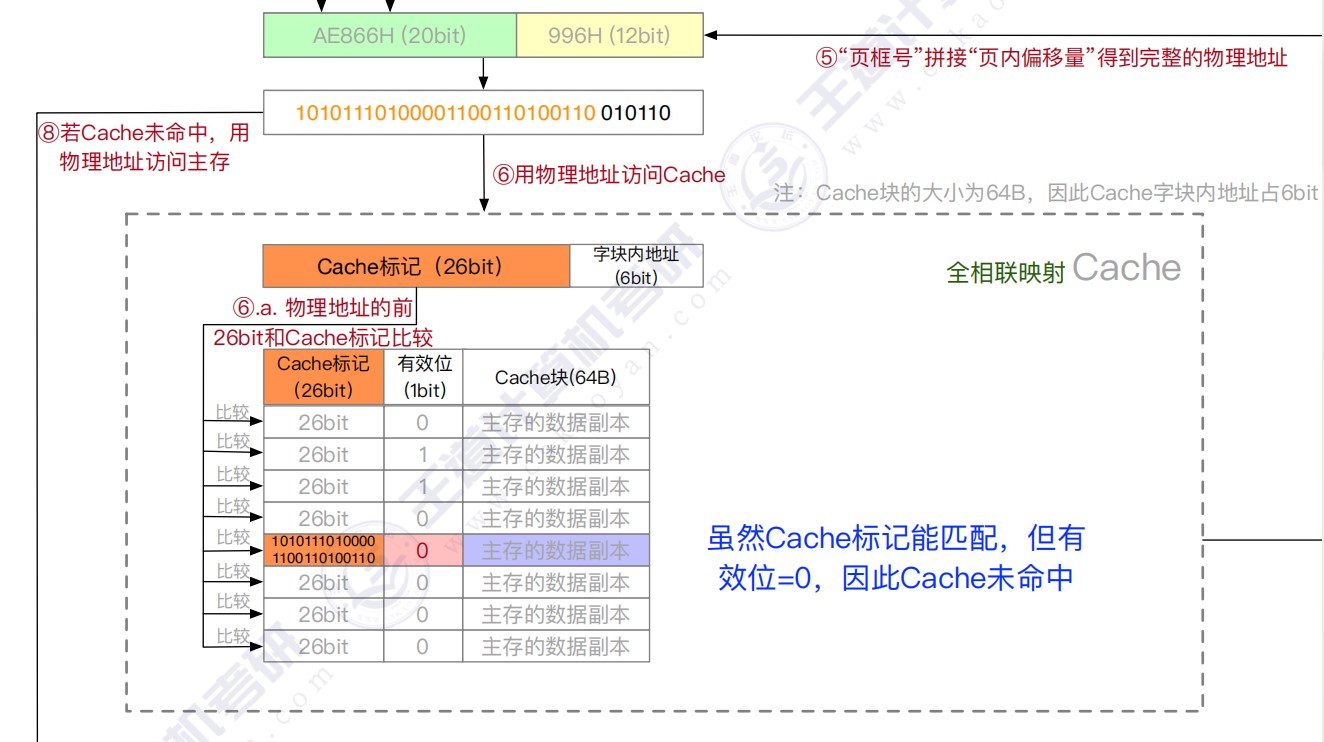
全相联
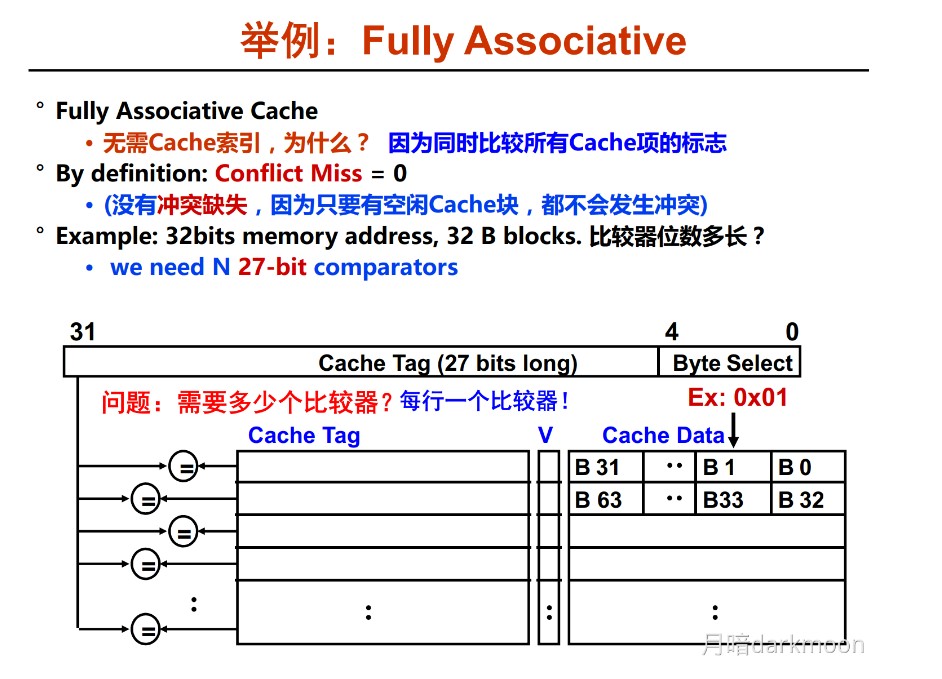
- 全相联映射,只要有空闲Cache行,就不会发生冲突,可以装入Cache中的任何位置;但是标记的比较速度较慢,通常需要采用按内容寻址的相联存储器
- 每个Cache行都设置一个比较器,比较器位数=标记字段的位数,其查找过程是一种按内容访问,是一种相联存储器,时间开销和硬件开销都很大,不适合大容量Cache
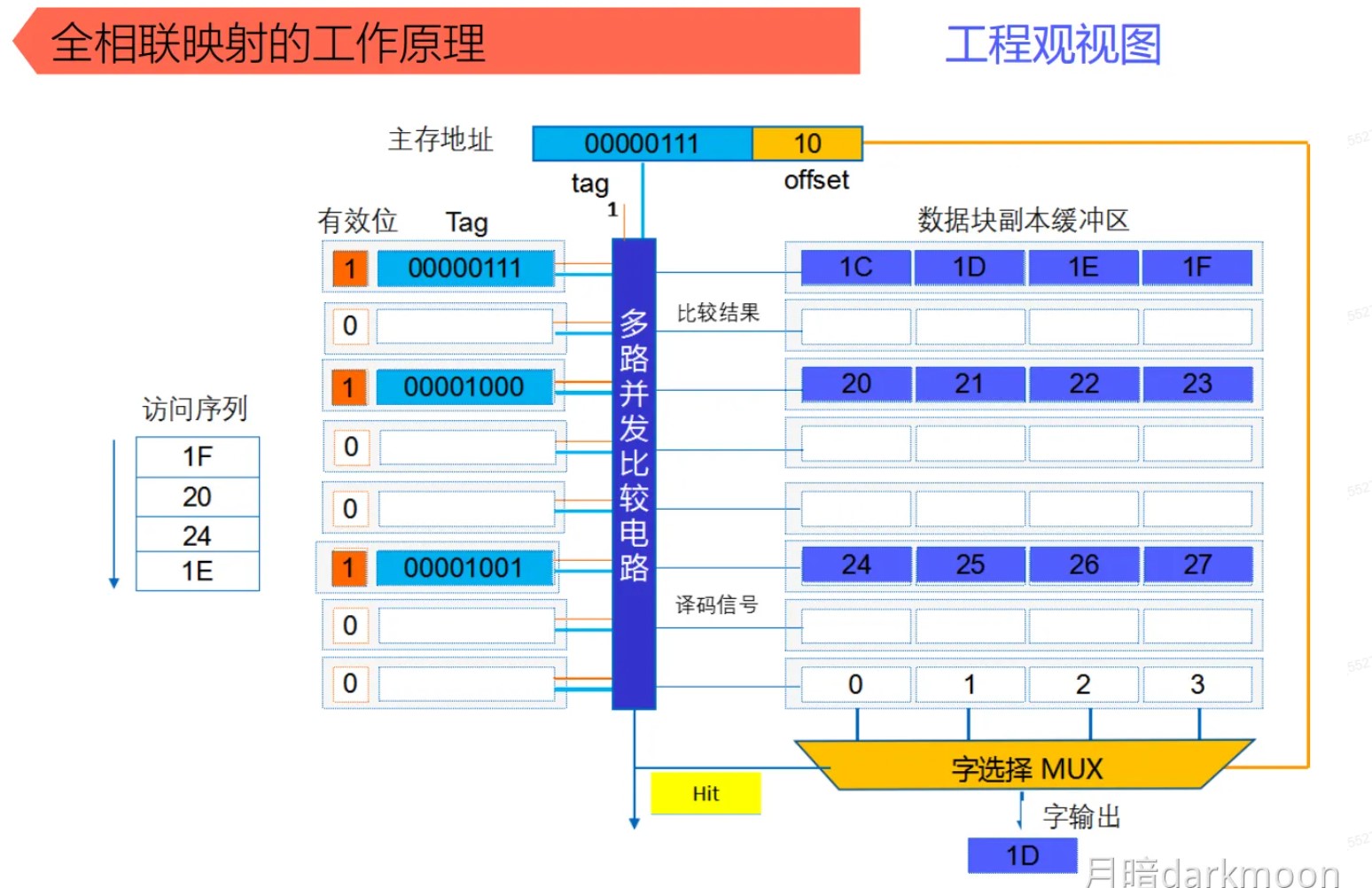
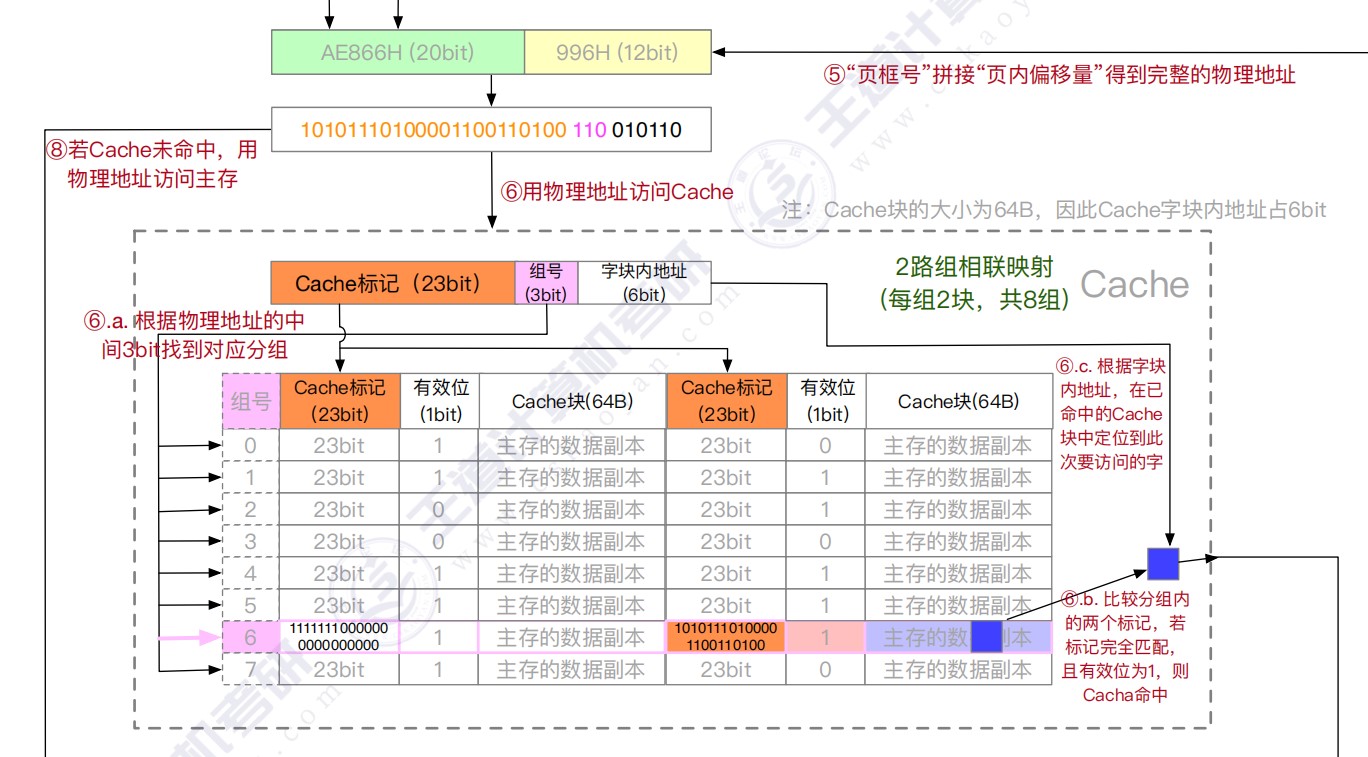
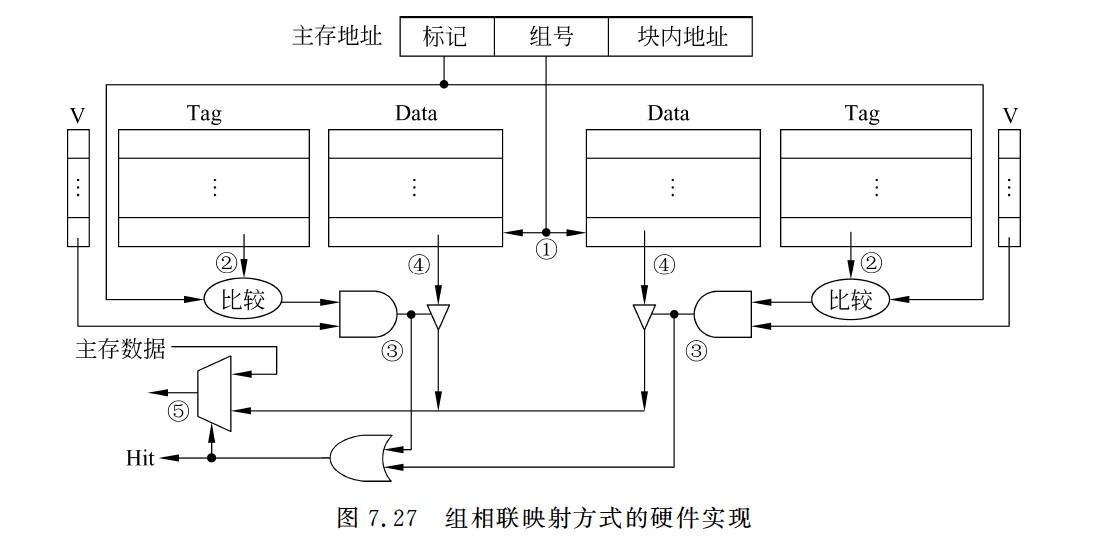
组相联
- Cache组号=主存块号 % Cache组数
- 直接映射只需要1个比较器,r路组相联映射需要在对应分组中与r个Cache行进行比较,因此需要设置r个比较器
- 组间直接映射,组内全映射
LRU和LFU的区别
- LRU替换的依据是时间维度,LFU替换的依据是频率
- LRU有三条计数规则
- LFU只有一条计数规则,即每行设置一个计数器,新装入的从0开始计数,被访问则+1,替换时将最小的换出,计数值只依赖于自己的访问次数
- LFU的计数器的值可能是0到很大的数,需要用比较长的二进制比特位标识
一致性问题
- 为了减少全写法直接写入主存的时间损耗,在Cache和主存之间加一个写缓冲,CPU同时写数据到Cache和写缓冲中,写缓冲再将内容弄个写入主存,写缓冲是一个FIFO队列,可以解决速度不匹配的问题,但是若出现频繁写,会使写缓冲饱和溢出
- 各级Cache间一般用全写法+非写分配法;Cache和主存之间一般用写回法+写分配法
- 全写法+非写分配法适合写操作频繁且对数据一致性要求较高的场景
- 回写法+写分配法适合写操作较少或者写操作集中在特定数据上的场景,可以有效减少对主存的写操作次数,提升缓存利用率
访存相关
- Cache与主存之间交换的是主存块,主存与外存之间交换的是页。
- Cache-主存层次和主存-外存层次的区别在于前者主要解决速度不匹配问题,用软件实现会影响速度,因此Cache-主存层次替换算法由硬件实现;而主存-外存层次替换算法由软件实现。
- Cache-主存层次可采用回写法或全写法;主存-外存层次通常采用回写法,即页面被修改后,仅当被换出时才写回外存,访问外存的代价很大,采用全写法的开销过高。
- 访问外存的代价很大,提高命中率是关键,因此主存-外存层次通常采用全相联映射;而Cache-主存层次可采用直接映射、组相联或全相联。
Cache的命中率、平均访问时间、访问效率
- Cache命中率

- Cache平均访问时间

- Cache访问效率

TLB和Cache和页表的内容
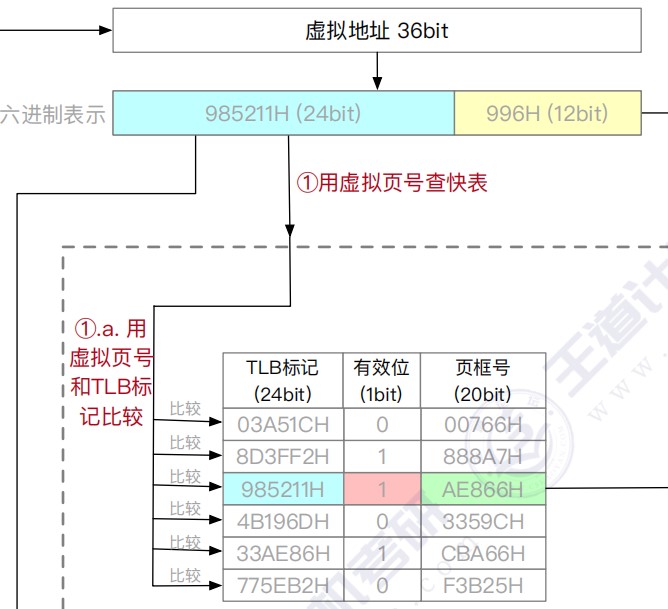
TLB
- 全相联TLB
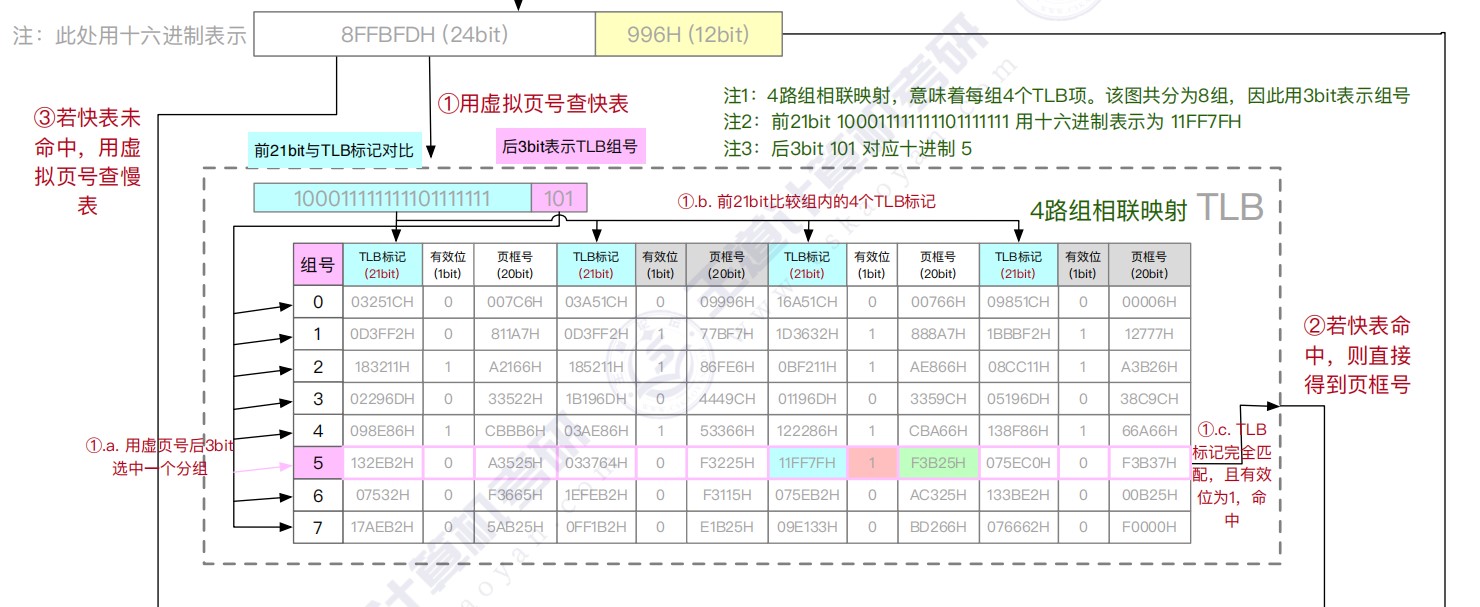
- 组相联TLB
Cache
- 直接映射
- 全相联
- 组相联
页表
- 一级页表
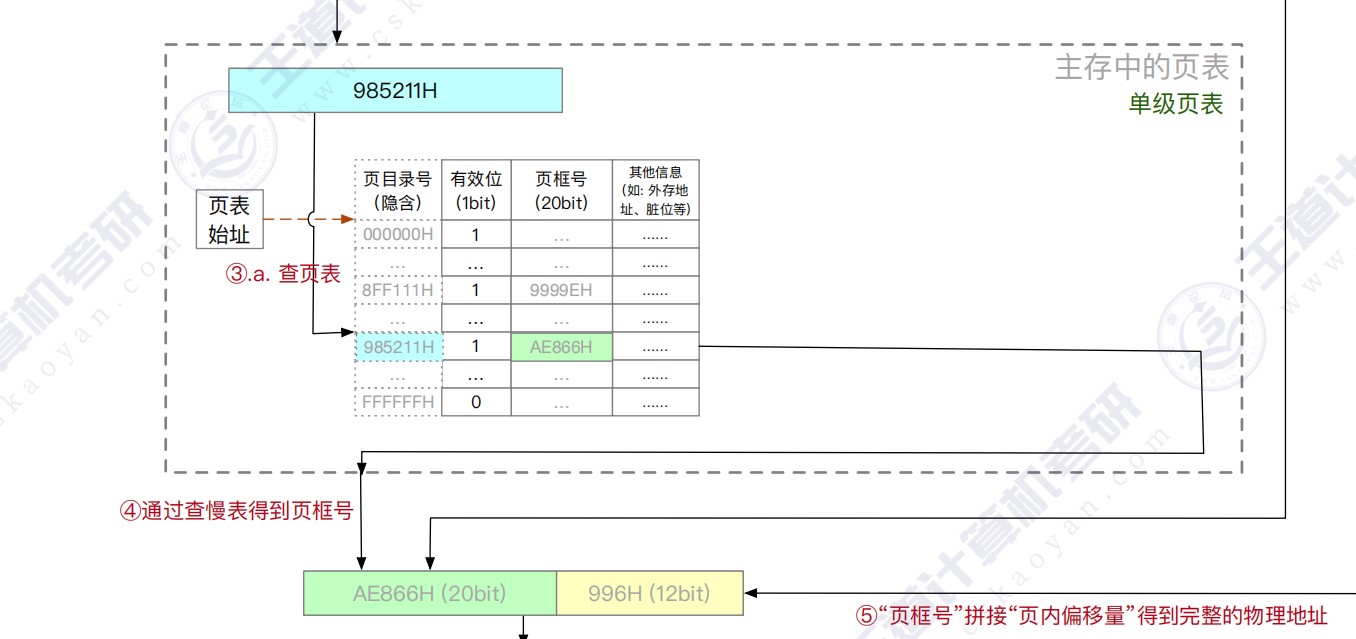
- 二级页表
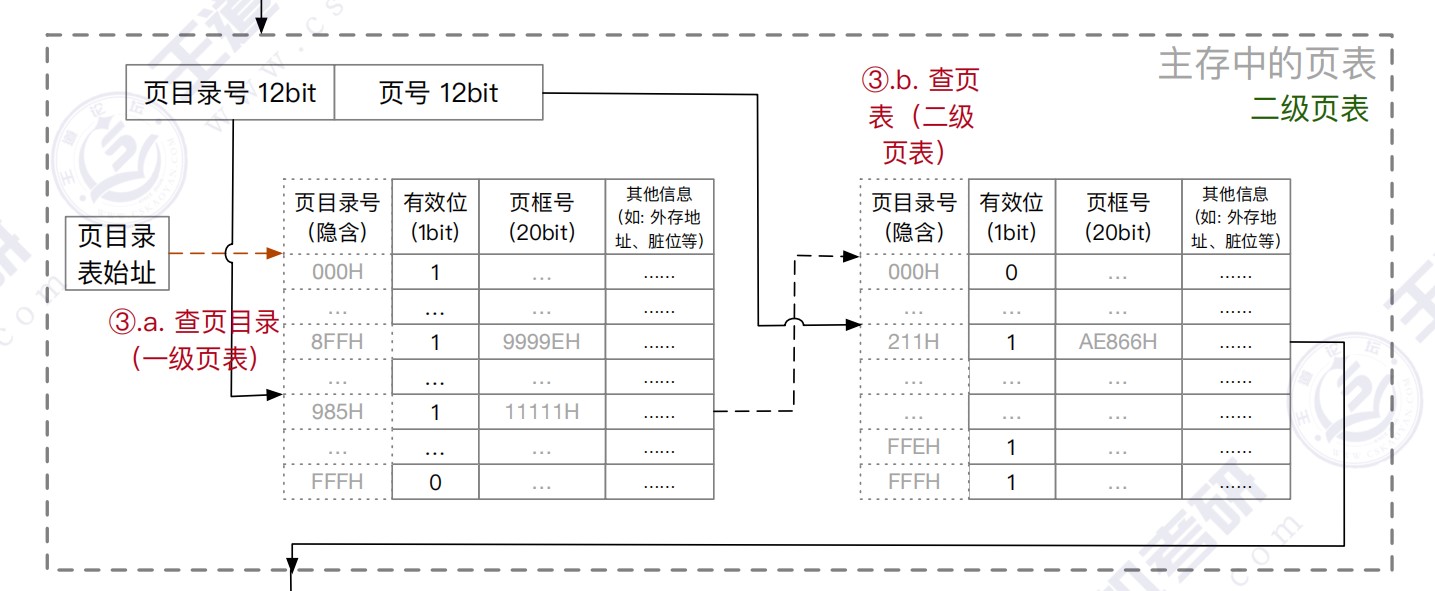
虚拟存储器
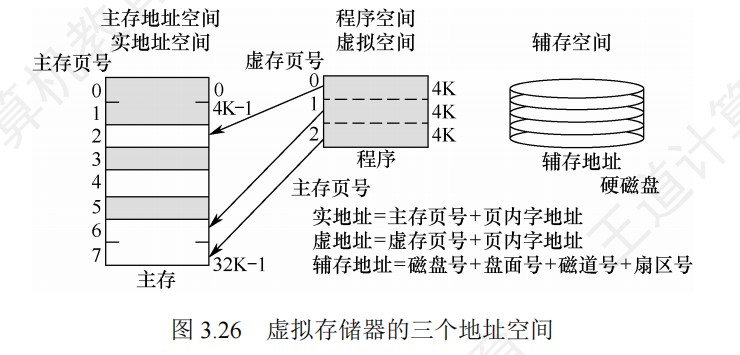
-
虚拟存储器中,指令本身地址,操作数地址都是虚拟地址,需要转化为物理地址
-
段式的比较先后:
- 越界与否→缺失与否→越权与否

-
逻辑地址空间的大小受限于CPU的寻址能力(如32位CPU理论上可以寻址4GB,64位CPU则大得多),而这些逻辑地址空间中的内容,一部分在物理内存中,大部分则存放在外存(通常是磁盘的交换区或对换区)上。因此,虚拟存储的总容量可以理解为物理内存和可用外存空间之和,但实际上限更多地由CPU寻址范围和外存大小决定
- 虚拟存储器的大小就是虚拟地址空间的大小,由虚拟地址的位数决定,与系统中的磁盘容量和内存容量没有直接关系
-
对于应用程序员而言,虚拟存储器是透明的
-
虚拟存储器将主存或辅存的地址空间统一编址,形成一个庞大的地址空间,在这个空间内,用户可以自由编程,而不必在乎实际的主存容量和程序在主存中实际的存放位置
-
虚拟存储机制采用全相联映射,每个虚页面可以存放到对应主存区域的任何一个空闲页位置。此外,进行写操作时,不能每次写操作都同时写回磁盘,因此,在处理一致性问题上,采用回写法
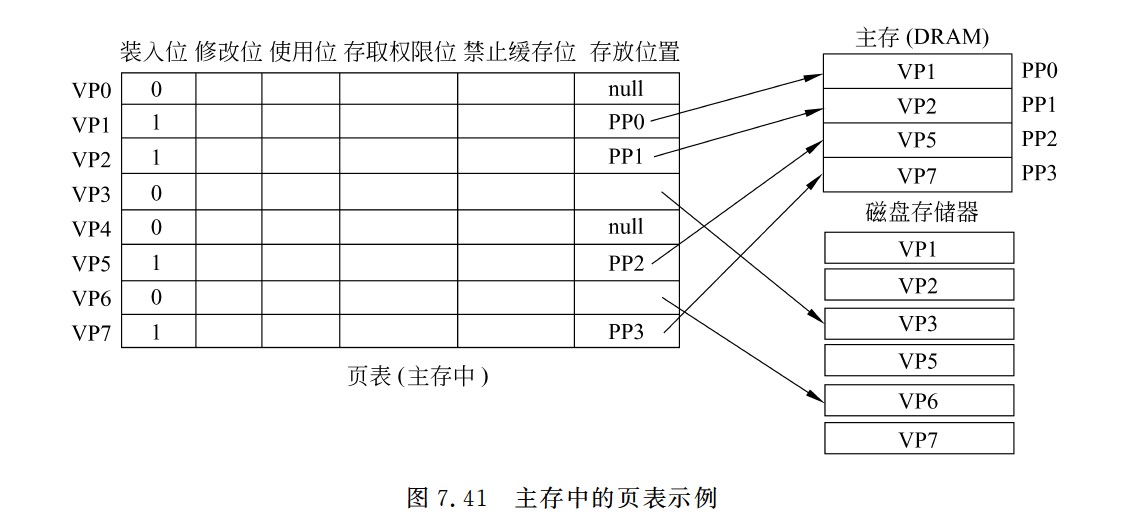
-
有效位为1,虚拟页已从外存调入主存,此时页表项存放该页的物理页号;若为0,则表示没有调入主存,此时页表项可以存放该页的物理地址
-
引用位也称使用位,用来配合替换算法进行设置,例如是否实现最先调入(FIFO位)或最近最少用(FRU位)策略等
-
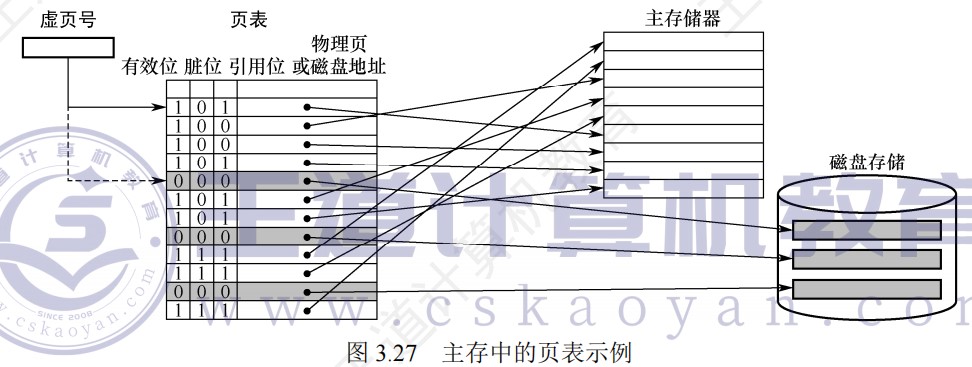
页式存储中,每个进程都有一个页表基址寄存器,存放该进程的页表首地址(物理地址),据此找到对应的页表首地址,然后根据虚拟地址高位的虚拟页号找到对应的页表项,若装入位为1,则取出物理页号,和虚拟地址低位的页内地址拼接,形成实际物理地址。若装入位为0,说明缺页,需要操作系统进行缺页处理
-
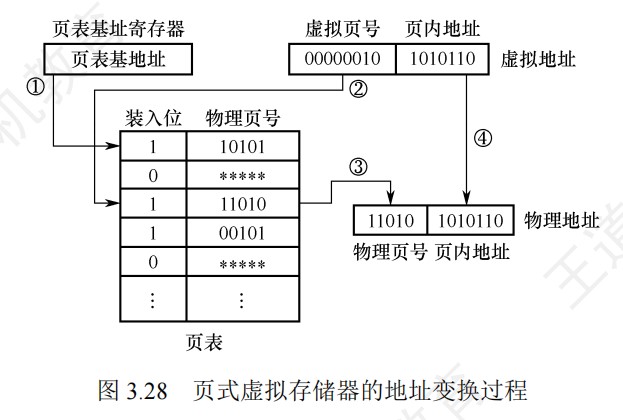
快表用SRAM实现(TLB = CAM(存标签/虚拟页号) + SRAM(存数据/物理页框号)),通常采用全相联或者组相联映射,TLB表项由页表表项内容和TLB标记组成,全相联映射下,TLB标记就是对应页表项的虚拟页号;组相联下,TLB标记则是对应虚拟页号的高位部分,而虚拟页号低位部分作为TLB组的组号
-
段式存储中,首先根据段表基地址与段号拼接成对应的段表项,然后根据该段表项的装入位判断该段是否已调入主存,已调入主存时,从段表读出该段在主存中的起始地址,与段内地址(偏移量)相加,得到对应的主存实地址。
- 段时逻辑结构上相对独立的程序块,因此段是可变长的
- 按程序中实际的段来分配主存,所以分配后的存储块是可变长的
-
段页式存储中,程序对主存的调入、调出仍然以页为基本交换单位。
- 每个程序对应一个段表,每段对应一个页表;段的长度必须是页长的整数倍,段的起点必须是某一页的起点
- 虚地址分为段号,段内页号、页内地址三部分。
- CPU根据虚地址访存时,首先根据段号得到段表地址;然后从段表中取出该段的页表起始地址,与虚拟地址段内页号核程,得到页表地址;最后从页表中取出实页号,与页内地址拼接形成主存实地址
- 段页式在地址变换过程中需要两次查表,系统开销较大
-
最大容量:地址结构确定;实际容量:min(内存+外存,CPU寻址)
-
堆内存的分配和释放由程序员控制,通常不遵循严格的先进后出或后进先出原则,而是根据程序的需要进行。
-
多级页表
- (二级)页表的每个页表项中,存放的是进程的某页对应的物理块号
- 如0号页存放在1号物理块中
- 在外层(一级)页表的每个页表项中,存放的是某个页表分页的始址
- 如0号页表存放在3号物理块中
- 总结:一级页表的一个页表项对应一个页表,二级页表的一个页表项对应一个页框。目录索引指向某个页表,页表索引指向对应页表的某个页表项
- (二级)页表的每个页表项中,存放的是进程的某页对应的物理块号
Cache和虚拟存储器对比
- Cache主要解决系统速度,而虚拟存储器却是为了解决主存容量
- Cache全由硬件实现,是硬件存储器,对所有程序员透明,而虚拟存储器由OS和硬件共同实现,是逻辑上的存储器,对系统程序员不透明,对应用程序员透明
- 虚拟存储器系统不命中时对系统性能影响更大
- Cache不命中时,主存能和CPU直接通信,同时将数据调入Cache;而虚拟存储器系统不命中时,只能先由硬盘调入主存,而不能直接和CPU通信
不同层级之间交换的单位
| 层级 | 交换单位 |
|---|---|
| CPU-Cache | 字 |
| Cache-主存 | Cache块 |
| 页式虚拟主存-外存 | 页 |
| 文件系统主存-外存 | 磁盘块 |
| DMA和设备 | 位/字节 |
| DMA和主存 | 字 |
指令系统

-
调用指令第一条指令必须显式给出转移的目标地址,否则无法调用子程序
-
一条指令的处理时间为:取指令时间+执行指令时间+中断周期时间(关中断、保存断点、中断服务程序入口地址送PC),中断周期时间不包括中断服务程序的执行时间
-
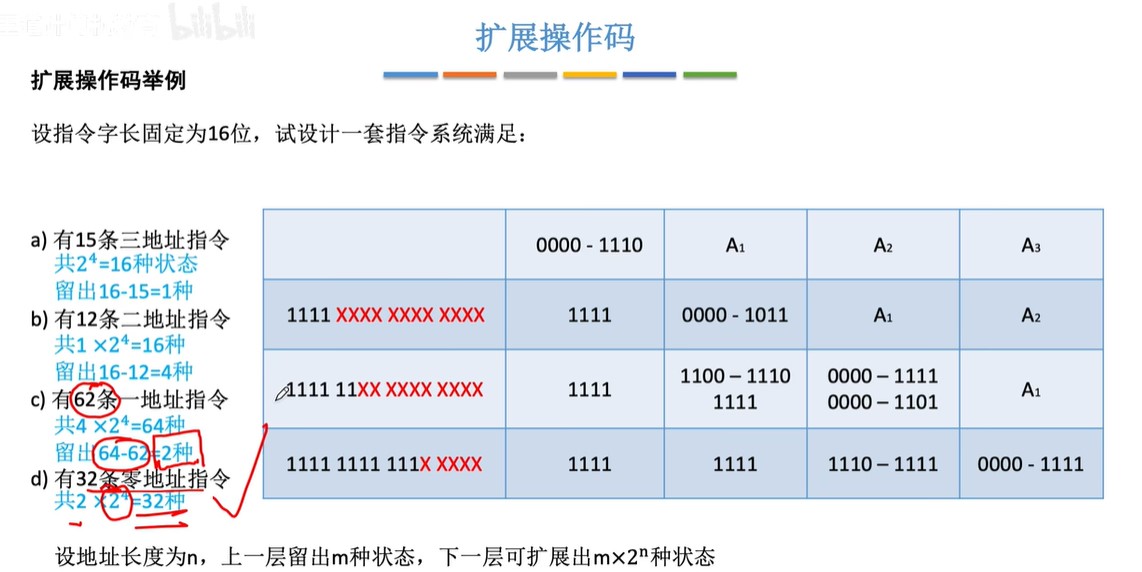
扩展指令码
- 扩展指令码上层是多地址指令,下层是少地址指令,少地址指令
- 前缀不能相同
- 对使用频率较高的指令分配较短的操作码,对使用频率较低的指令分配较长的操作码
- 调用指令和转移指令的区别
- 执行调用指令时必须保存下一条指令的地址(返回地址),当子程序执行结束时,根据返回地址返回到主程序继续执行,而转移指令则不返回执行
- 通用寄存器、指令指针寄存器(IP)和标志寄存器(PSW),这些都是程序员可见寄存器
- IP(PC)是用户可见的寄存器,汇编程序员可以通过指定待执行指令的地址改变PC的值
- 执行后一定会改变程序的执行顺序的指令
- 无条件跳转指令
- 过程调用指令
- 过程返回指令
- 自陷指令
- 中断返回指令
- 条件跳转指令要根据标志位进行是否跳转的,因此不一定发生跳转
- 定长指令字的每条指令长度固定,可以简单地实现PC的自增功能,不需要专门的PC增量器,变长指令字的每条指令长度不固定,需要一个专门的PC增量其来进行PC自增的计算
- 变长指令字每次可以按照最长的指令长度来读取,然后根据指令中特定位的规定对各个字段进行划分
ISA
- ISA规定的内容
- 异常和中断相关
- 指令
- 操作数
- 寻址方式和地址空间大小
- 寄存器
- 编址方式
- 控存
- 机器工作状态的定义和切换
- 存储保护方式
- 输入/输出结构和数据传送方式
寻址方式
-
遇到基址寻址计算操作数地址的时候,都可以将基址寄存器的内容和形式地址进行符号扩展以后的结果直接相加


-
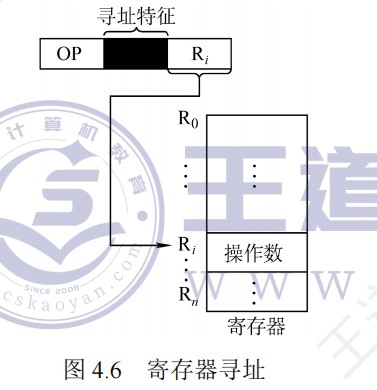
若为寄存器间接寻址,则寄存器的位数决定了可寻址的范围
-
立即数采用补码表示
-
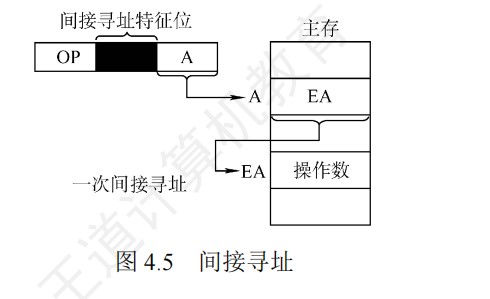
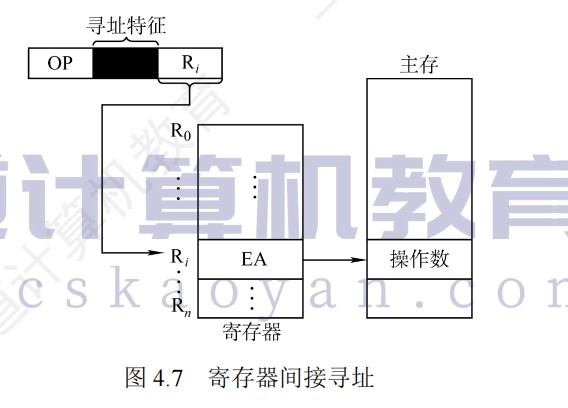
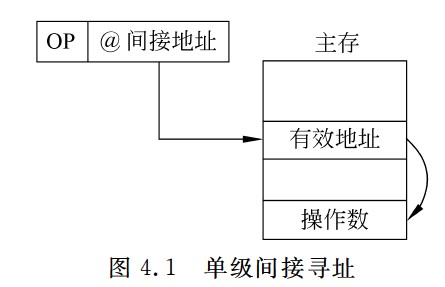
间接寻址可以方便完成子程序返回,但由于执行速度较慢,一般为了扩大寻址范围时,通常采用寄存器间接寻址
-
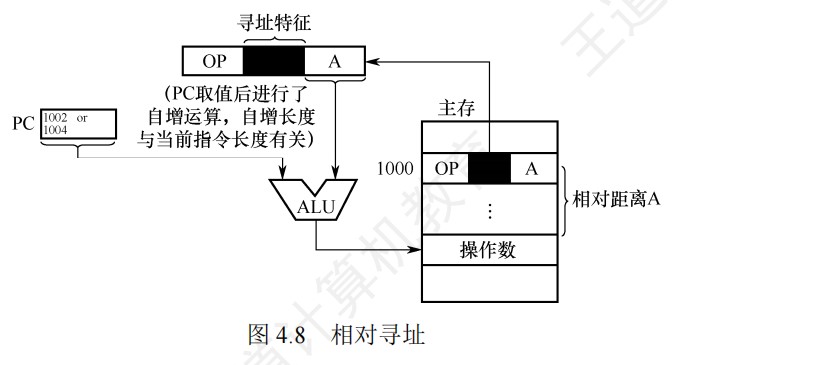
相对寻址中,(PC)+A里的A可正可负,补码表示
- 寻找中断服务程序入口使用相对寻址
-
相对寻址便于程序浮动,广泛应用于转移指令
-

-
基址寄存器是面向操作系统的,其内容由操作系统或管理程序确定,主要用于解决程序逻辑空间与存储器物理空间的无关性。在程序执行过程中,基址寄存器的内容不变(注意,PC的内容是会变的),作为基地址,形式地址可变,作为偏移量。采用通用寄存器作为基址寄存器时,可由用户决定哪个寄存器作为基址寄存器,其内容仍然由操作系统确定。
- 优点:可以扩大寻址范围(基址寄存器的位数大于形式地址A的位数),用户不必考虑自己的程序存于主存的具体位置(pc+a需要考虑a),因此有利于多道程序设计,并可用于编制浮动程序,但偏移量(形式地址A的位数较短)
- 用于程序的动态重定位,为逻辑地址到物理地址变换提供了支持
- 编写程序不必考虑程序位于主存的具体位置
-
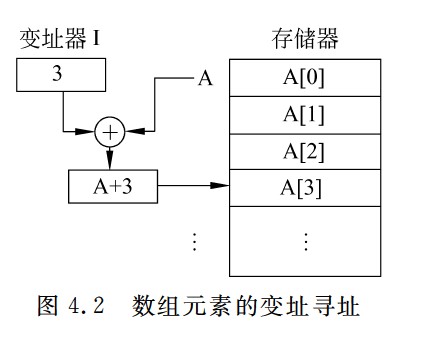
变址寄存器是面向用户的,在执行的过程中,变址寄存器IX的内容(作为偏移量)可由用户改变,形式地址A不变(作为基地址),经典应用是数组和循环程序
-
基址寻址和变址寻址的区别
- 面向对象不同
- 基址寻址面向系统,基址寄存器内容通常由操作系统或管理程序确定,在程序的执行过程中其值不可变,而指令字中的A是可变的
- 变址寻址面向用户,变址寄存器的内容由用户设定,在程序执行过程中其值可变,而指令字中的A是不可变的
- 应用场景不同
- 基址寻址用于多道程序或数据分配存储空间或短地址访问大空间
- 变址寻址用于处理数组、字符串、表格问题
- 操作对象不同
- 基址寻址中,程序员操作的是偏移地址
- 变址寻址中,程序员操作的是变址寄存器
- 面向对象不同
-
基址寻址的程序重定位和相对寻址公共子程序浮动的区别
- 程序重定位:多道程序运行的系统中,每个用户程序在一个逻辑地址空间里编写程序,装入运行时,由操作系统给用户程序分配主存空间,每个用户程序有一个基地址,放在基址寄存器中,在程序执行时,通过基址寄存器的值加上指令中的形式地址,就可以形成实际的主存单元地址
- 程序的起始地址存放在PCB中
- 基址寻址方式下,逻辑地址对应的是偏移量,而这段程序在主存中存储的起始位置就是它的基址寄存器内容;
- 而在相对寻址的情况下,由于公共子程序是共享的,位置不需要发生改变,当有一个程序需要用到该子程序的时候,利用相对寻址即改变PC值跳转到子程序开始执行即可,相当于相对寻址实现函数调用
- 程序重定位:多道程序运行的系统中,每个用户程序在一个逻辑地址空间里编写程序,装入运行时,由操作系统给用户程序分配主存空间,每个用户程序有一个基地址,放在基址寄存器中,在程序执行时,通过基址寄存器的值加上指令中的形式地址,就可以形成实际的主存单元地址
-
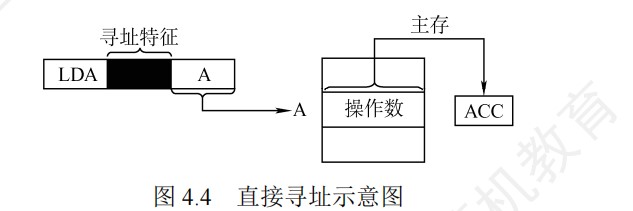
直接寻址下,地址只能是正,因此A当作无符号数处理
-
立即寻址通常用于给寄存器赋初值
-
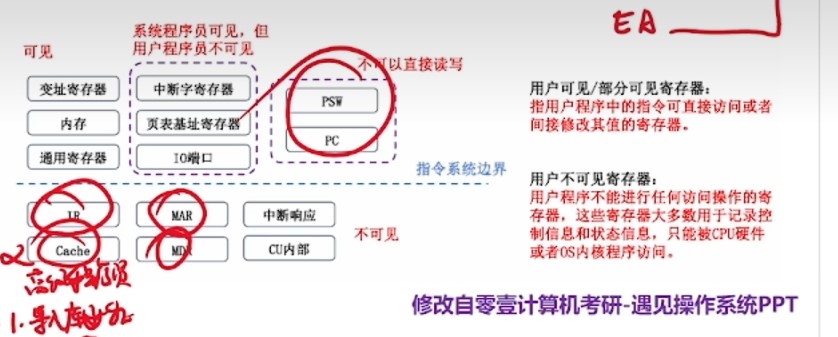
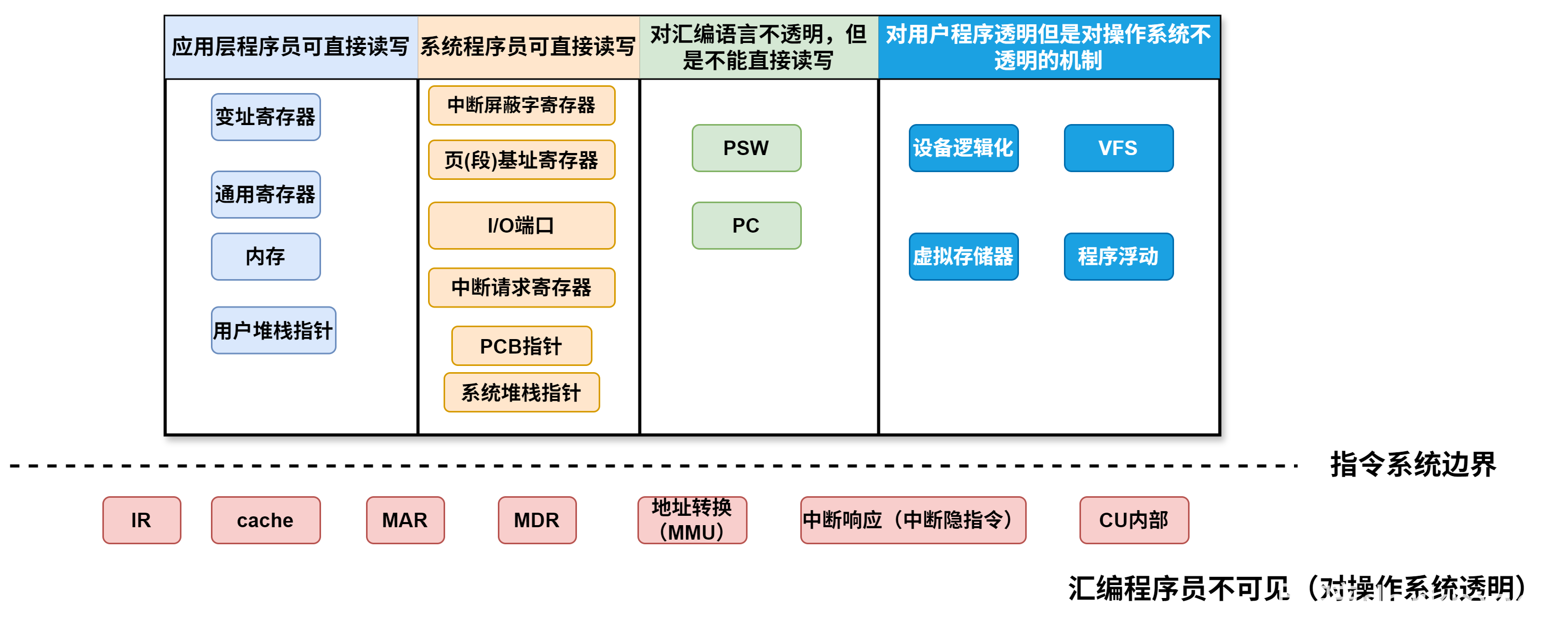
EA是操作数的有效地址,(EA)才是操作数
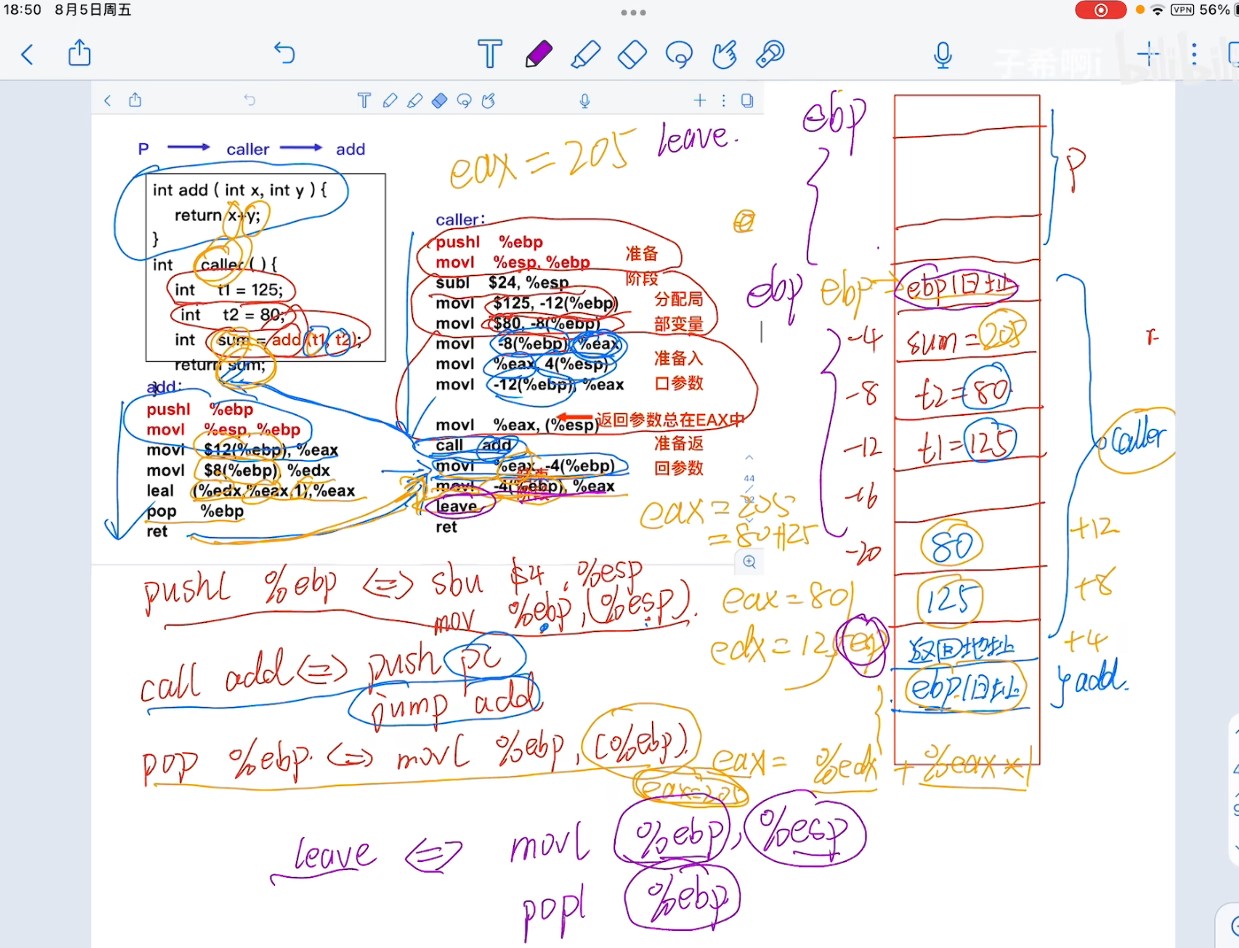
机器级代码表示(函数执行)
超硬核!408考研重点!汇编语言表示程序函数的过程调用!23王道计算机组成原理指令系统-被木窄干了-稍后再看-哔哩哔哩视频
-
双操作数指令的两个操作数不能都是内存
-
栈中元素固定32bit,向低地址方向增长
-
imul有符号整数乘法指令,两个数相乘,结果保存在第一个操作数中,第一个操作数必须为寄存器;三个数相乘,将第二个和第三个数相乘,将结果保存在第一个操作数中,第一个操作数必须为寄存器
-
idiv有符号整数除法指令,只有一个操作数,即除数X,而被除数在edx:eax中,操作结果有两部分:商和余数,商从到eax,余数送到edx
-
cmp指令的功能相当于sub指令,用于比较两个操作数的值,test指令的功能相当于and指令,对两个操作数进行逐位与运算,这两类指令不保存操作结果,仅根据运算结果设置CPU状态字中的条件码
-
常见的算术逻辑运算指令会设置条件码,还有cmp和text指令只设置条件码而不改变任何其他寄存器
-
过程调用中,调用者负责将实参和返回地址压栈保存
- 被调用者负责保存和恢复调用者的现场(通用寄存器的内容),并为自己的非静态局部变量分配空间,放置结果,释放空间,取出返回地址,转移回调用者
-
EAX、ECX和EDX是调用者保存寄存器,当P调用Q时,若Q需要用到这些寄存器,则由P将这些寄存器的内容保存到栈中,并在返回后由P恢复他们的值
- 寄存器EBX、ESI、EDI是被调用者保存寄存器,当P调用Q时,Q必须先将这些寄存器的内容保存在栈中才能使用他们,并在返回P之前先恢复它们的值。
-
push的是要存入的数,pop的是弹出的数要存的地方,一个是数值一个是地址
-
当子程序调用CALL指令时,首先需要将程序断点(PC值)保存在栈中,然后将CALL指令的地址码送入PC。
- 注意:栈地址的增减恒定为1,与指令长度无关
- 入栈的是逻辑地址,取指令的时候系统才按照逻辑地址根据一定的规则转换为物理地址再去访存,因此入栈的是PC的内容,即逻辑地址。
-
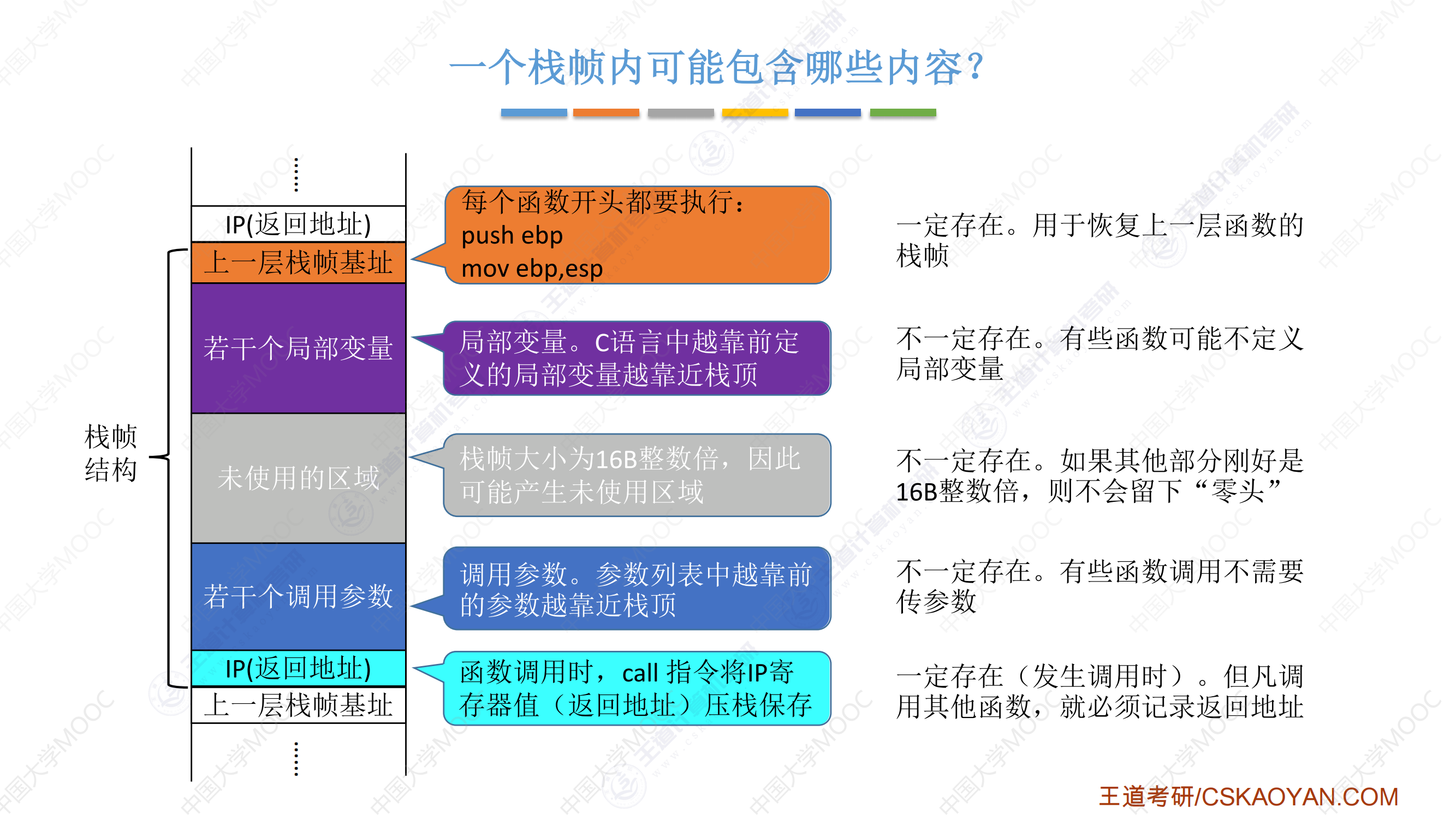
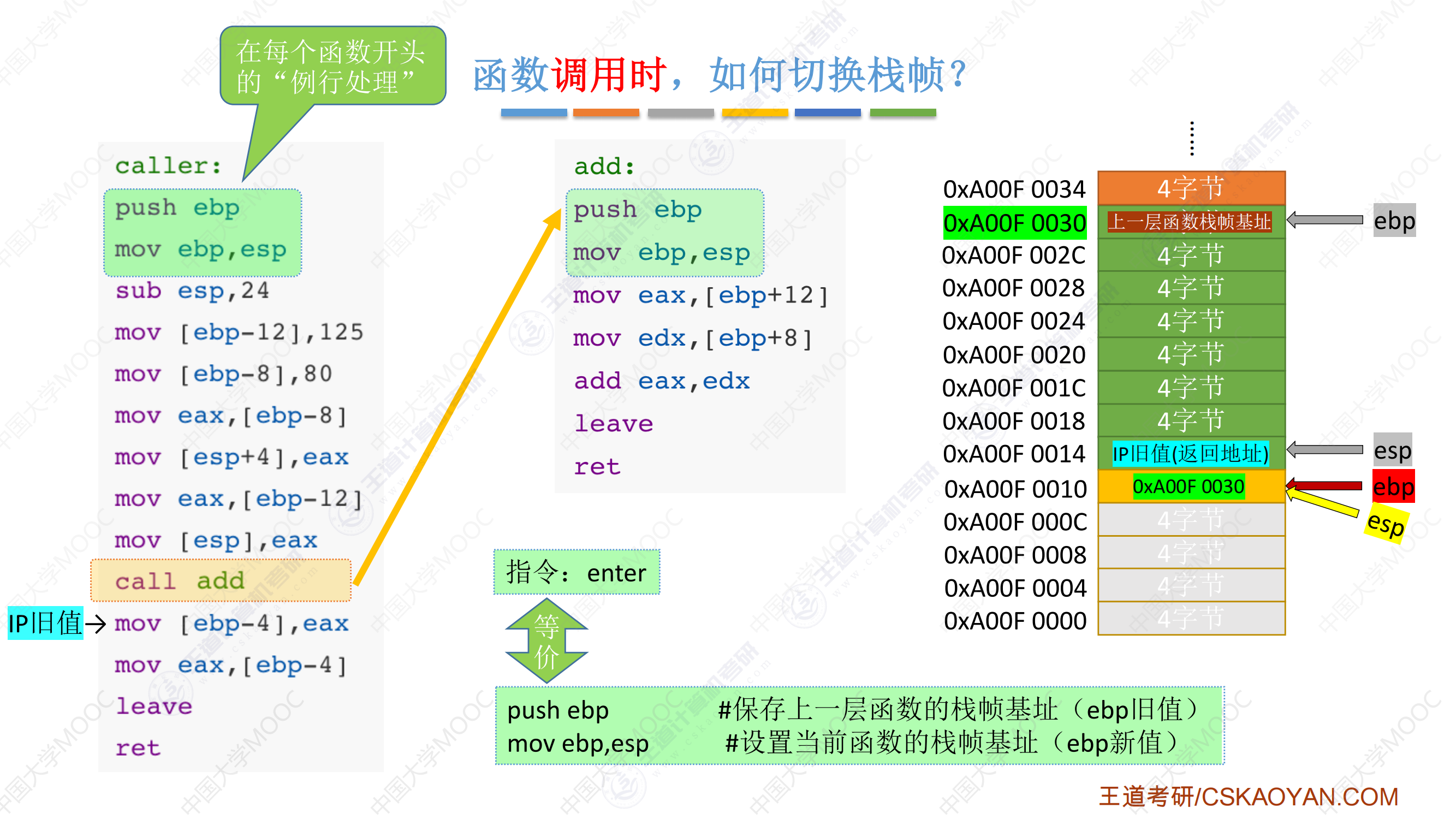
IP旧值和上一层函数栈帧基址的区别
-
IP 旧值(返回地址):指的是函数 调用返回后的地址(本来要执行,PC都设置好了,但是遇到了调用),也就是函数执行完毕后,程序应该跳转到的地方。对于
call指令来说,IP 旧值是指向call指令之后的下一条指令。每次call指令都会将这个返回地址压入栈中,以便函数执行完毕后跳转回去。栈帧基址:指的是 当前栈帧的基址(即当前函数栈帧的底部)。它用于帮助访问当前栈帧中的局部变量和参数,并且在函数调用时会被保存在栈中。通过基址指针
EBP,你可以访问当前栈帧中的数据。
-
-
为什么需要分别保存IP旧值和栈帧基址
-
IP 旧值 是函数执行完毕后 返回时的目标地址,它指向调用函数之后的下一条指令,也就是程序调用函数时的“跳转目标”。
栈帧基址(
EBP)是函数调用时保存的栈帧的起始位置,它用于恢复栈的结构,在函数返回时确保栈能够正确地恢复,防止栈指针错误。
-
-
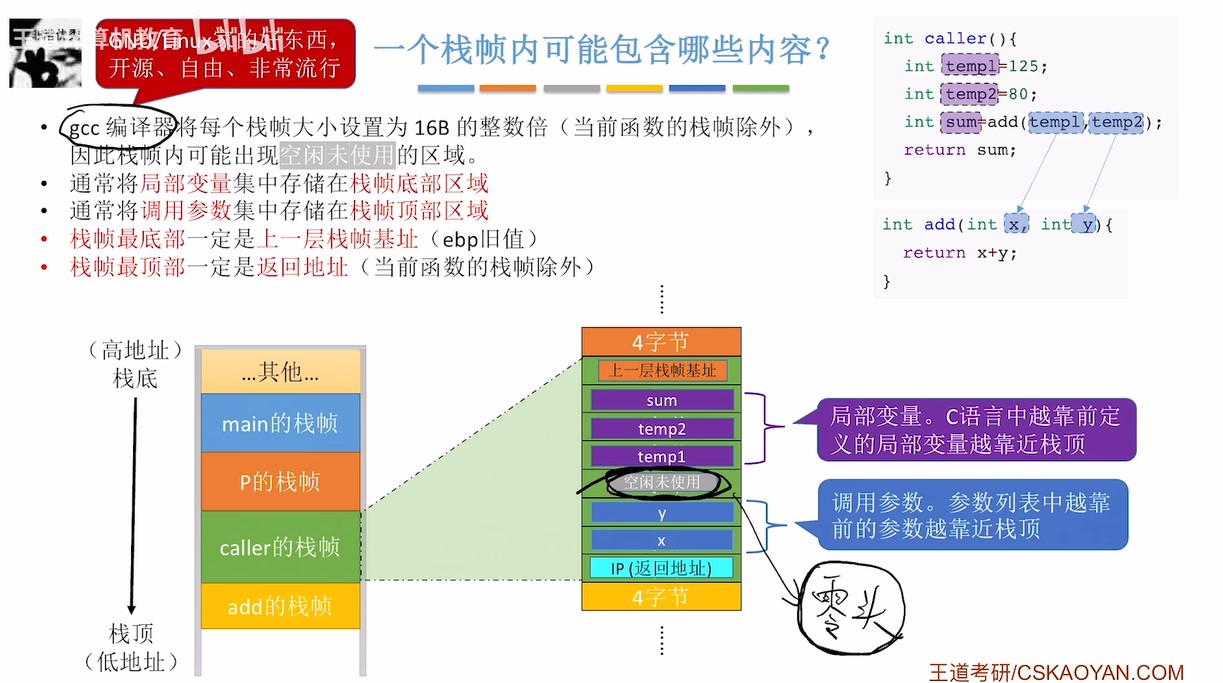
栈帧最底部一定是上一层栈帧基址,最顶部一定是返回地址;越靠前定义的局部变量越靠近栈顶,越靠前的参数越靠近栈顶
- 这里的call函数并没有给出具体的汇编代码,只是执行压入IP旧值,跳转到IP新值
汇编格式

intel下
MIPS情况下

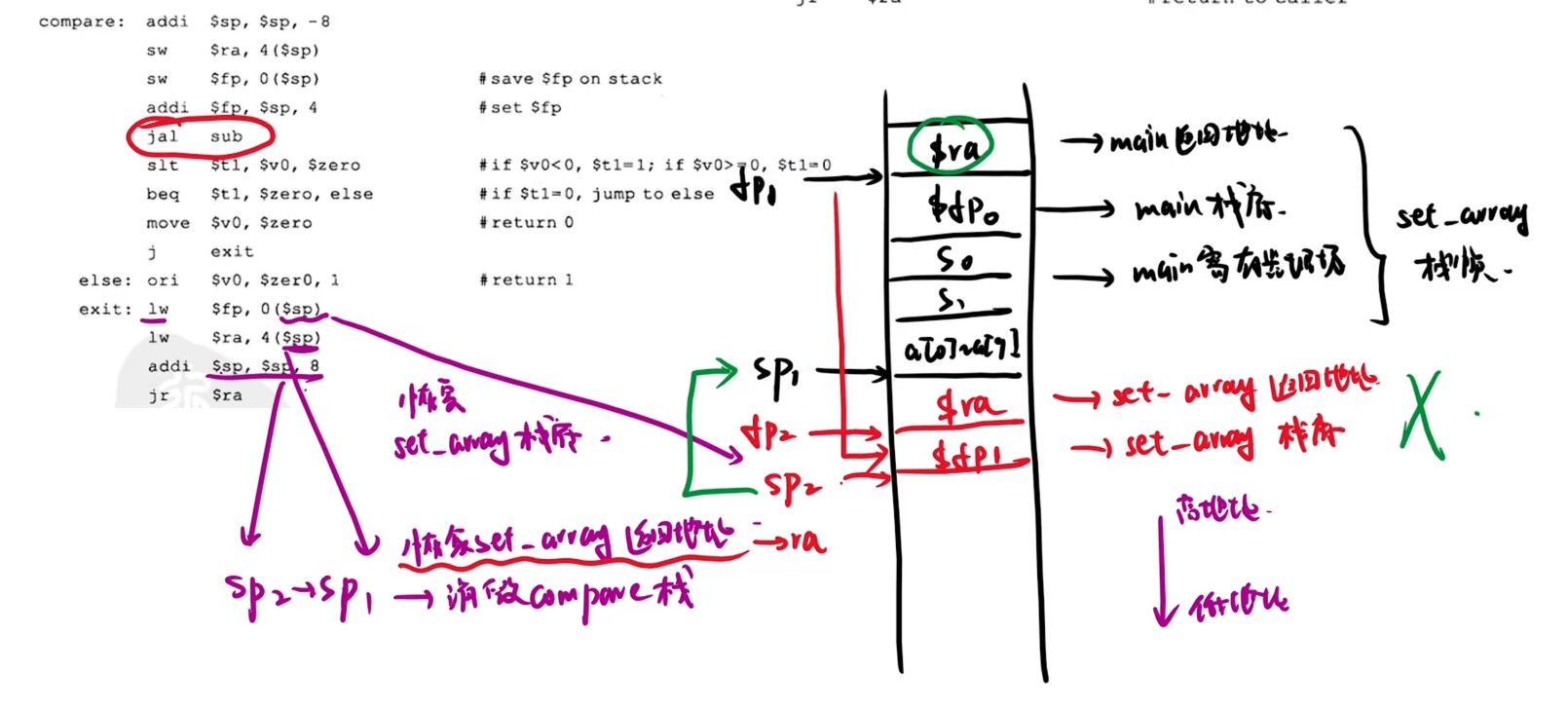
- 在MIPS架构中,
$sp(栈指针)指向的是栈顶元素的地址,而不是下一个位置。
详细解释:
栈操作方式
MIPS采用向下增长的栈(从高地址向低地址扩展),$sp始终指向当前栈顶的有效数据:
text
1 | |
栈操作示例
压栈操作(push):
mips
1 | |
出栈操作(pop):
mips
1 | |
函数调用中的使用
mips
1 | |
关键点总结:
$sp指向当前栈顶的有效数据- 栈向低地址方向增长
- 压栈时先移动指针再存储数据
- 出栈时先读取数据再移动指针
- 这种设计符合直觉,便于直接通过
0($sp)访问栈顶元素
RISC和CISC
- RISC一定采用指令流水线技术,大部分指令在一个时钟周期内完成。
- RISC更能充分利用芯片的面积,便于设计,可降低成本,提高可靠性,机器设计周期短,逻辑简单,出错概率低,可靠性高,有利于编译程序代码优化,大部分用组合逻辑控制
中央处理器
- 硬件多线程的基本思想是在一个处理器中同时维护多个线程的上下文,当一个线程因等待资源而暂停时,处理器可以切换到另一个线程继续执行,提高处理器利用率。
- 若是处于关中断/无中断请求,没有中断需要响应,指令周期就没有中断周期这个阶段
- 异常和中断处理逻辑属于数据通路
- 注意区分中断机构和中断检测和处理逻辑,前者是中断控制器,是硬件,后者属于软件:处理中断的内容,前者属于控制部件,后者属于数据通路
- 所有信号在一个时钟周期内从状态单元1经组合逻辑到达状态单元2,信号到达状态单元2所需的时间决定了时钟周期的长度
- 时钟周期以相邻状态单元间组合逻辑电路的最大延迟为基准确定
- 若单周期处理器中所有指令的指令周期为一个时钟周期,则可以采用多总线结构的数据通路
- PC的值由CPU在执行指令的过程中进行修改
- 用字地址表示指令地址的情况下,指令必须采用按边界对齐的方式存放,此时PC的位数=存储器地址的位数-log2(指令字长的字节数)
- PC的位数取决于存储器容量和字长
- 机器指令中不能显式使用PC
- 用户不能直接修改PSW的值
- 指令译码器仅对操作码字段进行译码,借以确定指令的操作功能
- 指令周期
- 取指周期:取出指令
- 间址周期:取出操作数地址
- 执行周期:取出操作数,运算,存结果
- 中断周期:检查和响应中断
- 单周期处理器(CPI=1)不能采用单总线方式,因为单总线将所有寄存器都连接到一条公共总线上,一个时钟内只允许一次操作,无法完成一条指令的所有操作
- 微程序和硬布线控制器的PC和IR是相同的,但确定和表示指令执行步骤的方法及给出控制各部件运行所需要的控制信号的方案是不同的
- 硬布线控制器也有微命令与微操作的概念,并非微程序控制器的专有概念,但微指令为微程序控制器专属
- SIMD组织运行于并行硬件上,SISD组织并运行在串行硬件上
- SIMD在使用for循环处理数组时最有效,在使用case或switch语句时效率最低。
- AR、DR、IR寄存器并不是必须的,另外运算器内部的通用寄存器组GR(又称寄存器堆)和程序状态字寄存器PSW属于用户可见存储器,在汇编编程时可以直接使用。其他寄存器为控制器内部使用,用于控制指令的进行
- PSW还可以用于保存中断和系统工作的状态信息,以便CPU能及时了解计算机运行的状态,从而便于控制程序
- 暂存寄存器用于暂存从主存读过来的数据
- 变长指令系统中指令的字节长度需要指令译码后才能确定
- 指令字中的地址码部分由地址生成逻辑对寻址方式进行译码并生成目标地址或数据,根据寻址方式的不同将目标地址送入程序计数器PC,地址寄存器MAR或运算部件。
- MAR不是必须的,部分计算机可以直接将访存地址加载在地址总线上实现访存
- 用户可见和用户可修改的区别
- 用户可见是指能读,不能保证能写
- PSW和PC可见但不能直接修改
- 中断屏蔽字寄存器可见
- 用户可修改是指能读也能写
- 用户可见是指能读,不能保证能写
- MIPS架构里,通常使用RA寄存器作为程序计数器,此时RA寄存器由于可以通过汇编指令显式保存,因此RA对于汇编程序员来说,可以直接读写
- 变址寄存器面向用户,应用程序员可直接读写
- CPU处于用户态时,SP指向用户栈栈顶,此时应用程序员可直接读写,当CPU处于内核态时,SP指向内核栈栈顶,此时应用层程序员没有权限读写,只有系统程序员可以读写。
- 缓存命中率是缓存系统的固有属性,不受寄存器数量影响
- 程序计数器用来保存下一条要执行的指令的地址,这个是必须的,因为CPU需要知道从哪里取下一条地址,否则无法顺序执行或跳转处理。
- 一条指令周期内PC的值可能改变2次,但是单周期处理器中,PC的值只会改变一次
- 单周期处理器的PC,仅在指令周期结束时被更新一次:
- 如果是顺序指令,PC更新为PC+4(或其他增量)
- 如果是分支/跳转指令,PC直接更新为目标地址
- 整个周期,PC不会在中间阶段被修改,因为所有操作是组合逻辑的组合,PC的更新是原子操作(发生在时钟边沿)
- 单周期处理器没有中间阶段的概念,因此PC只能被修改一次(在周期末尾时钟信号跳变时)
- 单周期处理器的PC,仅在指令周期结束时被更新一次:
- 间接寻址中,Ad(IR)字段的值(地址)可能需要暂存或处理
- 在间接寻址中,Ad(IR)的值可能先被复制到MDR,再用于后序操作(如设置MAR或进行地址计算)
- 单周期处理器里面取数指令里的访存,指的是读数据存储器
- 单周期处理器里面存数指令里,写的是数据存储器
- MIPS架构中,只有lw和sw可以访问内存
时钟周期和指令序列
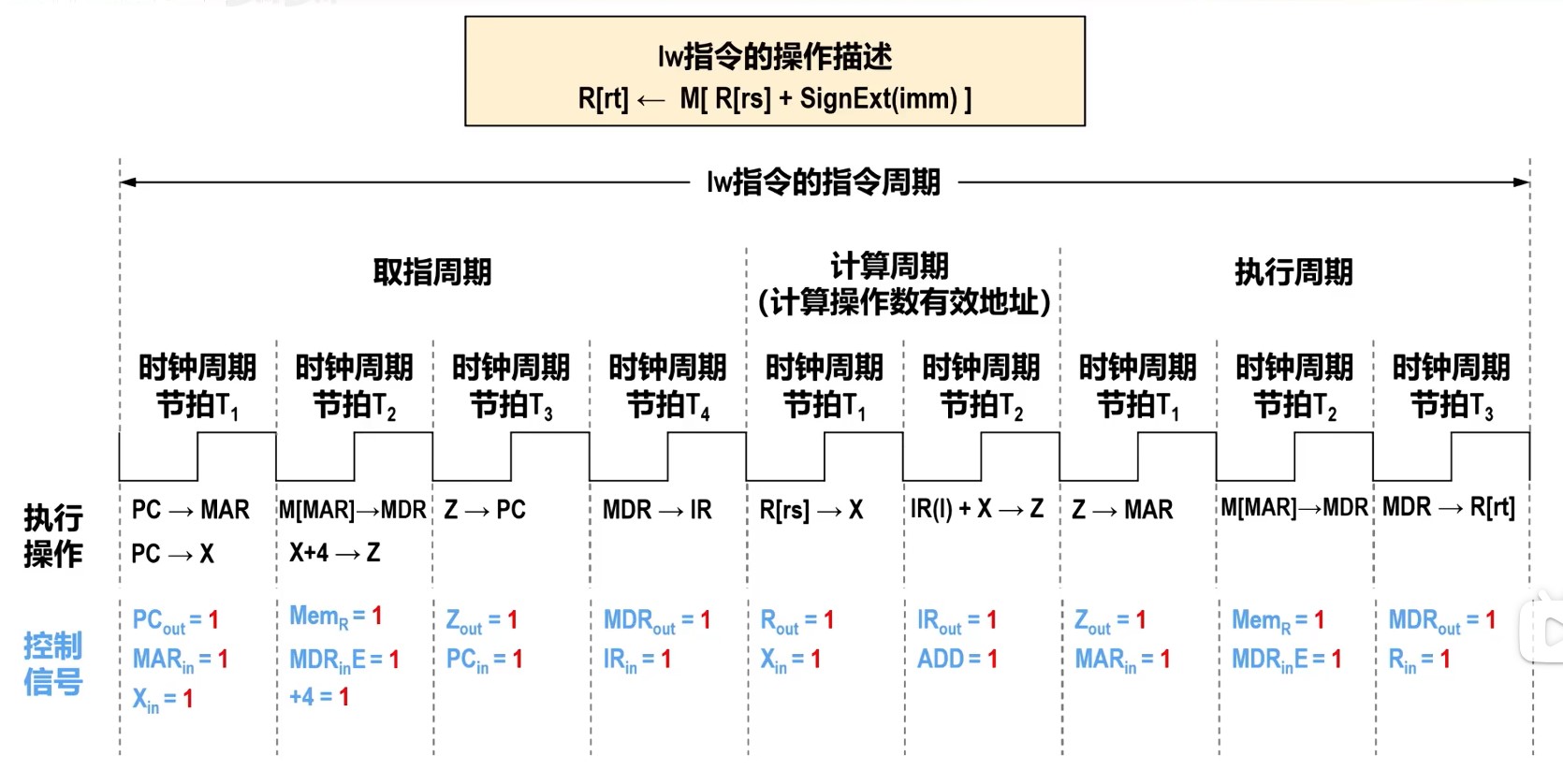
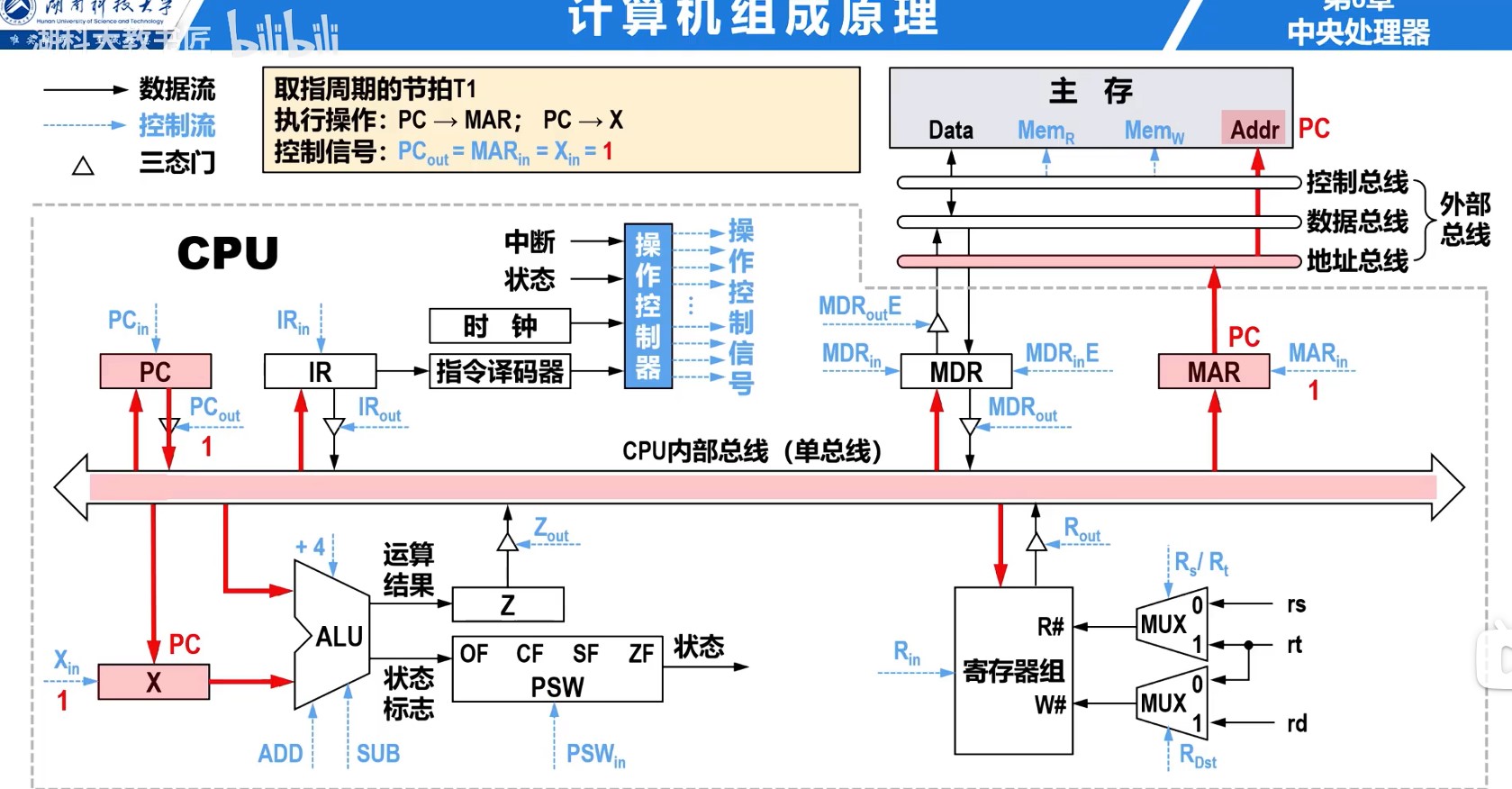
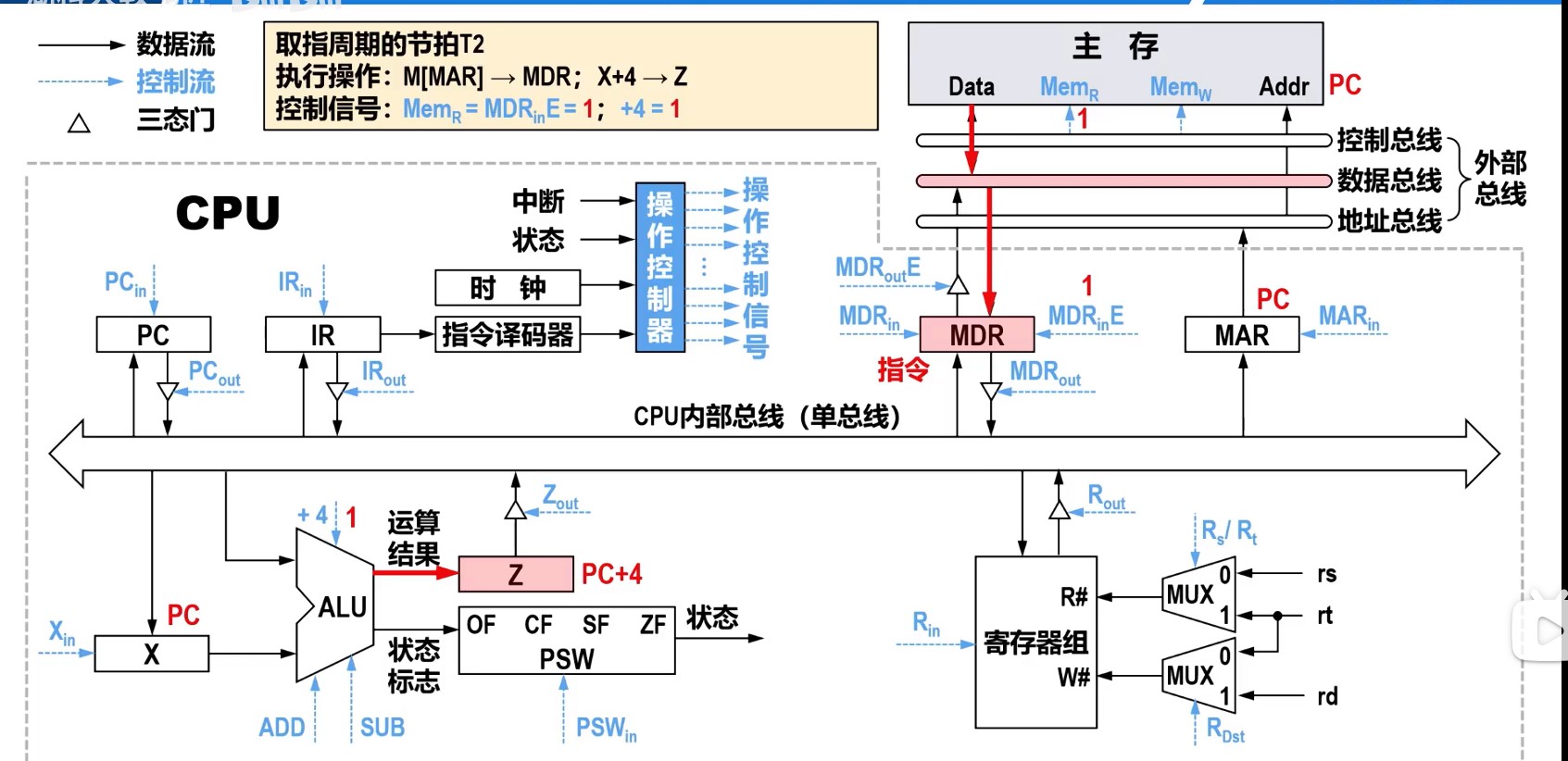
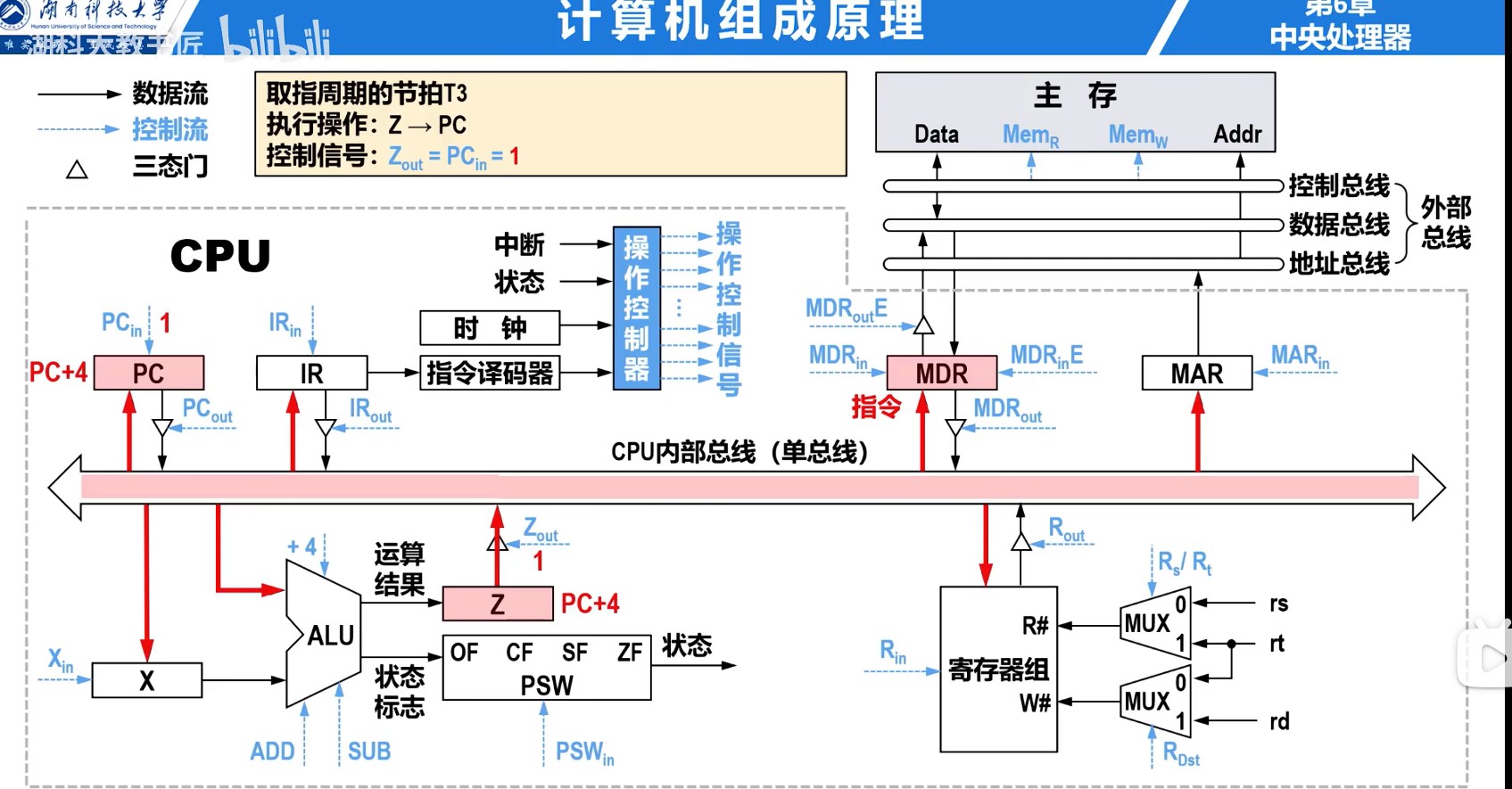
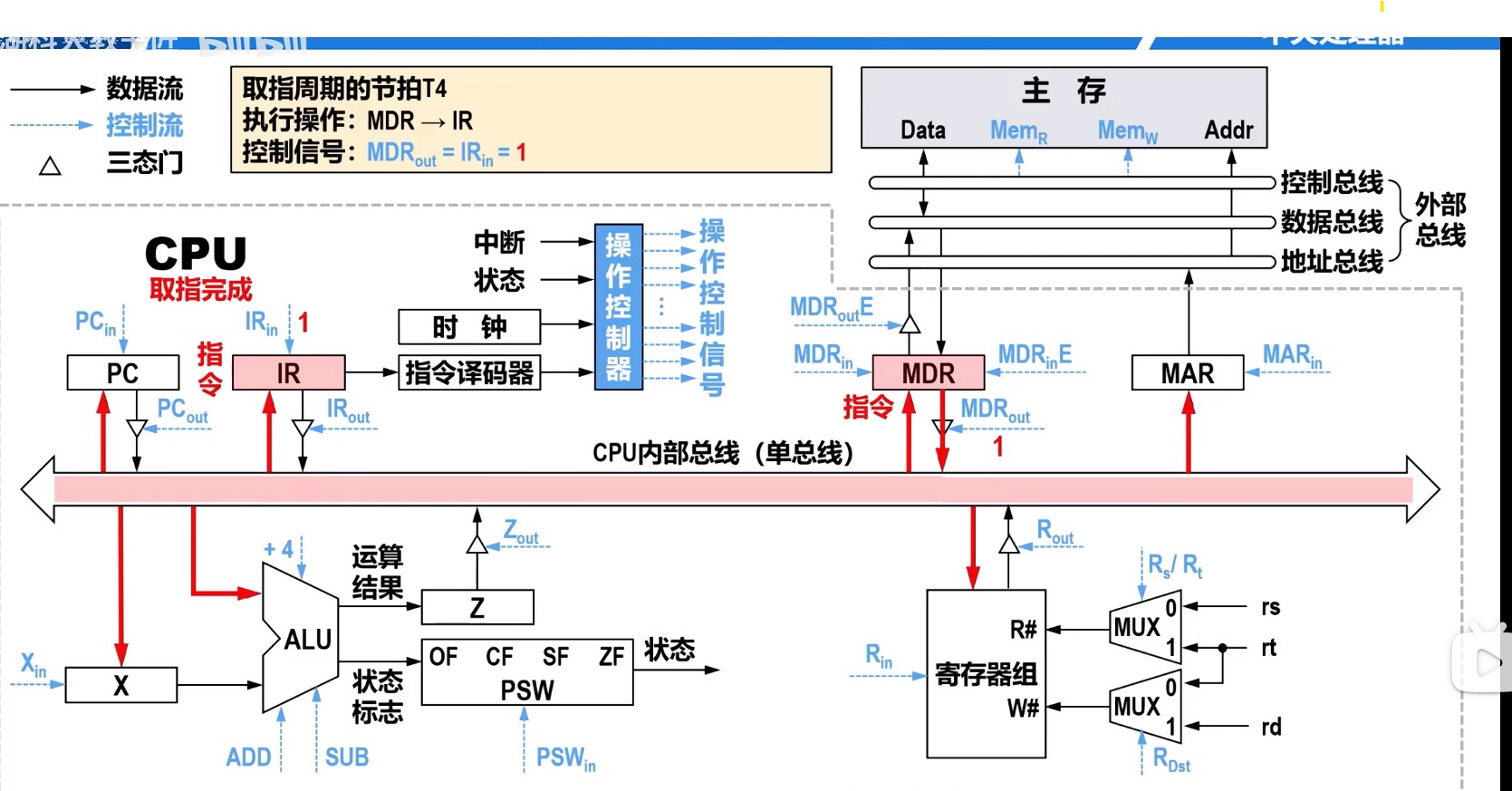
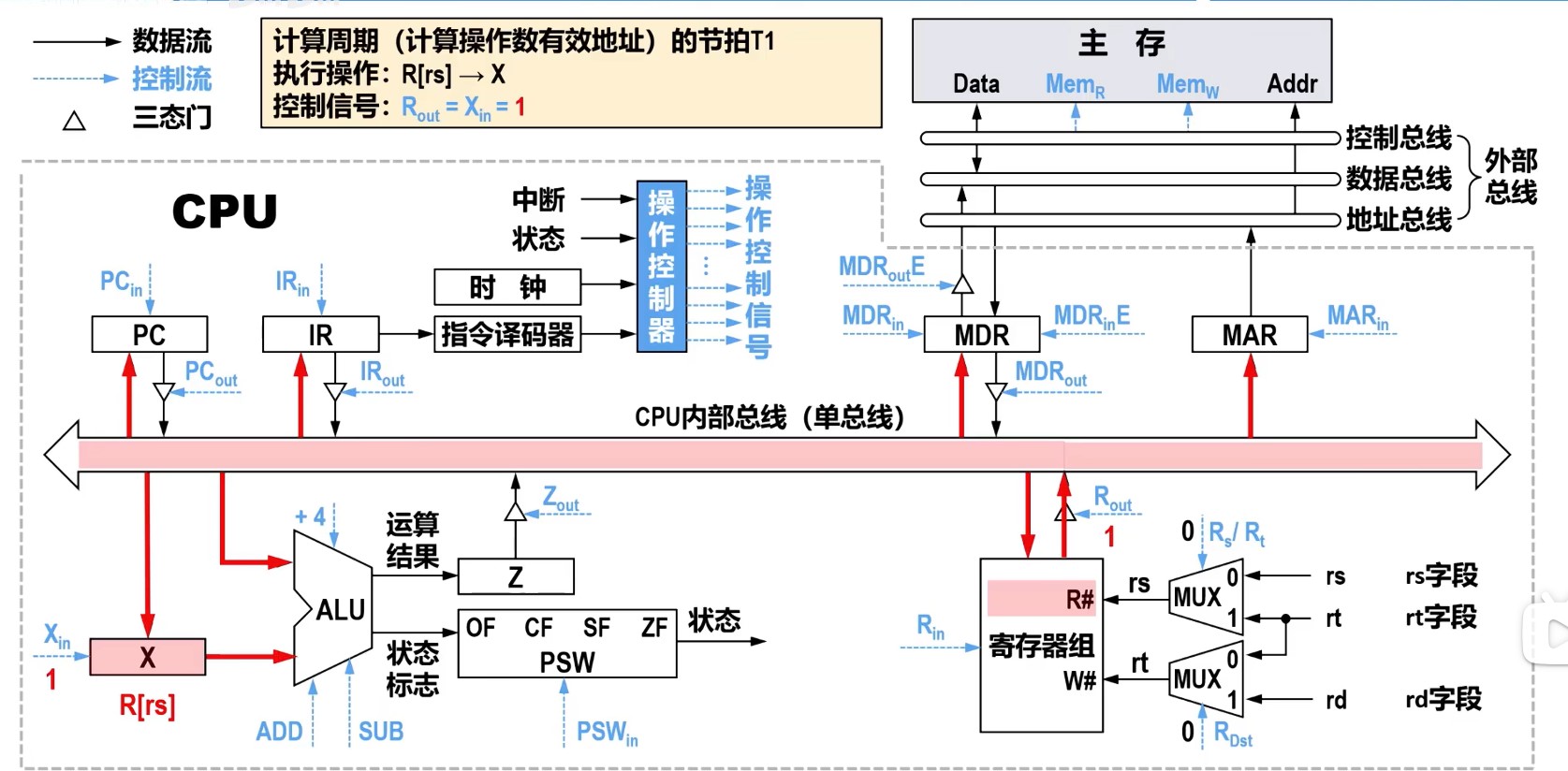
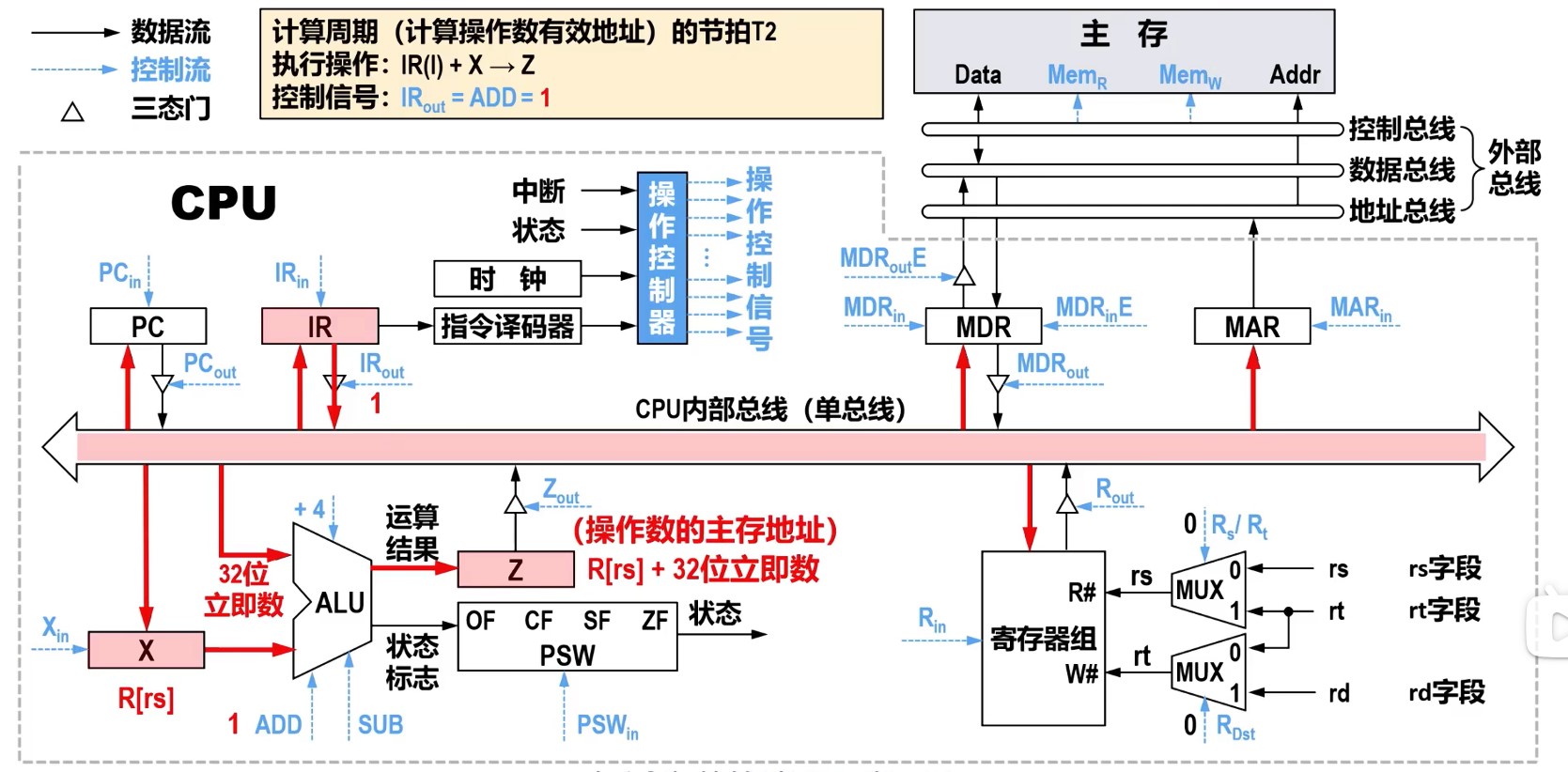
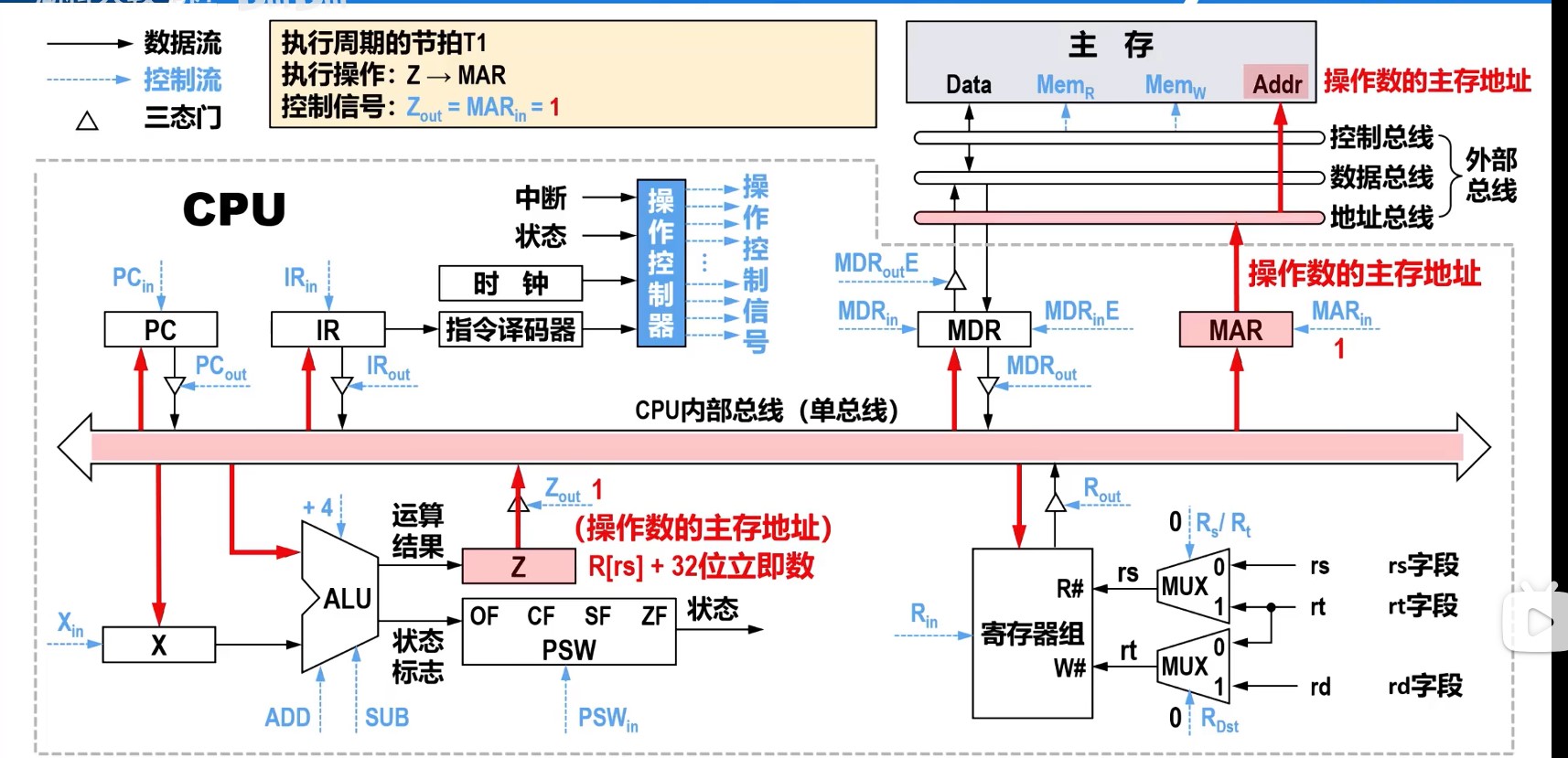
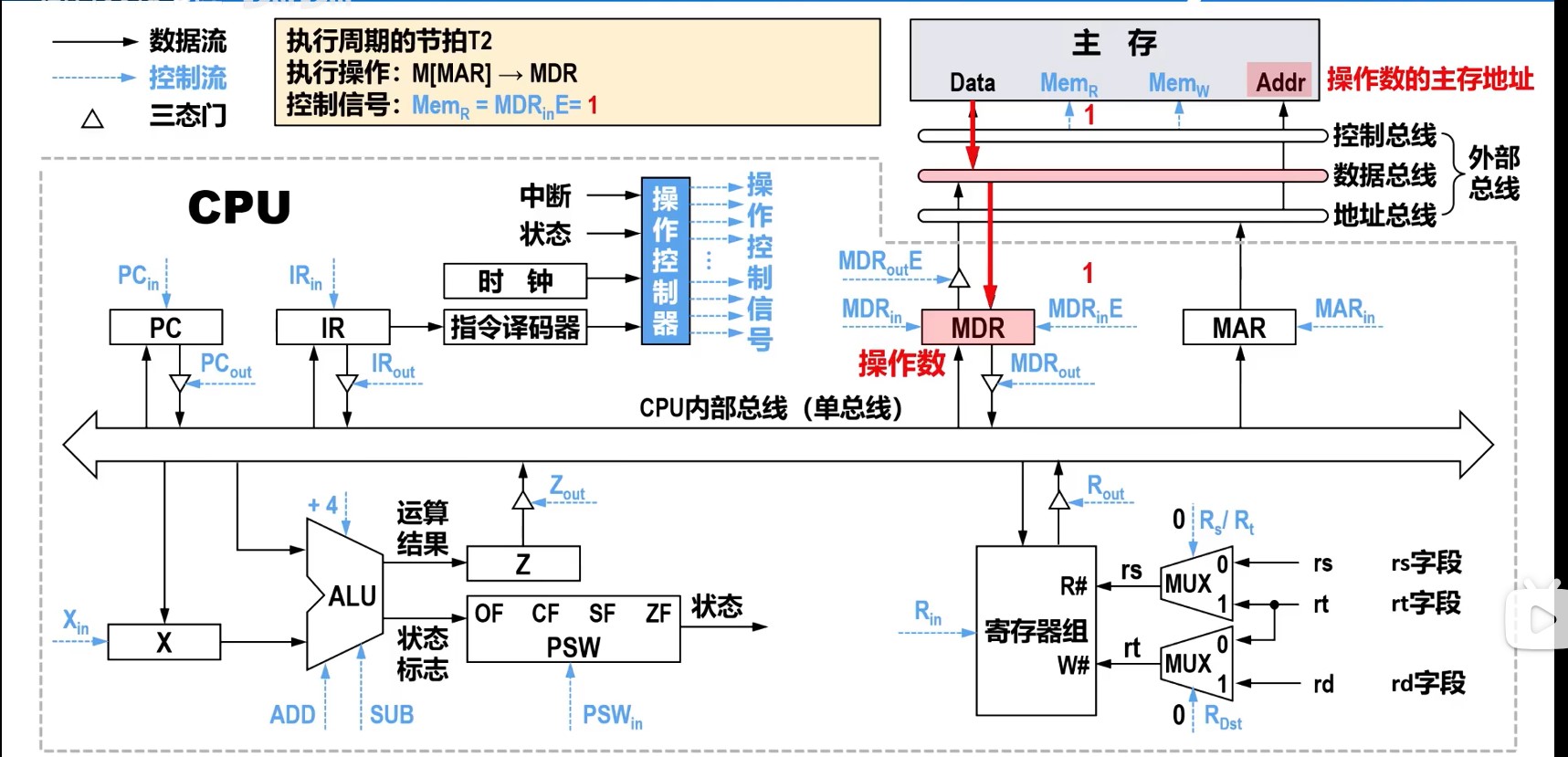
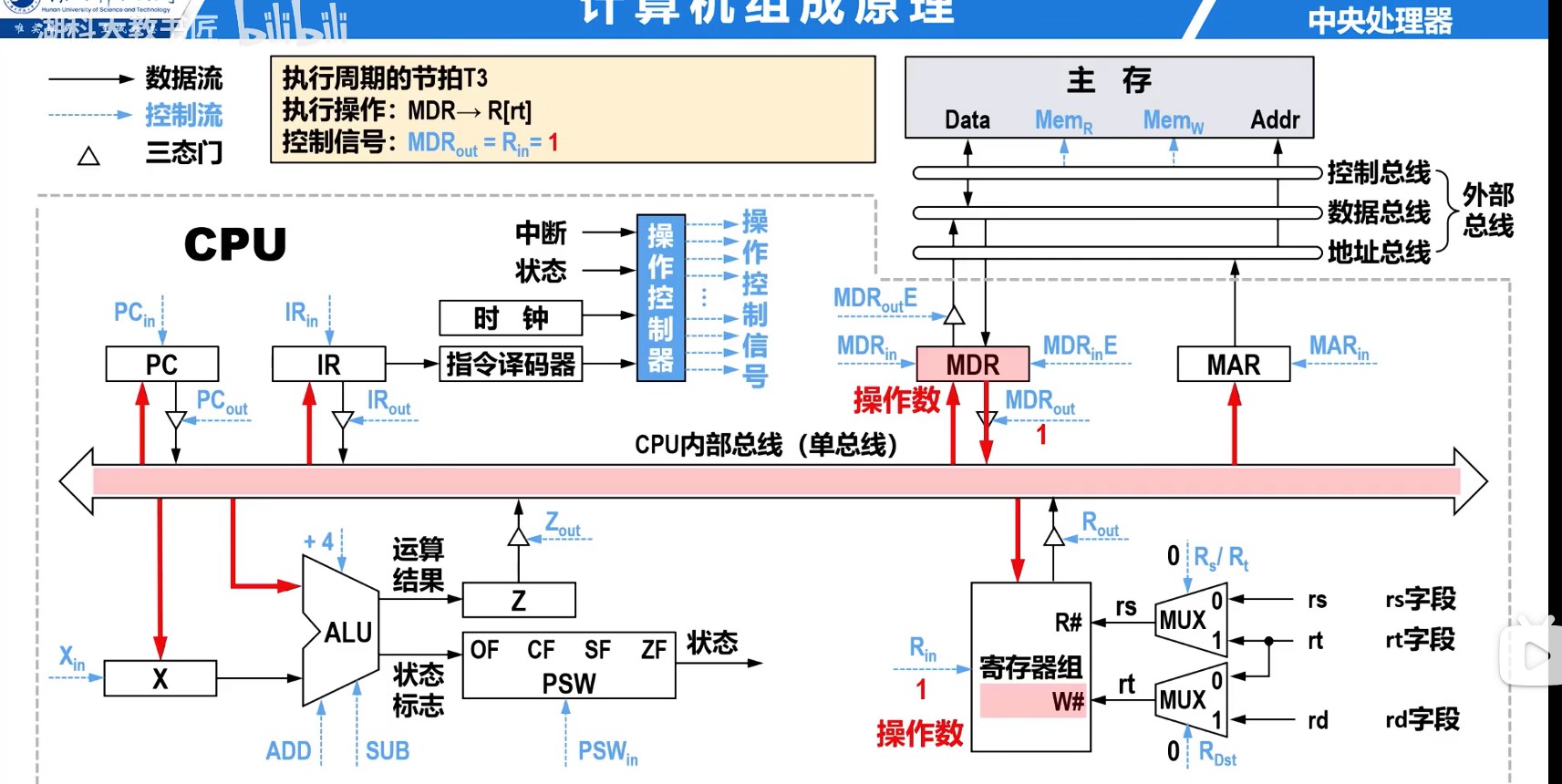
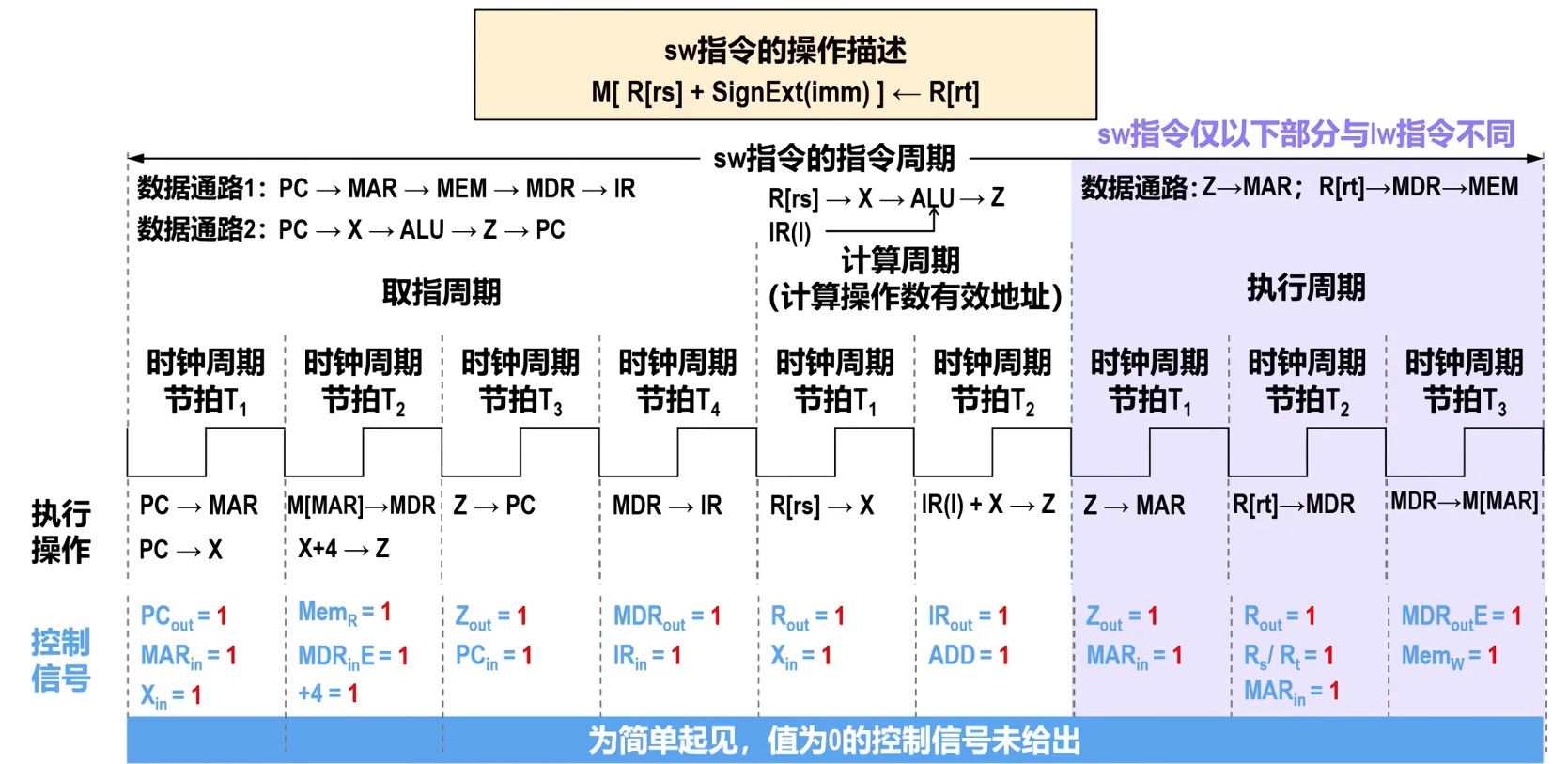

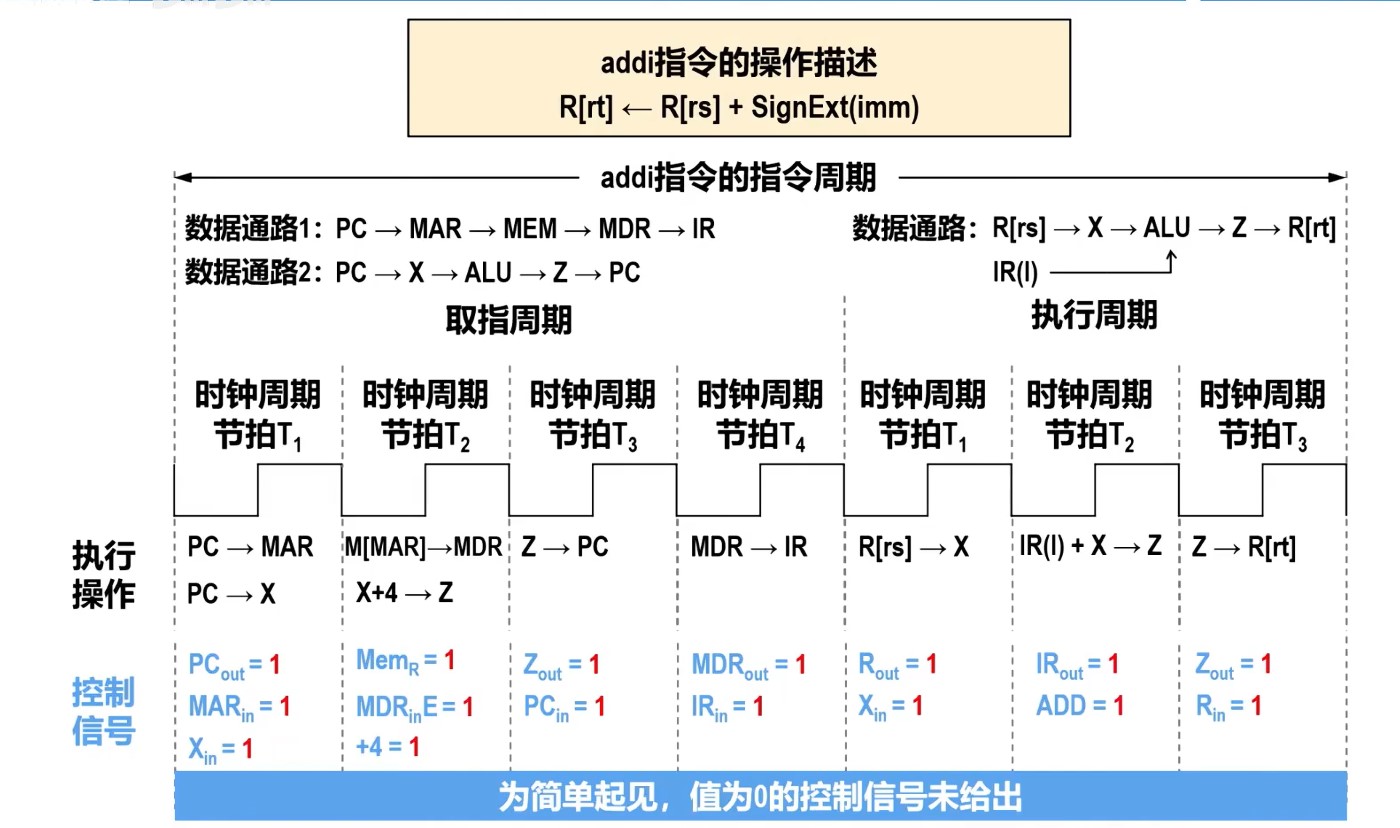
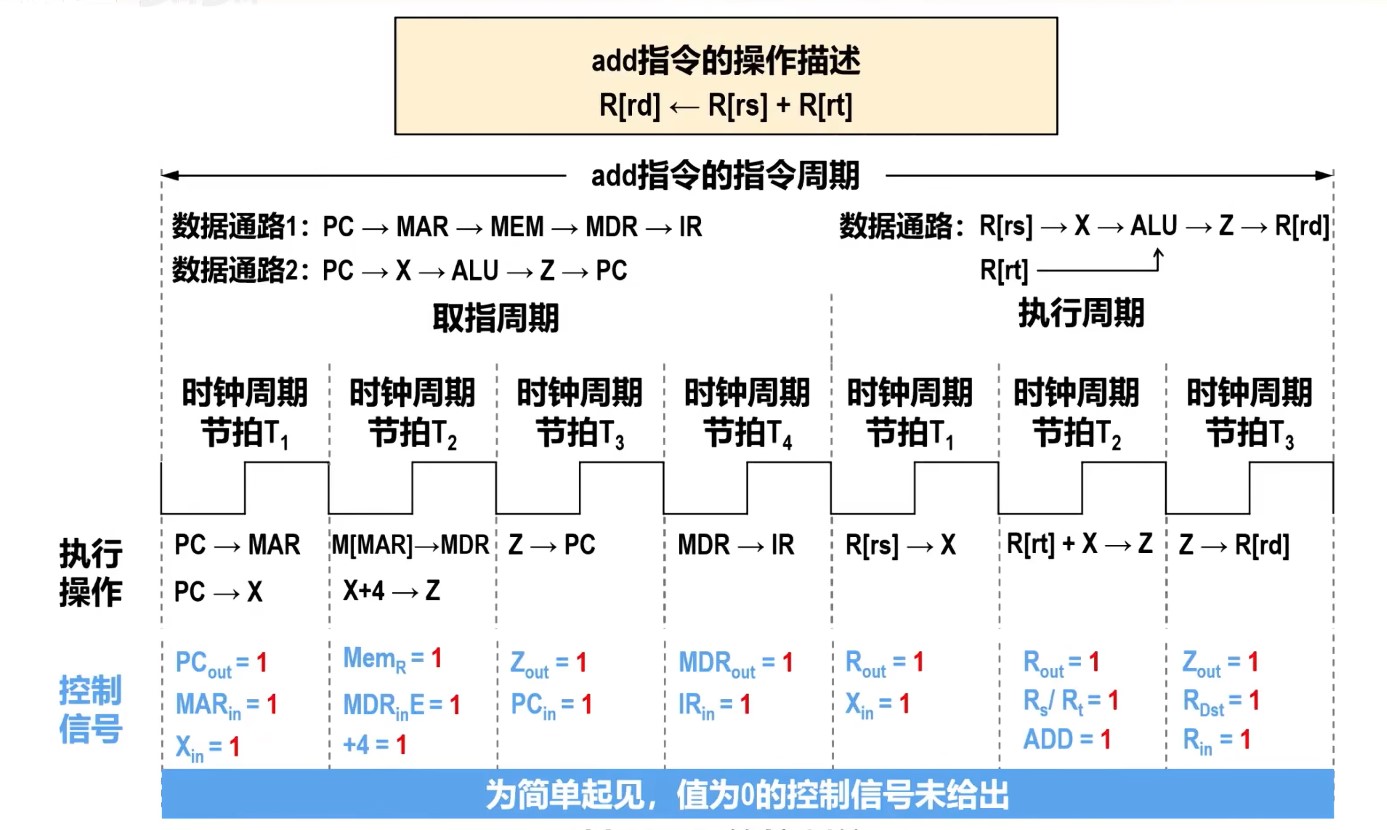
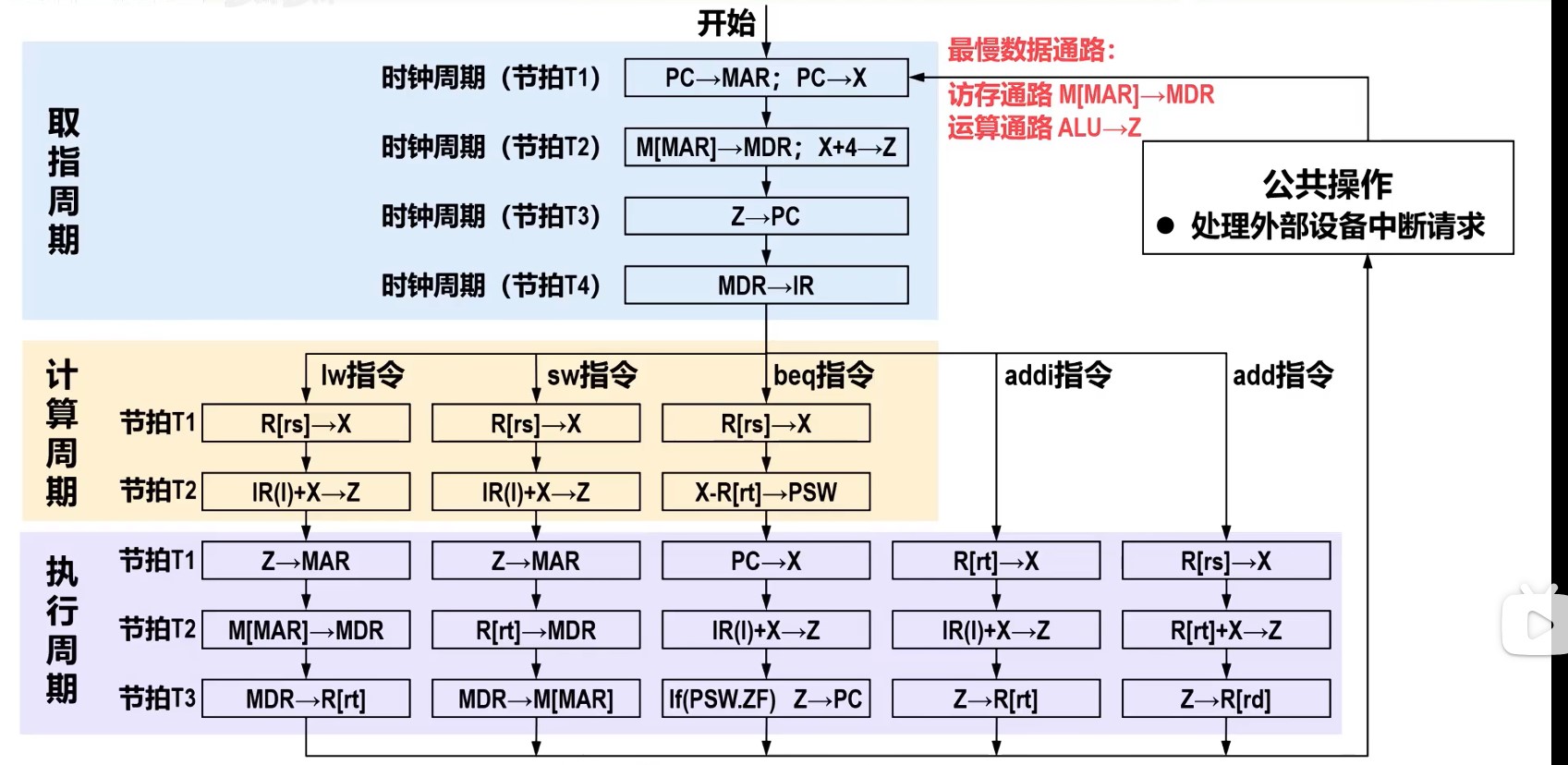
理想CPI

多线程技术
- 细粒度多线程
- 一个时钟周期切换一次线程,需要硬件支持上下文频繁切换,适合实时系统
- 粗粒度多线程
- 某个线程出现了较大阻塞才切换线程,适合计算密集型指令
- 同时多线程
- 超线程
- 把一个物理核模拟成多个逻辑核,多个线程在一个时钟周期内并行执行。只要两个线程的指令在功能部件上不冲突,就可以并行发射,比如一个机算一个访存,这两个线程就是并行发射执行
- 超线程
- 多线程技术是一种共享单处理器中功能部件的技术。每个线程相当于一个指令序列,为了支持多线程并发执行,必须为每个线程提供单独的通用寄存器组、单独的程序计数器等,并提供快速的线程切换。
- 备份n份现场,n个线程,n个PC,n个通用寄存器组,直接从自己专用的取

硬布线控制器
-
个别指令的操作不仅受操作码控制,而且还受状态标志控制,因此CU的输入来自操作码译码电路、节拍发生器及状态标志,其输出到CPU内部或外部控制总线上。
-
功能由逻辑门组合实现,其速度主要取决于电路
-
采用时序逻辑技术实现,采用组合逻辑电路和状态寄存器进行设计的控制器,纯硬件实现
-
硬布线控制器适合于简单或规整的指令系统
-
硬布线控制器逻辑表达式的推导



- ①确定在哪一个周期里面
- ②在哪个节拍进行操作
- ③哪些指令会执行这个微操作
- 同时与,并列或
微程序控制器
-
-
在并行微程序控制器中,由于取微指令和执行微指令的操作是在两个完全不同的部件中执行的,因此,可以将这两部分操作同时进行
-
微程序控制器中,执行指令微程序的首条微指令地址是指令操作码译码得到的
- 微指令中的微地址码字段,用于控制产生下一条要执行的微指令地址
- 起始和转移地址形成部件(简称微地址形成部件),用于产生初始和后继微地址,用以保证指令的连续执行
-
硬布线控制器又名组合逻辑控制器
-
取指微程序是每条机器指令公共的微程序,入口地址通常固定(μPC初始置0,即CM中的首条就是取指微程序的首地址,然后执行取指微程序进行取指)
-
控制存储器(CM)用于存放微程序,在CPU内部,用ROM实现。存放微指令的存储控制器的单元地址称为微地址
-
控制存储器中的微程序能解释执行整个指令系统的所有指令
-
每条指令都要访问控制存储器
-
取指微程序和机器指令微程序的关系和区别
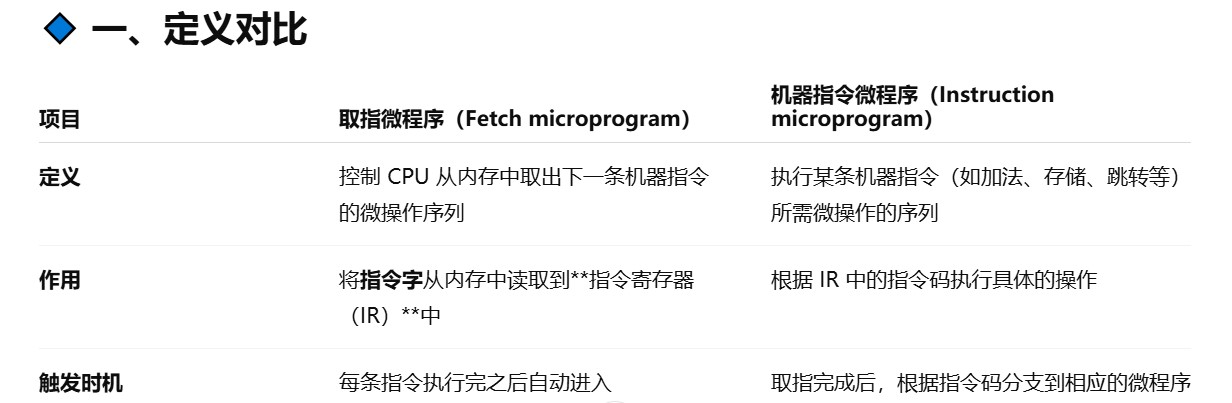




-
微程序是计算机设计者事先编制好并存放在控制存储器中的,一般不提供给用户。对于程序员来说,系统中微程序的功能和结构是透明的。
-
工作过程
-
①取指。机器自动将取指微程序的入口地址送μPC,并从CM中读出相应的微指令并送入μIR。
-
取指微程序:取指操作(Fetch Cycle)是所有指令共享的通用操作,它不属于任何特定指令的执行微程序。取指微程序的入口地址通常是固定的(例如,地址0或某个硬连线的地址),不是由操作码产生的。CPU在复位或开始执行指令时,总是先进入这个固定的取指微程序。
-
在CPU开始运行(例如,上电复位或复位信号触发)时,μPC会被硬件强制初始化为这个固定的取指微程序入口地址。这是通过复位逻辑实现的,而不是由操作码产生的。
-
在指令执行过程中,当一条指令的微程序执行完毕时,地址形成部件会自动将μPC设置为取指微程序的入口地址,从而开始下一条指令的取指周期。这通常是通过一个“返回”机制实现的,例如,在微指令中包含一个字段指定下一个地址源为“取指入口”。
-
假设CPU正在执行一条指令(如ADD)。当ADD指令的微程序完成后,地址形成部件会检测到“指令结束”状态,并自动将取指微程序的入口地址加载到μPC。
-
计数器法下,微指令中没有地址码字段,实际上,取指微程序的入口地址由上一条机器指令对应的微程序最后一条微指令的控制字段给出,下图是一种实现方式,当控制字段为00的时候,直接将0(取指微程序地址)送μPC。
-
也即,开始时是硬件实现,后面是控制字段实现
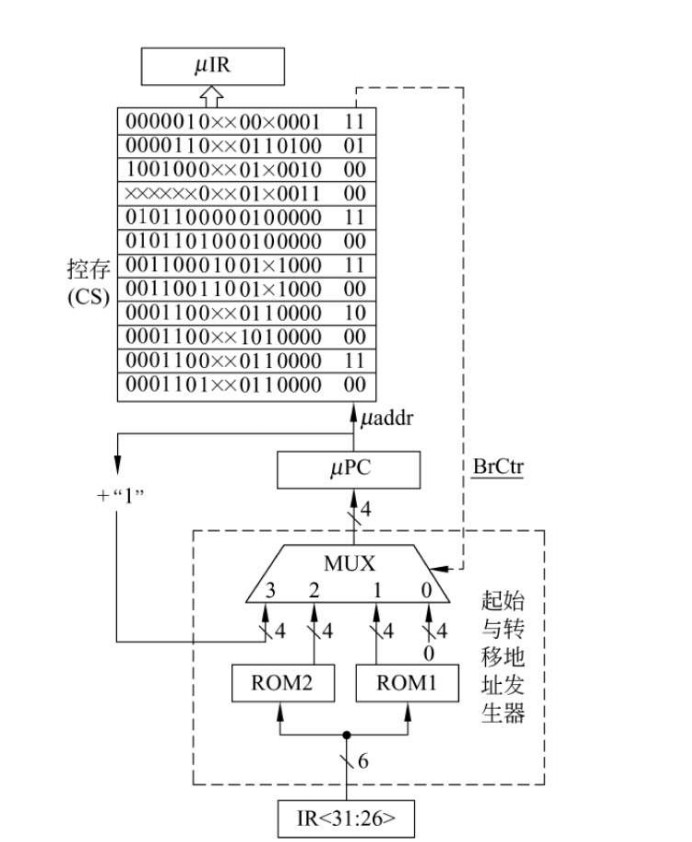
-
-
-
②由机器指令的操作码字段通过微地址形成部件产生该机器指令所对应的微程序的入口地址,并送入μPC
- 每次把新指令装入IR的时候,微地址形成部件将根据指令内容,生成微程序入口地址放入μPC中
-
③从CM中逐条取出对应的微指令并执行
-
④执行完对应于一条机器指令的一个微程序后,又回到取指微程序的入口地址,继续第①步,以完成取下一条机器指令的公共操作。
-
总结:取指微程序初始化→取出指令→根据取出指令的操作码找到对应的微程序→开始执行
-
微指令中的转移控制部分被送微地址形成部件,根据条件码和相应微命令产生新的微指令地址送入μPC
-
若当前执行的是某条机器指令对应微程序的最后一条微指令,则下一条微指令就是取指令微程序的第一条微指令
- 若执行完取指令微程序的最后一条微指令,则下一条微指令就是当前指令对应微程序的首条微指令
- 若在某个微程序执行过程中,则可能按顺序取出下一条微指令执行,或者无条件转到另一处微指令执行,或根据条件码或指令操作码选择不同分支处的微指令执行。
-
-
控制存储器中的微程序个数应为机器指令数再加上对应取指、间址和中断周期公共的微程序数
-
计数器法转移执行时,在当前微指令后添加一条转移微指令,并在微指令中添加专门的转移控制字段,将转移微指令或转移控制字段中的控制信息送到微指令地址发生器,与相应的指令操作码以及条件码等组合,生成转移地址送μPC。
- 当转移分支很多时,相应的微地址生成逻辑电路很复杂。为简化微地址生成逻辑,通常采用PLA或ROM来实现。
-
微程序相对固定,通常不放在主存内
微指令地址的确定
-
计数器法
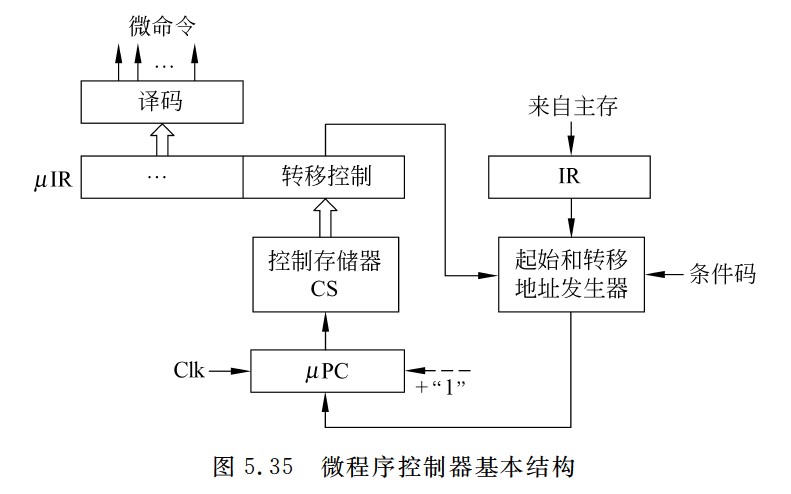
- 使用一个专门的微程序计数器μPC,将下条微指令地址隐含地存放在μPC中,因此,这种方法称为计数器法。
- 顺序执行时,根据μPC+1→μPC,得到下一条微指令地址;转移执行时,在当前微指令后添加一条转移微指令,并在微指令中添加专门的转移控制字段,将转移微指令或转移控制字段中的控制信息送到微指令地址发生器,与相应的指令操作码以及条件码等组合,生成转移地址送μPC。
- 图5.35所示的就是采用计数器法的微程序控制器基本结构。当转移分支很多时,相应的微地址生成逻辑电路很复杂。为简化微地址生成逻辑,通常采用PLA或ROM来实现。
-
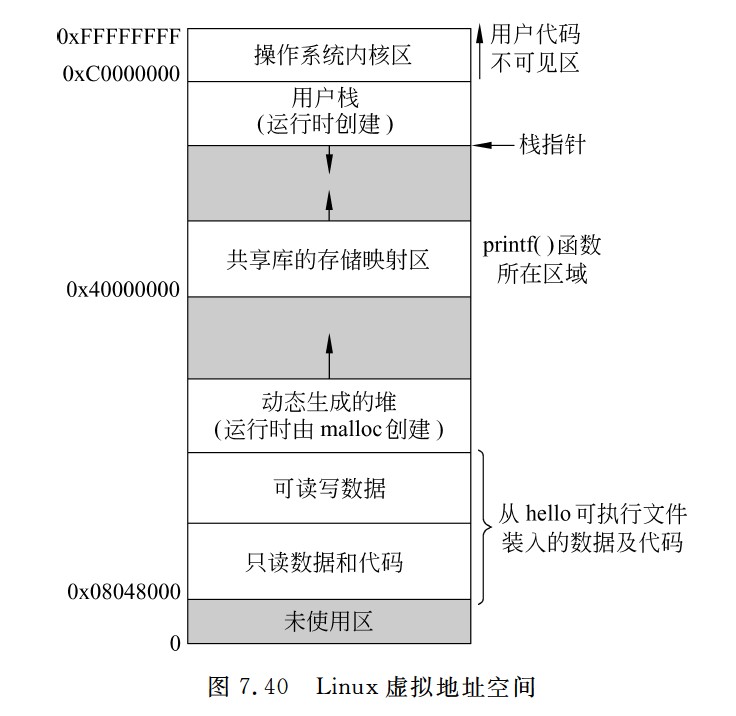
断定法
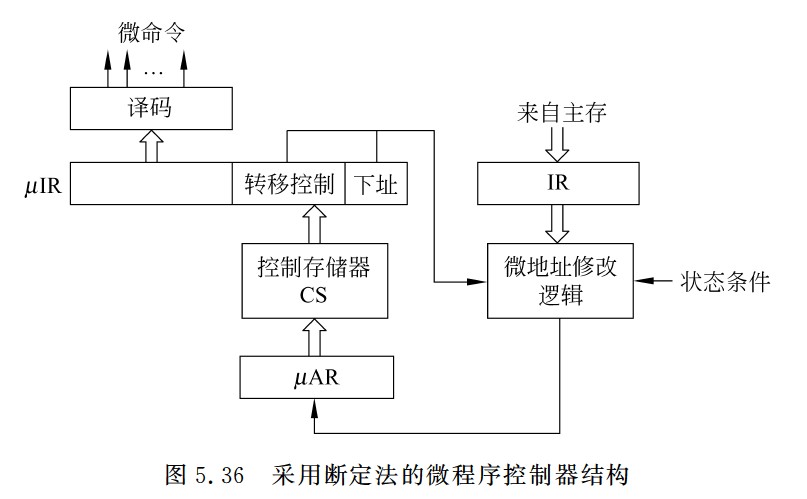
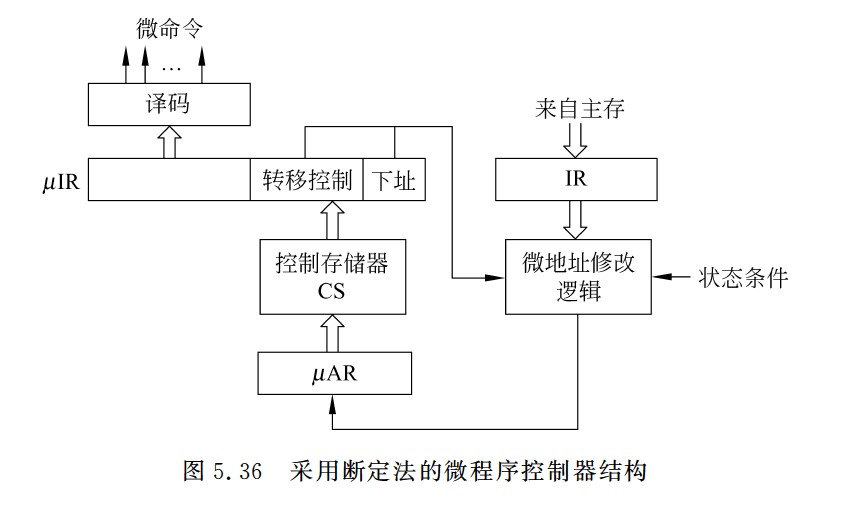
- 计数器法的缺点是必须在不连续执行的微指令之间加入转移微指令,这样,在增加微指令条数的同时,还严重影响指令执行速度。如果在微指令中直接明确指定下一条微指令地址,这样,相当于每条都是转移微指令,即使不连续执行也没有关系。这种方法称为断定法,也称为下址字段法。断定法虽然加快了指令执行速度,但因为增加了微指令的长度,从而影响控制存储器的有效利用。例如,假定一个采用微程序控制器的处理器的控存容量为4KB,共有500条左右的微指令,这意味着下址字段至少有9位,微指令长度为64位左右,其中除了下址字段以外,还有一些其他如控制多分支转移的条件测试和转移控制字段等,也都用于控制微指令的寻址,因此,大约有五分之一的控存空间用于微指令寻址,真正用来存放微命令的空间只有五分之四左右。
此方法最明显的优点是消除了专门的转移微指令,而且在给微指令分配地址时不需要考虑如何排列,也不需要对μPC增量,而用一个简单的微指令地址寄存器(μAR)来存放当前微地址。采用断定法的微程序控制器结构如图5.36所示,其中,微地址修改逻辑根据当前指令、状态条件、下址字段和转移控制字段来确定微程序的执行顺序。
- 计数器法的缺点是必须在不连续执行的微指令之间加入转移微指令,这样,在增加微指令条数的同时,还严重影响指令执行速度。如果在微指令中直接明确指定下一条微指令地址,这样,相当于每条都是转移微指令,即使不连续执行也没有关系。这种方法称为断定法,也称为下址字段法。断定法虽然加快了指令执行速度,但因为增加了微指令的长度,从而影响控制存储器的有效利用。例如,假定一个采用微程序控制器的处理器的控存容量为4KB,共有500条左右的微指令,这意味着下址字段至少有9位,微指令长度为64位左右,其中除了下址字段以外,还有一些其他如控制多分支转移的条件测试和转移控制字段等,也都用于控制微指令的寻址,因此,大约有五分之一的控存空间用于微指令寻址,真正用来存放微命令的空间只有五分之四左右。
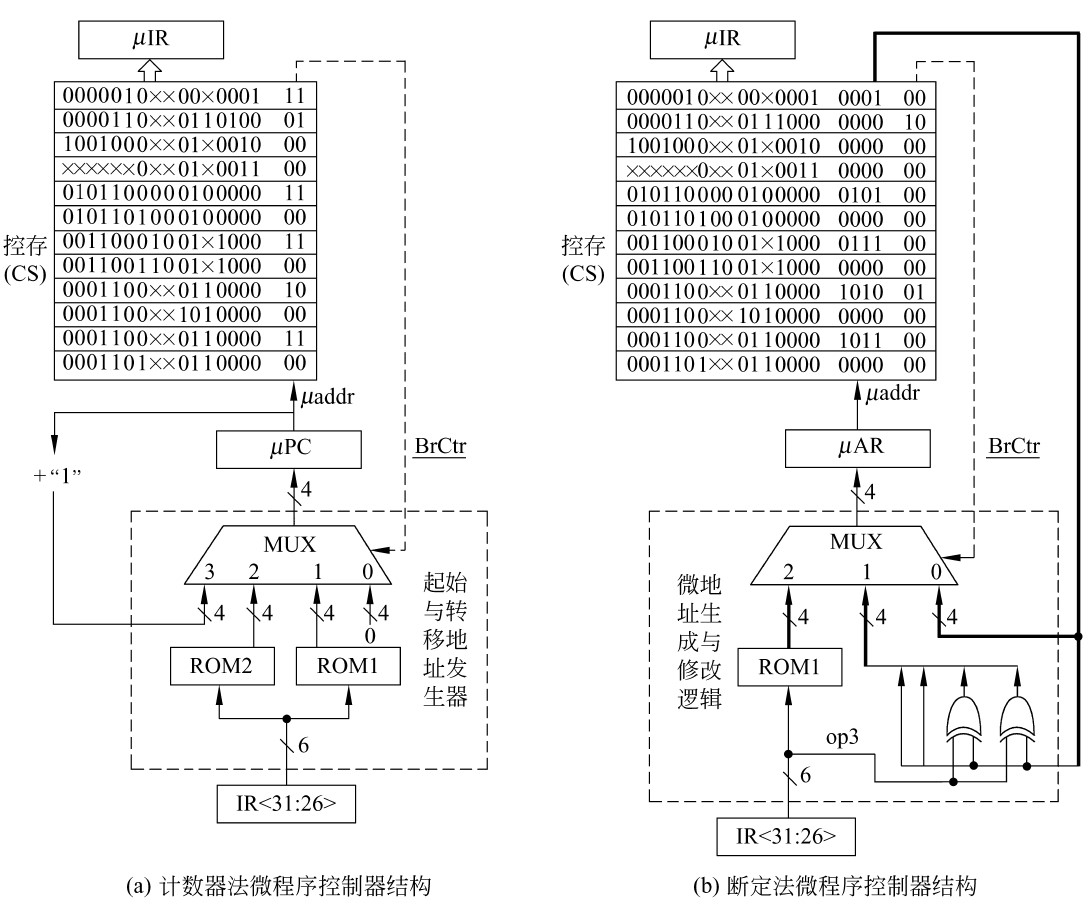
计数器:
- BrCtr=00:转到取指令微程序首条微指令执行。
- BrCtr=01:转到由**ROM1的输出所指的微指令(执行微程序的第一条指令)**执行。
- BrCtr=10:转到由R**OM2的输出所指的微指令(lw/sw指令的分支跳转)**执行。
- BrCtr=11:按顺序执行。
断定法:
- BrCtr=00:转到微指令的下址字段指出的微指令执行。
- BrCtr=01:转到由op3修改后的微地址所指的微指令执行。
- BrCtr=10:转到由ROM1的输出所指的微指令执行。
- ROM1:存放的是各指令微程序的首地址。取指令微程序的首地址为0000,地址0001处的为指令执行结束后,可能会转到不同指令(执行微程序)对应的微程序指令,其分支转移功能由ROM1实现
- ROM2:两个单元,分别存放1001和1010,lw和sw指令的微程序中有一个分支转移点,需要根据当前指令是lw还是sw来决定1000处的微指令执行后是转到1010处执行还是1001处执行。lw/sw指令微程序中的分支功能由ROM2实现。
- 第一条微指令的地址是根据当前指令从
μIR中取得的,并由μPC指向。 - 后续的微指令则由
μPC自动递增,指向下一个微指令的地址。
单周期处理器
华科大计组配套视频 单周期mips数据通路_哔哩哔哩_bilibili
-
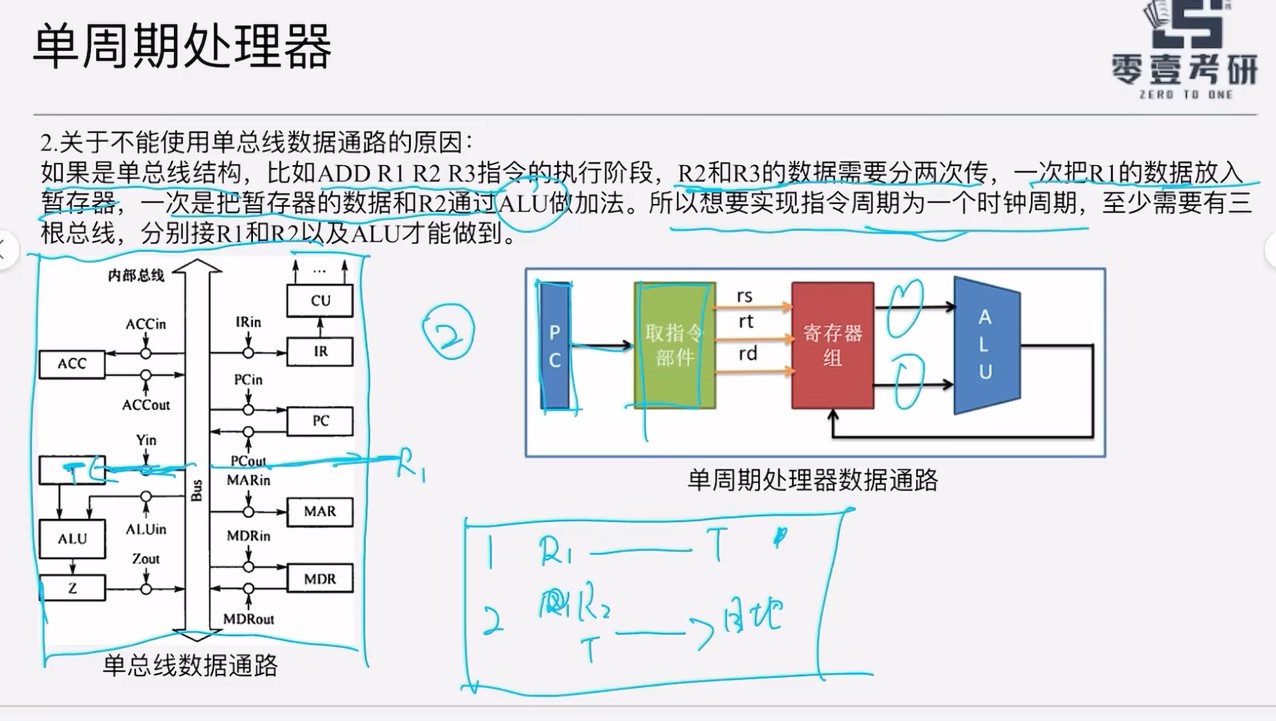
单周期处理器使用硬连线控制和非总线结构(如直接控制和多路选择器),是专用数据通路而非多总线。总线式结构更常见于多周期或微程序控制处理器中。
-
单周期处理器的整个数据通路中只可以存在两个状态单元,因此,指令Cache被设计成只读的组合逻辑单元,CPU不能对指令Cache进行写操作,只能执行读操作。
-
由于指令寄存器是只读的,因此单周期处理器将其设计为无需控制信号的控制,只需要给出指令地址,经过一定的取数时间后,指令被送出
-
单周期处理器中,取指阶段并不会直接将指令输出。而是将指令的控制信号,源操作数和目的操作数输出
-
要想实现指令周期为一个周期,至少需要有三根总线,分别接R1和R2以及ALU才能做到
-
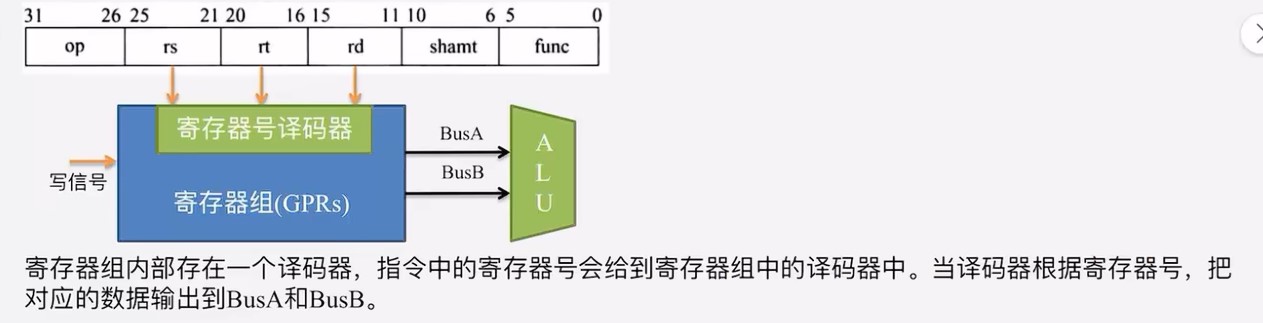
寄存器组在单周期处理器中,既允许执行读操作,也允许执行写操作。若执行读操作时,寄存器组当作组合逻辑部件。若需要写寄存器时,CPU给出写信号,寄存器组此时变成状态逻辑部件
-
单周期处理器,指令执行过程中控制信号不变
-
单周期处理器在取指令的时候,并不会将指令取出,而是根据 PC中的值,由取指部件经过一段取指时间后,直接输出指令的控制信号和需要的操作数。
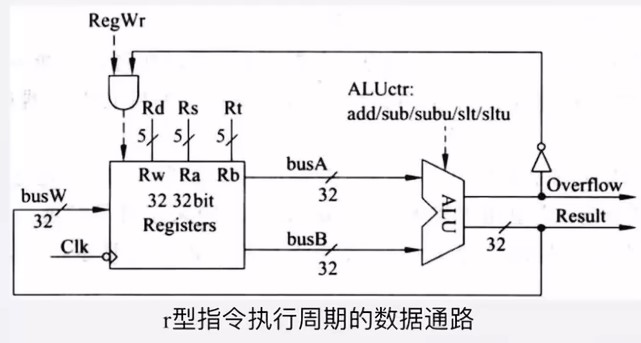
-
寄存器堆的读操作,被设计成自动执行的操作,不需要其他的控制信号,但是写寄存器必须明确写控制信号
-
单周期处理器的数据通路中,除了存在有效的数据流,还同时存在无效的数据流。这是单周期处理器本身无法避免的一个缺陷。
-
红色有效数据流,蓝色无效数据流
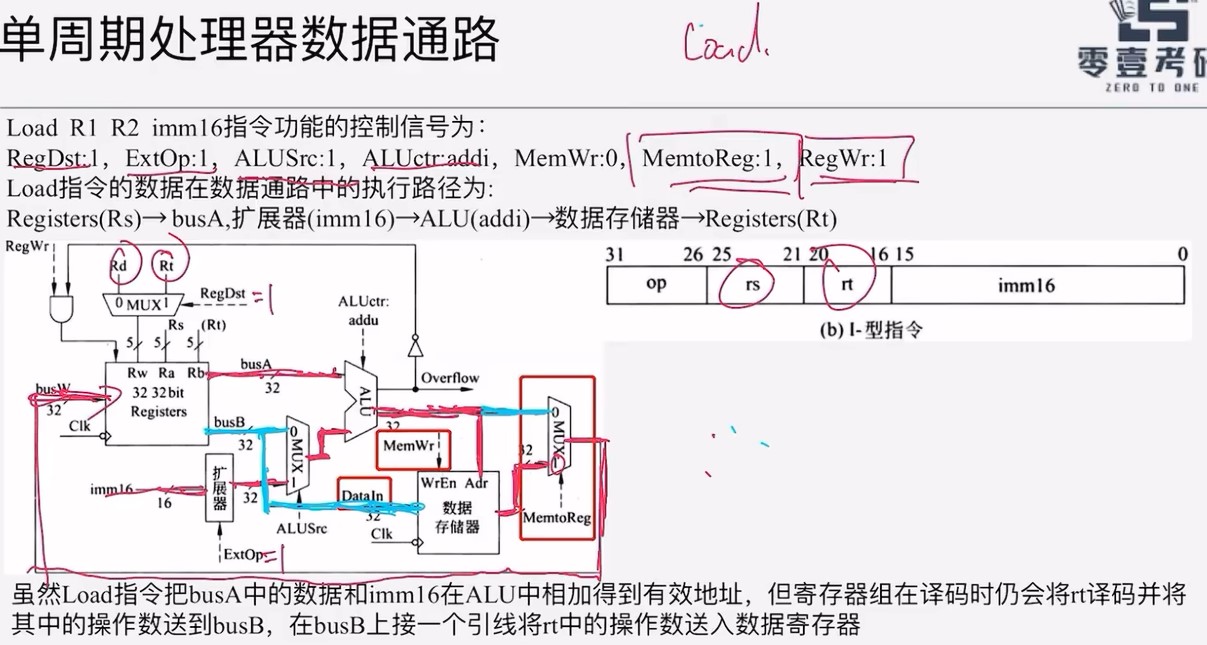
-
ADD指令的计算结果会从ALU输出。这个结果也会被当作成主存地址,并且数据存储器会将地址中的数读出,这个操作是十分危险,却无法避免的。因为数据寄存器Adr并不知道ALU输出的是地址还是计算结果,只会机械地将所有ALU输出的值当作主存地址,并将对应的数据读出
-
Store指令的功能是通过计算得到主存地址,然后将寄存器里面的数据写到主存地址中
- 会把无效数据写入计算机中
-
对于多路选择器来说,0和1均表示有效信号,以选择不同的输入作为输出
-
指令执行的过程中,所需要使用的功能部件都应该能够完全并发,同一功能部件需要多次使用时,就应该设置多个相同的功能部件
- 每个控制信号被送到向相应的控制点,一直作用在数据通路中,每个部件只完成一种功能,不会被多次使用。
-
取指令操作的延时主要由存储器的取数时间决定
-
寄存器组的作用:同时提供两路读一路写
- 图中Rs,Rt前面的25:21是指指令中读取哪几位,根据指令格式,对应的是寄存器的编号
-
寄存器组(Register File)
R1#、R2#:读端口寄存器号(由指令的 rs、rt 字段决定)。R1、R2:对应的 Read Data(RD),即读出的源操作数。W#:写寄存器号。WD:Write Data,要写回目标寄存器的内容。
数据存储器(Data Memory)
A:访问地址。RD:Read Data,存储器取出的内容(比如 lw 指令读出的数据)。WD:Write Data,要写进存储器的内容(比如 sw 指令写进去的寄存器值)。
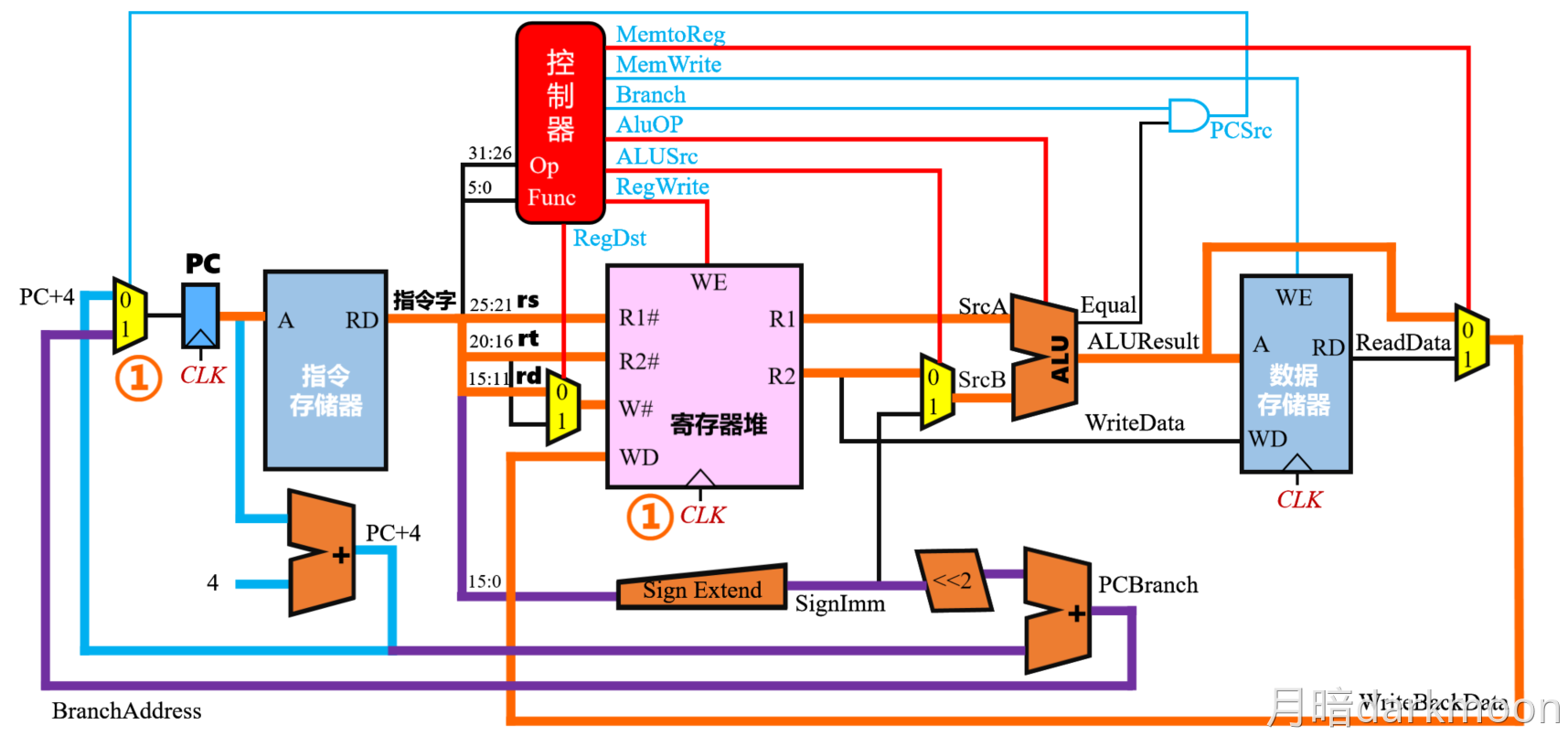
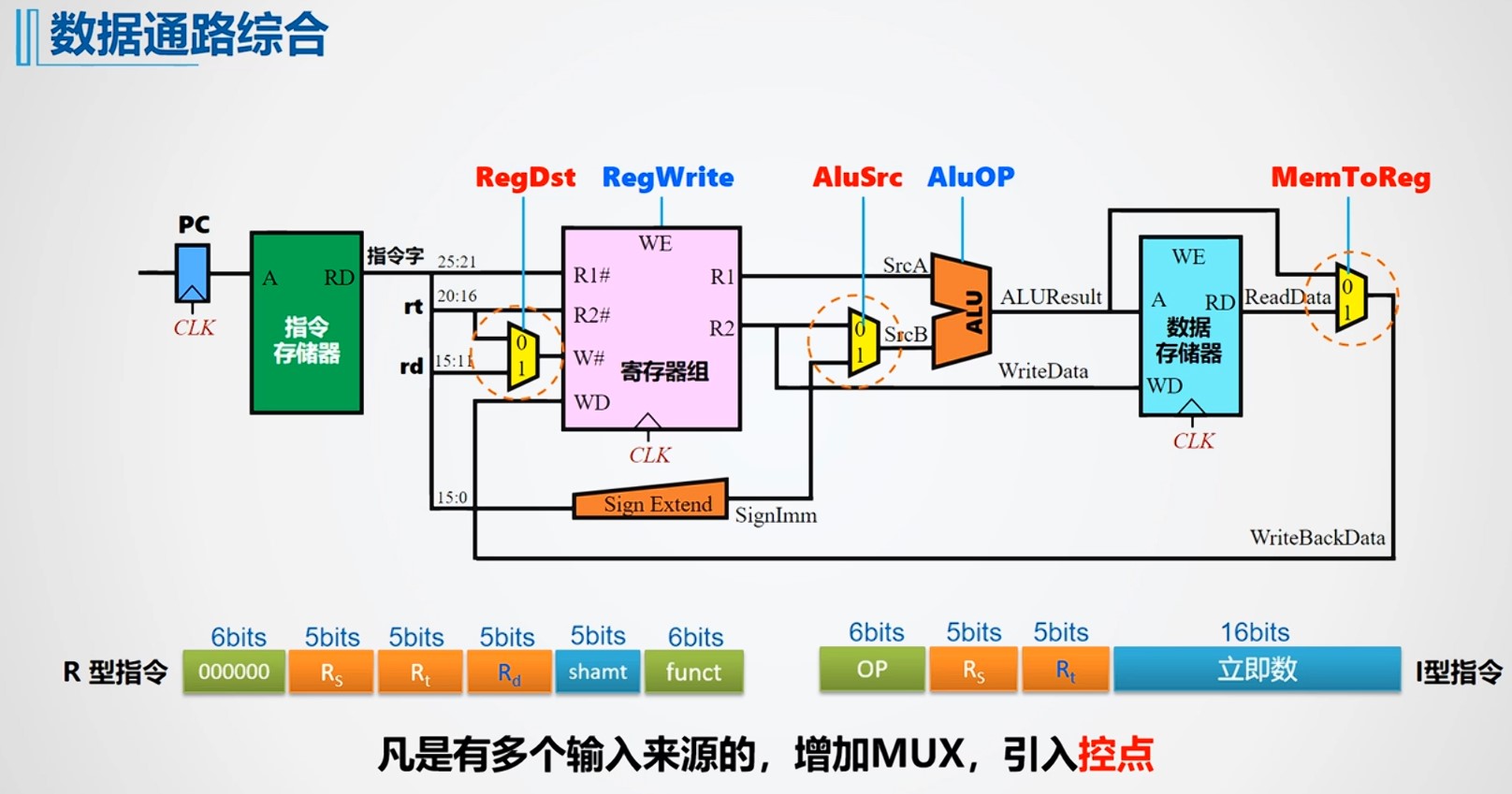
- RegDst:由于在I型指令和R型指令中,目的寄存器的不同,所以当数据通路综合的时候,需要一个MUX多路控制器控制选择RD还是RT作为写入寄存器编号
- AluSrc:第二个操作数既可能来自寄存器也可能是操作数扩展的结果,因此需要一个多路选择器进行选择
- MemToReg:写回的时候,对应的数据有可能来自数据存储器,也有可能来自ALU的运算结果,因此需要一个多路选择器
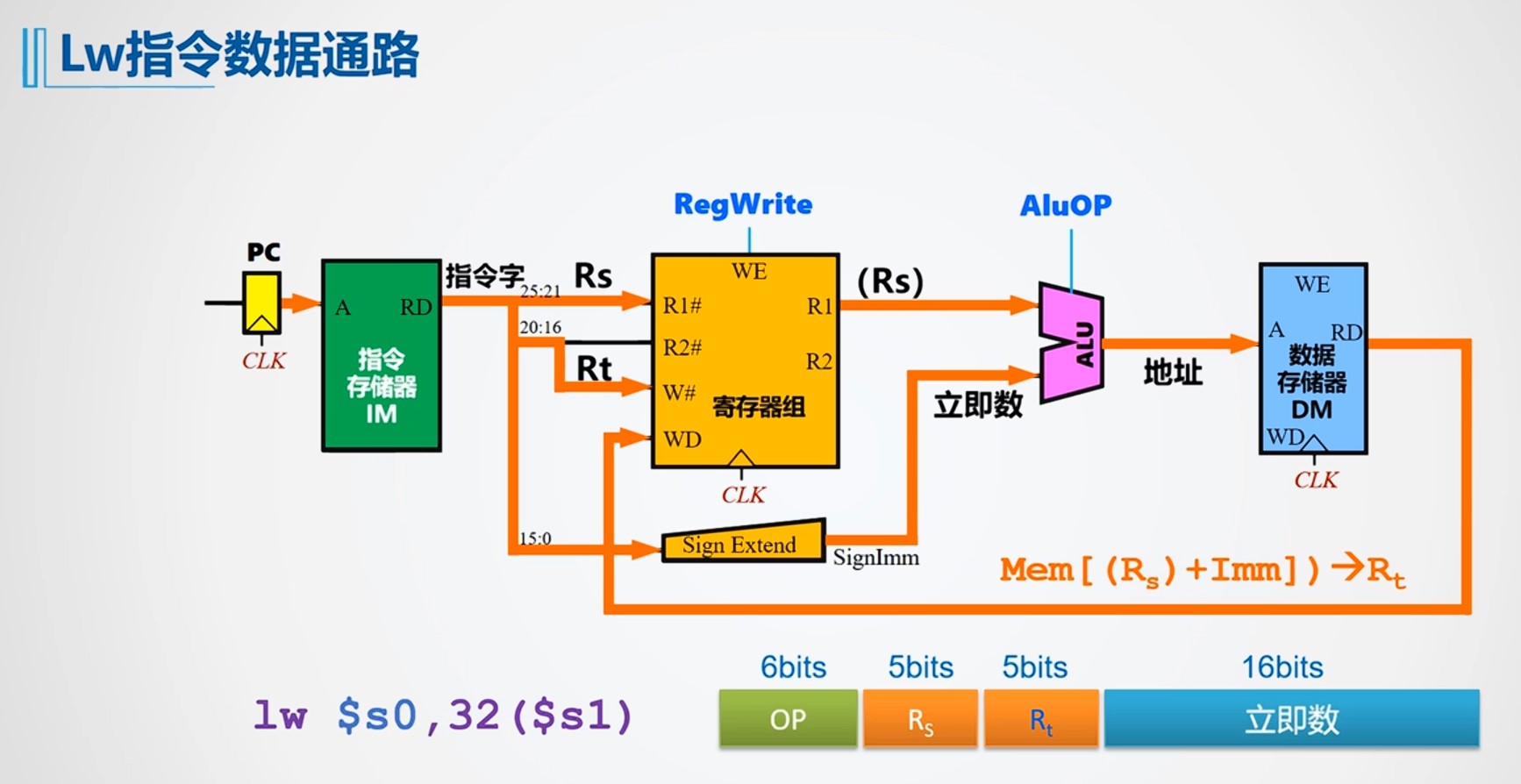
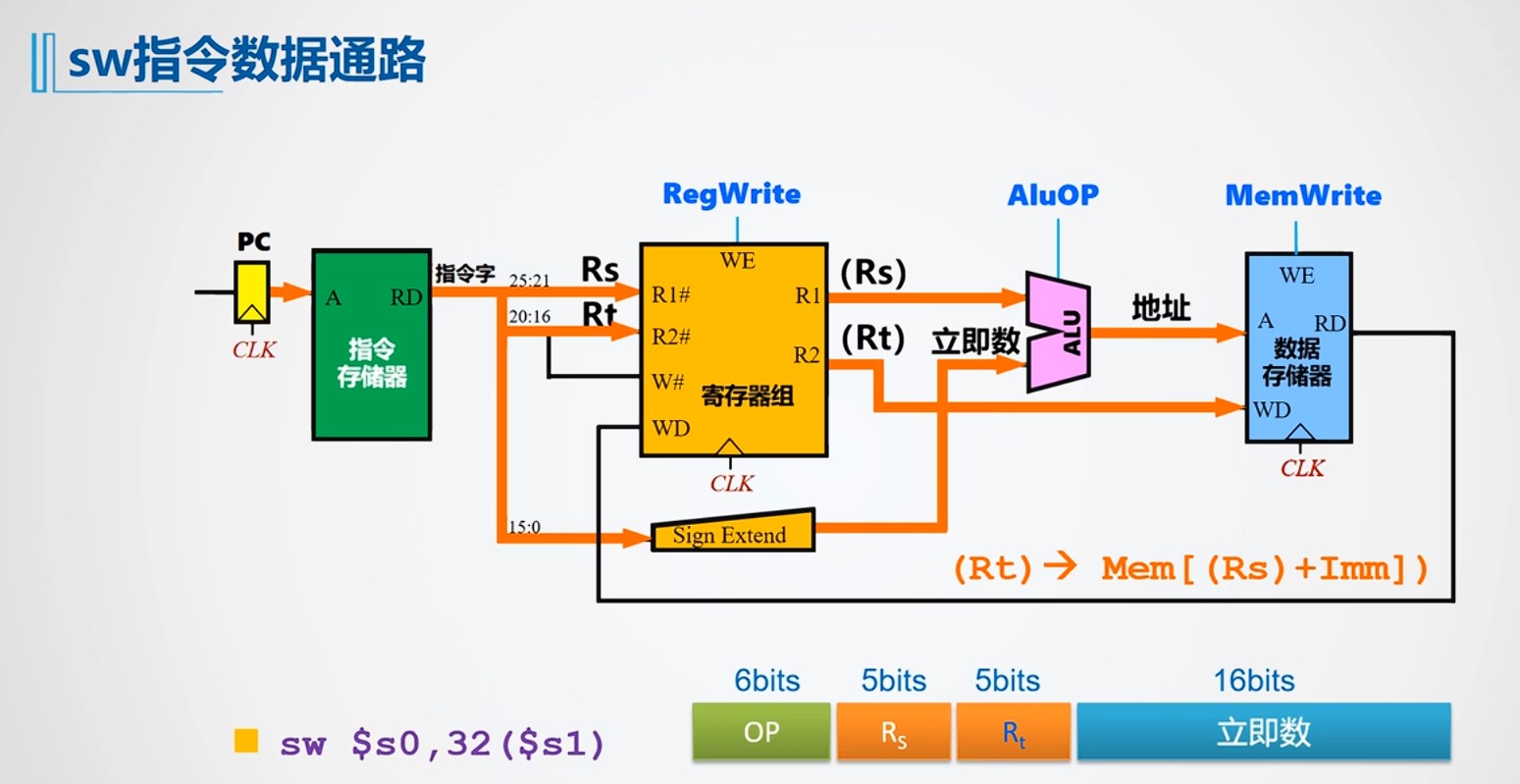
单周期数据通路指令的运算/时钟周期的选择
单周期数据通路延迟参数统一总结如下(取指/数据存储器=3ns;ALU/加法器=2ns;寄存器读=1ns;寄存器写=1ns;忽略MUX/控制/传输延迟)。
| 指令类型 | 典型形式 | 执行流程(顺序) | 用时计算 | 总用时 |
|---|---|---|---|---|
| RR型运算(R型) | add rD, rS, rT |
取指(3) → 读寄存器rS,rT(1) → ALU运算(2) → 写回rD(1) | 3 + 1 + 2 + 1 | 7 ns |
| 立即数运算(I型算术) | addi rT, rS, imm |
取指(3) → 读寄存器rS(1) → 立即数符号扩展(≈0,忽略) → ALU运算(2) → 写回rT(1) | 3 + 1 + 2 + 1 | 7 ns |
| Load(取数) | lw rT, off(rS) |
取指(3) → 读寄存器rS(1) → 符号扩展off(≈0) → ALU算有效地址(2) → 读数据存储器(3) → 写回rT(1) | 3 + 1 + 2 + 3 + 1 | 10 ns |
| Store(存数) | sw rT, off(rS) |
取指(3) → 读寄存器rS,rT(1) → 符号扩展off(≈0) → ALU算有效地址(2) → 写数据存储器(3) | 3 + 1 + 2 + 3 | 9 ns |
| Branch(条件分支) | beq rS, rT, off |
取指(3) → 读寄存器rS,rT(1) → ALU比较/零检测(2) → 加法器形成分支目标地址(2) | 3 + 1 + 2 + 2 | 8 ns |
| Jump(无条件跳转) | j target |
取指(3) → 形成目标地址/更新PC(拼接/移位,忽略延迟) | 3 | 3 ns |
时钟信号





.png)
数据通路和控制器的组成
| 分类 | 部件 |
|---|---|
| 数据通路 | ALU、通用寄存器、状态寄存器、Cache、MMU、浮点运算逻辑、异常和中断处理逻辑 |
| 控制部件 | PC、IR、ID、MAR、MDR、控制单元(CU)、时序信号产生部件 |
可见/不可见
- 写代码的时候感觉不到它的存在的,就是不可见的,如何实现我们不知道,那就是不可见的
硬件指令周期
指令流水线
-
指令流水线一般指RISC即MIPS架构的指令周期,所以除了Lw和Sw指令在M阶段访问内存,其他阶段的取数都是在寄存器中获取,结果写回寄存器
-
指令流水线的五个阶段功能
-
取指(IF):从指令存储器或Cache中取指令
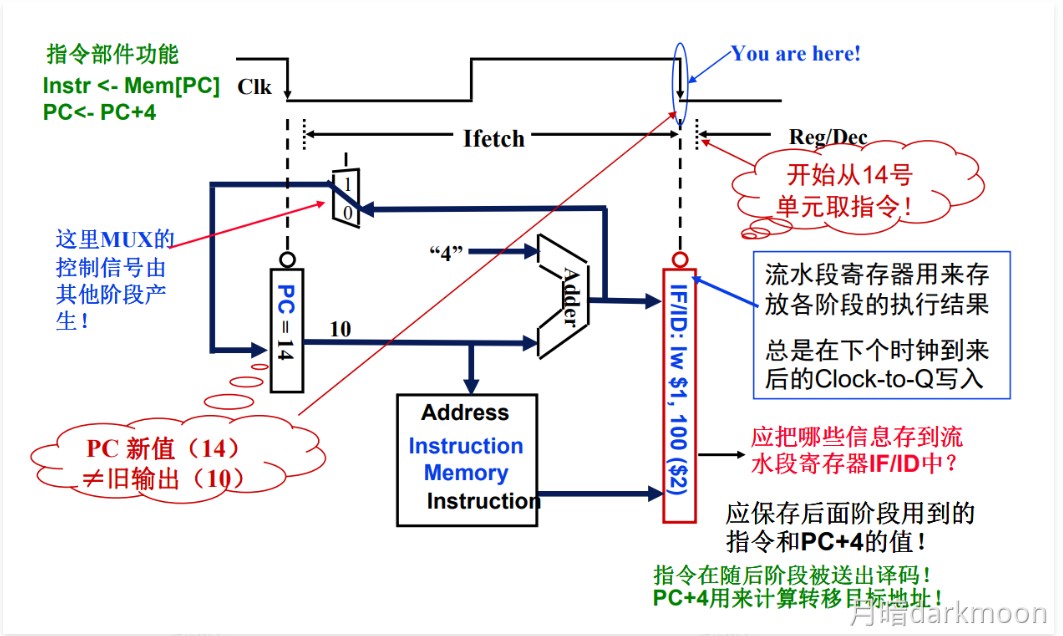
- IF-ID寄存器中需要保存的结果:
- 从IM中取出的指令
- 如果是分支指令,PC+4的值要在后面用来计算相对地址,因此也要保存。
- 多路选择器MUX的控制端,在Mem阶段产生的Branch信号和Zero标志来控制
- branch信号只有在对分支指令beq译码后才取值为1,其他情况下,branch总是为0
- 在执行beq指令时,在M段将得到转移目标地址,此时,若Zero=1,则将转移目标地址选择送到PC的输入端
- IF-ID寄存器中需要保存的结果:
-
译码/读寄存器(ID):操作控制器对指令进行译码,同时从寄存器堆中取操作数
- 也就是说,只有当操作数存在寄存器中的时候,才需要从寄存器中读数,如果是从内存中取数,这一段只是用来取用于地址运算的寄存器里面的数,即下面的计算地址
- 指令本身就不再需要保存在ID/EX寄存器中
-
指令/计算地址(EX):执行运行操作或计算地址
-
功能:
- 计算内存地址
- 计算转移目标地址
- 一般ALU计算
-
控制信号
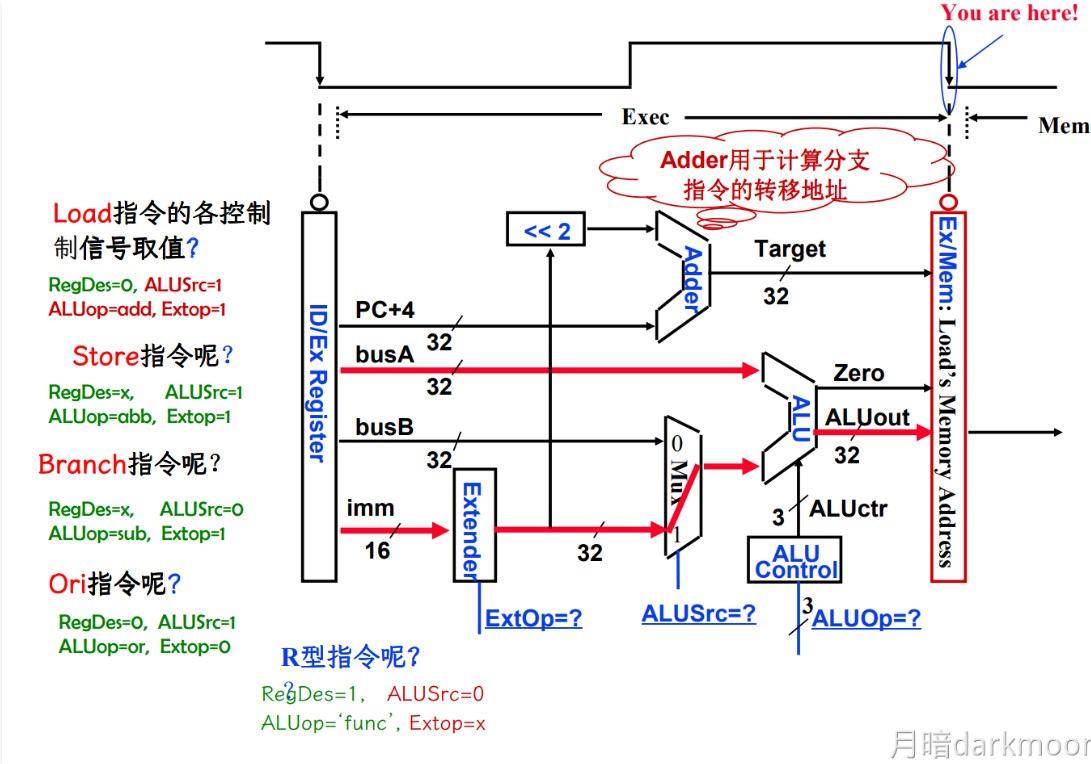

-
-
访存(MEM):对存储器进行读/写操作
-
间接寻址中根据EX段计算出来的有效地址,进行访存
-
条件转移指令的情况下,在该阶段将EX段生成的转移目标地址更新到PC中
-
无条件转移指令在该阶段将目标PC值写回PC
-
-
写回(WB):将指令执行结果写回寄存器堆
-
这里的结果写回的是寄存器,取数时也是取回寄存器
-
读寄存器发生在ID(译码/读寄存器),写寄存器发生在WB(写回)
-
-
-
虽然增加流水线级数可能缩短每级延迟,但“必然”提高主频的说法过于绝对。实际中,流水线级数增加会引入额外的寄存器延迟(如建立时间、保持时间),且若各阶段延迟不均衡,最慢阶段仍会限制主频。此外,过深的流水线可能导致控制复杂度上升,反而影响性能。因此,当段数达到一定数量时,流水线技术增加不一定会提高主频了。
-
流水线的时钟周期必须覆盖最慢阶段的延迟(包括组合逻辑延迟和流水线寄存器延迟),否则会导致数据无法正确传递。因此,CPU的最高频率由流水线中最关键路径(即延迟最大的阶段)决定。
-
流水线技术的核心优势在于提高吞吐率(单位时间内完成的指令数),而非减少单条指令的执行时间。由于流水线寄存器延迟的存在,单条指令的总执行时间可能反而略有增加(如从单周期变为多周期)。虽然主频提高可能缩短时钟周期,但单条指令仍需经历多个阶段,其总执行时间并未减少
-
流水线级数的核心思想正是通过指令级并行(ILP)实现多条指令的不同阶段同时执行。
-
控制冲突的情况下,比较指令在EX阶段通过计算设置条件码,并在MEM阶段确定是否将PC值更新为转移地址
-
Cache缺失的处理过程也会引起流水线阻塞
-
超流水线CPU的CPI=1,但主频更高
-
多发射流水线CPI<1,但成本更高、控制更复杂
-
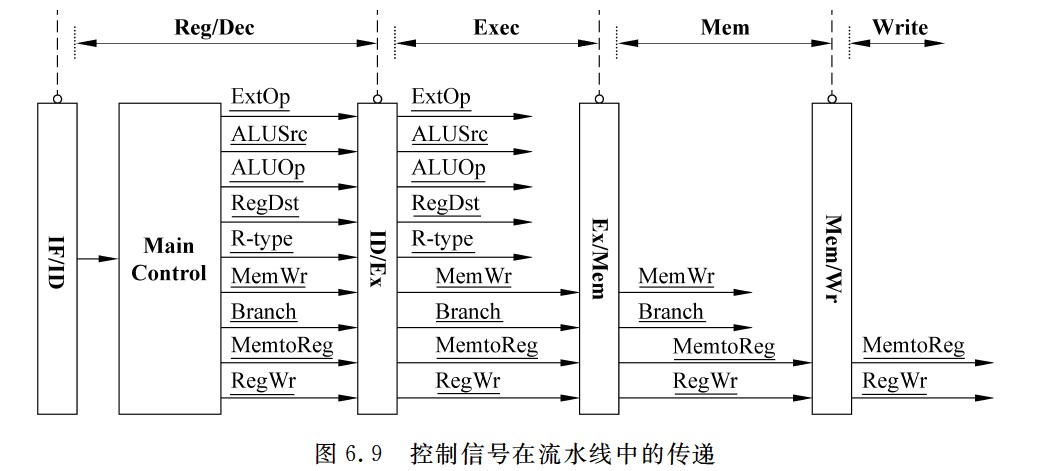
指令译码得到的控制信号需要通过流水段寄存器传递到下一个流水段,每个流水段之间的寄存器位数不一定相同,流水段寄存器对用户透明
-
避免结构冒险的基本做法是使每个指令在相同流水段中使用相同的部件
- 解释:Load指令在第四个时钟周期即它的M阶段使用DM;同样在第四周期,下一条指令在EX阶段,仅使用ALU,下下条指令在ID阶段,只用到了存储器堆的写口;由此可见,若遵守每条指令在相同流水段使用相同部件,这样可以保证在同一个时钟周期下,由于各指令分别处于不同的流水段,因此不会使用到同一个部件。
-
PC和各个流水段寄存器都没有写使能信号,因为每个时钟都会改变PC的值,所以PC不需要写使能控制信号。
- 每个流水段寄存器在每个时钟都会写入一次,因此,流水段寄存器也不需要写使能控制信号。
- 前两个流水段的功能每条指令都相同,是公共流水段,因此,也不需要控制信号
-
结构冒险对浮点运算的性能影响较大,控制冒险更多出现在整数运算程序中
-
超标量技术通过指令相关性检测和动态分支预测手段,当指令阻塞时,可以到后面找指令来执行
- 超标量技术不依赖于编译器,主要靠硬件在执行过程中优化
-
指令预取
- 在指令执行前,预先把指令取到CPU的指令缓冲器中。这样,在指令执行时,不需要再去取指令,可以很快地直接执行指令。流水线指令执行方式通常采用指令预取。
-
超流水线技术时间上并行
-
多发射技术空间上并行
-
五段式流水线CPU的时钟周期=最长的功能部件时间+流水段寄存器的时间
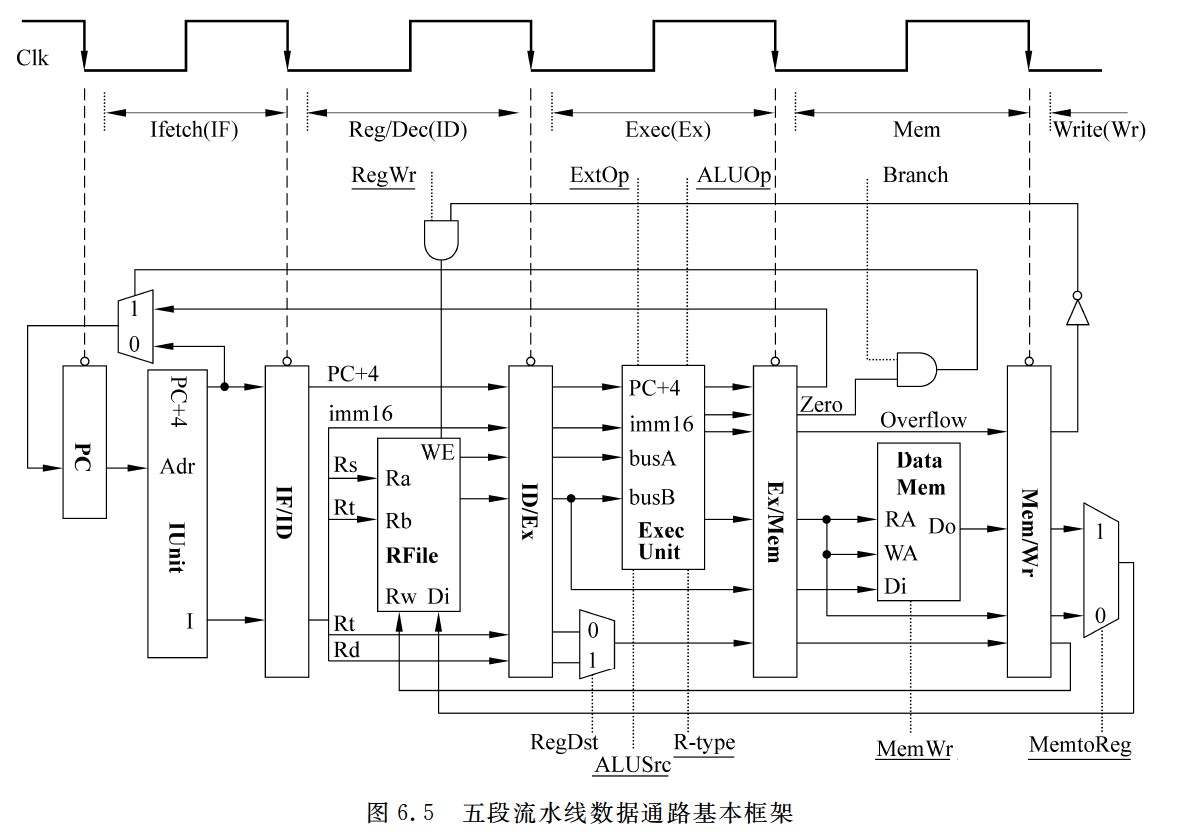
五段流水线数据通路基本框架
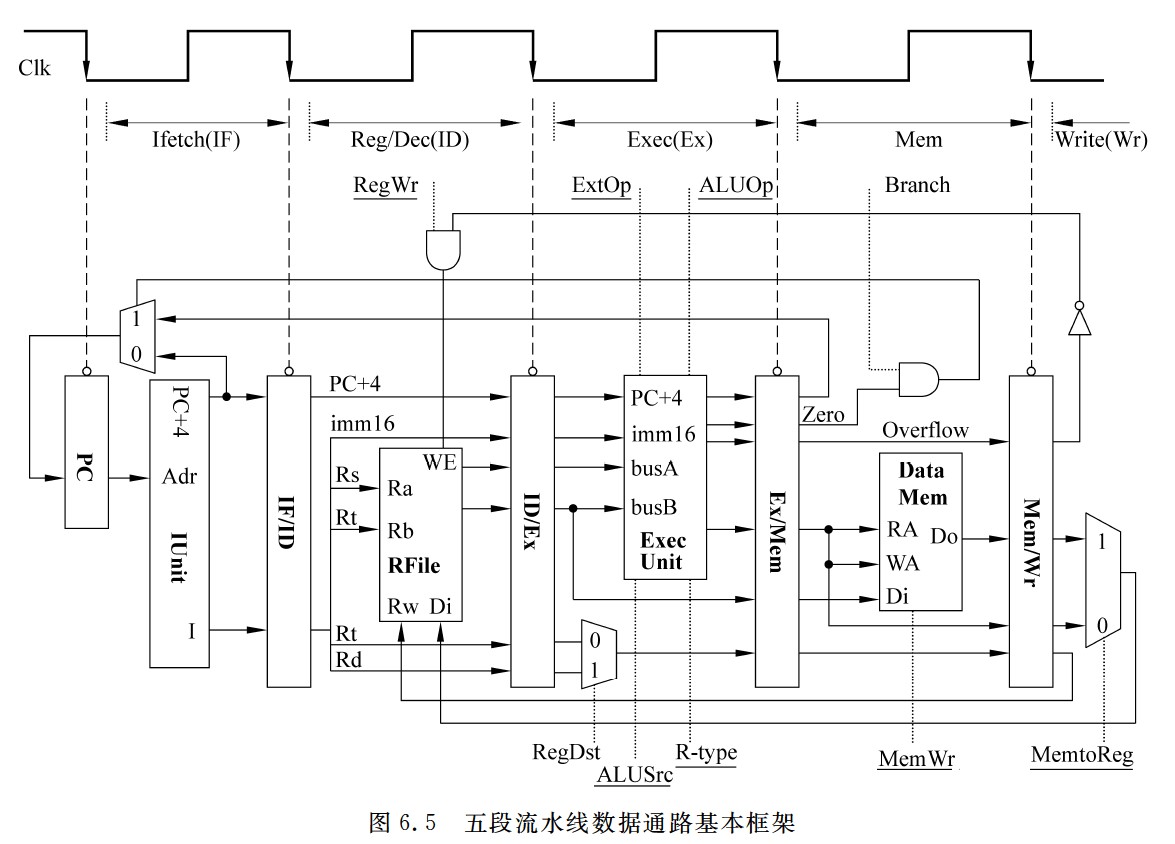
- 图6.5中给出了数据通路用到的所有控制信号,用点虚线连到所控制的功能部件。可以看出,PC和各个流水段寄存器都没有写使能信号。这是因为每个时钟都会改变PC的值,所以PC不需要写使能控制信号;每个流水段寄存器在每个时钟都会写入一次,因此,流水段寄存器也不需要写使能控制信号。此外,前两个流水段的功能每条指令都相同,是公共流水段,因此,也不需要控制信号。其余段的控制信号如下。
- Exec段的控制信号有以下5个。

IF

ID

EX
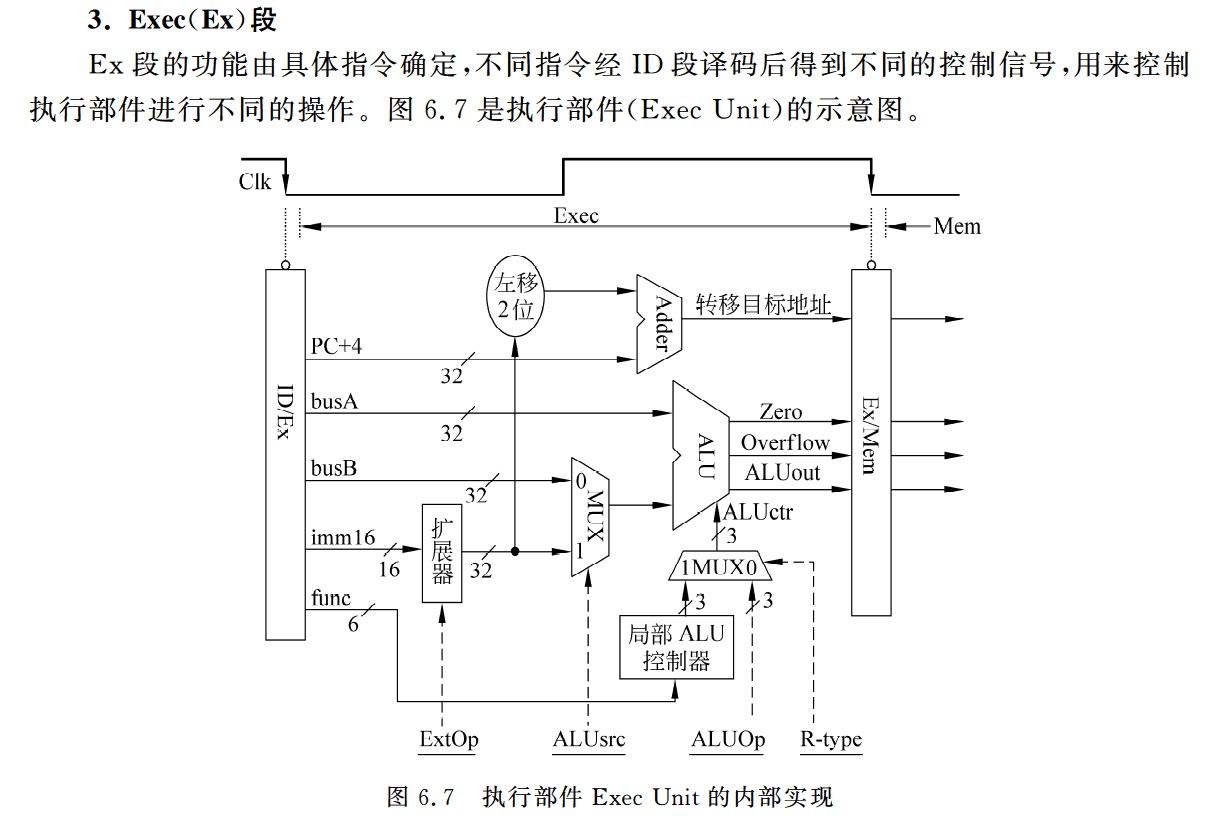

R-型指令

I-型运算类指令

lw/sw指令


beq指令

j指令

M

WB

数据冒险
-
旁路转发技术和load-use冒险:
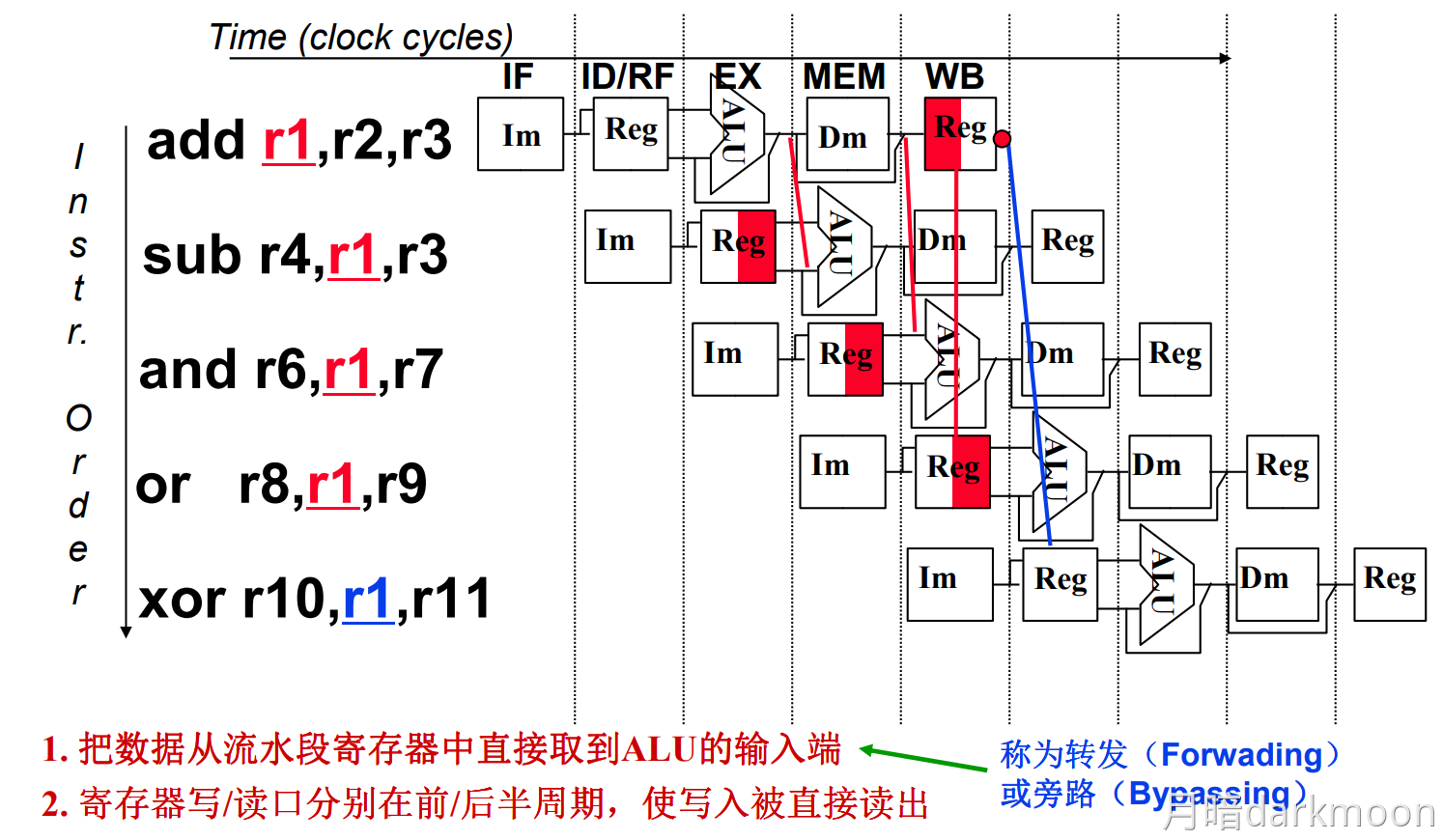
- load指令在第四周期即M访存阶段结束时,数据在流水段寄存器中已经有值,在此时可以采用数据转发技术可以使load指令后面第二条指令得到所需的指,但不能解决load指令和随后的第一条指令之间的数据冒险,要延迟执行一条指令
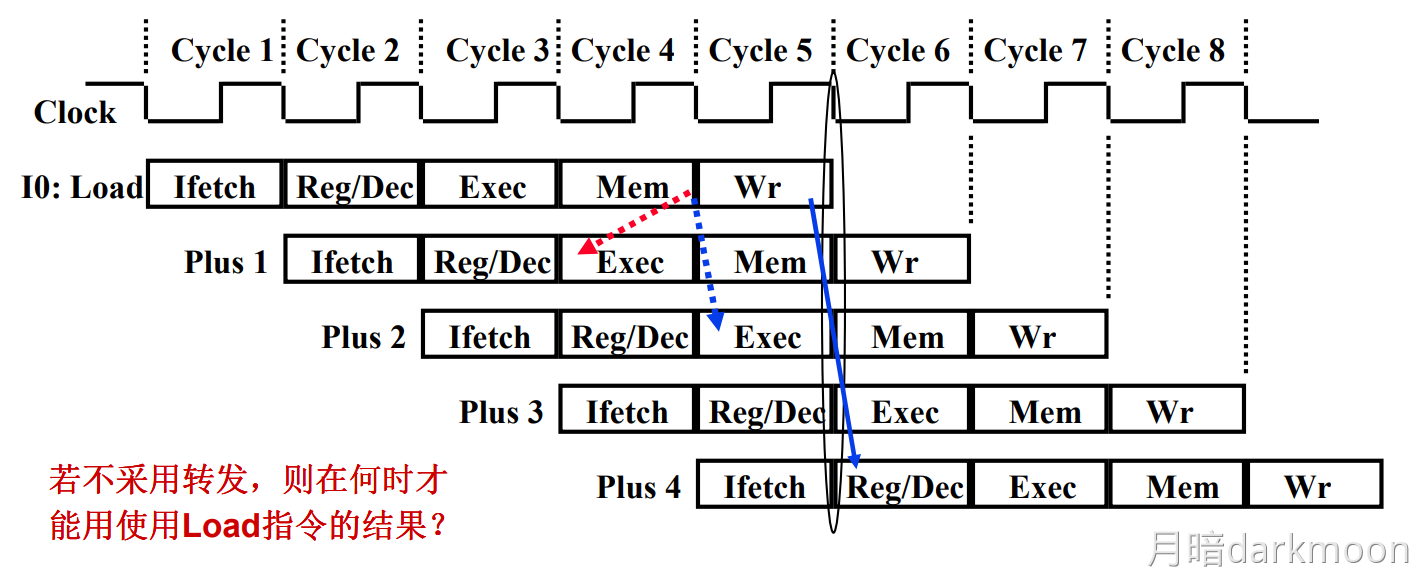
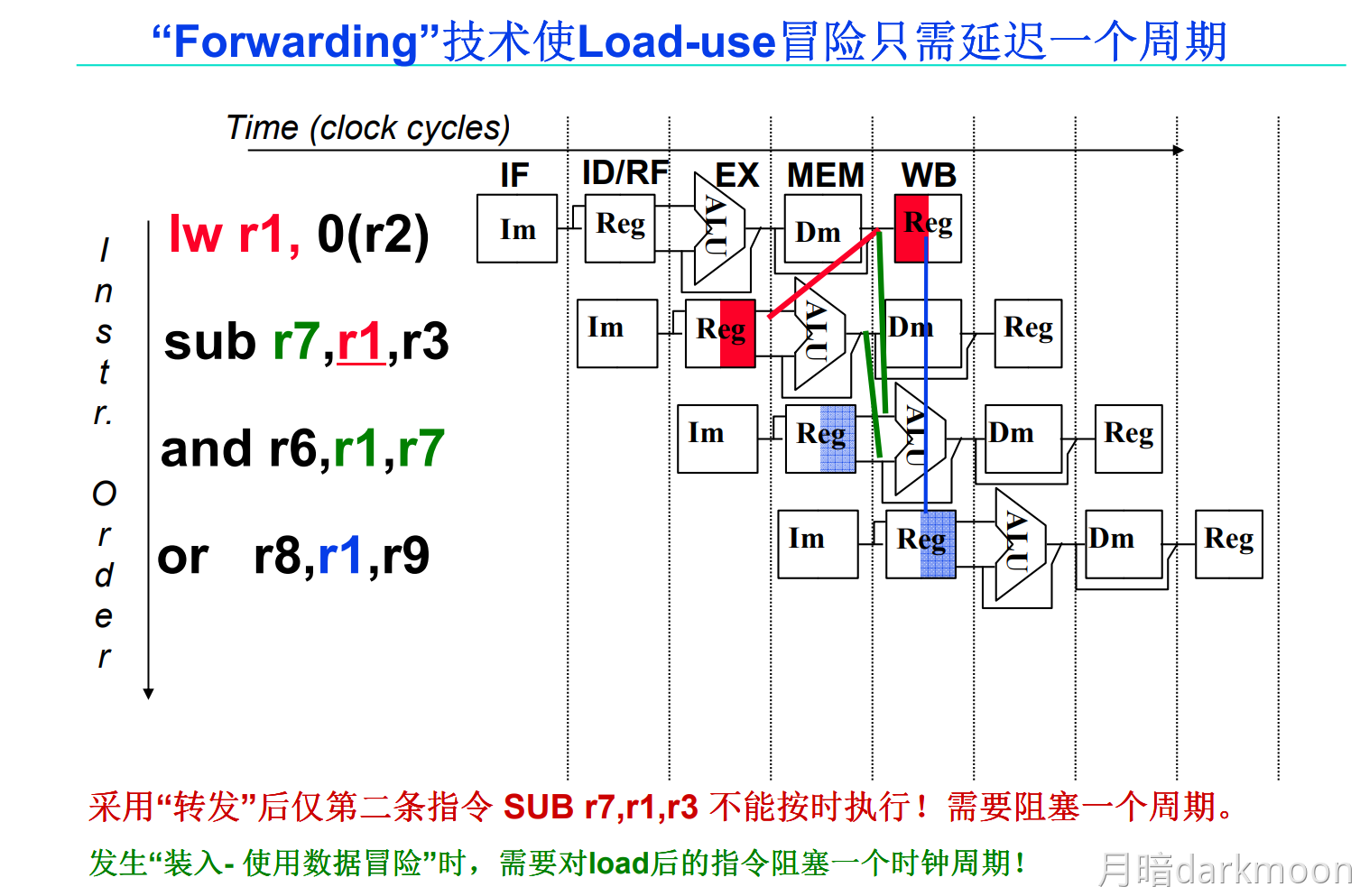
- 普通数据冒险采用旁路转发技术不需要阻塞,而load-use需要阻塞一个时钟周期的根本原因是所需数据产生的阶段不同,使用ALU计算获得结果(所需数据)的在EX阶段可以产生所需数据,而load指令在M阶段从内存中获取所需数据
- load指令中的ID和EX是在获取所需数据的内存地址,M访存获得所需数据
-
lw指令:从内存中读取一个字,并将其放在一个寄存器中
sw指令:将一个寄存器中的字写入内存中
控制冒险
-
分支延迟槽
在分支指令后面,通常会有一个或多个 延迟槽,用来放置那些 与分支指令无关 的指令。这样,即使 分支指令 会影响程序的执行流,延迟槽中的指令仍然可以按顺序执行,从而有效地利用流水线,减少停顿。
-
静态预测一般是默认不跳转
指令流水线的实现
- Load指令的五个阶段
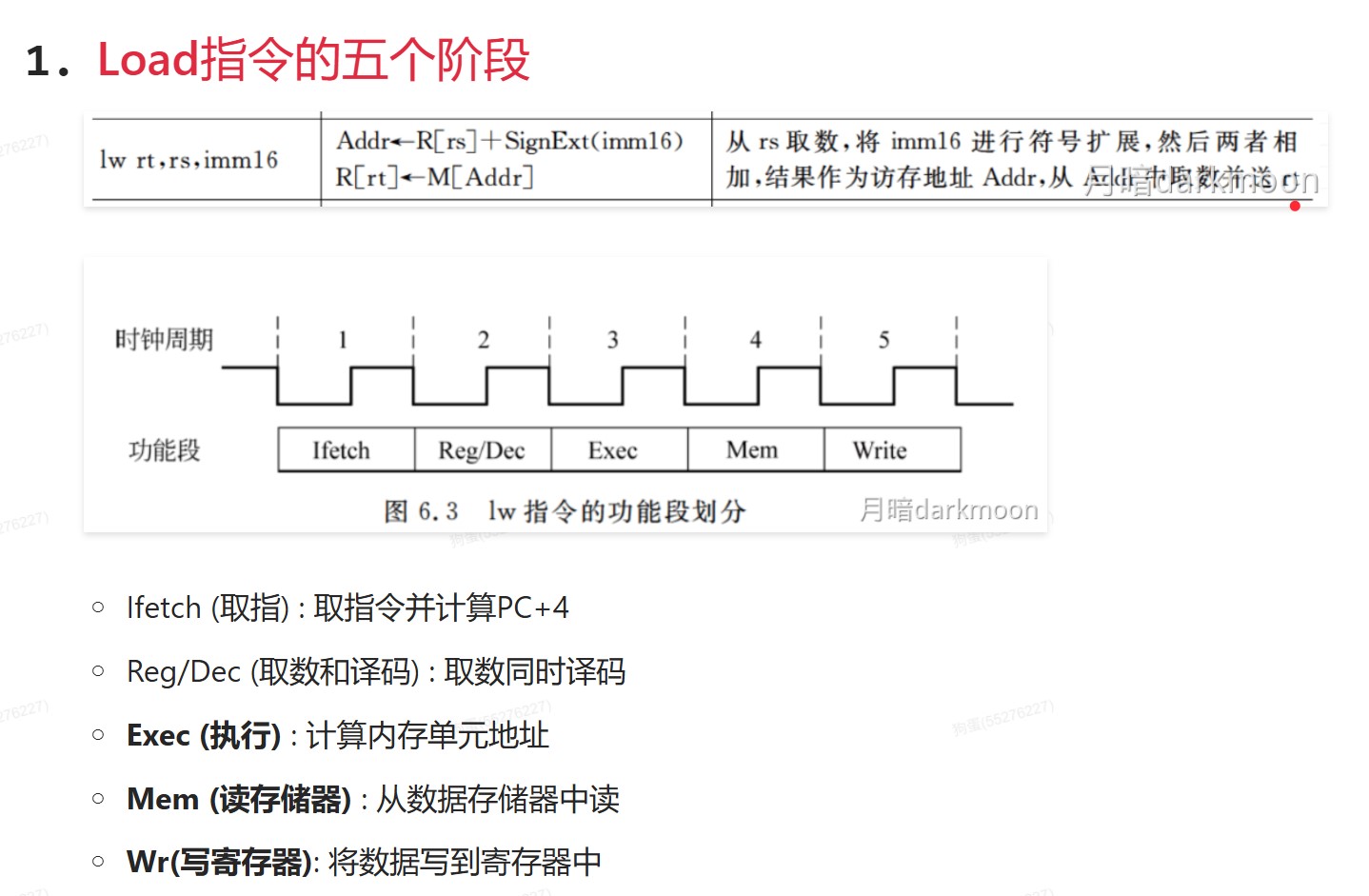
- R和I型运算类指令的4个阶段

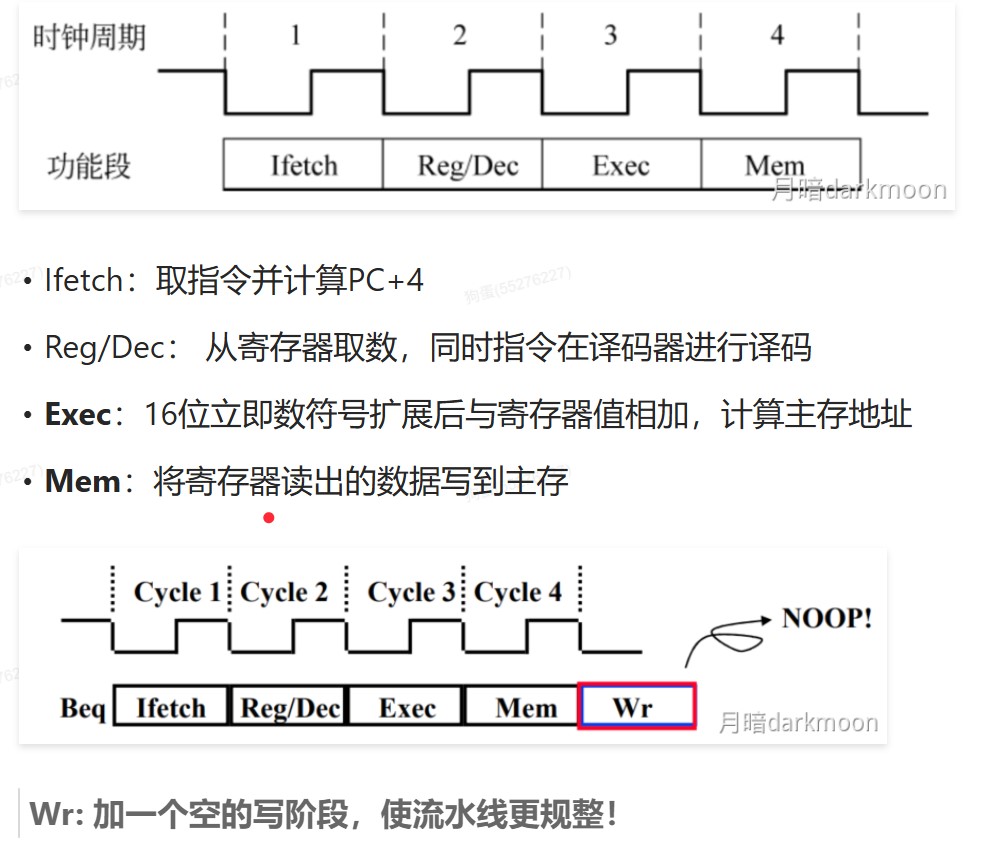
- store指令的四个阶段
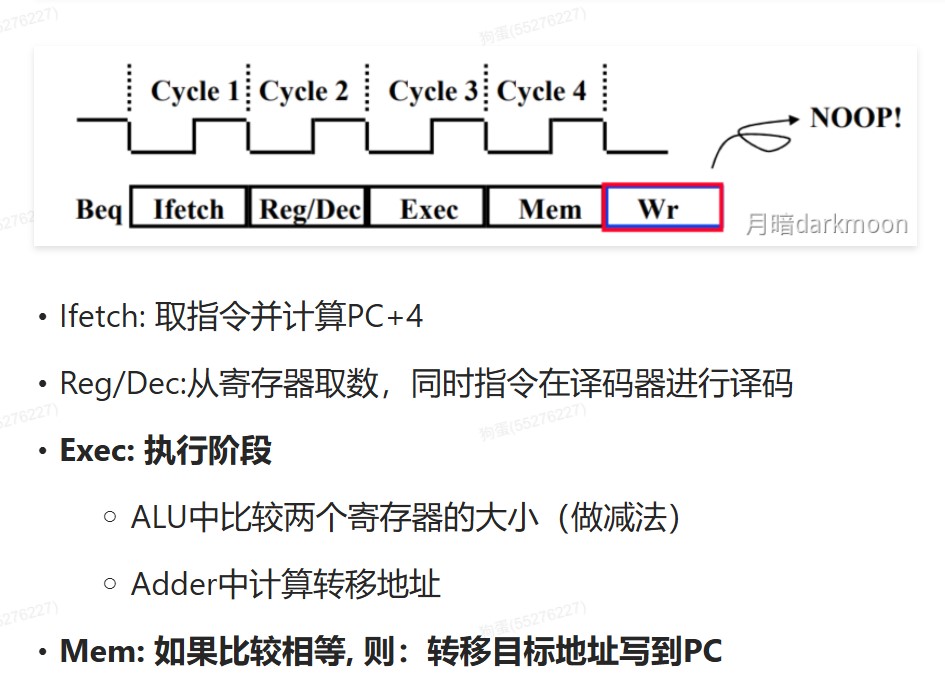
- Beq指令
- j指令

总线
- 采用数据/地址总线复用技术,总线中保留数据线,地址经过数据线传输
- 数据总线传输中断类型号
- 地址总线传输I/O端口地址
- 控制总线传输定时信号、总线请求、允许、中断请求、回答、传输确认
- 总线工作频率是指1s内传送几次数据,总线周期=N个时钟周期,则总线的工作频率=时钟周期/N;此外,若一个时钟周期可以传送K次数据,则总线工作频率是总线时钟频率的K倍
- 总线带宽(最大数据传输率)是理想情况(所有总线周期都在传送数据)下,不需要考虑每个总线事务的具体情况,而计算(平均)数据传输率才需要考虑每个总线事务的具体情况
- 总线带宽指总线的最大数据传输率,即总线在进行数据传输时单位时间内最多可传输的数据量,不考虑其他如总线裁决、地址传送等所花的时间
- 总线带宽=总线宽度 x 总线时钟频率 x 每个时钟周期传送数据的次数
- 同步通信仅在数据块的开头和结尾添加开始和结束标记,异步通信每个字符都要用开始位和停止位作为字符开始和结束的标志
- 三总线结构多见于专用的CPU结构,而个人计算机中并没有专门的DMA总线这种结构,设备与主存之间的DMA传输都是通过系统总线完成的
- 三总线下,高速设备靠近CPU,慢速设备远离CPU
- 不同层次总线之间采用桥接方式连接和缓冲
- 多总线结构的发展趋势
- 采用分层次的多总线结构,不同层次总线之间采用桥接方式连接和缓冲
- 将I/O设备与主存之间的通信与处理器的活动分离开来
- 高速设备靠近CPU,低速设备远离CPU
- 桥接芯片高度集成,形成了经典的南北桥架构。南桥芯片就是I/O控制芯片
- QPI总线是一种基于包传输的串行高速点对点连接协议,采用差分信号与专门的时钟信号进行传输。QPI总线有20条数据线,发送方(TX)和接收方(RX)有各自的时钟信号,每个时钟周期传输两次。一个QPI数据包包含80位,需要两个时钟周期或4次传输才能完成整个数据包的传送。在每次传输的20位数据中,有16位是有效数据,其余4位用于循环冗余校验,以提高系统的可靠性。
- 由于QPI是双向的,在发送的同时也可以接收另一端传输来的数据,这样,每个QPI总线的带宽计算公式如下:
每秒传输次数×每次传输的有效数据×2
- 由于QPI是双向的,在发送的同时也可以接收另一端传输来的数据,这样,每个QPI总线的带宽计算公式如下:
- 总线连接结构的优点:
- 灵活和成本低
- 部件可以在使用相同总线的计算机系统之间互换
- 有些总线没有单独的地址线,地址信息通过数据线来传送,这种情况称为数据线和地址线复用
- 如何使各个部件在需要时使用总线,需靠控制线来协调
- 控制信息可以双向传输,但是一根控制线通常只传一类控制信号,且方向固定,比如读写命令是CPU传给内存或者外设(I/O接口),外设(I/O接口)传输握手信号和中断请求信号给CPU
- 同步总线事务可以是突发传输方式,这种情况下,一个总线事务中可以传输多个连续的数据,每次传输的数据位数不超过总线宽度
- 同步总线由时钟信号定时,时钟频率不一定等于工作频率
- 异步总线由握手信号定时,每次握手的过程完成一次通信,但一次通信往往会交换多位而不是一位数据
- 传统的并⾏总线(如PCI)在提⾼频率时会遇到信号串扰和时钟偏斜(即多条线路的信号到达时间不⼀致)等问题,这限制了其速度的进⼀步提升。现代⾼速总线,如PCI Express (PCIe)、SATA、USB等,都采⽤了串⾏传输技术。虽然每次只传输⼀位数据,但它们可以通过极⾼的传输频率来获得远超并⾏总线的总带宽,并且使⽤的引脚更少,抗⼲扰能⼒更强。
- 处理器总线和存储器总线都⽐ I/O 总线快,多总线结构正是为了将不同速率的设备挂载在不同的总线上,避免慢速设备拖慢整个系统。多总线结构的⼀个核⼼优势就是通过桥接器等设备实现总线间的并发操作。
- 同步总线⽀持猝发传输模式。在猝发模式下,主设备只需发送⼀个起始地址,就可以在后续连续多个时钟周期内连续传输多个数据字。这整个过程被视为⼀次总线事务,但它完成了多次数据交换。这种⽅式在连续读写存储器块时效率很⾼。
总线的基本特性
- 控制线每根单向,但是两根实现双向,所以控制信息双向传输,控制线单向传输
总线事务
总线定时
| 定时方式 | 应用场景 | 优点 | 缺点 | 工作原理 | 特点 |
|---|---|---|---|---|---|
| 同步总线定时 | 适用于对传输速率要求较高的场景。 | 设备协调简单,传输速率较高。 | 对时钟偏移问题敏感,可能导致时序错误。 | 所有设备与一个时钟同步,数据传输根据时钟周期进行。 采用并行传输方式。 |
总线适用于时间敏感的系统,如实时数据处理系统。 |
| 异步总线定时 | 适用于设备不需要同步时序的系统。 | 无需严格时钟同步,设备间工作速度可不同。 | 传输效率较低,可能导致延迟增加和复杂性上升。 | 不依赖固定时钟信号,而是使用设备间的握手信号进行数据传输。 | 避免时钟偏移问题,但需额外协议进行时间控制。 |
| 半同步总线定时 | 适用于需要部分同步,其他部分灵活的系统。 | 结合了同步和异步的优点,保证同步部分的同时允许灵活。 | 若设备速度差异大,可能出现传输效率低下。 | 使用同步信号控制关键组件,其他部分异步控制,使用等待信号控制数据流。 | 适用于数据传输速率和时序不同的系统。 |
| 分离式总线定时 | 适用于多阶段数据处理或多个设备访问总线的系统。 | 提高资源利用率,多个设备可同时使用总线,避免冲突。 | 实现和管理复杂,需要协调设备访问。 | 总线分为两个阶段,分别用于数据传输和接收。 | 允许多个设备高效使用总线,减少空闲时间。 |
- 半同步方式就是在时钟的同步下控制发出和采样异步应答信号
- 同步

- 异步


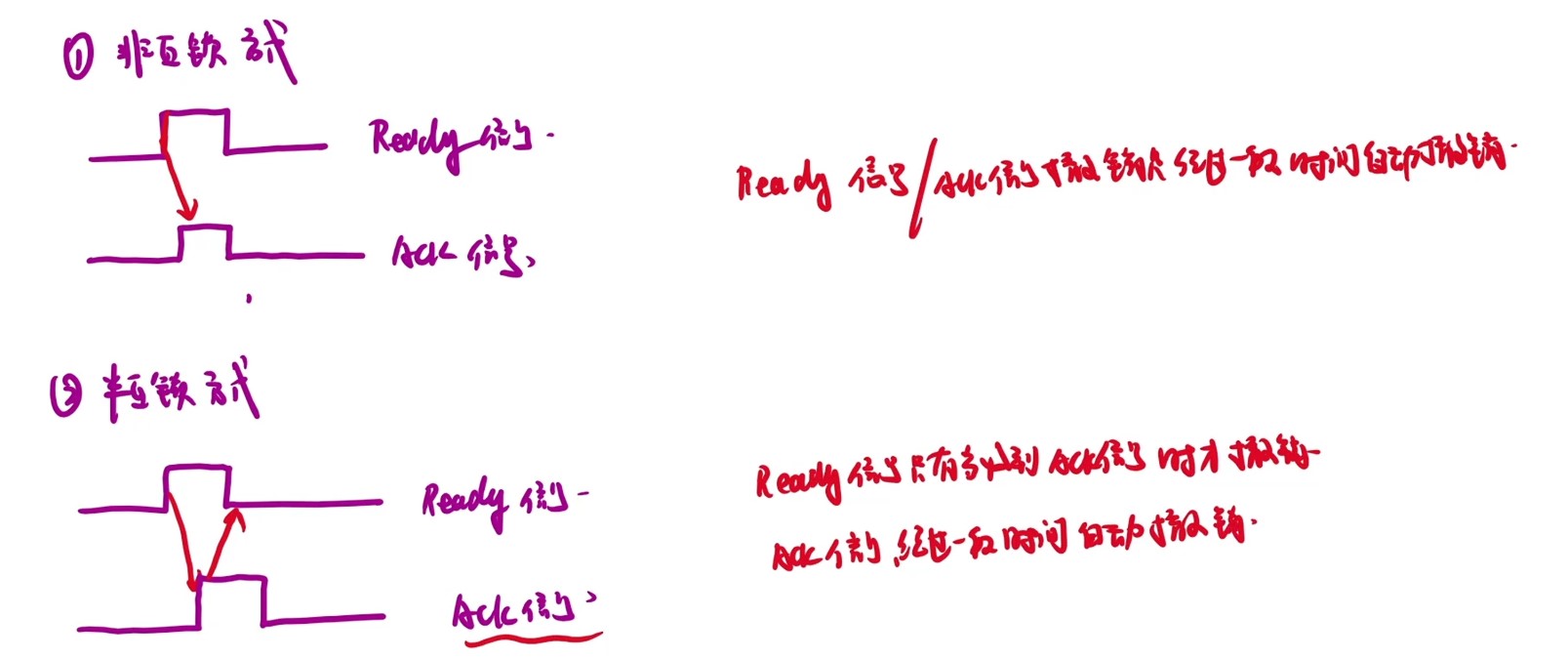

I/O接口
- 对数据缓存寄存器、状态/控制寄存器对的访问操作是通过相应的指令来完成的,通常称这类指令为I/O指令,I/O指令只能在操作系统内核的底层I/O软件中使用,它们是一种特权指令
- 通常,DMA接口与主存之间的传送单位为字,而DMA与设备之间的传送单位可能为字节或位
- CPU通过设备驱动程序设置DMA控制器的参数
- 可编程的中断控制器属于I/O接口
定时查询的计算
-
最多间隔查询时间=数据缓冲器大小/数据率
- 每秒查询次数=1s/最多间隔查询时间
- 每秒CPU用于外设I/O时间=每秒查询次数*查询1次所用时钟周期数
- 占整个CPU时间的百分比=每秒用于外设I/O的时钟周期数/总的时间周期数
-
定时查询的流程
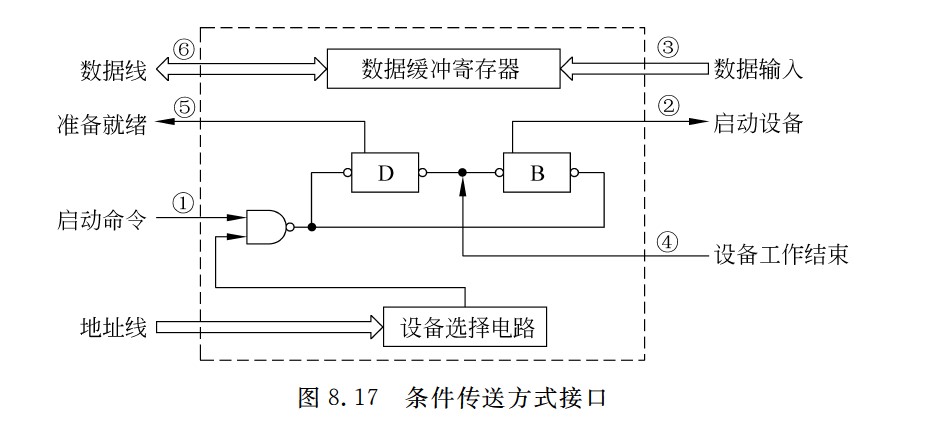
- ①CPU执行相应的I/O指令向该接口送出“启动”命令,设备选择电路对CPU送出的地址进行译码,选中本I/O接口,这样,与非门输出信号使“完成”状态触发器D清零,而使“启动”命令触发器B置1
- ②I/O接口通过连接电缆向外设发送“启动设备”命令;
- ③外设准备好一个数据,通过电缆向I/O接口中的数据缓冲寄存器输入数据;
- ④外设向I/O接口回送“设备工作结束”状态信号,使状态触发器D置1,使命令触发器B清零;
- ⑤CPU通过执行指令不断读取I/O接口状态。因触发器D已经被置1,所以,查询到外设“准备就绪”;
- ⑥CPU通过执行I/O指令从数据缓冲寄存器读取数据。通过以上6个步骤,CPU和外设之间完成一次数据交换过程。
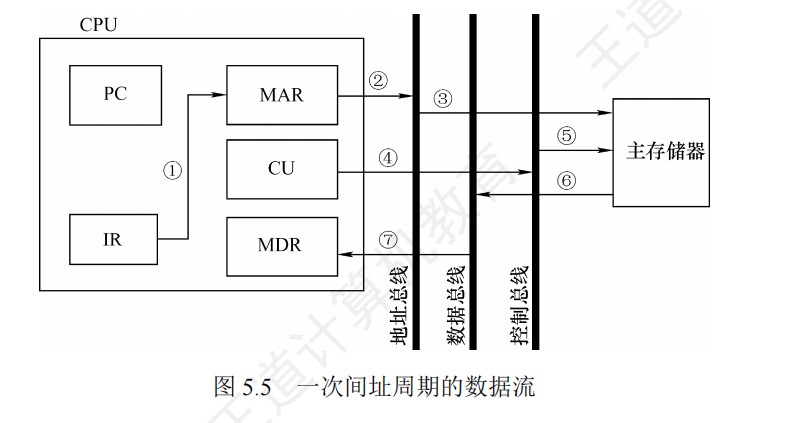
程序中断的计算
- 如何判断外设能否用中断I/O方式?
- ①计算出中断处理所用的时间A
- ②计算出外设准备好数据的时间B
- ③如果A>B,则不可以
DMA方式的计算
-
外设每秒的DMA次数为外设数据率/每次DMA传送块大小
-
CPU用于外设I/O的总时间为每秒DMA次数*DMA处理的时钟周期数
-
占CPU总时间的百分比=CPU用于外设I/O的时钟周期数/计算机每秒的时钟周期数
-
DMA响应时间应该少于一个总线周期
-
dma接口与主机之间的数据传输以块为单位,dma接口与i/o设备的传输以字为单位
-
无论采用何种 DMA 方式,当整个数据块传输完成后,DMA 控制器均会向 CPU 发送中断请求,通知传输结束
-
DMA控制器占⽤总线时,CPU只是暂时不能访问主存,但如果CPU正在执⾏的指令不涉及访存操作(例如,在内部寄存器之间进⾏运算),CPU仍然可以继续执⾏。只有在“停⽌CPU访存”模式下,或者CPU恰好需要访存时,CPU才会进⼊等待状态。
-
发生缺页中断时,若在缺页处理程序中将缺页调入内存采用 DMA 方式,则需要把磁盘物理地址写入 DMA 控制器中的设备地址寄存器 DAR,需要在预处理的初始化中将交换数据的主存起始位置(即该页面的页基址)写入DMA 接口中的主存地址寄存器。
-
三个阶段:
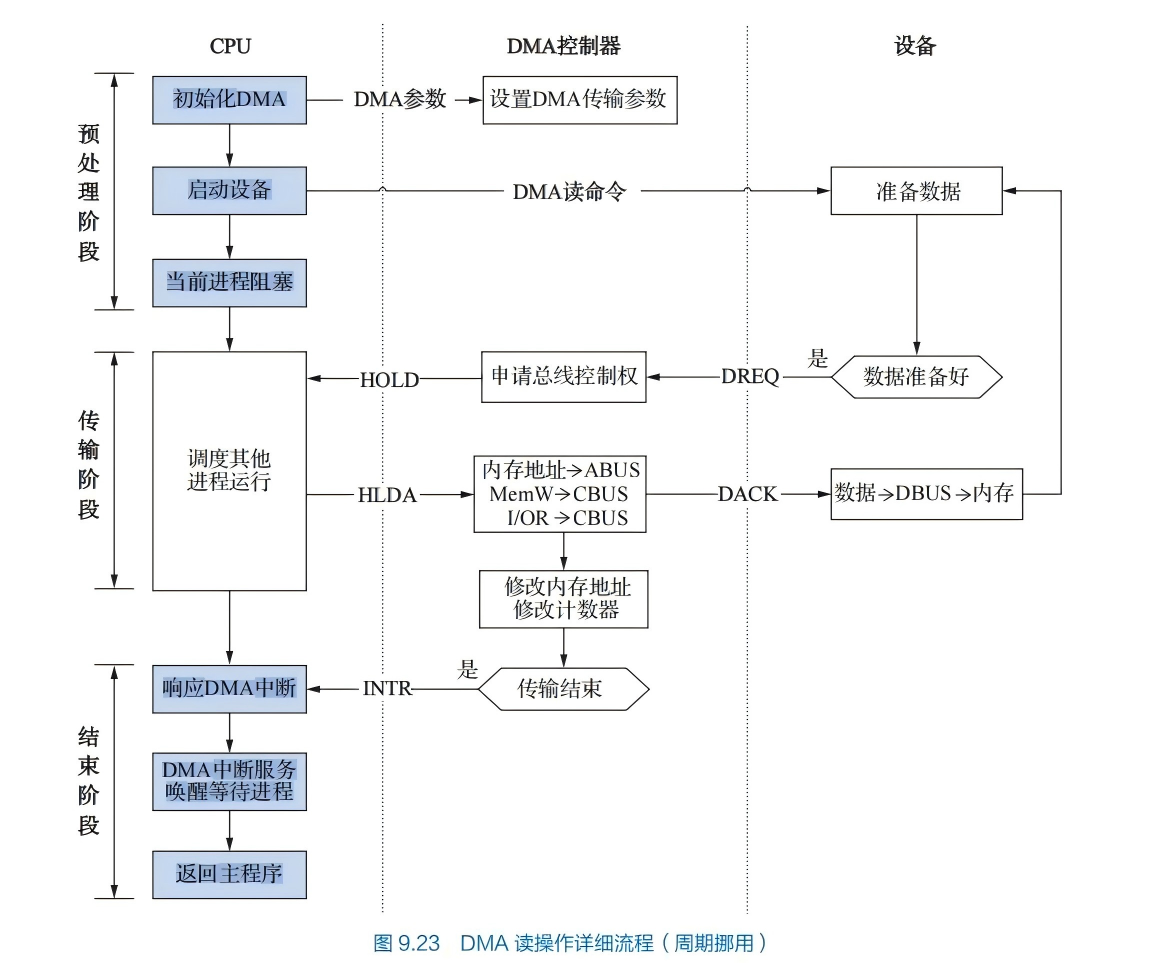
- 预处理阶段:确定数据传输方向、选择并启动设备、初始化主存地址寄存器和字计数器。
- 传送过程:
- 设备发送一个字至DMA的数据缓冲寄存器中,作为选通信号
- 设备向DMA控制器发送DMA请求(DREO)
- DMA接口向CPU申请总线控制权(HRO)
- CPU发回总线应答信号(HLDA)
- DMA控制器发送主存地址到总线
- DMA控制器向设备发送DMA应答信号(DACK)
- 传送数据至内存,同时修改主存地址寄存器和字计数器的值、检查数据块是否传送结束。
- 后处理:校验已传输的数据是否正确、决定是否用DMA传输其他数据块
-
周期挪用方式中,I/O 设备每挪用一个主存周期都要申请和归还总线控制权。传输一个字的数据时,数据传输本身可能只需要 1 个主存周期,DMA 接口需要占用多个主存周期。因此适合I/O 设备的读写周期大于存取周期的情况
- DMA 与 CPU 交替访存适用于 CPU 的工作周期比主存存取周期长的情况。将一个 CPU 工作周期分为两个部分,分别用于 DMA 访存和 CPU 访存
- 周期挪用是一种单字传输方式
- 这里的字指的是I/O接口的数据缓冲寄存器宽度/存储器总线宽度
中断和异常

-
概念厘清
- 中断向量
- 中断处理程序的入口地址(首地址)
- 中断类型号
- 标识中断类型的编号
- 中断向量地址
- 保存中断向量的内存地址,在中断响应阶段由中断向量地址形成部件(硬件)生成
- 中断优先级
- 中断响应优先级
- 硬件产生且不可更改
- 中断处理优先级
- 由排队器、中断屏蔽字等硬件决定
- 中断响应优先级
- 中断向量表
- 记录了中断编号和中断向量的对应关系
- 中断向量
-
可屏蔽中断指通过可屏蔽中断请求线INTR向CPU发出的中断请求,CPU可以通过在中断控制器中设置相应的屏蔽字来屏蔽它或不屏蔽它,被屏蔽的中断请求将不被送到CPU
- 不可屏蔽中断指通过专门的不可屏蔽中断请求线NMI向CPU发出的中断请求,通常是非常紧急的硬件故障
-
所有的异常和中断事件都是由硬件检测发现的
-
优先级:
- 不可屏蔽中断>内部异常>可屏蔽中断
- 内部异常中,硬件故障>软件中断
-
中断允许(IF)触发器设置为1,开中断,设置为0,关中断
-
异常的识别大多采用软件识别方式,而中断可以采用软件识别方式或硬件识别方式
- 软件识别方式:
- CPU设置一个异常状态寄存器,用于记录异常原因。操作系统使用一个统一的异常或中断查询程序,按优先级顺序查询异常状态寄存器,以检测异常和中断类型,先查询到的先被处理,然后转到内核中相应的处理程序
- 硬件识别方式(向量中断):
- 异常或中断处理程序的首地址称为中断向量,所有中断向量都存放在中断向量表中。每个异常或中断都被指定一个中断类型号。在中断向量表中,类型号和中断向量一一对应,因此可以根据类型号快速找到对应的处理程序。
- 整个响应过程是不可被打断的,中断响应过程结束后,CPU就从PC中取出对应中断服务程序的第一条指令开始执行,直至中断返回,这部分任务是由CPU通过执行中断服务程序完成的,整个中断处理过程是由软/硬件协同完成的
- 异常/中断的响应由硬件完成,后续中断服务程序是软件完成
- 软件识别方式:
-
中断响应(硬件):
-
关中断
-
PC/PSW(压入内核栈)(保存在中断保留区/中断栈中)
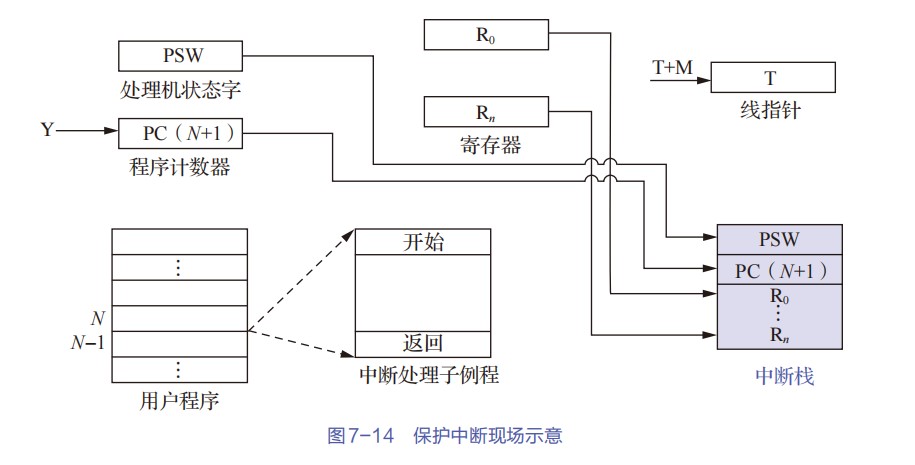
-
中断向量寻址
-
-
OS:
-
保存现场和屏蔽字(有多重中断就保存)
- 现场是包括PC/PSW的,但是为什么让硬件保存PC/PSW,因为指令没有办法直接读写PC/PSW
-
更新中断屏蔽字(多重中断下)
-
开中断
-
中断处理
-
关中断
-
恢复旧的现场和屏蔽字
- 从内核栈中弹出之前保存的通用寄存器等上下文(除了PC和PSW)
- 操作系统用普通指令(
pop/mov)从当前进程的内核栈中恢复通用寄存器、段寄存器等。 - 恢复中断屏蔽寄存器(如x86的
IF标志、APIC的中断优先级)
-
清除中断请求
- 向中断控制器发送EOI(End Of Interrupt)
- 清除设备的中断挂起位
- 注意:在某些设计中,这可能在更早阶段完成
-
开中断
-
中断返回
-
执行特殊的返回指令(如x86的
IRET),该指令会从内核栈中弹出PC和PSW,并可能切换特权级和栈。 -
执行特权返回指令(x86的
IRET/IRETQ,ARM的ERET等)。此时硬件自动:a) 检查并弹出内核栈上的硬件保存帧
从当前内核栈弹出:
- PC(
EIP/RIP) - 代码段选择字(
CS) - PSW/标志寄存器(
EFLAGS/RFLAGS)
b) 特权级检查
比较返回后的
CS选择子中的CPL与当前CPL:- 如果特权级不变(如内核->内核):直接使用当前内核栈
- 如果特权级降低(如内核->用户):需要切换栈
c) 用户栈恢复(当特权级降低时)
从内核栈额外弹出:
- 用户栈指针(
ESP/RSP) - 用户栈段选择字(
SS)
至此,栈指针自动切换到用户栈,中断返回完成。
- PC(
-
-
-
在中断处理程序结束后的执行iret指令过程中,会从内核栈中弹出异常/中断响应时保存的PC和PSW信息(即断点信息),并且会检查异常/中断响应前、后系统是否处于同一个特权级,如果检查出响应前、后处于同一个特权级(即异常/中断是在内核程序执行时发生的,若是中断即表示发生了多重中断),则不需要从内核栈中弹出用户栈指针,因为在这种情况下,异常/中断响应时并没有在内核栈中保存用户栈顶指针。如果检查出前、后不是同一个特权级,则需要弹出用户栈指针。
-
中断返回指令(IRET)的工作
在x86架构中,IRET指令用于从中断或异常处理程序返回。它会根据当前特权级和从栈中弹出的内容进行以下操作:弹出返回地址和标志寄存器:从栈中依次弹出EIP、CS和EFLAGS。
特权级检查:如果返回的目标代码段特权级与当前特权级不同(例如从内核态返回用户态),则还会弹出用户栈的指针(ESP和SS)。
切换栈:如果特权级改变,CPU会自动切换栈,即使用弹出的SS:ESP作为栈指针,从而从内核栈切换到用户栈。
内核栈指针的管理
在整个中断处理过程中,内核栈指针(ESP)始终指向当前中断上下文保存的位置。在中断发生时,硬件会自动将SS、ESP、EFLAGS、CS、EIP等压入栈(如果发生特权级切换,还会压入用户栈的SS和ESP)。然后,操作系统软件再压入其他寄存器。在返回前,操作系统软件会先恢复通用寄存器,并将栈指针调整到合适的位置,使得执行IRET时,栈顶正好是硬件保存的上下文。这样,IRET就能正确地弹出所有硬件保存的信息。
特权级切换的栈操作
如果中断发生在用户态(特权级3),而中断处理程序运行在内核态(特权级0),那么:中断发生时:硬件会自动从当前任务的TSS(任务状态段)中加载内核栈的SS和ESP,然后将用户态的SS、ESP、EFLAGS、CS、EIP依次压入内核栈。
中断返回时:当执行IRET时,CPU会从内核栈中弹出EIP、CS、EFLAGS,然后检查CS中的特权级。如果发现特权级变化(从0变为3),则会继续弹出用户栈的ESP和SS,从而切换回用户栈。
-
-
异常和中断的差异:异常指令通常并没有执行成功,异常处理后要重新执行,所以其断点通常是当前指令的地址。中断的断点则是下一条指令的地址
-
中断处理优先级是利用中断屏蔽技术动态调整,若不使用中断屏蔽技术,则处理优先级和响应优先级相同。
-
通过配置中断屏蔽字,可以动态改变中断处理优先级,但不能改变中断响应优先级,屏蔽字改变的是能否被响应,而不是响应顺序
-
中断屏蔽字寄存器的内容只有在执行中断服务程序时才会被更新,所以中断屏蔽只在CPU运行中断服务程序时才有用
- 其并不能改变CPU运行主程序时的中断响应优先级。即使在CPU运行中断服务程序时,同时到达的多个未屏蔽中断请求的处理也只能按中断判优电路的响应优先级进行处理。
- 因为是进入前看响应优先级,进入后再看处理优先级,所以在响应优先级A>B,处理优先级B>A的情况下,AB同时到达,先响应A,B排队中。A关中断,保存PC和PSW,找到中断向量入口,响应完毕,B等待响应,A保存现场然后开中断准备处理的时候,B由于处理优先级更高,所以当响应完以后,B进入处理。
- 注意,此处的响应只是排队,每次处理的时候还要走一遍响应(保存当前程序的断点)+执行中断服务程序
-
中断或异常处理执行的代码不是一个进程,而是内核控制路径,它代表异常或中断发生时正在运行的当前进程在内核态执行一个独立的指令序列
-
异常由CPU内部硬件(如控制单元、运算单元、MMU等)检测并触发,不可屏蔽,需立即处理
-
定时器超时属于外部中断
-
缺页可以回到发生故障的指令重新执行
- 上溢出、除数为0、非法指令、内存保护错等:终止当前进程
-
对于除数为0的情况,根据是定点除法指令还是浮点除法指令有不同的处理方式
- 对于浮点数除0,异常处理程序可以选择将指令执行结果用特殊的值(NaN或∞)表示,然后返回到用户进程继续执行除法指令后面的一条指令
- 对于整数除0,则会发生整除0故障,通常调用abort例程来终止当前用户进程
-
若一个I/O设备的中断请求被屏蔽,则它的中断请求信号将不会被送到CPU,一般外设中断源引起的中断都是可屏蔽中断
-
当CPU处于开中断状态,且在当前指令执行完毕时,若检测到有效的可屏蔽中断请求,将立即启动中断响应流程(即使是多重中断,CPU正在处理某个中断的过程中,由于中断屏蔽字的存在,CPU检测不到处理优先级更低的中断请求信号,若检测到中断请求信号,则说明其处理优先级更高,会优先相应)
-
中断结束是由CPU(通过软件)通知中断控制器,而不是外设或控制器主动发给CPU
-
处理器在响应非屏蔽中断时,通常不需要像常规中断那样从外部硬件获取中断向量号。在很多处理器中,不可屏蔽中断所对应的中断向量号固定为2(因此它在被响应时无中断响应周期)
-
硬件判优方法
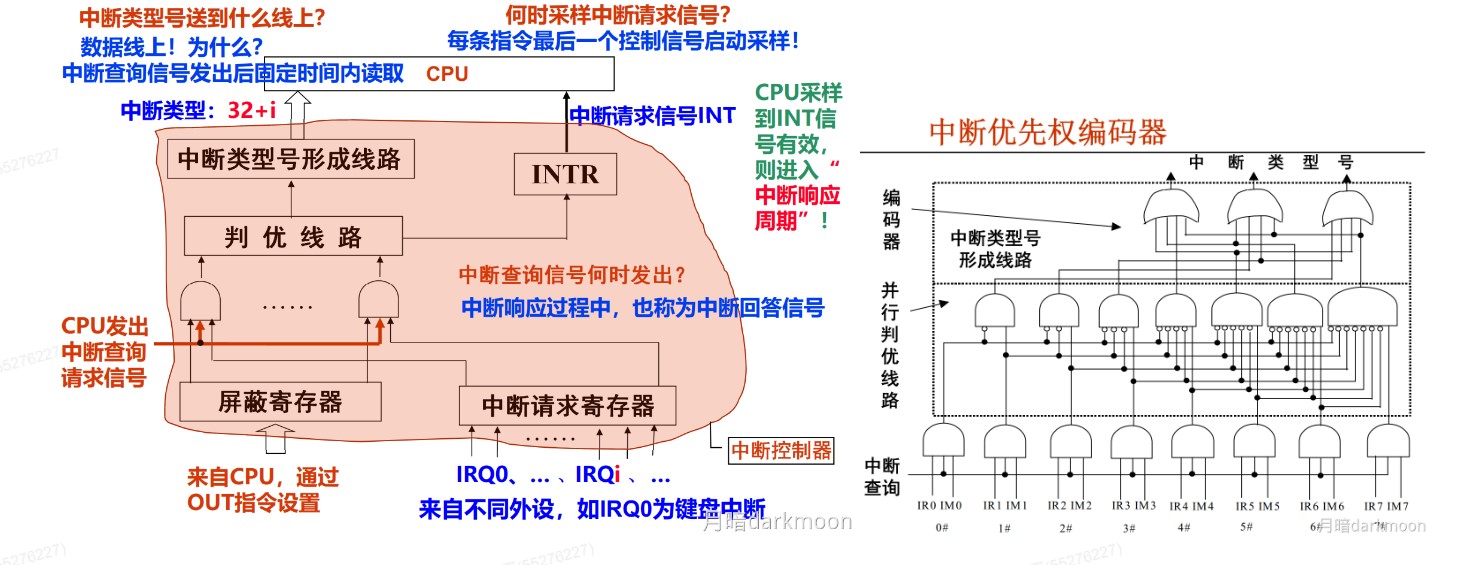
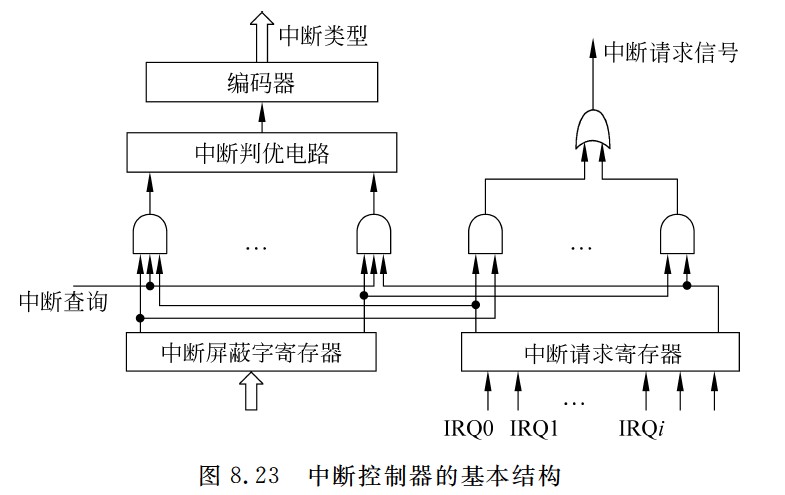
- 除数为0异常在ID周期进行检测
- 溢出、无效数据地址异常在EX周期进行检测
- 无效指令在ID周期进行检测
- 无效指令地址、缺页和访问越权异常在IF周期检测
- 缺页和访问越权异常在M周期检测
- 中断可在每条指令的最后一个周期的最后进行检测
- 除了在中断响应阶段可以由CPU对中断允许位进行设置外,也可以在异常或中断处理程序中执行相应的指令来设置或清楚中断允许位
- 为了能够支持异常或中断的嵌套处理,大多数处理器将断点保存在栈中,如果系统不支持多重中断嵌套处理,则可以将断点保存在特定寄存器中,而不需要送到栈保存
- 通常是由CPU外部的中断控制器根据I/O设备的中断请求和中断屏蔽情况,结合中断响应优先级,来识别当前请求的中断类型号,并通过数据总线将中断类型号送到CPU
- 中断不会发生地址空间的切换,进程切换才会切换进程地址空间,需要切换页表基址寄存器PTBR的内容,而TLB的内容也无需保存,因为其本来就是内存中页表的副本,进程切换后,把TLB里的内容冲刷即可(把有效位都清0)
- 保护现场和旧屏蔽字和恢复现场和旧屏蔽字分别通过压栈和出栈指令或取数指令来实现,设置新屏蔽字和清除中断请求通过执行I/O指令来实现
- 屏蔽字1表示屏蔽,0表示正常申请,开中断IF1表示开中断,0表示关中断
- 外设准备数据的时间应大于或等于中断处理时间,否则会导致数据丢失
- 无论中断处理还是子程序调用,为了保证执行流能正确返回并恢复执行,都需要保存当前执行上下文:
- 程序寄存器PC
- 中断由中断隐指令完成
- 子程序调用由CALL指令完成
- 执行call指令时,处理器先将当前的PC值压入栈,再将PC设置为被调用子程序的入口地址
- 部分通用寄存器
- 对于子程序调用,通用寄存器的保存通常由软件(编译器生成的代码或程序员显式编写的代码)根据调用约定来完成。硬件的call指令本身不负责保存所有通用寄存器
- 程序寄存器PC
- 中断可能引起处理器状态变化(如从用户态进入内核态、中断被屏蔽),因此必须保存程序状态字寄存器(PSW),而子程序调用通常在同一特权级内进行,不改变系统状态,无须专门保存PSW
- 进程切换一般也不保存PSW
- CPU的数据通路中有相应的异常和中断的检测和响应逻辑,在外设接口中有相应的中断请求和控制逻辑,操作系统中有相应的中断服务程序。
- 中断控制器负责接收外设设备控制器中的中断并进行排队和判优,所以和外设的设备控制器直接相连,当选中中断后,会把该中断的中断类型号放入CPU特定的寄存器中
- 断电是外部因素(如电源故障)引起的,通常由计算机硬件(如电源监控电路)检测并向CPU发出中断信号,属于外部中断
- 中断服务程序的最后一条指令是中断返回指令,当其执行结束时,即中断返回至原程序的断点处
- 中断技术使得多道批系统和I/O设备可以与CPU并行工作
- 缺页异常的断点是当前PC值减去后面那条指令的长度,因此在发生缺页时,已经在取指令状态执行了PC+“1”,所以需要减去“1”才能重新执行发生异常的指令
- 终止是一种硬件故障,无法确定哪条指令出现问题
- 中断控制器是一个单独的硬件或者说I/O控制器,连接到各个外设
时钟中断全流程
- 时钟和时间片(分配给进程的时间)是OS用来感知时间的,可以通过软件方式设置
- 时钟中断全流程
- ①用户程序执行ing
- ②CPU时钟到达
- ③时钟中断处理
- ④中断响应阶段
- ⑤保存现场和屏蔽字
- ⑥开中断(允许多重中断)
- ⑦中断服务程序执行(更新进程时间片)
- ⑧可能进程切换
- ⑨关中断
- ⑩恢复现场
- 11、开中断
- 12、中断返回
- 13、返回用户态继续执行
两种中断对比

- 需不需要检测IF(中断使能标志),是可屏蔽中断和不可屏蔽中断的关键区别
- 非可屏蔽中断的优先级高于所有可屏蔽中断,因此不需要检查INTR是否有请求
- 非可屏蔽中断自动禁用可屏蔽中断:CPU在响应时自动清除IF标志
- 不屏蔽非可屏蔽中断,允许非可屏蔽嵌套
- 即使是不可屏蔽中断,CPU仍需在指令边界响应中断,原因是CPU内部执行机制决定
- NMI 优先级高、不可屏蔽,但并不是瞬间中断 CPU,而是 最快在当前指令执行完毕后响应。
- NMI 不受中断屏蔽标志控制,但仍然需要等到 CPU 到达 中断检测点(通常在指令完成后) 才能响应。
- 不可屏蔽仅指跳过IF标志检查,但不改变CPU的原子执行原则
- 非可屏蔽中断是多重中断系统中的概念
- 不可屏蔽中断需要保存断点和中断服务程序寻址,NIM的向量号固定且不可配置,但必须通过向量表跳转,否则CPU无法知道处理程序位置
中断控制器
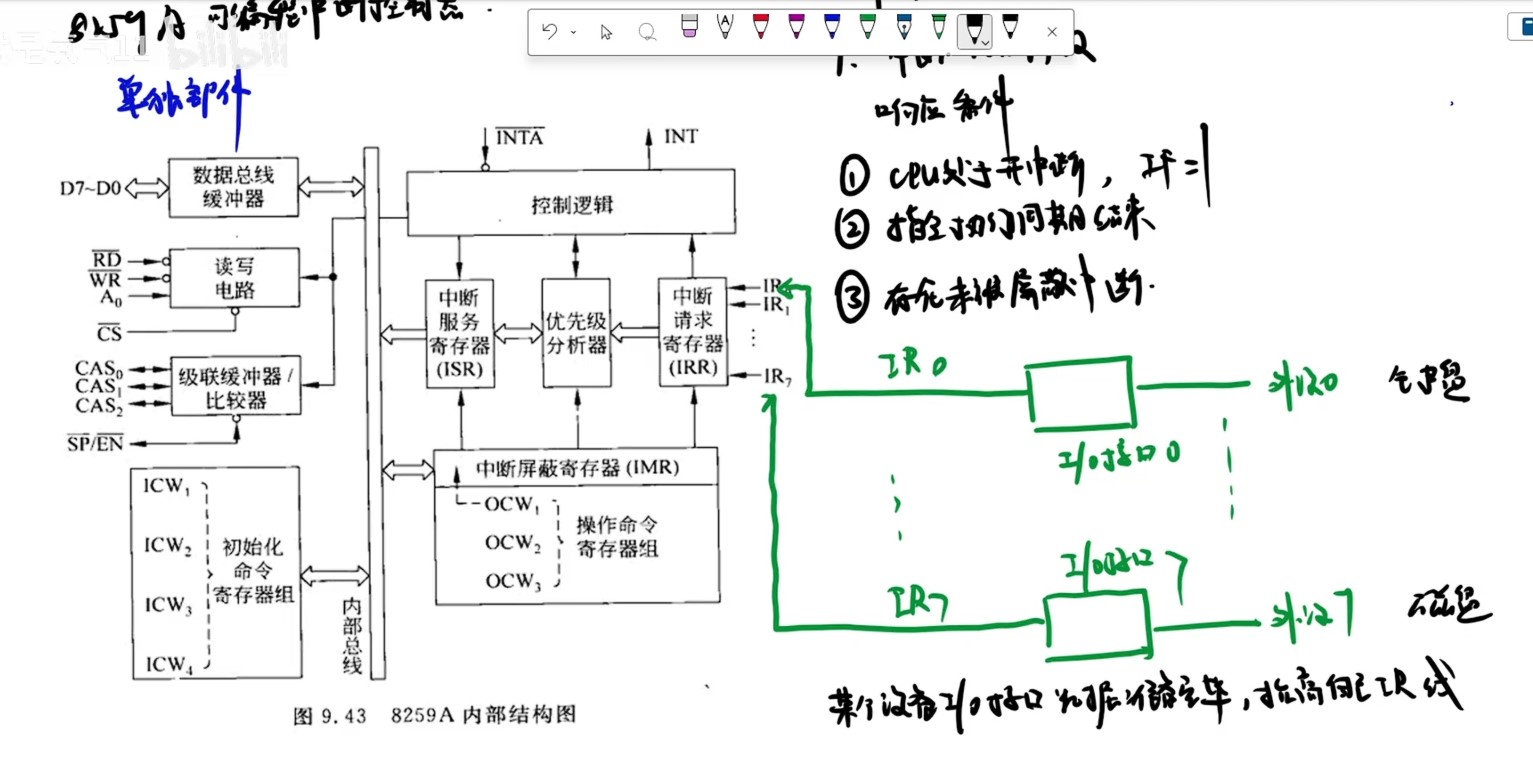
- 中断服务寄存器ISR里面存的是中断类型号
两种优先级的比较

- 支持多重中断的系统,当CPU响应了第一个外部中断,进入中断服务程序以后会设置中断屏蔽字,就是写入中断屏蔽字寄存器,之后 开中断,后面在执行中断服务程序的过程中,如果来了一些外部中断,中断控制器会根据中断屏蔽字寄存器里的内容选择屏蔽一些外部中断请求,然后没有被屏蔽的被送到中断排队器根据响应优先级排队,最高优先级的先响应
- 如果CPU刚执行完一条指令,这时中断控制器来了很多中断请求,这时候中断屏蔽字寄存器里面没有内容,所有中断请求都不会被屏蔽,都一起送过去中断判优,看谁响应优先级最高先响应谁
- 然后响应优先级最高的中断被选中处理了,之后设置中断屏蔽字,这时候才用到处理优先级
- 若当前正在执行主程序,发生中断,只检查中断响应优先级
- 若当前正在执行中断处理程序,先检查中断处理优先级,如果有若干个(>1个)更高级中断到达,再检查中断响应优先级
中断处理过程
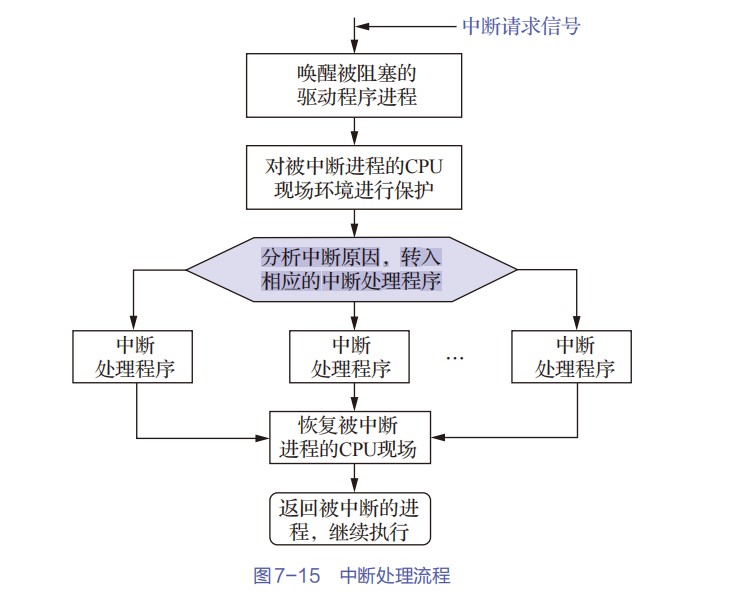
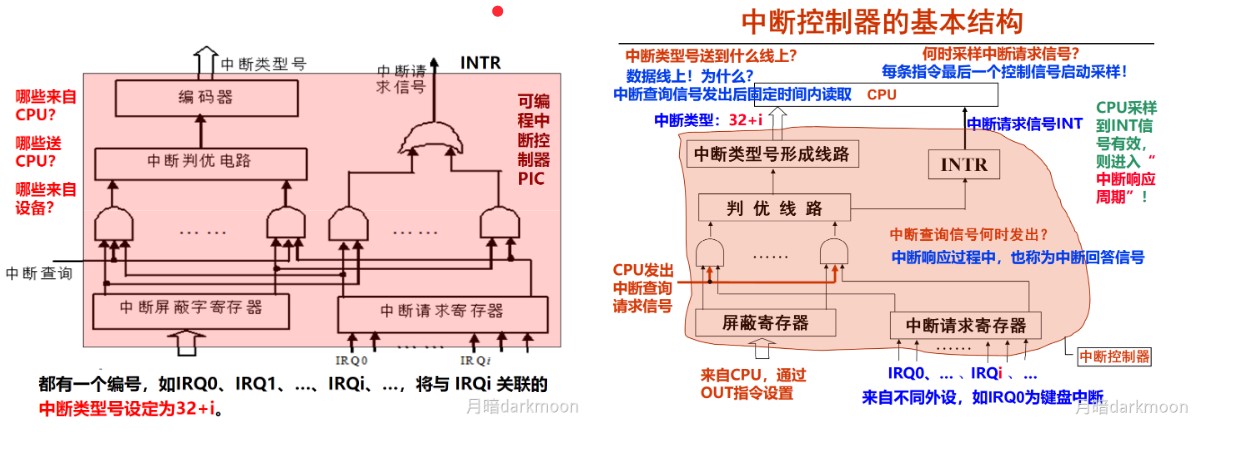
- 上图为中断系统的基本结构图,从图中可以看出,来自各个外设的中断请求记录在中断请求寄存器中的对应位,每个中断源有各自对应的中断屏蔽字,在进行相应的中断处理之前它被送到中断屏蔽字寄存器中。
- 在CPU执行程序代码时,每当完成当前指令的执行、取出下一条指令之前,都会通过采样中断请求信号引脚(如IA-32中的re)来自动查看有无中断请求信号。
- 若有,则会发出一个相应的中断回答信号,启动图中的“中断查询”线
- 在该信号线的作用下,所有未被屏蔽的中断请求信号一起送到一个中断判优电路中
- 判优电路根据中断响应优先级选择一个优先级最高的中断源,然后用一个编码器对该中断源进行编码,得到对应的中断源设备类型号(即中断源的标识信息,称为中断类型号)。
- CPU取得中断源的标识信息后,经过一系列相应的转换,就可得到对应的中断服务程序的首地址(中断向量),在下一个指令周期开始,CPU执行相应的中断服务程序。
- 若有,则会发出一个相应的中断回答信号,启动图中的“中断查询”线
- “保护现场和旧屏蔽字”、“恢复现场和旧屏蔽字”分别通过**“压栈”和“出栈”指令**来实现
- “设置新屏蔽字”和“清除中断请求”通过执行I/O指令来实现,这些I/O指令将对可编程中断控制器(PIC)中的中断请求寄存器和中断屏蔽字寄存器进行访问,以使这些寄存器中相应的位清零或置1。
- 在设备驱动程序和中断服务程序中使用到的I/O指令、“开中断”和“关中断”指令都是特权指令,只能在操作系统内核程序中使用。
I/O中断机制中事件处理的初始入口

常见中断问题
- 禁止中断和屏蔽中断是同一个概念吗?
- 不是
- 禁止中断就是关中断,即将中断允许触发器置为0,此时,任何中断请求都得不到响应。
- 屏蔽中断是多重中断系统中的一个概念,是指某个中断正在被处理的时候,如果有其他新的中断请求发生,那么,通过设置中断屏蔽位,可以确定是否允许响应新发生的中断。它反映了正在处理的中断与其他各中断之间的处理优先级顺序,所以每个中断都有一个中断屏蔽字,其中的每一位对应一个中断的屏蔽位。响应某个中断后,就会把该中断的中断屏蔽字送到中断屏蔽字寄存器中,在中断排队前,其中的每一位和中断请求寄存器中的对应位进行“与”操作,因而,只有未被屏蔽的中断源进入排队线路,才有可能得到响应。
- DMA方式下,在主存和外设之间有一条物理通路直接相连吗?
- 没有
- 通常所说的DMA方式下数据在主存和外设之间直接进行传送,其含义并不是说在主存和外设之间建立一条物理上的直接通路,而是在主存和外设之间通过外设接口、系统总线以及总线桥接部件等连接,建立起一个信息可以互相通达的通路。“直接通路”是逻辑上的含义,物理上磁盘和主存不是直接相连的。
- 两句话的对错
- 系统处于开中断时,检测到中断请求就会立即响应(正确)
- 系统处于开中断时,有中断请求就会立即响应(错误)
- 谁发送中断结束信号?
- 关键误解:谁发送“中断结束信号”?
- 外部设备不会直接或间接向CPU发送“中断结束信号”。
- 实际流程如下:
- a.外设产生中断请求→通过中断控制器向CPU发送INTR信号;
- b.CPU响应中断,执行中断服务程序(ISR);
- c.在ISR结束前,由软件(操作系统)向中断控制器发送“中断结束命令”(EOI,End of Interrupt);
- d.中断控制器收到EOI后,清除当前中断状态,允许后续中断。
- “中断结束”是由CPU(通过软件)通知中断控制器,而不是外设或控制器主动发给CPU。
键盘输入的完整数据流
键盘输入
用户先输入的情况
- ①用户按键
- ②键盘硬件将键码发送至键盘控制器的数据寄存器
- ③控制器触发中断请求
- ④CPU响应中断,执行键盘中断服务例程
- ⑤中断服务例程从数据寄存器读取键码
- ⑥将数据存入内核缓冲区(如输入缓冲区)
- ⑦中断服务例程执行结束
- ⑧后续由用户程序通过系统调用(如read)从内核缓冲区读取数据,复制到用户缓冲区A
进程通过执行系统调用从键盘接收一个字符
这个情况是数据未就绪的情况,即用户在请求后输入
- ①将进程p插入阻塞队列
- 进程p执行read()等系统调用等待键盘输入,但输入尚未到达
- 操作系统将其状态设为阻塞,并插入阻塞队列(或等待队列)
- CPU调度其他进程运行
- ②用户在键盘上输入字符
- 用户按下按键,键盘硬件产生键码
- ③启动键盘中断程序
- 键盘控制器向CPU发出中断请求
- CPU响应中断,切换到内核态,启动键盘中断处理程序
- ④将字符从键盘控制器读入系统缓冲区
- 中断处理程序从I/O端口读取键码
- 存入内核缓冲区
- 属于键盘驱动程序的职责
- ⑤将进程P插入就绪队列
- 中断处理程序发现有进程P正在等待输入
- 将其从阻塞队列移出,插入就绪队列
- 表示进程P已具备继续执行的条件
- ⑥进程P从系统调用返回
- 当进程P被调度执行的时候,从系统调用的阻塞点恢复
- 返回用户态,继续执行后续指令(如printf输出读到的字符)
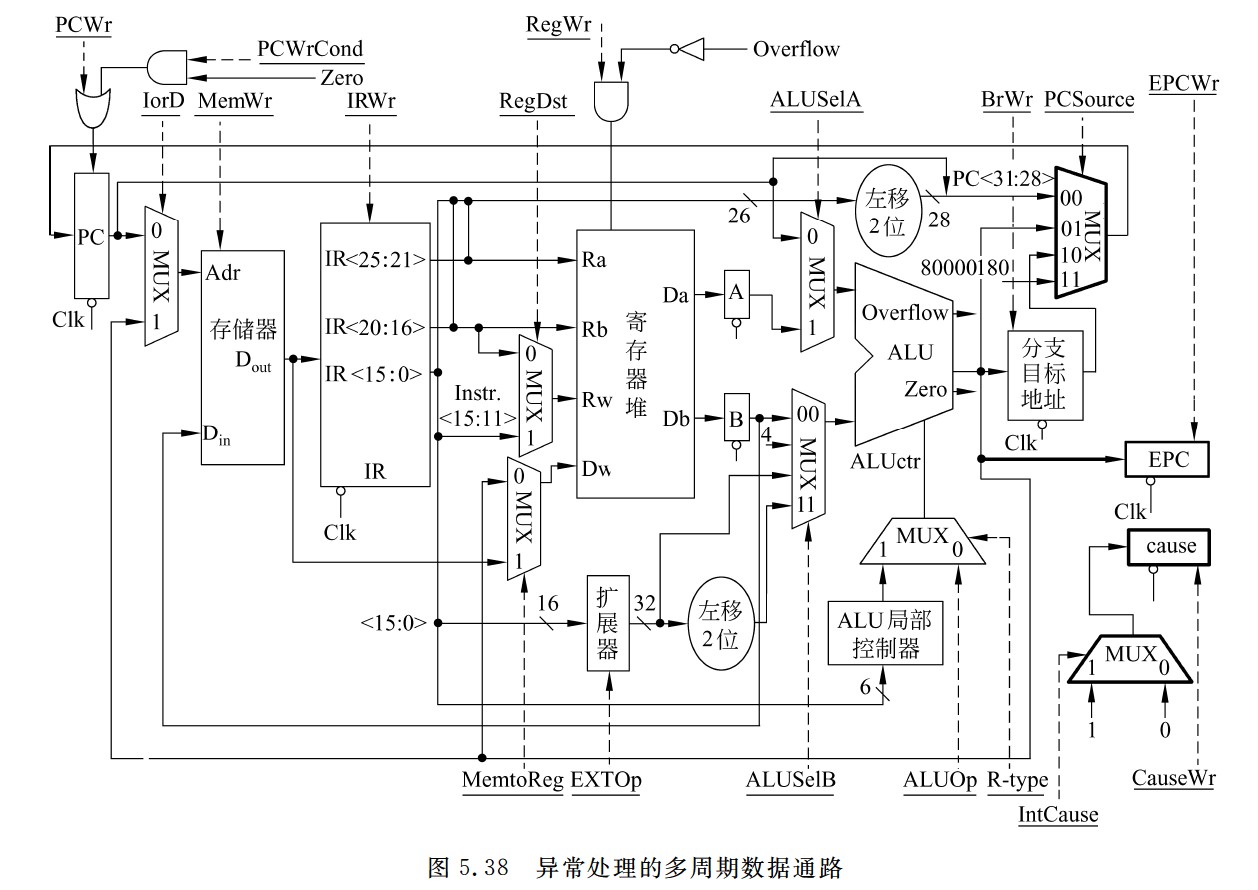
异常处理的多周期数据通路

计组常用硬件图
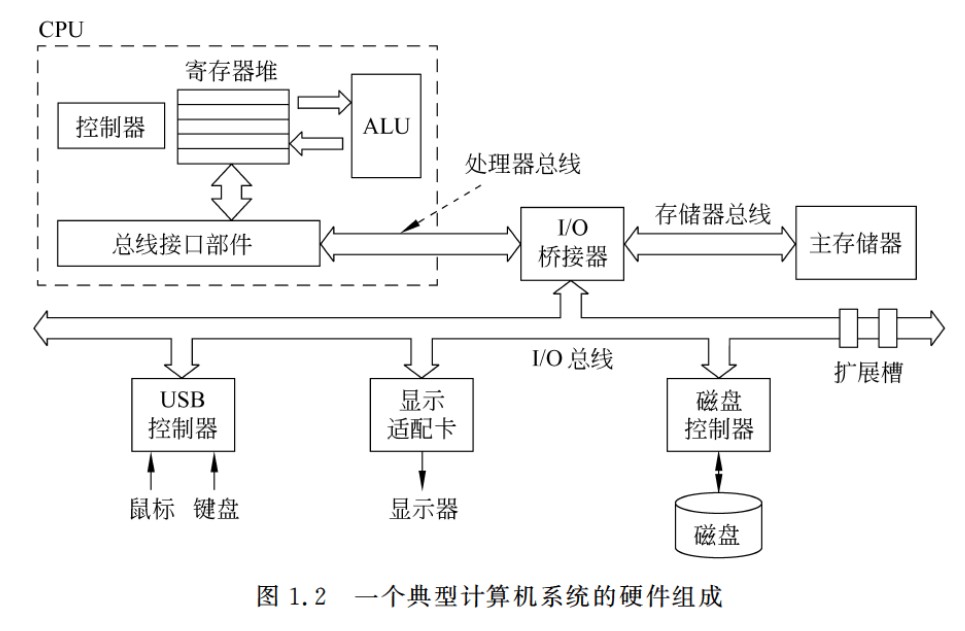
经典计算机系统的硬件组成
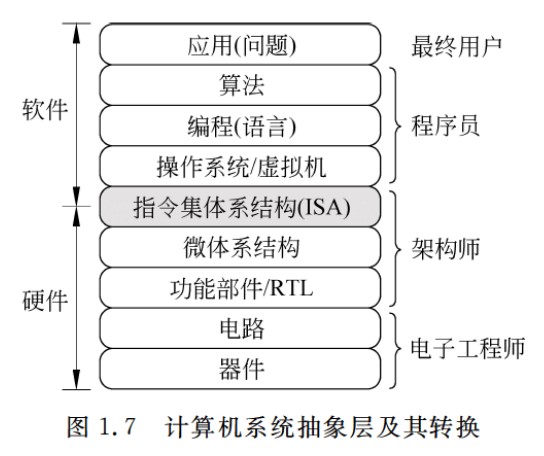
计算机系统抽象层的转换
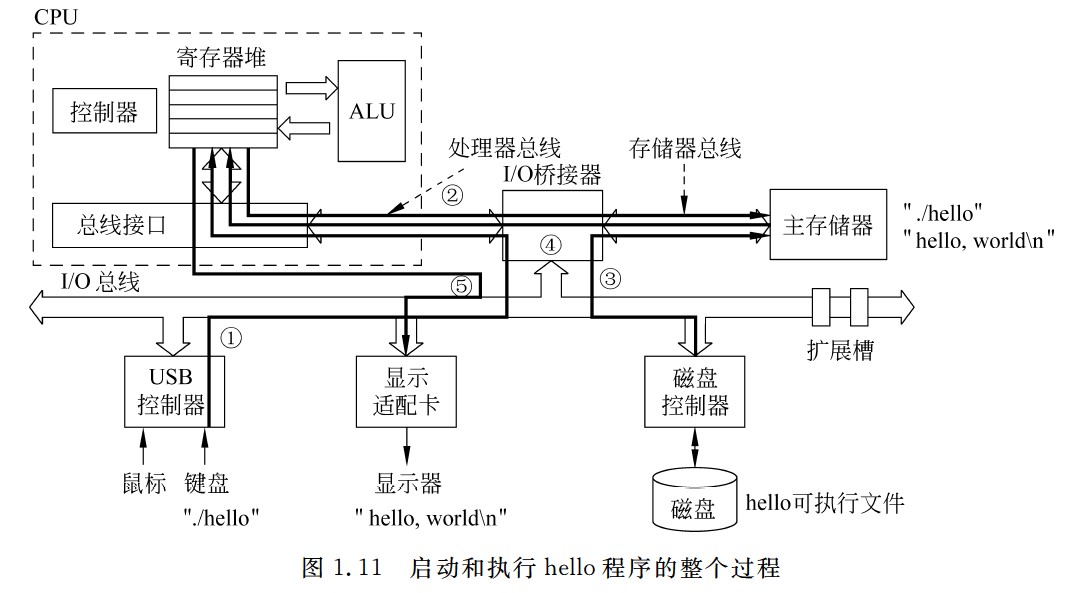
启动和执行hello程序的整个过程
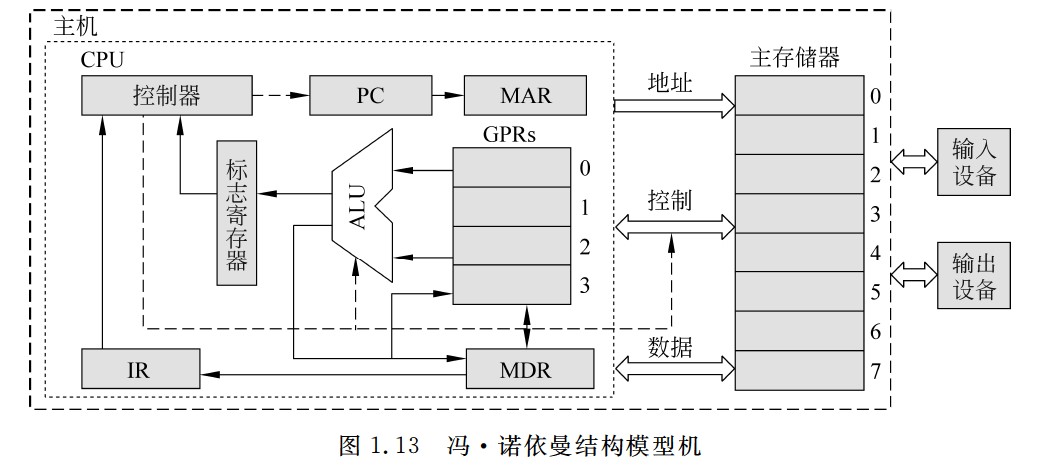
冯诺依曼结构模型机
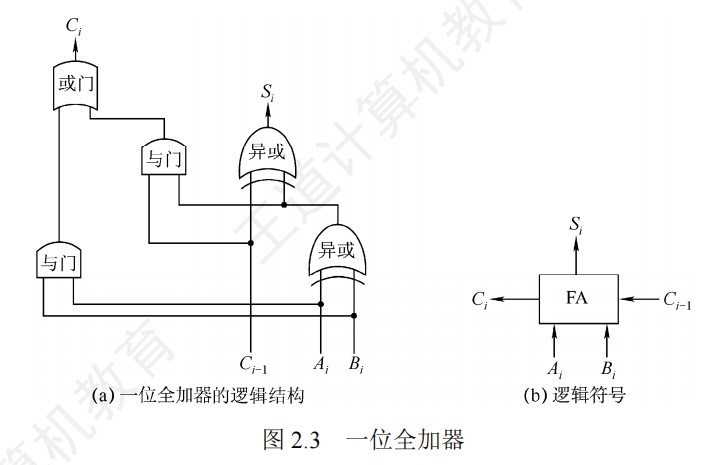
一位全加器
全加和和全加进位
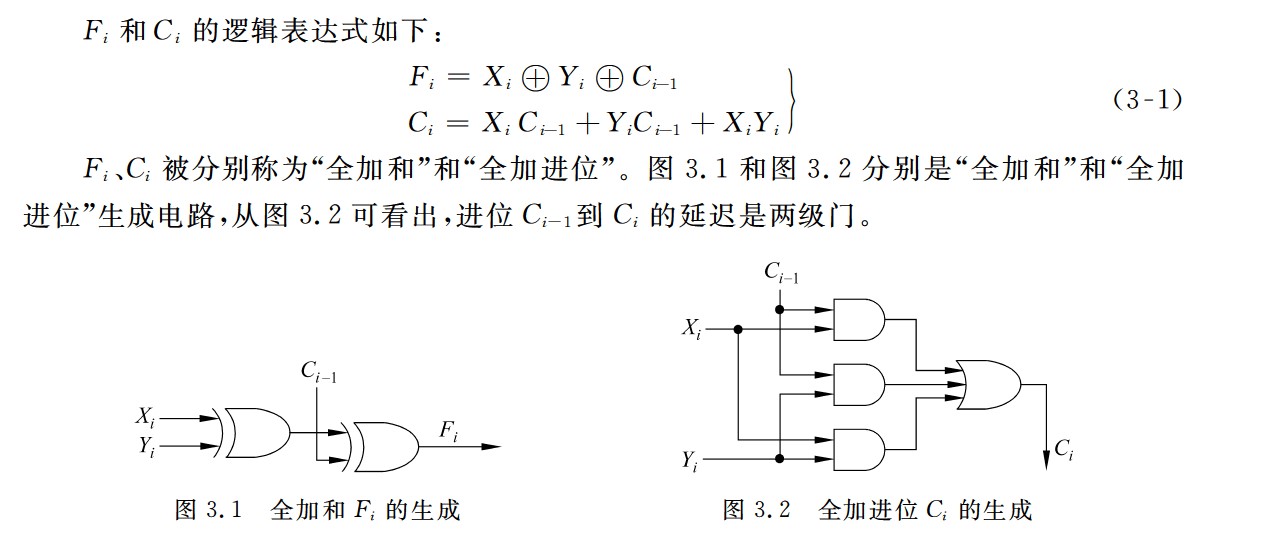
串行进位加法器
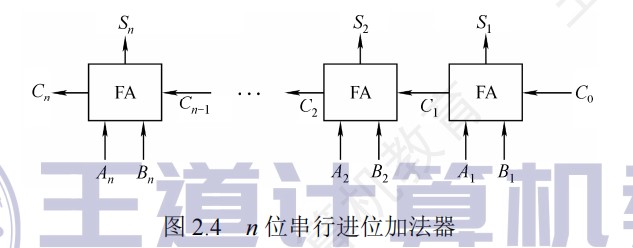
- 计算速度主要取决于进位产生和传递的速度
- 每一级进位直接依赖于前一级的进位
- 最长运算时间:由进位信号的传递时间决定
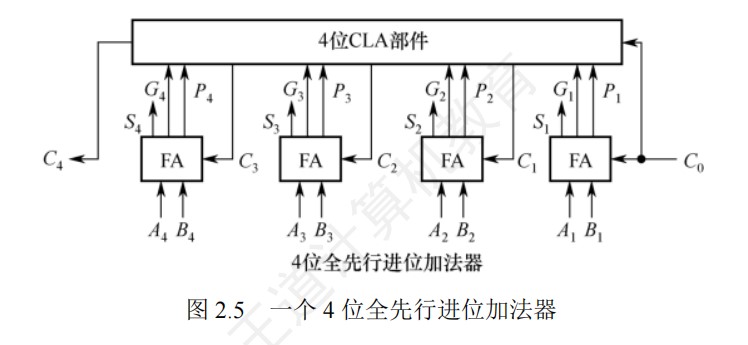
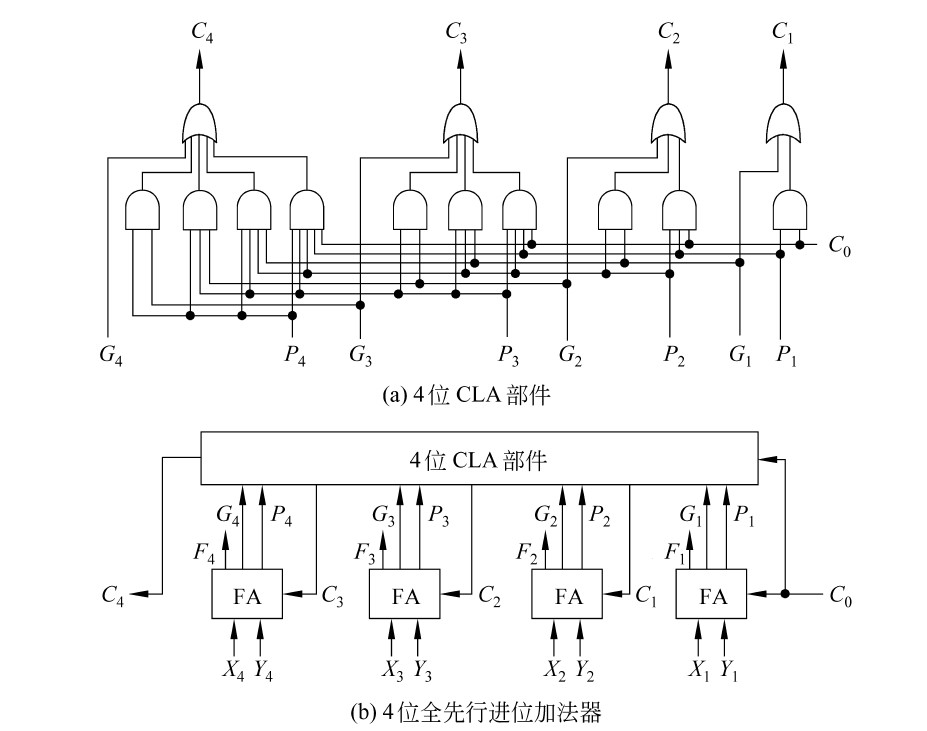
4位全先行进位加法器
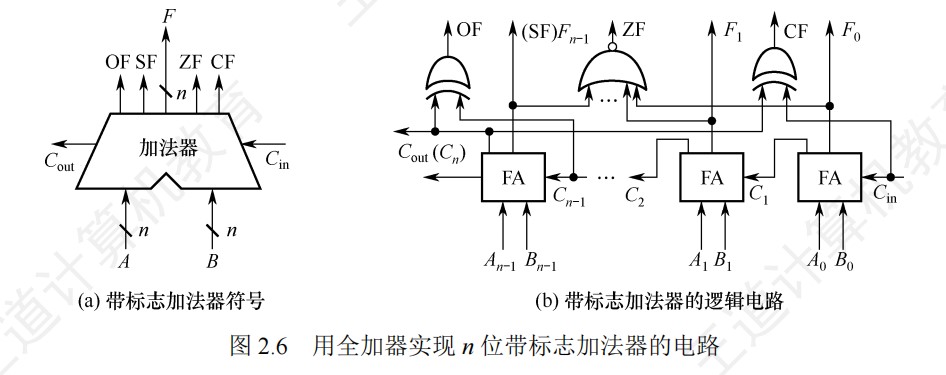
n位带标志加法器
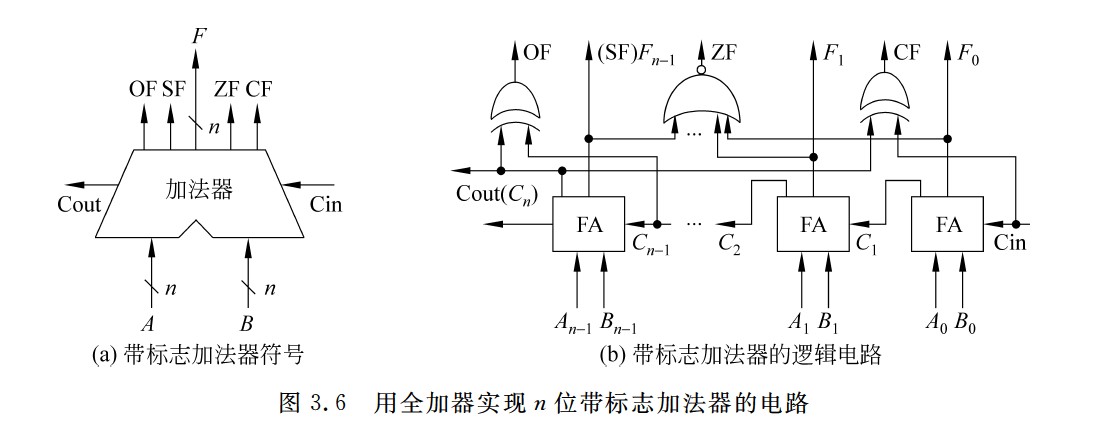
ALU
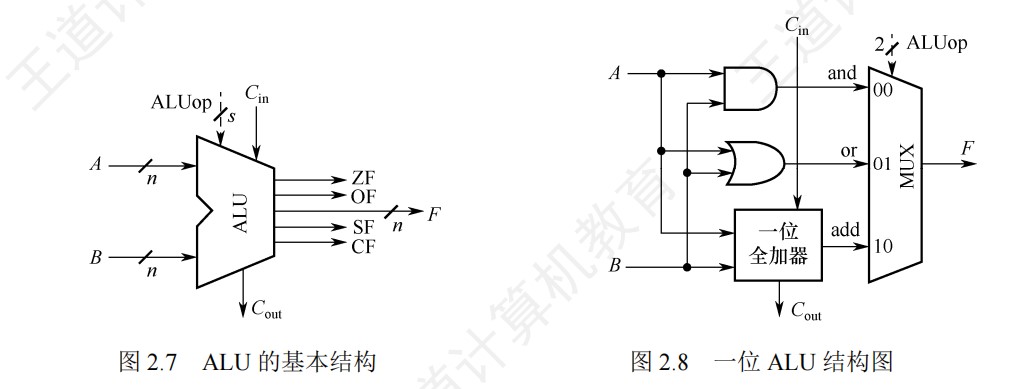



加减运算部件
32位无符号数乘法的逻辑电路
32位无符号数除法的逻辑电路
32位无符号数除法和乘法的逻辑电路对比
补码一位乘和原码一位乘的电路对比
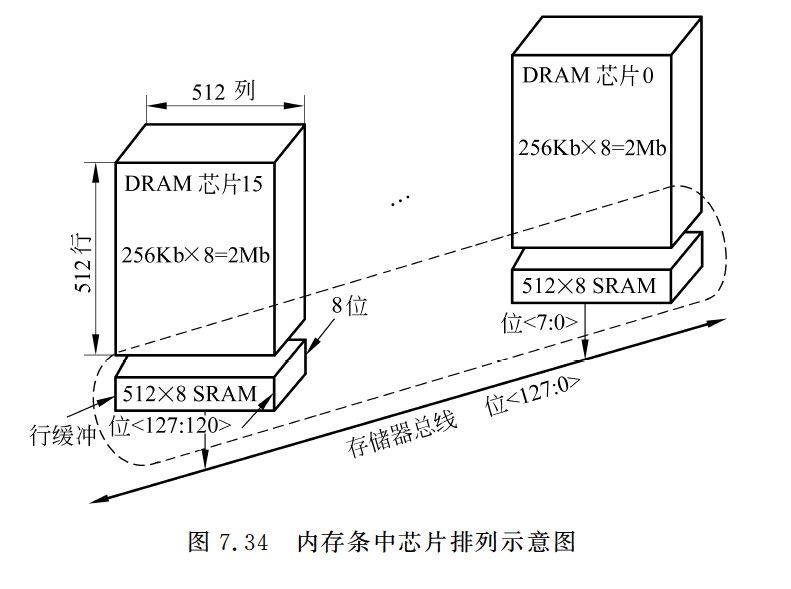
DRAM芯片的内部结构
主存储器的基本结构
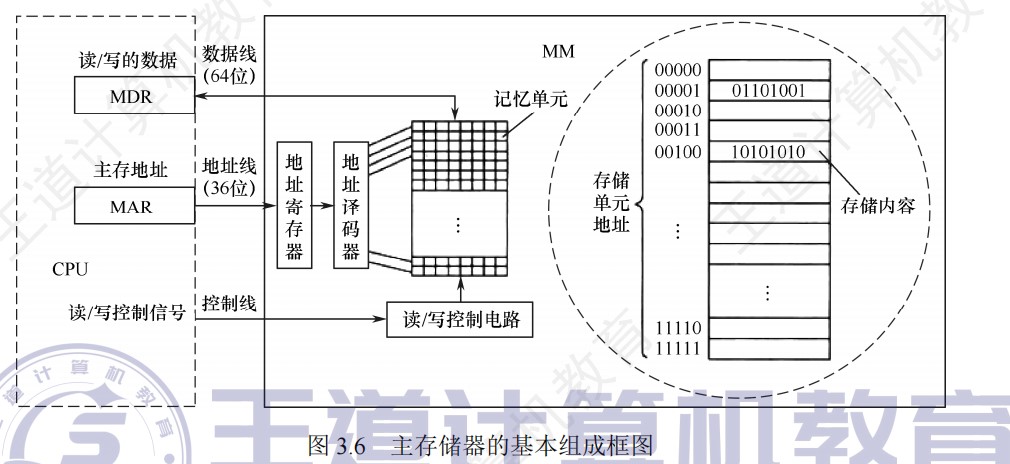
单体多字存储器
高位交叉编址
低位交叉编址
字扩展示意图
位扩展示意图
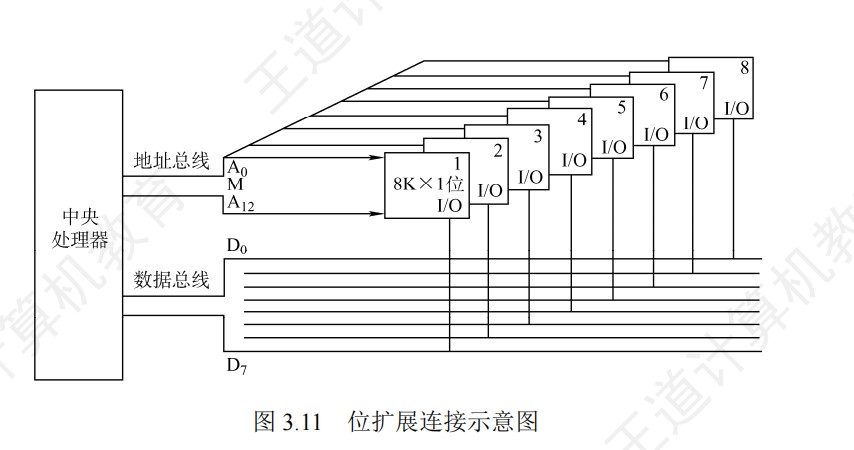
字位同时扩展示意图
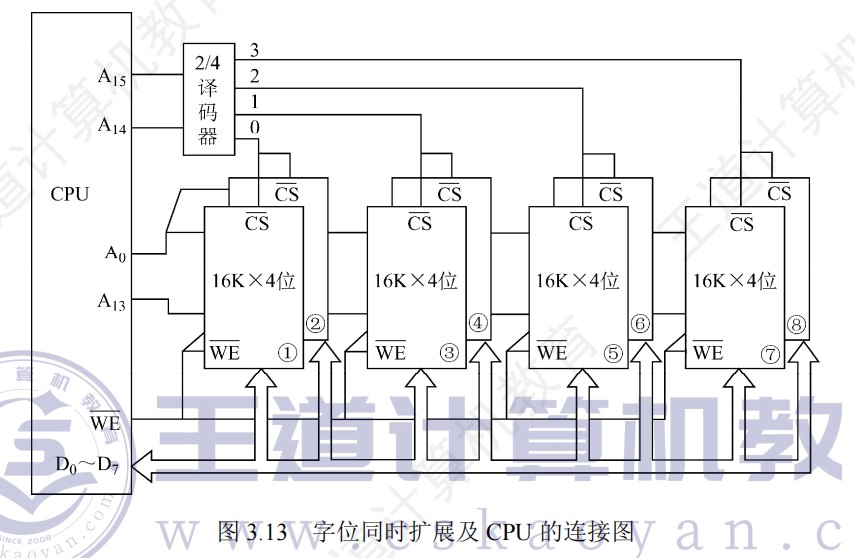
磁盘驱动器
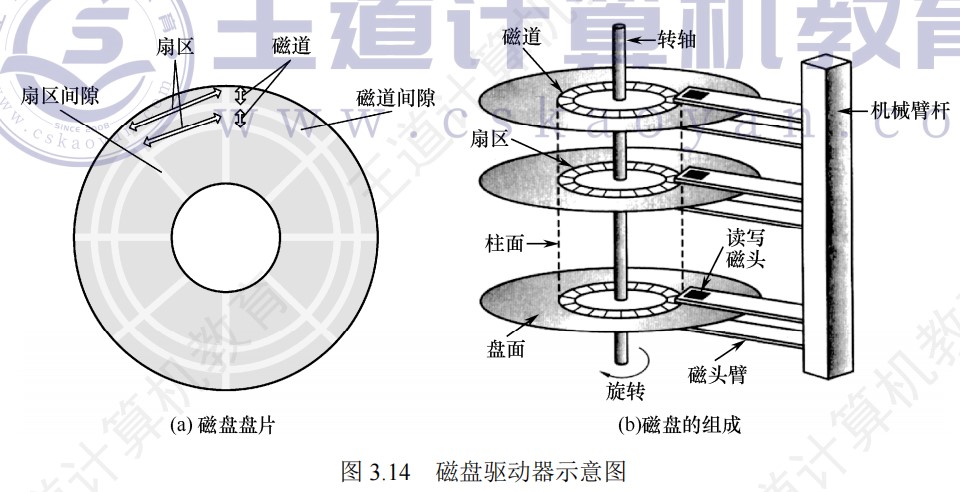
Cache的工作原理
直接映射
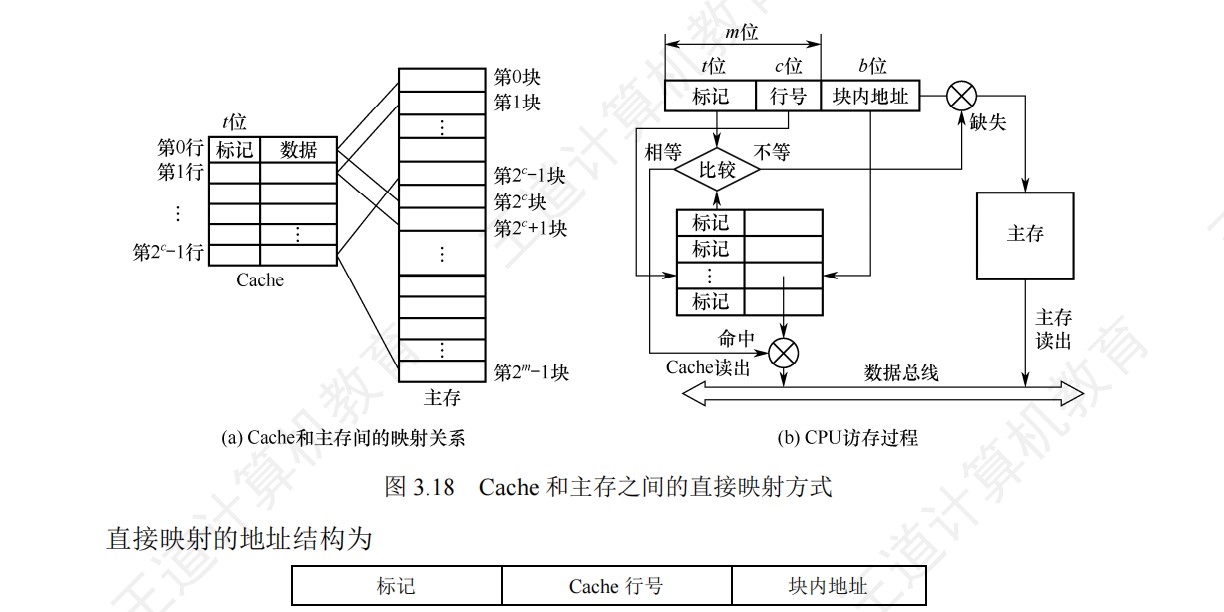
全相联映射
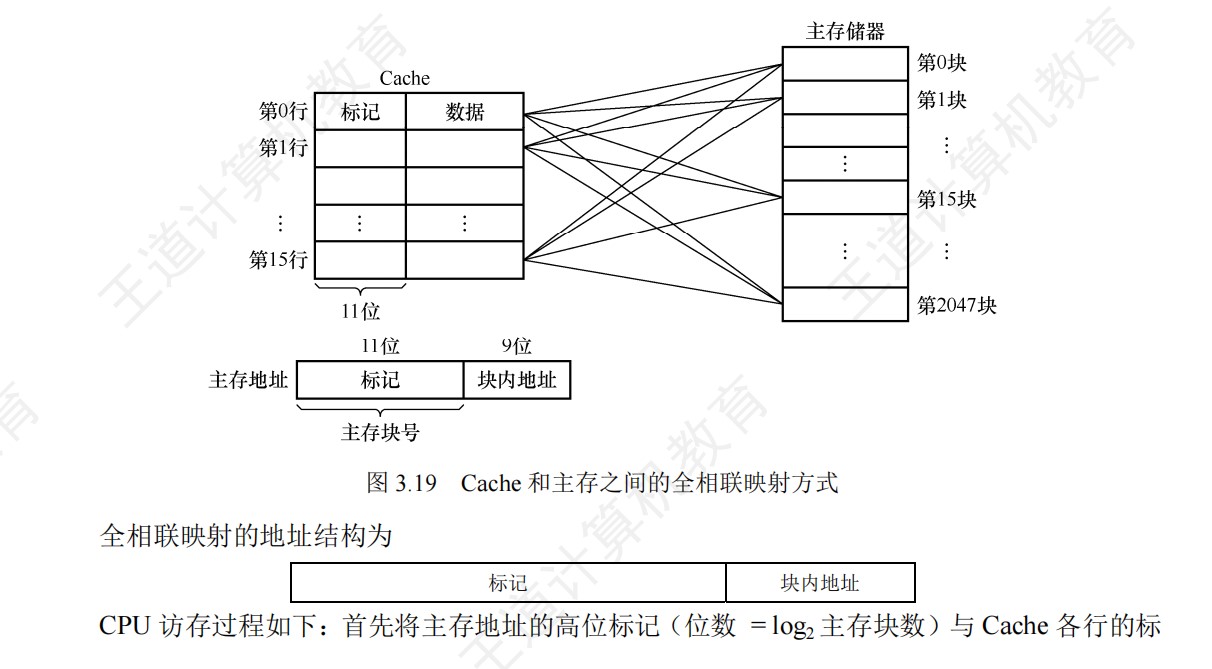
组相联映射
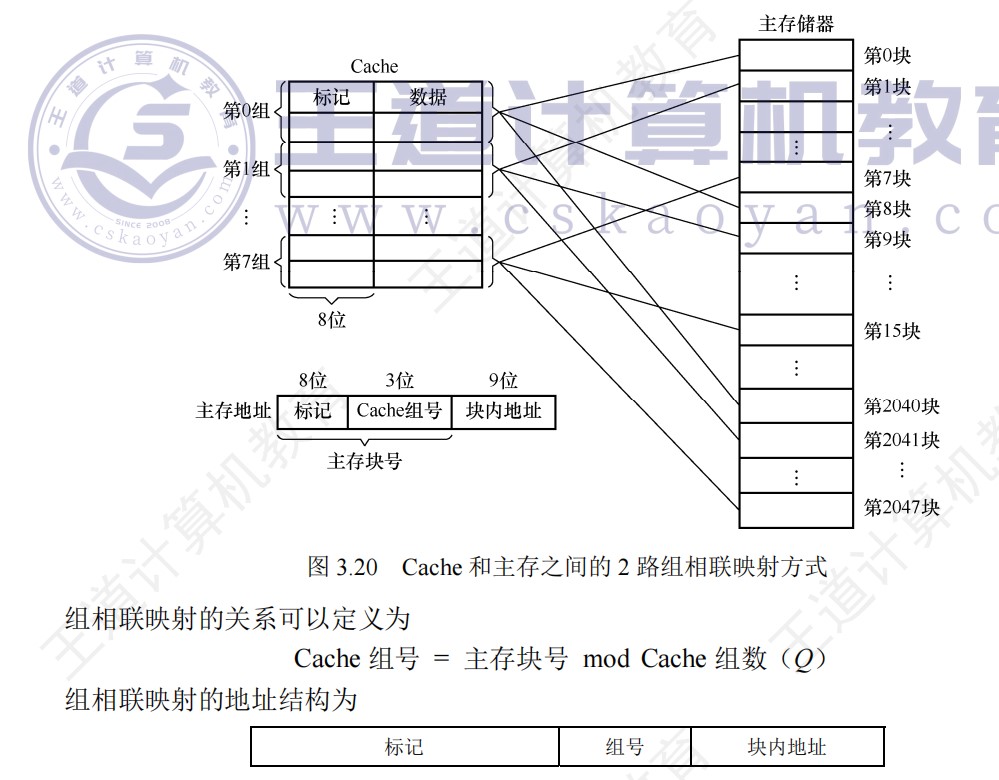
Cache行的存储容量示意图
虚拟存储器的三个地址空间
主存中的页表示例
页式虚拟存储器的地址变换过程
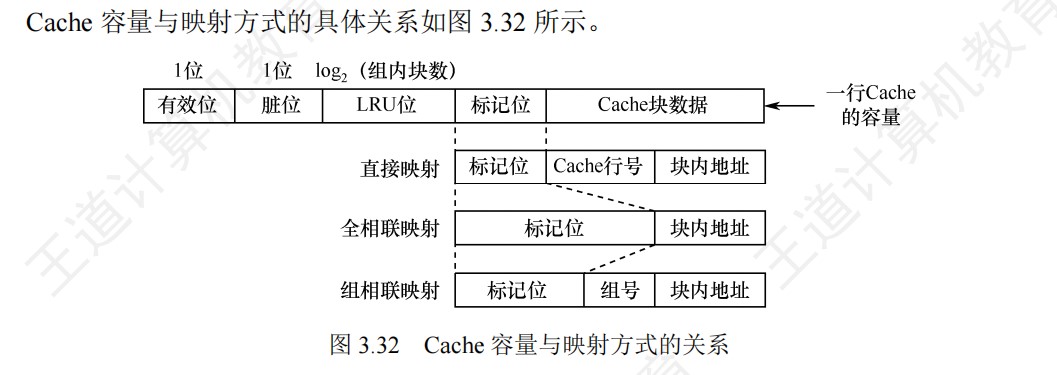
TLB和Cache的访问过程
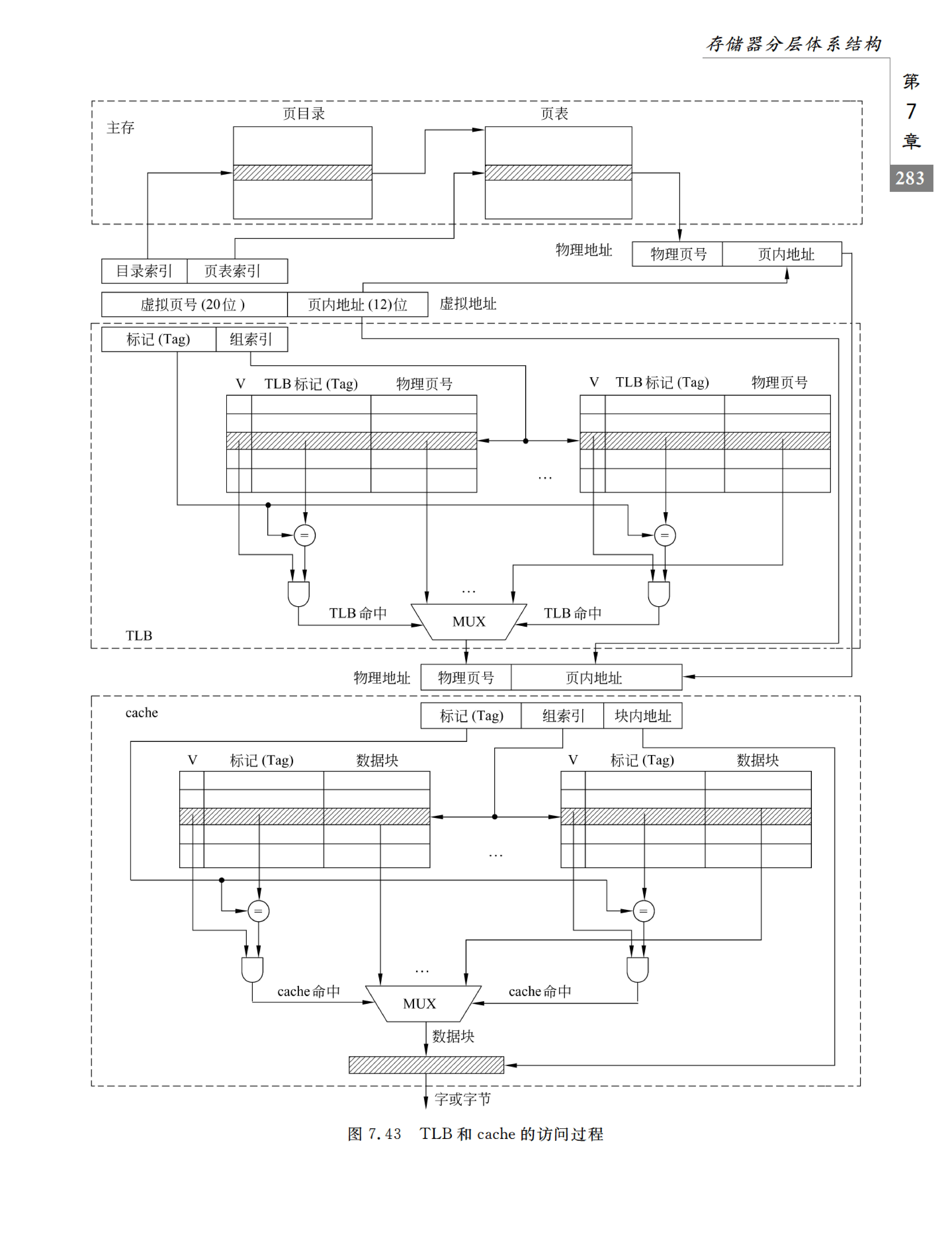
带TLB虚拟存储器的CPU访存过程
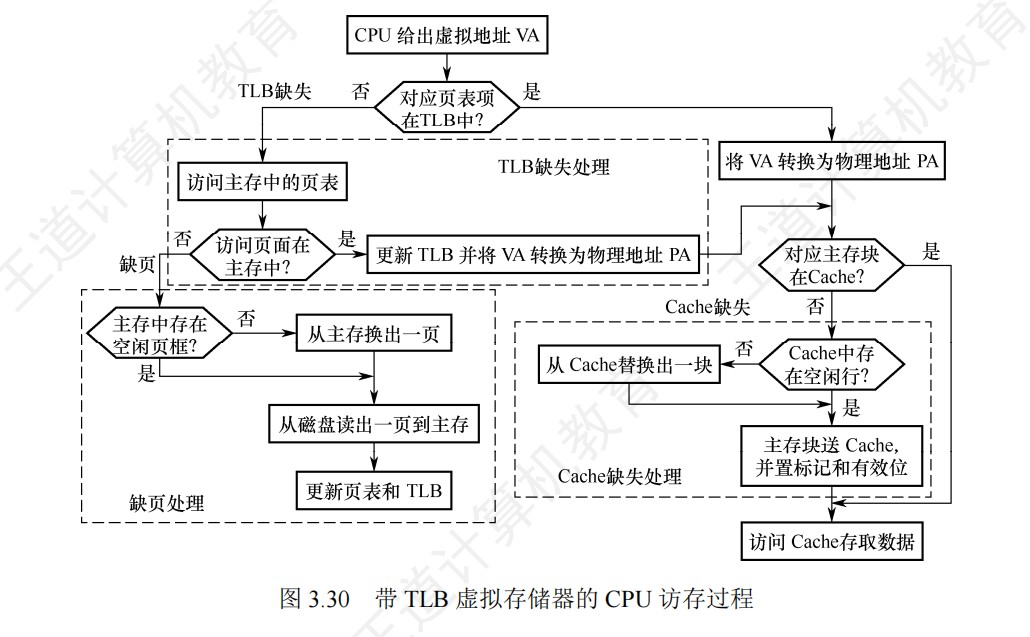
段式虚拟存储器的地址变换过程
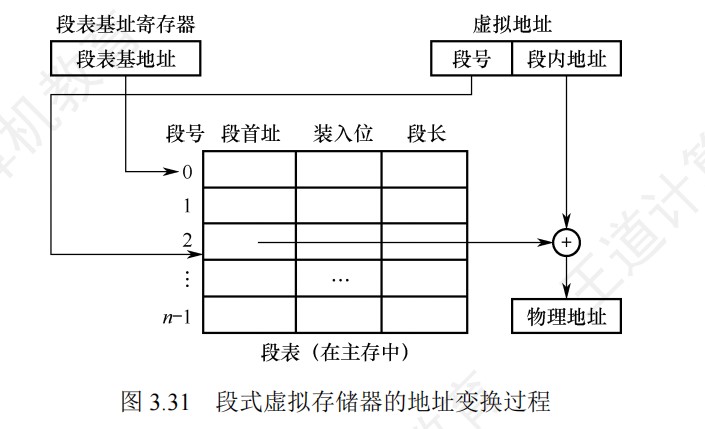
Cache容量与映射方式的关系
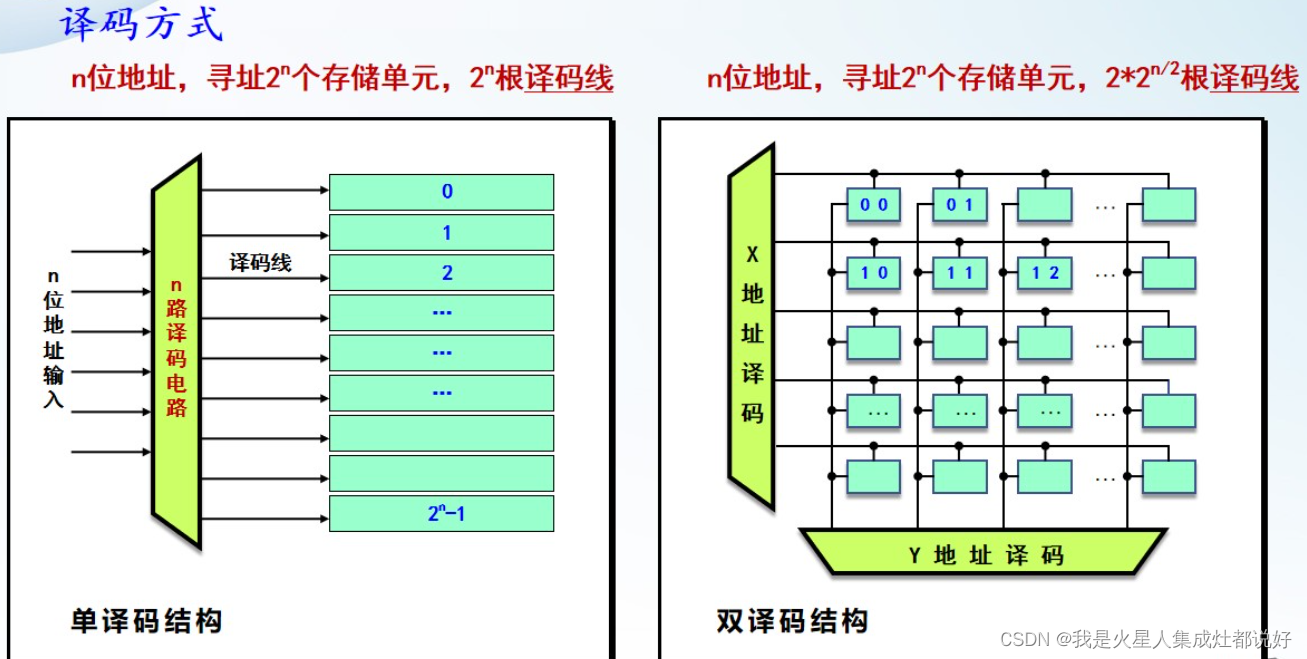
译码方式
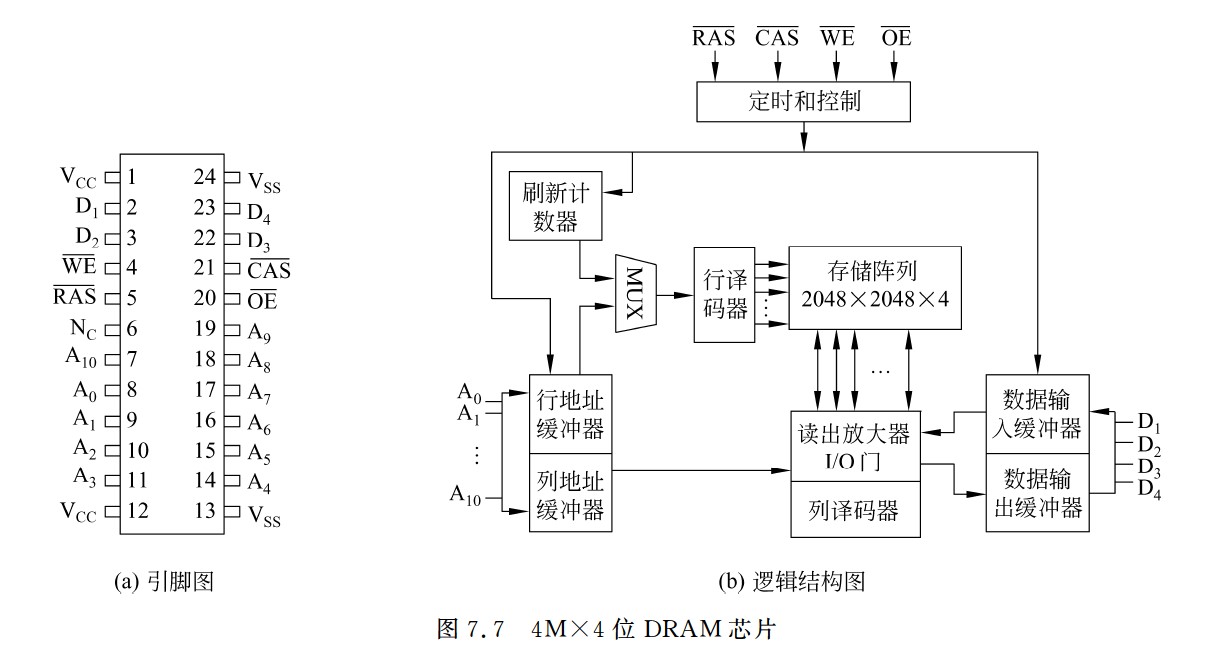
DRAM芯片
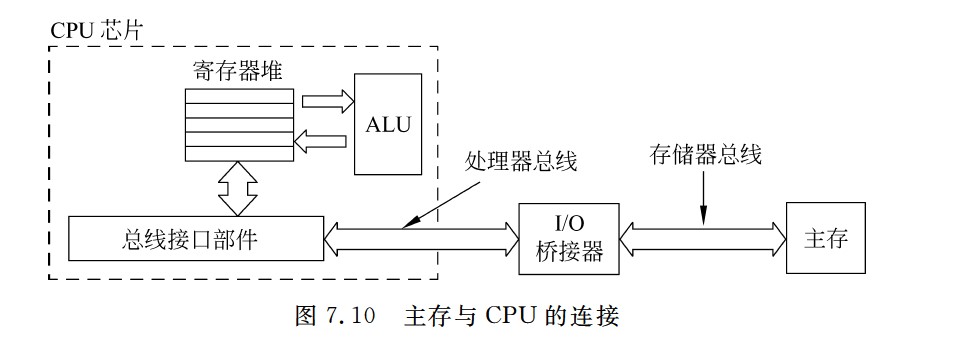
主存和CPU的连接
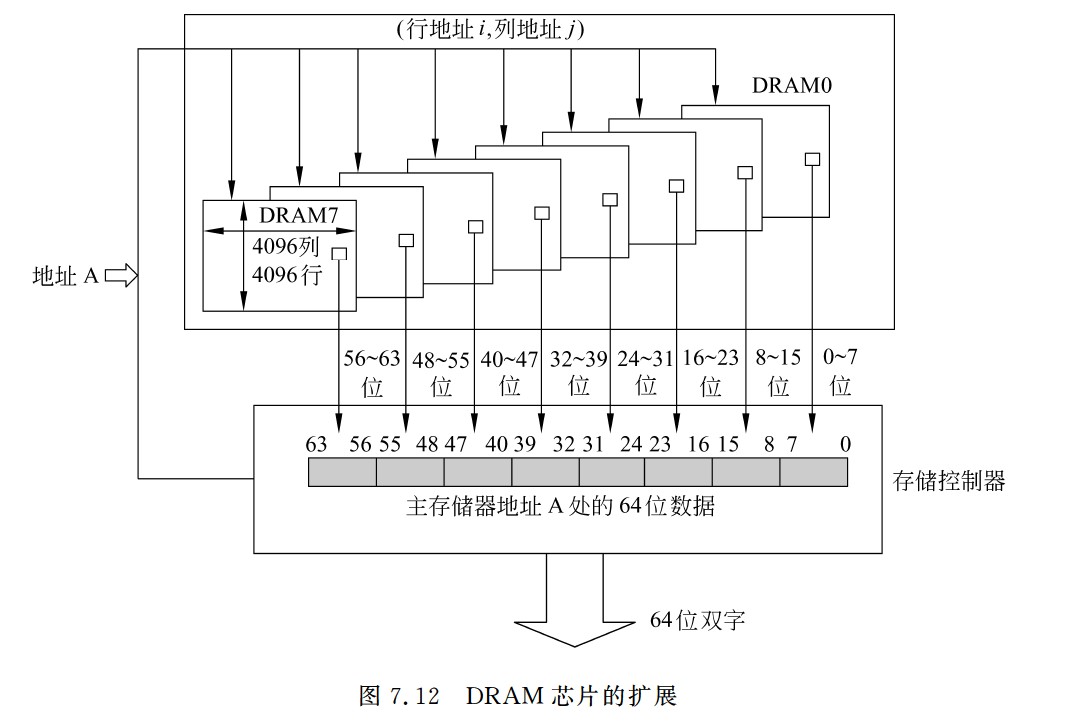
DRAM芯片的扩展
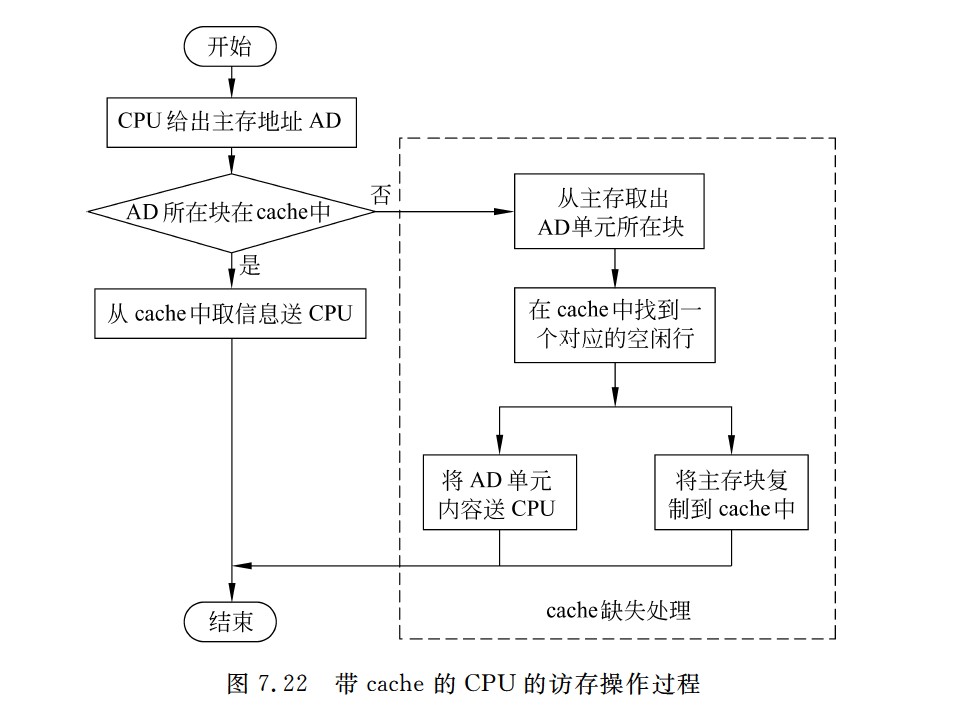
带Cache的CPU的访存操作过程
直接映射方式的实现
组相联映射方式的硬件实现
主存块在主存-总线-Cache之间的传送过程
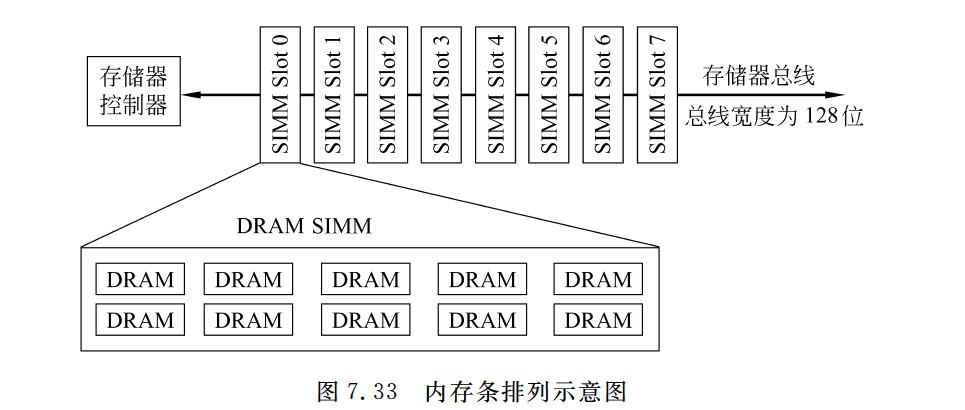
内存条和内存条中芯片排列示意图
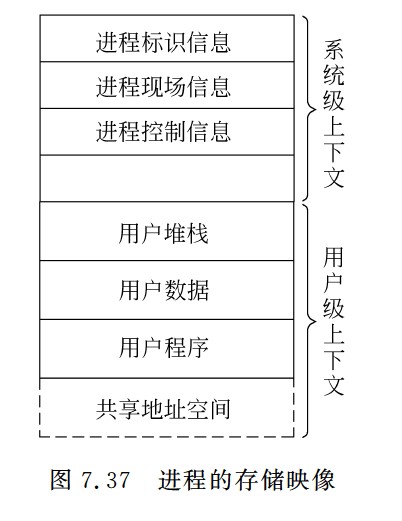
进程的存储映像
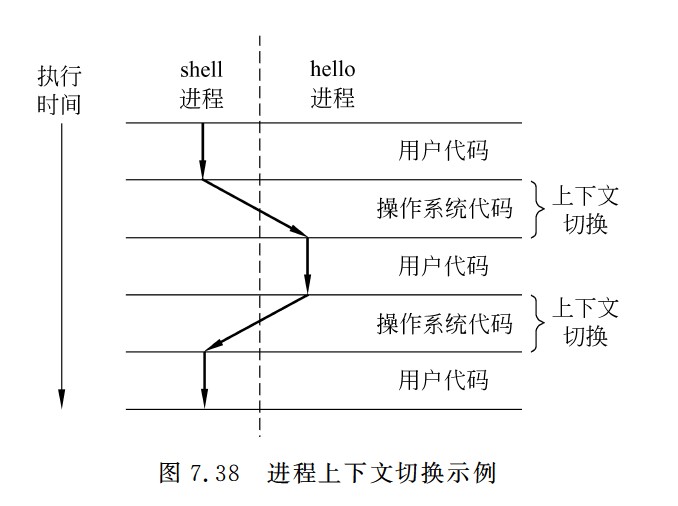
进程上下文切换示例
Linux虚拟地址空间
主存中的页表示意
寻址方式汇总
取指周期的数据流
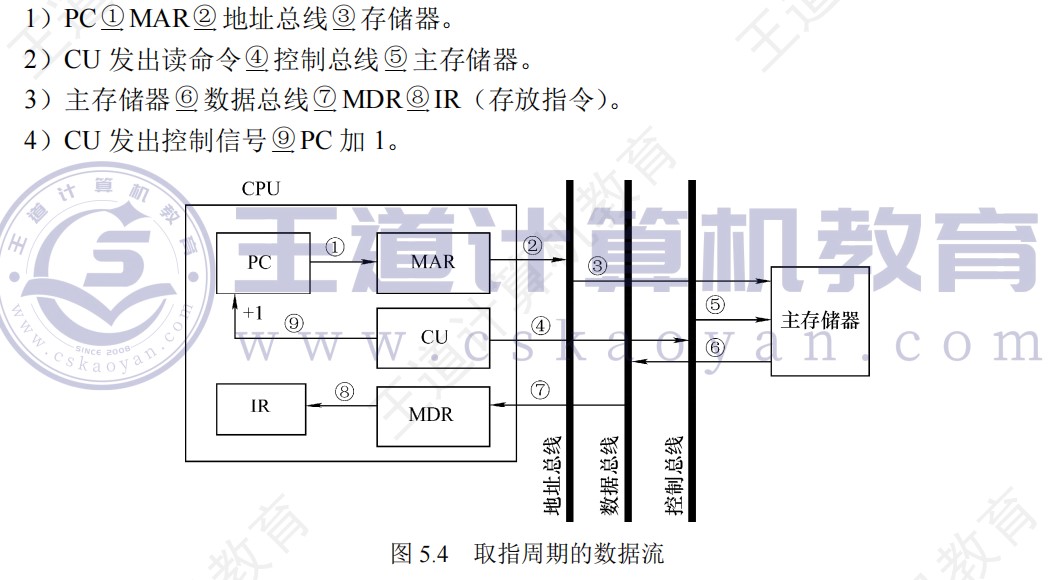
间址周期的数据流
中断周期的数据流
数据通路中几种常用组合逻辑元件
单总线的数据通路和控制信号
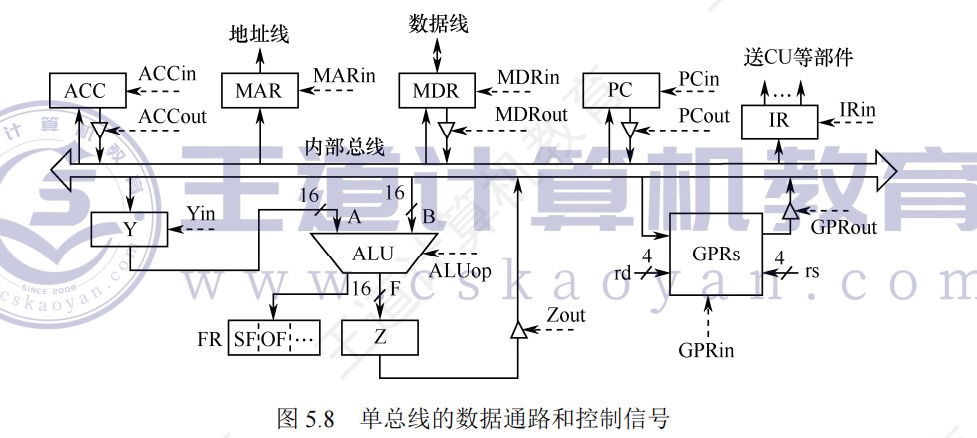
计算机硬件系统和控制器部件组成
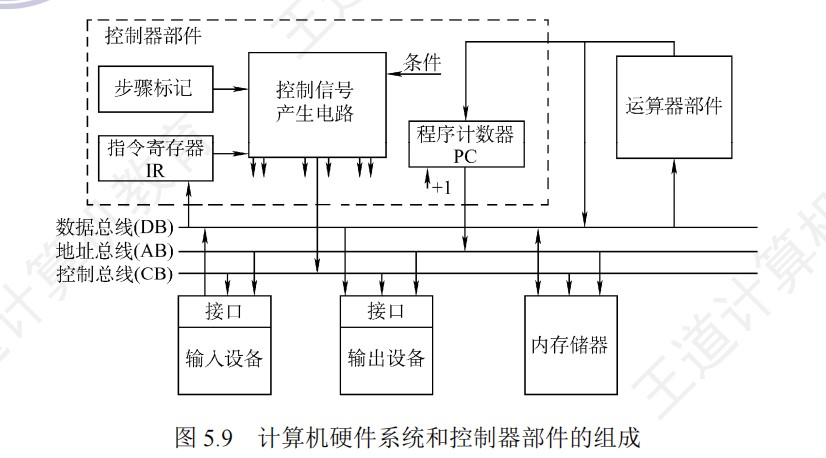
带指令译码器和节拍输入的简化的控制单元
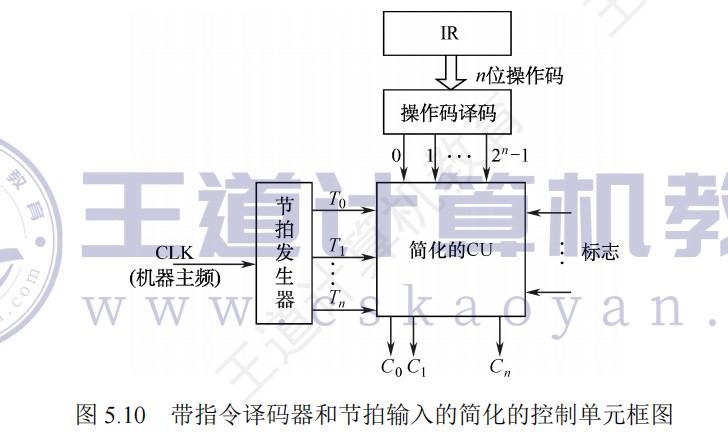
微程序控制器的基本结构
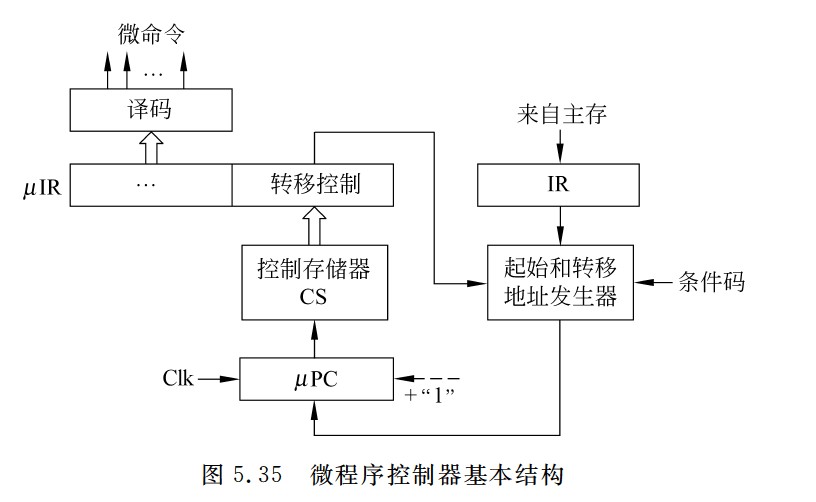
流水线的逻辑结构图

不同类型指令在各流水段中的操作
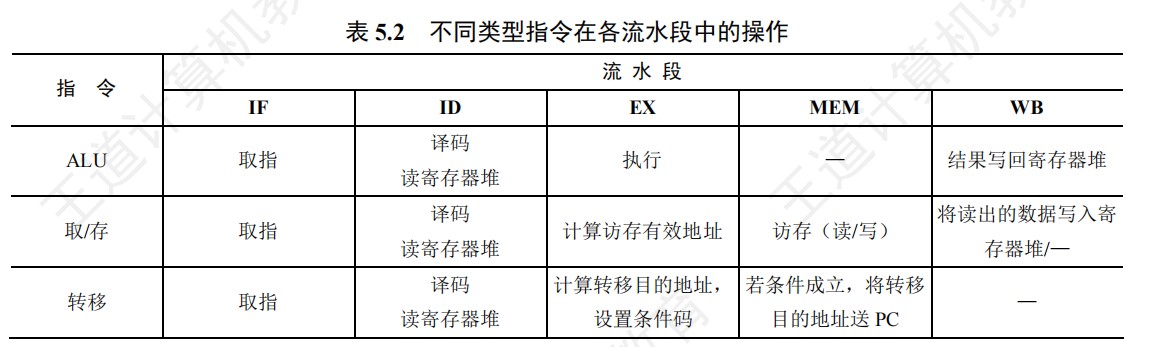
CPU基本组成原理图
11条目标指令的ALU实现
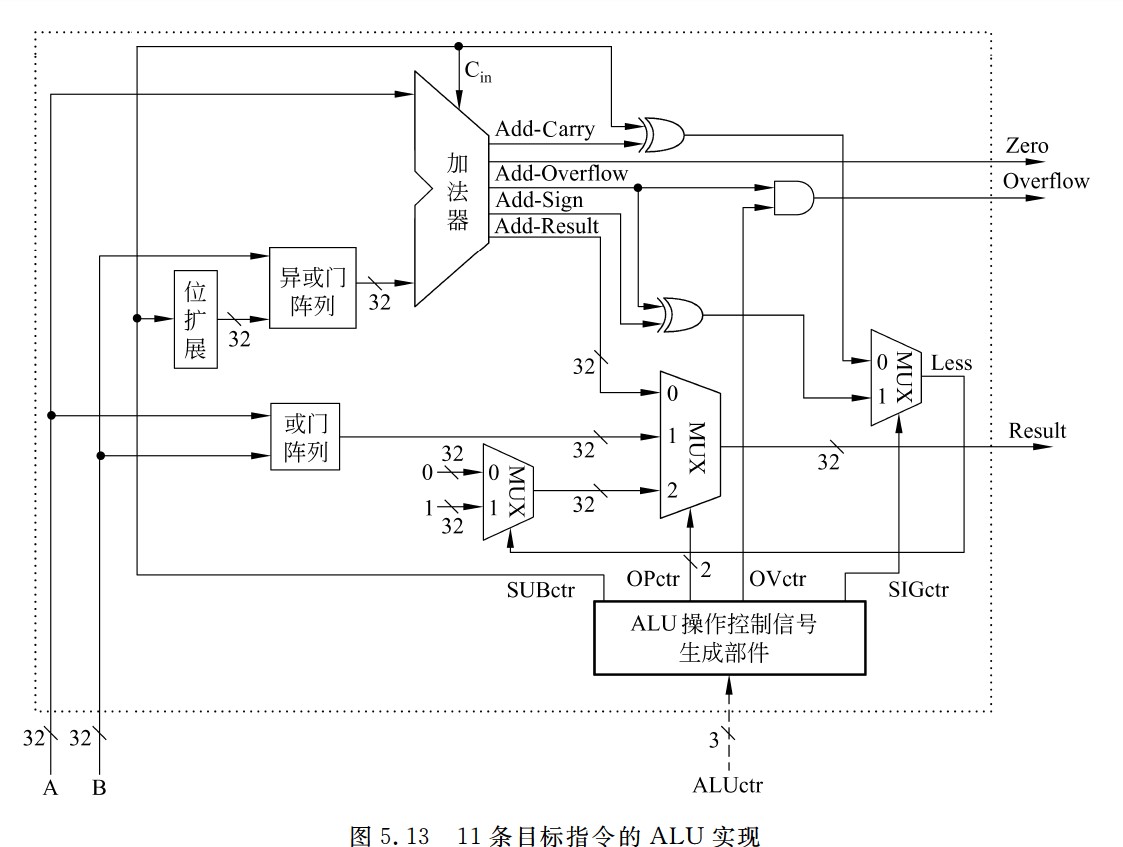
- 图中异或门阵列,减数同1进行异或,相当于取反
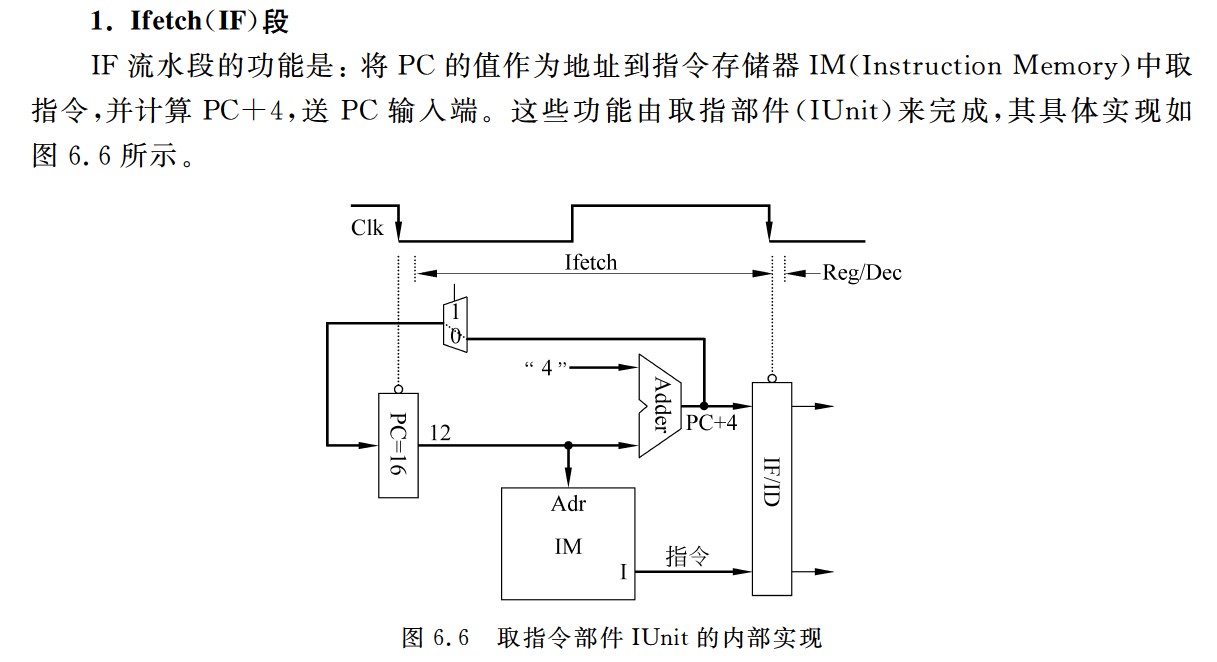
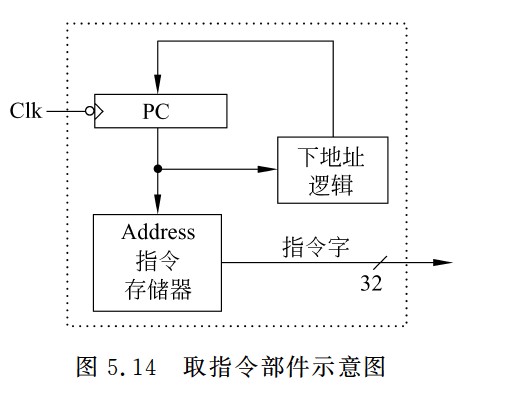
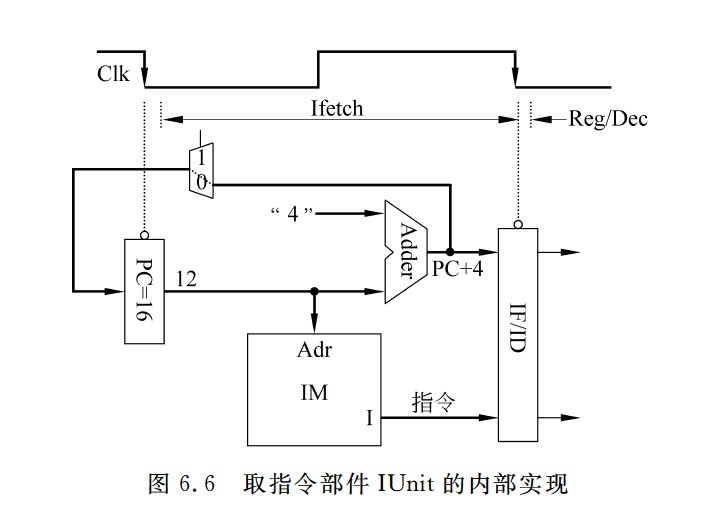
取指令部件示意图
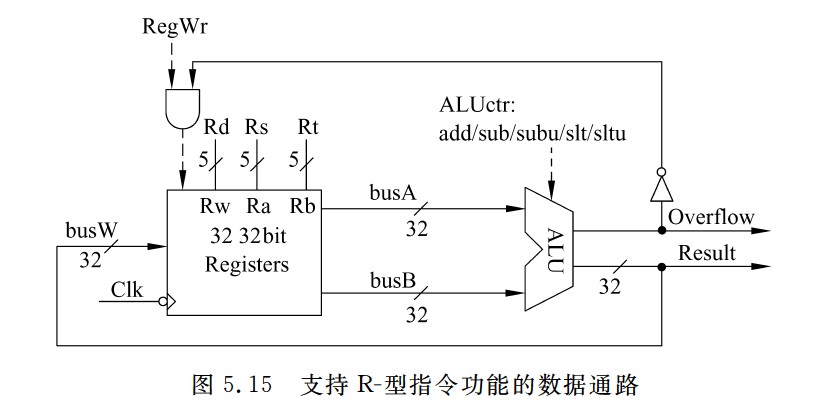
支持R-型指令功能的数据通路
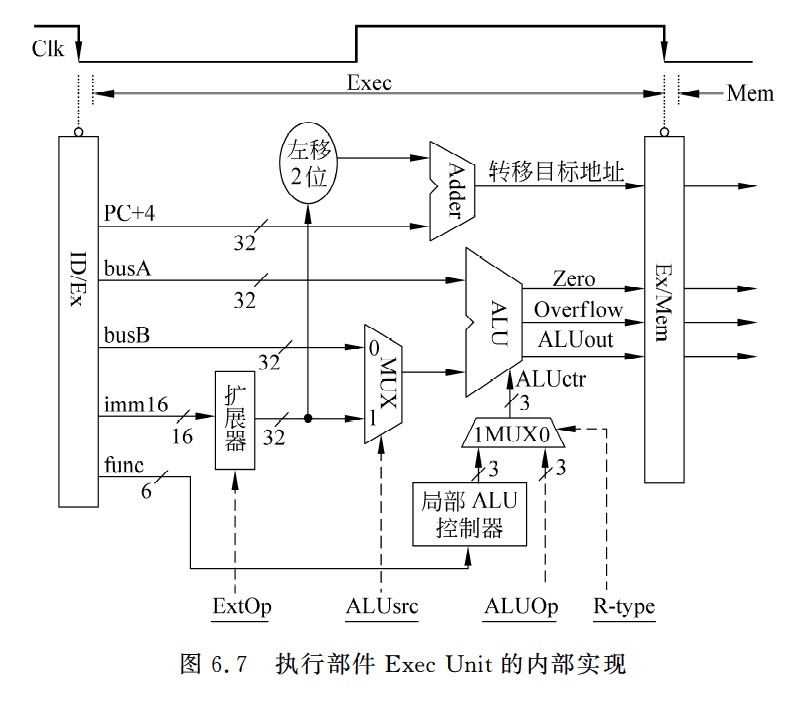
立即数运算指令的数据通路
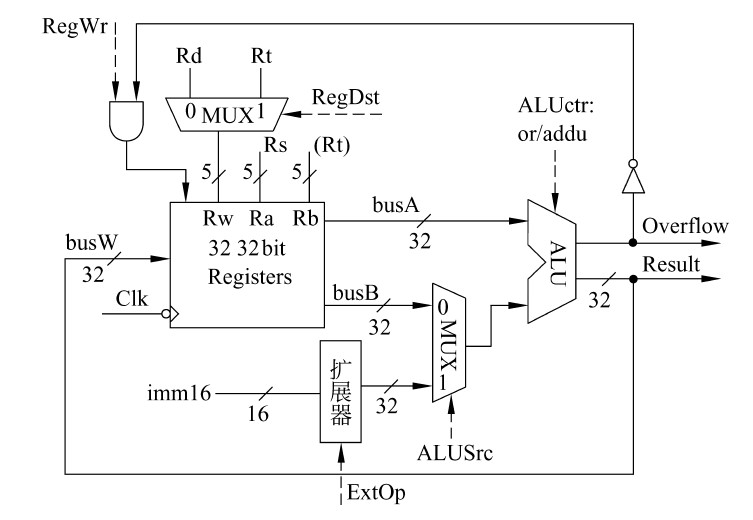
- 对于按位逻辑运算,应采用0扩展,对于算术运算,应采用符号扩展,因此,在数据通路中应该增加一个扩展器,由控制信号ExtOp控制进行符号扩展还是零扩展。
Load/Store指令的数据通路
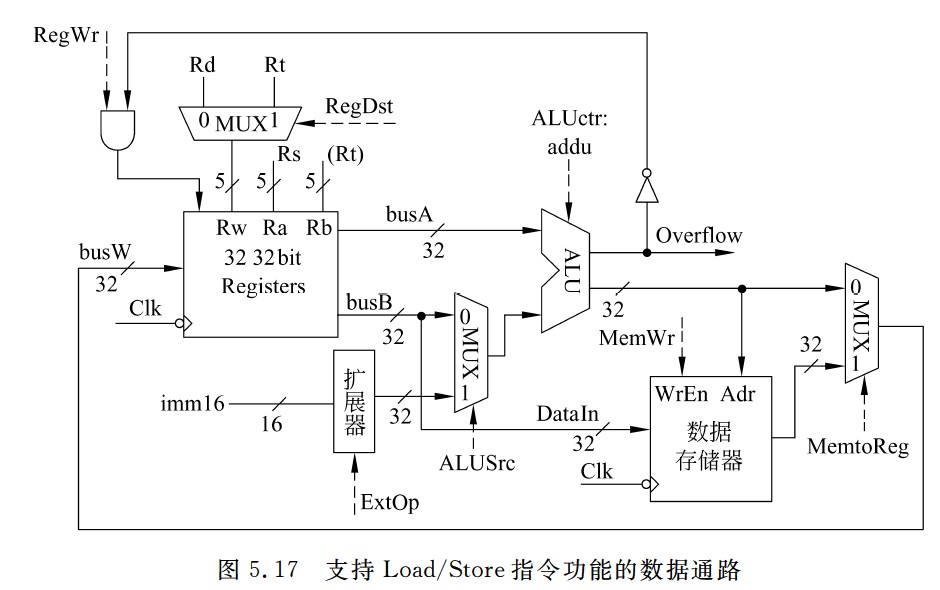
支持分支指令功能的数据通路
- 对于转移目标地址的计算,需要先对立即数imm16进行符号扩展再乘以4,然后和基准地址PC+4相加,所以,ALU的输出Zero标志需送到下地址逻辑,立即数imm16和PC也要送到下地址逻辑,控制信号Branch表示当前指令是否是分支指令,也应该送到下地址逻辑,以决定是否按分支指令方式计算下一条地址。
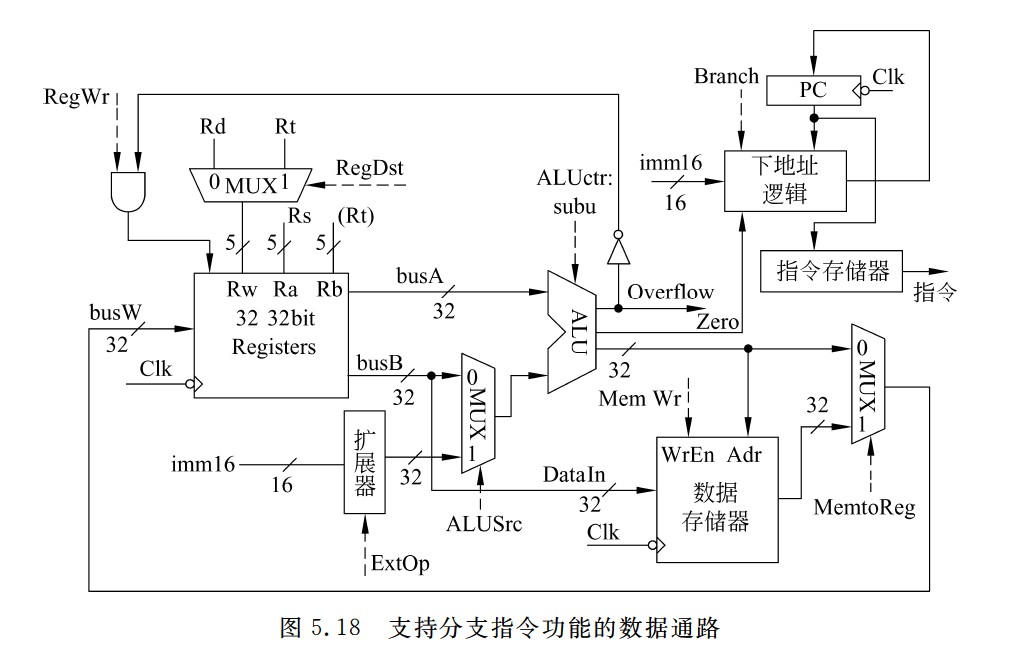
- 因为指令长度32位,主存按照字节编址,所以指令地址总是4的倍数,即最后两位总是00,因此,PC中只需存放前30位地址,即PC<31 : 2>
- 因此符号扩展x4也是为了地址对齐,必须左移2位,否则产生的地址低2位不是00,会导致非对齐访问异常,这不是合法的指令地址。
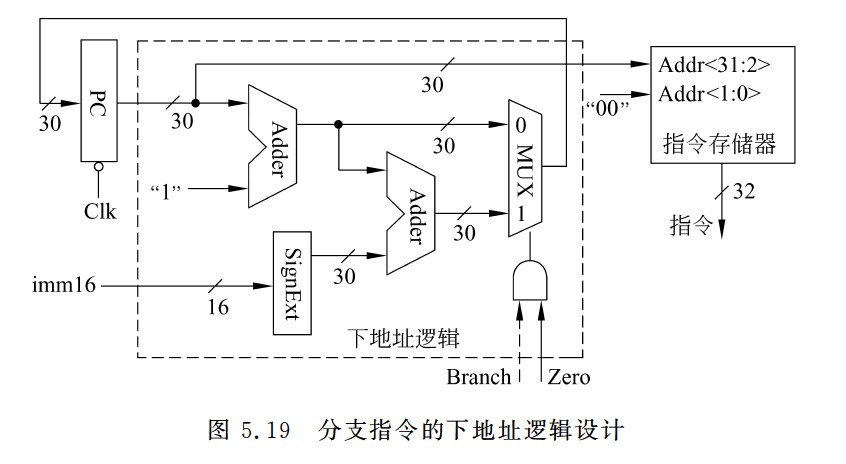
分支指令的下地址逻辑设计
完整的取指令部件
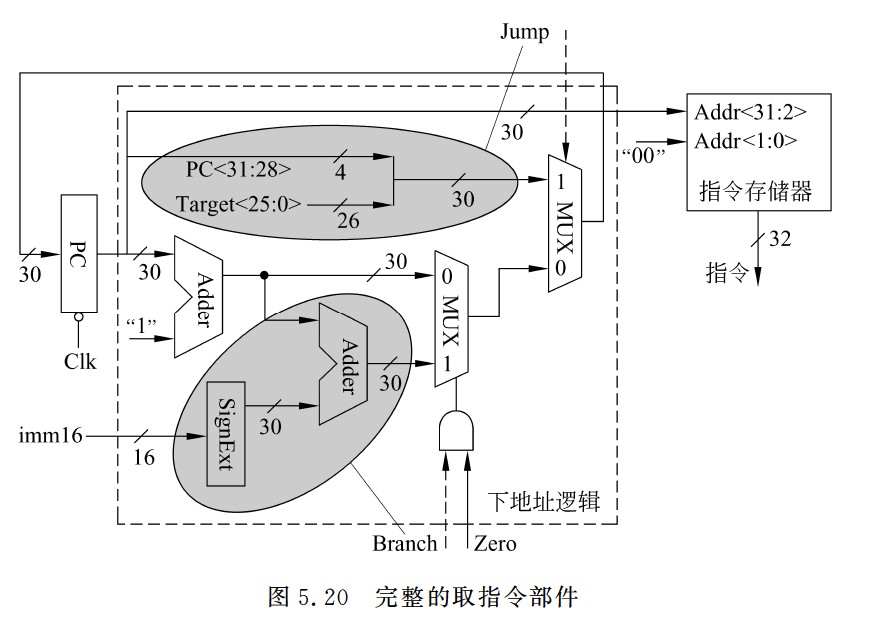
- 取指令阶段开始时,新指令还未被取出和译码,因此取指令部件中的控制信号的值还是上一条指令产生的旧值,此外,新指令还未被执行,因而标志也为旧值。但是,由这些旧控制信号值确定的地址只被送到PC输入端,并不会写入PC,因此不会影响取指令功能。只要保证在下一个时钟Clk到来之前能产生正确的下一条指令地址即可。单周期方式下,所有指令都在单个时钟周期内完成执行,因而下一个时钟会在足够长的时间(最长的指令周期)后到来,此时,控制信号早就是新取出的当前指令对应的控制信号了,因而,取指令部件能得到正确的下一条指令地址,并在下一个时钟到来之前被送到PC的输入端,一旦下一个时钟到来后,该地址开始写入PC,并作为新指令的地址从指令存储器中取出新的指令。
- 取指令部件的输出是指令,输入有3个:标志Zero,控制信号Branch和Jump。下地址逻辑中的立即数imm16和目标地址target<25:0>都直接来自取出的指令。
- 分支指令执行阶段
- 其数据在数据通路中的执行路径为:
- Register File(Rs,Rt)→busA,busB→ALU(subu)→Zero标志→取指令部件
- beq指令各控制信号的取值如下:
- Branch=1,
- Jump=0,
- RegDst=x,
- ALUsrc=0,
- ALUctr=subu,
- MemtoReg=x,
- RegWr=0,
- Mem Wr=0,
- ExtOp=x。
- 其数据在数据通路中的执行路径为:
- 无条件转移指令执行阶段
- 在11条指令中,无条件转移指令最简单,除了改变PC的值外,不做任何其他工作。因此,只在取指令部件中由控制信号Jump控制下一条指令地址的计算,其控制信号取值只要保证:①Branch=0,Jump=1,以使取指令部件能正确得到下条指令地址;②RegWr=0,MemWr=0,以使寄存器堆和数据存储器在本指令执行时不被写入任何结果。其他控制信号的取值无所谓。
完整的单周期数据通路
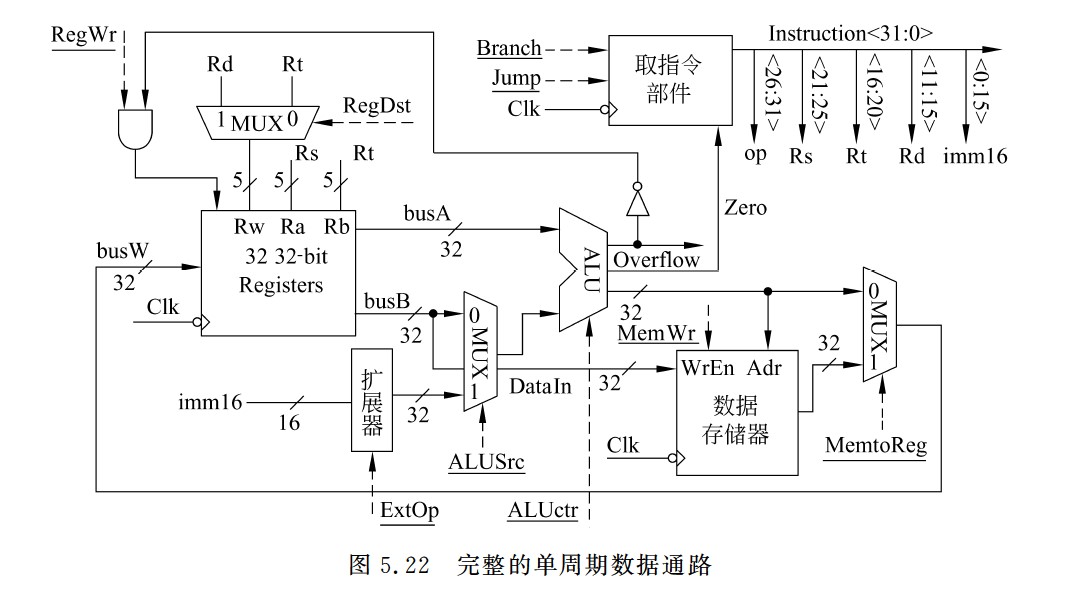
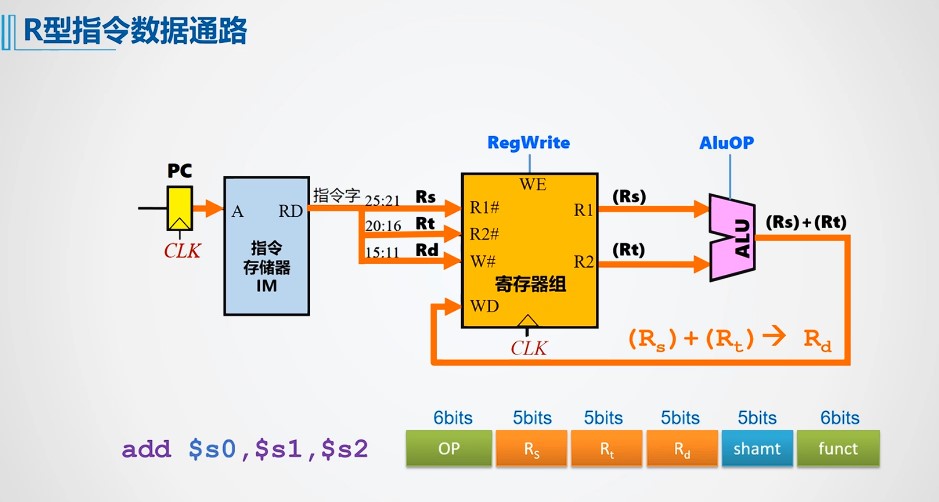
R-型指令执行过程
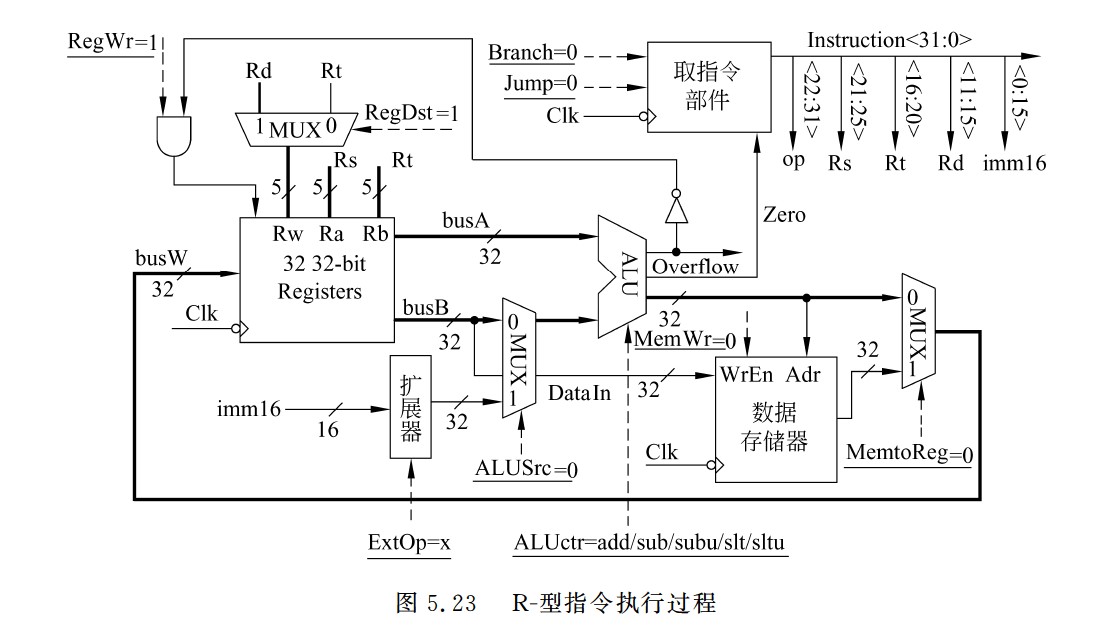
- 粗线描述了R-型指令的数据在数据通路中的执行路径
- Register File(Rs,Rt)→busA,busB→ALU→Register File(Rd)
- 控制信号的取指分析如下
- Branch=Jump=0:因为不是分支指令和无条件跳转指令。
- RegDst=1:因为R-型指令的目的寄存器为Rd。
- ALUsrc=0:保证选择busB作为ALU的B口操作数。
- ALUctr=add/sub/subu/slt/sltu:5条R-型指令的操作各不相同,因而对应5种类型。
- MemtoReg=0:保证选择ALU输出送到目的寄存器。
- RegWr=1:保证在下个时钟到来时,在不发生溢出的情况下结果被写到目的寄存器。
- MemWr=0:保证在下个时钟到来时,不会有信息写到数据存储器。
- ExtOp=x:因为ALUsrc=0,所以扩展器(Extender)的值不会影响执行结果,故ExtOp取0或1都无所谓。
I-型运算指令执行过程
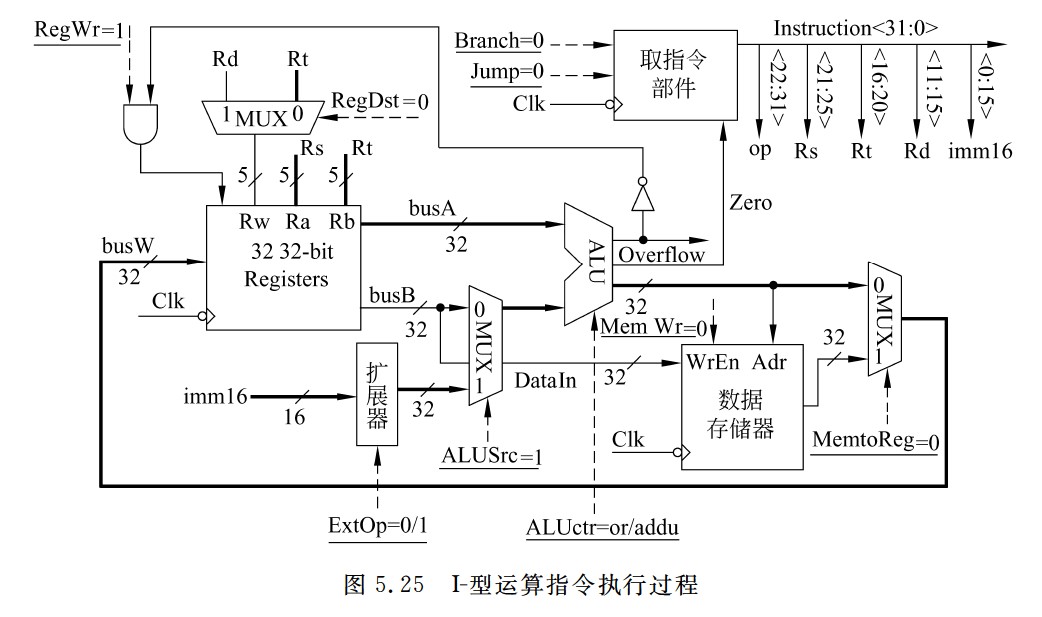
- 其数据在数据通路中的执行路径为:
- Register File(Rs)→busA,扩展器(imm16)→ALU→Register File(Rt)
- 各控制信号的取值如下:
- Branch=Jump=0
- RegDst=0
- ALUsrc=1
- ALUctr=or/addu(ori指令为or,addiu指令为addu)
- MemtoReg=0
- RegWr=1
- MemWr=0
- ExtOp=0/1(ori指令为0,addiu指令为1)
Load指令的执行过程
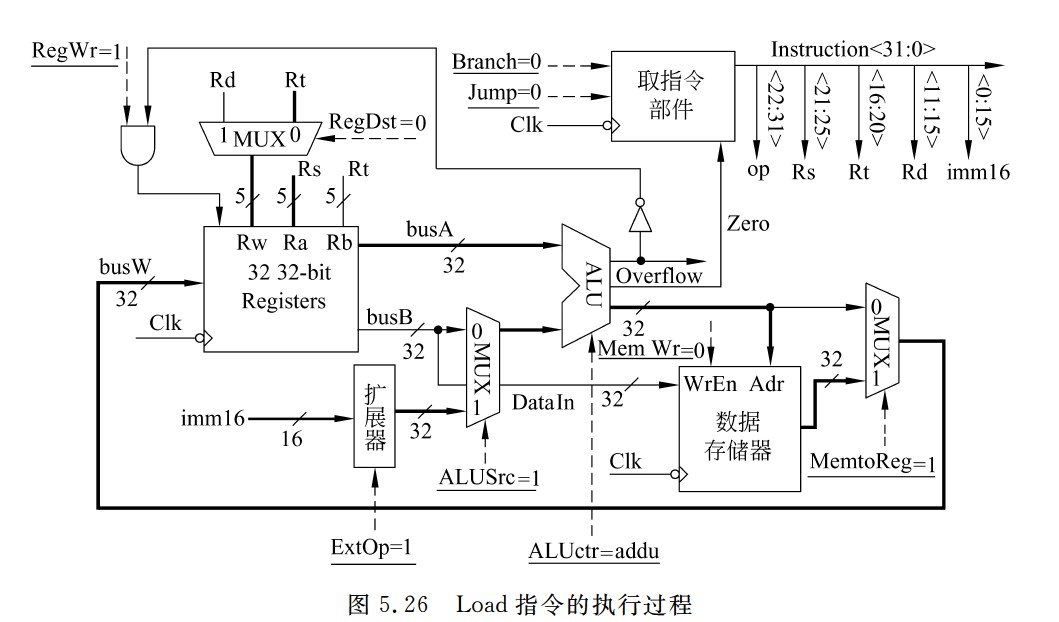
- 数据在数据通路中的执行路径为:
- Register File(Rs)→busA,扩展器(imm16)→ALU(addu)→数据存储器→Register File(Rt)
- 各控制信号的取值如下:
- Branch=Jump=0
- RegDst=0
- ALUsrc=1
- ALUctr=addu
- MemtoReg=1
- RegWr=1
- MemWr=0
- ExtOp=1(符号扩展)
Store指令的执行过程
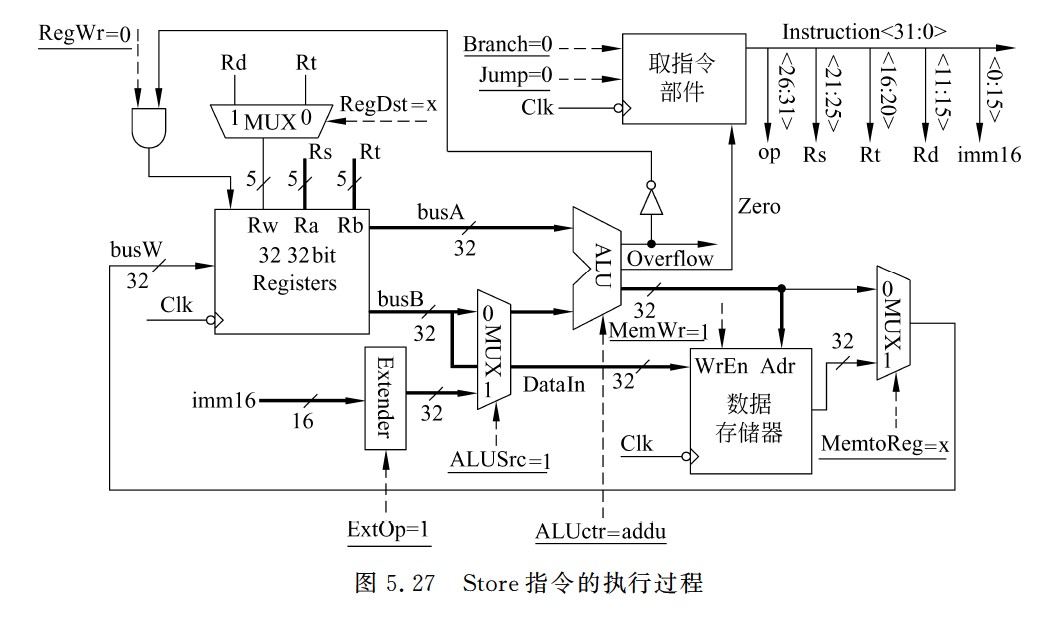
- 数据在数据通路中的执行路径为:
- Register File(Rs,Rt)→busA,扩展器(imm16),busB→ALU(addu),busB→数据存储器
- Store指令各控制信号的取值如下:
- Branch=Jump=0,
- RegDst=x,
- ALUsrc=1,
- ALUctr=addu,
- MemtoReg=x,
- Reg Wr=0,
- MemWr=1,
- ExtOp=1(符号扩展)
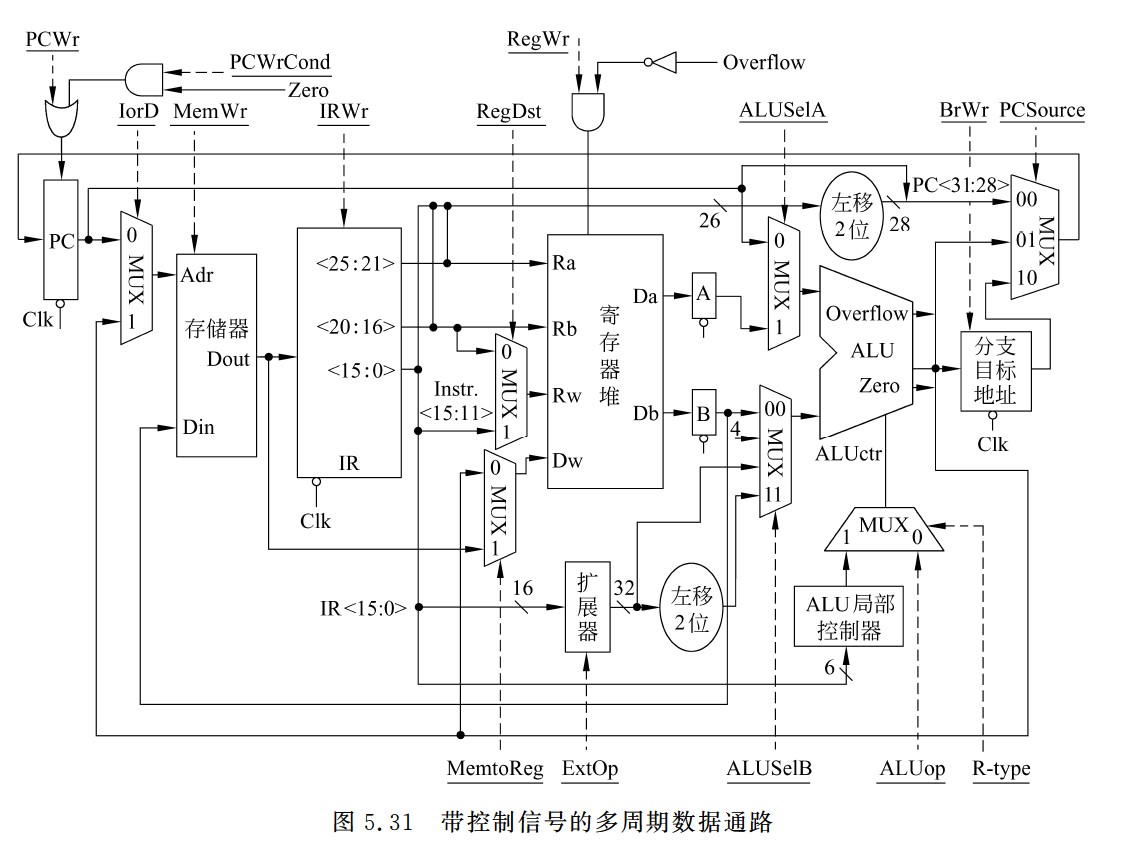
带控制信号的多周期数据通路
采用断定法的微程序控制器结构
CPU内部单总线示意图
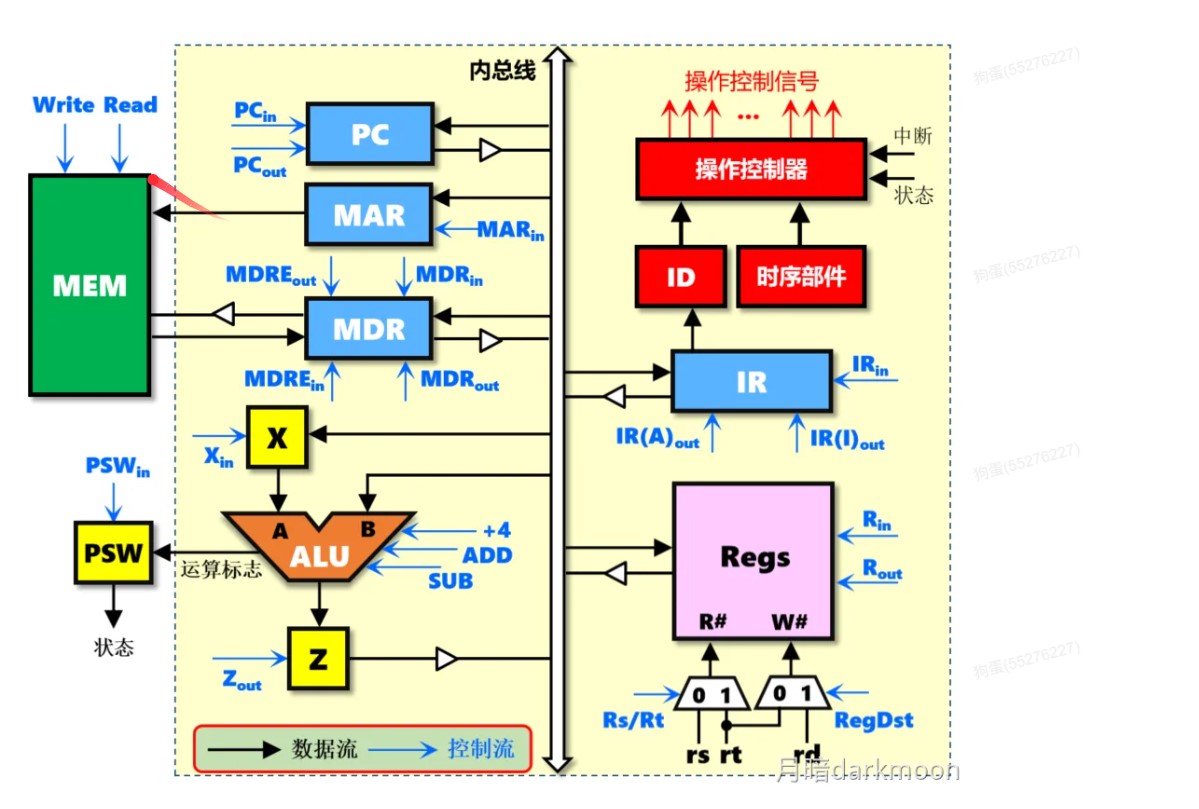
I/O接口的通用结构
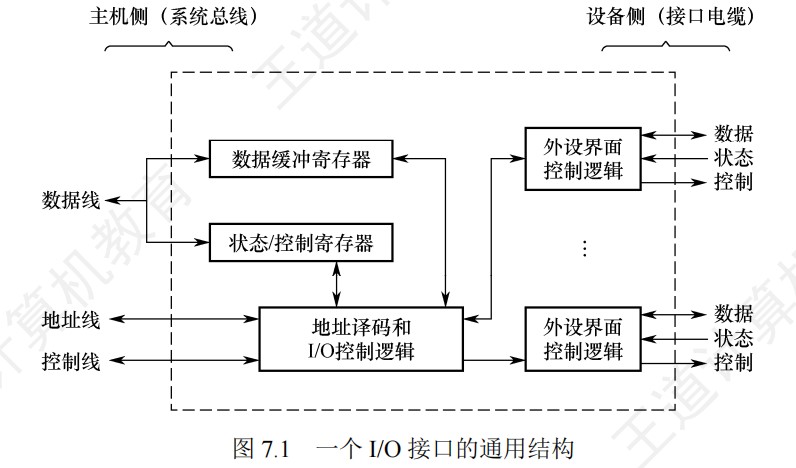
程序中断方式示意图
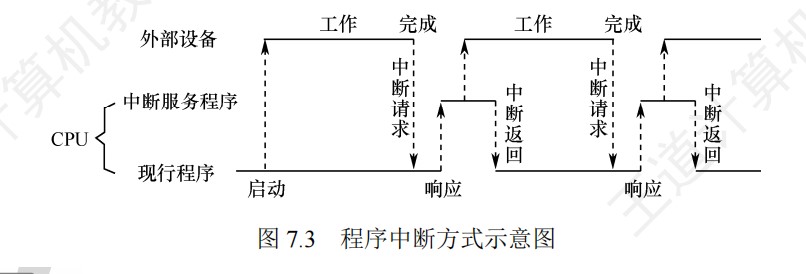
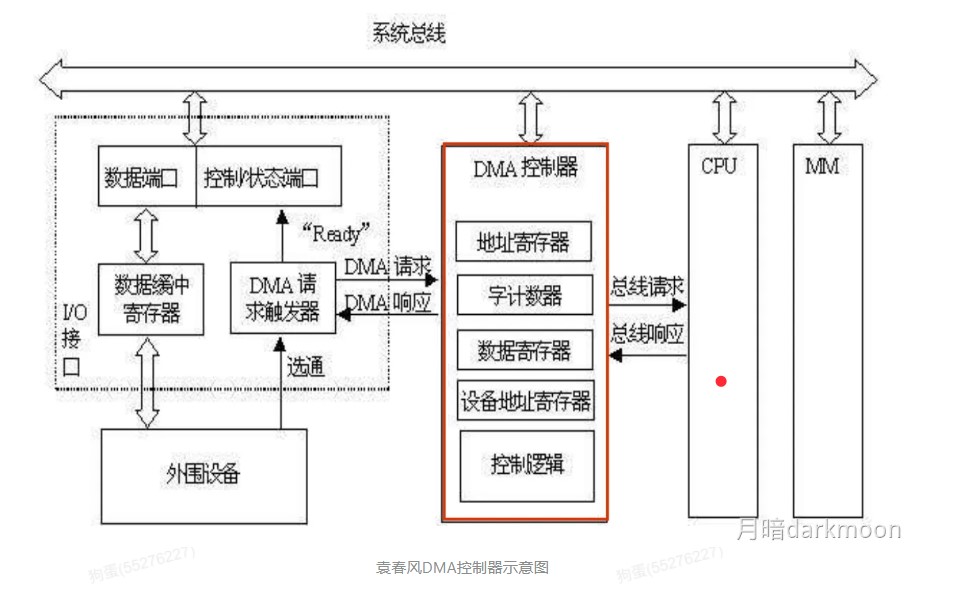
DMA控制器
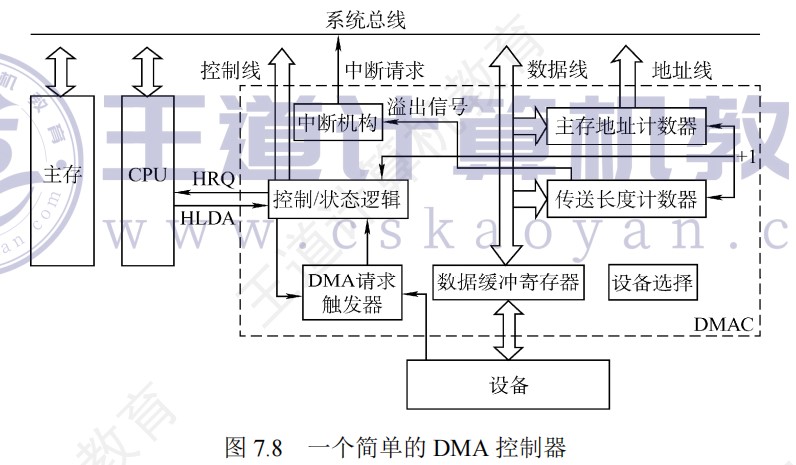
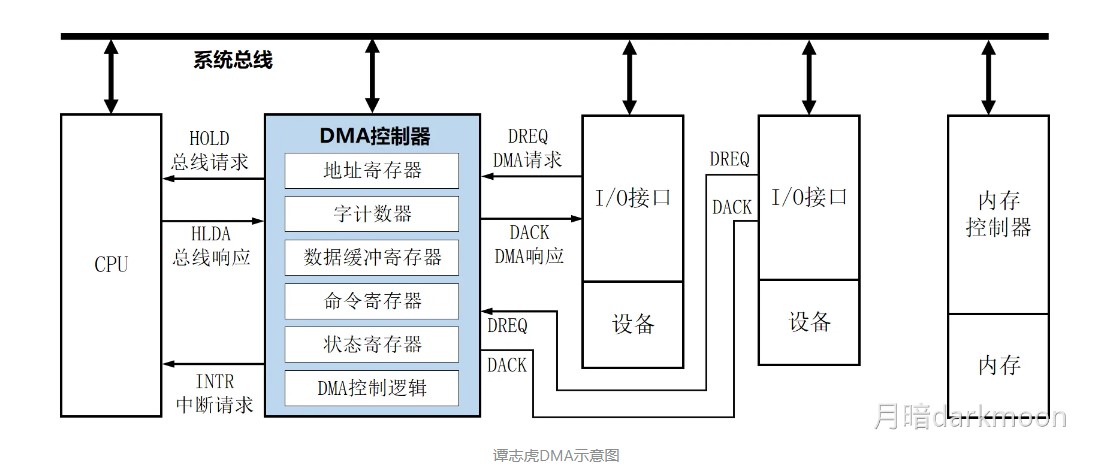
DMA的传送流程
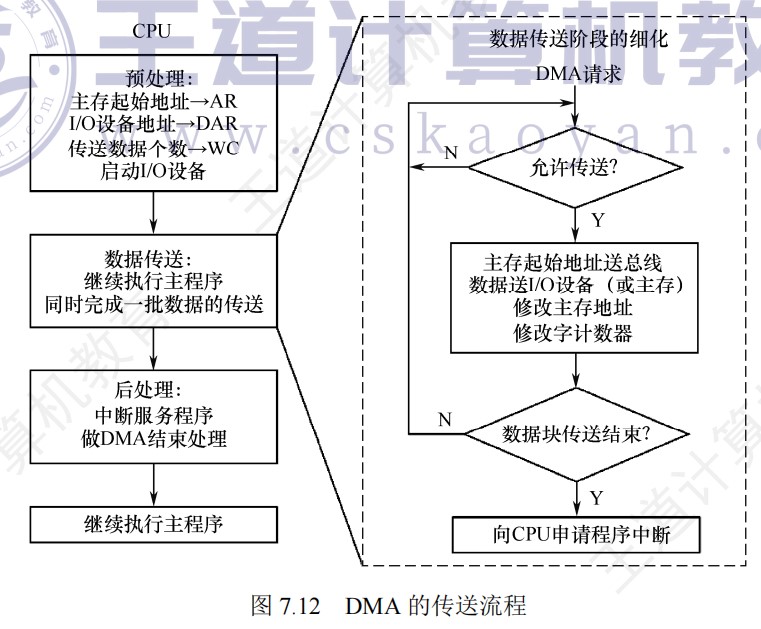
突发传送和普通传送对比

硬件判优方法(中断向量法)
五段流水线数据通路基本框架图
取指令部件的内部实现
执行部件的内部实现
控制信号的传输
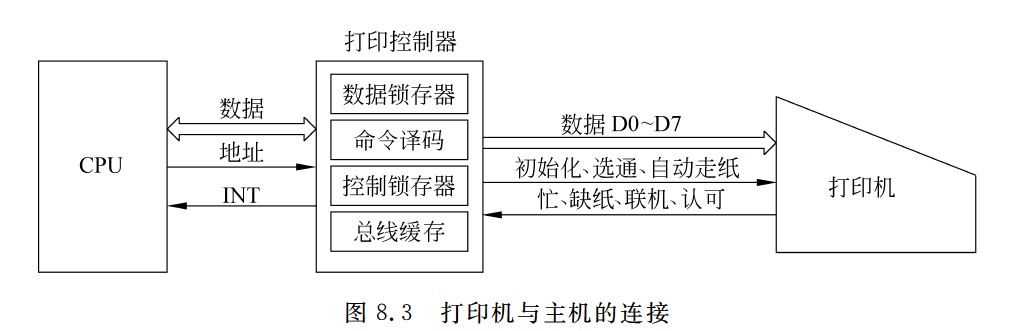
打印机与主机的连接
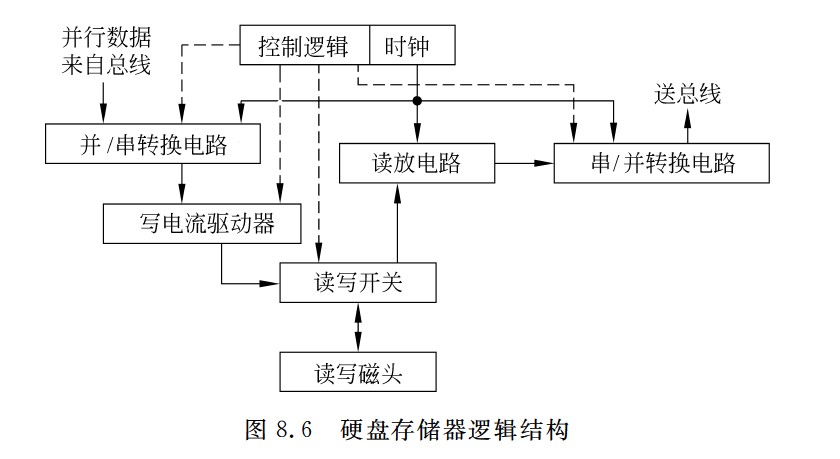
硬盘存储器逻辑结构
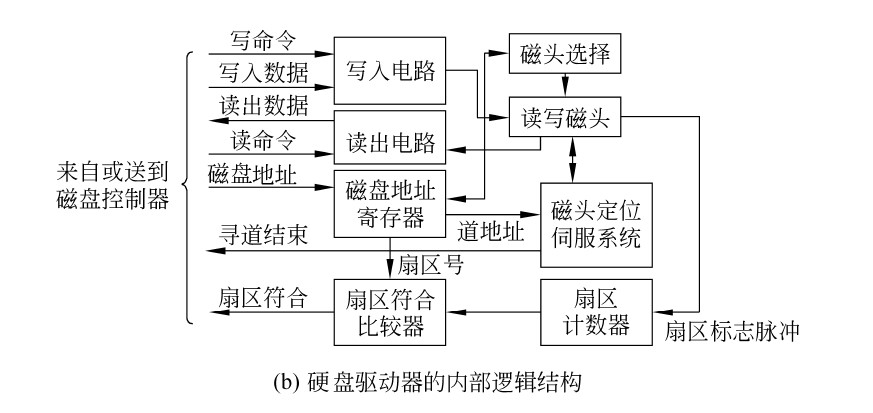
磁盘驱动器的内部逻辑结构
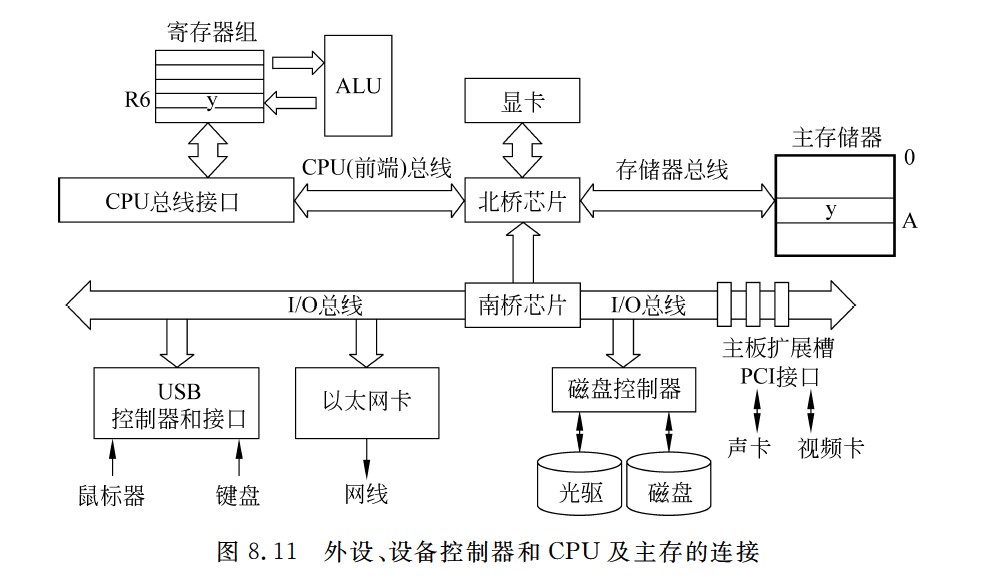
外设、设备控制器和CPU及主存的连接
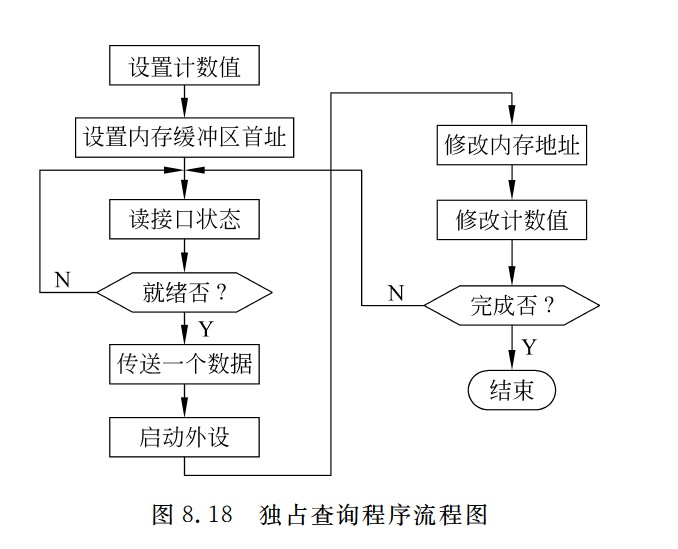
独占查询程序流程图

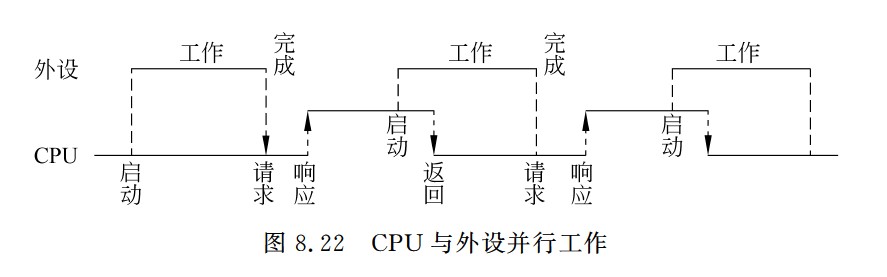
CPU与外设并行工作
中断控制I/O过程
中断控制器的基本结构
中断服务程序的典型结构
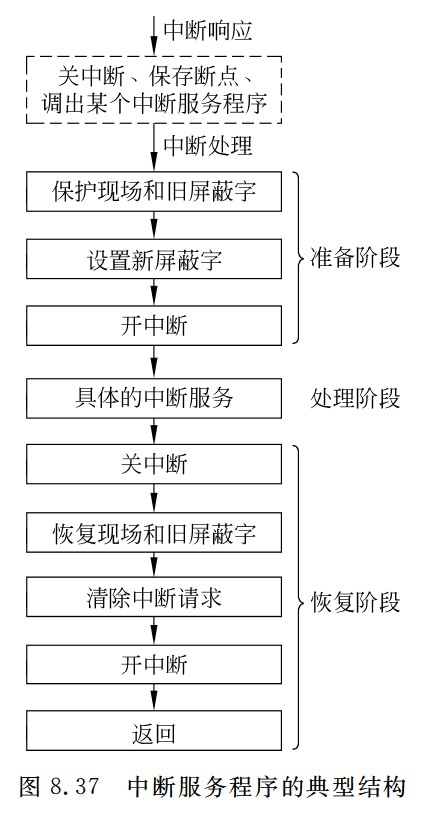
通用寄存器组
袁书笔记补充
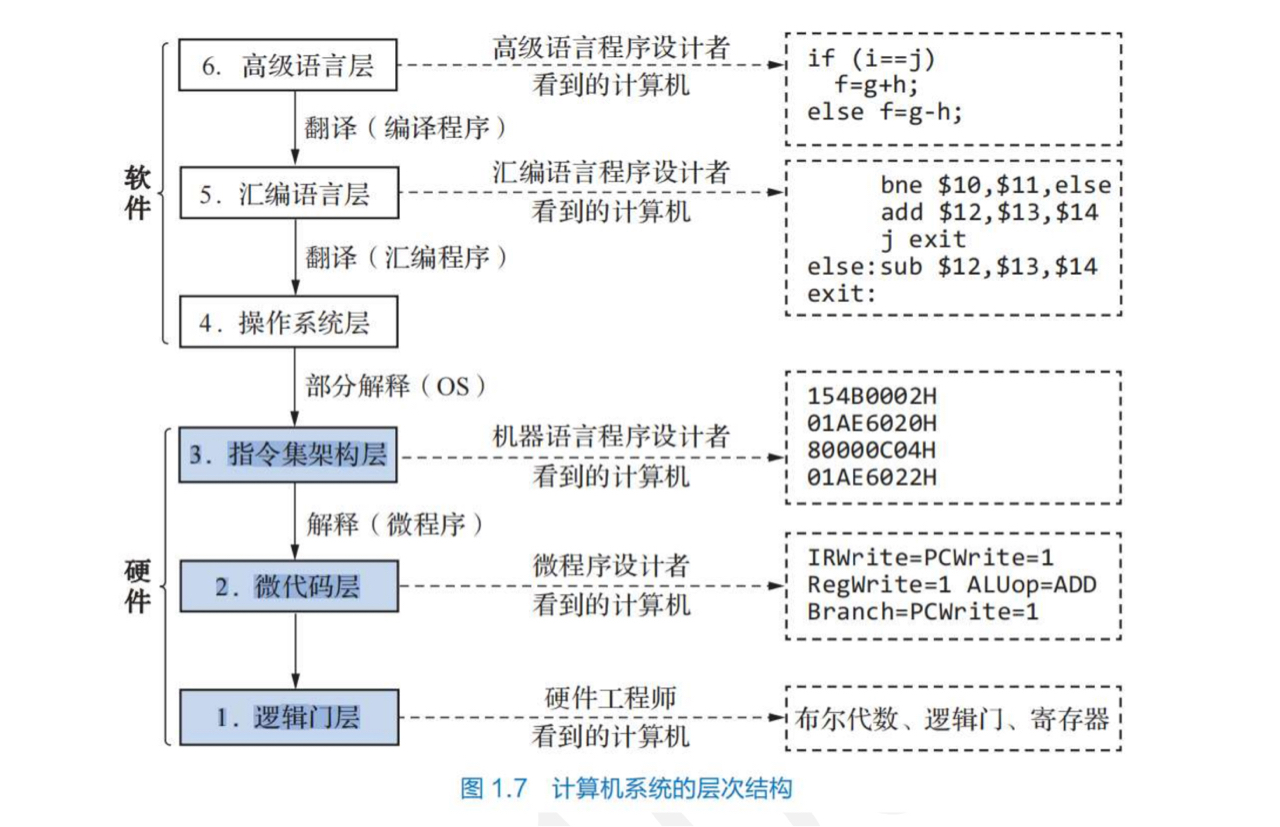
计算机系统概述
-
ISA和微体系结构是两个不同层面的概念,微体系结构是软件不可感知的部分,比如加法器采用串行进位方式还是并行进位方式属于微体系结构,相同的ISA可能有不同的微体系结构
-
有相同的ISA,即使微体系架构不同,一种处理器上运行的程序也能在另一种处理器上运行
-
启动和执行程序的过程


-
指令和操作地址都是一组连续存储单元中最小的地址
-
CPU性能和系统性能不等价
-
在逻辑功能上,软件和硬件是等价的
-
计算机系统层次结构
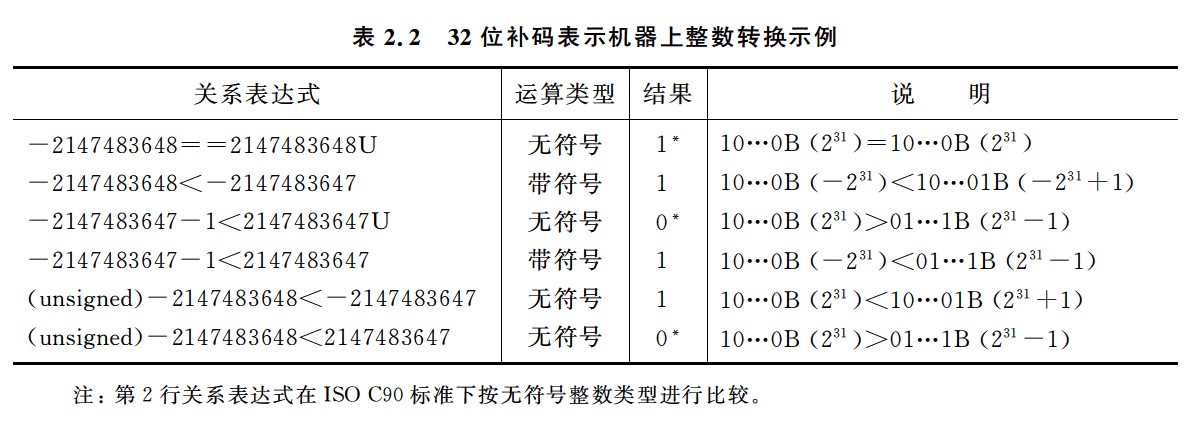
数据的机器级表示
-
同一个真值在不同位数的补码表示中,其对应的机器数不同
-
在机器内部,编码的位数就是机器中运算部件的位数
-
如果执行一个运算时同时有无符号数和带符号整数参加,那么,C编译器会隐含地将带符号整数强制类型转换为无符号数
-
计算机中专门用浮点数来表示实数
-
①若被除数为0,除数不为0,或者定点整数除法时|被除数|<|除数|,则说明商为0,余数为被除数,不再继续执行
- ②若被除数不为0,除数为0,对于整数,则发生“除数为0”异常;对于浮点数,则结果等于无穷大
- ③若被除数和除数都为0,对于整数,则发生除法错异常;对于浮点数,则有些机器产生一个不发信号的NaN,或者产生NaN信号,取决于最高有效位
-
当结果出现尾数为0的时候,不管阶码是什么,都将阶码取为0
-
若基数为R,则规格化数的标志是,尾数部分真值的绝对值>=1/R(一般来说,1/R这个边界值要舍掉)
-
逻辑数据和数值数据都是一串0/1序列,在形式上无任何差异,需要通过指令的操作码类型来识别他们
-
IEEE754移码为2^(n-1)-1的好处
- ①尾数可表示的位数多1位,因而使浮点数的精度更高
- ②指数的可表示范围更大,因而使浮点数的范围更大
-
非规格化数可用于处理解码下溢,使得出现比最小规格化数还小的数时程序也能继续进行下去
-
当操作数为无穷大时,系统可以有两种处理方式
- 产生不发信号的非数NaN
- 产生明确的结果
-
NaN
- 当最高有效位为1的时候,为不发信号NaN,当结果产生这种非数时,不发异常通知,即不进行异常处理;当最高有效位为0时为发信号NaN,当结果产生这种非数时,则发一个异常操作通知,表示要进行异常处理
- 除了第一位有定义外其余的位没有定义,所以可用其余位来指定具体的异常条件
- 一些没有数学解释的计算,会产生一个NaN
-
平时所说的xxx位机就是机器字长xxx位
-
字长就是机器字长,等于CPU内部用于整数运算的运算器位数和通用寄存器宽度
-
字和字长概念不同,字用来表示被处理信息的单位,用来度量各种数据的宽度,也就是说,字只出现在描述某一变量类型是半字,单字,双字之类的场景;一个是软件(字)上的概念,一个是硬件(字长)上的概念,字和字长可以一样也可以不一样
-
长整数的长度与机器字长的宽度相同,这也就是为什么long在32位机上是4B,在64位机上是8B
-
指针和长整数的宽度一样,也等于机器字长的宽度
-
为什么会有大端小端方式
- ①计算机按字节编址
- ②程序中对每个数据只给定一个地址
- ③因此当一个数据(比如int)的大小超过1B,就要考虑这个数据n个字节在给定的地址空间中的排列
- ④因此,大端小端是指某个数据在给定的地址空间中,它的不同字节的排列顺序,每个数据的大小端存储以其被分配的存储空间(地址范围)为限
-
对正数来说,原码和补码的编码相同, 所以其整数(补码表示)和浮点数尾数的有效位数一样,对于负数来说,其整数表示和浮点数表示中不一定会有相同的一段位序列(第一个1之前相反)
-
MIPS指令系统涉及的运算有
- ①按位逻辑运算
- ②逻辑移位
- ③算术移位
- ④带符号整数的加减乘除
- ⑤无符号整数加减乘除
- ⑥带符号整数的符号扩展
- ⑦无符号数的0扩展
- ⑧单精度浮点数加减乘除
- ⑨双精度浮点数加减乘除
- MIPS指令中没有专门的算术左移指令
-
float的有效位数是24位,相当于十进制7位,double的有效位数是53位,相当于十进制17位,int的有效位是31位,相当于十进制10位
-
类型 二进制有效位 十进制有效位 数值范围 用途 float 24位 约7位 ±10³⁸ 一般精度计算 double 53位 约16位 ±10³⁰⁸ 高精度计算 int 31位 约10位 ±2.1×10⁹ 精确整数计算 -
特性 数值范围 有效位数 定义 能表示的最小值和最大值 能精确表示的数字位数 关注点 数的大小 数的精度 决定因素 指数位的位数 尾数位的位数 类比 尺子的总长度 尺子的最小刻度 -
可表示的数据个数取决于编码所采用的位数,编码位数一定,则编码出来的数据个数就是一定的,n位编码最多只能表示2^n个数,但是,有时由于一个值可能有两个或多个编码对应,编码个数会有少量差异
-
定点小数补码的模是2,定点整数补码的模是2^(n+1)
运算方法和运算部件
-
标志位的逻辑

-
ALU中可以实现左(右)移一位和两位的操作,当然也可用一个移位寄存器实现移位,单这两种方式每次都只能固定移动一位或两位,有时移位指令要求一次移动若干位,对于这种一次左移或右移多位的操作,通常用一个做在ALU之外的桶型移位器实现。桶形移位器不同于普通移位寄存器,它利用大量多路选择器来实现数据的快速移位,移位操作能够一次完成。在ALU外单独设置桶型移位器,还可简化ALU的控制逻辑,并实现移位操作和ALU操作的并行性
-
两个n位定点正整数相除,ACC全0,MQ中为被除数X;两个n位定点正小数相除,ACC中为被除数,MQ中全0
-
并行进位加法器中高位的进位依赖于低位,是指依赖于C0
-
标志寄存器不需要单独编号,本身就是一个专用的状态寄存器,通过标志位而非编号来标识功能
-
标志寄存器中的内容,是执行指令的过程中,cpu根据指令执行的结果生成的,用户不能通过指令直接指定标志寄存器的编号或者修改它
-
快速阵列乘法器中没有移位器,而是并行计算部分积,通过大量一位全加器构成全加器阵列累加求和,无需移位
- 一位booth乘法时间复杂度:O(n^2)
阵列乘法器O(n)
两位乘法运算比一位乘法运算速度约快一倍
- 一位booth乘法时间复杂度:O(n^2)
-
标准的ASCII码为7位
-
全加器有3个输入(2bit的输入位,1个低位进位输入)两个输出(1bit进位输出,1bit求和结果),可以处理低位的进位
- 半加器有2个输入(2个bit的输入位,无低进位输入)两个输出(1bit进位输出,1bit求和结果),半加器不考虑低位进位,不能完成多位二进制数相加)
-
除数寄存器Y存放除数;余数寄存器R开始时置被除数的高32位,作为初始中间余数R0的高位部分,结束时存放的是余数;余数/商寄存器Q开始时置被除数的低32位,作为初始中间余数40的地位部分,结束时存放的是32位商
存储器分层体系结构
-
发生指令缺失时的处理过程是什么?这是由硬件还是软件完成的?
- 每条指令执行的第一步是取指令,若在cache中取当前指令时发生缺失,则处理器必须按照如下步骤完成:
- ①把程序计数器PC的值回复到当前指令的地址,然后通过总线中的地址线送到存储器中的地址缓冲器中,以便存储器对地址译码
- ②控制存储器执行一次读操作(若一个主存块只有一条指令,则一次读操作读一条指令即可;若一个主存块占用多条指令,则控制一次读出多条指令或读若干次),对主存的访问要通过总线完成,一次总线事务完成一次读操作。
- ③读出的指令写到Cache中,并把主存地址的高位写到标记字段,最后设置有效位。
- ④重新执行当前指令的第一步操作,即取指令,这次在Cache中取指令时便能命中
- Cache缺失不是内部异常,更不是外部中断,不会引起对当前正在执行程序的中断,因而不会调出操作系统内核程序来处理Cache缺失,即上述处理过程不是由软件完成的,而是由CPU这个硬件完成的
- 每条指令执行的第一步是取指令,若在cache中取当前指令时发生缺失,则处理器必须按照如下步骤完成:
-
虚拟存储器的大小就是虚拟地址空间的大小,它由虚拟地址的位数决定,与系统中所安装的磁盘容量和内存容量没有直接关系
-
虽然两个用户程序中用到的逻辑地址可能是一样的,但是由于两个用户程序被存放到了不同的内存区,因而,不会发生信息被相互读写的问题
-
如果采用的是动态重定位(即指令中给定的是虚拟地址),则执行指令的过程中如果进行内存访问,则总是要先进行逻辑地址到物理地址的转换;如果采用的是静态重定位(即指令中已经给出了物理地址),则内存访问时不需要进行逻辑地址到物理地址的转换
- 动态重定位下,由专门的存储器管理部件(MMU)实现逻辑地址到物理地址转换。
- 静态重定位方式下,由连接程序或加载程序实现地址转换
-
为了减少引脚数量和简化设计,DRAM没有独立的片选线,使用行地址选通线和列地址选通线来选择和访问存储单元
- 为了表示传送的是行地址还是列地址,需要额外两根行选通线和列选通线,此时片选线的功能可由行选通线替代,所以不需要片选线。
-
系统程序区用ROM,用户程序区用RAM
-
固态硬盘支持随机访问,采用电路
-
Cache并不能增加系统存储容量
-
CPU执行指令时,需要的操作数大部分都来自寄存器,如果需要从存储器中读取数据(或向其中存数据)时,先访问cache,如果不在cache,则访问主存,不在主存,则访问硬盘,此时,操作数从硬盘中读出送到主存,然后从主存送到cache
-
SRAM和DRAM都是MOS型RAM
-
SRAM的存储原理可以看作是对带时钟的RS除法器的读写过程,DRAM的存储原理可看作是对电容充、放电的过程
-
一维方式的线选法或者单译码法适合小容量的静态存储器,二维方式的重合法或双译码法,适用于容量较大的动态存储器
-
双译码法:
- 2^n个存储单元,需要n条地址线,2^(2/n) * 2根译码输出线线
-
行地址缓冲器和刷新计数器通过一个多路选择器将选择的行地址输出到行译码器,刷新计数器的位数和行地址的位数相同,一次刷新相当于对一行数据进行一次读操作,每次读后再生
-
2048x2048x8bit,2048x2048构成一个位平面,x8bit说明有8个位平面,选中一行一列以后,该行列的所有位平面同时读取
-
刷新不需要外部提供行地址信息,这是一个内部的自动操作。
- DRAM芯片内部有一个行地址生成器(也称刷新计数器),由它自动生成行地址。
-
DDR SDRAM
- 通过芯片内部I/O缓冲中数据的两位预取功能,并利用存储器总线上时钟信号的上升沿与下降沿进行两次传送,以实现一个时钟内传送两次数据的功能。
- 频率x2x总线宽度/8=带宽
- 通过芯片内部I/O缓冲中数据的两位预取功能,并利用存储器总线上时钟信号的上升沿与下降沿进行两次传送,以实现一个时钟内传送两次数据的功能。

-
DDR2 SDRAM
- 利用芯片内部的I/O缓冲可以进行4位预取,使得一个时钟内有4个数据被取到I/O缓冲中,存储器总线在每个时钟内传送两次数据。
- 带宽=频率x4x总线宽度/8
- 利用芯片内部的I/O缓冲可以进行4位预取,使得一个时钟内有4个数据被取到I/O缓冲中,存储器总线在每个时钟内传送两次数据。

-
DDR3 SDRAM
- 可以进行8位预取,存储器总线在每个时钟内可以传送2次数据。
- 带宽=频率x8x总线宽度/8
- 可以进行8位预取,存储器总线在每个时钟内可以传送2次数据。

-
DDRN SDRAM
- 进行2^n位预取,内部时钟频率为a的情况下,存储器总线上的时钟频率为ax2^n/2(因为上升沿和下降沿各传送一次),带宽为2^n x a x每次传送的位数/8=(工作频率 x2 x带宽) /8
- 工作频率=内部时钟频率x预取位数/2(因为内部也是上升沿下降沿各传送一次)
- 本质上是内部传输数据的次数要和外部总线传输的次数相同,对齐,带宽还是总线工作频率x数据宽度/8
-
U盘和存储卡都是Flash存储器,也用于存放BIOS
-
芯片的读写
- 注:每个芯片都有自己的行缓冲器
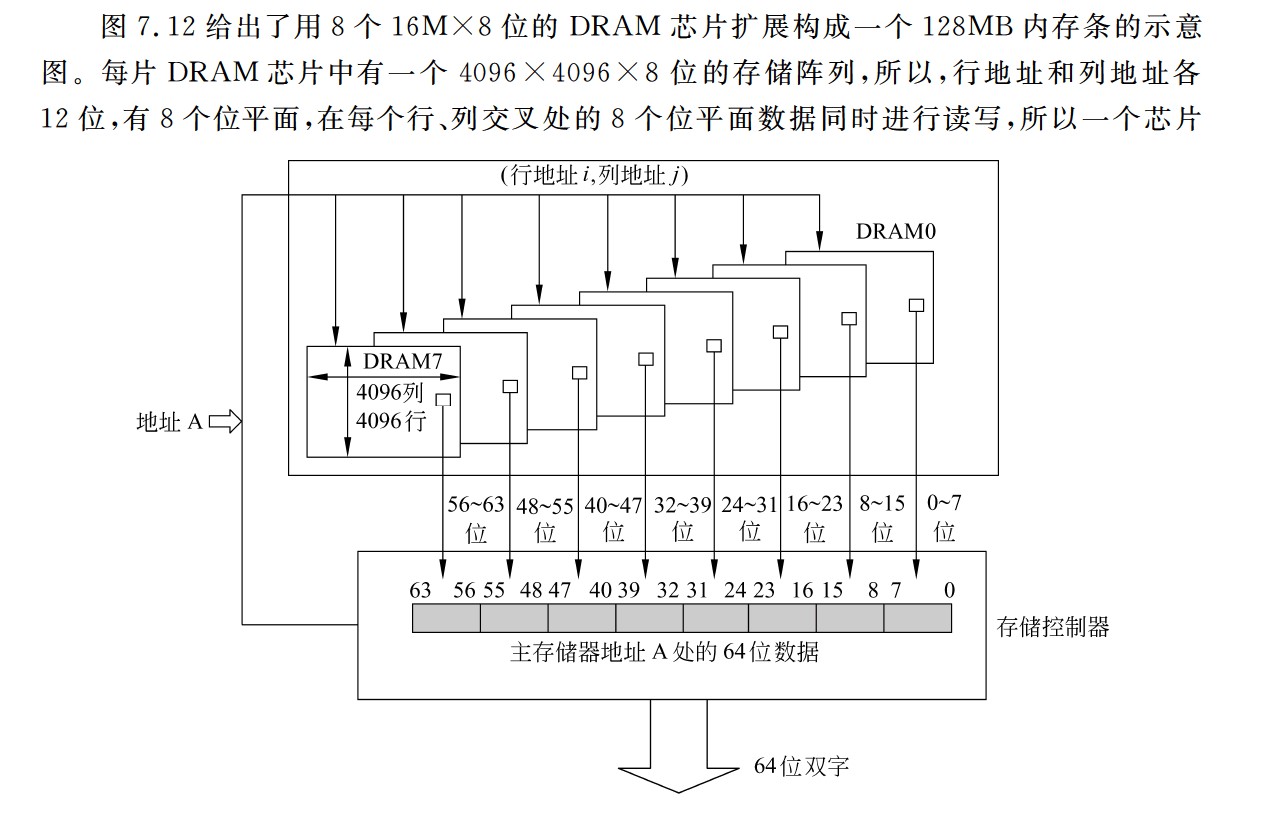

-
Flash的读操作速度和写操作速度相差很大,其读取速度与半导体RAM芯片相当,而写数据(快擦—编程)的速度则与硬磁盘存储器相当
-
改善主存速度的方法可从三个方面考虑
- 提高DRAM芯片本身的速度,如SDRAM,DDR
- 采用并行结构技术,如多模块存储器
- 在CPU和主存之间增加高速缓冲存储器
-
连续编址(高位交叉编址)的方式下,CPU总时按顺序访问存储模块,即存储模块并不倍并行访问,因而不能提高存储器的吞吐率,但是如果在CPU访问某个存储模块的同时,DMA控制器正控制在外设和另一个存储模块之间实现数据传输操作,那么两个存储模块可独立并行工作,这种情况下就能提高存储器的吞吐率
-
低位交叉编址一般模块数取2的方幂,这样硬件比较简单,但是,有的机器为了减少存储器冲突,采用质数个模块
-
Cache对程序员是透明的,因此程序员编程时不用考虑信息存放在主存还是在Cache
-
同余内存块被映射到同一个Cache行
-
直接映射模式下,如果块的大小被设置为一个字节,程序访问的空间局部性没有被利用;在Cache行数不变的情况下,块太小使得映射到同一个Cache行的主存块数增加,发生冲突的概率变大,引起频繁交换
-
LRU算法是栈算法,并不是组越大越好,因为组内采用全相联映射,随着组增大,实现的复杂度也会增加。当程序中的分块局部化范围(即程序中某段时间集中访问的存储区)超过了Cahce组的大小时,命中率可能变得很低,这种现象称为抖动
- LRU通过硬件修改计数值
-
Cache一致性问题的出现场景
- 对Cache的内容进行更新时
- 当多个设备都允许访问主存时
- 例如,像磁盘这类高速I/O设备可通过DMA方式直接读写主存,如果cache中的内容被CPU修改而主存块没有更新,则从主存传送到I/O设备的内容就无效;若I/O设备修改了主存块的内容,则对应cache行中的内容就无效。
- 当多个CPU都带有各自的Cache而共享主存时
- 在多CPU系统中,若某个CPU修改了自身cache中的内容,则对应的主存块和其他CPU中对应的cache行的内容都变为无效。
-
Cache性能评估

-
CPI越小,Cache缺失引起的阻塞对系统总体性能影响越大,CPU时钟频率越高,Cache缺失损失就越大,处理器性能越高,Cache的性能就越重要
-
在采用两级Cache的系统中,CPU总是先访问L1Cache,访问缺失,再从L2Cache中找。若L2Cache包含所请求信息,则缺失损失为L2Cache的访问时间,若L2Cache访问缺失,则需要从主存取信息并同时送L1Cache和L2Cache,此时的缺失损失较大
- 多级Cache中,位置不同,设计目标也不同,两级Cache的情况下,对L1,更关注速度而不要求有很高的命中率,因为即使L1Cache不命中,还可以到L2Cache中访问,L2Cache的速度比主存速度快得多;而对于L2,要求尽量提高其命中率,因为若L2Cache不命中,则必须要到慢速的主存中访问,其缺失损失会很大而影响总体性能
-
主存-总线-Cache间的连接结构问题
- CPU从主存取一块信息到Cache的过程
- ①发送地址和读命令到主存
- ②从主存准备好一个数据
- ③从总线传送一个数据
- 主存、总线和Cache之间的连接方式
- ①窄形结构
- 在主线、总线和Cache之间每次按一个字的宽度进行传送
- ②宽形结构
- 在他们之间每次传送多个字
- ③交叉存储器结构
- 主存采用多模块交叉存取方式,总线和Cache之间每次按一个字的宽度进行传送
- ①窄形结构
- CPU从主存取一块信息到Cache的过程
-
DRAM结构、总线事务类型与Cache的配合问题
- 若发生Cache缺失,则到主存取数据或指令,而主存是由DRAM芯片实现的,每次缺失时,都要从DRAM中读取一块信息到Cache
- 图所示的存储器总线宽度为128位,连接在其上的每个内存条一次最多能读出128位数据。
- 每个内存条上排列有多个DRAM芯片可用16个2Mb的DRAM芯片配置一个4 MB的内存条,每个芯片内有一个512×8的SRAM行缓冲,16个芯片共8KB缓冲。
- 每个芯片有512行×512列,并有8个位平面,每次读写各芯片内同行同列的8位,16个芯片共16×8=128位。
- 当CPU访问一块连续的主存区域(即行地址相同的区域)时,可直接从行缓冲读取,行缓冲用SRAM实现,速度极快。
- 当cache缺失而要求从主存读一块信息到cache时,只要给定一个首地址,采用突发传输方式就可以在一次总线事务中完成一个主存块的传输。
- 特别是当采用DDR SDRAM、DDR2 SDRAM或DDR3 SDRAM芯片时,在芯片内部采用交叉多数据预取,并在存储器总线上采用时钟上升沿和下降沿各传送一次的方式,使得从主存到cache的数据块传送效率更高。
-
程序运行时装入内存页框的过程对程序员是透明的
-
每个进程的虚拟地址空间是私有的
-
内核区在高端地址上,用来存放操作系统内核代码和数据以及与每个进程相关的数据结构(如进程标识信息、进程现场信息、页表等进程控制信息以及内核栈等),其中内核代码和数据区在每个进程的地址空间中都相同。用户程序没有权限访问内核区

- 主存页框和虚拟页框之间采用全相联映射,处理一致性问题时,采用回写法
- 页表放在进程地址空间的内核区
- 虚拟地址到物理地址的地址转换工作由CPU的MMU(存储器管理部件)完成
- 为了降低替换算法开销,TLB通常采用随机替换策略
- cache缺失处理由硬件完成
- 缺页处理由软件完成,操作系统通过“缺页异常处理程序”来实现
- 而对于TLB缺失,则既可以用硬件也可以用软件来处理。用软件方式处理时,操作系统通过专门的“TLB缺失异常处理程序”来实现。
进程与进程的上下文切换
-
进程的实体(代码和 数据等)和支持进程运行的环境合称进程的上下文。
-
由用户进程的程序块、数据块和堆栈等组成的用户区地址空间,被称为用户级上下文
-
由进程标识信息现场信息、控制信息和系统内核栈等组成的系统区地址空间,被称为系统及上下文
-
处理器中各个寄存器的内容被称为寄存器上下文
-
在进行进程上下文切换时,操作系统把换下进程的寄存器上下文保存到系统级上下文的现场信息位置
-
用户级上下文地址空间和系统级上下文地址空间一起构成了一个进程的整个存储器映像
-
shell命令行执行过程中shell进程和hello进程的上下文切换过程
- ①运行shell进程
- ②从shell命令行中读入字符串“./hello”到主存
- ③当shell进程读到字符“[Enter]"(回车)后,转到操作系统执行
- ④由操作系统进行上下文切换,以保存shell进程的上下文并创建hello进程的上下文
- ⑤hello进程执行结束后,再转到操作系统完成将控制权从hello进程交回给shell进程
指令系统
-
微指令是微程序级指令,属于硬件范畴,伪指令是由若干机器指令组成的指令序列,属于软件范畴;机器指令介于二者之间,处于硬件和软件的交界面
-
为了实现冯诺依曼结构的计算机,一条指令中必须明确地(显式)或隐含地包含以下信息:
- 操作码
- 源操作数或其地址
- 结果的地址
- 下一条指令地址
-
规整型指定采用定长指令字和定长操作码,虽然能够减少时间开销,但是会增加空间上的开销
- 因此,希望降低空间开销时,采用紧凑的变长操作码和变长指令字;希望降低时间开销以取得更好性能时,应该采用定长操作码和定长指令字
-
用户进程的指令中能用的寄存器是用户可见寄存器,也称为通用寄存器,通用寄存器过多会使寄存器存取延迟变长,因而影响指令执行速度,通用寄存器多还会增大CPU成本
-
通常把指令中给出的操作数所在存储单元的地址称为有效地址,存储单元地址可能是主存物理地址,也可能是虚拟地址。如果不采用虚拟存储基址,有效地址就是主存物理地址;若采用虚拟存储基址,则有效地址就是虚拟地址
-
寄存器数量远小于内存单元数,故寄存器编号比存储地址短,因而寄存器寻址方式的指令较短
-
变址寻址应用于数组元素的实例
- 变址寄存器的内容是变化的,反映的是所访问的数据到数组首地址的距离,称为变址值。这种应用场合下,形式地址的位数较长,而变址值位数少。变址寻址方式的指令一般包含在一个循环体内。每次进入循环时,变址值都增或减一个定长值,定长值等于数组元素的长度
- 加减操作如何实现?
- 硬件实现:变址寻址的加减操作是 硬件实现的。在大多数现代处理器中,变址寄存器的值会与 元素的大小 相乘(例如 4 字节的整数或 1 字节的字符),从而计算出 每个数组元素的地址。
- 例如,假设数组
A存储的是 4 字节的整数,每次访问数组时,变址寄存器的值(IX)会根据指令自动加上 4(即元素的大小)。处理器内部会根据指令自动计算出新的地址,不需要软件干预。
- 例如,假设数组
- 硬件自动加减:当访问数组时,
IX寄存器会自动加上数组元素的长度,这通常是由硬件在 EX阶段 自动完成的。这个过程是 透明的,无需程序员手动干预,也无需通过软件实现,之后在M阶段,计算机根据EX阶段计算出来的地址进行访存
- 硬件实现:变址寻址的加减操作是 硬件实现的。在大多数现代处理器中,变址寄存器的值会与 元素的大小 相乘(例如 4 字节的整数或 1 字节的字符),从而计算出 每个数组元素的地址。

-
前变址和后变址
- 某些计算机中还允许变址与间址结合使用。假定指令中给出的变址寄存器为I,形式地址为A,则先变址后间址时,操作数的有效地址为EA=((I)+A),称为前变址;先间址后变址时,则EA=(I)+(A),称为后变址。
-
当外设中的I/O地址空间和主存地址空间统一编址时,可以不设置这类指令,而用访存指令完成I/O操作;非统一编址需要设置输入输出指令。
-
寄存器的个数不能太多,否则,成本高且会延长存取时间而使得时钟周期变长。当然,寄存器个数也不能太少,否则,辩一起只能把许多变量分配到地址单元,每次都要去内存访问操作数,因而会影响程序的性能。
-
RISC指令系统下,除了Load/Store指令外,其他指令都只需要一个或小于一个时钟周期就可以完成,指令周期短
-
在一个过程内对栈中信息的访问大多通过ebp进行
-
规整型指令系统一般在一条指令中只包含一种寻址方式,这样,就可以在指令操作码中隐含寻址方式,不需要专门有寻址方式字段,但是,对于不规整指令系统,一条指令中的若干操作数可能存放在不同的地方,因而每个操作数可能有各自的寻址方式字段
-
操作数可能在
- 内存单元
- 指令以某种方式给出存储单元的地址
- 寄存器
- 指令中直接给出寄存器的编号
- 栈
- 若有专门的栈指令,则指令中不需要给出操作数的地址,数据的地址隐含地由栈指针给出
- I/O端口中
- 当某个I/O端口中的寄存器内容要和CPU中的寄存器内容交换时,要用I/O指令,在I/O传送指令中,需要提供I/O端口号。
- 立即数
- 直接从指令中的立即数字段取操作数
- 内存单元
-
返回指令不一定要有地址字段
- 返回地址保存在栈中的时候,返回指令中不需要明显给出返回地址,直接从栈顶取地址作为返回地址
- 如果不采用栈保存返回地址,而是存放到其他不确定的地方,则返回指令中必须有一个地址码,用来指出返回地址或指出返回地址的存放位置
-
为什么J-型指令中的跳转目标地址最后两位要添0?如何实现该功能?
- 因为MIPS机器采用32位定长指令字,其存储单位采用字节编址,所以一条指令占4个存储单元,因而,指令地址总是4的倍数,即地址最后两位总是0,无需在指令中显示给出,只要在实现指令功能的数据通路中具有添加00的电路即可
扩展操作码指令数量的计算


- ①确认操作码位数和每个地址码位数(OP|NUM)
- ②从多地址指令开始计算,以该题为例,最高的地址数是二地址指令,因此从二地址指令开始计算
- ③二地址指令的情况下,所有的地址码都要用到,只有OP能够用来编码,因此最多的指令数量为2^(OP位数)=2^4=16个
- ④二地址指令的数量为15,因此剩余16-1种状态留给一地址指令
- ⑤一地址指令只需要用到一个地址码,剩余可用来编码操作的有地址码+操作码区域,又因为操作码部分,二指令用了15个,因此一地址指令最多剩下(16-15)*2^(一条地址位数)=1 *2^6=64种指令数量
- ⑥根据题目,一地址指令有34个,因此一地址指令剩下了64-34=30种状态给零地址指令
- ⑦零地址指令因为用不到地址码,因此本地址块都可以用于编码,数量为30* 2^6种
RISC和CISC对比
| 特点 | CISC(复杂指令集计算机) | RISC(精简指令集计算机) |
|---|---|---|
| 指令数量 | 指令系统复杂,指令数量一般为 200 条以上 | 指令数量较少,指令较为简单 |
| 指令长度 | 指令长度不固定,指令格式种类多,寻址方式多 | 指令长度固定,指令格式较少,寻址方式种类少 |
| 可访寻指令 | 可访寻的指令不受限制 | 仅有 LOAD/STORE 指令访问内存,其他指令的操作在寄存器之间进行 |
| 指令执行频率差异 | 各指令使用频率差异较大,执行时间不一致 | 大多数指令需要一个时钟周期即可完成,执行时间差异较小 |
| 指令执行时间差异 | 各种指令执行的时间差异大,许多指令需要多个时钟周期才能完成 | 大多数指令在一个时钟周期内完成 |
| 控制器设计 | 使用微程序控制,硬件复杂 | 使用硬连线控制,控制器较为简单,指令执行更高效 |
| 程序优化 | 难以进行编译优化,因为指令多,目标代码优化困难 | 易于进行编译优化,减少目标代码大小 |
| 执行效率 | 由于指令复杂,难以提升执行效率 | 简单指令集优化了计算机的执行效率 |
| 存储器使用 | 存储器管理复杂,使用寄存器较少,依赖内存 | 大量使用寄存器,存储器管理简化 |
| 适用场景 | 适用于需要复杂计算的任务,如计算机的高级应用 | 适用于执行简单计算的任务,注重高效和快速执行 |
- 总结
- CISC 系统的指令集较为复杂,指令多样,执行时间差异较大,适合处理复杂操作。但由于指令复杂,编译优化困难,执行效率较低。
- RISC 系统则通过精简指令集来提高执行效率,所有指令执行时间较为一致,指令执行更高效,适合高效能、优化的计算任务。
中央处理器
- Cache、MMU、浮点运算逻辑、异常和中断处理逻辑都是数据通路的一部分
- 有的机器PC本身有+1的功能,有的机器借助运算部件完成
- 译码器无需控制信号进行控制
- 读操作属于组合逻辑操作,无须时钟控制。写操作属于时序逻辑操作,需要时钟信号控制
- 数据通路的基本结构为:——状态单元——操作元件(组合电路)——状态单元——
- 只有状态单元能存储信息,所有操作元件都须从状态单元接收输入,并将输出写入状态单元中
- 在很多计算机CPU内部结构中,寄存器堆之间没有直接的通路,因此寄存器之间的数据传送需要经过ALU来实现,此时,控制操作要响应复杂一些
- 采用单总线或三总线方式连接的数据通路很难实现指令流水执行
- 取指令部件的设计
- 指令专门放在指令存储器中,因此无需控制信号的控制,只要给出指令地址,经过一定的“取数时间”后,指令被送出。指令的地址来自PC,由专门的下地址逻辑来计算下条指令的地址,然后送PC。因为是单周期处理器,每个时钟周期执行一条指令,所以每来一个时钟,PC的值都会被更新一次,因而,PC无须写使能信号控制。
- **因为指令长度为32位,主存按字节编址,所以指令地址总是4的倍数,即最后两位总是00,因此,PC中只需存放前30位地址,即PC< 31:2 >。**这样下条指令地址的计算方法如下:
- 顺序执行时:PC< 31:2 >←PC< 31:2 >+1。
- 转移执行时:PC< 31:2 >←PC< 31:2 >+1+SignExt[Imm16]。
- 取指令时:指令地址=PC< 31:2 >||“00”。
- 每来一个时钟CLK,当前PC作为指令地址被送到指令存储器去取指令的同时,下地址逻辑计算下一条指令地址并送PC的输入端,在下一个时钟到来后写入PC
- 计算机性能(即程序执行速度)由3各关键因素决定:
- 指令数目
- 由编译器和指令集决定
- 时钟周期
- 处理器设计
- CPI
- 处理器设计
- 指令数目
- 硬布线控制器速度快,适合于简单或规整的指令系统,如MIPS指令集
- 一条微指令中最多可同时发出的微操作数就是微命令字段的个数
- 终止与故障和自陷不同,不是由特定指令产生的,而是随机发生的
- 故障的断点是发生故障的当前指令的地址,自陷的断点则是自陷指令后面一条指令的地址
- 为了能够支持异常或中断的嵌套处理,大多数处理器将断点保存在栈中,如果系统不支持多重中断嵌套处理,则可以将断点保存在特定寄存器中,而不需送到栈保存。
- PC和各个流水段寄存器都没有写使能信号,因为每个时钟都会改变PC的值,所以PC不需要写使能控制信号;每个流水段寄存器在每个时钟都会写入一次,因此,流水段寄存器也不需要写使能控制信号。此外,前两个流水段的功能每个指令都相同,是公共流水段,因此,也不需要时钟控制信号。
- 异常或中断引起的控制冒险
- 通过在数据通路的不同流水段中加入相应的检测逻辑可检测出哪条指令发生了异常。
- “溢出”可在Exec段检出
- “无效指令”可在ID段检出
- “除数为0”可在ID段检出
- “无效指令地址”可在IF段检出
- “无效数据地址”可在Load/Store指令的Ex段检出
- 外部中断的检测可以放在第一个流水段IF或最后一个流水段Wr中进行。
- 若放在IF中检测,因为可在取指令前进行,若发现有中断请求发生,则能确保在该时钟周期就开始执行中断服务程序,并让已经在流水线中的指令继续执行完,不需要进行指令冲刷;
- 若放在Wr阶段进行,则需要将刚执行完的指令后面几条指令从流水线中清除掉。
- 优先级确定原则是,在同一个时钟周期内的指令序列中,最先执行的指令所产生的异常最先被响应,外部中断请求最后响应,即,对同时在5个指令流水段中发生的异常进行排序时,其顺序为WB>M>Ex>ID>IF。
- 处理器硬件对异常和中断引起的冒险的处理大致的做法如下:当检测到有异常或中断后,首先,清除发生异常的指令以及其后在流水线中的所有指令,然后保存断点,并将异常处理程序的首地址送PC的输入端。指令清除的方式和上述分支预测错误时指令清除方式类似,通常是通过相应的冲刷(Flush)控制信号将指令或指令的控制信号清零(主要保证写信号RegWr和MemWr清零)来实现。
- 通过在数据通路的不同流水段中加入相应的检测逻辑可检测出哪条指令发生了异常。
寄存器传送语言(真题)

多周期处理器的控制信号
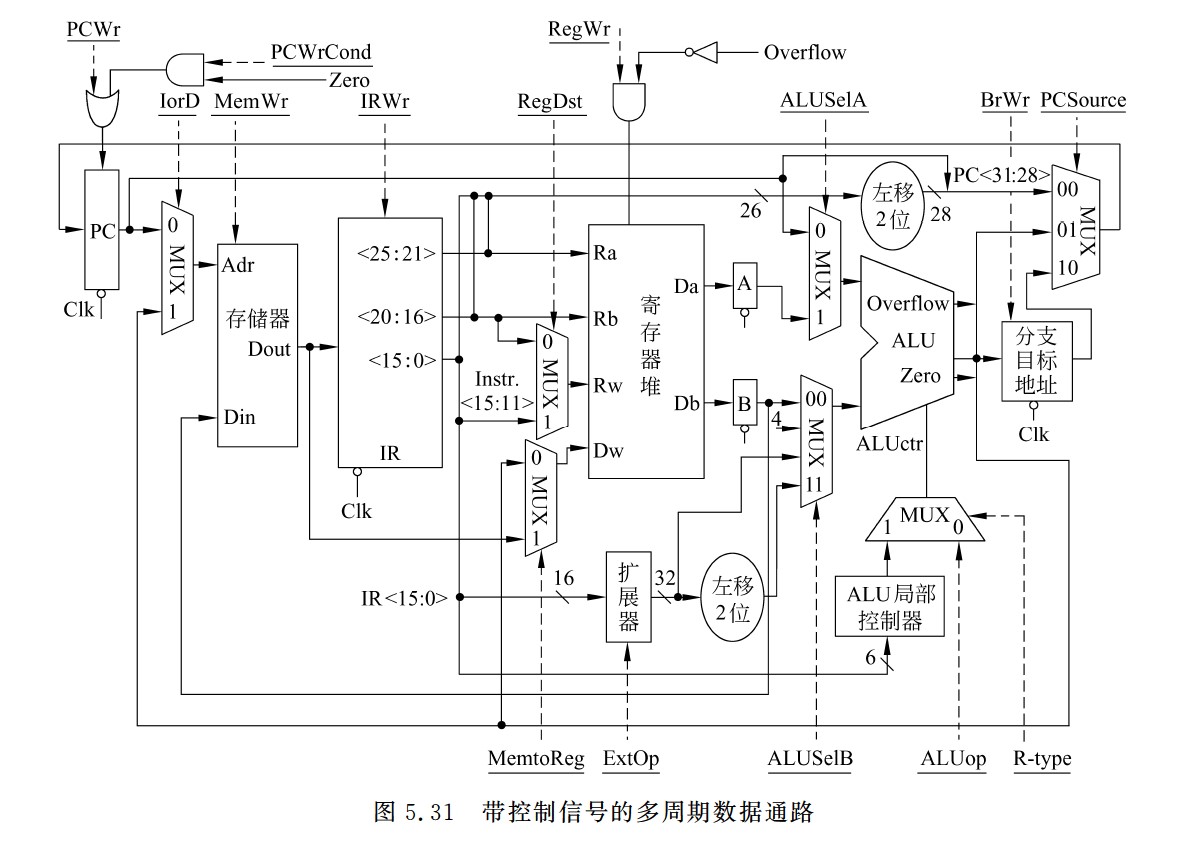
- R-型指令、I-型运算指令和sw指令的CPI都为4,lw指令的CPI最大,CPI=5,分支指令和跳转指令的CPI=3,如果不在译码/取数阶段投机计算分支目标地址,则分支指令的CPI=4
取指令、指令译码/取数阶段
- 取指令状态

取指令状态的控制信号设置:
- IorD = 0:
- 作用:选择从指令存储器(Memory)中读取数据。
- 原因:在取指令阶段,程序计数器(PC)给出指令的地址,内存从这个地址读取指令,因此选择
0来指示访问指令存储器。
- ALUSelA = 0:
- 作用:将 ALU 的第一个操作数设置为
0。 - 原因:在取指令阶段,ALU 不需要进行任何计算,所以
ALUSelA被设置为0,表示没有参与运算。
- 作用:将 ALU 的第一个操作数设置为
- ALUSelB = 1:
- 作用:将 ALU 的第二个操作数设置为常数
4。 - 原因:在取指令阶段,程序计数器(PC)要增加 4,以便准备好下一个指令的地址。这个常量
4是加法操作中的操作数之一。
- 作用:将 ALU 的第二个操作数设置为常数
- ALUOp = add:
- 作用:将 ALU 操作设置为加法(add)。
- 原因:在取指令阶段,PC 的值需要增加 4,所以需要将 ALU 的操作设置为加法,计算出下一条指令的地址。
- PCSource = 01:
- 作用:选择下一条指令的地址是由
PC + 4计算得出的。 - 原因:在取指令阶段,程序计数器(PC)值应当加 4,指向下一条指令的地址。因此,
PCSource设置为01,表示 PC 的值加上 4。
- 作用:选择下一条指令的地址是由
- PCWr = 1:
- 作用:允许更新程序计数器(PC)。
- 原因:取指令阶段需要更新程序计数器(PC),将其指向下一条指令的位置。因此,
PCWr设置为1。
- IRWr = 1:
- 作用:允许将内存中读取的指令写入到指令寄存器(IR)。
- 原因:在取指令状态,程序需要将从内存读取的指令存入 IR,供后续阶段使用。所以,
IRWr设置为1,允许写入 IR。
- MemWr = 0:
- 作用:禁止内存写操作。
- 原因:在取指令阶段,我们并不需要将数据写入内存,仅仅是从内存读取指令。因此,
MemWr设置为0。
- RegWr = 0:
- 作用:禁止寄存器写操作。
- 原因:取指令阶段并不涉及寄存器的写操作,因此
RegWr设置为0,避免对寄存器进行不必要的写入。
- BrWr = 0:
- 作用:禁止分支操作。
- 原因:在取指令阶段,程序计数器按照顺序指向下一条指令,不进行分支操作。因此,
BrWr设置为0,禁止分支。
- R-type = 0:
- 作用:表示当前指令不是 R-type(寄存器类型)指令。
- 原因:在取指令阶段,我们还无法知道指令的具体类型,通常指令类型的判断会在后续的阶段进行,因此在取指令时,
R-type设置为0。
- 译码/取数状态
IR[31:26] → CU (控制单元):
- 作用:控制单元(CU)根据指令的高 6 位(IR[31:26])确定指令的类型和操作。
- 原因:这是指令解码的第一步,用于识别指令的操作码(opcode)。
A ← R[IR[25:21]],B ← R[IR[20:16]]:
- 作用:将寄存器
IR[25:21]和IR[20:16]指定的寄存器中的值读取到 ALU 的操作数 A 和 B。 - 原因:这一步从寄存器堆中提取源操作数,以便 ALU 使用。
IR[25:21]是源寄存器 1 的地址,IR[20:16]是源寄存器 2 的地址。
ALU 为闭环:
- 作用:ALU 不执行任何计算,只用于数据传递,因此不进行任何运算操作。
- 原因:在此阶段,ALU 只用于传递操作数,并且不进行算术运算。
分支目标地址计算方法:PC + 4 + (SignExt(imm16) * 4):
- 作用:计算分支目标地址。如果当前指令是分支指令,则使用
PC + 4作为基础地址,并将立即数(imm16)通过符号扩展后乘以 4 得到偏移量。 - 原因:这是因为立即数表示的地址是按 4 字节对齐的,因此需要将其乘以 4 来获得正确的字节偏移。
控制信号:
- ExtOp = 1:表示使用符号扩展(Sign Extension)来扩展立即数(imm16),以便在计算分支目标时得到正确的偏移量。
- ALUSelA = 0, ALUSelB = 11:选择 ALU 操作数。
ALUSelA = 0表示 ALU 操作数 A 来自寄存器(在此为寄存器R[IR[25:21]]);ALUSelB = 11表示 ALU 操作数 B 来自符号扩展后的立即数。 - PCWrCond = 1:表示程序计数器(PC)将在条件成立时更新。若当前为分支指令,并且满足条件,则更新 PC 为计算得到的目标地址。
- IRWr = 1:指令寄存器(IR)写操作使得取到的指令能够正确保存。
- MemWr = 0:内存写操作禁用,因为在这个阶段并不涉及内存写操作。
- RegWr = 0:寄存器写操作禁用,因为在译码阶段并不涉及向寄存器写数据。
- R-type = 0:表示当前指令不是 R 类型指令(不需要进行寄存器操作),因为这是一个指令解码的阶段。
R-型指令运算阶段

IR[31:26] → CU (控制单元):
- 作用:控制单元(CU)根据指令的高 6 位(IR[31:26])确定指令的类型和操作。
- 原因:这是指令解码的第一步,用于识别指令的操作码(opcode)。
A ← R[IR[25:21]],B ← R[IR[20:16]]:
- 作用:将寄存器
IR[25:21]和IR[20:16]指定的寄存器中的值读取到 ALU 的操作数 A 和 B。 - 原因:这一步从寄存器堆中提取源操作数,以便 ALU 使用。
IR[25:21]是源寄存器 1 的地址,IR[20:16]是源寄存器 2 的地址。
ALU 为闭环:
- 作用:ALU 不执行任何计算,只用于数据传递,因此不进行任何运算操作。
- 原因:在此阶段,ALU 只用于传递操作数,并且不进行算术运算。
分支目标地址计算方法:PC + 4 + (SignExt(imm16) * 4):
- 作用:计算分支目标地址。如果当前指令是分支指令,则使用
PC + 4作为基础地址,并将立即数(imm16)通过符号扩展后乘以 4 得到偏移量。 - 原因:这是因为立即数表示的地址是按 4 字节对齐的,因此需要将其乘以 4 来获得正确的字节偏移。
控制信号:
- ExtOp = 1:表示使用符号扩展(Sign Extension)来扩展立即数(imm16),以便在计算分支目标时得到正确的偏移量。
- ALUSelA = 0, ALUSelB = 11:选择 ALU 操作数。
ALUSelA = 0表示 ALU 操作数 A 来自寄存器(在此为寄存器R[IR[25:21]]);ALUSelB = 11表示 ALU 操作数 B 来自符号扩展后的立即数。 - PCWrCond = 1:表示程序计数器(PC)将在条件成立时更新。若当前为分支指令,并且满足条件,则更新 PC 为计算得到的目标地址。
- IRWr = 1:指令寄存器(IR)写操作使得取到的指令能够正确保存。
- MemWr = 0:内存写操作禁用,因为在这个阶段并不涉及内存写操作。
- RegWr = 0:寄存器写操作禁用,因为在译码阶段并不涉及向寄存器写数据。
- R-type = 0:表示当前指令不是 R 类型指令(不需要进行寄存器操作),因为这是一个指令解码的阶段。
I-型指令立即数运算阶段

ALU 操作:对于 I 型运算指令,如 addiu,会使用 ALU 执行即时数(immediate)的扩展。该指令执行计算的同时会更新程序计数器(PC),并通过 ALU 将寄存器 R[IR[20:16]] 和立即数 IR[15:0] 计算并存储结果。
控制信号设置:
- ALUSelA = 1:选择
A操作数来自寄存器堆(R[IR[20:16]])。 - ALUSelB = 10:选择
B操作数为立即数(经过符号扩展)。 - ALUOp = add:指定 ALU 执行加法操作。
- ExtOp = 1:符号扩展操作(扩展立即数)。
- PCWrCond = 1:如果需要更新 PC(如分支或算术运算),该信号会被启用。
- IRWr = 1:指令寄存器(IR)写操作,使得取到的指令保存。
- RegWr = 1:寄存器写操作,指令结果被写入寄存器堆。
- MemWr = 0:不进行内存写操作。
- BrWr = 0:不进行分支写操作。
- R-type = 0:指令不是 R 型指令。
lw指令执行阶段

- 状态 1:访问地址计算状态(MemAdr)
- ALUSelA = 1:
- 作用:选择 ALU 的第一个操作数
A,它来自寄存器堆。具体来说,它是从R[IR[25:21]]中读取的值,也就是指令中的第一个寄存器操作数。 - 原因:ALU 需要使用寄存器中的数据来进行地址计算,因此选择寄存器作为操作数 A。
- 作用:选择 ALU 的第一个操作数
- ALUSelB = 10:
- 作用:选择 ALU 的第二个操作数
B,它来自立即数(SignExt(IR[15:0]))。立即数是从指令的低 16 位(IR[15:0])提取并通过符号扩展处理后的数据。 - 原因:由于
lw指令使用立即数来计算内存地址,因此立即数需要通过符号扩展后作为操作数B传递给 ALU。
- 作用:选择 ALU 的第二个操作数
- ALUOp = add:
- 作用:ALU 执行加法操作。
- 原因:ALU 的任务是计算内存地址,所以它需要执行加法(即
A + SignExt(IR[15:0]))。add操作用于将寄存器的值与符号扩展的立即数相加,得出内存的地址。
- ExtOp = 1:
- 作用:启用符号扩展操作。
- 原因:符号扩展用于将指令中的立即数(16 位)扩展为 32 位,以便进行加法运算。符号扩展确保了立即数的符号正确传递。
- IorD = 1:
- 作用:选择数据内存操作(读操作)。
- 原因:在
lw指令中,ALU 计算出的地址需要用来从数据存储器中读取数据,因此IorD被设置为1,表示访问数据存储器。
- RegWr = 0:
- 作用:禁止寄存器写入操作。
- 原因:在地址计算阶段不需要写入寄存器,只是进行内存地址的计算,所以不进行寄存器写操作。
- PCWrCond = 1:
- 作用:允许程序计数器(PC)更新。
- 原因:此阶段并未影响 PC 的更新,但可能会作为状态的控制信号之一,为后续阶段的 PC 更新做准备。
- IRWr = 1:
- 作用:指令寄存器写操作。
- 原因:指令寄存器(IR)在获取指令时需要更新。
- MemWr = 0:
- 作用:禁止内存写操作。
- 原因:在访问地址计算阶段,我们只是计算内存地址,不执行内存写操作,因此
MemWr被设置为0。
- BrWr = 0:
- 作用:禁止分支操作。
- 原因:此时不进行任何分支操作,因此将
BrWr设置为0。
- R-type = 0:
- 作用:指示当前指令不是 R 型指令。
- 原因:
lw是 I 型指令,因此R-type设置为0。
- 状态 2:存储器取数状态(MemFetch)
- ExtOp = 1:
- 作用:符号扩展操作。
- 原因:保持符号扩展后的立即数供后续使用。
- ALUSelA = 1:
- 作用:ALU 的第一个操作数来自寄存器堆。
- 原因:继续保持寄存器堆中的数据作为操作数 A。
- ALUSelB = 10:
- 作用:ALU 的第二个操作数来自立即数。
- 原因:继续保持立即数扩展后的数据作为操作数 B。
- ALUOp = add:
- 作用:ALU 执行加法操作。
- 原因:计算内存地址。
- IorD = 1:
- 作用:从内存读取数据。
- 原因:数据内存需要根据 ALU 计算出的地址进行读取。
- RegWr = 0:
- 作用:不写入寄存器。
- 原因:在这一状态下,我们只进行内存读取操作,而不是写入寄存器。
- PCWrCond = 1:
- 作用:条件更新程序计数器。
- 原因:用于更新程序计数器。
- MemWr = 0:
- 作用:禁止内存写操作。
- 原因:此时只是从内存读取数据,不进行写操作。
- BrWr = 0:
- 作用:禁止分支操作。
- 原因:该阶段不涉及分支操作。
- 状态 3:结果写入寄存器状态(lwFinish)
- RegWr = 1:
- 作用:启用寄存器写操作。
- 原因:在
lw指令中,数据从内存读取并写入寄存器,所以需要启用寄存器写操作。
- 其他信号不变:
- 这一步仅是将数据写入寄存器,其他控制信号保持不变。
sw指令执行阶段

ALU 操作:对于 sw 指令,ALU 用于计算内存地址(A + SignExt(IR[15:0])),然后执行内存写操作。
控制信号设置:
- ALUSelA = 1:选择 ALU 的第一个操作数(来自寄存器
R[IR[25:21]])。 - ALUSelB = 10:选择 ALU 的第二个操作数(立即数)。
- ALUOp = add:执行加法操作。
- MemWr = 1:执行内存写操作。
- PCWrCond = 1:PC 更新。
- RegWr = 0:不进行寄存器写操作。
- BrWr = 0:不进行分支操作。
分支指令执行阶段

ALU 操作:对于 beq 指令,ALU 执行减法(A - B)并检查结果是否为零。如果为零,则进行分支操作。
控制信号设置:
- ALUSelA = 1:选择 ALU 的第一个操作数(来自寄存器
R[IR[25:21]])。 - ALUSelB = 00:选择 ALU 的第二个操作数(来自寄存器
R[IR[20:16]])。 - ALUOp = sub:执行减法操作。
- PCWrCond = 1:如果结果为零,则更新 PC,执行分支操作。
- PCSource = 10:选择分支目标地址。
- RegWr = 0:不进行寄存器写操作。
- MemWr = 0:不进行内存写操作。
- BrWr = 1:执行分支操作。
无条件跳转指令执行阶段

ALU 操作:对于 jump 指令,直接修改程序计数器(PC)为目标地址。
控制信号设置:
- PCSource = 00:选择跳转目标地址。
- PCWr = 1:更新程序计数器(PC)。
- RegWr = 0:不进行寄存器写操作。
- IRWr = 0:不更新指令寄存器(IR)。
- MemWr = 0:不进行内存写操作。
- BrWr = 0:不进行分支操作。
互连及输入输出组织
-
鼠标、键盘、显示器、打印机等设备与主机交换信息以字符为单位,所以又称为字符型设备或面向字符的设备
-
磁盘与主机交换信息时采用成批方式,以几十、几百甚至更多字节组成的信息块为单位,因此属于成块传送设备
-
北桥是一个主存控制器集线器(Memory Controller Hub,MCH)芯片,本质上是一个DMA(Direct Memory Access)控制器,因此,可通过MCH芯片直接访问主存和显卡中的显存。
- 南桥是一个I/O控制器集线器(I/O Controller Hub,ICH)芯片,其中可以集成USB控制器、磁盘控制器、以太网控制器等各种外设控制器,也可以通过南桥芯片引出若干主板扩展槽,用以接插一些I/O控制卡。
-
对于数据缓冲寄存器、控制/状态寄存器的访问操作是通过相应的指令来完成的,通常把这类指令称为I/O指令。是一种特权指令
-
设备是否适合采用条件传送方式,主要取决于I/O设备本身的特点以及设备是否能够独立启动I/O等。
- 键盘和鼠标等是随机启动的低速I/O设备,当用户按下键盘按键、移动鼠标或单击鼠标按钮时,便启动了I/O设备的输入操作。对于这类自身能独立启动I/O的设备,虽然可以采用定时程序查询方式,但是,由于设备的启动是由用户随机进行的,所以,有可能用户长时间没有输入而引起查询程序长时间等待,从而降低处理器的使用效率,因此,这类设备大多采用后面介绍的中断方式进行I/O;
- 对于由操作系统启动的设备,则只有被操作系统激活后才需要查询。磁盘、磁带和光盘存储器等成块传送设备一旦被启动,便可连续不断地传送一批数据,处理器无需对每个数据的传送进行启动,而且每个数据之间的传输时间很短,如果用定时查询方式,则会因为频繁查询而使处理器为I/O操作所花费的时间比例变得很大,因此,不适合采用程序查询方式。像针式打印机等字符类设备,每个字符之间的传输时间较长,并且每传送一个字符需要启动一次,因而可以采用程序查询方式。
-
当然,如果CPU同时要竞争存储器,存储器由于用于DMA传送,因而CPU会被延迟与存储器交换数据。
- 但通过使用cache,CPU可避免大多数访存冲突。因此,通常存储器带宽的大部分都可让给外设的DMA传送使用。
-
DMA是以虚拟地址还是以物理地址工作呢?
-
若用虚拟地址,则在DMA接口中必须将页面的虚拟地址转换为物理地址
-
使用物理地址所带来的问题是,每次DMA传送不能跨页。如果一个I/O请求跨页,那么,一次请求的一个数据块在送到主存时,就可能不在主存的一个连续的存储区中,因为每个虚页可以映射到主存的任意一个实页框中,所以多个连续的虚页不可能正好对应连续的实页框。
-
因此,如果DMA采用物理地址,就必须限制所有的DMA传送都必须在一个页面之内进行。
-
2. 为什么还会出现“跨页问题”?
问题的根源在于:
- 虚拟地址空间是连续的(进程眼里看到的一大块缓冲区);
- 但物理地址空间不一定连续(虚拟页可能映射到不同的物理页框,物理页框之间可能不相邻)。
例如:
- 程序申请了一个 8KB 缓冲区(虚拟地址连续)。
- 操作系统分配给它 2 个物理页框:
- 虚拟 [0x0000–0x0FFF] → 物理 [0x10000–0x10FFF]
- 虚拟 [0x1000–0x1FFF] → 物理 [0x30000–0x30FFF]
在虚拟空间里这块内存是连续的,但物理空间里其实是 断开的。
3. DMA 为什么会出错?
DMA 控制器只知道“物理地址起点 + 长度”,它假设这一段物理内存是连续的。
如果您让 DMA 从 0x10000 搬运 8KB,它会顺着物理地址搬到 0x12000。
但问题是:0x11000–0x12000 这一段物理内存根本不属于程序的缓冲区,而是别的东西!这样就会出错。所以才说:DMA 传输不能跨页,即一次传输必须落在同一个物理页框内,否则就可能访问到错误的物理内存。
4. 您的问题的答案
您问的是:
难道这个意思是虚拟存储系统无法选中一片连续的物理地址空间分配给 DMA 传输的数据?
✔️ 正解就是这个!
- 操作系统确实不能保证每次申请的虚拟缓冲区背后都映射到连续的物理内存。
- 所以,如果 DMA 不支持虚拟地址,就必须由 OS 保证 DMA 传输的数据缓冲区物理上是连续的。
- 方法:用“锁页 + 物理连续分配”来保证。
- 或者分多次 DMA,每次在一个物理页框里搬。
- 在更先进的系统里,会引入 IOMMU,让 DMA 也能处理虚拟地址,自动跨页。
✅ 总结一句:
DMA 控制器不懂虚拟地址,也不会走页表。它只能拿着 CPU 给的起始物理地址连续搬运。但虚拟地址连续 ≠ 物理地址连续,所以才会有“DMA 传输不能跨页”的说法,除非 OS 保证分配到一块连续物理内存,或者引入 IOMMU。
-
-
-
否则,DMA就只能采用虚拟地址,在这种情况下,DMA接口中应该有一个小的类似页表的地址映射表,用于将虚拟地址转换为物理地址。在DMA初始化的时候,由操作系统进行地址映射。这样,DMA接口就不用关心传送数据在主存的具体位置了。
-
另外一种方法是操作系统把一次传送分解成多次小数据量传送,每次只限定在一个物理页面内进行。
-
-
每个系统调用的封装函数会被转换为一组与具体机器架构相关的指令序列,这个指令序列中**,至少有一条陷阱指令**,在陷阱指令之前可能还有若干条传送指令,用于将I/O操作的参数送入相应的寄存器
程序查询打印机打印过程
- ①用户进程P中使用了某个I/O函数,请求在打印机上打印一个具有n个字符的字符串
- ②用户进程P通过一系列过程调用后,执行一个系统调用打开打印机
- ③若打印机空闲,则用户进程P可正常使用打印机,因而就通过一个系统调来对打印机进行写操作,从而陷入操作系统内核进行字符串打印。
- ④操作系统内核通常将用户进程缓冲区中的字符串首先复制到内核空间
- ⑤查看打印机是否“就绪”。
- ⑥如果“就绪”,则将内核空间缓冲区中的一个字符输出到打印控制器的数据端口中,并发出“启动打印”命令,以控制打印机打印数据端口中的字符;如果打印机“未就绪”,则等待直到其“就绪”
- ⑦上述过程循环执行,直到字符串中所有字符打印结束。
程序中断打印机打印过程

-
①当前进程P₁需要进行一个I/O操作时,它会先启动外设进行第一个数据的I/O操作,并挂起执行I/O操作的进程P₁使其被阻塞
- 在“字符打印”系统调用服务例程中启动打印机后,它就调用处理器调度程序scheduler来调出进程P₂执行,而将用户进程P₁阻塞。
-
②然后从就绪队列中选择另一个进程P₂执行,此时,外设和CPU并行工作。
- 在CPU执行进程P2的同时,打印机在进行打印操作,CPU和打印机并行工作。
- 若打印机打印一个字符需要5ms,则在打印一个字符期间,其他进程可以在CPU上执行5ms的时间。对于程序直接控制I/O方式,CPU在这5ms的时间内只是不断地查询打印机状态,因而整个系统的效率很低。
-
③当外设完成I/O操作,便向CPU发中断请求。CPU响应请求后,就中止正在执行的用户进程P₂,转入一个“中断服务程序”,在**“中断服务程序”中再启动随后数据的I/O传送任务**。
- 中断服务程序首先判断是否已完成字符串中所有字符的打印,若是,则将用户进程P₁解除阻塞,使其进入就绪队列;否则,就向数据端口送出下一个欲打印字符,并启动打印,将未打印字符数减1和下一个打印字符指针加1后,执行中断返回,回到被打断的进程P₂继续执行。
- 注意,由于打印机是字符型设备,因此是打印一个字发送一个中断请求
- 在打印机打印好一个字以后,会发出一个中断请求,CPU响应请求后,转入中断服务程序
- 由于打印机的数据寄存器只能存一个字符,因此打印机每打印一个字就要发起中断请求,让CPU执行中断服务程序,把下一个字符传到打印机数据端口,并对相应参数进行调整
-
④**“中断服务程序”执行完后,返回原被中止的进程P₂的断点处继续执行。**此时,外设和CPU又开始并行工作。
键盘键入过程
- ①键盘发出串行数据
- ②主机的键盘控制电路将8位数据通过串并转换,形成并行数据送入缓冲寄存器
- ③向CPU发出键盘中断请求
- ④CPU响应该中断后,由键盘中断服务程序把扫描码转换成ASCII码,送入主存中的键盘数据缓冲区
中断过程
- ①来自各个设备的中断请求记录在中断请求寄存器中的对应位,每个中断源有各自对应的中断屏蔽字,在进行相应的中断处理之前它被送到中断屏蔽字寄存器中。
- ②在CPU运行程序时,每当CPU完成当前指令的执行、取出下一条指令之前,就会通过采样中断请求信号引脚(如Intel处理器中的INTR)来自动查看有无中断请求信号。
- ③若有,则会发出一个相应的中断回答信号,启动图中的“中断查询”线
- ④在该信号线的作用下,所有未被屏蔽的中断请求信号一起送到一个中断判优电路中,判优电路根据中断响应优先级选择一个优先级最高的中断源
- ⑤用一个编码器对该中断源进行编码,得到对应的中断源设备类型号(即中断源的标识信息,称为中断类型)。
- ⑥CPU取得中断源的标识信息后,经过一系列相应的转换,就可得到对应的中断服务程序的首地址,在下一个指令周期开始,CPU执行相应的中断服务程序。
磁盘DMA过程
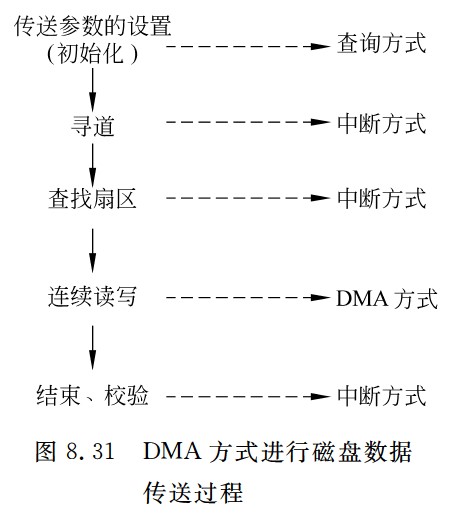

- 在用DMA方式进行硬盘等高速设备的数据传输过程中,也要用到程序查询和中断I/O方式。
- ①首先,进程P₁采用程序查询方式设置传送参数,通过执行相应的指令对有关参数寄存器进行初始化
- ②然后CPU执行I/O指令发出“寻道”命令到磁盘控制器,由磁盘控制器控制磁盘驱动器开始移动磁头,同时,CPU切换到其他进程(如P₂)执行
- ③当磁盘完成寻道操作后,向CPU发出“寻道结束”中断请求
- ④CPU响应并处理该中断请求,中止正在执行的进程P₂,在中断服务程序中通过执行I/O指令发出“查找扇区”命令到磁盘控制器,CPU启动“查找扇区”命令后,返回被中止的进程P₂执行;
- ⑤当磁盘完成扇区查找操作,就向CPU发出“查找结束”中断请求;CPU响应并处理该中断,又一次中止正在执行的进程P₂,然后在中断服务器程序中启动进行DMA传送,由DMA控制器控制数据在主存和磁盘之间进行数据传送;
- ⑥CPU启动DMA传送后,又回到被中止的进程P₂继续执行,直到DMA传送结束;此时,由DMA控制器发出“DMA结束”中断请求,CPU响应并处理该中断请求,对传送的数据进行校验等后处理。
I/O子系统的工作过程
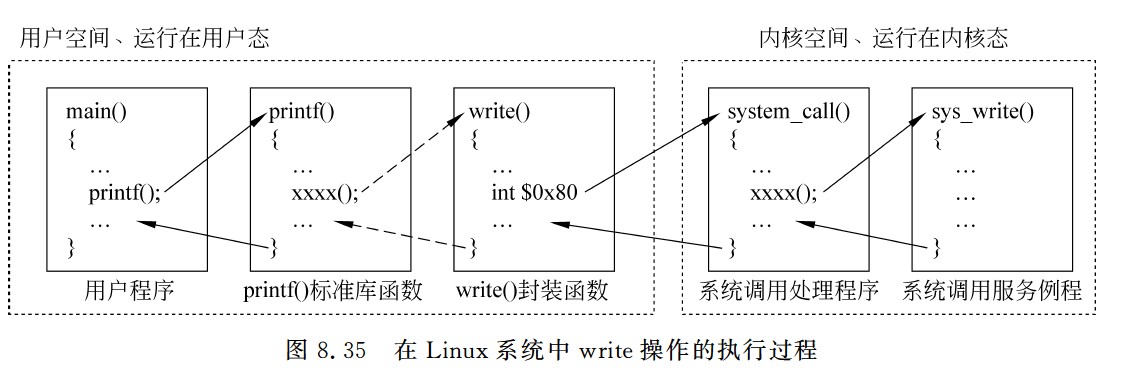
- ①首先,CPU在用户态执行用户进程,当CPU执行到系统调用的封装函数对应的指令序列中的系统调用指令时,会从用户态陷入内核态
- ②转到内核态执行后,CPU根据系统调用指令执行时EAX寄存器中的系统调用号,选择执行一个相应的系统调用服务例程
- ③在系统调用服务例程的执行过程中可能需要调用具体设备的驱动程序
- ④在设备驱动程序执行过程中启动外设工作
- ⑤外设准备好后发出中断请求,CPU响应中断后,就调出中断服务程序执行,在中断服务程序中控制主机与设备进行具体的数据交换。
在Linux系统中write操作的执行过程
- ①假定用户程序中有一个语句调用了库函数printf(),在printf()函数中又通过一系列的函数调用,最终转到调用write()函数。
- ②在write()函数对应的指令序列中,一定有一条用于系统调用的陷阱指令,该陷阱指令执行后,进程就从用户态陷入到内核态执行。
- ③Linux中有一个系统调用的统一入口,即系统调用处理程序system_call()。CPU执行陷阱指令后,便转到system_call()的第一条指令执行。
- ④在system_call()中,将根据EAX寄存器中的系统调用号跳转到当前系统调用对应的系统调用服务例程sys_write()去执行。
- ⑤system_call()执行结束时,从内核态返回到用户态下的陷阱指令后面一条指令继续执行。
用户程序调用fopen()函数到内核I/O软件执行的过程
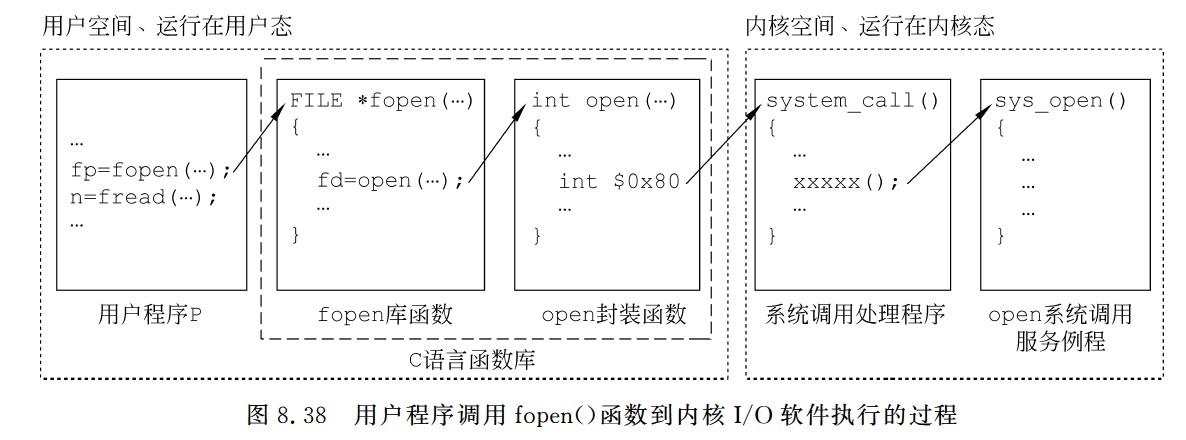
- ①当执行到用户程序P中第4行语句时,将转入C标准库函数fopen()执行
- ②fopen()调用系统调用函数open(),而open系统调用对应的指令序列中有一条自陷指令,当执行到该自陷指令时,将从用户态陷入内核态执行
- ③在内核态首先执行的是system_call程序,该程序中再根据系统调用号转到对应的open系统调用服务例程sys_open执行,文件打开的具体工作由sys_open()完成
用户程序调用fread()函数到内核I/O软件执行的过程
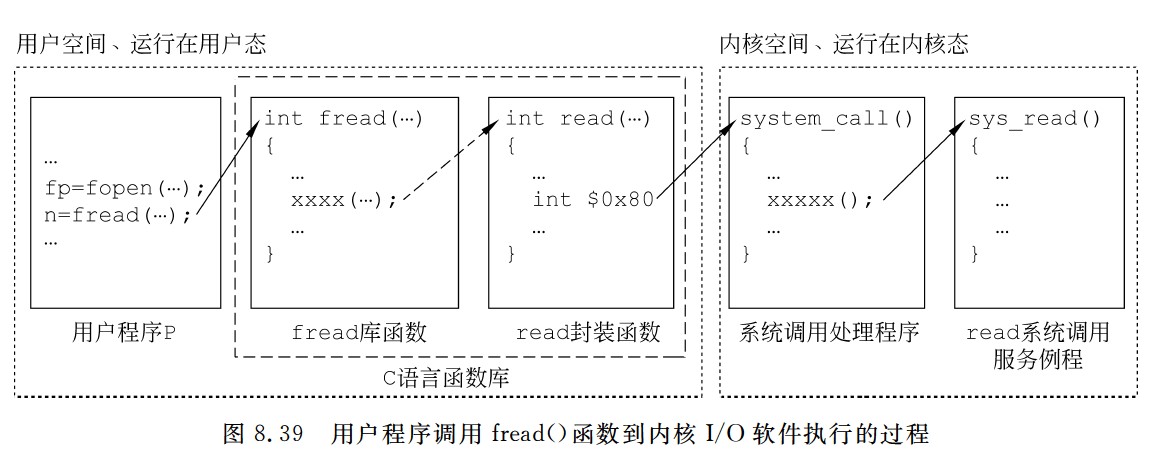
- 因为用户进程使用fread()函数读取的是一个普通的磁盘文件,所以应采用DMA控制I/O方式进行磁盘读操作。通过系统调用陷入内核后,底层的内核I/O软件的大致处理过程如下:
- (1)由内核空间中与设备无关的I/O软件完成以下相关操作:
- ①根据文件bin_file的文件描述符fd(执行fopen()函数后得到一个指向结构FILE的指针fp,在fp所指结构中包含了打开文件的文件描述符fd),找到对应的文件描述信息
- ②根据相应的文件描述信息可确定相应的磁盘设备驱动程序
- ③根据文件当前指针确定所读数据在抽象的块设备中的逻辑块号
- ④检查用户所需数据是否在高速缓存RAM中,以判断是否需要读磁盘
- 因为文件bin_file未曾被读取过,所以肯定不会在高速缓存RAM中,同时也不会在用户缓冲区,因而需要调用相应的磁盘驱动程序执行读磁盘操作。
- (2)在磁盘驱动程序中,将会完成以下操作:
- ①检查磁盘驱动器的电机是否运转正常,将逻辑块号转换为磁盘物理地址(柱面号、磁头号、扇区号)
- ②对将要接受磁盘数据的主存空间进行初始化,对DMA控制器中的各个I/O端口进行初始化
- ③然后,发送“启动DMA传送”命令以启动具体的I/O操作
- ④最后调用处理器调度程序以挂起当前用户进程P,并使CPU转而执行其他用户进程。
- (3)当DMA控制器完成I/O操作后,向CPU发送一个**“DMA完成”中断请求信号**,CPU调出相应的中断服务程序执行。CPU在中断服务程序中,解除用户进程P的阻塞状态而使其进入就绪队列,然后中断返回,再回到被打断的进程继续执行。下次处理器调度时用户进程P有可能会被调度到处理器上继续执行。
与设备无关的I/O软件
- 一旦通过陷阱指令调出系统调用处理程序执行,就开始执行内核空间的I/O软件。
- 首先执行的是与具体设备无关的I/O软件,主要完成所有设备公共的I/O功能,并向用户层软件提供一个统一的接口。通常,它包括以下几个部分:设备驱动程序统一接口、缓冲处理、错误报告、打开与关闭文件以及逻辑块大小处理等。
- Linux系统调用函数执行过程中,刚陷入内核后所执行的system_call()函数就是与设备无关的I/O软件的一部分。
- 虽然很多错误与特定设备相关,必须由对应的设备驱动程序来处理,但是,所有I/O操作在内核态执行时所发生的错误信息都是通过与设备无关的I/O软件返回给用户进程的,也就是说,错误处理的框架是与设备无关的。
- 有些错误属于编程错误。例如,请求了某个不可能的I/O操作;写信息到一个输入设备或从一个输出设备读信息;指定了一个无效的缓冲区地址或者参数;指定了不存在的设备。这些错误信息由设备无关I/O软件检测出来并直接返回给用户进程,无须再进入更底层的I/O软件处理。
- 还有一类是I/O操作错误,例如,写一个已被破坏的磁盘扇区;打印机缺纸;读一个已关闭的设备。这些错误由相应的设备驱动程序检测出来并处理,若驱动程序无法处理,则驱动程序将错误信息返回给设备无关I/O软件,再由设备无关I/O软件返回给用户进程。
设备驱动程序
- 通过执行设备驱动程序,CPU可以向控制端口发送控制命令来启动外设,可以从状态端口读取状态来了解外设或设备控制器的状态,也可以从数据端口中读取数据或向数据端口发送数据等。
- 设备驱动程序中包含了许多I/O指令,通过执行I/O指令,CPU可以访问设备控制器中的I/O端口,从而控制外设的I/O操作。
- 中断请求是由于执行了设备驱动程序而产生的,外设完成驱动程序要求的I/O操作后,设备控制器或DMA控制器会向CPU发出中断请求,从而调出中断服务程序执行。
多处理器系统
- 多处理器系统是共享存储多处理器系统的简称,它是一种具有共享的单一地址空间的并行处理系统
- 每个处理器都访问一个全局的主存储器,因而每个处理器在执行指令时所产生的物理地址都属于同一个物理地址空间
- 采用单地址空间的多处理器系统中,每个处理器可以通过load和store指令访问共享存储器,处理器之间通过共享内存变量进行通信,因而,可能会同时有多个处理器访问同一个共享变量,所以需要处理器之间进行相互协调,需要进行同步控制。常用的同步机制是通过对共享变量加锁的方式来控制处理器对共享变量互斥访问
- 硬件多线程技术本身并不依赖于多核处理机架构,硬件多线程技术是一种在单个处理器核心上实现并行执行多个线程的技术,它通过复制核心上的部分资源(如通用寄存器组和程序计数器等用于存放现场信息的资源)来同时管理线程的指令流。
- 在一些对性能稳定性要求较高的场合,可能会限制适用甚至关闭多核和硬件多线程技术
- Flynn分类

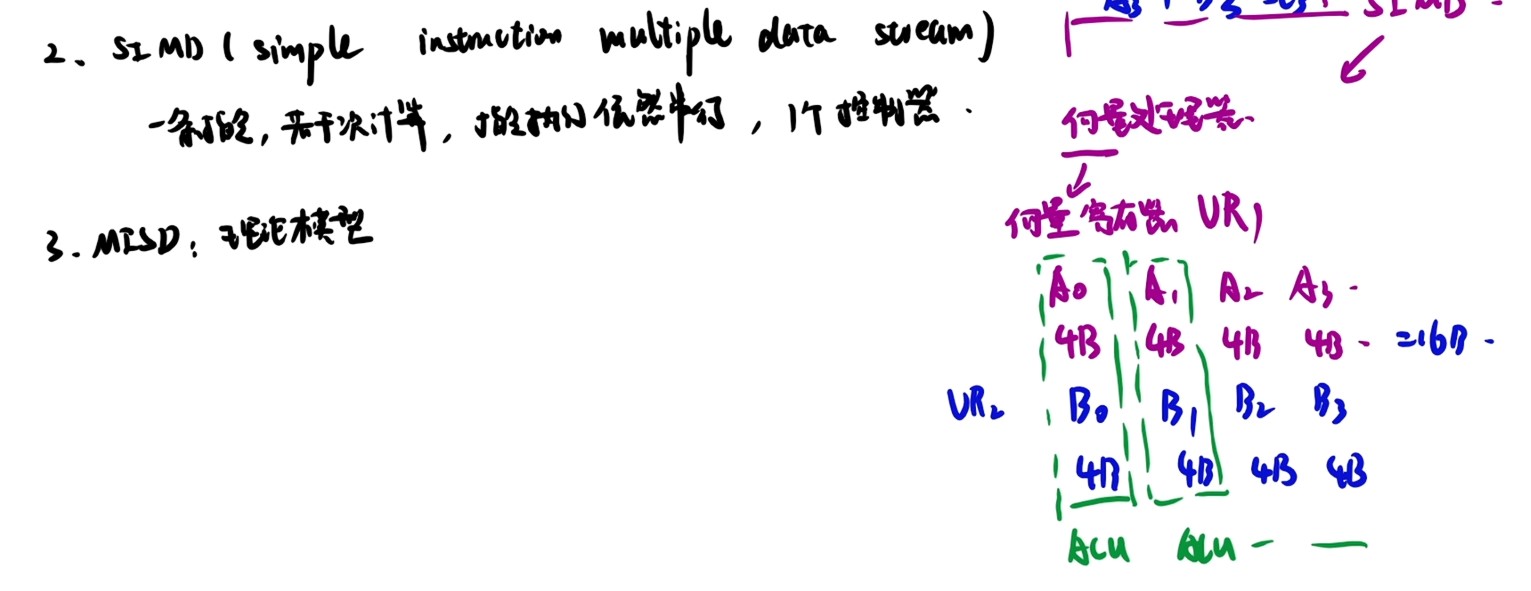
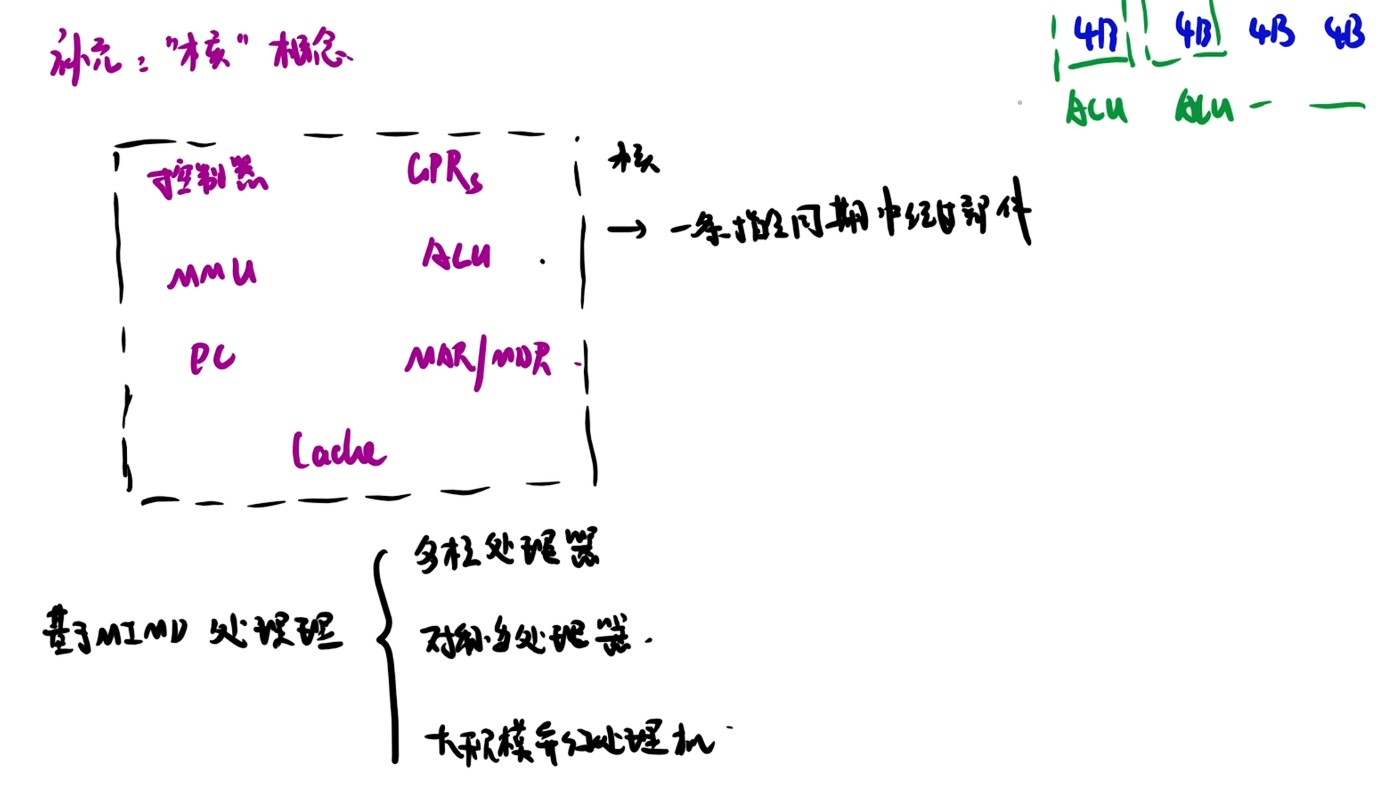

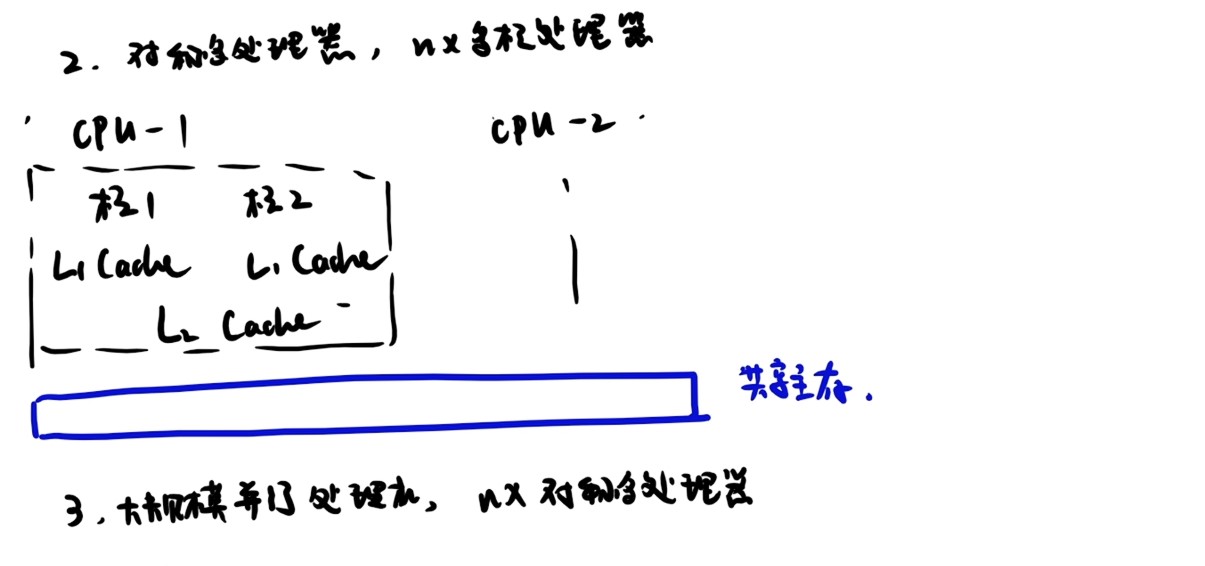
OS(操作系统)
PV操作个人总结版
生产者-消费者问题
- ①分析题目中包含的同步互斥关系
- ②写出每个进程文字描述的在干什么
哲学家进餐问题

- ①将拿筷子的操作封锁成一个临界区,对这个临界区加大锁
操作系统概述
- 调用子程序的过程完全属于软件处理过程
- 子程序的入口地址是由call指令中的地址码给出的
- 定时器产生时钟中断后,由时钟中断服务程序更新的部分内容是:
- 内核中时钟变量的值
- 当前进程占用CPU的时间
- 当前进程在时间片内的剩余执行时间
- 时钟中断的主要工作是处理和时间有关的信号以及决定是否执行调度程序,和时间有关的所有信息,包括系统时间、进程的时间片、延时、使用CPU的时间、各种定时器。
- 读时钟可以在用户态读,写时钟要在内核态写
- 程序接口是用户程序获得OS服务的唯一途径
- 命令行程序通常在用户态运行,只有在需要访问系统资源时,程序才会通过系统调用进入内核态。
- 用户可以通过操作系统提供的程序接口(系统调用、标准库函数等)实现自己的命令行界面(CLI)。这种实现方式可以帮助用户模拟现有操作系统的行为,或者开发定制化的命令行工具。实际开发中,很多操作系统提供的 shell(如 Bash、PowerShell 等)就是基于这种思路构建的。
- 多道程序系统必须存在地址保护机制
- 系统时钟可以由操作系统来进行设定和初始化
- 中断、IO、异常都可能发⽣在内核态。⽽访管指令是⽤户程序主动请求操作系统提供服务(即系统调⽤)的唯⼀途径。
虚拟化
- 第二类VMM负责把虚拟机程序的虚拟地址转换为宿主操作系统中的虚拟地址(这个虚拟地址在虚拟机OS看来是物理地址),再由宿主操作系统转换为物理地址
- 第一类VMM的非敏感指令执行在ring1层,而敏感指令执行在ring0层(内核态),由于部分敏感指令不是特权指令,执行这些指令的时候不会自动trap,而是被VMM捕获。几乎所有现代CPU都支持硬件虚拟化,这些不会trap的敏感指令,是通过允许VMM捕获并仿真敏感指令来实现的,可以在用户态执行
- 当且仅当敏感指令是特权指令的子集时,机器才是可以虚拟化的。
- 第一类VMM较第二类VMM在安全性、隔离性、性能、稳定性上具有优势
- 例如,第一类VMM虚拟地址到物理地址的转换只需要两次变化:第一次:客户虚拟地址到客户物理地址,第二次是客户物理地址到主机物理地址,而第二类需要三次:第一次是客户机虚拟地址向客户机物理地址变换,第二次是客户机物理地址向主机虚拟地址变换,第三次是主机虚拟地址向主机物理地址变换。
- 第一类VMM常用于服务器,第二类VMM常用于个人计算机
- 第二类VMM实际上也运行在内核态,只不过不是内核态唯一运行的程序
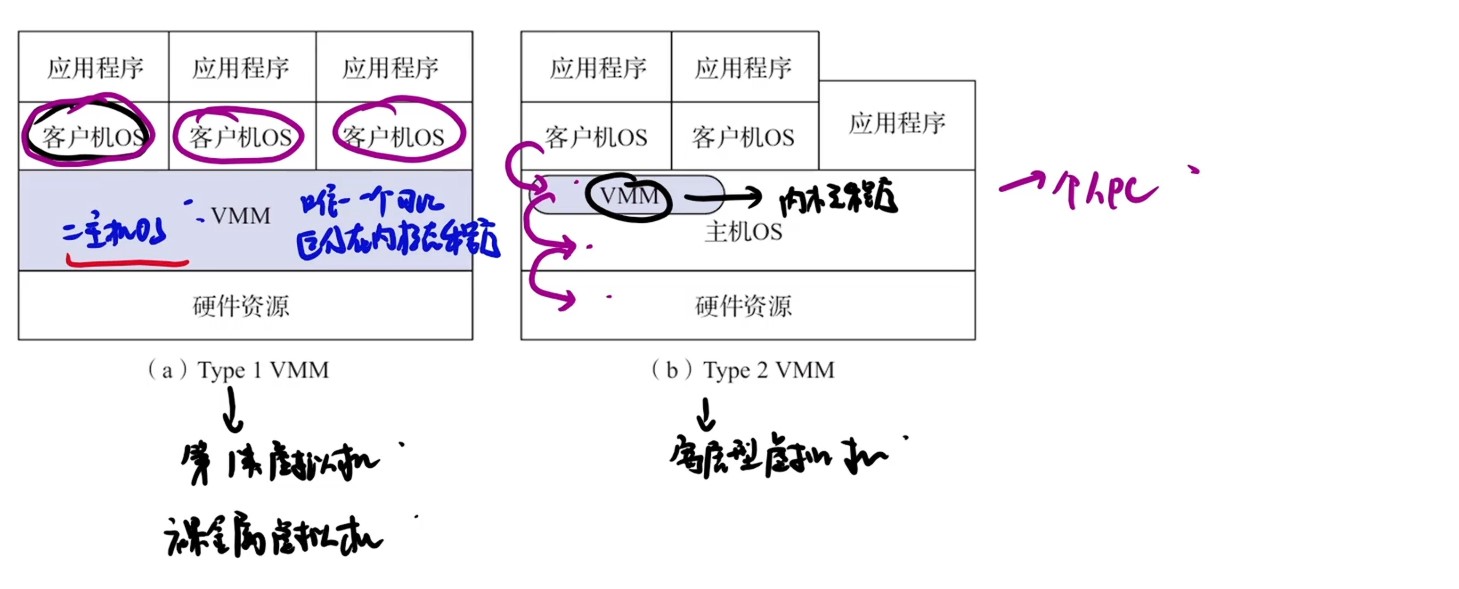
操作系统发展历程
- 多道批处理系统的主要特征:制约性、间断性、共享性
- 多道批系统能够让I/O设备和CPU并行,因为可以单处理器多核
操作系统内核
- 常见的内核数据结构
- 进程控制块PCB
- 存储关于系统中每个进程的信息,包括
- 进程状态
- 进程编号PID
- 程序计数器、寄存器集的状态
- 内存管理信息(页表)
- 账户信息
- I/O状态信息(如分配给进程的文件描述符)
- 执行统计
- 存储关于系统中每个进程的信息,包括
- 文件描述符表
- 每个进程都有一个文件描述符表,表中的每个条目指向一个文件表,其中包含文件的位置、读写位置和访问权限
- 内存管理结构
- 页表
- 段表
- 伙伴系统
- 空闲内存列表或位图
- 调度队列
- 等待队列
- 中断向量表
- 同步原语的数据结构
- 信号量
- 互斥锁
- 条件变量
- 设备驱动表
- 包含系统中所有设备的驱动程序的指针和状态信息
- 缓冲区和缓存管理
- 缓冲区高速缓存和页缓存
- 进程控制块PCB
- 内核态除了访管指令外,可执行一切指令
- 发生在用户态的
- 系统调用
- 外部中断
- 缺页
- 从内存中读取一个普通变量的值到寄存器,通常对应一条普通的数据传送指令。如果该变量所在的内存地址是合法有效的,并且对应的页面在物理内存中,那么这条指令会在用户态正常完成,不会导致模式切换。只有在地址非法或发生缺页时,才会间接引发异常导致模式切换,但这并非读取普通变量的必然结果。
- 访问虚拟内存是进程直接访问内存,由MMU完成虚拟地址向物理地址的转换,这个过程由硬件完成不需要操作系统参与,只有发生缺页时才会触发缺页异常,由操作系统完成异常处理,装入页面
- 发生在内核态的
- 进程切换
- 缺页处理
- 在用户态执行的
- 陷阱指令
- 跳转指令
- 数据传送指令
- 设置断点指令
- 在调试过程中,用户程序可以设置断点指令来中断程序执行并进行调试操作
- 设置断点是调试程序时常用的一种手段,在某些体系结构中, 有专门的断点中断指令,该指令可以在用户态执行,执行后会引发一个调试异常,使CPU陷入内核态,由调试器或操作系统内核接管处理。
- 设置断点的目的是为了让程序在运行至断点位置时触发中断,而设置断点这一步骤是可以发生在用户态的
- 从内存中取数
- 改变程序计数器的值(跳转指令)
- 在内核态执行的
- 特权指令
- 关中断、I/O指令
- 特权指令
- 进程在处理中断或者异常因此从用户态进入内核态,或中断异常处理完从内核态返回到用户态的过程中,均不涉及进程的切换,也就是说进程的用户程序与为其服务的内核程序均属于同一个进程,共用同一虚拟地址空间
- 一个进程同时拥有用户栈和内核栈,当发生特权级切换时,由硬件自动实现堆栈的切换
- 当CPU执行的系统调用完成时,会触发从内核态转换到用户态。在执行系统调用期间,CPU首先会从用户态切换到内核态,然后操作系统执行相应的操作,最后该操作完成时,CPU将再次切换回用户态。系统调用结束后,CPU可以继续执行用户程序。
进程的状态
- 挂起态通常是由于终端用户请求、父进程请求、系统负荷调节或者操作系统自身需要等原因,将进程置于静止状态
- 进入终止状态的进程不能再被执行,但在OS中依然会保留一个记录,其中会保存状态码和一些计时统计数据以供其他进程收集。一旦其他进程完成了对其信息的提取,系统就会删除该进程,即将其PCB清零,并将该空白PCB返还OS。
- “应用请求”这类事件,则需要由用户进程自己创建新进程,以使新进程以同创建进程并发执行的方式完成特定任务。
- 新进程即子进程
- 父进程创建子进程的时候,如果资源不足,子进程处于创建态等待内存资源,而创建该进程的父进程被阻塞
- 七种状态转换图
- 僵尸进程:
- 已经终止运行但尚未被父进程回收资源的进程。其PCB仍然保留在系统进程表中,以便父进程查询其终止状态
- 产生原因
- 父进程创建子进程后,子进程执行完毕并通过exit()终止。父进程未调用wait()或waitpid()来获取子进程的终止状态
- 特点
- 占用进程表资源:僵尸进程的PID和退出状态信息仍占用系统进程表。
- 无法被终止:僵尸进程已经死亡,无法通过信号(如sigkill)杀死
- 长期存在:如果父进程一直不回收,僵尸进程会持续存在,可能导致进程表耗尽
- 解决方法
- 父进程调用wait()或waitpid():主动回收子进程资源
- 忽略sigchld信号:通过signal(sigchld,sig_ign)通知内核无需保留子进程状态
- 父进程终止:当父进程终止时,僵尸进程会被init进程接管并清理
- 孤儿进程:
- 父进程提前终止,导致子进程被init进程(PID为1)接管。操作系统自动处理孤儿进程的资源回收。
- 产生原因:父进程在子进程终止前意外退出(如崩溃或被终止)
- 特点:
- 由init进程接管:操作系统将孤儿进程的父进程设为init。
- 自动回收:当孤儿进程终止时,init进程会调用wait()回收其资源。
- 无资源泄露:不会长期占用进程表
- 处理机制:操作系统自动将孤儿进程的父进程设置为init。init进程周期性调用wait()回收终止的子进程。
| 特性 | 僵尸进程 | 孤儿进程 |
|---|---|---|
| 父进程状态 | 父进程存活但未调用 wait() |
父进程已终止 |
| 资源占用 | 占用进程表资源,可能导致资源耗尽 | 无长期资源占用,由 init 自动回收 |
| 处理方式 | 需父进程主动回收或父进程终止 | 由 init 进程自动处理 |
| 系统影响 | 可能引发进程表满的问题 | 无负面影响 |
- 总结:
- 僵尸进程可能导致进程表资源耗尽,需及时处理。孤儿进程由系统自动管理,无需干预。
- 僵尸进程:父进程未及时回收的子进程残留,需手动处理。
- 孤儿进程:父进程意外终止后的子进程,由init自动接管。
系统调用
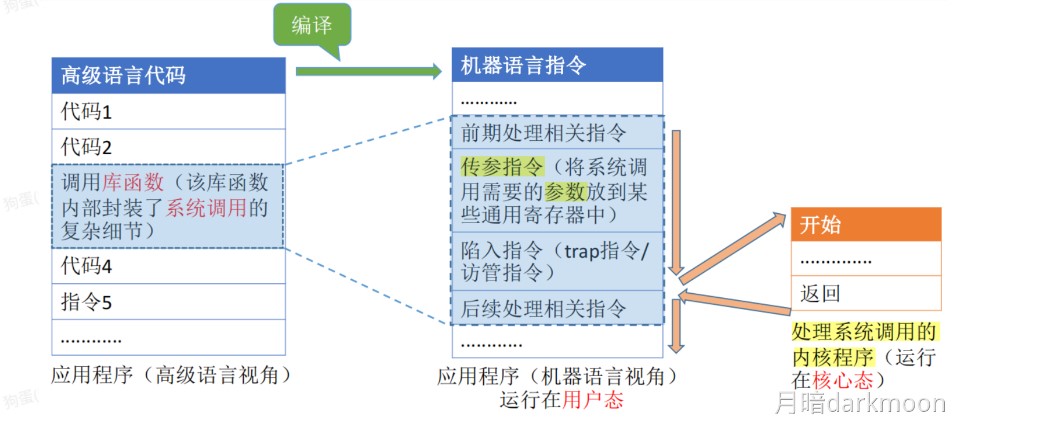
-
从用户态到内核态
- 执行一条当前CPU不支持的指令
- 引发“非法指令”异常(内中断)
- 当CPU检测到无法识别的指令时,会强制从用户态切换到内核态,由操作系统内核处理该异常,因此,这会导致模式切换
- 地址非法/缺页
- 执行系统调用
- 执行系统调用会主动引发陷入(trap),使cpu从用户态切换到内核态
- 除数为0
- 引发算数异常(内中断),强制从用户态切换到内核态,由操作系统内核处理该异常
- 执行一条当前CPU不支持的指令
-
系统调用=用户发起+硬件切换+操作系统服务
- 操作系统不控制底层硬件切换机制,但负责后续的现场保护和服务执行
-
陷入指令并非特权指令,且需要在用户态下执行。发生在用户态,响应在内核态
- 用户态下发出系统调用请求,内核态下处理系统调用请求
- 系统调用不一定需要专门的硬件;进程调度是由调度算法决定cpu使用权,由操作系统实现,不需要硬件支持,一定需要专门硬件的有地址映射和中断系统
-
系统调用的处理过程
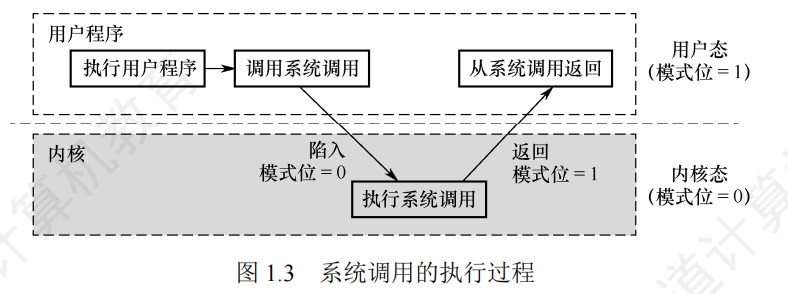
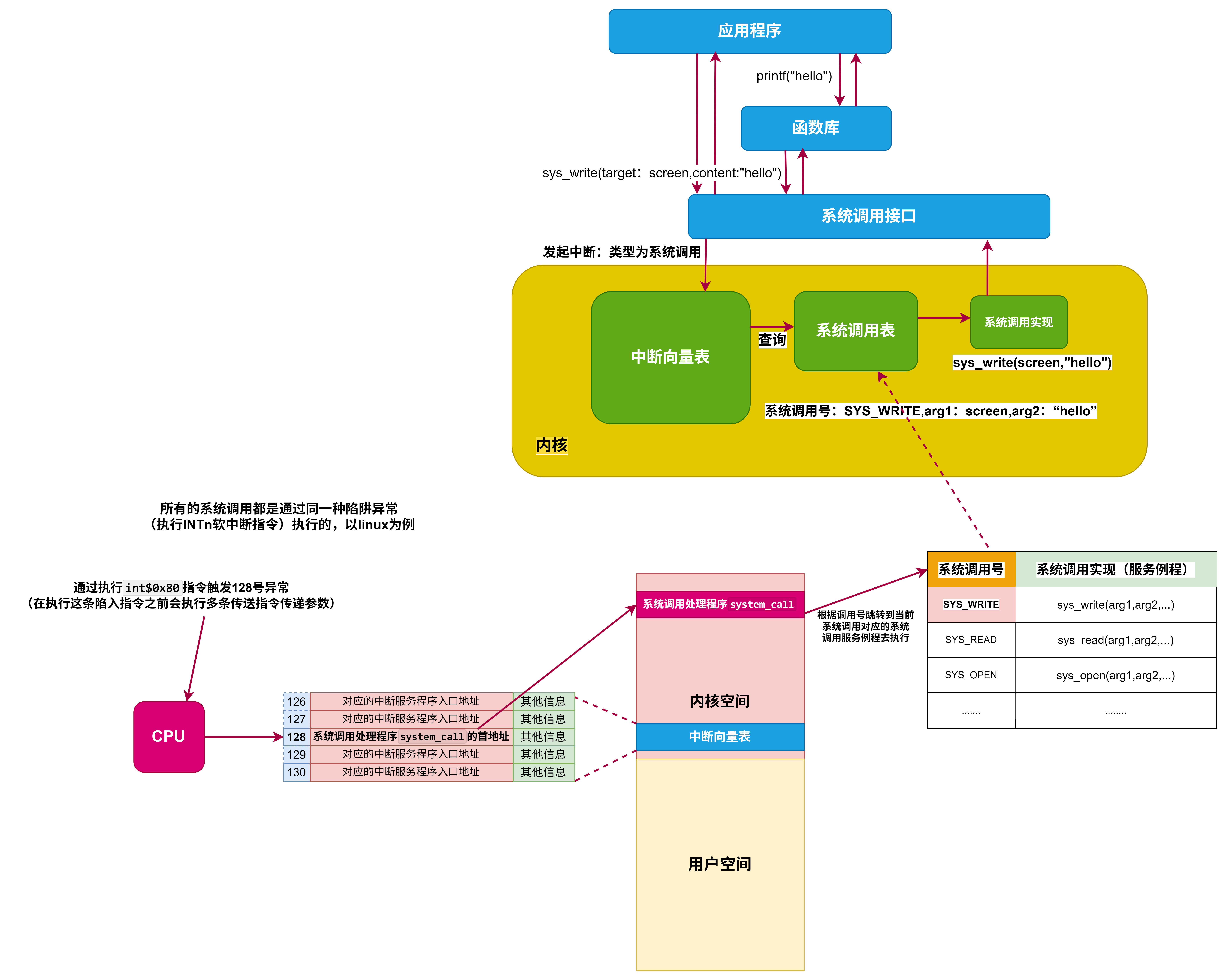
- ①用户程序首先将系统调用号和所需的参数压入堆栈**(用户态)**
- ②调用实际的调用指令,然后执行一个陷入指令,将CPU状态从用户态转为内核态**(用户态→内核态)**
- 陷入指令对应的中断服务程序为系统调用的入口程序
- 执行陷入指令以后立即引发一个内中断,使CPU进入核心态。
- ③再后由硬件和操作系统内核程序保护被中断进程的现场,将程序计数器(PC)、程序状态字(PSW)及通用寄存器内容等压入堆栈
- 这里保存PSW的时候顺便修改PSW值完成状态切换
- ④分析系统调用类型,转入相应的系统调用处理子程序
- 在系统中配置了一张系统调用入口表,表中的每个表项都对应一个系统调用,根据系统调用号可以找到该系统调用处理子程序的入口地址
- ⑤在系统调用处理子程序执行结束后,恢复被中断的或设置新进程的CPU现场,然后返回被中断进程或新进程,继续往下执行。
-
一般过程调用的被调用程序与调用程序运行在同一个状态,可能是系统态也可能是用户态
-
在采用了抢占式(剥夺)调度方式的系统中,在被调用过程执行完成后,要对系统中所有要求运行的进程做优先级分析。当调用进程仍具有最高优先级时,才返回到调用进程继续执行;否则,将重新调度,以便让优先级最高的进程优先执行。此时,将把调用进程放入就绪队列。
-
在linux系统中,系统调用所用的参数通过寄存器传递,而不是像过程调用那样用栈来传递,因此,在封装函数对应的机器级代码中,将使用传送指令把系统调用所需要的参数传送到相应的寄存器
- 封装函数对应的机器级代码有一个统一的结构:总是若干条传送指令后跟上一条陷阱指令。传送指令用来传递系统调用所用的参数,陷阱指令用来陷入内核进行处理。
-
假如用户程序希望将字符串“hello,world!\n”中的14个字符显示在标准输出设备文件stdout上,则可以调用系统write,它的封装函数用一下机器级代码(汇编指令)实现

-
在linux中, 有一个系统调用的统一入口,即系统调用处理程序system_call的首地址
-
CPU执行指令int$0x80后,便转到system_call的第一条指令开始执行。
-
在system_call中,将根据调用号跳转到当前系统调用对应的系统调用服务例程去执行。
-
system_call执行完后返回到int $0x80指令后面一条指令继续进行。
-
返回参数在EAX中,为整数值,若是正数或0表示成功,负数表示出错码
-
-
发生系统调用时,CPU通过执行软中断指令让CPU的运行模式从用户态切换到内核态,该过程与中断和异常的响应过程相同, 由硬件负责保存断点和程序状态字,并将CPU模式改为内核态,然后执行操作系统内核的系统调用入口程序,该内核程序负责保存通用寄存器的内容,再调用执行特定的系统调用服务例程。
-
在系统调用的过程中,发生了两次CPU上下文切换:
- 首先,保存了原用户态的指令位置
- 然后,CPU寄存器更新为内核态指令的位置以执行内核任务
- 完成系统调用后,CPU寄存器恢复原来保存的用户态,使进程能够继续在用户空间执行
- 系统调用过程中并不涉及进程的切换,进程上下文切换指的是从一个进程切换到另一个进程的运行状态,而系统调用过程中一直是同一个进程在执行。
-
与系统调用相比,进程上下文切换多了一步:
- 在保存当前进程的内核态和CPU寄存器之前,需要先保存该进程的虚拟内存状态;而在加载下一个进程的内核态之后,还需要恢复该进程的虚拟内存和用户态。
-
中断上下文切换并不涉及进程的用户态资源,即使中断打断了一个正在执行用户态代码的进程, 也不需要保存或恢复其虚拟内存和全局变量
-
由OS向用户提供的所有功能,用户进程都必须通过系统调用来获取,或者说,系统调用是应用程序取得OS所有服务的唯一途经。
-
内核提供了OS的基本功能,而库函数扩展了OS内核,使用户能方便地取得OS的服务。在许多现代OS中,系统调用本身已经采用C语言编写,并以函数形式提供,因此在使用C语言编写的用户程序中可以直接使用这些系统调用。
操作系统引导过程
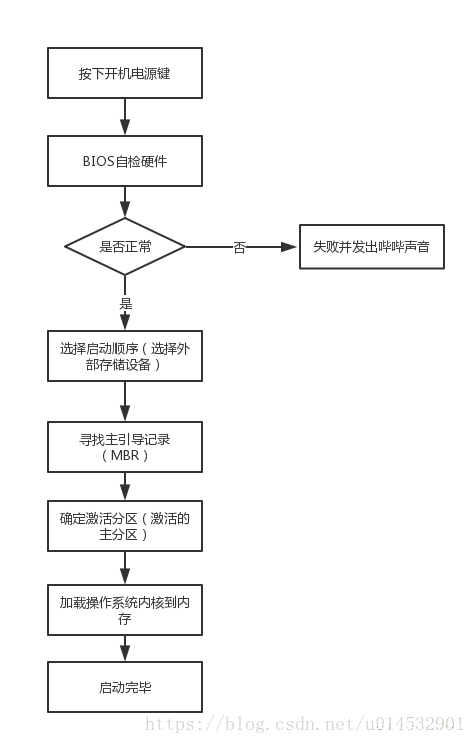

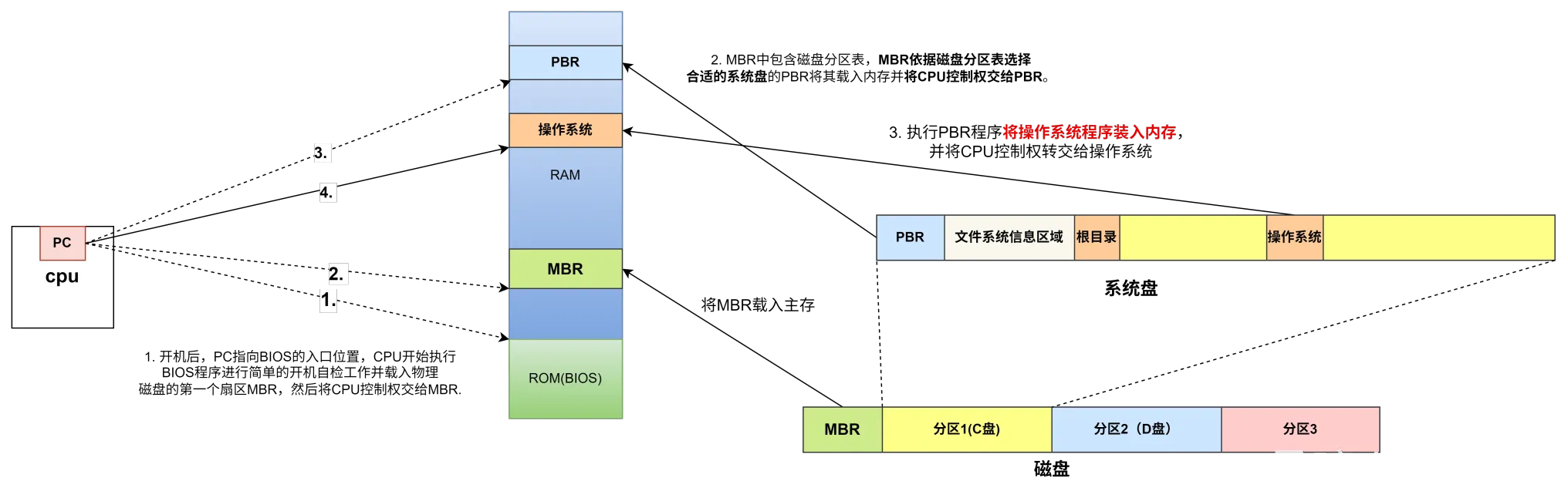
-
①激活CPU。
按下开机键,电源开始向主板供电,CPU收到一个reset信号,开始复位初始化,读取内存ROM中的BIOS程序(固化在芯片中的程序),将IR设置为BIOS的第一条指令并开始执行(CPU初始化后执行的第一条指令)- 复位后,CPU将在0xfffffff0处执行一条长跳转指令,直接跳到固化在ROM中的启动代码即BIOS处,将其加载到RAM,然后执行BIOS的代码
-
②硬件自检。
BIOS构建中断向量表,开始POST(通电自检/硬件自检) -
③加载带有操作系统的硬盘。
硬件自检完成后,BIOS开始读取Boot Sequence,找到启动顺序排在第一位的存储设备,将控制权转交给下一阶段的启动程序,然后CPU将该存储设备引导扇区的内容加载到内存中 -
④加载主引导记录(MBR)(引导装入程序)
计算机读取该设备的第一个扇区,也就是前512B(主引导记录MBR),如果这512B的最后两个字节是0x55和0xAA,说明这个设备可以用于启动;如果不是,表明设备不能用于启动,控制权于是被转交给启动顺序中的下一个设备,如无其他启动设备,就会死机。主引导记录的作用是告诉计算机到硬盘的哪一个位置去找操作系统。
主引导记录包括①调用操作系统的机器码(找PBR活动分区)(磁盘引导程序)②分区表③主引导记录签名- 读取启动设备的MBR,并放入指定的位置(0x7c000)内存中,是BIOS的最后一个任务。
-
⑤扫描硬盘分区表,并加载硬盘活动分区。
MBR包含硬盘分区表,硬盘分区表以特定的标识符区分活动分区和非活动分区(第一个字节如果为0x80,则代表该主分区是激活分区,控制权要转交给这个分区,n个分区中只能有一个是激活的)。主引导记录MBR扫描硬盘分区表,进而识别含有操作系统的硬盘分区(活动分区)。找到硬盘活动分区后,开始加载硬盘活动分区,将控制权交给活动分区。- MBR 是硬盘的第一个扇区,其大小为 512 字节,通常位于硬盘的最前面。它独立于于任何分区,它是硬盘的“引导区域”,用于存储启动引导信息和硬盘的分区表。
-
⑥加载分区引导记录PBR。
读取活动分区的第一个扇区,这个扇区称为分区引导记录(PBR),其作用是寻找并激活分区根目录下用于引导操作系统的程序(启动管理器),然后将控制权交给操作系统,操作系统的内核首先被载入内存。-
MBR的机器码:计算机开机后,CPU 会首先读取硬盘的 MBR。MBR 中的机器码检查分区表,识别活动分区,假设活动分区是分区 1。
PBR的机器码:MBR 将控制权交给分区 1 的第一个扇区(即 PBR)。PBR 中的引导程序负责加载操作系统的引导程序(例如,GRUB 或 Windows 启动管理器)。
操作系统引导程序:PBR 会启动操作系统引导程序,操作系统的内核就会被加载到内存中,并完成操作系统的初始化。
-
-
⑦加载启动管理器。分区引导记录PBR搜索活动分区的启动管理器
-
⑧加载操作系统。将操作系统的初始化程序加载到内存中执行
顺序:BIOS通过bootsequence→硬盘通过MBR→分区通过PBR→操作系统引导程序

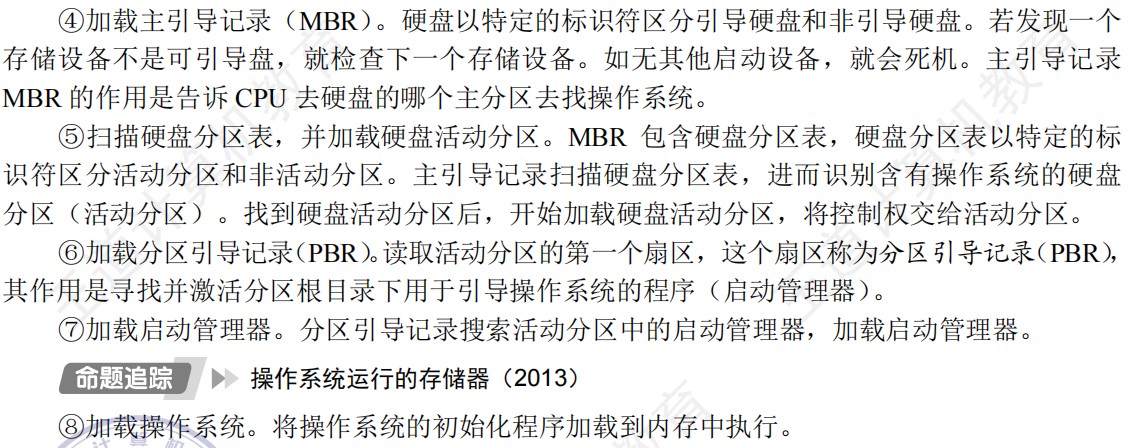

-
PBR和操作系统引导程序的关系:
-
PBR 通常包含以下几部分内容:
- 分区引导程序(Boot Loader):
- 这是 PBR 中的主要内容,包含了用于引导操作系统的机器码。通常这个引导程序会非常小,负责将操作系统的更大部分(如启动管理器或操作系统内核)加载到内存中。
- 引导程序也会通过加载操作系统的启动管理器(如 GRUB 或 Windows 引导程序),进一步引导系统进入操作系统内核的启动过程。
- 文件系统信息:
- PBR 中也可能包含一些与分区文件系统相关的信息,比如分区的类型(如 FAT32、NTFS、EXT4 等)和一些文件系统的启动信息,这样操作系统的引导程序才能理解如何访问分区内的数据。
- 操作系统引导程序的地址:
- 在 PBR 中,引导程序会知道如何找到并加载操作系统的主引导程序。通常这包括操作系统内核或者启动管理器的文件路径和位置。这个过程对于多操作系统的启动至关重要。
- 引导记录签名:
- PBR 的最后 2 字节通常是 0x55AA,这个签名用于验证该扇区是否有效。如果 PBR 中的签名正确,表示该分区有一个有效的引导记录,可以继续加载操作系统。否则,启动过程会失败。
- 分区引导程序(Boot Loader):
-
PBR 读取并执行内嵌的引导程序,该程序负责将操作系统的启动程序加载到内存中。
启动程序(如 GRUB 或 Windows 引导程序)加载操作系统的内核到内存并启动操作系统。
-
PBR 是活动分区的第一个扇区,包含了启动操作系统所需的引导程序。
PBR 中的引导程序会加载操作系统的主引导程序(如 GRUB 或 Windows 启动管理器),进而启动操作系统。
引导操作系统的程序通常是非常小的,它的主要任务是将操作系统的核心部分加载到内存中,并确保操作系统能够正确启动。
-
-
开机后首先在实地址模式下工作
-
BIOS是针对具体的主板设计的,与安装的操作系统无关
- bios中包含了各种基本设备的驱动程序,通过执行BIOS程序,这些基本设备驱动程序以中断服务程序的形式被加载到内存中,以供基本I/O系统调用。一旦进入保护模式,就不再使用BIOS
-
根目录是在文件系统创建时(如格式化磁盘时)创建的。操作系统只需要加载即可,无须创建
-
硬盘分区表是硬盘逻辑格式化之前创建的,在OS引导过程中,即MBR中读出来即可,无需创建
-
索引节点表在文件系统创建时建立,用来记录文件的元数据。启动时之需要加载即可。
-
OS初始化完成的工作:
- 初始化中断机制
- 设置中断向量表并注册中断服务程序,设置IF位(启用中断)
- 初始化内存管理系统
- 建立页/段表、开启虚拟内存、地址转换机制(MMU)、内存分配机制
- 初始化定时器和时钟中断
- 初始化内核数据结构
- 如就绪队列、内核缓存、系统调用表、设备驱动管理表
- 初始化设备驱动
- 探测硬件和注册对应驱动函数、供内核调用
- 初始化VFS层(虚拟文件系统),注册各类具体文件系统(读取超级块登)、挂载根文件系统
- 创建首个进程(如init())
- 初始化中断机制
操作系统结构
| 分类结构 | 特性、思想 | 优点 | 缺点 |
|---|---|---|---|
| 分层结构 | 内核多层,每层间调用更低一层提供的接口 | 1. 易调试和验证,底层与上层层间接口清晰 2. 易扩充和易维护,各层间调用接口清晰固定 | 1. 仅可调用相邻低层,难以合理定义各层的边界 |
| 模块化 | 将内核划分为多个模块,各模块之间相互协作。 内核=主模块+可加载内核模块 主模块:只负责核心功能,如进程调度、内存管理 可加载内核模块:可以动态加载新模块入内核,而无需重新编译整个内核 | 1. 模块间链路清晰,确定模块接口后即可多模块同时开发 2. 支持动态加载新的内核模块(如:安装设备驱动程序、安装新的文件系统模块到内核),增强OS活跃度 3. 任何模块都可以直接调用与其他模块,无需采用消息传递通信,效率高 | 1. 效率低,不可跨层调用,系统调用执行时间长 2. 模块间的接口不可定义,未必合理、实用 |
| 宏内核(大内核) | 所有的系统功能都在内核里(大内核结构的OS通常也采用了‘模块化’的设计思想) | 1. 性能高,内核内部各种功能都可以直接相互调用 | 1. 模块间接口依赖,更难调试和验证 |
| 微内核 | 只把中断、原语、通信管理等核心的功能放入内核,进程管理、设备管理、设备管理等功能由用户程序的形式运行在用户态 | 1. 内核小功能简单,内核可维护 2. 大内核中某个功能模块出错,就可能导致整个系统崩溃 | 1. 内核负担太重,难以维护 |
| 外核(exokernel) | 内核负责进程调度、进程通信等功能,内核负责用户进程与系统调用的硬件资源 | 1. 性能低,需要频繁的切换内核/用户态 2. 内核中的各个功能模块不可与直接相关互通,只能通过内核的消息传递来实现 | 1. 外核不可直接向进程分配独特的资源,使用程序可以更灵活地使用硬件资源 2. 减少了系统的依赖性 |
-

-
写入内核的驱动程序(静态驱动程序)再启动内核时加载,其他的在系统初始化时由内核加载,支持即插即用的设备再插入时加载,不支持即插即用的驱动程序需要手动安装。驱动程序的加载过程中需要申请中断号并且注册中断向量表。
-
外核
- 把请求硬件的系统调用变成了过程调用
进程和线程
-
在调度到某个进程后,要根据其PCB中所保存的CPU状态信息,设置该进程恢复运行的现场,并根据其PCB中的程序和数据的内存始址,找到其程序和数据。
- 当进程由于某种原因暂停运行时,又需将其断点的CPU环境(CPU中各寄存器的值)保存在PCB中
-
操作系统只负责为通信进程提供可共享使用的存储空间和同步互斥工具,而具体交换则由用户自己安排读/写指令完成
-
想让两个进程共享空间,必须通过特殊的系统调用实现,而进程内的线程是自然共享进程空间的
-
消息传递方式下,通信过程对用户透明
-
在进程的PCB中,用至少n位向量记录该进程的待处理信号。若给某个进程发送一个信号,则把该类信号对应的位修改为1,一旦该信号被处理,就把对应的位修改为0。此外,还用另一个n位向量记录被阻塞(被屏蔽)的信号。当某个位为1时,表示该位对应的信号类型将被进程忽略
-
当操作系统把一个进程从内核态切换到用户态时(如系统调用返回时),会检查该进程是否有未被阻塞的待处理信号,若有,则强制进程接收信号,并立即处理信号(若有多个待处理信号,则通常先处理序号更小的信号)。
- 进程可为某类信号自定义信号处理程序
- 信号处理程序运行结束后,通常会返回进程的下一条指令继续执行
-
引入进程的目的是更好地使多道程序并发执行,提高资源利用率和系统吞吐量;而引入线程的目的则是减小程序在并发执行时所付出的时空开销,提高操作系统的并发性能。
-
进程切换时涉及进程上下文的保存和切换,而线程切换时只需保存和设置少量寄存器的内容
-
通常,线程被终止后并不立即释放它所占有的资源,只有当进程中的其他线程执行了分离函数后,被终止线程才与资源分离,此时的资源才能被其他线程利用。被终止但尚未释放资源的线程仍可被其他线程调用,以使被终止的线程重新恢复运行。
-
全局变量是对同一进程而言的,在不同进程中是不同的变量,没有任何联系,所以不能用于交换数据
-
每个进程只调入一次,调出一次
-
进程调度是最基本的一种调度,在各种操作系统中都必须配置这级调度。进程调度的频率很高
-
在对CPU进行切换时,会发生两对上下文的切换操作:
-
①将当前进程的上下文保存到其PCB中,再装入分派程序(分配新的进程的程序)的上下文
-
②移出分派程序的上下文,将新选进程的CPU现场信息装入CPU的各个相应寄存器
-
在上下文切换的时候,需要执行大量的load和store指令,以保存寄存器的内容,因此会花费较多时间
-
现在已有硬件实现的方法来减少上下文切换的时间。通常采用两组寄存器,其中一组供内核使用,一组供用户使用,这样,上下文切换时,只需要改变指针,让其指向当前的寄存器组即可
-
为什么这种方式能够减少上下文切换的时间?
-
传统方式(开销大)
- CPU 只有一组通用寄存器。
- 进程切换时必须把 当前进程寄存器的内容 存到内存(PCB 里),再把 下一个进程的寄存器内容 从内存取回寄存器。
- 这种方式要执行大量 load/store 指令,因为内存访问相对寄存器非常慢,所以上下文切换代价高。
-
硬件优化方式(减少切换开销)
- CPU 设计成 有多组寄存器(register windows / register sets)。
- 举例:有两组寄存器:
- 一组供内核态使用;
- 一组供用户态使用。
- 上下文切换时,不需要把所有寄存器内容都写回内存,而是 切换寄存器组的指针(比如寄存器窗口指针 RW pointer)。
这样:
-
旧进程的上下文仍然保存在之前那一组寄存器里;
-
新进程直接用另一组寄存器;
-
切换开销 ≈ 修改一个指针,而不是大规模内存读写。
-
短期切换:如果寄存器组足够多,多个进程可以同时“挂起”在不同寄存器组里,切换时几乎零开销。
长期切换 / 进程数远超寄存器组数量时:仍然需要把某些寄存器组的内容保存到内存,再分配给新进程用。
-
内核态寄存器组:
CPU 执行操作系统内核代码(比如分派程序)时用的寄存器。
它们不会直接保存某个用户进程的上下文,而是 OS 自己运行所需要的。用户态寄存器组:
CPU 执行用户进程代码时用的寄存器。
这些寄存器里保存的就是该进程的上下文(通用寄存器、程序计数器、栈指针等)。 -
传统单寄存器组:
- 进程 A → 进程 B:必须把 A 的寄存器内容存到内存,再从内存加载 B 的内容到寄存器。
多寄存器组优化:
- 当进程 A 被换下时,它的上下文还留在 用户态寄存器组 1;
- 进程 B 被换上时,直接切换指针到 用户态寄存器组 2,B 的上下文已经在那里或立即装载进去;
- 内核态寄存器组只在运行内核代码(比如分派程序时)用,不直接存放用户进程上下文。
-
举个流程例子
- 进程 A 正在运行,它用的是 用户寄存器组 #1。
- 时钟中断 → CPU 切换到 内核态寄存器组,执行分派程序。
- 内核挑选出进程 B。
- CPU 切换到 用户寄存器组 #2,恢复 B 的上下文,开始执行 B。
- A 的上下文还保存在用户寄存器组 #1 里,不用马上写回内存。
-
-
-
-
进程切换时上下文究竟保存在哪里?
- 现场切换时,操作系统内核将原进程的现场信息推入当前进程的内核堆栈来保存他们,并更新堆栈指针。内核完成从新进程的内核栈中装入新进程的现场信息、更新当前运行进程的空间指针、重设PC寄存器等相关工作后,开始运行新的进程。
- PCB 里只保留了一个指针,指向这个内核栈的栈顶;
- 下次恢复时,通过这个指针就能找到寄存器现场,把它恢复回 CPU。
- PCB 本身不直接存放所有寄存器内容,而是 记录内核栈的位置,真正的寄存器值存放在 内核栈 里。
- 现场切换时,操作系统内核将原进程的现场信息推入当前进程的内核堆栈来保存他们,并更新堆栈指针。内核完成从新进程的内核栈中装入新进程的现场信息、更新当前运行进程的空间指针、重设PC寄存器等相关工作后,开始运行新的进程。
-
闲逛进程不需要CPU之外的资源,不会被阻塞
-
上下文切换只能发生在内核态
-
进程可以忽略特定的信号,但是sigkill和sigstop信号是不可忽略的
-
低级进程通信对用户不透明
-
基于共享存储区的通信方式,数据的形式和位置(甚至访问)均由进程负责控制,而非OS。
-
用户级线程甚至可以在不支持线程机制的OS平台上实现
-
在有的系统中,为了减少在创建和撤销一个线程时的开销,在撤销一个线程时,并不会立即回收该线程的资源和TCB,这样,当以后再要创建一个新线程时,便可直接将已被撤销但仍持有资源的TCB作为新线程的TCB。
-
不论是在传统OS中,还是在多线程OS中,系统资源都是由内核管理的。在传统OS中,进程是利用OS提供的系统调用来请求系统资源的,系统调用通过软中断(如trap)机制进入OS内核,由内核来完成相应资源的分配。ULT是不能利用系统调用的。当线程需要系统资源时,其须将该要求传送给运行时系统,由后者通过相应的系统调用来获得系统资源。
-
父进程和子进程共享部分全局资源,但不会共享地址空间(注意区分复制与共享)
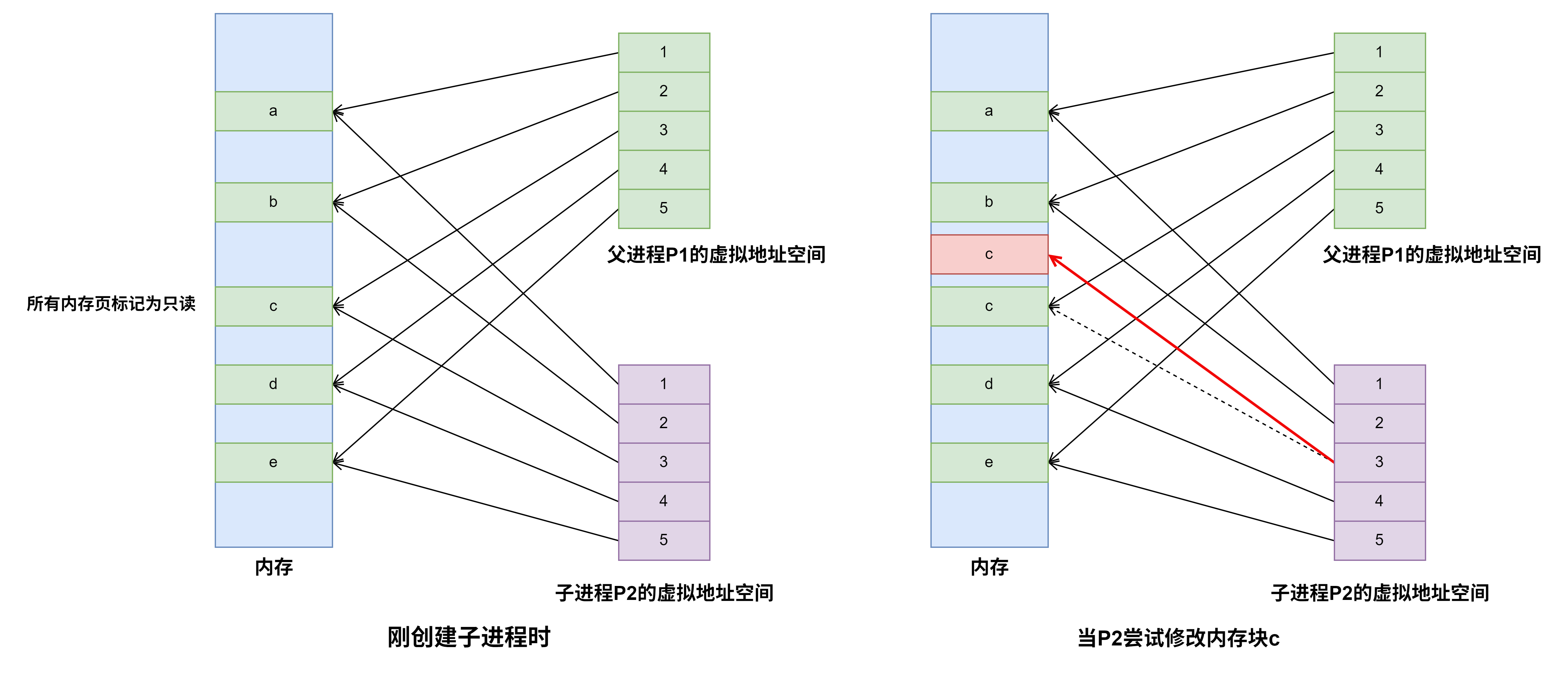
- fork之后,子进程复制父进程的地址空间,也就是虚拟地址空间的副本,其代码段、数据段、堆栈等完全相同。
- 不过通常会使用写时复制技术,也就是说,在fork之后,父子进程的虚拟地址空间映射到相同的物理内存页,但一旦任一进程试图修改某个页,就会触发复制,生成该页的副本,这样他们就不会共享同一物理页
- 不过,从虚拟地址空间的角度来看,初始时他们的地址空间内容是一样的,但各自独立,不是共享的。
- 共享意味着一个进程修改了数据,另一个进程能看到变化,但fork后的子进程在修改数据时会有自己的副本,所以虚拟地址空间并不是共享的
- 父子进程在创建之初有相同且独立的地址空间。父进程和子进程可以共享相同的代码和数据,但又能**保持各自的独立性,**使得进程间的数据隔离和安全性得以保障
-
在撤销父进程时,通常也会同时撤销其所有的子进程,这句话对吗?
- 这个问题的答案取决于具体的操作系统。
- 在Unix和类Unix系统(如Linux)中,当父进程结束时,并不会自动结束其所有的子进程。而是这些子进程会被init进程(进程ID为1)接管,这些被接管的子进程被称为孤儿进程(Orphaned Process)。孤儿进程会继续运行,直到它们自己结束。
- 在Windows系统中,父进程和子进程的关系与Unix类系统不同。在Windows中,父进程创建子进程时可以选择创建一个进程组,如果父进程结束,那么同属于一个进程组的所有子进程也会被结束。
- 这个问题的答案取决于具体的操作系统。
-
共享内存直接分配一个共享空间,每个进程都可以直接访问,不需要陷入内核态或者系统调用
- 一般来说,共享内存位于进程的用户地址空间,可直接通过虚拟地址访问
- 进程像操作普通内存一样读写共享内存区域,无需系统调用
- 共享内存位于进程的用户空间,而不是在内核空间
- 建立共享内存的操作在内核态,因为只有内核态下才可以修改页表
- 访问共享数据的操作是在用户态下进行,因为共享数据属于用户的地址空间
-
虽然说内核空间是共享的,但是每个进程在内核态执行时需要使用独立的内核栈,用于保存进程处于内核态时内核函数调用的返回地址、局部变量和中断上下文,每个进程的内核栈指针位于该进程的PCB中
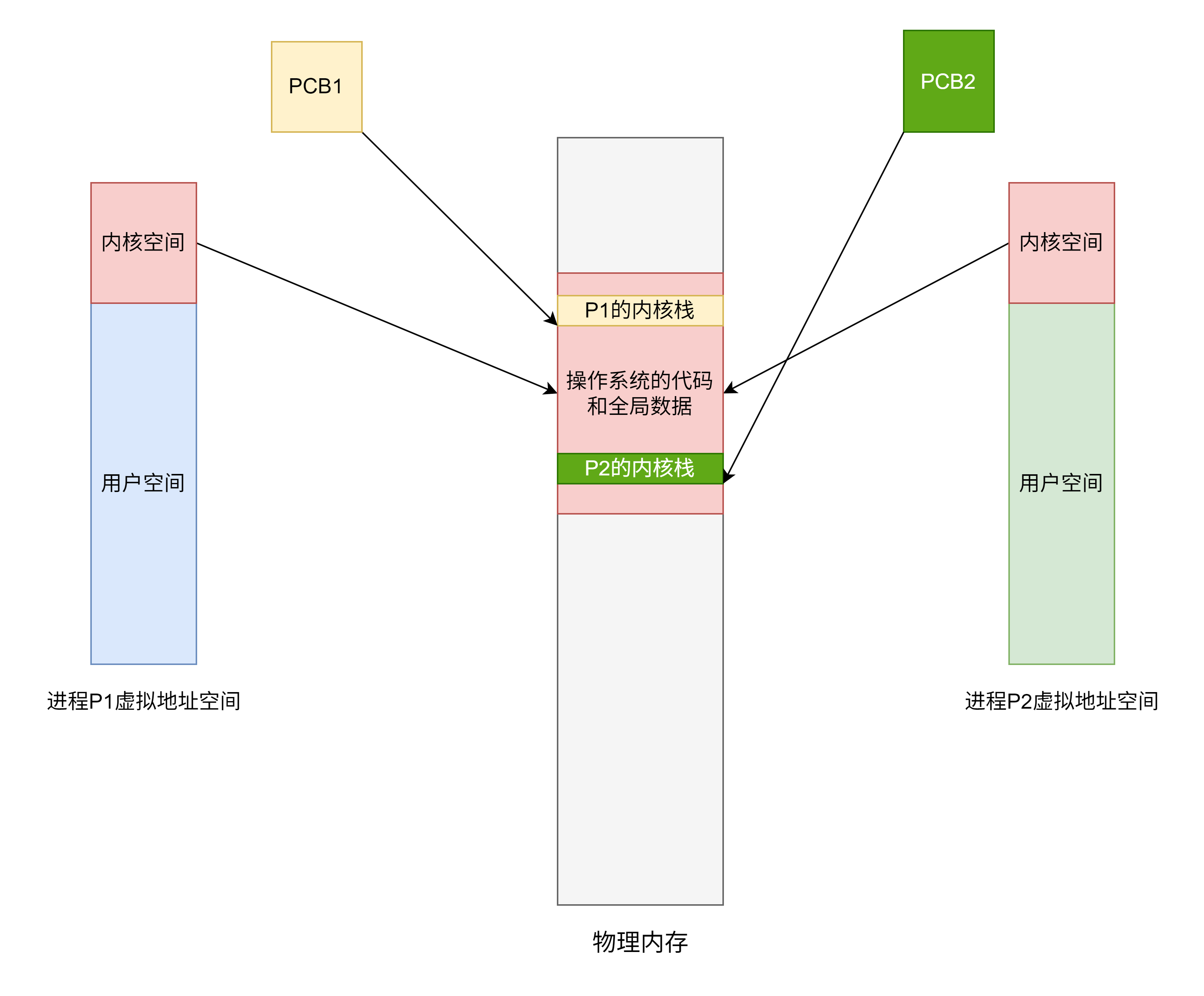
-
消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销,因为进程写入数据到内核中的消息队列时,会发生从用户态拷贝数据到内核态的过程,同理另一进程读取内核中的消息数据时,会发生从内核态拷贝数据到用户态的过程。
-
一个线程的崩溃可能会导致整个进程崩溃
-
闲逛指令只运行在内核态下
-
等待时间为进程处于就绪态的时间之和
-
批处理作业初始化通常指的是将作业加载到内存并为其创建进程的过程,与作业调度密切相关
-
文件创建是通过系统调用实现的, 通常由当前进程完成,不会创建新进程
-
用户级进程的调度依赖于用户空间的实现,若未设计公平的调度算法,可能不如内核级线程的调度公平。
-
多线程可以提高CPU利用率,不能提高内存利用率
-
PCB中可能包含进程当前持有的信号量或等待的信号量的引用,但信号量本身的数据结构并不在PCB中
-
进程的代码通常存储在内存或磁盘中,PCB只保存代码段的起始地址,而非代码本身
-
无论哪个进程切换到内核态,访问的内核代码和全局数据(如中断向量表、系统调用表、设备驱动、内存管理结构等)都是同一份物理内存的映射
-
虽然内核空间是共享的,但是每个进程在内核态执行时需要使用独立的内核栈,用于保存进程处于内核态时内核函数调用的返回地址、局部变量和中断上下文(进程响应中断/异常时,会把用户态下的断点/现场信息压入内核栈),每个进程的内核栈指针位于该进程的PCB中
-
软亲和性指由进程调度程序尽量保证亲和性,硬亲和性指由用户进程通过系统调用,主动要求操作系统分配固定的CPU,确保亲和性
-
PCB组织方式
进程控制块(PCB)是操作系统⽤来管理和描述进程的唯⼀数据结构,它位于内核空间。因此,创建新进程时,操作系统内核(进程管理模块)负责分配内存、初始化和维护新进程的 PCB(包括设置进程ID、状态、优先级、程序计数器等信息),⽽不是由⽤户态的⽗进程负责。
管道
管道是一个特殊的共享文件,也称pipe文件
-
管道存在于内存中,没有存在于文件系统中
- 进程写入的数据都是缓存在内核中,另一个进程读数据时候自然也是从内核中获取,每次数据的写入和读取都需要经过用户态与内核态之间的拷贝过程。
-
管道满的时候,对管道的wirte()调用默认被阻塞
-
管道空的时候,对管道的read()调用默认被阻塞
-
管道只能由创建进程所访问,当父进程创建一个管道后,管道是一种特殊文件,子进程会继承父进程的管道,并用它来与父进程进行通信。
-
普通管道只允许单向通信,若要实现两个进程双向通信,则需要定义两个管道
-
一根管道里,数据只能单方向流动。
-
父进程调用
pipe(fd)后会得到一对文件描述符:fd[0](读端)、fd[1](写端)。fork()之后,子进程也会继承这两个文件描述符。这时父子进程就各自持有同一对管道的读端和写端。
如果需要单向通信,比如 父进程写、子进程读:
- 父进程关闭
fd[0](读端),只保留写端。 - 子进程关闭
fd[1](写端),只保留读端。 - 这样数据就能从父 → 子单向传输。
- 父进程关闭
-
如果你换个方向(让子进程写、父进程读),就需要双方分别关闭掉相反的端口:
- 子进程关闭读端
fd[0],只保留写端fd[1]。 - 父进程关闭写端
fd[1],只保留读端fd[0]。 - 这样就能实现 子 → 父 的单向通信。
- 子进程关闭读端
但是,正如你说的,它并不是全双工,因为一根管道不能同时做到父→子和子→父。
- 你可以通过“分时复用”来做到“先父写子读,再子写父读”,这就是半双工通信。
- 如果想要真正意义上的双向同时通信(全双工),那就必须用两根管道,分别负责两个方向。
-
-
管道和共享存储的区别:
- 共享存储方式中,数据的读/写在地址空间的位置是任意的,管道需要遵循FIFO的方式按顺序读/写(本质上是循环队列),不支持文件定位操作
-
对管道的读写操作都需要互斥进行,同一时刻,管道只允许一个读进程对管道执行读操作或一个写进程对管道执行写操作
- 从管道中读数据是一次性操作,读完就失效
-
管道通信的数据直接在内存中,非磁盘。
-
管道文件位于内核区中,是在内核中的环形数据缓冲区(数据结构为循环队列),读写操作需要通过系统调用
-
当所有引用管道的文件描述符都被关闭后,内核直接回收管道的缓冲区资源
- 只有持有管道读/写端文件描述符的进程数量均为0时,内核才会销毁管道并释放其缓冲区内存
- 即使某些进程未正确关闭描述符,当所有进程终止时,内核仍会清理管道
-
管道通信是以字符流为单位进行写入和读出的
-
管道的同步与互斥机制通过mutex互斥锁,等待队列实现
- 共享内存本身没有同步互斥机制,一般需要和信号量一同使用。
-
管道的大小通常为内存上的一页,它的大小不受磁盘容量的限制
-
匿名管道只能由创建它的进程(以及它的子进程)访问,而命名管道可以由任何可以访问对应文件的进程访问
-
共享存储基于数据结构或存储区,而管道是使用共享文件进行通信
-
消息队列适用于进程间传递消息的场景,但不适合多个进程之间的连续数据传递
信号
-
也叫用户态中断,或者软中断,是在软件层次上对中断机制的一种模拟,不适合用于复杂的数据传输任务
-
信号可以直接进行用户空间进程和内核进程之间的交互,内核进程也可以利用它来通知用户空间进程发生了哪些系统事件
-
信号处理:一旦进程接收到信号,内核会检查信号的处理方式。根据注册的信号处理方式,可以有以下几种情况:
- 忽略信号:即对信号不做任何处理,但是两个信号不能忽略:SIGKILL以及SIGSTOP
- 捕捉信号:当信号发生时,执行用户自定义的信号处理函数
- 执行默认操作:对于大多数信号,操作系统定义了默认的行为。这些默认行为通常是终止进程,生成核心转存储文件,或暂停进程执行等。当进程收到信号时,如果没有设置信号的自定义处理函数,将会执行操作系统默认的行为。
-
信号处理过程:如果信号的处理方式是执行自定义的信号处理函数,进程将会调用该函数来处理信号。处理函数可以完成一系列操作,比如修改全局变量、执行清理操作等。在信号处理函数执行期间,进程可能会被阻塞在信号处理函数中。
-
信号返回:一旦信号处理函数执行完毕,程序将会从信号处理函数中返回,程序回复执行之前的代码。
-
注:信号传递不支持排队,当在很短时间内传递多个相同信号,该信号只会被处理一次
-
在Linux系统中,信号的传递流程通常是由内核负责进行管理和调度。
-
信号不携带数据,仅用于指示事件的发生,用于异常处理、进程控制等场景
-
信号的“传递”和“初始响应”由内核在核心态完成;而信号的“处理逻辑”(也就是你写的信号处理函数)是在用户态执行的。

-
1. 信号产生(内核态或用户态)
信号可以由内核产生,也可以由用户进程产生。
- 内核态产生:例如,硬件异常(如除零错误、段错误SIGSEGV)、定时器到期、子进程退出(SIGCHLD)、终端控制信号(如Ctrl+C产生的SIGINT)。
- 用户态产生:例如,一个进程调用
kill()系统调用向另一个进程(或自己)发送信号。
-
2. 信号递送前的内核管理(内核态)
这是完全在内核态进行的:
- 当信号事件发生时,内核会为目标进程在其进程控制块(PCB)中设置一个标志位,表示“有一个XX类型的信号待处理”。这相当于内核为进程贴了一个便签。
- 此时信号处于 “未决” 状态。
- 内核会检查该信号是否被进程阻塞(屏蔽)。如果被阻塞,信号会保持未决状态,直到解除阻塞。
- 当进程即将从内核态返回用户态(例如,完成系统调用、发生时钟中断或处理完硬件异常后)时,内核会检查该进程是否有未决且未被阻塞的信号。
-
3. 信号递送与处理(内核态切入用户态再返回)
这是最核心的协作环节:
- 步骤A:内核准备递送(内核态)
内核发现有待处理的信号,并且进程没有忽略或阻塞它,就开始安排递送。如果进程为这个信号设置了自定义的处理函数(通过signal()或sigaction()),内核会为用户态执行做准备。 - 步骤B:切换到用户态执行处理函数(用户态)
内核会临时修改用户进程的栈和指令指针(IP),使得进程一旦返回到用户态,不是继续执行被中断的代码,而是直接跳转到预先注册好的信号处理函数去执行。
这个信号处理函数是用户自己写的代码,运行在用户态。 内核在这里扮演了“调度员”的角色。 - 步骤C:处理函数执行完毕,返回内核态(用户态 -> 内核态)
信号处理函数执行完毕后,它会调用一个特殊的返回指令(如sigreturn)。这实际上是一个系统调用,它会再次陷入内核。 - 步骤D:内核恢复现场(内核态)
内核收到sigreturn后,知道信号处理已经完成。它会清理现场,恢复之前保存的原始栈和上下文,然后安排进程返回到最初被信号中断的地方继续执行。
- 步骤A:内核准备递送(内核态)
-
-
重要特例:SIGKILL 和 SIGSTOP
- 这两个信号的处理完全在内核态。
- 它们不允许用户程序设置自定义处理函数(会被忽略或报错)。
- 内核收到这两个信号后,会直接在核心态执行默认动作(杀死进程SIGKILL或停止进程SIGSTOP),无需切换到用户态。
| 阶段 | 发生位置 | 说明 |
|---|---|---|
| 信号产生与记录 | 内核态 | 内核在目标进程的PCB中标记信号。 |
| 信号递送决策 | 内核态 | 决定何时、是否将信号送给进程。 |
| 信号处理逻辑执行 | 用户态 | 执行用户注册的信号处理函数。 |
| 处理后的清理与恢复 | 内核态 | 通过 sigreturn 系统调用恢复被中断的现场。 |
- 所以,不能说信号处理完全在内核态或用户态。它是一个典型的“内核通知,用户响应”的异步协作机制。内核负责可靠地投递通知,而具体的响应行为则由用户程序在用户态安全地定义和执行。这种设计既保证了内核的安全性(不让用户代码在内核态运行),又赋予了程序处理异步事件的灵活性。
共享内存
-
共享内存位于进程的用户空间,而不是在内核空间
-
共享内存是最快的IPC方式,因为数据不需要在进程间复制
-
共享内存通信工作过程
- 创建共享内存
- 系统调用:创建共享内存
- 内核在物理内存中分配一块连续区域,指定共享内存的访问权限(如读写权限)和大小
- 附加共享内存到进程地址空间
- 系统调用:将共享内存映射到自己的虚拟地址空间
- 页表映射:内核修改进程的页表,将指定的虚拟地址范围映射到共享内存的物理页框。多个进程的虚拟地址可以不同,但最终指向同一物理内存
- 进程获得共享内存的虚拟地址,一般来说,共享内存位于进程的用户地址空间,可直接通过虚拟地址访问
- 读写共享内存
- 直接访问:进程向操作普通内存一样读写共享内存区域,无需系统调用,实现零拷贝高效通信
- 同步机制
- 必要性:共享内存(属于临界资源)本身不提供同步,需要结合信号量、互斥锁等机制避免竞态条件
- 分离共享内存
- 系统调用:解除虚拟地址与共享内存的映射
- 页表更新:内核移出该进程页表中对应的映射关系,但共享内存的物理内存仍保留
- 销毁共享内存段
- 系统调用:标记共享内存为待删除
- 内核回收:当所有附加进程分离且无引用时,内核释放物理内存
- 创建共享内存
-
共享内存直接分配一个共享空间,每个进程都可以直接访问,不需要陷入内核态或者系统调用
- 一般来说,共享内存位于进程的用户地址空间,可直接通过虚拟地址访问
- 进程像操作普通内存一样读写共享内存区域,无需系统调用
- 共享内存位于进程的用户空间,而不是在内核空间
- 建立共享内存的操作在内核态,因为只有内核态下才可以修改页表
- 访问共享数据的操作是在用户态下进行,因为共享数据属于用户的地址空间
-
虽然说内核空间是共享的,但是每个进程在内核态执行时需要使用独立的内核栈,用于保存进程处于内核态时内核函数调用的返回地址、局部变量和中断上下文,每个进程的内核栈指针位于该进程的PCB中
通信机制总结
| 特性 | 共享内存 | 消息传递(eg 消息队列) | (匿名)管道 | 信号(Signal) |
|---|---|---|---|---|
| 数据形式 | 原始字节流(直接内存访问) | 结构化消息(带类型/优先级) | 字节流(无结构) | 简单整型信号(无数据或少量数据) |
| 通信方向 | 双向 | 双向(消息队列) | 单向(半双工) | 单向(发送→接收) |
| 同步需求 | 需要(如信号量、互斥锁) | 部分需要(如阻塞接收) | 内核自动同步(缓冲区阻塞) | 无(异步通知) |
| 性能 | 极高(零拷贝) | 中(数据拷贝开销) | 中(内核缓冲区拷贝) | 极高(无数据传输) |
| 复杂度 | 高(需管理同步和内存映射) | 中(需处理消息格式) | 低(API简单) | 低(API简单) |
| 进程关系 | 任意进程 | 任意进程(消息队列) | 仅亲缘进程(父子/兄弟) | 任意进程(需知道PID) |
| 持久性 | 进程分离后需重新映射 | 内核维护(消息队列) | 随进程终止销毁 | 无(瞬时触发) |
| 典型应用场景 | 高频数据交换(eg 视频处理) | 微内核 | 简单线性通信(Shell管道) | 事件通知(进程终止、用户中断) |
- 共享内存是一种高效的IPC方式,适用于大量数据交换,因为多个进程可以同时访问共享内存,避免了数据复制和系统调用的开销。
- 消息传递是一种安全可靠的IPC方式,适用于小量数据高速交换,因为通过消息队列可以实现异步通信和数据同步
- 管道是一种半双工的IPC方式,适用于进程间有序通信,因为数据只能单向流动,且遵循先进先出原则
- 共享存储、消息传递、管道和信号都是高级通信方式,PV操作(信号量)、管程也可用于进程通信,属于低级通信方式。
- 消息队列通信的速度不是最及时的,每次数据的写入和读取都需要经过用户态和内核态之间的拷贝过程
互斥
-
进程同步的概念是一个大的范畴,协作进程间的制约关系可以统称为进程同步。根据制约形式的不同,其又可细分为同步关系和互斥关系,互斥是同步的一个特例。同步强调的是保证进程之间操作的先后次序的约束,而互斥强调的是对共享资源的互斥访问。
-
自旋锁具有随机性,不能保证按先来后到的顺序使用cpu资源
- 自旋锁:当进程申请锁之败后,会已知循环申请锁直到成功
- TS指令、swap指令和单标志法都是互斥锁

- 自旋锁:当进程申请锁之败后,会已知循环申请锁直到成功
-
创建共享内存需要通过系统调用实现,需要先进入内核态,内核在物理内存中分配一块连续区域,指定共享内存的访问权限(如读写权限)和大小,然后进程再通过系统调用将共享内存映射到自己的虚拟地址空间。
-
408范围内只有记录型信号量和管程(条件变量)可以实现让权等待
-
条件变量和信号量的重要区别
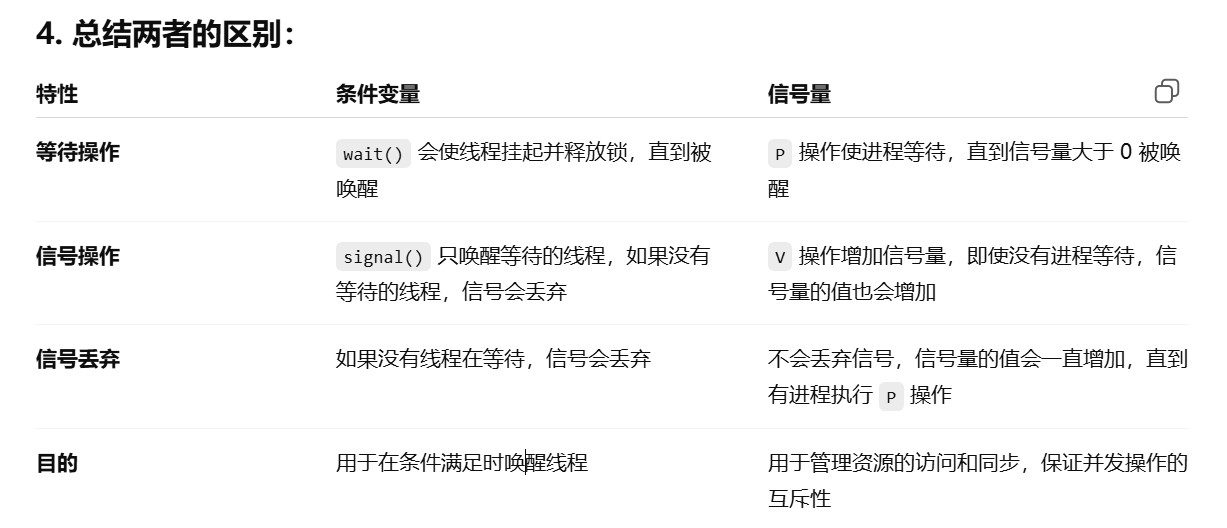

- 条件变量没有值,仅实现了排队等待的功能;信号量是有值的,信号量的值反映了剩余资源数。
- 在管程中,剩余资源数用共享数据结构记录
- 条件变量的wait/signal操作与信号量不同,如果在管程中的一个进程发信号,但没有在这个条件变量上等待的任务,则丢弃这个信号
- 条件变量的设计目的是在特定条件下让线程等待,并在条件满足时唤醒等待线程。信号的丢弃防止了不必要的唤醒,也避免了不必要的资源浪费
- 条件变量没有值,仅实现了排队等待的功能;信号量是有值的,信号量的值反映了剩余资源数。
-
条件变量是没有值的,仅实现了排队等待功能,而信号量是有值的,信号量的值反映了剩余资源数,而在管程中,剩余资源数用共享数据结构记录
-
信号量表示当前的可用相关资源数,当信号量K>0时,表示还有K个相关资源可用,而当信号量K<0时,表示有|K|个进程正在等待该资源。
-
实现临界区互斥的基本方法
| 算法 | 实现方式 | 违背的原则 |
|---|---|---|
| 单标志法 | 设置一个公共整型变量 turn,值为 0 表示允许 P0 进入,值为 1 表示允许 P1 进入;两个进程必须交替进入临界区。 | 空闲让进 |
| 双标志先检查法 | 设置布尔数组 flag[2],进程进入临界区前,先检查对方标志;若对方想进入则等待,否则再设置自己的标志进入。 | 忙则等待 |
| 双标志后检查法 | 设置布尔数组 flag[2],进程进入临界区前,先设置自己的标志,再检查对方标志;若对方标志为真则等待。 | 有限等待 |
| Peterson 算法 | 综合前两类方法,进程进入临界区前,先设置自己的 flag,再把 turn 赋值给对方;进入前检测 (flag[j] && turn==j),保证互斥并避免饥饿。 | 无(满足三原则) 但未遵循让权等待原则 |
| 方法 | 原理 | 违背/未遵循的原则 | 优点 | 缺点 |
|---|---|---|---|---|
| 中断屏蔽法 | 在进程进入临界区时禁止中断,执行完临界区代码后再开中断,保证执行期间不会被切换。 | 空闲让进、有限等待 | 实现简单,能保证互斥。 | ① 限制了 CPU 的并发执行能力,系统效率低;② 若用户进程滥用关中断可能导致系统崩溃;③ 不适用于多处理器系统。 |
| TestAndSet 指令 | 提供原子操作,读出并设置锁变量(lock),若返回值为 false 表示锁空闲,可以进入临界区并加锁;否则等待。 | 让权等待 | 硬件支持,简单高效,适用于多处理器系统。 | ① 等待进程会占用 CPU 忙等,浪费资源;② 不能实现“让权等待”。 |
| Swap 指令 | 提供原子操作,交换两个布尔变量的值,进程用 key 与共享 lock 交换,若 key=false 表示加锁成功。 | 让权等待 | 简单,易于验证正确性,支持任意数量进程和多处理器系统。 | ① 等待进程会忙等,占用 CPU;② 可能导致某些进程长期得不到进入机会,出现“饥饿”。 |
| 方法 | 原理 | 违背/未遵循的原则 | 优点 | 缺点 |
|---|---|---|---|---|
| 单标志法 | 设置 turn 变量,0 表示 P0 进临界区,1 表示 P1 进临界区;两个进程必须交替进入。 | 空闲让进 | 实现简单,能保证互斥。 | 若一方不再进入,另一方也无法进入,资源利用率低。 |
| 双标志先检查法 | 设置 flag[2],进入前先检查对方标志,若对方想进则等待,否则设置自己标志进入。 | 忙则等待 | 不需交替进入,可连续使用。 | 检查和设置操作不是原子,可能导致同时进入临界区。 |
| 双标志后检查法 | 设置 flag[2],进入前先设置自己标志,再检查对方标志,若对方想进则等待。 | 有限等待 | 思路简单,避免了先检查后设置的问题。 | 双方同时设置标志后会都进不去,导致“饥饿”。 |
| Peterson 算法 | 结合 flag 和 turn,进入前设置自己 flag 并把 turn 让给对方,同时检查 (flag[j] && turn==j)。 | 无(满足三原则) | 满足空闲让进、忙则等待、有限等待,能避免饥饿。 | 只适用于两个进程,效率受限。 |
| 中断屏蔽法 | 进入临界区前关中断,退出时开中断,保证临界区代码不被打断。 | 空闲让进、有限等待 | 实现简单,保证互斥。 | ① 降低并发性;② 用户若滥用关中断可能导致系统崩溃;③ 不适合多处理机。 |
| TestAndSet 指令 | 原子操作:返回旧值并设置 lock=true;若旧值为 false 表示锁空闲,可进入临界区。 | 让权等待 | 硬件支持,简单高效,适用于多处理器系统。 | 等待进程忙等,占用 CPU,无法实现“让权等待”。 |
| Swap 指令 | 原子操作:交换局部变量 key 与 lock 值,若 key=false 表示加锁成功。 | 让权等待 | 简单,易验证正确性,支持任意数量进程和多处理器系统。 | 等待进程忙等,可能导致饥饿。 |
-
临界区是代码段,但要按“进程”来算:
- 每个进程里都会有一段访问 A 的代码,这一段就是该进程的“临界区”。
- 即使这 5 个进程的代码完全相同,操作系统也要把它们看作 5 个独立的临界区,因为它们属于不同的进程。
-
PV操作是一种低级的进程通信原语,不是系统调用
-
管程为被动工作方式,进程则为主动工作方式
- 进程之间能够并发执行,而管程则不能与其调用者并发
-
如何判断软件实现方法是否遵循四个原则
- 判断是否遵循空闲让进
- 观察是否有可能让表达式1与表达式2同时成立
- 观察没有p1的话,p0能否通过循环进入临界区,没有p0的话,p1能否通过循环进入临界区
- 判断是否遵循忙则等待
- 当p0通过while循环,但是没有进入临界区,此时切换P1,看P1能否也通过while循环,若可以,则不符合忙则等待,完了再反向检查一下
- 判断是否遵循有限等待
- 当p1处于临界区,p0卡在进入区一直通过不了while循环,此时新来了一个p1进程后,仍然可以比p0先进入临界区,那么p0则不满足有限等待,有可能会饥饿
- 所有的软件实现方法都不遵循让权等待:上图进入区的while(表达式);含义为如果表达式为真,则会一直执行这个循环,直到因为时间片到期被剥夺处理机或者因为表达式为假,方可跳出循环,该循环的循环体为空语句,这就是所谓的忙等
- 判断是否遵循空闲让进
-
并发进程并不能保证load和store的原子性
-
通过硬件支持实现临界段问题的方法称为低级方法,或称元方法
-
如果两个TS指令同时执行在不同CPU上,那么他们会按任意次序来顺序执行。
-
TS硬件指令可适用于共享内存的多处理机环境,因为当该指令执行时,CPU将锁住内存总线,禁止其他CPU在本条指令结束前访问内存
-
TS和Swap指令把功能塞进了一条指令的执行周期中,而单条指令不会被打断。注意While(TSL(&lock))语句在开中断下执行,虽然该程序段中TSL指令是原子指令,但其实就相当于一条指令,这段程序还有其他指令,因此如果该程序执行过程中关中断,那么无法响应其他中断源的中断请求。开中断后也不会破坏它的原子性,因为如果有中断请求到来,即使该程序在执行TSL语句,那么可以执行到时间片结束之后再响应中断请求,如果整个程序都关中断的话,则可能很久都不会响应。
-
硬件实现:CPU 专门设计了一条机器指令(如
TSL),电路级保证不可分割。CPU 内部专门提供的原子(不可分割)操作,在硬件电路层面就保证了执行过程中不会被打断。
例子:
Test-and-Set (TS)、Compare-and-Swap (CAS)、Exchange (XCHG)等。特点:
- 一条机器指令就能完成复杂操作(例如“读某个内存 + 修改它 + 返回旧值”)。
- 在多处理器环境下,硬件会自动锁住总线或使用缓存一致性协议,确保操作互斥。
- 优点:速度快、保证原子性、适合并发场景。
- 缺点:CPU 要额外提供电路支持,不同体系结构指令不同,可移植性差。
-
软件实现:CPU 没有这样的指令,需要靠一段机器码(很多条指令)+ OS 配合来“模拟”这个效果。
- 含义:硬件没提供现成的原子指令时,用一段普通机器指令的组合,再配合操作系统机制(例如禁止中断或自旋锁)来实现。
- 例子:
- 用 关中断 → 读写变量 → 开中断 来模拟原子操作(单 CPU 情况可行)。
- 在高层语言里用
while(lock == 1); lock = 1;的方式,编译成普通的 load/store 指令,依赖软件逻辑保证正确性。
- 特点:
- 不是真正的单条原子硬件指令。
- 需要操作系统或编译器协助,执行效率不如硬件原子指令。
- 可移植性好(只要有 CPU + OS 就能实现)。
-
-
如果将自旋锁用在单处理机上,需要抢占式的调度机(即不断通过时钟中断一个线程,运行其他线程),否则自旋锁单在CPU上无法使用,因为一个自旋的线程永远不会放弃处理机。
- 自旋锁下,一直自旋的进程如果时间片用完,则被剥夺处理机,处于就绪态。
-
互斥锁有两种类型
-
自旋锁
-
无忙等待锁

-
互斥锁通常采用上面的硬件实现方法所述的硬件机制来实现
- 采用中断机制,在获取锁之前关中断;不过该方式只对单处理机系统有效
- 原子操作指令
- 使用TSL指令实现自旋锁
- 使用TSL指令实现无忙等待锁
-
-
考试中,自旋锁≠互斥锁,自旋锁是一种忙等机制,无法实现让权等待,而互斥锁是一个简化版的信号量,互斥锁加锁失败后,线程释放CPU,给其他线程,可以实现让权等待。
-
自旋锁具有随机性,顺序可能乱
- 进程在等待锁的时候,没有上下文切换
- 自旋锁不提供任何公平性保证,可能导致饿死
-
无忙等待锁由于等待队列的存在,因此可以实现申请锁的进程的先来后到,较为公平
- 未申请到锁时不需要忙等,但需要阻塞自己,切换其他进程,因此由一些切换上下文的代价。
-
使用原子操作实现的互斥锁还有可能导致死锁的发生,比如某个低优先级进程拿到了锁,在使用这把锁的时候,来了一个高优先级的进程获得处理机,并且它也想进入临界区,这时就发生了死锁。
-
在具有忙等待的信号量经典定义(即整型信号量)中,信号量的值不能为负值。如果信号量为负值,那么它的绝对值就是等待它的进程数。出现这种现象的原因是在实现wait操作时互换了递减和测试顺序。
-
实现互斥的P操作必须在实现同步的P操作之后
-
Swap指令原子地交换一个CPU寄存器的内容和内存中锁变量的内容。
- TS指令和核心功能是原子地读一个内存字的旧值,并同时设置该内存字为一个新的预定值
-
整型信号量和记录型信号量


管程
- 在入口等待队列中的线程,都是条件满足情况未知或曾经满足过条件的线程,它们等待管程的新一轮执行,而条件变量的等待队列中的线程必须等到满足该条件后才可以重新回到入口等待队列中去。
- 对管程的实现互斥由编译器负责
- 信号量的互斥是紧紧靠着信号量的,而管程的互斥是在头和尾。
经典同步问题
生产者消费者问题解题模板
- ①分析有几类进程
- 根据题意,区分有几类进程,每类进程对应一个函数。若进程是不断重复地可以加一个while(1)循环;
- ②在函数内部,用中文描述动作
- ③添加PV操作,用中文描述里面的操作
- 同步操作
- 在每一个动作开始前思考是否需要消耗资源(例如缓冲区的空位或产品),需要的话P一下,并在产生该资源的地方添加V操作;因为PV操作时成对出现的,所以这种方法可以有效避免漏操作
- 互斥操作
- 注意对缓冲区的互斥访问,进入缓冲区的前后分别加上PV操作
- 同步操作
- ④定义信号量
- 所有的PV操作写完后便可以定义相应的信号量
- 对于互斥信号量,初值为1
- 对于同步信号量(前驱后继),初始值一般为0
- 其他一般信号量根据题意定义初始值
- 例如生产者消费者问题中未运行之前缓冲区空位数为N,产品数为0,则可以定义信号量empty=N,full=0
- 注意如果根据题意缓冲区的空位为1,则此时只需要一个记录空位的一般信号量即可,这个信号量可以充当互斥信号量
- 所有的PV操作写完后便可以定义相应的信号量
- ⑤检查是否会出现死锁
- 检查连续的P操作是否会出现死锁
- 这里连续的P操作是指对一般信号量的连续P操作,不包括互斥信号量的P操作
- 像这种出现连续P操作的题目,进程所需要的资源个数一般大于1。根据死锁定理,进程获得资源就不会释放,满足请求并保持条件,因此如果两个进程的资源数不够,但是又互相拿着对方所需的资源,那么就会发生死锁。
- 如果有死锁的可能,我们可以在连续的P操作头尾加上互斥锁,使其一气呵成地完成。
- 即使不是连续的P操作,也可能发生死锁
- 这种情况发生在一个进程既需要多个资源,又需要进行多个操作的情况,因为获得资源和完成操作是交错进行的,既不能一次性获得所有资源,又不能一次性完成所有操作,这时候就容易导致死锁。
- 解决方法:把所有申请资源的P操作都写在一起,转化为连续的P操作,这样就变成了先前所述的第一种情况,用先前所述办法解决即可
- 检查共享缓冲区是否有隐含的死锁
- 当多个进程共享同一个缓冲区时,就可能出现其中一个进程推进过快,而导致缓冲区先行被该进程的产品所占满,其他进程无法放入产品的情况。
- 解决方法:将问题转化为两个缓冲区来解决,方法是构造两个虚拟的缓冲区。放产品的时候,需要同时往真实的缓冲区和虚拟缓冲区放。进程先检测真实缓冲区是否有空位,如果有,再检测自己的虚拟缓冲区是否有空位,如果也有,才能放进真实缓冲区和虚拟缓冲区。
- 检查连续的P操作是否会出现死锁
读者写者问题
- 具体看笔记
- 通用解题模板
- 第一个进程开始访问临界资源前,需要对资源加上互斥锁,后面的进程再访问时就不用再对资源加互斥锁了,直到最后一个进程访问完后,发现自己是最后一个进程,就解锁互斥锁。
进程调度
.png)
- 进程调度的时机:
- 阻塞一个进程
- 中断返回之前
- 在每次系统调用和中断之后,标志位need_resched被例程检查,如果标志位为1,那么调度程序需要在此时被调用。
- need_resched是linux内核中的一个调度标志,用于标记当前的CPU是否需要进行进程切换(上下文切换)
- resched是re-schedule的缩写,意思是重新调度
- 在每次系统调用和中断之后,标志位need_resched被例程检查,如果标志位为1,那么调度程序需要在此时被调用。
- 终止一个进程
- 内核锁属于内核数据结构,内核临界区不能发生进程调用
- SJF短作业调度算法的平均等待时间、平均周转时间是最优的。
- 多级队列调度每个队列可以实施不同的调度算法
- 多级反馈队列调度算法中,若CPU正在执行第i级队列中的某个进程时,又有新进程进入任何一个优先级较高的队列,此时须立即将正在运行的进程放回第i级队列的末尾,而将CPU分配给新到的高优先级进程。
- 事实上,如果仅为了获得高的系统吞吐量,则应尽量多地选择短作业运行。
- 如果仅为了使处理机的利用率高,则应尽量多地选择计算量大的作业运行。
| 调度算法 | 能否可抢占 | 优点 | 缺点 | 适用于 |
|---|---|---|---|---|
| 先来先服务 | 否 | 公平,实现简单 | 不利于短作业 | CPU繁忙型作业,不利于I/O繁忙型作业 |
| 短作业优先 | 可以 | 平均等待时间、平均周转时间最优 | 长作业会饥饿,估计时间不易确定 | 批处理系统 |
| 高响应比优先 | 否 | 兼顾长短作业 | 计算响应比的开销大 | 无 |
| 时间片轮转 | 可以 | 兼顾长短作业 | 平均等待时间较长,上下文切换浪费时间 | 分时系统 |
| 多级反馈队列 | 队列内算法不一定 | 兼顾长短作业,有较好的响应时间,可行性强 | 最复杂 | 相当通用 |
- 可以抢占的算法
- 短作业优先
- 优先级调度
- 多级反馈队列
- 时间片轮转
- 时间片轮转调度算法只能用于进程调度的原因
- 作业只有放入内存建立相应进程后,才能被分配处理机时间片
- **处于临界区的进程也可能因中断或抢占而导致进程调度。**此外,若进程在临界区内请求的是一个需要等待的资源(比如打印机)则它主动放弃CPU,让其他进程运行
- 需要区分进程调度与上下文切换的不同:
- 调度是资源分配的行为,包括了调度程序的决策和上下文切换
- 如果调度程序决定切换任务,则会调用上下文切换函数
- 在等待I/O完成的期间其实进程也是在被服务的,所以不计入等待时间
- 进程在操作系统内核程序临界区中不能进行调度与切换
- 进程处于临界区时可以进行处理机调度
| 类型 | 切换内容 | 是否切换页表 | 开销大小 | 说明 |
|---|---|---|---|---|
| 进程切换 | CPU寄存器、程序计数器、栈指针、页表、文件描述符等 | 需要 | 最大 | 会导致TLB失效,缓存失效,资源上下文完整切换 |
| 内核级线程切换 | CPU寄存器、程序计数器、栈指针 | 同进程:不需要 跨进程:需要 |
中等 | 内核调度,若线程在同一进程则只切换轻量上下文 |
| 用户级线程切换 | 用户态寄存器、用户栈 | 不需要 | 最小 | 在用户态完成,内核不可见,速度快但无法利用多核 |
-
三类上下文切换的开销对比
- 进程切换
- 需要切换内容:
- CPU 寄存器、程序计数器
- 虚拟地址空间(页表)
- 文件描述符表、I/O 映射关系
- 可能导致 TLB 失效、高速缓存失效
- 开销最大:因为资源上下文要全部切换。
- 内核级线程切换(KLT)
- 同一进程内部线程切换:
- 只切换寄存器、程序计数器、栈指针等 线程私有上下文
- 不需要切换页表(内存空间共享)
- 开销比进程切换小得多
- 跨进程的线程切换:
- 本质上要切换进程资源上下文,等价于进程切换
- 用户级线程切换(ULT)
- 完全在用户态调度,由运行库/线程库(如 pthread 用户态实现)完成
- 内核并不知道这些线程的存在
- 切换只涉及用户态寄存器和用户栈,不涉及特权级切换,也不触发内核调度
- 开销最小,但无法利用多核(因为在内核眼里只有一个进程)。
-
高级调度主要用于多道批处理系统中,而在分时和实时系统中,不设置高级调度
-
什么时间点不能进行调度
- 当前进程处于中断处理过程中
- 进程在访问操作系统内核临界区中
- 比如调度器访问就绪队列,这就是访问内核临界区,就绪队列就是内核数据结构,只能操作系统内核才可以访问
- 用户级别的临界区中可以进行进程调度
- 禁用中断(屏蔽中断过程中)
- 原语执行过程中(如加锁、解锁、中断现场保护、恢复等原子操作。原子操作不可中断一气呵成,连中断都要屏蔽,更不应该进行进程调度与切换)
-
408考试主义的细节
- 若题目未特殊说明,所提到的“短作业/进程优先算法”默认是非抢占式的
- 在有前提条件“**所有进程可同时运行”或“所有进程几乎同时到达”**的情况下,我们可以说采用SJF的调度算法的平均等待时间、平均周转时间最少,若未加该前提条件,则应该说“抢占式的短作业/进程调度算法(STRN)的平均等待时间、平均周转时间最少
- 如果选择题中遇到SJF的平均等待时间、平均周转时间最少的选项,最好先别判断别的选项是否有明显错误,若无更合适选项,那也该选择该选项
-
高响应比优先调度算法是理想型的调度算法,现实中是实现不了的
-
时间片轮转算法中,做题时若某一时刻进程P1下处理机,同一时刻进程P2到达,那么默认新到达的进程先进入就绪队列
-
时间片轮转调度是通过时钟中断来触发的。时钟中断处理程序负责中断当前运行的进程,更新时间片,以及发现时间片用完之后设置调度标志NEED_RESCHED触发调度
-
在执行系统调用服务例程也用可能触发调度
- 如P1执行read()系统调用读文件时,会主动阻塞自己,从而触发调度,直到数据读入内核缓冲区P1才会被唤醒
-
进程在访问操作系统内核临界区中不应被剥夺处理机资源(注意在用户级别的临界区中可以进行进程调度)
-
不可调度的情况
- 进程处理中断的过程中
- 进程执行原子操作中
- 进程处于内核程序临界区
- 关中断状态下
-
一个正在访问临界资源的进程由于申请I/O操作而被阻塞时,进程调度程序将调度其他就绪程序占用CPU执行,但禁止其他进程进入访问该临界资源的临界区。
实时系统的进程调度算法
-
非抢占式调度算法
- 非抢占式轮转调度算法
- 适用于要求不太严格的实时控制系统
- 非抢占式优先级调度算法
- 如果系统中含有少数具有一定要求的实时任务,可采用这种方式。系统会为这些任务赋予较高的优先级。当这些实时任务到达时,系统会把它们安排在就绪队列的队首。等待当前任务自我终止或运行完成后,再通过调度执行队首的高优先级进程,因而可以用于有一定要求的实时控制系统。
- 非抢占式轮转调度算法
-
抢占式调度算法
- 基于时钟中断的抢占式优先级调度算法
- 在某实时任务到达之后,如果它的优先级高于当前任务的优先级,则此时并不立即抢占当前任务的处理机,而是等到时钟中断发生后,调度程序才会剥夺当前任务的执行,将处理机分配给新到的高优先级任务。该算法能获得较好的响应效果,可用于大多数的实时系统。
- 立即抢占的优先级调度算法
- 要求OS具有快速响应外部中断事件的能力。一旦出现外部中断,只要当前任务未处于临界区,便能立即剥夺当前任务的执行,把处理机分配给请求中断的紧迫任务。该算法能够获得非常快的响应,其调度时间大幅度降低。
- 基于时钟中断的抢占式优先级调度算法
-
最早截止时间优先算法
-
根据任务的截至时间确定任务的优先级,任务的截至时间越早,其优先级越高,具有最早截止时间的任务排在队列前面。调度程序在选择任务时,总是选择就绪队列中的第一个任务,并为之分配处理机。
-
EDF算法既可以用于抢占式调度方式中,也可以用于非抢占式调度方式中
-
非抢占式调度方式用于非周期实时任务

-
抢占式调度方式用于周期实时任务
-
-
-
最低松弛度优先算法

- 最低松弛度优先(least laxity first,LLF)算法在确定任务的优先级时,根据的是任务的紧急程度(或松弛度)。任务紧急程度越高,赋予该任务的优先级就越高,以使其可被优先执行。
- 例如,一个任务在200ms时必须完成,而它本身所需的运行时长是100ms,因此调度程序必须在100ms之前调度执行,该任务的松弛度为100ms。再如,另一任务在400ms时必须完成,它本身需要运行150ms,因此其松弛度为250ms。
- 在实现该算法时,要求系统中有一个按松弛度排序的实时任务就绪队列,松弛度最低的任务排在最前面,调度程序会选择队列中的队首任务执行。
- 该算法主要用于抢占式调度方式之中。
- 最低松弛度优先(least laxity first,LLF)算法在确定任务的优先级时,根据的是任务的紧急程度(或松弛度)。任务紧急程度越高,赋予该任务的优先级就越高,以使其可被优先执行。
优先级倒置
-
优先级倒置的形成原因:
- 高优先级进程(或线程)被低优先级进程(或线程)延迟或阻塞。
- 低优先级进程抢占了高优先级所需的临界资源

-
解决方法
- ①规定:在进程进入临界区后,其所占用的处理机就不允许被抢占。如果系统中的临界区都较短且不多,则该方法是可行的。如果P3临界区非常长,则高优先级进程P1仍会等待很长的时间,其效果是无法令人满意的。
- ②动态优先级继承,该方法规定:当高优先级进程P1要进入临界区去使用临界资源R时,如果已有一个低优先级进程P3正在使用该资源,则此时一方面P1会被阻塞,另一方面会由P3继承P1的优先级,并一直保持到P3退出临界区。这样做的目的在于,不让比P3优先级稍高但比P1优先级低的进程(如P2)插进来,导致延缓P3退出临界区。
- 该方法已在一些OS中得到了应用,且在实时系统中是一定会用到的
进程切换过程

- 中断响应与进程切换的上下文切换区别
- 中断响应保存和恢复上下文是分开进行的,分别位于中断响应和中断返回的过程中;而进程切换的上下文保存与恢复是连续进行的(两个不同进程间)
- 中断响应保存的上下文是中断前进程执行的上下文,进程切换保存的是当前中断服务程序正在执行过程中的上下文。更进一步说,中断响应维护的上下文可能是用户上下文,进程切换维护的一定是内核态下的上下文
- 中断响应不涉及地址空间切换(仅切换了内核态以及由用户堆栈切换到内核堆栈,中断前后仍然属于同一地址空间),进程切换涉及地址空间切换。
- 中断响应可能发生特权级切换,进程切换全程在内核态下进行。
- 注意区分CPU模式切换和进程切换
- 进程切换和模式切换都涉及上下文的保存与恢复,但是它们有本质的不同。
- 模式切换发生在用户态下响应中断或异常(用户态→核心态)和处理完用户态下的中断异常后返回用户态(核心态→用户态)这两种情况下,本质工作是处理中断异常和中断异常返回。
- 模式切换是同一进程在自身用户态和内核态下的切换,二者共用地址空间,涉及到特权级的切换以及用户栈与内核栈的切换,而且只需要保存和恢复用户态的上下文(主要就是通用寄存器,PC、PSW和SP等,即所谓的断点和现场信息)不需要保存和恢复内核态的上下文。而进程切换发生在内核态,在进程切换发生之前,一定存在某些事件使P0进程离开运行态,而这一处理本来就是在内核态下完成的,因此进程切换P0保存在PCB中的是P0处于内核态下的上下文,同样的道理,从P1的PCB中获取的上下文一定也是P1位于内核态下时存放的上下文。所以,进程的调度和切换均发生在内核态下,是从一个进程的内核态切换到另一个进程的内核态。
- 切换永远发生在两个进程的内核态之间
- PCB保存的是进程在内核态被切换时的完整状态
- 用户态恢复依赖中断返回机制,不是进程切换的直接结果
- 进程切换需要切换地址空间(MMU页表),而中断处理就不用切换地址空间,因此我们说中断处理程序的执行不算进程切换
- 发生中断只是把CPU的控制权由用户进程交给了os内核,没有发生进程切换
- 进程切换的标志是地址空间切换(切换页表)
- 当中断发生时,CPU 自动切换到内核模式,但仍使用当前进程的地址空间,只是权限提升,执行os提供的中断服务例程,他只是去执行内核区代码了
- 只有进程调度或exec()等系统调用才会切换地址空间,因为这时需要完全切换到另一个执行环境。
- 抢占点的触发时机?
- 在中断/异常/系统调用处理结束返回用户空间时,内核会检查当前进程的NEED_RESCHED标志,若有效则出发调度
- 中断处理返回的宏观流程
- 中断服务程序主体执行完毕
- 准备退出中断
- 检查need_schedule标志并决定是否调度
- 执行调度或返回原进程
- 如果需要调度,执行调度程序,选择下一个要运行的进程,并进行上下文切换
- 如果不需要调度:则直接准备返回到被中断的进程
- 恢复现场和屏蔽字
- 执行iret(或eret等)指令,真正从硬件上返回
- 当前进程的页表基址和栈基址不会因为进程的执行而改变,因此当发生进程切换时,不一定需要保存,但是一定要更新
- PSW寄存器的内容在进程切换的过程中不需要保存或更新,在进程P1切换到进程P2,进程P2返回用户态时才会更新
死锁
.png)
- 死锁是指组内的每个进程都在等待一个事件,而该事件只可能由组内的另一个进程产生。
- 饥饿:进程在信号量内无穷等待的情况
| 对比点 | 死锁(Deadlock) | 饥饿(Starvation) |
|---|---|---|
| 进程数量 | 至少两个或以上进程相互等待(循环等待)。 | 可能只涉及一个进程(例如总是被推迟)。 |
| 产生原因 | 循环等待资源分配(相互占有对方所需资源,互相等待)。 | 调度策略不公平、优先级设置不合理,导致长期得不到资源。 |
| 进程状态 | 死锁进程必定处于 阻塞态(等待资源)。 | 饥饿进程可能处于 就绪态(长期得不到 CPU)或 阻塞态(长期等不到 I/O 资源)。 |
| 是否能自行解脱 | 不能,必须外力干预(如操作系统解除死锁)。 | 有可能被调度器选中而继续执行,但等待时间可能无限长。 |
| 本质区别 | 系统性僵局 → 多个进程互相等待,谁也走不下去。 | 资源分配不公 → 个别进程长期得不到调度机会。 |
- 资源分配图含圈而系统又不一定有死锁的原因是,同类资源数大于1。但若系统中每类资源都只有一个资源,则资源分配图含圈就变成了系统出现死锁的充分必要条件。
| 策略 | 资源分配策略 | 各种可能模式 | 主要优点 | 主要缺点 |
|---|---|---|---|---|
| 死锁预防 | 保守,宁可资源闲置 | 一次请求所有资源、资源剥夺、资源按序分配 | 适用于突发式处理的进程,不必进行剥夺 | 效率低,初始化时间延长;剥夺次数过多;不便灵活申请新资源 |
| 死锁避免 | 是预防和检测的折中(在运行时判断是否可能死锁) | 寻找可能的安全允许顺序 | 不必进行剥夺 | 必须知道将来的资源需求;进程不能被长时间阻塞 |
| 死锁检测 | 宽松,只要允许就分配资源 | 定期检查死锁是否已经发生 | 不延长进程初始化时间,允许对死锁进行现场处理 | 通过剥夺解除死锁,造成损失 |
-
系统处于安全状态,则一定不会发生死锁;若系统进入不安全状态,则有可能发生死锁(处于不安全状态未必就会发生死锁,但发生死锁时一定是处于不安全状态)

-
银行家算法步骤
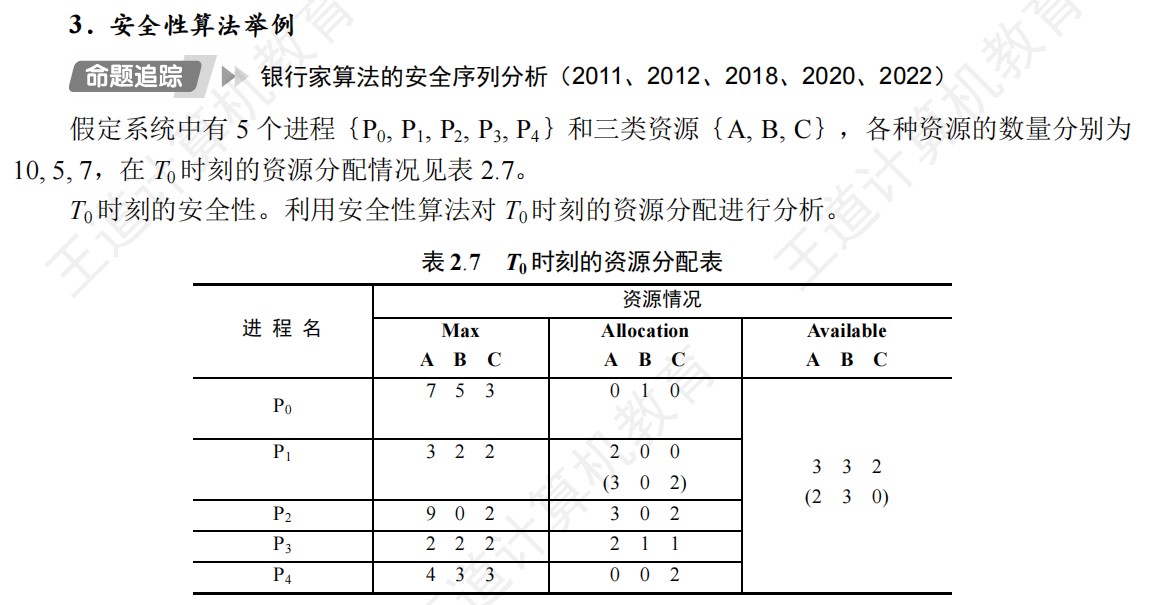
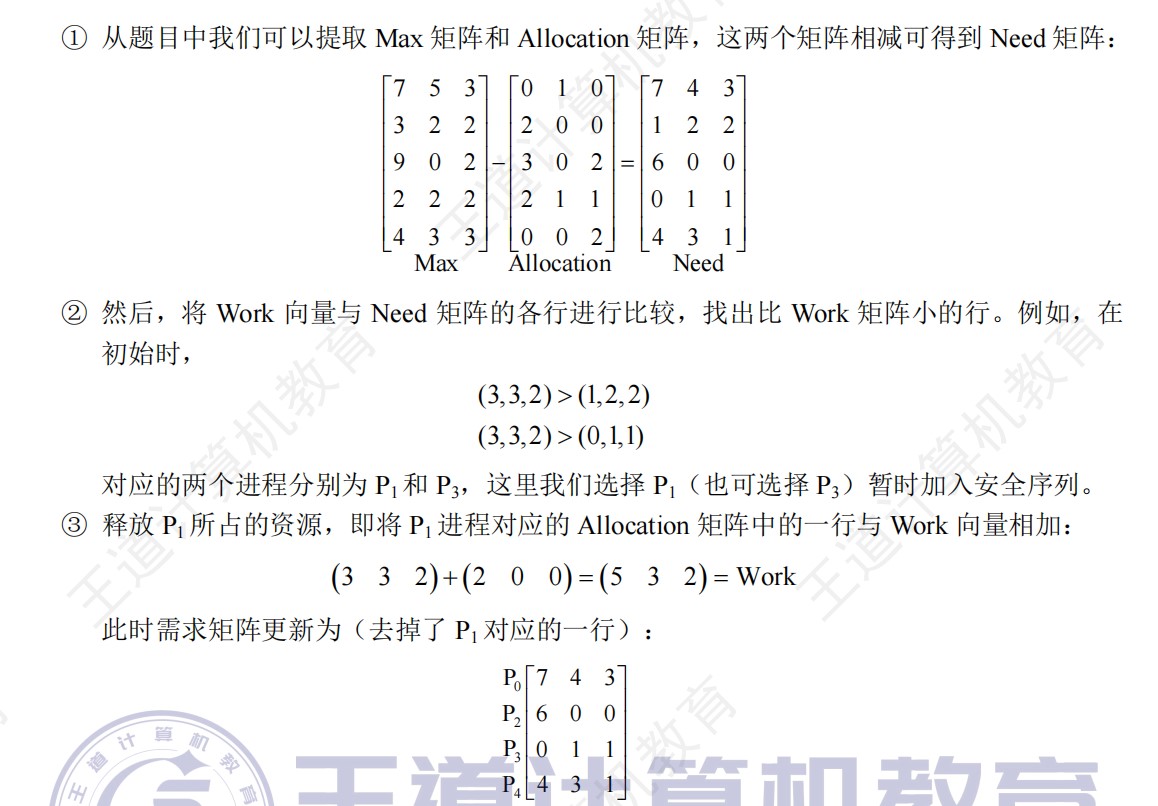
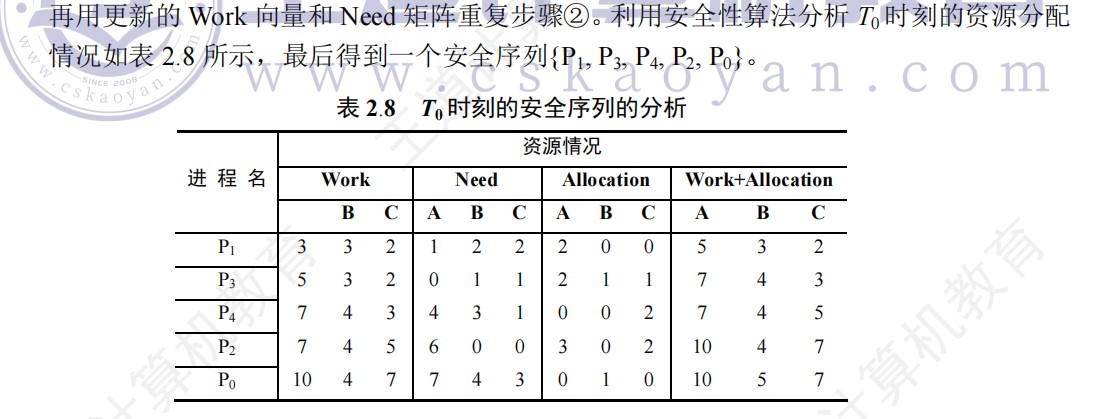
-
银行家算法个人总结版
- ①算出available(总量-已分配)矩阵
- ②算出Need矩阵(资源最大需求-已分配)
- ③拿available找满足的Need行
- ④更新available
- ⑤重复②-④直到全部进程分配完毕
-
设M为设备的数量,K是进程的数量,R是每个进程最多需要设备的数量,若M<=K(R-1)则系统可能发生死锁
-
不仅对不可抢占资源进行争夺时会引起死锁,而且对可消耗资源进行争夺时也会引起死锁。
-
仅仅有优先级并不能完全避免死锁
- 比如一个高优先级进程可能等待一个低优先级进程持有的资源,而低优先级进程又在等待另一个资源。如果这个等待链形成循环,即使有优先级,死锁仍然可能发生。优先级调度可能影响饥饿现象,但不能直接消除所有类型的死锁。
-
资源分配图
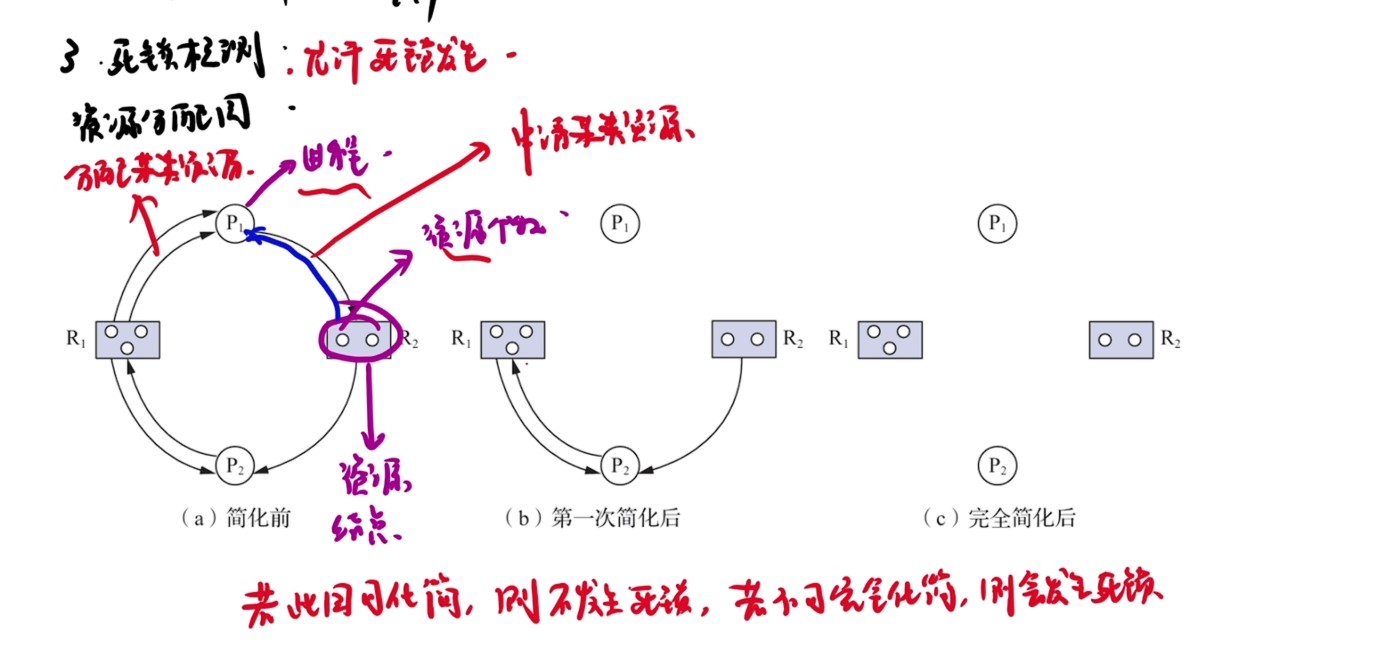
-
破坏请求和保持条件的两种方法都可能导致饥饿
-
死锁检测算法会根据系统真实情况设置合适的时间间隔,每隔一段时间执行一次来检测系统是否存在死锁
进程虚拟空间
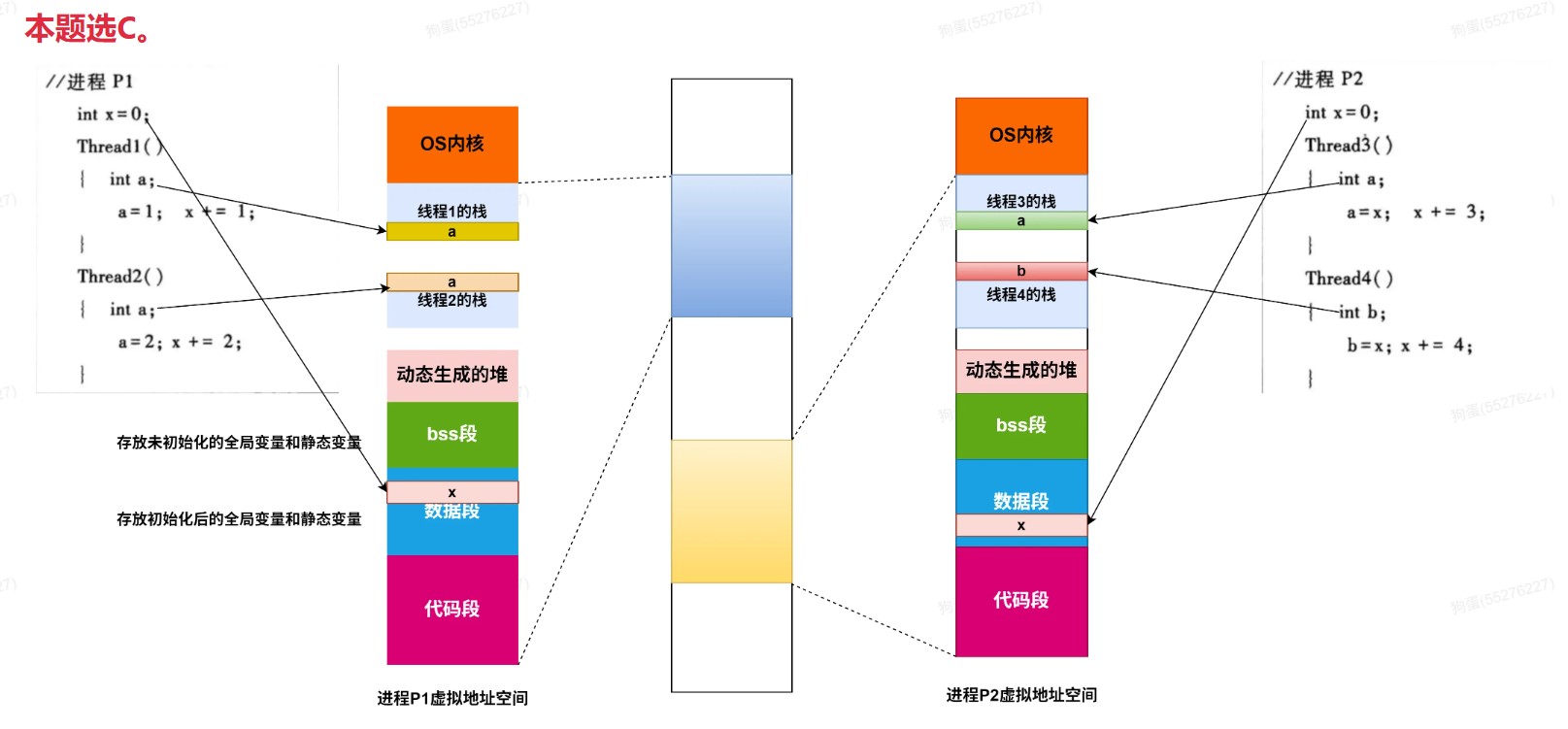
- 栈
- 局部变量
- 函数内部变量(包括main函数)
- 堆
- malloc
- BSS段
- 未初始化的全局变量
- 定义在函数外
- 未初始化的全局变量
- 数据段
- 初始化的全局变量
- 代码段
- 指令
- 只读常量const
- 代码段和数据段在程序调⼊内存时就指定了⼤⼩,⽽堆和栈不⼀样。当调⽤像 malloc 和 free这样的C标准库函数时,堆可以在运⾏时动态地扩展和收缩。⽤户栈在程序运⾏期间也可以动态地扩展和收缩,每次调⽤⼀个函数,栈就会增⻓;从⼀个函数返回时,就会收缩。
- 共享库代码应该放在共享库的存储映射区。
- 函数的参数、函数的返回地址以及函数内定义的局部变量(包括局部指针变量)都存放在栈(Stack)中。
- 进程控制块(PCB)存放在系统内核区。操作系统通过 PCB 来控制和管理进程。
线程的实现
- 一对一模型
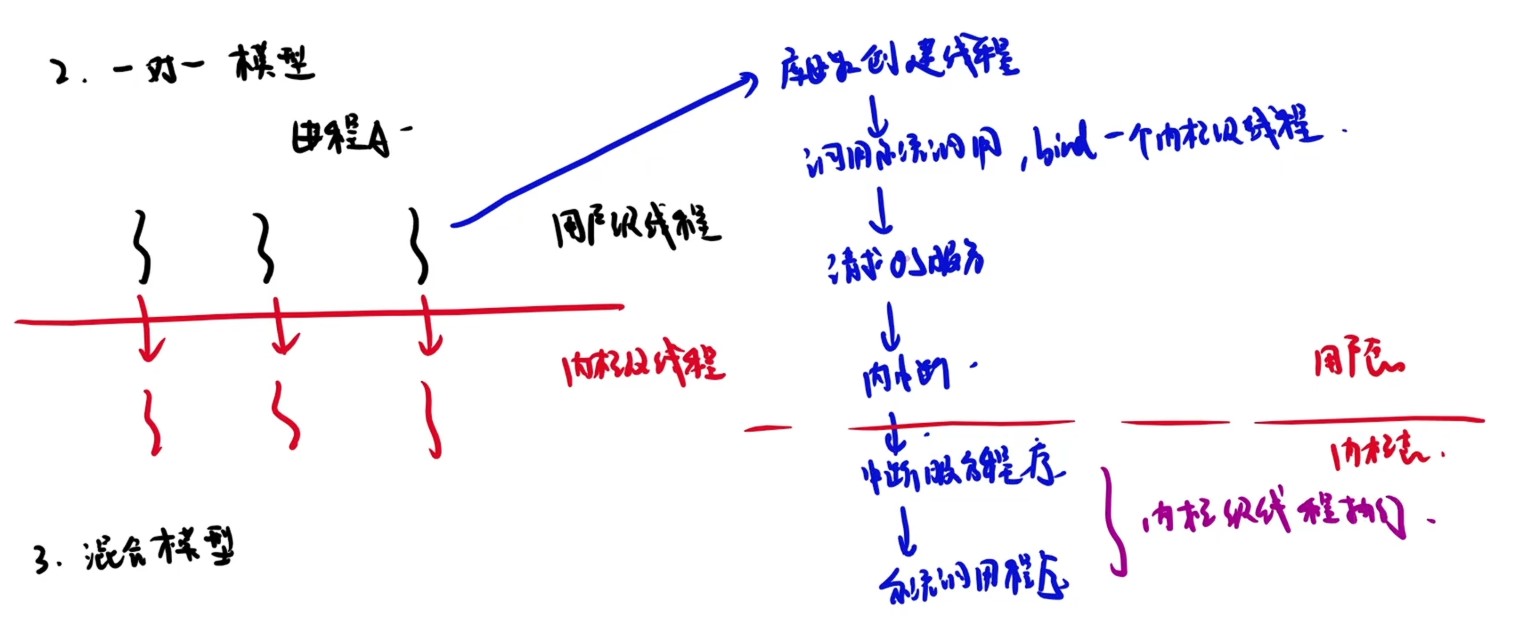
I/O
-
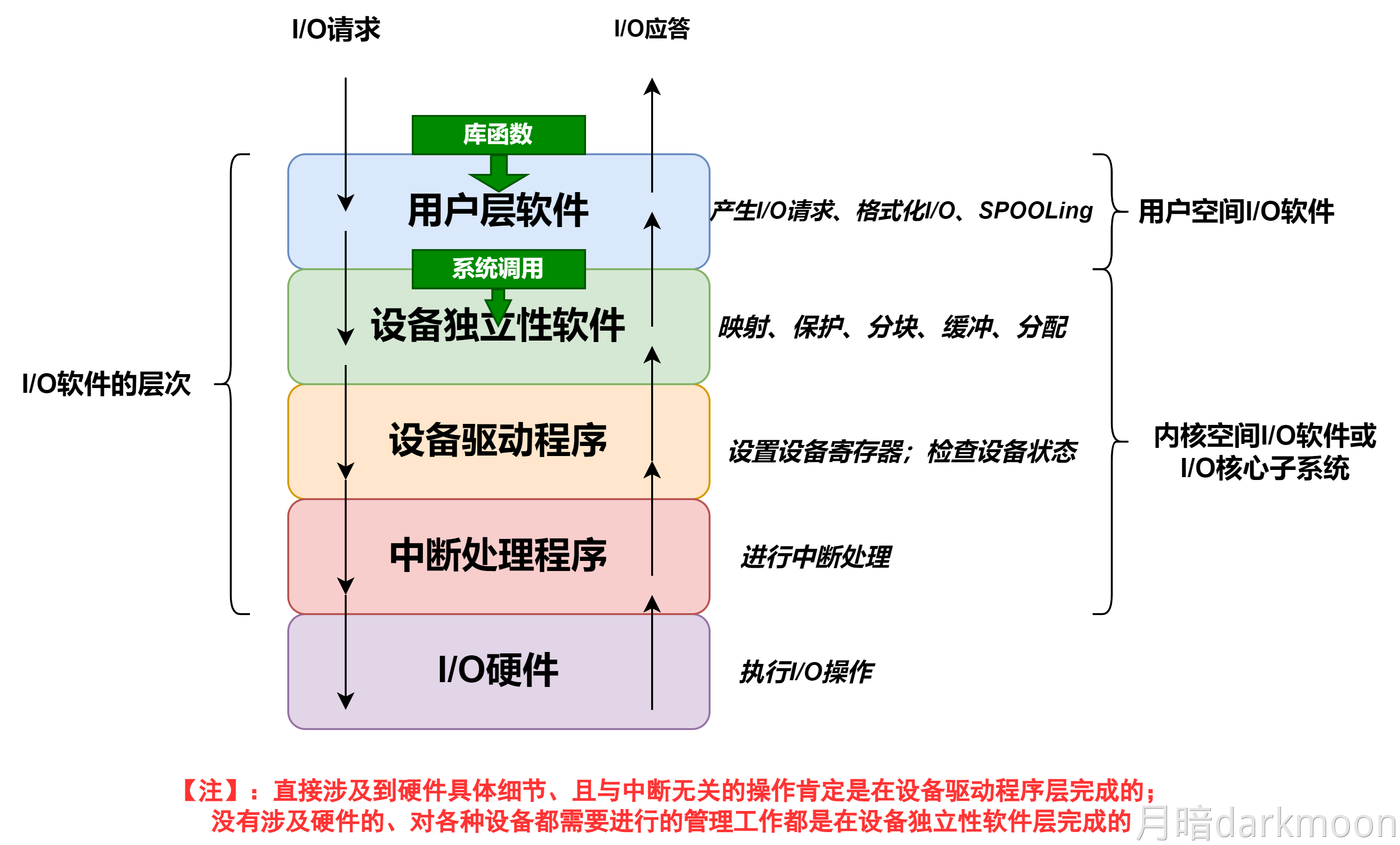
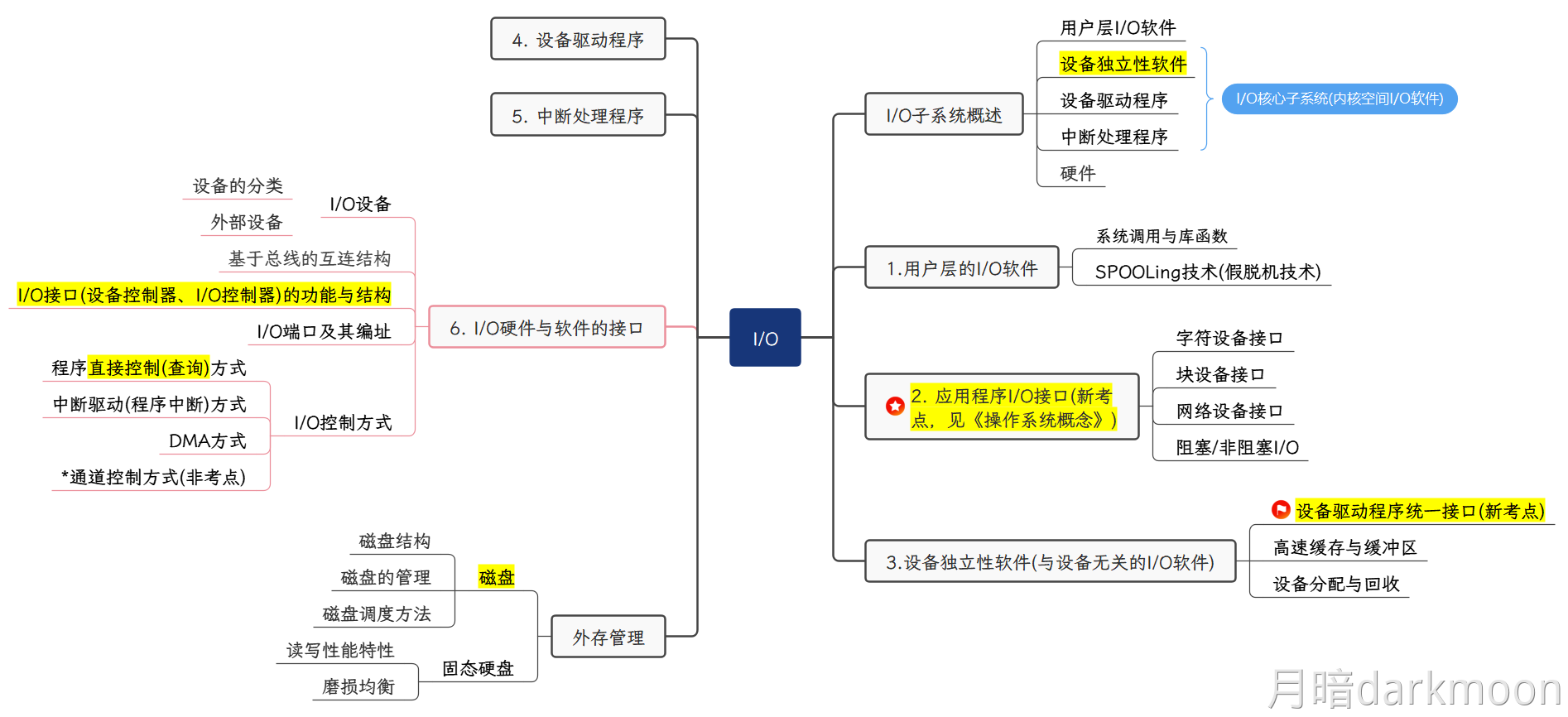
-
ARM、MIPS等RISC处理器常采用统一编址,Interx86处理器采用独立编址
-
无论是统一编址还是独立编址,热拔插设备的端口地址都是在计算器启动过程中动态分配的。
-
统一编址方式下,I/O地址是存储地址的一部分,可以直接用访存指令访问I/O设备,区分存储单元和I/O设备是依靠它们的地址码
- 即使采用统一编址(内存映射I/O),映射到I/O设备寄存器的内存地址通常也受到内存保护机制的控制。用户程序在用户态下试图直接访问这些受保护的地址(即I/O端口)仍然会引发保护异常或需要通过系统调用请求操作系统内核来执行实际的I/O操作。允许用户程序“自由读写任何I/O端口,无需操作系统干预”会破坏系统的安全性和稳定性。
- I/O地址虽然映射到了主存空间,但是由于接口中的数据是动态变化的,因此不能用Cache进行缓存,否则CPU无法了解设备的实时状态变化
-
独立编址方式下,需要用专门的I/O指令来访问I/O设备,区分存储单元和I/O设备是依靠指令类型
- 不同的指令会生成不同的总线控制信号来表示地址总线上的地址是主存还是I/O地址
-
唤醒因为I/O操作被阻塞的进程由中断服务程序完成。
- 阻塞I/O操作进程由对应的系统调用服务例程完成
- 将数据从设备控制器的寄存器送往内核缓冲区由中断服务程序完成
- 将数据从内核缓冲区送往用户缓冲区由系统调用服务程序在唤醒后完成
- 初始化外设的代码在驱动程序中
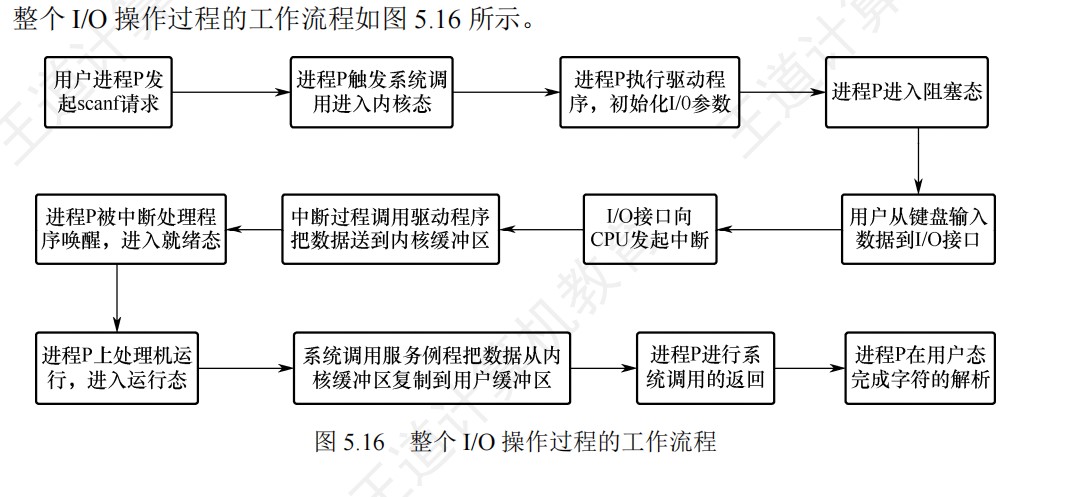
-
由于CPU处理时间比I/O设备短得多,因此设立缓冲区机制,用于缓和CPU与I/O设备的速度差异,提高CPU与I/O设备之间的并行性;当I/O花费的时间比CPU处理时间短得多,则缓冲区的存在就毫无意义了
-
由于字符设备不可以寻址,只能采取顺序存取的方式,通常为字符设备建立一个字符缓冲区。
-
共享设备必须是可寻址的和可随机访问的设备
- 因为操作系统需要高效地在多个进程的I/O请求之间来回切换
- 可寻址是切换的基础。
- 可随机访问保证了切换的效率。
- 因为操作系统需要高效地在多个进程的I/O请求之间来回切换
-
对设备分配的算法通常只采用先来先服务或优先级高者优先分配算法。
-
控制命令虽然是CPU发出的,但是控制命令是设备控制器提供的,每种设备控制器都对应一组相应的控制命令。
-
系统为每台设备确定一个编号以便区分和识别设备,这个确定的编号称为设备的绝对号。
-
在设备控制器中应配置地址译码器。
-
人机交互类设备通常是以字节为单位进行数据交换
-
不同I/O接口的I/O端口不重复
I/O系统中各种I/O模块之间的层次视图
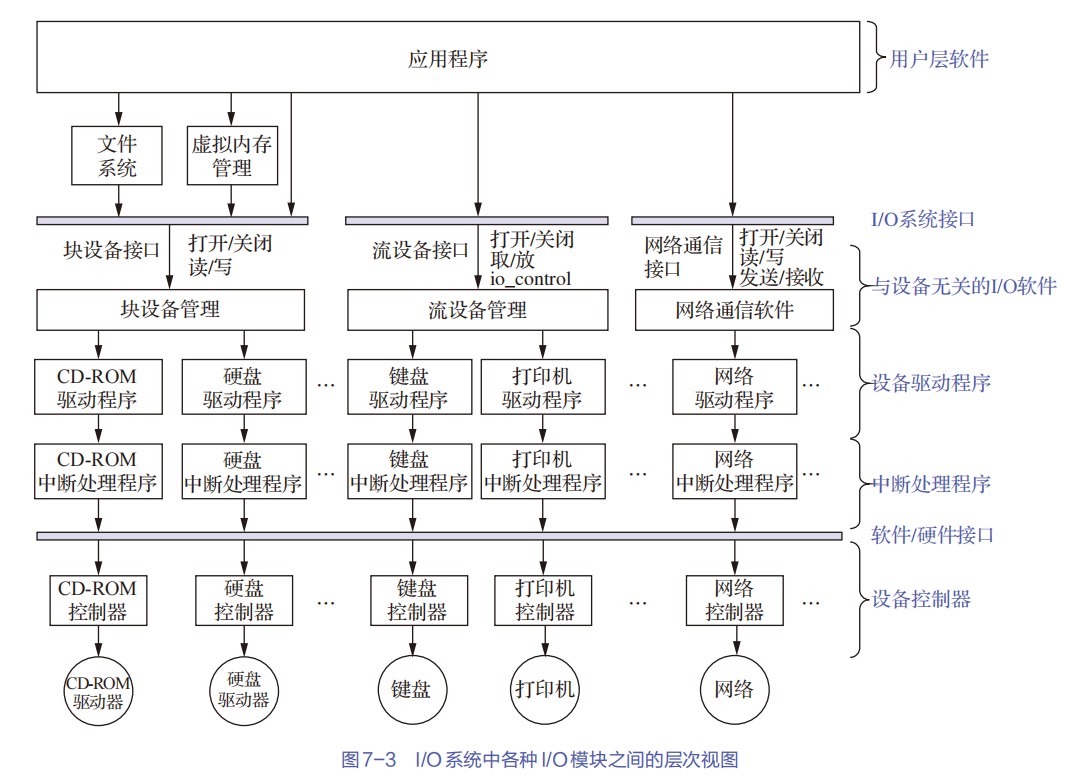
-
① I/O系统接口。上接口是I/O系统接口,它是I/O系统与上层系统之间的接口,向上层系统提供对设备进行操作的抽象I/O命令,以方便上层系统对设备进行使用。有不少OS在用户层提供了与I/O操作有关的库函数供用户使用。在上层系统中有文件系统、虚拟存储器系统以及用户进程等。
② 软件/硬件接口。下接口是软件/硬件接口。它的上面是中断处理程序和用于不同设备的设备驱动程序。它的下面是各种设备的控制器。
-
1、用户通过调用用户层软件提供的库函数发出I/O请求
- 2、用户层软件通过系统调用请求设备独立性软件层的服务
- 3、设备独立性软件层根据LUT调用设备对应的设备驱动程序
- 4、驱动程序向I/O控制器发出具体命令
-
设备独立性软件把符号化的设备名映射到适当的驱动程序上, 由操作系统对每个设备设置访问权限。
I/O模型:阻塞I/O和非阻塞I/O
- 阻塞I/O与非阻塞I/O的核心区别,在于他们如何等待数据准备
- 阻塞I/O
- 当应用程序发起一个I/O系统调用时,如果内核发现数据还没有准备好,不会立即返回。相反,操作系统会将这个应用程序的线程/进程从“运行”状态切换到**等待(阻塞)**状态。
- 此时,CPU可以去执行其他线程/进程。直到数据完全准备好,内核才会唤醒该线程,继续执行系统调用服务例程将数据从内核空间复制到用户空间然后返回用户态,程序继续执行。
- 优点:代码逻辑是线性的、顺序的,非常直观易懂。数据=read(),下一行代码执行时,数据一定是有效的
- 缺点:并发能力差,一个线程在任何时刻都只能处理一个I/O请求。在等待I/O时,整个线程被完全挂起,造成了计算资源的浪费。如果大量线程都因I/O而阻塞,系统的吞吐量会急剧下降。
- 非阻塞I/O
- 当应用程序发起一个I/O系统调用时,如果内核发现数据还没有准备好,它会立即返回一个错误码。它不会让线程进入等待状态。应用程序收到这个错误码后,就知道数据还没有准备好
- 线程可以先去处理其他任务,然后反复地、主动地去调用这个I/O系统调用,检查数据是否准备好了。一旦轮询发现数据已准备好,此时再进行I/O调用把内核缓冲区的数据复制到用户空间。
- 优点:具有高并发潜力,单个线程可以在等待一个I/O操作的同时,去处理其他计算任务,或者去轮询其他的I/O通道。线程的利用率大大提高,使得一个线程管理多个连接称为可能。
- 缺点:编程模型复杂,应用程序需要编写一个循环来不断轮询,这会使代码逻辑变得复杂;CPU资源消耗,在轮询的循环中,即使大部分时间I/O都没有就绪,这个循环本身也在消耗CPU时间(忙等待)
- 为什么非阻塞I/O的并发度更高?
- 核心在于线程资源的释放。
- 在阻塞模型下,一个线程与I/O通道绑定等死,线程的生命周期被漫长的I/O等待所占据
- 而在非阻塞模型下,线程在发起I/O调用后立即被释放,而它可以转而去为其他I/O通道服务(去轮询他们的状态),或者执行其他计算任务。
- 核心在于线程资源的释放。
I/O方式
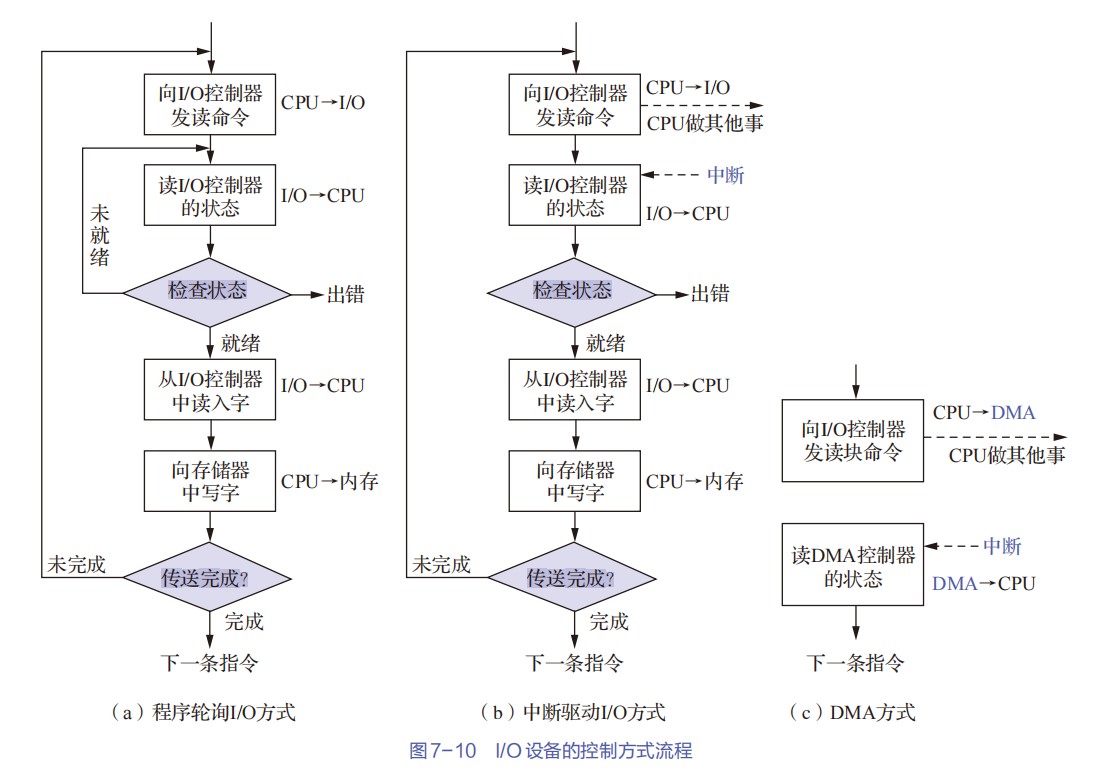
- 程序查询方式:完全由软件进行控制
- 程序中断方式:通过硬件产生中断,通过执行软件进行数据传输
- DMA方式:完全由硬件控制
- 通道:通过硬件产生中断+通过执行通道程序(软件)完成数据传输
- 程序查询方式&中断方式
- 都需要通过CPU来进行数据传输,故I/O端口中不需要传递主存地址信息
- DMA方式&通道方式:直接与主存进行数据交换,无需CPU参与,故在I/O端口中需要传递主存地址信息(主存地址信息需要DMA控制器或通道自行处理)
- 任何方式都需要传递设备地址信息
DMA方式
- DMA进行数据传送之前,CPU先执行一段初始化程序,完成对DMA控制器中各参数寄存器的初始值的设定,因此通过软件完成对DMA控制器中各参数寄存器的初始值的设定
- 发生缺页中断时,若在缺页处理程序中将缺页调入内存采用DMA方式,则需要把磁盘物理地址写入DMA控制器中的设备地址寄存器DAR,将交换数据的主存起始位置(该页面的页基址)写入DMA接口中的主存地址寄存器
- 对于外中断的请求响应发生在每个指令周期结束后,对DMA请求的响应发生在每个总线事务结束之后
- DMA控制器是一个独立的硬件,有自己独立的寄存器控制数据传输,在传输数据时不需要CPU的参与,也不需要修改CPU的现场信息,无须保护现场,而中断方式需要CPU运行中断服务程序进行数据传输,因此需要保存CPU现场信息
- DMA的预处理程序和后处理程序都运行在内核态
- 字计数器(传送长度计数器)WC用于记录传送数据的总字数,通常以交换字数的补码值预置。在DMA传送过程中,每传送一个字,字计数器+1,直到计数器为0,即最高位产生进位时,表示该批数据传送完毕(若交换字数以原码值预置,则每传送一个字,字计数器-1,直到计数器为0时,表示该批数据传送结束)
- WC溢出,由“溢出信号”通过中断机构向CPU产生中断请求(传输结束)
- DMA与主存之间采用字传送,而DMA与设备之间可能是字节或位传送
- 以周期窃取的DMA方式下完成的数据输入为例:
- ①当设备准备好一个字时,发出选通信号,将该字读到DMA的数据缓冲寄存器中,表示数据缓冲寄存器满(如果I/O设备时面向字符的,则一次读入一个字节,组装成一个字)
- ②与此同时设备向DMA接口发送DMA请求
- ③DMA接口向CPU申请总线控制权
- ④CPU发回HLDA信号,表示允许将总线控制权交给DMA接口
- ⑤将DMA主存地址寄存器中的主存地址送地址总线,并命令存储器写
- ⑥通知设备已被授予一个DMA周期,并为交换下一个字做准备
- ⑦将DMA数据缓冲寄存器的内容送数据总线
- ⑧主存将数据总线上的信息写至地址总线指定的存储单元中
- ⑨修改主存地址和字计数值
- 这里应该释放总线
- ⑩判断数据块是否传送结束,若未结束,则继续传送, 通过循环实现(这一循环也是由DMA控制器实现);若已结束,(字计数器WC溢出),则向CPU申请程序中断。
- 若为输出数据,则应完成以下操作:
- ①当DMA数据缓冲存器已将输出数据送至I/O设备后,表示数据缓冲存器已“空”。
- ②设备向DMA接口发请求(DREQ)。
- ③DMA接口向CPU申请总线控制权(HRQ)。
- ④CPU发回HLDA信号,表示允许将总线控制权交给DMA接口使用。
- ⑤将DMA主存地址寄存器的主存地址送地址总线,并命令存储器读。
- ⑥通知设备已被授予一个DMA周期(DACK),并为交换下一个字做准备。
- ⑦主存将相应地址单元的内容通过数据总线读入到DMA的数据缓冲寄存器中。
- ③将DMA数据缓冲寄存器的内容送到输出设备,若为字符设备,则需将其拆成字符输出。
- ⑨修改主存地址和字计数值。
- ⑩判断数据块是否已传送完毕,若未完毕,继续传送;若已传送完毕,则向CPU申请程序中断。
- 周期挪用的办法比较适合于I/O设备的读写周期大于主存周期的情况
- DMA和CPU交替访存,适用于CPU的工作周期比主存存取周期长的情况。
- 这种方式不需要总线使用权的申请、建立和归还过程,总线使用权时通过周期分时控制的。
- 具有很高的DMA传送效率
- 这种方式下,CPU既不会停止主程序的运行也不会进入等待状态,但是硬件逻辑更为复杂
- DMA方式下,CPU接收到DMA中断时,磁盘数据恰好进入内核缓冲区
- 而在中断方式下,中断服务程序完成时,数据才进入内核缓冲区,因为数据传送是通过中断服务程序进行的。
- 停止CPU访问内存
- 适用场景:对数据传输速率要求极高,且可以容忍CPU短时间无响应的场景,例如系统刚启动时从磁盘加载操作系统核心
程序查询方式
-
程序直接控制I/O方式包含无条件传送和条件传送,无条件传送较为简单,无状态等交互信息,只需定时查询即可,适合于巡回检测采样系统或过程控制系统,以及非随机启动的字符型设备。
- 条件传送方式下,接口中含有“就绪”“完成”等状态,可继续分为独占查询和定时查询
-
程序直接控制I/O方式下,用户进程在I/O过程中不会被阻塞,内核空间的I/O软件一直代表用户进程在内核态进行I/O处理(在这种情况下,驱动程序实际上是一个查询程序,而且也不再调用中断服务程序)
-
对于字符设备,一次轮询只能传输一个字节或字,而块设备一次轮询可以传输一个数据块
-
相比独占式程序查询方式,中断控制方式不需要轮询设备状态。另外,设备主动请求中断的方式比定时查询方式更具有实时性,不需要考虑定时轮询频率的问题,可有效消除CPU轮询开销,大大提高了I/O效率,是现代计算机中普遍采用的一项重要技术。
- 但也需要注意,中断控制方式也是有时间开销的,相对程序查询方式,它的额外开销是用于进程调度的两次上下文切换时间以及中断服务程序本身的开销,其提高I/O效率的前提是这些额外开销小于设备准备时间,当设备准备数据时间较长的时候没有问题。
- 但对于极高速外部设备,设备准备数据的时间很短,当这个时间比两次上下文切换加中断服务的开销还短时,使用中断控制方式的效率反而比忙等待轮询方式的效率更低,中断就会称为瓶颈。所以程序查询方式并不一定只适合慢速设备,在一些高速设备中也被普遍采用,例如最新的NVMe SSD硬盘在处理同步I/O时,就不再采用中断控制方式,而是采用程序查询方式进行数据交互。
通道
- I/O通道是一种特殊的处理机,它可执行一系列通道指令。设置通道后,CPU只需向通道发送一条I/O指令,指明通道程序在内存中的位置和要访问的I/O设备,通道收到该指令后,执行通道程序,完成规定的I/O任务后,向CPU发出中断请求。通道方式可以实现CPU、通道和I/O设备三者的并行工作,从而更有效地提高整个系统的资源利用率。
- 通道与一般处理机的区别是:通道指令的类型单一,没有自己的内存,通道所执行的通道程序是放在主机的内存中的,也就是说通道与CPU共享内存。
- 通道与DMA方式的区别是:DMA方式需要CPU来控制传输的数据块大小、传输的内存位置,而通道方式中这些信息是由通道控制的。另外,每个DMA控制器对应一台设备与内存传递数据,而一个通道可以控制多台设备与内存的数据交换。
- I/O通道方式的引入,使得对I/O操作的组织和数据的传输,都能独立进行而无需CPU的干预
- 通道程序结束位P,用于表示通道程序是否结束;P=1表示本条指令是通道程序的最后一条指令。
- 记录结束标志R,R=0表示本通道指令与下一条指令所处理的数据同属于一个记录,R=1表示这是处理某记录的最后一条指令。
整个I/O操作的大致过程

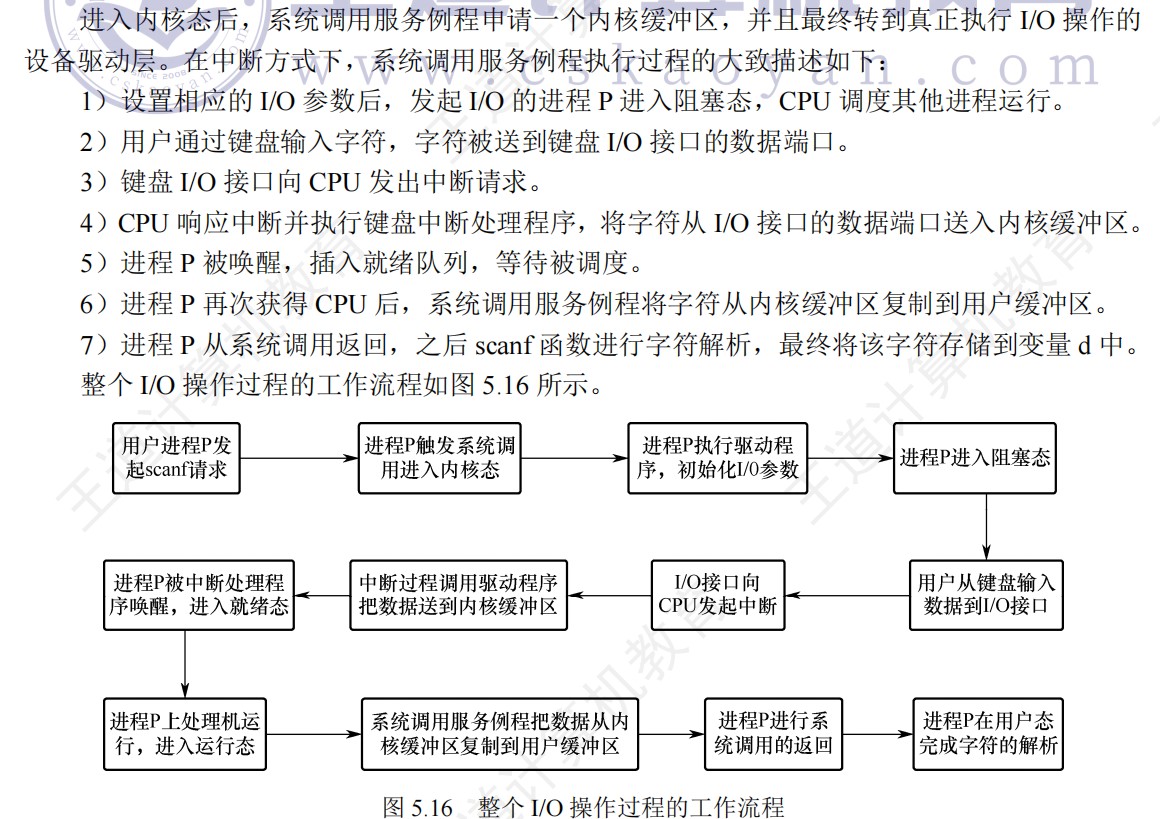
- 设备驱动程序的处理过程
- 将抽象要求转化为具体要求
- 对服务请求进行校验
- 检查设备状态
- 传递必要的参数
- 启动I/O设备
- 当一个进程因执行系统调用(例如,请求键盘输入)而被阻塞后,等待用户输入字符,其后的处理流程如下:
- 1、键盘硬件:
- 用户在键盘上键入一个字符。键盘硬件检测到按键,生成相应的编码,并将其存入键盘控制器的内部寄存器中。
- 2、中断处理程序:
- 键盘控制器向CPU发出一个中断请求。CPU响应中断,暂停当前执行的程序(如果CPU正处于空闲状态,则直接响应;如果正在执行其他进程或内核代码,则根据中断屏蔽和优先级决定何时响应),保存当前现场,然后转去执行操作系统内核中预设的键盘中断处理程序。
- 3、设备驱动程序:
- 中断处理程序会调用键盘的设备驱动程序。设备驱动程序从键盘控制器读取输入的字符数据,可能会进行一些转换(例如,从扫描码转换成ASCII码),然后通常会将这个字符放入操作系统内核维护的一个输入缓冲区(例如,终端缓冲区或行缓冲)。此时,由于等待该输入的进程之前是被阻塞的,设备驱动程序(或中断处理程序的一部分)会唤醒这个等待输入的进程,将其状态从阻塞态变为就绪态,并放入就绪队列。
- 4、进程调度:
- 当中断处理和设备驱动程序的相关工作完成后(通常中断处理程序执行时间很短),如果被唤醒的进程的优先级足够高,或者当前没有其他更高优先级的进程在运行,操作系统的进程调度程序可能会选择这个被唤醒的进程投入运行。也可能在中断返回后,继续执行之前被中断的进程,而被唤醒的进程只是进入了就绪队列。
- 5、系统调用返回:
- 当被唤醒的进程(即原先请求输入的进程)再次获得CPU并被调度执行时,它会从之前系统调用的阻塞点继续执行。系统调用处理程序此时可以从内核的输入缓冲区中获取到用户输入的字符,并将这个字符作为系统调用的结果返回给用户程序。CPU从内核态切换回用户态。
- 6、用户程序:
- 用户程序获得系统调用返回的字符,继续执行后续逻辑。
- 1、键盘硬件:
write调用的过程
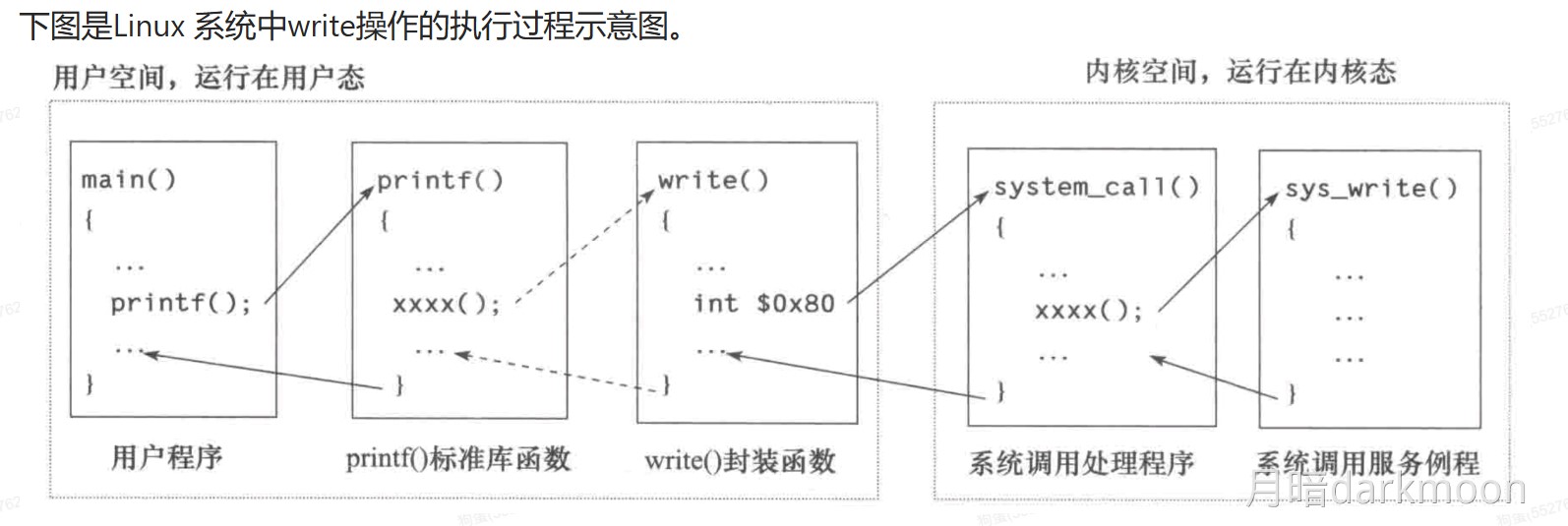

- 最后才阻塞本进程进行进程调度
-
详解

-
copy_string_to_kernel(strbuf,kernelbuf,n)://将字符串复制到内核缓冲区
- 进程P执行了系统调用进入内核态之后,仅仅发生了特权级和堆栈的切换,但是地址空间没有变,此时并没有切换进程,在执行完这条指令之后,会将我们想要打印输出的“darkmoon”复制到内核缓冲区,以便更多进程共享
-
while(printer_status!=ready);//等待直到打印机状态为就绪
- 通过读打印机的设备控制器里的状态寄存器(例如1表示就绪,0表示未就绪)读取状态;(也叫I/O端口)
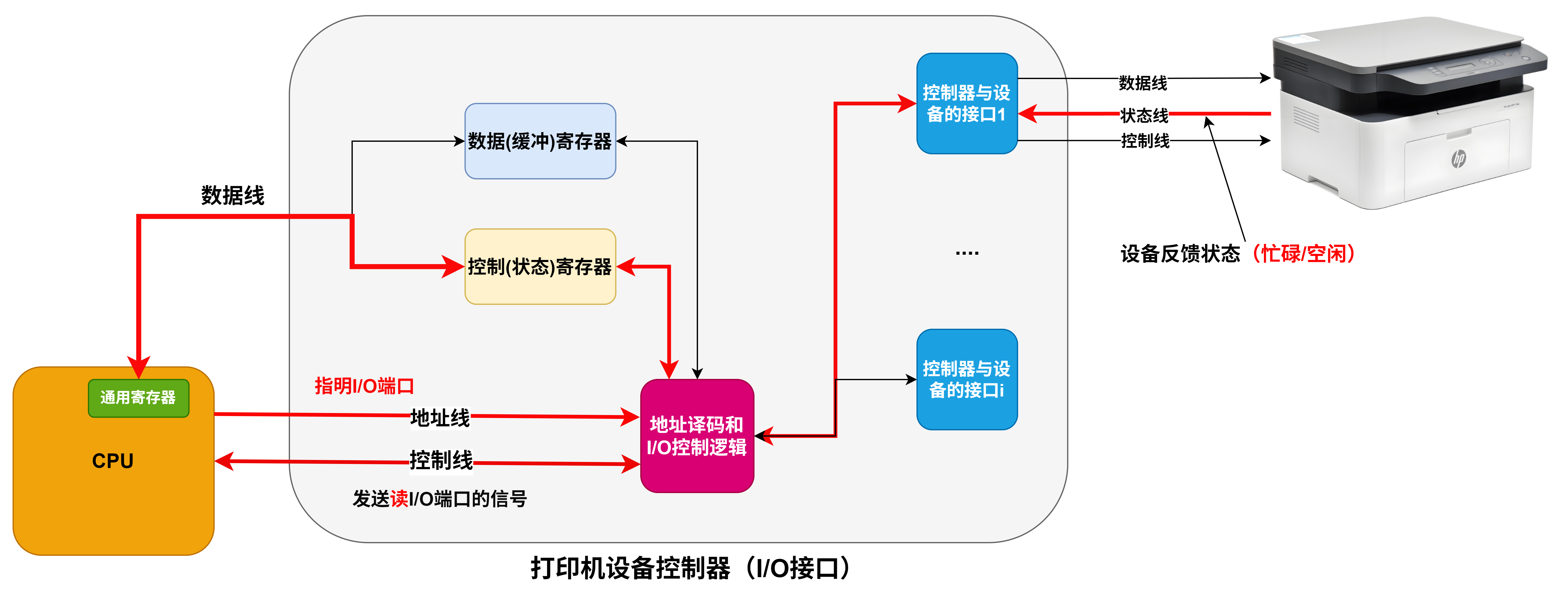
-
*printer_data_port=kernbuf[il;//向数据端口输出第一个字符
- CPU通过执行设备驱动程序从内核缓冲区读取字符串的第一个字符”d“,先读到CPU里的通用寄存器,然后执行驱动程序里的I/O指令将其写入设备控制器里的数据寄存器(I/O端口)
- 注意:设备驱动程序往打印机控制器的端口写数据(访问I/O端口)的方式有两种:
- 如果主存和I/O端口独立编址,需要通过I/O端口号访问相应的设备寄存器,将通用寄存器的信息写入I/O端口执行out命令、将I/O端口的信息读入通用寄存器则用in命令;这两个I/O指令都是特权指令,运行在内核态
- 如果主存和I/O端口是统一编址,那么I/O端口将被映射到内存物理空间,通过Load/Store的同一访存指令(非特权指令)便可完成I/O操作
- 设备驱动程序将对I/O端口的具体访问细节封装成供外部访问的write()接口,打印机设备的中断处理程序只需要调用write()接口即可实现将内核缓冲区的数据写入I/O端口(即打印机设备控制器的数据寄存器)
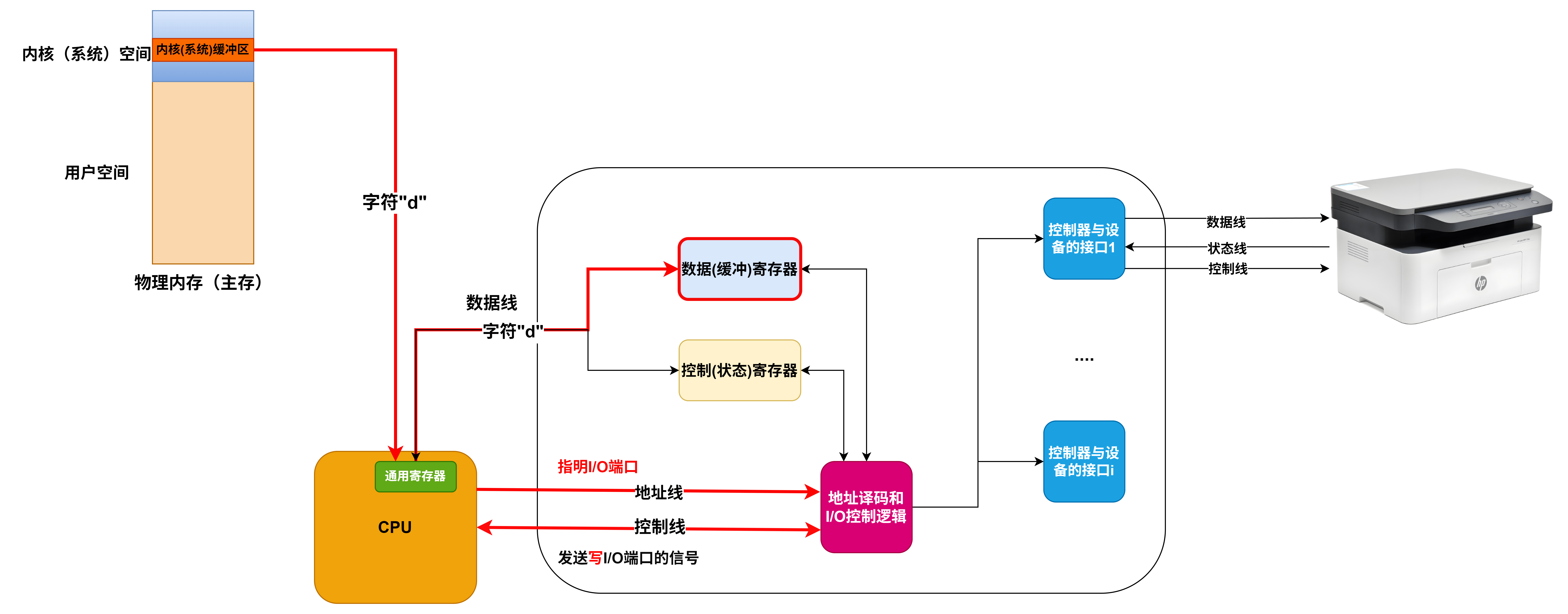
-
*printer_control_port=START;//发送”启动打印“命令
- CPU通过执行设备驱动程序向打印机设备控制器里的控制寄存器发送”启动打印“命令
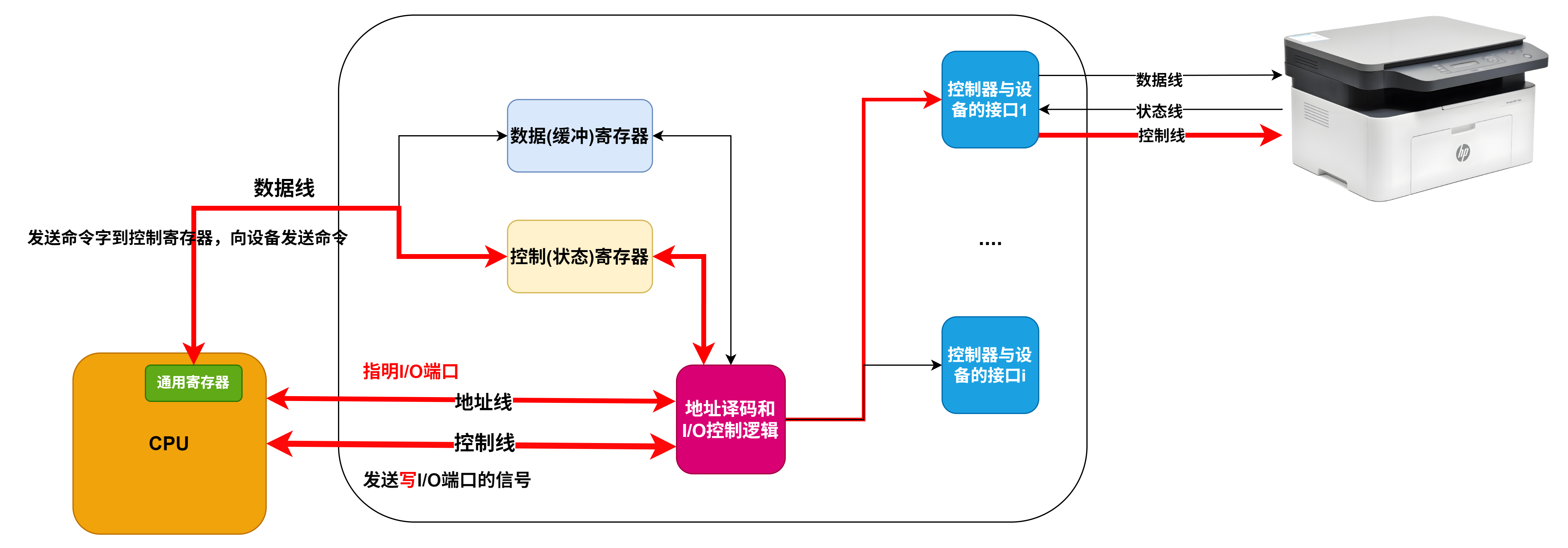
-
scheduler();//阻塞用户进程P,调度其他进程执行
- 由于当前进程P主动发起I/O,需要等打印机打印完这个字符之后P进程才能继续运行,因此CPU此时执行调度程序,修改当前进程P的状态由运行态变为阻塞态(注意,这是主动阻塞),然后将P挂入阻塞队列;
- 调度器从就绪队列选择一个进程Q,修改它的PCB,将其从就绪态修改为运行态,之后执行进程上下文切换(切换地址空间(例如页表基址寄存器的值等)、当前CPU上下文(断点、现场)等),进程Q上处理机
-
在这之后,CPU执行进程Q,与此同时,打印机也在工作,当打印机取出设备控制器里数据寄存器的字符”d“打印后,控制器里的I/O控制逻辑会发出一个中断请求信号给CPU,CPU此时正在执行进程Q,当执行完一条指令去检查是否有中断,然后收到中断信号后,切换特权级,执行中断隐指令(关中断、保存断点、中断服务程序寻址),然后跳转到”字符打印“中断服务程序执行,如下:
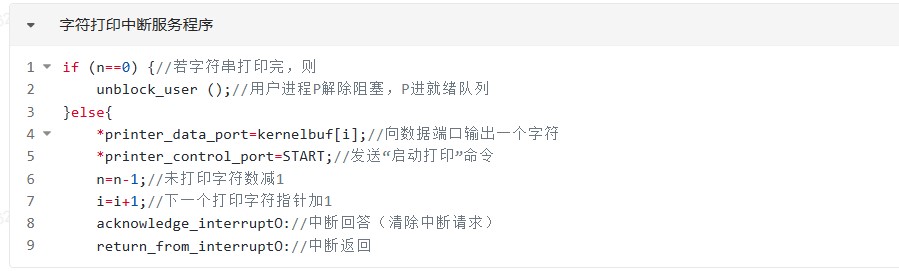
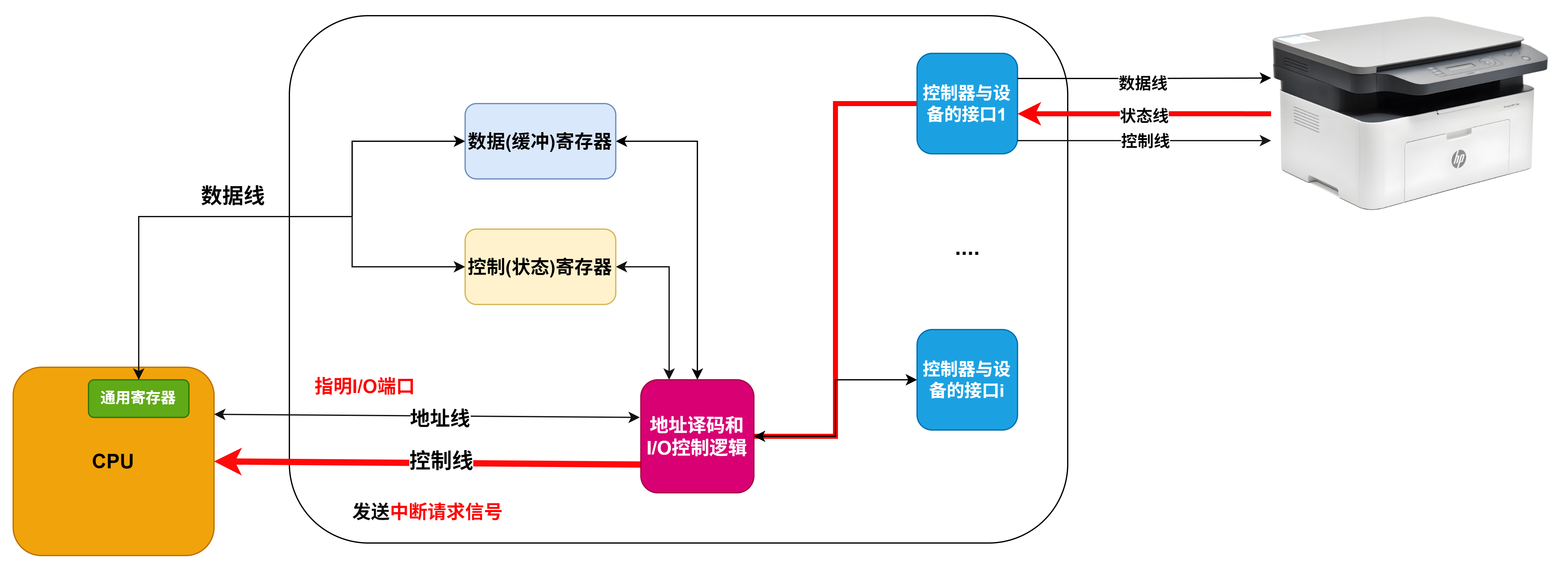
-
由此可见,字符串”darkmoon“的第一个字符打印是在sys_write系统调用服务例程的控制下进行的,剩下的字符打印都是由字符打印中断服务程序控制进行。
-
在执行该中断服务的过程中,CPU仍然运行在进程Q的环境之中,地址空间也是进程Q的,但是CPU却要执行进程P发起的打印任务;如果之前没有把要打印的字符串复制到内核缓冲区,而是放在进程P的用户地址里面,那么此时就没办法拿到这个字符串了,为什么放在内核缓冲区就可以解决这个问题,因为每个进程都有内核区区域的同映射,因此可以利用内核空间作为中介来进行数据的传递,通常我们在内核中分配一个多进程可读写的内存区域作为内核缓冲区;
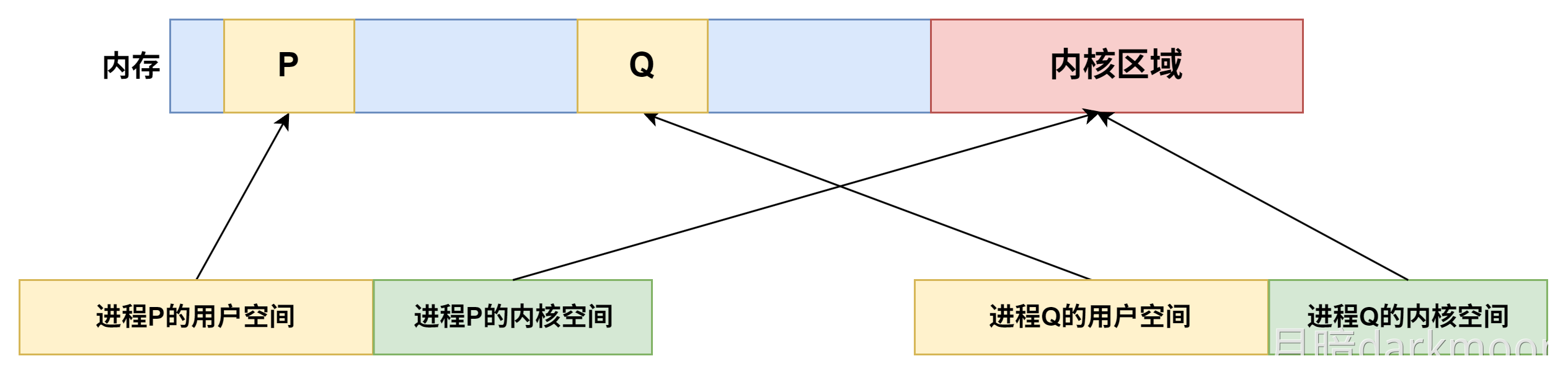
-
-
后面剩余的字符串打印都是由中断服务程序负责控制的,每次执行的时候先检查是否打印结束,如果没有,再从内核缓冲区取出该打印的字符先放入通用寄存器再送入I/O端口,然后发送”启动打印“命令,再中断返回,继续执行进程Q
-
进程Q继续执行,收到中断信号再去处理,周而复始,直到字符串全部打印结束,这时候中断服务程序会去修改进程P的状态,由阻塞态变为就绪态,将其从阻塞队列取出,放入就绪队列;然后返回继续执行进程Q
-
之后,如果进程Q释放了处理机,并且调度其从就绪队列选择了进程P上处理机,那么P会执行系统调用的最后阶段,返回用户态继续执行;
-
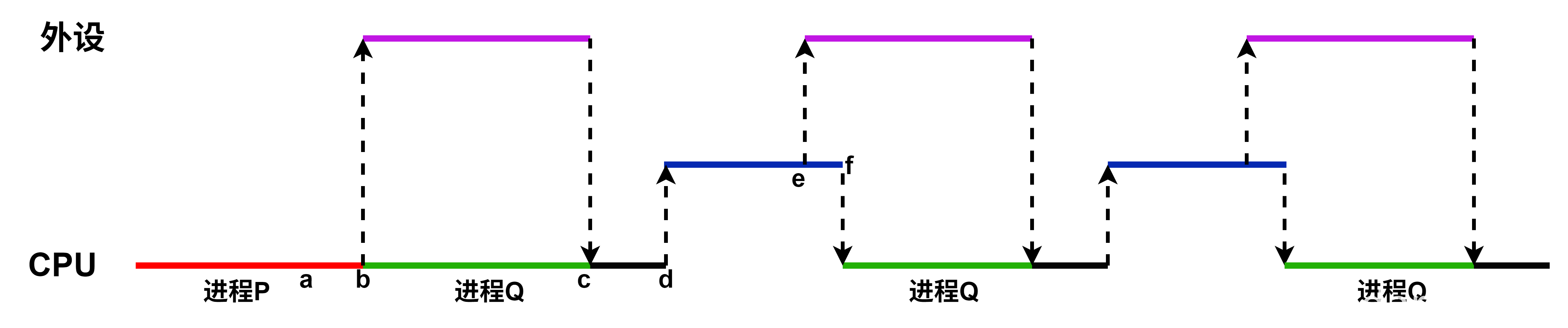
-
紫色段外设在执行打印操作,即打印机从设备控制器里的数据寄存器取出字符并打印;黑色段在执行中断隐指令(关中断、保存断点、中断服务程序寻址);蓝色段在执行字符打印中断服务程序;
- a点发起系统调用,然后查找系统调用表,执行sys_write()系统调用服务例程;
- b点启动外设打印第一个字符,与此同时,修改进程P的状态由运行态变为阻塞态,ab段是在内核态下执行的,在a点发起系统调用执行trap指令,之后执行关中断、保存断点、中断服务程序寻址,找到了system_call系统调用服务程序开始执行;
- 图中的绿色段CPU与外设都是并行执行的
- C点打印机打印结束,发来中断请求信号,进程Q在执行完一条指令后响应该中断,因此cd段在执行中断隐指令;d点找到了字符打印的中断服务程序的入口地址,之后CPU开始执行该中断服务程序;
- 在执行字符打印中断服务程序的过程中,检测到字符串没有打印结束,在e点将字符从内核缓冲区取出通过通用寄存器传送到打印机控制器里的数据寄存器,同时发出字符打印的命令,让外设工作;f点中断返回,cpu由内核态切换为用户态,进程Q继续执行;
- a点由于执行trap指令会关中断、C点响应中断请求信号后会关中断;
-
外设工作(本例子中,打印机从I/O接口里的数据寄存器取出字符打印)
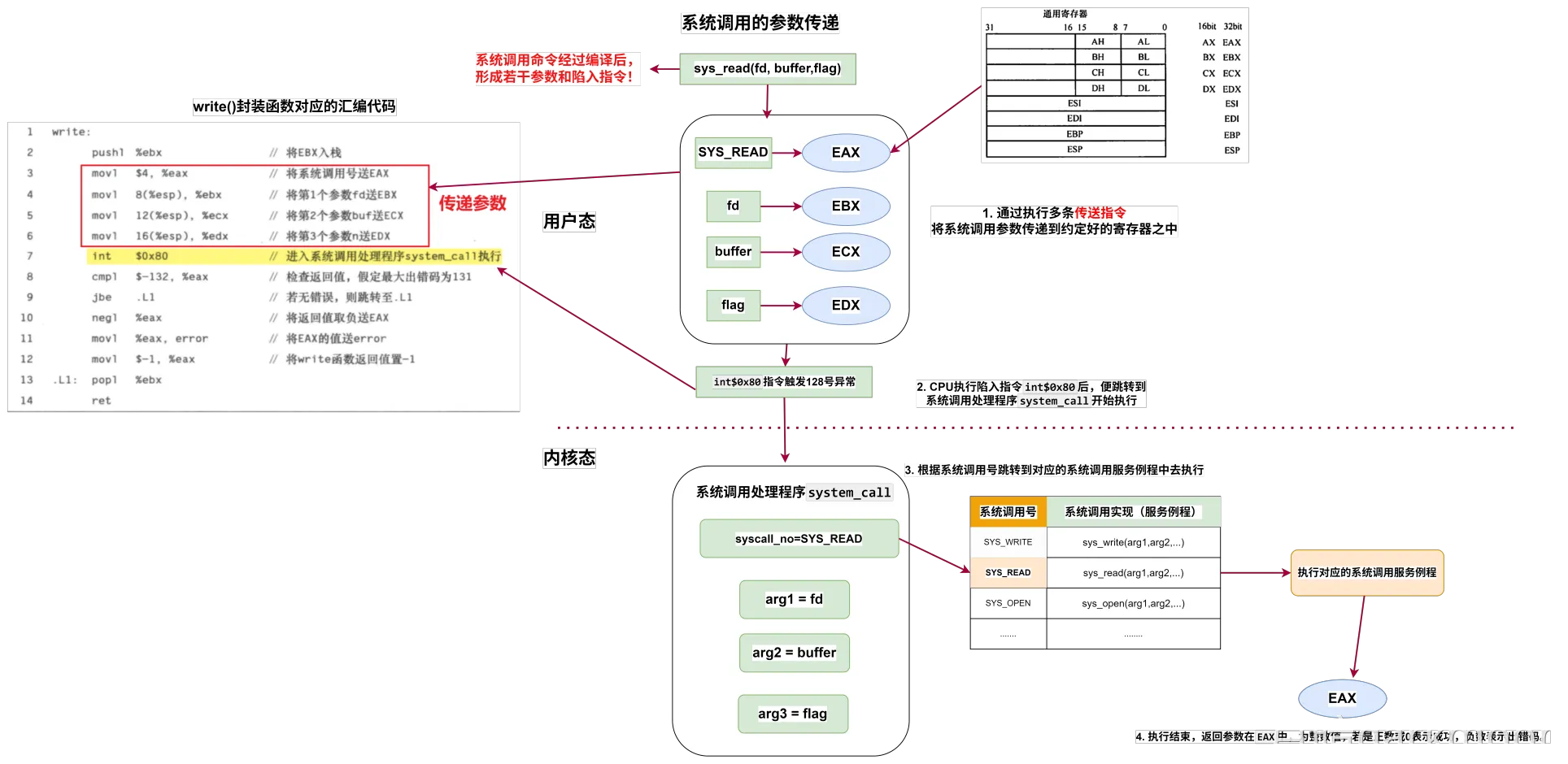
- ①进程P发起系统调用
- ②执行system_call系统调用处理程序
- ③执行sys_write系统调用服务例程
- ④将字符串复制到内核缓冲区
- ⑤将字符串的第一个字符从内核缓冲区写入打印机控制器的数据端口
- ⑥将进程P插入阻塞队列
- ⑦从就绪队列选择进程Q执行
- ⑧打印机打印完第一个字符
- ⑨启动字符打印中断处理程序
- ⑩将进程P插入就绪队列
- 11、继续执行进程Q
- 12、Q时间片到期
- 13、调度机选择P上处理机
- 14、P从系统调用返回
应用程序I/O结构(I/O系统接口)
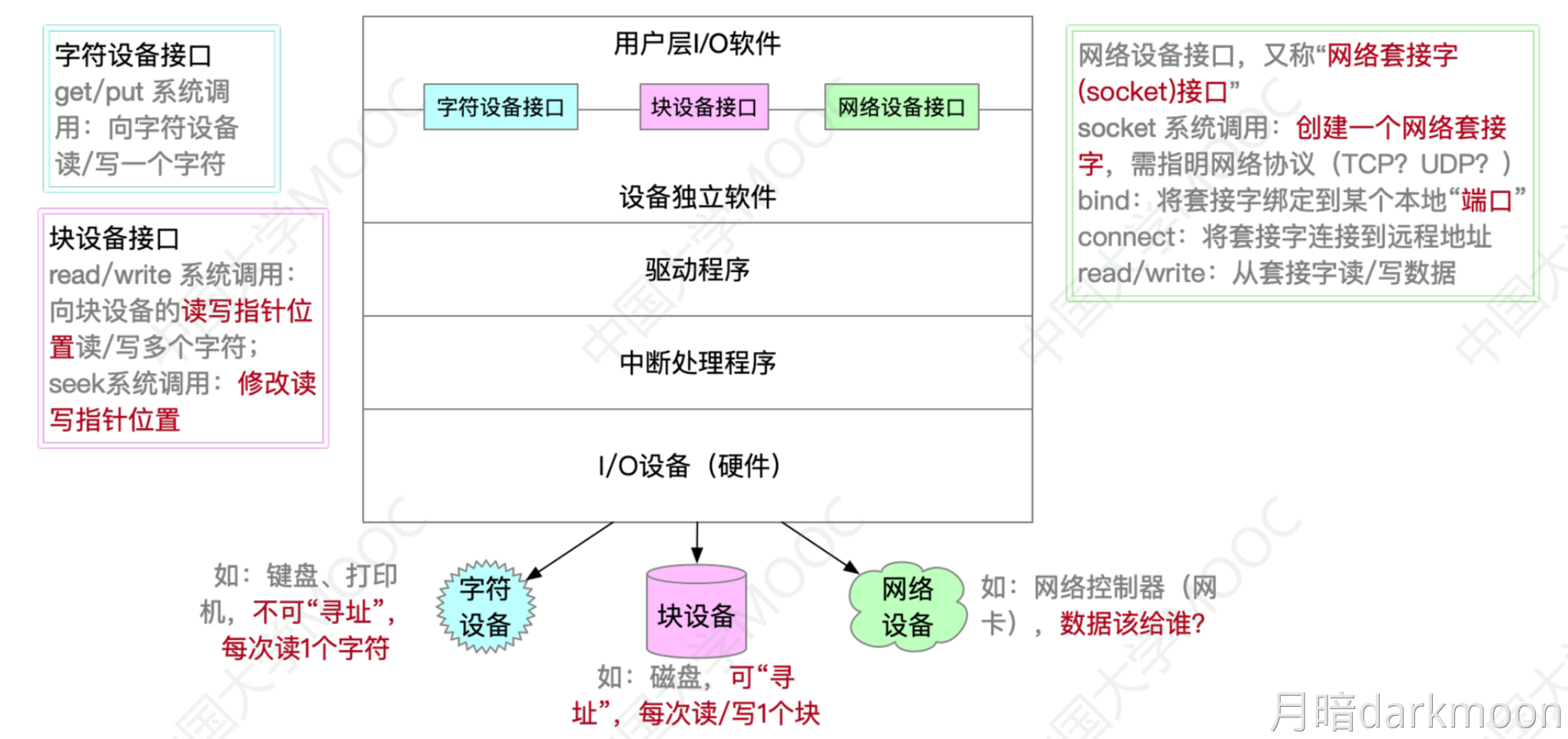
- 字符设备都属于独占设备,为此接口中还需要提供打开和关闭操作,以实现互斥共享
- 网络套接字接口
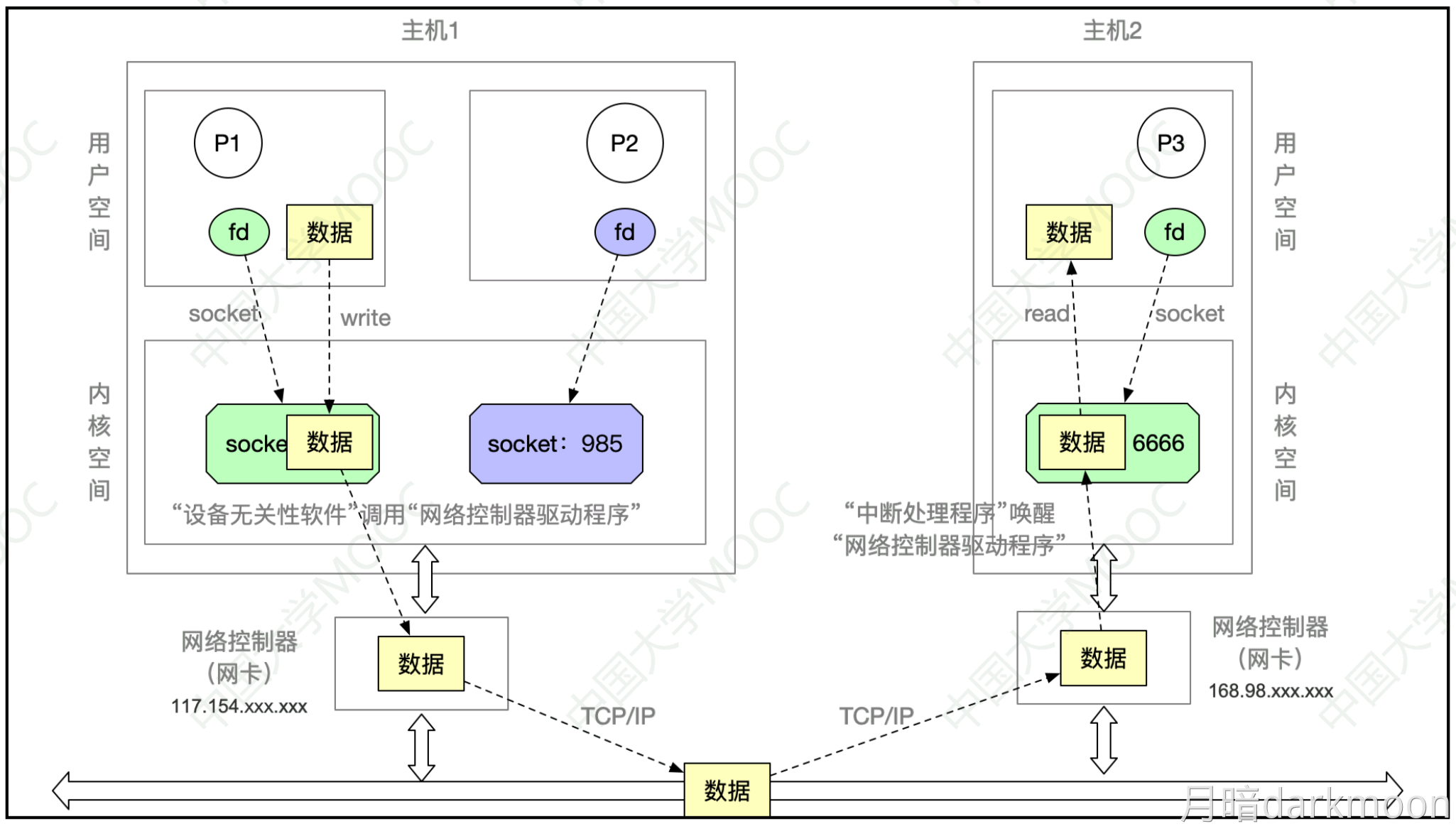
I/O软件层次结构
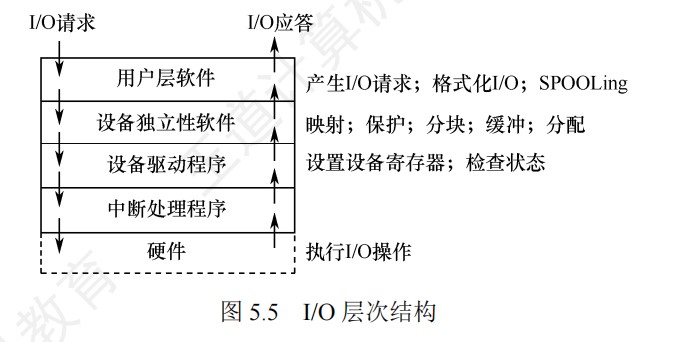
- 内核缓冲区和用户缓冲区之间的拷贝由设备独立性软件实现,通常位于系统调用服务程序内,系统调用服务程序属于设备独立性软件的层次。设备独立性软件向用户提供统一的设备I/O接口即系统调用
- 对设备的统一操作接口是由驱动程序向上层提供的
- I/O接口到内核缓冲区的数据传输代码在设备驱动程序里
- 设备驱动程序在加载时,必须向操作系统注册其中断服务程序(ISR)
- 检查对I/O设备的请求的合法性是在设备驱动程序里完成的,比如对打印机进行读操作就是非法的,应该向I/O系统报告I/O请求出错。
- 检查参数的合法性是在设备独立性软件实现的
- 所有跟设备相关的逻辑都由设备驱动程序实现
- 在应用程序中,使用逻辑设备名来请求使用某类设备,而在系统实际执行时,必须将逻辑设备名映射成物理设备名
- 设备独立性软件翻译解析用户的命令并且转换为设备操作命令,然后设备驱动程序选择对应的设备的命令进行具体的执行
- 设备独立性软件为设备管理和数据传输提供必要的存储空间
- 直接涉及到硬件具体细节、且与中断无关的操作肯定是在设备驱动程序层完成的没有涉及硬件的、对各种设备都需要进行的管理工作都是在设备独立性软件曾完成的
设备独立性软件和设备驱动程序提供统一接口的区别
-
设备独立性软件提供的接口面向应用
- 设备独立性软件面向用户或文件曾提供统一逻辑接口,如统一使用read/write、open/close等系统调用去访问各种设备
- 设备独立性软件定义的是用户可见、跨设备一致的I/O抽象接口
-
设备驱动程序提供的接口(面向硬件设备)
- 接收来自设备独立性软件的统一I/O请求(如read/write),然后将其翻译为具体硬件的控制命令,并通过总线或控制器与设备交互
- 系统内部用于驱动特性设备的接口和实现
-




-
.jpg)
-
设备独立性软件:
- 检查用户是否有权使用设备属于设备保护,在独立性软件中完成
- 有没有钥匙能进门(权限问题)
- 检查用户是否有权使用设备属于设备保护,在独立性软件中完成
-
设备驱动程序
- 检查用户I/O请求的合法性是在设备驱动程序完成的。
- 进门后要求的事情对不对(操作是否合法)
- 检查用户I/O请求的合法性是在设备驱动程序完成的。
设备驱动程序
-
功能
-
①接收由与设备无关的软件发来的命令和参数,并将命令中的抽象I/O要求转换为与设备相关的低层操作序列;
-
②检查用户I/O请求的合法性,了解I/O设备的工作状态,传递与I/O设备操作有关的参数,设置I/O设备的工作方式;
-
③发出I/O命令,如果I/O设备空闲,则立即启动它,完成指定的I/O操作;如果I/O设备忙碌,则将请求者的请求块挂在I/O设备队列上等待;
-
④及时响应由设备控制器发来的中断请求,并根据其中断类型,调用相应的中断处理程序进行处理。
-
-
设备驱动程序应允许可重入,一个正在运行的设备驱动程序常会在一次调用完成前被再次调用。
- eg:驱动程序在相应系统调用处理I/O请求的过程中,被该设备完成上一次操作所产生的硬件中断所打断
- 驱动程序的代码(如处理write系统调用的部分)正在执行时,一个硬件中断到来,导致CPU切换去执行该驱动程序的另一部分代码(中断服务程序)。如果这两部分代码使用了共享的全局变量或静态变量而没有特殊保护,就可能导致数据错乱。可重入函数通过不适用这类共享数据或有特殊保护,来保证在这种“自我打断再进入”的情况下依然能正确工作。
-
设备驱动程序的执行过程
-
1.将抽象要求转换为具体要求
- 例如,将抽象要求中的盘块号转换为磁盘的盘面号、磁道号及扇区号。而这一转换工作只能由设备驱动程序来完成,因为在OS中只有设备驱动程序是同时了解抽象要求和设备控制器中的寄存器情况的,也只有它才知道命令、数据和参数应分别送往哪个寄存器。
-
2.校验服务请求
-
3.检查设备的状态
-
设备驱动程序在启动设备之前,要先把状态寄存器中的内容读入CPU的某个寄存器中,通过测试寄存器中的不同位来了解设备的状态
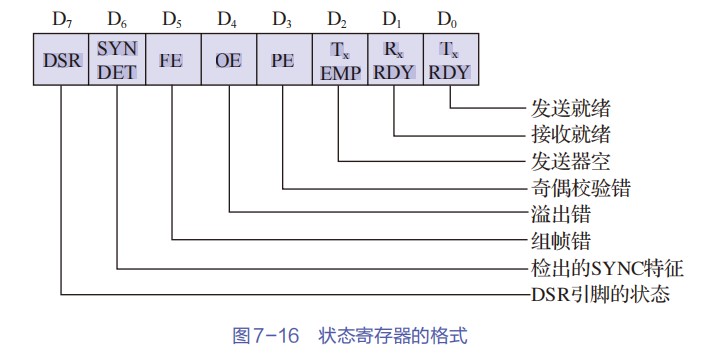
-
-
4.传送必要的参数
-
5.启动 I/O 设备
-
-
为了实现设备无关性,在UNIX和Linux系统中,设备被作为特别文件处理,用户的I/O请求、对命令的合法性检查以及参数处理任务等,都在文件系统中统一处理。只在需要各种设备执行具体操作时,系统才会通过相应的数据结构(如UNIX系统的块设备转接表、字符设备转接表等)转入不同的设备驱动程序。
-
设备驱动程序可在系统初启时初始化,也可在需要时动态加载。初始化的一项重要工作就是设备登记(或注册),即把设备驱动程序的地址登记在设备表的相应表项中。经登记后,**只要知道设备的主设备号,就可以找到该类设备的各种驱动函数。**这样,在设备驱动程序上的其他内核模块中就可以“看见”这个模块了。当关闭设备时,要从内核中注销设备驱动程序。
-
设备驱动程序(或中断处理程序的一部分)会唤醒等待输入的进程,将其状态从阻塞态变为就绪态,并放入就绪队列
-
驱动程序不允许系统调用,驱动程序本身就运行在内核态,而系统调用是用户态的程序请求使用内核态的服务。
-
设备驱动程序会及时响应由设备控制器发来的中断请求,并根据其中断类型,调用相应的中断处理程序进行处理
-
设备驱动程序必须在初始化时,就向系统的中断管理模块注册自己的中断服务程序,这样当中断发生时,操作系统才知道应该调用哪段代码来处理后续事宜(如唤醒等待的进程、检查错误等)。
设备驱动程序的统一接口
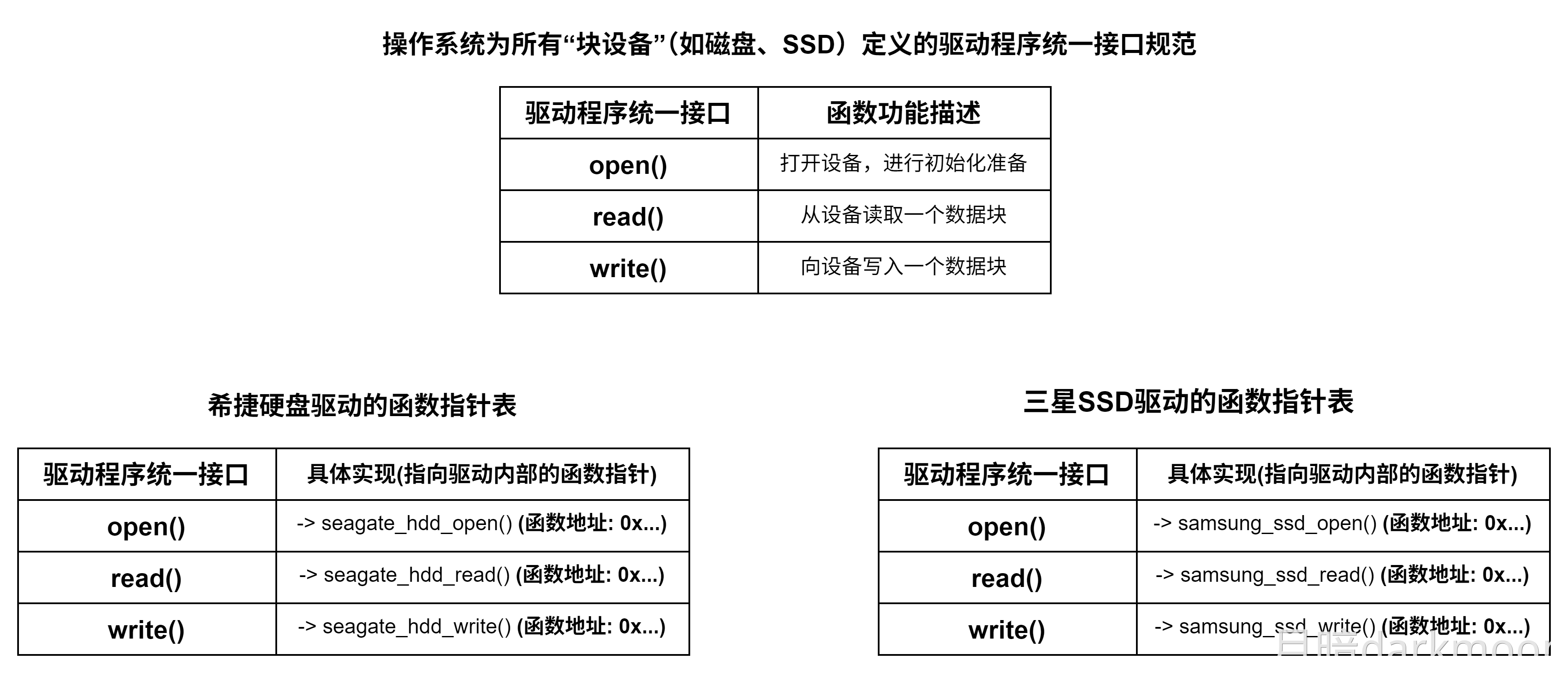
- 工作流程:当一个应用程序需要从三星SSD中读取数据时,操作系统内核的上层软件会发出一个通用的read()请求。内核根据这个请求是发往三星SSD的,就会去查找“三星SSD驱动的函数指针表”,看到标准read()接口对应的是samsung_ssd_read()这个具体函数的地址,然后内核就会间接调用Samsung_ssd_read()函数来完成实际的硬件操作。
- 同一个操作系统对同类型的所有设备的驱动程序提出了统一的接口规范要求,因此不同型号的同类设备为同一个系统提供的接口是一样的,而不同系统提出的接口规范可能是不一样的。
设备无关软件
- 与设备无关的I/O软件还可实现I/O重定向。所谓I/O重定向,是指用于I/O操作的设备可以更换(即重定向),而不必改变应用程序。例如,我们在调试一个应用程序时,可将程序的所有输出送往屏幕显示。而在程序调试完后,若须正式将程序的运行结果打印出来,此时便须将I/O重定向的数据结构——逻辑设备表中的显示终端改为打印机,而不必修改应用程序。
- 一般来说,设备出现故障后,主要由设备驱动程序对其进行处理。而与设备无关的I/O软件只处理那些设备驱动程序无法处理的错误。
- 内核中设备无关的I/O软件必须将不同的设备名和文件名映射到对应的设备驱动程序
- unix系统中,主设备号确定设备类型,被系统用来确定设备驱动程序,次设备号被驱动程序用来确定具体的设备。
- 设备独立性通过逻辑设备名和OS内部映射这两个关键手段,将应用程序与物理硬件解耦。因此,更换物理设备只需要修改OS层面的配置,而不需要修改应用程序。
- SPOOLING技术属于设备无关软件
设备分配与回收
-
安全分配方式:为进程分配一个设备后就将进程阻塞,本次I/O完成后才将进程唤醒,一个时段内,每个进程只能使用一个设备
- 优点:破坏了请求和保持条件,不会死锁
- 缺点:对于一个进程来说,CPU和I/O设备只能串行工作
-
不安全分配方式:进程发出I/O请求后,系统为其分配I/O设备,进程可继续执行,之后还可以发出新的I/O请求。只有某个I/O请求得不到满足时才将进程阻塞。一个进程可以同时使用多个设备
- 优点:进程的计算任务和I/O任务可以并行处理,使进程迅速推进
- 缺点:由于可能具备请求并保持条件,因此可能发生死锁(解决方法:死锁避免、死锁的检测和解除)
-
当某进程释放某设备,且无其他进程请求该设备时,系统将该设备DCT中的设备状态改为空闲,即可实现“设备回收”。
-
安全分配方式摒弃了造成死锁的四个必要条件之一的“请求和保持”条件,故设备分配是安全的。
-
设备分配步骤:
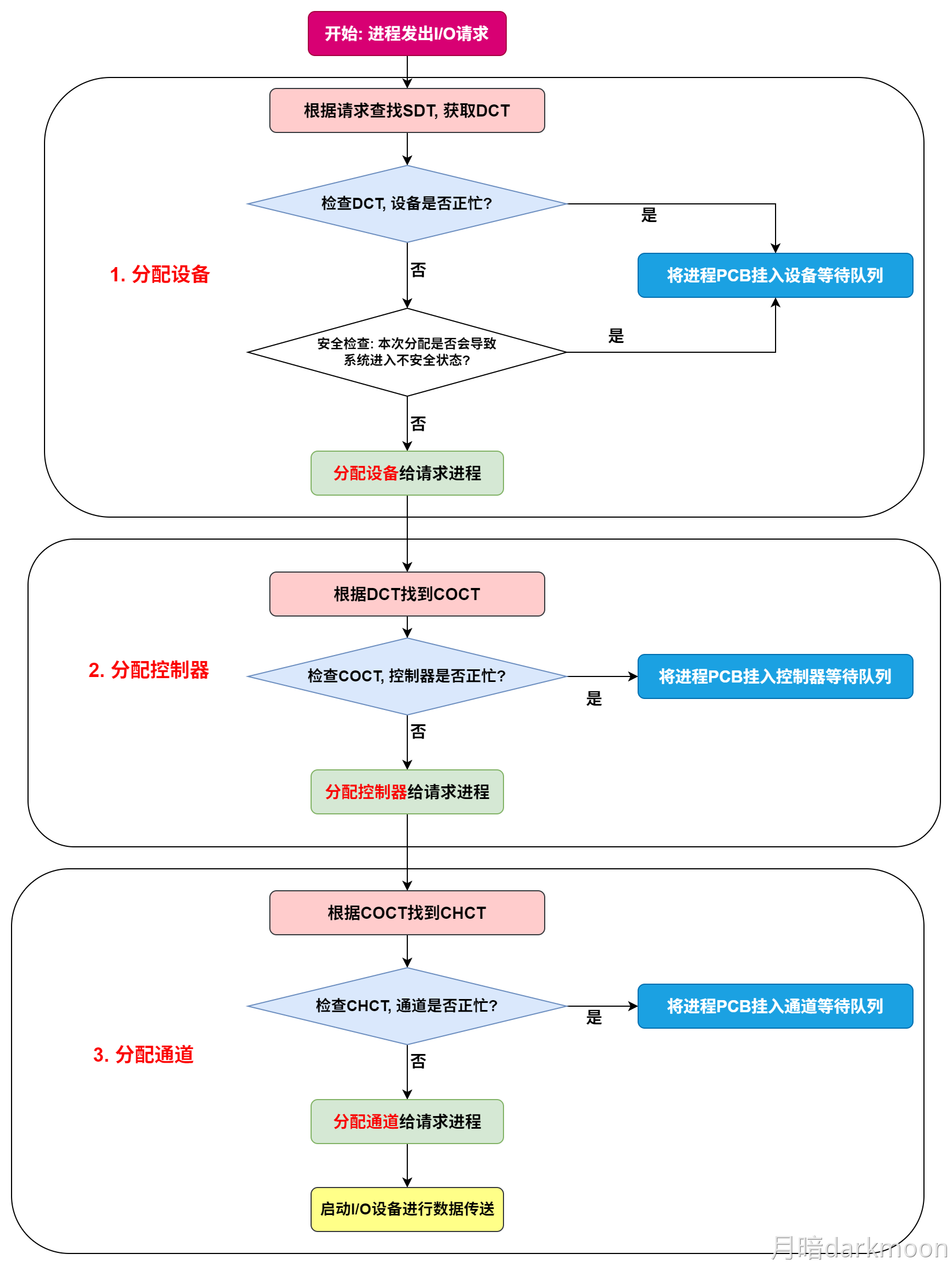
- ① 分配设备。首先根据I/O请求中的物理设备名,查找SDT,从中找出该设备的DCT,再根据DCT中的设备状态字段获知该设备是否正忙。若忙,则将请求I/O的进程的PCB挂在设备队列上。否则,按照一定的算法计算本次设备分配的安全性。如果不会导致系统进入不安全状态,则将设备分配给请求进程。否则,仍将其PCB插入设备等待队列。
- ② 分配控制器。在系统把设备分配给请求I/O的进程后,再到其DCT中找出与该设备连接的控制器的COCT,从COCT的状态字段中可知该控制器是否正忙。若忙,则将请求I/O进程的PCB挂在该控制器的等待队列上。否则,将该控制器分配给进程。
- ③ 分配通道。在该COCT中又可找到与该控制器连接的通道的CHCT。根据CHCT内的状态信息可知该通道是否正忙。若忙,则将请求I/O的进程挂在该通道的等待队列上;否则,将该通道分配给进程。只有在设备、控制器和通道三者都分配成功时,这次的设备分配才算成功。然后,便可启动该I/O设备进行数据传送。
- SDT→DCT→COCT→CHCT
-
设备类型:逻辑设备名
- 设备标识符:物理设备名
-
独占设备,既可以动态分配也可以静态分配,往往采用静态分配
- 静态分配是一种非抢占式的分配,资源一旦分配给某进程,只有在该进程运行结束或主动释放后才能被收回。
-
共享设备采用动态分配,每个I/O传输的单位时间内只被一个进程所占有,通常采用先请求先分配和优先级高者先分的分配算法。
-
设备分配方式解决的是什么时候分,而设备分配安全性是分配后阻不阻塞
-
为了实现设备独立性,系统会建立逻辑设备表LUT来记录逻辑设备名到物理设备名的映射。
- 当进程首次请求设备分配时,系统为其分配一台相应的物理设备,同时在LUT中新增一个表项;以后如果该用户进程再次通过相同的逻辑设备名请求该设备,直接查表即可。
- 在多用户操作系统中,通常是为每个用户(或进程)建立一张LUT,存放在其PCB中。因此,当进程第二次用同一个逻辑设备名请求时,系统最高效的方式是直接查找该进程自己的LUT,获取已建立的映射关系。
缓冲区
- 用户进程在提出I/O请求时,指定的用来存放I/O数据的缓冲区在用户空间中。
- 例如,文件读函数fread(buf,size,num,f)中的缓冲区buf在用户空间中。通过陷阱指令陷入到内核态后,内核通常会在内核空间中再开辟一个或两个缓冲区,这样,在底层I/O软件控制设备进行I/O操作时,就直接使用内核空间中的缓冲区来存放I/O数据。
- 为何不直接使用用户空间缓冲区呢?
- 因为,如果直接使用用户空间缓冲区(即工作区),那么,在外设进行I/O期间,由于用户进程被挂起而使用户空间的缓冲区所在页面可能被替换出去,这样就无法获得缓冲区中的I/O数据。
- 其他原因包括:可解决不同块设备读写单位的不一致、便于共享等。
- 缓冲区是在内核空间里的系统缓冲区,而工作区则是在用户进程空间里的缓冲区;当然二者都是在内存中。
单缓冲
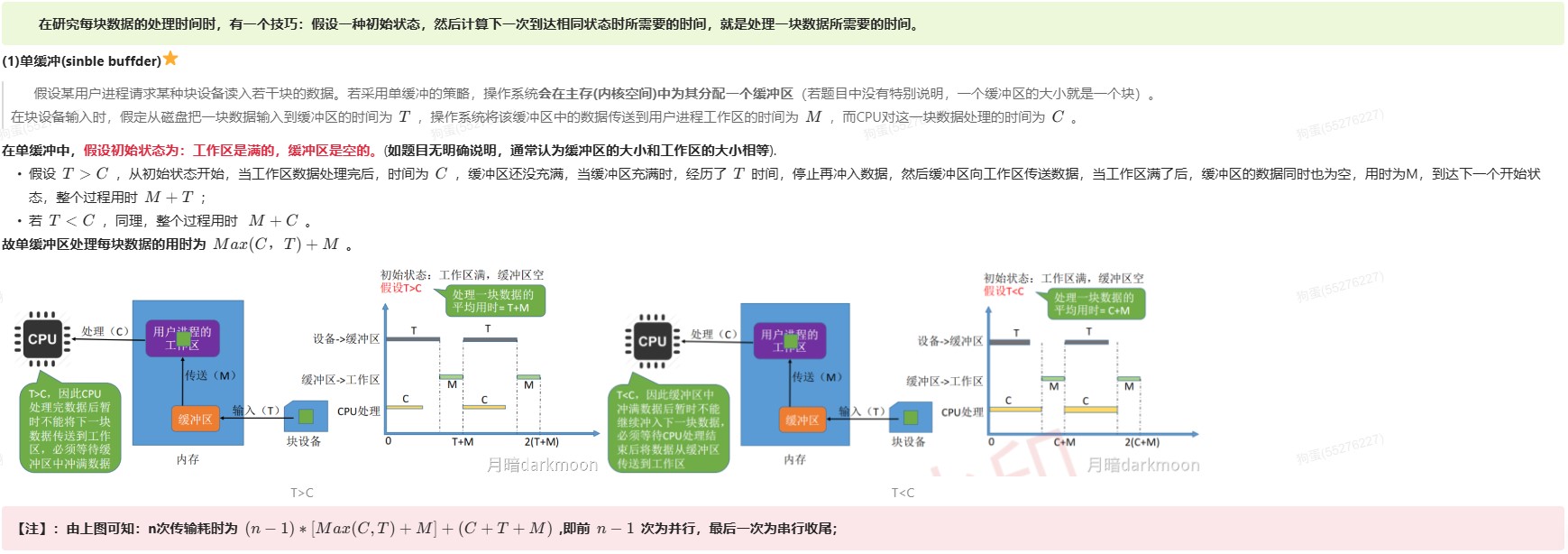
双缓冲
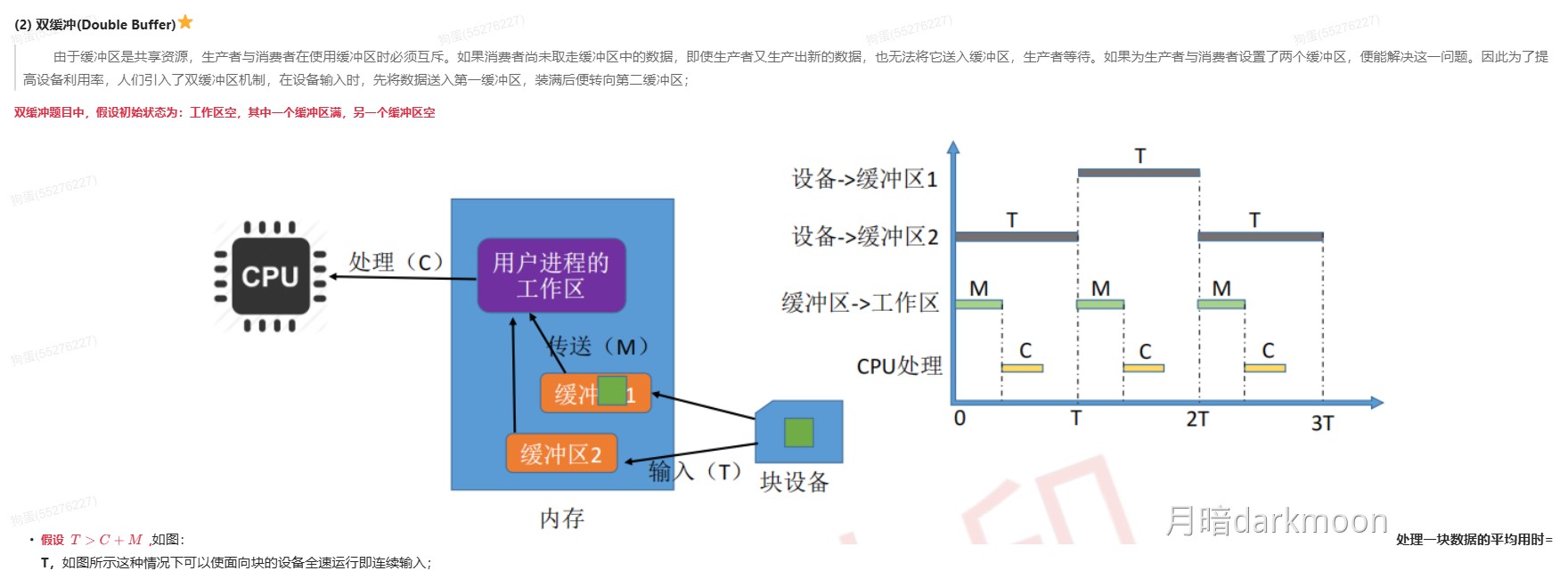
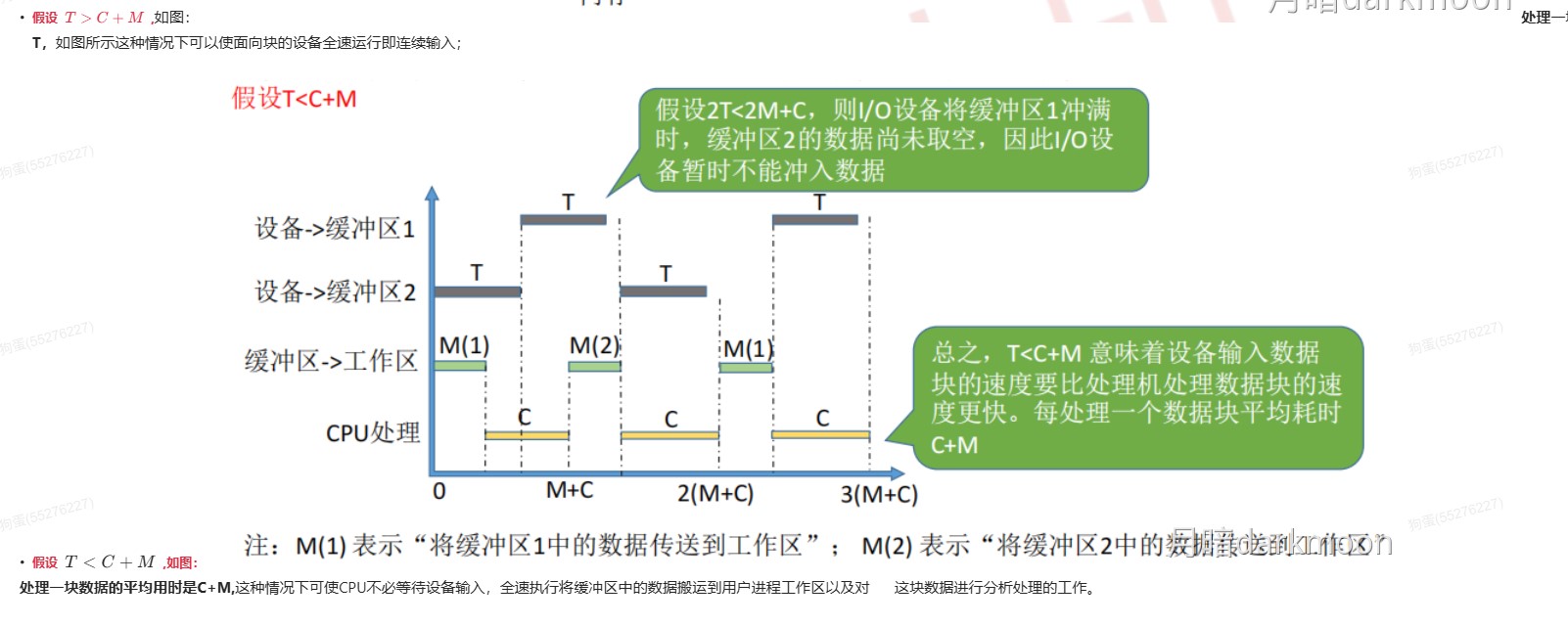
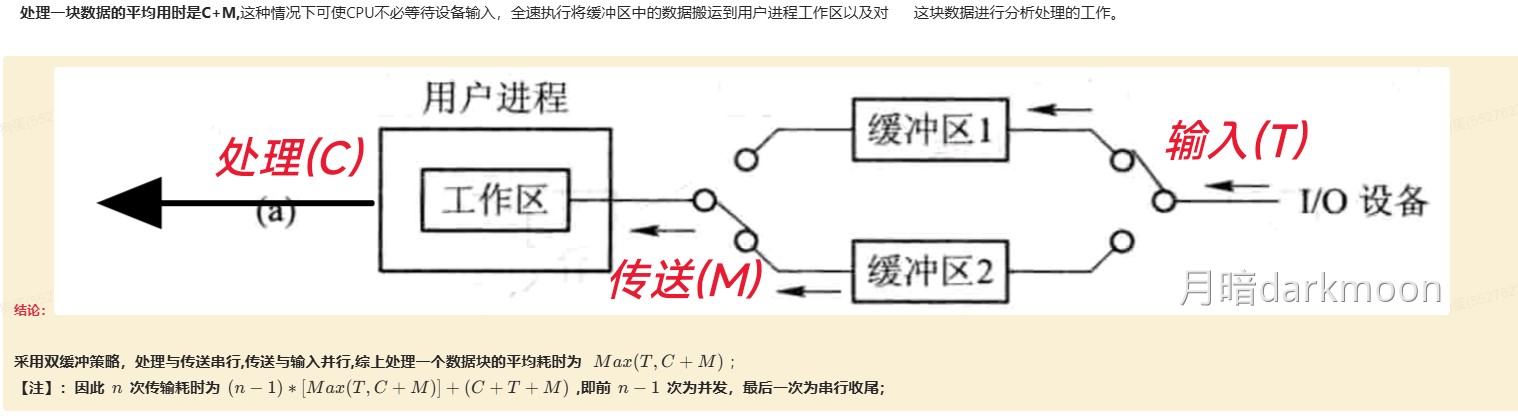
- 在双缓冲机制中,当输入和输出的速度基本匹配时,能取得较好的效果
环形缓冲区
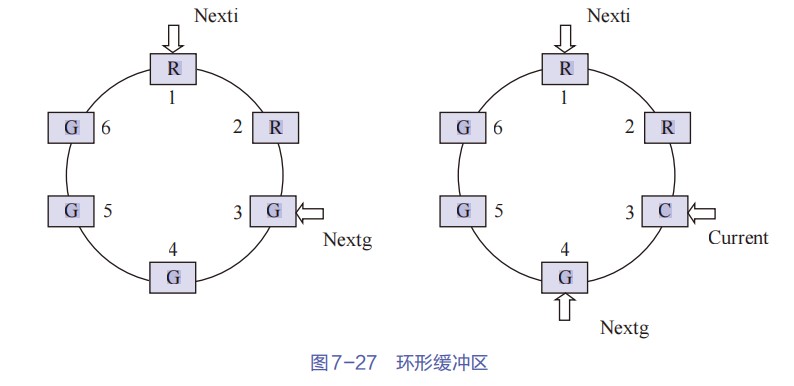
- 进程同步问题
- (1)Nexti指针追赶上Nextg指针。这意味着输入进程输入数据的速度大于计算进程处理数据的速度,已把全部可用的空缓冲区装满,再无缓冲区可用。此时,输入进程应阻塞,直到计算进程把某个缓冲区中的数据全部提取完,使之成为空缓冲区R,并调用Releasebuf过程将它释放后,才可将输入进程唤醒。这种情况被称为“系统受计算限制”
- (2)Nextg指针追赶上Nexti指针。这意味着输入数据的速度小于计算进程处理数据的速度,使装有输入数据的缓冲区都被抽空,再无装有数据的缓冲区供计算进程提取数据。这时,计算进程只能阻塞,直至输入进程又装满某个缓冲区,并调用Releasebuf过程将它释放后,才可将计算进程唤醒。这种情况被称为“系统受I/O限制”。
磁盘高速缓存在现代OS中的应用
- 页缓存(Page Cache):文件数据的核心缓存(文件内容在内存中的副本)
- 缓存对象:文件的数据内容本身,以及通过mmap映射的内存区域。
- 工作单位:内存页(Page),这使得它能与系统的虚拟存储管理无缝集成,效率极高。
- 核心职责:读取文件时,内核会首先在页缓存中查找。写入文件时,通常也是先写入页缓存(回写模式),然后由内核在后续某个时刻同步到磁盘。几乎所有的文件I/O都会经过它。
- 目录项缓存(Dentry Cache):为了解决“查找文件”这一高频操作而涉及的缓存
- 缓存对象:目录项,也就是文件名和其对应的索引节点(inode)编号之间的映射关系。(inode编号)
- 核心职责:当你要打开一个路径,内核需要逐级解析这个路径。
- a.在根目录/中找到home目录的inode编号。
- b.在home目录中找到user目录的inode编号
- c.在user目录中找到file.txt文件的inode编号。每一步都可能需要读取磁盘上的目录文件。Dentry缓存将这些“文件名→inode编号”的查找结果保存在内存中。如果一个路径的所有组成部分都在Dentry缓存中,那么整个路径解析过程就可以完全在内存中完成,无需任何磁盘I/O
- 索引节点缓存(inode Cache):当Dentry缓存帮我们找到了文件的inode编号后,inode缓存就登场了
- 缓存对象:索引节点inode本身,这个结构体包含了文件的所有元数据:权限、所有者、大小、创建/修改时间,以及指向文件数据块的指针等。
- 核心职责:将磁盘上存储的inode结构体缓存在内存中。当内核通过Dentry缓存拿到inode编号后,它会紧接着查询inode缓存,以获取该文件的所有属性信息。如果没有这个缓存,每次获取文件属性,都需要一次磁盘读取,系统会变得极慢
- 缓冲区缓存(Buffer Cache):块设备的对阶层
- 缓存对象:磁盘块的元信息,以及与Page Cache关联的缓冲区头
- 核心职责:在现代内核中,它不再是文件数据缓存的主力(这个工作已交给Page Cache)。他的主要职责变成了:缓存文件系统的元数据块:如超级块、块分配位图、inode所在磁盘块等,这些数据不属于任何一个文件,但对文件系统至关重要
以打开并读取文件/home/user/file.txt为例穿越讨论过的所有缓存层
- ①open系统调用
- 场景一:理想情况(所有缓存全部命中)
- 1、发起调用:应用程序调用open(),程序从用户态陷入内核态
- 2、路径解析开始(VFS层):
- 查询Dentry缓存:内核需要将路径/home/user/file.txt拆分并逐级查找。
- 它首先在Dentry缓存中查找home(相对于根目录/)。命中!立即获得home目录的inode编号。
- 接着查找user(相对于home)。命中!获得user目录的inode编号
- 最后查找file.txt(相对于user)。命中!获得file.txt的inode编号。
- 查询Dentry缓存:内核需要将路径/home/user/file.txt拆分并逐级查找。
- 3、获取文件属性:
- 查询inode缓存:内核使用上一步获得的file.txt的inode编号,在inode缓存中查找对应的inode对象。**命中!内核立刻获得了文件的所有元数据(权限、所有者、大小等)**而无需访问磁盘
- 4、权限检查:内核根据内存中的inode信息,检查当前进程是否有权限以只读方式打开该文件。检查通过。
- 5、返回结果:内核在进程的文件描述符表中创建一个新条目,指向一个代表这个已打开文件的内核对象,并最终将这个条目的索引作为文件描述符返回给应用程序
- 结论:在全部缓存命中的情况下, open操作完全在内存中完成,没有任何磁盘I/O
- 场景二:复杂情况(相关缓存均未命中)
- 1、发起调用:同上
- 2、路径解析(Dentry缓存未命中)
- 内核开始解析路径,但在查找file.txt(在user目录下)时,Dentry缓存未命中
- 内核此时必须亲自读取user目录文件的内容,来查找file.txt的条目
- 内核向页缓存(Page Cache)请求user目录文件的数据块,页缓存也未命中
- 内核被迫发起磁盘I/O,从磁盘中读取user目录文件的数据块,并将其加载到页缓存中。
- 现在,内核可以从内存(页缓存)中解析user目录的内容了,找到了file.txt对应的inode编号。同时,它将这个file.txt->inode编号的映射关系存入Dentry缓存
- 3、获取文件属性(inode缓存未命中)
- 内核拿着新找到的inode编号,去inode缓存中查找。再次未命中。
- 内核根据文件系统的元数据计算出该inode在磁盘上的物理位置(在哪个块,偏移多少)
- 内核向块设备层请求这个inode所在的磁盘块。这个请求会先经过缓冲区缓存,发现也没有。
- 内核发起第二次磁盘I/O,读取inode所在的块,并将其加载到缓冲区缓存。
- 内核从缓冲区缓存的原始数据中,解析出file.txt的inode结构,并将其存入inode缓存。
- 4、权限检查与返回:同理想情况,但此时使用的是刚刚从磁盘加载并缓存起来的inode
- 结论:在缓存未命中的情况下,open操作可能触发多次磁盘I/O(用于读取目录内容和文件的inode),并将结果填充到各级缓存中,为下一次访问铺平道路
- 第二步:read(fd,buffer,N_bytes)系统调用
- read操作的核心目的是将文件的数据内容,从内核空间复制到用户空间的buffer中。
- 场景一:理想情况(页缓存命中)
- 1、发起调用:应用程序调用read()。此时内核已经通过fd拥有了文件的所有上下文信息(包括已缓存的inode)
- 2、定位数据:内核根据文件当前的读写偏移量,计算出需要读取的数据对应在文件的哪些页上。
- 3、查询页缓存:内核到页缓存中查找这些页。命中!文件的数据已经在内存里了。
- 4、数据复制:内核将数据从页缓存直接复制到应用程序提供的用户空间buffer中。
- 5、返回结果:更新文件读写偏移量,并返回成功读取的字节数。
- 结论:在页缓存命中的情况下,read操作也完全在内存中完成,没有任何磁盘I/O,本质上是一次内存到内存的拷贝。
- 场景二:复杂情况(页缓存未命中)
- 1、发起调用:同上。
- 2、定位与查询(页缓存未命中):内核在页缓存中查找所需的数据页,但未命中。
- 3、查找数据位置:内核查看已在inode缓存中的文件inode,计算出所需数据在物理磁盘上的确切块地址。
- 4、发起磁盘I/O:内核向块设备层发出请求,读取这些数据块。这些请求会先经过缓冲区缓存,如果之前没有其他程序恰好读过这些裸块,那么也会未命中。
- 5、物理读取与填充:内核发起真正的磁盘I/O,从磁盘读取数据。
- 读取到的数据块被用来填充到页缓存中(通过缓冲区缓存作为媒介)
- 操作系统通常会进行预读入,即除了读取当前请求的块,还会一并读取后续的几个块,并也放入页缓存,因为猜测你马上就会需要他们(空间局部性原理)
- 6、数据复制与返回:一旦数据被加载到页缓存,流程就回到了理想情况的第4步。内核将数据从刚刚填充好的页缓存复制到用户buffer,然后返回
- 结论:在页缓存未命中的情况下,read操作会触发一次(或多次,取决于读取大小和预读策略)磁盘I/O,其主要目的是将数据从磁盘搬到页缓存中。这次读取会比较慢,但它会使后序对相同或相邻数据的读取变得飞快。
- 场景一:理想情况(所有缓存全部命中)
缓冲池
-
缓冲池与缓冲区的区别在于:缓冲区仅是一组内存块的链表,而缓冲池则是包含了一个用于管理自身的数据结构和一组操作函数的管理机制,用于管理多个缓冲区。
-
缓冲区是专门为特定的生产者与消费者设置的,它们属于专用缓冲。
-
广泛应用既可用于输入、又可用于输出的(公用)缓冲池(buffer pool),该池中设置了多个可供若干进程共享的缓冲区(请求分页中可变分配局部置换、可变分配全局置换中予以分配的系统空页队列)
-
三个队列、四种工作缓冲区
-
缓冲池的工作方式
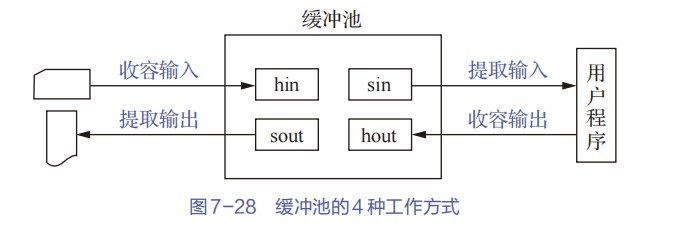
- (1)收容输入。输入进程可调用Getbuf (emq)过程,从空缓冲区队列emq的队首摘下一空缓冲区,并把它作为收容输入工作缓冲区hin。然后,把数据输入其中,装满后再调用Putbuf(inq,hin)过程,将它挂在输入队列inq上。
- (2)提取输入。计算进程可调用Getbuf (inq)过程,从输入队列inq的队首取得一缓冲区,并将它作为提取输入工作缓冲区sin,计算进程从中提取数据。计算进程用完该数据后,再调用Putbuf(emq,sin)过程,将它挂到空缓冲区队列emq上。
- (3)收容输出。计算进程可调用Getbuf (emq)过程,从空缓冲区队列emq的队首取得一空缓冲区,并将它作为收容输出工作缓冲区hout。当其中装满输出数据后,再调用Putbuf (outq,hout)过程,将它挂在输出队列outq末尾。
- (4)提取输出。输出进程可调用Getbuf (outq)过程,从输出队列的队首取得一装满输出数据的缓冲区,并将它作为提取输出工作缓冲区sout。在数据提取完后,再调用Putbuf(emq,sout)过程,将它挂在空缓冲区队列emq末尾。
-
缓存和缓冲的区别:缓冲可以保存数据项的唯一的现有版本;而根据定义,缓存只提供一个位于其他地方的数据项的更快存储副本。
SPOOLing和缓冲池区别
| 特征 | Spooling假脱机技术 | 缓冲池 |
|---|---|---|
| 目的 | 管理I/O任务队列,提升I/O设备的使用效率 | 临时存储数据,减少设备访问次数,提高数据访问速度 |
| 应用场景 | 主要用于打印任务、扫描等I/O操作 | 用于数据库、文件系统等领域的频繁I/O操作 |
| 工作方式 | 将任务存储在磁盘或内存中,按顺序执行 | 将数据存储在内存中,减少磁盘访问频率 |
| 数据处理 | 按顺序处理任务,避免设备空闲时没有任务 | 提前加载或缓存数据,提升响应速度 |
| 存储位置 | 存储在硬盘或内存的临时区域 | 存储在内存中(通常是内存缓冲区) |
- Spooling假脱机技术更多地关注任务管理和设备共享,而缓冲池则专注于提高数据访问效率,减少I/O操作的延迟。
磁盘
- 交换区是将内存中的部分数据临时转移到磁盘上,以释放内存空间,从而让内存能运行更多的程序或处理更大的数据。增大交换区并不能减少I/O速度
- 提高磁盘I/O速度的方法
- 设置磁盘缓冲区
- 磁盘缓冲区是内存中的一片区域,利用局部性原理,可以保留部分磁盘数据的拷贝,在命中时可以直接从磁盘缓冲区拿数据,无需磁盘I/O。
- 但是需要考量置换算法。
- 交付数据给用户的方式有两种:
- 数据交互
- 直接从磁盘缓冲区把数据传送到用户区
- 指针交付
- 只把磁盘缓冲区某区域的指针交付给进程,节省了数据的拷贝开销
- 数据交互
- 磁盘缓冲区是内存中的一片区域,利用局部性原理,可以保留部分磁盘数据的拷贝,在命中时可以直接从磁盘缓冲区拿数据,无需磁盘I/O。
- 提前读和延迟写
- 提前读是指把当前访问的盘块相邻的几个连续的盘快一起读入磁盘缓冲区,利用了空间局部性,命中时无需启动磁盘I/O
- 延迟写是指磁盘缓冲区的数据本应该立即写回磁盘,但考虑不久的将来该数据还会被访问,所以不会立即写回磁盘,而是会把它挂在空闲缓冲区队列的末尾,当有进程申请这片磁盘缓冲区时,才把该修改的内容写回磁盘,同样也可以减少I/O时间(其实是时间局部性)
- 优化物理块的分布
- 尽可能地为文件分配相邻的磁盘块,这样磁盘就无需多次寻道,减少I/O时间
- 虚拟盘
- 利用内存空间去仿真磁盘,进而形成所谓的虚拟盘,又称为RAM盘。该盘的设备驱动程序可以接受所有标准的磁盘操作,但这些操作的执行不是在磁盘上而是在内存中进行。它们对用户而言都是透明的
- 虚拟盘存在的主要问题是:它是易失性存储器,一旦系统或电源发生故障,或系统重启,原来保存在虚拟盘中的数据就会丢失
- 因此,虚拟盘通常用于存放临时文件,如编译程序所产生的目标程序等
- 虚拟盘与磁盘高速缓存的主要区别在于:虚拟盘中的内容完全由用户控制,而磁盘高速缓存中的内容则是由OS控制的。例如,虚拟盘在开始时是空的,仅当用户(程序)在其中创建了文件后,其中才会有内容
- 设置磁盘缓冲区
- 磁盘盘面上的记录密度
- 图8.5是磁盘盘面上的道密度和位密度示意图。左边采用的是低密度存储方式,所有磁道上的扇区数相同,所以每个磁道上的位数相同,因而内道上的位密度比外道位密度高;右边采用的是高密度存储方式,每个磁道上的位密度相同,所以外道上的扇区数比内道上扇区数多,因而整个磁盘的容量比低密度盘高得多。
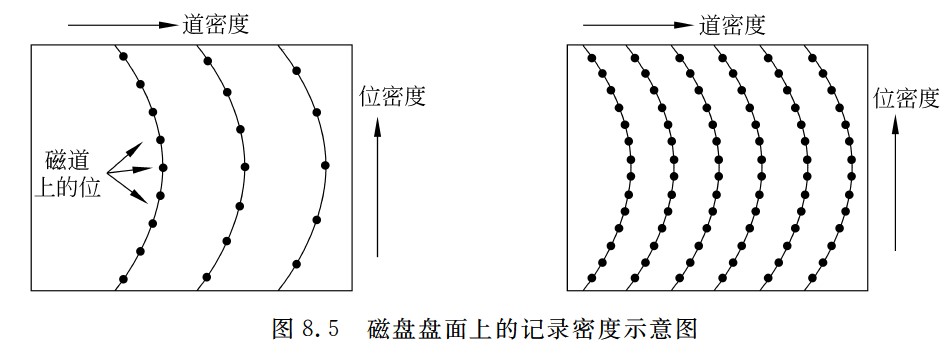
- 在读写磁盘时,总是写完一个柱面上所有磁道后,再移到下一个柱面。磁道从外向里编址,最外面的为磁道0。每个磁道按扇区为单位进行磁盘读写。
- 磁盘读写
- (1)寻道操作:硬盘控制器把磁盘地址送到磁盘驱动器的磁盘地址寄存器后,便产生寻道命令,启动磁头定位伺服系统进行磁头定位操作。此操作完成后,发出寻道结束信号给磁盘控制器,并转入旋转等待操作。
- (2)旋转等待操作:盘片旋转时,索引标志产生的脉冲将扇区计数器清零,以后每来一个扇区标志,扇区计数器加1,把计数内容与磁盘地址寄存器中的扇区地址进行比较,如果一致,则输出扇区符合信号,说明要读写的信息已经转到磁头下方。
- (3)读写操作:扇区符合信号送给控制器后,控制器的读写控制电路开始动作。如果是写操作,就将数据送到写入电路,写入电路根据记录方式生成相应的写电流脉冲;如果是读操作,则由读出放大电路读出内容送磁盘控制器。
- 磁盘读写操作是串行的,不能在同一时刻读写,随机存取+顺序存取结合,DAM直接存取存储器
- 磁盘的传输速率,K,M,G,T一般是以10为底的单位,而不是以2为底
- 扇区、块/簇、页的关系
- 扇区:硬盘的最小读写单元
- 块/簇:操作系统针对硬盘读写的最小单元
- 页:内存与操作系统之间操作的最小单元
- 固态硬盘会维护一个逻辑地址到物理地址的映射表,每次读写时,可以直接通过逻辑地址直接查表得到物理地址
- 提高磁盘可靠性的方法
- 后备系统
- 磁盘容错技术
- RAID阵列
- 增大磁盘交换区并不能减少I/O速度
RAID
| RAID 类型 | 特点 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| RAID 0 | 无冗余,数据分布在多个磁盘上 | - 提高I/O性能,多个磁盘并行读取- 高吞吐量,适合大容量数据存储 | - 无数据冗余,磁盘故障会丢失数据 | 对I/O性能要求较高的应用,如视频流、CAD系统等。 |
| RAID 1 | 数据镜像存储在两个磁盘上 | - 数据冗余,磁盘故障时数据仍然可用 | - 需要双倍存储空间- 写操作速度较慢 | 需要高数据可靠性的应用,如服务器数据存储。 |
| RAID 2 | 使用汉明码进行错误校验 | - 错误校验,确保数据完整性 | - 成本高,性能较差,不常用 | 错误校验需求高的应用。 |
| RAID 3 | 字节级数据分条存储,使用专用奇偶校验盘 | - 顺序读写性能良好- 能从一个磁盘故障中恢复数据 | - 奇偶校验盘可能成为瓶颈,影响写性能- 至少需要3个磁盘 | 大规模数据处理系统,如视频编辑、数据存档。 |
| RAID 4 | 块级数据分条存储,使用专用奇偶校验盘 | - 比RAID 3性能更好,适合读写操作较多的应用 | - 写操作时奇偶校验盘可能成为瓶颈- 需要至少3个磁盘 | 高容量、读多写少的应用。 |
| RAID 5 | 块级数据分条存储,奇偶校验分布在所有磁盘上 | - 性能、存储效率和数据冗余平衡- 支持单盘故障恢复 | - 写性能较慢- 至少需要3个磁盘 | 一般用途,适合数据库服务器、大型存储系统等。 |
| RAID 6 | 块级数据分条存储,双重分布奇偶校验 | - 支持两个磁盘同时故障的容错性- 数据冗余性更高 | - 写性能比RAID 5慢- 至少需要4个磁盘 | 高数据可靠性需求的应用,适用于任务关键型应用。 |
| RAID 7 | 使用缓存技术提升写操作性能 | - 提高写性能,适合高速缓存存储- 适用于高性能数据访问系统 | - 高成本- 高度依赖缓存技术 | 高性能数据中心,要求高速读写和高可靠性的应用。 |
- 冗余磁盘阵列RAID技术的目的是增大容量,提高速度,并增强可靠性。
- 小条带方式RAID的数据传输率高,但I/O响应速度慢,适合应用于流媒体播放系统等
- 大条区方式RAID则相反,适合应用于银行证券等事务处理系统等。


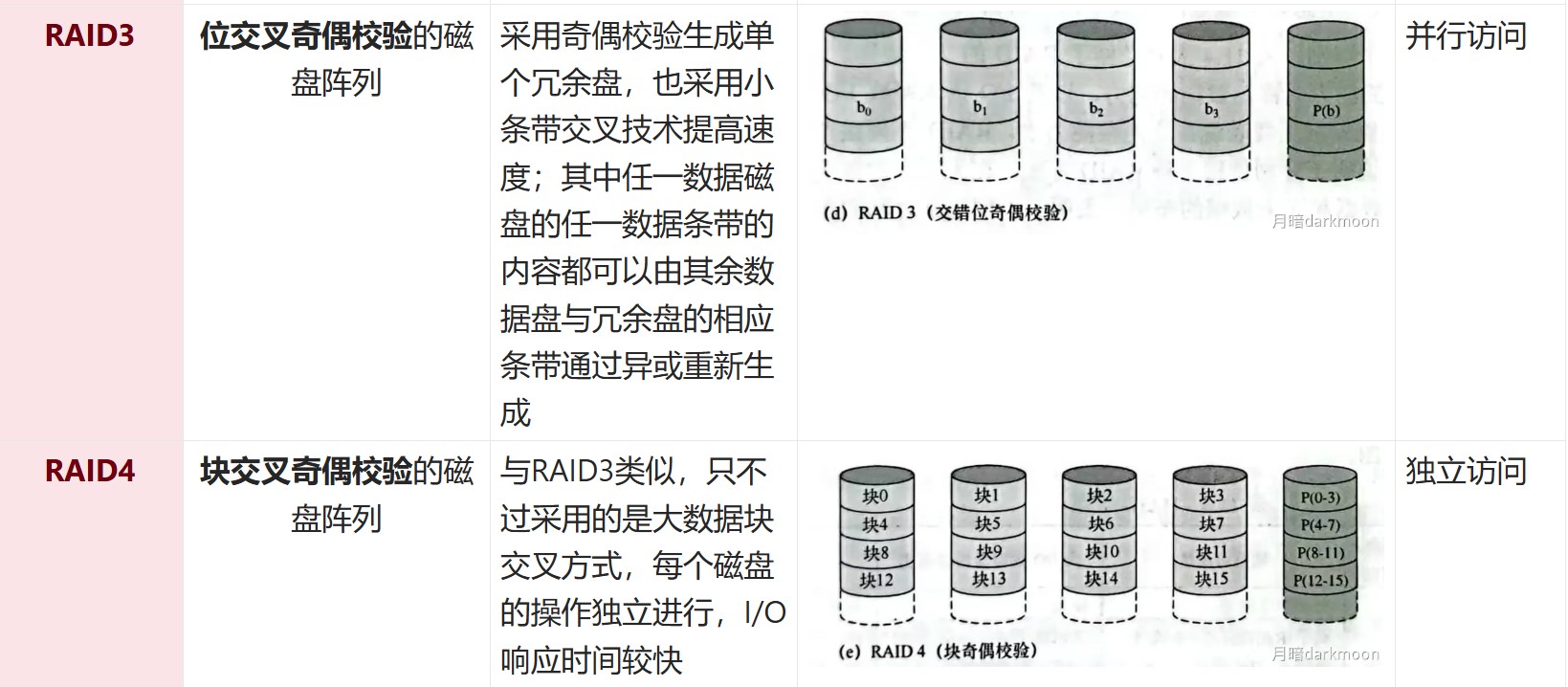
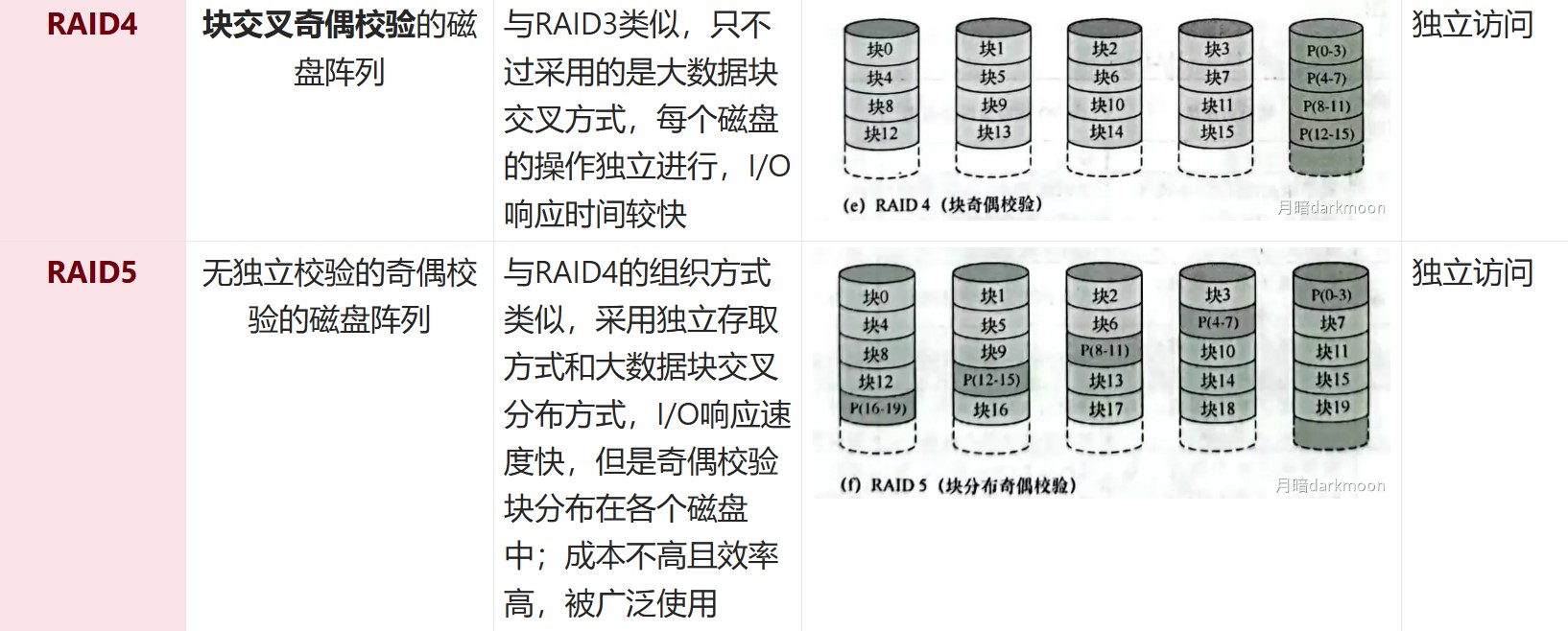
磁盘I/O的经典处理过程

磁盘计算
-
对于低密度存储方式,因为每个磁道的容量相等,所以,其未格式化容量的计算方法为:
- 磁盘总容量=记录面数×理论柱面数×内圆周长×位密度
-
数据传输率是单位时间内从磁盘盘面上读出或写入的二进制信息量。由于磁盘在同一时刻只有一个磁头进行读写,所以数据传输率等于单位时间内磁头划过的磁道弧长乘以位密度
- 数据传输率=每分钟转速÷60×内圆周长×位密度
-
磁盘响应读写请求的过程如下:首先将读写请求在队列中排队,出队列后由磁盘控制器解析请求命令,然后进行寻道、旋转等待和读写数据3个过程。
- 响应时间=排队延迟+控制器时间+寻道时间+旋转等待时间+数据传输时间
-
磁盘上的信息以扇区为单位进行读写,上式中后面3个时间之和称为平均存取时间T
-
T=寻道时间+旋转等待时间+数据传输时间
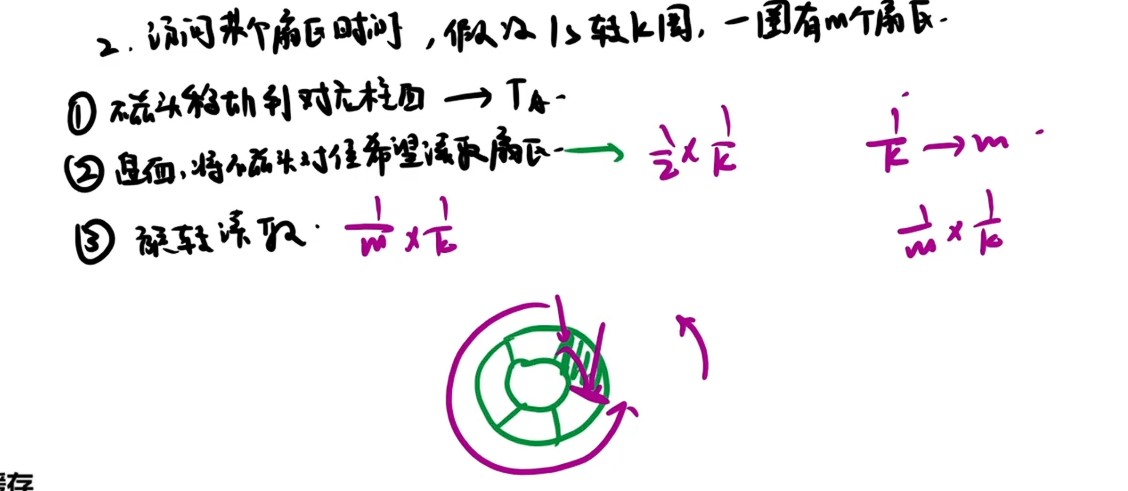
低级格式化和高级格式化
| 格式化类型 | 低级格式化 | 高级格式化 |
|---|---|---|
| 定义 | 低级格式化是指在磁盘上进行的物理分区和数据记录的初始化过程,通常在磁盘制造时进行。 | 高级格式化是在低级格式化完成后,对磁盘进行的逻辑结构化过程,设置文件系统和目录结构。 |
| 过程 | 包括将磁盘划分为若干个扇区,并且记录每个分区的相关信息。使用的是物理地址和磁道信息。 | 在低级格式化后,使用逻辑分区信息来设置文件系统(如FAT、NTFS等),同时划分空间用于文件存储。 |
| 数据结构 | 包括磁道、扇区、簇等物理存储单元,并对其进行编号。 | 包括文件系统结构、目录结构等,文件系统用于管理文件和文件夹,确保数据的访问和存储。 |
| 坏块处理 | 在低级格式化过程中,会检查并标记坏块。磁盘上的坏块会被从可用的存储区域中排除,以避免对数据存储的影响。 | 高级格式化不会涉及物理坏块的处理,坏块通常在低级格式化时就已经被标记和处理。 |
| 引导块 | 低级格式化时,磁盘的起始位置会有引导块,它包含引导信息,以便在系统启动时进行引导。 | 高级格式化中,操作系统会配置引导扇区,通常包括操作系统的引导程序,用于启动系统。 |
| 根目录 | 在低级格式化阶段并没有涉及根目录的概念,根目录通常由文件系统在高级格式化时设置。 | 高级格式化时,根目录会被创建并标记,根目录是文件系统中第一个目录,所有文件和子目录都在其下创建。 |
| 目的 | 确保磁盘的物理区域被正确标记为可以存储数据,避免设备上的数据冲突。 | 为用户提供一个可以存储数据的高效、可靠、易管理的环境。 |
| 实现方式 | 通过设置磁盘的起始区、结束区,以及各个扇区的标记来实现。常涉及磁道、柱面等物理结构。 | 通过分配文件系统并建立起数据块、目录、文件等结构来实现。 |
| 应用阶段 | 磁盘制造过程中进行,通常由磁盘生产商完成,用户通常无需干预。 | 完成低级格式化后进行,用户根据需求选择文件系统并进行操作。 |
| 是否影响磁盘内容 | 是的,低级格式化会清除磁盘上的所有数据,并重新组织磁盘的物理结构。 | 不会清除磁盘上的数据,主要是对磁盘的逻辑结构进行配置。 |
| 使用情况 | 一般不需要用户操作,仅在磁盘初次使用时或需要重新划分磁盘时进行。 | 需要用户操作,如在新磁盘或重装操作系统时进行。 |
- 在磁盘分区的过程中会产生磁盘引导程序MBR并创建磁盘分区表来标识各分区信息,先创建分区表是划分分区的前提,通过创建分区表来定义磁盘结构,然后具体划分分区之后再进行逻辑格式化。
- 逻辑格式化的对象是磁盘分区,通过逻辑格式化,分区内被填入了分区引导块PBR和文件系统相关信息以及设置根目录
- 设置超级块、inode表、目录结构
- 主要是文件系统安装和PBR生成
- 逻辑格式化将初始文件系统数据结构存储到磁盘上,这些数据结构包括空闲空间和已分配空间,一个初始为空的目录,以及建立根目录、初始化保存空闲块信息的数据结构
- 操作系统安装是在逻辑格式化之后执行的
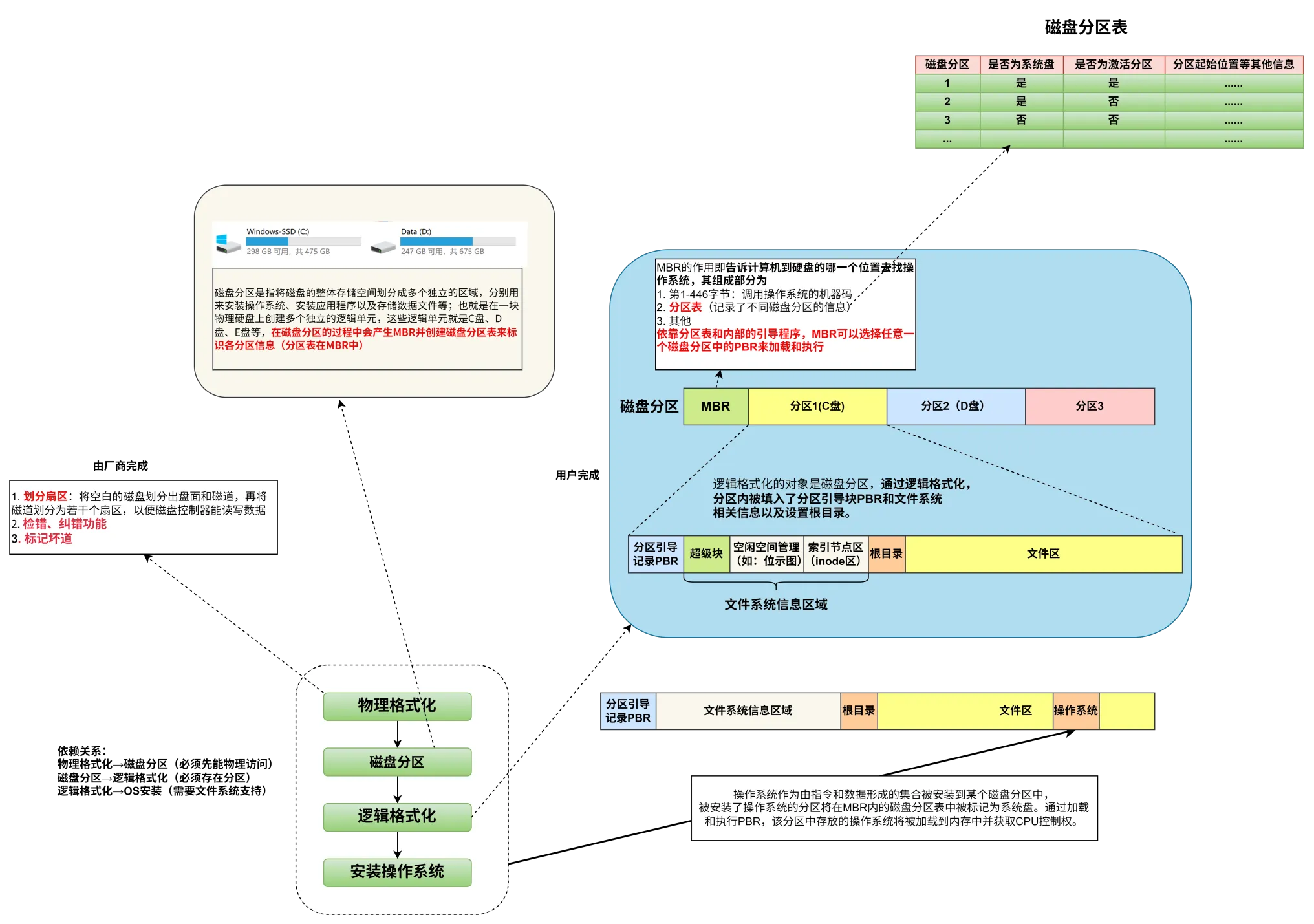
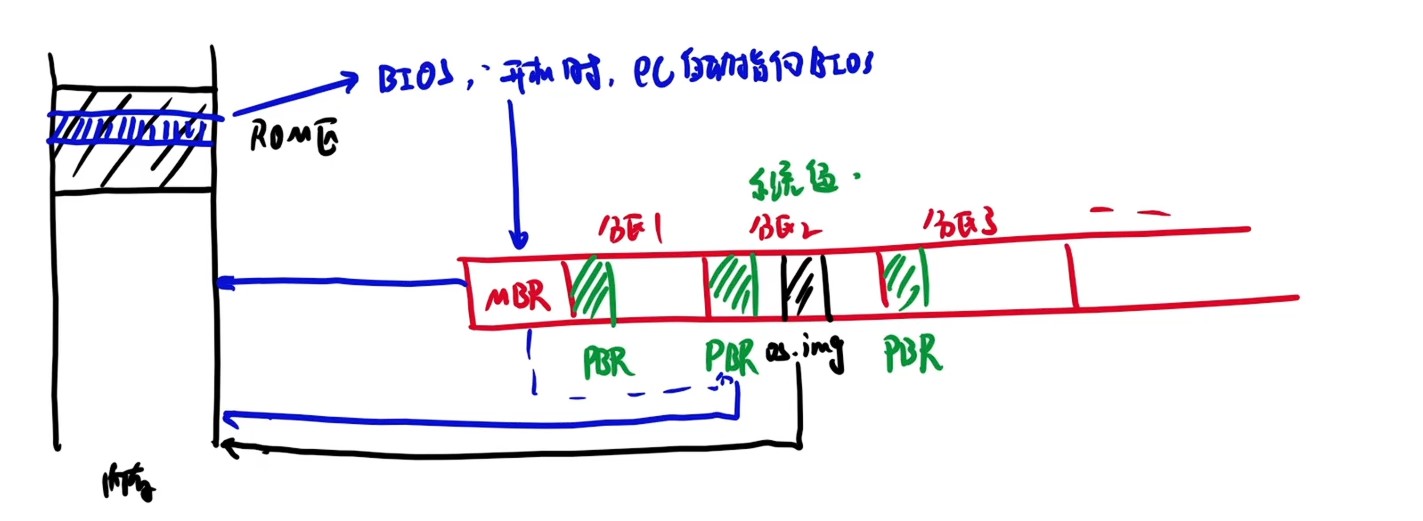
磁盘调度算法
- 采用SSTF、SCAN及CSCAN这几种调度算法,都可能出现磁臂停留在某处不动的情况.我们把这一现象称为“磁臂粘着”(armstickiness),在高密度磁盘上容易出现此现象。
- 例如,有一个或几个进程对某一磁道有较高的访问频率,即这个(些)进程反复请求对某一磁道进行I/O操作,从而垄断了整个磁盘设备。
- C-SCAN算法的快速移动中间经过的磁道是要计算在总数内的
- NStepSCAN调度算法
- N步SCAN调度算法(NStep SCAN调度算法)是将磁盘请求队列分成若干个长度为N的子队列,磁盘调度将按FCFS调度算法依次处理这些子队列。而每处理一个子队列时又采用SCAN调度算法,处理完一个子队列后,再处理其他子队列。当正在处理某个子队列时,如果又出现新的磁盘I/O请求,则将新请求进程放入其他子队列,这样就可避免出现磁臂粘着现象。当N值取得很大时,会使NStepSCAN调度算法的性能接近于SCAN调度算法的性能;当N =1时,NStepSCAN调度算法便蜕化成了FCFS调度算法。
- FSCAN调度算法
- FSCAN调度算法实质上是NStepSCAN调度算法的简化,即FSCAN调度算法只将磁盘请求队列分成两个子队列。一个是由当前所有请求磁盘I/O的进程所形成的队列,由磁盘调度按SCAN调度算法进行处理。在扫描期间,将新出现的所有请求磁盘I/O的进程放入另一个等待处理的请求队列。这样,所有的新请求都将被推迟到下一次扫描时进行处理。
坏块
- 简单的磁盘,逻辑格式化时注明坏扇区,坏块对操作系统不透明
- 复杂的磁盘,磁盘出厂前低级格式化的时候初始化坏块链,坏块对操作系统透明
计算
-
寻道时间+旋转延迟时间+读取扇区的时间
- 旋转延迟时间:(60s/转的数量)/2
- 读取扇区的时间:转一圈的时间/扇区数
-
柱面号|盘面号|扇区号

- 柱面号=块号/每个柱面的磁盘块数量
- 磁头号=(块号mod每个柱面的磁盘块数量)/每个磁道的磁盘块数量
- 扇区=块号mod每个磁道的扇区数量
SPOOLings假脱机技术
-
SPOOLing技术之前执行打印机任务的大致流程:用户空间的数据→内核的输出缓冲区→CPU的通用寄存器→I/O端口
-
通过多道程序技术可将一台物理CPU虚拟为多台逻辑CPU,从而允许多个用户共享一台主机,那么通过假脱机技术就可以将一台物理I/O设备虚拟为多台逻辑I/O设备,这样就可以允许多个用户共享一台物理I/O设备。
-
逻辑设备号和物理设备号是为了实现设备独立性,而假脱机技术是为了缓和CPU和I/O设备的速度矛盾(I/O比CPU慢)
-
当系统中引入多道程序技术后,系统便完全可以利用其中的一道程序来模拟脱机输入时的外围控制机功能,进而把低速I/O设备上的数据传送到高速磁盘上;再用另一道程序模拟脱机输出时外围控制机的功能,把数据从磁盘传送到低速输出设备上。这样,便可在主机的直接控制下实现以前的脱机输入/脱机输出功能。此时的外围操作与CPU对数据的处理同时进行
-
假脱机系统建立在通道技术和多道程序技术的基础上,以高速随机外存(通常为磁盘)为后援存储器,用软件的方式。
-
在内存中开辟的两个缓冲区,用于缓和CPU和磁盘之间速度不匹配的矛盾
-
SPOOLing的核心特征之一就是对用户作业的透明性
-
输出进程和输入进程都是运行在内核态下的程序
-
输出进程需要沟通磁盘和打印机这两种外设,因此需要至少两种设备驱动程序的支持
-
假脱机系统的组成
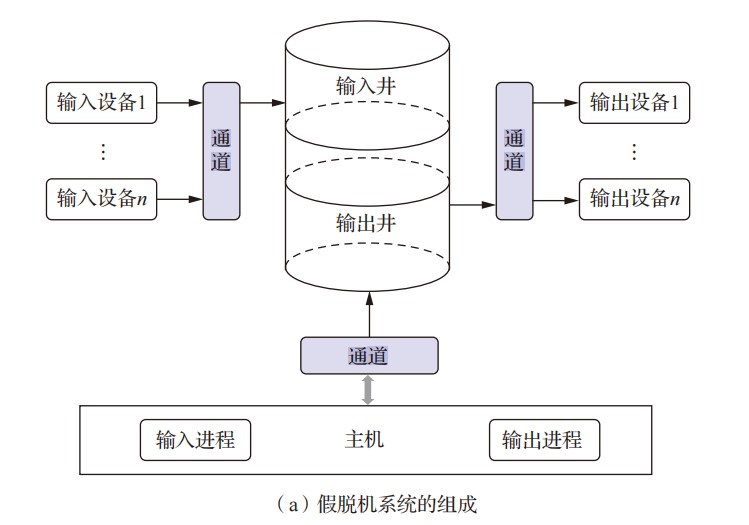
- 输入井模拟脱机输入时的磁盘,用于收容I/O设备输入的数据。输出井模拟脱机输出时的磁盘,用于收容用户程序的输出数据。输入井/输出井中的数据一般以文件的形式组织管理,我们把这些文件称为井文件。一个文件仅存放某一个进程的输入(或输出)数据,所有进程的数据输入(或输出)文件可链接成为一个输入(或输出)队列。
-
假脱机系统的工作原理
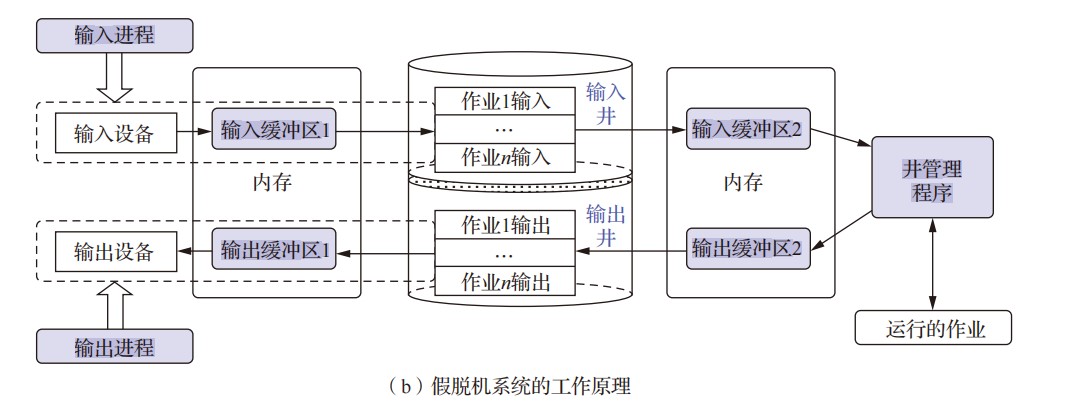
-
假脱机打印机系统的组成
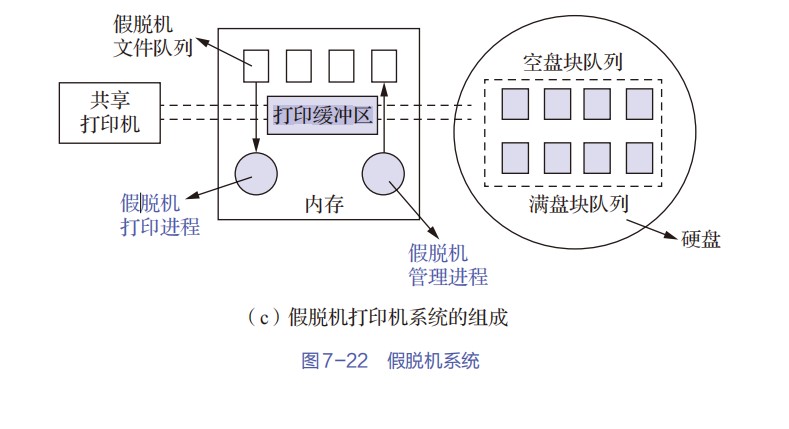
- 文件队列:订单纸,盘块:外卖
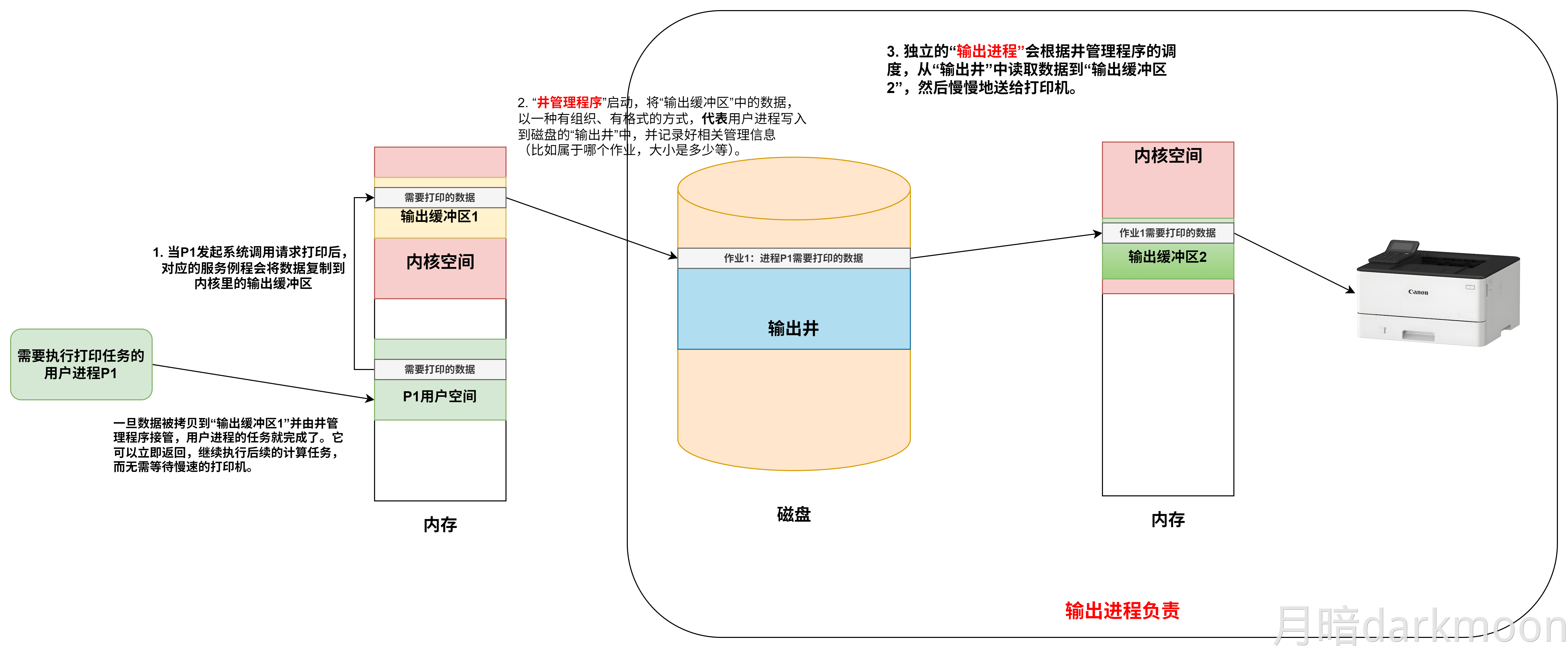
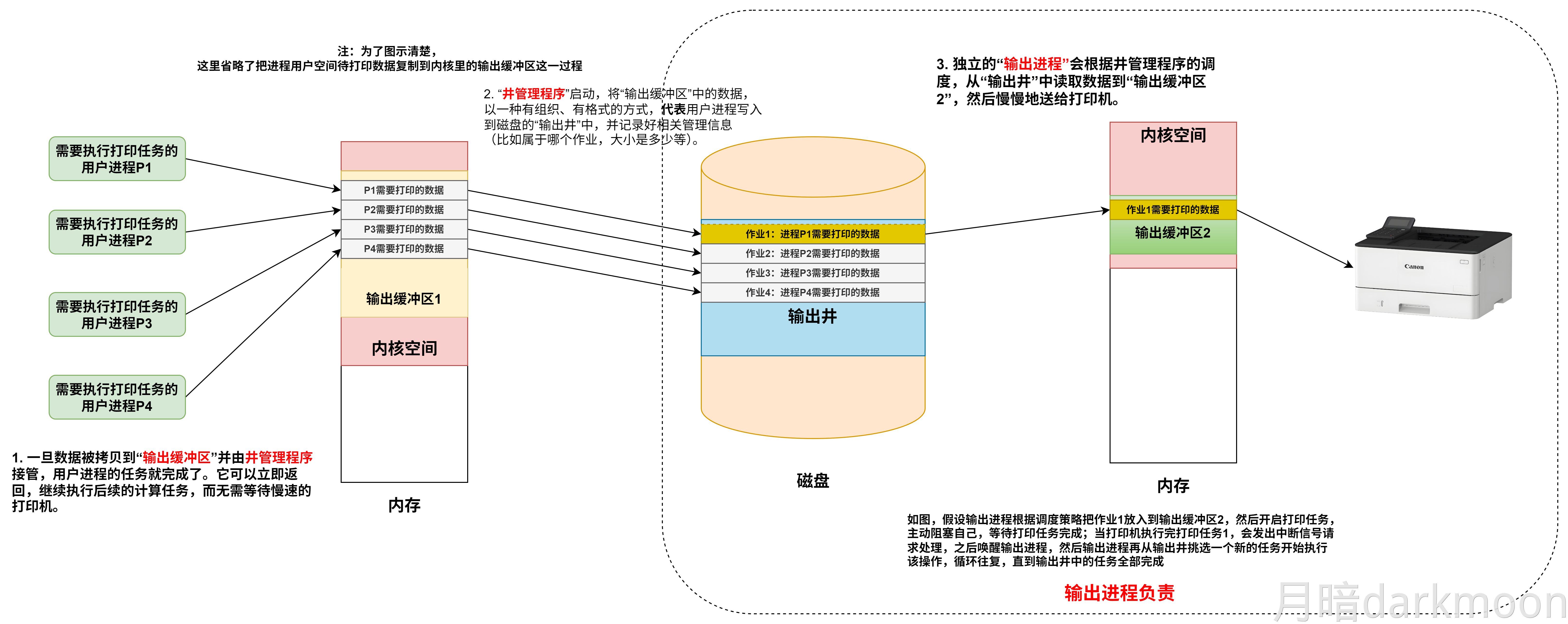
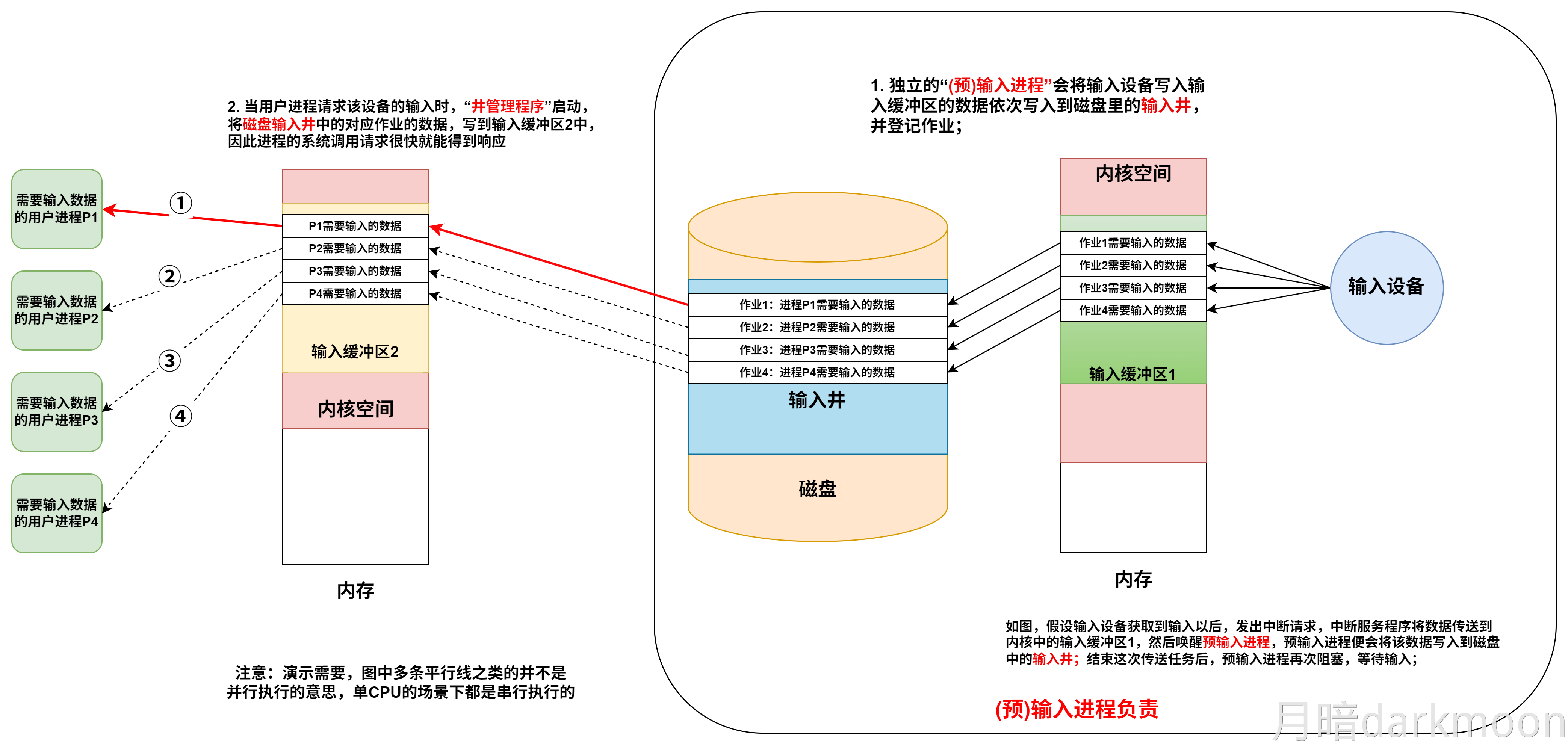
- ①在磁盘缓冲区中为之申请一个空闲盘块,并将要打印的数据送入其中暂存;
- ②为用户进程申请一张空白的用户请求打印表,并将用户的打印要求填入其中,再将该表挂到假脱机文件队列上。在这两项工作完成后,虽然还没有进行任何实际的打印输出,但对于用户进程而言,其打印请求已经得到了满足,打印输出任务已经完成。
- ③真正的打印输出是假脱机打印进程负责的,当打印机空闲时,该进程首先从假脱机文件队列的队首摘取一张请求打印表
- ④然后根据表中的要求将要打印的数据由磁盘缓冲区传送到内存缓冲区,再交付打印机进行打印。
- ⑤一个打印任务完成后,假脱机打印进程将会再次查看假脱机文件队列,若队列非空,则重复上述工作,直至队列为空。
- ⑥此后,假脱机打印进程会将自己阻塞起来,仅当再次有打印请求时,其才会被重新唤醒运行。
-
引入SPOOLing之后,CPU只参与两次高速的数据传输:
- 第一次:从P1用户空间拷贝到内核缓冲区1(内存→内存,极快)
- 第二次:井管理程序将数据从缓冲区1写入磁盘输出井(内存→磁盘,很快)
-
守护进程
-
为打印机建立一个守护进程,由它实现一部分原来由假脱机管理进程实现的功能,如为用户在磁盘缓冲区中申请一个空闲盘块,并将要打印的数据送入其中,将该盘块的起始地址返回给请求进程。另一部分功能由请求进程自己实现,每个要求打印的进程,首先生成一份要求打印的文件,其中包含对打印的要求和指向装有打印输出数据盘块的指针等信息,然后将用户请求打印文件放入假脱机文件队列(目录)中。
-
守护进程是允许使用打印机的唯一进程。所有需要使用打印机进行打印的进程,都需要将一份要求打印的文件放在假脱机文件队列(目录)中。如果守护进程正在睡眠,则将它唤醒,由它按照目录中第一个文件中的说明进行打印,打印完成后,再按照目录中第二个文件中的说明进行打印,如此逐份文件地进行打印,直到目录中的全部文件打印完毕为止,此时守护进程无事可做,便又去睡眠,同时等待用户进程再次发来打印请求。
-
凡在需要将独占设备改造为可供多个进程共享的设备时,都要为该设备配置一个守护进程和一个假脱机文件队列(目录)。同样,守护进程是允许使用该独占设备的唯一
进程,所有其他进程都不能直接使用该设备,而只能将对该设备的使用要求写入一份文件中,并将该文件放在假脱机目录中。由守护进程按照目录中的文件,依次来完成各进程对该设备的请求。这样就把一台独占设备改造成了可为多个进程共享的设备。
-
-
SPOOLing技术需要进行输入输出操作,单道批处理系统无法满足
多处理机
调度性能的评价因素
- 任务流时间
- 完成任务所需要的时间
- 调度流时间
- 一个调度流时间等于系统中所有处理机上的任务流时间的总和
- 平均流时间
- 等于调度流时间/任务数
- 处理机利用率
- 该处理机上任务流时间之和/最大有效时间单位
- 加速比
- 各处理机的忙时间之和/并行工作时间
- 并行工作时间=从第一个任务开始到最后一个任务结束所用的时间
- 调度和分配的区别
- 分配是给哪个处理机,调度是让哪个进程上处理机
主从式操作系统
-
在主从式操作系统(master-slave operating system)中,有一个特定的处理机被称为主处理机(master processor),其他处理机则被称为从处理机。OS程序始终运行在主处理机上,负责保持和记录系统中所有处理机的属性、状态等信息,而将其他从处理机视作可调度和分配的资源,并给它们分配任务。从处理机不具备调度功能,只能运行主处理机分配给它的任务。
-
工作流程:
-
由从处理机向主处理机提交任务申请,该请求被捕获后送
至主处理机,而后等待主处理机应答;
-
主处理机收到请求后中断当前任务,对该请求进行识别和判断,并转入相应的处理程序执行,然后将适合的任务分配给发出请求的从处理机
-
-
优缺点
- 易于实现
- 资源利用率低
- 安全性较差
-
主从式操作系统一般用于工作负载不是太重、从处理机数量不是太多、从处理机性能远低于主处理机的非对称多处理机系统中。
多处理机的进程分配
-
对称多处理机操作系统中的进程分配方式
-
(1)静态分配方式
-
指一个进程从开始执行直至其完成,都被固定地分配
到一个处理机上去执行。
-
须为每一处理机设置一专用的就绪队列,该队列中的各进程会先后被分配到该处理机上去执行。进程在阻塞后再次就绪时,还会被挂在这个就绪队列中,因而下次它仍会在此处理机上执行。
-
优点是进程调度开销小
-
缺点是会使各处理机忙闲不均
-
换言之,系统中可能有些处理机的就绪队列很快就变成了空队列,使处理机处于空闲状态,而另一些处理机则可能一直处于忙碌状态
-
-
(2)动态分配方式
- 可以在系统中仅设置一个公共的就绪队列,系统中的所有就绪进程都被放在该队列中。分配进程时,可将进程分配到任何一个处理机上
- 这样,对一个进程的整个运行过程而言,在每次被调度执行时,都是随机被分配到当时空闲的某一处理机上去执行的。
- 优点是消除了各处理机忙闲不均的现象。
- 对于紧密耦合共享存储器的多处理机操作系统,其每个处理机保存在存储器中的进程信息可被所有的处理机共享。因此,这种调度方式不会增加调度开销。
- 但对于松散耦合多处理机操作系统,会造成调度开销的明显增加。
-
-
非对称多处理机操作系统中的进程分配方式
- 非对称多处理机系统大多采用主从式操作系统,即OS的核心部分驻留在一台主机上,而从机上则只有用户程序,进程调度仅由主机执行。
- 从机每当空闲时,便会向主机发送一个索求进程的信号,然后便会等待主机为其分配进程。
- 在主机中有一个就绪队列,只要就绪队列不空,主机便会从队首摘下一进程分配给索求进程的从机。
- 从机接收到分配给它的进程后便运行该进程,该进程结束后从机又会向主机发送一个索求进程的信号。
- 优点是系统处理比较简单,这是因为所有的进程分配都由一台主机独自处理,这使进程间的同步问题得以简化,且进程调度程序也很易于从单处理机的进程调度程序演化而来。
- 但由一台主机控制一切也存在不可靠性,即主机一旦出现故障,将会导致整个系统瘫痪,而且也很易于因主机太忙(来不及处理)而形成系统瓶颈。
- 克服这些缺点的有效方法是利用多个而非一个处理机来管理整个系统,这样,当其中一个处理机出现故障时,可由其他处理机来接替其完成任务,从而不会影响系统运行,而且用多个处理机(管理整个系统)还可使系统具有更强的执行管理任务的能力,更不容易形成系统瓶颈
进程(线程)调度方式
- 自调度方式
- 在系统中设置一个公共的进程或线程就绪队列,所有的处理机在空闲时都可以到该队列中取一进程(或线程)来运行。
- 在自调度方式中,可采用在单处理机操作系统中所用的调度算法,如FCFS调度算法、最高优先级优先(highest priority first,HPF)调度算法和抢占式HPF调度算法等。
- 在单处理机操作系统中,FCFS调度算法并不是一种好的调度算法;然而在多处理机操作系统中,当把它用于线程调度时,其反而优于另外两种调度算法。
- 这是因为,线程本身是一个较小的运行单位,继其后而运行的线程不会有很大的时延;加之在系统中有多个(如N个)处理机,这使后面的线程的等待时间又可进一步减少为1/N。
- FCFS调度算法简单、开销小,目前已成为一种较好的自调度算法(方式)。
- 优点
- 首先,系统中的公共就绪队列可按照单处理机操作系统中所采用的各种方式加以组织;
- 其调度算法也可沿用单处理机操作系统中所用的算法,即很容易将单处理机操作系统中的调度机制移植到多处理机操作系统中
- 故自调度方式仍然是当前多处理机操作系统中较常用的调度方式。
- 其次,只要系统中有任务,或者说只要公共就绪队列不空,就不会出现处理机空闲的情况,也不会发生处理机忙闲不均的现象,这有利于提高处理机的利用率。
- 缺点
- 瓶颈问题
- 在整个系统中只设置一个就绪队列供多个处理机共享,这些处理机必须互斥地访问该队列,这很容易造成系统瓶颈。当系统中处理机数目不多时,该问题并不严重;但当系统中处理机数目达到数十个乃至数百个时,如果仍用单就绪队列,就会产生严重的瓶颈问题。
- 低效性
- 当线程阻塞后再重新就绪时,它只能进入这唯一的就绪队列,但却很少可能仍在阻塞前的处理机上运行。如果在每个处理机上都配有高速缓存,则此时在其中保留的该线程的数据已经失效,而在该线程新获得的处理机上又须重新建立这些数据的复制。一个线程在其整个生命期中可能要多次更换处理机,这使高速缓存的使用效率变得很低。
- 线程切换频繁
- 在一个应用中的多个线程都属于相互合作型,但在采用自调度方式时,这些线程很难同时获得处理机而同时运行,这会使某些线程因其合作线程未获得处理机运行而阻塞,进而被切换下来。
- 瓶颈问题
- 成组调度方式
- 将一个进程中的一组线程分配到一组处理机上去执行
- (1)面向所有应用程序平均分配处理机时间
- 假定系统中有N个处理机和M个应用程序,每个应用程序中至多含有N个线程,则每个应用程序至多可有1/M的时间去占有N个处理机。
- (2)面向所有线程平均分配处理机时间
- 优点
- 如果一组相互合作的线程能并行执行,则可有效减少线程阻塞情况的发生,从而可以减少线程的切换,使系统性能得到改善
- 此外,因为每次调度都可以解决一组线程的处理机分配问题,因而可以显著降低调度频率,从而减少调度开销
- 性能优于自调度方式
- 专用处理机分配调度方式
- 指在一个应用程序执行期间,专门为该应用程序分配一组处理机,每个线程配一个处理机。这组处理机仅供该应用程序使用,直至该应用程序完成。
- 会造成处理机的严重浪费
- 使用理由
- 在具有数十个乃至数百个处理机的高度并行的系统中,每个处理机的投资费用在整个系统中只占很小的一部分。对系统的性能和效率来说,单个处理机的利用率已远不像在单处理机系统中那么重要。
- 在一个应用程序的整个运行过程中,由于每个进程或线程专用一个处理机,因此可以完全避免进程或线程的切换,从而大大加速了程序的运行。
- 同时运行的应用程序所含的线程数总和不应超过系统中处理机的总数
- 动态调度方式
- 允许进程在执行期间动态地改变其线程的数目
- OS和应用程序就能够共同进行调度决策。OS负责将处理机分配给作业,而每个作业负责将分配到的处理机再分配给自己的某一部分可运行任务。
- OS的调度责任主要限于处理机的分配,并遵循以下原则
- (1)空闲则分配
- 当一个或多个作业对处理机提出请求时,如果系统中存在空闲的处理机,则将它(们)分配给这个(些)作业,以满足作业的请求。
- (2)新作业绝对优先
- 所谓新作业,是指新到达的、还没有获得任何一个处理机的作业。
- 对于请求处理机的多个作业,系统首先会将处理机分配给新作业,如果系统内已无空闲处理机,则从已分配获得多个处理机的任何一个作业中收回一个处理机,将其分配给新作业。
- (3)保持等待
- 如果系统的任何分配方式都不能满足一个作业对处理机的请求,则作业会保持未完成状态,直到有处理机空闲并可分配给它使用,或者作业自己取消了这个请求。
- (4)释放则分配
- 当作业释放了一个(或多个)处理机后,即为这个(或这些)处理机扫描处理机请求队列,并首先为新作业分配处理机,其次按FCFS原则分配剩余的处理机
- (1)空闲则分配
- 动态调度方式优于成组调度方式和专用处理机分配方式,但其开销之大有可能会抵消它的一部分优势,因此在实际应用中应慎重选择具体的调度方式
多处理机死锁

内存管理
.png)
-
影响系统缺页率的要素
-
页面置换算法
-
工作集的大小
- 工作集的大小决定了分配给进程的物理块数,分配给进程的物理块数越多,缺页率就越低
-
进程的数量
- 进程的数量越多,对内存资源的竞争越激烈,每个进程被分配的物理块数越少,缺页率也就越高
-
页缓冲队列的长度
- 页缓冲队列

-
程序的编制方法
- 编写程序的局部化程度越高,执行时的缺页率就越低,若存储采用的是按行存储,则访问时就要尽量采用相同的访问方式,避免按列访问造成缺页率过高的现象
-
-
clock页面淘汰算法,页面命中时,仅改变访问位,不改变页框指针;页面未命中时,从当前页框出发,访问位为1,则改为0,直到找到访问位为0的页框,此后将此页框访问位改1,页指针指向下一个页框
- 最开始的页框指针指向第一个被放入的页面
-
动态重定位是在作业运行到一条访存指令时再把逻辑地址转换为主存中的物理地址,实际是通过硬件地址转换机制实现的。
-
静态重定位下,程序被装入程序装入时即会实现逻辑地址向物理地址的转换,此后程序中的指令和数据的内存地址便完全确定了,因此是由装入程序完成的地址转换。
-
形成逻辑地址的阶段是在完成链接步骤时,若源程序采用的装入方式为绝对装入或可重定位装入方式,则在装入阶段形成物理地址。若源程序采用的装入方式为动态运行时装入方式,则在程序运行时完成逻辑地址到物理地址的转换。
-
对于静态链接,链接完成后形成的是一个装入模块(可执行文件)。在这个模块中,对外部符号的引用会被解析为相对地址(相对于装入模块的起始地址)或者需要重定位的地址。最终的绝对物理地址是在程序被装入内存时,根据装入方式(如绝对装入、可重定位装入、动态运行时装入)才确定的。
-
对于动态链接(包括装入时动态连接和运行时动态连接),连接本身就是在装入或运行时才进行的,其地址的解析和绑定同样会推迟,并且最终形成的地址也可能是逻辑地址(在动态运行时装入方式下),而不是立即转换为绝对物理地址。地址转换到物理地址是装入和运行时内存管理单元的工作
-
链接过程主要是解决模块间的符号引用,并将它们组织成一个统一的逻辑地址空间,而不是直接解析为绝对物理地址。
- 进程在运行时,看到和使用的都是逻辑地址。用户进程和程序员只知道逻辑地址,而内存管理的具体机制则是完全透明的。
- 不同的进程可以有相同的逻辑地址,因为这些相同的逻辑地址可以映射到主存的不同位置。
-
当装入程序将可执行代码装入内存时,必须通过地址转换将逻辑地址转化成物理地址,这个过程称为地址重定位
-
三种装入总结
- 绝对装入是指在编程阶段就把物理地址计算好。
- 可重定位是指在装入时把逻辑地址转换成物理地址,但装入后不能改变。
- 动态重定位是指在执行时再决定装入的地址并装入,装入后有可能换出,所以同一个模块在内存中的物理地址是可能改变的,在作业运行过程中,当执行到一条访存指令时,再把逻辑地址转换为主存的物理地址,实际上是通过地址变换机构实现的。
- 动态重定位下,装入内存后的所有地址仍是相对地址
-
系统提供给用户的物理地址空间为总大小-页表/段表的长度
-
对主存的访问,以字节或字为单位
-
重定位寄存器整个系统中只设置一个
-
文件区主要用于存放文件,主要追求存储空间的利用率,对文件区空间的管理采用离散分配方式。
- 对换区空间只占磁盘空间的小部分,被换出的进程数据存放在对换区。通常采用连续分配方式,兑换区的I/O速度比文件区的更快。
-
分配的内存空间是否连续决定了是连续分配还是非连续分配
- 而运行作业是是否要把作业的所有页面都装入内存才能运行,分为基本分页存储管理方式和请求分页存储管理方式
- eg:一个程序在内存中是非连续分配的,它的内容分散在内存的不同地方,但他们加在一起是一个完整的程序,这就是基本分页;加在一起只是一个程序的一部分,这就是请求分页
- 而运行作业是是否要把作业的所有页面都装入内存才能运行,分为基本分页存储管理方式和请求分页存储管理方式
-
在某些用于控制多个相同对象的控制系统中,由于每个对象的控制程序都是事先编好的,大小相同,其所需的数据也是一定的,故仍采用固定分区存储管理方式。
-
对页表施行离散分配的方法,虽然解决了对大页表无需大片连续存储空间的问题,但并未解决用较少的内存空间去存放大页表的问题。换言之,只用离散分配空间的办法并未减少页表所占用的内存空间。能够用较少的内存空间存放页表的唯一方法是,仅把当前需要的一批页表项调入内存,以后再根据需要陆续调入。
-
由操作系统设置上界和下界
-
对于访问方式保护,一般规定:
- 个程序对本程序所在的存储区可读可写
- 对共享区或已获授权的其他用户信息可读不可写
- 而对未获授权的信息(如操作系统内核、页表等)不可访问
- 通常,数据段可指定为可读可写或只读;程序段可指定可执行或只读
-
分页存储管理通常是静态链接,将用户空间链接成一个统一的逻辑地址空间,通过页表可离散地映射到内存中的页框中
地址生成过程
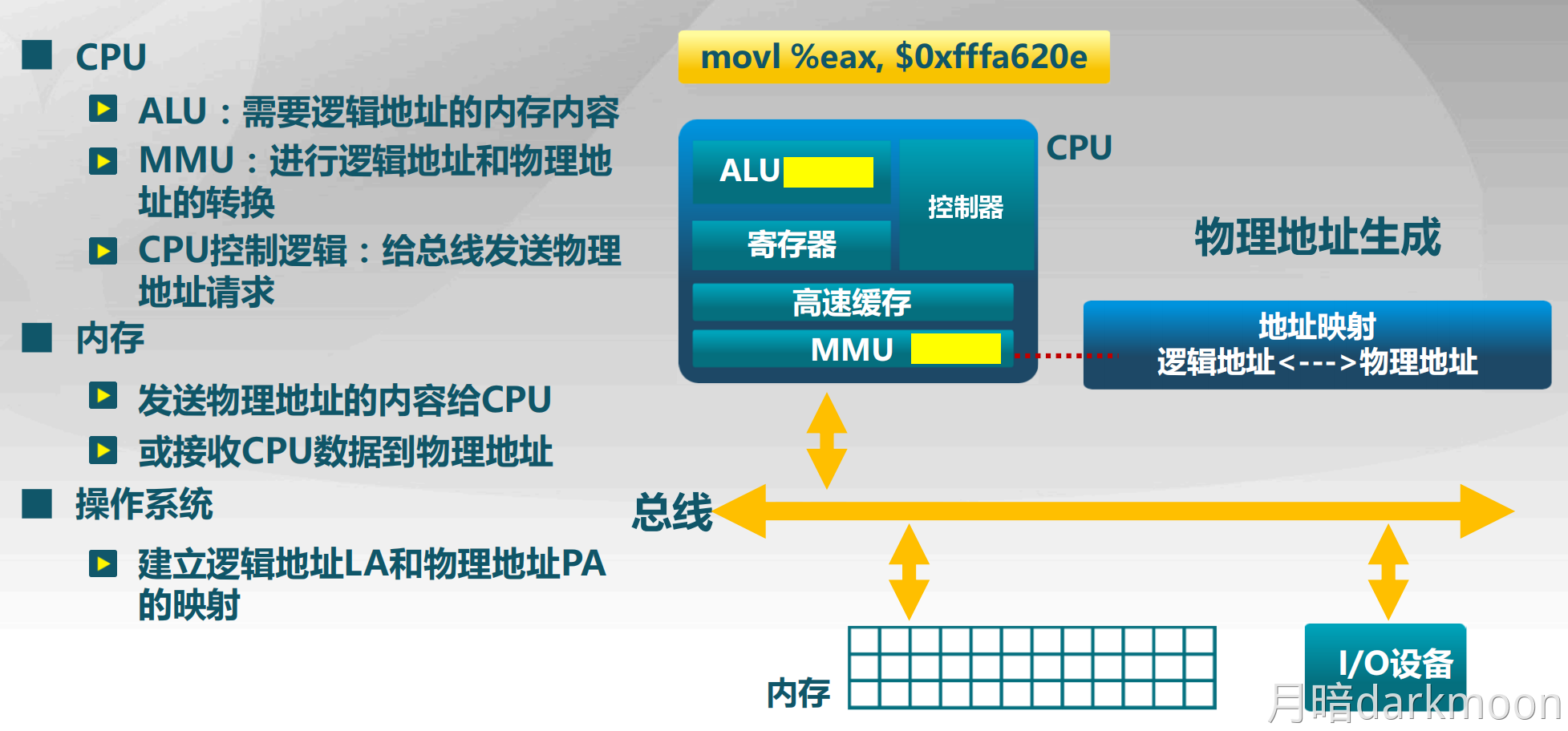
三种装入方式总结



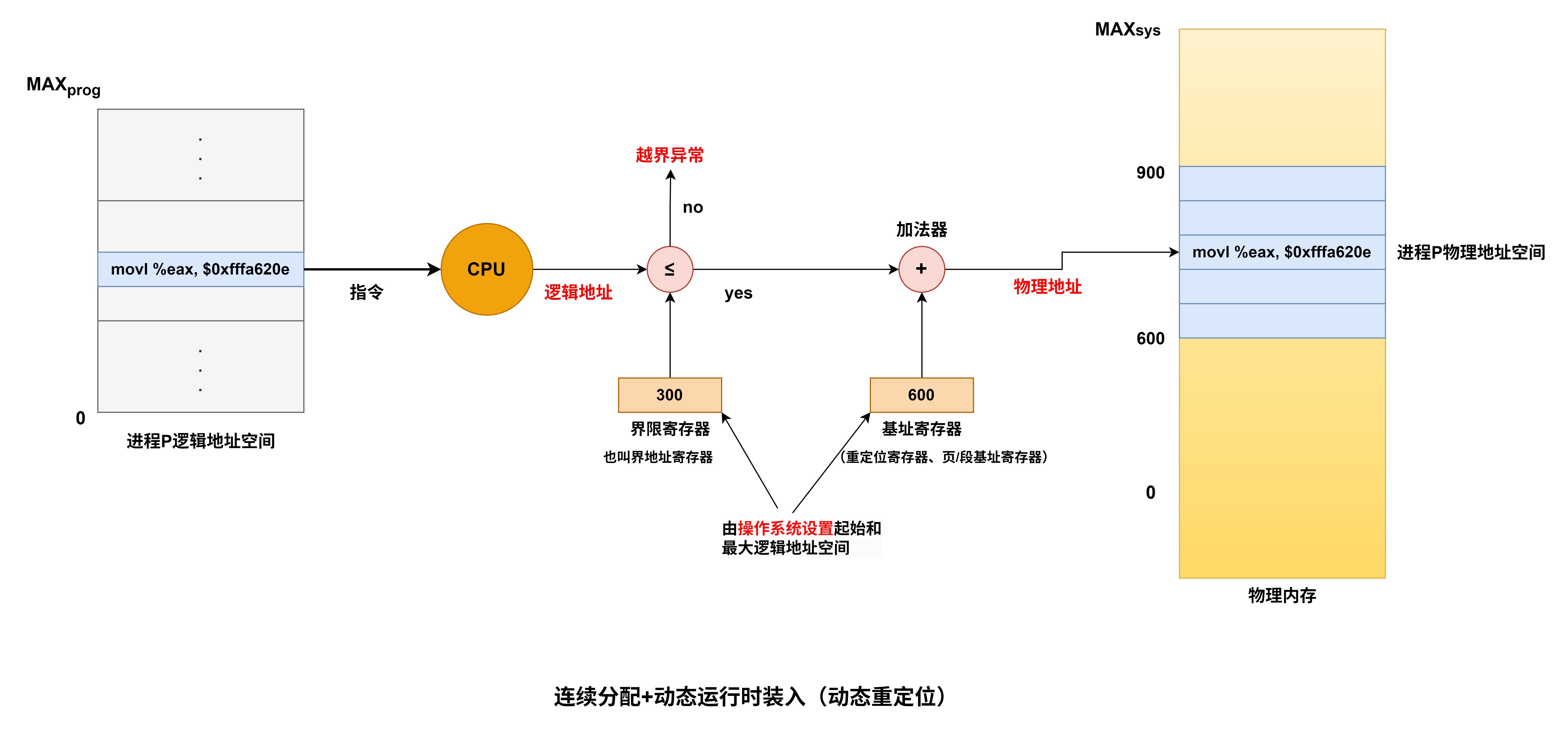
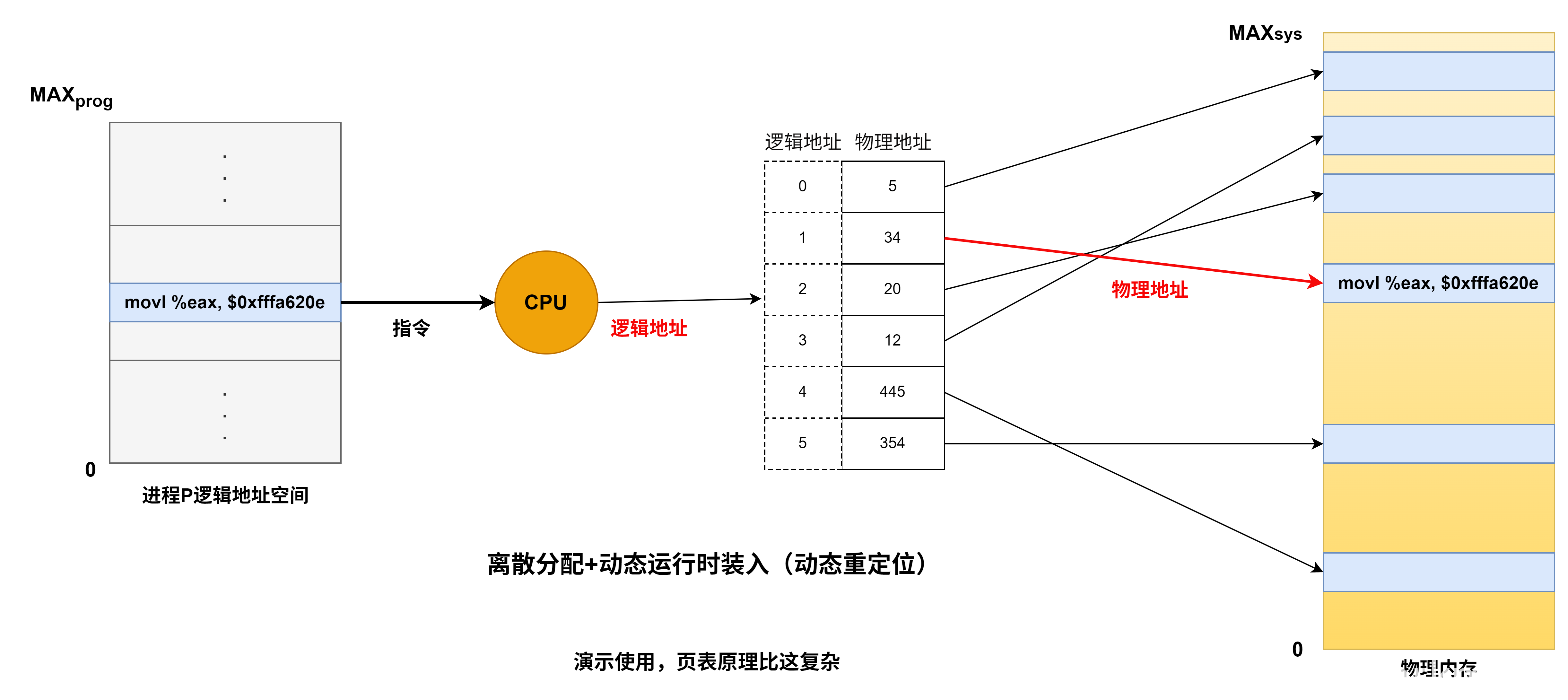
反置页表
- 反置页表则是为每个物理块设置一个页表项,并将它们按物理块的编号进行排序,其中的内容则是页号和其所隶属进程的标识符。
- 在利用反置页表进行地址变换时,会根据进程标识符pid和页号p检索反置页表。如果检索到了与之匹配的页表项,则该表项的序号i便是该页所在的物理块号,可用该块号i与页内地址d一起构成物理地址送往内存地址寄存器。若检索了整个反置页表都未找到匹配的页表项,则表明此页尚未装入内存。对于不具有请求调页功能的存储器管理系统,此时则显示地址出错。对于具有请求调页功能的存储器管理系统,此时则产生请求调页中断,系统将把此页调入内存。
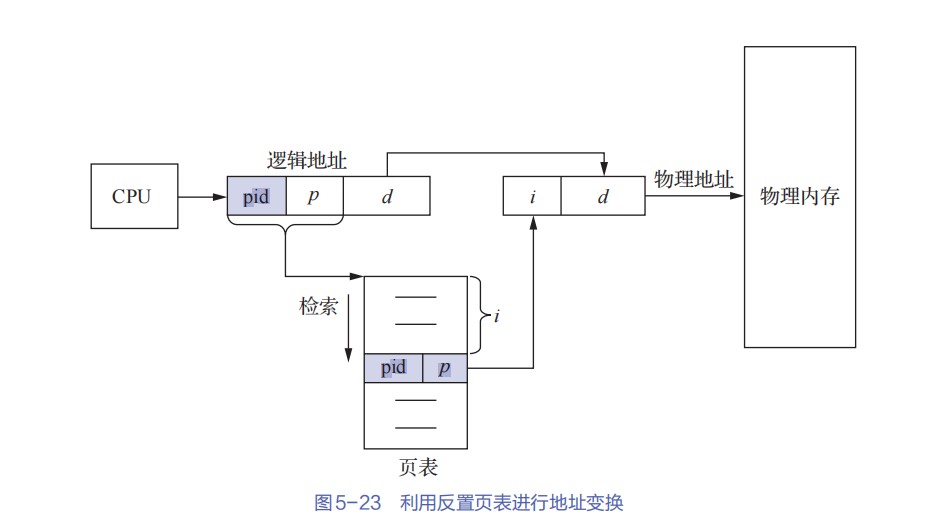
链接和装入
- 链接讨论的问题
- 共享库的链接
- 逻辑地址的生成时机
- 静态链接:经过连接器处理后写入外存,生成逻辑地址。链接多次共享库
- 动态链接,只会链接1次共享库
- 装入时动态链接
- 把外存装到内存,分配一些环境或执行现场的时候,这个时候就已经生成逻辑地址了
- 运行时动态链接
- 只有运行的时候发现这个模块里面还没有逻辑地址,才将其调入或者生成
- 装入时动态链接
- eg:对于动态库libc.so中的print模块,内存中只有一个printf副本,所有应用程序都可以通过动态地链接printf来使用它,说明动态链接的共享性。而在静态库连接方式下,静态库中的printf模块会在静态链接时被合并到每个可执行文件中,所以多个使用printf的进程同时在系统中执行时,内存中可能有多个printf的副本。动态链接库能够在程序加载或执行时进行连接,动态链接库更新后,每次加载或执行所连接的共享库都是最新的,动态链接器会对库中模块内的代码和数据进行重定位而无需对程序进行重新连接,强调动态链接相比于静态链接所具有的动态性。
运行时动态链接和装入时动态链接的区别
-
运行时动态链接
-
在执行过程中,当发现一个“被调用模块”尚未被装入内存时,立即由OS去找到该模块,将其装入内存,并链接到装入模块上。凡在执行过程中未被用到的目标模块,都不会被调入内存和被链接到装入模块上,这样不仅能加快程序的装入过程,而且可节省大量内存空间。
-
装入时动态链接 就像一次性把所有食材准备好,程序启动时就把所有需要的库加载到内存里,程序可以直接调用这些库。
运行时动态链接 就像根据需要随时去切菜台拿食材,程序在运行时根据需要加载和解析库中的函数,只有在需要时才加载。
-
-
装入时动态链接(Load-time Dynamic Linking)
- 装入时动态链接 是指在程序启动时,操作系统就会把程序所依赖的所有动态库模块加载到内存中,并完成符号解析(即将程序中的库函数和变量绑定到具体的地址)。
- 这些库函数的地址已经在程序启动时确定好,程序开始运行后不再需要进行动态链接。
- 所以,装入时动态链接意味着在程序启动时,所有必要的模块和库函数都会被加载到内存中,即使某些模块在程序执行过程中并不被使用。
- 这种方式启动时需要将所有相关库加载进内存,启动时间稍长,但是运行时不需要再次加载,访问库函数时非常迅速。
-
运行时动态链接(Run-time Dynamic Linking)
- 运行时动态链接 是指程序在运行过程中,根据需要动态地加载模块和库。程序开始时并不会立即加载所有的模块,而是只有在程序第一次使用到某个库函数时,操作系统才会去找到该库,加载到内存中,并进行符号解析(动态链接)。
- 这种方式的好处是,程序启动时不需要加载所有的库,启动时间较短,而且内存占用较少,因为只有在需要使用某些功能时,相关的模块才会被加载。
- 但这种方式的缺点是,程序在执行过程中可能会遇到延迟,因为某些库在第一次调用时才会被加载,而这涉及到磁盘I/O操作。
-
装入时动态链接 适合那些库比较稳定、固定的应用场景,启动时虽然加载时间长,但执行时非常高效。
- 运行时动态链接 适合插件系统或库经常变动的情况,比如一些需要根据环境或配置动态加载不同模块的应用(例如浏览器、游戏引擎等)。它的启动速度快,但第一次使用时会有额外的延迟,因为需要进行动态加载。
-
例子:
- 装入时动态链接:传统的桌面应用程序,启动时把所有相关的动态链接库(DLLs)都加载到内存中。
- 运行时动态链接:例如很多现代应用程序,比如某些插件驱动的应用程序或游戏。比如 GTA5,你启动游戏时,程序加载核心模块,但某些图形处理、音效处理模块会在你需要时才被动态加载进内存。
-
装入时动态链接:程序启动时,所有模块和库都已经被加载到内存,运行时不再需要加载。
运行时动态链接:程序启动时,核心程序加载完毕,只有在实际使用到库函数时,操作系统才会加载相应的库到内存中。
| 特性 | 装入时动态链接 | 运行时动态链接 |
|---|---|---|
| 加载时机 | 程序启动时,所有需要的库都被加载到内存中 | 程序启动时,只有部分库被加载,需要时再加载 |
| 启动过程 | 启动较慢(需要加载所有库) | 启动较快(只加载程序本身,库按需加载) |
| 内存使用 | 程序启动时内存占用较大 | 运行时按需加载,节省内存 |
| 程序执行时的性能 | 高效(库已加载,直接调用) | 可能有延迟(第一次调用库时需要加载) |
| 适用场景 | 库和程序的依赖关系较为固定的情况 | 动态插件或库可能会经常变动的情况 |
- 链接指的是把标准库连入程序的虚拟地址空间,静态链接在磁盘中就完成这一步,而动态链接在OS修改页表的一瞬间才链入主程序的虚拟地址空间;
- 装入时动态链接在装入模块的时候修改页表,具体来说,是主程序装入内存的时候看需要哪个动态库,就一起装入内存并修改页表;而运行时动态链接是主程序在执行的时候,运行到了某个函数发现是某个动态库里面的,就去把这个动态库调入内存并修改页表
访问内存的有效时间
- 不考虑快表
- 访问的页面在内存中
- ①第一次访问内存中页表,获取访问页的物理地址,用时n
- ②第二次访存,获取所访问的页,用时同样n
- 访问的页面不在内存中
- ①第一次访问内存中页表,用时n,发现该页没有调入内存
- ②进行缺页处理,更新页表,用时α
- ③获得物理地址后进行二次访存,获取所访问的页,用时n
- 访问的页面在内存中
- 考虑快表
- 访问页在内存中且快表命中
- ①访问快表,获取访问页的物理地址,用时m
- ②访问内存,获取所访问的页,用时m
- 访问页在内存中但快表未命中
- ①访问快表,用时m,但未命中(此处查询有两种方式:串行,先查询快表,后查询慢表;并行,快表和慢表一起查询)
- ②访问内存中页表,获取所访问的页,用时n
- ③访问快表对其进行修改,用时m(此处具体也要看题目要求)
- ④访存,获取所访问的页,用时n
- 访问页不在内存中
- ①访问快表,用时m,但未命中
- ②访问内存中页表,用时n,发现该页没有调入内存
- ③进行缺页处理,更新页表,用时α
- ④访问快表对其进行修改,用时m
- ⑤访存,获取所访问的页,用时n
- 访问页在内存中且快表命中
动态重定位分区分配
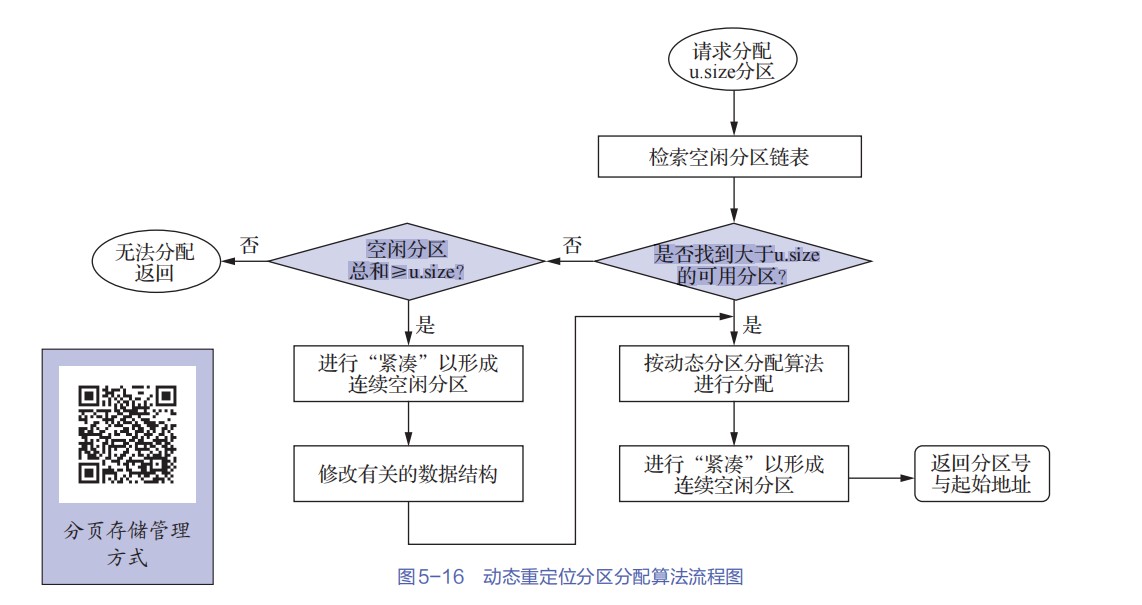
基于顺序搜索的动态分区分配算法(顺序分配算法)

基于索引搜索的分配算法
- 快速适应算法
- 伙伴系统
- 哈希算法
虚拟存储管理
-
页式存储管理方式的虚拟地址空间维度是一维的
- 段式存储管理方式的虚拟地址空间是二维的
- 段页式存储管理方式的虚拟地址空间是二维的
一、段式管理的"二维"特性
- 地址表示是二维的
在段式系统中,一个完整的地址必须由两个参数确定:
text
1
(段选择子, 偏移量)或更直观地:
text
1
段寄存器:偏移地址例如x86实模式的
CS:IP、DS:SI等。- 多个独立的地址空间
每个段都是一个独立的地址空间:
- 代码段:从0开始到段限长
- 数据段:从0开始到段限长
- 堆栈段:从0开始到段限长
关键:同一个偏移值在不同段中指向不同的物理位置!
- 二维的直观理解
想象你有多本书(多个段):
- 书1(代码段):第50页 → 书中内容A
- 书2(数据段):第50页 → 书中内容B
- 书3(堆栈段):第50页 → 书中内容C
要找到内容,你必须知道:
- 哪本书(段选择子)
- 第几页(偏移量)
这就是二维:需要两个坐标才能定位。
- 示例代码(x86汇编)
asm
1
2
3mov ax, [ds:si] ; 从数据段读取,DS决定段
jmp cs:next_label ; 跳转到代码段,CS决定段
push bp ; 写入堆栈段,SS决定段这里必须显式或隐式指定段,偏移量单独给出。
二、页式管理的"一维"特性
- 地址表示是一维的
在纯页式系统中,地址就是单一的数字:
text
1
2
30x00401000
0x7ffd1234
0xffffffff这个地址被硬件拆分为:
text
1
(虚拟页号, 页内偏移)但这对程序员不可见!程序员看到的就是一个连续地址空间。
- 单一的连续地址空间
整个虚拟地址空间是一个从0到最大值的线性空间:
text
1
2
3
4
5
6
7
8
90x00000000 ┌──────────┐
│ 代码区域 │
0x00400000 ├──────────┤
│ 数据区域 │
0x00600000 ├──────────┤
│ 堆区域 │
0x00800000 ├──────────┤
│ 栈区域 │
0x7fffffff └──────────┘所有区域都在同一个地址空间中,通过不同的地址范围区分。
- 一维的直观理解
想象一个超长的大楼(单一地址空间):
- 房间50:可能是办公室
- 房间150:可能是会议室
- 房间250:可能是休息室
要找到房间,你只需要一个房间号(虚拟地址)。
- 示例代码(页式系统)
c
1
2
3
4
5int* p = 0x00401000; // 直接使用线性地址
*p = 42;
void (*func)() = (void(*)())0x00402000;
func(); // 直接跳转到线性地址不需要指定"这是哪个段",所有地址都在同一个全局空间中。

-
页式存储管理中每个进程有一个页表
-
段式存储管理中每个进程都有一个段表
-
段页式存储管理中,每个进程都有一个段表,每个进程的每个段都有一个页表
-
物理地址=基地址+相对地址
-
页号=物理地址/页大小
-
如何确定页表项的大小?
- n位内存地址空间,编址方式,一页大小
- 地址空间/一页大小得到页的数量
- 根据页的数量得到需要的位数
- (位数/编址单位)上取整得到页表项的大小
- 基本分页里面页表项只有块号(页的数量)
- n位内存地址空间,编址方式,一页大小
-
在页式系统中,逻辑地址的页号和页内偏移量对用户是透明的,但在分段系统中,段号和段内偏移量必须由用户显示提供,在高级程序设计语言中,这个工作由编译程序完成。
-
如何确定段表项的大小
- 段表项=段长(该段的大小)+基址(该段在物理内存中的起始地址)
- 段内偏移量的位数(一段的范围)=段长所需要的位数
- 基址=整个物理内存中的任意地址,需要地址空间大小的位数
- 段表项的大小=段内偏移量位数+物理地址空间位数
-
为了实现段共享,在系统中配置一张共享段表,所有共享的段都在共享段表中占一个表项。表项中记录了共享段的段号、段长、内存始址、状态位、外存始址和共享进程计数count等信息。
- 共享进程计数count记录有多少进程正在共享该段,仅当所有共享该段的进程都不再需要它时,此时count=0,才回收该段所占的内存区。
- 对于一个共享段,在不同的进程中可以具有不同的段号,每个进程用自己进程的段号去访问该共享段。
-
地址越界保护将段表寄存器中的段表长度与逻辑地址中的段号比较,若段号大于段表长度,则产生越界中断;再将段表项中的段长和逻辑地址中的段内偏移进行比较,若段内偏移大于段长,也会产生越界中断。分页管理只需要判断页号是否越界,页内偏移是不可能越界的。
-
段页式存储管理中,在进行地址变换时,首先通过段表查到页表始址,然后通过页表找到物理块号,最后形成物理地址。进行一次访问实际需要三次访问主存,这里同样可以使用快表来加快查找速度,其关键字由段号、页号组成,值是对应的物理块号和保护码。
-
多级页表中,页号位数=一页的大小/页表项大小
-
编译形成的只是相对于该模块的逻辑地址,而链接形成的是整个程序的完整逻辑地址空间。
-
在多级页表中,页表基址寄存器存放的是顶级页表的起始物理地址。
-
快表是硬件,发生进程切换时,快表的内容也会被清除
-
注意区分Cache容量计算和页表项内容
-
请求分页管理中,页表项多加的表项,外存地址和状态位是必须有的
-
缺页的情况下,执行完调页之后,会重新执行引发缺页异常的指令,因此会重新执行一遍访存过程
-
由于段比页大,段表项的数目比页表项的数目少,其所需的联想存储器也相对较少。
-
虚拟存储器的实现,建立在离散分配方式的基础上
-
请求分页系统在实现上比请求分段系统简单
-
对于某些简单的机器,若是单地址指令,且采用直接寻址方式,则所需的最小物理块数为2。其中,一块是用于存放指令的页面,另一块则是用于存放数据的页面。如果该机器允许间接寻址,则至少要求有3个物理块。
-
TLB的页号是显式保存的
-
段页式管理实现内存共享
- 让共享段指向相同的页表,从而实现进程间的段共享
-
虚拟内存的最大容量是由计算机的地址结构(CPU寻址范围)确定的
- 虚拟内存的实际容量是min(内外存容量之和,CPU寻址范围)
-
程序分段对用户和操作系统都可见,但其分段多在用户编程时决定
-
访问某某地址要算入它访问内存的时间。
地址变换机构
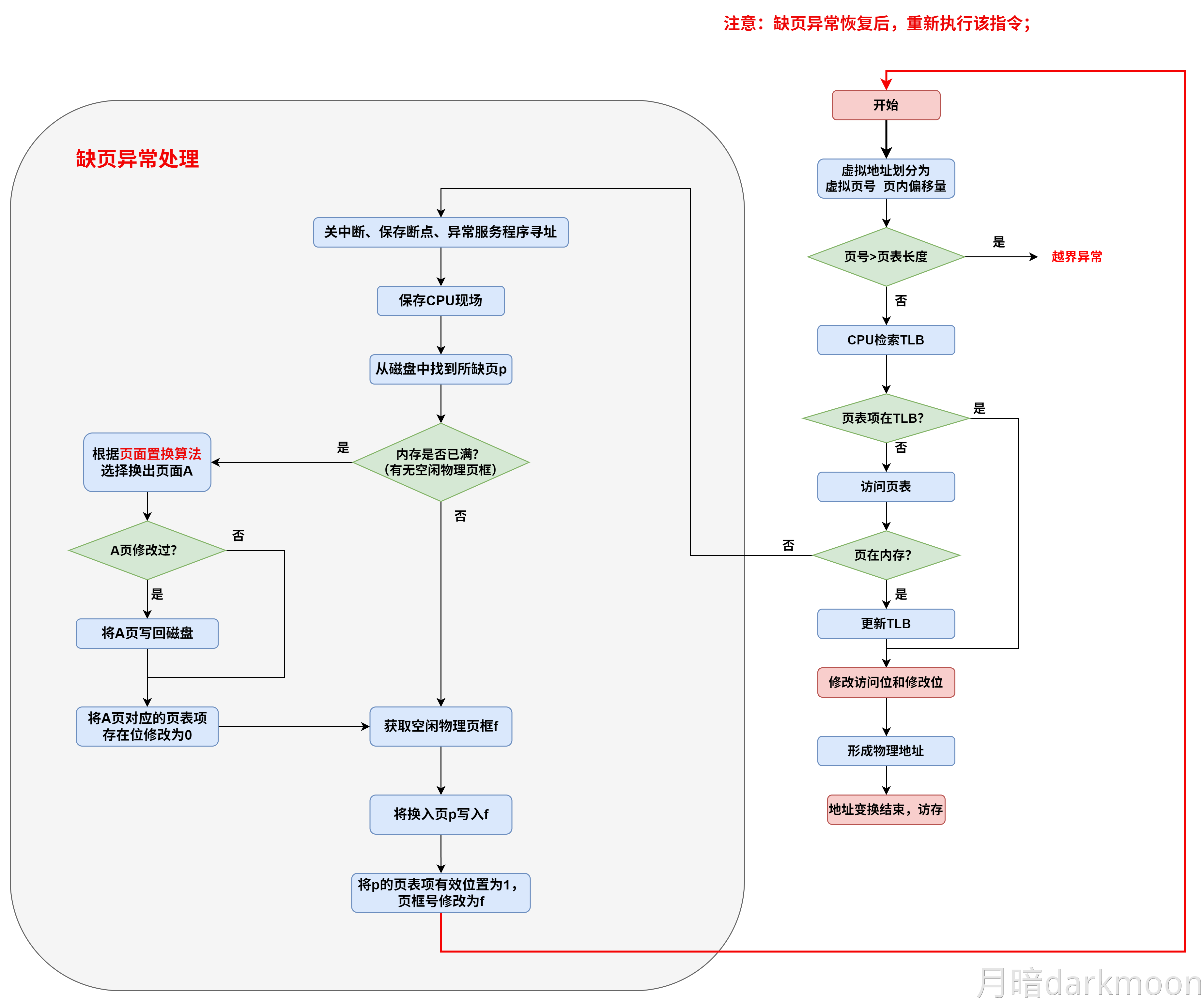
- 缺页异常后需要返回到被中断的位置,重新执行该指令,这时CPU还是跟之前一样去快表查记录,一般来说只会修改页表,不会修改快表,只有重新执行该指令后TLB缺失之后,才会更新快表。不过如果题目有题是,例如09年的处理缺页过程中会更新TLB和页表,那么需要根据题目体条件来,随机应变,不能死板。
- 注意题目条件中的
- 只修改页表还是同时修改页表和TLB
- 缺页异常处理将页面调入内存以后,是重新执行发生缺页的那条指令,还是直接拿到物理地址去访存
- 注意题目条件中的
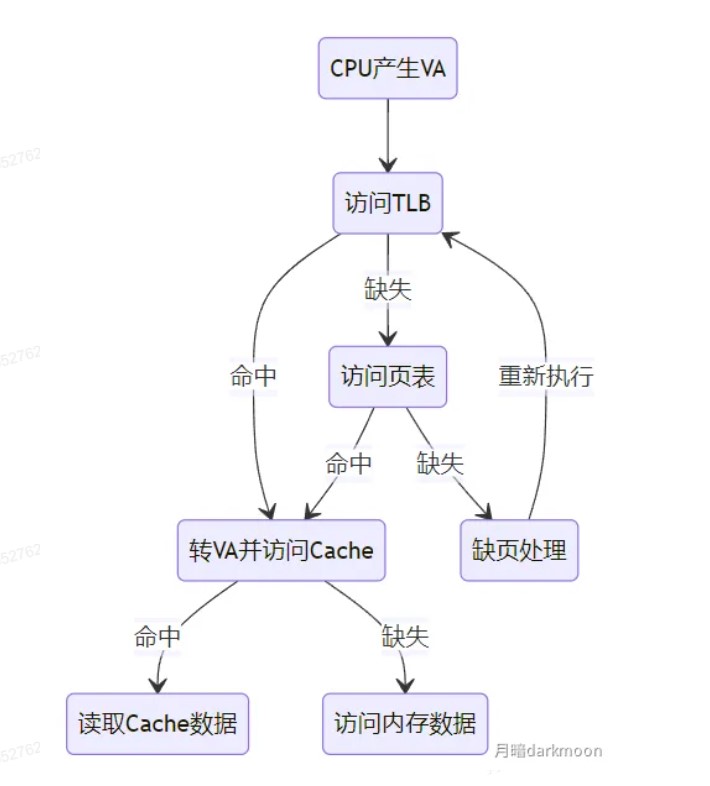
- 虚实地址的转换速度主要由硬件地址变换机构(如MMU)、快表(TLB)的命中率以及页表(或段表)的结构和访问效率决定。
是否会产生内外碎片总结
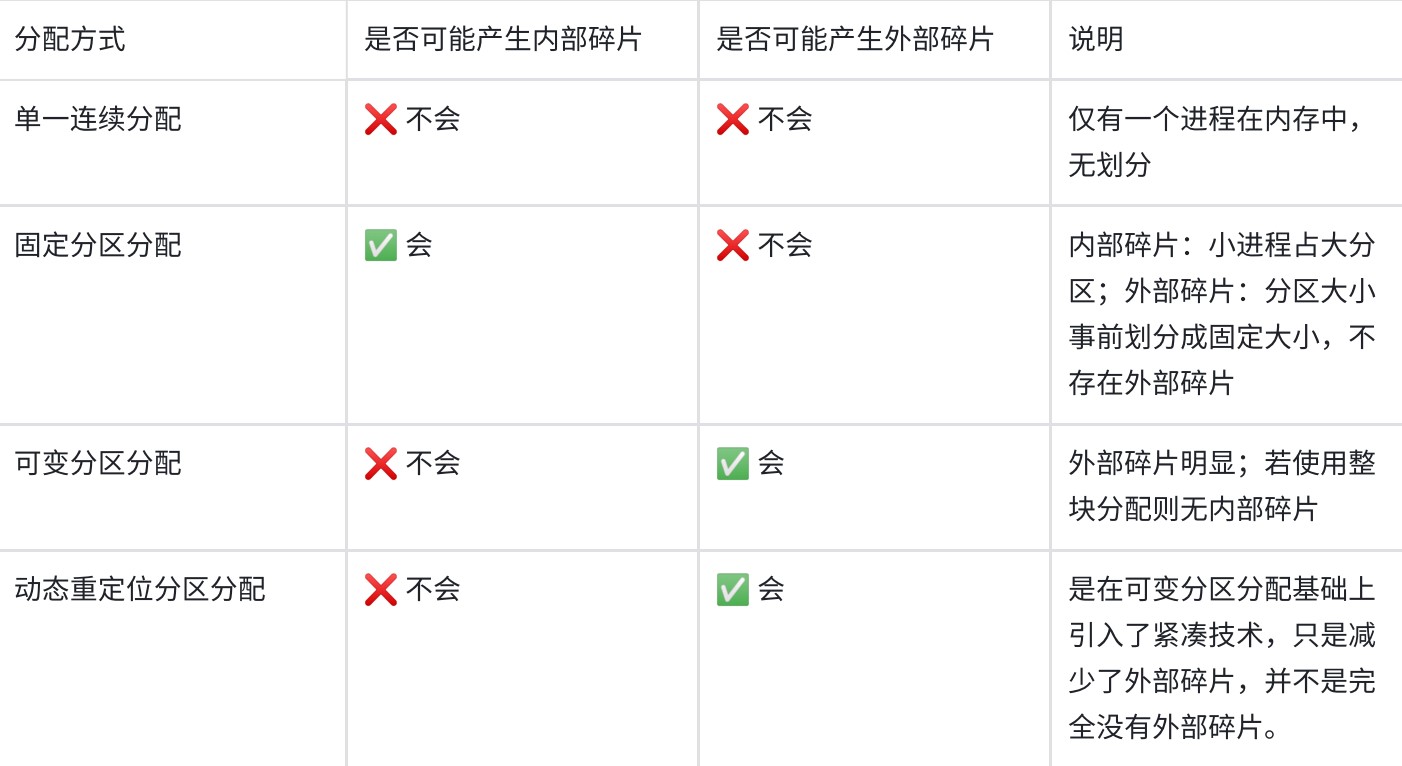
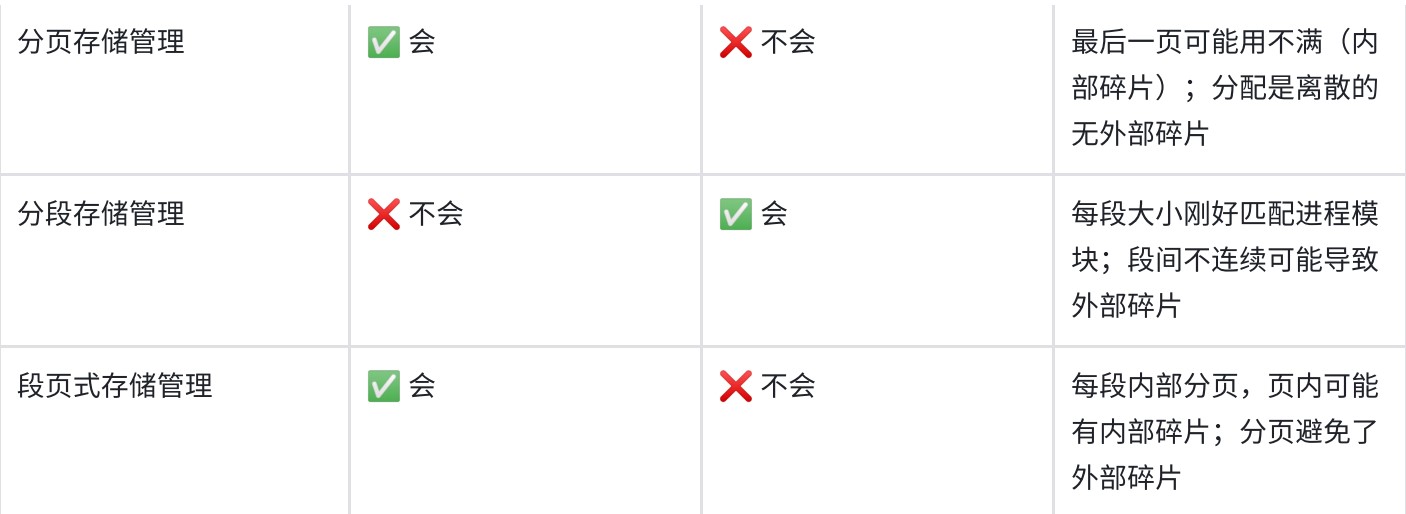
- 最佳适应算法产生最多的外部碎片
- 最坏适应算法产生碎片的可能性最小
- 快速适应算法在分配空闲分区时以进程为单位,一个分区只属于一个进程。
页面置换算法
-
会发生Belady现象的算法:FIFO,CLOCK,改进版CLOCK
- 不会发生Belady现象的算法:LRU和OPT
-
注意区分抖动和Belady异常,所有策略都会引起抖动,但是只有LRU和OPT算法不会出现Belady异常
-
FIFO队列的最大长度取决于系统为进程分配了多少个内存块
-
LRU的技巧:
- 若要淘汰页面,可以逆向检查访问序列。假设某进程分配了n个内存块,则逆向找到第n个不同且在内存中的页号(即逆向扫描过程中最后一个出现的页号),该页号就是要淘汰的页面。
-
LRU算法的软件实现


- 内核维护一个双向页面链表,表头是最近刚使用过的页面,表尾是最近最久没有使用的页面。该链表在每次该进程访问内存时都要进行更新,即遍历链表找到该页面,把它摘下来,移动到表头,每次缺页异常需要置换页面时,选择表尾页面淘汰,新页面挂到表头,因此开销很大
-
硬件实现:
- 为每个页面配置一个移位寄存器,记录页面使用情况
-
LRU用栈保存当前使用页面时栈的变化情况
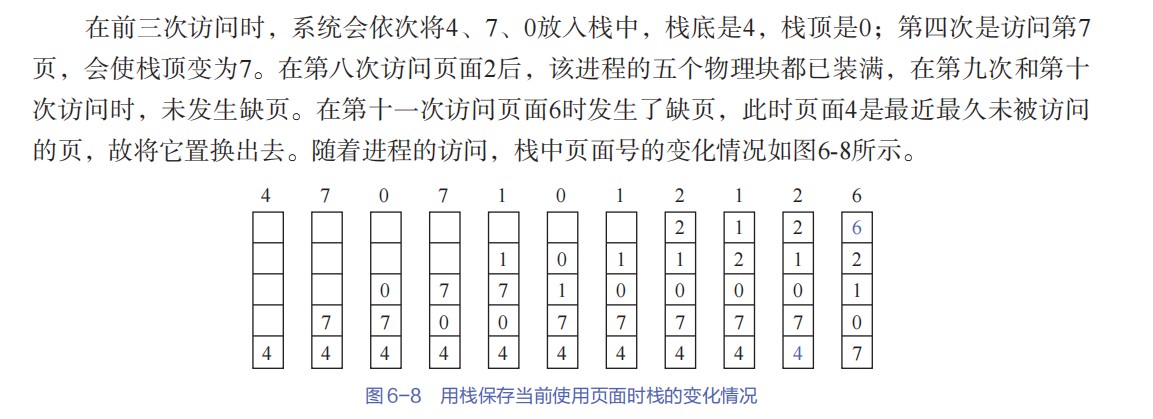
- 可利用一个特殊的栈,保存当前使用的各个页面的页面号。每当进程访问某页面时,便将该页面的页面号从栈中移出,并压入栈顶。因此,栈顶始终是最新被访问页面的页面号,而栈底则是最近最久未使用页面的页面号。
- 有点像俄罗斯方块,访问的就放在栈顶,然后它上面的块往下掉落,剩下的不变
- 可利用一个特殊的栈,保存当前使用的各个页面的页面号。每当进程访问某页面时,便将该页面的页面号从栈中移出,并压入栈顶。因此,栈顶始终是最新被访问页面的页面号,而栈底则是最近最久未使用页面的页面号。
-
Clock算法最开始的指针指向最先调入的页面
-
简单Clock算法最多会经过两轮扫描
- 改进型Clock最多进行四轮扫描
-
改进型Clock页面置换算法与简单Clock页面置换算法相比,可减少磁盘的I/O操作次数。但为了找到一个可置换的页,可能需要经过几轮扫描。换言之,实现该算法本身开销将有所增加。
-
置换不改变页框号,只改变页号(逻辑地址和物理地址的映射,物理地址不变,逻辑地址改变),因为替换是把同一页框号的内容覆盖,而不是另找页框
-
这句话在说“页面置换”的本质:当发生缺页而没有空闲页框(frame)时,操作系统会挑一个已有的物理页框作为“牺牲者”,把其中原来的那一页(虚拟页)淘汰掉,然后把新的虚拟页装进同一个物理页框。因此:
- 页框号不变:被选中的物理页框,比如 frame #17,一直是 #17;我们只是覆盖了它的内容。
- 页号改变:页表里“谁映射到 frame #17”的那条记录变了——把原来映射到 #17 的虚拟页 Pold取消(无效化/可能写回磁盘),再把新的虚拟页 Pnew的页表项改为“→ frame #17”。
一个小例子(置换前→置换后):
虚拟页号 物理页框号(置换前) 物理页框号(置换后) P_old #17 (无效/换出) P_new (无效/未装入) #17 置换流程要点(简化):
- 选牺牲页框 F(如 #17),若页脏则写回磁盘;
- 将 P_old 的页表项标记为无效(并更新其辅存位置等元数据);
- 把 P_new 从辅存读入同一个物理页框 F;
- 将 P_new 的页表项改为“有效,帧号=F”;
- 失效/更新相关 TLB 项(可能涉及 TLB shootdown)。
所以这句的核心是:置换是“改映射 + 覆盖同一帧”,而不是“另找一个新帧”。
(只有在系统本来就有空闲页框时,那是“分配”而非“置换”,这时会用到一个新的帧号。)
-
-
在408范围内,页面置换算法通常指局部置换的算法
常见页表项状态
| 虚拟地址区间 | 页表项存在? | Present/Valid | 含义/行为 |
|---|---|---|---|
| 未映射的空洞 | 否 | — | 无页表项;访问立即段错 |
| 已映射、未装入 | 是 | 0 | 按需调页:缺页异常 → 从文件/零页/匿名分配装入 |
| 已映射、在交换区 | 是 | 0 | 换出状态:缺页异常 → 从 swap 读回 |
| 已映射、在内存 | 是 | 1 | 正常访问;PTE含物理帧号 |
| 保护/Guard/不可写等 | 是 | 1 或 0 | 访问触发保护/扩栈/COW 等异常,由内核处理 |
- “有效位=0 的页表项”很常见:按需调页、换出、文件映射延迟装入、保护页等都用它来让内核在访问时接管。
- “换出去不一定立刻被新的页替代”这点是对的:那叫回收;只有在缺页要装入新页时,才会在同一物理帧上完成替换,表现为“页框号不变、页号改变”。
从哪里调入页面
- 若系统拥有足够的对换区空间
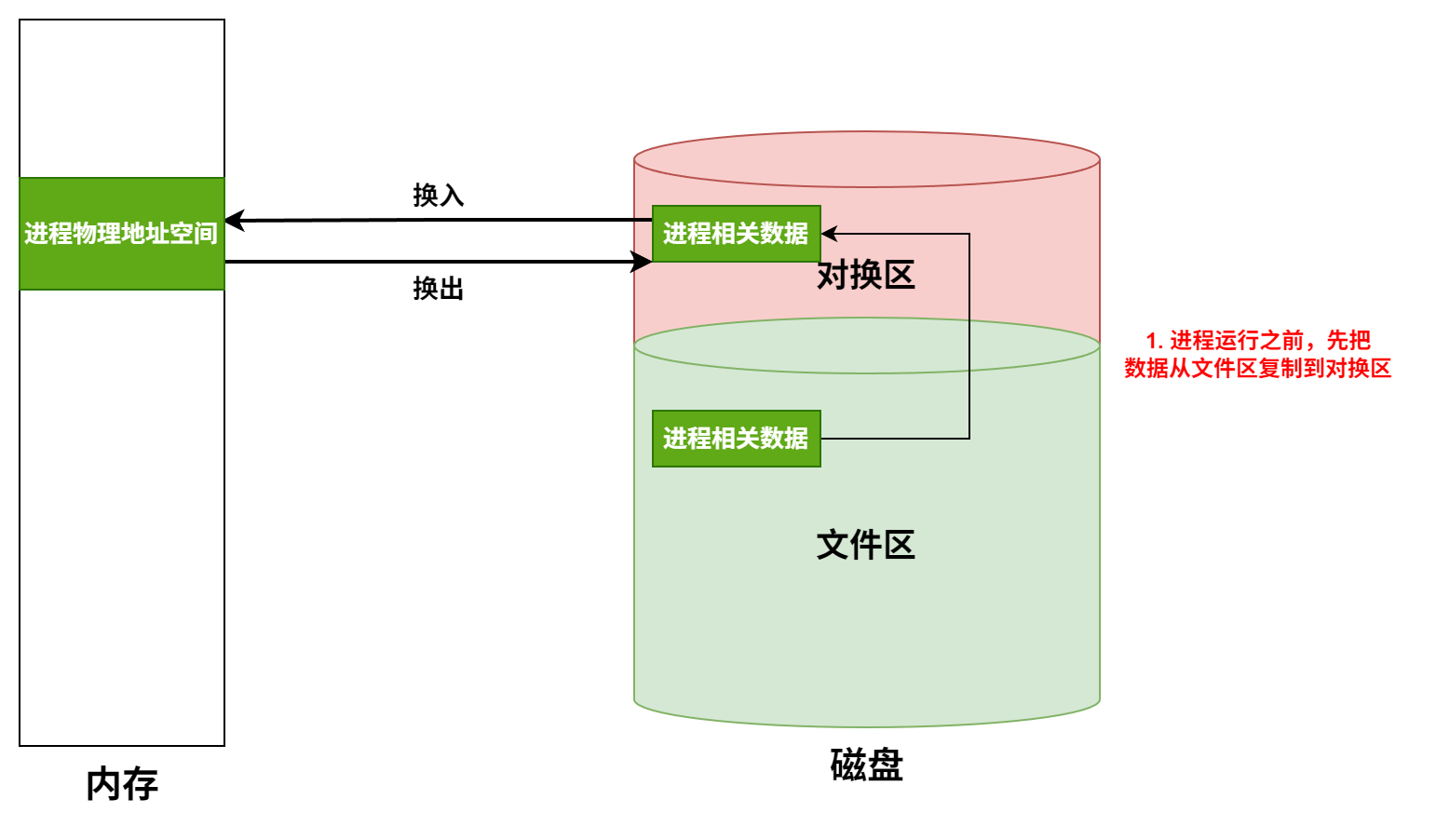
- 若系统没有足够的对换区空间
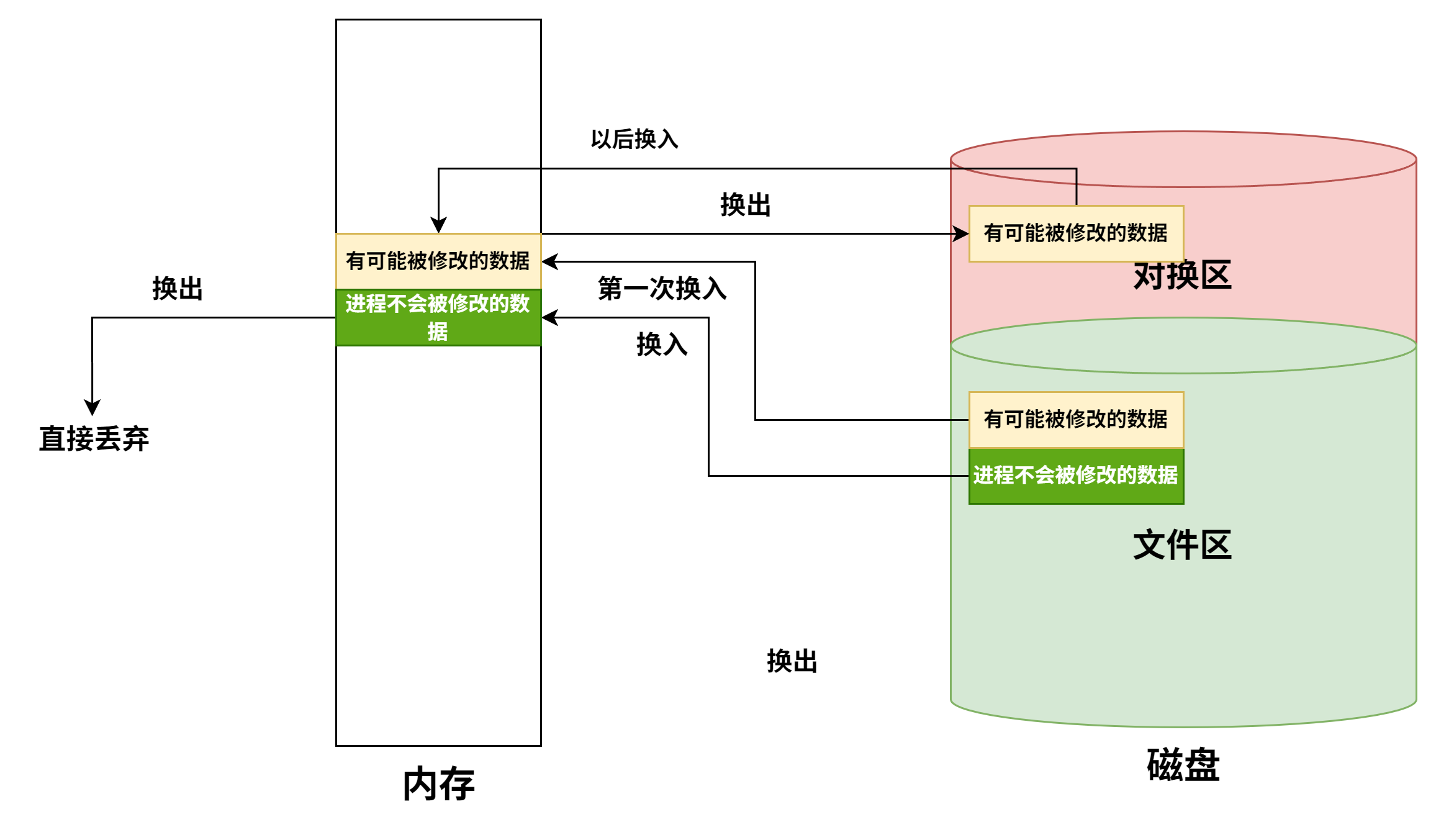
- UNIX方式
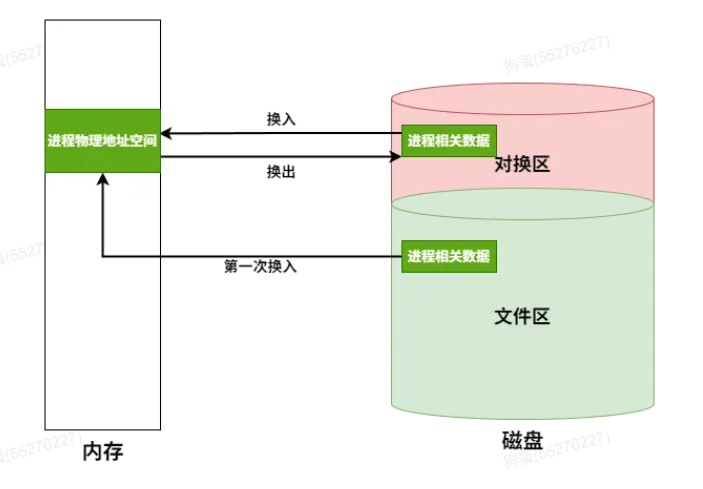
页面回收
- 文件页和匿名页的回收都是基于LRU算法
- 系统内存紧张的时候,就会进行回收内存(页框)的工作,主要有两类内存可以被回收,而且它们的回收方式也不同。
- 文件页(File-backed Page)
- 内核缓存的磁盘数据(Buffer)和内核缓存的文件数据(Cache)都叫作文件页。
- 大部分文件页,都可以直接释放内存,以后有需要时,再从磁盘重新读取就可以了。
- 而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。
- 所以,回收干净页的方式是直接释放内存,回收脏页的方式是先写回磁盘后再释放内存(如上,可能先挂到修改页面链表,暂时不写入磁盘)。
- 匿名页(Anonymous Page)
- 这部分内存没有实际载体,不像文件缓存有硬盘文件这样一个载体,比如堆、栈数据等。
- 这部分内存很可能还要再次被访问,所以不能直接释放内存,它们回收的方式是通过Linux的Swap机制,Swap会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。
- 再次访问这些内存时,重新从磁盘读入内存就可以了。
- 文件页(File-backed Page)
内存映射文件

-
内存映射文件利用了操作系统的请求调页机制。当文件被映射时,并不会立即将其全部内容调入物理内存。只有当进程实际访问到映射区域中的某个特定页面,而该页面尚未在物理内存中时,才会触发缺页中断,操作系统再负责将对应的文件部分从磁盘调入物理内存。这种按需调页的方式使得可以映射远大于可用物理内存的文件
-
创建共享内存需要通过系统调用实现,需要先进入内核态,内核在物理内存中分配一块连续区域,指定共享内存的访问权限(如读写权限)和大小,然后进程再通过系统调用,将共享内存映射到自己的虚拟地址空间。因此共享内存映射的建立发生在内核态下。
- 在虚拟页式内存管理的操作系统中,内存修改进程的页表,将指定的虚拟地址范围映射到共享内存的物理页框。多个进程的虚拟地址可以不同,但最终指向同一物理内存。
-
对共享内存的读写通常是在用户态下进行的。用户进程可以通过其虚拟地址直接读写内存共享空间
-
内存映射文件是磁盘文件与进程的虚拟地址空间之间建立映射关系
- 对比虚拟内存管理是在物理内存与进程虚拟地址空间建立映射关系。
-
页缓冲队列上的页面逻辑上已经被置换出去不在内存中,因此访问这些页面相当于缺页
- 页缓冲队列是将被淘汰的页面缓存下来,暂时不写回磁盘。发生缺页时,一定会修改页表和将对应物理页写入用户内存,也会重新执行缺页指令,但是由于页缓冲队列的存在,所以可能不必去磁盘获取页面。
-
传统的文件访问方式
- open系统调用——打开文件
- seek系统调用——将读写指针移到某个位置
- read系统调用——从读写指针所指位置读入若干数据(从磁盘读入内存)
- write系统调用——将内存中的指定数据,写回磁盘(根据读写指针确定写回什么位置)
- 这样访问文件的话需要经历一系列系统调用和磁盘I/O,系统调用需要切换到内核态,磁盘I/O也很耗时,这样看来时间开销很大
-
内存映射文件的访问方式:mmap系统调用会给程序员返回一个指向映射区域起始地址的指针
- ①以访问内存的方式访问文件数据:可以通过指针加上地址偏移量访问该指针后面的区域。
- ②文件数据的读入、写出由操作系统自动完成:在mmap系统调用的初始状态下,文件数据还没有被读入内存中,只是建立了内存地址空间和外存中文件数据的映射关系,在程序员通过指针访问该地址空间时,实际上是缺页状态;发生这种缺页时,操作系统将会把该地址空间映射的文件数据调入内存,而不需要程序员使用read系统调用。
- ③进程关闭文件时,操作系统自动将文件被修改的数据写回磁盘。
-
没有mmap()之前,访问磁盘上的文件数据需要通过read()/write()等系统调用,学习了I/O相关的知识我们直到,这需要先将磁盘上的文件复制到内核缓冲区,再将其复制到用户缓冲区;而mmap()由于建立了磁盘文件与进程虚拟地址空间的映射,在缺页中断I/O的过程中,直接将该文件读取进内存中的用户空间,不需要拷贝
-
mmap是一种将文件或设备直接映射到进程虚拟地址空间的机制,使得进程可以像访问内存一样读写文件,从而避免频繁的系统调用(read/write)和数据拷贝
-
内存映射文件的工作原理
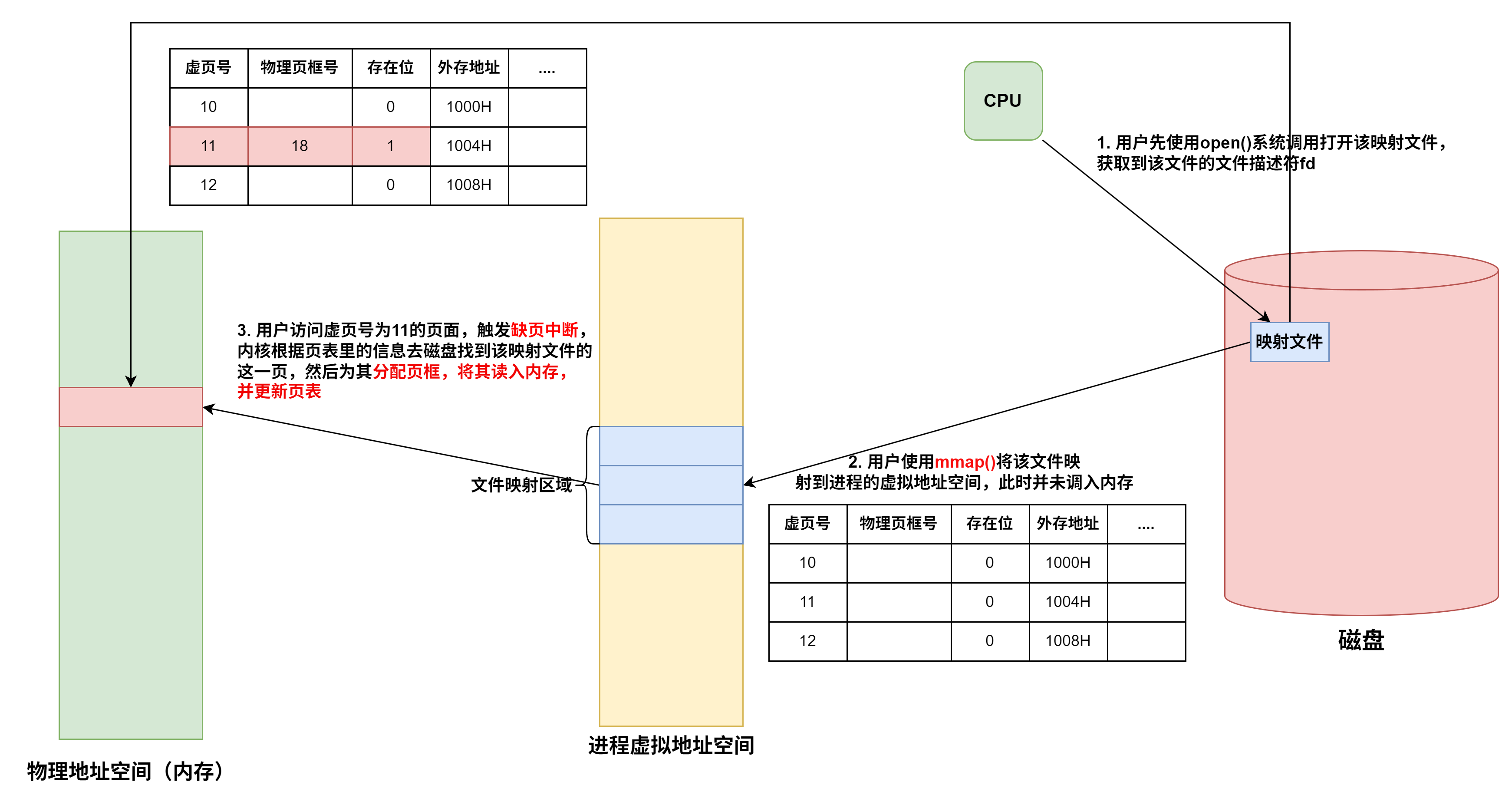
- ①用户使用open()打开映射文件,返回一个文件描述符fd;
- ②通过mmap(*addr,length,fd…)系统调用发起请求,内核会在进程的虚拟地址空间分配一段连续的虚拟内存区域,用于映射磁盘上的文件,如图页表所示
- ③正如上图所示,此时并没有立即加载文件数据到内存中
- ④按需加载:当进程首次访问这段虚拟内存的某个页面时,发现存在位为0,触发缺页中断,内核找到该页面对应的文件数据后,为其分配一个物理页框,然后将其加载到里面,并更新页表,此时才真正建立了虚拟内存到物理内存的映射
- ⑤至此,该页框里的数据即为磁盘中该文件在内存中的副本,后续对这段虚拟内存的读写会直接作用于内存中的该页(文件缓存页),修改该内存的内容会标记脏位,内核会在适当时机(如内存不足将该页面换出、或者关闭文件时)将修改写回磁盘。
-
内存映射文件的优点:
-
减少数据拷贝:
-
传统read/write需要数据在内核缓冲区和用户缓冲区之间拷贝,而mmap直接操作页缓存,零拷贝
-
更准确说是避免了内核/用户之间的二次拷贝,仍然有磁盘→内存的I/O
-
-
-
方便程序员访问磁盘文件:
- 对于已经建立映射的文件,可以像访问内存一样读写,尤其是频繁随机访问大文件的场景,无需多次lseek移动读写指针。
- 通过指针和内存访问指令(MOV)来直接读写文件内容
- 对于已经建立映射的文件,可以像访问内存一样读写,尤其是频繁随机访问大文件的场景,无需多次lseek移动读写指针。
-
文件的读入读出全部由操作系统内核实现(缺页异常服务程序读入数据,内核负责将脏数据写回磁盘),不需要用户使用read()、write()等各种系统调用。
-
方便多个进程共享同一个文件:
- 多个进程映射同一文件时,共享内存中的同一份页缓存,既可提升效率,也能够实现进程间通信
-
文件按需加载进内存,节约物理内存占用
- 访问到哪一页,从磁盘调入哪一页,不需要将整个文件读入内存
-
可以显著提升I/O密集型进程的效率
-
-
为什么read/write()需要数据在内核缓冲区和用户缓冲区之间拷贝,而mmap()缺页时就可以直接写到用户空间
- 首先,对于read/write(fd,*buf,count),os内核会根据进程打开文件表里的读写指针和需要读写的文件长度(count),确定所读区域位于fd所指的文件中的哪些磁盘块,然后依次将这些磁盘块通过dma读入内存中的内核缓冲区
- 注意,文件系统与主存的交换单位是磁盘块,一次只能读入一整块,不存在说只读入自己需要的部分像是半块这样子
- 之后,再将自己需要的指定字长的数据复制到用户指定空间buf里面
- 用户没有权限读入一整个磁盘块到用户空间,因为这一整块里面除了用户需要的数据,剩下的数据可能是敏感数据,不能放到用户空间
- 注意,在将磁盘块读入到内核缓冲区时,发起该系统调用的进程会阻塞,直到I/O完成才会将其唤醒,等待其被调度程序选择上处理机时才会继续执行剩下的部分,也就是把数据复制到buf里面;
- 而缺页异常处理的时候,也会发生阻塞,只不过这里跟磁盘交换的单位是页面
- 因此在DMA预处理的时候,直接将分配给该页的页框(内存)物理地址写到DMA控制器里的主存地址寄存器(相当于锁定了物理地址,无所谓阻塞引起进程切换发生的进程地址空间切换),之后DMA控制器负责直接将所需页面加载到指定页框里面(用户地址空间)
- 你可能会问,为什么这里就可以直接写到用户空间,不用先写到内核缓冲区?
- 这是因为缺页处理程序读入的是一整个页面,这个页面都是属于这个进程的,进程有权限访问这个页面的所有内容,不存在读入不该读的敏感数据,所以可以直接把整个页调入用户空间;
- 注意这里提到的磁盘块和页面,二者是没有关系的,操作系统以页为单位进行内存和磁盘的交换,而文件系统以块为单位管理磁盘存储。如果一个页面大小是磁盘块大小的n倍,那么一次缺页异常,文件系统可能需要读取多个块,只不过页面和块大小对齐更方便而已,二者的大小并没有实质上的关系
- 首先,对于read/write(fd,*buf,count),os内核会根据进程打开文件表里的读写指针和需要读写的文件长度(count),确定所读区域位于fd所指的文件中的哪些磁盘块,然后依次将这些磁盘块通过dma读入内存中的内核缓冲区
-
内存映射文件的关键在于,操作系统通过映射文件的内容到虚拟内存地址空间,让程序能够直接访问文件的内容,而不需要显式地读写文件。文件本身被分成很多虚拟页,而这些虚拟页的内容可能对应文件的某一部分,而不一定直接等于磁盘上的物理块。
-
在内存映射文件(memory-mapped files)中,操作系统将文件中的内容映射到进程的虚拟内存地址空间。在这个过程中,虚拟页号(虚拟内存中的页) 与文件内容之间建立了映射关系,但这并不是直接与磁盘块(通常是硬盘上存储数据的物理块)建立的映射。
-
虚拟页号 是映射到文件内容的(对于内存映射文件)。
物理页框号 是在页面加载到内存时,由操作系统根据需要分配的。
进程所需最小页框数的确定
-
硬件结构如何影响进程所需最小页框数?
-
1、指令格式与内存访问模式
- 单地址指令+直接寻址:至少需要2个页框。
- 指令页:存放当前执行的指令;数据页:存放指令操作数(直接寻址的目标地址所在页)
- 示例:指令LOAD R1,0X1000(从地址0x1000加载数据)需指令页和数据页同时驻留内存
- 间接寻址(单级):需要至少3个页框。
- 指令页
- 间接地址页:存放间接地址(如指令MOV AX,[BX]中,BX指向的地址所在页)
- 数据页:存放最终操作数(间接地址指向的数据所在页)
- 多级间接寻址:需要的页框数逐级增加。例如指令MOV AX,[[BX]]
- 第一级:BX指向的页(获取下一级地址)
- 第二级:该地址指向的页(获取最终数据)
- 若跨页访问,每级需独立页框
- 单地址指令+直接寻址:至少需要2个页框。
-
2、指令隐含的多页面访问
- 同时访问多页面
- eg:x86的MOV[A],[B],需要同时访问源地址B和目标地址A,若两者跨页,需要2个数据页+1个指令页,共3个页框
- eg:函数调用CALL0x2000若跨页(如指令末尾在0x1000FFC,目标地址在0x200000),需要2个代码页
- 同时访问多页面
-
3、典型架构所需最小页框数对比
架构特性 最小页框需求示例 原因 简单单地址指令 2 个页框(指令页 + 数据页) 直接寻址无需间接访问 x86 复杂指令 3+ 个页框(代码 + 数据 + 堆栈页) 指令可能同时操作代码、数据和堆栈段 RISC-V 精简指令 2~3 个页框(显式加载/存储设计) 减少隐式跨页访问,但需显式寻址支持 -
4、总结
- 最坏情况覆盖:最小页框数由最复杂指令执行时的最大页面需求决定。例如,某条指令需同时访问4个页,则最小页框数最少为4
- 硬件不可绕过:指令格式、寻址方式、对齐规则等硬件特性直接约束最小页框数,软件无法通过优化绕过
- 实际应用意义:操作系统需为不同架构的进程分配不同最小页框数。编写高效代码时,应减少跨页访问(如内存对齐、紧凑数据结构),以降低对最小页框数的依赖。
-
文件管理

-
FAT在文件系统挂载的时候就被全部或大部分读入内存,并常驻内存当中,而不是打开单个文件的时候才去读入
-
空闲链表法分为空闲盘块链和空闲盘区链,空闲盘区链可以把连续的空闲盘块合并成一个区,支持合并
-
在引入索引节点(inode)的文件系统中,目录项通常包含文件名与该文件名对应的索引节点号。目录本身是一个包含这些目录项的文件。索引节点是存储文件元数据(如文件大小、权限、物理位置等)的数据结构,他们通常集中存放在磁盘的特定区域(索引节点区)。因此,目录是文件名到索引节点号的映射集合,而不是索引节点本身的有序集合。
-
超级块通常在磁盘上有多个副本(备份)。主超级块通常位于文件系统的固定位置,而备份超级块则分布在文件系统的其他位置,如果主超级块损坏,系统可以尝试从备份中恢复。
-

-
FCB的有序集合称为文件目录,一个FCB就是一个文件目录项。
- 通常,一个文件目录也被视为一个文件,称为目录文件。每当创建一个新文件,系统就要为其建立一个FCB,用来记录文件的各种属性。
-
对文件的访问控制,常由用户访问权限和文件属性共同限制
-
删除一个文件时,会根据文件控制块回收相应的磁盘空间;将文件控制块回收;并删除目录中对应的目录项。
-
VFS并不是一种实际的文件系统,它只存在于内存中,不存在于任何外存空间中。VFS在系统启动时建立,在系统关闭时消亡。
-
根文件系统,它是在系统启动时直接安装的,也是内核映像所在的文件系统。除了根文件系统,所有其他文件系统都要先挂载到根文件系统中的某个目录后才能访问。其他文件系统要么在系统初始化时自动安装,要么由用户挂载在已安装文件系统的目录下。安装文件系统的这个目录称为安装点,同一个设备可以有多个安装点,同一个安装点同时只能挂载一个设备。将设备挂载到安装点之后,通过该目录就可以读取该设备中的数据。
-
文件一旦被打开,内核就不再使用文件名来访问文件,而使用文件描述符。内核内存中,所存放的进程打开表和系统打开表是没有文件名的,通过open打开文件返回给用户的是索引,而read系统调用就是通过索引访问进程打开表的
-
索引文件和定长记录的顺序文件支持随机存取
-
FAT表在系统启动时就会被读入内存,页表也是常驻内存,根目录也是启动时读入内存的。
- FAT表本身就在内存当中,不占用磁盘空间,占用内存空间,FAT表记录文件系统的时候,除非题目说明,不然不用考虑FAT表占用磁盘空间,直接按照最大簇号分配
-
显式链接支持随机访问,地址转换时不需要访问磁盘
- FAT表项的位数由磁盘总块数决定,FAT自身采用连续存储
- FAT中用特殊数字表示磁盘块是否空闲,也可用于管理空闲磁盘块
-
索引分配一个文件对应一个索引表,显式链接一个磁盘对应一个FAT表
-
采用K层索引结构,且顶级索引表未调入内存,则访问一个数据块只需要k+1次读磁盘操作
-
链接分配读入i号逻辑块需要i+1次磁盘I/O
-
支持随机访问的文件分配方式
- 顺序分配
- 显式链接
- 索引分配
- 索引顺序分配
-
为减少查找目录而读磁盘的次数采用索引节点的方法,为减少查找文件的记录而读磁盘的次数采取链接索引的方法
-
超级块中,存有文件系统的关键信息(文件系统的状态描述信息),在该文件系统首次被使用时加载到内存中。
- 块组描述符
- 数据位图和Inode位图
- inode列表
- 数据块
-
VNODE只会存在于主存中(由虚拟文件系统创建),而INODE(索引节点)存放在外存中,在使用时调入主存
-
VFS可以提高系统性能,最近最常使用的目录项对象被放在目录项高速缓存的磁盘缓存中,可以加速从文件路径名到最后一个路径分量的索引节点的转换过程。
-
对于直接文件,可根据给定的关键字直接获得指定记录的物理地址,关键词本身决定了记录的物理地址。
-
文件系统能够创建的文件数量与索引节点的数量有关。
-
进程打开表的物理位置被记录在PCB中,在内存的内核区域,不能在用户态下访问
-
索引顺序结构的计算技巧:要为N个记录的文件建立K级索引,则最优的分组是每组N^(1/k+1)个记录。检索一个记录的平均查找次数是(N^(1/k+1)/2)(K+1)
-
提前读是指在文件被请求访问之前,预先将文件的内容加载到内存或高速缓存中。通过提前读取文件的数据,可以减少后续对磁盘的实际读取次数,从而提高文件的访问速度。
-
延迟写是一种延迟文件写入操作的策略,主要用于提高系统性能和响应速度。在延迟写策略中,当应用程序执行写操作时,操作系统并不立即将数据写入存储设备(如磁盘),而是将数据缓存在内存中或者延迟到后续合适的时机再进行写入。延迟写的优点在于可以将多个写操作合并为一个较大的写操作,从而减少了磁盘写入的次数。这样可以提高磁盘的效率和整体系统的性能,特别是当有大量小型写操作发生时。通过延迟写,可以积极利用系统内存进行缓存,并减少对磁盘的频繁访问,从而降低了写操作的延迟和系统负载。
-
文件目录大小=FCB大小*文件目录项个数
-
文件链接计数和文件访问计数
特性 文件链接计数 文件访问计数 定义 文件的硬链接数量,即指向该文件 inode 的链接数 文件的访问次数,即文件被打开的次数 增加条件 每创建一个硬链接增加,删除硬链接时减少 每次打开文件时增加,关闭文件时减少 影响 文件的删除只有在链接计数为 0 时才会删除 仅影响文件的使用状态,与文件是否存在无关 文件存在与否 影响文件是否可以被删除,当链接计数为 0 时文件被删除 不会影响文件的删除,文件可以在访问计数为 0 时存在 -
文件链接计数是用于文件是否存在于文件系统中的计数,它决定了文件在文件系统中的“实际存在”状态。
文件访问计数是用于管理文件是否被访问的计数,它与文件是否被打开、是否仍然被使用有关,但不会影响文件的存在状态。
-
-
必须通过挂载操作,把设备上的文件系统嫁接到目录树的某个挂载点(通常是空目录),才能访问其中的文件。
-
未挂载的设备=存在但不可见/不可用
-
并不是根目录下任何一个目录都可以作为挂载点,由于挂载操作会使得原有目录中文件被隐藏,因此根目录以及系统原有目录都不要作为挂载点,会造成系统异常甚至崩溃,挂载点最好是新建的空目录。
-
当一个文件系统被挂载到一个目录上时,该目录就成为了该文件系统的挂载点。在该目录下创建的文件和目录都会被存储在该文件系统中,而不是存储在原来的文件系统中。如果该文件系统中已经存在同名的文件或目录,则会覆盖原来的文件或目录。
- 挂载后,访问该目录=访问设备上的文件系统。
- 挂载后,原挂载点目录的内容会被“遮盖”,但不会被删除!原目录内容在卸载(umount)后会重新出现。
-
文件挂载是将一个目录连到另一个目录,使其成为目录树的一部分,并与外部文件系统关联
-
FCB中存放的是文件的描述信息(元数据),例如文件数据存储在磁盘上的哪个位置(通过物理地址或索引块指针指示),但不包含文件内容本身的数据块。文件内容的数据是存储在磁盘的数据区中的,FCB的作用是指向这些数据。
-
inode的数量是在文件系统创建或格式化时确定的,并非动态调整的
-
用户打开表中主要记录了进程打开文件时的访问权限,读写指针和系统打开文件表索引。
-
文件描述符可以相同的原因是因为硬链接使得不同路径指向同一个 inode,操作系统会为多个进程分配文件描述符来访问同一个文件,因此它们可以共享相同的文件描述符,尽管它们是由不同的进程打开的。
-
直接文件,是指可根据给定的关键字直接获得指定记录的物理地址,而不是直接记录了文件的物理地址。
-
文件的顺序存取是按文件的逻辑号逐一存取
-
文件的所有者owner即使在创建者删除该文件后,只要该inode的计数值不为0,owner都是创建者。
-
inode大小=地址索引项数x索引项大小+其他信息
-
在多级目录结构中,对文件的访问是通过路径名(绝对路径或相对路径)进行的,无需单独使用用户目录名。
-
在记录式文件中,逻辑记录是用户对文件进行存取操作的基本单位;在流式文件中,逻辑记录可视为字节流,但通常也认可此说法。
操作系统引导再回顾(加上挂载文件系统)
-
总结:开机时,系统通过bootloader(如grub)从分区1加载内核和initramfs到内存
- 内核启动后,借助initramfs临时挂在真正的根文件系统(可能在另一个分区)
- 最后,系统根据/etc/fstab自动挂载其他分区
-
阶段1:BIOS+Bootloader(GRUB)
- 硬盘加电→BIOS启动
- BIOS读取硬盘的MBR(主引导记录)找到活动分区,然后读取该分区的第一个扇区即PBR(分区引导记录)
- 找到并执行Bootloader(如GRUB)
- GRUB启动→加载OS内核
- GRUB读取自己的配置文件(如/boot/grub/grub.cfg)
- 该配置文件指定了:内核镜像位置、initramfs位置、根文件系统设备(如root=/dev/sda2)
- 内核和initramfs存放在分区1(如/dev/sda1),通常是/boot分区(格式可能是ext4、FAT32等),但真正的根文件系统可能在分区2(如/dev/sda2),格式可能是ext4、XFS、Btrfs等
- GRUB能读取多种文件系统,所以它能从分区1读取内核
- 硬盘加电→BIOS启动
-
阶段2:内核启动+initramfs临时根文件系统
- 内核被加载到内存并执行:内核初始化硬件、内存、CPU、设备驱动等
- 内核发现启动参数中有root=/dev/sda2,但它此时还不能直接挂载/dev/sda2,因为内核刚启动时,没有文件系统驱动、没有设备管理、甚至没有/dev目录结构
- initramfs登场——临时根文件系统
- initramfs是一个压缩的、内存中的临时根文件系统,由GRUB一同加载
- 它包含:设备管理工具(udev或mdev)、文件系统驱动模块等
- initramfs的任务:
- 探索并创建设备结点(如/dev/sda1,/dev/sda2)
- 加载必要的内核模块(如ext4模块,用于挂载根分区)
- 执行/init脚本——核心流程控制
- 挂在真正的根文件系统(如mount/dev/sda2/mnt/root)
- 切换根(switch_root)到真正的根文件系统
- initramfs是桥梁,让内核有能力挂载真正的根文件系统。挂载真正的根文件系统后,initramfs会被丢弃,内存释放。
- 内核被加载到内存并执行:内核初始化硬件、内存、CPU、设备驱动等
-
阶段3:真正的根文件系统启动+systemd/init
- 内核执行/sbin/init(现在通常是systemd)
- systemd读取配置,启动系统服务。读取/etc/fstab文件,自动挂载其他分区。
- 关键点
- /boot(分区1)通常也会在fstab中再次挂载,因为initramfs用完就丢了,真正的系统需要它
- /home、/data、NTFS分区等都在此时挂载
- 所有挂载点称为Linux统一目录树的一部分。
-
阶段4:用户登录+系统就绪
-
所有服务启动完成(网络、SSH、GUI等)
-
用户登录,看到完整的文件系统结构
-
此时你可以访问:
- /boot→分区1(内核存放处)
- /→分区2(根文件系统)
- /home→分区3
- /data→分区4(XFS)
- /mnt/ntfs→可能是windows分区(NTFS)

-
物理结构
- 连续分配下单个文件的最大大小
- FCB中用多少个bit表示总块数
- 每个磁盘块的大小
- 单个文件最大大小=最大块数*磁盘块大小


- 隐式链接分配下单个文件的最大大小
- 一个磁盘块中,用多少bit表示下一块的连接指针
- 磁盘块大小
- 最大文件长度=2^连接指针位数*(磁盘块大小-连接指针大小)B



- 一个文件系统仅设置一张FAT,开机时,将FAT读入内存,并常驻内存。
- 最佳应用场景:文件长度经常改变,且要求随机读写
- 逻辑块号转物理块号的过程中不需要读磁盘操作,因此访问某记录时只需要1次访盘操作取出记录即可。
- 显示链接方式下单个文件的最大大小
- FAT表项占多少bit,磁盘块大小
- 最大大小=2^FAT表项所占bit*磁盘块大小



索引分配
- 直接索引
- 一级索引
- 二级索引
- 混合索引分配
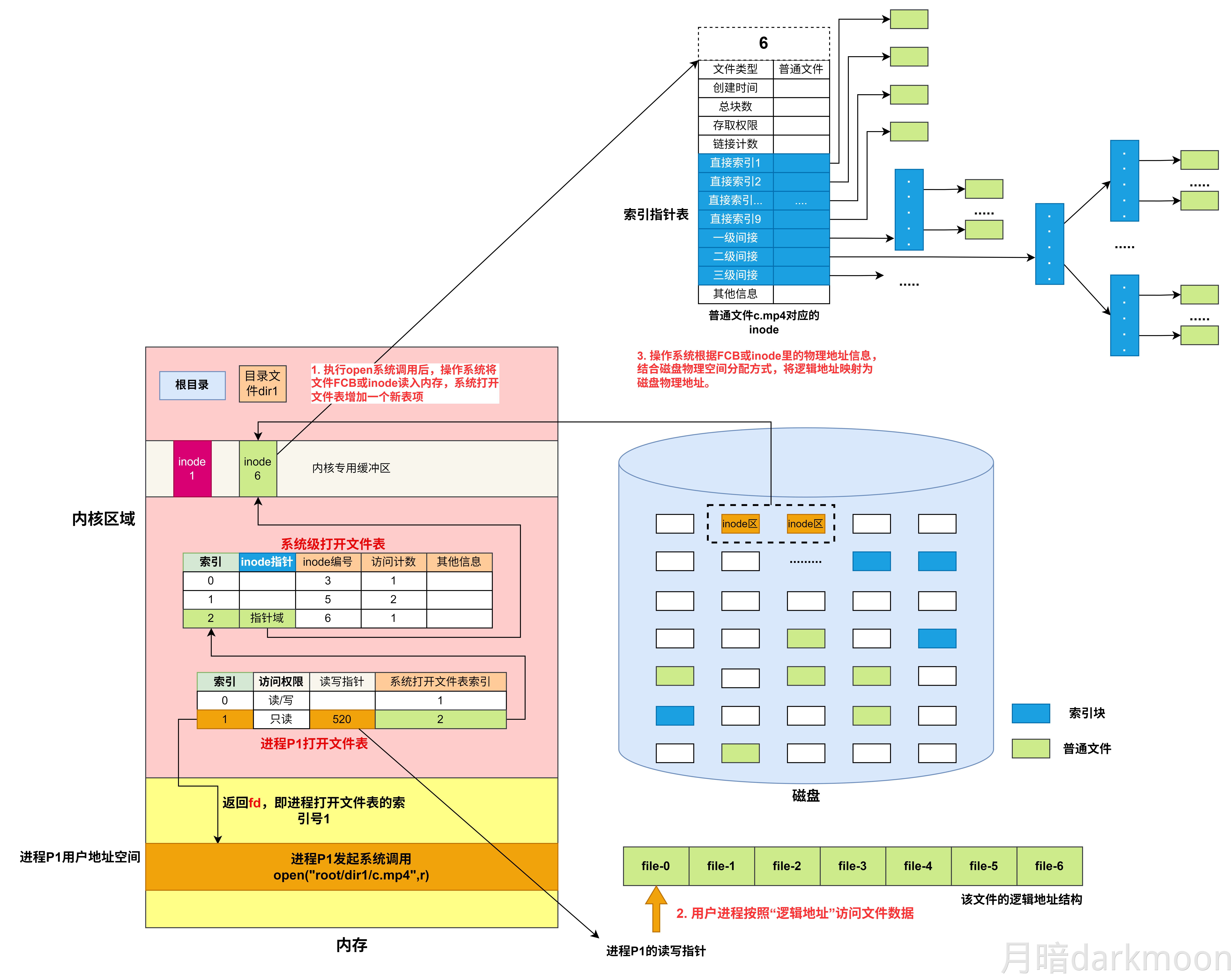



-
快速计算索引分配中磁盘块的I/O次数和所在磁盘块
- 按磁盘块对应,计算出直接/一级/二级对应的磁盘块编号
- 除得块数,然后根据范围找到所在位置
- 磁盘的I/O次数:读一级索引块+1次,数据块+1次,如果要修改放回再+1
-
由于树型目录结构中不同目录下文件的文件名可相同,因此在计算文件系统创建文件的上限时只需要考虑索引节点个数
-
平均I/O次数的计算:


-
注意区分找到和读出的区别
- 检索+1=读出
-
文件所占的磁盘块数,需要考虑索引块+文件本身所占的磁盘块数
-
针对中小型文件,索引块的利用率将会很低
文件分配
open过程
- 打开文件后,文件的读写和关闭都不再以文件路径为参数,而是以打开文件返回的文件标识符fd为参数,即必须打开文件后,才可以进行文件读写和关闭操作
- 同一个进程的所有线程共享当前进程的用户文件打开表,用相同的fd访问文件
- 子进程继可以承父进程的用户文件打开表,子进程可以访问父进程访问的文件
- open系统调用的处理过程
- ①根据路径查找各级目录,如果在目录缓存中没有命中,就去磁盘中将目录文件读入内存,逐层检查直到找到目标文件的目录项
- ②根据目录项,得到inode编号,然后根据该编号,去系统打开文件表中检索
- a.如果未命中,需要从磁盘中将该inode结点载入内核专用缓冲区,检查是否逾越访问权限,如果没有,在系统级打开文件表中新增一个表项,访问计数记为1,并将inode在内存中的位置信息记录在inode指针里;如果访问非法,则此次打开失败
- b.如果命中,且没有访问越权,则将访问计数值+1
- ③在进程打开文件表中,新建一个表项,并记录其对应的系统打开文件表索引
- ④将该表项的索引值作为fd返回给用户进程
- 文件指针用来记录各进程对文件的读写位置,被记录在用户打开表中。
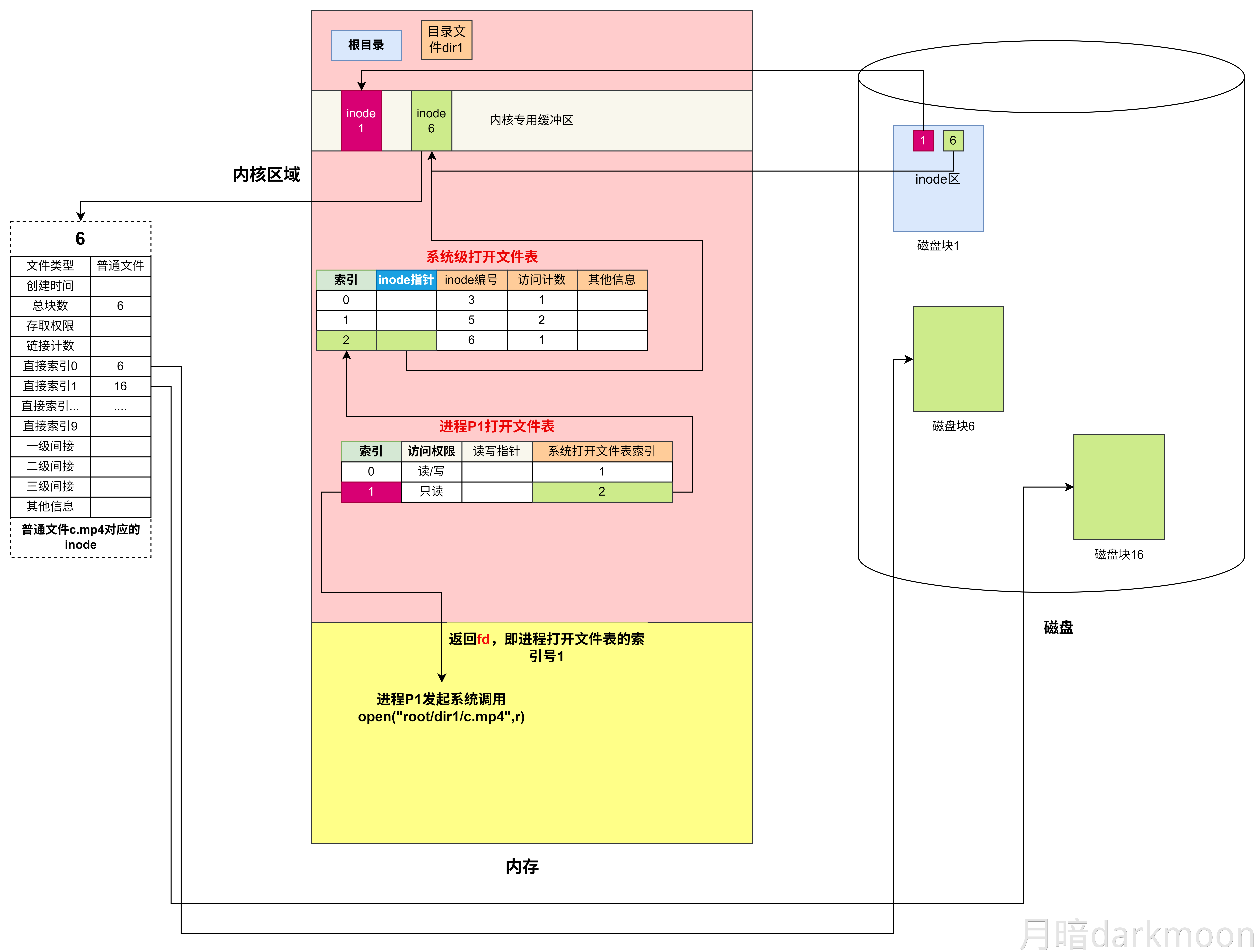
- 第一次open文件成功之后,会将该文件的inode结点调入内存,并且修改系统打开文件表和进程打开文件表,并且会返回给进程一个fd
- 之后进程需要访问该文件,只需要根据fd去查找自己的进程打开文件表(该表的起始地址在进程PCB里面),找到对应表项,再去查对应的系统打开文件表的表项,找到目标文件inode结点的物理位置信息,便能够访问该inode结点
- inode节点里面记录了该文件的磁盘物理地址信息
- open()调用的参数是文件路径,访问权限,它会在进程的用户级打开文件表中增加一个对应的表项,并且返回该表项的索引(文件描述符或句柄)。
- 系统级打开文件表只有在打开的文件实体(inode)并没有被任何一个进程打开时才会增添一个新表项,此时也才会通过文件I/O将对应inode从磁盘读入内存。
- 当不同的文件互为硬链接时,所对应的文件实体还是一样的。
多个进程打开同一个文件
- 多个进程同时打开同一个文件的情况:假设现在有另外一个进程P2,同样的想要打开文件c.mp4。
- 由于进程P1之前已经打开了文件c.mp4,同时文件c.mp4的inode已经被加载到内存当中,且在系统打开文件表中注册了表项,所以当进程P2打开文件c.mp4的时候,操作系统做的事情就是在进程P2的进程打开文件表当中,新建一个表项。
- 在这个表项当中,会用一个指针指向系统打开文件表。同时,系统打开文件表当中这个文件的访问计数+1。现在c.mp4的访问计数为2,表示此时有两个进程打开了文件。
- 值得注意的是,不同的进程在打开文件的时候,它的打开方式可以各不相同。比如在这个例子当中,进程P1是以只读的方式打开文件c.mp4的。
- 而进程P2是以读和写的方式打开这个文件的。打开文件的方式不同,那么接下来这两个进程可以对文件进行的操作就不同。对于进程P1来说,接下来只能去读这个文件。
- 而对于进程Q来说,可以读也可以写这个文件。
- 总之,在系统打开文件表当中,一个文件只会对应一个表项。如果这个文件被多个进程同时打开,那么会让这些进程的打开文件表去指向系统打开文件表相应的位置。
- 多个进程同时打开一个文件时,可以任意对文件进行读写操作,操作系统并不保证写的互斥性,进程可以通过系统调用对文件进行上锁,从而实现对文件内容的保护。
creat调用
- 目的:在指定路径path下创建一个空文件,可以指定该文件的类型和访问权限等
- 步骤:
- 查询磁盘里的inode表,为该文件分配一个空闲的inode,在里面登记文件类型,访问权限,创建时间等信息
- 打开path所对应的新创建文件所在目录,在该目录中加入一个新的目录项,目录项的文件名从path中截取,inode编号关联到给它新分配的inode上。
读写指针
- 读写指针记录了从文件开头到当前读写位置的字节偏移量
- 工作流程:从用户调用到磁盘访问
- 用户空间发起请求:你的进程在用户空间调用
read(fd, buffer, size)。 - 陷入内核:该系统调用触发一个软中断,CPU从用户态切换到内核态。
- 内核查找指针:内核根据你传递的文件描述符
fd,找到对应的“打开文件描述表”表项,并从中取出当前的读写指针(文件偏移量)。 - 逻辑到物理的映射:内核的文件系统模块(如ext4, NTFS)利用这个逻辑偏移量,结合文件的元数据(如inode中的索引结构),计算出这个偏移量对应的是磁盘上的哪些物理块(逻辑块地址LBA)。
- 这是一个复杂的过程,可能涉及多级索引、间接块等。
- 文件起始地址+读写指针=开始读的地址
- (文件起始地址+读写指针,文件起始地址+读写指针+size)即读写范围
- 执行磁盘I/O:内核向磁盘驱动程序发出指令,读取相应的物理块到内核缓冲区(Page Cache) 中。
- 数据拷贝到用户空间:内核将数据从内核缓冲区拷贝到用户提供的用户空间
buffer中。 - 更新读写指针:内核根据实际读取的字节数,增加文件读写指针的值。例如,如果指针原来是1024,读取了100字节,那么它就被更新为1124。
- 返回用户空间:系统调用返回,控制权和数据都回到了你的用户空间进程。
- 用户空间发起请求:你的进程在用户空间调用
read系统调用
-
用于从指定的文件描述符所对应的文件读取数据到用户空间缓冲区。文件描述符可以指向普通文件、设备文件、管道、套接字等支持读取操作的对象
-
read(int fd,void *buf,size_t count); -
由于用的是文件描述符fd,说明该文件已经打开,在系统打开文件表里面有记录
-
具体处理过程:
- 用户程序在用户态下调用read
- 根据fd找到进程打开文件表(文件描述符表)的对应表项,根据访问权限位判断是否支持读取操作
- 若支持读操作,再去系统打开文件表,然后找到文件对应的inode,根据读写指针位置,再根据inode里的文件位置信息,去将读区域所在的磁盘块读入内存中的内核缓冲区
- 将需要读取的数据从内核缓冲区读入用户空间的buf中
- 数据拷贝发生在内核态,即CPU调度之后,系统调用返回之前
- 读取完毕后内核更新文件读写指针
- 返回实际读取的字节数
- 若根据读写指针找到文件的读位置后发现从读位置到文件结束的位置所在区域的字节数小于期待读取的字节数,返回实际读取的字节数
- 返回-1的情况
- 文件描述符错误
- 无效/已关闭/只支持写操作
- 缓冲区错误
- 地址无效
- 发生系统级错误
- 文件描述符错误
- 磁盘、硬盘、U盘等存储设备基本都是Flash块设备,因为块设备硬件本身有读写限制等特征,块设备是以一块一块为单位进行读写的(一个块包含多个扇区,而一个扇区包含多个字节),一个字节的改动也需要将该字节所在的block全部读取出来进行修改,修改完成之后再写入块设备中,所以导致对块设备的读写操作非常不灵活
- 而内存可以按字节为单位来操作,而且可以随机操作任意地址数据,非常灵活,所以对操作系统来说,会先将磁盘中的静态文件读取到内存中进行缓存,读写操作都是针对这份动态文件,而不是直接去操作磁盘中的静态文件,不但操作不灵活,效率也会下降很多,因为内存的读写速率比磁盘读写快得多
write系统调用
-
具体处理过程
- ①用户程序在用户态下调用write(fd,*buf,count),陷入内核态
- ②根据fd找到进程打开文件表(文件描述符表)的对应表项,根据访问权限位判断是否支持写操作;若进程打开文件时是以只读的方式打开,那么执行write操作是不被允许的;
- ③若支持写操作,得先去系统打开文件表,然后找到文件对应的inode,根据读写指针位置和inode里的文件位置信息,将读区域所在的磁盘块读入内存中的内核缓冲区,然后再将用户空间buf里待写入的数据覆盖掉读入内存的磁盘块中指定区域的内容,之后将磁盘块再写回磁盘对应位置;
- 注意:文件系统的I/O以磁盘块为单位,因此不支持直接将用户空间buf里的数据写到内核缓冲区,再通过磁盘I/O写到指定的磁盘块里面这种操作。
-
提问:为什么发起read系统调用后,磁盘I/O不能直接将数据从磁盘读入用户空间,而是先读入内核缓冲区再读入用户空间的buf?
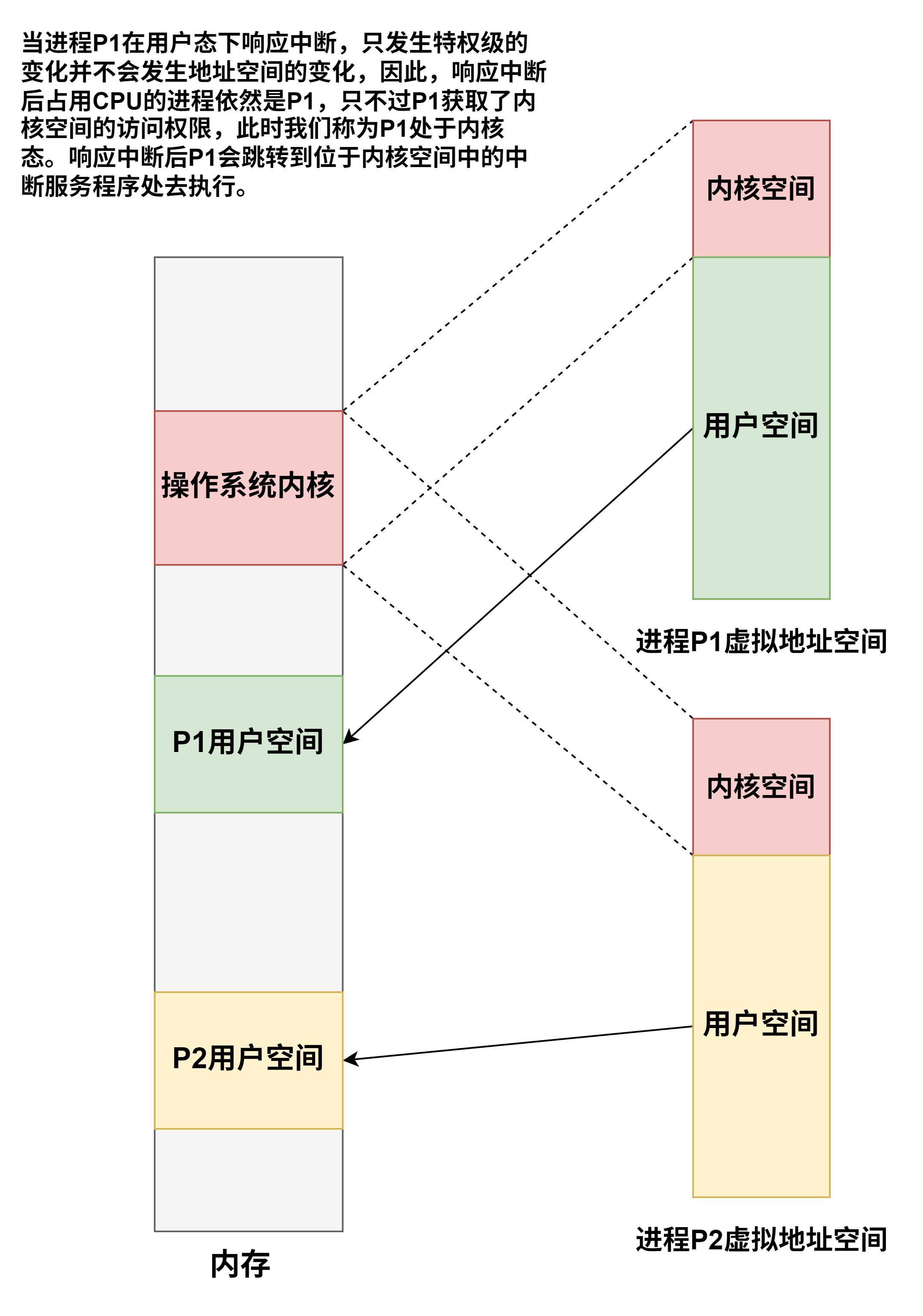
- 假设进程P1通过read(fd,* buf,count)系统调用请求读入磁盘指定区域数据,那么首先P1会通过trap指令陷入内核态
- 在read系统调用服务例程中,内核会做这些事:将*buf数组里的数据复制到内核缓冲区,然后开中断(允许设备控制器发出中断请求),查询磁盘状态,若为就绪,发送磁盘读入命令,之后主动阻塞进程P1;
- 调度器根据调度策略选择进程P2上处理机,P2在cpu上运行的时候,DMA控制器也在同步运行,负责把数据从磁盘读入内核缓冲区
- 当读入一批数据后,DMA控制器发出中断请求,P2进程响应中断陷入内核态,执行该中断对应的中断服务程序,也就是先判断需要的数据是否全部读入?
- 若没有,则对DMA接口重新初始化,继续启动一轮传送;
- 若已经全部读入,将进程P1唤醒,将其从阻塞态修改为就绪态,之后中断返回;若P1优先级不比P2大,那么P2回到用户态继续运行;
- 从上面描述的过程我们可以看到,执行中断服务程序的时候,是处于进程P2的地址空间之中,此时是无法将数据直接读入进程P1的用户空间,而内核区域由于被映射到每一个进程的内核空间,因此便可以作为一个通信中介先缓存这部分数据;
- 等到进程P1被调度上处理机的时候,便可以继续执行read系统调用剩下的事情,也就是把数据从内核缓冲区读入用户空间的buf中了,至此read系统调用执行完毕,返回用户态继续执行。
-
镜像问题:为什么发起write系统调用后,需要先将buf里待写入的数据复制到内核缓冲区,然后再通过磁盘I/O写入读写指针所指位置?而不是直接从用户空间写入磁盘?
目录
-
目录项的作用:目录项包含了文件的元数据(如文件名、存储位置、访问权限等),它与文件数据直接相关联。删除目录项可能会导致文件丢失或无法正确访问。
- 文件被打开和关闭的过程:当文件被打开时,操作系统会把文件的相关信息加载到内存中,文件的数据也会被读取。如果在文件关闭时删除目录项,操作系统可能无法找到该文件,从而引发错误或不可预期的行为。
- 删除目录项的后果:在大多数文件系统中,删除目录项相当于删除文件的“标识”。虽然文件的数据可能仍然存在于磁盘中,但没有了目录项的引用,操作系统无法再访问这些数据。
-
目录项对象在磁盘上没有特定的数据结构
-
UNIX采用树形目录结构,文件信息存放在索引节点中。超级块是用来描述文件系统的
-
文件目录通常存放在磁盘上。
-
在查找目录的过程中,必须先将存放目录文件的第一个盘块中的目录调入内存,然后将用户所指定的文件名与目录项中的文件名逐一比较。若未找到指定文件,则须将下一盘块的目录项调入内存。假设目录文件所占用的盘块数为N,按此方法查找,则查找一个目录项平均需要调入盘块
(N+1)/2次。
-
-
树型目录是不适合文件共享的
-
引入索引节点的文件系统中,目录是文件名到索引节点号的映射集合,而不是索引节点本身的有序集合
-
更改当前目录(或工作目录)操作会改变进程解析相对路径时的参照点,但不会改变文件系统中任何文件的物理位置或目录结构
-
打开文件是把open()系统调用的参数是文件路径,访问权限(如只读、读&写),它会在进程的用户级打开文件表中增加一个对应的表项,并且返回该表项的索引(文件描述符或句柄)。系统级打开文件表只有在打开的文件实体(inode)并没有被任何一个进程打开时才会增添一个新表项,此时也才会通过文件I/O将对应inode从磁盘读入内存。当不同的文件互为硬链接时,所对应的文件实体还是一样的。从辅存读到内存,而不是文件信息
-
硬链接允许一个文件在文件系统中有多个有效路径名,因为硬链接和原始文件共享同一个inode号,本质上是同一个文件,但它们在不同的位置(即有效路径名)。软链接相当于文件的快捷方式,并非原文件。
线性检索法
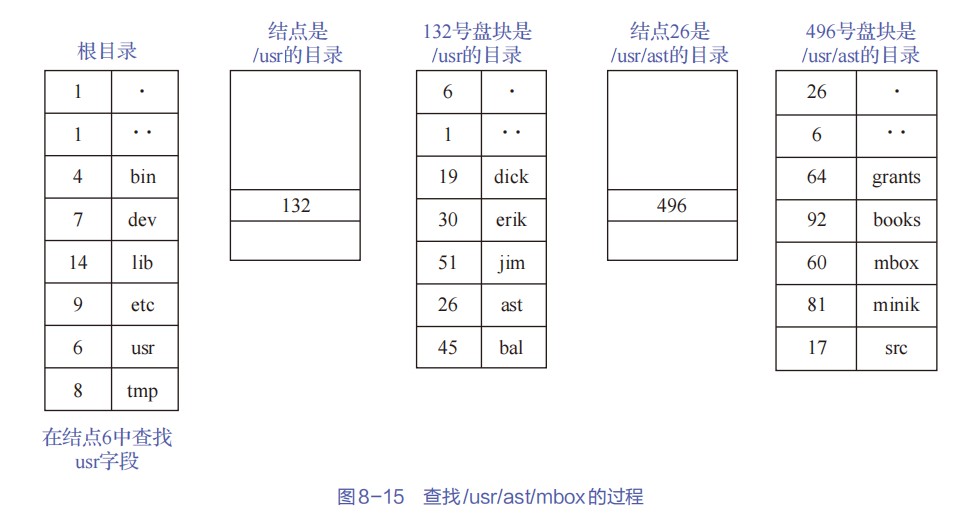
- 首先,系统应读入第一个文件分量名usr,用它与根目录文件(或当前目录文件)中各目录项中的文件名依次进行比较,从中找出匹配项,并得到匹配项的索引节点编号为6;再从6号索引节点中得知usr目录文件放在132号盘块中,将该盘块内容读入内存。
- 然后,系统读入路径名中的第二个分量名ast,用它与放在132号盘块中的第二级目录文件中各目录项的文件名依次进行比较,从中找到匹配项,并得知ast的目录文件放在26号索引节点中,再从26号索引节点中得知/usr/ast存放在496号盘块中,将该盘块的内容读入内存。
- 最后,系统读入该文件的第三个分量名mbox,用它与第三级目录文件/usr/ast中各目录项中的文件名依次进行比较,得知/usr/ast/mbox的索引节点编号为60,即在60号索引节点中存放了指定文件的物理地址。目录查询操作到此结束。如果在顺序查询过程中发现有一个文件分量名不能被找到,则应停止查询,并返回“文件未找到”信息。
内存中文件的系统结构
-
在多个进程可以同时打开文件的操作系统中,通常采用两级表:整个系统表和每个进程表。
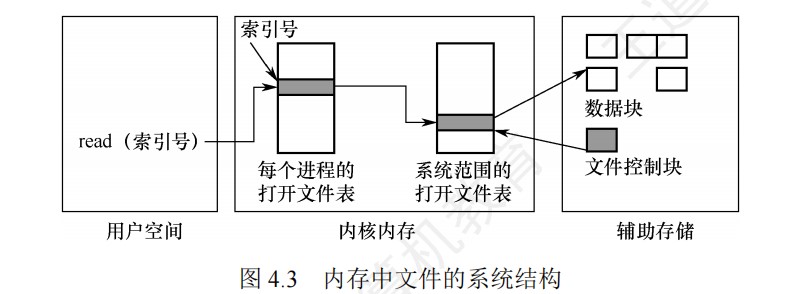
- 整个系统的打开文件表包含与进程无关的信息,如文件在磁盘上的位置、访问日期和文件大小。
- 每个进程的打开文件表保存的是进程对文件的使用信息,如文件的当前读/写指针、文件访问权限,并包含指向系统表中适当条目的指针。
- 一旦有进程打开了一个文件,系统表就包含该文件的条目。当另一个进程执行调用open时,只不过是在其打开文件表中增加一个条目,并指向系统表的相应条目。
- 通常,系统打开文件表为每个文件关联一个打开计数器(Open Count),以记录多少进程打开了该文件。当文件不再使用时,利用系统调用close关闭它,会删除单个进程的打开文件表中的相应条目,系统表中的相应打开计数器也会递减。当打开计数器为0时,表示该文件不再被使用,并且可从系统表中删除相应条目。
-
因此,只要文件未被关闭,所有文件操作都是通过文件描述符(而非文件名)来进行。
- 只要完成了文件打开open()系统调用,后面再使用read()、write()、Lseek()、close()等文件操作的系统调用,就不再使用文件名,而使用文件描述符。该考点已反复考过多次。
- 但是open()调用本身的参数含有文件名
-
FAT表占用的空间=块号/簇号占用的空间*块数/簇数
-
整个系统的打开文件表,包含每个打开文件的FCB副本
-
超级块:
- 位于目录区内一小块,存放:
- 空闲空间的“位向量表”或第一个成组链块
- 目录区、文件区的划分信息
- 在对卷中文件操作时需要先将超级块读入内存,且需要时刻保持内存、外存的超级块一致性。
- 位于目录区内一小块,存放:
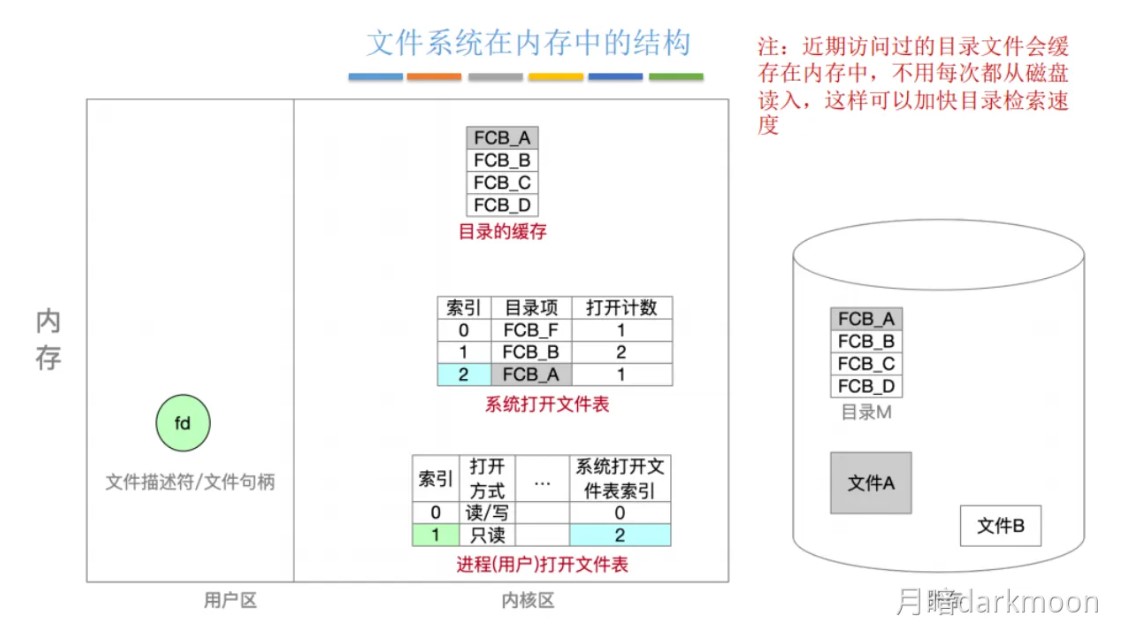
外存空闲空间管理
空闲表法
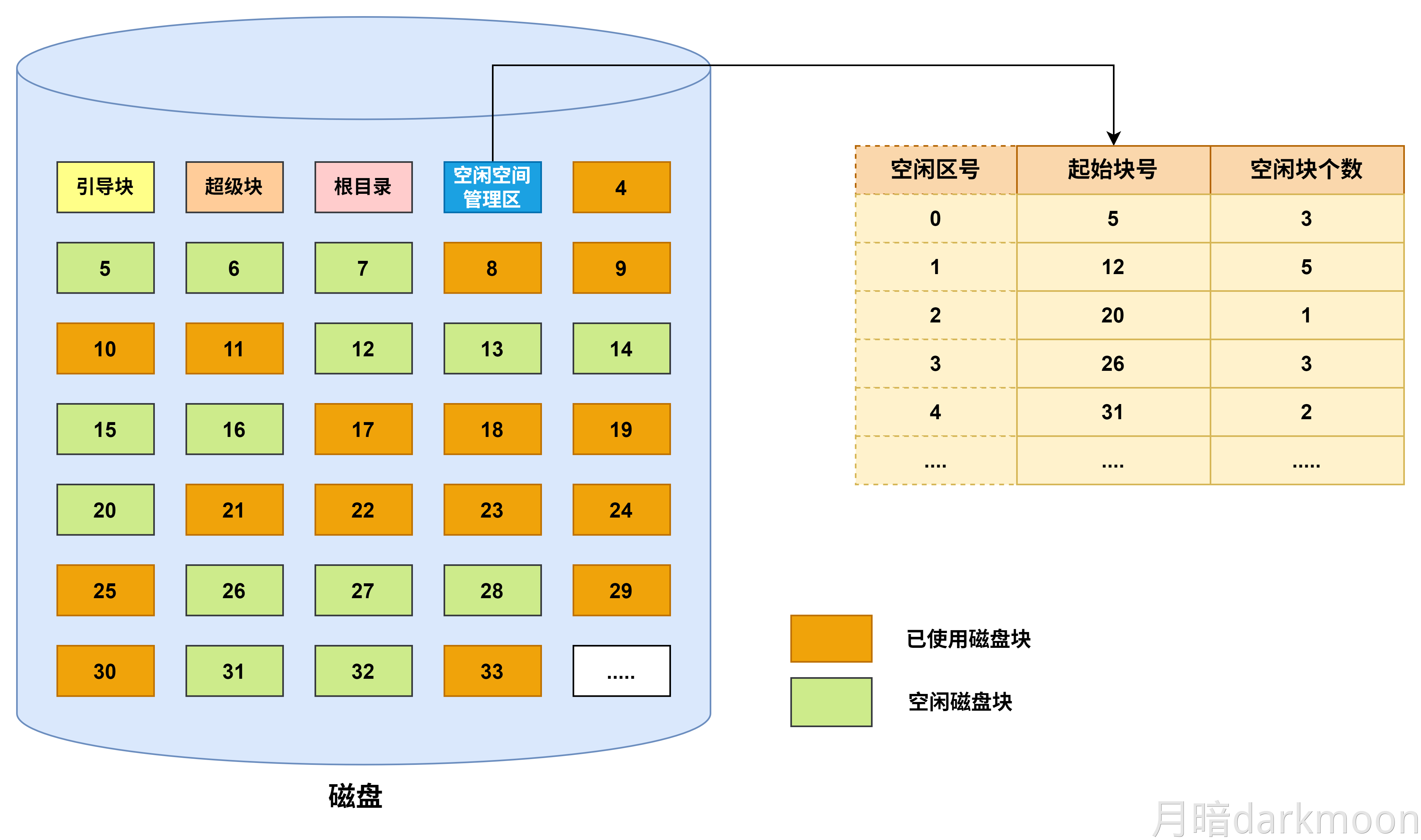
- 这个方式是连续分配的
- 首次适应、最佳适应、最坏适应
- 适用场合
- 仅当有少量的空闲区时才有较好的效果,因为,如果存储空间中有着大量的小的空闲区,则空闲表变得很大,这样查询效率会很低,因此不适合大型文件系统。
- 适用于建立连续文件
- 连续分配的场景
- 磁盘对换区
- 对于文件系统,文件较小时,采用连续组织方式为文件分配相邻的若干盘块;文件较大时,便采用离散组织方式
- 对多媒体文件,为了减少磁头的寻道时间,采用连续组织方式
空闲盘块链
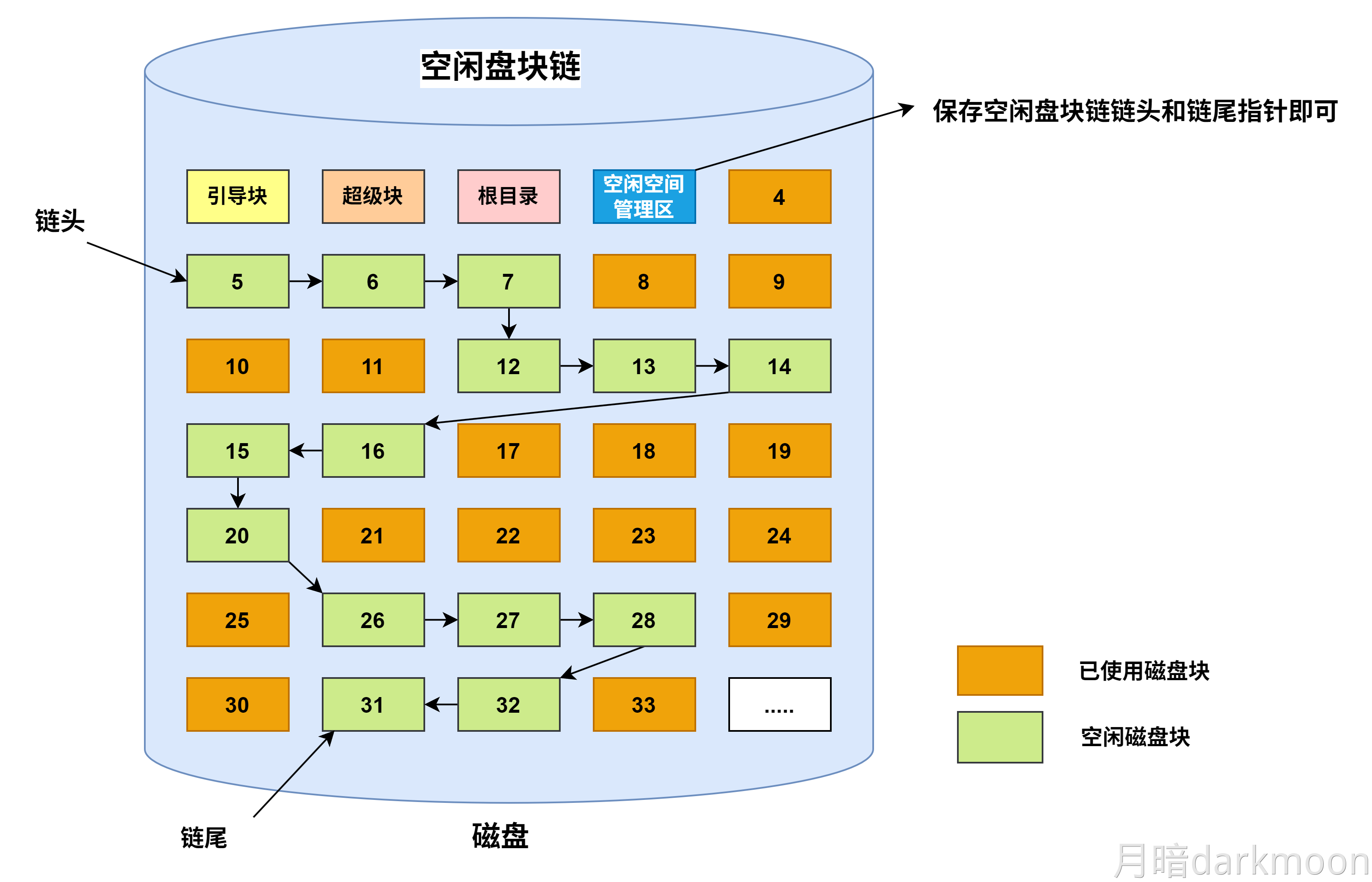
- 指针是物理地址的形式
- 文件系统中需要保存链头和链尾指针
- 如何分配:若某文件申请K个盘块,则从链头开始依次摘下K个盘块分配,并修改空闲链的链头指针
- 如何回收:回收的盘块依次挂到链尾,并修改空闲链的链尾指针。(回收的每一个磁盘块都得先读入内存修改指针后再写回磁盘,因此磁盘I/O开销很大)
- 适用场合:
- 离散分配的物理结构
空闲盘区链
- 适用场合
- 离散分配
- 连续分配
- 为一个文件分配多个盘块时效率更高
位示图法
- 在磁盘块的分配与回收过程中,需要将位示图所在的磁盘块读入内存(不需要都读入,根据需要读入指定位所在磁盘块即可),依据具体需要进行修改,在适当时机写回磁盘;由于位图占用磁盘空间小,因此在磁盘分配与回收时磁盘I/O次数也会很少
- 位示图存在于超级块中,文件系统挂载的时候随着超级块载入内存,但中途可能换出
- 位示图所占用的空间大小只取决于外存空间的总大小,而与当前空闲块数量无关。
成组链表法
-
成组链表法
- 原理
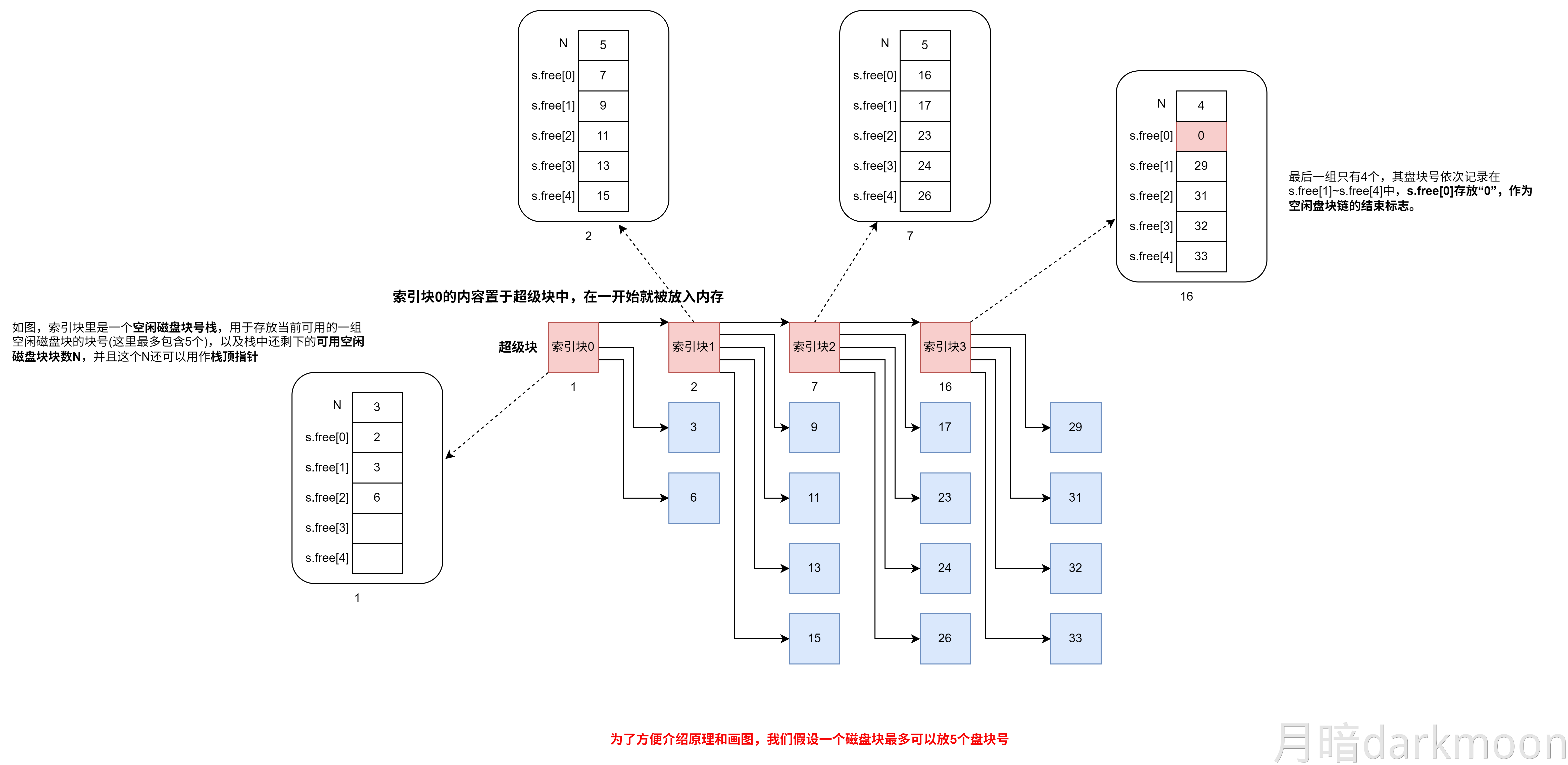
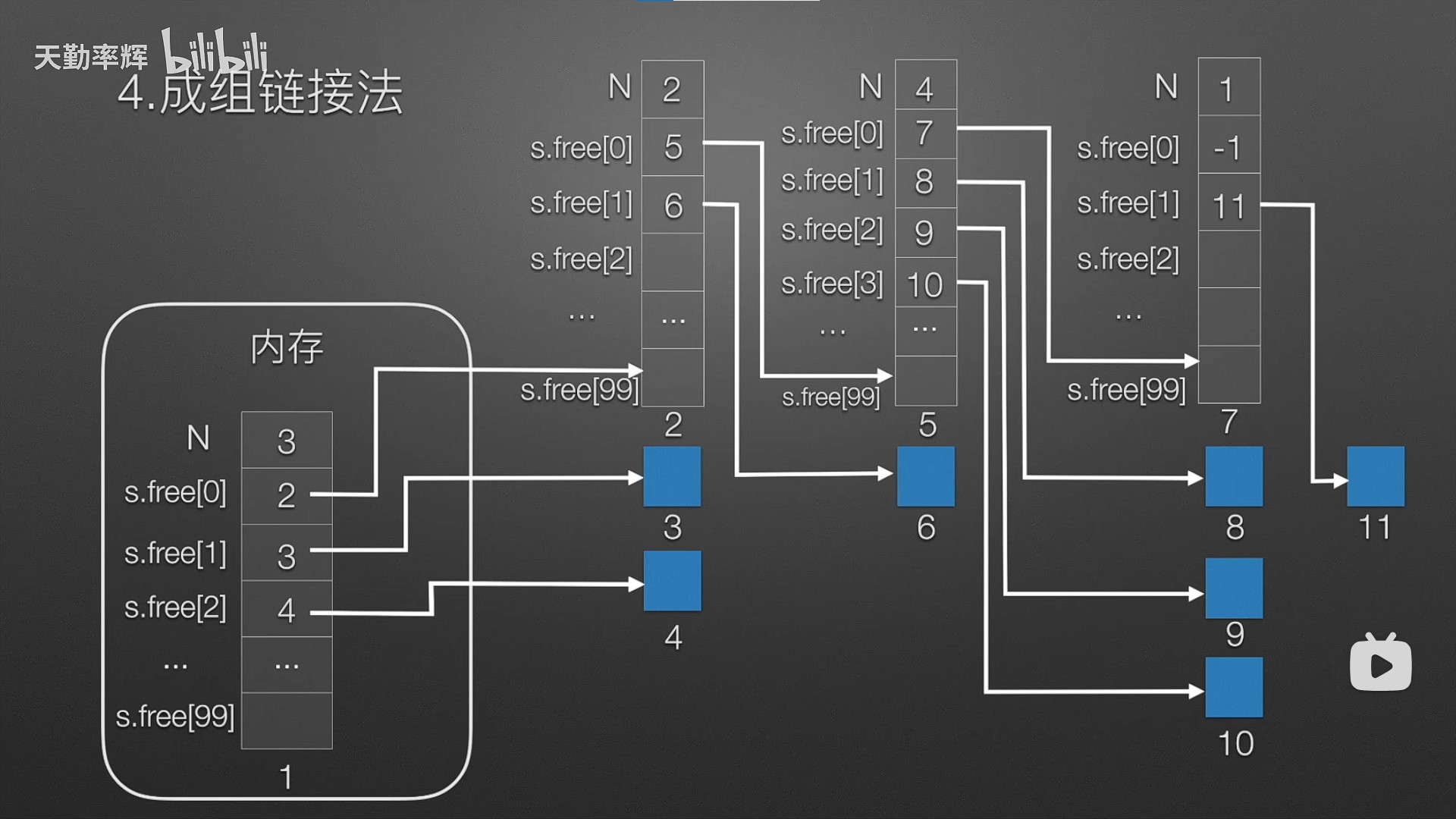
- 分配
- 回收
-
只有空闲盘块号栈存储在内存中,其他的存储在磁盘上
-
成组链接法的又是
- 分配时:只有当分组0的空闲盘块均分配完,才需要进行I/O操作
- 回收时:只有当分组0中的空闲盘块
-
空闲表法、空闲链表法不适用于大型文件系统,因为空闲表或空闲链表可能过大。UNIX系统中采用了成组链接法对磁盘空闲块进行管理。文件卷的目录去中专门用一个磁盘块作为超级块,当系统启动时组要将超级块读入内存。并且要保证内存与外存中的超级块数据一致
-
最末一组只有99个盘块,其盘块号分别记入其前一组的S.free(1)~S.free(99)中,而在S.free(0)中则存放“0”,作为空闲盘块链的结束标志。注意:最后一组的盘块数应是99,不是100,这是指可供使用的空闲盘块,编号为1~99,0号盘块中放空闲盘块链的结尾标志。
文件操作
- 读文件操作的正确次序
- ①按文件描述符在打开文件表中找到该文件的目录项
- ②按存取控制说明检查访问的合法性
- ③根据目录项中该文件的逻辑和物理组织形式,将逻辑记录号转换成物理块号
- ④向设备驱动程序发出I/O请求,完成数据交换工作
inode
-
inode不包含文件名,文件名存储在目录文件的目录项中,每个目录文件将文件名与inode号关联
-
对于 第一次打开文件,操作系统必须去硬盘读取对应的 inode,而不依赖于内存中的 inode 缓存。即使是其他 inode 已经被调入内存,只要是 第一次打开文件,操作系统都需要去硬盘读取该文件的 inode。下面我进一步澄清这个过程:
- 第一次打开文件时必须去硬盘读取 inode:
- 当进程请求打开一个文件时,文件系统必须找到该文件的 inode,而 inode 存储着文件的元数据。
- 即使其他 inode 已经被加载到内存中(比如在之前访问其他文件时已经调入),操作系统也不能直接假设该文件的 inode 已经在内存中。这是因为 inode 的存储是**按块(block)**来组织的,多个 inode 可能会被存储在同一个块中。操作系统在读取一个 inode 时,实际上是将该块从硬盘加载到内存中,而不是只读取一个单独的 inode。
- inode 缓存的作用:
- 操作系统会将访问过的 inode 缓存到内存中的 inode 缓存,以提高后续访问同一文件时的效率。如果 inode 已经在内存中,操作系统可以直接从内存中获取。
- 然而,第一次打开文件时,因为该文件的 inode 还没有被缓存到内存中,操作系统就必须去硬盘上查找和加载该 inode。
- 不存在“先查看内存”的步骤:
- 虽然操作系统会维护一个 inode 缓存,但它并不在第一次打开文件时先检查内存。操作系统在打开文件时会直接通过文件的路径来定位 inode(通常是通过目录项与 inode 的映射关系)。如果这个 inode 不在内存中,操作系统会去硬盘读取。
- 只有当文件的 inode 被加载到内存中后,才会通过 inode 缓存来提高后续对同一文件的访问效率。
- 总结:
- 第一次打开文件时,操作系统必须去硬盘读取 inode,并将其加载到内存中。
- 即使其他 inode 已经在内存中,也不能影响第一次打开文件的过程,因为每个 inode 都是单独按块存储的,而且操作系统无法预先知道该 inode 是否已经在内存中。
- inode 缓存只在后续访问同一文件时提供帮助,减少了磁盘 I/O 操作。
举个简单例子:
- 第一次打开文件时,操作系统必须去磁盘读取该文件的 inode。它会读取硬盘的目录结构,找到 inode 所在的块,将该块读取到内存中。
- 以后如果再次访问相同的文件,操作系统就可以直接从内存中的 inode 缓存中获取 inode,避免了磁盘读取。
- 访问某个文件的某一块,需要的磁盘I/O次数:读取目录项的索引节点号(inode)次数+访问文件本身1次,在n级间接就是n+1+1次
文件共享
-
硬链接和原文件共享一个inode,软连接是一个新的link文件,有自己的inode
-
count计数制的本质是该inode有几个主题共享
-
硬链接不能跨文件系统使用,因为每个文件系统各自维护自己的inode数据结构和列表,而软连接存的是文件路径,可以跨文件使用
- 符号链接文件有自己的索引节点和数据块
- 硬链接共享源文件的计数,软连接为全新文件,拥有自己的计数,创建时初值为1,当对软连接进行硬链接时,遵循普通文件的连接规则,即该软链接与硬链接计数均+1
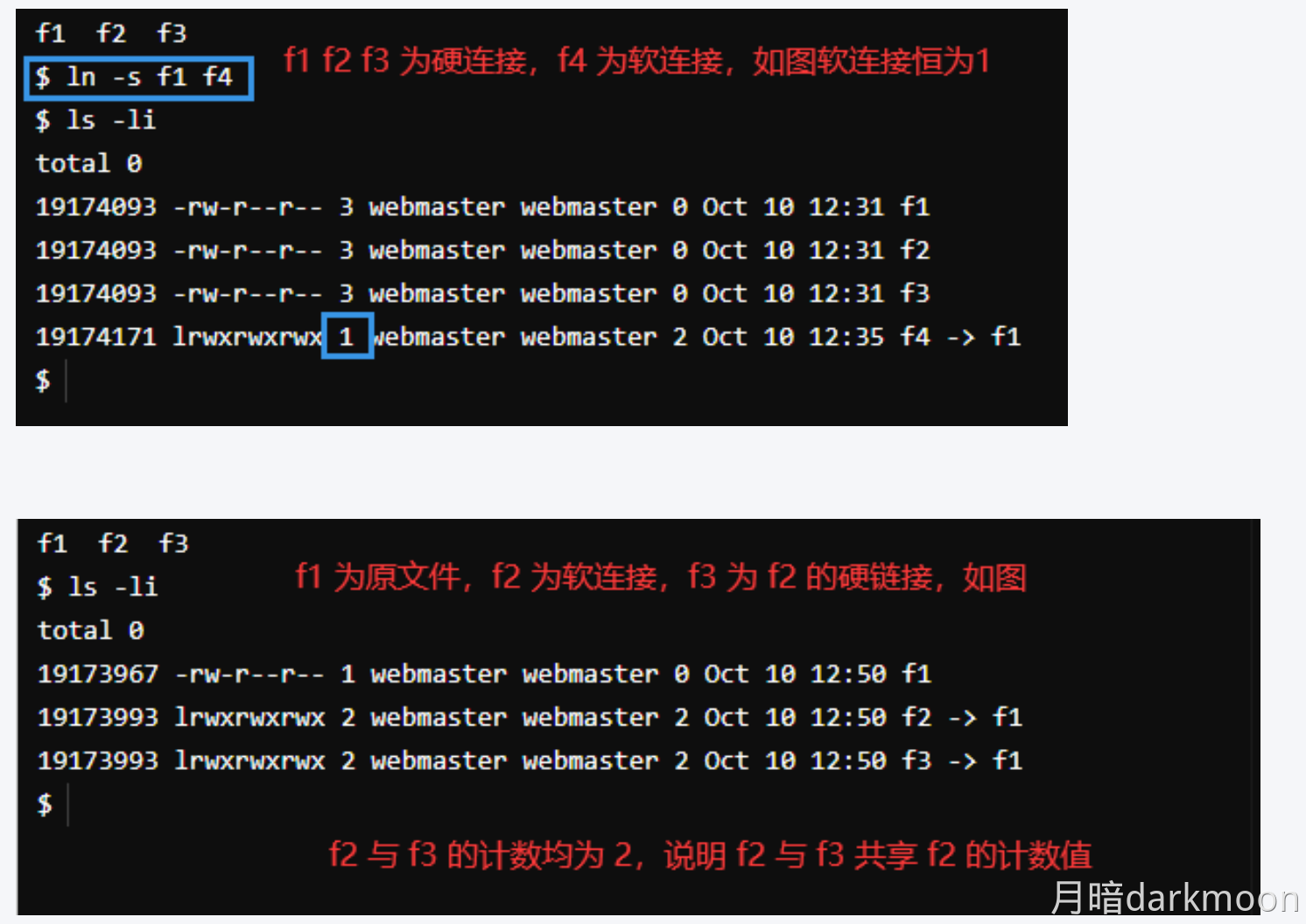
-
建立符号链接(软连接)时,引用计数值直接设置为1
-
每增加一条符号链接,就增加一个文件名。这在实质上就是每个用户都会使用自己的路径名去访问共享文件。当我们试图去遍历(traverse)整个文件系统时,将会多次遍历到该共享文件。例如,当有一个程序员要将一个目录中的所有文件都转存到磁盘上时,就可能会使一个共享文件产生多个复制。
-
若文件主删除共享文件的同时,另一用户创建同名路径的零一文件,Link文件仍然有效,但访问的已经不是同一文件了
-
在符号链的共享⽅式中,当其他⽤户读共享⽂件时,系统根据⽂件路径名依次查找⽬录,直⾄找到该⽂件的索引节点。因此,每次访问共享⽂件时,都可能要多次地读盘,增⼤了访问⽂件的开销。此外,符号链接也是⼀个⽂件,其索引节点也要耗费⼀定的磁盘空间。

- 符号链接和硬链接实现文件共享时所共有的问题是:
- 每个共享文件都有几个文件名,换言之,每增加一条链接就增加一个文件名,实质上是每个用户都使用自己的路径名去访问共享文件。当试图遍历整个文件系统的时候,将多次遍历到该共享文件,因此当要将一个目录中的所有文件都转存储到磁带上时,可能对一个共享文件产生多份副本
- 硬链接和软连接都是文件系统中的静态共享方法,在文件系统中还存在着另外的共享需求,即两个进程同时对一个文件进行操作,这样的共享称为动态共享。
层次结构
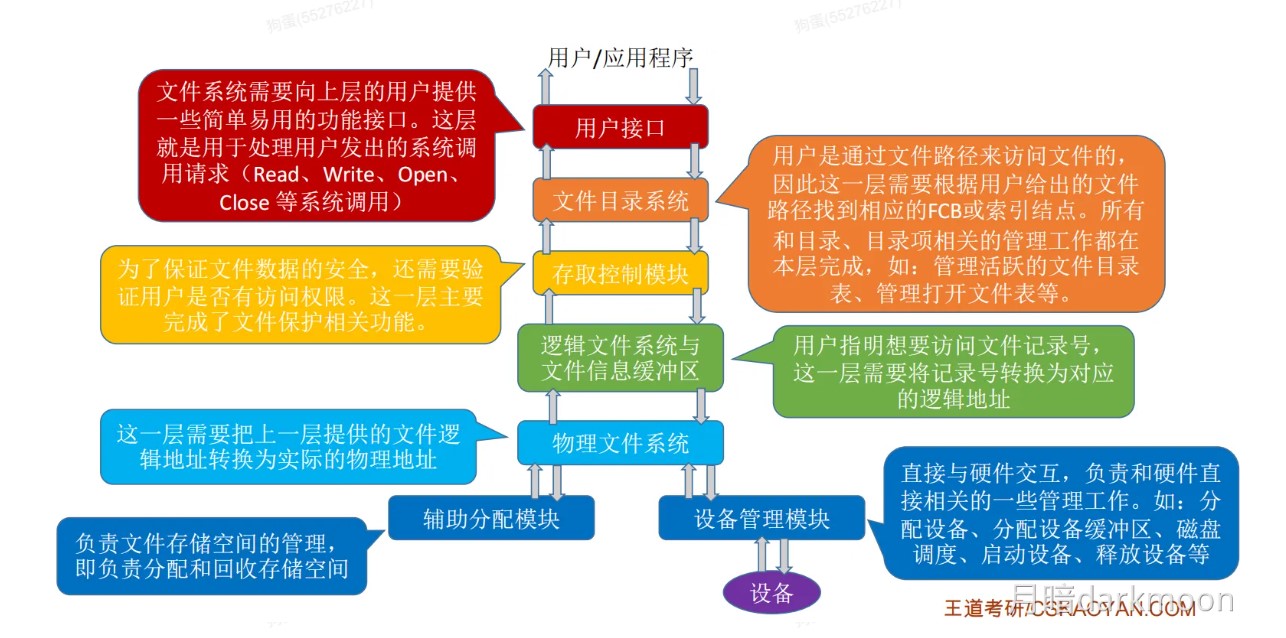
-
1.用户需要通过操作系统提供的接口发出上述请求——用户接口
- 2.由于用户提供的是文件的存放路径,因此需要操作系统一层一层地查找目录,找到对应的目录项——文件目录系统
- 3.不同的用户对文件有不同的操作权限,因此为了保证安全,需要检查用户是否有访问权限—存取控制模块(存取控制验证层)
- 4.验证了用户的访问权限之后,需要把用户提供的“记录号”转变为对应的逻辑地址——逻辑文件系统与文件信息缓冲区
- 5.知道了目标记录对应的逻辑地址后,还需要转换成实际的物理地址——物理文件系统
- 6.要删除这条记录,必定要对磁盘设备发出请求——设备管理程序模块
- 7.删除这些记录后,会有一些盘块空闲,因此要将这些空闲盘块回收——辅助分配模块
外存中的文件系统布局
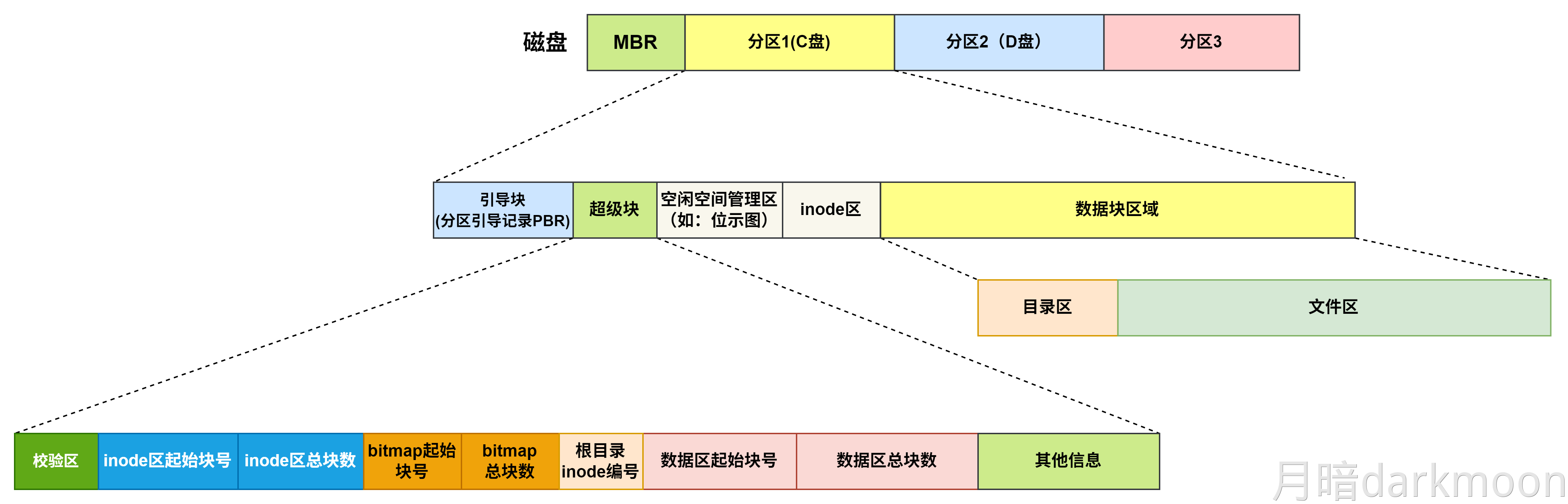
- 在系统启动时,内核需要读取根文件系统的超级块,以确认文件系统类型、块大小、inode布局等关键信息
- 超级块通常在挂载时被读取并缓存到内存中,后续操作(如读写文件)会直接使用缓存的超级块信息,无需重复读取磁盘
- 超级块通常存储在磁盘的固定偏移位置
- 一般来说,超级块有如下字段:
- 校验区:进行文件系统校验的字段,用于区分文件系统类型,检测文件系统合法性
- inode区起始块号:索引节点表占用的第一个物理磁盘块块号
- inode区总块数:索引节点表占用的磁盘块数
- bitmap起始块号:位示图占用的第一个物理磁盘块
- bitmap总块数:位示图占用的磁盘块数
- 数据区起始块:文件数据占用的第一个物理磁盘块块号
- 数据区总块数:文件数据总共占用的磁盘块数
- 其他信息
- 磁盘块大小
- inode大小
- 根目录的inode编号等
- 超级块的内容在逻辑格式化的时候写入


VFS
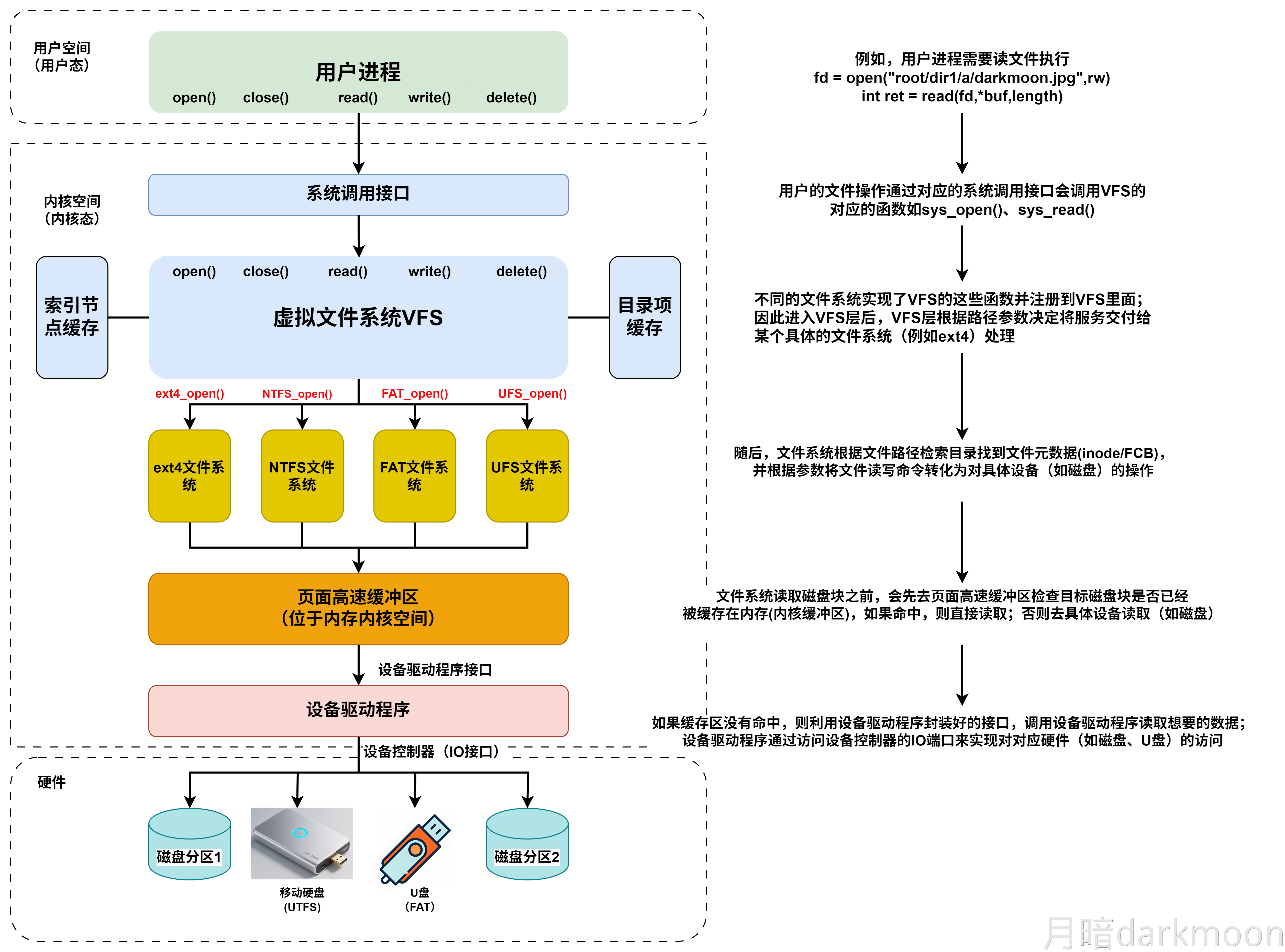
- 默认情况下,写操作会先写入Page Cache(这时应用就认为写入成功了),这被称为延迟写入。内核会在之后的某个时刻(比如系统空闲、内存紧张或定时)才将“脏”的缓存页面同步回磁盘。这个机制极大地提高了写入性能。
- 在页面高速缓存区和设备驱动程序之间,还有一个重要的层次叫做块设备I/O层,其中包含了I/O调度器,调度器的作用是发往磁盘的请求进行合并、排序(比如电梯算法),以减少磁头寻道时间,优化磁盘性能。
- VFS使用三个缓存来提升性能
- 索引节点缓存:每个目录和文件都用一个vnode表示,访问目录或文件会访问其索引节点,因此索引节点高速缓存中存储最近访问过的索引节点,可加快访问速度。
- 目录缓存:目录缓存中存储完整的目录名称和其索引节点号之间的映射,可加快列出目录的过程
- 页面高速缓存区:缓冲区高速缓存中存放文件的具体数据,当需要相同的数据时,可以从高速缓存中读取,而不是磁盘。
- 目标文件系统转换文件系统请求到面向设备的指令
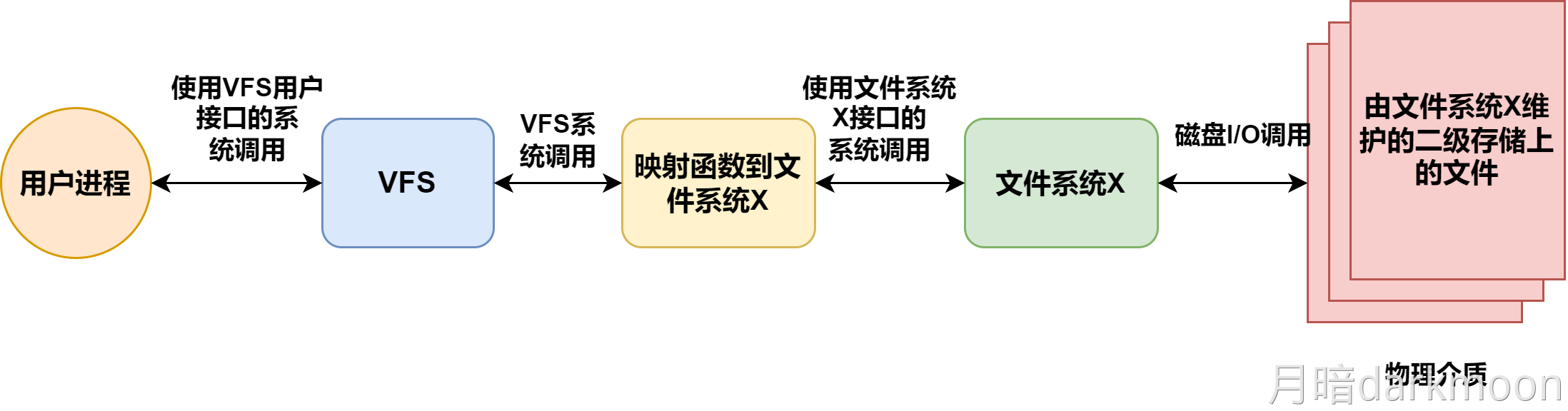
-
每打开一个文件VFS就在主存中新建一个VNODE,用统一的数据结构表示文件,无论该文件存储在哪个文件系统
- Vnode只存在于主存中,而inode既会被调入主存,也会在外存中存储
- 打开文件后,创建vnode,并将文件信息复制到vnode中,vnode的功能指针指向具体文件系统的函数功能
-
当内核在对一个文件系统进行初始化和注册时在内存为其分配一个超级块。此时的超级块为VFS超级块。也就是说,VFS超级块是具体各种文件系统在安装时建立的,并在这些文件系统卸载时被自动删除。
- VFS超级块只存放在内存中,对于每个具体的文件系统来说,都有各自的超级块。
-
普通文件由inode结点和数据块构成
-
目录文件由inode结点和目录块构成
-
构架
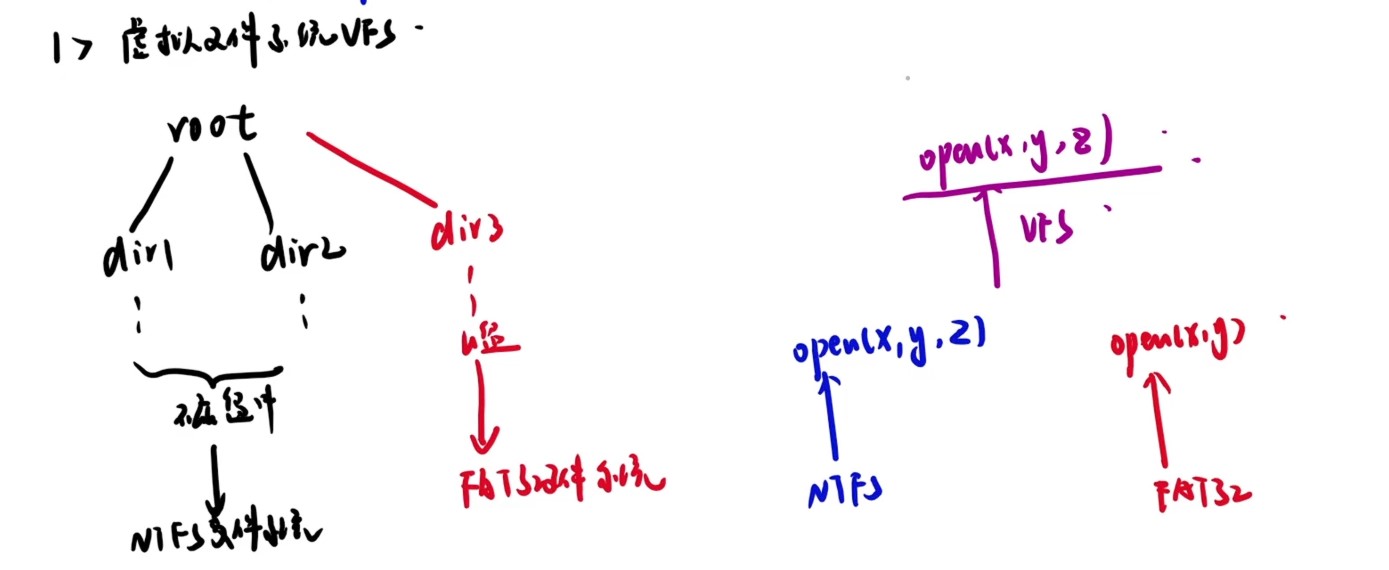
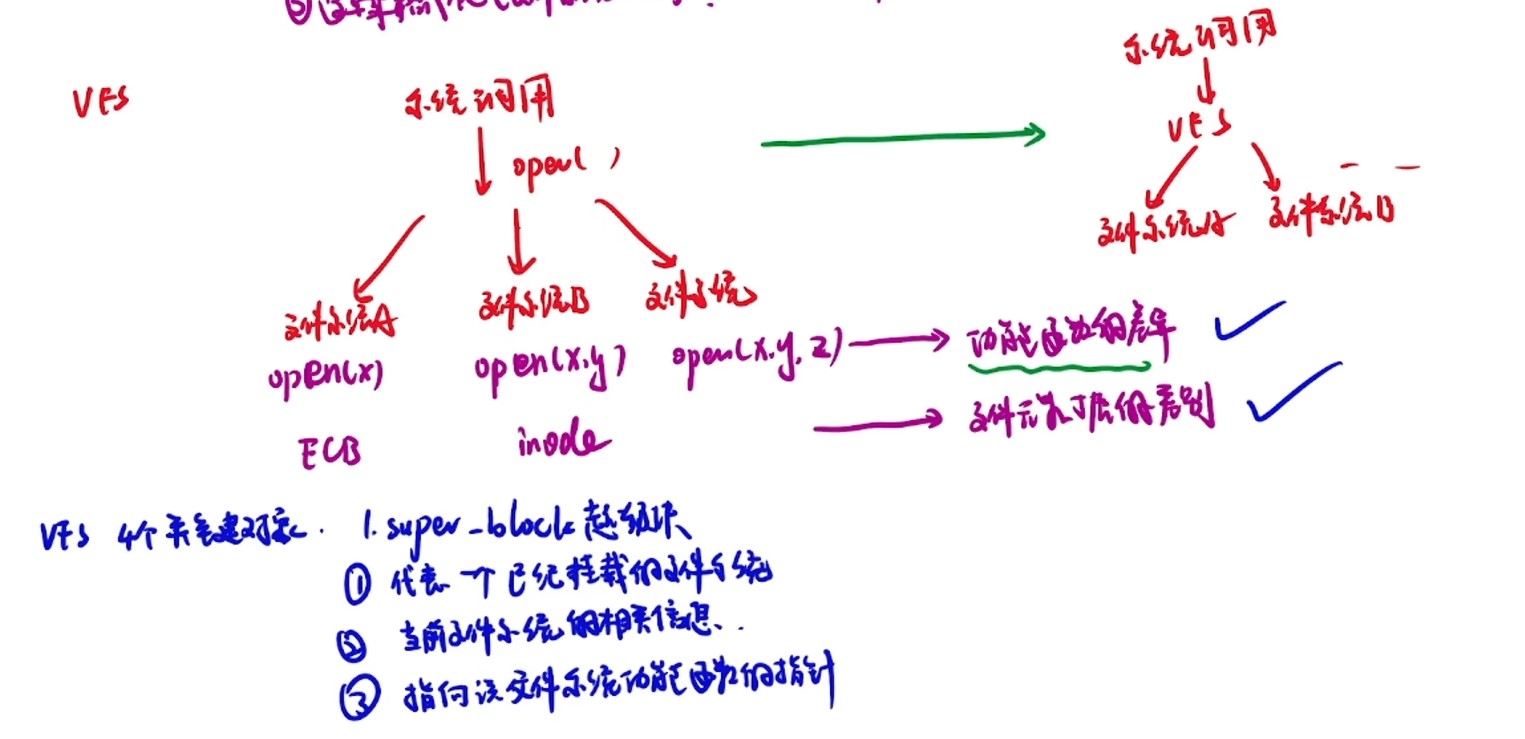


FAT文件系统
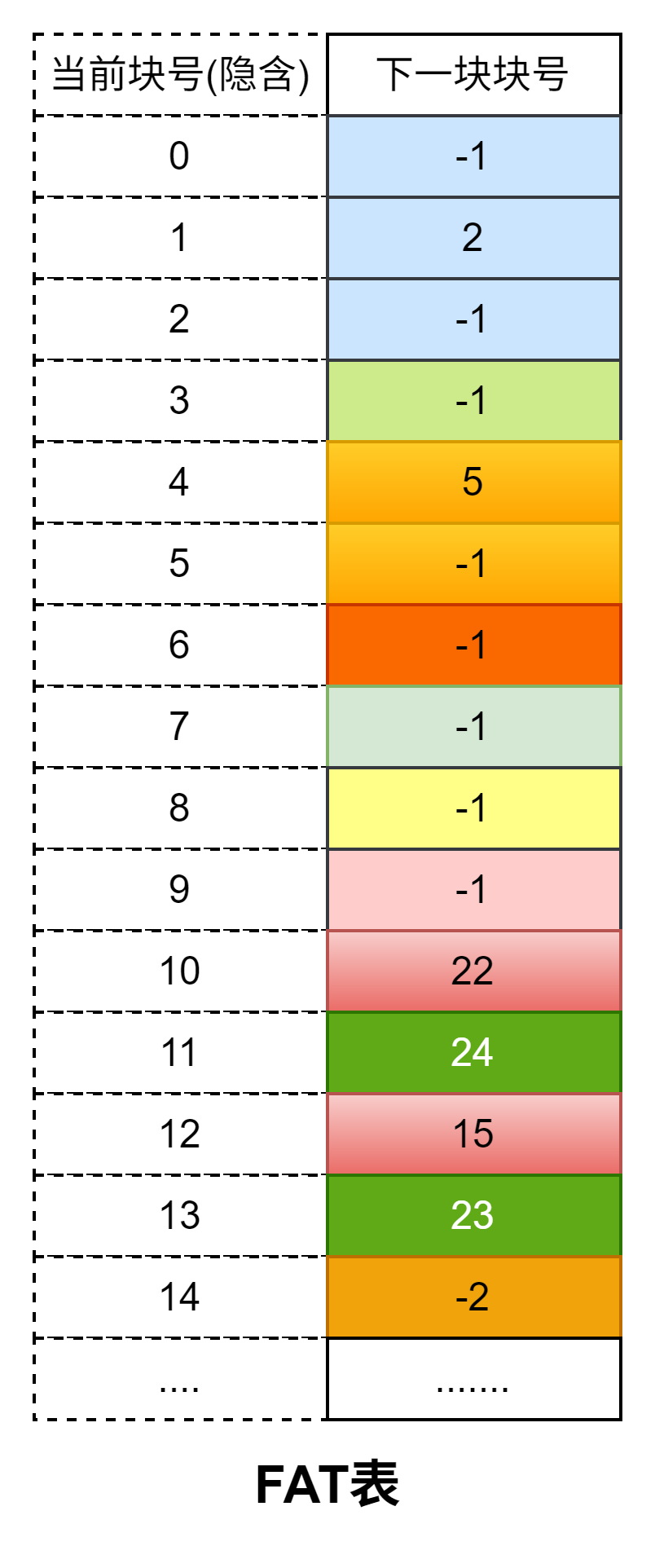
-
问题1:一个文件系统中(一个磁盘分区)有几个FAT表?
- 一个文件系统(磁盘分区只有一张FAT表,且存放在磁盘中的固定位置,开机后就会读入内存,每个文件在想要修改自己的磁盘块布局时部要修改FAT表;
-
问题2:FAT用到了哪种数据结构?可以用来管理空闲磁盘空间吗?可以的话,如何管理?
- 静态链表;可以;如上图,我们可以用-1表示一个文件的最后一块,用-2表示空闲的磁盘块,当需要为文件分配磁盘块时,遍历查找一个表项值为-2的磁盘块分配给它即可;回收磁盘块时,将表项值置为-2;
-
问题3:若文件分配方式采取FAT方式(显式链接分配),那么文件控制块(FCB,目录项)里的物理地址字段中应该保存什么信息?
- 保存起始块号即可;
-
问题4:如果进程想要访问文件dark.png,假设此时FAT表和该文件的FCB都已经读入内存,那么如果想要访问该文件的第3块,需要执行多少次磁盘I/O操作?如果想要修改第三块呢?
- 如果只是访问,一次磁盘I/O即可;若需要修改的话,则需要两次磁盘I/O,第一次先读入内存,第二次将修改好的内容写回磁盘;
-
问题5:FAT表中,每个表项的大小对文件系统有什么影响?
-
有如下影响:
-
a.对文件系统支持管理的最大磁盘块数有影响,如:每个FAT表项为16bit,则最多表示2¹⁶个块号;|
-
b.对FAT表的总大小有影响,每个表项的大小*表项数量=FAT表的大小;
-
-
-
问题6:简述操作系统是如何使用FAT表的?
- 开机后,就会把整个FAT表读入内存,系统运行过程中,FAT表会一直常驻内存,也就是说,查FAT表不需要读磁盘,若进程需要访问某个文件,则需要找到这个文件对应的目录项,从目录项中找到该文件的起始块号,再根据起始块号查FAT表就可以确定后续块号在磁盘中的存放位置了。
- 1、在该目录文件中,每个目录项都是一个文件的文件控制块(FCB),记录了该文件的相关信息,如果把该表项中除了文件名以外的信息组合起来放进一个结构体文件便构成了索引节点,也就是下面unix系统中的inode结点,此时,目录项中只需要记录文件名和inode编号即可;
- 2、如何确定目录文件dir1需要占几个磁盘块?
- 「(目录项的数量*每个目录项的大小)/磁盘块大小┓
- 3、目录文件dir1必须占用连续的磁盘块吗?
- 不需要,如果目录文件dir1增加新的表项后,原来的磁盘块不够用,那么可以通过遍历FAT表找到一个空闲磁盘块分配给它。根据FAT表我们可以知道dir1文件的最后一块为5号,那么我们还要修改FAT表的5号表项,将它指向新分配的块,新分配的块表项里面填-1;
- 4、如果现在从根目录开始查找,要将文件“root/dir1/k1.mp3”读入内存,那么这个过程背后发生了什么?
- 先查内存中的根目录,找到目录项dir1,根据其中记录的dir1文件的起始块号为4,先通过磁盘i/o读入dir1的第一块(4号磁盘块),然后遍历该磁盘块里的目录,尝试找k1.mp3的目录项;如果没找到,再去查FAT表,找到dir1的第二块块号,然后读入5号磁盘块,在里面遍历找到k1.mp3的目录项,根据里面的起始块号知道k1.mp3的第一个块的块号为19,再查FAT表,知道
第二块块号为6,因此可以通过磁盘I/O将这两个磁盘块读入内存。
- 先查内存中的根目录,找到目录项dir1,根据其中记录的dir1文件的起始块号为4,先通过磁盘i/o读入dir1的第一块(4号磁盘块),然后遍历该磁盘块里的目录,尝试找k1.mp3的目录项;如果没找到,再去查FAT表,找到dir1的第二块块号,然后读入5号磁盘块,在里面遍历找到k1.mp3的目录项,根据里面的起始块号知道k1.mp3的第一个块的块号为19,再查FAT表,知道
UNIX文件系统
- 磁盘的inode区介绍
- inode就是索引结点,在unix文件系统中,所有的磁盘索引结点集中连续存放,如图所示。每个inode结点大小相同,因此索引结点编号是隐含的,不会显式存放在inode结点里面,此外,用于表示“文件物理结构”的“混合索引表”被包含在inode结点中,通过混合索引表可以找到一个文件中每个块存储的物理位置。
- 在Unix文件系统中,每个文件必须对应一个inode结点,而inode结点的总数量是有上限的。
- 如:该示意图中,仅用两个磁盘块,即8KB作为inode区,假设每个inode大小为64B,则该文件系统最多只能存储8KB/64B=128个inode结点,相应地,该系统最多只能支持128个文件。
- 当一个进程通过open系统调用打开某个文件时,操作系统需要将该文件对应的inode结点读入主存。
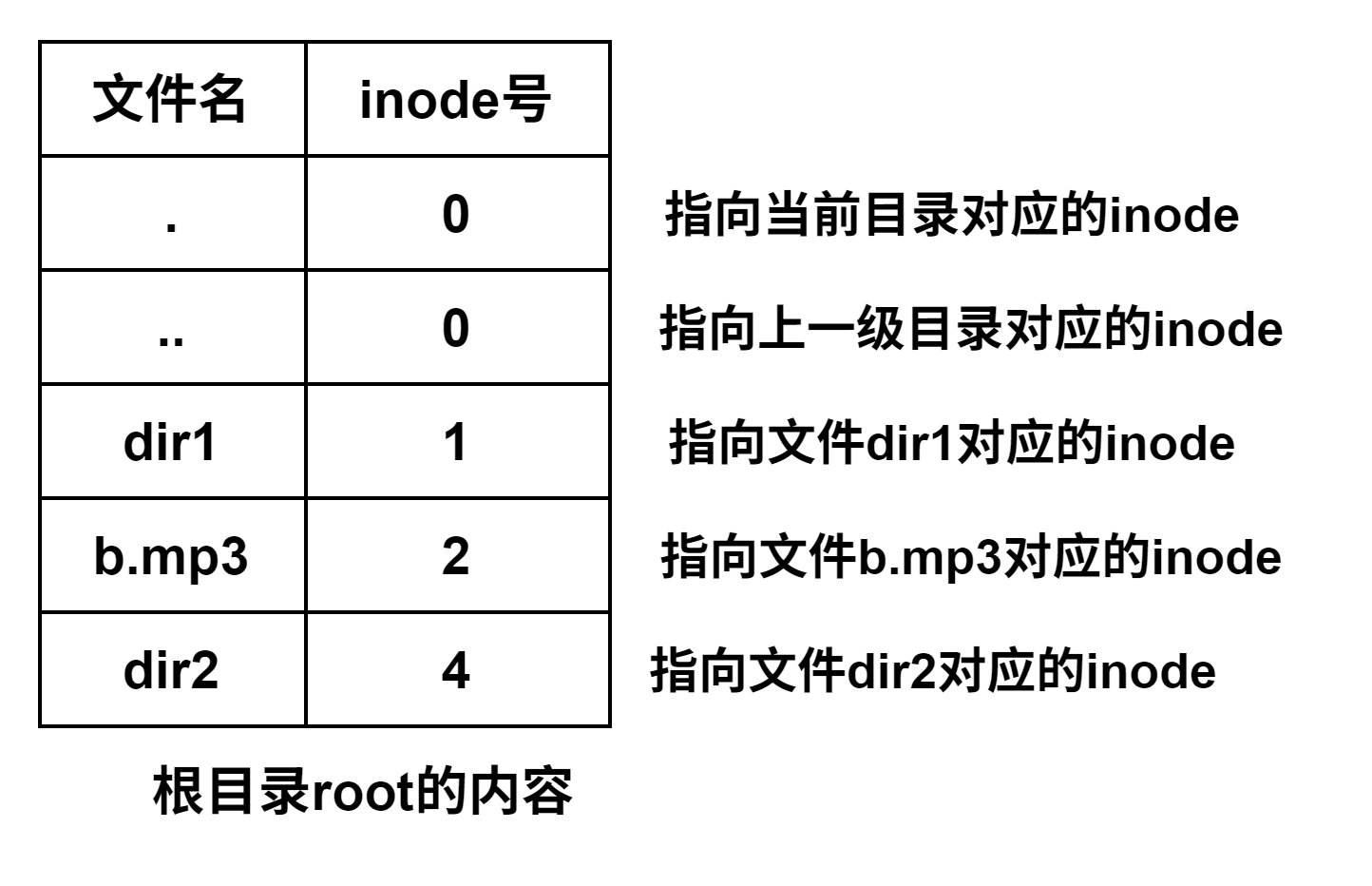
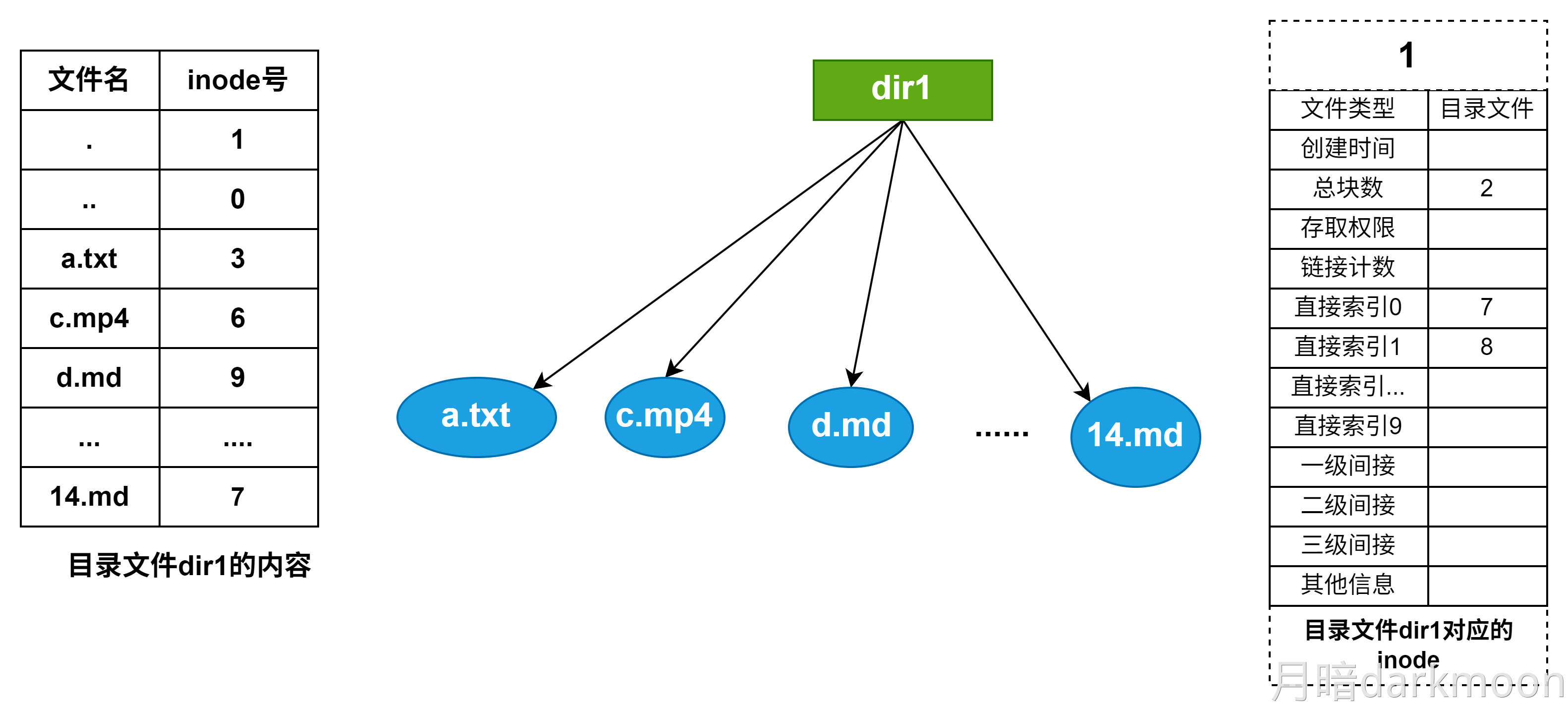
- 磁盘中的根目录介绍
- 1、根目录的信息存储在磁盘的固定位置,这样可以保证开机时,能够找到根目录,再从根目录出发找到其他信息
- 2、开机时,根目录的内容通常会被加载到内存,并一直常驻内存
- 3、由于Unix文件系统采用了“索引节点”,因此每个目录项只需包含“文件名、inode号”,文件的具体属性包含在inode中
- 4、每个目录文件中默认包含两个目录项,分别是“.”和“…“,”.“”表示当前目录,”…”表示上一级目录。根目录比较特殊,没有所谓的“上一级目录”,因此它的目录项“…”指向自身
- 假设在UNIX文件系统下有一进程利用open系统调用打开路径为/dir1/14.md的文件(从根目录开始查找)
- 1、通过开机常驻内存的根目录找到目录项dir1,根据目录项dir1可知目录文件dir1对应的inode号为1
- 2、从磁盘的inode区将该inode结点读入内存,通过1号inode结点可以得到目录文件dir1的索引信息,也就知道了目录文件dir1的每一块存储在什么位置,接下来,先读入目录文件dir1的第一块(7号磁盘块),尝试查找目录项14.md,如果没找到,再读入目录文件dir1的第二块(8号磁盘块),找到目录项14.md
- 3、当找到文件14.md的目录项后,根据目录项记录的7号inode结点,将该inode结点加载进内存专用缓冲区,并且在系统打开文件表中登记表项,指针域记录该inode结点在内存中的物理位置,同时登记其他信息,设置文件打开计数(访问计数)为1,表示当前有一个进程正在使用14.md文件。
- 4、发起open调用的进程会有进程打开文件表,需要在进程打开文件表中新建一个条目,记录其打开方式以及系统打开文件表索引,最后返回该条目对应的fd。在进程打开文件表中不会记录文件的inode结点,而是用系统打开文件表的索引找到系统打开文件表中对应文件的inode结点。
- 5、根据open调用返回的fd,即可对该文件进行操作。
易混淆的逻辑结构、物理结构、存储空间管理汇总
-
文件的逻辑结构
-
无结构文件
-
有结构文件
-
顺序文件

-
索引文件
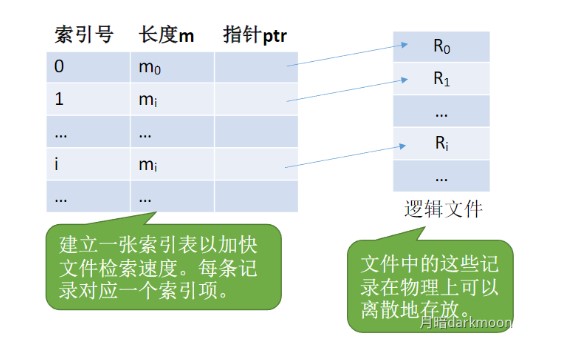
-
索引顺序文件
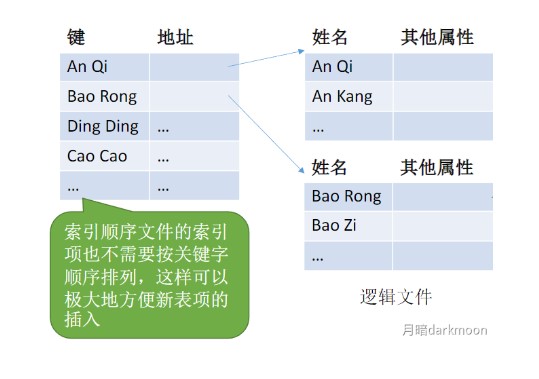
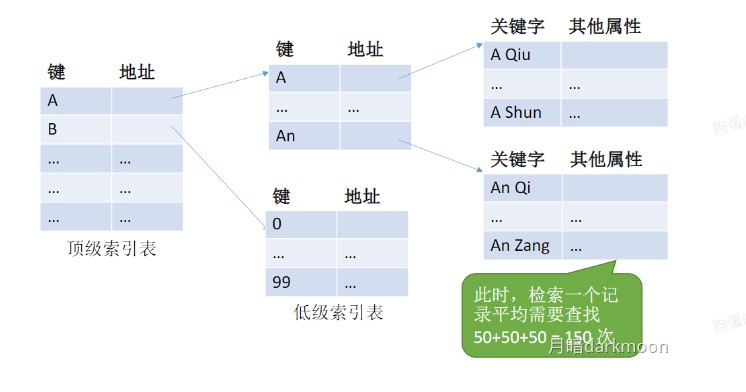
-
散列/直接文件
-
-
文件的物理结构/外存上的组织形式
-
连续分配
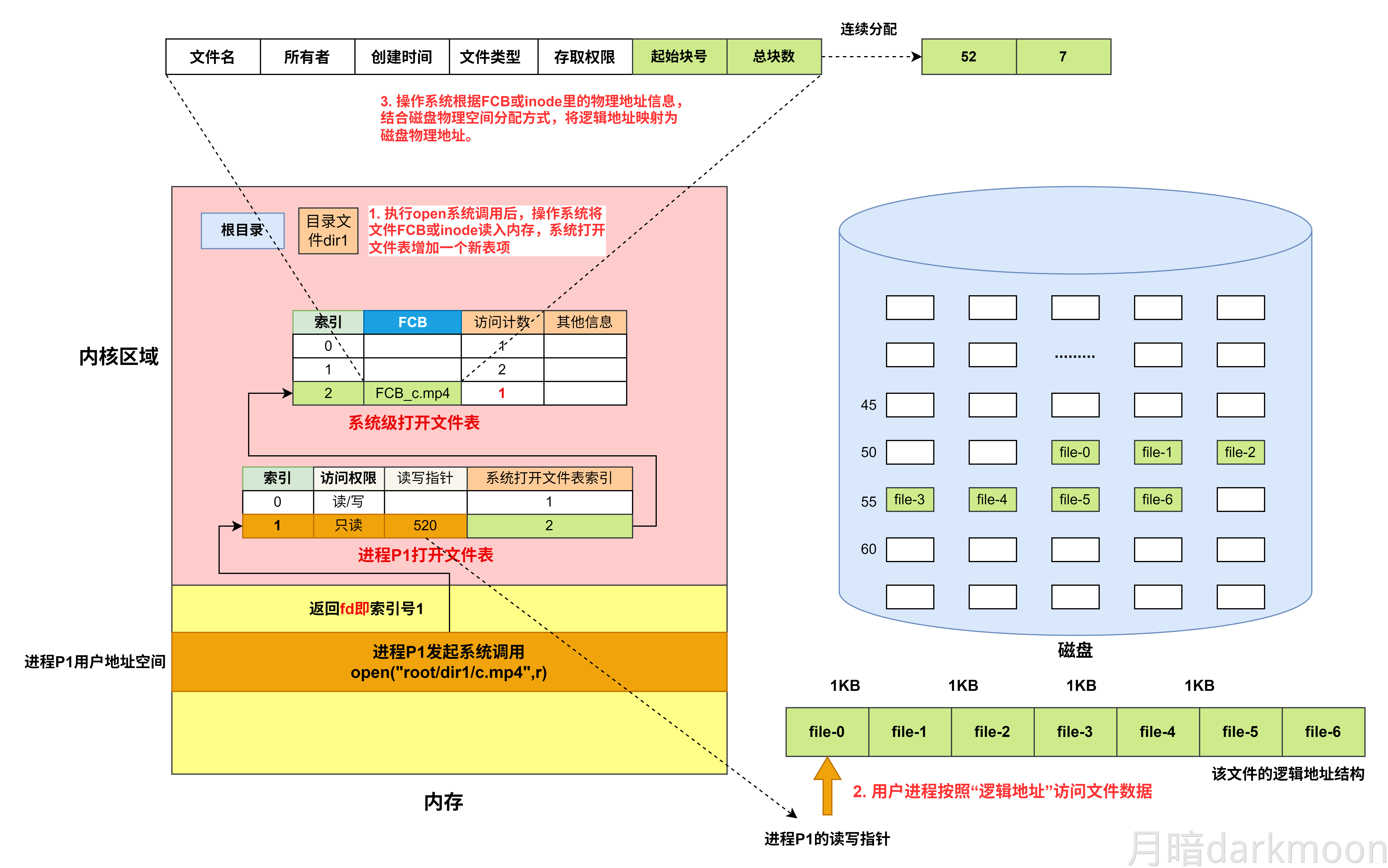
-
链接分配
-
隐式链接
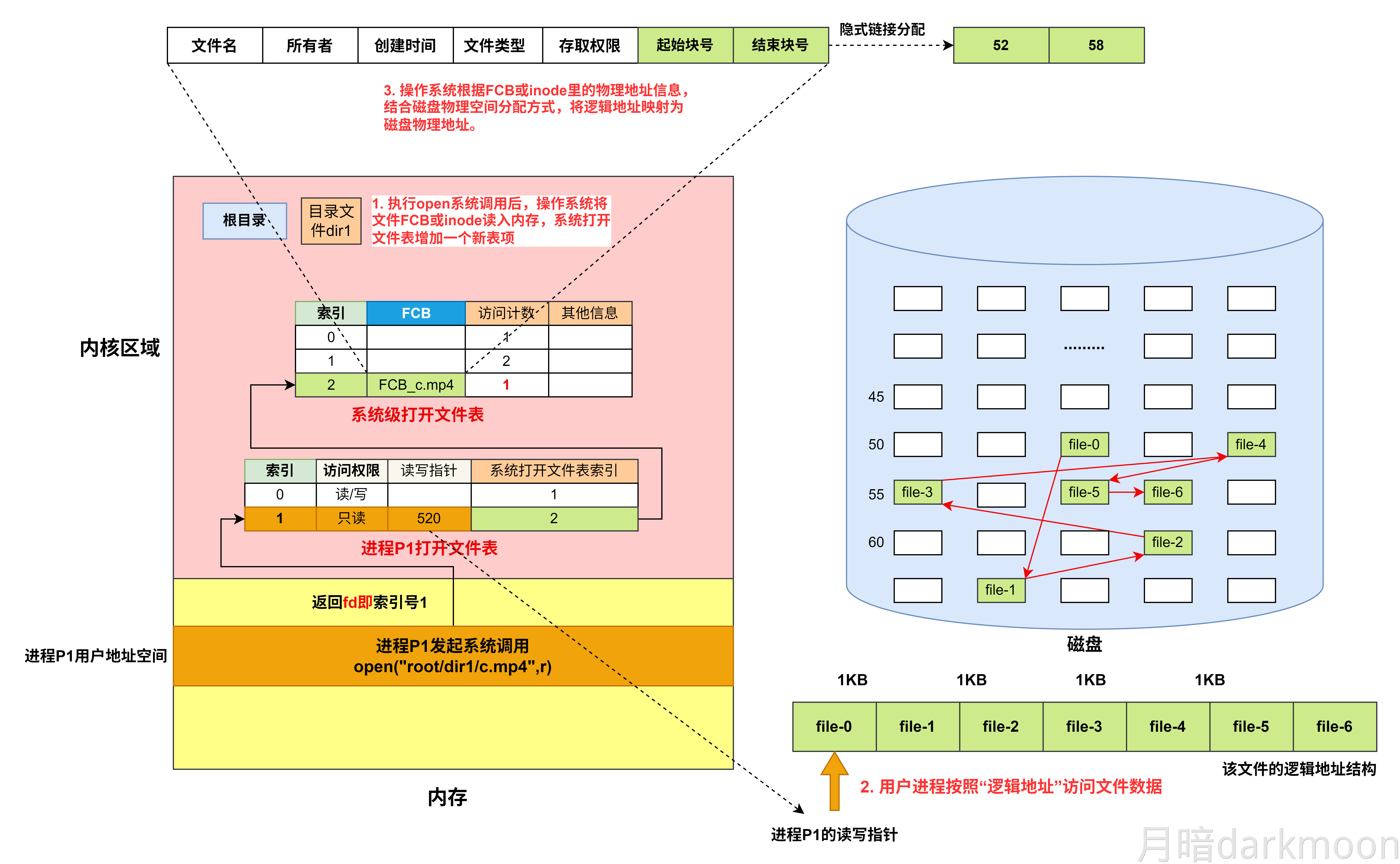
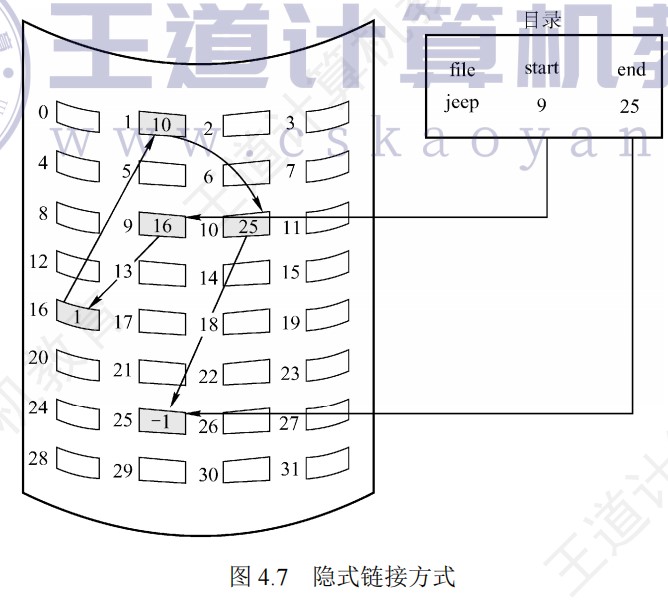
-
显式链接
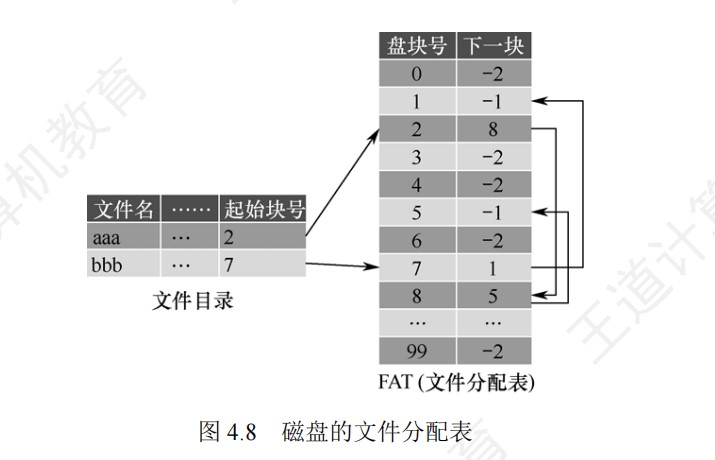
-
-
索引分配
-
直接索引
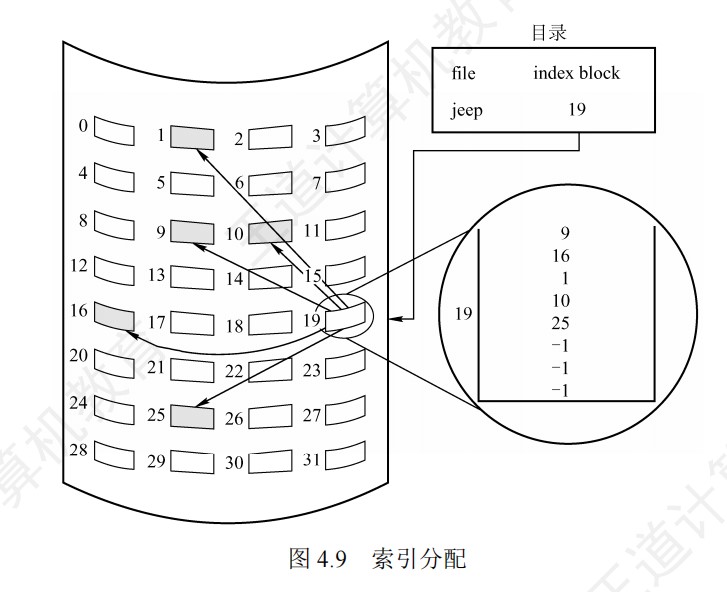
-
一级索引
-
二级/多级索引
-
混合索引
-
-
-
空闲/存储空间管理
-
空闲表
-
空闲链表法
-
空闲盘块链
-
空闲盘区链
-
-
位示图
-
成组链接法
-
磁盘索引节点和内存索引节点
| 磁盘索引节点 | 内存索引节点 |
|---|---|
| 存放在磁盘Inode区,进程通过检索目录获取文件名对应的目录项,并根据里面的inode号将对应的索引节点载入内存,索引节点里面存放着文件的元数据。 | 当磁盘索引节点调入内存(内核专用缓冲区)以后,可以供多个进程共享使用,因此要增加一些内存属性以便操作系统使用 |
| 文件类型:标识该文件是目录/普通文件/软连接等 | inode编号:表示对应外存的inode编号 |
| 存取权限:控制文件的访问权限 | 状态位:包含修改位(决定是否需要写回外存) |
| 物理地址(直接索引、间接索引等):实现逻辑地址到磁盘物理地址的映射 | 互斥锁:保证多进程共享访问时的互斥 |
| 链接计数:记录文件被硬链接的次数 | 访问计数:记录文件被打开的次数 |
| 其他信息:文件大小、创建时间等辅助信息 | device号:表示inode所在的逻辑设备号 |
文件系统综合串联
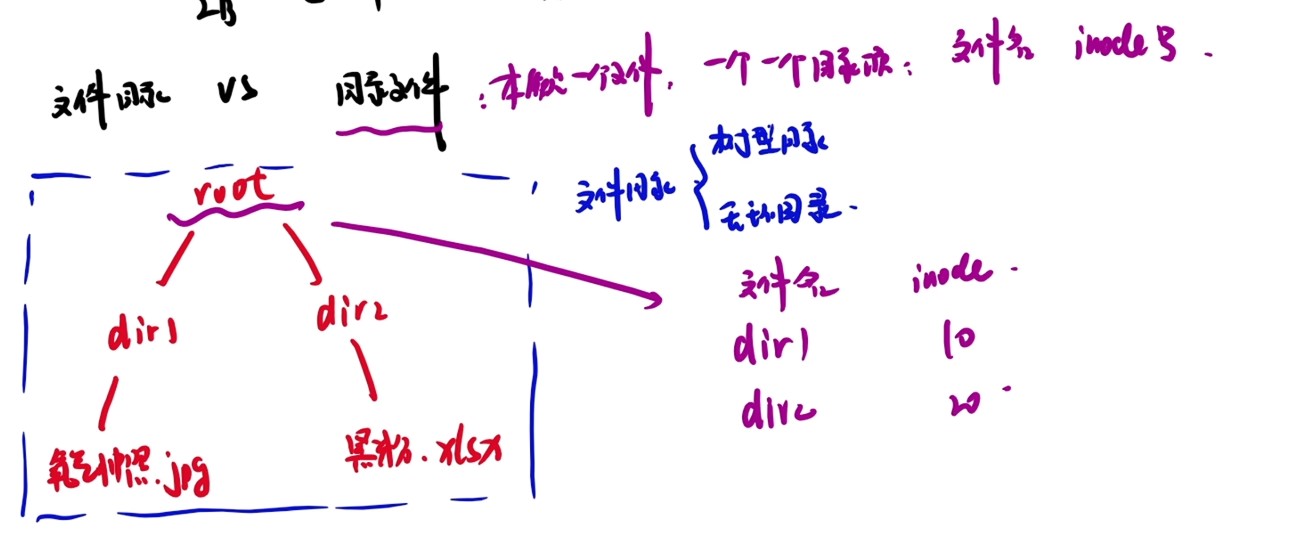
read系统调用全流程

-
1、open系统调用
-
读取dir2的目录文件内容

- 先读入20号inode:
- 如何根据20号inode找到dir2的目录文件内容
- inode里面有起始块号和块数
- 先读入20号inode:
-
读入对应的磁盘块,调入dir2目录文件内容
-
读入黑粉.xlsl第2条记录

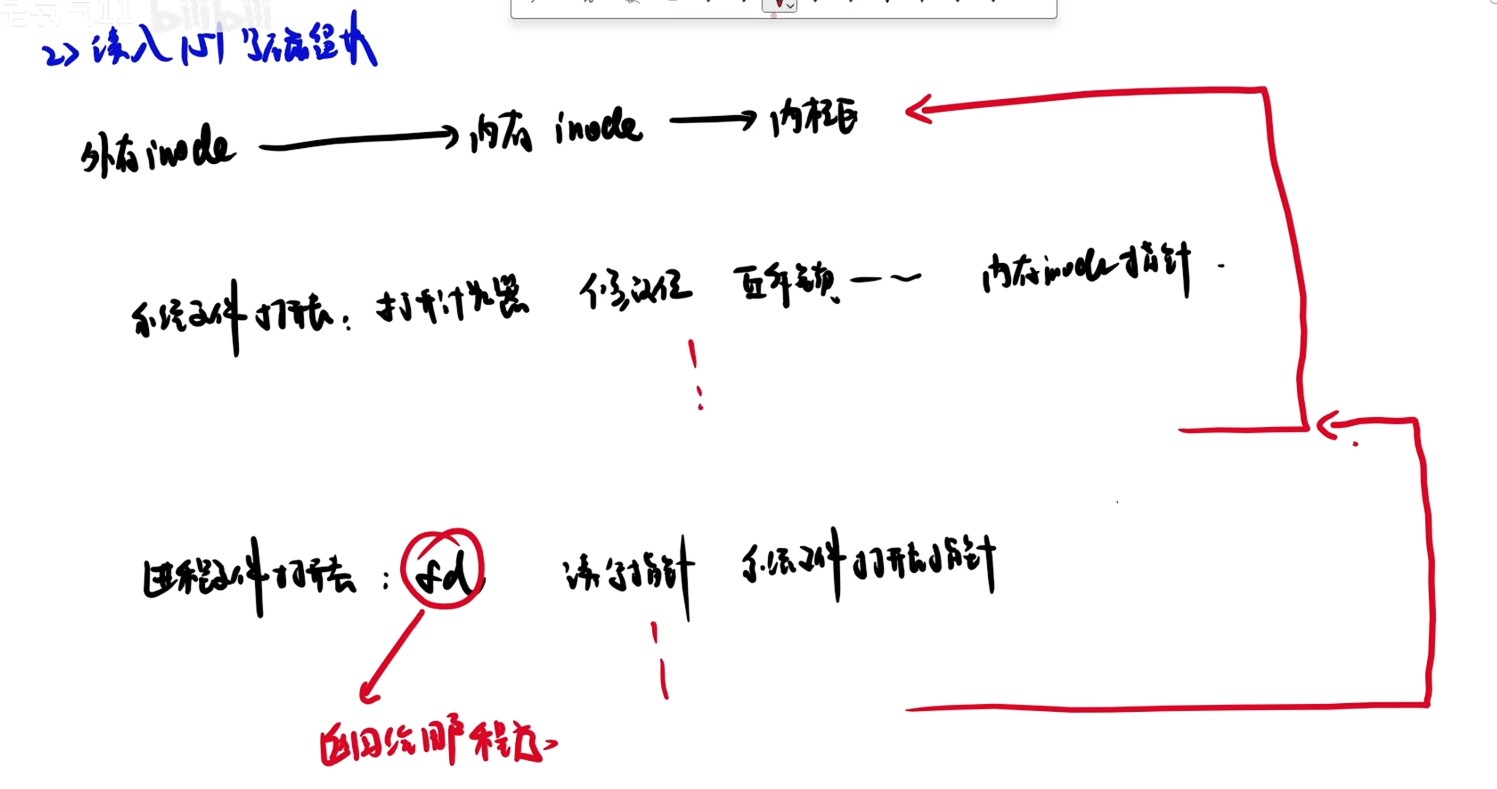

- 读入100号inode
- 读入151号磁盘块
-
-
2、read系统调用
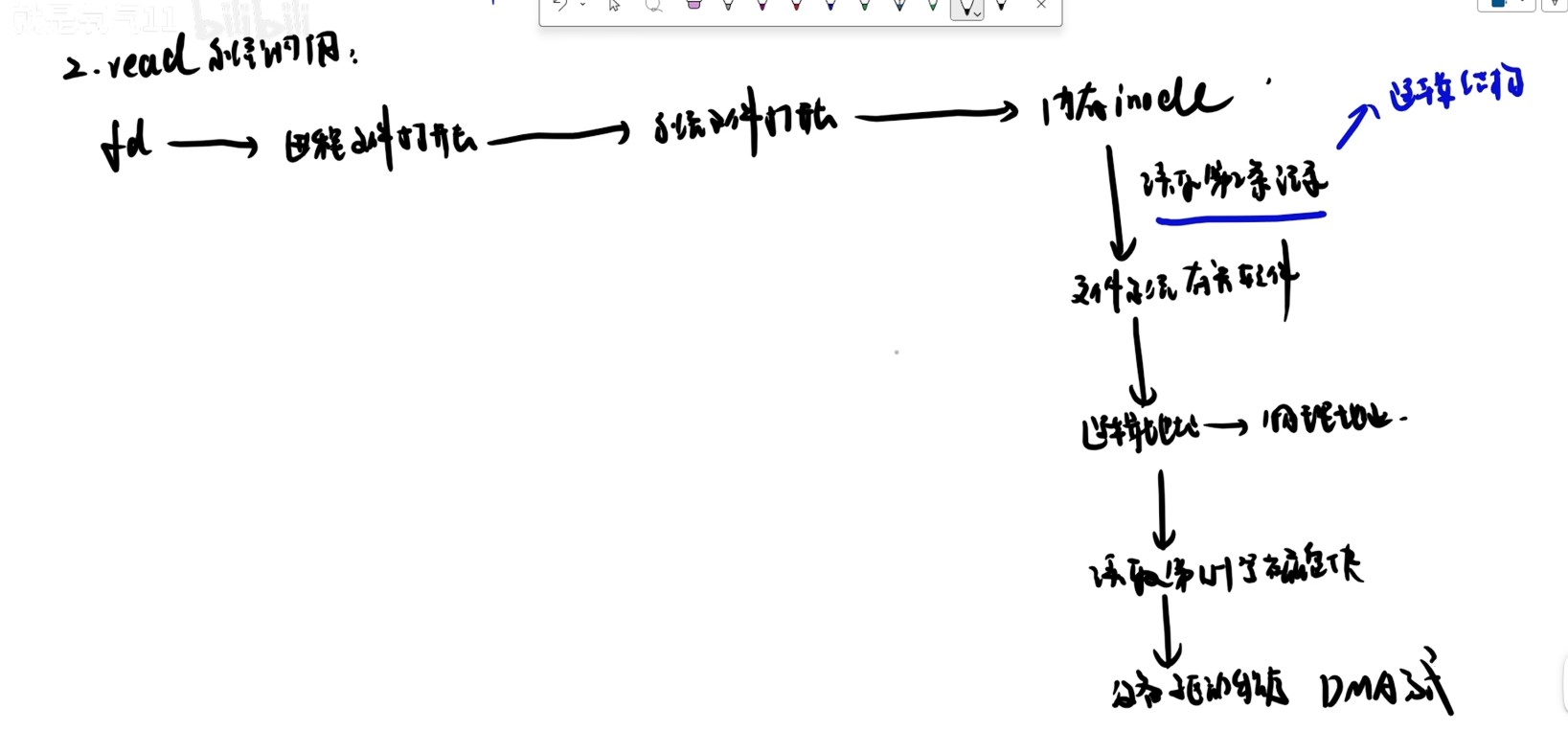
CN(计网)
计算机网络体系结构
-
网络体系结构
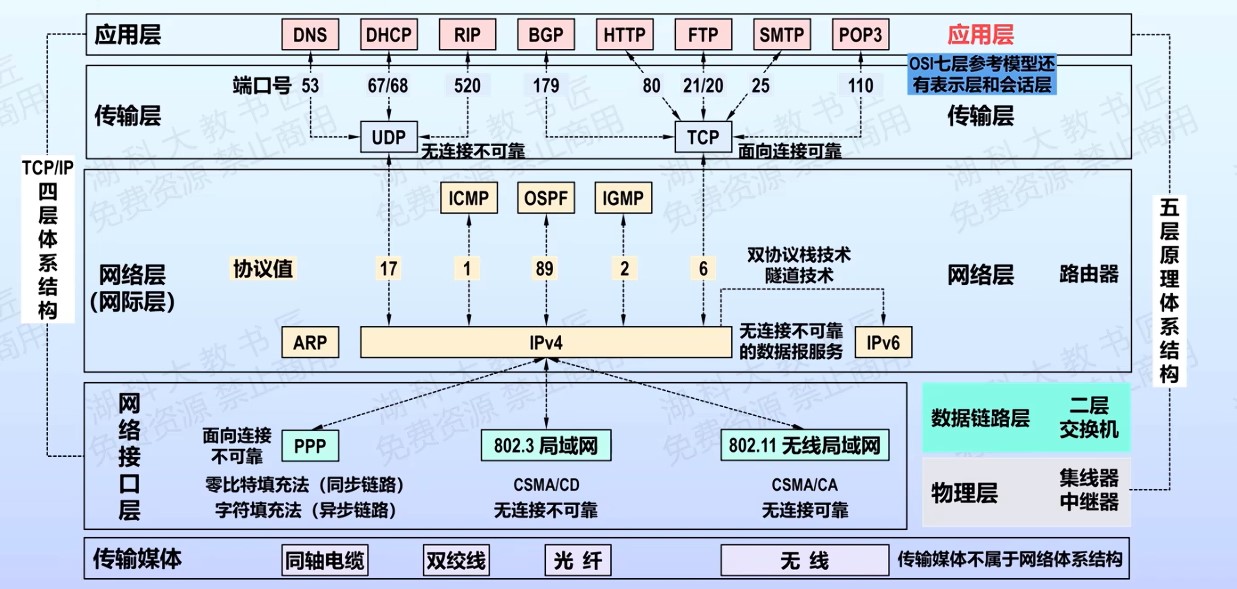
-
传输媒体(线)不属于网络体系结构
-
网络层参与拥塞控制
-
无确认无连接服务适用于实时性要求高的场景
-
协议是计算机网络的核心
-
电路交换难以实现差错控制
-
广域网是互联网的核心部分
-
传统上,局域网广播,广域网使用分组交换技术,广域网中的无线、卫星通信网络也采用广播技术,局域网接入广域网主要通过路由器实现
-
主机A给主机B发送数据的最高理论速率取决于链路带宽以及主机A、主机B网卡速率中的最小者。
-
分组交换速率的计算可以借助流水线,T=nr+(m-1)r(不考虑传播时延的情况下)
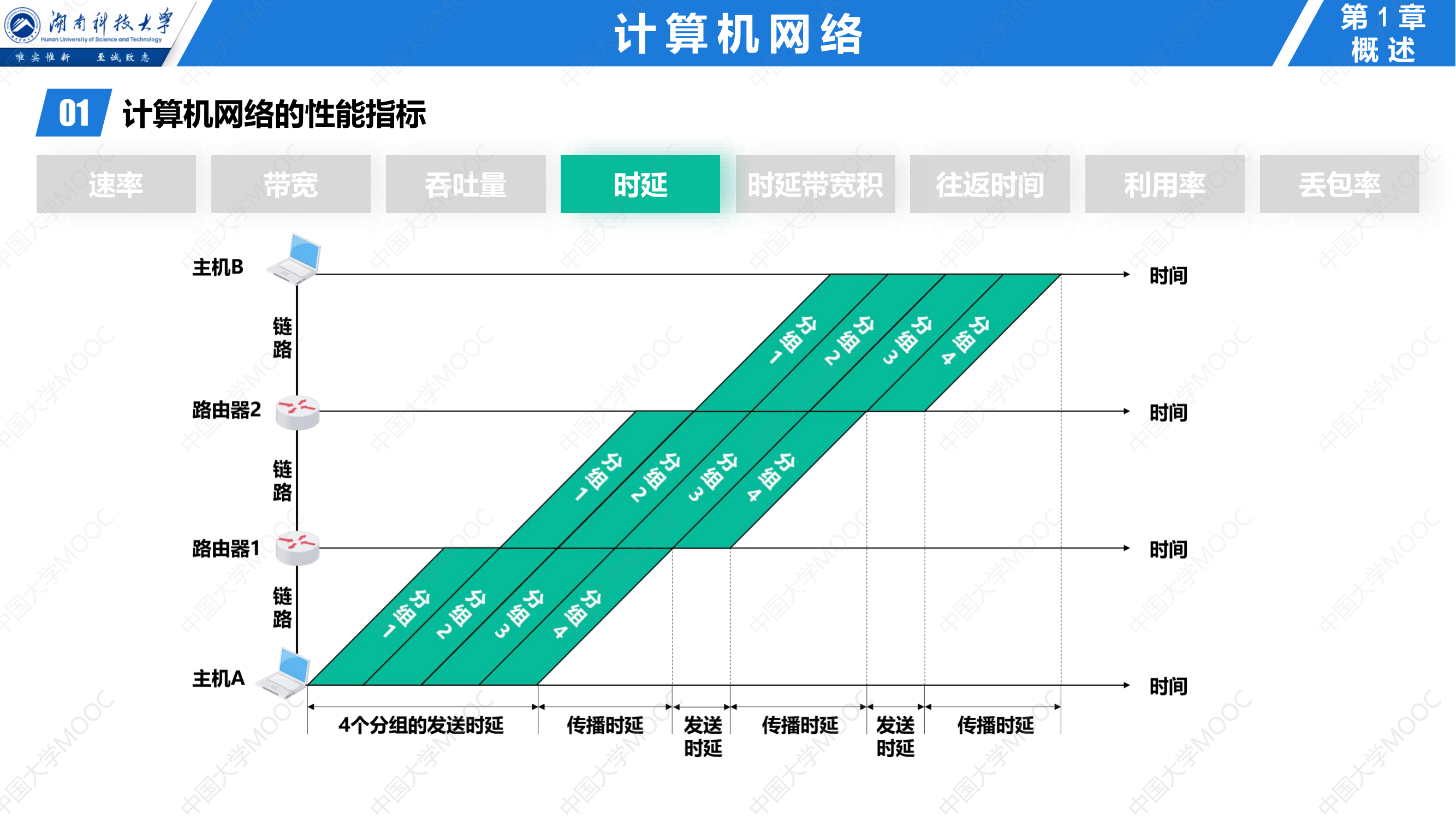
- n是有几段传输路径,m是总共有多少个分组,r是传输一个分组的时间
- 在考虑传播时延的情况下,对方全部接收的时间=nr+(m-1)r+nt
- t是传播时延
-
有应答服务由传输系统内部自动实现应答,不由用户实现
- 如文件传输服务
-
传输信息所用的一些物理介质(如双绞线、光缆、无线信道等)并不在物理层协议之内,而在物理层协议之下
-
会话层包含一种称为检查点的机制来维持可靠会话,使通信会话在通信失效时从检查点继续恢复通信,即断点下载的原理。
-
网络吞吐量为下载速率和上传速率的总和
-
光速310^8m/s,铜线:2.3 * 10^8m/s,光纤:210^8m/s
-
短分组是暂存在路由器的内存中而不是存储在磁盘里的
-
为了提高分组交换网的可靠性,互联网的核心部分常采用网状拓扑结构
-
分组交换无法确保通信时端到端所需的带宽
-
对于高速网络链路,我们提高的仅仅是数据的发送速率而不是bit在链路上的传播速率,传播速率取决于通信线路的介质材料
-
有效数据率=数据长度/发送时间+rtt
-
D0表示网络空闲时的时延,D表示网络当前的时延,U表示利用率,D=D0/1-U
-
信道或网络的利用率过高会产生非常大的时延
-
解释bit代表的意思,就不是物理层任务
-
并非在一个层内完成的全部功能都称为服务。只有那些能够被高一层实体看得见的功能才能称之为服务
-
分组交换分为数据报服务和虚电路服务。(网络层提供)
- ①数据报服务可能出现失序、丢失或重复分组的情况,分组到达目的节点时,要对分组按编号进行排序等工作。
- 发送的分组中要包含发送端和接收端的完整地址(源地址和目的地址)
- ②虚电路服务则没有失序问题,但有呼叫建立、数据传输和虚电路释放三个过程
- 虚电路的路由选择体现在连接建立阶段,连接建立确定传输路径
- 虚电路网络中的每个结点上都维持一张虚电路表
- 分组首部不包含目的地址,包含虚电路标识符
- 虚电路检测到拥塞时,可以通过信令机制(如发送特定的控制分组)同之源端调整发送速率。
- 在进行数据交换的两个端系统之间,可以有多条虚电路为不同进程服务
- ①数据报服务可能出现失序、丢失或重复分组的情况,分组到达目的节点时,要对分组按编号进行排序等工作。
-
数据链路层的SAP是MAC地址,网络层的SAP是IP地址,传输层的SAP是端口号。
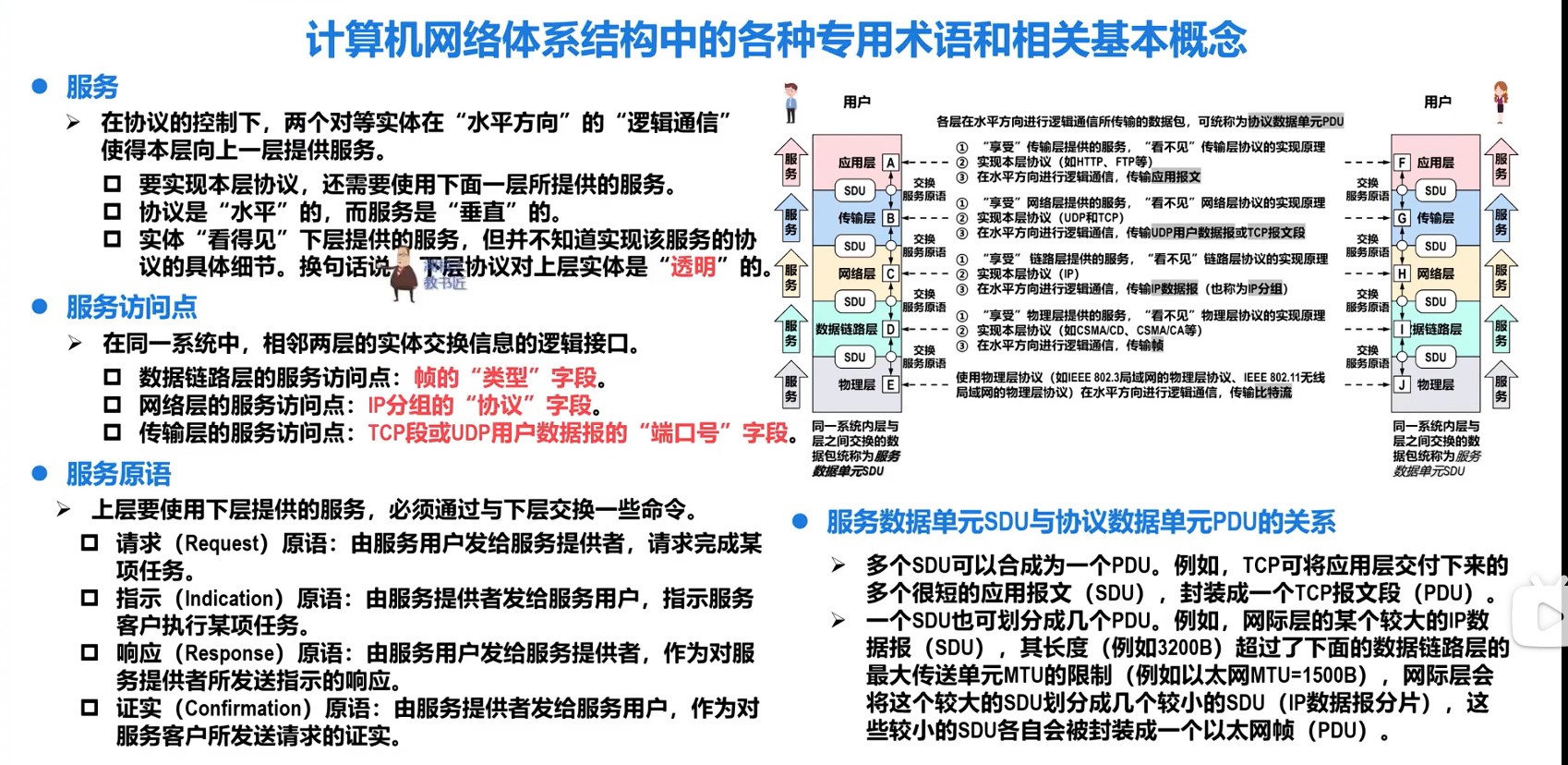
- 具体来说:
- 数据链路层的服务访问点:帧的类型字段
- 网络层的服务访问点:IP数据报的协议字段
- 传输层的服务访问点:TCP报文段或者UDP用户数据报的端口号字段
- 应用层的服务访问点:用户界面
- 具体来说:
-
在OSI参考模型中,对于相邻的两层,第N+1层实体通过服务访问点SAP将一个接口数据单元IDU传递给第N层实体。
-
IDU由服务数据单元SDU和接口控制信息ICI组成。
-
为了传递SDU,第N层实体可能将SDU分为若干段,每一段加上一个报头后作为独立的协议数据单元PDU传送出。
-
简单地说,SDU就是同一结点内层与层之间交换的数据单元,而PDU就是不同节点的对等层之间交换的数据单元
-
主机A给主机B发送数据的最高理论速率(传输效率)=min{A的网卡速率,A与B之间的链路带宽,B的网卡速率}
-
语法:定义收发双方交换信息的格式
-
语义:定义收发双方要完成的操作
-
同步:定义收发双方的时序关系
性能指标
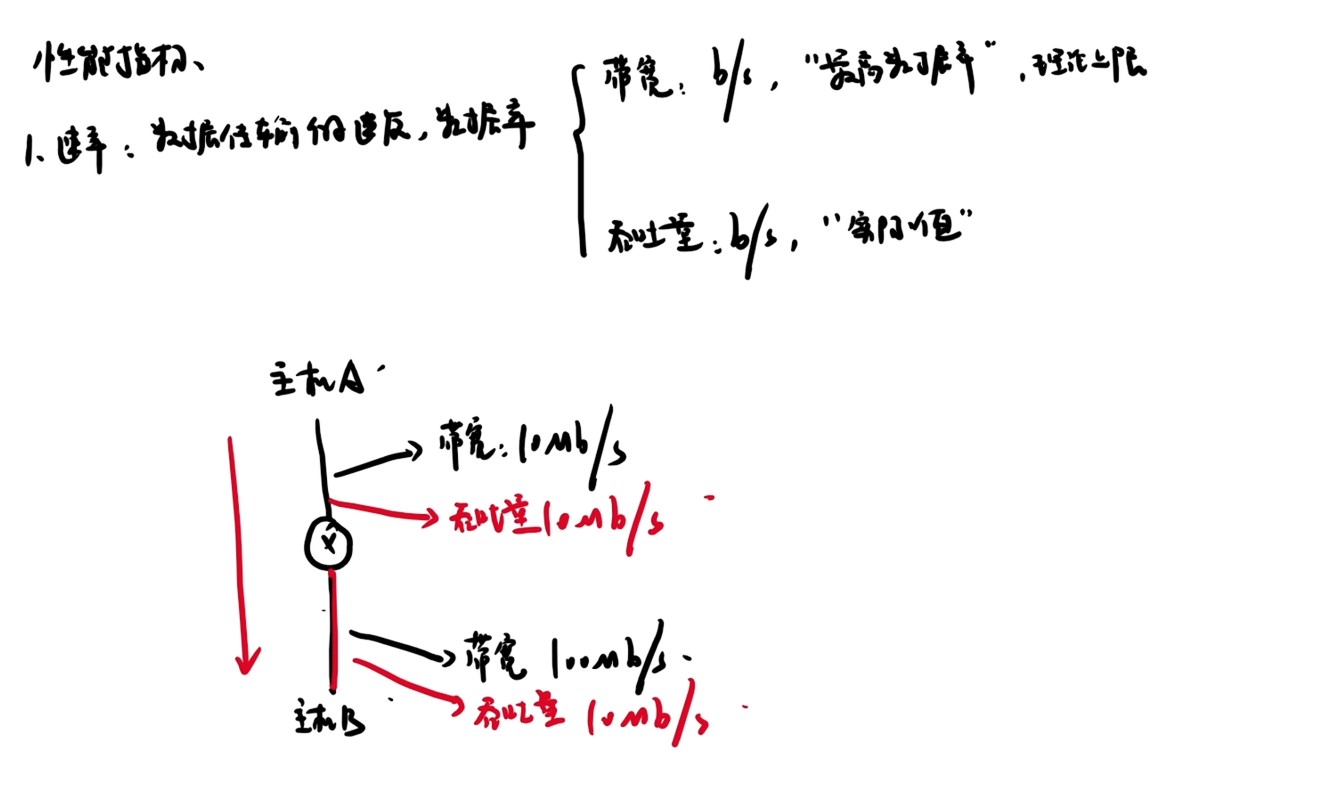
- 发送时延发生在机器内部的发送器中(一般就是发生在网络适配器中),与传输信道的长度(或信号传送的距离)没有任何关系。
- 传播时延则发生在机器外部的传输信道媒体上,而与信号的发送速率无关。信号传送的距离越远,传播时延就越大。
- 对于高速网络链路,我们提高的仅仅是数据的发送速率而不是比特在链路上的传播速率,传播速率取决于通信线路的介质材料。提高数据的发送速率只是减少了发送时延

TCP/IP模型和I/O层次结构的联动
- 应用层和传输层对应进程,它们之间的数据处理是进程内部的,不涉及设备驱动。
- 主机内的网络层是操作系统管理的,IP数据报位于内核空间内,数据经过处理后从用户进程空间进入操作系统的内核空间也不需要设备驱动程序
- 数据链路层的数据帧在内核空间封装好后需要传送到网卡设备中,对网卡设备的访问需要借助设备驱动程序。
物理层
- 电路交换:
- 一旦专用电路建立,路径上的任何障碍都会导致整个连接中断
- 全双工通信,没有冲突,双方有不同的信道,不会出现争用物理信道的情况
- 既可以传输模拟信号也可以传输数字信号
- 无数据存储能力
- 数据报分组交换
- 每个分组独立路由,某个后继路由器故障后,发往该路由器的分组将失败,除非路由协议(如OSPF,RIP)能够检测到故障并找到一条不经过该路由器的新路径到达目的服务器,否则后续分组将无法到达
- 报文交换
- 如果报文已经完整到达某路由器,但是下一跳路由器故障,某路由器无法将报文转发出去。该报文可能会在某路由器的存储中因超时而丢弃,或者如果系统有动态路由能力且存在备用路径,可能会尝试重路由(但这超出了基本报文交换的范畴,更接近高级网络功能)。基本情况下可以认为报文受阻于某路由
- 只适用于数字信号
- 从第四代蜂窝移动通信网开始,无论是话音通信还是数据通信,都要采用分组交换。
- 传输时延:电路交换<分组交换<报文交换,出错率:电路交换<分组交换<报文交换
- 过程特性定义了在物理连接的建立、维持和释放过程中,各种事件发生的合法顺序。
- 5-4-3规则:在采用粗同轴电缆的10BASE5以太网规范中,互相串联的中继器的个数不能超过4个,而且用4个中继器串联的5段通信介质中,只有3段可以挂接计算机,其余2段只能用作扩展通信范围的链路段,不能挂接计算机
- 单向通信只需要一个信道,而半双工通信或全双工通信都需要两个信道,每个方向一个信道,但是半双工只有一条物理介质,全双工有两条物理介质
- 香浓定理得出的是极限信息传输速率,实际信道能达到的要低
- 香农公式说明只要信息传输速率低于信道的极限传输速率,就能找到某种方法实现无差别的传输
- 规定各条线上的电压范围,以及电缆长度的限制,属于电气特性
- 指明某条线上出现的某一电平的电压表示何种意义,以及每条线的功能(数据线、控制线、时钟线)属于功能特性

- 时分复用更有利于数字信号的传输
传输介质
-
光纤非中空
-
物理层完成传输方式的转换
-
双绞线绞合可以减少对相邻导线的电磁干扰,为了进一步提高抗电磁干扰的能力,还在双绞线外层加上一层金属丝编织的屏蔽层
- 距离太远时,对于模拟传输,要用放大器放大衰减信号,对于数字传输,要用中继器来对失真的信号进行整形
-
无论是哪种类别的双绞线,衰减都随频率的升高而增大,使用更粗的导线可以减少衰减,却增加了导线的重量和价格。信号应当有足够大的振幅,以便在噪声干扰下能够在接收端正确地检测出来。
-
局域网领域基本用双绞线作为传输介质
| 双绞线 | 同轴电缆 | 光纤 | 无线传输介质 | |
|---|---|---|---|---|
| 构成 | 由两根采用一定规则并排绞合、互相绝缘的铜导线组成 | 由内导体、绝缘层、网状编织屏蔽层和塑料外层构成 | 利用光导纤维传递光脉冲来进行通信,由纤芯和包层构成 | 无线电波、微波、红外线和激光 |
| 分类 | ①带有金属丝编织的屏蔽层叫屏蔽双绞线STP ②无屏蔽层的非屏蔽双绞线UTP |
按特性阻抗分为 ①50Ω同轴电缆 ②70Ω同轴电缆 |
①多模光纤 ②单模光纤 |
|
| 特点 | 绞合减少相邻导线的电磁干扰,价格便宜,最常用 | 外导体屏蔽层具有良好的抗干扰特性,传输速率更高,传输距离更远,价格较贵 | ||
| 适用场景 | 在局域网和传统电话网中普遍使用,模拟/数字传输都适用 | 50Ω同轴电缆用于传送基带数字信号,在局域网广泛应用; 70Ω同轴电缆用于传送宽带信号,主要用于有线电视系统 |
多模光纤适用于近距离传输 | 移动电话领域 |
物理层设备
| 中继器/集线器 | 网桥/交换机 | 路由器 | |
|---|---|---|---|
| 能否分割冲突域 | 不能 | 能 | 能 |
| 能否分割广播域 | 不能 | 不能 | 能 |
| 功能 | 信号再生放大 | 根据MAC地址进行路径选择 | 连接异构网络、路由转发 |
| 带宽 | N台计算机连接在带宽为M的集线器上同时工作,每台计算机的带宽都是M/N | 拥有N个带宽为M的端口的全双工交换机,总带宽是N*M | |
| 转发形式 | 广播(除自己外的端口) | 根据交换表单播或广播(除自己外的端口),有自学习功能 | 根据路由表、转发表 |
| 交换模式: ①直通式:只检查目的MAC地址(6B) ②存储转发式:整个帧 |
|||
| 互联的网络/段 | 物理介质(0层)可以不相同,两网段的速率必须相同(介质访问协议相同) | 直通式交换机通信的两个端口速率必须相同,链路层协议要一致。 存储转发式交换机通信的两个端口速率可以不同,链路层协议可以不一致 |
可以互联异构网络 |
- 转发器是物理层设备,不能识别数据链路层的帧,也无寻址功能,只有放大信号功能
- 中继器不仅传送有用信号,也传送噪音和冲突信号
- 使用中继器的局域网在物理上是一个星形网,逻辑上是一个 总线网
- 使用集线器的以太网在逻辑上仍是一个总线网,各站共享逻辑上的总线,使用的还是CSMA/CD协议,网络中的各站必须竞争对传输媒体的控制,并在同一时刻至多只允许一个站发送数据。
- 集线器网络在拓扑结构上属于星型结构
- 集线器在物理层扩大了物理网络的覆盖范围,但无法解决冲突域(第二层交换机可以解决)与广播域(第三层交换机可解决)的问题,而且增大了冲突的概率。
- 集线器没有寻址功能,从一个端口收到数据后,从其他所有端口转发出去。
- 若某个网络设备没有存储转发功能,则认为它不能连接两个不同的协议。中继器没有存储转发的功能,因此它连接两个不同速率的网段可能会出现问题,若两个网段的速率不同,则选择速率低的哪个。
- 放大器放大的是模拟信号,原理是放大衰减的信号;中继器放大的是数字信号,其原理是整形再生衰减的信号
- 集线器Hub若同时有两个或多个端口输入,则输出时将发生冲突,致使这些数据无效
- Hub是共享式网络,但逻辑上仍是总线网,Hub每隔端口连接的是同一网络的不同网段,Hub只能在半双工的状态下工作。
- 集线器不能分割冲突域,集线器的所有端口都属于同一个冲突域。
- 因为物理层设备没有存储转发功能,所以不能连接不同速率的局域网,也不能连接不同数据链路层协议的局域网
- 如果设备没有存储转发功能,则认为它不能连接两个不同的协议
- 集线器是物理层设备,会将收到的信号广播到除接收端口以外的所有端口。所有链接到集线器的设备共享同一个冲突域,因此同一时间只能有一个设备发送数据,否则会发生冲突
- 集线器链接的以太网构成一个冲突域,所有设备共享带宽,采用CSMA/CD机制,工作在半双工模式
- 集线器作为物理层设备,它不对数据帧的内容进行检查,包括帧的长度。它接收到比特流之后,会进行信号放大和再生,然后将其转发出去。处理短帧是更高层(如数据链路层,由网卡或驱动程序负责填充)或接收端的事情,集线器本身会按原样转发它接收到的比特信号。
- 集线器工作在物理层,它的每个接口仅仅简单地转发比特——收到1就转发1,收到0就转发0,不进行碰撞检测,碰撞检测的任务由各站点中的网卡负责。若两个接口同时有信号输入(即发生碰撞),那么所有的接口都将收不到正确的帧。
- 集线器一般都有少量的容错能力和网络管理功能。例如,假定在以太网中有一个适配器出了故障,不停地发送以太网帧。这时,集线器可以检测到这个问题,在内部断开与出故障的适配器的连线,使整个以太网仍然能够正常工作。
- 中继器实现了物理层,但是不能互联两个物理层不同的网段,因为中继器不是存储转发设备,是直通式设备
- 设备汇总
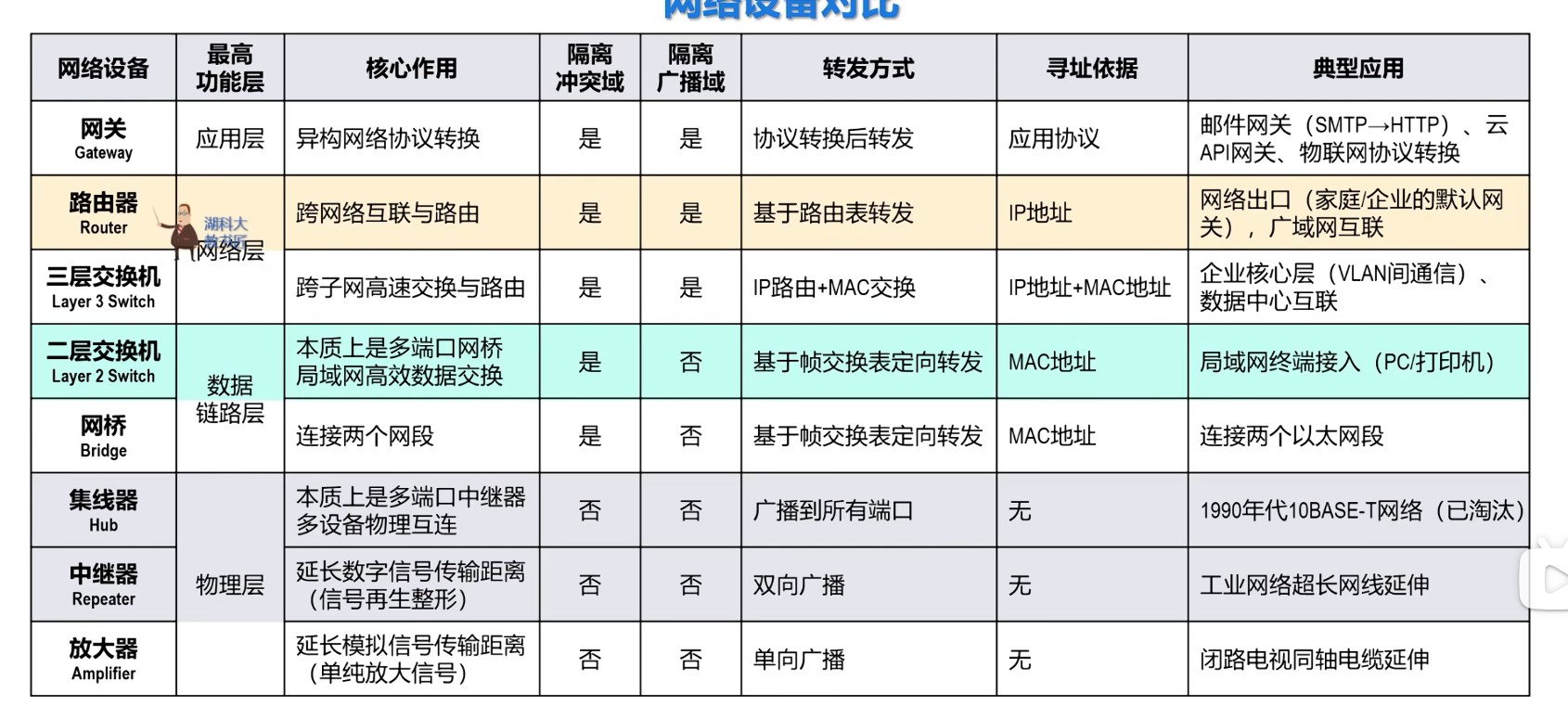
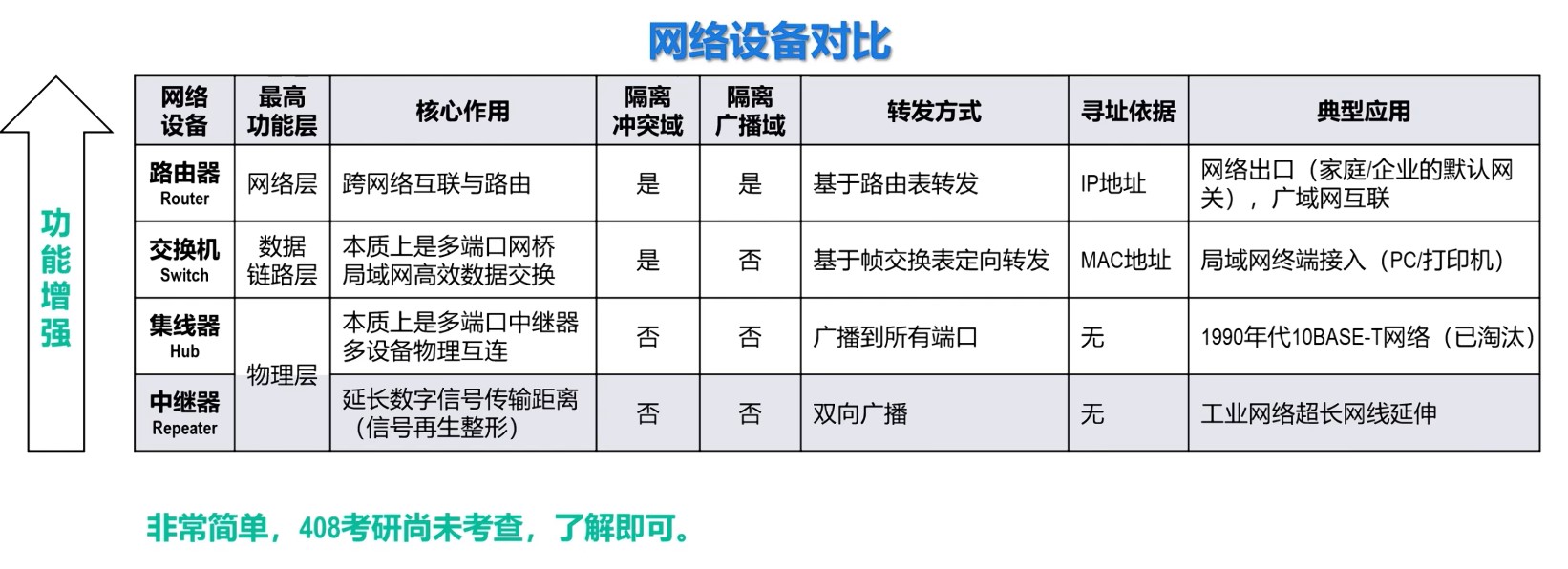
编码和调制
- 标准以太网使用的是曼切斯特编码,而差分曼切斯特编码则被广泛用于宽带高速网中,差分曼切斯特编码拥有更强大的抗干扰能力。
- 采样频率必须>=模拟信号最大频率的两倍
- 数字数据调制技术在发送端将数字信号转换为模拟信号,而在接收端将模拟信号还原为数字信号,分别对应于调制解调器的调制和解调过程。
- 调幅抗干扰能力差,调频抗干扰能力强,目前应用广泛
- 波特率B,m个相位,每个相位n种振幅,QAM的数据传输速率R=Blog2(mn)
- ASK、FSK、PSK这三种基本的带通调制方法,各自只能调制出两种不同的码元,1个码元只能表示1个bit的信息量
- 离散值要log
- 采样频率大于波特率的上限2W无意义
- 虽然信号在信道上传输时会不可避免地产生失真,但只要我们在接收端从失真的波形中能够识别出原来的信号,那么这种失真对通信质量就没有影响
- 曼切斯特编码每位数据都需要两个电平来表示,频带宽度是原始基带宽度的两倍。
- 曼切斯特系列编码,2个码元表示1bit信息,码元传输速率(波特率)是数据传输速率(比特率)的两倍
- 曼切斯特编码中间电平跳变既作为时钟信号,又作为数据信号,差分曼切斯特中间电平跳变仅表示时钟信号,不表示数据
- 反向非归零编码既能传输时钟信号,又能尽量不损失系统带宽。
- 调制作用的实质:
- 把各种信号的频谱搬移,使他们互不重叠地占据不同的频率范围,即信号分别托付于不同频率的载波上,接收机可以分离出所需要的频率的信号,不致相互干扰(实现了多路复用)
| 传输方式 | 信号分类 | 信道 |
|---|---|---|
| 基带传输 | 基带信号 | 数字信道 |
| 频带传输 | 频带信号 | 模拟信道 |
- 宽带传输的所有信道能同时互不干扰地发送信号,链路容量大大增加
- 基带信号直接传送到数字信道上的传输方式称为基带传输;把基带信号经过调制后送到模拟信道上的方式称为频带传输
- 基带对应数字信号,宽带对应模拟信号
- 调制解调技术用于模拟信道传输数字数据通信方式,模拟信道传输模拟信号不需要调制解调技术
| 数字→数字 | 数字→模拟 | 模拟→数字 | 模拟→模拟 | |
|---|---|---|---|---|
| 转换设备 | 数字放大器 | 调制解调器 | 脉码调制PCM(采样、量化、编码) | 放大调制器 |
| 技术 | 编码技术: 非归零编码 归零编码 反向非归零编码 曼切斯特编码 差分曼切斯特编码 |
4中形式: ①移幅键控(ASK):用载波的两种不同幅度来表示二进制的两种状态 ②移频键控(FSK):用载波频率附近的两种不同频率来表示二进制的两种状态 ③移相键控(PSK):用载波信号相位移动来表示数据 ④正交振幅调制法(QAM):QAM结合了相位调制和幅度调制,通过改变载波的幅度和相位来传输信息 |
涉及采样定理:f采样=2f,也称奈奎斯特定理,常用于模拟信号 | 频分复用技术 |
| 场景 | 主机到调制解调器 | 音频 | 电话机到本地端局 |
数据链路层
- 信道:
- 点对点:PPP
- 广播:
- 有线:CSMA/CD
- 无线:CSMA/CA
- 负载均衡:允许多路并行转发数据,最大吞吐量为多路带宽之和
- 透明传输:无论什么样的比特组合数据,都能够按照原样无差错地在这个数据链路上传输。
- 信道带宽=信道频率范围上限-信道频率范围下限
- 时延带宽积=传播时延*信号带宽
- 交换机(或网桥)对终端设备透明,不改变帧的MAC地址。路由器在将IP数据报从一个网络转发到另一个网络时,需要重新封装数据链路层帧头,此时源MAC地址是路由器出接口的MAC,目的MAC地址是下一跳或最终目标主机的MAC
- 传输数据量只用在意时间内发送方能发送多少,不需要在意对方收没收到
- 交换机是数据链路层设备,每个端口都是一个独立的冲突域,当端口连接单个设备时,可以工作在全双工模式下,同时收发数据而不会发生冲突。
- 在OSI体系结构中,数据链路层具有流量控制的功能。而在TCP/IP体系结构中,流量控制功能被移到了传输层。它们控制的对象不同。对数据链路层来说,控制的是相邻节点之间的数据链路上的流量,而对传输层来说,控制的则是从源端到目的端之间的流量。
- 现在,在通信质量较差的无线传输中,数据链路层依然使用确认和重传机制,向上提供可靠的传输服务。
- 对于通信质量良好的有线链路,数据链路层已不再使用确认和重传机制,即不要求向上提供可靠传输的服务,而仅需进行CRC检错,目的是将有差错的帧丢弃,保证上交的帧都是正确的,而对出错的帧的重传任务则由高层协议(如传输层TCP)完成。
- 在网络中信息是以帧为最小单位进行传输的。
- 令牌环网通常应用于高速局域网(LAN)环境和数据中心网络,其中有较高的数据传输需求和对数据可靠性的要求,令牌环网可以提供有序的数据传输和冲突的避免,适用于这些场景。广域网(WAN)连接与无线传感网络等则通常不会使用令牌环网
透明传输和差错检验
-
当传送的帧是用文本文件组成的帧时(文本文件中的字符都是从键盘上输入的),其数据部分显然不会出现像SOH或EOT这样的帧定界控制字符。可见不管从键盘上输入什么字符都可以放在这样的帧中传输过去。
-
零比特后插,字节填充前插
-
局域网IEEE802标准采用违规编码法,不采用任何填充技术便能实现数据的透明传输,但只适用于采用冗余编码的特殊编码环境。
- 因为字符计数法中计数字段的脆弱性和字节填充法实现上的复杂性与不兼容性,所以目前较常用的组帧方法是零比特填充法和违规编码法
-
奇偶检验码只能检测奇数位的出错情况,但不知道哪些位错了,也不能发现偶数位的出错情况。
-
HDLC协议中,用标识位F(01111110)来标识帧的开始和结束
-
数据链路层帧尾部的帧检验字段(FCS)会检验包括IP分片在内的整个帧的内容。一旦发生比特差错,数据链路层在收到该帧时就会因FCS校验失败而发现错误并将其丢弃。
- 网络的IP头部检验和只管头部,不管数据
-
CRC循环冗余码,如果首位是 1,就商 1;如果首位是 0,就商 0。
- 除法过程用异或
- 当部分余数位数小于除数位数,该余数即为最后余数
-
发送方的FCS生成和接收方的CRC检验都是由硬件实现的,处理很迅速,不会影响数据的传输。
-
水平奇偶校验码
- 后面加校验位
-
垂直奇偶校验码
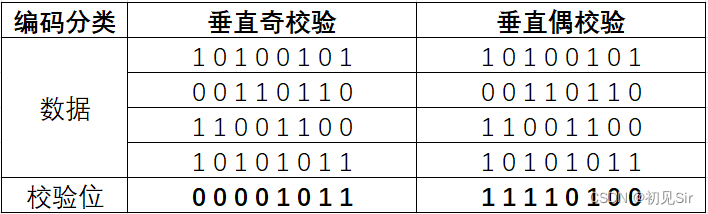
- 把数据分为若干组,一组数据占一行,排列整齐,再加一行校验码,针对每一列采用奇校验或偶校验。
- 方块校验字符BCC是由垂直奇偶校验产生的,其目的是用于差错检测,而不是数据压缩。
-
单独的水平或垂直奇偶校验都属一一维奇偶校验,无法检测出任意偶数个同时发生的错误。
-
水平垂直校验码
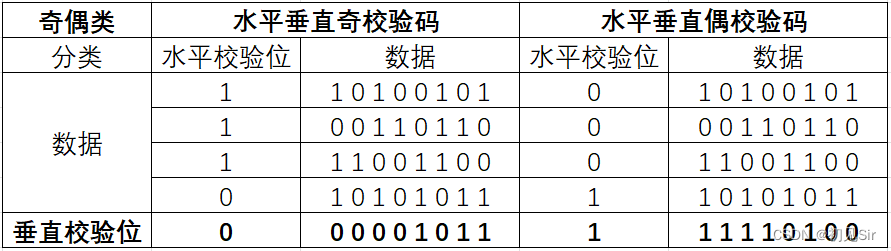
-
在垂直校验码的基础上,对每个数据再增加一位水平校验码。
-
可以检测出单个bit,两个bit以及三个bit的错误。
-
当仅发生单个bit错误时,该错误会同时导致所在行和所在列的校验出错,通过行列交叉点可以唯一确定该错误比特,进而进行纠正。
-
网卡/网络适配器
- 网卡工作在数据链路层
- 适配器不仅能实现与局域网传输介质之间的物理连接和电信号匹配,还涉及帧的发送与接收、帧的封装与拆封、介质访问控制、数据的编码与解码及数据缓存等功能。当适配器收到正确的帧时,就使用中断来通知该计算机,并交付协议栈中的网络层。当计算机要发送IP数据报时,就由协议栈把IP数据报向下交给适配器,组帧后发送到局域网
- 适配器在接收和发送各种帧的时候,不使用计算机的CPU
- 计算机硬件地址(物理地址/MAC地址)在网络适配器(网卡)的ROM中,计算机软件地址(IP地址)在计算机的内存中
- 由于网络上的数据率和计算机总线上的数据率并不相同,因此在适配器中必须装有对数据进行缓存的存储芯片。在主板上插入适配器时,还必须把管理该适配器的设备驱动程序安装在计算机的操作系统中。这个驱动程序以后就会告诉适配器,应当从存储器的什么位置上把多长的数据块发送到局域网,或者应当在存储器的什么位置上把局域网传送过来的数据块存储下来。
- 驱动程序负责驱动网卡发送和接收帧
- 所有的适配器都至少应当能够识别前两种帧,即能够识别单播和广播地址。有的适配器可用编程方法识别多播地址。当操作系统启动时,它就把适配器初始化,使适配器能够识别某些多播地址。显然,只有目的地址才能使用广播地址和多播地址。
- 一般情况下,普通用户计算机中往往会包含两块网卡
- 一块是用于接入有线局域网的以太网卡
- 另一块是用于接入无线局域网的WIFI网卡
- 每块网卡都有一个全球唯一的MAC地址
可靠传输
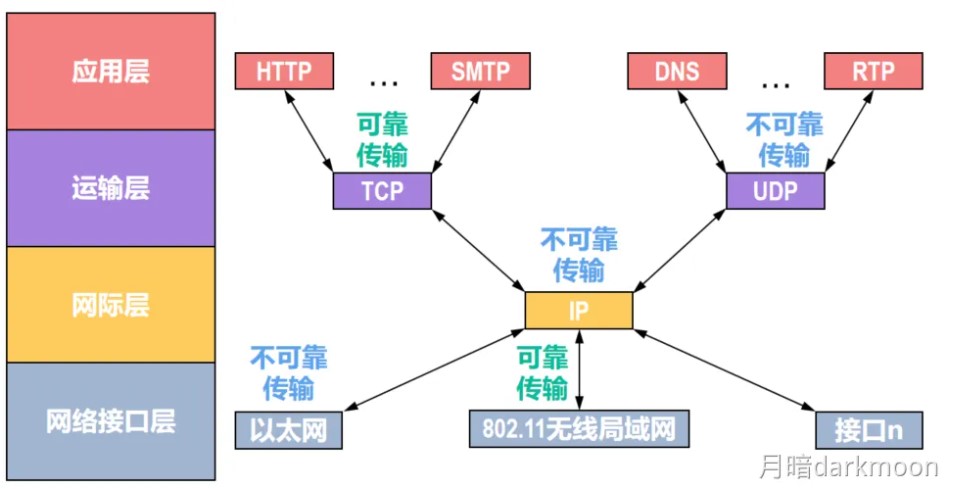
- TCP提供面向连接的可靠传输服务
- UDP提供无连接、不可靠传出服务
- IP提供无连接、不可靠传输服务
- 802.11无线局域网要求数据链路层实现可靠传输
- 以太网不要求数据链路层实现可靠传输
- 在OSI参考模型中,数据链路层不一定要提供可靠的、无差错的数据传输,可以可靠(HDLC)也可以不可靠(以太网)
流量控制
- 滑动窗口协议和窗口大小的关系






-
后退N帧的情况下,接收方只允许按顺序接收帧
-
后退N帧协议中,发送窗口内某个已发送的数据分组产生超时重传时,发送窗口内该数据分组的后序已发送的数据分组也必须全部重传。
-
当信道误码率较大时,后退N帧协议不一定优于停止-等待协议。
-
信道利用率

- 停止-等待协议中,当发送时延<RTT的时候,信道利用率很低
- 数据帧长越大,信道利用率就越高,因此计算信道利用率最高的至少帧序号比特数,要用最小帧长进行计算
-
数据链路层和传输层流量控制的差别
- 数据链路层控制的是相邻节点之间的流量,而传输层控制的是端到端的流量。
- 数据链路层的控制手段是接收方收不下时就不返回确认。传输层的控制手段是接收方通过确认报文段中的窗口值来调整发送方的发送窗口。
- 数据链路层的流量控制和可靠传输机制以帧为单位;传输层流量控制以字节为单位。
-
注意区分三者概念
- n个比特对帧编号
- 滑动窗口大小
- 发送窗口大小
-
选择重传协议不支持累计确认,需要对每一个正确的帧逐个确认。
-
选择重传协议下,接收端所需缓冲区数目=窗口大小
-
在数据链路层实现停止-等待协议可以不用给确认分组编号。
-
一般超时重传时间TRTO设置为略大于收发双方的平均往返时间RTT
-
确认分组ACKn表明序号为n以及之前的所有数据分组都已正确接收。
-
停止-等待协议下,收到重复的数据分组,丢弃该重复帧,并重新发送对上一个正确接收帧的确认
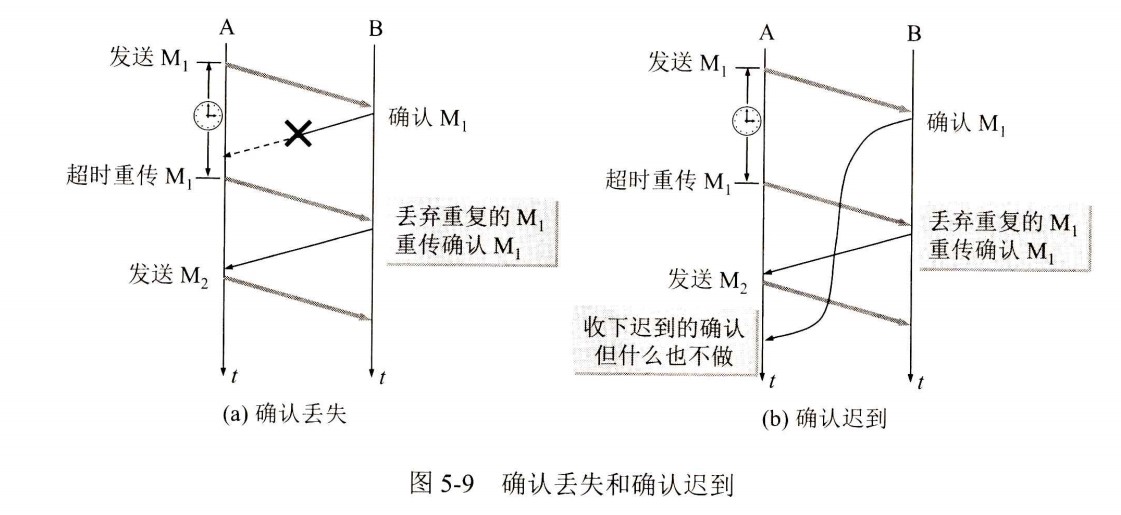
- 检测出错:直接丢弃,什么也不做
- 发完以后必须保留以发送的分组的副本,只有在收到相应的确认后才能清除暂时保留的副本
- 收到重复确认:收下后丢弃,什么也不做
-
SR选择重传协议中,只有在按序收到数据分组后,接收窗口才能向前滑动到相应位置,此外,SR协议中,接收方的接收窗口长度不变且连续。

-
甲乙之间最大平均数据传输速率=min{信道带宽,信道平均(实际)数据传输速率}
- 信道平均(实际)数据传输速率=发送周期内发送的数据量/发送周期
-
滑动窗口协议除非超时,不能重发,在问未收到新的确认段之前,还可以继续发送的段/帧不算已发送未超时未确认的
-
超时重传
- 停止等待协议
- 重传超时帧
- 后退N帧协议
- 重传超时帧和超时帧后已经发送的帧
- 选择重传协议
- 只重发超时帧
- 停止等待协议
介质访问随机控制

- p-坚持CSMA只适用于时分信道
- ALOHA协议若在一段时间内未收到确认,则该站点就认为传输过程中发生了冲突,发送站点需要等待一段随机时间后再发送数据,直至发送成功
- TDMA:时分多址接入,依赖时间同步,硬件复杂且不适用于无基础设施场景。
- 1-坚持CSMA:在信道空闲时多个节点可能同时发送,群集时冲突概率高
- 非坚持CSMA:在信道忙时随即退避,减少同时发送的可能,抗冲突能力较好;硬件需载波侦听,但相对简单。
- 纯ALOHA:硬件最简单,但冲突概率极高,群集时性能差。
海明码
海明码!不用记!本质就是分组校验!(25全新版、附带例题)-青灯夜雨V-稍后再看-哔哩哔哩视频
-
常规的海明码可以检2位错,纠1位错
-
海明码其实是由多组奇偶校验码实现的,即把一串传输的数据分为多组,通过分组校验来确定哪一位出现了错误
-
每个分组异或产生自己的奇偶校验码
-
由于每一个位的分组属性唯一,因此,我们可以分别校验分组,因而知道哪些分组出了错。由于只有一位出错,因此出错的分组必然包含了该位,进而通过位的分组树型唯一确定这一个位
-
分组依据
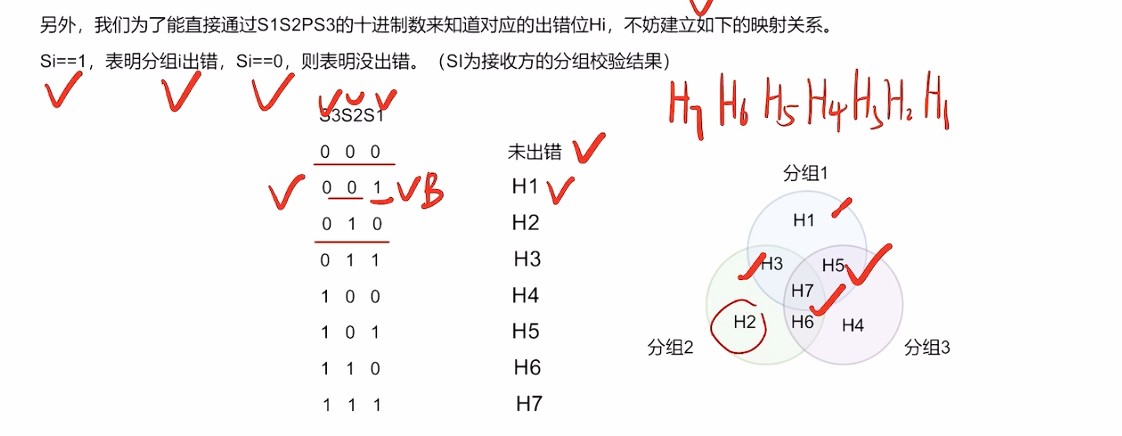

-
-
接收方收到比特之后,由于之前约定好了如何进行分组,因此接收方就能去计算每个分组是否出错,即把分组里的比特进行异或,得到的结果是否满足奇偶校验码的规则
-
做题步骤
- ①确定位数
- ②将检验位摆放好
- ③将数据位摆放好
- ④列出矩阵,异或产生检验位
- ⑤看题目要求做什么
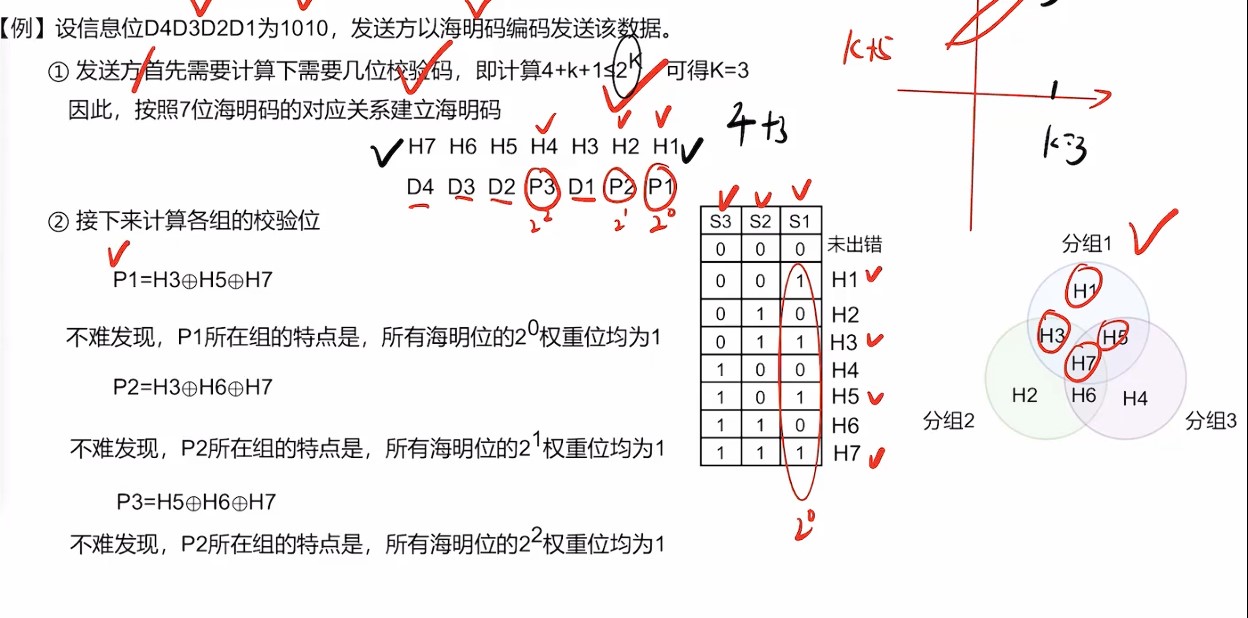

- 海明距离
- 码距为1的编码方案无法检测任何错误。
- 即码距1越大,其检错的位数d就越大,纠错的位数c也就越大,且纠错能力恒小于或等于检错能力(能纠错必然能检错)。
- 检测e位错误,d>=e+1
- 纠正t位错误,d>=2t+1
- 纠正t位错误,检测s位错误,s>t,d>=t+s+1

TDM
- TDM在发送端将不同用户的信号相互交织在不同的时间片内,沿同一个信道传输,在接收端再将各个时间片内的信号提取出来,还原成原始信号。
- 为了实现TDM,必须满足如下条件:
- 介质的位速率(即每秒传输的二进制位数)大于单个信号的位速率。
- 介质的带宽(即所能传输信号的最高频率与最低频率之差)大于结合信号的带宽(即所有信号经过调制后形成的复合信号的带宽)。
STDM统计时分复用
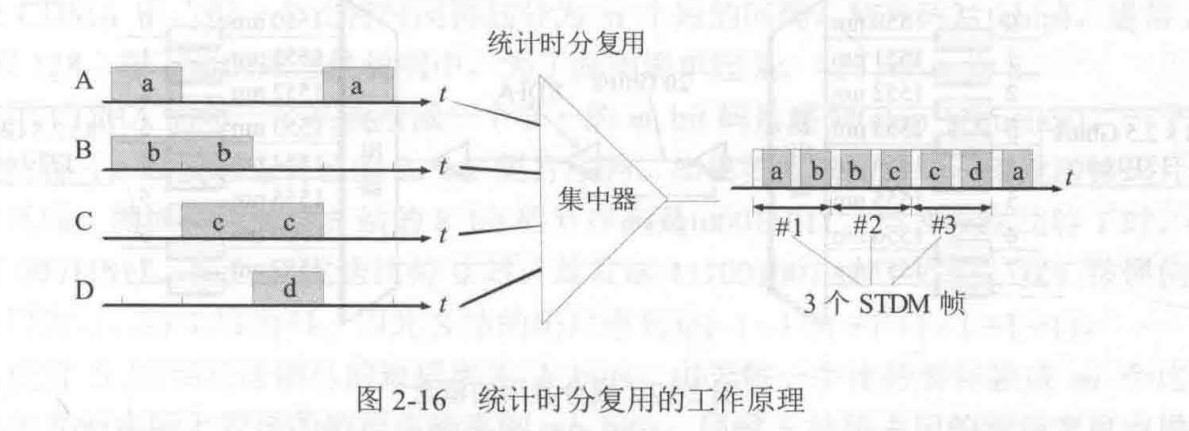
- 统计时分复用使用STDM帧来传送复用的数据。每一个STDM帧中的时隙数小于连接在集中器上的用户数。各用户有了数据就随时发往集中器的输入缓存,然后集中器按顺序依次扫描输入缓存,把缓存中的输入数据放入STDM帧中。对没有数据的缓存就跳过去。当一个帧的数据放满了,就发送出去。
- STDM帧不是固定分配时隙,而是按需动态地分配时隙,当终端有数据要传送时,才会分配到时间片。
- 统计时分复用可以提高线路的利用率。
- 在输出线路上,某一个用户所占用的时隙并不是周期性地出现。因此统计复用又称为异步时分复用,而普通的时分复用称为同步时分复用。
- 这里应注意的是,虽然统计时分复用的输出线路上的数据率小于各输入线路数据率的总和,但从平均的角度来看,这二者是平衡的。假定所有的用户都不间断地向集中器发送数据,那么集中器肯定无法应付,它内部设置的缓存都将溢出。所以集中器能够正常工作的前提是假定各用户都是间歇地工作。
- 由于STDM帧中的时隙并不是固定地分配给某个用户,因此在每个时隙中还必须有用户的地址信息,这是统计时分复用必须要有的和不可避免的一些开销。在图2-16输出线路上每个时隙之前的短时隙(白色)就是放入这样的地址信息。
- 使用统计时分复用的集中器也叫做智能复用器,它能提供对整个报文的存储转发能力(但大多数复用器一次只能存储一个字符或一个比特),通过排队方式使各用户更合理地共享信道。此外,许多集中器还可能具有路由选择、数据压缩、前向纠错等功能。
码分复用
- 码分复用,每一个用户可以在同样的时间使用同样的频带进行通信,由于各用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。
- 在CDMA中,每一个比特时间再划分为m个短的间隔,称为码片。
- 使用CDMA的每一个站被指派一个唯一的m bit码片序列,一个站如果要发送bit1,则发送它自己的m bit码片序列,如果要发送bit 0,则发送该码片序列的二进制反码。为了方便,我们一般将码片中的0写成-1,将1写为+1。
- 假定S站要发送信息的数据率为b bit/s,由于每一个bit要转换成m个bit的码片,因此S站实际上发送的数据率提高到mb bit/s,同时S站所占用的频带宽度也提高到原来数值的m倍。这种方式要求每个站分配的码片序列不同,且相互正交。


- CDMA系统的实际通信中,分为上行通信和下行通信两个部分
- 上行通信中,由主机给基站发送数据序列,如果想发送比特1,就发送自己的码片序列,想发送0,就发送码片序列的反码。基站收到多个主机发来的信号后,根据各主机的码片序列依次解析出收到的信息,并从信息中获取目的站,
- 在下行通信中,基站根据目的站的码片序列来发送数据,也即将主机发给基站的数据序列按照目的站的序列重新编码发送,目的站收到信息后,根据自己的码片序列来解析出比特信息。
CSMA/CA
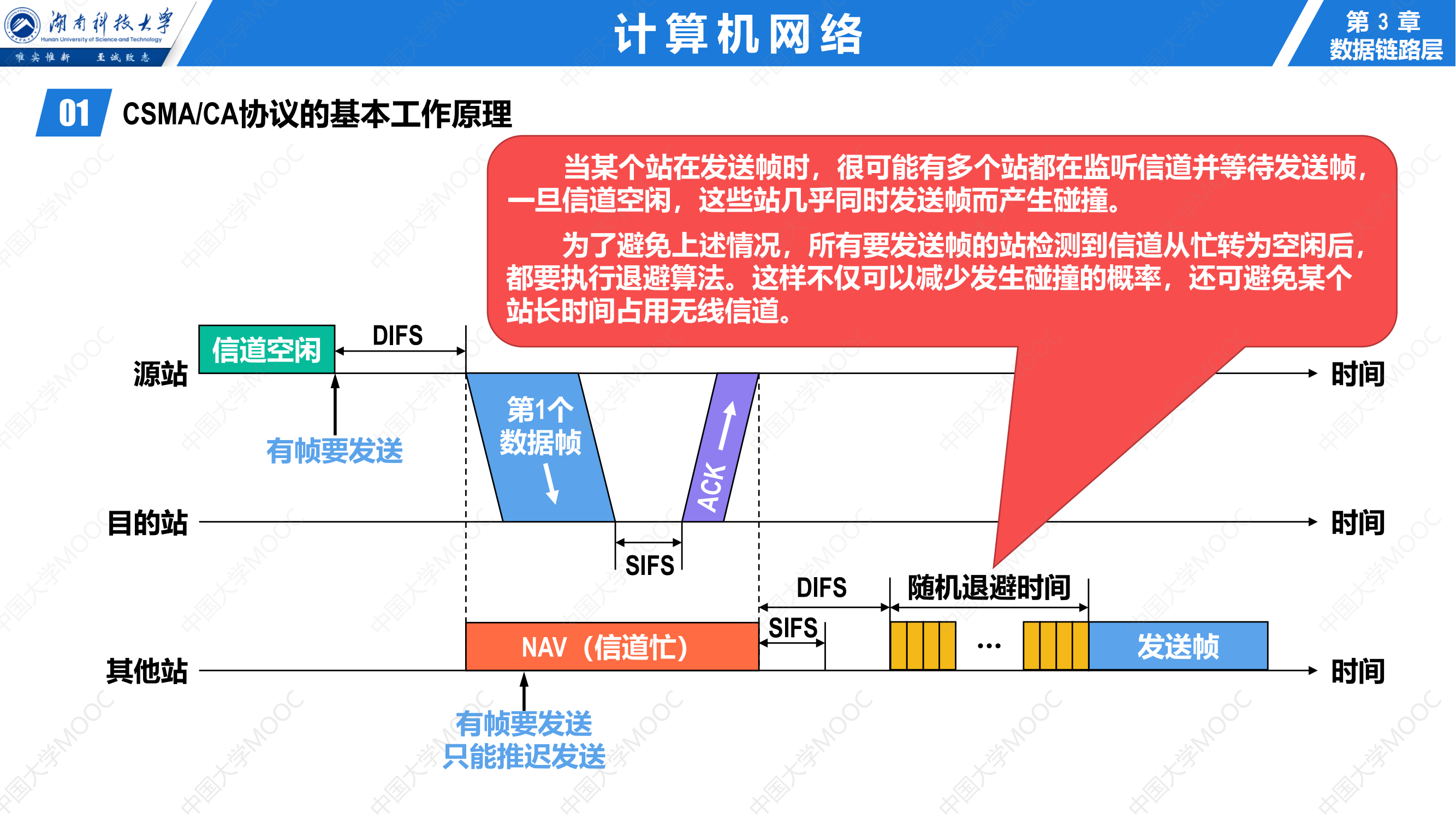


- 802.11无线局域网不使用冲突检测,一旦站点开始发送一个帧,就会完全发送该帧,但冲突存在时仍发送整个帧(尤其是长数据帧)会严重降低网络的效率,所以要采用冲突避免技术来降低冲突的概率。

- 无线局域网可能出现检测错误的情况:
- 检测到信道空闲,其实信道并不空闲**(隐蔽站)**;
- 即使距离很近,之间若有障碍物,也可能出现隐蔽站的问题
- 有时检测到信道忙,其实信道并不忙**(暴露站)**。
- 检测到信道空闲,其实信道并不空闲**(隐蔽站)**;
- 因为无线信道的通信质量远不如有线信道,所以802.11标准使用链路层确认/重传(ARQ)方案,即站点每通过无线局域网发送完一帧,就要在收到对方的确认帧后才能继续发送下一帧。可见,802.11标准无线局域网采用的停止-等待协议是一种可靠传输协议。
- 802.11标准还规定各站采用虚拟载波监听机制,即让**源站将它要占用信道的持续时间(包括目的站发回ACK帧所需的时间)**及时通知给所有其他站
- 某个站认为信道处于忙态就有两种可能,一种可能是由于其物理层的载波监听检测到信道忙,另一种可能是由于MAC层的虚拟载波监听机制指出了信道忙。
- SIFS实际上是在校验
- DCF和PCF
- 自组网络没有PCF子层,PCF使用集中控制的介入算法,用类似于探寻的方法把发送数据权轮流交给各个站,从而避免了碰撞的产生。对于时间敏感的业务,如分组话音,就应该使用提供无争用服务的点协调功能PCF

-
DIFS=SIFS+时隙时间x2
-
CSMA/CA的二进制退避算法用最新的


-
NAV值的分析
- 当某个站检测到正在信道中传送的帧首部中的“持续时间”字段时,就调整自己的网络分配向量。
- 源站在RTS帧中填写的所需占用信道的持续时间,是从收到RTS帧后,到目的站最后发送完ACK帧为止的时间,即**“SIFS(AP发给源站的时间间隔)+CTS+SIFS(源站发给AP的时间间隔)+数据帧+SIFS(AP发给源站的时间间隔)+ACK”**。
- 而AP在CTS帧中填写的所需占用信道的持续时间,是从收到CTS帧后,到目的站最后发送完ACK帧为止的时间,即“SIFS(源站发给AP的时间间隔)+数据帧+SIFS(AP发给源站的时间间隔)+ACK”。
- 收到DATA帧的栈:NAV : A在DATA帧中填写的时间
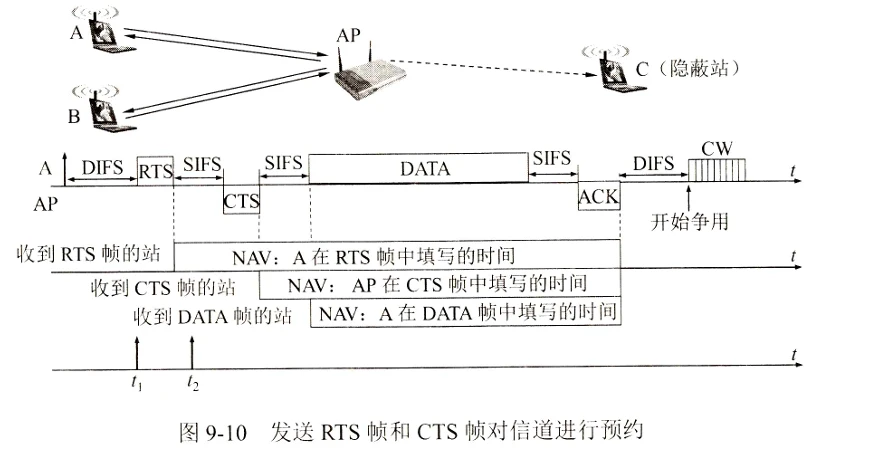
-
一个站点收到一个带有持续时间字段的帧时,它会检查该帧中的持续时间值。
- 如果该值大于其当前NAV计时器的值,站点就会用这个更大的值来更新自己的NAV。
- 如果收到的持续时间值小于当前的NAV,则忽略该值,保持NAV不变。

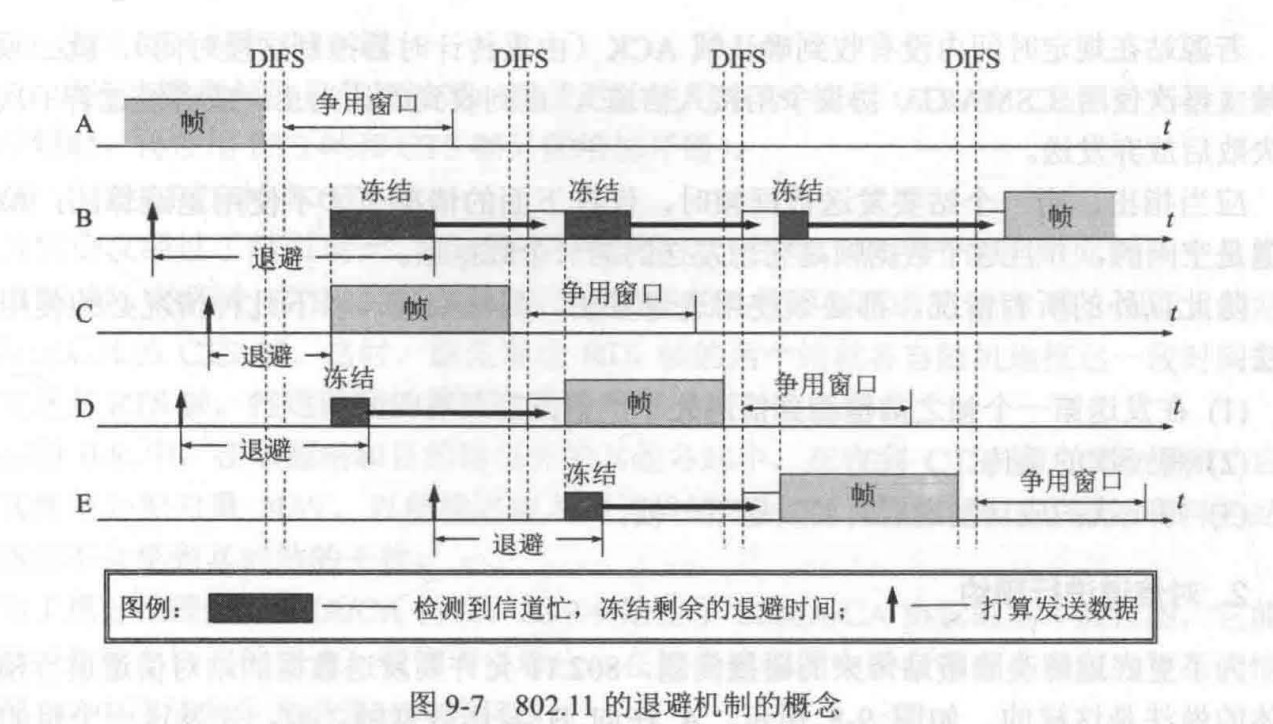
- CSMA/CA当信道从忙态变为空闲时,任何一个站要发送数据帧时,只要不是要发送的第一个帧,不仅都必须等待一个DIFS的间隔,而且还要进入争用窗口,并计算随机退避时间,以便再次重新试图接入到信道。
- 当某个要发送数据的站,使用退避算法选择了争用窗口中的某个时隙后,就根据该时隙的位置设置一个退避计时器(backoff timer)。当退避计时器的时间减小到零时,就开始发送数据。也可能当退避计时器的时间还未减小到零时而信道又转变为忙态,这时就冻结退避计时器的数值,重新等待信道变为空闲,再经过时间DIFS后,继续启动退避计时器(从剩下的时间开始)。这种规定有利于继续启动退避计时器的站更早地接入到信道中。
- 当一个站要发送数据帧时,仅在下面的情况下才不使用退避算法:
- 检测到信道是空闲的,并且这个数据帧是它想发送的第一个数据帧。
- 除此以外的所有情况,都必须使用退避算法。具体来说,以下几种情况必须使用退避算法:
- (1)在发送第一个帧之前检测到信道处于忙态。
- (2)每一次的重传。
- (3)每一次的成功发送后再要发送下一帧。
CSMA/CD
-
载波监听多路访问/冲突检测(CSMA/CD)协议是CSMA协议的改进方案,适用于总线形网络或半双工网络环境。对于全双工网络,因为全双工采用两条信道,分别用来发送和接收,在任何时候,发收双方都可以发送或接收数据,不可能产生冲突,所以不需要CSMA/CD协议。
-
A站在开始发送数据后最多经过时间2t(端到端传播时延的2倍)就能知道有没有发生冲突(当δ→0时)。因此,把以太网的端到端往返传播时延2t称为争用期(也称冲突窗口)。每个站在自己发送数据后的一小段时间内,存在发生冲突的可能性,只有经过争用期这段时间还未检测到冲突时,才能确定这次发送不会发生冲突。
- 检测到碰撞需要经过的最短时长是单程传播时延
- 检测到碰撞需要经过的最长时长是往返传播时延
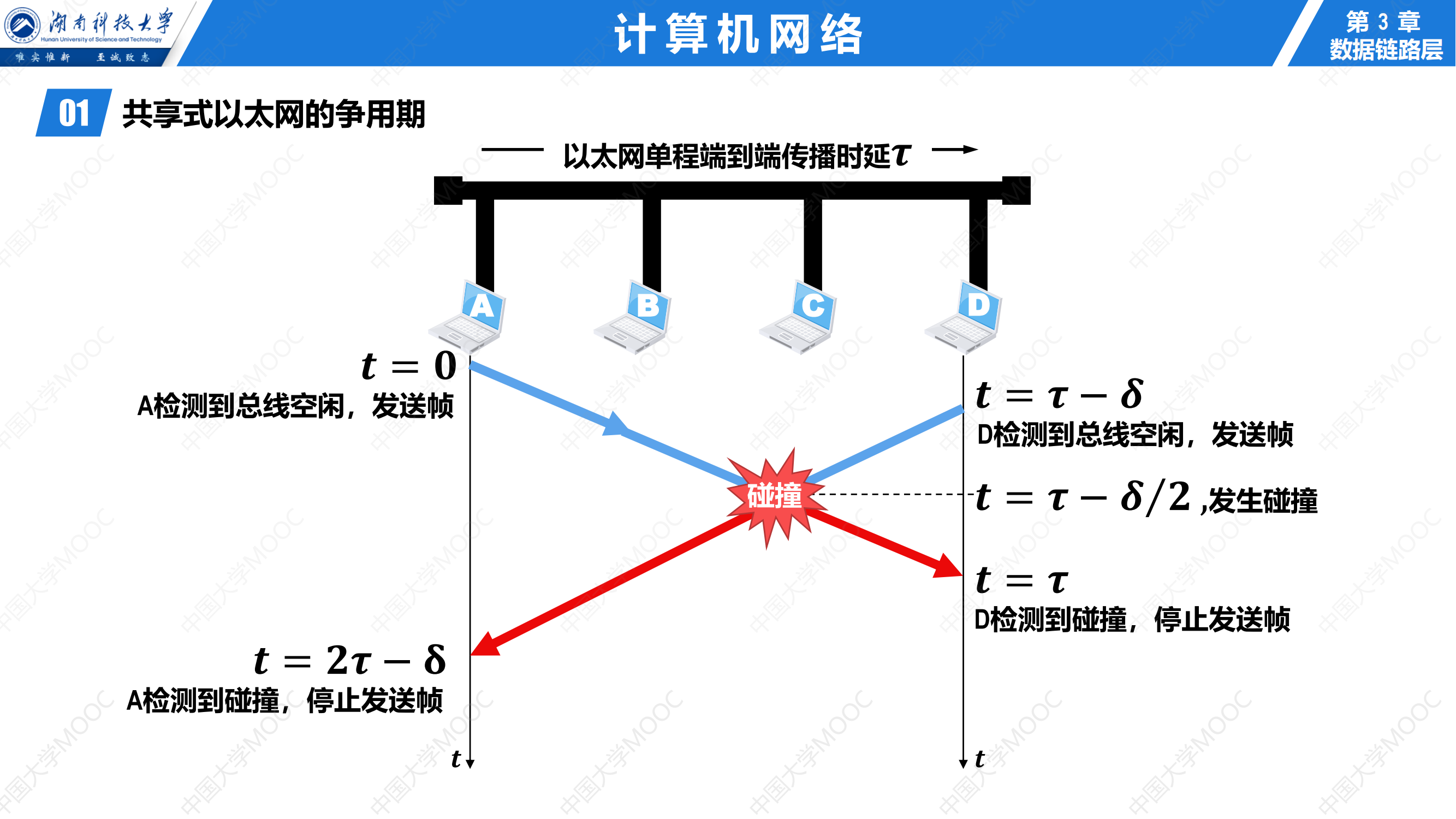
-
CSMA/CD最短帧长的理解和相关计算
- 最短帧长=最大单向传播时延×数据传输速率×2
- 最短帧长=(两端距离/传播速率)×数据传输速率×2
- 最大单向传播时延=最短帧长÷数据传输速率÷2
- 例如,以太网规定51.2μs为争用期的长度。对于10Mb/s的以太网,在争用期内可发送512bit,即64B。当以太网发送数据时,若前64B未发生冲突,则后续数据也不会发生冲突(表示已成功抢占信道)。换句话说,若发生冲突,则一定在前64B。因为一旦检测到冲突就立即停止发送,所以这时发送出去的数据一定小于64B。于是,以太网规定最短帧长为64B,凡长度小于64B的帧,就都是因为冲突而异常中止的无效帧,收到这种无效帧时应立即丢弃。
若只发送小于64B的帧,如40B的帧,则需要在MAC子层中于数据字段的后面加一个整数字节的填充字段,以保证以太网的MAC帧的长度不小于64B。 - 在冲突域不变的情况下减少线路中的中继器数量会降低传播时延,争用期变短,最短帧长变短。
- 最短帧长=最大单向传播时延×数据传输速率×2
-
二进制退避算法的应用

- 当重传达16次仍不成功时,说明网络太拥挤,认为该帧永远无法正确发出,抛弃该帧并向高层报告出错(这个条件容易忽略,请读者注意)。
- 使用二进制指数退避算法的理由:考虑了网络负载对冲突的影响
-
归纳

-
路由器是网络层设备,只认识目的主机的IP地址,无法看见链路层的AP,因此如果ARP表为空,会广播ARP请求报文,获取目的主机的MAC地址
-
路由器发到AP的是以太网帧,AP将以太网帧转换成802.11帧后转发
-
CSMA/CD用于有线局域网
-
使用CSMA/CD协议,一个站不可能同时进行接收和发送(但边发边监听),使用CSMA/CD协议的以太网只能进行双向交替通信(半双工通信 )
-
帧间距9.6μs,用来清理接收缓存,做好接受下一帧的准备
-
发送一个帧需要的占用信道时间=传输时间+端到端的传播时延
-
若检测到信道空闲,并在96比特时间内信道保持空闲(保证了帧间最小间隔),就发送这个帧。
-
以太网每发送完一帧,一定要把已发送的帧暂时保留一下。如果在争用期内检测出发生了碰撞,那么还要在推迟一段时间后再把这个暂时保留的帧重传一次。
-
强化碰撞
- 这就是当发送数据的站一旦发现发生了碰撞时,除了立即停止发送数据外,还要再继续发送32比特或48比特的人为干扰信号(jamming signal),以便让所有用户都知道现在已经发生了碰撞
- 发生碰撞使A浪费时间TB+Tj。可是整个信道被占用的时间还要增加一个单程端到端的传播时延T。因此总线被占用的时间是TB+Tj+t
-
信道利用率

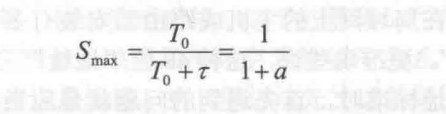
- 当信号传播延迟趋近于0的时候,信道利用率趋近100%
-
10Mb/s共享总线以太网的争用期为51.2μs,最小帧长64B
CSMA和CSMD的不同
-
①CSMA/CD可以检测冲突,但无法避免;CSMA/CA发送数据的同时不能检测信道上有无冲突,本节点处没有冲突并不意味着在接收节点处就没有冲突,只能尽量避免。
-
②传输介质不同。CSMA/CD用于总线形以太网,CSMA/CA用于无线局域网802.11a/b/g/n等。
-
③检测方式不同。CSMA/CD通过电缆中的电压变化来检测;而CSMA/CA采用能量检测、载波检测和能量载波混合检测三种检测信道空闲的方式。
-
总结:
- CSMA/CA在发送数据帧之前先广播告知其他站点,让其他站点在某段时间内不要发送数据帧,以免发生冲突。
- CSMA/CD在发送数据帧之前监听,边发送边监听,一旦发生冲突,就立即停止发送。
-
纯CSMA发生冲突后还是要坚持把数据帧发送完,而CSMA/CD检测到冲突就停发

-
CSMA/CA当信道从忙态变为空闲时,任何一个站要发送数据帧时,只要不是要发送的第一个帧,不仅都必须等待一个DIFS的间隔,而且还要进入争用窗口,并计算随机退避时间,以便再次重新试图接入到信道。
-
在以太网的CSMA/CD协议中,要发送数据的站,在监听到信道变为空闲就立即发送数据,同时进行碰撞检测。如果不巧发生了碰撞,马上执行退避算法,大家都停止发送,这样就立即使信道恢复到空闲状态。网络资源被浪费得很少。
-
但在无线局域网802.11标准的CSMA/CA协议中,因为没有像以太网那样的碰撞检测机制,所以,在信道从忙态转为空闲时,为了避免几个站同时发送数据(一旦发送就要把一帧发送完,不能中途停止),所有想发送数据的站就都要执行退避算法。这样做不仅大大减小了发生碰撞的概率,而且也避免了一个站连续发送长帧,垄断了整个的无线信道。
局域网
- 以太网(目前使用范围最广)。逻辑拓扑是总线形结构,物理拓扑是星形结构。
- 令牌环(Token Ring,IEEE 802.5)。逻辑拓扑是环形结构,物理拓扑是星形结构。
- FDDI(光纤分布数字接口,IEEE 802.8)。逻辑拓扑是环形结构,物理拓扑是双环结构。
- IEEE802标准定义的局域网参考模型只对应于OSI参考模型的数据链路层和物理层,并将数据链路层拆分为两个子层:逻辑链路控制(LLC)子层和介质访问控制(MAC)子层。
- 与接入传输介质有关的内容都放在MAC子层,它向上层屏蔽对物理层访问的各种差异,主要功能包括:组帧和拆卸帧、比特传输差错检测、透明传输。
- LLC子层与传输介质无关,它向网络层提供无确认无连接、面向连接、带确认无连接、高速传送四种不同的连接服务类型。
- 以太网无连接,无确认,不可靠,纠错高层完成,曼切斯特编码
- 以太网的传输介质
- 用集线器连接的以太网一定工作在半双工状态
- 用交换器连接的以太网既可以工作在半双工状态,又可以工作在全双工状态。
- 全双工方式下无碰撞工作,不使用CSMA/CD协议
- 一根光纤内部至少包含两条光纤,用以实现全双工通信,不存在争用问题,因此用光纤连接的以太网不采用CSMA/CD协议
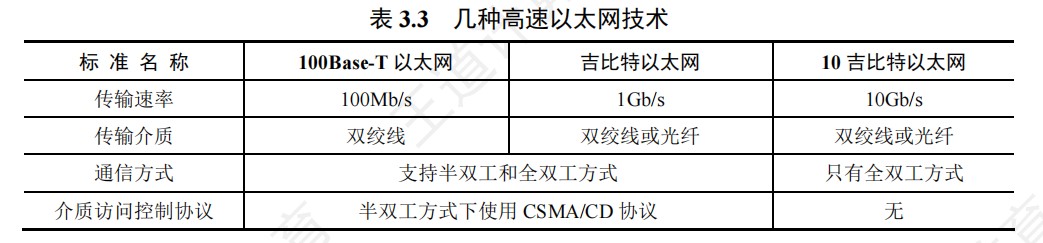
-
一台计算机只要没有更换适配器,不管其地理位置如何变化,其MAC地址都不会变化。
-
当路由器通过适配器连接到局域网时,适配器上的MAC地址就用来标志路由器的某个接口。路由器若同时连接到两个网络上,则它需要两个适配器和两个MAC地址。
-
以太网帧:662N4,收发协数验
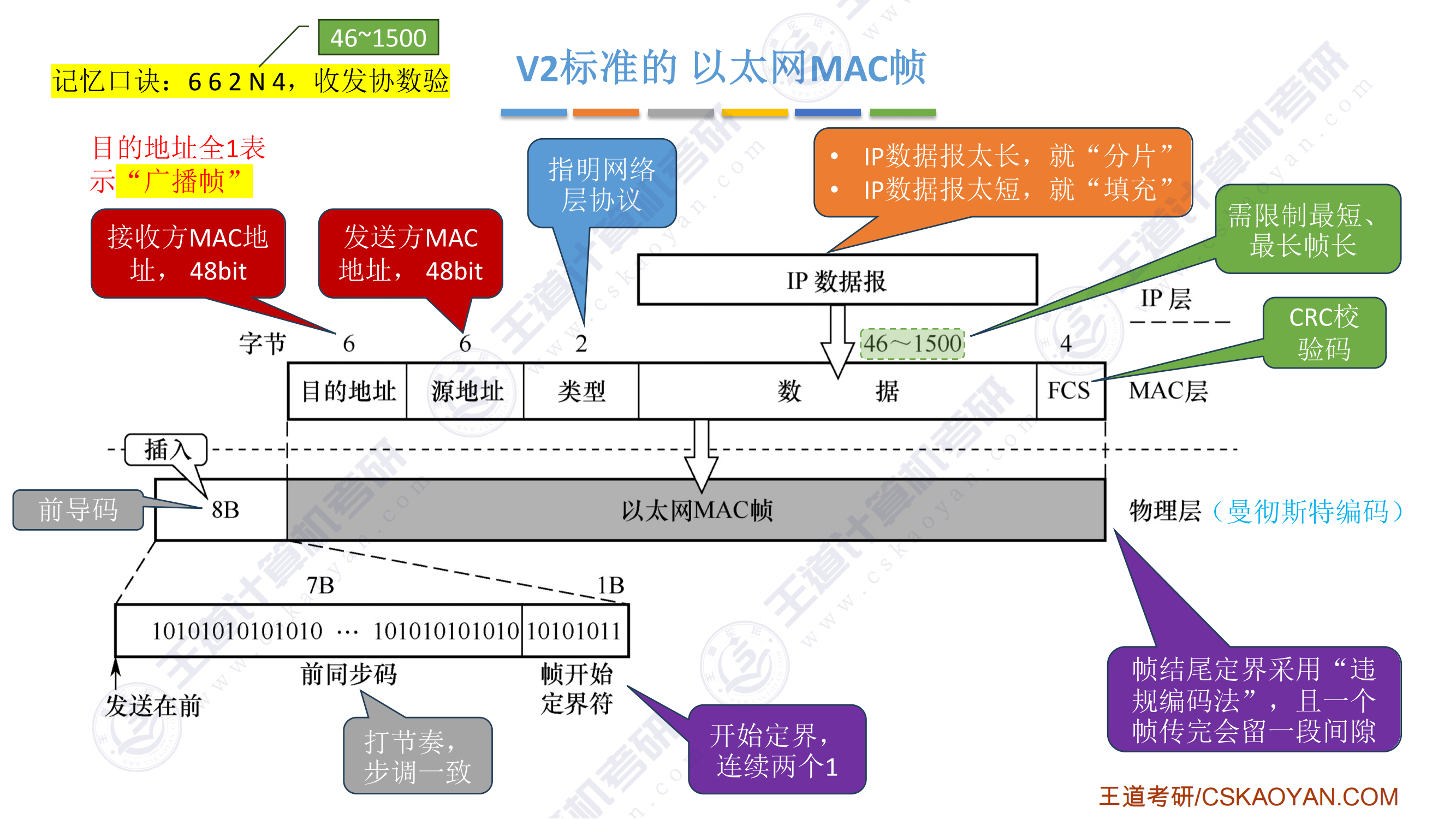
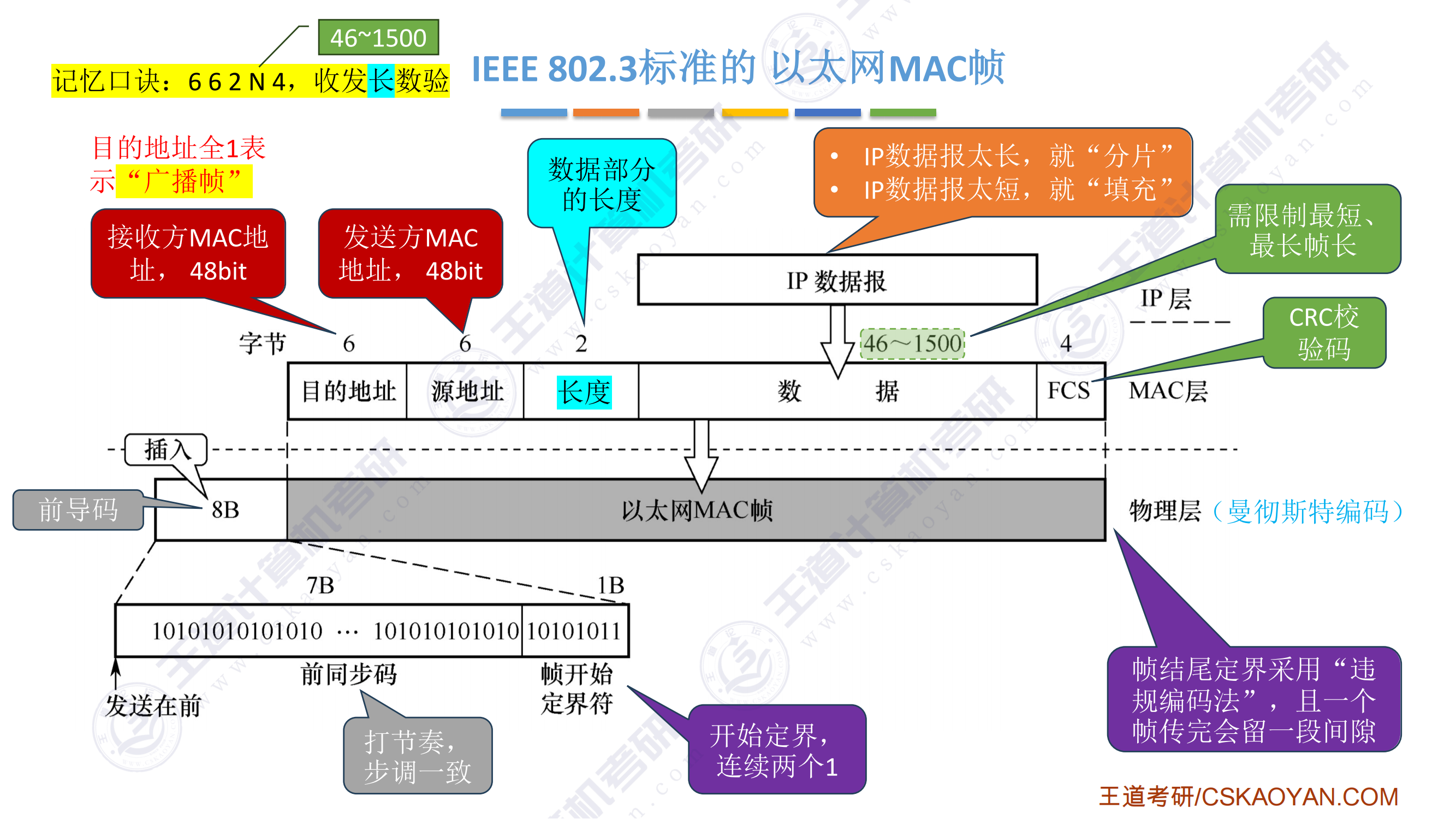
- 802.3帧的长度字段只指实际数据的长度,不包括填充字段的长度
-
以太网帧不需要帧结束定界符,因为当以太网传送帧时,各帧之间必须有一定的间隙。因此,接收方只要找到帧开始定界符,其后面连续到达的比特流就都属于同一帧。实际上,以太网采用了违规编码法的思想,因为以太网使用曼彻斯特编码,所以每个码元中间都有一次电压的跳变。发送方发完一帧后,发送方网络接口上的电压不再变化,这样接收方就能很容易地找到帧的结束位置,这个位置往前数4字节就是FCS字段,于是就能确定数据字段的结束位置。
- 以太网V2帧首部没有帧长度字段同理
- 当物理层检测到信道上不再有信号(载波信号停止)时,就认为一帧已经结束
-
在有填充字段的情况下,接收端的MAC子层在剥去首部和尾部后就把数据字段和填充字段一起交给上层协议。
- 上层协议如何知道填充字段的长度呢?(IP层应当丢弃没有用处的填充字段)
- 上层协议必须具有识别有效的数据字段长度的功能。我们知道,当上层使用IP协议时,其**首部就有一个“总长度”字段。因此,“总长度”加上填充字段的长度,应当等于MAC帧数据字段的长度。**例如,当IP数据报的总长度为42字节时,填充字段共有4字节。当MAC帧把46字节的数据上交给IP层后,IP层就把其中最后4字节的填充字段丢弃。
- 上层协议交给数据链路层的实际数据长度不足,数据链路层会通过填充0来达到规定的长度。根据协议,填充后的数据长度为46字节,并且在长度字段中注明原始数据长度。
- 上层协议如何知道填充字段的长度呢?(IP层应当丢弃没有用处的填充字段)
-
检验码的检验范围从目的地址段到数据字段,采用CRC冗余验证码方式,不检验前导码
-
从MAC子层向下传到物理层时还要在帧的前面插入8字节(由硬件生成),它由两个字段构成。第一个字段是7个字节的前同步码(1和0交替码),它的作用是使接收端的适配器在接收MAC帧时能够迅速调整其时钟频率,使它和发送端的时钟同步,也就是“实现位同步”(位同步就是比特同步的意思)。第二个字段是帧开始定界符,定义为10101011。它的前六位的作用和前同步码一样,最后的两个连续的1就是告诉接收端适配器:“MAC帧的信息马上就要来了,请适配器注意接收”
- 在使用SONET/SDH进行同步传输时则不需要用前同步码,因为在同步传输时收发双方的位同步总是一直保持着的。
- 在以太网上传送数据时是以帧为单位传送的。以太网在传送帧时,各帧之间还必须有一定的间隙。因此,接收端只要找到帧开始定界符,其后面的连续到达的比特流就都属于同一个MAC帧。可见以太网不需要使用帧结束定界符,也不需要使用字节插入来保证透明传输。
- 如果没有前同步码,当一个站在刚开始接收MAC帧时,由于适配器的时钟尚未与到达的比特流达成同步,因此MAC帧的最前面的若干位就无法接收,结果使整个的MAC成为无用的帧
-
IEEE 802.3标准规定凡出现下列情况之一的即为无效的MAC帧:
- 帧的长度不是整数个字节;
- 用收到的帧检验序列FCS查出有差错;
- 收到的帧的MAC客户数据字段的长度不在46~1500字节之间。考虑到MAC帧首部和尾部的长度共有18字节,可以得出有效的MAC帧长度为64~1518字节之间。
- 对于检查出的无效MAC帧就简单地丢弃。以太网不负责重传丢弃的帧,没有重传机制。
-
MAC地址发送顺序
- 字节的发送顺序:从左到右,最低字节优先。
- 比特的发送顺序:在每个字节内部,最低有效位优先。
-
100BASE-T以太网仍然使用IEEE802.3和CSMA/CD协议,最小帧长仍然是64B,网段缩减到100m,争用期为5.12μs,帧间最小间隔缩小到0.96μs,当然如果用交换机,全双工工作不用CSMA/CD协议
-
吉比特以太网(千兆以太网)
-
全双工/半双工
-
网段最大长度100m,最小帧长64B
-
载波延伸:将争用期增大为512字节的发送时间而保持最小帧长仍为64字节,只要发送的MAC帧的长度不足512字节时,就在MAC帧尾部填充一些特殊字符,使MAC帧的长度增大到512字节。

- 在使用载波延伸的机制下,如果原本发送的是大量的64字节长的短帧,则每一个短帧都会被填充448字节的特殊字符,这样会造成很大的开销。
-
分组突发(Packet Bursting)功能:
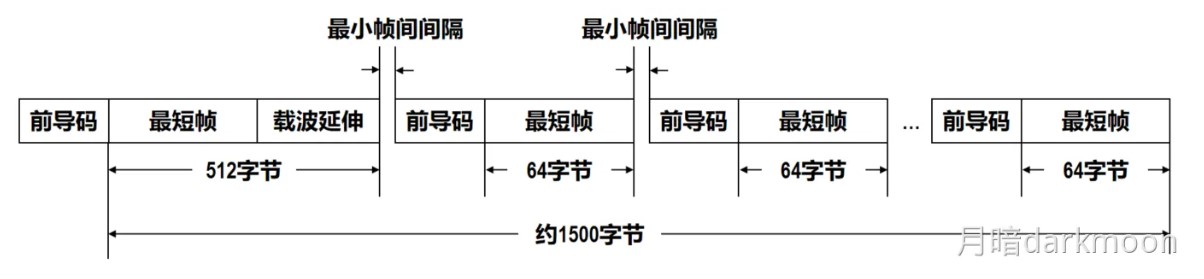
- 当有很多短帧要连续发送时,只将第一个短帧用载波延伸的方法进行填充,而其后面的一系列短帧不用填充就可一个接一个地发送,它们之间只需空开必要的帧间最小间隔即可。
- 这样就形成了一连串分组的突发,当累积发送1500字节或稍多一些停止。
-
当千兆以太网工作在全双工方式时,不使用CSMA/CD协议,也不会使用载波延伸和分组突发
-
-
如果在使用静态地址的系统中有重复的硬件地址,两个设备都无法通信,在局域网中的每台设备必须有唯一的硬件地址。
-
MAC地址
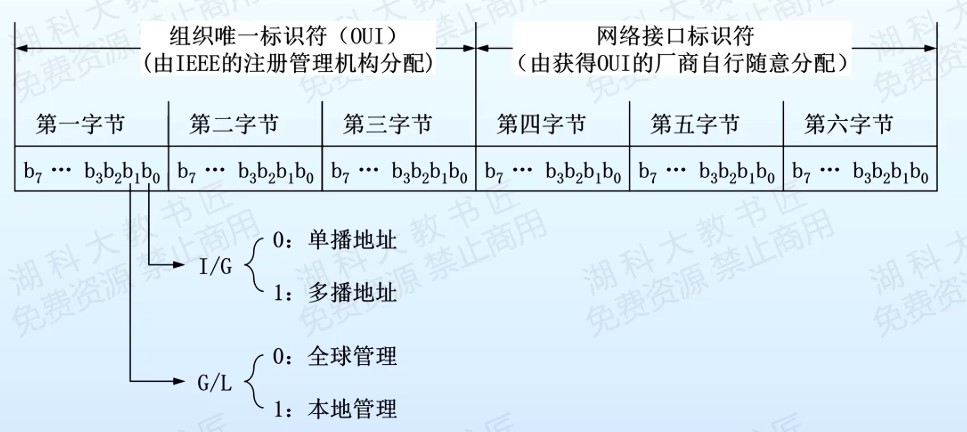
802.11
- 数据帧格式
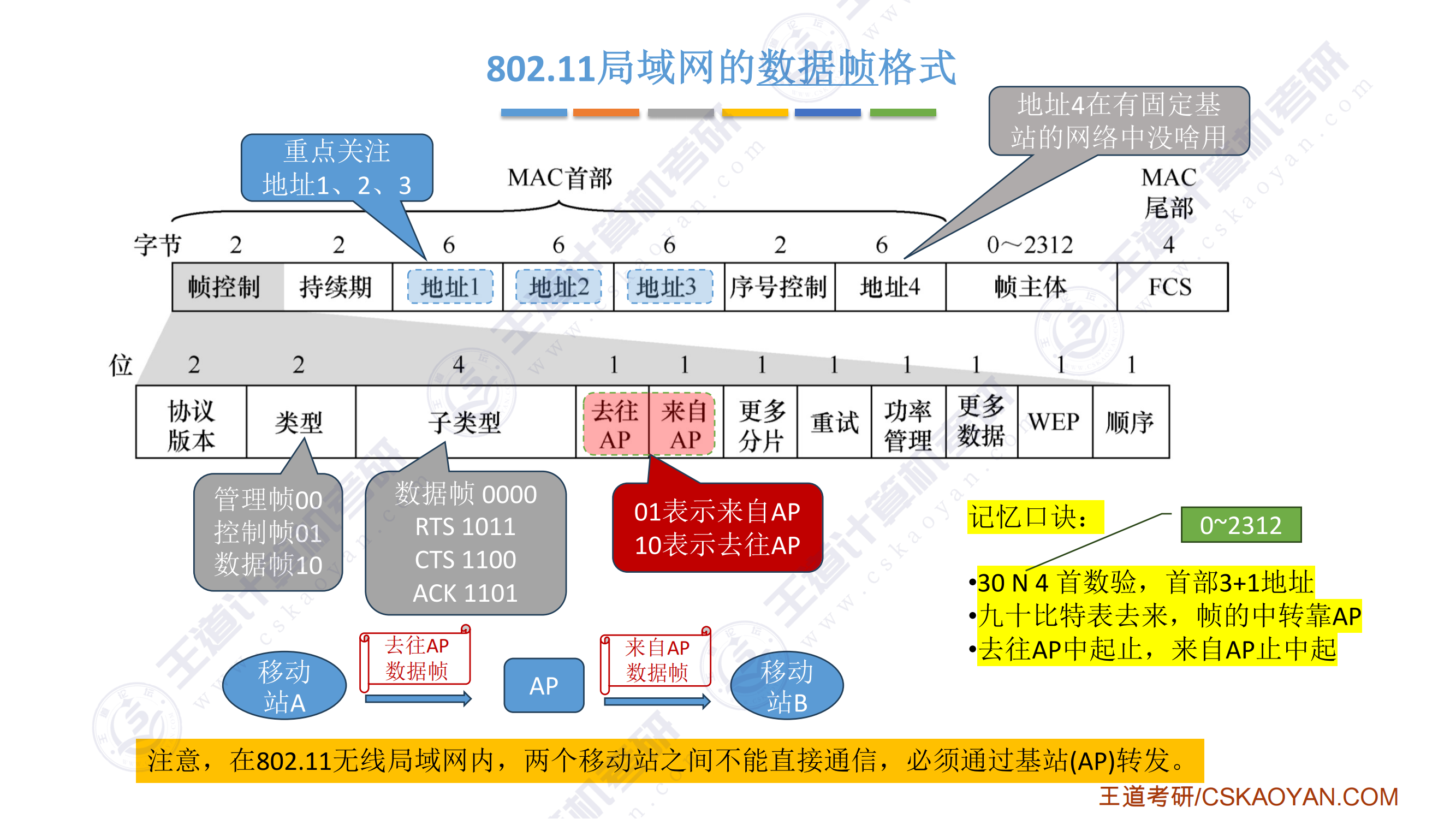
-
DS的作用是使ESS对上层的表现就像一个BSS一样。也就是说,ESS对上层所呈现的仍然是一个局域网。另外,ESS还可为无线用户提供到其他非802.11无线局域网的接入,例如到有线连接的因特网。
-
802.11帧中必须要携带AP的MAC地址,而以太网帧中却不需要携带AP的MAC地址。
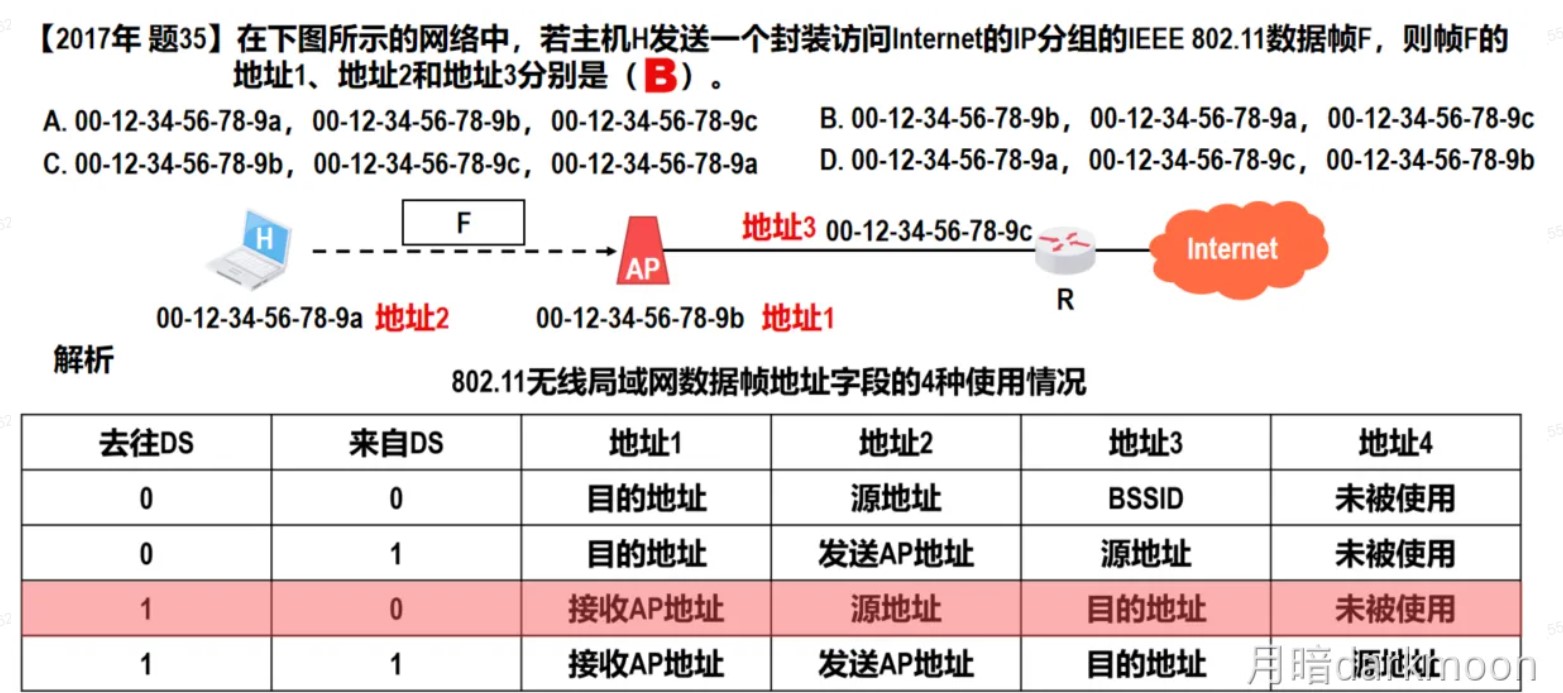
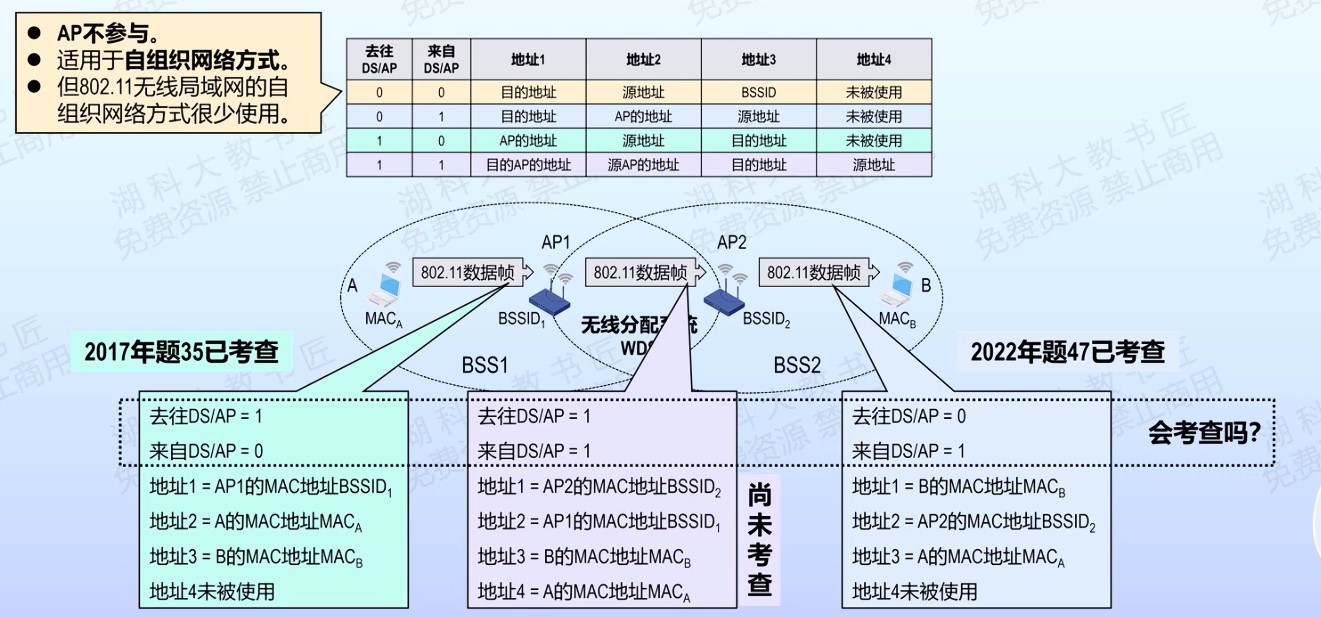
- 在以太网中,AP与透明网桥一样,对各站点是透明的,因此以太网帧中就不需要指出AP的MAC地址。然而在802.11无线局域网中,在站点的信号覆盖范围内可能会有多个AP共享同一个物理信道,但站点只能与其中的一个AP建立关联,因此802.11帧中就必须携带AP的MAC地址(即站点所在BSS的BSSID)来明确指出转发该帧的AP。
- 帧控制字段中的**“去往AP”和“来自AP”位的值都为0的情况,被用于802.11的自主网络模式**。
- 当通信的两个站点位于同一个独立的BSS时,它们之间可以直接通信而不需要AP的转发。数据帧首部中的地址1字段的值设置为目的站的MAC地址,地址2字段的值设置为源站的MAC地址,地址3字段的值设置为这些站点所属同一个BSS的ID,即BSSID。
- 帧控制字段中的**“去往AP”和“来自AP”位的值都为1的情况,被用于连接多个BSS的分配系统(DS)也是一个802.11无线局域网的情况**。
- 若DS也是802.11无线局域网,位于BSS1的站点A发送数据帧给位于BSS2的站点C,当AP1通过无线DS将数据帧转发给AP2时,帧控制字段中的“去往AP”和“来自AP”位的值都被设置为1,并且地址1字段的值设置为AP2的MAC地址,地址2字段的值设置为AP1的MAC地址,地址3字段的值设置为站点C的MAC地址,地址4字段的值设置为站点A的MAC地址。但是,若DS是以太网,则AP1转发给AP2的就是以太网帧,帧中仅携带站点A和C的MAC地址,而不携带AP1和AP2的MAC地址。
-
BSS使用两种标识符:
- SSID(服务集标识符)和BSSID(基本服务集标识符)。
- SSID是用户可见的、用来标识一个无线网络的字符串名称(用户可以自己命名的),用于网络发现和连接。
- 而BSSID则是在MAC层唯一标识一个BSS的标识符,在有基础设施的BSS中,BSSID就是该BSS中AP的MAC地址。
-
为了实现客户端在ESS内不同AP间的无缝漫游,这些AP通常会配置相同的SSID,让客户端感觉连接的是同一个网络。
-
802.11无线局域网的MAC帧,包含有用于其他站点调整自身NAV的字段的是
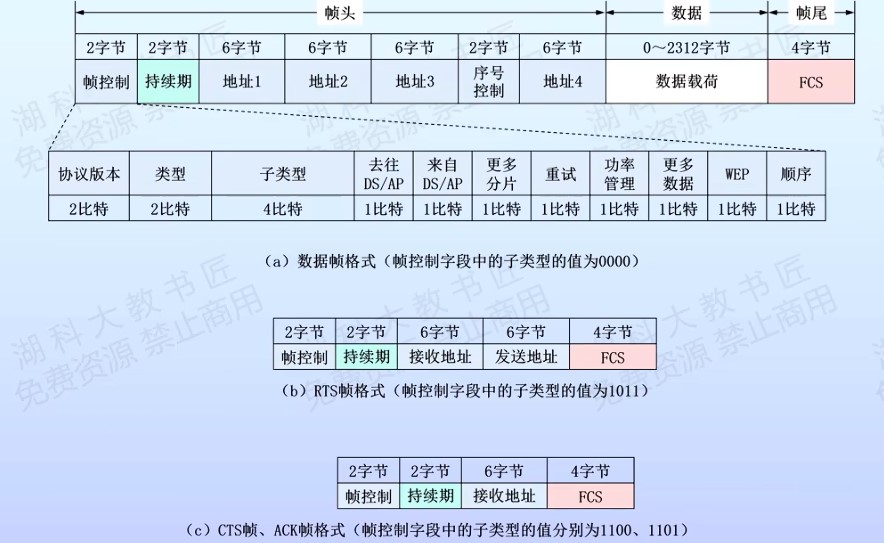
- 数据帧
- ACK帧
- RTS帧
- CTS帧
广域网
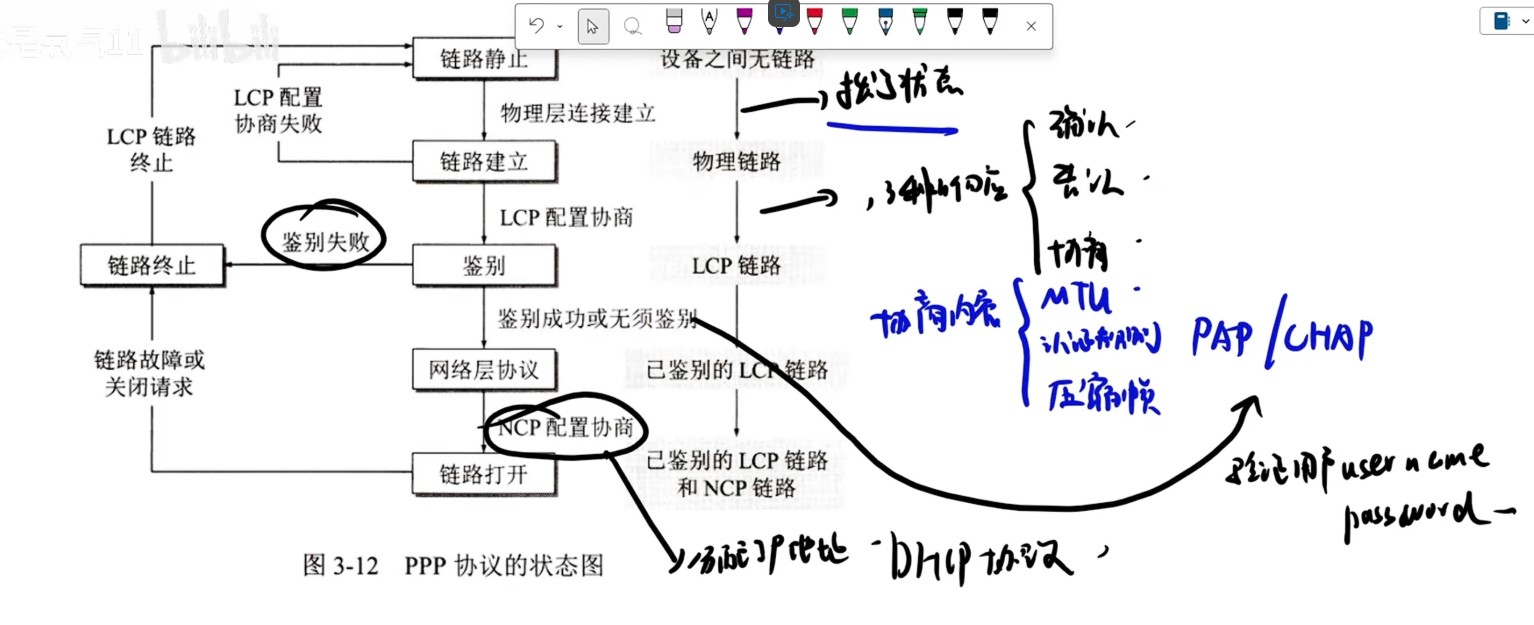
- PPP是用户和ISP通信用的数据链路层协议
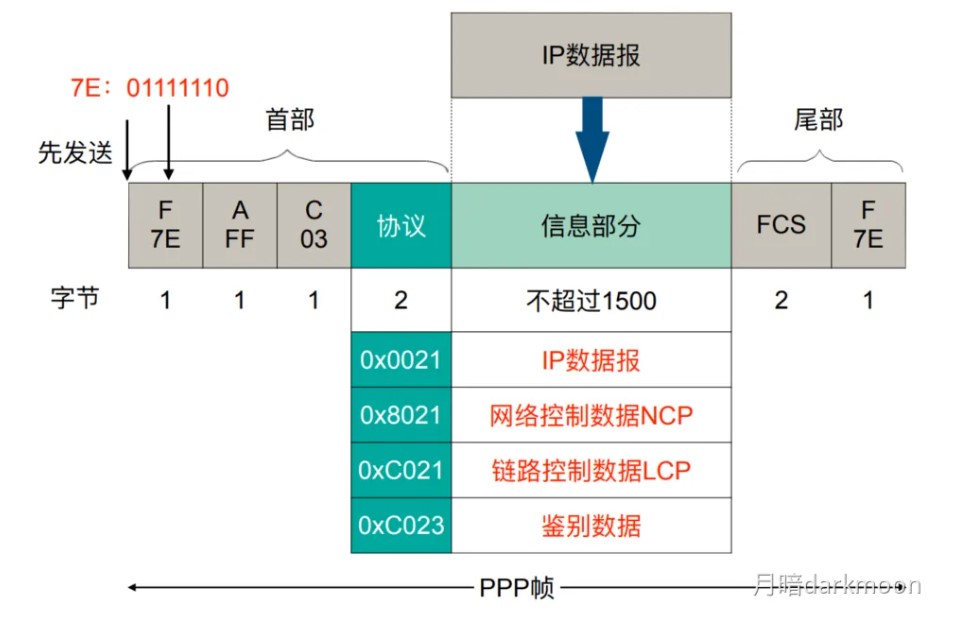
- 因为PPP是点对点的,并不是总线形,只支持全双工,所以无须使用CSMA/CD协议,自然就不会有最短帧长的限制,所以信息段占0~1500字节,而不是46~1500字节。
-
当PPP使用异步传输时,采用字节填充法,使用的转义字符是0x7D(01111101)。当PPP使用同步传输时,采用零比特填充法来实现透明传输。

- 同步传输(SONET/SDH链路):面向比特的传输,同步的单位是帧
- 同步传输收发双方时钟统一、字符间传输同步无间隔。
- 异步传输:面向字节的传输,异步传输的单位是字符
- 异步传输效率低,告诉链路开销大
- 同步问题:
- 异步传输通过字符起止的开始和停止码进行同步,线路空闲时携带着代表比特1的信号,传输开始位使信号变为0,数据传输结束后,停止位使信号重新变为1;
- 同步传输在数据中提取同步信息**(帧定界比特组合)**
- 同步传输(SONET/SDH链路):面向比特的传输,同步的单位是帧
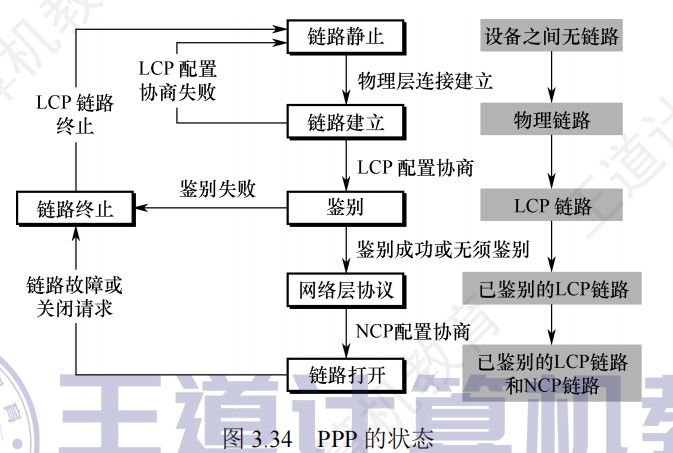
-
具体过程
- ①PPP链路的起始和终止都是链路静止状态,这时用户与ISP之间不存在物理层的连接。
- ②当检测到调制解调器的载波信号并建立物理层连接后,PPP就进入链路建立状态。
- ③在链路建立状态下,链路控制协议(LCP)开始协商一些配置选项(包括最大帧长、鉴别协议等)。若协商成功,则进入鉴别状态。若协商失败,则退回到链路静止状态。
- ④协商成功后,双方就建立了LCP链路,然后进入鉴别状态。若通信双方无须鉴别或鉴别身份成功,则进入网络层协议状态。若鉴别失败,则进入链路终止状态。
- ⑤进入网络层协议状态后,双方采用网络控制协议(NCP)配置网络层。网络层配置完毕后,就进入链路打开状态,双方就可以进行数据通信。
- ⑥数据传输结束后,链路一方发出终止请求且在收到对方发来的终止确认后,或者链路出现故障时,进入链路终止状态。载波停止后,回到链路静止状态。
-
当PPP链路的一端检测到其物理层不再可用时(例如,调制解调器检测到载波丢失),PPP链路状态会转换到链路死亡状态。
-
当链路的底层不可用(例如物理连接断开,载波丢失等)时,无论链路之前处于何种状态,它都会回到Dead状态。只有当物理层条件恢复后,才可能尝试从Dead状态开始重新建立链路。
-
注意区分链路故障和链路的底层不可用
-
链路故障是一个更广泛的概念,可能涉及物理层、数据链路层或更高层的网络故障。
链路的底层不可用仅涉及物理层的问题,通常指硬件或物理介质的失败。
-
-
-
PPP的特点
- PPP虽然在连接建立的过程中使用了确认机制,但在数据帧的发送过程中只保证无差错接收(通过CRC检验),不使用序号和确认机制,因而是不可靠服务。
- PPP只支持全双工的点对点链路,不支持多点线路。
- PPP的两端可以运行不同的网络层协议,但仍可使用同一个PPP进行通信。
- PPP是面向字节的,所有PPP帧的长度都是整数个字节。
- 在因特网环境下,PPP的信息字段放入的数据是IP数据报,数据层的可靠传输并不能保证网络层的传输是可靠的
-
广域网使用的协议主要在网络层,广域网为单一的网络,其通信子网主要使用分组交换技术
-
MTU是数据链路层的帧可以载荷的数据部分的最大长度,而不是帧的总长度
-
如果高层协议发送的分组过长并超过MTU的数值,PPP就要丢弃这样的帧,并返回差错
-
PPP提供网络层的网络层地址协商
-
PPP不需要的功能包括
- 纠错
- 流量控制
- 序号
- 多点线路
- 半双工/单工
以太网交换机
-
特点

- 能同时连通多对接口,无冲突地传输数据,这样就不需要使用CSMA/CD协议。
- 当交换机的接口连接集线器时,只能使用CSMA/CD协议且只能工作在半双工方式。当前的交换机和计算机中的网卡都能自动识别上述两种情况。
- 即插即用设备,其内部的帧转发表是通过自学习算法,基于网络中各主机间的通信,自动地逐渐建立的
- 收到广播帧,不用进行查表,直接从除接收该广播帧的接口的其他接口转法该广播帧
- 转发表中的每条记录都有其有效时间,到期自动删除
-
交换模式
- ①直通交换方式。接收到帧的同时就立即按该帧的目的MAC地址决定转发接口,然后通过其内部基于硬件的交叉矩阵进行转发,而不必把整个帧先缓存后再进行处理。这种方式的转发时延非常小,缺点是不检查差错就直接转发,因此可能将一些无效帧转发给其他站。直通交换方式不适用于需要速率匹配、协议转换或差错检测的线路。
- ②存储转发交换方式。首先缓存接收到的帧,然后检查帧是否正确(可能还需要进行速率匹配或协议转换),确认无误后,根据目的MAC地址决定转发接口;若帧出错,则将其丢弃。优点是可靠性高,且支持不同速率接口间的转换,缺点是时延较大。
- 直通交换方式的输入接口接收到一个帧时,只检查帧的目的MAC地址决定输出接口,引入的转发时延至少为读取目的MAC地址所需的时间。目的MAC地址共6B,引入的转发时延至少为6×8bit-100Mb/s=0.48μs。存储转发方式引入的转发时延则至少为读取整个帧的时间。
-
利用交换机可以实现VLAN(虚拟局域网),VLAN不仅可以隔离冲突域还可以隔离广播域
- 同一个VLAN中的设备互相通信时,主机先把信息发送给交换机,交换机在转发前给帧加上VLAN标签再发送给另一个交换机
- 不同VLAN内的机器之间的通信需要借助路由器或第三层交换机
- 即使A和C都连接到同一个交换机,但它们已经处在不同的网络中(VLAN-10和VLAN-20),这要由网络层的路由器来解决。
- 当局域网内的某个VLAN中的主机要逻辑迁移到另一个VLAN时,无需重新布线或移动设备,只需要在相关交换机上调整VLAN配置
-
总容量是n*W,单个用户(单个接口)能占用的带宽还是W
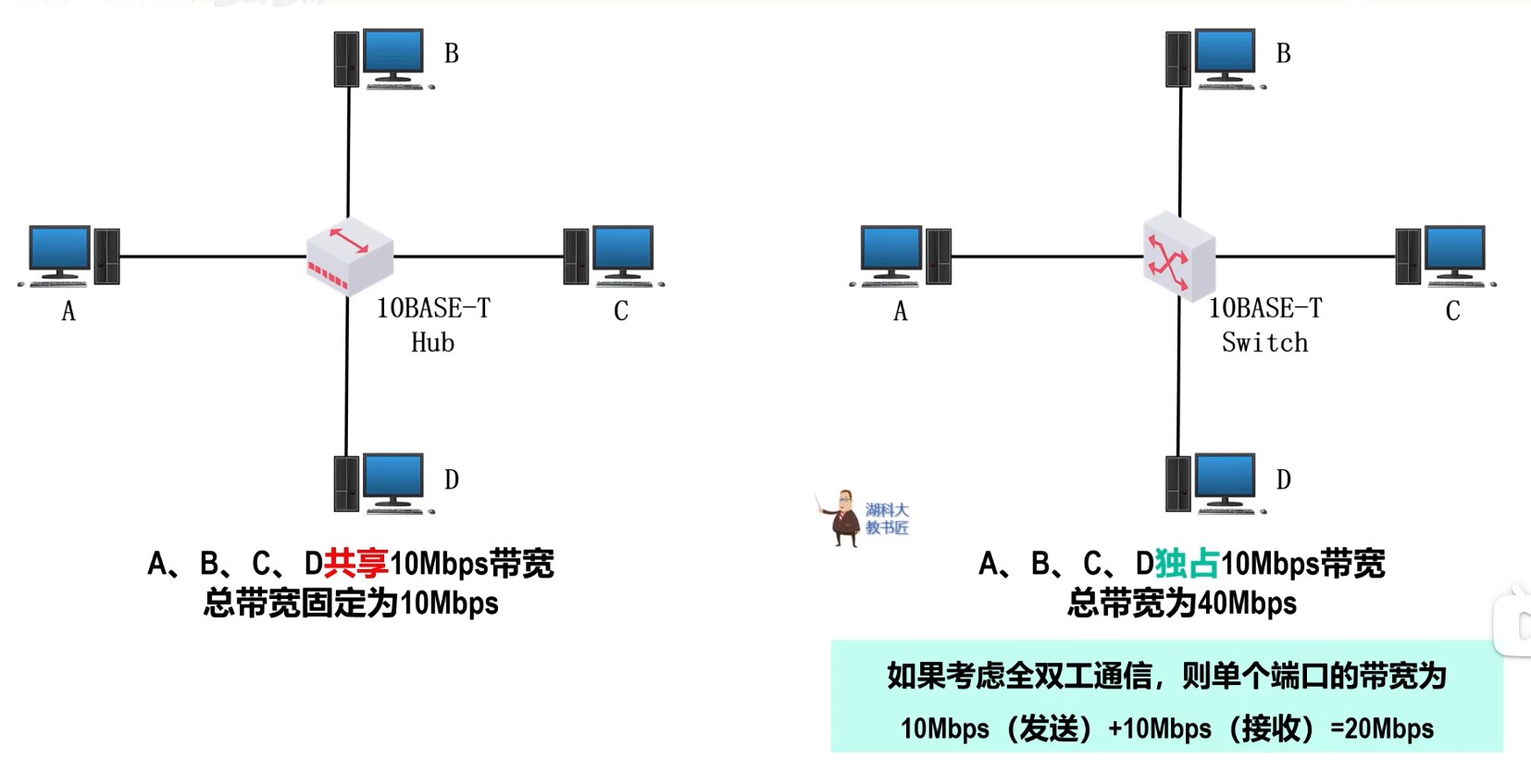
- 使用以太网交换机(全双工方式)连接这些主机时,虽然从每个接口到主机的带宽还是10Mb/s,但是因为一个用户通信时是独占带宽的(而不是和其他网络用户共享传输介质带宽的),所以拥有N个接口的交换机的总容量为N×10Mb/s。这正是交换机的最大优点。
-
当以太网的通信大部分在本局域网内进行,则适合用交换机,如果大部分在局域网和因特网进行,则可以使用集线器
- 因为集线器全部是广播,而交换机有转发表,如果用集线器,使用CSMA/CD协议,很容易产生冲突,会一直冲突导致重发。而交换机可以分割冲突域,精准转发,减少冲突。
-
独占传输媒体是指每个主机和交换机之间的通信是独立且没有碰撞的,而同时通信是指交换机可以在多个端口之间同时进行数据传输,支持多对主机并行通信。通过交换机的交换机制和全双工工作模式,这两者可以同时存在而不冲突。
-
10BASE-T以太网中每个站点到集线器的距离不能超过100m,因此两站点间的通信距离最大不能超过200m,可以使用光纤和光纤调制解调器来扩展站点与集线器之间的距离
-
交换式以太网:使用交换机;共享式以太网:使用集线器
-
不同网络层协议的网络互联属于网络层范围,以太网交换机无法处理
-
交换机不修改通过它的数据帧和源MAC和目的MAC地址(透明传输),路由器在转发IP数据报时通常会修改帧的源MAC和目的MAC地址。
-
广播风暴产生于网络层,因此只有网络层设备才能抑制。链路层设备和物理层设备对网络层的数据报是透明传输,对是否为广播报文是不可知的。
-
冲突域是基于第一层(物理层);广播域是基于第二层(链路层)
-
若交换机组成了环路,为了避免出现广播帧在环路中永久兜圈,应该采用STP生成树协议
-
全双工信道不存在碰撞域
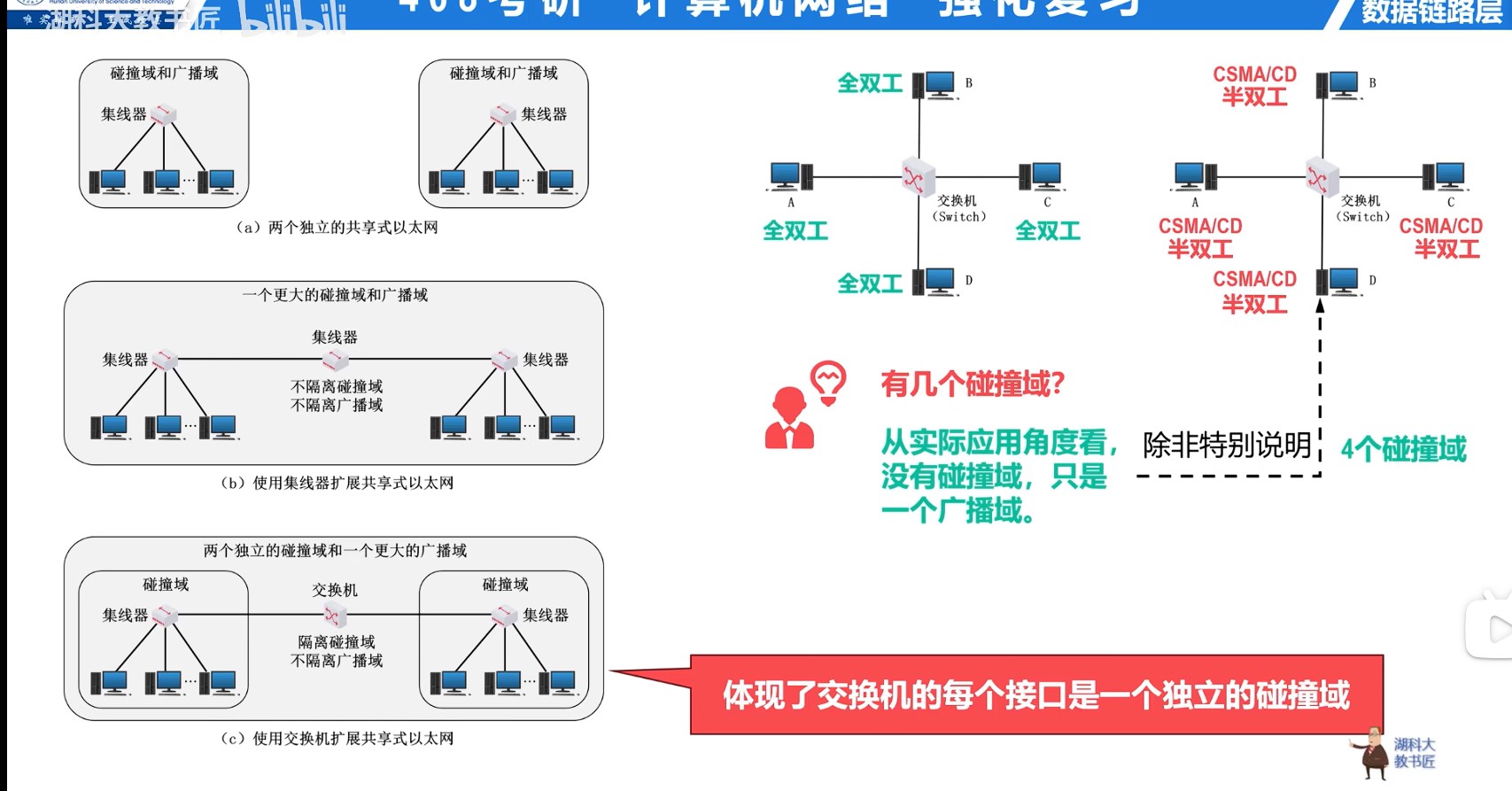
VLAN
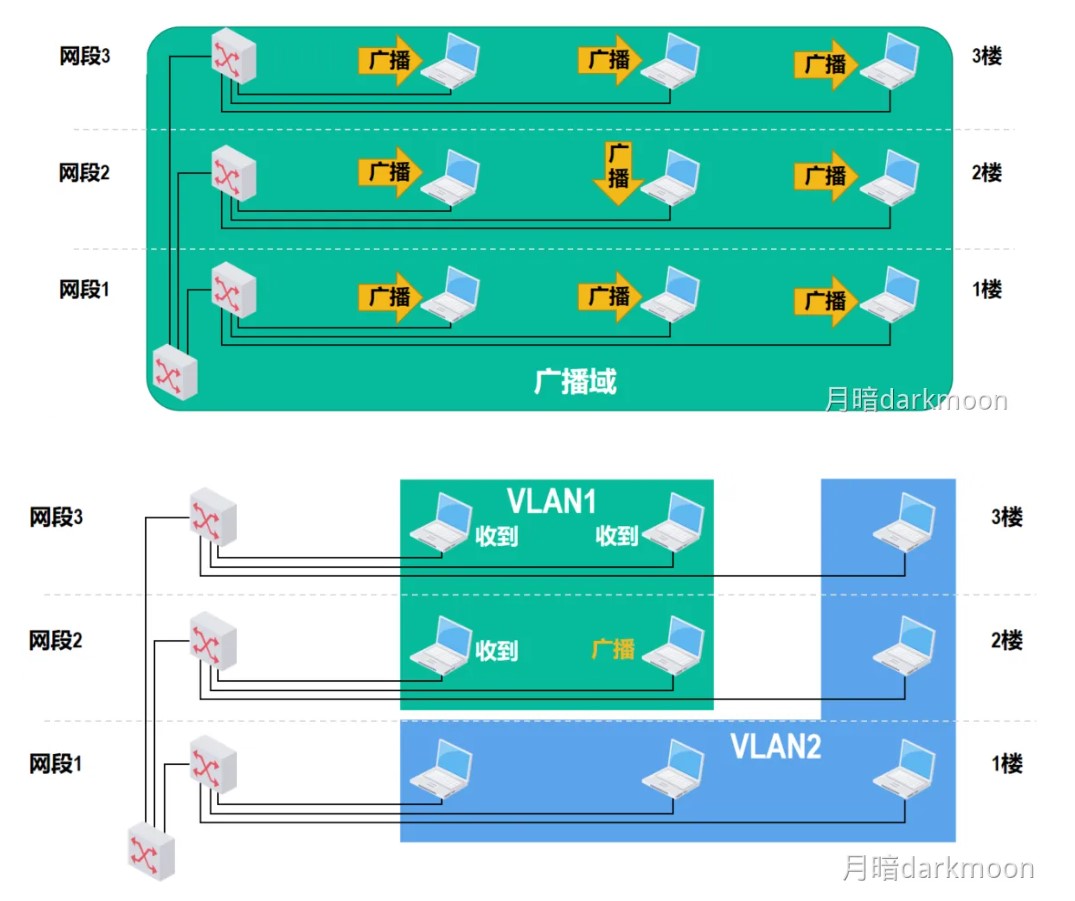
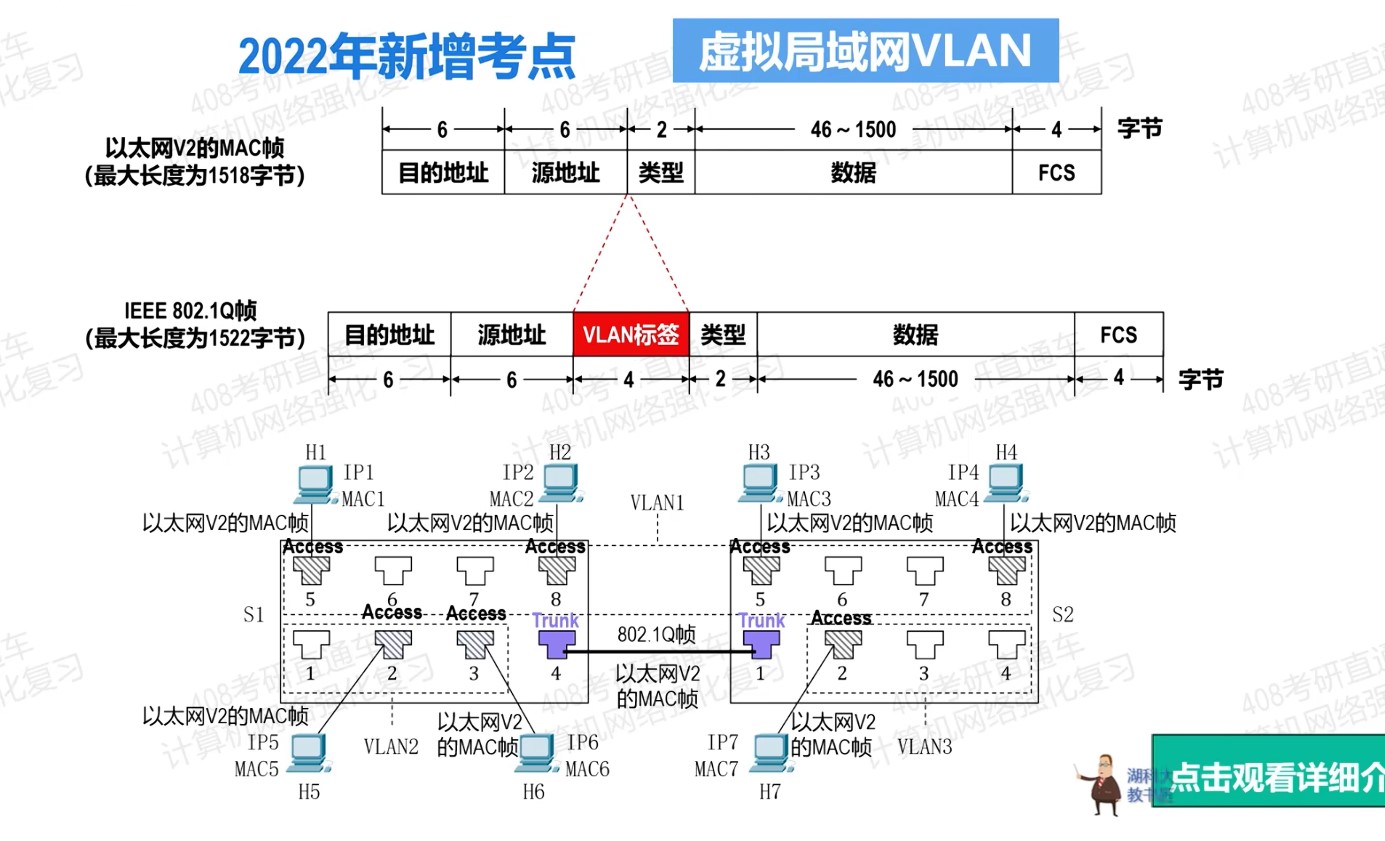
-
利用交换机可以实现VLAN(虚拟局域网),VLAN不仅可以隔离冲突域还可以隔离广播域
-
同一个VLAN中的设备互相通信时,主机先把信息发送给交换机,交换机在转发前给帧加上VLAN标签再发送给另一个交换机
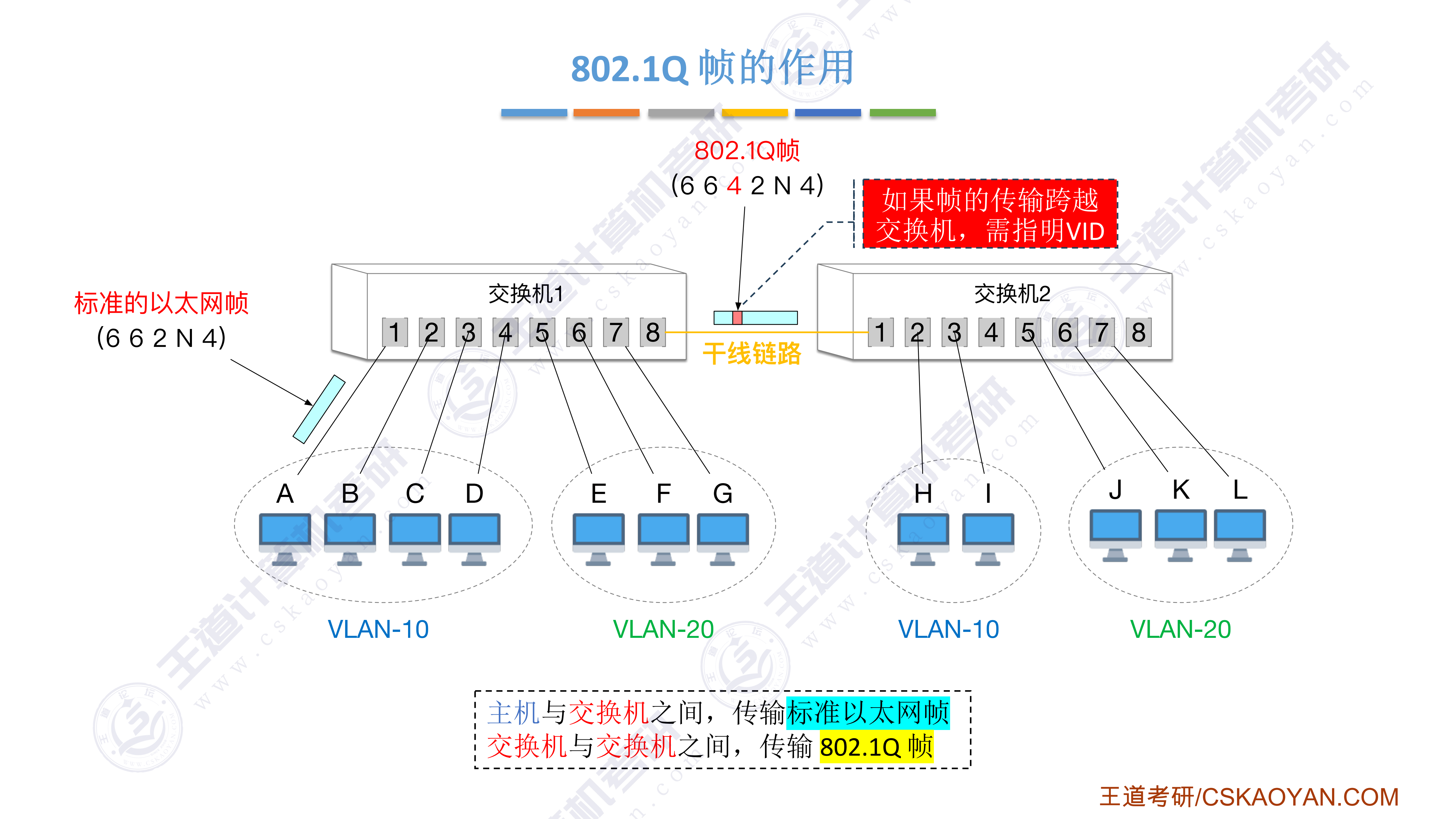
-
不同VLAN内的机器之间的通信需要借助路由器或第三层交换机
- 因此从数据链路层的角度看,不同VLAN中的站点之间不能直接通信
-
当局域网内的某个VLAN中的主机要逻辑迁移到另一个VLAN时,无需重新布线或移动设备,只需要在相关交换机上调整VLAN配置
-
-
属于同一VLAN的站点之间可以直接进行通信,而不同VLAN中的站点之间不能直接通信
-
广播帧只在同一VLAN内转发,这样就将广播域限制在了一个VLAN内
-
网络管理员可对局域网中的各交换机进行配置来建立多个逻辑上独立的VLAN
- 连接在同一交换机上的多个站点可以属于不同的VLAN,而属于同一VLAN的多个站点可以连接在不同的交换机上
-
VLAN并不是一种新型网络,它只是局域网能够提供给用户的一种服务
-
802.1Q帧
- 802.1Q帧一般不由用户主机处理,而是由以太网交换机来处理:
- 当交换机收到普通的以太网MAC帧时,会给其插入4字节的VLAN标签使之成为802.1Q帧,该处理简称为**“打标签”**。
- 当交换机转发802.1Q帧时,可能会删除其4字节的VLAN标签使之成为普通的以太网MAC帧,该处理简称为**“去标签”。交换机转发802.1Q帧时也有可能不进行“去标签”处理,是否进行“去标签”处理取决于交换机的接口类型。**
- 802.1Q帧一般不由用户主机处理,而是由以太网交换机来处理:
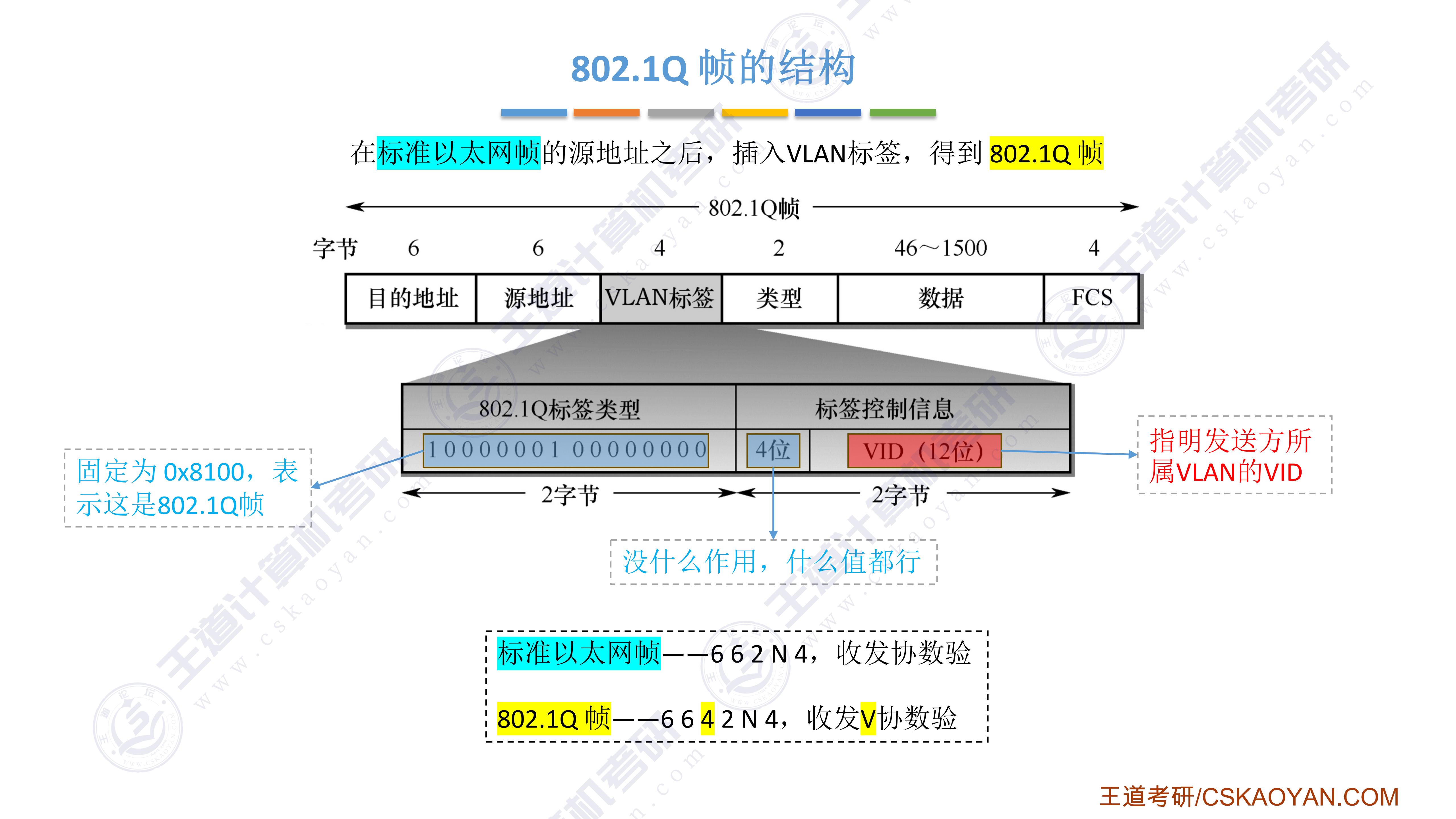
- 接口类型

-
划分方式
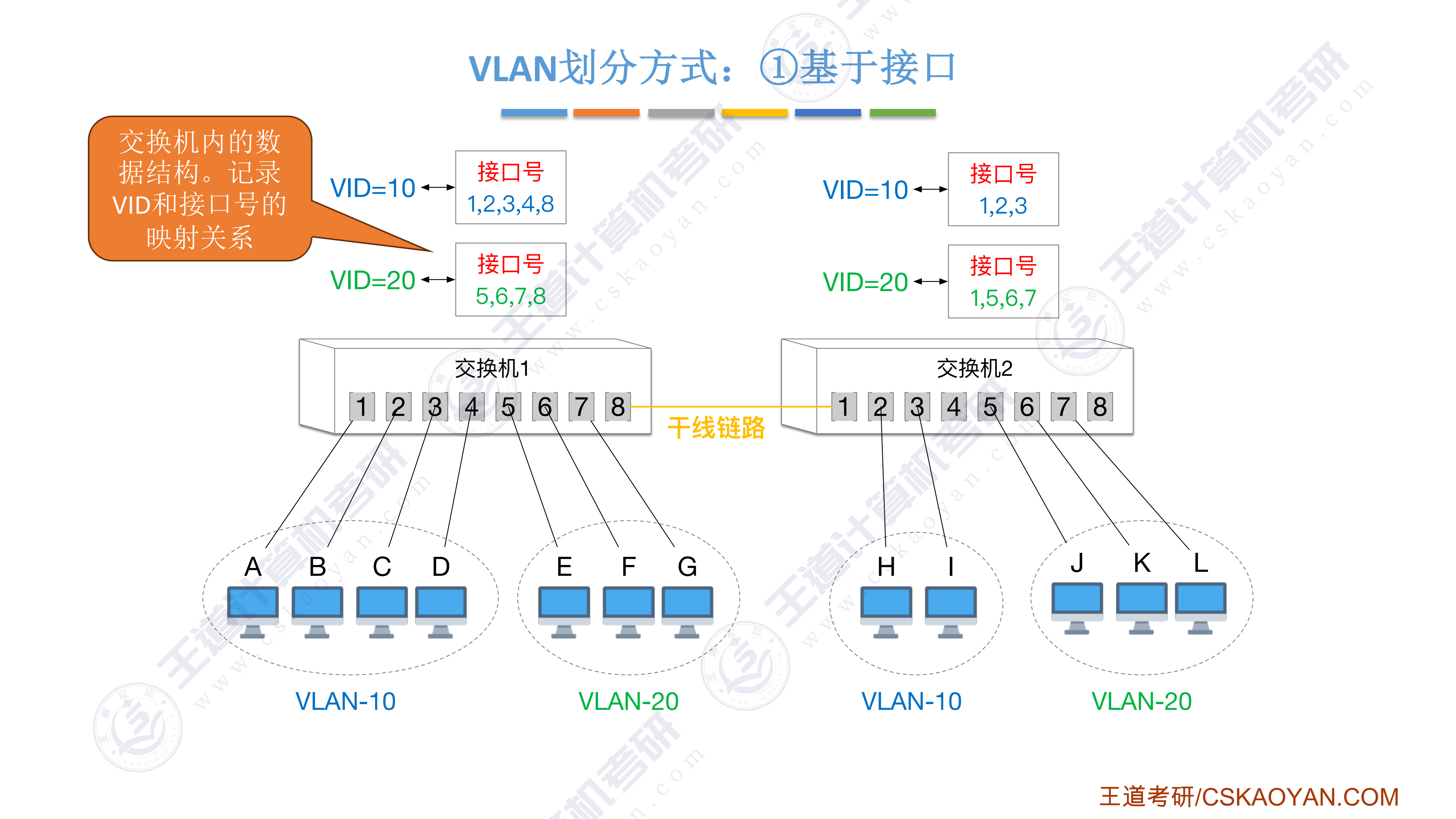
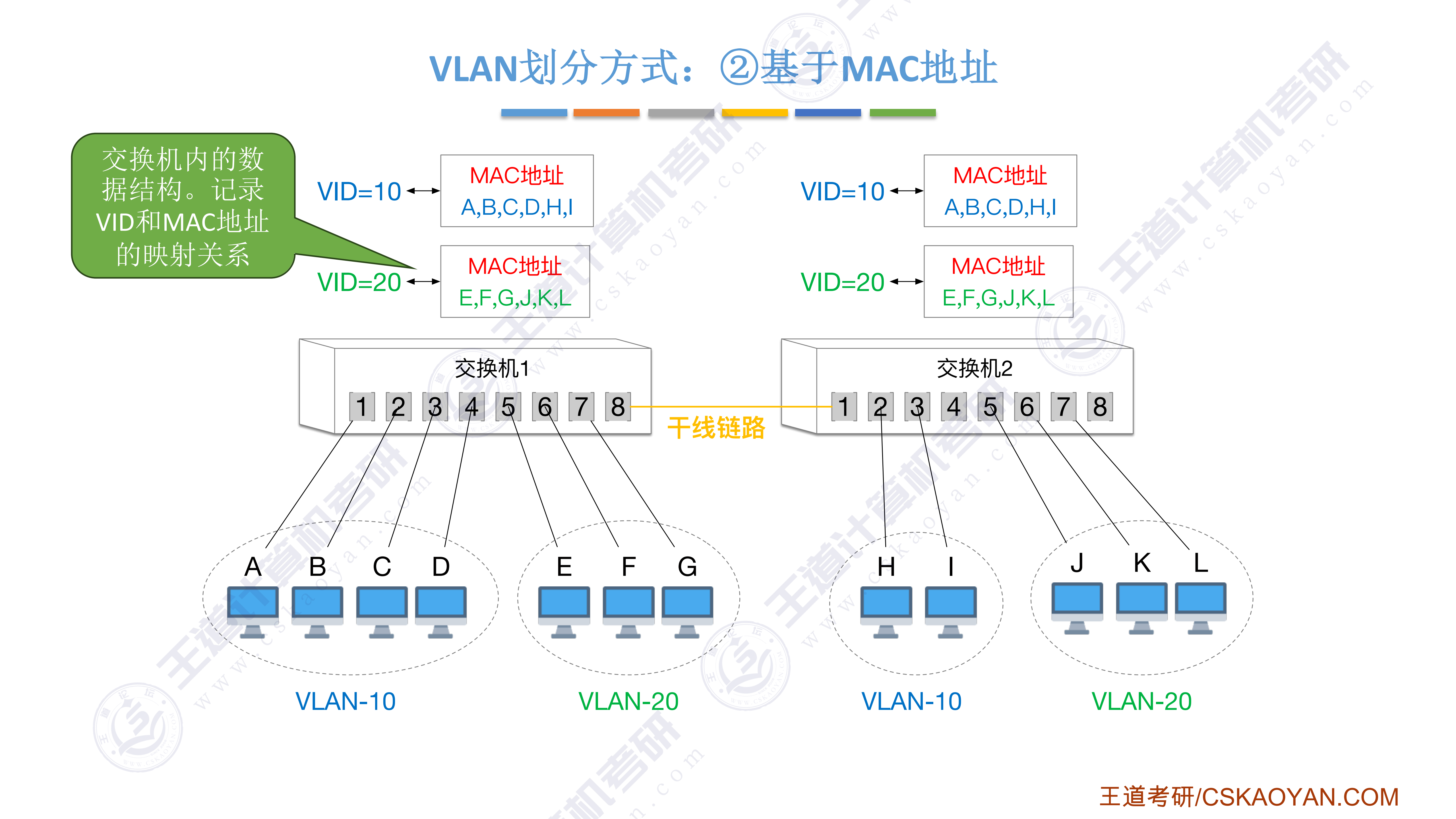
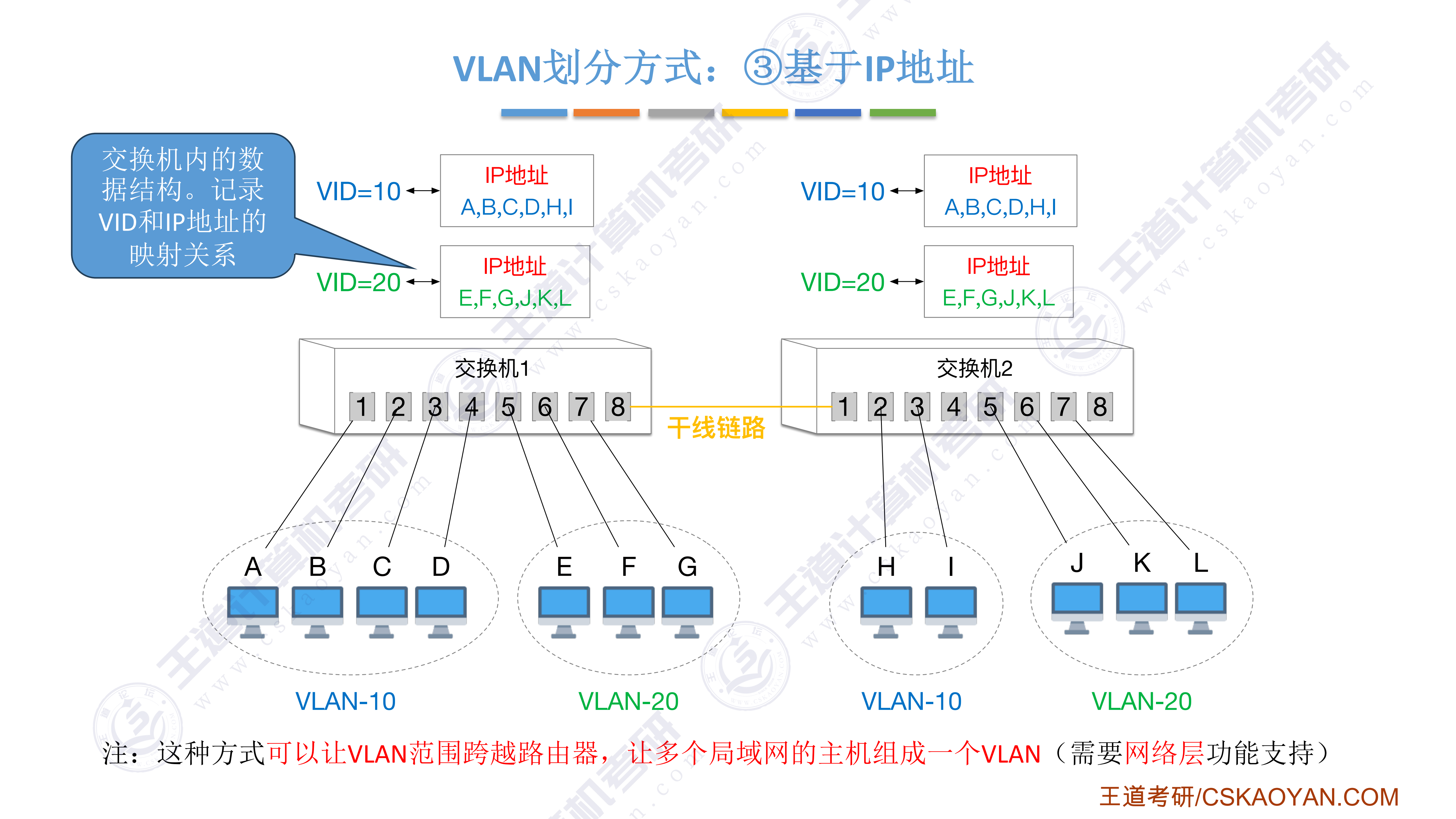
-
重复
利用交换机可以实现VLAN(虚拟局域网),VLAN不仅可以隔离冲突域还可以隔离广播域
- 同一个VLAN中的设备互相通信时,主机先把信息发送给交换机,交换机在转发前给帧加上VLAN标签再发送给另一个交换机
- 不同VLAN内的机器之间的通信需要借助路由器或第三层交换机
- 即使A和C都连接到同一个交换机,但它们已经处在不同的网络中(VLAN-10和VLAN-20),这要由网络层的路由器来解决。
- 当局域网内的某个VLAN中的主机要逻辑迁移到另一个VLAN时,无需重新布线或移动设备,只需要在相关交换机上调整VLAN配置
网络层
-
OSI主张在网络层使用面向连接的虚电路服务,认为应由网络自身来保证通信的可靠性。在TCP/IP体系结构中,网络层只向上提供简单灵活的、无连接的、尽最大努力交付的数据报服务。
-
异构网络始址数据链路层协议和物理层协议至少有一个不同
-
路由器在查找路由表时使用最长前缀匹配原则来确定最佳路由。交换机在查找MAC地址表时,是进行精准匹配,级查找与帧目的MAC地址完全相同的表项。如果找不到,则泛洪(对未知单播)。没有“最长匹配”的概念用于交换机的MAC地址表查找。
-
NAT路由器会修改源IP和源端口
-
节点交换机和路由器都用来转发分组,它们的工作原理也类似。节点交换机在单个网络中转发分组,而路由器在多个网络构成的互联网中转发分组
-
转发是数据平面实现的功能,而路由选择是控制平面实现的功能
-
路由器至少应该具有两个或两个以上的IP地址,每个端口都有一个不同网络号的IP地址。
- 用转发器或交换机等连接的若干局域网LAN仍然是同一个网络(同一个广播域),因此该LAN中所有主机的IP地址的网络号必须相同,但主机号必须不同。
-
私有IP地址不能直接用于互联网,必须通过网关利用NAT将私有IP地址转换为互联网中合法的全球地址后,才能出现在互联网上。
-
普通路由器仅工作在网络层,而NAT路由器转发数据报时需要查看和转换传输层的端口号
-
路由表中的表项
- 目的网络地址
- 子网掩码
- 下一跳地址
-
CIDR查找路由表的方法:为了更有效地查找最长前缀匹配,通常将无分类编址的路由表存放在一种层次式数据结构(通常采用二叉线索)中,然后自上而下地按层次进行查找。
-
NAT路由器工作子传输层,ARP协议工作在网络层(tcp/ip),OSI将其归类在数据链路层
-
DHCP采用UDP而不采用TCP的原因也很明显:TCP需要建立连接,若连对方的IP地址都不知道,则更不可能通过双方的套接字建立连接。
-
一些特殊用途的IP地址
-
受限广播地址 (255.255.255.255):用于本地网络,不会被路由器转发,DHCP等协议使用
直接广播地址 (网络号.255):用于向特定远程网络发送广播,可以被路由器转发
-
网络号全0,主机号特定,用于当某个主机向同一网络上的其他主机发送报文时,分组被路由器挡住,把分组限制在本地网络上的一种方法
-
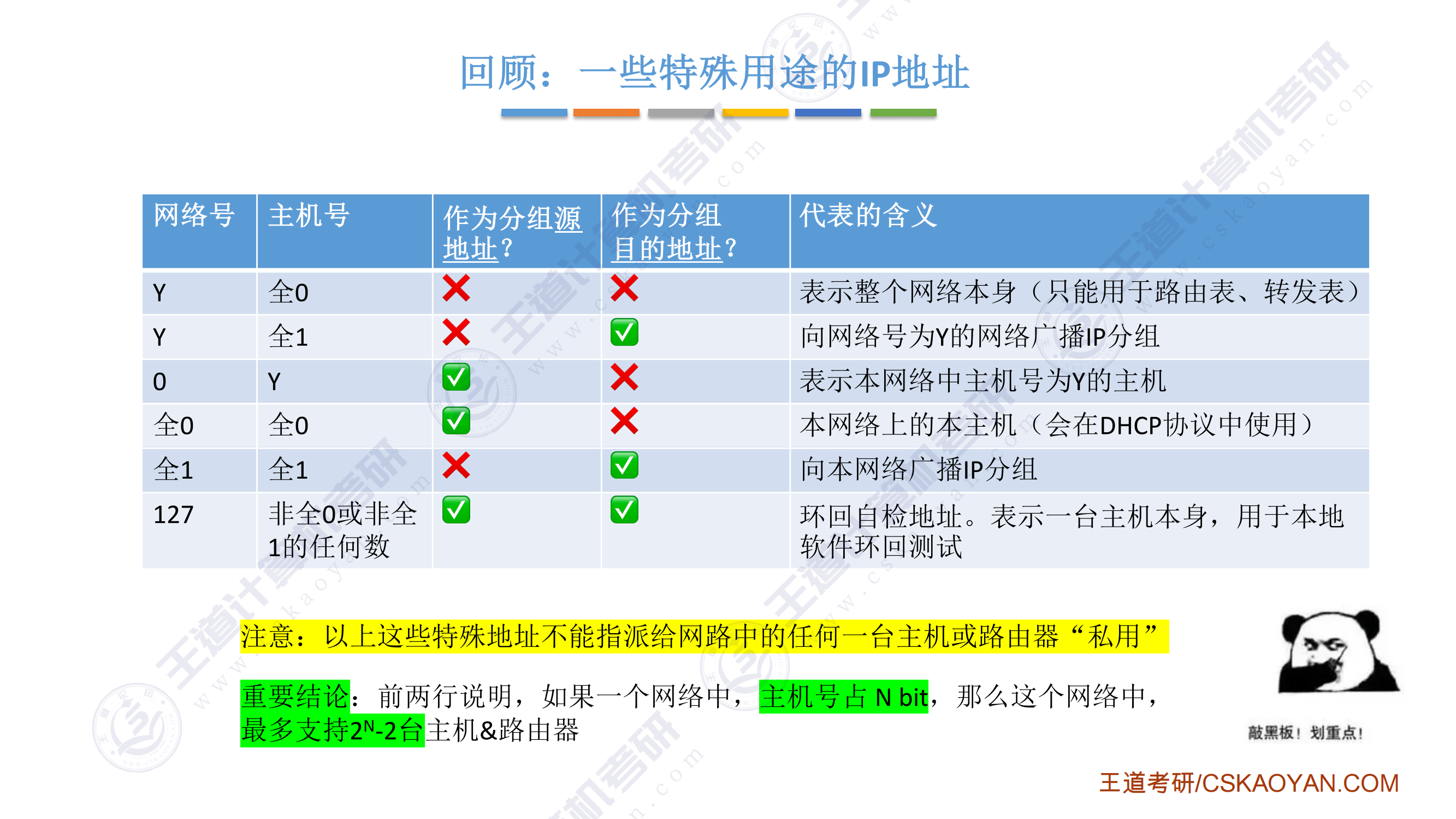
- 在任何情况下,路由器都不转发目的地址为受限广播地址的IP分组,这种IP分组仅出现在本地网络中
- 同一网络不需要路由器就可以正常进行IP通信,不同网络下才需要路由器进行IP通信
- 偏移量是针对数据部分
- 在同一个网络中传递数据无须路由器的参与,而跨网络通信必须通过路由器进行转发
- 标准的路由表有四个项目:
- 目的网络IP地址
- 子网掩码
- 下一跳IP地址
- 接口
- 转发表的内容
- 目的网络
- 下一跳(MAC地址)
- 路由表总是软件实现的,转发表可以软件也可以硬件实现。
- 路由表需要对网络拓扑变化最优化,转发表需要查找过程最优化。
- 转发只涉及一个路由器,路由选择涉及很多个路由器
- 路由表≠转发表,实际的分组转发查的是转发表而不是路由表
- 路由器只能根据IP地址转发
- 当路由器收到一个待转发的数据报时,由路由表得出下一跳路由器的IP地址后,不是把这个地址填入数据报,而是送交数据链路层的网络接口软件。网络接口软件负责把下一跳路由器的IP地转换成硬件地址(使用ARP),并将此硬件地址写入MAC帧的首部,然后根据此硬件地址找到下一跳路由器。可见,当发送一连串的数据报时,上述的查找路由表、用ARP得到硬件地址、把硬件地址写入MAC帧的首部等过程,将不断地重复进行,造成了一定的开销。
- 路由器是第三层设备,向传输层上层次隐藏下层的具体实现,物理层、数据链路层、网络层协议可以不同
- 网络层以上的协议是路由器不能处理的,网络层以上的高层协议必须相同
- PPP的MTU=298B,以太网MTU=1500B
- 在不同网络中传送时,MAC帧中的源地址和目的地址要发生变化,但是网桥转发帧时,不改变帧的源地址
- 非NAT的情况下,MAC地址在每一跳都会变化,而IP地址(在不经过NAT时)从源到目的全程保持不变
- 通过NAT路由器的通信必须由专用网内的主机发起,这种专用网内部的主机不能充当服务器使用,因为互联网上的客户无法请求专用网内的服务器提供服务(只含IP的NAT)
- 需要使用一些特殊的NAT穿透技术来解决
- 当考虑运输层的端口号后,这句话并不完全正确。通过适当的端口映射,专用网内部的主机仍然可以充当服务器,接受外部客户的请求。
- 运用端口号以后,可以使内部专用网中使用专用地址的大量主机,共用NAT路由器上的1个全球IP地址,因而可以同时与因特网中的不同主机进行通信。
- 现在很多家用路由器将家中各种智能设备(手机、平板、笔记本电脑、台式电脑、物联网设备等)接入因特网,这种路由器实际上就是一个NAPT路由器,但往往并不运行路由选择协议。
- NAT路由器中的转换表在NAT路由器上自动生成,在TCP的情况下,建立TCP连接首次握手时的SYN包一经发出,就会生成这个表,后又随着收到关闭连接时发出FIN包的确认应答从表中被删除。
- 路由器是第三层设备,向传输层及上层次隐藏下层的具体实现,所以物理层、数据链路层、网络层协议可以不同,而网络层以上的协议是路由器所不能处理的,因此网络层以上的高层协议必须相同。
- 路由器是第三层设备,要处理的内容比第二层设备交换机更多,因而转发速度比交换机慢(设备所在层次越高,延迟越大)
- 集线器某个端口收到信号时,立即向所有其他端口转发,传输时延最小
- 路由器有拥塞控制功能:
- IP路由器队列长度达到某个值得警惕的数值时,也就是网络出现了某些拥塞征兆时,就主动丢弃到达的IP数据报来造成发送方的超时重传,进而降低发送方的发送速率,因而有可能减轻网络的拥塞程度,甚至不出现网络拥塞。
- 路由算法决定了转发表中的值。
- 路由器到互联网的路由实质上相当于一个默认路由,因此目的地址为0.0.0.0/0,子网掩码为0.0.0.0
- 子网掩码不需要知道对方的,只需要知道自己的
- 能否正常IP通信:同一个子网,直接交付,不同子网,交给默认网关,由默认网关进行转发
- 默认网关:当主机发送IP分组,目的IP和主机不是同一个子网,就会把IP分组发送给默认网关,由默认网关进行转发
- 给路由器各接口配置了IP地址和子网掩码后,路由器就可自行得出各接口的直连网络
- 因此要人工配置的静态路由条目只有非直连网络的路由条目
- IP地址是标志一台主机(或路由器)和一条链路的接口。当一台主机同时连接到两个网络上时,该主机就必须同时具有两个相应的IP地址,其网络前缀必须是不同的。这种主机称为多归属主机。
- IP地址是逻辑地址、虚拟地址、软件地址,是用软件实现的。
IP数据报
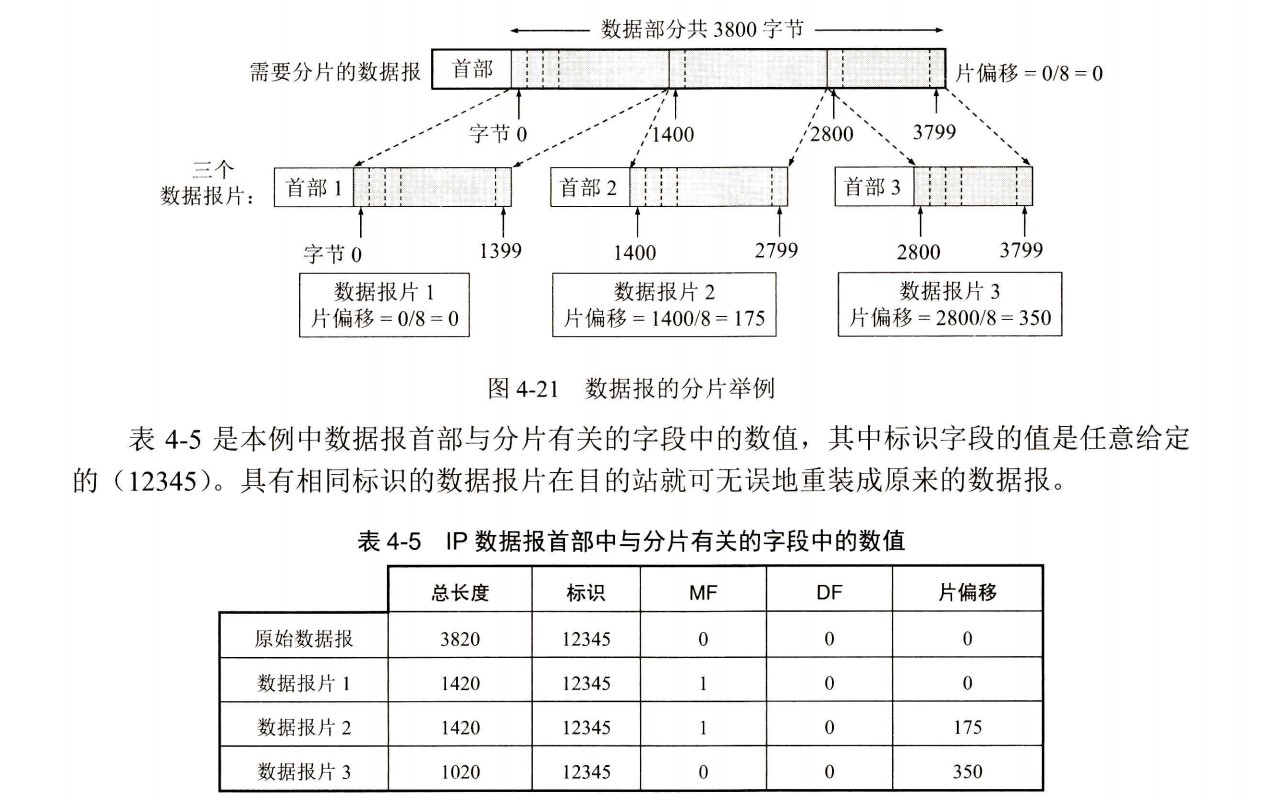
- TTL=1,意味着这个数据报只能在本局域网中传送,因为这个数据报一传送到局域网上的某个路由器,在被转发之前TTL值就减小到0,所以会被这个路由器丢弃
移动IP
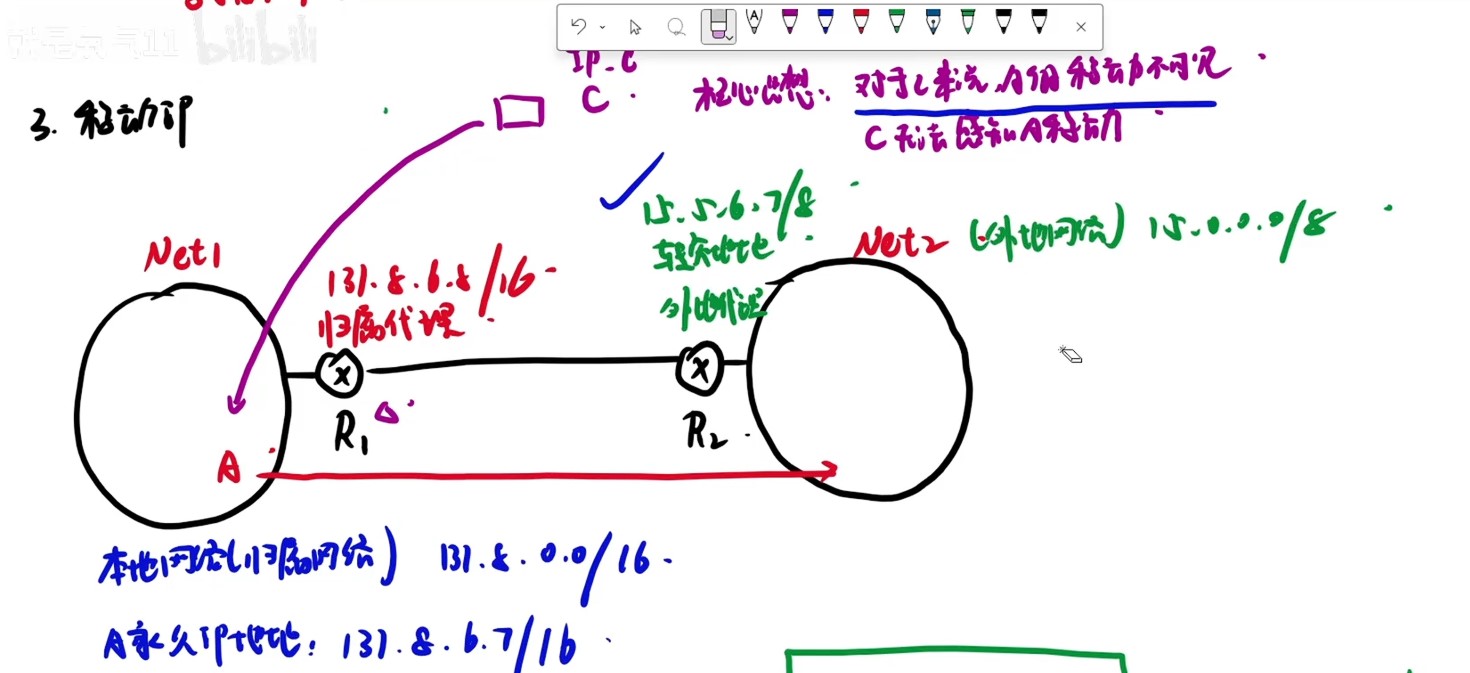
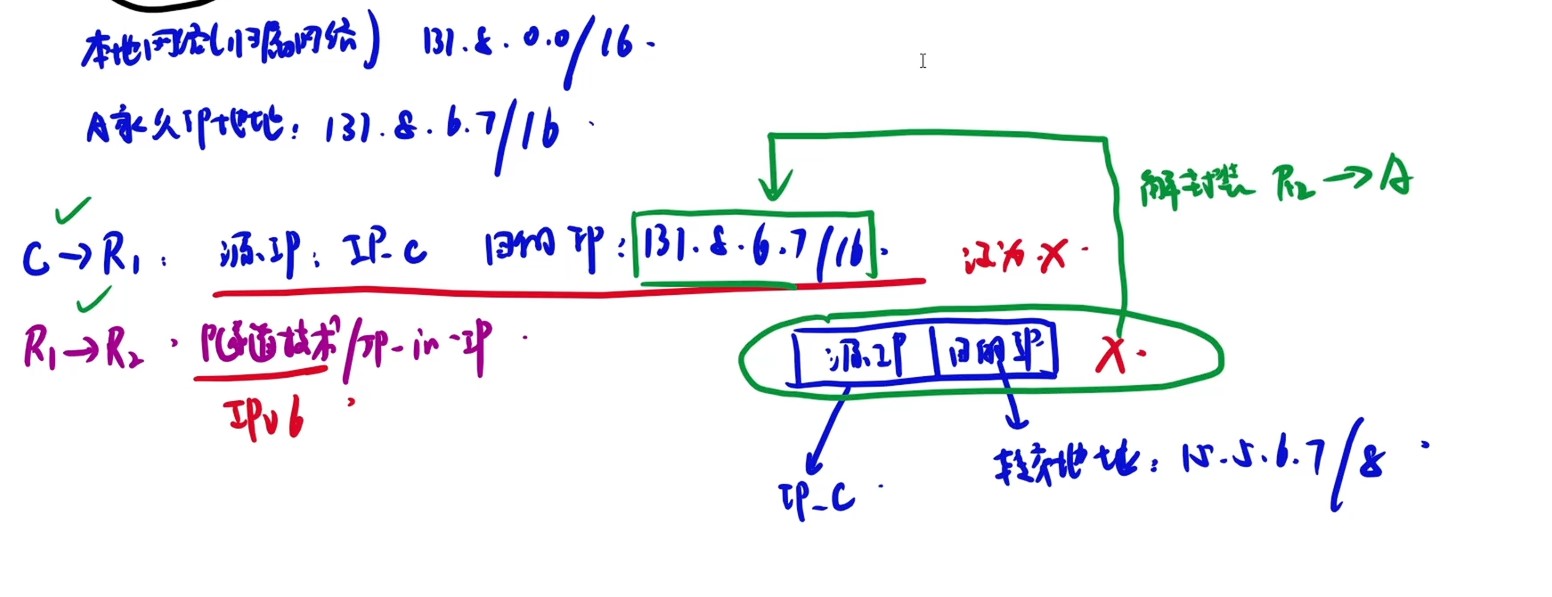
-
归属代理通常是连接到归属网络上的路由器,然而它实现的代理功能是在应用层完成的,因此归属代理既是路由器,也是主机
-
转交地址是供移动站、归属代理及外地代理使用的,各种应用程序都不会使用。外地代理要向连接在被访网络上的移动站发送IP分组时,直接使用移动站的MAC地址
- 转交地址在互联网中并不具有唯一性。这就是说,外地代理可以给好几个移动站指派同样的转交地址,甚至把自己的IP地址指派为移动站的转交地址。
- 这样做并不会引起混乱。这是因为当外地代理要向连接在被访网络上的移动站发送数据报时,并不会像通常那样使用地址解析协议ARP,而是直接使用这个移动站的MAC地址(当移动站首次和外地代理通信时,外地代理就记录下这个移动站的MAC地址)。
- 转交地址在互联网中并不具有唯一性。这就是说,外地代理可以给好几个移动站指派同样的转交地址,甚至把自己的IP地址指派为移动站的转交地址。
-
移动IP的基本通信流程如下:
-
①移动站A在归属网络时,按传统的TCP/IP方式进行通信。
-
②移动站A漫游到被访网络时,向外地代理进行登记,以获得一个临时的转交地址。外地代理要向A的归属代理登记A的转交地址。
- 移动站A离开后,外地代理并不需要注销其在归属代理登记的转交地址,因为当移动站A进入另一个网络时,新的被访网络的转交地址会取代旧的转交地址
-
③归属代理知道移动站A的转交地址后,会构建一条通向转交地址的隧道,将截获的发送给A的IP分组进行再封装,并通过隧道发送给被访网络的外地代理。
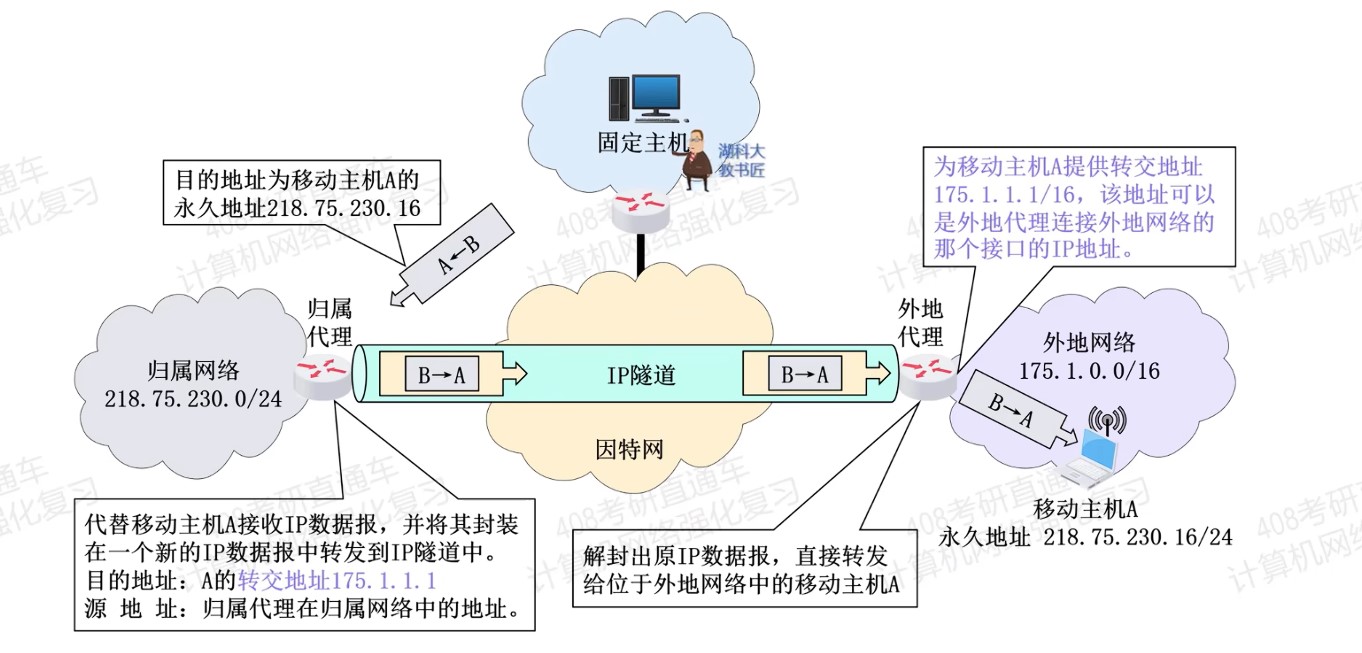
- 再封装后新的数据报的目的地址是A的转交地址。
-
④外地代理把收到的封装的IP分组进行拆封,恢复成原始的IP分组,然后发送给移动站A,这样A在被访网络就能收到这些发送给它的IP分组。
-
⑤移动站A在被访网络对外发送IP分组时,仍然使用自己的永久地址作为IP分组的源地址,此时显然无须通过A的归属代理来转发,而是直接通过被访网络的外部代理。
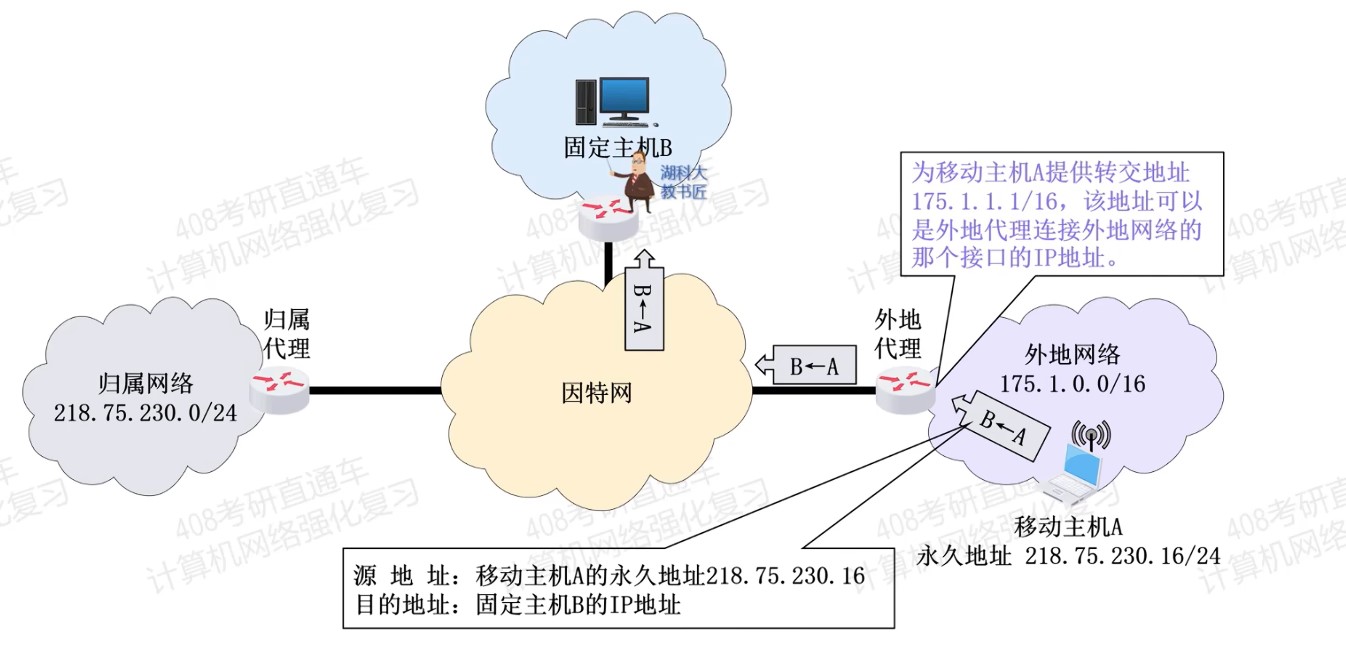
-
⑥移动站A移动到另一被访网络时,在新外地代理登记后,然后新外地代理将A的新转交地址告诉其归属代理。无论如何移动,A收到的IP分组都是由归属代理转发的。
-
⑦移动站A回到归属网络时,A向归属代理注销转交地址。
-
-
为什么需要固定IP地址:
- 我们需要在移动中上网。这时就希望移动站所建立的TCP连接在移动站漫游时一直保持连接,否则我们的上网就会变为断断续续的(因为TCP连接的建立是需要时间的,不可能瞬间就建立好)。可见,只要移动站的IP地址改变了,TCP连接就必须先中断再重新建立。因此,IP地址的改变对这样的移动用户来说就显得非常重要。
-
当移动主机不在归属网络时,归属代理会以自己的MAC地址应答所有对该移动主机的ARP请求。
SDN
-
SDN结构中,不需要路由选择协议,路由器之间不再互相交换路由信息
- 控制层面利用软件来控制数据层面中的许多设备
-
OpenFlow协议可以被看成是SDN体系结构中控制层面与数据层面之间的通信接口
-
SDN
- 传统
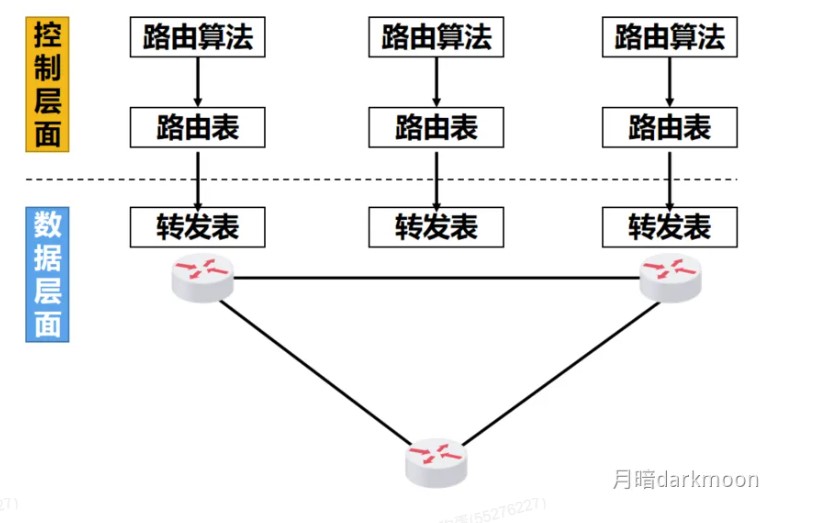
- SDN
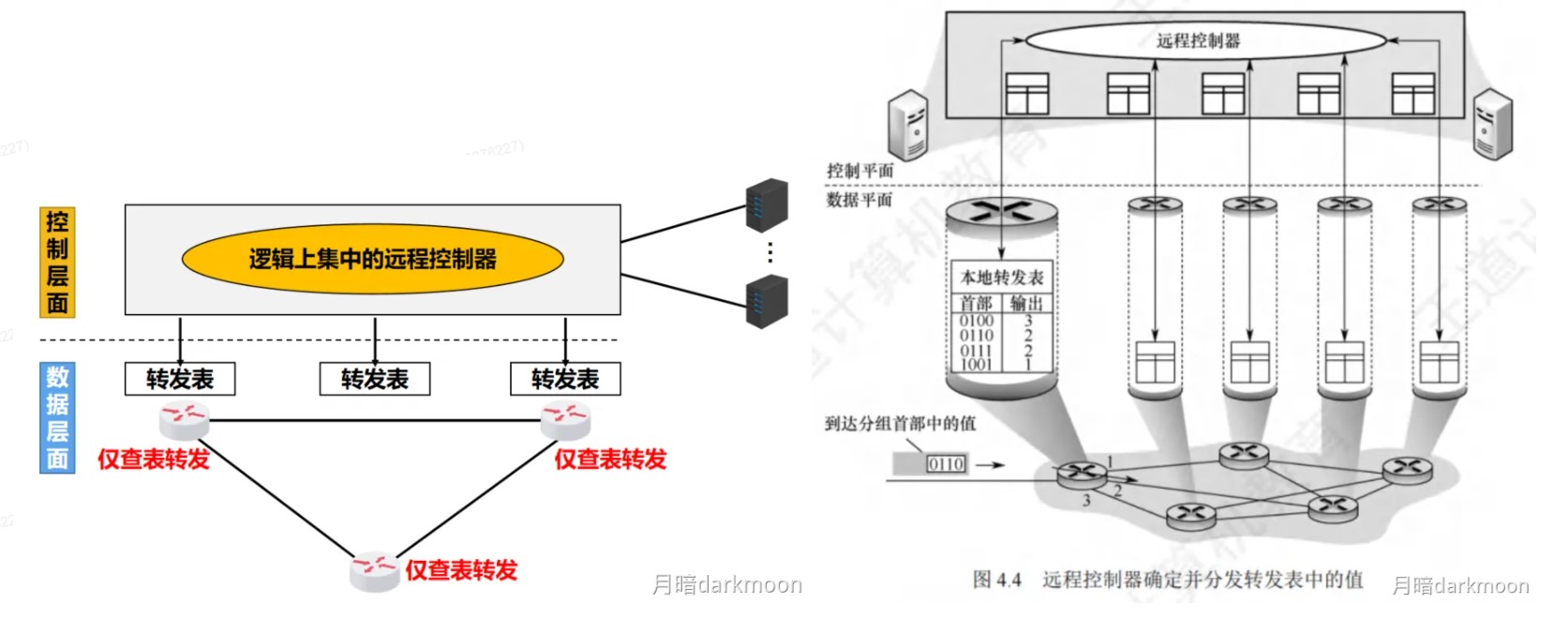
-
传统意义上的数据层面的任务
- 进行“匹配”:查找转发表中的网络前缀,进行最长前缀匹配。
- 执行“动作”:把分组从匹配结果指明的接口转发出去。
-
SDN广义转发分为以下两个步骤
-
进行“匹配”:能够对网络体系结构中各层(数据链路层、网络层、运输层)首部中的字段进行匹配。
-
执行“动作”:不仅转发分组,还可以负载均衡、重写IP首部(类似NAT路由器中的地址转换)、人为地阻挡或丢弃一些分组(类似防火墙一样)。


- 负载均衡:可以把具有同样目的地址的分组从不同的接口转发出去
-
-
在OpenFlow交换机中,既可以处理数据链路层的帧,也可以处理网际层的IP数据报,还可以处理运输层的TCP或UDP报文
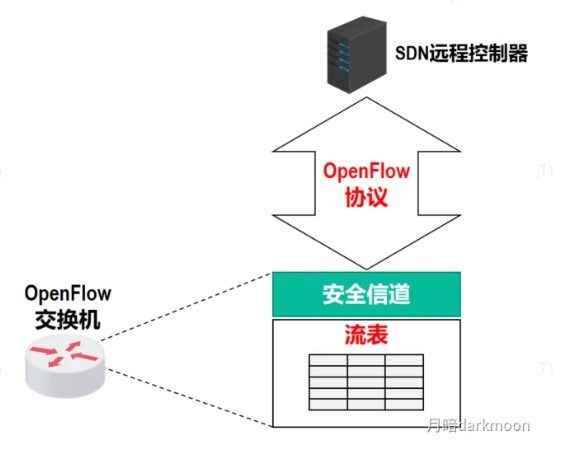
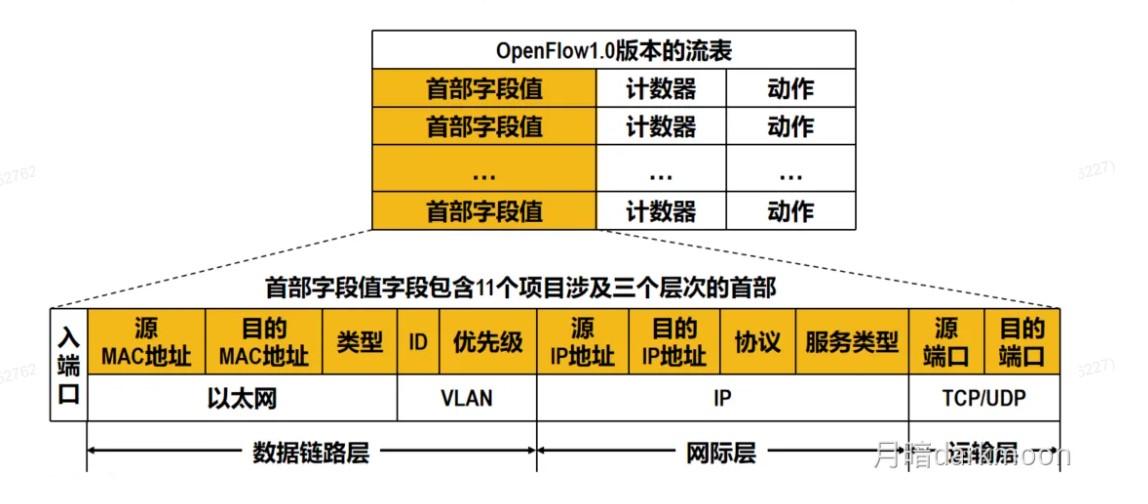
- 每个流表项包含三个字段:首部字段值(或称匹配字段)、计数器、动作。
- 首部字段值字段包含有一组字段,用来使入分组(Incoming Packet)的对应首部与之匹配,因此又称为匹配字段。匹配不上的分组就被丢弃,或被发送到SDN远程控制器做更多的处理。
- 在OpenFlow交换机中,既可以处理数据链路层的帧,也可以处理网际层的IP数据报,还可以处理运输层的TCP或UDP报文。
- 计数器字段是一组计数器:
- 记录已经与该流表项匹配的分组数量的计数器;
- 记录该流表项上次更新到现在经历时间的计数器。
- 动作字段是一组动作,当分组匹配某个流表项时,执行该流表项中动作字段指明的以下某个或多个动作:
- 把分组转发到指明的端口
- 丢弃分组
- 把分组进行复制后再从多个端口转发出去
- 重写分组的首部字段(包括数据链路层、网际层以及运输层的首部)
- 首部字段值字段包含有一组字段,用来使入分组(Incoming Packet)的对应首部与之匹配,因此又称为匹配字段。匹配不上的分组就被丢弃,或被发送到SDN远程控制器做更多的处理。
- 关键特征
- 基于流的转发
- 数据层面和控制层面分离
- 位于数据层面分组交换机之外的网络控制功能
- 可编程的网络
- 优点
- 全局集中式控制和分布式高速转发,既利于控制平面的全局优化,又有利于高性能的网络转发
- 灵活可编程与性能的平衡,控制和转发功能分离后,使得网络可以由专门的自动化工具以编程方式配置
- 降低成本,控制和数据平面分离后,尤其是在使用开放的接口协议后,就实现了网络设备的制造与软件功能的开发相分离,从而有效降低了成本。
- 控制与转发功能分离/控制平面集中化/接口开放可编程
- 缺点
- 安全问题,集中管理容易受攻击,若崩溃,则整个网络会受到影响
- 瓶颈问题,原本分布式的控制平面集中化后,随着网络规模的扩大,控制器可能成为网络性能的瓶颈。
ICMP
-
分类
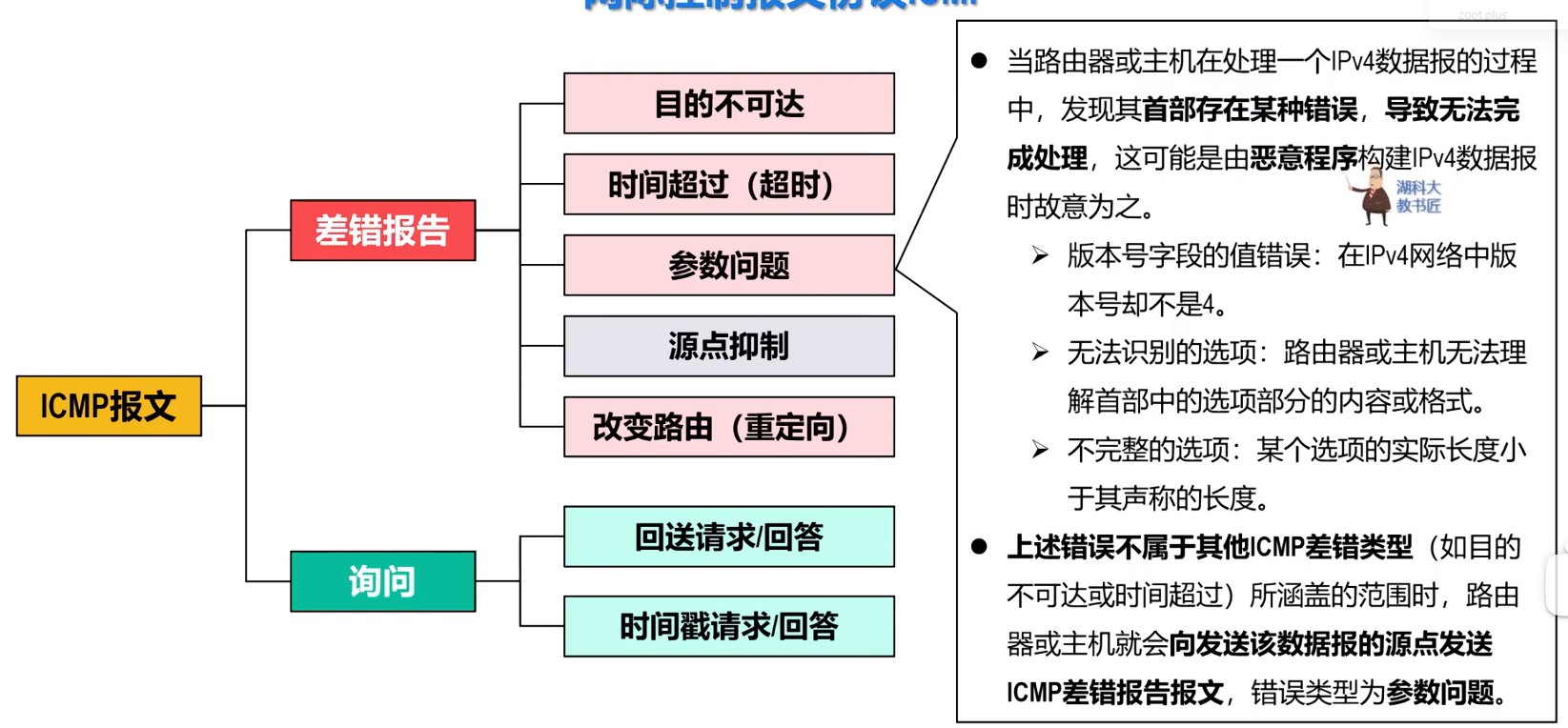

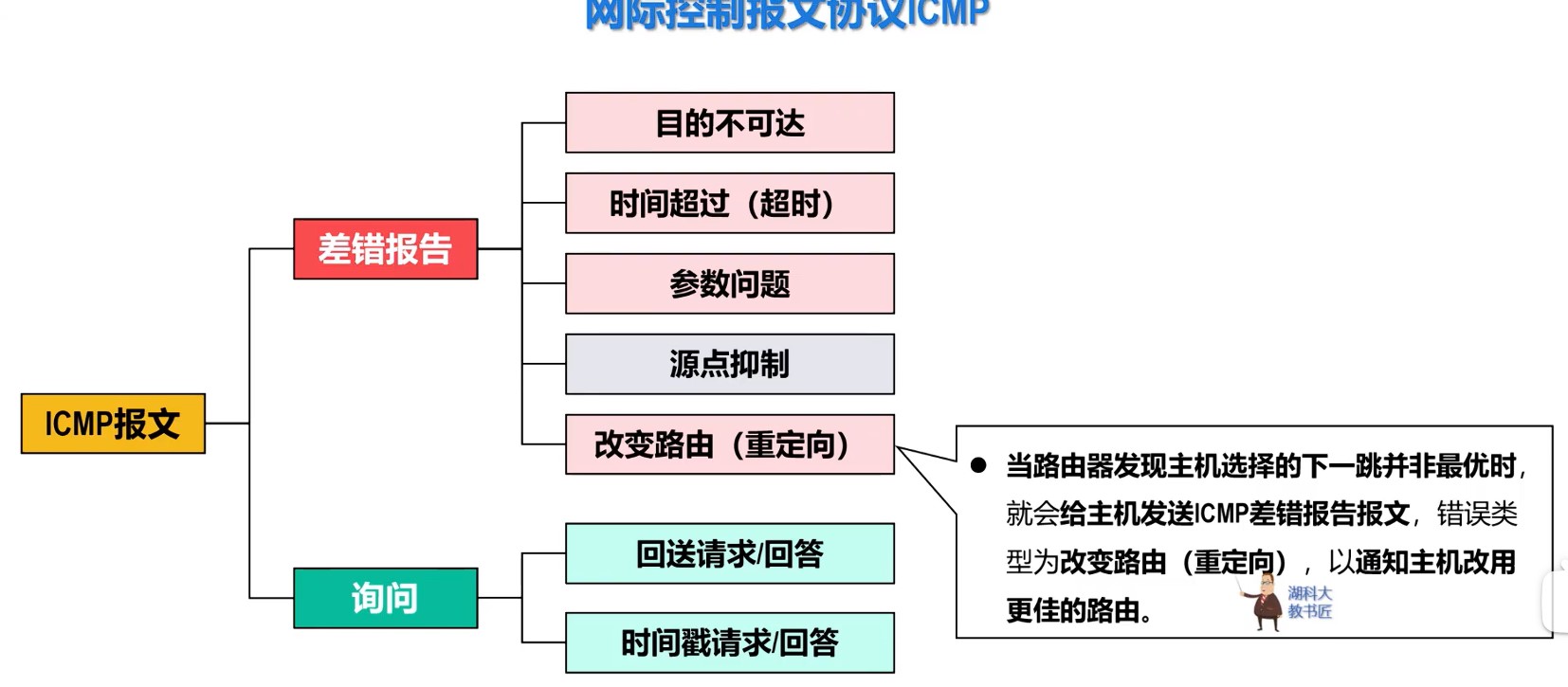
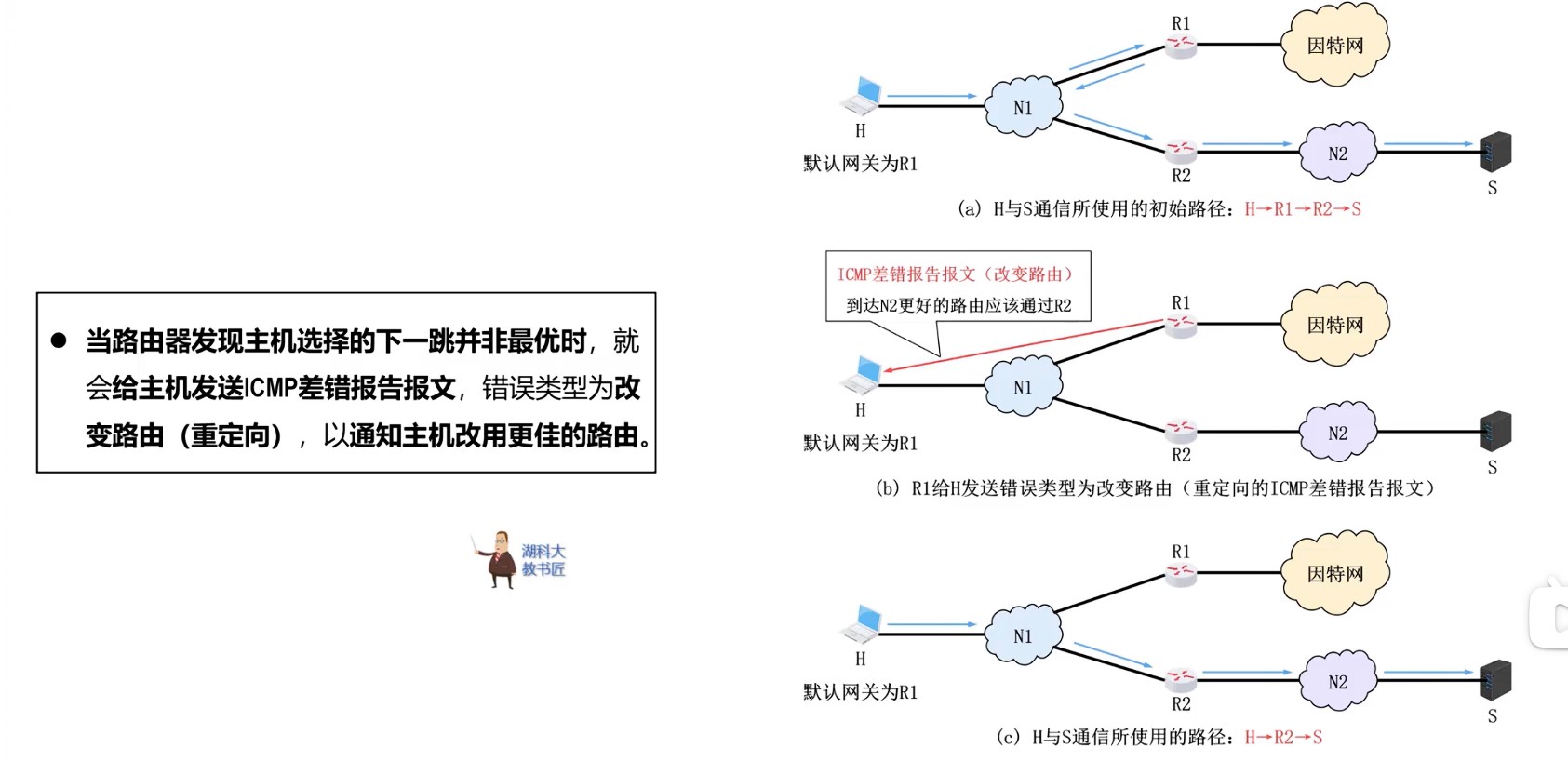
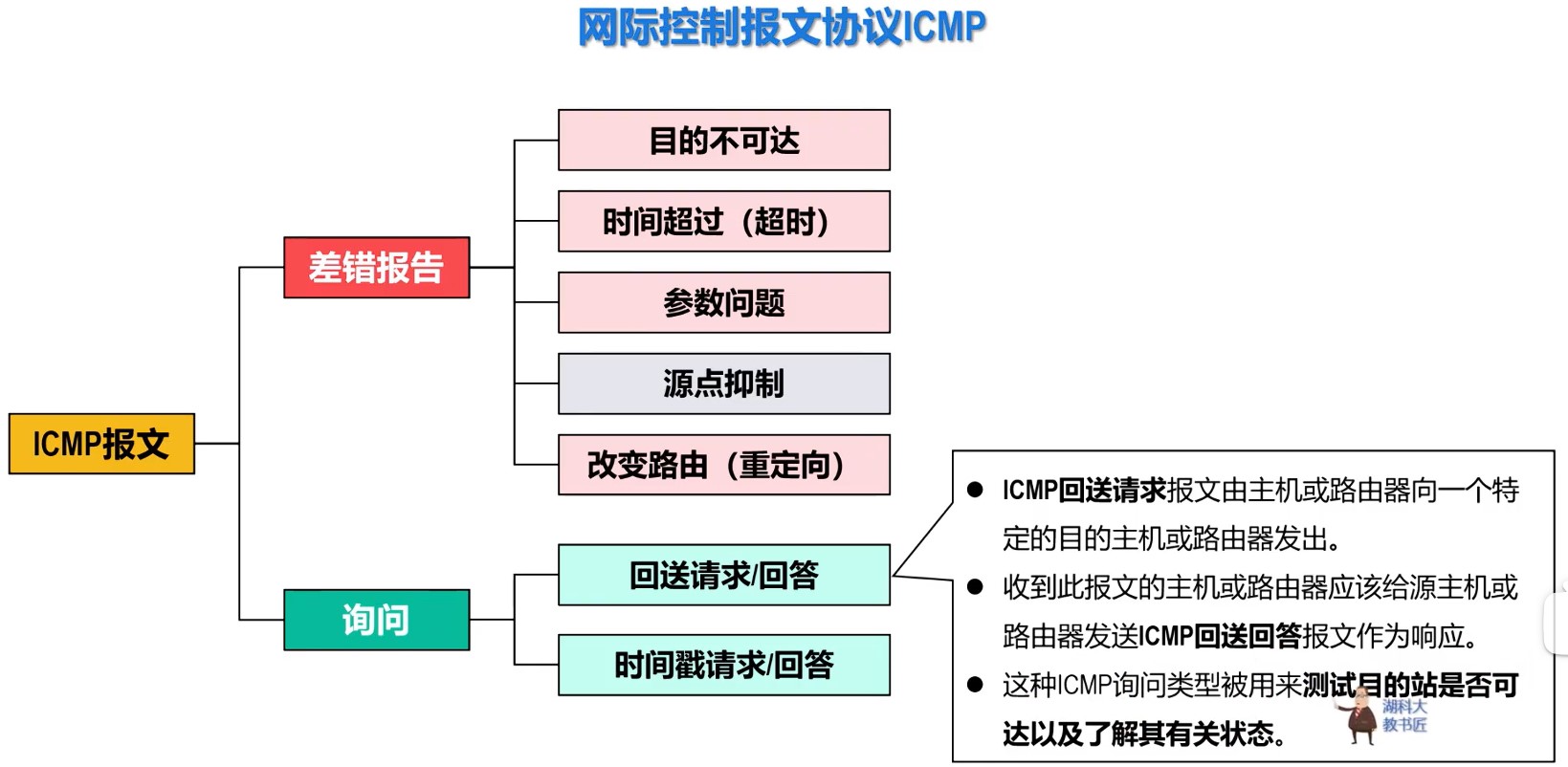
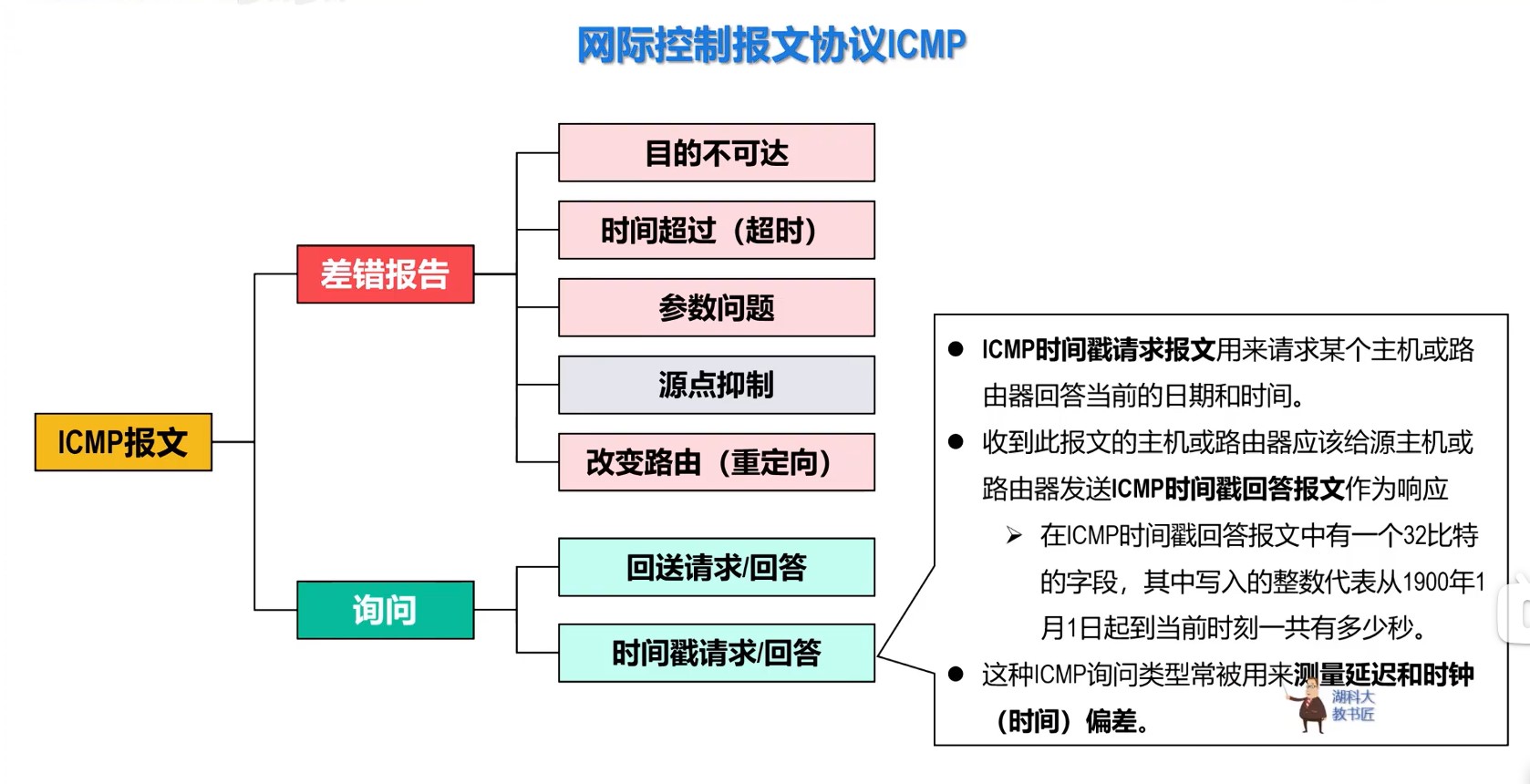
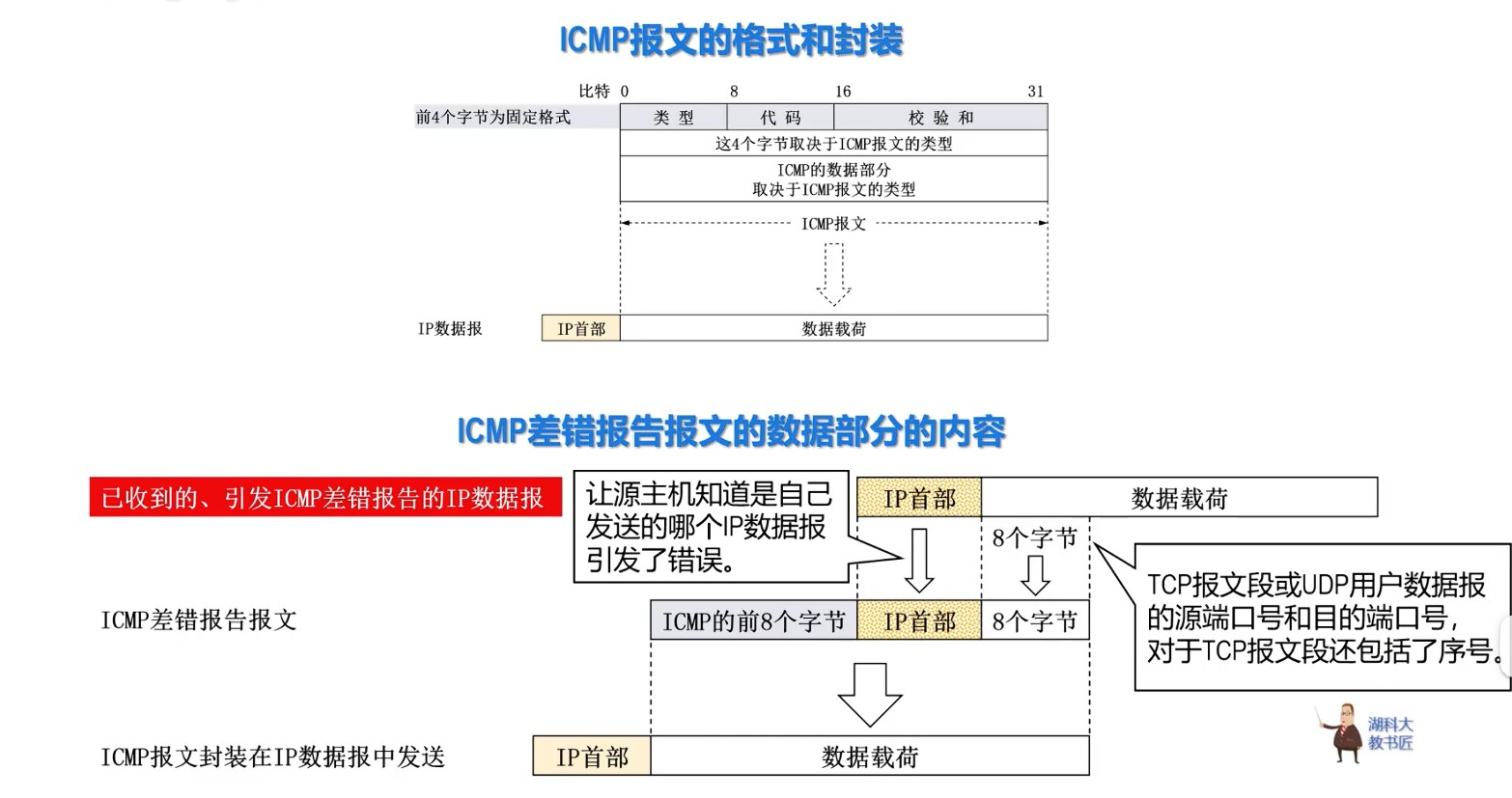
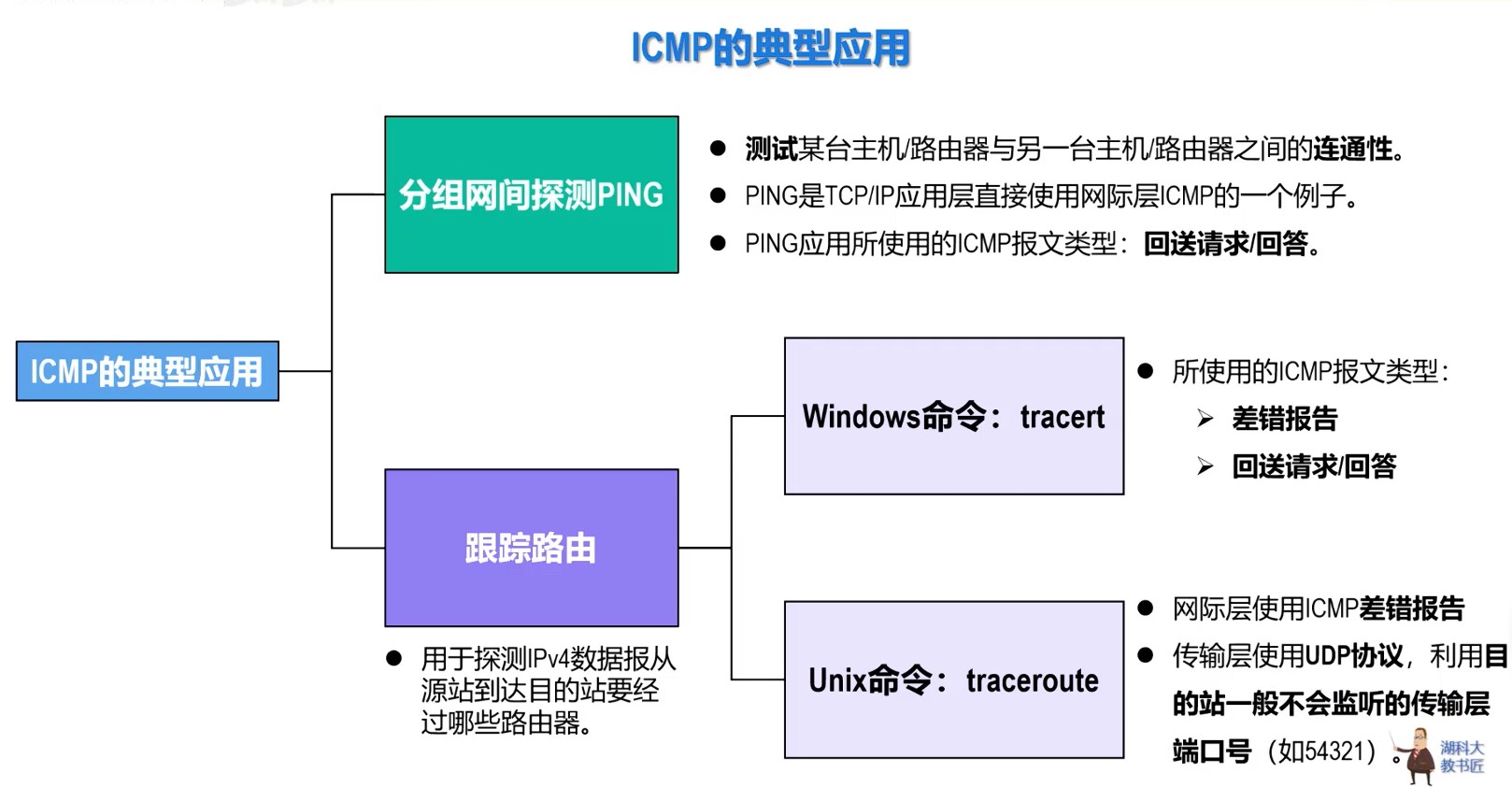
-
若没有匹配目的地址的路由记录,路由器也没有配置默认路由记录,则路由器丢弃该IP分组,并给发送该IP分组的源主机发送终点不可达ICMP差错报文
-
当路由器检测到拥塞时,可以合理丢弃IP分组,并向发出该IP分组的源主机发送源点抑制ICMP报文
-
分组>MTU且DF=1→ICMP终点不可达差错报告报文
-
PING工作在应用层,它直接使用网络层的ICMP,没有通过TCP或者UDP;
-
使用回送请求和回答报文
-
为什么使用的是回送请求和回答报文,而不是时间戳请求和回答报文?
-
PING使用ICMP回送请求和回答报文,是因为它的核心目标是测试网络的“连通性”和“可达性”
-
而时间戳请求/回答报文的主要目的是进行“时钟同步”和“时间测量”
-
1. 核心目标不同
- PING(回送请求/回答):
- 主要目的:回答一个最基本的问题——“你能听到我吗?” 也就是连通性测试。
- 实现方式:它发送一个数据包,对端收到后必须立即回复一个完全对应的数据包。通过计算发送和接收之间的时间差,可以间接计算出往返时间。
- 结果:如果能收到回复,说明网络路径是双向连通的,并且可以大致知道延迟。
- 时间戳请求/回答):
- 主要目的:进行时间同步或精确计算单向延迟。
- 实现方式:报文包含三个时间戳:
- 原始时间戳:发送方发送报文的时间。
- 接收时间戳:接收方收到报文的时间。
- 传送时间戳:接收方回复报文的时间。
- 结果:理论上,接收方可以利用这三个时间戳来计算网络延迟和双方的时钟差。
2. 为什么时间戳请求/回答不适用于PING?
尽管时间戳报文看起来能提供更精确的时间信息,但它有几个致命的弱点,使其不适合作为通用的连通性测试工具:
- 严重依赖时钟同步:这是最核心的问题。要使得时间戳有意义,通信双方的系统时钟必须是高度精确和同步的。在互联网上,无数主机的时钟可能存在几秒、几分钟甚至更长时间的偏差。如果主机A的时钟比主机B快10分钟,那么计算出的延迟将毫无意义,甚至是负数。而PING的往返时间计算只依赖于一台主机(发送方)的时钟,避免了这个问题。
- 计算复杂:
- PING的延迟计算:
延迟 = 接收时间 - 发送时间。非常简单。 - 时间戳的延迟计算:需要双方协调,并且要处理时钟偏差,计算逻辑复杂。
- PING的延迟计算:
- 实用性和可靠性:
- PING 非常“轻量”,它只关心数据包是否回来以及花了多长时间。
- 时间戳请求 需要对方主机提供高精度的、可信的系统时间,这在许多情况下是不现实的(例如,一台普通PC的时间可能随时被用户或系统调整)。
- 安全与过滤:
- 由于时间戳协议可能被用于探测系统信息(如系统运行时间),许多网络防火墙会直接过滤掉ICMP时间戳请求和回答报文。这意味着即使网络是通的,你也可能收不到回复,从而错误地判断为网络不通。
- 而ICMP回送请求/回答是公认的、最基础的网络诊断工具,虽然也可能被过滤,但其被允许的概率远高于时间戳报文。
- PING(回送请求/回答):
特性 ICMP回送请求/回答 (PING) ICMP时间戳请求/回答 主要目的 测试连通性和估算往返延迟 时钟同步和计算单向延迟 时钟依赖 只依赖发送方的时钟 依赖通信双方的时钟高度同步 计算复杂度 低 高 实用性 高,简单可靠 低,受时钟精度和网络策略影响大 普遍性 几乎所有系统都支持并响应 很多系统默认不响应或已被防火墙过滤 -
-
-
-
Traceroute/Tracert工作在网络层。

-
使用ICMP时间超过报文
-
📌 Traceroute 的基本原理
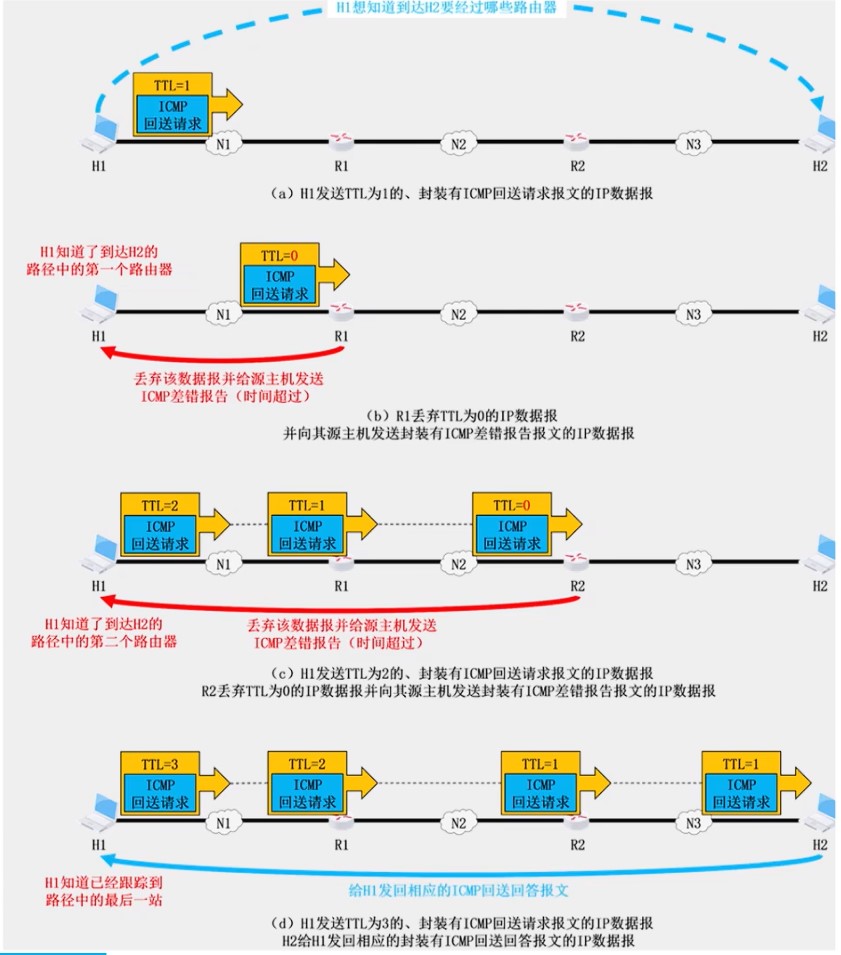
-
利用 TTL(Time To Live)机制
- 源主机向目的主机发送一系列探测报文(通常是 UDP 报文,也可以是 ICMP Echo)。
- 第一个报文 TTL=1,经过第一个路由器时 TTL-1=0,该路由器丢弃数据报,并返回一个 ICMP 时间超过(Time Exceeded) 差错报文给源主机。
- 源主机就知道了第一个路由器的 IP 地址。
-
逐步增加 TTL
- 第二个报文 TTL=2,能走过第一个路由器,到达第二个路由器时 TTL 归零,被丢弃并返回 ICMP 时间超过报文。
- 源主机于是知道了第二个路由器的 IP 地址。
依此类推,每次 TTL 增加 1,就能得到路径上下一个路由器的 IP 地址。
-
到达目的主机时
- 当数据报的 TTL 足够大,报文能到达目的主机。
- 但是报文封装的是一个“无法交付的 UDP 报文”(目的端口号很大、没人监听)。
- 于是目的主机返回一个 ICMP 端口不可达(Port Unreachable) 报文。
- 源主机据此得知已经到达了目的地。
-
-
Traceroute 会把每次收到的 ICMP 报文中路由器(或主机)的 IP 地址打印出来。
同时测量每个路由器返回 ICMP 报文的往返时间 (RTT),通常显示三次探测的结果。
输出的就是一条从源主机到目的主机的逐跳路径。
-
Windows里面,是ICMP时间超过报文和ICMP回送请求和回送回答报文。
-
-
当路由器或目的主机收到的数据报的首部中**有的字段(注意不是任意字段)**的值不正确时,就丢弃该数据报,并向源点发送参数问题ICMP差错报告报文。
-
IP首部字段出现非法值
- 例如:首部长度(IHL)小于5(最小长度),超过允许范围。
- 总长度字段小于首部长度。
- 协议字段(Protocol)为系统未定义或不支持的值。
- 源地址/目的地址非法(如全0、全1、保留地址等,在不允许的场景下出现)。
-
IP选项字段出现错误
- 比如某个选项格式不对、长度错误、或出现了未定义的选项类型。
-
分片相关字段异常
- 标志位、片偏移组合不合法。
-
ICMP 参数问题报文主要是针对 IP 数据报首部(尤其是首部字段或选项字段)出现无法识别或非法取值 时触发的,而不是针对数据部分。
-
-
ICMP被封装在IP数据报里发送,是网络层协议
-
ICMP差错报告报文的数据字段的内容
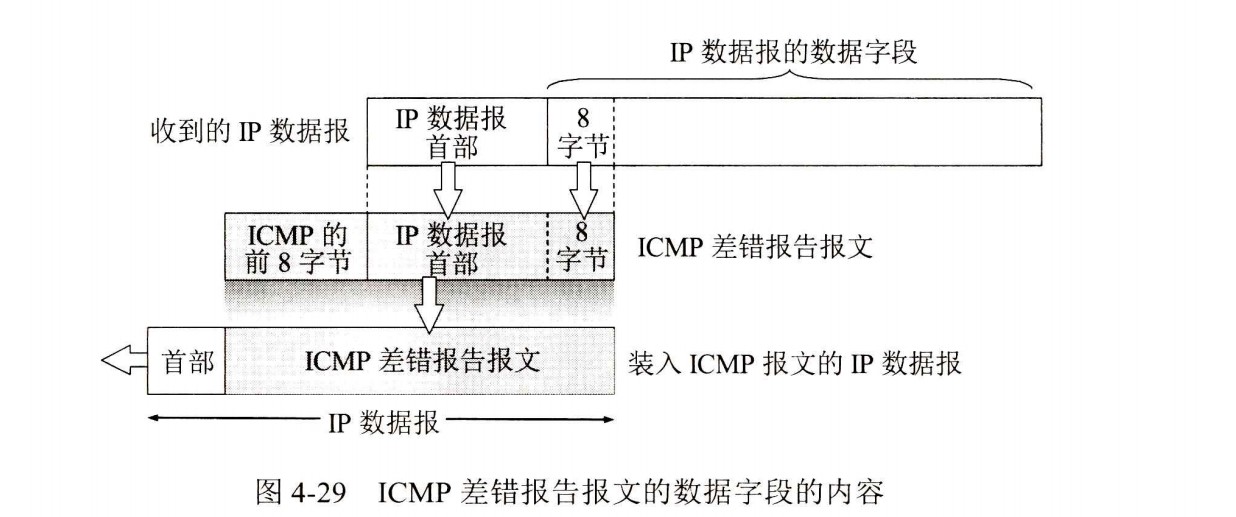
- 提取收到的IP数据报的数据字段前8个字节是为了得到运输层的端口号(对于TCP和UDP)以及运输层报文的发送序号(对于TCP)。
多播

-
多播地址只能用于目的地址,而不能用于源地址
- 对多播数据报不产生ICMP差错报文
- 因此,若在PING命令后面键入多播地址,将永远不会收到响应。
- 对多播数据报不产生ICMP差错报文
-
在互联网上进行多播的最后阶段,还是要把多播数据报在局域网上用硬件多播交付给多播组的所有成员
-
多播机制仅用于UDP,即IP多播的应用层协议是IGMP(严格来说不把IGMP划分到某一层),传输层是UDP
-
多播需要路由器的支持才能实现
-
并非所有的D类地址都可以作为组播地址
-
因为局域网支持硬件多播,所以只要把IP多播地址映射成多播MAC地址,即可将IP多播数据报封装在局域网的MAC帧中,而MAC帧首部的目的MAC地址字段就设置为由IP多播地址映射成的多播MAC地址。这样,就很方便地利用硬件多播实现了局域网内的IP多播。
-
以太网多播地址和IP地址是一对多的关系(只映射后23位)
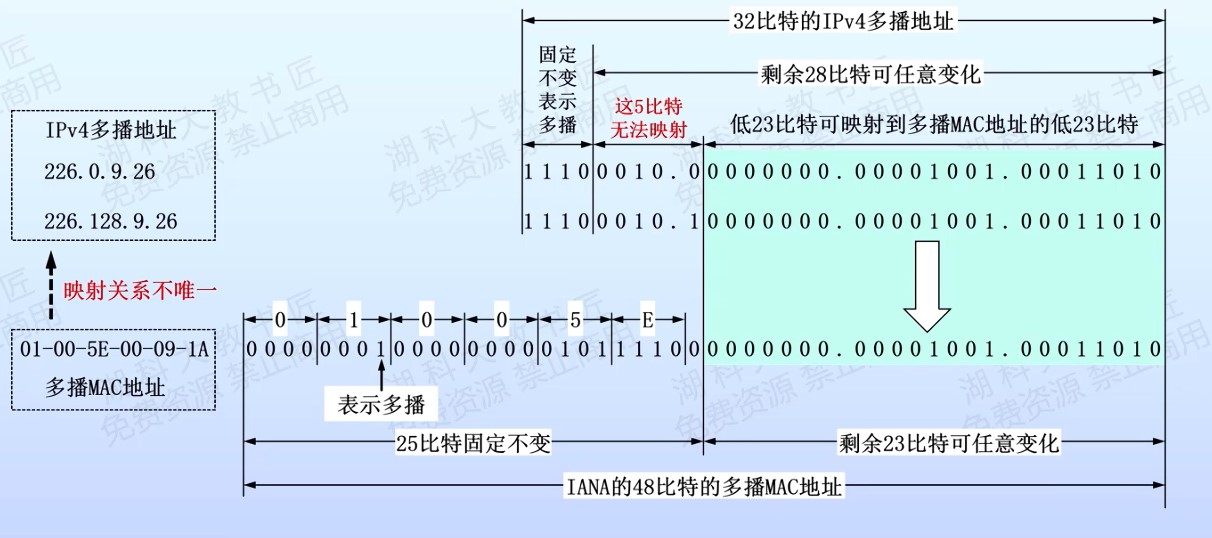
- 因此收到多播数据报的主机,还要在IP层利用软件进行过滤,把不是本主机要接受的数据报丢弃
- 组播数据报的过滤两种情况
- MAC组播匹配不上,在数据链路层过滤
- MAC组播匹配,IP组播不匹配,网络层过滤
-
-
IGMP是让连接到本地局域网上的多播路由器,知道本局域网上是否有主机参加或退出了某个多播组。IGMP并不是在互联网范围内对所有多播组成员进行管理的协议。IGMP不知道IP多播组包含的成员数,也不知道这些成员分布在哪些网络上。
-
IGMP成员查询报文目的地址固定:224.0.0.1

- 224.0.0.1所有系统组播组,所有设备(本网络中的所有参加多播的路由器和主机)都对该地址进行监听,用于查询报文的目的地址
- 224.0.0.2所有路由器组播组,只有本网络中所有多播路由器对该地址进行监听,用于通知所有路由器主机已离组
-
在IGMP(Internet Group Management Protocol)协议中,报文的TTL(生存时间)确实必须设置为1。这是协议的明确要求,目的是确保IGMP报文仅在本地局域网内传播,而不会被路由器转发到其他网络。
-
IGMP报文被封装在IP数据报中传送,但它也向IP提供服务。因此不把IGMP视为一个单独的协议,而视为整个网际协议IP的一个组成部分。
-
多个单播可以仿真多播,但是一个多播所需的带宽要小于很多个单播带宽之和;
- 用多个单播仿真一个多播时,路由器的时延将很大,而处理一个多播分组的时延是很小的
-
仅有IGMP协议是不能完成多播任务的。连接在局域网上的多播路由器还必须和互联网上的其他多播路由器协同工作,以便把多播数据报用最小代价传送给所有的组成员。这就需要使用多播路由选择协议。
-
多播转发必须动态地适应多播组成员的变化(这时网络拓扑并未发生变化)。
- 单播路由选择通常是在网络拓扑发生变化时才需要更新路由。
-
多播路由器在转发多播数据报时,不能仅仅根据多播数据报中的目的地址,而是还要考虑这个多播数据报从什么地方来和要到什么地方去。
-
单播只需要考虑目的IP
-
多播之所以需要同时考虑源地址(S) 和组播组地址(G),而不仅仅是目的地址,核心原因就是为了构建一个无环、最优的转发路径树,并从根本上避免数据包的重复接收和循环转发。
-
特性 单播 组播 转发依据 目的地址 (D) 源地址 (S) + 组播组地址 (G) 路由表状态 基于网络前缀 基于 (S, G)对路径形态 到目的网络的最短路径 以源为根的到所有接收者的最短路径树 防环机制 路由协议算法(如SPF)本身保证 逆向路径转发 (RPF) 检查
-
-
多播数据报可以由没有加入多播组的主机发出,也可以通过没有组成员接入的网络。
-
硬件多播和IP多播的区别
-
特性 硬件多播 / MAC层多播 IP多播 工作层级 数据链路层(第二层) 网络层(第三层) 地址 MAC地址( 01-00-5E-xx-xx-xx)IP地址( 224.0.0.0 ~ 239.255.255.255)作用范围 单个本地网络(广播域) 全球性,可跨网络路由 关键协议 无独立协议,由交换机管理和IGMP Snooping驱动 IGMP, PIM, DVMRP, MSDP等 主要任务 在本地网段内精确投递帧 在不同网络间路由数据包
-
-
IGMP工作阶段
- 第一阶段:当某台主机加入新的多播组时,该主机应向多播组的多播地址发送一个IGMP报文,声明自己要成为该组的成员。本地的多播路由器收到IGMP报文后,还要利用多播路由选择协议把这种组成员关系转发给互联网上的其他多播路由器。
- 第二阶段:组成员关系是动态的。本地多播路由器要周期性地探询本地局域网上的主机,以便知道这些主机是否还继续是组的成员。只要有一台主机对某个组响应,那么多播路由器就认为这个组是活跃的。但一个组在经过几次的探询后仍然没有一台主机响应,多播路由器就认为本网络上的主机已经都离开了这个组,因此也就不再把这个组的成员关系转发给其他的多播路由器。
-
IGMP采用的一些具体措施
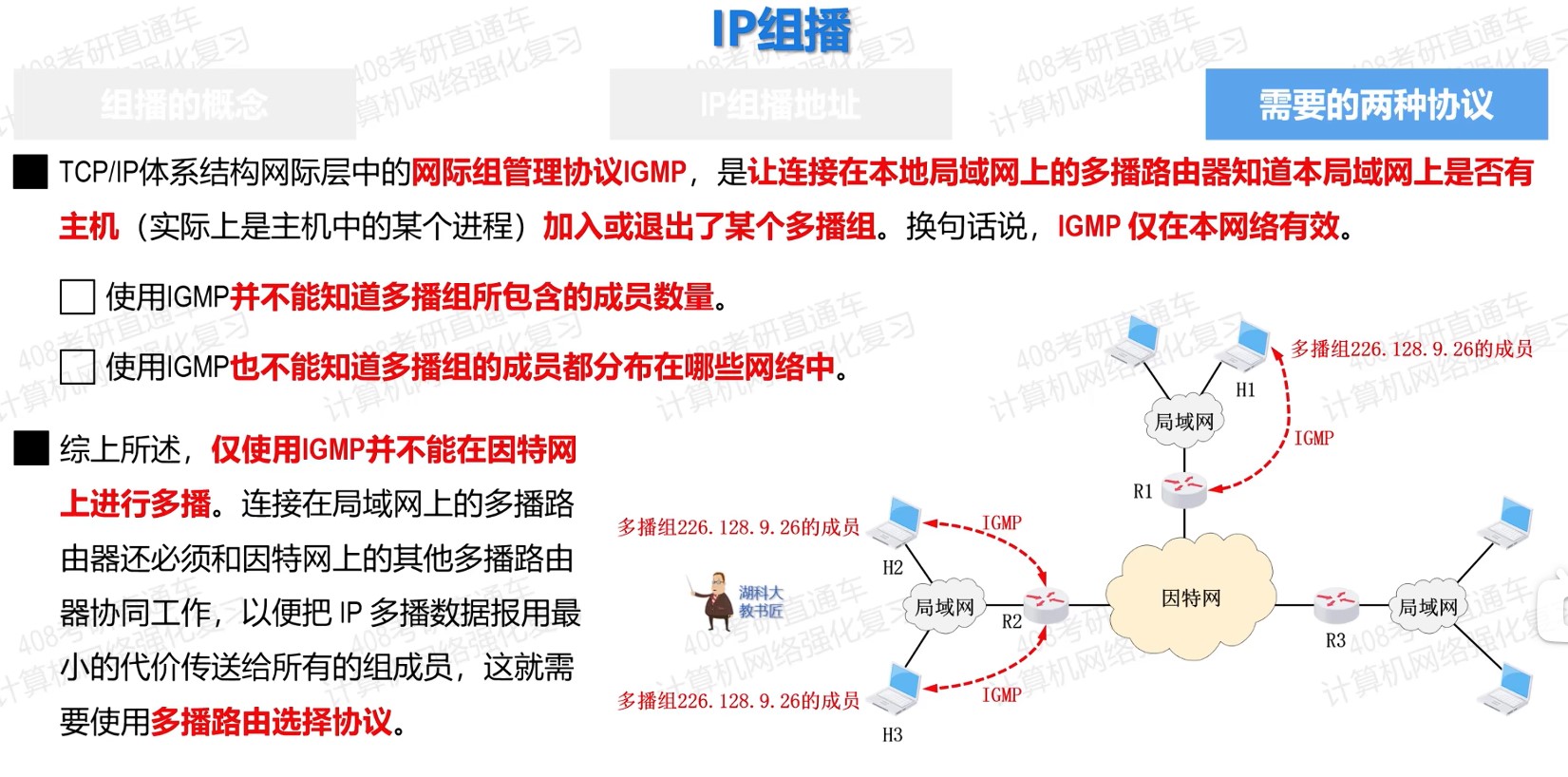
- 在主机和多播路由器之间的所有通信都是使用IP多播。只要有可能,携带IGMP报文的数据报都用硬件多播来传送。因此在支持硬件多播的网络上,没有参加IP多播的主机不会收到IGMP报文。
- 多播路由器在探询组成员关系时,只需要对所有的组发送一个请求信息的询问报文,而不需要对每一个组发送一个询问报文(虽然也允许对一个特定组发送询问报文)。默认的询问速率是每125秒发送一次(通信量并不太大)。
- 当同一个网络上连接有几个多播路由器时,它们能够迅速和有效地选择其中的一个来探询主机的成员关系。因此,网络上多个多播路由器并不会引起IGMP通信量的增大。
- 在IGMP的询问报文中有一个数值N,它指明一个最长响应时间(默认值为10秒)。当收到询问时,主机在0到N之间随机选择发送响应所需经过的时延。因此,若一台主机同时参加了几个多播组,则主机对每一个多播组选择不同的随机数。对应于最小时延的响应最先发送。
- **同一个组内的每一台主机都要监听响应,只要有本组的其他主机先发送了响应,自己就可以不再发送响应了。**这样就抑制了不必要的通信量。
- 多播路由器并不需要保留组成员关系的准确记录,因为向局域网上的组成员转发数据报是使用硬件多播。多播路由器只需要知道网络上是否至少还有一台主机是本组成员即可。实际上,对询问报文每一个组只需有一台主机发送响应。
- 多播数据报的发送者和接收者都不知道(也无法找出)一个多播组的成员有多少,以及这些成员是哪些主机。互联网中的路由器和主机都不知道哪个应用进程将要向哪个多播组发送多播数据报,因为任何应用进程都可以在任何时候向任何一个多播组发送多播数据报,而这个应用进程并不需要加入这个多播组。
-
洪泛与剪除适用于规模较小的多播组,而所有的组成员接入的局域网也是相邻接的。
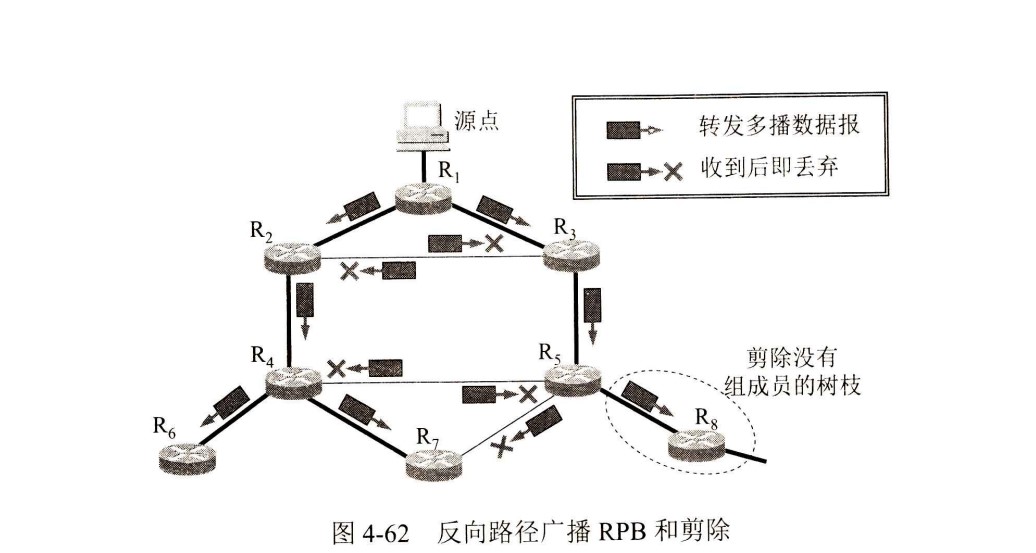
-
隧道技术适用于多播组的位置在地理上很分散的情况
-
基于核心的发现技术,对多播组的大小在较大范围内变化时都适合。
-

整个转发过程
-
路由器总流程
-
①从收到的数据报的首部提取目的IP地址D(目的地址)
-
②判断是否为直接交付,判断网络是否直接与路由器相连:
-
用各接口网络的子网掩码和D逐位相与,判断结果是否和相应的网络地址匹配?
- 若匹配,则把分组进行直接交付,将D通过ARP将IP地址转成MAC地址,封装成MAC帧发送出去
- 则就是间接交付,执行③
-
-
③若路由表中有目的地址为D的特定主机路由,则把数据报传送给路由表所指明的下一跳路由器,否则执行④
- 特定主机路由条目中的目的网络前缀往往是/32,即最长的网络前缀。路由器在查找转发表转发IP数据报时,遵循“最长前缀匹配”的原则,因此特定主机路由条目的匹配优先级最高。
- 进行静态路由配置需要认真考虑和谨慎操作,否则可能出现以下问题:
- 路由条目配置错误,甚至导致出现路由环路
- 聚合路由条目时可能引入不存在的网络
-
④对路由表中的每一行,用其中的子网掩码和目的ip地址D逐位相与,结果为N,若N与该行的目的网络地址匹配,则把数据报传送给该行指明的下一跳路由器,否则,执行⑤
-
⑤若路由表中有一个默认路由0.0.0.0/0(全0掩码和任何目的地址进行按位与运算,结果必然为全0,即必然和前缀0.0.0.0/0相匹配),则把数据报传送给路由表中所指明的默认路由器,否则,执行⑥
-
⑥报告转发分组出错(终点不可达ICMP差错报告报文)(例如若生存时间TTL=0,丢弃并报告出错)
-
-
路由器不转发广播IP数据报,即路由器隔离广播域。
-
路由表的数据结构一般用Trie树
-
路由器在直接交付时的完整流程
- 当路由器查路由表发现是直接交付时,意味着目标IP地址与路由器发出接口在同一个本地网络中。此时路由器会执行以下步骤:
- ①查询ARP缓存:
- 路由器首先检查自己的ARP缓存表,看是否已经有目标IP地址对应的MAC地址。
- 如果找到了:路由器直接使用这个MAC地址。
- ②ARP请求(仅在需要时):
- 如果ARP缓存中没有对应的条目,路由器会广播一个ARP请求报文,询问:“谁的IP地址是[目标IP]?”
- 注意:这个ARP广播只是为了获取MAC地址,不是转发数据报本身。
- 其他主机收到该广播帧后,网卡会交付上层处理
- ③获取ARP响应:
- 目标主机会响应这个ARP请求,单播回复自己的MAC地址给路由器。
- 路由器将这个IP-MAC映射记录到自己的ARP缓存中。
- ④封装并单播转发:
- 路由器使用目标主机的MAC地址作为目的MAC地址,将自己的接口MAC地址作为源MAC地址,重新封装IP数据报成一个数据链路层帧。
- 然后通过单播方式将这个帧从相应接口发送出去。
- 交换机收到这个帧后,会根据MAC地址表将其准确转发到目标主机所在的端口。
-
转发过程中物理层、数据链路层、网络层的设备
- 路由器:接收来自其他网络的IP数据报,查得下一跳地址后交给数据链路层ARP查到MAC地址,MAC帧修改然后发出去
- 交换机:根据交换机转发表,有就直接精准转发,没有就从除了接收口以外的所有其他端口转发出去。
- 集线器/中继器:无脑转发
-
同一网段(同一子网)下的主机是可以进行通信的,不同网段的主机需要找路由器发送ARP请求查找MAC地址,如果需要寻找的主机没有配置对应的网关或者对应的路由网关配置错误,ARP就无法查找到这个主机,此时这两个网段的主机就无法通信
- 一个路由接口不能连接两个网段,因为一个接口只属于其中一个网段,该网段能够正常进行对外交流,但是另一个网段无法与路由器直接通信,因为不在一个网段,两个网段之间也无法通过路由器通信,因为虽然他们不在一个网段,但是路由器认为他们在同一个网段。
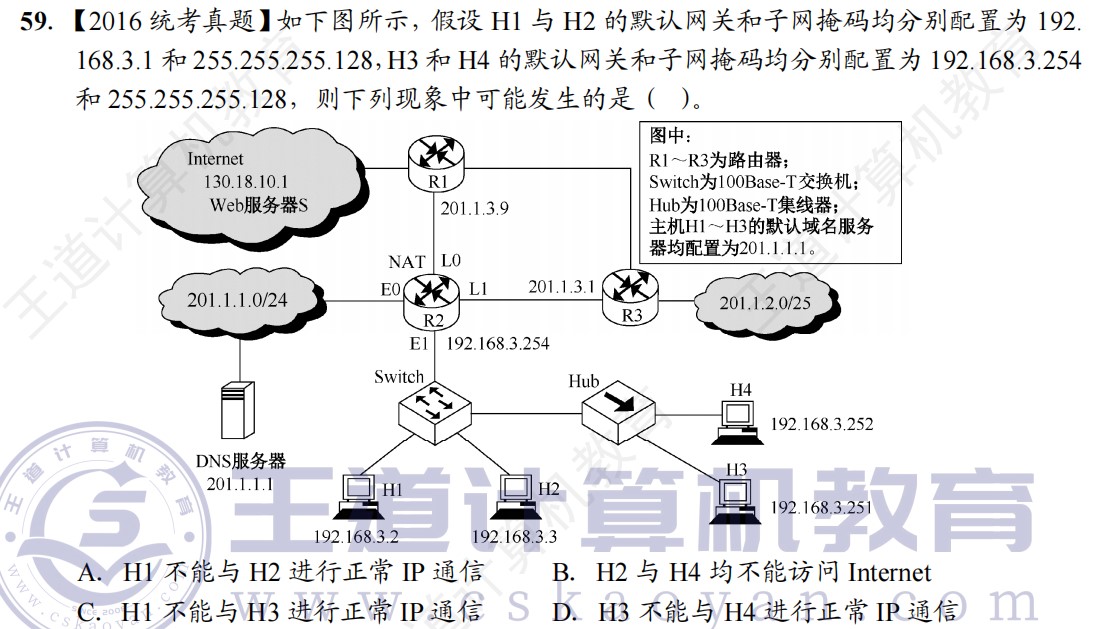

-
默认网关是离主机最近的路由器的接口地址
-
子网划分
首部检验和
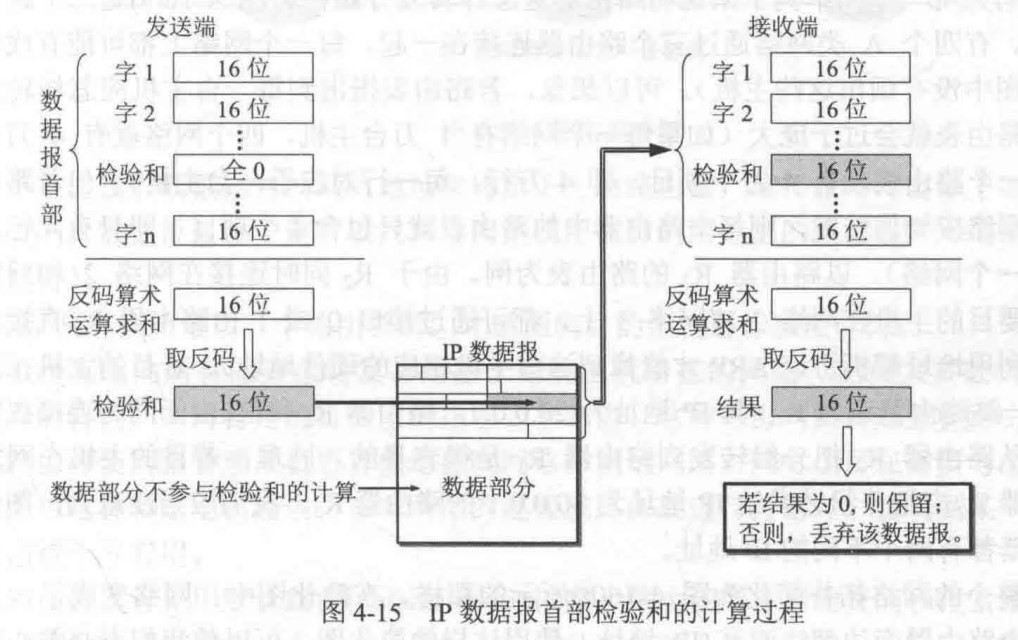
- 计算方法:
- ①在发送方,先把IP数据报首部划分为许多16位字的序列,并把检验和字段置零。
- ②用反码算术运算
- 两个数进行二进制反码求和的运算很简单。它的规则是从低位到高位逐列进行计算。0和0相加是0,0和1相加是1,1和1相加是0但要产生一个进位1,加到下一列。若最高位相加后产生进位,则最后得到的结果要加1。
- ③把所有16位字相加后,将得到的和的反码写入检验和字段。
- ④接收方收到数据报后,将首部的所有16位字再使用反码算术运算相加一次。将得到的和取反码,即得出接收方检验和的计算结果。若首部未发生任何变化,则此结果必为0,于是就保留这个数据报。否则即认为出差错,并将此数据报丢弃。
常用协议和协议号字段

ARP

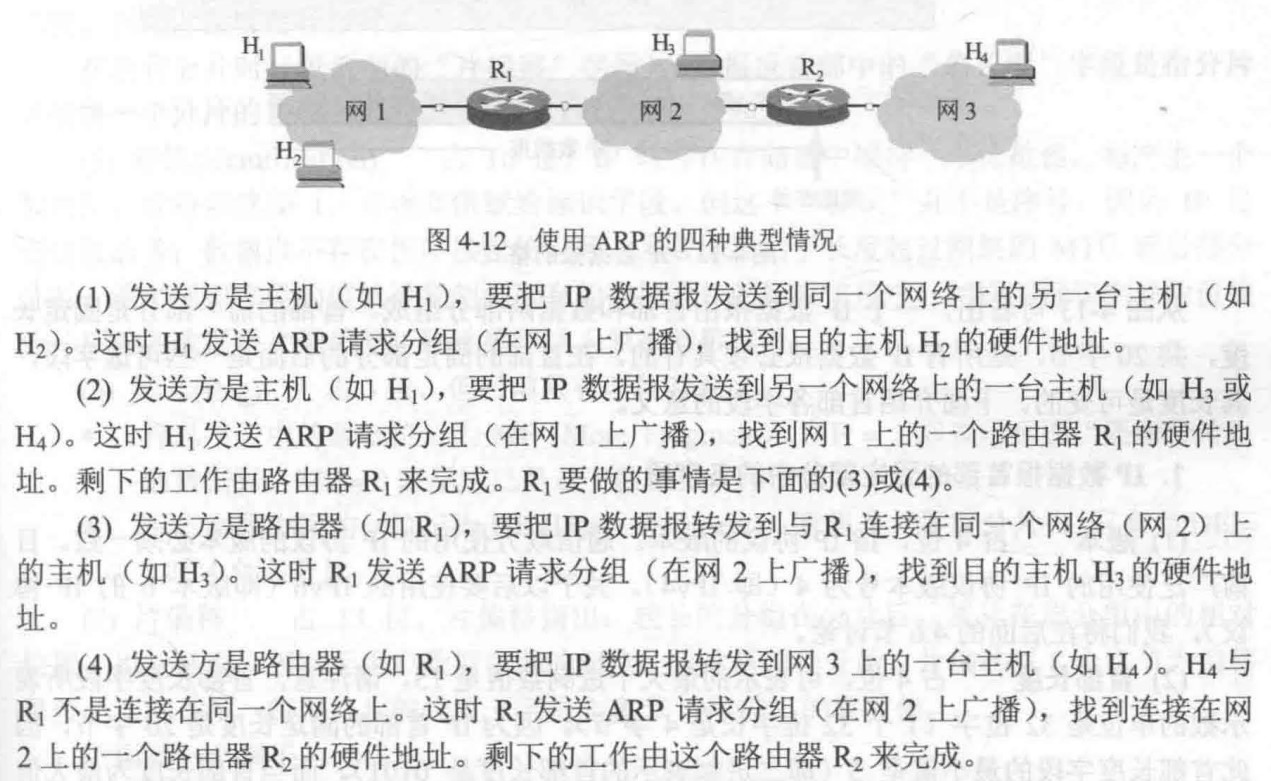
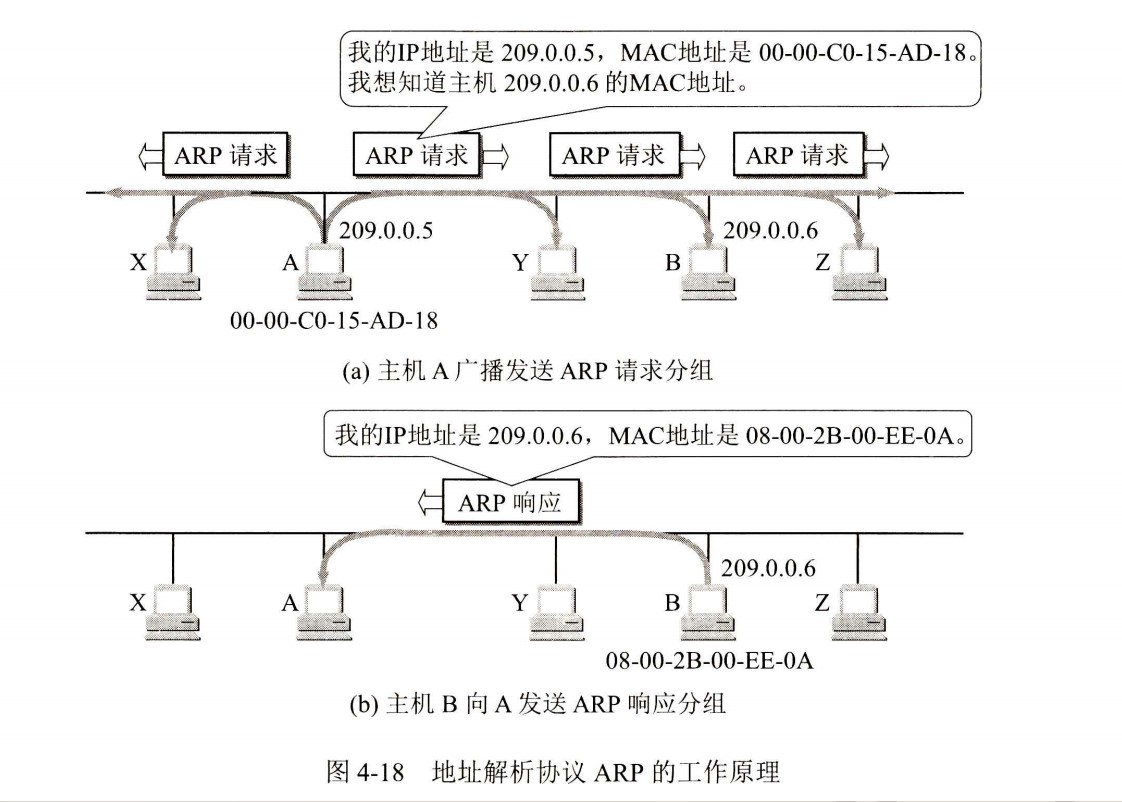
- ARP用于解决同一局域网上的主机或路由器的IP地址和硬件地址的映射问题。若目的主机和源主机不在同一个局域网上,则要通过ARP找到本局域网上的某个路由器的硬件地址,然后把分组发送给这个路由器,让这个路由器把分组转发给下一个网络,剩下的工作就由下一个网络来做。尽管ARP请求分组是广播发送的,但ARP响应分组是普通的单播。
- ARP请求和响应报文不是封装在IP数据报中,而是直接封装在以太网帧(数据链路层帧)中。
- ARP协议最初设计时并未考虑复杂的安全问题,因此它本身缺乏有效的身份验证机制。这使得ARP欺骗等攻击成为可能
- ARP协议除了ARP请求报文和响应报文外,还有其他类型的报文,例如用于检测IP地址冲突的“无故ARP”
- ARP是网络层协议
OSPF和RIP
| OSPF | RIP |
|---|---|
| OSPF是网络层协议,直接用IP数据报发送 | RIP是应用层协议,在传输层用UDP |
| OSPF支持负载均衡 | 而RIP协议只能找到一条最短路径(具体能否等价负载均衡看题目条件,如果题目说了负载均衡,就新增一条表项) |
| OSPF路由器在收到OSPF链路状态更新分组时,会对该链路更新分组发送链路状态确认分组 | 在RIP中,当路由器收到相邻路由器发来的路由更新信息时,若发现有更优的路由,则直接更新自己的路由表,并向其他相邻路由器广播自己的新路由 RIP路由器在收到更新但路由表无变化时,不会发送任何确认信息给邻居,不发生任何动作 |
| OSPF链路状态发生变化或者每隔一段时间(30min),路由器会向所有路由器用洪泛法发送链路状态信息 |
RIP一般每隔30s就交换一次信息(为了加快RIP收敛速度,当网络拓扑发生变化时,路由器要及时向相邻路由器通告拓扑变化后的路由信息,即触发更新),若180s没有收到某条路由条目的更新报文,则把该路由条目标记为无效(RIP=16),若再过一段时间120s还没有收到该路由条目的更新报文,则把该路由条目从路由表中删除 |
| 链路状态算法的只告诉到邻居的距离 | 距离-向量算法告诉到其他所有点的距离 |
| OSPF所有的路由器最终都能建立一个链路状态数据库(全网的拓扑结构图),在全网范围内一致(同步) | RIP协议的每一个路由器虽然知道到所有的网络的距离以及下一跳路由器,但却不知道全网的拓扑结构(只有到了下一跳路由器,才能知道再下一跳应当怎样走)。 |
-
OSPF不用UDP而是直接用IP数据报传送(其IP数据报首部的协议字段值为89)。OSPF构成的数据报很短。这样做可减少路由信息的通信量。数据报很短的另一好处是可以不必将长的数据报分片传送。分片传送的数据报只要丢失一个,就无法组装成原来的数据报,而整个数据报就必须重传。
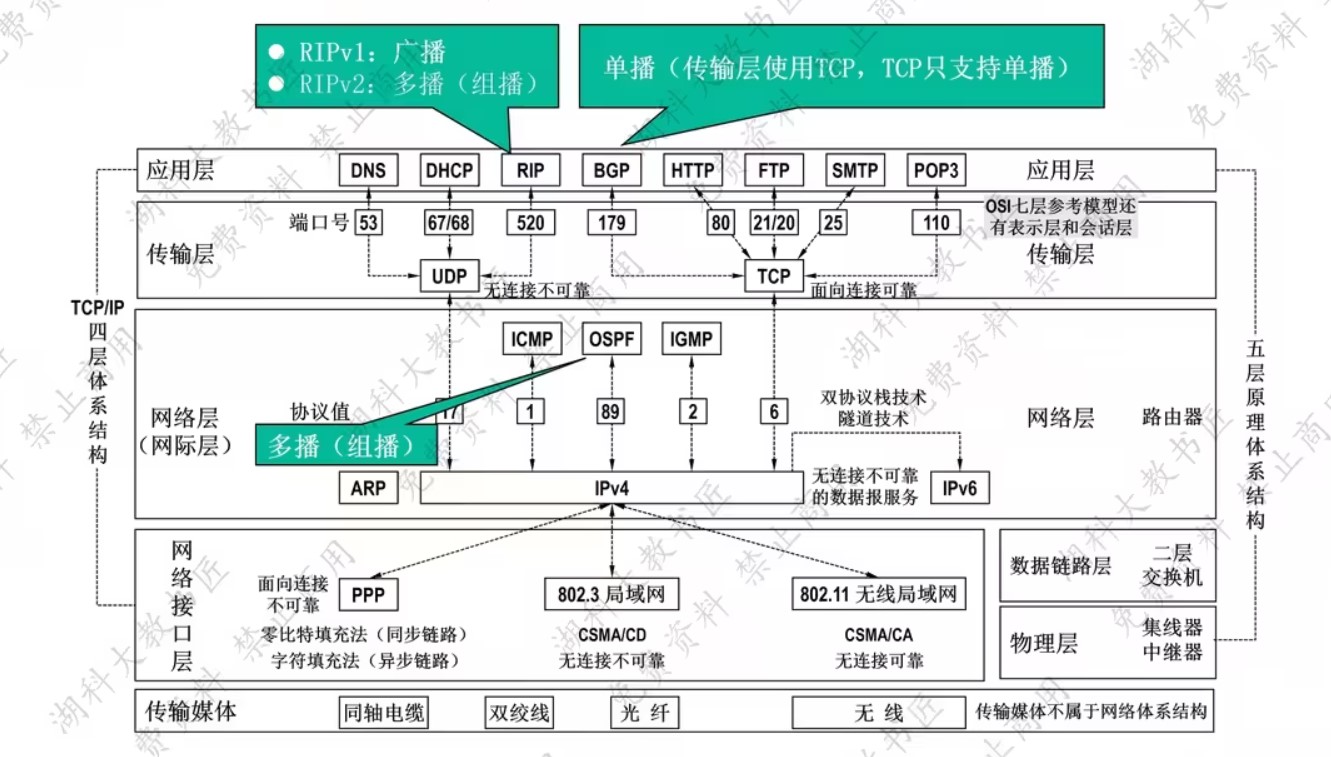
-
RIP一条路径最多只能包含15个网络,14个路由器,距离=15最长,距离16不可达
-
减少坏消息传得慢(路由环路/RIP距离无穷级数问题的措施):
- 限制最大RIP距离为15(16表示不可达)
- 当路由表发生变化时就立即发送路由更新报文(触发更新),而不是周期性发送
- 让路由器记录收到某个特定路由信息的接口,而不让同一路由信息再通过此接口向反方向传送(水平分割)
- 上述措施仍然无法彻底解决问题,因为在距离向量算法中,每个路由器都缺少到达目的网络整个路径的完整信息,无法判断所选的路由是否出现了坏路。
-
OSPF算法不会产生路由环路。
-
划分区域的好处是
- 将利用洪泛法交换链路状态信息的范围局限在每个区域内,而不是整个自治系统
- 在一个区域内部的路由器只知道本区域的网络拓扑,而不知道其他区域的网络拓扑情况
- 采用分层次划分区域的方法虽然使交换信息的种类增多了,同时也使OSPF协议更加复杂了,但是,这样做却能使每个区域内部交换路由信息的通信量大大减少,进而使OSPF协议能够用于规模很大的自治系统中。
- OSPF规定,任何两个非骨干区域之间的路由信息交换,都必须经过骨干区域中转,因此所有非骨干区域都必须与骨干区域直接相连
-
若N个路由器连接在一个以太网上,则每个路由器要向其他(N-1)个路由器发送链路状态信息,因而共有N(N-1)个链路状态要在这个以太网上传送。OSPF协议对这种多点接入的局域网采用了指定的路由器(designated router)的方法,使广播的信息量大大减少。指定的路由器代表该局域网上所有的链路向连接到该网络上的各路由器发送状态信息。
-
三种协议对比
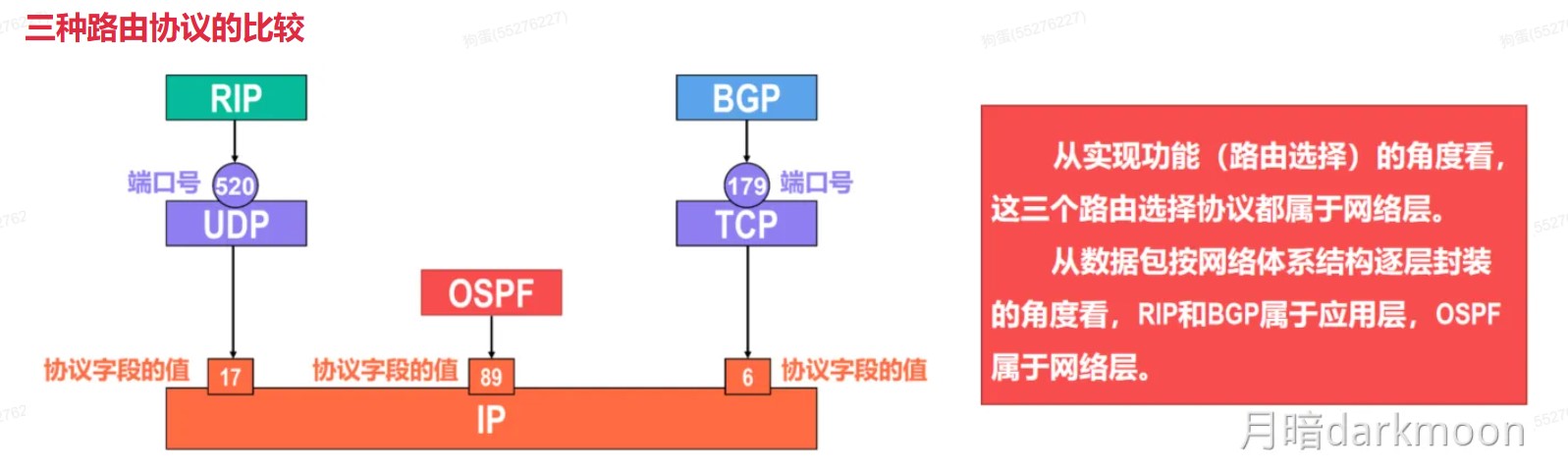
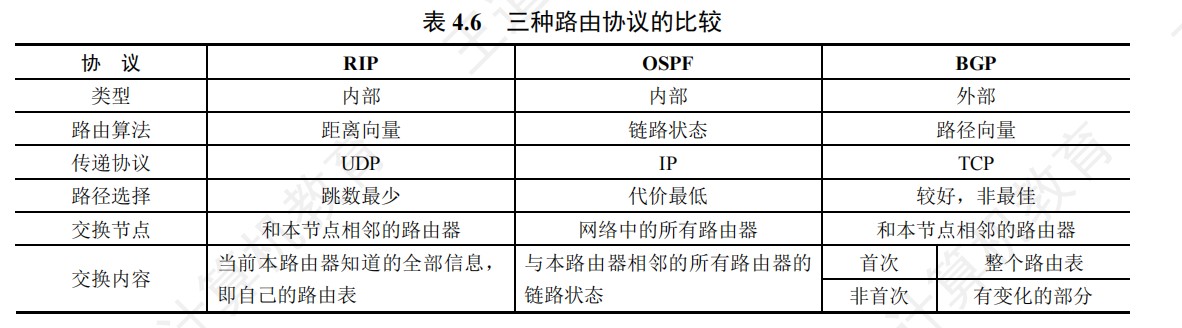
-
距离向量算法的运行过程
-
每个结点保存:
- 到邻居的链路费用
- 到网络中其他结点的链路费用(距离向量)
- 收到的每个邻居的距离向量(邻居到网络中其他节点的费用)
-
①每个节点定期向它的邻居发送它的距离向量副本
-
②收到的结点x根据此用bellmanford算法更新自己的距离向量副本
-
③将更新后的距离向量发给邻居,如果没有变化,就不用发送更新报文
-
路由器刚开始工作时,只知道自己到直连网络的RIP距离为1
- 每个路由器仅和相邻路由器周期性地交换并更新路由信息
- 若干次交换和更新之后,每个路由器都知道到达本自治系统AS内各网络的最短距离和下一跳路由器,叫做收敛。
-
-
OSPF的基本操作

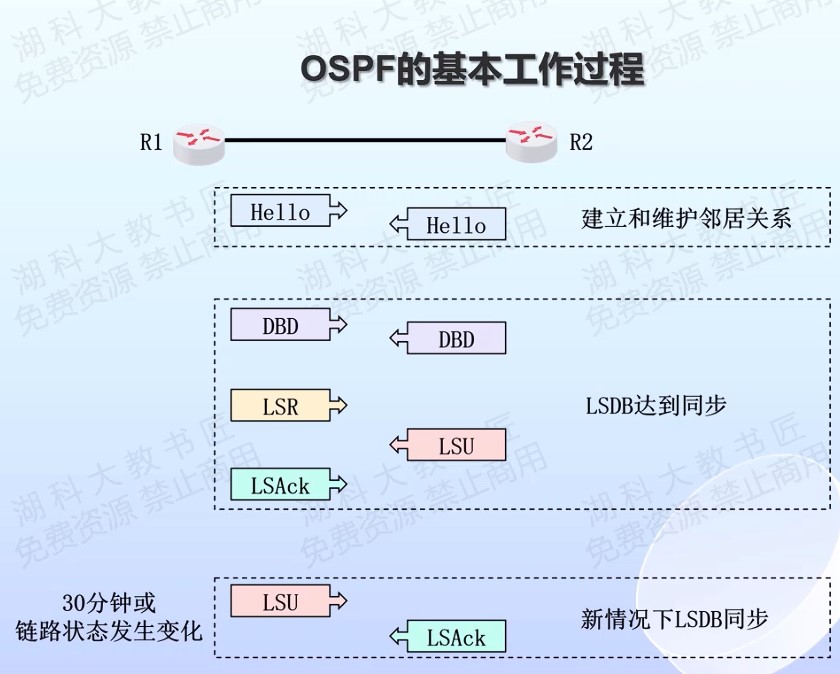
-
OSPF规定,每两个相邻路由器每隔10秒钟要交换一次问候分组。这样就能确知哪些邻站是可达的。对相邻路由器来说,“可达”是最基本的要求,因为只有可达邻站的链路状态信息才存入链路状态数据库(路由表就是根据链路状态数据库计算出来的)。在正常情况下,网络中传送的绝大多数OSPF分组都是问候分组。若有40秒钟没有收到某个相邻路由器发来的问候分组,则可认为该相邻路由器是不可达的,应立即修改链路状态数据库,并重新计算路由表。
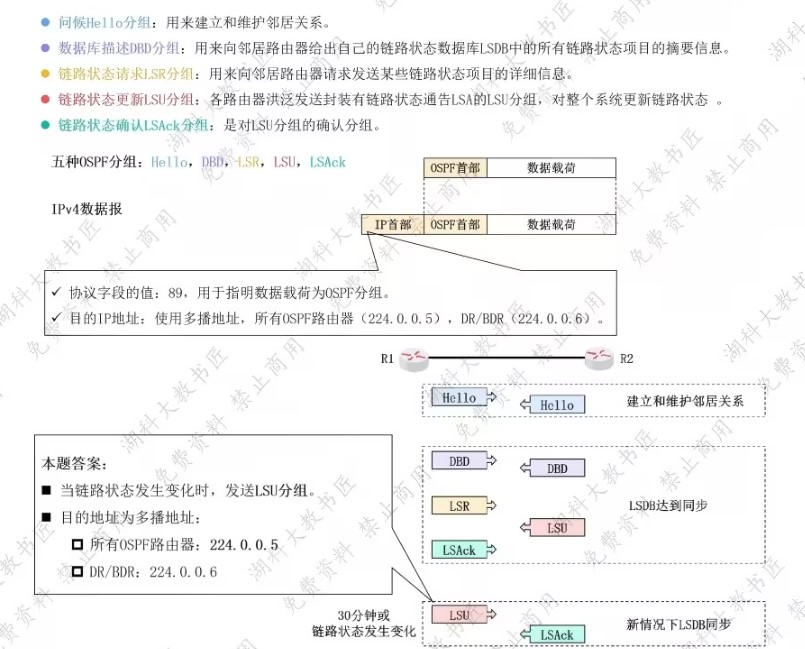
- 问候分组封装在IP数据报中,发往组播地址224.0.0.5,IP数据报首部中的协议号字段的取值为89,表明IP数据报的数据载荷为OSPF分组
-
其他的四种分组都是用来进行链路状态数据库的同步。所谓同步就是指不同路由器的链路状态数据库的内容是一样的。两个同步的路由器叫做“完全邻接的”(fully adjacent)路由器。不是完全邻接的路由器表明它们虽然在物理上是相邻的,但其链路状态数据库并没有达到一致。
-
当一个路由器刚开始工作时,它只能通过问候分组得知它有哪些相邻的路由器在工作,以及将数据发往相邻路由器所需的“代价”。如
-
**OSPF让每一个路由器用数据库描述分组和相邻路由器交换本数据库中已有的链路状态摘要信息。**摘要信息主要就是指出有哪些路由器的链路状态信息(以及其序号)已经写入了数据库。经过与相邻路由器交换数据库描述分组后,路由器就使用链路状态请求分组,向对方请求发送自己所缺少的某些链路状态项目的详细信息。通过一系列的这种分组交换,全网同步的链路数据库就建立了。
-
-
LSA(Link State Advertisement)更新周期:
30分钟的设置可能是与 LSA的更新时间 相关。在OSPF中,每个LSA有一个 老化时间,默认情况下,LSA的寿命是 30分钟(即 1800秒)。这意味着如果没有收到更新的LSA报文,路由器会认为该LSA已经过期,并将其从LSDB中删除。这是为了确保网络拓扑信息是最新的。
在某些情况下,LSA的 刷新周期 可能会设置为更长的时间间隔(例如30分钟),以降低频繁的更新和网络负担。但是,这通常是为了避免不必要的LSA传播,且必须谨慎设置,因为可能会导致网络拓扑信息过时。
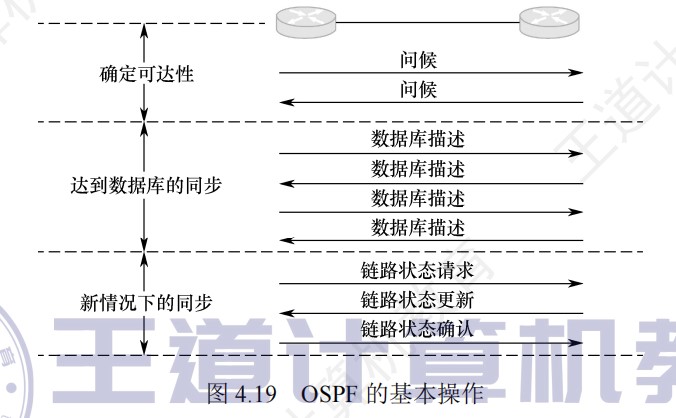
-
可靠的洪泛法是在收到更新分组后要发送确认(收到重复的更新分组只需要发送一次确认)
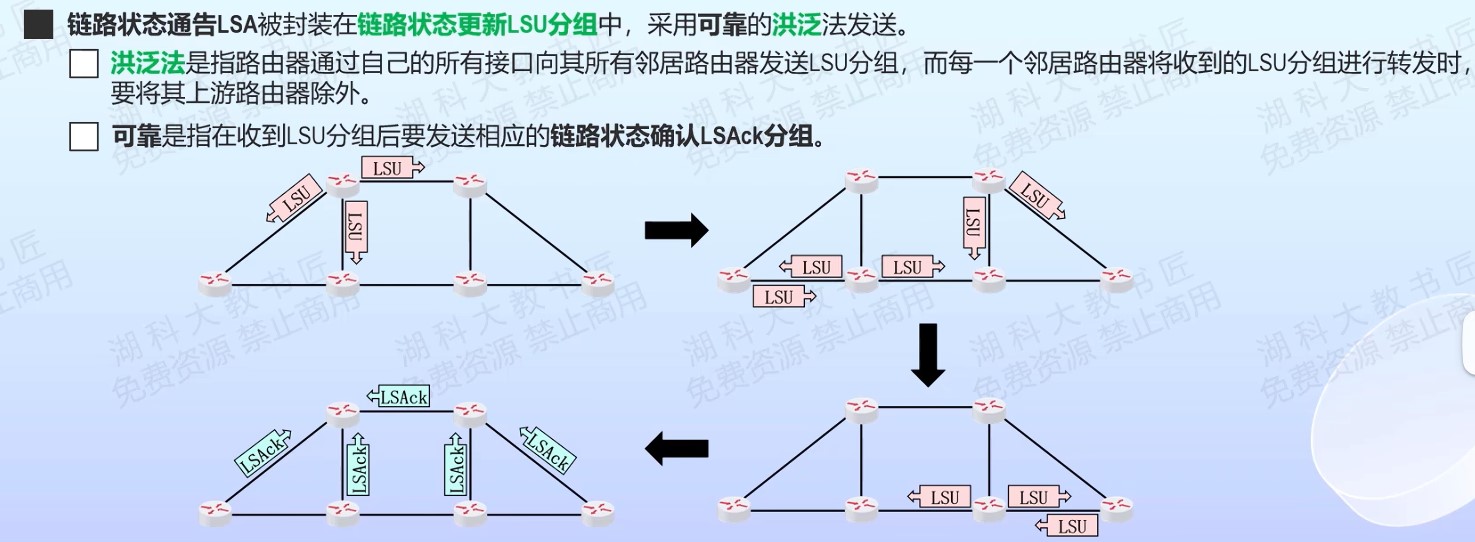
- 每一台接收到LSU的路由器都会向其上游发送方回复LSAck进行确认。因此,LSAck并非一定是发回给最初产生这条LSA的源路由器。
-
链路状态算法易于查找故障
-
在OSPF协议中,**主干区域的32位标识符被规定为0,可以用点分十进制形式0.0.0.0表示 **
-
OSPF分组中采用洪泛方式发送的只有链路状态更新(LSU)分组
BGP
-
BGP刚运行时,BGP的邻站交换整个BGP路由表,但以后只需在发生变化时更新有变化的部分。
-
若两个邻站属于两个不同AS,而其中一个邻站打算和另一个邻站定期地交换路由信息,这就应当有一个商谈的过程(因为很可能对方路由器的负荷已很重因而不愿意再加重负担)。因此,一开始向邻站进行商谈时就必须发送OPEN报文。如果邻站接受这种邻站关系,就用KEEPALIVE报文响应。这样,两个BGP发言人的邻站关系就建立了。
- 一旦邻站关系建立了,就要继续维持这种关系。双方中的每一方都需要确信对方是存在的,且一直在保持这种邻站关系。为此,这两个BGP发言人彼此要周期性地交换KEEPALIVE报文(一般每隔30秒)。KEEPALIVE报文只有19字节长(只用BGP报文的通用首部),因此不会造成网络上太大的开销。
- UPDATE报文是BGP协议的核心内容。BGP发言人可以用UPDATE报文撤销它以前曾经通知过的路由,也可以宣布增加新的路由。撤销路由可以一次撤销许多条,但增加新路由时,每个更新报文只能增加一条。
-
BGP交换路由信息的节点数量级是自治系统的数量级
-
BGP可以很容易地解决距离向量路由选择算法中的“坏消息传播得慢”这一问题。当某个路由器或链路出故障时,由于BGP发言人可以从不止一个邻站获得路由信息,因此很容易选择出新的路由。距离向量算法往往不能给出正确的选择,是因为这些算法不能指出哪些邻站到目的站的路由是独立的。
-
RIP是应用层协议,在传输层用UDP,OSPF是网络层协议,直接用IP数据包发送,BGP是应用层协议,在传输层用TCP
-
BGP路由必须指出通过哪些AS,但不指出路由要经过哪些路由器
-
如果一个BGP发言人收到了其他BGP发言人发来的路径通知,它就要检查一下本自治系统是否在此通知的路径中。如果在这条路径中,就不能采用这条路径(因为会兜圈子)。
-
BGP交换的网络可达性信息是到某个目的网络(用网络前缀表示)所要经过的各个自治系统序列而不仅仅是下一跳。
-
在AS内部,两个路由器之间还需要建立iBGP连接,iBGP连接也使用TCP连接传送BGP报文
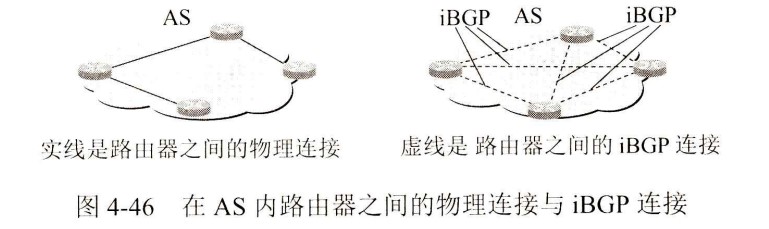
-
协议BGP并非仅运行在AS之间,而且也要运行在AS内部
-
协议BGP规定,在一个AS内部所有的iBGP必须是全连通的。即使两个路由器之间没有物理连接,但他们之间仍然有iBGP连接。
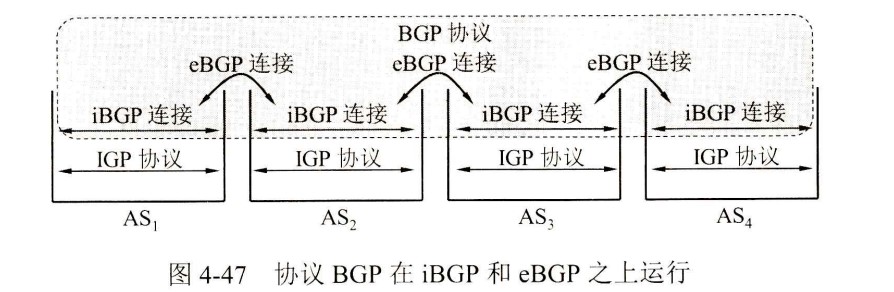
-
eBGP和iBGP并不是两个不同的协议。根据RFC 4271,eBGP是在不同AS的两个对等端之间的BGP连接,而iBGP是同一AS的两个对等端之间的BGP连接。在这两种不同连接上传送的BGP报文,都遵循同样的协议BGP,使用同样的报文格式和具有同样的属性类型。唯一的不同点就是在发送BGP路由通告时的规则有所不同。这就是,从eBGP对等端收到的BGP路由,可通过iBGP告诉同一AS内的对等端。反过来也是可以的,即从iBGP对等端收到的BGP路由,可通过eBGP告诉在不同AS的对等端。但是,从iBGP对等端收到BGP路由,不能转告给同一个AS内不同iBGP的对等端。
-
-
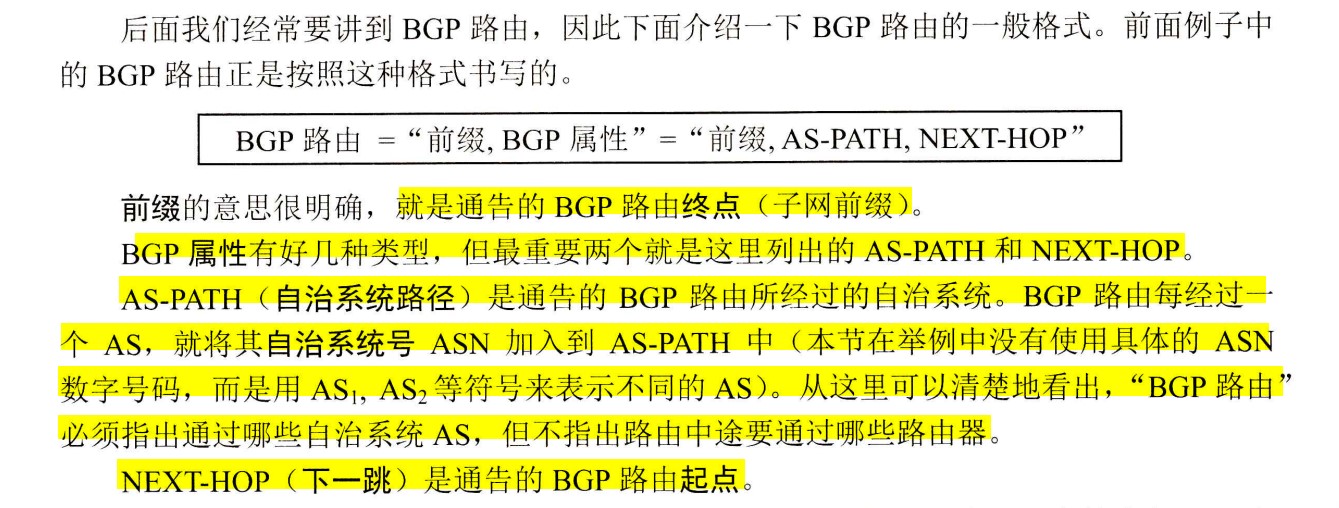
-
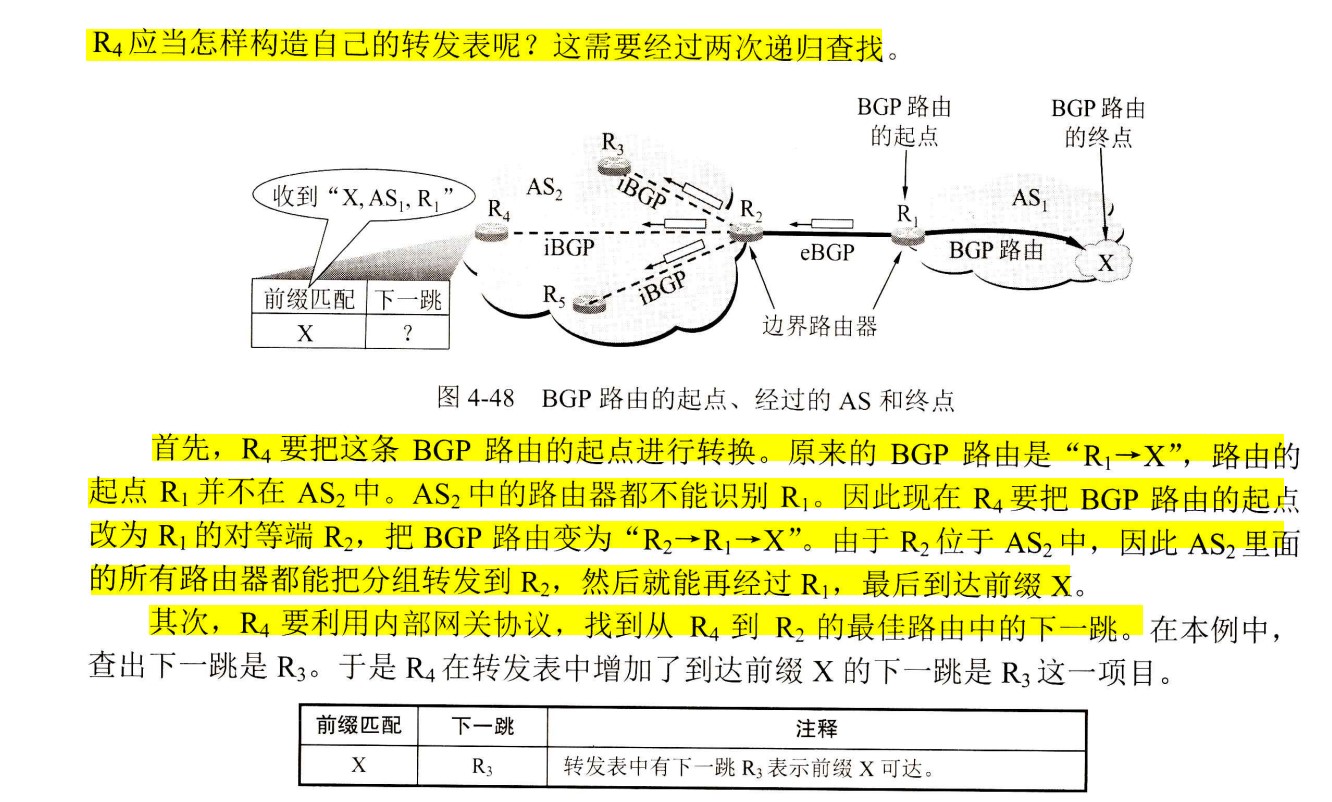
-
IBGP和EBGP的结合
-
BGP路由选择规则
-
三种不同类型的AS
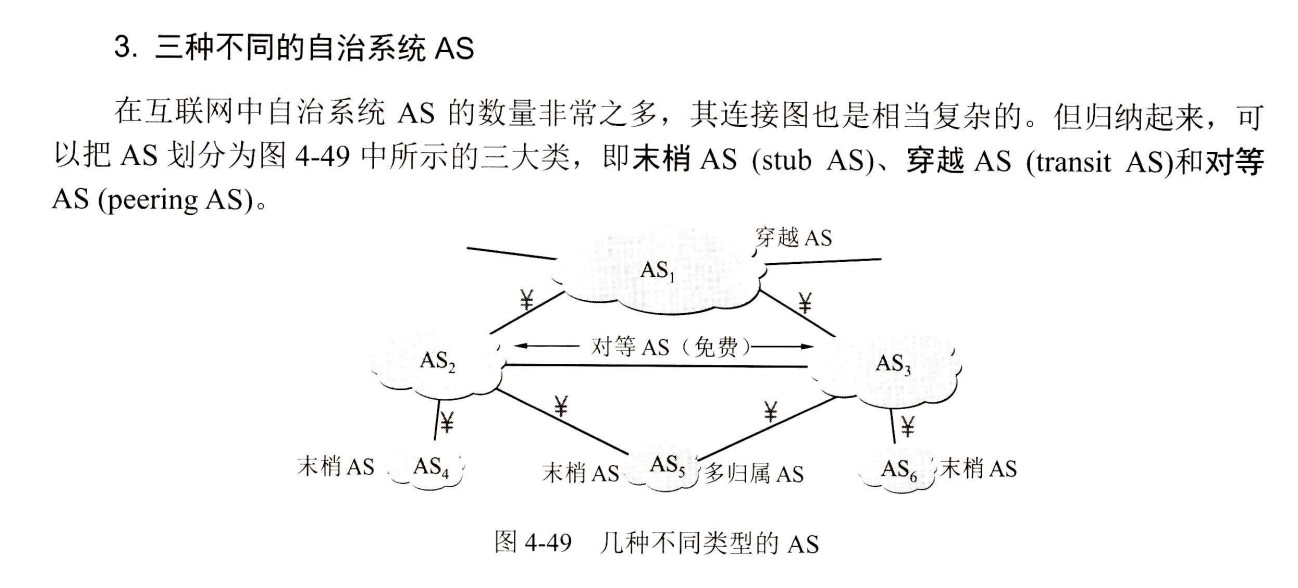

-
BGP路由在AS边界路由器上通过eBGP从外部AS学习后,可通过iBGP通告给同一个AS内的其他路由器,以实现内部传播。
- 路由器从同一个AS内的iBGP对等方学习到的路由(如本地生成的或从外部学到的),可经过属性修改(如添加本地AS号到AS_PATH)后,通过eBGP通告给不同AS内的对等方。
- 从一个iBGP对等方学习到的路由不会通告给同一AS内的其他iBGP对等方,这是为了防止AS内的路由环路。
- 在基本BGP实现中,iBGP要求所有路由器在逻辑上建立全互联对等会话,以确保路由信息一致并防止环路,也就是说,即使路由器之间没有直连的物理链路,只要IP可达,iBGP会话即可建立。
IPv4和IPv6
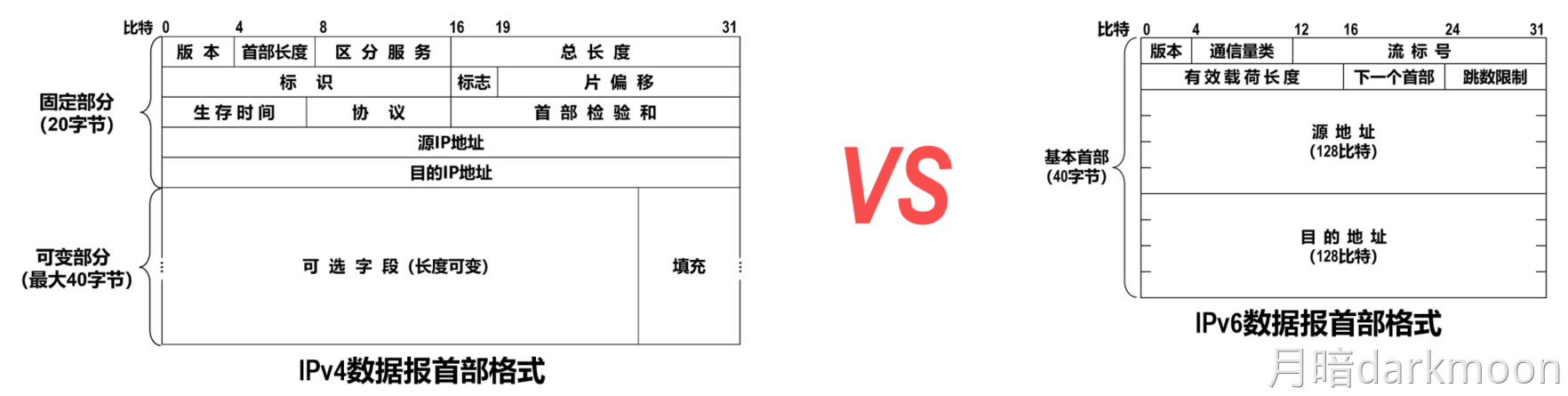
- IPv4的协议字段:
- 6表示TCP
- 17表示UDP
- 1表示ICMP
- 2表示IGMP
- 89表示OSPF
- 路由器对IPv6的扩展首部不进行处理,扩展首部留给路径两短的源点和终点主机来处理



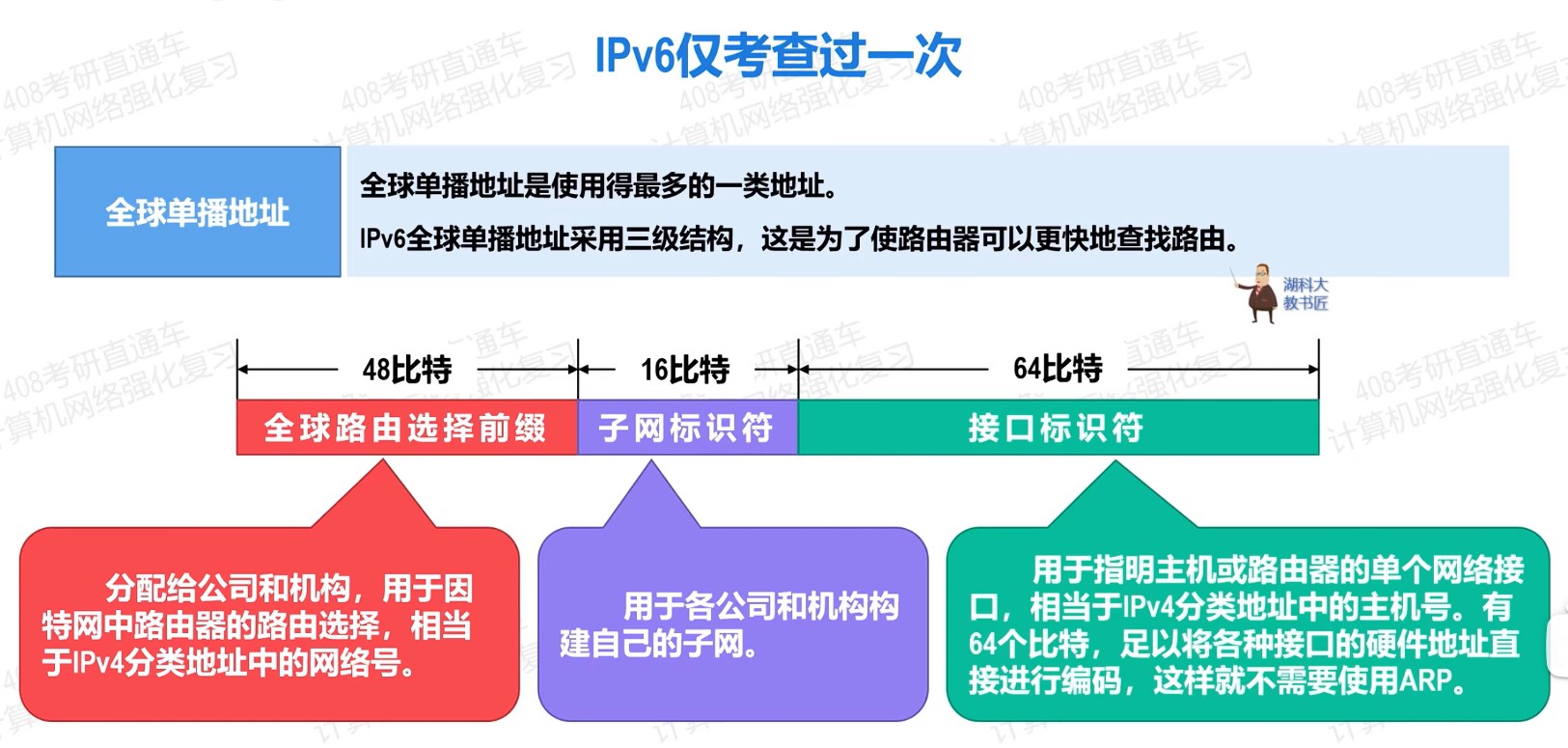
-
一个主机同时连在多个网络上时,该主机就必须由多个IP地址
-
IPv6和IPv4的区别
-
IPv6首部长度固定40B,选项放在有效载荷中,灵活可变;而IPv4所规定的选项固定不变,其选项放在首部的可变部分
-
IPv6即插即用(自动配置),不需要DHCP协议
-
IPv6支持资源的预分配
-
IPv6只有源主机才能分片,端到端的,不允许类似于IPv4在中间路由器进行分片,若数据报太大则丢弃,然后向发送方发送ICMP报文
-
IPv6取消了首部检验和字段,不再计算首部检验和
-
IPv6可以直接从最后64位地址中提取出硬件地址,而不需要使用地址解析协议ARP进行地址解析
-
IPv6利用ICMPv6报文中的邻居请求和邻居通告报文来完成机制解析的功能
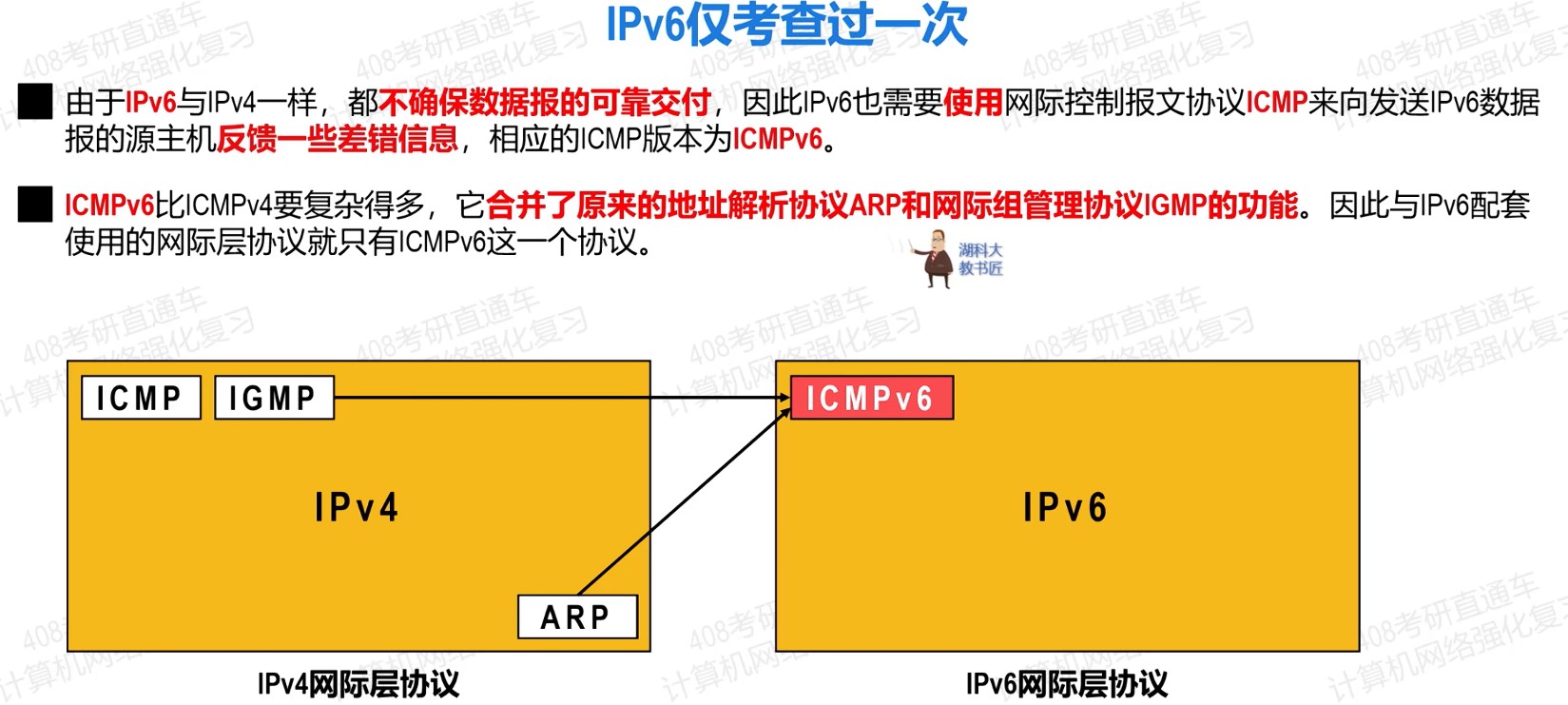
- ARP和IGMP都被整合进了ICMPv6
-
-
-
IPv4中,DF=1且分组长度超过MTU,则丢弃该分组,并用ICMP差错报文向源主机报告
-
在数据链路层对检测出有差错的帧就丢弃。在运输层,当使用UDP时,若检测出有差错的用户数据报就丢弃。当使用TCP时,对检测出有差错的报文段就重传,直到正确传送到目的进程为止。因此在网络层的差错检测可以精简掉。
-
IPv4向IPv6过渡策略

- 双协议栈
- IPv6中的某些字段无法恢复
- IPv6数据包的流标号无法对应到IPv4数据报中的任一字段。
- 通过域名系统DNS查询目的主机采用的IP地址
- IPv6中的某些字段无法恢复
- 隧道技术
- 双协议栈
-
划分子网
- 减少了广播域的大小
- 减少主机的数量
- 仅提高了地址的利用率,并不增加网络的数量
-
IPv6是解决资源不足的根本方法
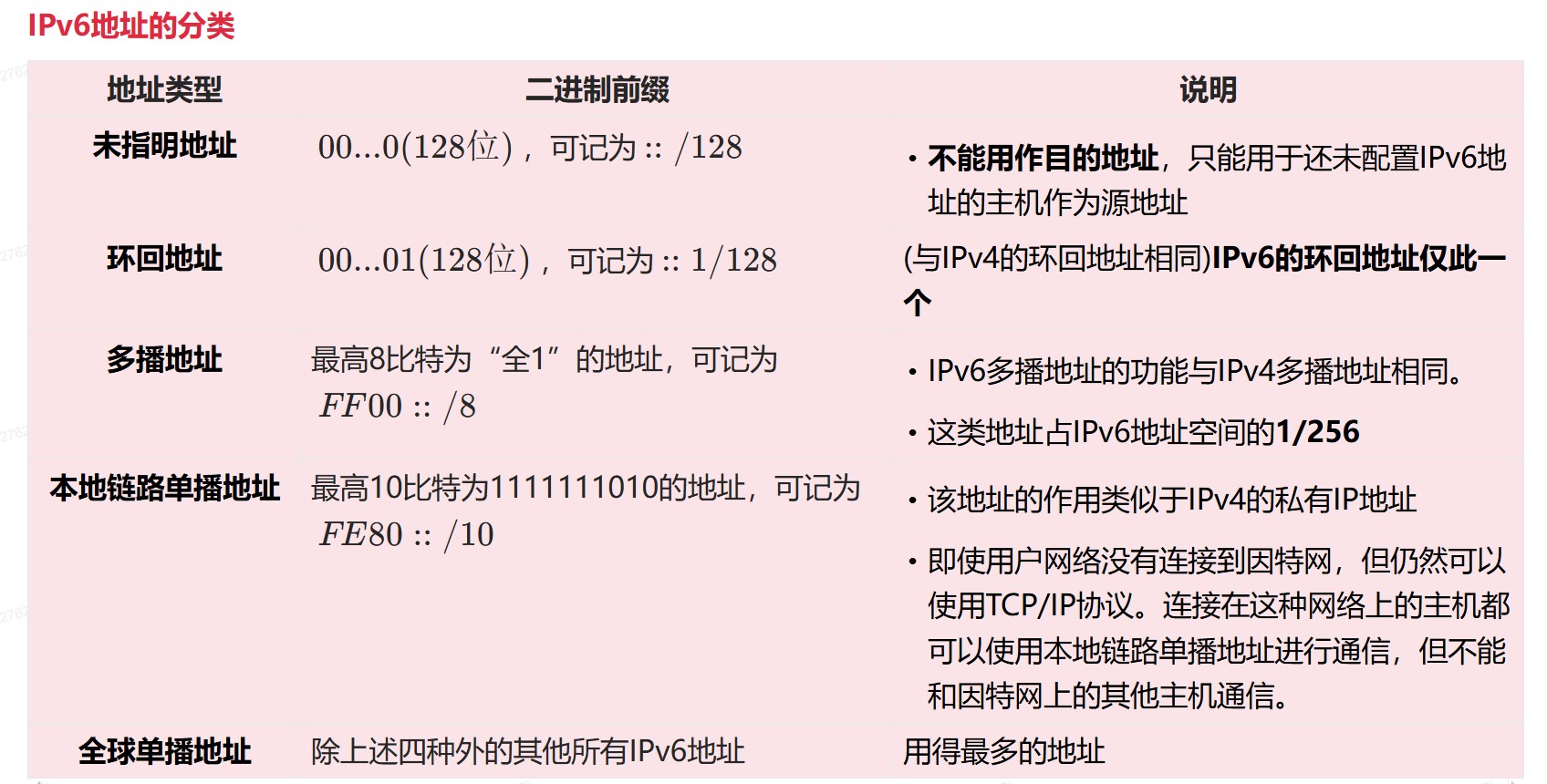
DHCP和ARP帧的MAC和IP地址
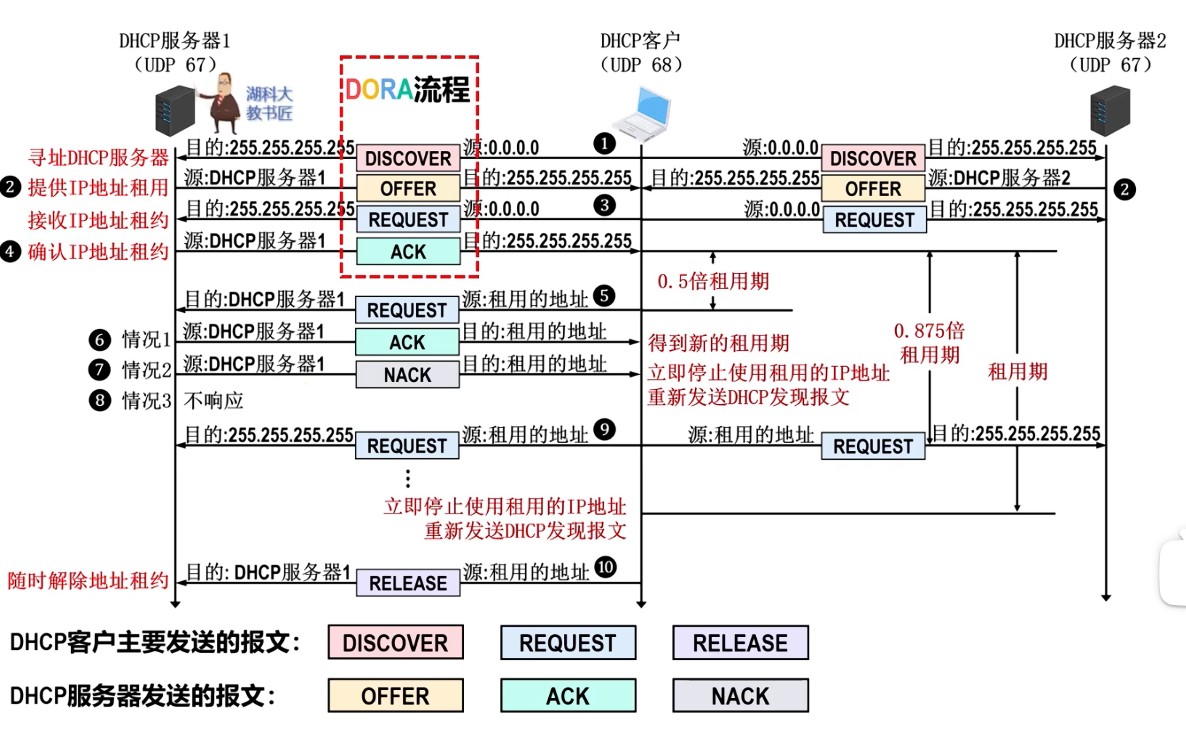


-
DHCP
-
①DHCP发现报文
-
源IP:0.0.0.0
-
目的IP:255.255.255.255(广播)
-
源MAC:客户MAC地址
-
目的MAC:FF-FF-FF-FF-FF-FF
-
-
②DHCP提供报文
- 源IP:DHCP服务器IP
- 目的IP:255.255.255.255
- 源MAC地址:服务器MAC地址
- 目的MAC地址:客户MAC地址
-
③DHCP请求报文
- 源IP:0.0.0.0
- 目的IP:255.255.255.255(广播)
- 源MAC地址:客户MAC地址
- 目的MAC地址:FF-FF-FF-FF-FF-FF
-
④DHCP确认报文
- 源IP:服务器IP
- 目的IP:255.255.255.255
- 源MAC:服务器MAC
- 目的MAC:客户MAC
-
-
ARP请求报文
- 源IP:请求者自己
- 目的IP:被请求者
- 源MAC:请求者自己
- 目的MAC:FF-FF-FF-FF-FF-FF广播
-
DHCP服务器在给DHCP客户挑选IP地址时,使用ARP来确保所选地址未被占用
-
DHCP客户在使用所租的IP地址前,会使用ARP来检测该地址是否被使用。
-
DHCP客户可以随时提前中止租约期,直接给DHCP服务器发送DHCP释放报文(DHCP RELEASE),源IP0.0.0.0,目的IP255.255.255.255
-
DHCP配置
- IP地址
- 子网掩码
- 默认路由器的IP地址
- 域名服务器的IP地址
-
现在是使每一个网络至少有一个DHCP中继代理(通常是一台路由器),它配置了DHCP服务器的IP地址信息。当DHCP中继代理收到主机A以广播形式发送的发现报文后,就以单播方式向DHCP服务器转发此报文,并等待其回答,收到DHCP服务器回答的提供报文后,DHCP中继代理再把此提供报文广播发回主机A。

- 在DHCP中继代理的情况下,以下是完整的DHCP过程及步骤的详细描述:
- 客户端发送DHCP发现报文(DHCP Discover):
- 客户端启动DHCP过程时,首先会发送一个DHCP Discover报文,它是一个广播报文(通常目的地址为255.255.255.255),以寻找网络中的DHCP服务器。
- 由于客户端可能不在与DHCP服务器同一子网,因此这个广播消息不能直接到达DHCP服务器。为了确保消息能够到达DHCP服务器,客户端通过DHCP中继代理来发送该请求。
- DHCP中继代理转发DHCP发现报文:
- DHCP中继代理(通常是一个路由器或交换机)接收到客户端的DHCP Discover报文后,会将这个广播报文转换为单播,并将其转发给指定的DHCP服务器。这时,DHCP中继代理会在报文中加入一个选项(
DHCP Relay Agent Information Option,Option 82),它包含了客户端的IP地址(0.0.0.0)和其他网络信息,以便DHCP服务器知道客户端的原始位置。
- DHCP中继代理(通常是一个路由器或交换机)接收到客户端的DHCP Discover报文后,会将这个广播报文转换为单播,并将其转发给指定的DHCP服务器。这时,DHCP中继代理会在报文中加入一个选项(
- DHCP服务器发送DHCP提供报文(DHCP Offer):
- DHCP服务器接收到中继代理转发的DHCP Discover报文后,会检查其可用的IP地址池并选择一个IP地址,并向客户端发送一个DHCP Offer报文,这个报文是单播发送给中继代理的。
- DHCP Offer报文中包含了以下信息:
- IP地址:服务器为客户端分配的IP地址。
- 子网掩码、网关、DNS服务器等信息。
- 租约时间:客户端可以使用该IP地址的时间。
- DHCP中继代理转发DHCP提供报文:
- 中继代理收到来自DHCP服务器的DHCP Offer报文后,会将其转发给客户端。这个报文通常会被单播到客户端。
- 中继代理负责处理报文的转发,并确保其携带的相关信息(如客户端信息)在转发过程中不会丢失。
- 客户端发送DHCP请求报文(DHCP Request):
- 客户端收到来自DHCP服务器的多个DHCP Offer报文后,会选择一个服务器的报文,并发送一个DHCP Request报文,表明它接受某个服务器提供的IP地址,并请求该地址。
- 此时,DHCP Request报文是一个广播报文,目的是通知所有的DHCP服务器(如果有多个)它已选择了某个服务器。
- DHCP中继代理转发DHCP请求报文:
- DHCP中继代理收到客户端的DHCP Request报文后,会将该请求报文转发给选定的DHCP服务器。此时,这个报文会被单播发送。
- DHCP服务器发送DHCP确认报文(DHCP Ack):
- DHCP服务器接收到客户端的DHCP Request报文后,会确认该请求,并发送一个DHCP Ack报文(DHCP确认报文)。这个报文是单播发送给客户端的,表示客户端已经成功获取了一个IP地址以及其他配置。
- DHCP Ack报文中包含客户端使用该IP地址的租约时间和其他配置信息(如子网掩码、网关、DNS等)。
- DHCP中继代理转发DHCP确认报文:
- 最后,DHCP中继代理会将服务器发出的DHCP Ack报文转发给客户端,完成整个DHCP过程。
- 客户端发送DHCP发现报文(DHCP Discover):
- 在DHCP中继代理的情况下,以下是完整的DHCP过程及步骤的详细描述:
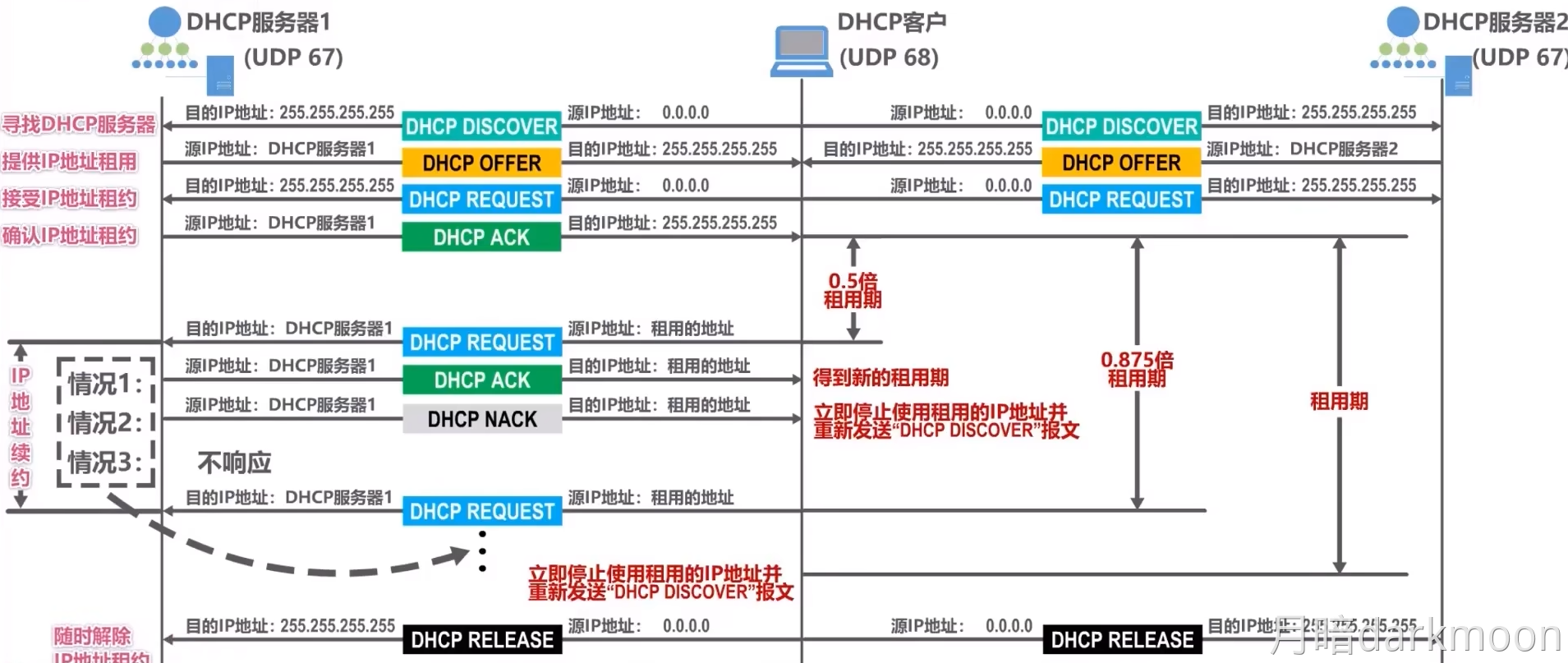

虚电路
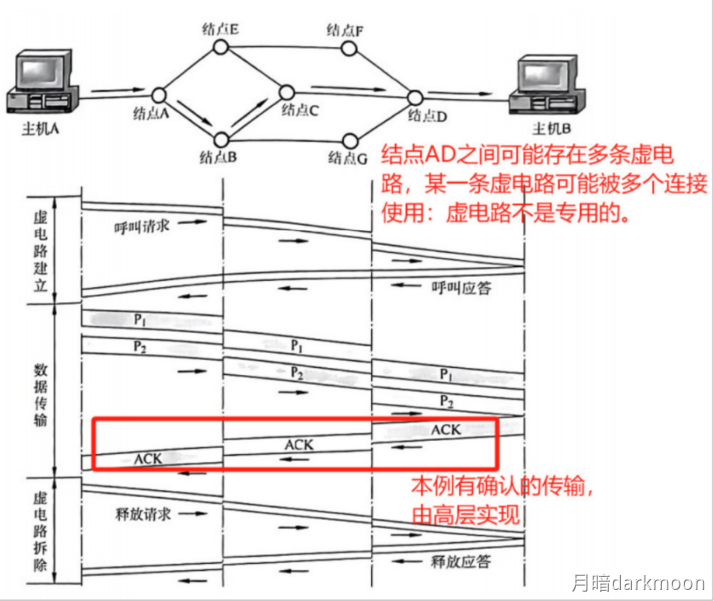
- 网络层虚电路服务本身并不强制要求有确认机制ACK,确认机制是可选工具。
- 虚电路只在网络层建立,TCP在传输层建立的只能叫可靠连接不能叫虚电路。
- 虚电路服务于点到点的通信而非端到端的通信,因此两台主机之间的多条虚电路服务于主机,主机可以分配不同进程使用不同虚电路,因此虚电路不单独为某个进程服务,而是为多个进程服务。
- 只有一条虚电路也可以为不同进程服务
- 虚电路是分组交换技术的一种,沿着逻辑虚电路(并不是建立了一条物理链路,区别于电路交换)按照存储转发方式传送
- 虚电路中,分组的首部仅在连接建立时使用完整的目的地址,之后每个分组的首部只需要携带这条虚电路的编号
- 在虚电路网络中的每个结点上都维持一张虚电路表,表中每项记录一个打开的虚电路的信息包括在接收链路和发送链路上的虚电路号、前一结点和下一结点的标识,它是在虚电路建立过程中确定的
- 电路交换会为连接预留并独占带宽资源。而虚电路虽然路径固定,但其所经过的物理链路资源(如带宽)是由多条虚电路共享的,并不会为某一条虚电路预留专用带宽。
- 虚电路在建立连接时预分配逻辑资源,数据传输时动态共享物理资源。在连接建立阶段,会分配虚电路号(VCI)并在沿途节点创建转发表项,这可以看作是“预分配资源”。但在数据传输阶段,物理链路的带宽等资源是由多条虚电路动态共享的,并非独占。数据报不预分配,完全动态共享。没有连接建立过程。每个数据报在到达路由器时,才临时动态地请求和使用转发所需的资源(缓存、处理等)。资源是在“逐个分组”的基础上进行分配和共享的。
路由表相关


- 默认路由 0.0.0.0/0 0.0.0.0
- 特定主机路由XXX.XXX.XXX.XXX/32 255.255.255.255
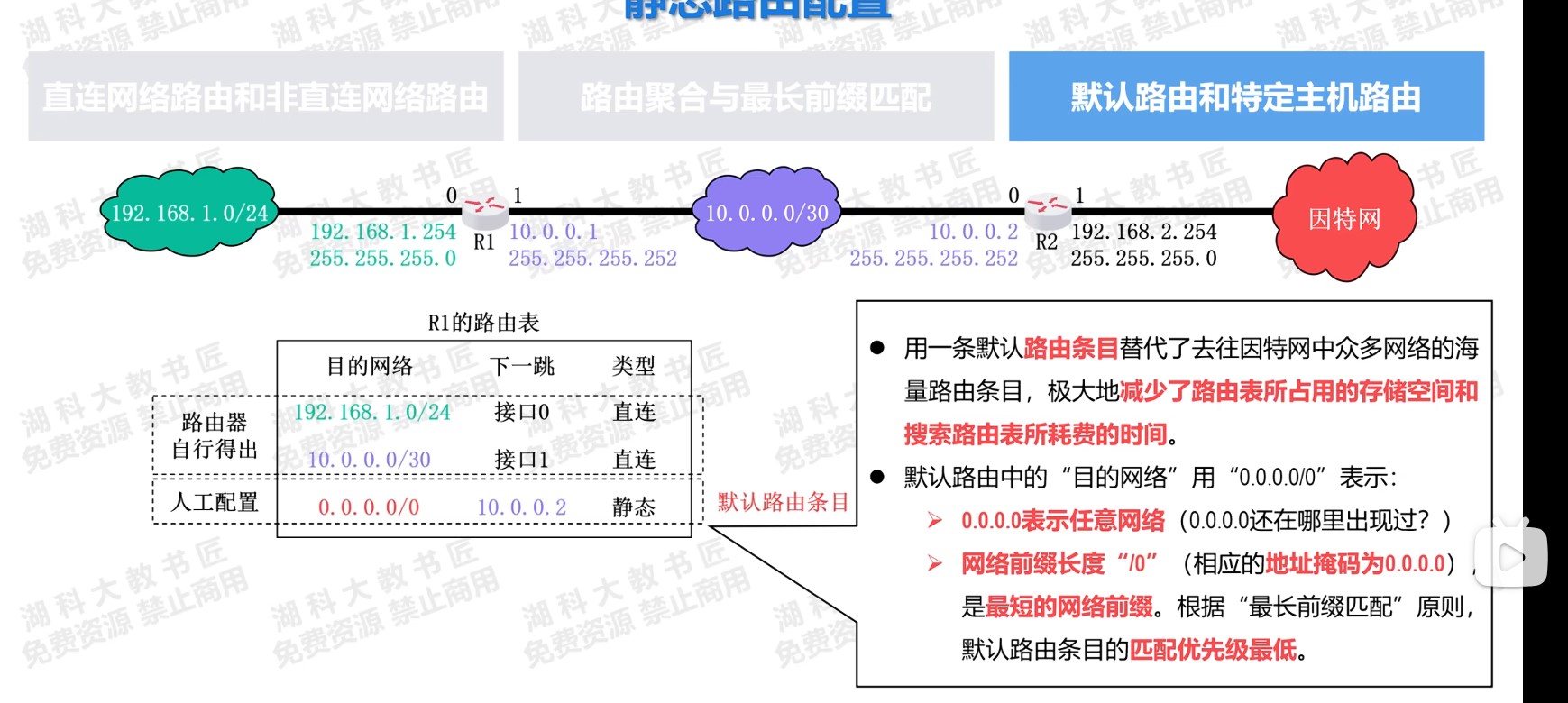

- Internet的路由表
- 目的网络0.0.0.0
- 子网掩码0.0.0.0
- 路由器的IP地址是每个子网的第一个地址
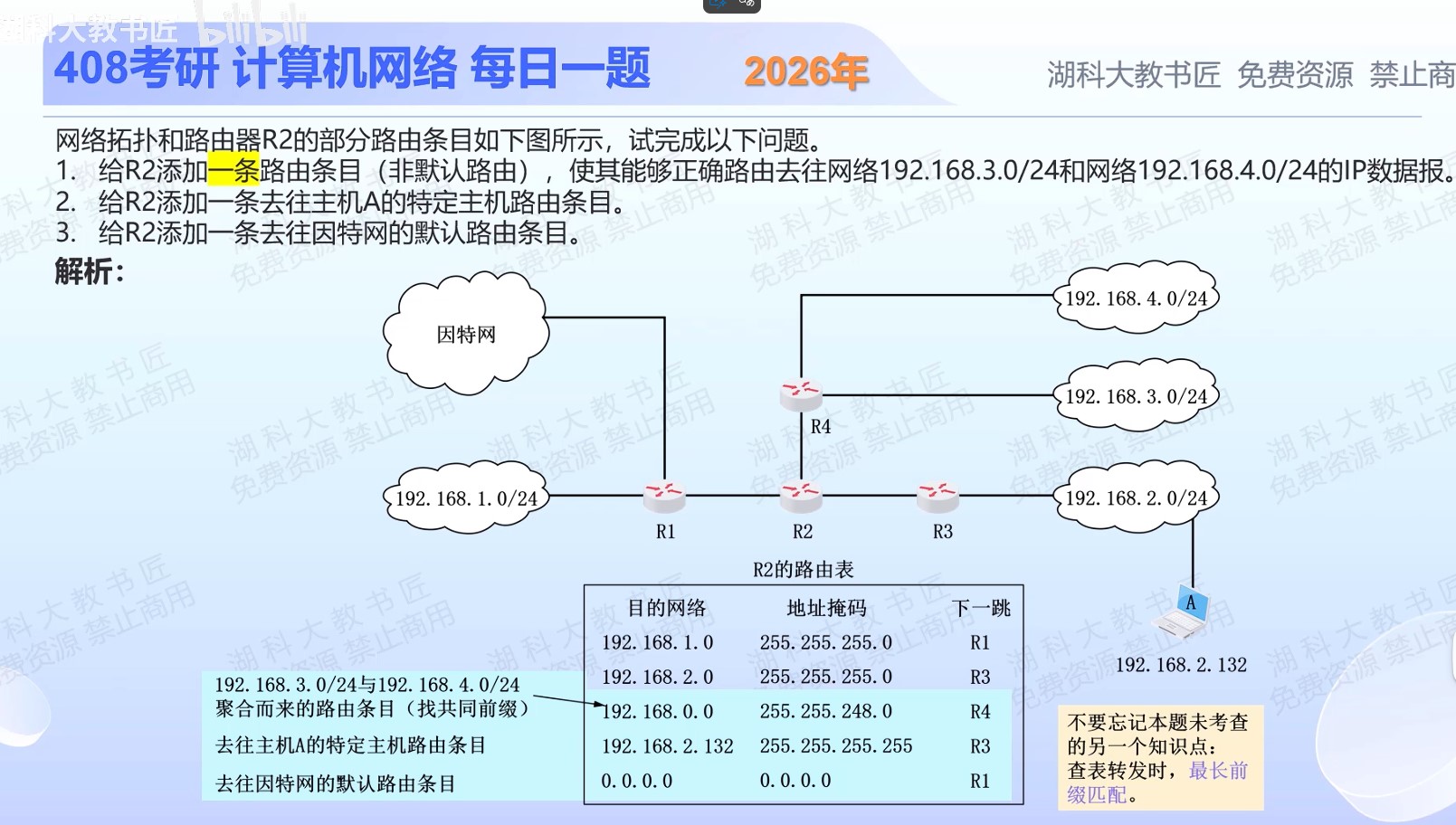
- 使用二叉线索查找转发表
- 为了进行更加有效的查找,通常是把无分类编址的转发表存放在一种层次的数据结构中,然后自上而下地按层次进行查找。
- IP地址中从左到右的比特值决定了从根节点逐层向下层延伸的路径,而二叉线索中的各个路径就代表转发表中存放的各个地址。
- 为了简化二叉线索的结构,可以先找出对应于每一个IP地址的唯一前缀(unique prefix)。所谓唯一前缀就是在表中所有的IP地址中,该前缀是唯一的。这样就可以用这些唯一前缀来构造二叉线索。在进行查找时,只要能够和唯一前缀相匹配就行了。
- 从二叉线索的根节点自顶向下的深度最多有32层,每一层对应于IP地址中的一位。一个IP地址存入二叉线索的规则很简单:先检查IP地址左边的第一位,如为0,则第一层的节点就在根节点的左下方;如为1,则在右下方。然后再检查地址的第二位,构造出第二层 的节点。依此类推,直到唯一前缀的最后一位。由于唯一前缀一般都小于32位,因此用唯 一前缀构造的二叉线索的深度往往不到32层。图中较粗的折线就是前缀0101在这个二叉线索中的路径。二叉线索中的小圆圈是中间节点,而在路径终点的小方框是叶节点(也叫作外 部节点)。每个叶节点代表一个唯一前缀。节点之间的连线旁边的数字表示这条边在唯一前 缀中对应的比特是0或1。假定有一个IP地址是10011011011110100000000000000000,需要查找该地址是否在此二叉线索中。我们从最左边查起。很容易发现,查到第三个字符(即前缀10后面的0)时,在二叉线索中就找不到匹配的,说明这个地址不在这个二叉线索中。
- 显然,要将二叉线索用于转发表中,还必须使二叉线索中的每一个叶节点包含所对应的网络前缀和子网掩码。当搜索到一个叶节点时,就必须将寻找匹配 的目的地址和该叶节点的子网掩码进行按位AND运算,看结果是否与对应的网络前缀相匹配。若匹配,就按下一跳的接口转发该分组。否则,就丢弃该分组。总之,二叉线索只是提供了一种可以快速在转发表中找到匹配的叶节点的机制。但这 是否和网络前缀匹配,还要和子网掩码进行一次逻辑AND运算。
- 为了提高二叉线索的查找速度,广泛使用了各种压缩技术。。例如,在图4-27中的最后两个地址,其最前面的4位都是1011。因此,只要一个地址的前4位是1011,就可以跳过前面4位(即压缩了4个层次)而直接从第5位开始比较。这样就可以减少查找的时间。当然,制作经过压缩的二叉线索需要更多的计算,但由于每一次查找转发表时都可以提高查找速度,因此这样做还是值得的。

NAT
- 私有IP地址不会出现在公有网络(因特网)中,这是没问题的。但是并不表示不能作为目的IP出现在路由表中,想想看,有一个小型互连网,内部有若干网络通过若干路由器互连,它们都使用私有地址,仅其中一个路由器与公网连接,那么这些内部路由器中肯定记录的是内部若干网络的路由。
- 全世界可能有很多不同机构的私有网络具有相同的IPv4地址,但这并不会引起麻烦,因为这些私有IPv4地址仅在机构内部使用
- 在因特网中的所有路由器,对目的地址是私有IPv4地址的IP数据报一律不进行转发,这需要由因特网服务提供者ISP对其拥有的因特网路由器进行设置来实现
- 外网主机不能主动发起到内网主机的通信
- 拥有私有IPv4地址的主机不能直接充当因特网中的服务器,对于目前点对点P2P这类需要因特网中的主机主动与私有网络中的主机进行通信的网络应用,在通过NAT时会遇到问题,需要网络应用自身使用一些特殊的NAT穿透技术来解决
传输层
- 传输层属于面向通信部分的最高层,同时也是用户功能中的最低层。
- 在通信子网中没有传输层,传输层只存在于通信子网以外的主机中。
- 网络层和传输层都有分用和复用的功能
- 传输层的复用是指发送方不同的应用进程都可以使用同一个传输层协议传送数据。分用是指接收方的传输层在剥去报文的首部后能够把这些数据正确交付到目的应用进程。
- 网络层的复用是指发送方不同协议的数据都可被封装成IP数据报发送出去,分用是指接收方的网络层在剥去首部后把数据交付给相应的协议。
- 数据链路层的服务访问点为帧的“类型”字段,网络层的服务访问点为IP数据报的“协议”字段,传输层的服务访问点为“端口号”字段,应用层的服务访问点为“用户界面”。
- 表示层SAP:具体网络应用进程中的用户表示
- 会话层SAP:具体网络应用会话进程
- 传输层SAP:端口
- 网络层SAP:IP地址
- 数据链路层SAP:MAC地址
- 物理层SAP:网络通信中设备的具体物理接口
- 在协议栈层间的抽象的协议端口是软件端口,它与路由器或交换机上的硬件端口是完全不同的概念。硬件端口是不同硬件设备进行交互的接口,而软件端口是应用层的各种协议进程与传输实体进行层间交互的一种地址。传输层使用的是软件端口。
- IP数据报和UDP数据报的区别:
- IP数据报在网络层要经过路由器的存储转发;
- 而UDP数据报封装成IP数据报在网络层传输时,UDP数据报的信息对路由器是不可见的。
- 序号和序号绕回的关系:
- 以字节为单位标记序号的情况下,序号的长度>=数据传输率*最大生存时间
一些经典互联网应用所用的TCP/IP应用层协议和传输层协议
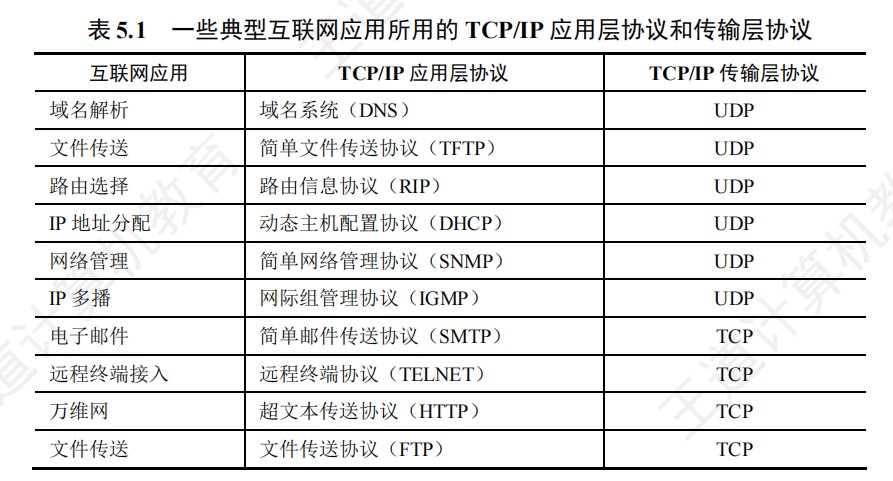
UDP
- UDP在IP层之上仅提供两个附加服务
- 复用分用
- 差错检测
- 某些专用服务器使用UDP时,一般都能支持更多的活动客户机
- UDP不保证可靠交付,但这并不意味着应用对数据的要求是不可靠的,所有维护可靠性的工作可由用户在应用层来完成。应用开发者可根据应用的需求来灵活设计自己的可靠性机制。
- UDP源端口在需要对方回信时选用,不需要时可用全0
- 如果检验和的计算结果恰好为0,则将检验和字段置为全1
- 检验和字段可选的,当源主机不想计算检验和时,则直接令该字段为全0。
- 若UDP检验和检验出UDP数据报是错误的,则可以丢弃,也可以交付给上层,但是需要附上错误报告,即告诉上层这是错误的数据报。
- 通过伪首部,不仅可以检查源端口号、目的端口号和UDP用户数据报的数据部分,还可以检查IP数据报的源IP地址和目的地址。
- UDP不使用拥塞控制和流量控制,因此常用于一次性传输较少数据的网络应用,如DNS、SNMP等,允许在网络发生拥塞时丢失一些数据,不允许太大时延。
- UDP是面向报文的,应用层交给UDP多长的报文,UDP照样发送,一次发送一个报文。接收方UDP对IP层交上来的UDP数据报,在去除首部后原封不动地交付给上层应用进程,一次交付一个完整的报文。
- 报文不可分割,是UDP数据报处理的最小单位,若报文太长,UDP把它交给IP层后,可能会导致分片;若保温太短,交给IP层后,会导致IP数据报的首部相对长度太大
TCP
-
网络节点不会为TCP预留宽带资源。
-
TCP是面向字节流的,虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序交下来的数据仅视为一连串的无结构的字节流。
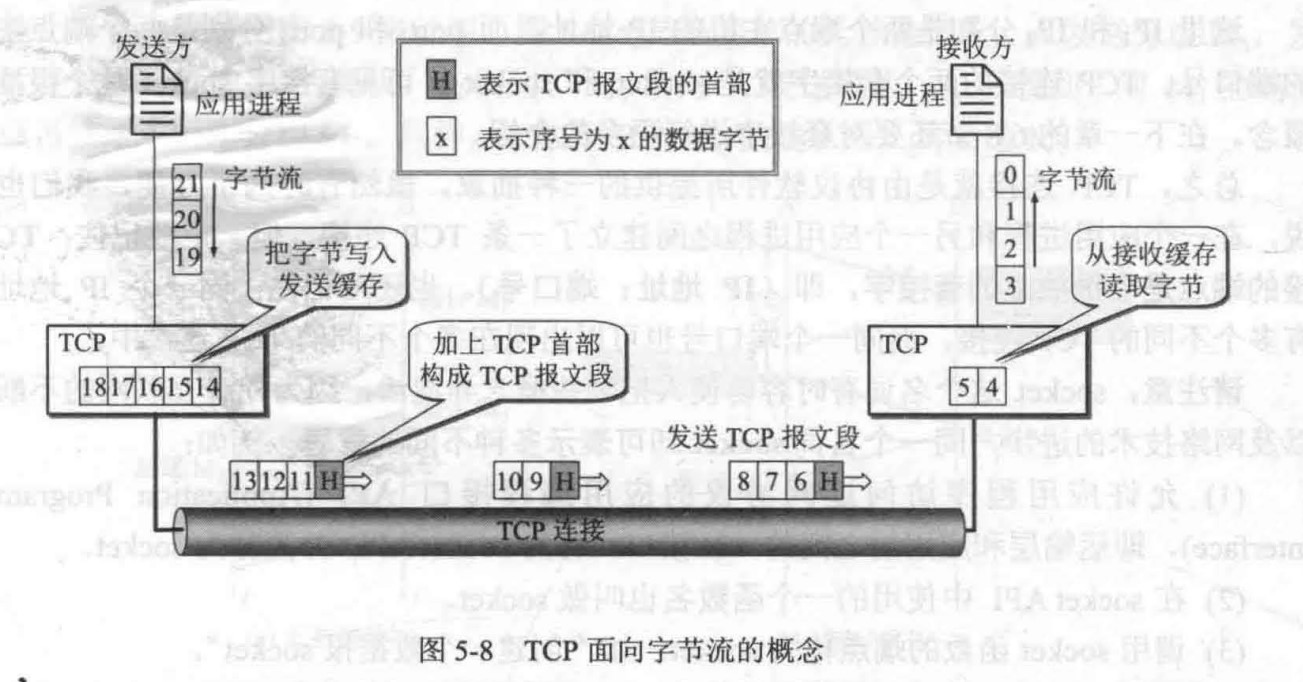
-
TCP首部的序号字段用来保证数据能有序提交给应用层,TCP把数据视为一个无结构但有序的字节流,序号建立在传送的字节流之上,而不建立在报文段之上。
-
TCP连接传送的数据流中的每个字节都编上一个序号。序号字段的值是指本报文段所发送的数据的第一个字节的序号。
- 纯确认段不消耗序号,如果B发给A的一个纯确认段序号为ACK=x,则上一个字节序号=x-1,因此等待接收的下一个序号是x-1+1=x,所以A发给B的ack=x
-
TCP序号绕回时间的计算:
- T=2^32B/带宽

-
-
TCP不保证接收方应用程序所收到的数据块和发送方应用程序所发出的数据块具有对应大小的关系,但接收方应用程序收到的字节流必须和发送方应用程序发出的字节流完全一样。当然,接收方的应用程序必须有能力识别收到的字节流,把它还原成有意义的应用层数据。
- 例如,发送方应用程序交给发送方的TCP共10个数据块,但接收方的TCP可能只用了4个数据块就把收到的字节流交付上层的应用程序
-
-
TCP连接是一条虚连接(也就是逻辑链接),而不是一条真正的物理连接
-
TCP为每个连接设有一个持续计时器,只要发送方收到对方的零窗口通知,就启动持续计时器。若计时器超时,就发送一个零窗口探测报文段(携带1B数据),而对方就在确认这个探测报文段时给出现在的窗口值。若窗口仍然为零,则发送方收到确认报文段后就重新设置持续计时器。
- 零窗口探测报文段也有重传计时器,超时后也会被重传
-
传输层和数据链路层的流量控制的区别是:
- 传输层实现的是端到端,即两个进程之间的流量控制;
- 数据链路层实现的是两个中间的相邻节点之间的流量控制。
- 数据链路层的滑动窗口协议的窗口大小不能动态变化
- 传输层的窗口大小则可以动态变化。
-
UDP报文的长度由发送应用进程决定,而TCP报文的长度则根据接收方给出的窗口值和当前网络拥塞程度来决定。若应用进程传送到TCP缓存的数据块太长,则TCP就把它划分得短一些再传送;若太短,则TCP也可等到积累足够多的字节后再构成报文段发送出去。
-
注意区分数据链路层后退N帧累计确认时ACKn代表n和n之前的序号都已经收到,而TCP的ACKn代表n-1及之前的序号都已经收到
-
TCP首部中的数据偏移指的是首部的总长度,TCP首部中,并不会专门记录TCP数据报数据部分长度
-
两个应用进程进行交互式通信时,都希望在键入一个命令后立即就能收到对方的响应,此时发送方TCP把PSH置1,接收方TCP收到PSH=1的报文段后,就尽快交付给接收应用进程,而不再等到整个缓存都填满了后再向上交付。
-
窗口值告诉对方,从本报文段首部中的确认号算起,接收方目前允许对方发送的数据量(以字节为单位)。接收方的数据缓存空间是有限的,因此窗口值作为接收方让发送方设置其发送窗口的依据。

- 例如,设确认号是701,窗口字段是1000。这表明,从701号算起,发送此报文段的一方还有接收1000字节数据(字节序号为701~1700)的接收缓存空间。
-
紧急指针仅在URG=1时才有意义,它指出本报文段中的紧急数据的字节数(紧急数据在报文段数据的最前面)。即使窗口为零,也可以发送紧急数据。
-
即使接收窗口的值为0,也必须接受零窗口探测报文段、确认报文段(正常传输过程中的ACK)以及携带有紧急数据的报文段
-
每条TCP连接有两个端点,TCP连接的端点不是主机,不是主机的IP地址,不是应用进程,也不是传输层的协议端口。TCP连接的端口即为套接字(Socket)
- 每一条TCP连接唯一地被通信的两个端点(两个套接字)所确定。还应注意:同一个IP地址可以有多个不同的TCP连接,而同一个端口号也可以出现在多个不同的TCP连接中。
-
除时间等待计时器外,TCP还使用一个保活计时器,以避免客户机突然出现故障,而导致服务器一直无效等待。服务器每收到一次客户的数据,就会重置保活计时器,若计时到期后还没有收到客户的数据,服务器就每隔75秒发送一个探测报文段。若连续发送10个探测报文段后仍未收到客户的响应,则服务器认为客户机出了故障,关闭这个连接。
-
持续计时器用在流量控制/拥塞控制,保活计时器用在维持TCP连接
-
TCP收到两个相同的分组,说明一个确认报文段丢失了,应该丢掉相同分组的后一个,然后再发送一个确认。
-
TCP报文段发送时机
- TCP维持一个变量,等于最大报文段长度MSS。只要缓存中存放的数据达到MSS字节时,就组装成一个TCP报文段发送出去
- 由发送方的应用进程指明要求发送报文段,即TCP支持的推送(push)操作
- 发送方的一个计时器期限到了,就把当前已有的缓存数据装入报文段(长度不能超过MSS)发送出去。
- 若接收窗口没有MSS大小,应等待接收窗口达到MSS一半或者MSS,两者任一时机再发送。
-
建立连接
- 状态变化:
- 最开始,客户处于CLOSED阶段,服务器处于LISTEN阶段
- 客户发出握手①以后,进入SYN-SENT;
- 服务器收到握手①以后,发回确认的握手②进入SYN-RCV
- 客户收到握手②以后,向服务器发出握手③,进入ESTABLISHED
- 服务器收到握手③,进入ESTABLISHED
- 服务器收到握手①,发出握手②以后(完成第二次握手),为该TCP连接分配缓存和变量。服务器容易受到SYN洪泛攻击
- 客户收到握手②,发出握手③之后(完成第三次握手),为该TCP连接分配缓存和变量
- 握手③不携带数据则不消耗序号
- 如果把三次握手改为两次握手,则可能发生死锁
- 第一种情况:客户端握手①出现问题
- 客户端发出握手①,但是因为网络拥塞未能到达服务器,在超时后,客户端重新发送握手①,这次成功到达服务器。服务器收到并发出握手②,连接成功建立。客户端和服务器开始通信,最后释放连接。之前的滞留握手①在经过一段时间后最终被服务器接收,服务器误认为是新的握手①,再次发送握手②。
- 如果只进行两次握手,服务器会认为连接成功,开始等待客户端发送数据。客户端收到确认但没有发出新请求,因此丢弃该报文。服务器错误地认为连接已建立,造成资源浪费。
- 第二种情况:服务器握手②出现我呢提
- 客户端给服务器发送握手①,服务器收到了握手①,并发送了握手②,但是握手②在传输过程中丢失。按照两次握手,服务器认为链接已经建立,可以开始发送数据分组。客户端在握手②丢失的情况下,不知道服务器是否同意建立连接,认为连接尚未建立,将忽略服务器发送过来的任何数据分组,只等待握手②。而服务器在发出的数据分组超时后,重复发送同样的分组,形成死锁。
- 这种情况下,服务器和客户端出现了死锁:客户等待服务器的握手②,服务器一直在发送重复的数据,导致双方无法正常通信。
- 第一种情况:客户端握手①出现问题
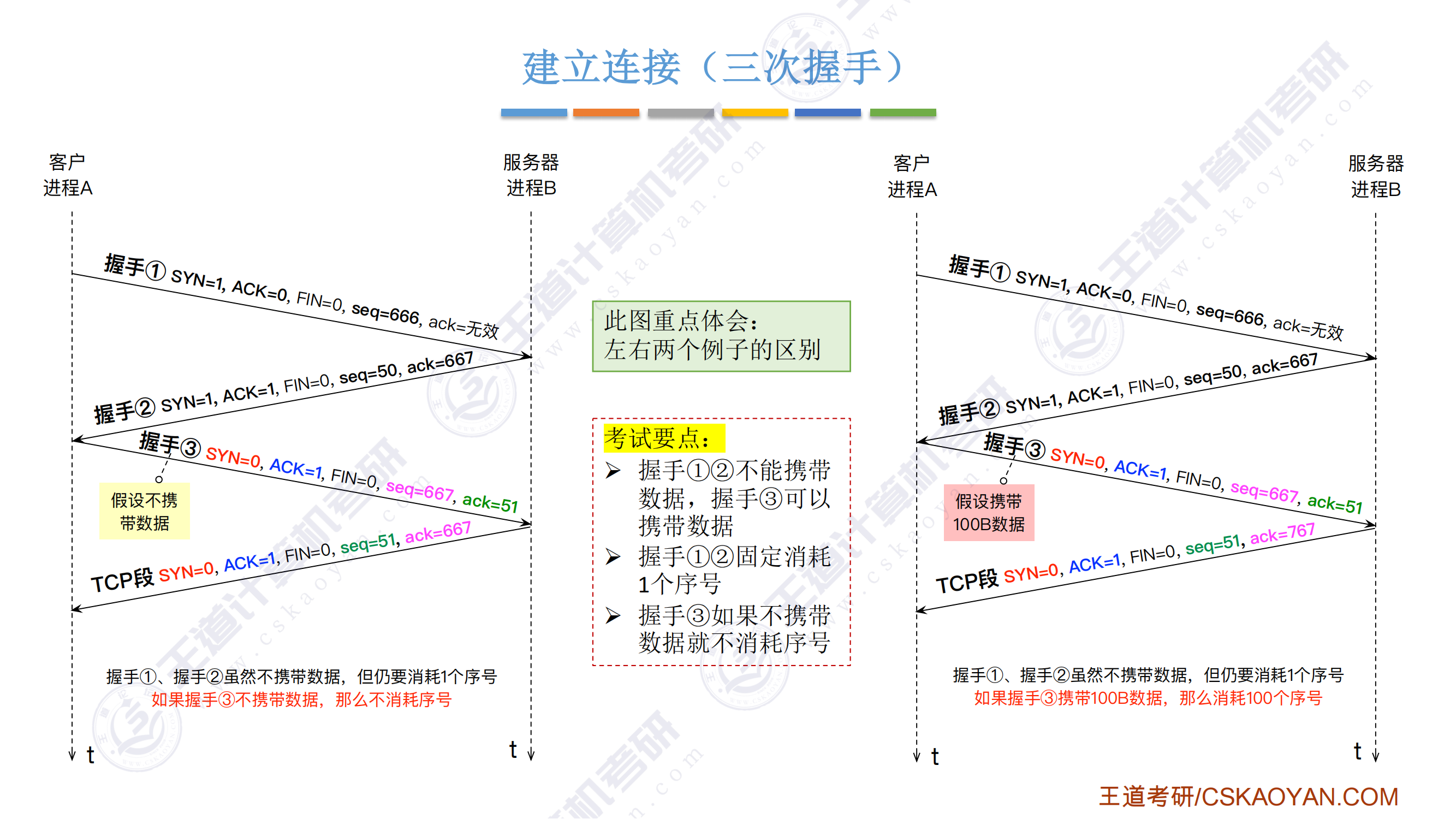
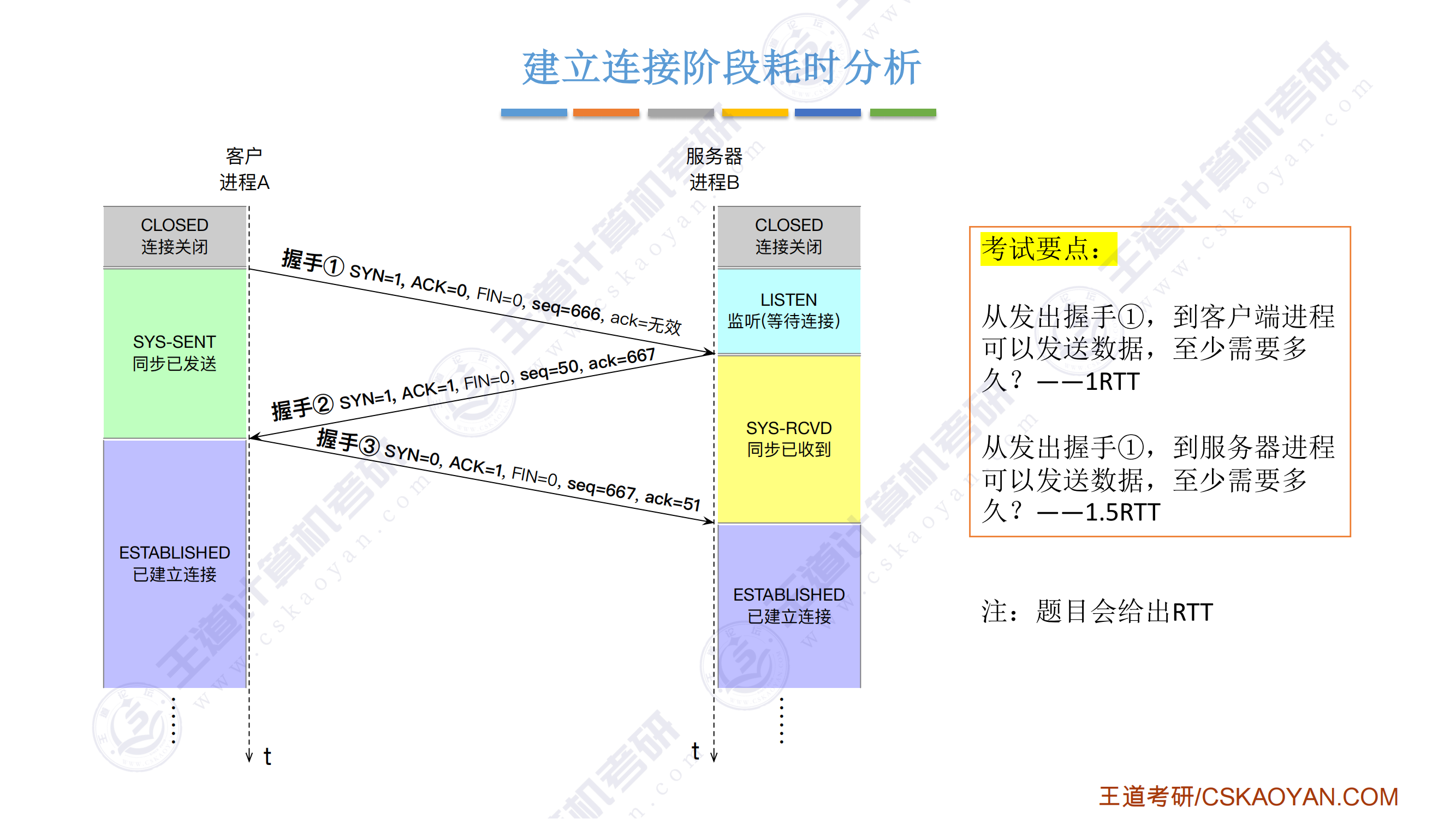
- 状态变化:
-
释放连接
- 状态变化
- 初始状态,两者都是ESTABLISHED
- 客户发出挥手①,进入FIN-WAIT-1
- 服务器收到挥手①,发出挥手②,进入CLOSE-WAIT
- 客户收到挥手②,进入FIN-WAIT-2
- 服务器发出挥手③,进入LAST-ACK
- 客户收到挥手③,发出挥手④,进入TIME-WAIT
- 服务器收到挥手④,进入CLOSED状态
- 客户经过2MSL以后,进入CLOSED状态
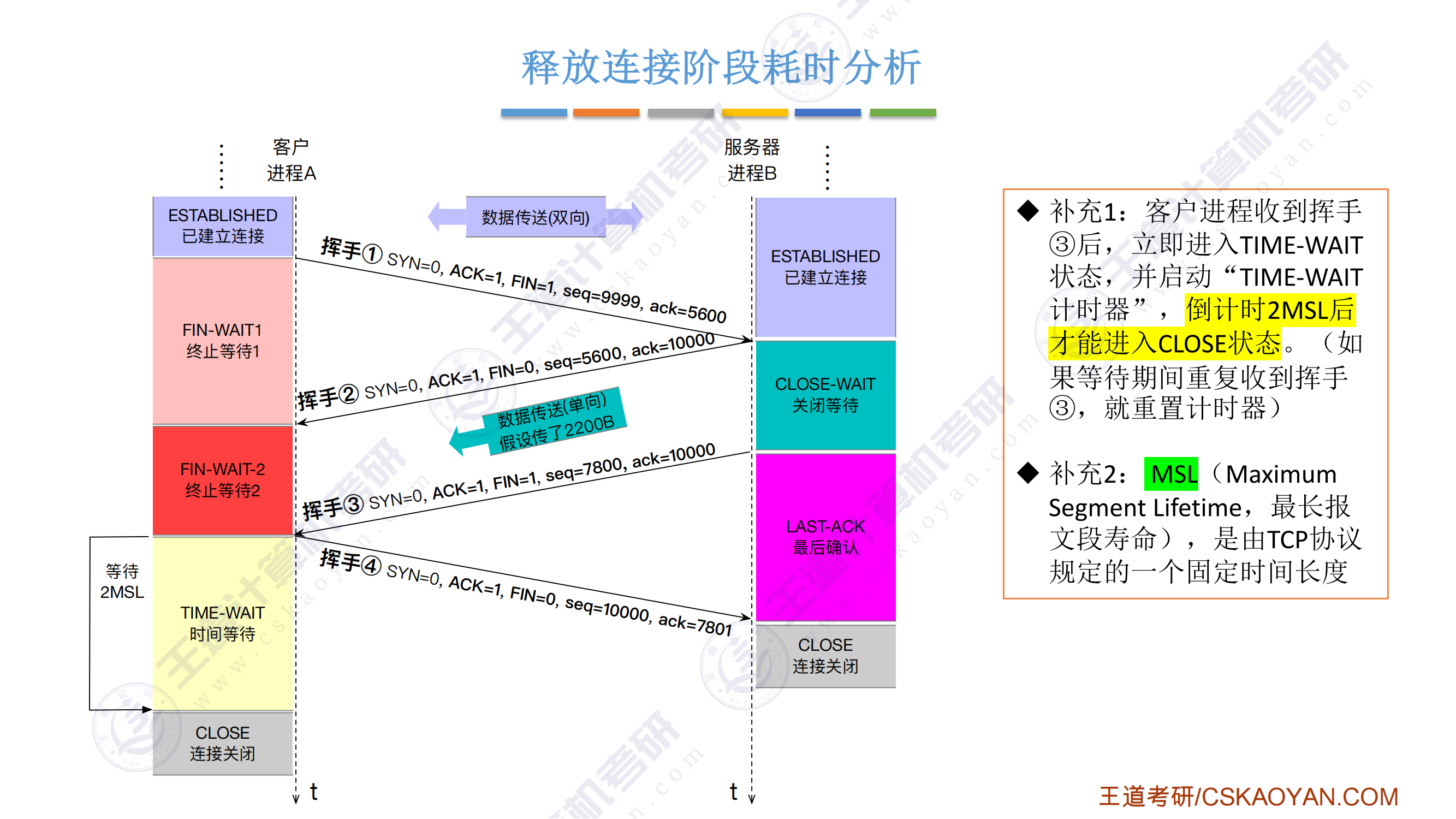
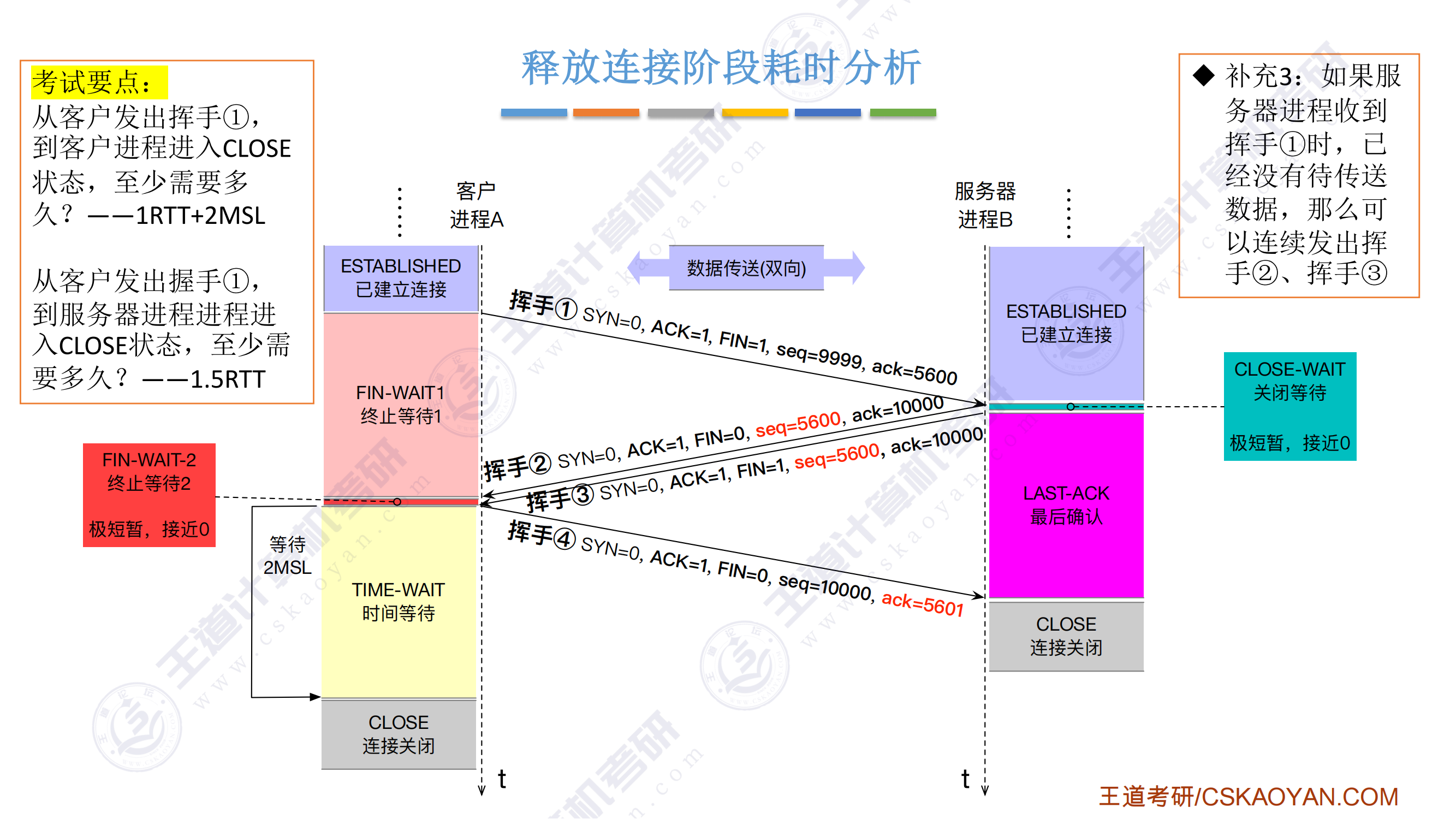
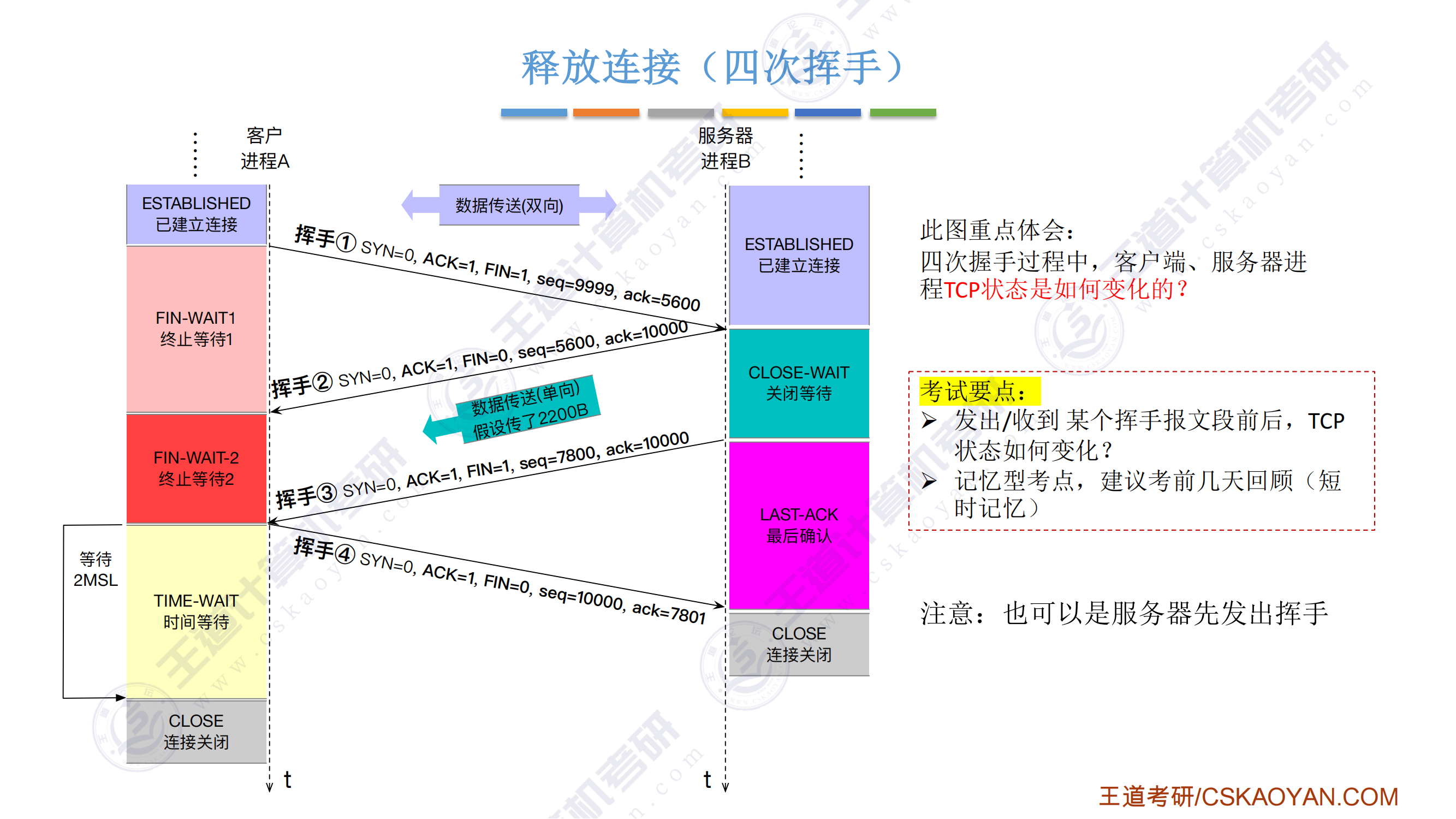
- 状态变化
-
MSL的必要性:
- ①为了保证A发送的最后一个ACK报文段能够到达B。
- 这个ACK报文段有可能丢失,因而使处在LAST-ACK状态的B收不到对已发送的FIN+ACK报文段的确认。B会超时重传这个FIN+ACK报文段,而A就能在2MSL时间内收到这个重传的FIN+ACK报文段。接着A重传一次确认,重新启动2MSL计时器。最后,A和B都正常进入到CLOSED状态。如果A在TIME-WAIT状态不等待一段时间,而是在发送完ACK报文段后立即释放连接,那么就无法收到B重传的FIN +ACK报文段,因而也不会再发送一次确认报文段。这样,B就无法按照正常步骤进入CLOSED状态。
- ②防止“已失效的连接请求报文段”出现在本连接中。
- A在发送完最后一个ACK报文段后,再经过时间2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
- B只要收到了A发出的确认,就进入CLOSED状态。同样,B在撤销相应的传输控制块TCB后,就结束了这次的TCP连接。我们注意到,B结束TCP连接的时间要比A早一些。
- ①为了保证A发送的最后一个ACK报文段能够到达B。
-
四个计时器:

- 时间等待计时器
- 超时重传
- 持续计时器
- 零窗口
- 保活计时器
- TCP连接
- 时间等待计时器
拥塞控制
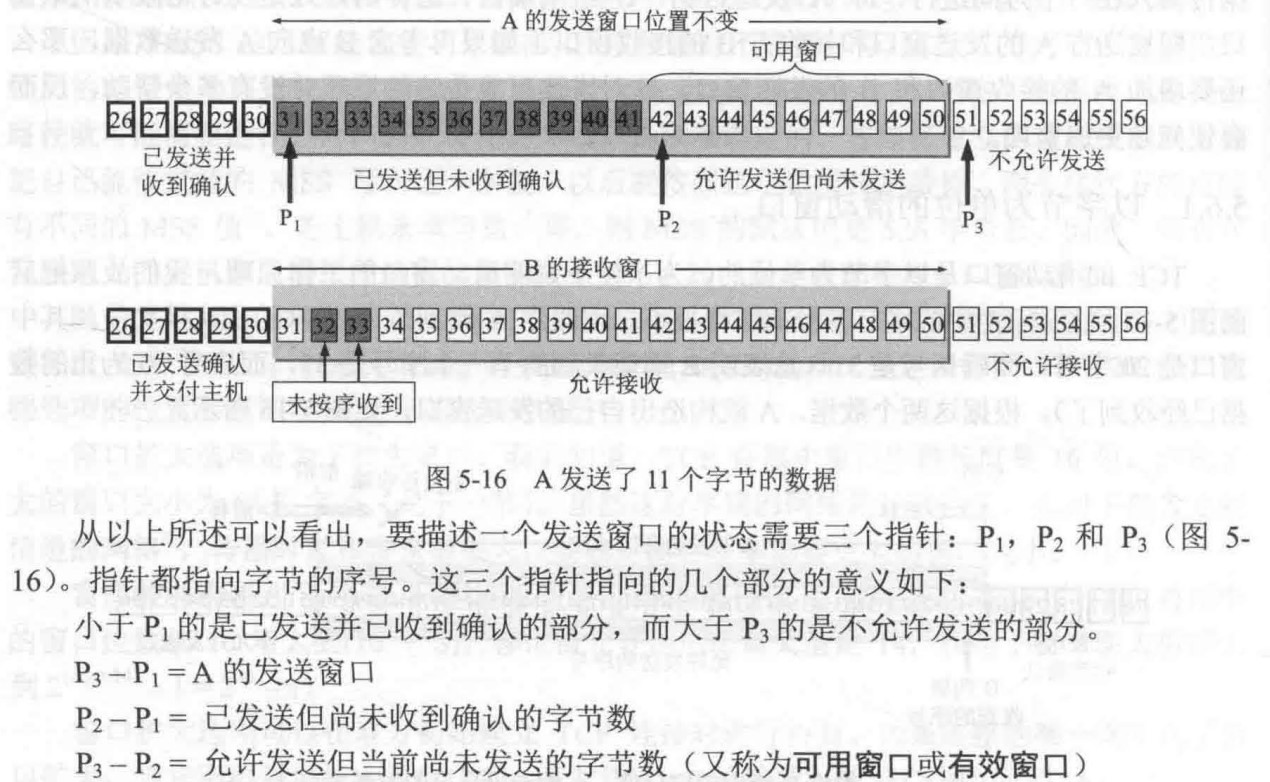
-
连续回的n个ack卡在了阈值之间,然后有一个ack导致cwnd到达阈值,然后之后的同一个RTT内的所有其他阈值都不再加cwnd,因为到达阈值的那一个ack已经是让cwnd+1的ack了
- 在慢开始阶段,若2cwnd>ssthresh,则下一个RTT后的cwnd等于ssthresh,而不等于2cwnd。第16个轮次时cwnd=8、ssthresh=12,则第17个轮次时cwnd=12,而不等于16。
-
拥塞避免算法,在拥塞避免阶段,每收到1个mss确认,拥塞窗口之+(1/cwnd)
-
出现拥塞后减少一半的阈值不能小于2,即至少=2
-
在流量控制中,发送方发送数据的量由接收方决定;
- 而在拥塞控制中,则由发送方自己通过检测网络状况来决定。
-
接收方的缓存空间总是有限的。发送方发送窗口的大小由流量控制和拥塞控制共同决定。当题目中同时出现接收窗口(rwnd)和拥塞窗口(cwnd)时,发送方发送窗口的实际大小是由rwnd和cwnd中较小的那一个确定的。
-
最大报文段长度MSS时TCP报文段中数据字段的最大长度(仅仅是数据字段)
- 两个传输方向可以有不同的MSS值
- 主机未填写则默认MSS=536B,加上20B首部一共556B
-
分组丢失是网络发生拥塞的征兆而不是原因
-
快重传机制要求发送方一旦收到3个冗余ACK就立即重传,且不允许使用捎带确认。
-
TCP的缓存与窗口的关系
- 发送缓存用来暂时存放:
- (1)发送应用程序传送给发送方TCP准备发送的数据;
- (2)TCP已发送出但尚未收到确认的数据。
- 发送窗口通常只是发送缓存的一部分。已被确认的数据应当从发送缓存中删除,因此发送缓存和发送窗口的后沿是重合的。发送应用程序最后写入发送缓存的字节减去最后被确认的字节,就是还保留在发送缓存中的被写入的字节数。发送应用程序必须控制写入缓存的速率,不能太快,否则发送缓存就会没有存放数据的空间。
- 接收缓存用来暂时存放:
- (1)按序到达的、但尚未被接收应用程序读取的数据;
- (2)未按序到达的数据。
- 如果收到的分组被检测出有差错,则要丢弃。如果接收应用程序来不及读取收到的数据,接收缓存最终就会被填满,使接收窗口减小到零。反之,如果接收应用程序能够及时从接收缓存中读取收到的数据,接收窗口就可以增大,但最大不能超过接收缓存的大小。图5-19(b)中还指出了下一个期望收到的字节号。这个字节号也就是接收方给发送方的报文段的首部中的确认号。
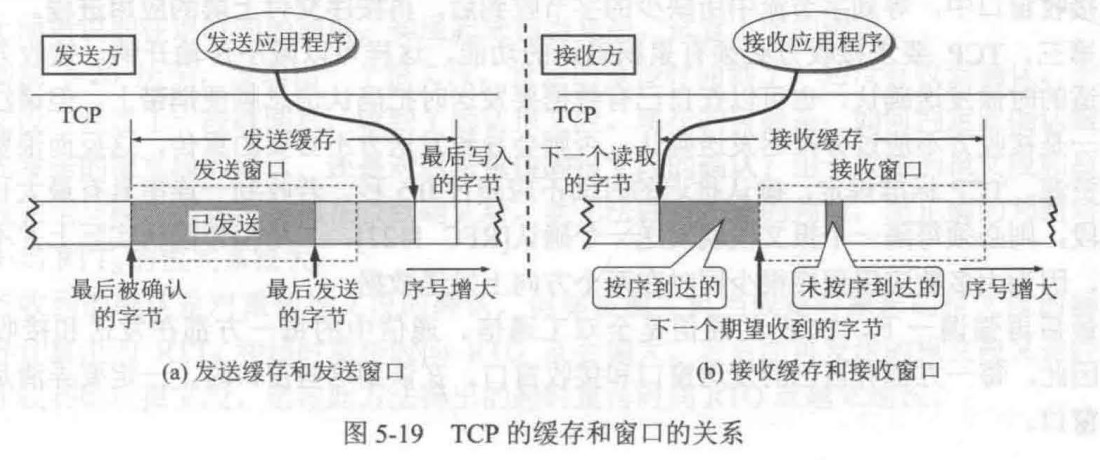
- 发送缓存用来暂时存放:
-
Nagle算法
- 若发送应用进程把要发送的数据逐个字节地送到TCP的发送缓存,则**发送方就把第一个数据字节先发送出去,把后面到达的数据字节都缓存起来。当发送方收到对第一个数据字符的确认后,再把发送缓存中的所有数据组装成一个报文段发送出去,同时继续对随后到达的数据进行缓存。只有在收到对前一个报文段的确认后才继续发送下一个报文段。**当数据到达较快而网络速率较慢时,用这样的方法可明显地减少所用的网络带宽。
- **当到达的数据已达到发送窗口大小的一半或已达到报文段的最大长度时,就立即发送一个报文段。**这样做,就可以有效地提高网络的吞吐量。
-
糊涂窗口综合征
- 设想一种情况:TCP接收方的缓存已满,而交互式的应用进程一次只从接收缓存中读取1个字节(这样就使接收缓存空间仅腾出1个字节),然后向发送方发送确认,并把窗口设置为1个字节(但发送的数据报是40字节长)。接着,发送方又发来1个字节的数据(请注意,发送方发送的IP数据报是41字节长)。接收方发回确认,仍然将窗口设置为1个字节。这样进行下去,使网络的效率很低。
- 可以让接收方等待一段时间,使得或者接收缓存已有足够空间容纳一个最长的报文段,或者等到接收缓存已有一半空闲的空间。只要出现这两种情况之一,接收方就发出确认报文,并向发送方通知当前的窗口大小。此外,发送方也不要发送太小的报文段,而是把数据积累成足够大的报文段,或达到接收方缓存的空间的一半大小。
-
选择确认SACK
- SACK报道的是收到的不连续字节块的边界
-
全局同步
- 路由器的尾部丢弃往往会导致一连串分组的丢失,这就使发送方出现超时重传,使TCP进入拥塞控制的慢开始状态,结果使TCP连接的发送方突然把数据的发送速率降低到很小的数值。更为严重的是,在网络中通常有很多的TCP连接(它们有不同的源点和终点),这些连接中的报文段通常是复用在网络层的IP数据报中传送。在这种情况下,若发生了路由器中的尾部丢弃,就可能会同时影响到很多条TCP连接,结果使这许多TCP连接在同一时间突然都进入到慢开始状态。这在TCP的术语中称为全局同步(globalsyncronization)。全局同步使得全网的通信量突然下降了很多,而在网络恢复正常后,其通信量又突然增大很多。
-
主动队列管理AQM
- 应当在队列长度达到某个值得警惕的数值时(即当网络拥塞有了某些拥塞征兆时),就主动丢弃到达的分组。
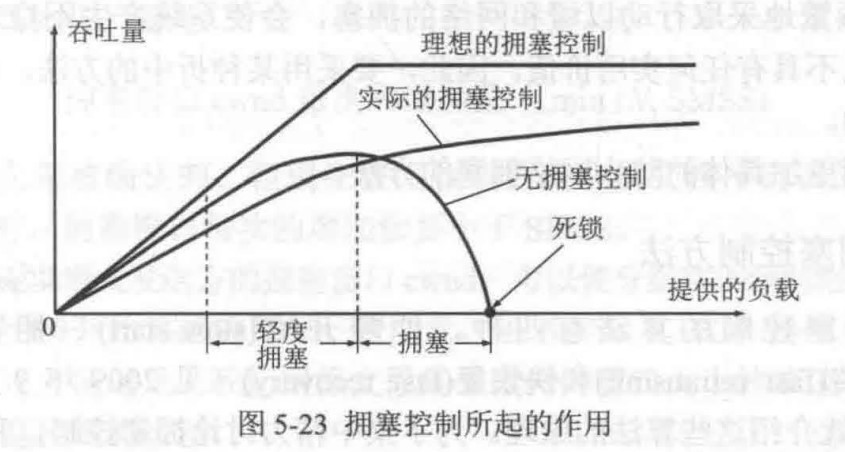
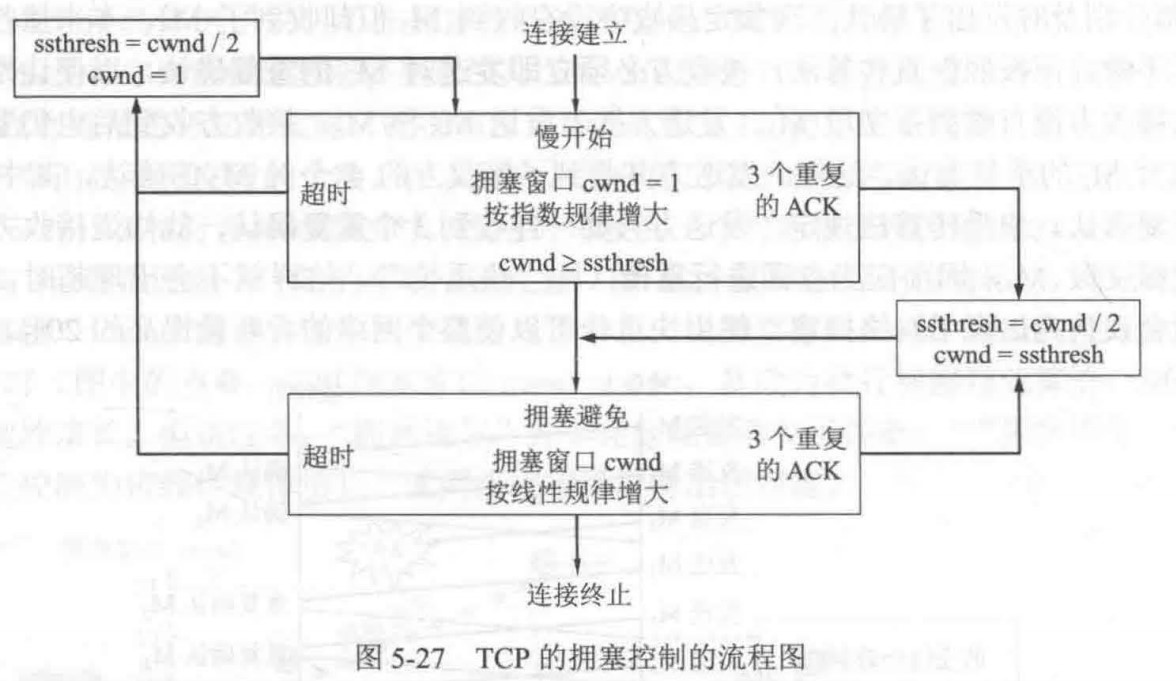
差错检验机制
- MAC帧
- 首部+数据
- CRC循环冗余检验码FSC
- IP数据报
- 首部
- 二进制反码求和
- UDP
- 首部+数据
- 二进制反码求和
- 关于二进制反码求和全1的问题
- 只有参与所有反码算术求和的每个16位数都是全0的情况下(伪首部和UDP用户数据报都为全0,显然标准情况下不可能,但是恶意或某种错误导致就有可能),得到结果为全0,取反为全1,作为检验和。
端口号
-
UDP之间的通信要用到端口号,但是由于UDP的通信是无连接的,因此不需要使用套接字来建立连接
- TCP必须在两个套接字之间建立连接
-
我们往往需要利用目的主机提供的功能来识别终点,而不需要知道具体实现这个功能的进程是哪一个(例如,要和互联网上的某个邮件服务器联系,并不一定要知道这个服务器功能是由目的主机上的哪个进程实现的)。在运输层使用协议端口号(protocol port number),或通常简称为端口(port)。这就是说,虽然通信的终点是应用进程,但只要把所传送的报文交到目的主机的某个合适的目的端口,剩下的工作(即最后交付目的进程)就由TCP或UDP来完成。
-
端口号只具有本地意义,即端口号只标识本计算机应用层中的各进程,在因特网中不同计算机的相同端口号是没有联系的
-
DHCP服务器使用的UDP端口号为67,DHCP客户端使用的UDP端口号为68
-
RIP基于UDP,使用端口号520

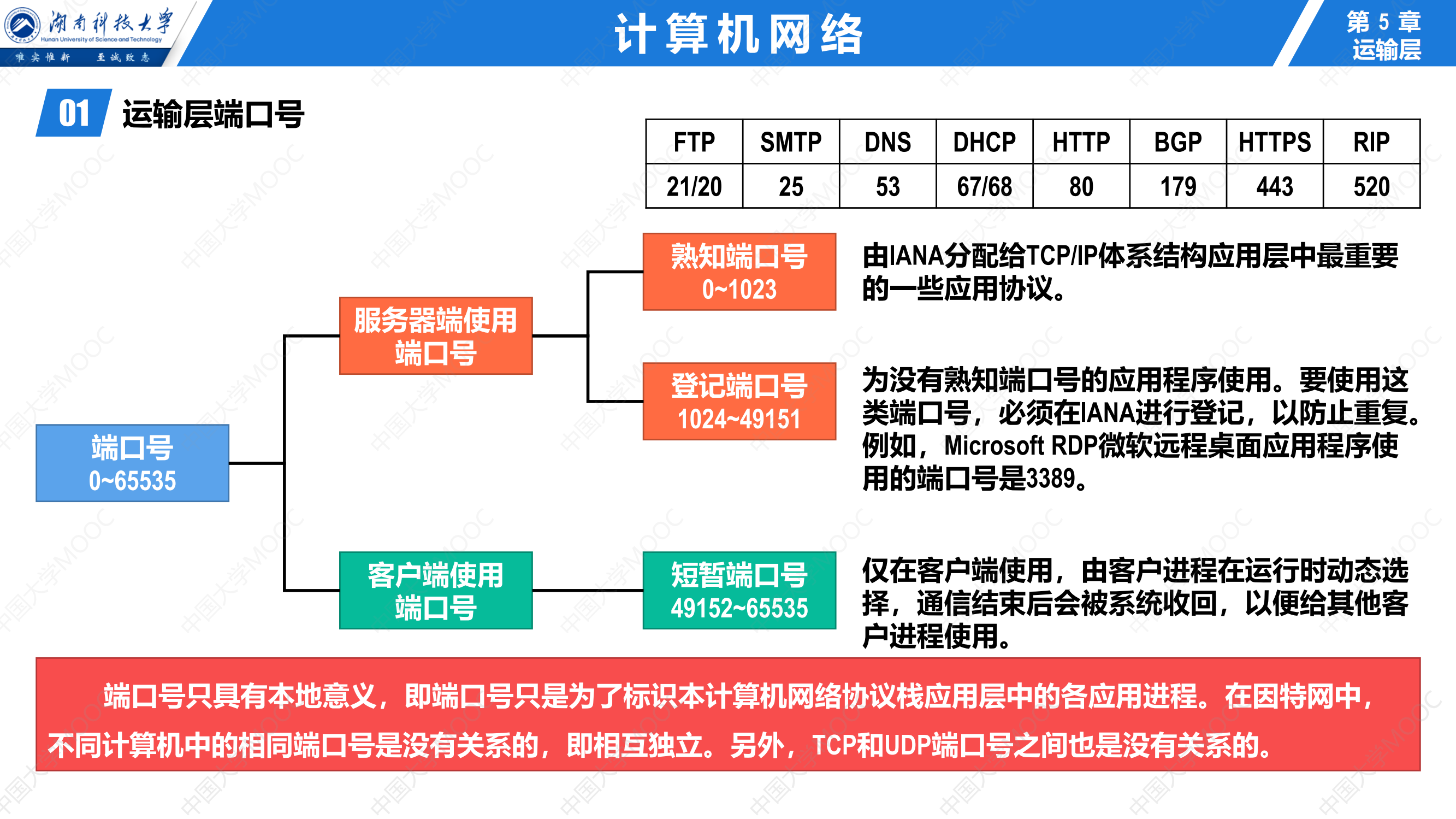
- POP3:110,IMAP:143
应用层

- C/S模型中,服务器性能的好坏决定了整个系统的性能。
- 客户之间不直接通信
- P2P应用:文件共享、即时通信、分布式存储、p2p媒体
- 多个用户之间可以共享文档
- 网络健壮性强
- 会影响个体的整机速度
FTP
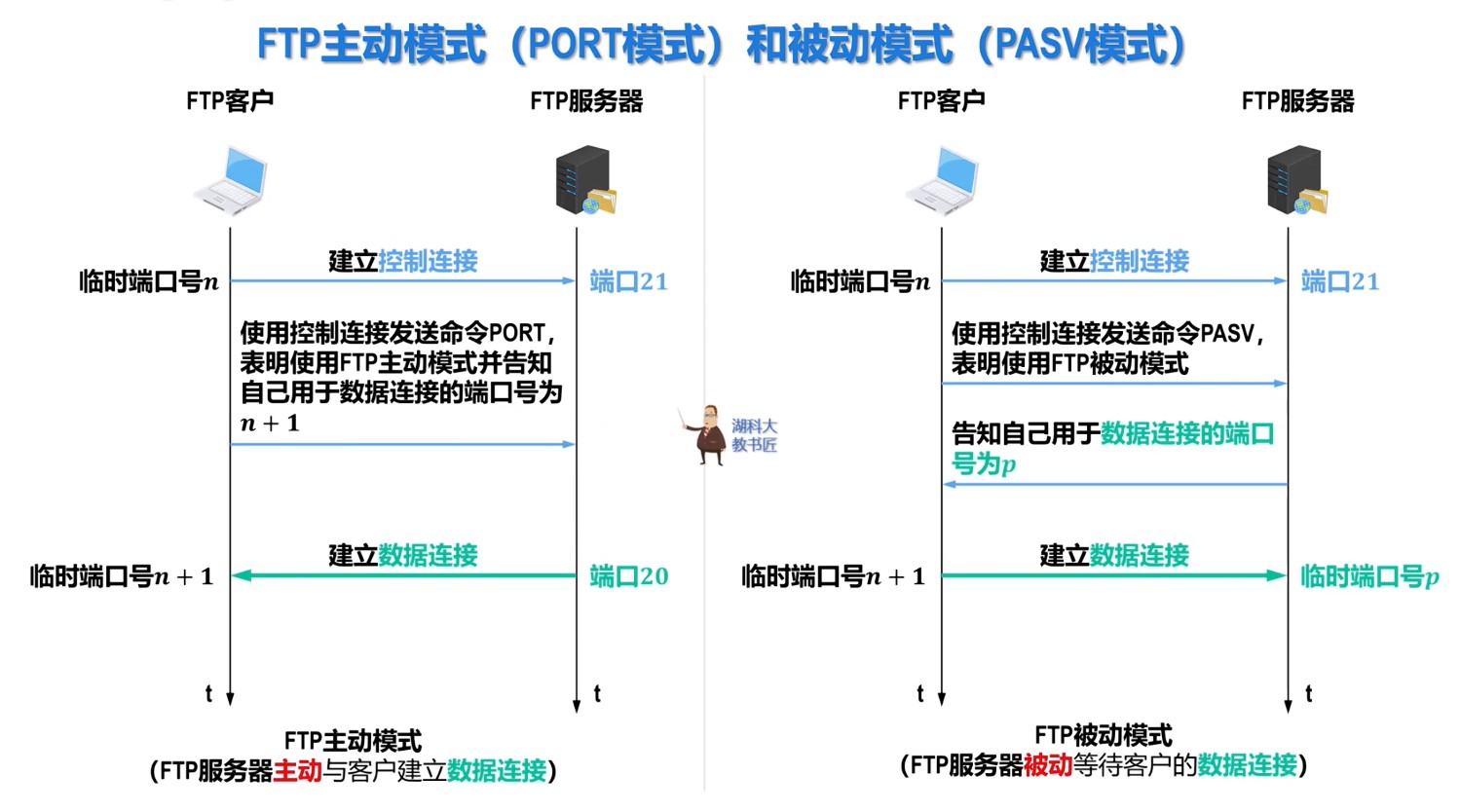
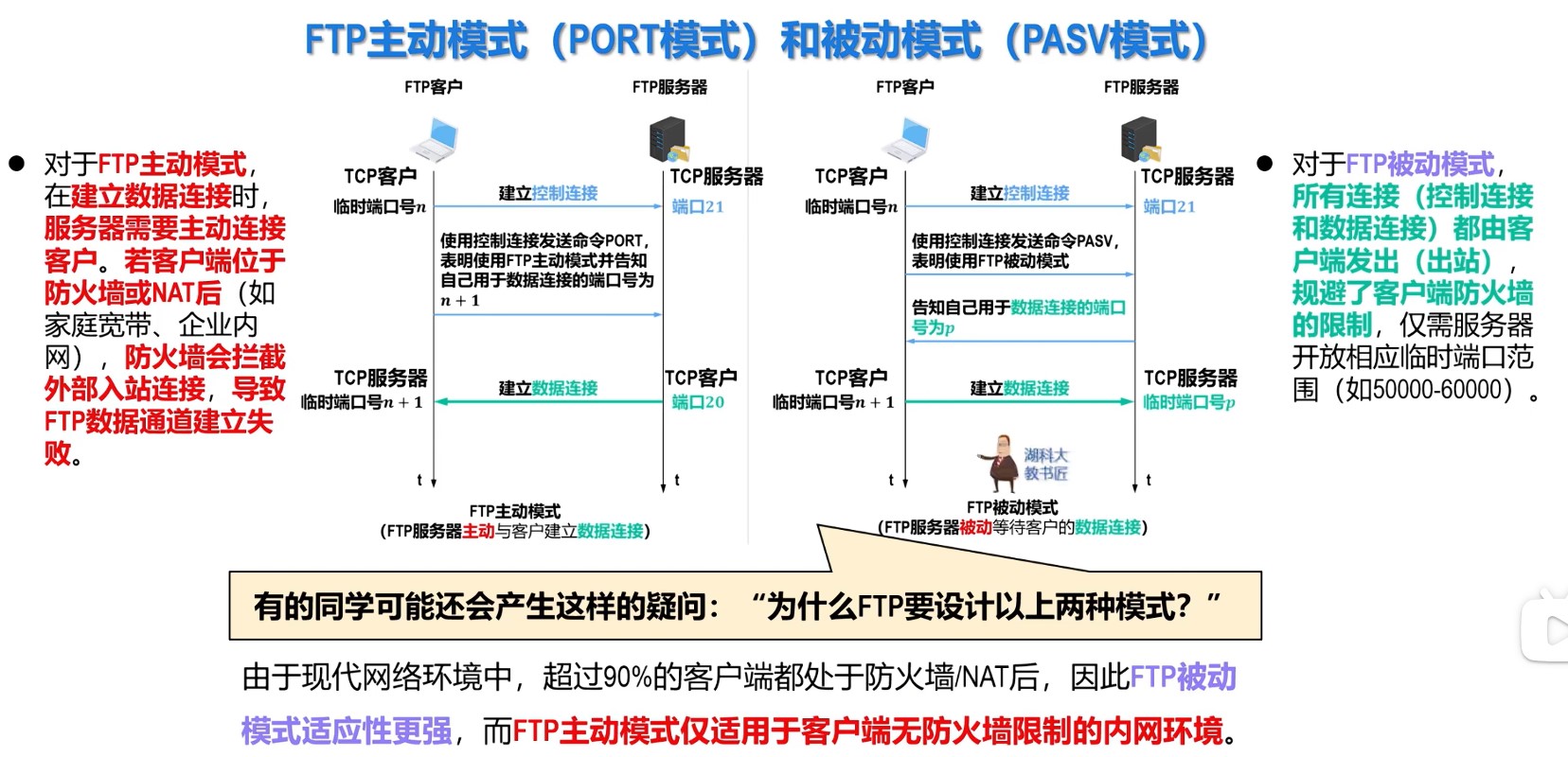

- FTP协议在整个会话期间,只使用一条TCP连接来传输控制命令(如登录、改变目录、上传/下载文件的请求等),这个连接在会话开始时建立,在会话结束时关闭。每当有一次实际的文件传输(无论是上传还是下载)发生时,FTP都会新建一条临时的TCP数据连接,文件传输完成后,该数据连接就会关闭。
- FTP提供交互式的访问,允许客户指明文件的类型与格式(如指明是否使用ASCII码),并允许文件具有存取权限(如访问文件的用户必须经过授权,并输入有效的口令)。
- FTP以用户权限管理的方式提供用户对远程FTP服务器上的文件管理能力
- 以匿名FTP的方式提供共用文件共享的能力
- 基于TCP的FTP和基于UDP的简单文件传送协议TFTP,它们都是文件共享协议中的一大类,即复制整个文件,其特点是:若要存取一个文件,就必须先获得一个本地的文件副本。如果要修改文件,只能对文件的副本进行修改,然后再将修改后的文件副本传回到原节点。
- 参考hexo
- 文件共享协议中的另一大类是联机访问(on-line access)。联机访问意味着允许多个程序同时对一个文件进行存取。
- 和数据库系统的不同之处是用户不需要调用一个特殊的客户进程,而是由操作系统提供对远地共享文件进行访问的服务,就如同对本地文件的访问一样。
- 这就使用户可以用远地文件作为输入和输出来运行任何应用程序,而操作系统中的文件系统则提供对共享文件的透明存取。
- 透明存取的优点是:将原来用于处理本地文件的应用程序用来处理远地文件时,不需要对该应用程序作明显的改动。
- FTP的主要功能是减少或消除在不同操作系统下处理文件的不兼容性。
- FTP的控制信息是带外传送的。
- FTP控制信息都以7位ASCII格式传送
- 数据连接有两种传输模式:主动模式PORT和被动模式PASV。(选择权在客户端)
- PORT模式的工作原理:客户端连接到服务器的21端口,登录成功后要读取数据时,客户端随机开放一个端口,并发送命令告知服务器,服务器收到PORT命令和端口号后,通过20端口和客户端开放的端口连接,发送数据。
- PASV模式的不同点是,客户端要读取数据时,发送PASV命令到服务器,服务器在本地随机开放一个端口,并告知客户端,客户端再连接到服务器开放的端口进行数据传输。可见,是用PORT模式还是PASV模式,选择权在客户端。
- 简单概括为,主动模式传送数据是“服务器”连接到“客户端”的端口;被动模式传送数据是“客户端”连接到“服务器”的端口。
- 很多教材并未介绍这两种模式,若无特别说明,则可默认为采用主动模式。
- 端口号20、21都是服务器端口号,客户端的端口号由客户端系统自行分配
- FTP并非对所有的数据传输都是最佳的。
- 例如,计算机A上运行的应用程序要在远地计算机B的一个很大的文件末尾添加一行信息。若使用FTP,则应先将此文件从计算机B传送到计算机A,添加上这一行信息后,再用FTP将此文件传送到计算机B,来回传送这样大的文件很花时间。实际上这种传送是不必要的,因为计算机A并没有使用该文件的内容。
- 然而网络文件系统NFS则采用另一种思路。NFS允许应用进程打开一个远地文件,并能在该文件的某一个特定的位置上开始读写数据。这样,NFS可使用户只复制一个大文件中的一个很小的片段,而不需要复制整个大文件。
- 对于上述例子,计算机A中的NFS客户软件,把要添加的数据和在文件后面写数据的请求一起发送到远地的计算机B中的NFS服务器,NFS服务器更新文件后返回应答信息。在网络上传送的只是少量的修改数据。
| 特点 | NFS | FTP |
|---|---|---|
| 类比场景 | 共享文档 / 网络共享文件夹(比如企业网盘、腾讯文档、共享盘) | 邮件附件 / 网盘下载(比如发一封带附件的邮件,或者网盘上传下载) |
| 使用方式 | 直接打开远程文件,就像本地文件一样操作 | 必须先下载一份文件副本,修改后再上传回去 |
| 更新方式 | 修改即生效,其他人马上能看到 | 必须重新上传完整文件,别人才能看到最新版本 |
| 并发访问 | 支持多人同时在线访问(依靠文件锁等机制避免冲突) | 协议本身无并发控制,容易发生“谁后上传覆盖谁” |
| 体验感 | 就像远程磁盘 / 云盘 | 就像快递文件 / 搬运文件 |
| 适合场景 | 实时协作、大型系统共享存储 | 文件分发、网站更新、软件镜像下载 |
- TFTP
- 使用UDP
- 当需要将程序或文件同时向许多机器下载时就往往需要使用TFTP
- 有自己的差错改正措施
- 只支持文件传输而不支持交互
- 没有一个庞大的命令集,没有列目录的功能,也不能对用户进行身份鉴别
- TFTP代码所占的内存较小
- 这对较小的计算机或某些特殊用途的设备是很重要的。这些设备不需要硬盘,只需要固化了TFTP、UDP和IP的小容量只读存储器即可。当接通电源后,设备执行只读存储器中的代码,在网络上广播一个TFTP请求。网络上的TFTP服务器就发送响应,其中包括可执行二进制程序。设备收到此文件后将其放入内存,然后开始运行程序。这种方式增加了灵活性,也减少了开销。
- 支持ASCII码或二进制传送。
- TFTP的工作很像停止等待协议。发送完一个文件块后就等待对方的确认,确认时应指明所确认的块编号。发完数据后在规定时间内收不到确认就要重发数据PDU。发送确认PDU的一方若在规定时间内收不到下一个文件块,也要重发确认PDU。
- 工作流程:
- 在一开始工作时。TFTP客户进程发送一个读请求报文或写请求报文给TFTP服务器进程,其熟知端口号码为69。
- TFTP服务器进程要选择一个新的端口和TFTP客户进程进行通信。
- 若文件长度恰好为512字节的整数倍,则在文件传送完毕后,还必须在最后发送一个只含首部而无数据的数据报文。若文件长度不是512字节的整数倍,则最后传送数据报文中的数据字段一定不满512字节,这正好可作为文件结束的标志。
- 使用UDP
TELNET
- 用户用TELNET就可在其所在地通过TCP连接注册(即登录)到远地的另一台主机上(使用主机名或IP地址)。TELNET能将用户的击键传到远地主机,同时也能将远地主机的输出通过TCP连接返回到用户屏幕。
- TELNET能够适应许多计算机和操作系统的差异。
- 客户软件把用户的击键和命令转换成NVT格式,并送交服务器。服务器软件把收到的数据和命令从NVT格式转换成远地系统所需的格式。向用户返回数据时,服务器把远地系统的格式转换为NVT格式,本地客户再从NVT格式转换到本地系统所需的格式。
DNS
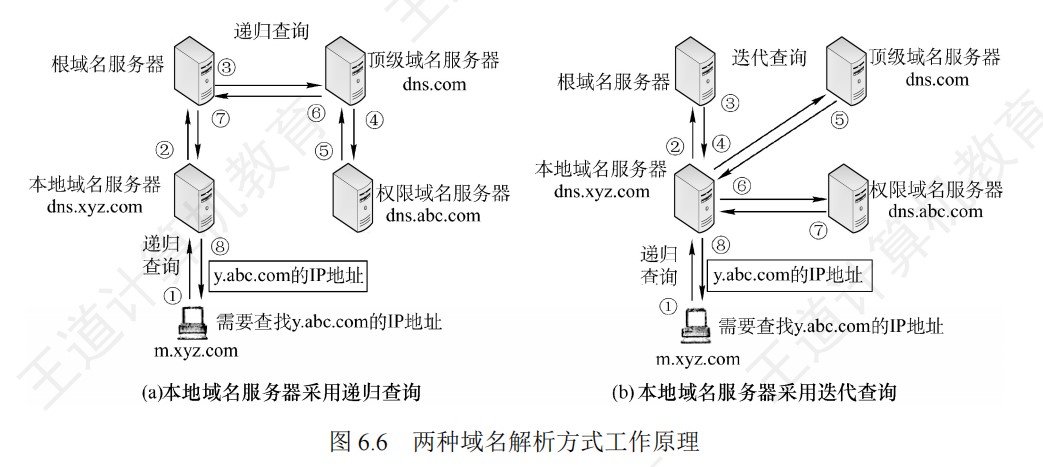
- DNS域名解析最多需要8个UDP报文:4查询报文,4回答报文
- 域名到IP地址的解析过程的要点:
- 当某一个应用进程需要把主机名解析为IP地址时,该应用进程就调用解析程序(resolver),并成为DNS的一个客户
- 把待解析的域名放在DNS请求报文中,以UDP用户数据报方式发给本地域名服务器(使用UDP是为了减少开销)。
- 本地域名服务器在查找域名后,把对应的IP地址放在回答报文中返回。应用进程获得目的主机的IP地址后即可进行通信。
- 域名解析过程可能需要查询多个权限域名服务器,这一过程可能逐级重复。
- 根域名服务器采用了任播技术,因此当DNS客户向某个根域名服务器的IP地址发出查询报文时,互联网上的路由器就能找到离这个DNS客户最近的一个根域名服务器。这样做不仅加快了DNS的查询过程,也更加合理地利用了互联网的资源。
- 任播的IP数据报的终点是一组在不同地点的主机,但具有相同的IP地址。IP数据报交付离源点最近的一台主机
- 当所要查询的主机也属于同一个本地ISP时,该本地域名服务器立即就能将所查询的主机名转换为它的IP地址,而不需要再去询问其他的域名服务器。
- 为了提高域名服务器的可靠性,DNS域名服务器都把数据复制到几个域名服务器来保存,其中的一个是主域名服务器(master name server),其他的是辅助域名服务器(secondaryname server)。当主域名服务器出故障时,辅助域名服务器可以保证DNS的查询工作不会中断。主域名服务器定期把数据复制到辅助域名服务器中,而更改数据只能在主域名服务器中进行。这样就保证了数据的一致性。
- 本地域名服务器的缓存中如果有顶级域名服务器的IP地址,那么本地域名服务器可以不向根域名服务器进行查询,而是直接向顶级域名服务器发送查询请求报文。
- 许多主机在启动时从本地域名服务器下载名字和地址的全部数据库,维护存放自己最近使用的域名的高速缓存,并且只在从缓存中找不到名字时才使用域名服务器。
- DNS缓存是被动的,不会主动刷新
- DNS 缓存依赖于查询请求来更新,而不会主动去检测是否有新的 DNS 信息。
- DNS 缓存 在过期后不会主动刷新,直到你下次访问相关网站时,系统才会重新查询 DNS 服务器,获取新的域名解析信息。如果之前的缓存过期了,系统会重新向 DNS 服务器发送请求,查询最新的 IP 地址,并更新缓存
- DNS缓存是被动的,不会主动刷新
- 域名/IP/MAC与主机都不具有一一映射的关系,1台主机可能对应着多个不同的域名/IP/MAC
- 本地域名服务器的IP地址需要直接配置在域名解析的主机里
- 本地域名服务器完成域名解析时,最多的请求查询次数(迭代次数)为域名的段数(除去www、dns等)+1(这是根域名的一次查询)
- edu,gov,mil三个顶级域名是美国专用
- 本地主机的DNS地址就是本地域名服务器地址

万维网
- 分布式的和非分布式的超媒体系统有很大区别。在非分布式系统中,各种信息都驻留在单个计算机的磁盘中。由于各种文档都可从本地获得,因此这些文档之间的链接可进行一致性检查。所以,一个非分布式超媒体系统能够保证所有的链接都是有效的和一致的。
- 万维网把大量信息分布在整个互联网上。每台主机上的文档都独立进行管理。对这些文档的增加、修改、删除或重新命名都不需要(实际上也不可能)通知到互联网上成千上万的节点。这样,万维网文档之间的链接就经常会不一致。
- 例如,主机A上的文档X本来包含了一个指向主机B上的文档Y的链接。若主机B的管理员在某日删除了文档Y,那么主机A的上述链接显然就失效了。
- URL实际上就是互联网上的资源的地址,互联网上的所有资源,都有一个唯一确定的URL
- “资源”是指在互联网上可以被访问的任何对象,包括文件目录、文件、文档、图像、声音等,以及与互联网相连的任何形式的数据。
- URL相当于一个文件名在网络范围的扩展。因此,URL是与互联网相连的机器上的任何可访问对象的一个指针。
- URL的第一部分是最左边的<协议>。这里的**<协议>就是指出使用什么协议来获取该万维网文档**。现在最常用的协议就是http(超文本传送协议HTTP),其次是ftp(文件传送协议FTP)。
- 在<协议>后面的“:/1”是规定的格式。它的右边是第二部分<主机>,它指出这个万维网文档是在哪一台主机上。这里的**<主机>就是指该主机在互联网上的域名**。再后面是第三和第四部分<端口>和<路径>,有时可省略。
- 用户使用URL并非仅仅能够访问万维网的页面,而且还能够通过URL使用其他的互联网应用程序,用户在使用这些应用程序时,只使用一个程序,即浏览器。
- 浏览器和万维网客户是同义词
HTTP
-
HTTP既可使用非持续连接(HTTP/1.0),又可使用持续连接(HTTP/1.1支持)。
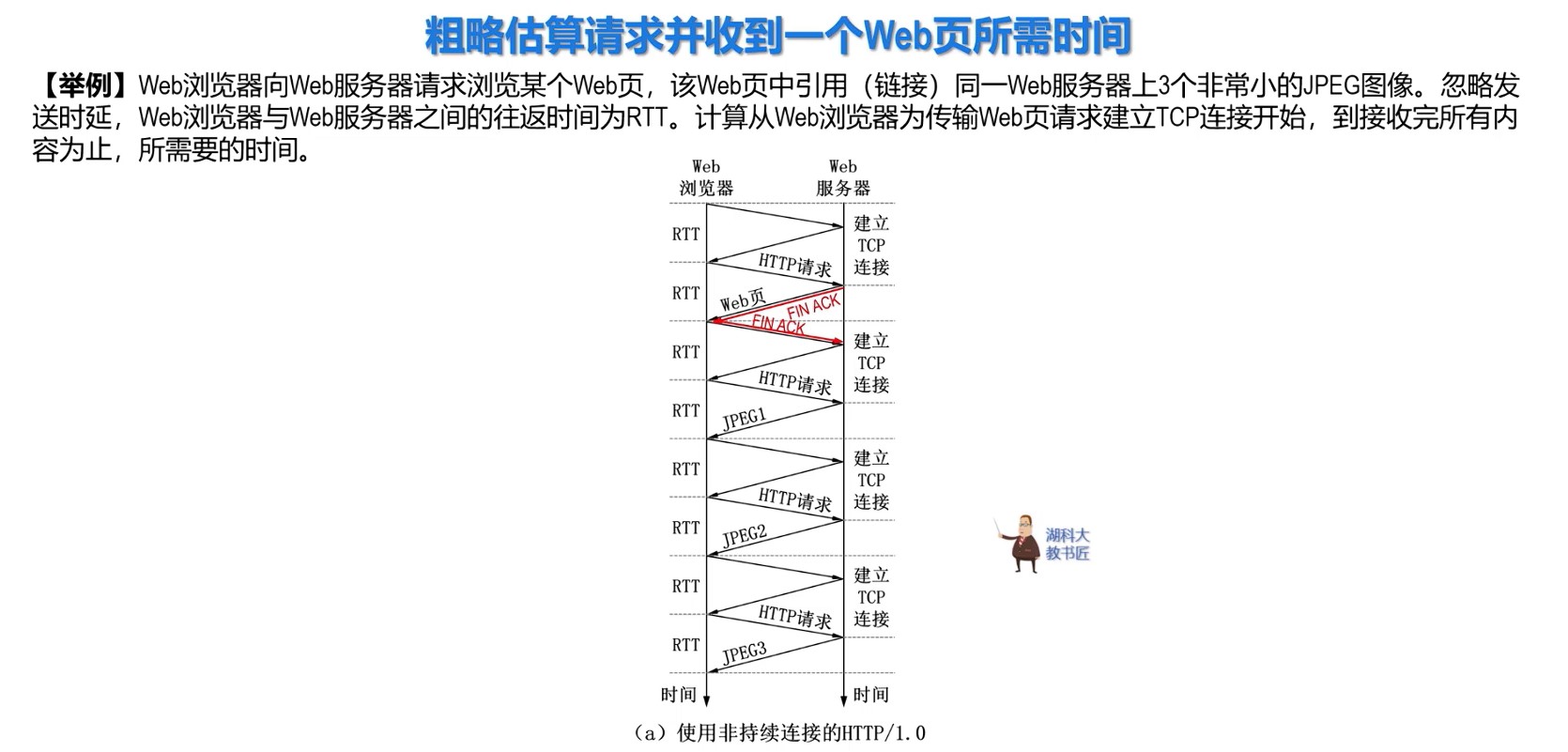
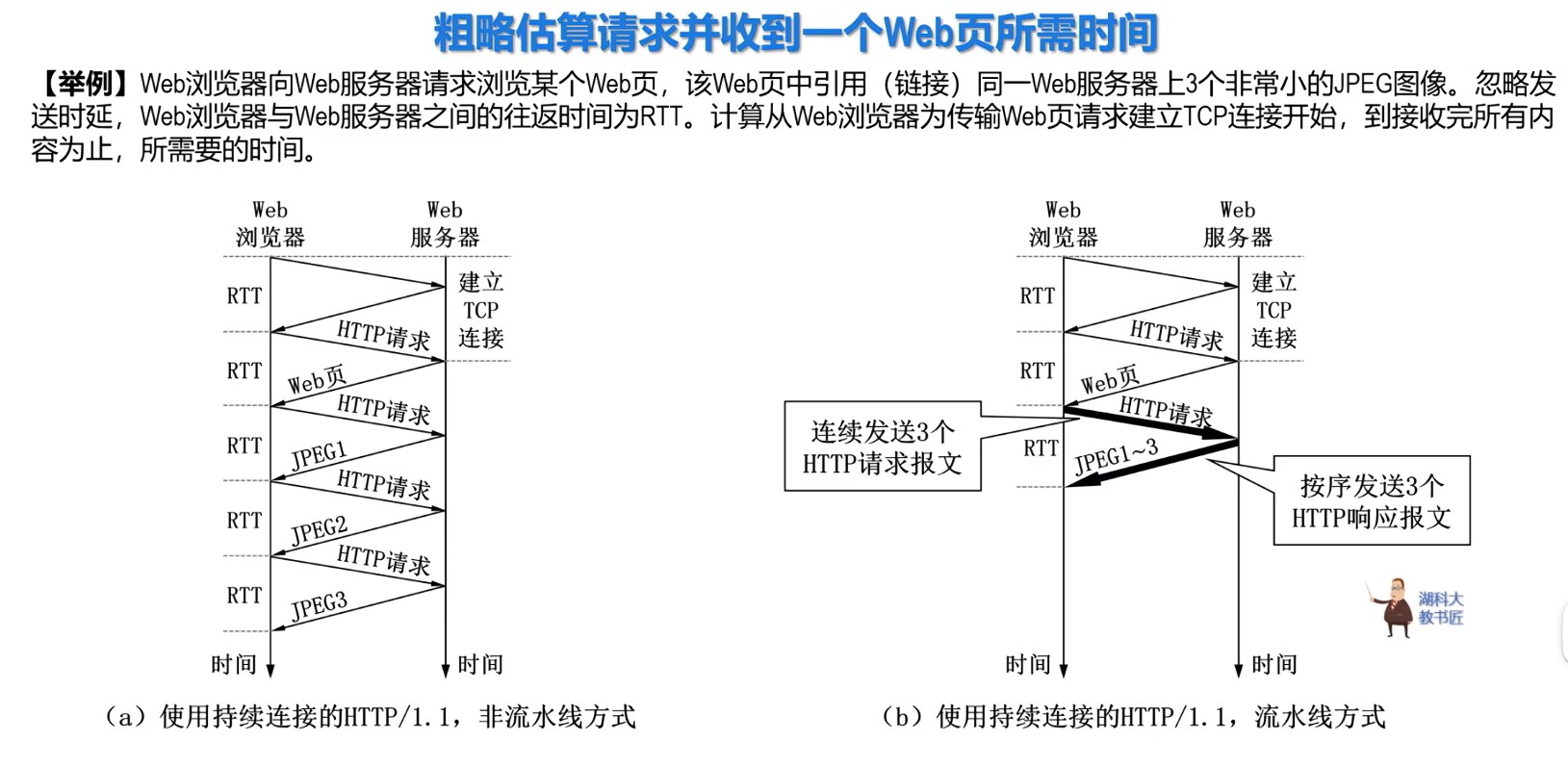
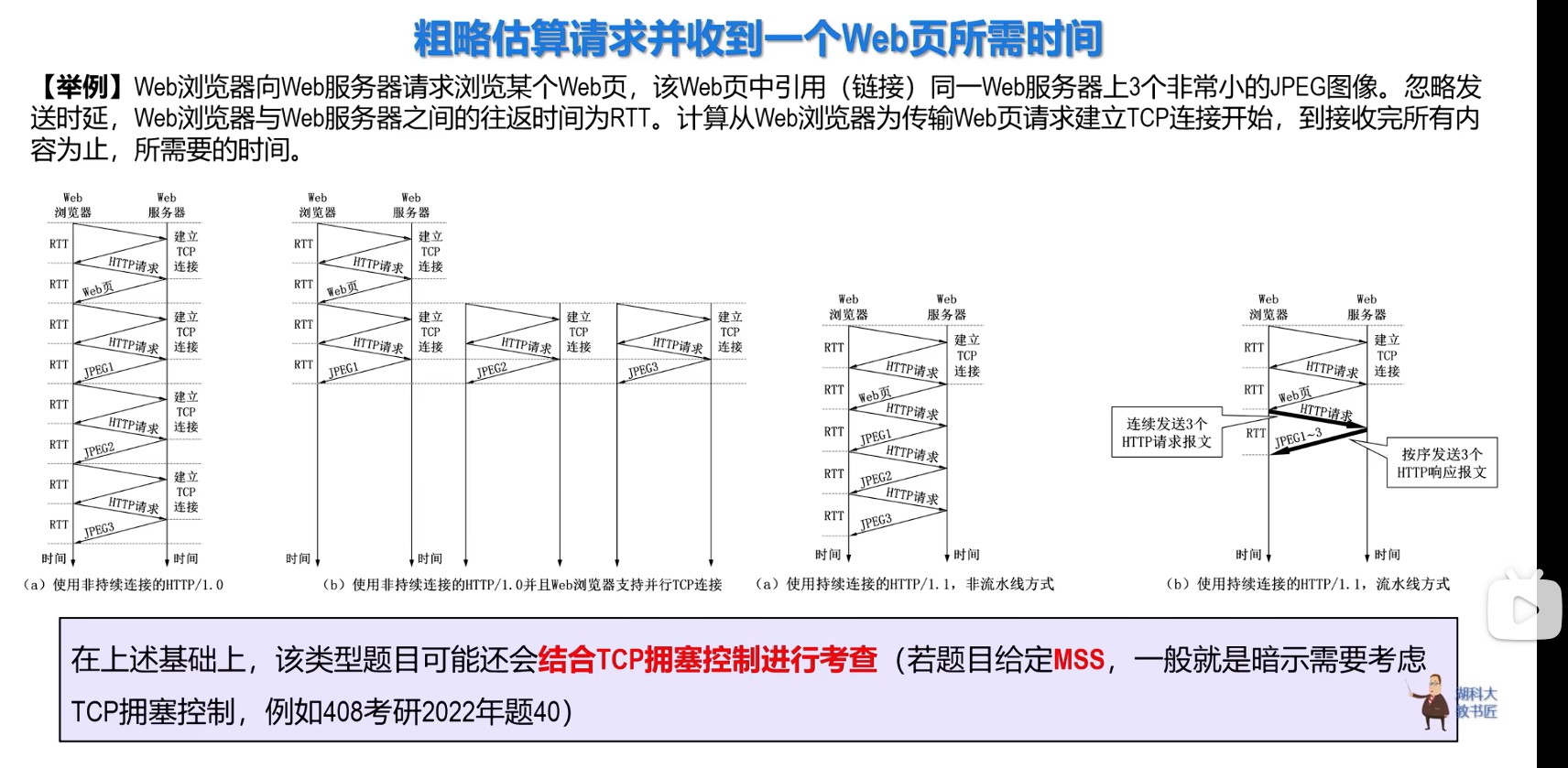
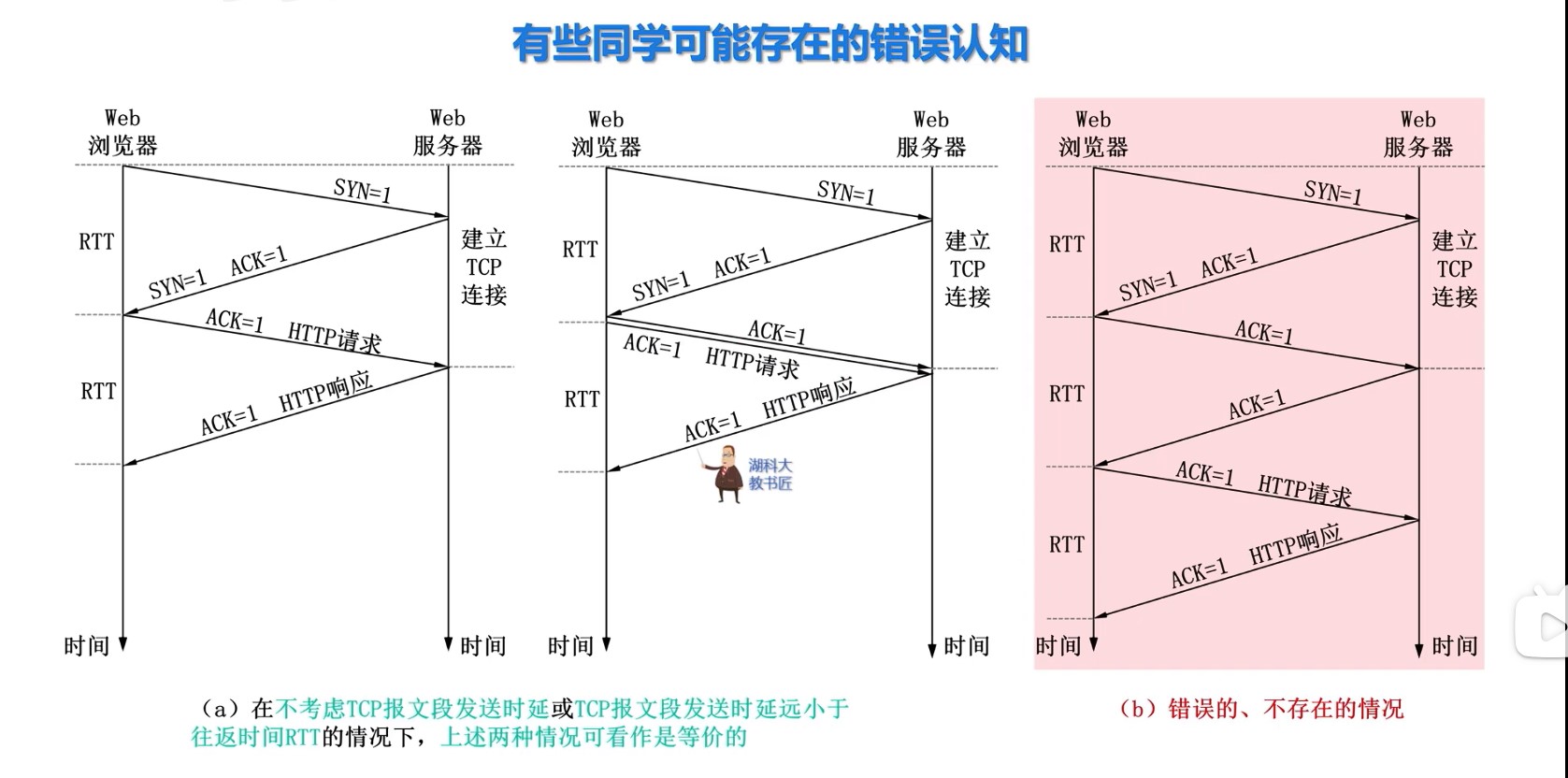
- 对于非持续连接,每个网页元素对象(如JPEG图形、Flash等)的传输都需要单独建立一个TCP连接。请求一个万维网文档所需的时间是该文档的传输时间(与文档大小成正比)加上两倍往返时间RTT(一个RTT用于TCP连接,另一个RTT用于请求和接收文档)。每请求一个对象都导致2×RTT的开销,此外每次建立新的TCP连接都要分配缓存和变量,使万维网服务器的负担很重。为了减小时延,浏览器通常会建立多个并行的TCP连接以同时请求多个对象。
- 并行情况下,多个并行下载的数据传输速率的总和不能超过网络线路的带宽
- 所谓持续连接,是指万维网服务器在发送响应后仍然保持这条连接,使同一个客户和该服务器可以继续在这条TCP连接上传送后续的HTTP请求报文和响应报文
- 持续连接又分为非流水线和流水线两种工作方式。
- 对于非流水线方式,客户在收到前一个响应后才能发出下一个请求,服务器在发送完一个对象后,其TCP连接就处于空闲状态,浪费了服务器资源。
- 对于流水线方式,客户可以连续发出对各个对象的请求,服务器就可连续响应这些请求。若所有的请求和响应都是连续发送的,则引用所有对象共计经历1RTT延迟,而不是像非流水线方式那样,每个对象都必须有1RTT延迟。这种方式减少了TCP连接中的空闲时间,提高了效率。
- 此外,因为HTTP是基于TCP的,所以每RTT内传送的数据量还要受到TCP发送窗口的限制。
- 对于非持续连接,每个网页元素对象(如JPEG图形、Flash等)的传输都需要单独建立一个TCP连接。请求一个万维网文档所需的时间是该文档的传输时间(与文档大小成正比)加上两倍往返时间RTT(一个RTT用于TCP连接,另一个RTT用于请求和接收文档)。每请求一个对象都导致2×RTT的开销,此外每次建立新的TCP连接都要分配缓存和变量,使万维网服务器的负担很重。为了减小时延,浏览器通常会建立多个并行的TCP连接以同时请求多个对象。
-
HTTP使用了面向连接的TCP作为运输层协议,保证了数据的可靠传输。HTTP不必考虑数据在传输过程中被丢弃后又怎样被重传。但是,HTTP协议本身是无连接的。这就是说,虽然HTTP使用了TCP连接,但通信的双方在交换HTTP报文之前不需要先建立HTTP连接。
-
HTTP协议是无状态的(stateless)。也就是说**,同一个客户第二次访问同一个服务器上的页面时,服务器的响应与第一次被访问时的相同**(假定现在服务器还没有把该页面更新),因为服务器并不记得曾经访问过的这个客户,也不记得为该客户曾经服务过多少次,服务器默认不会在不同HTTP请求之间保留客户端的状态信息,HTTP的无状态特性简化了服务器的设计,使服务器更容易支持大量并发的HTTP请求。
-
非持续非流水线请求n个文件:2RTT*N+2RTT(获取HTML文件)
- 非持续并行请求文件:2RTT+2RTT(获取HTML文件)
- 持续非流水线:2RTT(获取HTML文件)+RTT*N
- 持续流水线:2RTT(获取HTML文件)+RTT
- HTTP/1.1默认使用流水线的持久连接
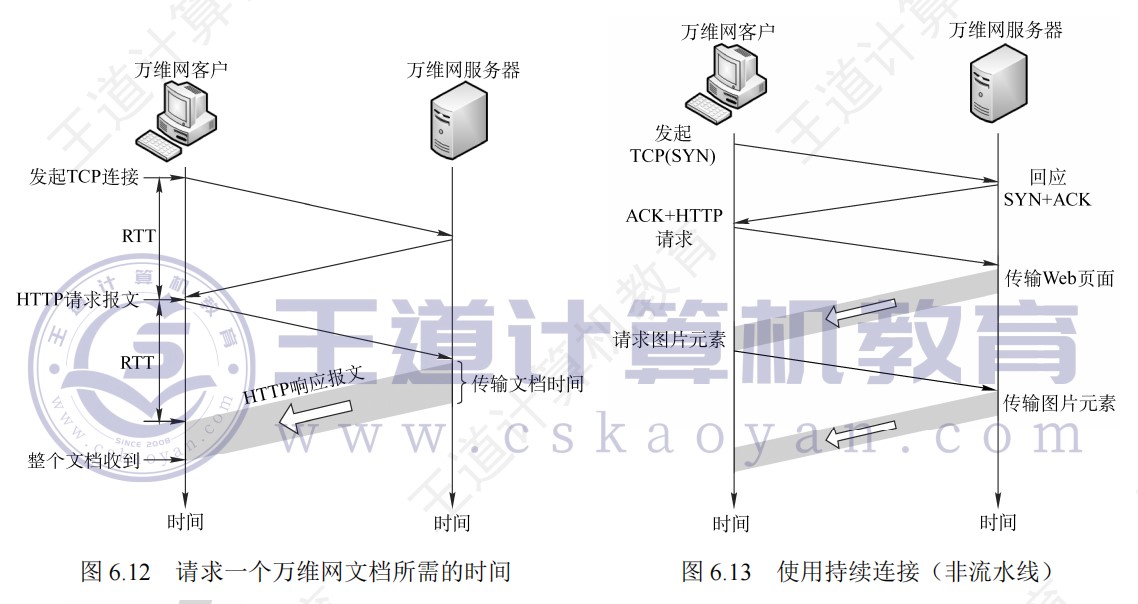
-
代理服务器(proxy server)是一种网络实体,它又称为万维网高速缓存(Web cache)。代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的请求相同,就返回暂存的响应,而不需要按URL的地址再次去互联网访问该资源。代理服务器可在客户端或服务器端工作,也可在中间系统上工作。
- 设图6-11(a)是校园网不使用代理服务器的情况。这时,校园网中所有的计算机都通过2Mbit/s专线链路(R₁-R₂)与互联网上的源点服务器建立TCP连接。因而校园网各计算机访问互联网的通信量往往会使这条2 Mbit/s的链路过载,使得时延大大增加。
- 图6-11(b)是校园网使用代理服务器的情况。这时,访问互联网的过程是这样的:
- (1)校园网的计算机中的浏览器向互联网的服务器请求服务时,就先和校园网的代理服务器建立TCP连接,并向代理服务器发出HTTP请求报文(见图6-11(b)中的0)。
- (2)若代理服务器已经存放了所请求的对象,代理服务器就把这个对象放入HTTP响应报文中返回给计算机的浏览器。
- (3)否则,代理服务器就代表发出请求的用户浏览器,与互联网上的源点服务器建立TCP连接(如图6-11(b)中的②所示),并发送HTTP请求报文。
- (4)源点服务器把所请求的对象放在HTTP响应报文中返回给校园网的代理服务器。
- (5)代理服务器收到这个对象后,先复制在自己的本地存储器中(留待以后用),然后再把这个对象放在HTTP响应报文中,通过已建立的TCP连接给请求该对象的浏览器。
- 我们注意到,代理服务器有时是作为服务器(当接受浏览器的HTTP请求时),但有时却作为客户(当向互联网上的源点服务器发送HTTP请求时)。
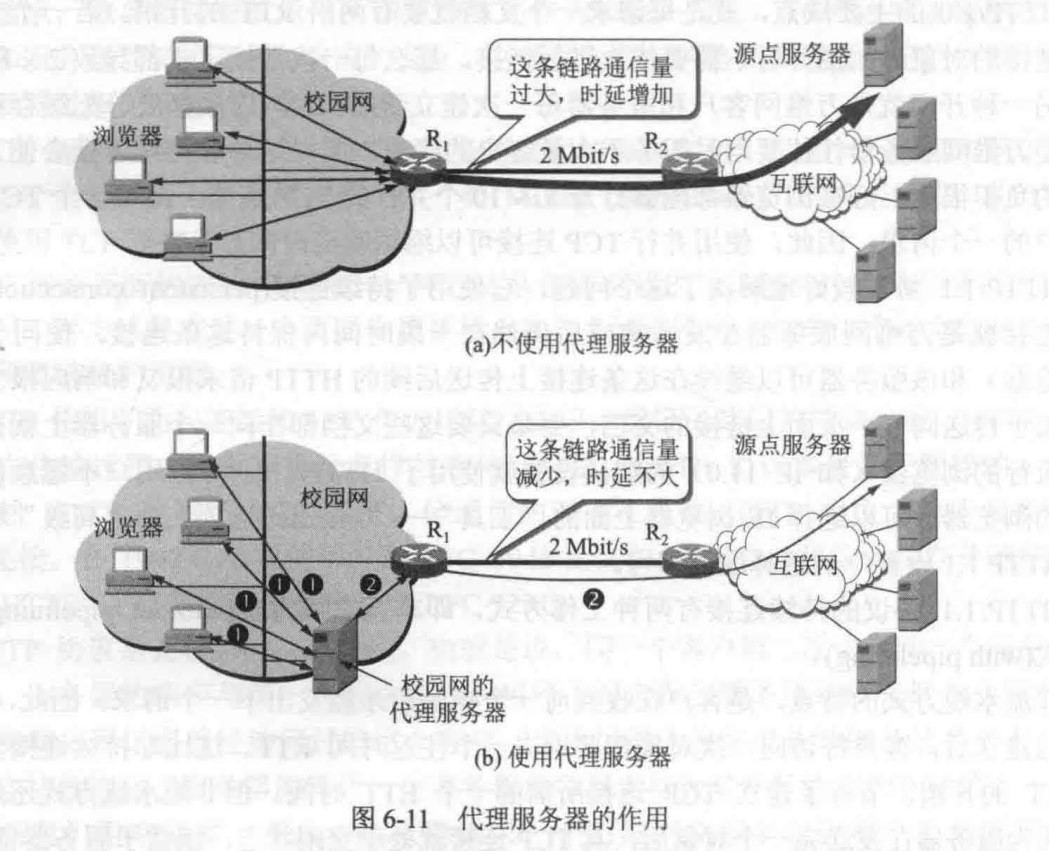
-
HTTP的报文结构
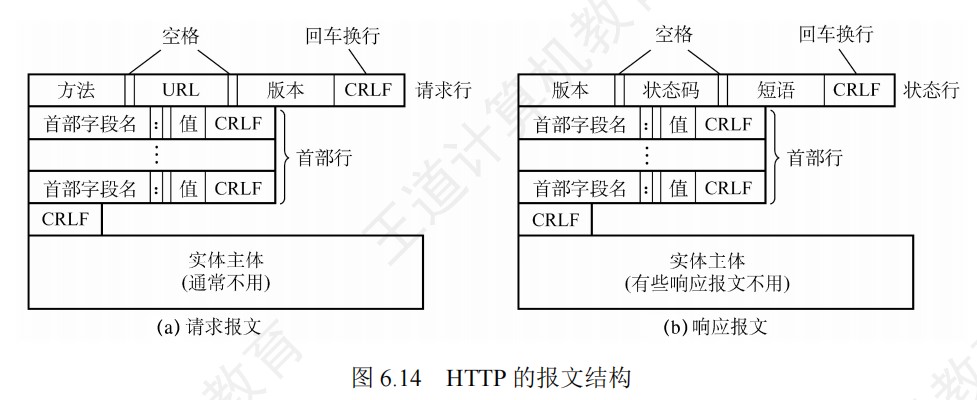
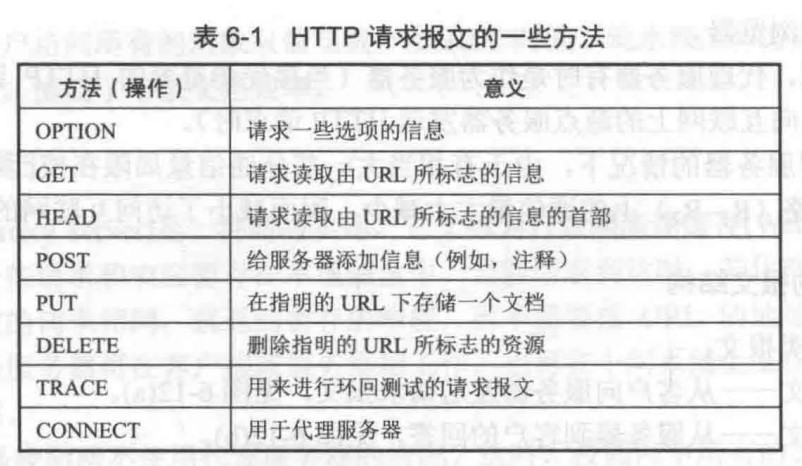
- POST用于向服务器发送数据


-
1xx表示通知信息,如请求收到了或正在进行处理。
2xx表示成功,如接受或知道了。
3xx表示重定向,如要完成请求还必须采取进一步的行动。
4xx表示客户的差错,如请求中有错误的语法或不能完成。
5xx表示服务器的差错,如服务器失效无法完成请求。 -
HTTP/2把服务器发回的响应变成可以并行发回(使用同一个TCP连接),这就大大缩短了服务器的响应时间。
-
“并行发回”指的是HTTP/2协议的一个特性,即能够让服务器同时并行地发送多个响应,而不是像HTTP/1.1那样必须按照请求顺序依次发送。
在HTTP/1.1中,客户端在建立TCP连接后,可以发送多个请求,但必须等待一个请求的响应完成后才能发送下一个请求,这种顺序发送方式可能会导致响应延迟。如果服务器无法及时处理一个请求并返回响应,客户端会被迫等待。
而在HTTP/2中,服务器通过多路复用(multiplexing)的方式,允许多个请求的响应在同一个TCP连接上并行返回,这样就避免了HTTP/1.1中的“请求-响应顺序排队”问题。服务器可以同时发送多个响应,不需要等待上一个请求的响应完成,这大大减少了响应的等待时间,提高了效率。
总结来说,“并行发回”即是在HTTP/2协议中,服务器能够并行地返回多个请求的响应,从而提升整体的响应速度和效率。
-
Cookie
- Cookie是HTTP实现状态化的核心机制,以便万维网服务器能够识别并记住用户。
-
Cookie识别码是由服务器端产生,并通过HTTP相应的Set-Cookie头部发送给客户端。
-
Cookie识别码存储在客户端(如服务器中),服务器端本身只存储与识别码关联的会话数据,而非识别码本身
-
Cookie的主要作用是让服务器识别客户端(用户),例如维持登陆状态
-
Cookie的传输方式取决于网络协议:使用Http时,Cookie以明文传输;使用Https时,Cookie以密文加密传输,因此,Cookie识别码的传输方式既可能是明文也可能是密文
-
Cookie
- Cookie是这样工作的:
- 当用户A浏览某个使用Cookie的网站时,该网站的服务器就为A产生一个唯一的识别码,并以此作为索引在服务器的后端数据库中产生一个项目。
- 接着在给A的HTTP响应报文中添加一个叫做Set-cookie的首部行。这里的“首部字段名”就是“Set-cookie”,而后面的“值”就是赋予该用户的“识别码”。
- 例如这个首部行是这样的:
Set-cookie:31d4d96e407aad42
- 例如这个首部行是这样的:
- 当A收到这个响应时,其浏览器就在它管理的特定Cookie文件中添加一行,其中包括这个服务器的主机名和Set-cookie后面给出的识别码。
- 当A继续浏览这个网站时,每发送一个HTTP请求报文,其浏览器就会从其Cookie文件中取出这个网站的识别码,并放到HTTP请求报文的Cookie首部行中:
Cookie:31d4d96e407aad42 - 于是,这个网站就能够跟踪用户31d4d96e407aad42(用户A)在该网站的活动。
- 服务器并不需要知道这个用户的真实姓名以及其他的信息。但服务器能够知道用户31d4d96e407aad42在什么时间访问了哪些页面,以及访问这些页面的顺序。
- 如果A是在网上购物,那么这个服务器可以为A维护一个所购物品的列表,使A在结束这次购物时可以一起付费。
- 如果A在几天后再次访问这个网站,那么他的浏览器会在其HTTP请求报文中继续使用首部行Cookie:31d4d96e407aad42,而这个网站服务器根据A过去的访问记录可以向他推荐商品。
- 如果A已经在该网站登记过和使用过信用卡付费,那么这个网站就已经保存了A的姓名、电子邮件地址、信用卡号码等信息。
- 这样,当A继续在该网站购物时,只要还使用同一个电脑上网,由于浏览器产生的HTTP请求报文中都携带了同样的Cookie首部行,服务器就可利用Cookie来验证出这是用户A,因此以后A在这个网站购物时就不必重新在键盘上输入姓名、信用卡号码等信息。
- Cookie是这样工作的:
-
TCP和HTTP结合的题目中,注意:
- 挥手③发出HTML请求,服务器回复HTML文件的时候,是0RTT-1RTT这段,之后客户都要发ACK,然后对面的窗口才会增大
HTML
-
HTML并不是应用层的协议,它只是万维网浏览器使用的一种语言
-
仅当HTML文档是以.html或.htm为后缀时,浏览器才对这样的HTML文档的各种标签进行解释。如果HTML文档改为以.txt为其后缀,则HTML解释程序就不对标签进行解释,而浏览器只能看见原来的文本文件。
-
并非所有的浏览器都支持所有的HTML标签。若某一个浏览器不支持某一个HTML标签,则浏览器将忽略此标签,但在一对不能识别的标签之间的文本仍然会被显示出来。
-
链接的终点可以是其他网站上的页面。这种链接方式叫做远程链接。这时必须在HTML文档中指明链接到的网站的URL。有时链接可以指向本计算机中的某一个文件或本文件中的某处,这叫做本地链接。这时必须在HTML文档中指明链接的路径。
-
XML是可扩展标记语言,用于标记电子文件,使其具有结构性的标记语言,可用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。
- XML不是要替换HTML,而是对HTML的补充。XML标记由文档的作者定义,并且是无限制的。HTML标记则是预定义的;HTML作者只能使用当前HTML标准所支持的标记。
-
XHTML是可扩展超文本标记语言。
-
CSS是层叠样式表,它是一种样式表语言,用于为HTML文档定义布局。CSS与HTML的区别就是:HTML用于结构化内容,而CSS则用于格式化结构化的内容。例如,在浏览器上显示的字体、颜色、边距、高度、宽度、背景图像等方面,都能够给出精确的规定。现在所有的浏览器都支持CSS。
-
动态文档和静态文档
-
静态文档在文档创作完毕后就存放在万维网服务器中,在被用户浏览的过程中,内容不会改变。由于这种文档的内容不会改变,因此用户对静态文档的每次读取所得到的返回结果都是相同的。
- 静态文档的最大优点是简单,缺点是不够灵活,变化频繁的文档不适于做成静态文档。
-
动态文档是指文档的内容是在浏览器访问万维网服务器时才由应用程序动态创建的。当浏览器请求到达时,万维网服务器要运行另一个应用程序,并把控制转移到此应用程序。接着,该应用程序对浏览器发来的数据进行处理,并输出HTTP格式的文档,万维网服务器把应用程序的输出作为对浏览器的响应。由于对浏览器每次请求的响应都是临时生成的,因此用户通过动态文档所看到的内容是不断变化的。
- 动态文档的主要优点是具有报告当前最新信息的能力,但动态文档的创建难度比静态文档的高,因为动态文档的开发不是直接编写文档本身,而是编写用于生成文档的应用程序,这就要求动态文档的开发人员必须会编程,而所编写的程序还要通过大范围的测试,以保证输入的有效性。
- 动态文档一旦建立,它所包含的信息内容也就固定下来而无法及时刷新屏幕。另外,像动画之类的显示效果,动态文档也无法提供。
-
-
浏览器屏幕显示的连续更新
-
有两种技术可用于浏览器屏幕显示的连续更新
-
①服务器推送,将所有的工作都交给服务器。服务器不断地运行与动态文档相关联的应用程序,定期更新信息,并发送更新过的文档。
- 尽管从用户的角度看,这样做可达到连续更新的目的,但这也有很大的缺点。首先,为了满足很多客户的请求,服务器就要运行很多服务器推送程序。这将造成过多的服务器开销。其次,服务器推送技术要求服务器为每一个浏览器客户维持一个不释放的TCP连接。随着TCP连接的数目增加,每一个连接所能分配到的网络带宽就下降,这就导致网络传输时延的增大。
-
②活动文档
- 把所有的工作都转移给浏览器端。每当浏览器请求一个活动文档时,服务器就返回一段活动文档程序副本,使该程序副本在浏览器端运行。这时,活动文档程序可与用户直接交互,并可连续地改变屏幕的显示。只要用户运行活动文档程序,活动文档的内容就可以连续地改变。由于活动文档技术不需要服务器的连续更新传送,对网络带宽的要求也不会太高。
- 从传送的角度看,浏览器和服务器都把活动文档看成是静态文档。在服务器上的活动文档的内容是不变的,这点和动态文档是不同的。
-
SMTP、POP3、IMAP

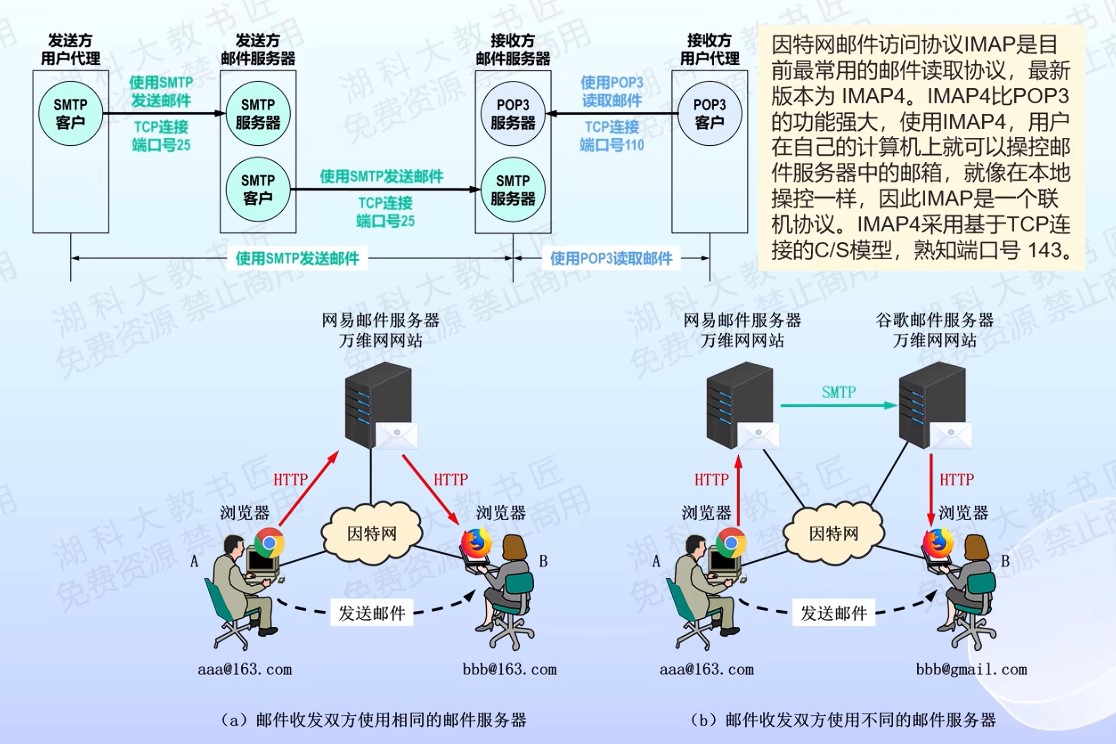
-
发件人的用户代理向发送方邮件服务器发送邮件,以及发送方邮件服务器向接收方邮件服务器发送邮件,都是使用SMTP协议。而POP3或IMAP则是用户代理从接收方邮件服务器上读取邮件所使用的协议。
- 邮件读取协议:POP3,IMAP
- 邮件发送协议:SMTP
- SMTP地址出错:不能发送邮件;
- POP3地址出错:不能接收邮件
- HTTP地址出错:即不能发也不能收
- mail地址出错:发错人或者发不出(查无此人)
-
SMTP只能传送可打印的7位ASCII码
-
邮件服务器必须能够同时充当客户和服务器
-
SMTP、POP3、IMAP都是使用TCP连接来传送邮件的。
-
邮件不会在互联网中的某个中间邮件服务器落地。如果SMTP客户还有一些邮件要发送到同一个邮件服务器,那么可以在原来已建立的TCP连接上重复发送。如果SMTP客户无法和SMTP服务器建立TCP连接(例如,接收方服务器过负荷或出了故障),那么要发送的邮件就会继续保存在发送方的邮件服务器中,并在稍后一段时间再进行新的尝试。如果SMTP客户超过了规定的时间还不能把邮件发送出去,那么发送邮件服务器就把这种情况通知用户代理。
-
MIME(多⽤途互联⽹邮件扩展)并不是⼀个独⽴的传输层协议,⽽是⼀个互联⽹标准,主要⽤于扩展电⼦邮件格式,使其能够⽀持⾮ ASCII 字符、⼆进制格式附件(如图⽚、⾳频)等。MIME 依然依赖 SMTP(或 HTTP 等应⽤层协议)进⾏传输,⽽不是替代 SMTP。
-
POP3服务器和POP3客户之间的通信是POP3用户发起的
-
SMTP通信有以下三个阶段
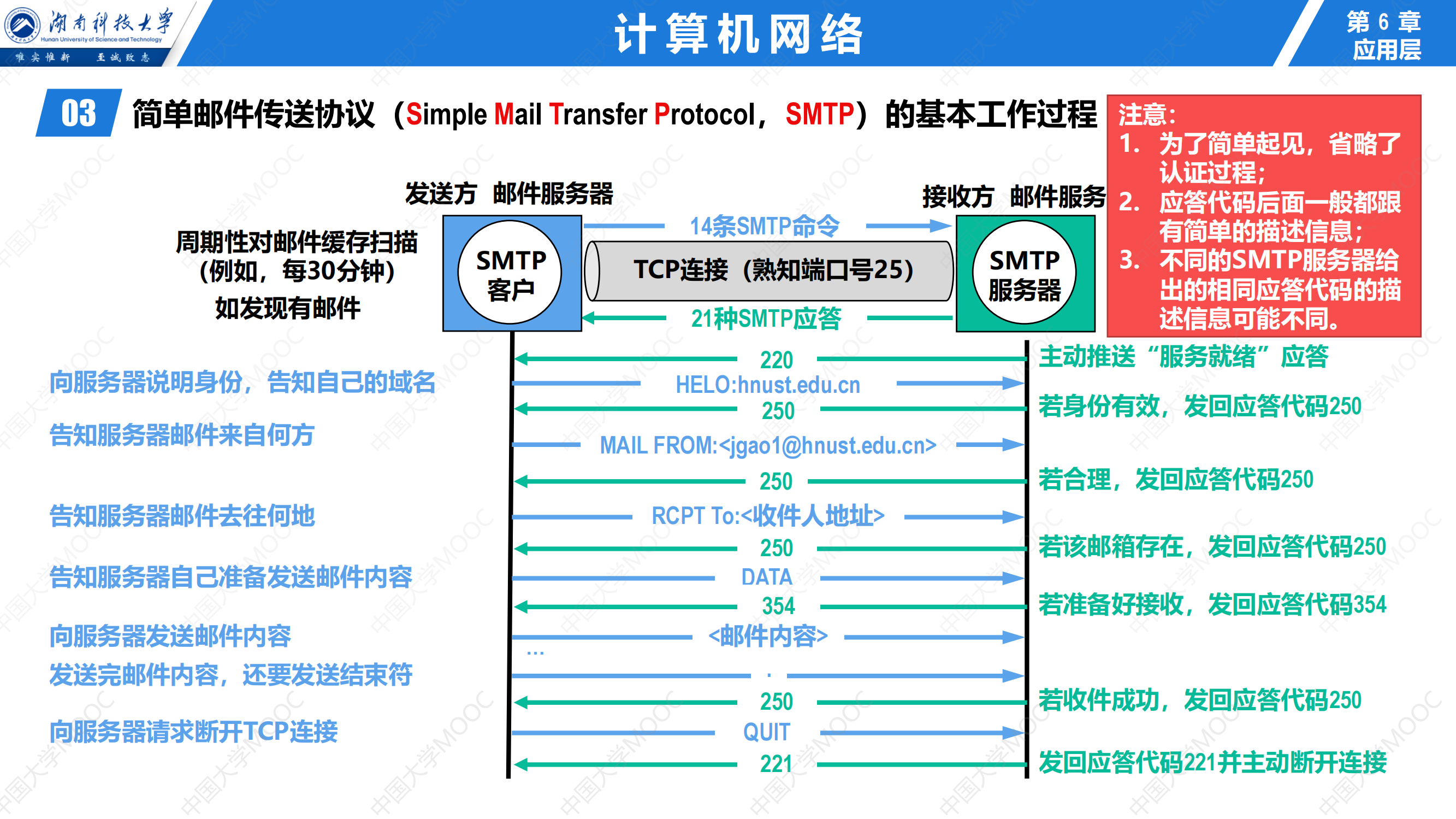
- 1、连接建立
- 发件人的邮件送到发送方邮件服务器的邮件缓存后,SMTP客户(发送方邮件服务器)就每隔一定时间(例如30分钟)对邮件缓存扫描一次。
- 如发现有邮件,就使用SMTP的熟知端口号码25与接收方邮件服务器的SMTP服务器建立TCP连接。
- 发送方邮件服务器和接收方邮件服务器都使用端口25
- 在连接建立后,接收方SMTP服务器要发出“220 Service ready”(服务就绪)。
- 然后SMTP客户(发送方邮件服务器)向SMTP服务器(接收方邮件服务器)发送HELO命令,附上发送方的主机名。
- SMTP服务器(接收方邮件服务器)若有能力接收邮件,则回答:“250 OK”,表示已准备好接收。
- 若SMTP服务器不可用,则回答“421 Service not available”(服务不可用)。
- 如在一定时间内(例如三天)发送不了邮件,邮件服务器会把这个情况通知发件人。
- SMTP不使用中间的邮件服务器。
- 2、邮件传送
- 邮件的传送从MAIL命令开始。MAIL命令后面有发件人的地址。
- 如:MAIL FROM:xiexiren@tsinghua.org.cn。
- 若SMTP服务器已准备好接收邮件,则回答“250 OK”。
- 否则,返回一个代码,指出原因。如:451(处理时出错),452(存储空间不够),500(命令无法识别)等。
- 下面跟着一个或多个RCPT命令,取决于把同一个邮件发送给一个或多个收件人,其格式为RCPT TO:<收件人地址>。
- RCPT是recipient(收件人)的缩写。每发送一个RCPT命令,都应当有相应的信息从SMTP服务器返回,如:“250 OK”,表示指明的邮箱在接收方的系统中,或“550 No such user here”(无此用户),即不存在此邮箱。
- RCPT命令的作用就是:先弄清接收方系统是否已做好接收邮件的准备,然后才发送邮件。这样做是为了避免浪费通信资源,不至于发送了很长的邮件以后才知道地址错误。
- 再下面就是SMTP客户发送DATA命令,表示要开始传送邮件的内容了。**对于DATA命令SMTP服务器返回的信息是:“354 Start mail input;end with< CRLF > .< CRLF >”。**这里< CRLF >是“回车换行”的意思。
- 若不能接收邮件,则返回421(服务器不可用),500(命令无法识别)等。
- 接着SMTP客户就发送邮件的内容。发送完毕后,再发送< CRLF >.< CRLF >(两个回车换行中间用一个点隔开)表示邮件内容结束。实际上在服务器端看到的可打印字符只是一个英文的句点。
- 若邮件收到了,则SMTP服务器返回信息“250 OK”,或返回差错代码。
- 虽然SMTP使用TCP连接试图使邮件的传送可靠,但**“发送成功”并不等于“收件人读取了这个邮件”。**
- 当一个邮件传送到接收方的邮件服务器后(即接收方的邮件服务器收下了这个邮件),再往后的情况如何,就有好几种可能性。
- 接收方的邮件服务器也可能接着就出了故障,使收到的邮件全部丢失(在收件人读取信件之前)。也可能被邮件服务器的软件当作垃圾邮件删除了。也可能收件人在清理自己的邮箱时,把尚未读取的邮件一起都删除了。有时收件人由于某种原因,很久没有查阅自己的邮箱,根本不知道自己的邮箱中有一些来信。
- 因此,一个邮件即使是“发送成功”,收件人也不一定会读取到这个邮件。尽管如此,基于SMTP的电子邮件通常都被认为是可靠的。
- 虽然SMTP使用TCP连接试图使邮件的传送可靠,但**“发送成功”并不等于“收件人读取了这个邮件”。**
- 邮件的传送从MAIL命令开始。MAIL命令后面有发件人的地址。
- 3、连接释放
- 邮件发送完毕后,SMTP客户应发送QUIT命令。**SMTP服务器返回的信息是221(服务关闭),表示SMTP同意释放TCP连接。**邮件传送的全部过程就此结束。
- 1、连接建立
-
SMTP的缺点:
- **发送电子邮件不需要经过鉴别。**这就是说,在FROM命令后面的地址可以任意填写。这就大大方便了垃圾邮件的作者,给收信人添加了麻烦
- SMTP本来就是为传送ASCII码而不是传送二进制数据设计的。虽然后来有了MIME可以传送二进制数据,但在传送非ASCII码的长报文时,在网络上的传输效率是不高的。
- 此外,SMTP传送的邮件是明文,不利于保密。
- SMTP没有认证功能。
-
POP3服务器只有在用户输入鉴别信息(用户名和口令)后,才允许对邮箱进行读取
-
POP3有两种工作方式
- 下载并保留
- 下载并删除
- 不允许用户在邮件服务器上管理自己的邮件
-
IMAP
- 在使用IMAP时,在用户的计算机上运行IMAP客户程序,然后与接收方的邮件服务器上的IMAP服务器程序建立TCP连接。用户在自己的计算机上就可以操纵邮件服务器的邮箱,就像在本地操纵一样,因此IMAP是一个联机协议。
- 当用户计算机上的IMAP客户程序打开IMAP服务器的邮箱时,用户就可看到邮件的首部。
- 若用户需要打开某个邮件,则该邮件才传到用户的计算机上。
- 用户可以根据需要为自己的邮箱创建便于分类管理的层次式的邮箱文件夹,并且能够将存放的邮件从某一个文件夹中移动到另一个文件夹中。用户也可按某种条件对邮件进行查找。
- 在用户未发出删除邮件的命令之前,IMAP服务器邮箱中的邮件一直保存着。
- IMAP最大的好处就是用户可以在不同的地方使用不同的计算机随时上网阅读和处理自己在邮件服务器中的邮件。
- IMAP还允许收件人只读取邮件中的某一个部分。
- 例如,收到了一个带有视像附件(此文件可能很大)的邮件,而用户使用的是无线上网,信道的传输速率很低。为了节省时间,可以先下载邮件的正文部分,待以后有时间再读取或下载这个很大的附件。
- IMAP的缺点是如果用户没有将邮件复制到自己的计算机上,则邮件一直存放在IMAP服务器上。要想查阅自己的邮件,必须先上网。
-
IMAP和POP3对比

-
基于万维网的电子邮件
- 使用万维网电子邮件不需要在计算机中再安装用户代理软件。浏览器本身可以向用户提供非常友好的电子邮件界面(和原来的用户代理提供的界面相似),使用户在浏览器上就能够很方便地撰写和收发电子邮件。
- 例如,你使用的是网易的163邮箱,那么在任何一个浏览器的地址栏中,键入163邮箱的URL(mail.163.com),按回车键后,就可以使用163电子邮件了,这和在家中一样方便。你曾经接收和发送过的邮件、已删除的邮件以及你的通讯录等内容,都照常呈现在屏幕上。
- 使用万维网电子邮件不需要在计算机中再安装用户代理软件。浏览器本身可以向用户提供非常友好的电子邮件界面(和原来的用户代理提供的界面相似),使用户在浏览器上就能够很方便地撰写和收发电子邮件。
-
在浏览器和互联网上的邮件服务器之间传送邮件时,仍然使用HTTP协议。但是在各邮件服务器之间传送邮件时,则仍然使用SMTP协议。
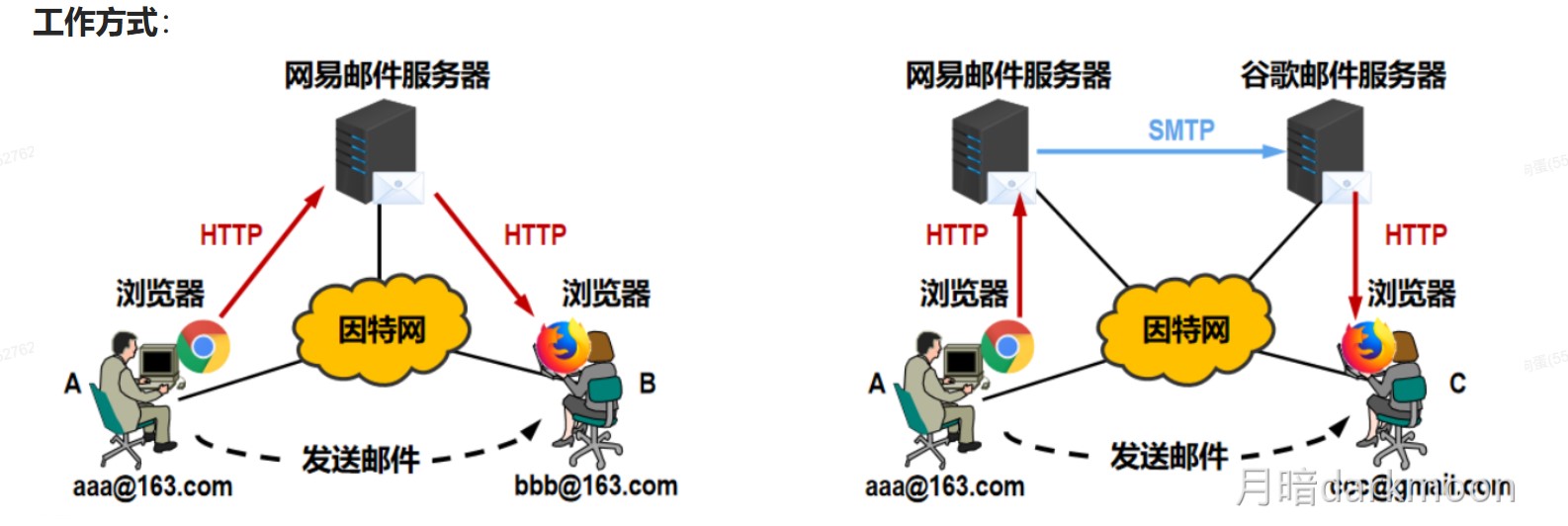
格式汇总
-
以太网V2帧
-
802.3帧
-
802.1Q帧
-
802.11帧
-
PPP帧
-
IPv4帧
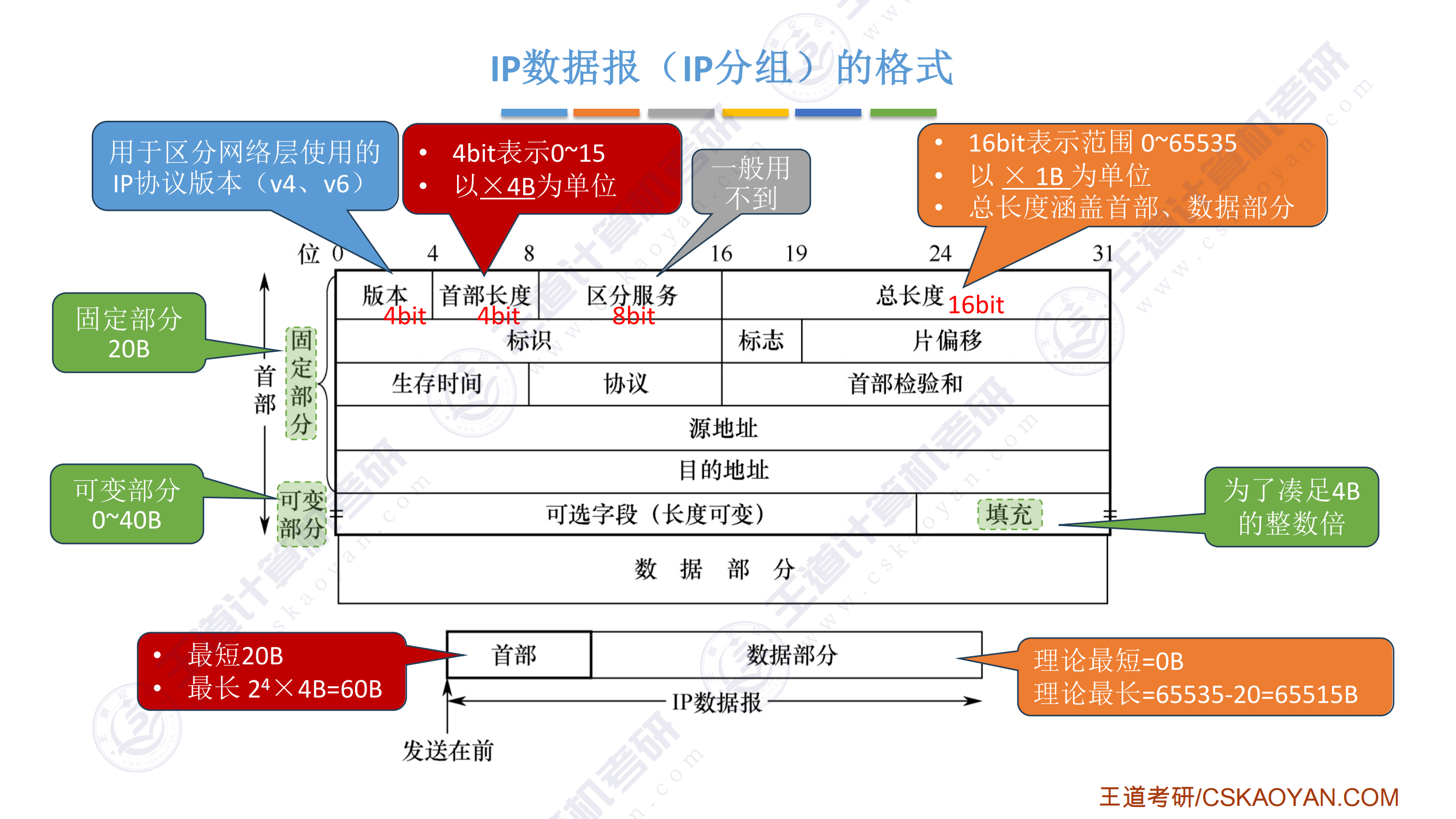
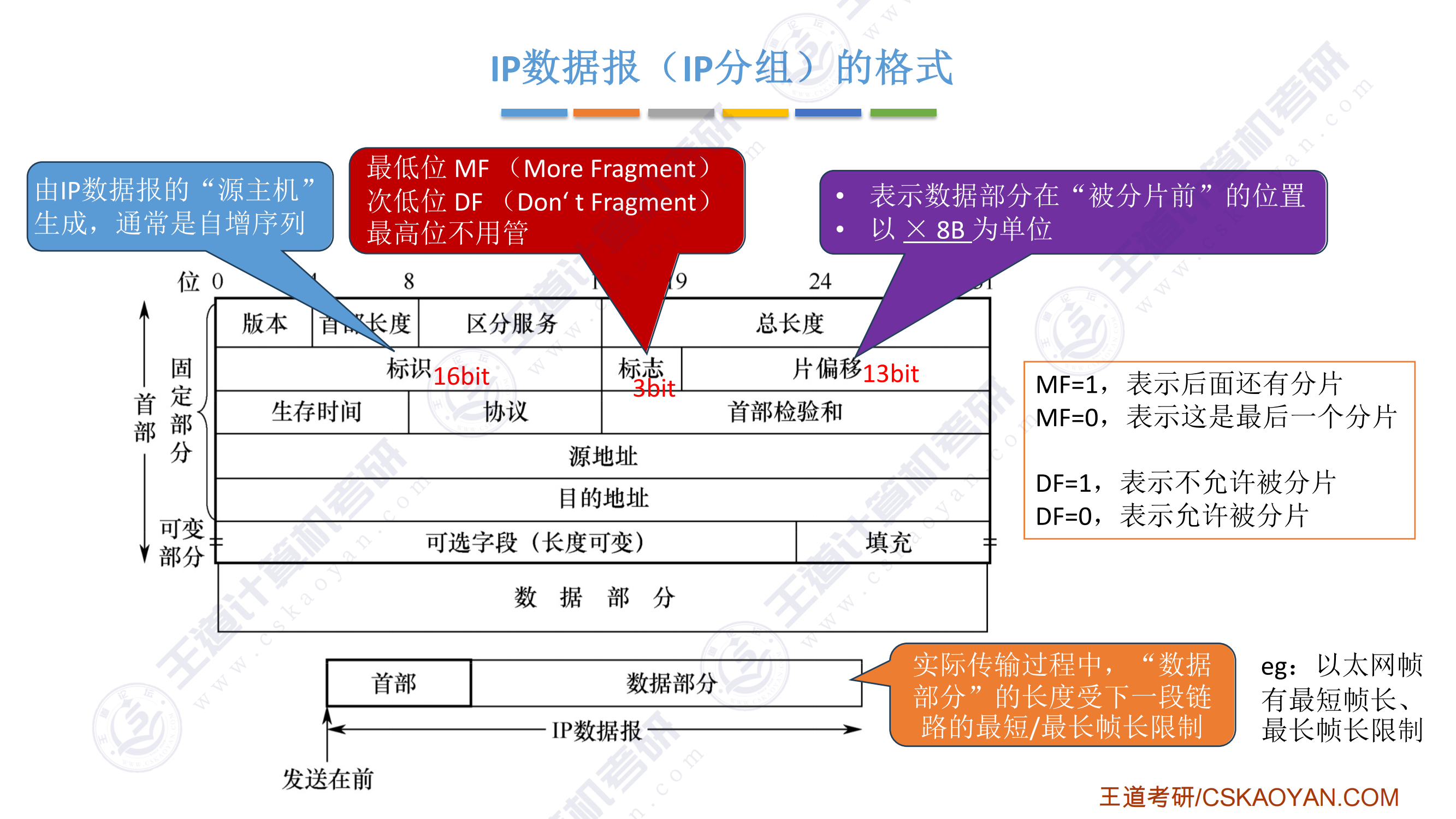
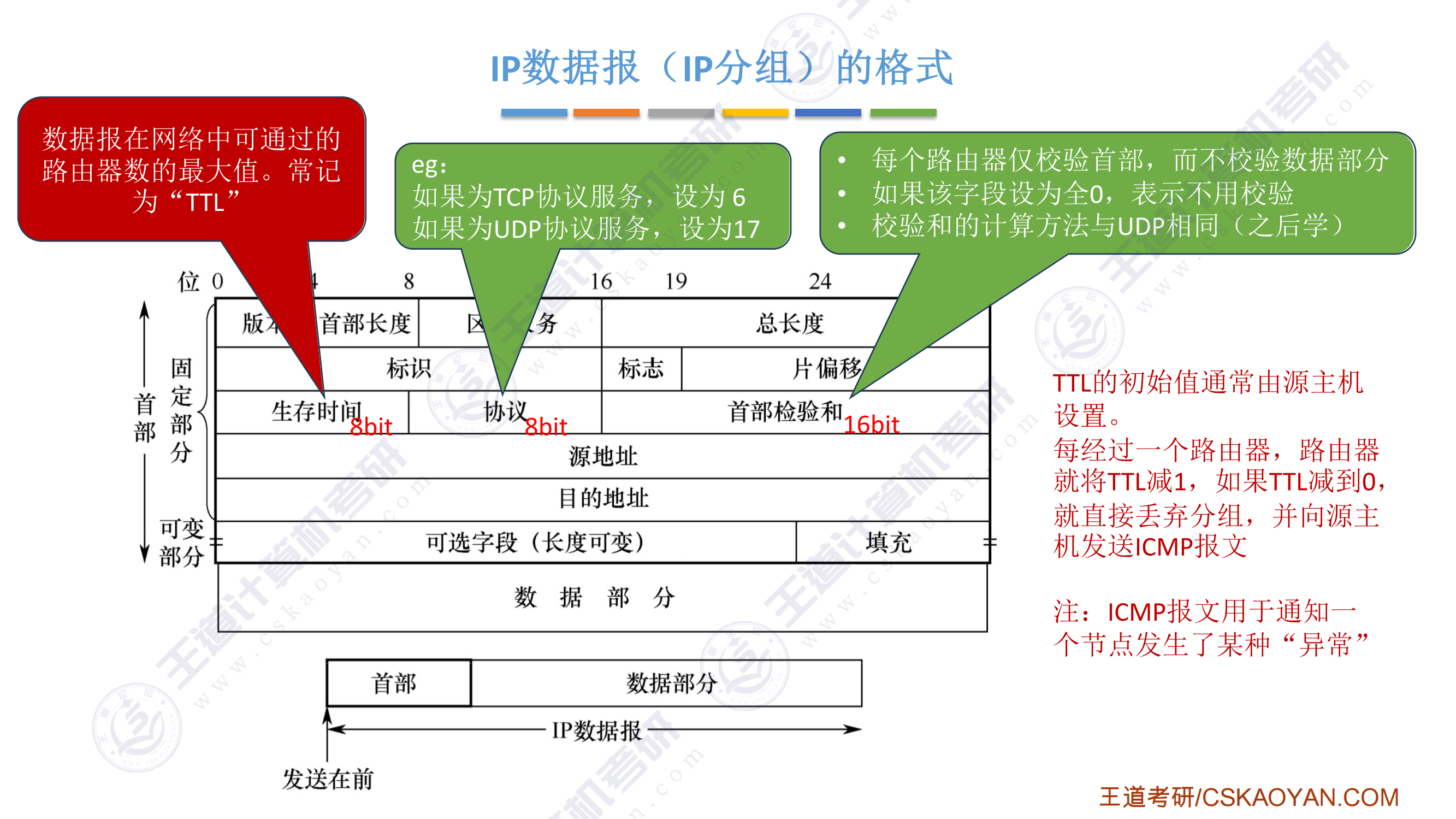
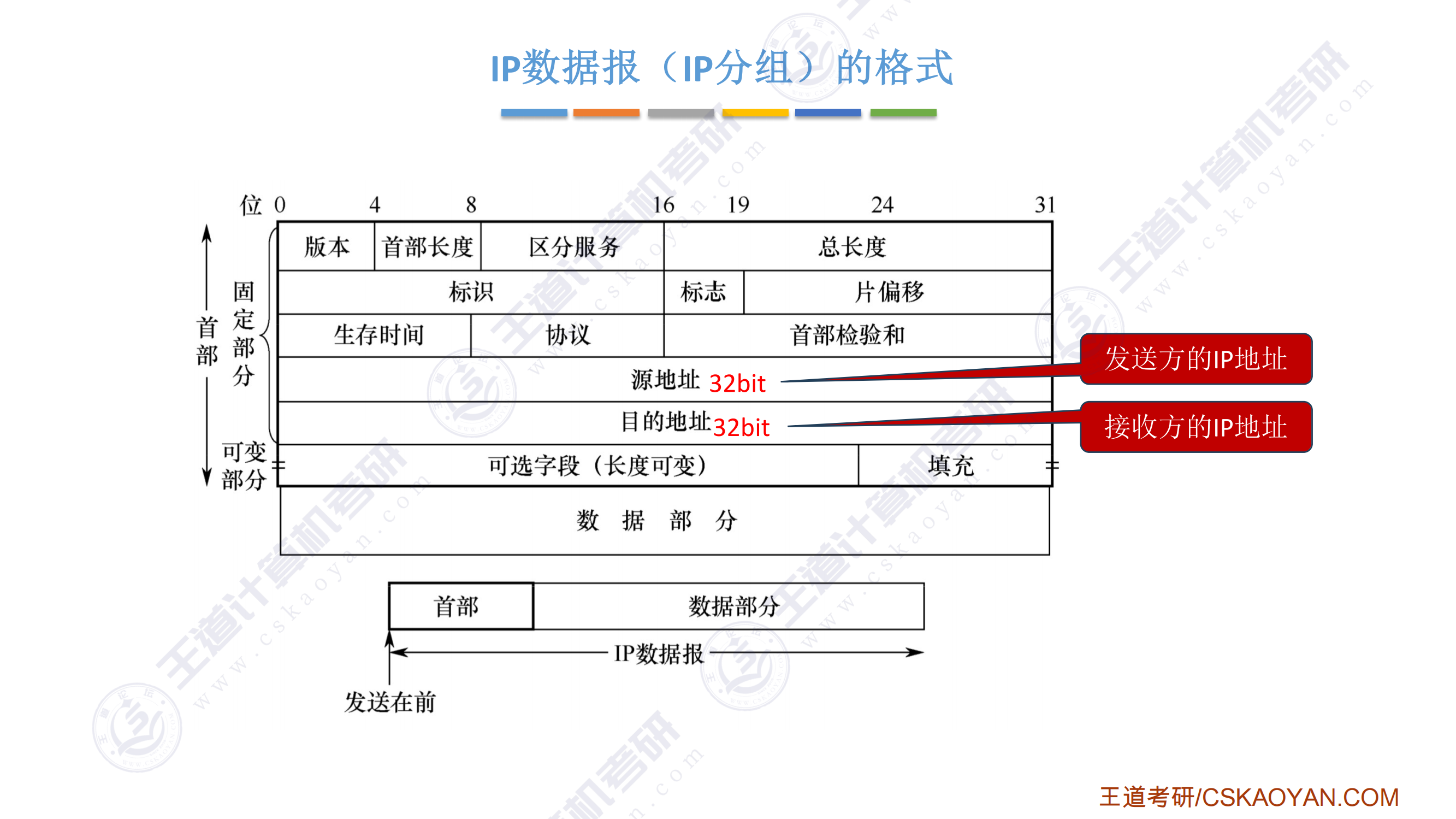
-
IPv6



-
UDP
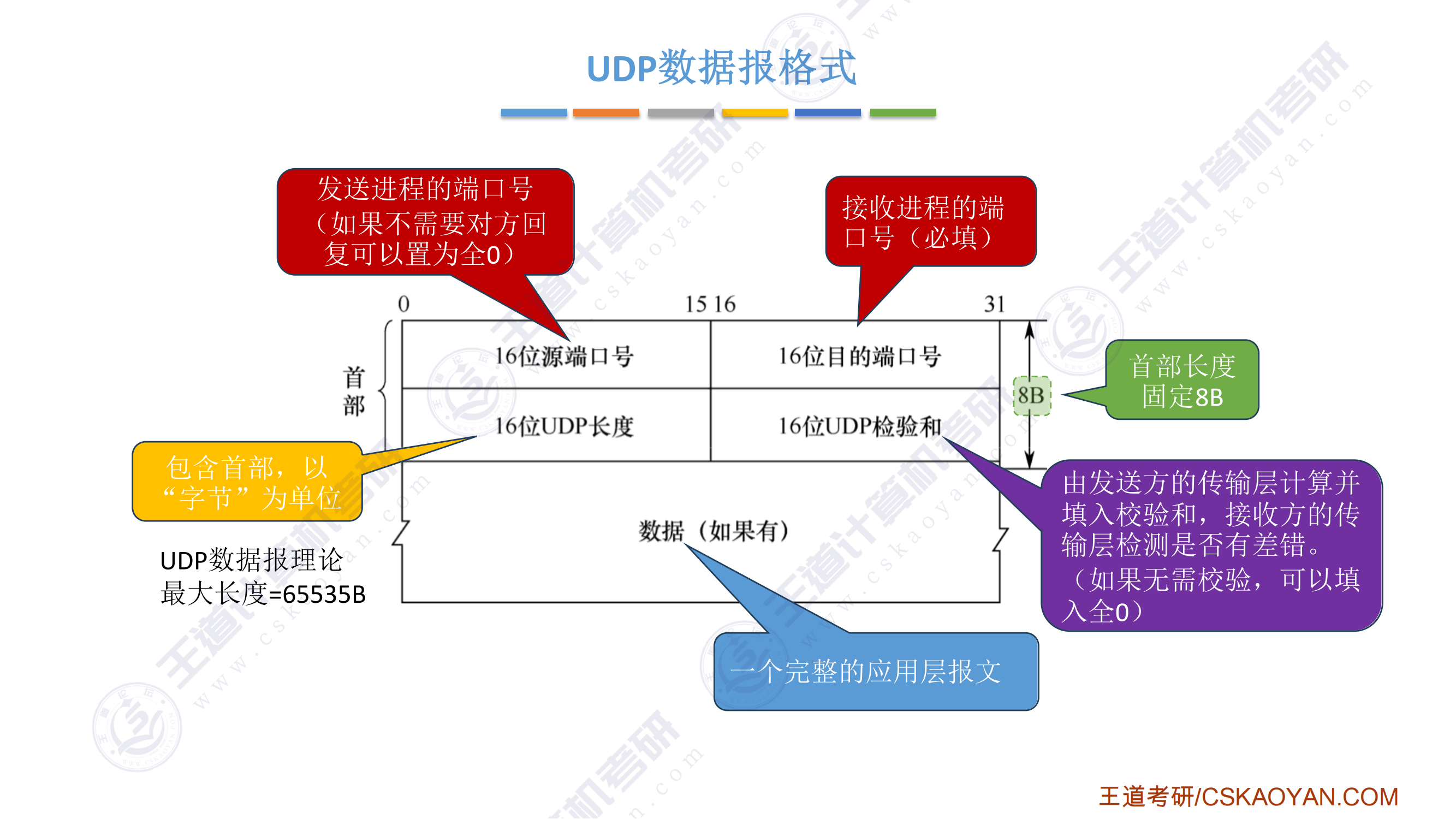
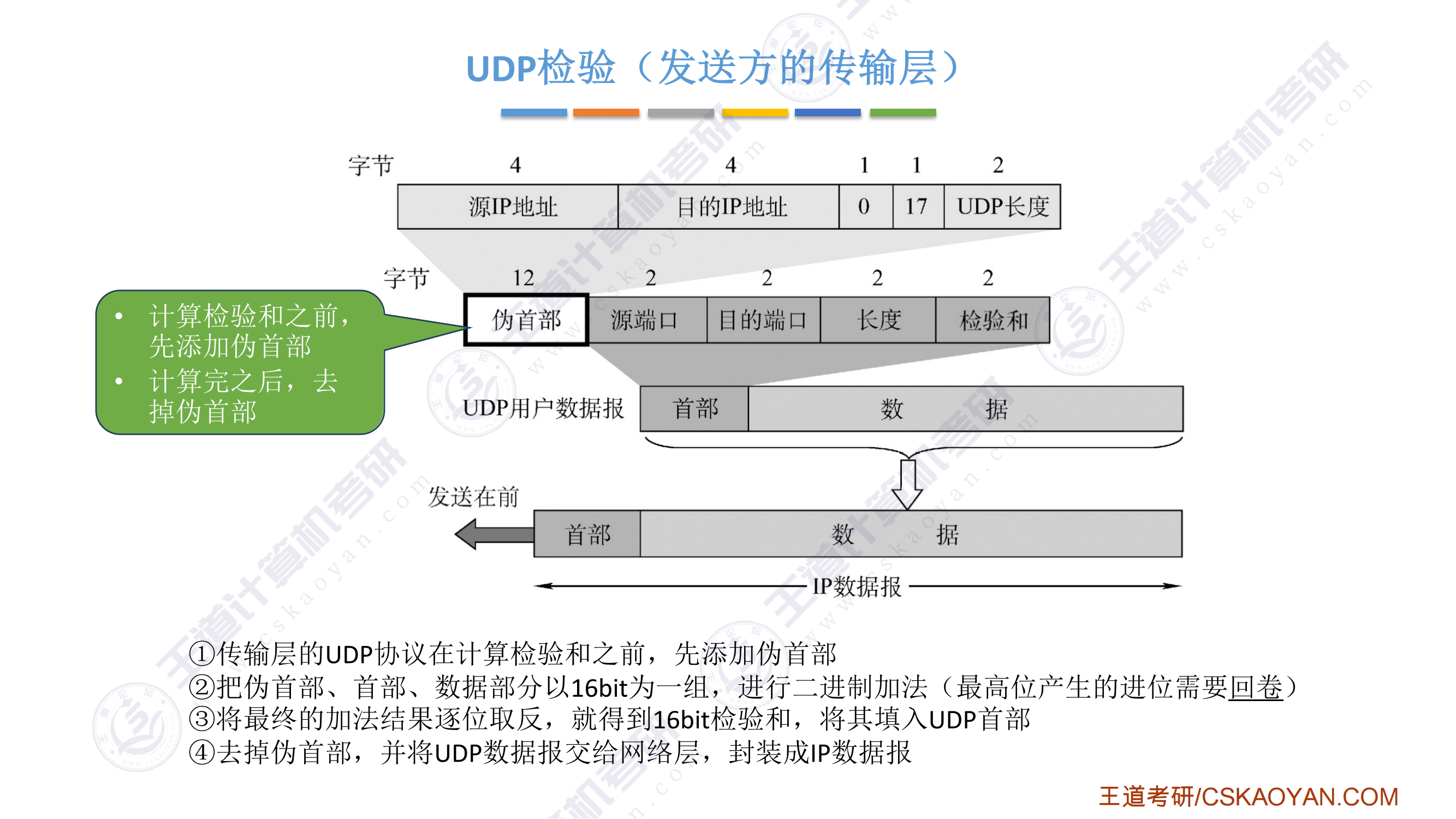
-
TCP
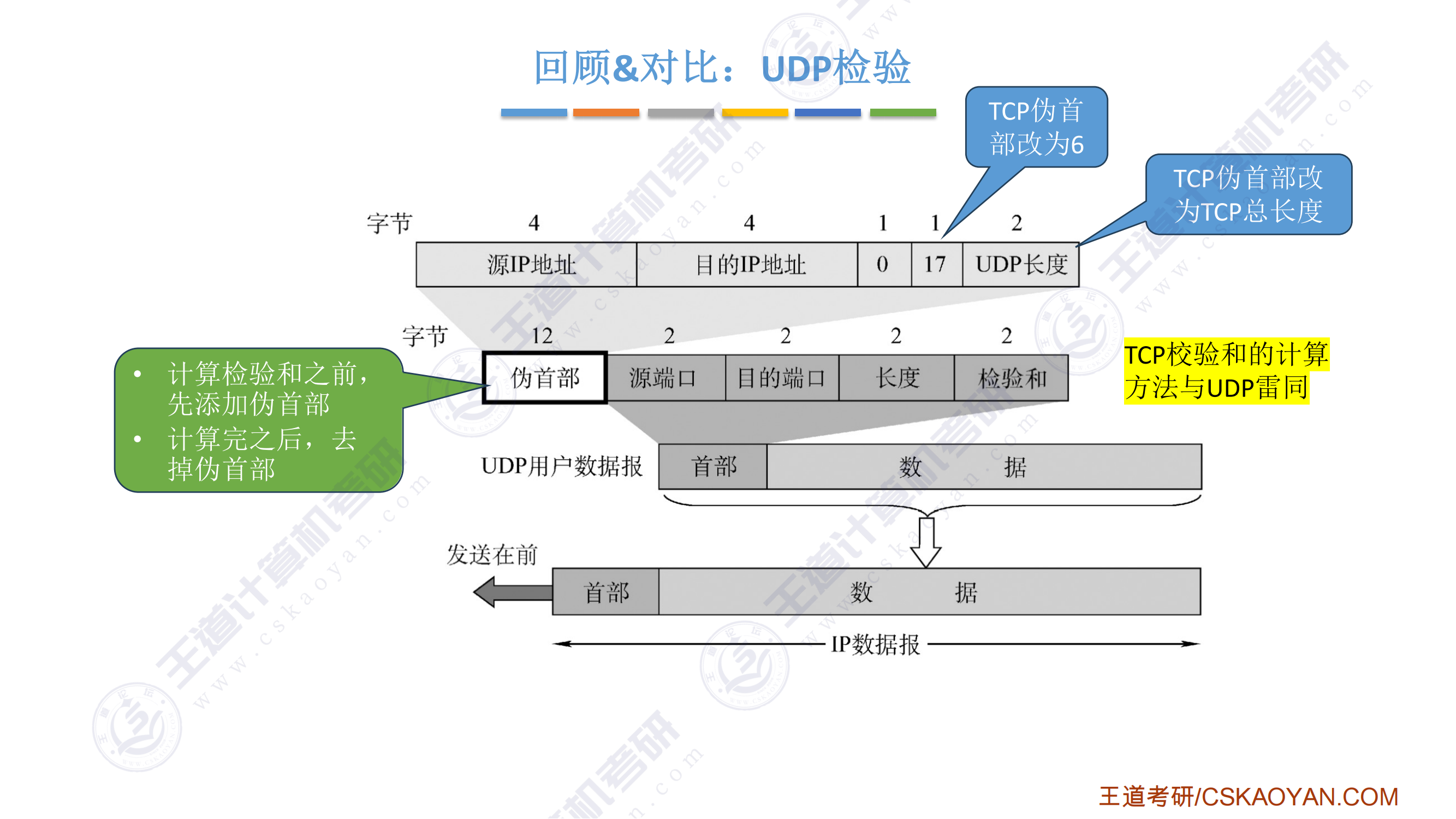
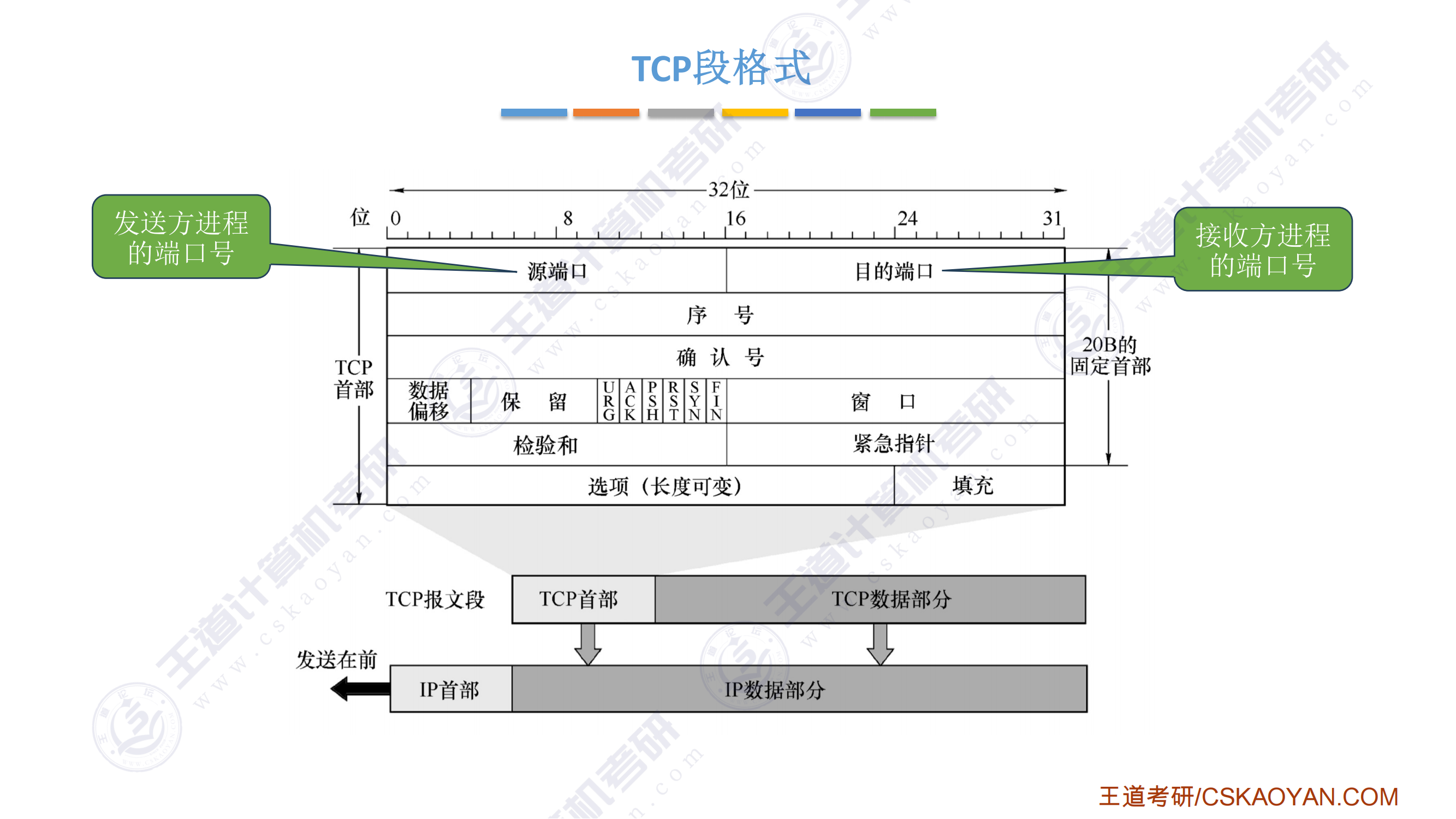
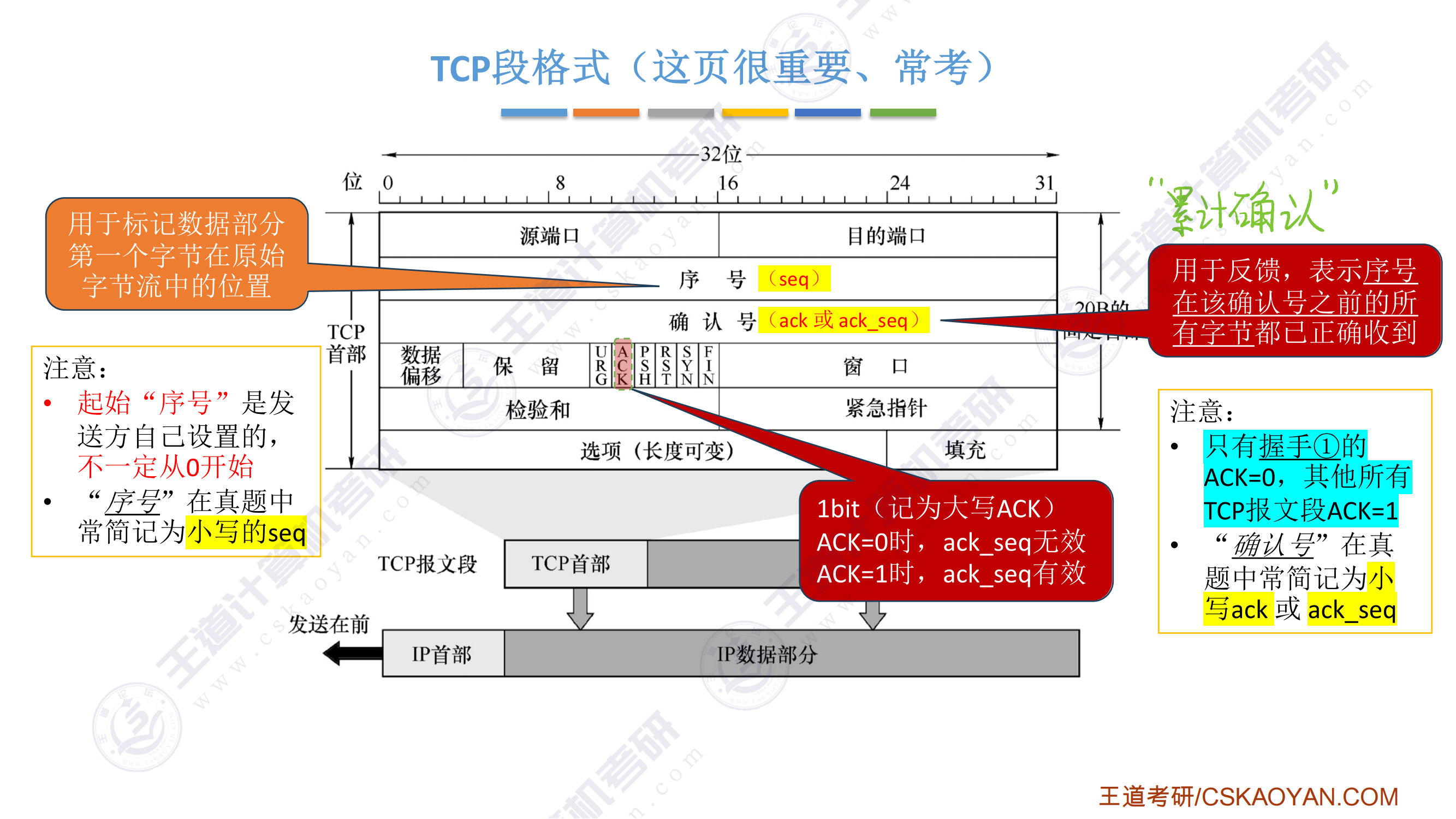
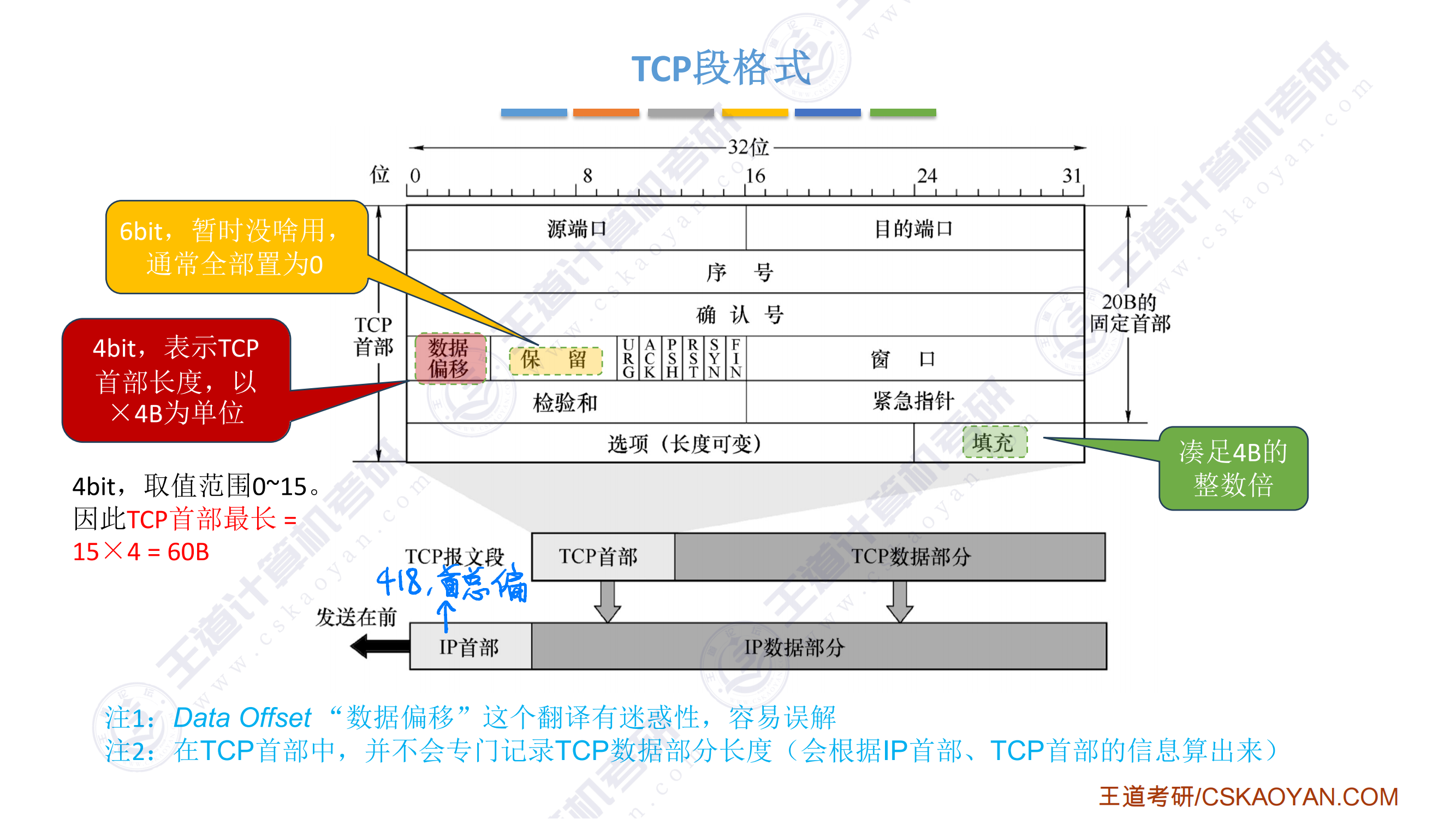
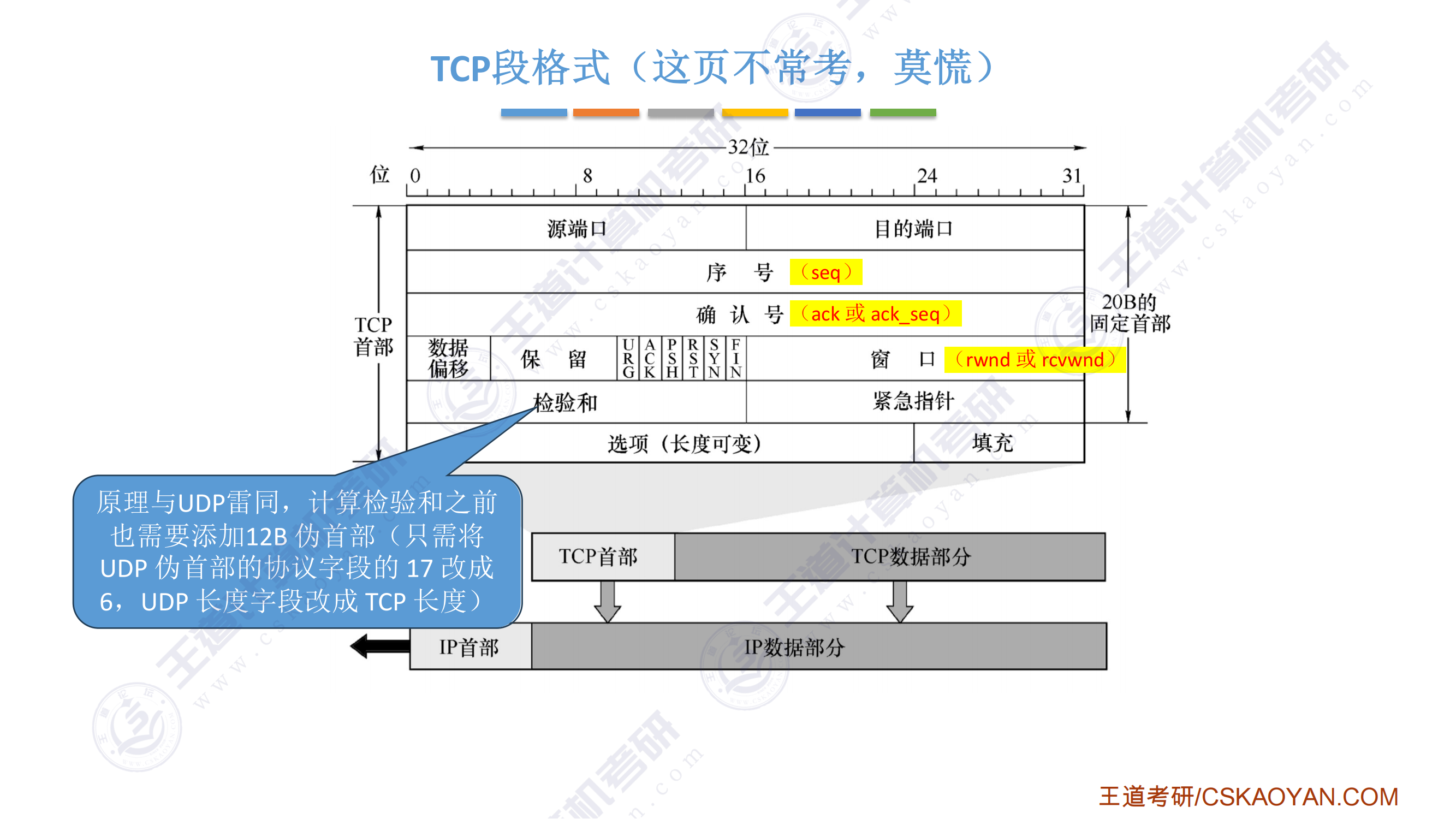
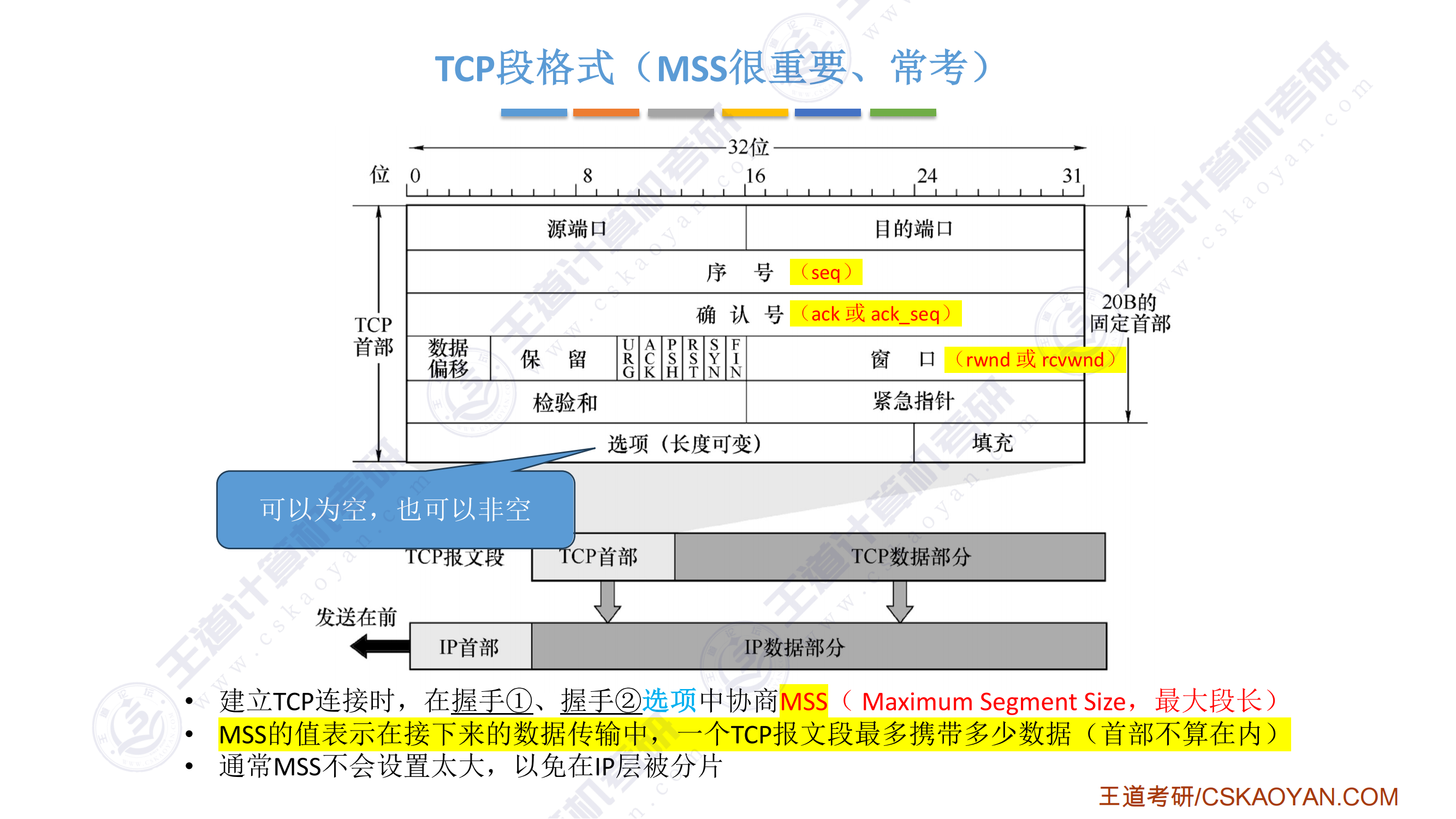
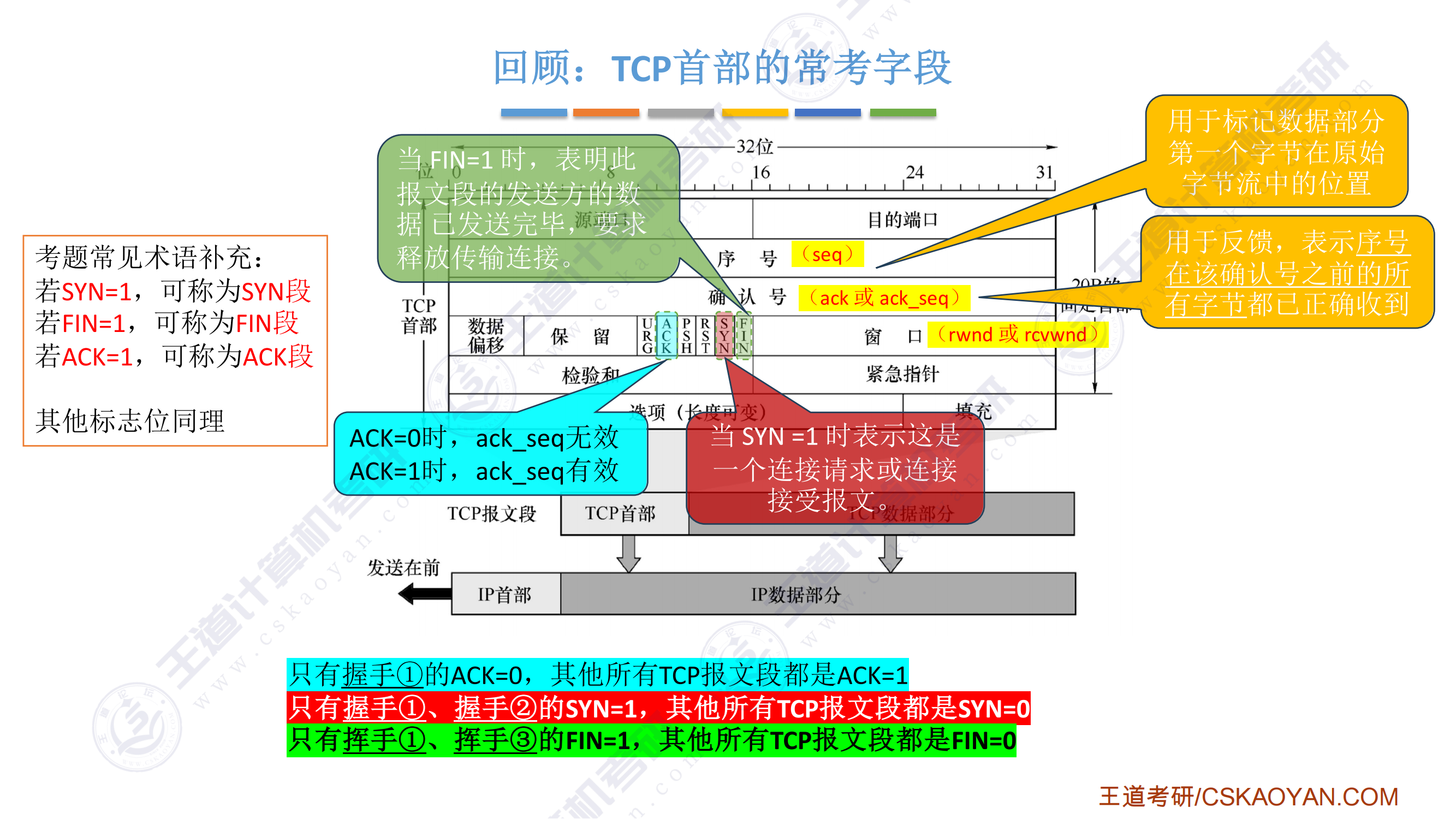
-
HTTP报文结构
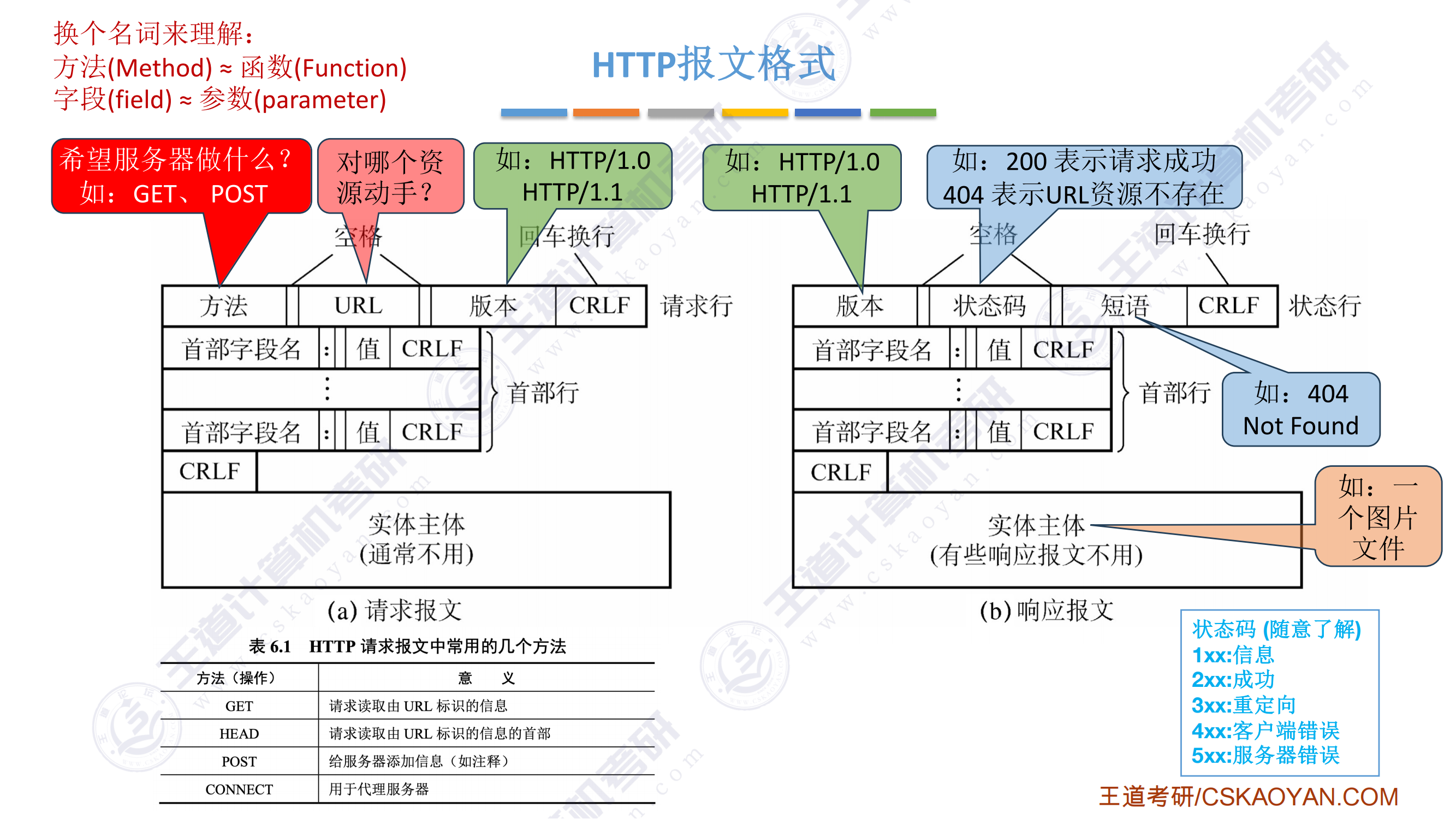
名词汇总
- 以太网V2帧
- IP数据报
- UDP数据报
- TCP报文段
- ARP请求报文
- ARP响应报文
- DHCP发现报文
- DHCP提供报文
- DHCP请求报文
- DHCP确认报文
- ICMP差错报告报文
- ICMP询问报文
- IGMP报文
- DNS查询请求报文
- DNS回答报文
- OSPF问候分组
- OSPF数据库描述分组
- OSPF链路状态请求分组
- OSPF链路状态更新分组
- OSPF链路状态确认分组