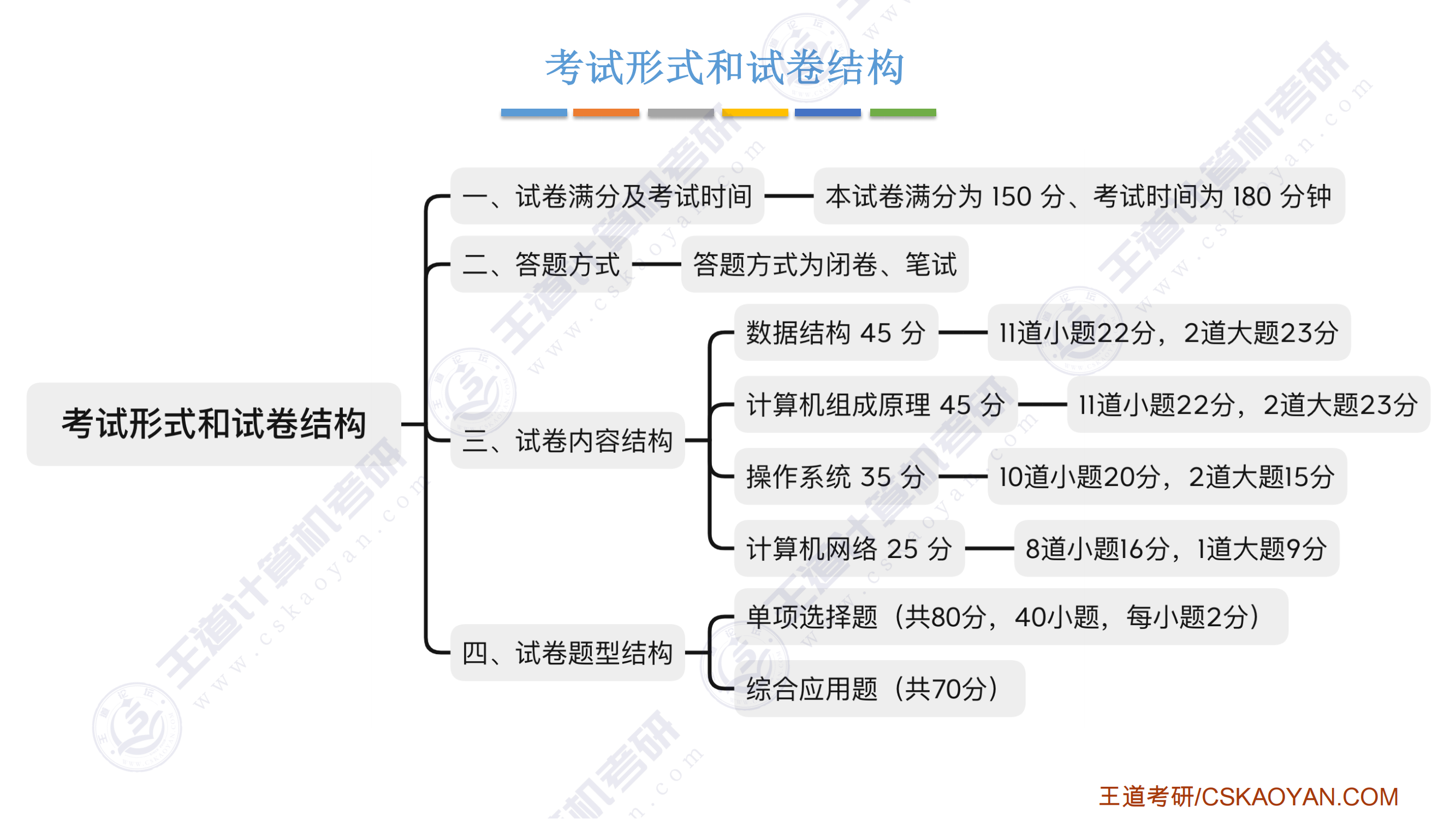
数据结构算法笔试
如何备考数据结构大题



- 数据结构的小题最好的复习方法是把王道书的课后习题二刷
- 多做题少听课
- 主动发现自己不足的地方,去查缺补漏而不是遍历课本
大题的题型
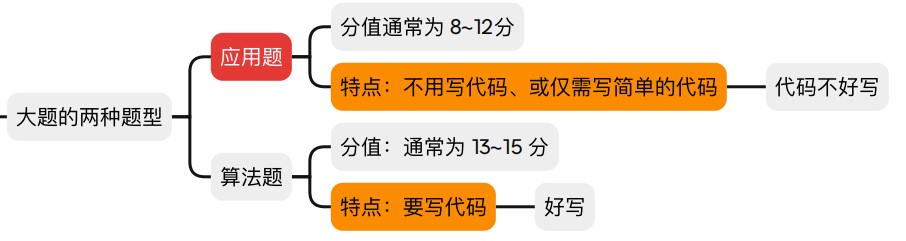
- 应用题侧重于算法的逻辑而不是算法代码的实现
- 大纲里面应用相关即大题要考的考点
- 应用题备考思路:
- 画数据结构和算法运行过程
- 训练数据结构定义的简单代码
- 基本操作的简单代码
八大考点
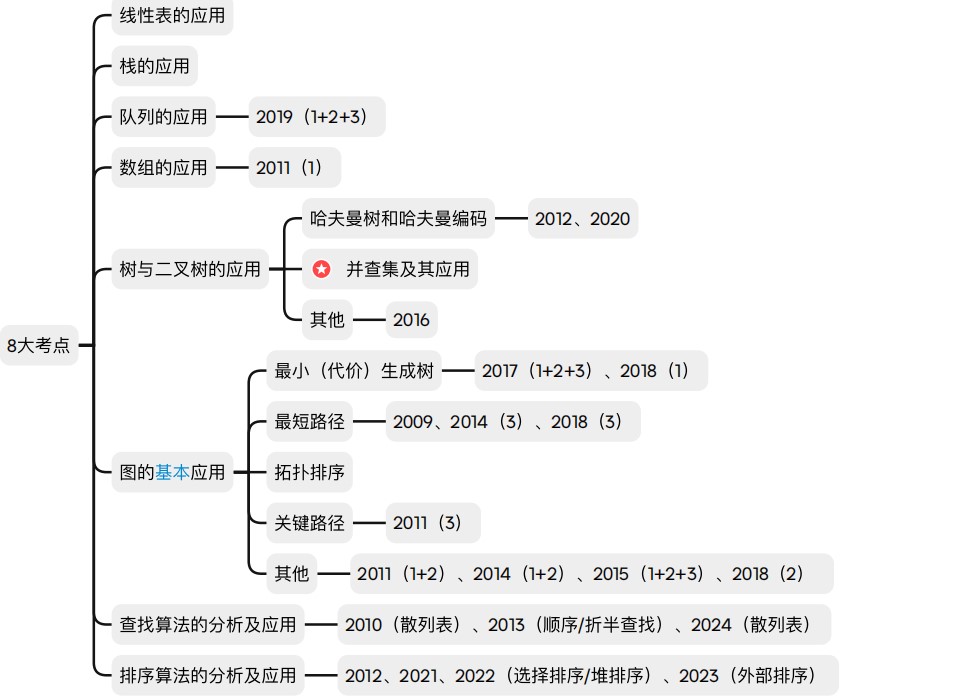
①线性表的应用
②栈的应用
③队列的应用
④数组的应用
⑤树与二叉树的应用
- 二叉树基本考的就是哈夫曼树和哈夫曼编码,并查集及其应用。其他的题型通常是定义数据结构或者实现基本操作
⑥图的基本应用
- 比较基本的应用
- 应用题一般不用写代码但是要手算,能够懂这些算法运行的逻辑
最小(代价)生成树
- 最小生成树考察的是一个图中包含多个点的总路线代价最短
- 而单源最短路径只考虑两点之间最短距离的路径
最短路径
拓扑排序
关键路径
其他
- 数据结构定义
- 画图
⑦查找算法的分析及应用
-
二叉搜索树、平衡二叉树和红黑树可能和树与二叉树考点进行比较深度的结合
- 比如给出一个关键字序列,从一个空的二叉树开始插入这些关键字,然后画出插入以后的平衡二叉树的形态,同时给出这个平衡二叉树的数据结构定义
- 大概率应用题而不是代码
- 尤其是平衡二叉树和红黑树
-
散列(哈希)表
- 大概率应用题而不是代码
-
B树及其基本操作
- 不太可能在应用题当中考察,只考基本概念,不用管基本操作,b树小题里面一般可能考
-
分块查找
- 应用题
-
字符串模式匹配
- 大概率应用题而不是代码
-
查找算法的性能分析,分析平均查找长度,成功的ASL和失败的ASL
⑧排序算法的分析及应用
- 希尔排序
- 更容易考小题而不是应用题
- 堆排序
- 基数排序
- 外部排序
七大考法
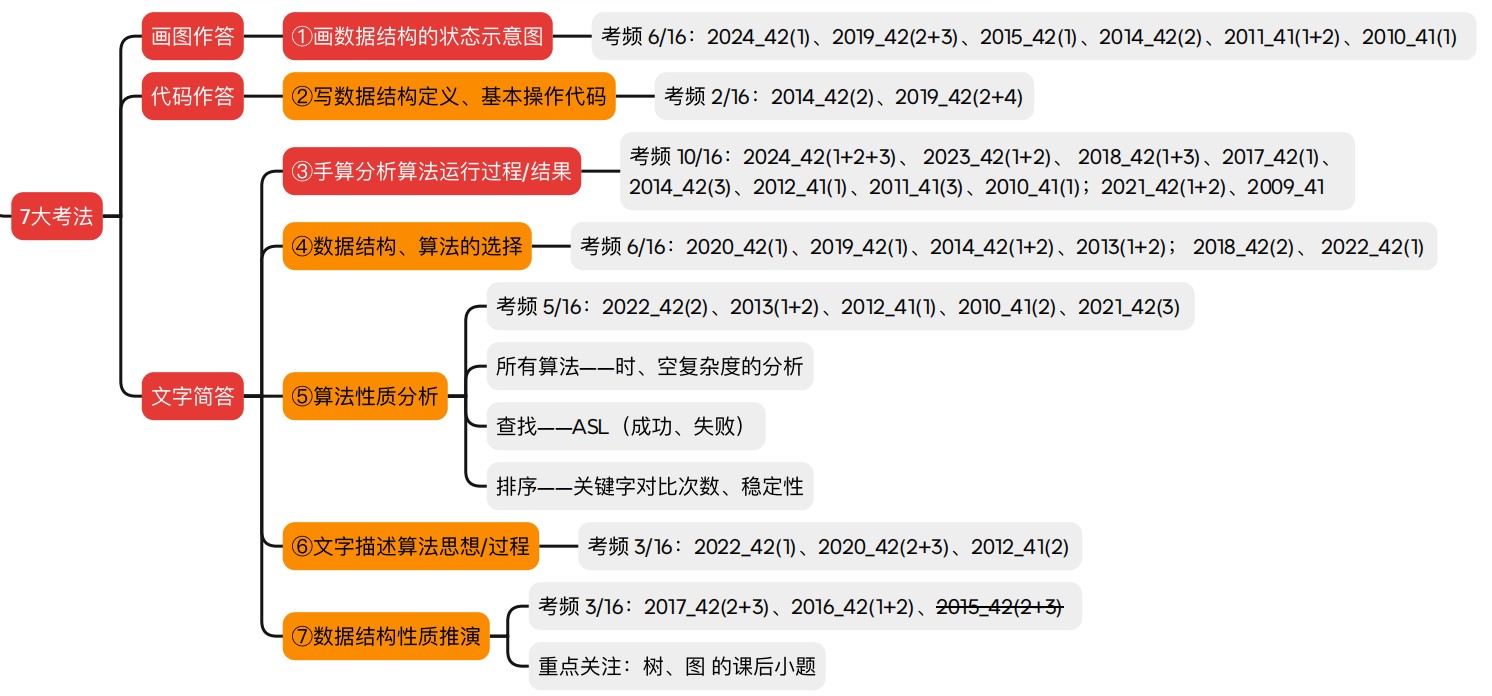
①画图作答
- (1)画数据结构的状态示意图
- 重中之重
- 一般是考察比较复杂的数据结构的图示
②代码作答
- (1)写数据结构定义、基本操作代码
- 简单的代码
- 基本操作/功能的代码片段,比如判断队空或者插入
- 比较复杂的数据结构不会考很复杂的算法题,但可能考数据结构的代码定义以及基本操作的代码实现
③文字简答
- (1)手算分析算法运行过程/结果
- (2)数据结构、算法的选择
- 基于应用场景选择一种合适的数据结构
- 基于应用场景选择一种性能比较好的算法
- (3)算法性质分析
- 分析算法的时间复杂度和空间复杂度
- 所有算法都有可能考
- 查找算法
- 分析平均查找长度
- 成功ASL和失败ASL
- 排序算法
- 分析关键字的对比次数
- 某一趟排序当中关键字的对比次数是多少
- 排完序关键字的总对比次数是多少
- 稳定性
- 分析关键字的对比次数
- 分析算法的时间复杂度和空间复杂度
- (4)文字描述算法思想/过程
- 可以通过示意图去解释算法的运行过程,用文字描述也可以解和画图去做
- 将画数据结构的状态示意图和手算分析算法运行过程/结果结合起来,从这两个角度去把各个算法的运行过程和数据结构的示意图捋清楚
- (5)数据结构性质推演
- 树和图的性质推演
- 主要根据王道书的课后小题来复习
- 树和图的性质推演
应用题
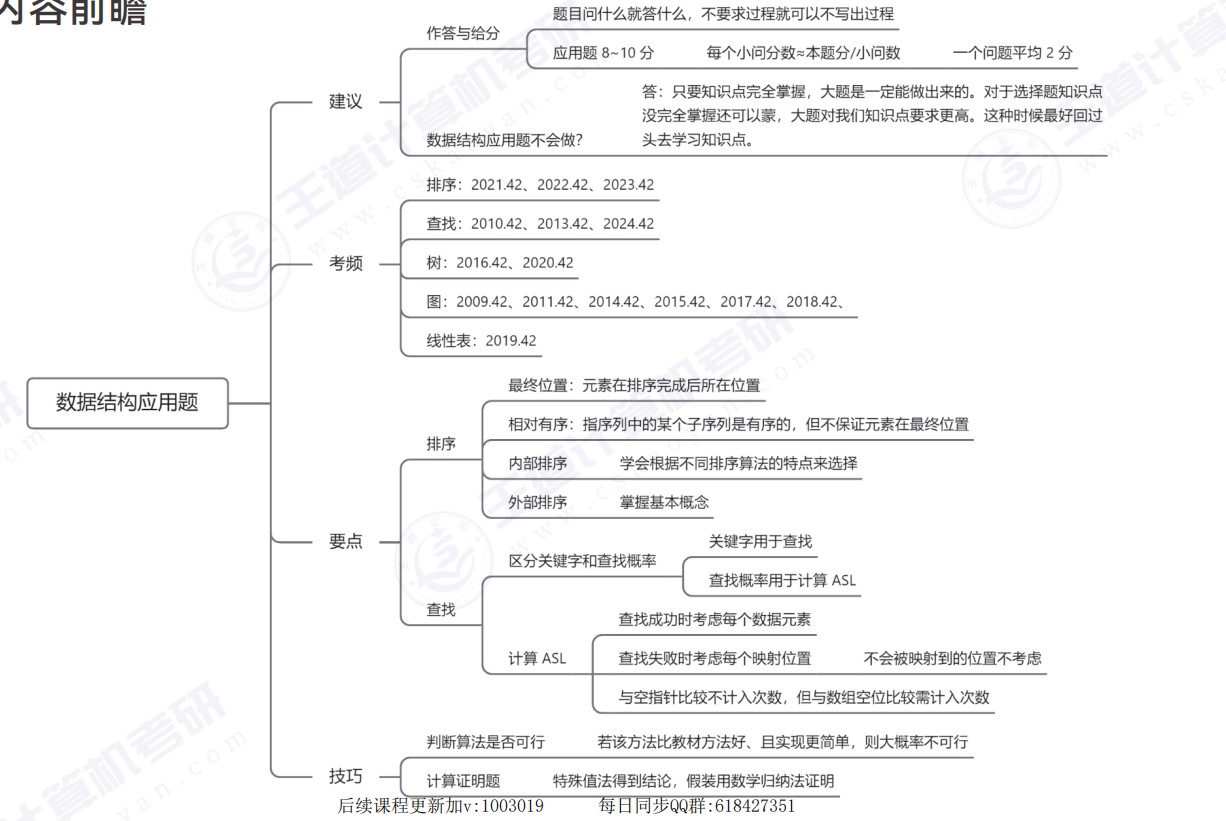
- 先找到题目中的线索,然后遍历一下这类问题的做法
排序类应用题
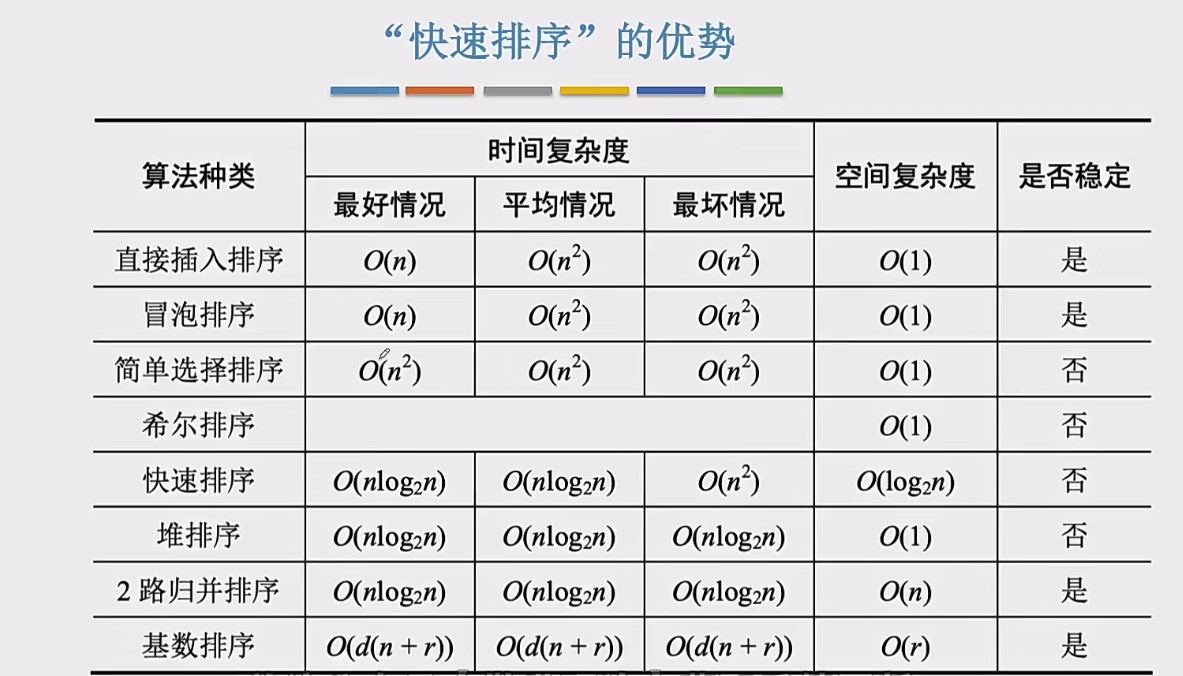
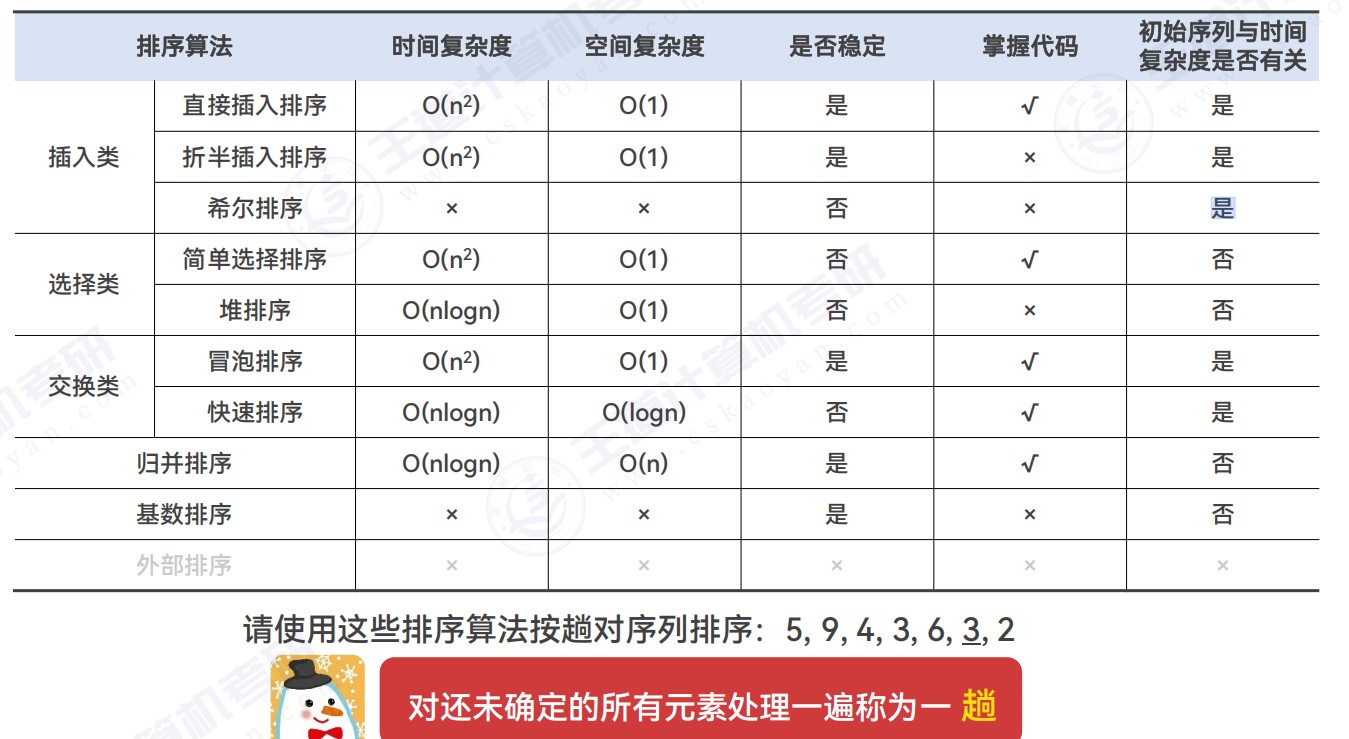
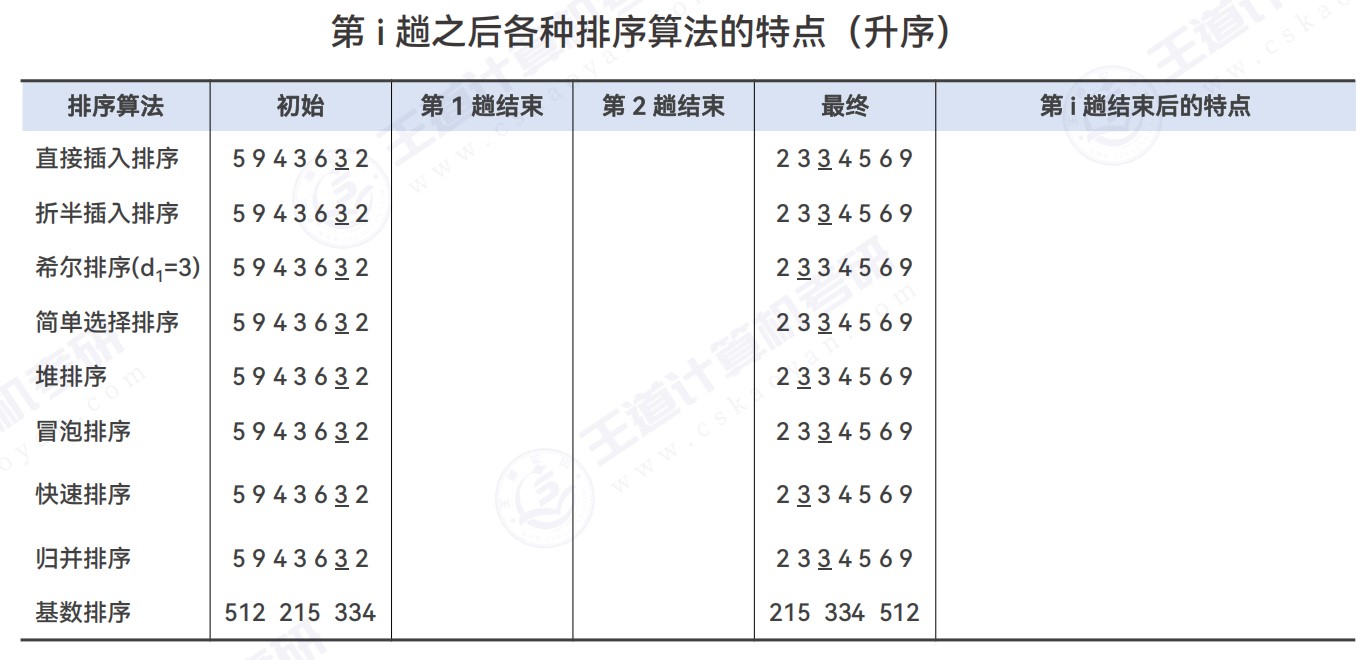
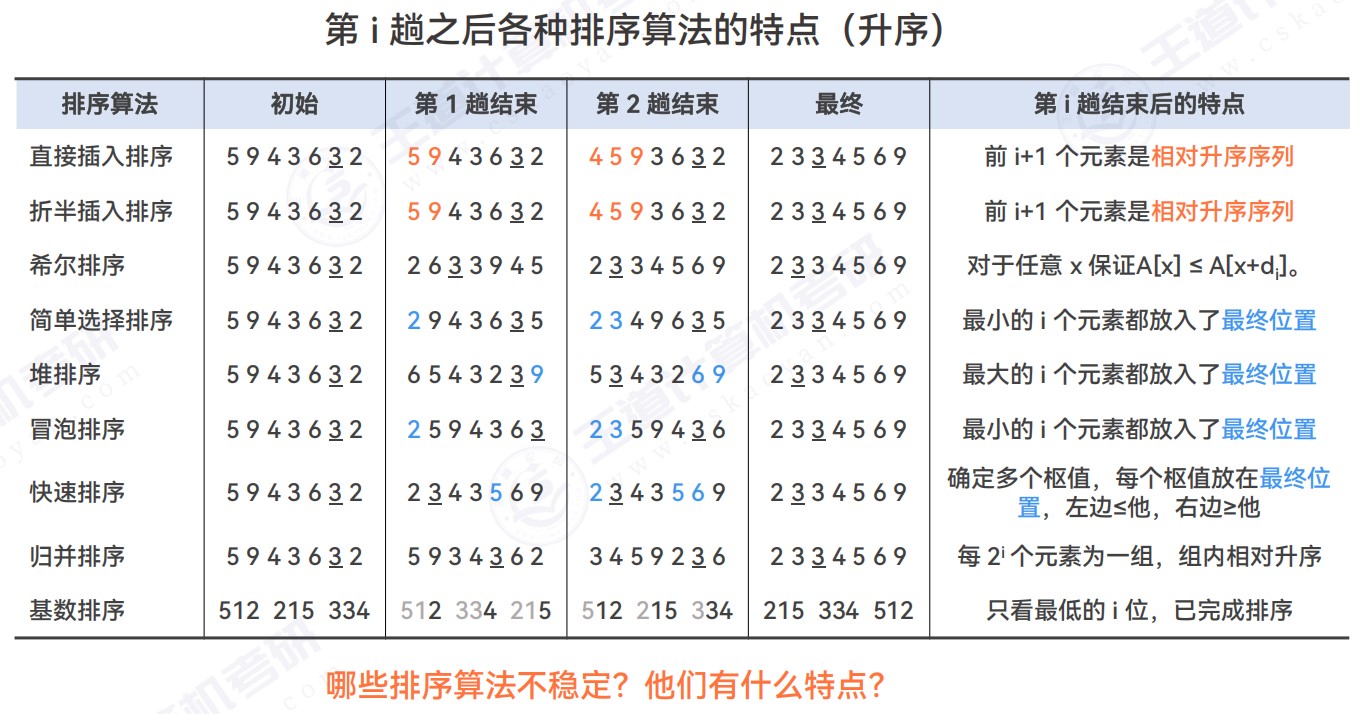

- 插入类排序:直接插入排序、折半插入排序、希尔排序
- 能够保证相对升序的序列(有可能是跳跃的,也有可能是前面的i+1个
- 选择类排序:简单选择排序、堆排序
- 堆排序:(大根堆)每次选择堆顶元素放在最后(和堆底元素交换),每次将最大的元素放在最后面
- 第一趟排序是先顺序存进一个二叉树,调整成为一个大根堆,再把它那个最大的元素换到最后面,再次调整为大根堆的结果
- 每次都有一个元素被放在最终位置
- 堆排序:(大根堆)每次选择堆顶元素放在最后(和堆底元素交换),每次将最大的元素放在最后面
- 交换类排序:冒泡排序、快速排序
- 每次根据逆序对进行交换
- 快速排序:
- 枢值一般选取序列的第一个元素
- 不稳定排序算法的特点
- 对于一种排序算法,我们要交换前两个位置的时候,如果它看不到前面有一个和他相同的元素,就有可能出现不稳定
查找类应用题
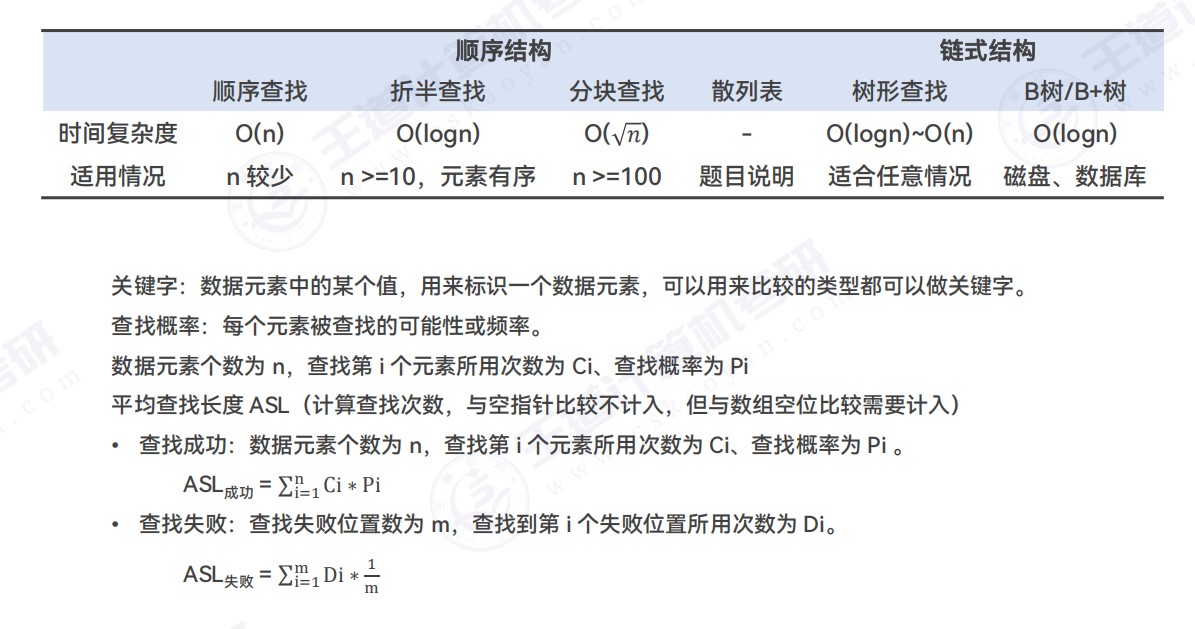
- 折半查找
- 元素有序,顺序表
- 散列查找查找失败的情况
- 线性探测法,查找到空位的时候说明查找失败,比较空的数组元素会计入一次比较次数
- 链地址法,比较到一个空指针的位置才是查找失败,但是该比较空指针不会算进比较次数
- 装填因子在链地址法中可以大于1,但是存储效率一定是小于等于100%的
- 查找成功的时候分母是元素数量,查找失败的时候分母是取模后面的那个数字(因为无法映射到其他更大的数字)

- 链式存储,考虑二叉搜索树
- 顺序存储,顺序查找和折半查找(注意排序)比较常见
树类应用题
图类应用题
线性表类应用题
算法题

- 算法题
- 一题多解,分数高中低三档
- 可以先写第二小问再写第一小问
- 顺序表和链表一般情况下要考察时间复杂度
- 树和图一般不考时间复杂度和空间复杂度,分析要求低一点,但依旧要记得
- 树和图能解决问题比高效解决问题最重要,只要能解决问题笨方法也可以,只要能掌握常规代码即可
- 备考方法
- 阶段一:完成历年真题
- 阶段二:分模块训练
- 阶段三:少食多餐,增加做题量
- 阶段四:考前保持手感,再刷历年真题
排序
顺序表
-
快排和堆排是所有排序算法中效率最高的,但是快排代码简单,堆排代码复杂,所以快排最优
-
考试按照时间复杂度给分
- 通常来说,408算法题不会限制具体使用哪种算法
- 408算法题通常按照复杂度给分,复杂度越低,给分越高
- 若题目没有特别要求,答题时回答“平均复杂度”即可
-
套路型算法:
- 快速排序
- 能快排就快排,不能用快排的再考虑用其他排序
- 快排只能在顺序表和数组(静态链表)中使用,链表当中不能用快排,因此当涉及顺序表(数组)的题目,考虑能否使用到快速排序。
- 如果题目中给的是一个乱序数组的话,如果把这个乱序数组变成有序,我们用快排的套路,先把它变成有序,能否更加轻松的解决这个问题,从这个角度思考
- 时间复杂度O(nlogn)
1
2
3
4
5
6
7
8
9
10
11
12void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
while (i < j)
{
do i ++ ; while (q[i] < x);
do j -- ; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j), quick_sort(q, j + 1, r);
}- 归并排序
- 时间复杂度O(nlogn)
- 如果我们在考题当中遇到排序类的题目,要求把一个乱序的数组排成一个更大的数组,如果这个数组本身部分有序,那么我们采用归并排序比快速排序更加优秀
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19void merge_sort(int q[], int l, int r)
{
if (l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ];
else tmp[k ++ ] = q[j ++ ];
while (i <= mid) tmp[k ++ ] = q[i ++ ];
while (j <= r) tmp[k ++ ] = q[j ++ ];
for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];
}- 快速排序更擅长将一个原本乱序的数组排成有序
- 二路归并排序更擅长将两个原本有序的数组合并为一个,时间复杂度仅为O(n)
- 通常来说,对乱序数组的排序,用归并不如用快排
- 如果题目中给的是两个有序表,并且需要将两个有序表合并为一个,可以考虑用归并思想
- 快速排序
链表
- 不支持随机访问,算法较少
- 考察偏向于考基本功
- 按位序查找
- 按关键字条件查找+删除某个节点
- 按关键字条件查找+插入某个节点
- 头插法(可实现原地逆置)
- 尾插法(保持原序)
树
- 掌握前中后序遍历、层序遍历、递归算法
- 非递归算法不用掌握
- 基于这些算法解决思维导图中列出的问题,然后做一下王道书的剩余算法题
图
-
数据结构层面
- 邻接矩阵和邻接表的遍历
- 邻接矩阵可以for循环遍历
- 但是邻接表只能bfs或者dfs
- 邻接多重表和十字链表的定义
- 邻接矩阵和邻接表的遍历
-
算法备考
- 栈、队列的数组表示(用来理解下面的代码)
1
2
3
4
5
6
7
8
9
10
11
12// tt表示栈顶
int stk[N], tt = 0;//stk表示栈,tt表示栈顶下标
// 向栈顶插入一个数
stk[ ++ tt] = x;
// 从栈顶弹出一个数
tt -- ;
// 栈顶的值
stk[tt];
// 判断栈是否为空,如果 tt > 0,则表示不为空
if (tt > 0) not empty;
else empty;
//栈顶
stk[tt];
1 | |
1 | |
- DFS,BFS
1 | |
1 | |
- 拓扑排序
1 | |
一休的算法题建议
评分细则
- 顺序表、链表注意复杂度
- 分数差别主要在于时间复杂度
- 树、图注意细节
- 分数差别主要在于特殊情况是否考虑到
- 序列就是数组
答题技巧
-
顺序表和链表
- 暴力解
- 枚举
- 其他解
- 有序
- 折半查找
- 链表不适用
- 适用于有序数组
- 多指针法(归并思想)
- 折半查找
- 无序
- 散列表
- 典型应用:计数器
- 先排序再按有序做
- 快排思想
- 散列表
- 有序
- 目标:尽量优化自己的算法,让自己的复杂度变低
- 暴力解
-
树
- 核心是遍历(递归)
- 先序
- 中序
- 后序
- 层序
- 实际上王道书上的树的递归算法可以跳过,因为不同的先序、后序、中序算法都是不一样的,还有不一样的写法。
- 如果递归的话,先中后逻辑都是一样的,实际上只有三行核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//先序(根→左→右)
void preorder(btnode *p){
if(p==NULL){
return;
visit(p);//对p结点访问等,这道题真正要写的东西,比如题目要求我们做什么,树的每道题不同的点就在于这个visit
preorder(p->lchild);
preorder(p->rchild);
//这三条语句,visit在先就是先序,在中就是中序,在后就是后序
}
}
//中序(左→根→右)
void inorder(btnode *p){
if(p==NULL)
return ;
inorder(p->lchild);
visit(p);
inorder(p->rchild);
}
//后序(左→右→根)
void postorder(btnode *p){
if(p==NULL)
return;
postorder(p->lchild);
postorder(p->rchild);
visit(p);
} - 核心是遍历(递归)
-
图
- 基本遍历
- 最小生成树
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30//普利姆prim算法,时间复杂度O(n^2)
int n; // n表示点数
int g[N][N]; // 邻接矩阵,存储所有边
int dist[N]; // 存储其他点到当前最小生成树的距离
bool st[N]; // 存储每个点是否已经在生成树中
//到集合的距离就是一个点连接集合的所有边中最短的那一条
// 如果图不连通,则返回INF(值是0x3f3f3f3f), 否则返回最小生成树的树边权重之和
int prim()
{
memset(dist, 0x3f, sizeof dist);//初始化最短距离
int res = 0;
for (int i = 0; i < n; i ++ )//n次迭代
{
int t = -1;//不在集合当中的距离最小点的编号
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
if (i && dist[t] == INF) return INF;
if (i) res += dist[t];//只要不是第一个点
st[t] = true;
for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]);
}
return res;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43//克鲁斯卡尔Kruskal算法,时间复杂度O(mlogn)
int n, m; // n是点数,m是边数
int p[N]; // 并查集的父节点数组
struct Edge // 存储边
{
int a, b, w;
bool operator< (const Edge &W)const//重载小于号
{
return w < W.w;
}
}edges[M];
int find(int x) // 并查集核心操作
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);//把所有边排序
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集
int res = 0, cnt = 0;
for (int i = 0; i < m; i ++ )//从小到大枚举所有边
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);//让a,b分别等于祖宗节点
if (a != b) // 如果两个连通块不连通,则将这两个连通块合并
{
p[a] = b;//合并两个连通块
res += w;//存的是最小生成树中所有树边的权重之和
cnt ++ ;//存的是当前加入了多时少条边
}
}
if (cnt < n - 1) return INF;//图不是联通的
return res;//输出所有树边的权重之和
}- 最短路径
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40//朴素dijkstra算法,时间复杂度O(n^2)
int g[N][N]; // 存储每条边
int dist[N]; // 存储1号点到每个点的最短距离
bool st[N]; // 存储每个点的最短路是否已经确定
// 求1号点到n号点的最短路,如果不存在则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);//初始化其他距离
dist[1] = 0;//初始化第一个点的距离
for (int i = 0; i < n - 1; i ++ )
{
int t = -1; // 在还未确定最短路的点中,寻找距离最小的点
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))//当前点还没有确定最短路;没有赋值或者不是最短的
t = j;//赋值
// if(t==n)break;//优化可以加上
// 用t更新其他点的距离
for (int j = 1; j <= n; j ++ )
dist[j] = min(dist[j], dist[t] + g[t][j]);
//判断长度,得出最小距离并更新
st[t] = true;
}
if (dist[n] == 0x3f3f3f3f) //不连通
return -1;
return dist[n];
}
//输入输出
cin >> n>>m;
memset(g,0x3f,sizeof g);
while(m--){
int a,b,c;
cin>>a>>b>>c;
g[a][b]=min(g[a][b],c);
}
int t =dijkstra()l
cout<<t;
return 0;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55//堆优化版dijkstra算法,时间复杂度O(mlogn)
typedef pair<int, int> PII;
int n; // 点的数量
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N]; // 存储所有点到1号点的距离
bool st[N]; // 存储每个点的最短距离是否已确定
void add(int a,int b,int c){
e[idx]=b,w[idx]= c,ne[idx]=h[a],h[a]=idx++;
}
// 求1号点到n号点的最短距离,如果不存在,则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;//定义小根堆
heap.push({0, 1}); // first存储距离,second存储节点编号
while (heap.size())//堆里面非空
{
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;//编号;距离
if (st[ver]) continue;//冗余备份
st[ver] = true;
for (int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > distance + w[i])
{
dist[j] = distance + w[i];//更新距离
heap.push({dist[j], j});//放入堆
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
int main(){
cin >> n>>m;
memset(h,-1,sizeof h);
while(m--){
int a,b,c;
cin >> a >> b>>c;
add(a,b,c);
}
int t = dijkstra();
cout<<t;
return 0;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//Floyd算法,时间复杂度O(n^3)
cosnt int INF=1e9;
初始化:
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
// 算法结束后,d[a][b]表示a到b的最短距离
void floyd()
{
for (int k = 1; k <= n; k ++ )
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}- 拓扑排序
- 关键路径
- 目标:考虑一些细节是否到位
-
能不能直接调用函数
- 5行以下的随便调用
1
2
3
4
5
6pop();
push();
swap(a,b);
abs();
pow(x,y);//x的y次幂
sqrt();//平方根 -
过程
- 考前最好复习一遍常用的算法模板
1 | |
- 空间复杂度的分析
- 申请了哪些数组
- 申请了哪些结点
- 递归的时候有多少层的递归(树的高度,递归的层数)
栈、队列的一些代码模板
数组实现栈
1 | |
链表实现栈
1 | |
双向链表实现栈(栈顶在链尾)
1 | |
数组实现循环队列
1 | |
单链表实现队列
1 | |
树的一些代码模板
数组实现二叉树
1 | |
1 | |
二叉树的先中后序遍历
先序遍历
1 | |
中序遍历
1 | |
后序遍历
1 | |
树的存储结构
双亲表示法
1 | |
孩子表示法
1 | |
孩子兄弟表示法
1 | |
并查集
1 | |
图的一些代码模板
邻接矩阵实现图的顺序存储
1 | |
邻接表实现图的链式存储
1 | |
dijkstra算法的文字过程描述
1 | |
bfs算法的文字过程描述
1 | |
拓扑排序的文字过程描述
1 | |
关键长度的意义
1 | |
朴素版prim算法
1 | |
408图论算法复杂度+适用场景(含负权边/负环)
| 算法 / 存储结构 | 时间复杂度 | 空间复杂度 | 适用场景 | 说明 |
|---|---|---|---|---|
| 邻接矩阵 | —— | O(V²) | 稠密图 | 查询边是否存在快 O(1),遍历慢 O(V) |
| 邻接表 | —— | O(V+E) | 稀疏图 | 遍历快 O(V+E),查询边是否存在慢 O(deg(v)) |
| 十字链表(有向图) | —— | O(V+E) | 需要同时高效处理出度和入度的有向图 | 每条边存两次引用 |
| 邻接多重表(无向图) | —— | O(V+E) | 需要避免无向边重复存储 | 每条边只存一次结点 |
| DFS(邻接表) | O(V+E) | O(V+E) | 遍历所有顶点与边;拓扑排序;连通分量;检测环 | 深度优先搜索 |
| DFS(邻接矩阵) | O(V²) | O(V²) | 小规模稠密图遍历 | 遍历邻接点需扫一行 |
| BFS(邻接表) | O(V+E) | O(V+E) | 无权图最短路径;分层遍历;连通分量 | 广度优先搜索 |
| BFS(邻接矩阵) | O(V²) | O(V²) | 小规模稠密图遍历 | |
| Prim 算法(朴素版,邻接矩阵) | O(V²) | O(V²) | 稠密图最小生成树 | 每次扫描所有顶点选最小边 |
| Prim 算法(堆优化版,邻接表) | O(E log V) | O(V+E) | 稀疏图最小生成树 | 用优先队列维护候选边 |
| Kruskal 算法 | O(E log E)≈O(E log V) | O(V+E) | 稀疏图最小生成树 | 边排序 + 并查集 |
| Dijkstra(朴素版,邻接矩阵) | O(V²) | O(V²) | 稠密图,单源最短路径(不允许负权边) | 每次找最近点 O(V) |
| Dijkstra(堆优化,邻接表) | O(E log V) | O(V+E) | 稀疏图,单源最短路径(不允许负权边) | 用堆维护最短距离 |
| Floyd 算法 | O(V³) | O(V²) | 多源最短路径,小规模稠密图,允许负权边;可检测负环(dist[i][i]<0) |
若有负环则无解 |
| Bellman-Ford 算法 | O(VE) | O(V+E) | 单源最短路径,允许负权边;可检测负环(松弛 V 次后仍变化) | 若有负环则无解 |
| SPFA 算法 | 平均 O(E),最坏 O(VE) | O(V+E) | 单源最短路径,允许负权边;可检测负环(某点入队 ≥ V 次) | 若有负环则无解 |
| 算法 / 存储结构 | 时间复杂度 | 空间复杂度 | 适用场景 | 说明 |
|---|---|---|---|---|
| 邻接矩阵 | —— | O(V²) | 稠密图 | 查询边是否存在快 O(1),遍历慢 O(V) |
| 邻接表 | —— | O(V+E) | 稀疏图 | 遍历快 O(V+E),查询边是否存在慢 O(deg(v)) |
| 十字链表(有向图) | —— | O(V+E) | 需要同时高效处理出度和入度的有向图 | 每条边存两次引用 |
| 邻接多重表(无向图) | —— | O(V+E) | 需要避免无向边重复存储 | 每条边只存一次结点 |
| DFS(邻接表) | O(V+E) | O(V+E) | 遍历所有顶点与边;拓扑排序;连通分量;检测环 | 深度优先搜索 |
| DFS(邻接矩阵) | O(V²) | O(V²) | 小规模稠密图遍历 | 遍历邻接点需扫一行 |
| BFS(邻接表) | O(V+E) | O(V+E) | 无权图最短路径;分层遍历;连通分量 | 队列实现 |
| BFS(邻接矩阵) | O(V²) | O(V²) | 小规模稠密图遍历 | |
| 拓扑排序(邻接表) | O(V+E) | O(V+E) | DAG 的线性序;任务调度;编译依赖 | 常用 Kahn 算法(队列)或 DFS |
| 拓扑排序(邻接矩阵) | O(V²) | O(V²) | 小规模稠密图 | 每次找入度=0 需扫一列 |
| Prim 算法(朴素版,邻接矩阵) | O(V²) | O(V²) | 稠密图最小生成树 | 每次扫描所有顶点选最小边 |
| Prim 算法(堆优化版,邻接表) | O(E log V) | O(V+E) | 稀疏图最小生成树 | 用优先队列维护候选边 |
| Kruskal 算法 | O(E log E)≈O(E log V) | O(V+E) | 稀疏图最小生成树 | 边排序 + 并查集 |
| Dijkstra(朴素版,邻接矩阵) | O(V²) | O(V²) | 稠密图,单源最短路径(不允许负权边) | 每次找最近点 O(V) |
| Dijkstra(堆优化,邻接表) | O(E log V) | O(V+E) | 稀疏图,单源最短路径(不允许负权边) | 用堆维护最短距离 |
| Floyd 算法 | O(V³) | O(V²) | 多源最短路径,小规模稠密图,允许负权边;可检测负环(dist[i][i]<0) |
若有负环则无解 |
| Bellman-Ford 算法 | O(VE) | O(V+E) | 单源最短路径,允许负权边;可检测负环(松弛 V 次后仍变化) | 若有负环则无解 |
| SPFA 算法 | 平均 O(E),最坏 O(VE) | O(V+E) | 单源最短路径,允许负权边;可检测负环(某点入队 ≥ V 次) | 若有负环则无解 |
排序的一些代码模板
快速排序
1 | |
归并排序
1 | |
错题本
2010 线性表 三次翻转

1 | |
1 | |
2011 线性表 二分搜索
1 | |
1 | |
2013 线性表 摩尔投票法
1 | |
1 | |
1 | |
🎭 这个算法其实是在模拟“投票大战”!
想象你现在有一群人,每人代表一个数。你的目标是找出 有没有某个数在这群人里占多数(超过一半)。
🥊 摩尔投票的逻辑是:
- 你一开始不知道谁是主角,所以从第一个人开始猜;
- 如果后来遇到和当前猜测一样的人(站你这边),你就信心 +1;
- 如果遇到和你猜的不一样的人(反对你),你就信心 -1;
- 如果信心掉到 0,就说明你现在这个候选人支持和反对打平了,需要换人重新开始;
- 最后剩下来的“赢家”有可能是主角,但得再数一遍确认一下它是不是真的超过一半。
🎯 那为什么 count-- 是必要的?
因为每遇到一个“不同”的数,就是“主元素”的一个反对票。
如果主元素真的超过一半,那其他所有数都不够把它抵消掉,它一定能撑到最后!
比如数组:
1 | |
- 主元素是 5,它有 5 票;
- 剩下的 3、7、1 只有 3 票;
- 即使这 3 票全都拿来反对 5,5 还是赢了!
所以你在每遇到一个“异类”时,就等于主角被反对了一次,要 count--。
✅ 总结一句话:
count--是为了让反对的声音抵消掉主元素的票数,看它能不能最终剩下来。
2018 线性表 原地哈希法
1 | |
1 | |
1 | |
1 | |
2020 线性表
1 | |
1 | |
2009 单链表
1 | |
1 | |
2012 单链表
1 | |
1 | |
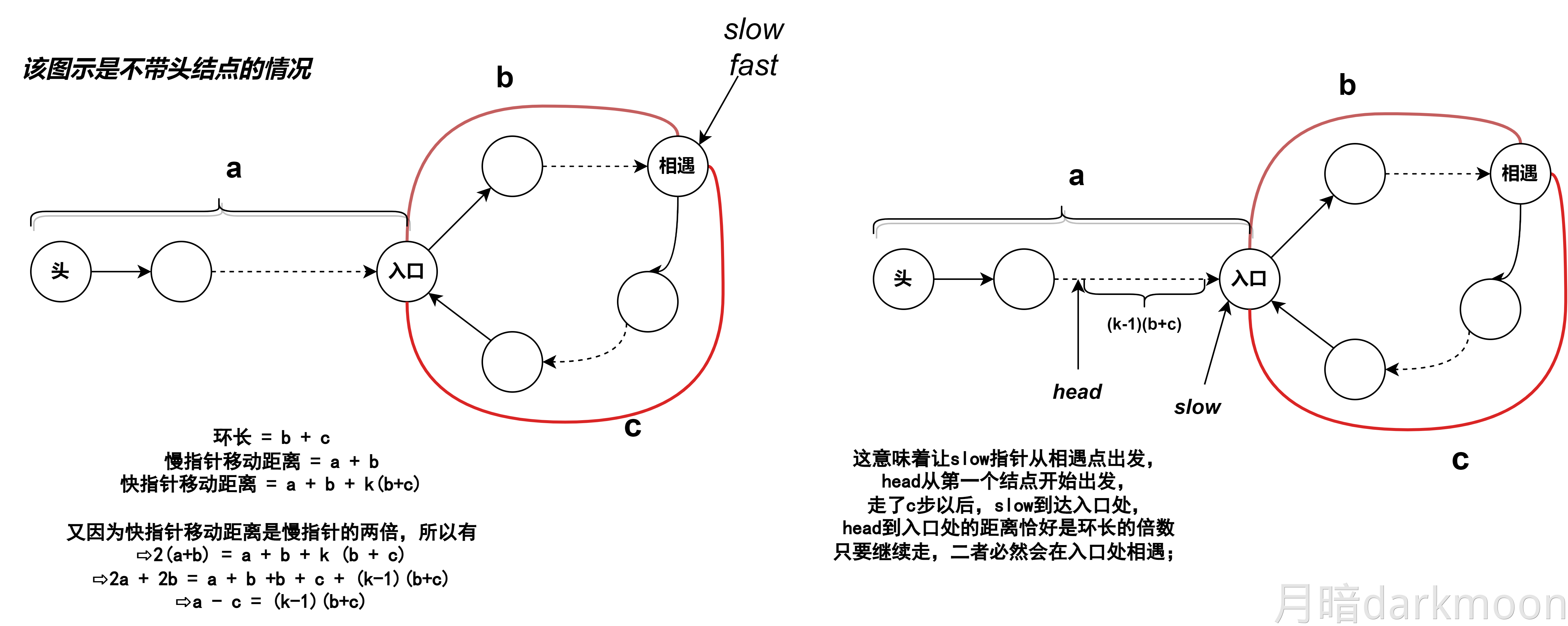
顺序遍历两个链表到尾结点时,并不能保证两个链表同时到达尾结点。这是因为两个链表的长度不同。假设一个链表比另一个链表长k个结点,我们先在长链表上遍历k个结点,之后同步遍历两个链表,这样就能够保证它们同时到达最后一个结点。因为两个链表从第一个公共结点到链表的尾结点都是重合的,所以它们肯定同时到达第一个公共结点。
1)算法的基本设计思想:
①分别求出str1和str2所指的两个链表的长度m和n。
②将两个链表以表尾对齐:令指针p、q分别指向str1和str2的头结点,若m≥n,则指针p先走,使p指向链表中的第m-n+1个结点;若m<n,则使q指向链表中的第n-m+1个结点,即使指针p和q所指的结点到表尾的长度相等。
③反复将指针p和q同步向后移动,并判断它们是否指向同一结点。当p、q指向同一结点,则该点即所求的共同后缀的起始位置。
1 | |
2015 单链表
1 | |
1 | |
1 | |
2019 单链表 快慢指针找链表中点
1 | |
1 | |
你问:“为什么快指针 q 走两步,慢指针 p 走一步,最后 q 到达链尾时 p 正好在链表中间?”
这个其实是快慢指针(龟兔赛跑)找链表中点的经典原理,我给你详细解释一下:
原理说明
- 设链表长度为 n。
- 慢指针 p 每次走一步,快指针 q每次走两步。
- 当快指针 q 到达链表末尾(或越过末尾)时,慢指针 p 所指节点就是链表的中点。
为什么成立?
-
由于 q速度是 p的两倍,假设 p走了 k 步,那么 q走了 步。
-
当 q 到链尾时,链表总长度是 n,因此:
-
即慢指针 p 走了链表长度一半的步数,停在中点。
直观示例
| 链表长度 | q走的步数 | p 走的步数 | p 位置 |
|---|---|---|---|
| 5 | 4~5 | 2~3 | 第3个节点(中间) |
| 6 | 6 | 3 | 第4个节点(中间) |
代码示例
1 | |
总结
- 快指针两步,慢指针一步。
- 快指针到末尾时,慢指针刚好走一半,指向中点。
- 这是链表中点查找的最常用技巧。
形象文字图
1 | |
- 每次循环,p向右走一个节点,q向右走两个节点。
- 当q到达链尾或超出链尾时,p所在的位置就是中点。
1 | |
2022 二叉搜索树
1 | |
1 | |
2023 邻接矩阵
1 | |
2021 邻接矩阵
1 | |
1 | |
2024 拓扑序列
1 | |
2016 排序
1 | |
1 | |
YXC版强化
时间复杂度、矩阵展开;排序、进位制
时间、空间复杂度
- 只考虑次数不考虑常数
- 常见复杂度
- O(1)
- O(n)
- O(n^k)
- O(logn)
- O(nlogn)
- O(根号n)
特殊矩阵的展开
- 给出展开方式,求下标位置
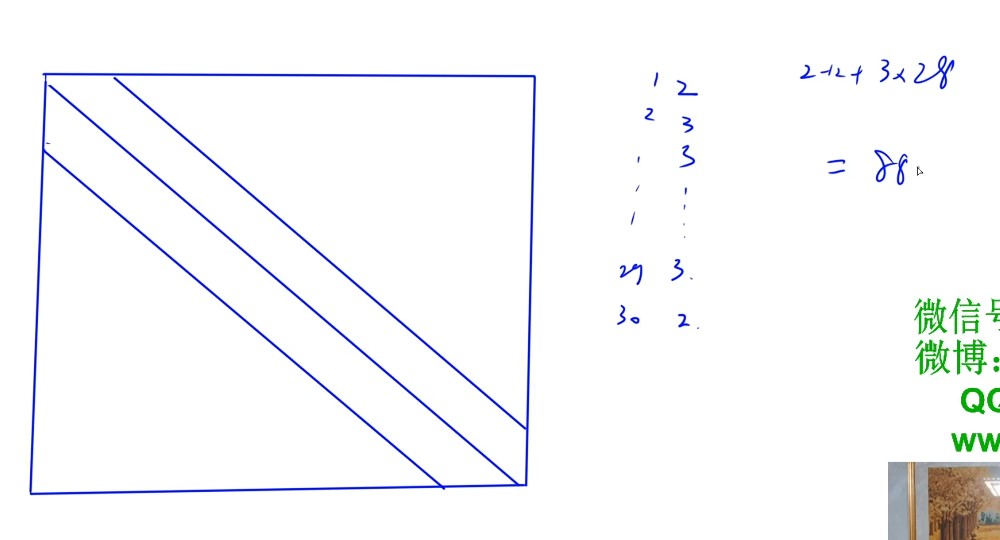
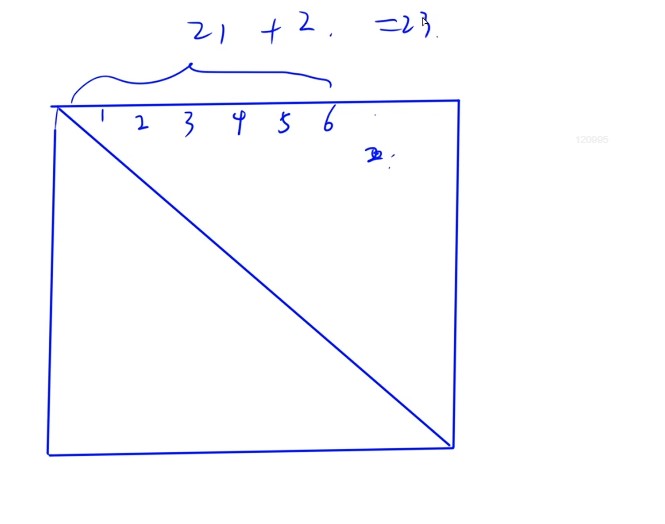
- 可以先列出每行的元素个数,然后求和,是第几个元素,然后从0开始就-1
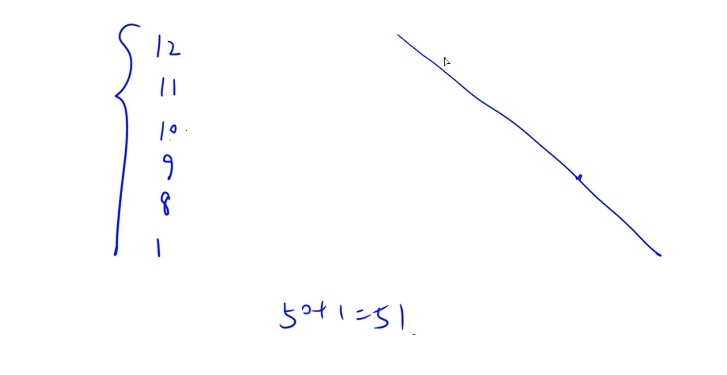
线性表
1 | |
栈与队列
-
栈的链式存储
- 头结点当栈顶,尾结点当栈底,头插法,头删
-
队列的链式存储
1
2
3
4
5//队尾指针指向下一个要存的位置
node *front = new Node(),*rear=front;
rear->val=1;
rear->next=new node();
rear=rear->next; -
只有需要回到上一层才需要用到栈,尾递归不涉及栈
-
栈dfs,队列bfs
-
表达式求值
- 两个栈,一个用来存操作数,一个存操作符
- 数栈遇到数则压栈
- 运算符栈遇到(压栈,遇到)操作到(
- ±*/操作到遇到(或者栈顶优先级<当前
- 操作完运算符栈,数栈栈顶就是答案
1 | |
树
-
二叉树节点计算的常用方法:
-
数学归纳法
-
递推
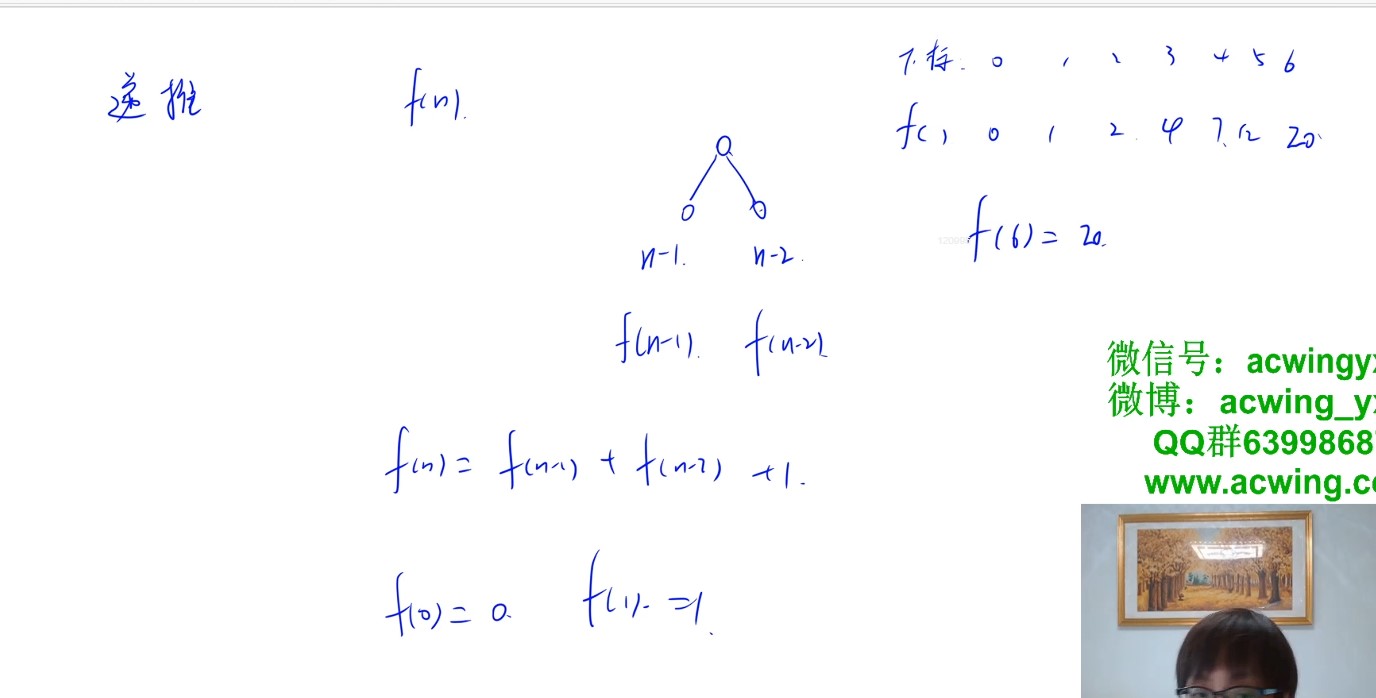
-
解方程/等式代换
- 先求点数再求边数
- 边数=点数-1
-
-
前驱:中序遍历的前一个点
-
后继:中序遍历的后一个点
-
树与二叉树的转换:原树中叶子节点数=转换后的树中有右孩子的结点数+1
-
原树中叶子节点个数 = 转换后的树中有右儿子的节点数 + 1
-
原树中分支节点个数 = 转换后的树中无右儿子的节点数 - 1
-
转换后的树中有右儿子的节点数 = 原树中有右兄弟的节点数
-
节点总数 = 原树中原树中叶子节点个数 + 原树中原树中分
支节点个数 = 转换后的树中有右儿子的节点数 + 转换后的树中无右儿子的节点数
-
-
森林与二叉树的转换
- 森林中的叶节点个数=转换后二叉树中有右孩子的结点数+森林的颗树
-
森林的前序遍历就是树二叉树的前序遍历
-
森林的后序遍历就是二叉树的中序遍历
- 因为只有二叉树能找到左右,森林分不出左右只能分子树和根
-
所有节点都有0个孩子或者2个孩子的时候,前序遍历和后序遍历可以唯一确定一个二叉树,但是当有结点只有1个孩子的时候,前序遍历和后序遍历不可以唯一确定一个二叉树
-
二叉搜索树(BST):中序遍历有序的二叉树
- 插入
- O(logn)
- 每次插入必然插入到叶子节点
- 删除
- O(logn)
- 叶子节点直接删除
- 只有左子树或者右子树,用左子树或者右子树的根节点替换掉删除的结点
- 左右子树皆有,用中序遍历前驱替代删除的点
- 查找
- O(logn)
- 插入
1 | |
-
平衡二叉树
- 平衡因子:左-右
- 左旋右旋只改变高度不改变中序遍历顺序
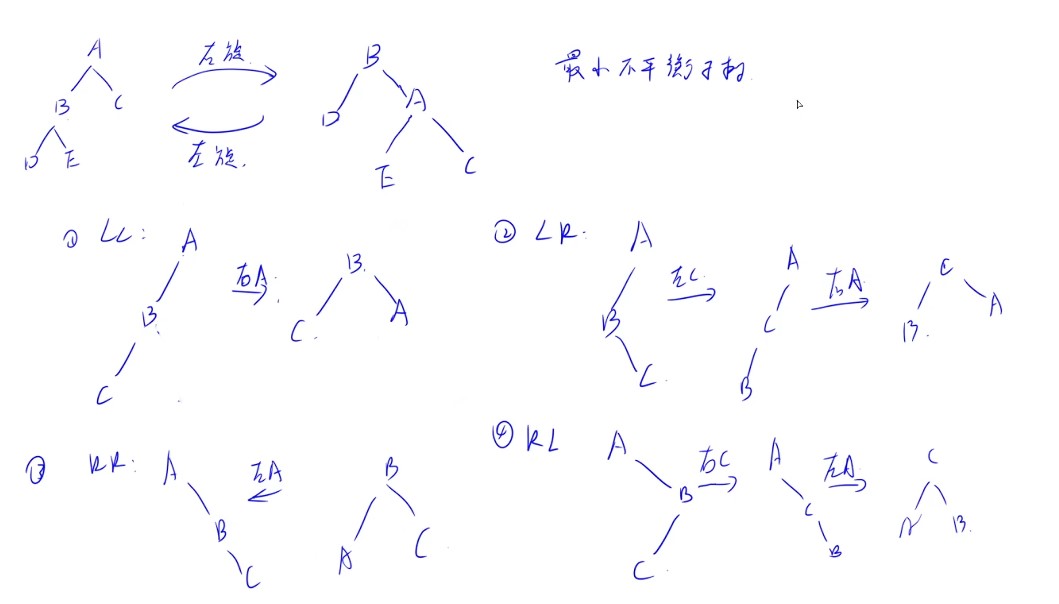
-
表达式树是二叉树,分支节点都是运算符,叶子节点都是数字/字符
- 从左到右,按照顺序构造
- 前缀表达式:表达式树的前序遍历
- 后缀表达式:表达式树的后序遍历
-
如何判断关键字序列能否构成二叉排序树中的查找路径
- 画出序列构成的二叉树,然后进行中序遍历看是否有序
-
哈夫曼树
- 前缀编码→所有编码均对应叶节点
- 从下往上构造一棵树,每次合并根节点值最小的子树
- 所有点的度数不为1
- 一定有一个最优解,使得权值最小的两个点互为兄弟
-
并查集
- 按秩合并就是按照大小,小树合到大树
图
- 邻接多重表理论上找无向图的反向边比邻接表方便
- 十字链表是对邻接矩阵的优化,实际上也可以存无向图
- 邻接矩阵和十字链表无法存重边,邻接表和邻接多重表可以存重边
- 三元组表也能存重边
- 判断dijkstra算法最短路径的快捷方法
- 直接看每个点到起点的距离,然后从小到大排序
- 判断连通性

查找
有序线性表的查找
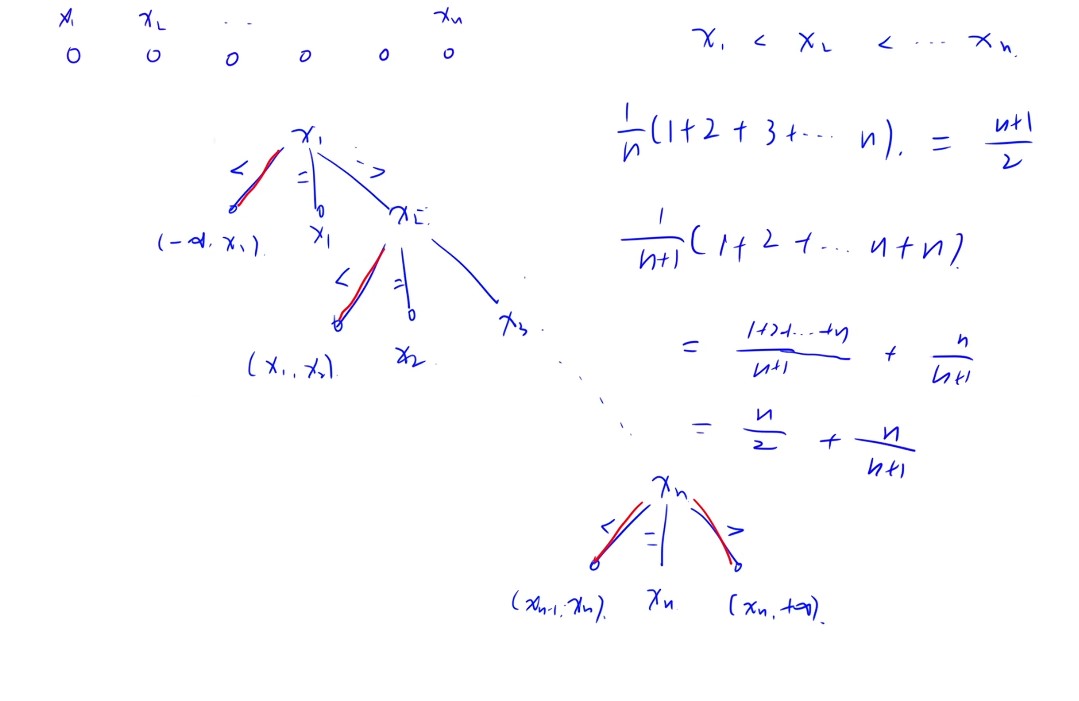
二分查找
- (low+high)/2下取整
- (low+high+1)/2上取整
- 二分要保持一致,上取整就一直上取整,下取整就一直下取整
- 小于则右端点=mid-1,大于则右端点=mid+1
- 平均成功查找长度=log(n+1)-1
- 折半查找中序遍历有序
- 判定折半查找判定树:看上下取整是否一致,也就是说上取整要一直上取整,下取整要一直下取整
- 快速判定:要么左边一直比右边节点多,要么右子树一直比左子树结点多
分块查找
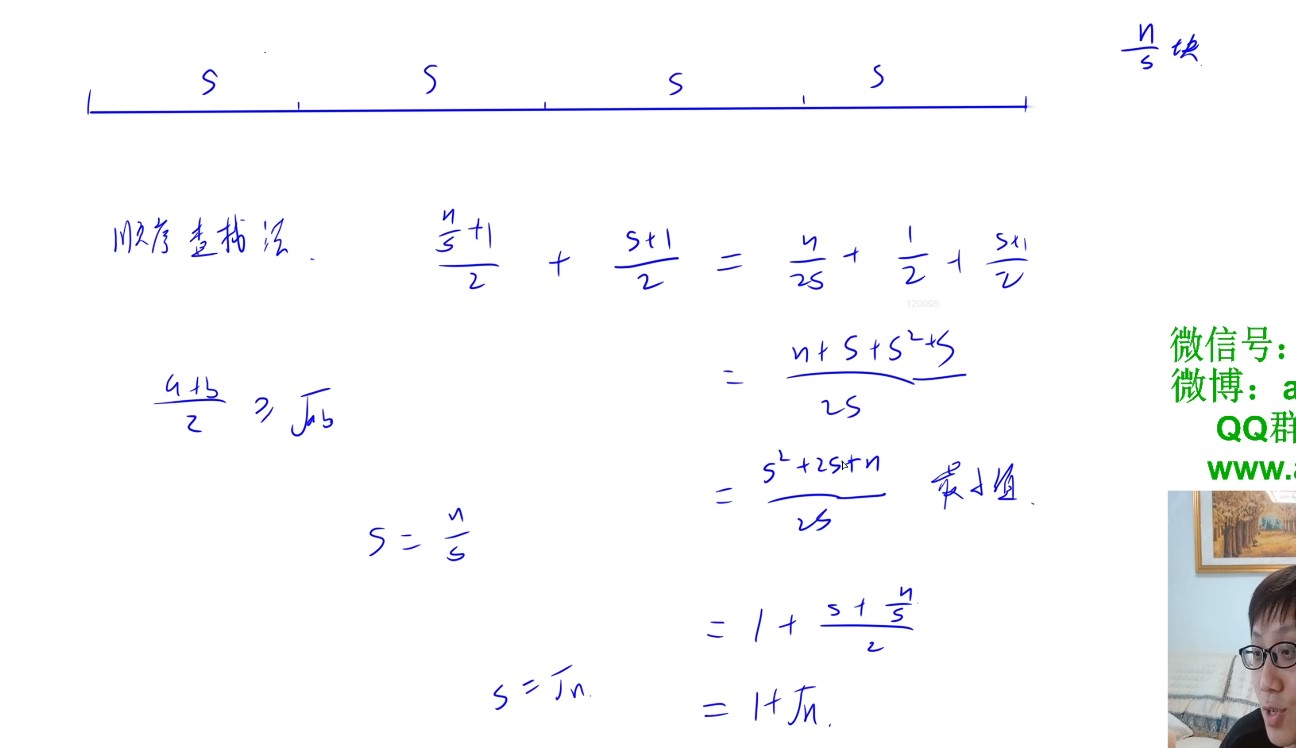
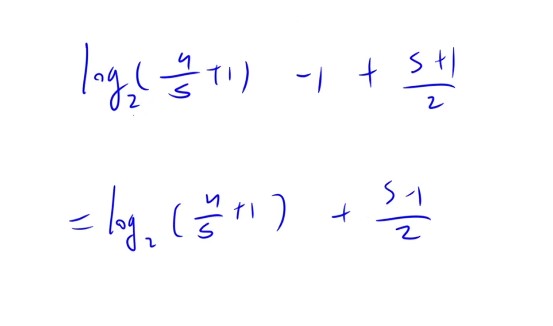
B树和B+树
- 主要用于硬盘或者文件系统管理、数据库
- 读写慢
- 文件大
- B树中间的点有信息
- 而B+树中间的点仅作区分分类用,不保留信息,信息全部存储在根节点
- 全部放在叶节点,局部性很好,方便一块读,全在同一层
- 上取整(m/2)-1=m/2下取整

- B树向上分裂的时候,中间节点存在上一层的结点,但是B+树向上分裂的时候,由于所有信息存储在叶节点,所以上面分离出去的只是索引节点,而分裂出来的两组叶节点中,双亲结点的信息存储在右边那一组
- 如果分裂的是索引节点,则直接分裂不用存多次
- 索引节点不需要重复
- B+树每次数据查询的次数都一样,因为都是查找到叶节点
- B树的删除情况
- 兄弟够借
- 删左左旋
- 删右右旋
- 兄弟不够借
- 删左,合并双亲节点一起左旋
- 删右,合并双亲结点一起右旋
- 兄弟够借
- B树和B+树的区别:
- B树的关键字和子树个数差1,而B+树关键字个数=子树个数
哈希表
- 拉链法又称为开散列法
- 开放寻址法又称为闭散列法
- 负载因子=已有元素数/数组长度
- 负载因子越低,效率越高
- 哈希函数
- 乘余取整法:n*(A * x的小数部分),A是0-1之间的数
- 平方取中法:先平方,然后取中间几位
- 基数转换法:换成其他进制,然后取其中几位
- 线性探测法、二次探查法、随机探查法,都容易产生二级聚集问题
- 查找效率指的是时间,存储效率指的是空间
- 哈希表的查找失败长度是针对整数域来讲的,也就是说key%M,分母就是1/M,分子0~M-1的对应失败查找次数,要查到空才停止
红黑树
- 所有根节点都是黑色不是指的实结点,而是指的空黑叶节点
- 黑路同,值得也是从任意节点出发,到达任一空叶节点的路径上经过的黑节点数量相同(包括黑空叶节点)
- 所有操作的时间复杂度都是log(n)
- 红黑树的删除:单子树直接删,双子树用后继替代,接着递归调整直到符合红黑树的性质
查找算法时间复杂度表

排序
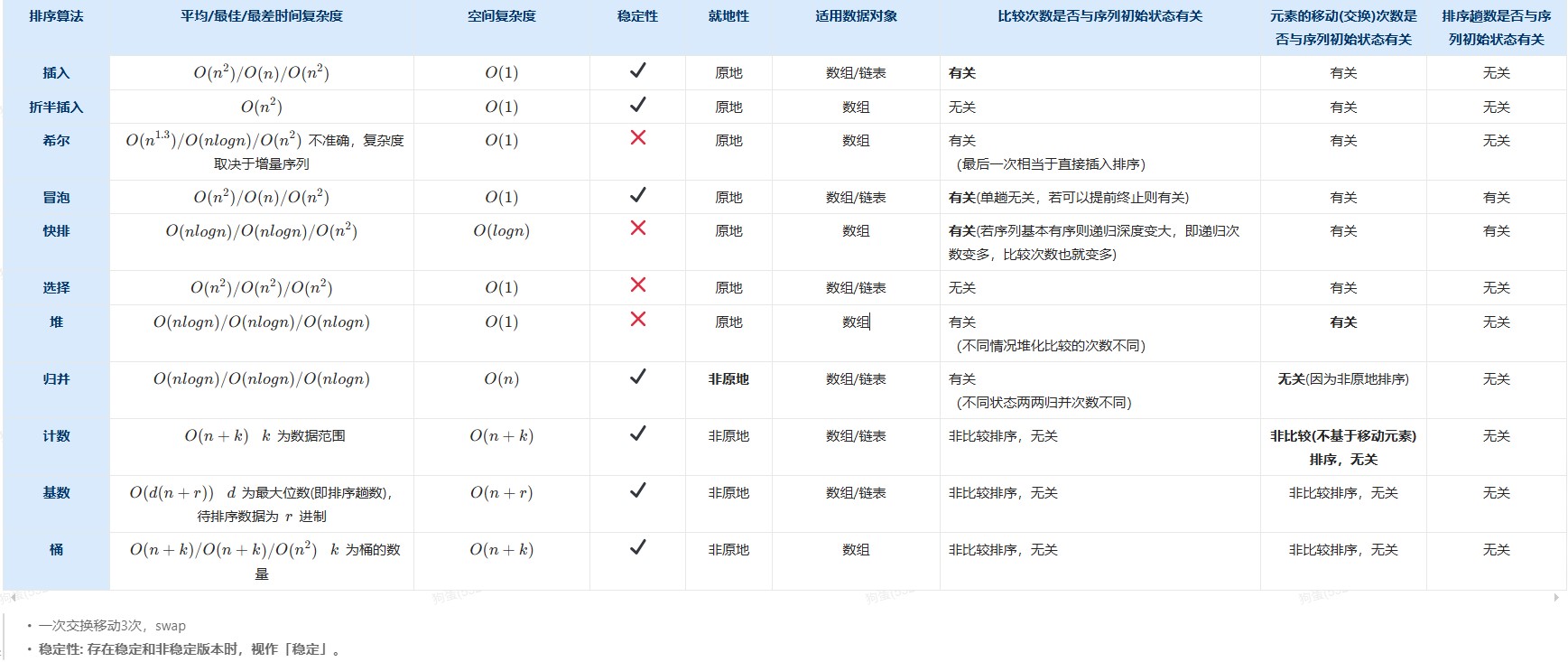
排序算法对比表
| 算法 | 最好时间复杂度 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 适用 |
|---|---|---|---|---|---|---|
| 直接插入排序 | O(n)(表中元素有序) | O(n²)(表中元素逆序) | O(n²) | O(1) | 稳定 | 顺序存储和链式存储的线性表 基本有序的排序表和数据量不大的排序表 链式存储结构上无需移动元素 |
| 折半插入排序 | 先比较左右两边大小:O(n) 不比较直接二分查找:O(logn) |
O(n²) | O(n²) | O(1) | 稳定 | 顺序存储的线性表 数据量不算很大的排序表 |
| 冒泡排序 | O(n) | O(n²) | O(n²) | O(1) | 稳定 | 顺序存储和链式存储的线性表 |
| 简单选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 | 顺序存储和链式存储的线性表 关键字较少的情况 |
| 希尔排序 | — | O(n^1.5) | O(n²) | O(1) | 不稳定 | 顺序存储的线性表 代码量小,在内存非常宝贵的情况下很有用 |
| 快速排序 | O(n log n) | O(n log n) | O(n²) | O(log n) 最好O(log n) 最坏O(n) |
不稳定 | 顺序存储的线性表 不适用于对原本有序的记录序列进行排序 |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | 不稳定 | 顺序存储的线性表 适用于关键字较大的情况,关键字较少,不建议使用堆排序 适用于求解top-k问题 找maxk,建立小根堆,找mink,建立大根堆 |
| 二路归并排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | 稳定 | 顺序存储的线性表和链式存储的线性表 归并排序的递归顺序与二叉树的后序遍历相同 |
| 桶排序 | O(n + m) | O(n + m) | O(n + m) | O(n + m) | 稳定 | 按桶分区域,区域间有序,再对区域内进行排序,参考分块查找,只不过要对块内进行排序 适用于数据量很大的情况 比如可以将100w个数据分成1000个桶,然后分别对每个桶进行排序,然后将结果合并 |
| 基数排序 | O(d(n + r)) | O(d(n + r)) | O(d(n + r)) | 顺序基数排序O(n + r) 链式基数排序O® |
稳定 | 顺序存储和链式存储的线性表 如果关键字的取值范围很大,采用最高位优先 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(n+k)数组给定的情况下O(n) | 稳定 | 顺序存储的线性表 适用于序列中的元素是整数且元素范围不能太大,否则会造成辅助空间的浪费 |
| 排序算法 | 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 就地性 | 适用数据对象 | 比较次数与初始状态关系 | 移动次数与初始状态关系 | 排序趟数与初始状态关系 |
|---|---|---|---|---|---|---|---|---|---|---|
| 插入排序 | O(n²) | O(n) | O(n²) | O(1) | ✔ 稳定 | 原地 | 数组/链表 | 有关 | 有关 | 无关 |
| 折半插入 | O(n²) | O(n²) | O(n²) | O(1) | ✔ 稳定 | 原地 | 数组 | 无关 | 有关 | 无关 |
| 希尔排序 | O(n^1.3) | O(n log n) | O(n²) | O(1) | ✘ 不稳定 | 原地 | 数组 | 有关 | 有关 | 无关 |
| 冒泡排序 | O(n²) | O(n) | O(n²) | O(1) | ✔ 稳定 | 原地 | 数组/链表 | 有关 | 有关 | 有关 |
| 快速排序 | O(n log n) | O(n log n) | O(n²) | O(log n) | ✘ 不稳定 | 原地 | 数组 | 有关 | 有关 | 有关 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | ✘ 不稳定 | 原地 | 数组/链表 | 无关 | 有关 | 无关 |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | ✘ 不稳定 | 原地 | 数组 | 有关 | 有关 | 无关 |
| 归并排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | ✔ 稳定 | 非原地 | 数组/链表 | 有关 | 无关(非原地算法,在辅助空间进行排序,而非在原始数组上直接进行交换) | 无关 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(n+k) | ✔ 稳定 | 非原地 | 数组 | 无关 | 无关 | 无关 |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | 顺序基数排序O(n + r) 链式基数排序O® |
✔ 稳定 | 非原地 | 数组 | 无关 | 无关 | 无关 |
| 桶排序 | O(n+k) | O(n+k) | O(n²) | O(n+k) | ✔ 稳定 | 非原地 | 数组 | 无关 | 无关 | 无关 |
快排
- 第一层分界点不是端点,第二层必然存在左右半边,因此必然至少有三个点在正确的位置上
- 第一层分界点是端点,第二层只有一个区间,因此该区间内只有一个分界点,因此至少有两个点在正确的位置上,且其中一个点为端点
堆排
- 堆排只要求子树范围内,根结点最大,二叉排序树要求严格左中右递增
外部排序
- ①预处理
- 置换选择排序生成尽量长的串(内存里操作)
- ②归并(k路归并)
- 流程
- ①置换选择排序生成初始串
- ②哈夫曼树选择要进行归并的k路
- ③败者树进行k路归并
算法题刷题
题表:
散题:
- 1451. 单链表快速排序 - AcWing题库
- 34. 链表中环的入口结点 - AcWing题库
- 1636. 按照频率将数组升序排序 - 力扣(LeetCode)
- 179. 最大数 - 力扣(LeetCode)
- 977. 有序数组的平方 - 力扣(LeetCode)
- 268. 丢失的数字 - 力扣(LeetCode)
- 1877. 数组中最大数对和的最小值 - 力扣(LeetCode)
- 950. 按递增顺序显示卡牌 - 力扣(LeetCode)
- 785. 快速排序 - AcWing题库
- 786. 第k个数 - AcWing题库
- https://leetcode.cn/tag/linked-list/problemset/力扣链表题集
- https://leetcode.cn/problems/remove-zero-sum-consecutive-nodes-from-linked-list/
- 408之2023年算法题预测 - 知乎
- https://leetcode.cn/problems/reverse-nodes-in-k-group/
- 3302. 表达式求值 - AcWing题库
- 206. 反转链表 - 力扣(LeetCode)
- 20. 有效的括号 - 力扣(LeetCode)
- 18. 重建二叉树 - AcWing题库
- 104. 二叉树的最大深度 - 力扣(LeetCode)
- 111. 二叉树的最小深度 - 力扣(LeetCode)
- 112. 路径总和 - 力扣(LeetCode)
- 113. 路径总和 II - 力扣(LeetCode)
- 129. 求根节点到叶节点数字之和 - 力扣(LeetCode)
- 257. 二叉树的所有路径 - 力扣(LeetCode)
- 100. 相同的树 - 力扣(LeetCode)
- 101. 对称二叉树 - 力扣(LeetCode)
- 110. 平衡二叉树 - 力扣(LeetCode)
- 199. 二叉树的右视图 - 力扣(LeetCode)
- 226. 翻转二叉树 - 力扣(LeetCode)
- 1026. 节点与其祖先之间的最大差值 - 力扣(LeetCode)
- 1080. 根到叶路径上的不足节点 - 力扣(LeetCode)
- 1110. 删点成林 - 力扣(LeetCode)
- 1372. 二叉树中的最长交错路径 - 力扣(LeetCode)
- 98. 验证二叉搜索树 - 力扣(LeetCode)
- 230. 二叉搜索树中第 K 小的元素 - 力扣(LeetCode)
- 501. 二叉搜索树中的众数 - 力扣(LeetCode)
- 700. 二叉搜索树中的搜索 - 力扣(LeetCode)
- 1373. 二叉搜索子树的最大键值和 - 力扣(LeetCode)
- 236. 二叉树的最近公共祖先 - 力扣(LeetCode)
- 235. 二叉搜索树的最近公共祖先 - 力扣(LeetCode)
- 102. 二叉树的层序遍历 - 力扣(LeetCode)
- 103. 二叉树的锯齿形层序遍历 - 力扣(LeetCode)
- 513. 找树左下角的值 - 力扣(LeetCode)
- 104. 二叉树的最大深度 - 力扣(LeetCode)
- 111. 二叉树的最小深度 - 力扣(LeetCode)
- 199. 二叉树的右视图 - 力扣(LeetCode)
- 144. 二叉树的前序遍历 - 力扣(LeetCode)
- 94. 二叉树的中序遍历 - 力扣(LeetCode)
- 145. 二叉树的后序遍历 - 力扣(LeetCode)
- 107. 二叉树的层序遍历 II - 力扣(LeetCode)
- 404. 左叶子之和 - 力扣(LeetCode)
- 108. 将有序数组转换为二叉搜索树 - 力扣(LeetCode)
- 958. 二叉树的完全性检验 - 力扣(LeetCode)
- 109. 有序链表转换二叉搜索树 - 力扣(LeetCode)
- 1334. 阈值距离内邻居最少的城市 - 力扣(LeetCode)
- 210. 课程表 II - 力扣(LeetCode)
算法积累
从无序顺序表中删除所有值为x的元素
- 时间复杂度O(n),空间复杂度O(1)

1 | |
无序表删除值为s到t之间的所有元素
- 思路:快慢指针

1 | |
有序表中删除值为s到t之间的所有元素
- 思路:找到第一个和最后一个值处于该区间的元素下标,然后将该区间的后面的元素依次前移即可。
1 | |
删除重复元素
1 | |
数组逆置
1 | |
删除倒数第k个数
- 快慢指针,快指针先运行k步
1 | |
带有头结点的链表逆序输出每个节点的值
1 | |
反转链表
- 头插法
1 | |
- 迭代法
1 | |
反转部分链表
1 | |
快慢指针应用
链表中间结点
1 | |
删除链表中间结点
1 | |
判断链表中是否存在环
1 | |
从无序数组中删除所有值为x某元素
1 | |
重排链表(快慢指针找中间节点/反转链表/链表的交叉连接)
1 | |
回文链表
1 | |
链表排序
1 | |
合并升序链表
1 | |
表达式求值
1 | |
中缀表达式转后缀表达式
1 | |
表达式树
1 | |
哈夫曼树
1 | |
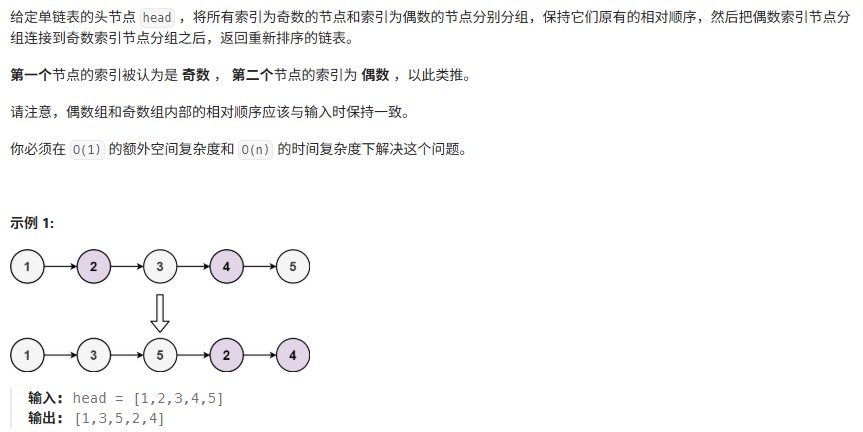
奇偶链表
1 | |
定义和基本操作模板
单链表
单链表结点的定义
1 | |
单链表的初始化
1 | |
单链表求表长(不含头结点)
1 | |
单链表的按位查找
1 | |
单链表的按值查找
1 | |
头插法建立单链表
1 | |
尾插法建立单链表
1 | |
插入节点操作
1 | |
删除节点操作
1 | |
双链表
双链表的数据结构定义
1 | |
双链表的插入
1 | |
双向链表的删除操作
1 | |
循环单链表
循环单链表的初始化
1 | |
循环双链表
循环双链表初始化
1 | |
静态链表
静态链表的定义
1 | |
二叉树
二叉树的顺序存储
1 | |
二叉树的链式存储
1 | |
迭代法先序遍历
1 | |
迭代法中序遍历
1 | |
1 | |
迭代法后序遍历
1 | |
二叉树的层序遍历
1 | |
重建二叉树
1 | |
二叉排序树
1 | |
线索二叉树的结构体定义
1 | |
中序线索二叉树的构造
1 | |
中序线索二叉树找后继/前驱/遍历
1 | |
先序线索化
1 | |
后序线索化
1 | |
二叉树的带权路径长度
1 | |
二叉树的最大深度
1 | |
表达式树
1 | |
树与森林的存储
双亲表示法
1 | |
孩子表示法
1 | |
孩子兄弟表示法
1 | |
并查集
- 朴素版
1 | |
- 路径压缩版
1 | |
图
图的邻接矩阵存储结构
1 | |
图的邻接表存储结构体
1 | |
十字链表存储结构
1 | |
邻接多重表存储结构
1 | |
基于BFS/DFS的拓扑排序
1 | |
1 | |
朴素版prim算法
1 | |
kruskal算法
1 | |
BFS算法(邻接矩阵)
1 | |
BFS算法(邻接表)
1 | |
DFS算法(邻接矩阵)
1 | |
DFS算法(邻接表)
1 | |
朴素版dijkstra算法
1 | |
拓扑排序
1 | |
1 | |
1 | |
查找
一般线性表的顺序查找
1 | |
有序表的顺序查找
1 | |
二分查找
1 | |
二分不用考虑有没有解

整数二分
- 有单调性的题目可以二分,但可以二分不一定有单调性,二分的本质不是单调性
- 二分的本质是性质,使得一部分满足红色性质,一部分满足绿色性质,整个区间可以一分为二,二分可以寻找性质的边界

①红点
-
mid=l+r+1>>1;
if(check(mid)) true ->[mid,r] l = mid;//mid满足红色性质
false->[l,mid-1] r = mid-1;//mid不满足红色性质,在绿色性质区域
②绿点
-
mid = l+r>>1;
if(check(mid)) true->[l,mid] r = mid;//mid满足绿色性质
false->[mid+1,r] l = mid+1;//mid满足红色性质,不满足绿色性质
1 | |
1 | |
浮点数二分
注:判断是否满足绿色性质
1 | |
二叉搜索树
查找
1 | |
插入
1 | |
二叉搜索树的构造
1 | |
Hash表
-
存储结构
-
开放寻址法
-
拉链法
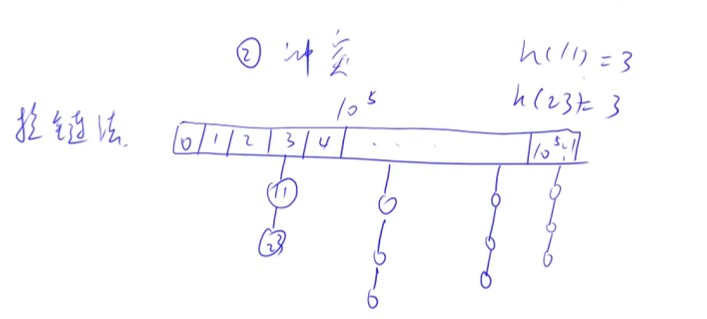
-
-
字符串哈希
-
作用:把一个比较庞大的空间(值域)映射到比较小的空间,映射后的函数叫做哈希函数
- x %10^5 ∈(0,10^5)
- 模的数一般要取成质数,所以一般要遍历寻找最小的质数
- 冲突:两个不一样的数映射成了同一个数,处理冲突的方式可以分为开放寻址法和拉链法
- x %10^5 ∈(0,10^5)
拉链法
1 | |
1 | |
开放寻址法
- 只开一个数组,但是开的长度一般是输入数据的2-3倍
1 | |
字符串哈希
字符串前缀哈希法
-
先预处理出所有前缀的哈希

把字符串看成是p进制的数字,每一位上的字母就表示p进制上的每一位数字,然后再取模,就可以把字符串映射到从0到Q-1
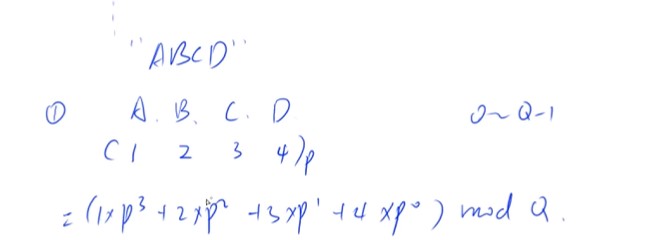
-
A-Z不能映射成0,一般从1开始
-
字符串哈希假定不存在冲突,因此不考虑冲突
-
好处是可以利用前缀哈希算出来任意一个子串的哈希值
-
作用:
快速判断两个字符串是否相同,哈希值相同,两个字符串相同,如果哈希值不同,则两个字符串不同
1 | |
排序
综合
1 | |
快排
1 | |
插入排序
1 | |
归并排序
1 | |
堆排序
1 | |
计数排序
1 | |
408中c++stl可用的情况
栈
1 | |
队列
1 | |
代码每日一题
Day1

1 | |
1 | |
Day2

1 | |
Day3

1 | |
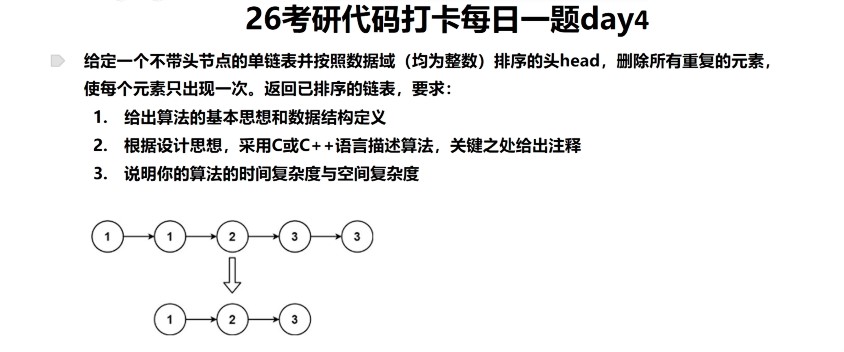
Day4
1 | |
Day5

1 | |
Day6

1 | |
Day7

1 | |
Day8

1 | |
1 | |
Day9 重要,连通性问题

1 | |
1 | |
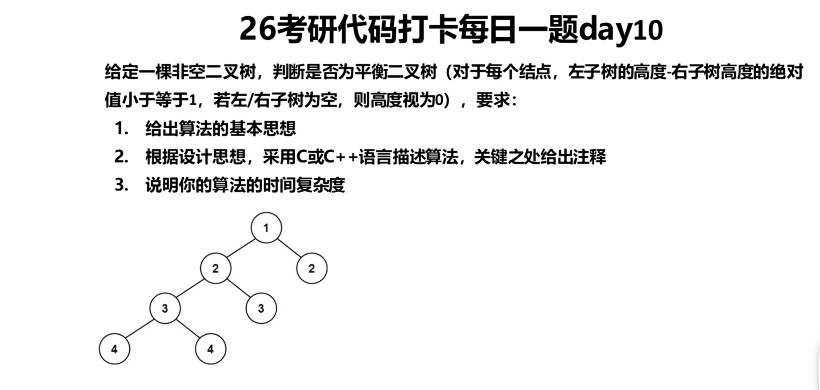
Day10 重点,树的后序遍历
1 | |
1 | |
Day11 重点图的遍历

1 | |
1 | |
Day12

1 | |
1 | |
Day13

1 | |
1 | |
Day14

1 | |
1 | |
Day15

1 | |
1 | |
Day16

1 | |
1 | |
Day17

1 | |
1 | |
Day18

1 | |
1 | |
Day19
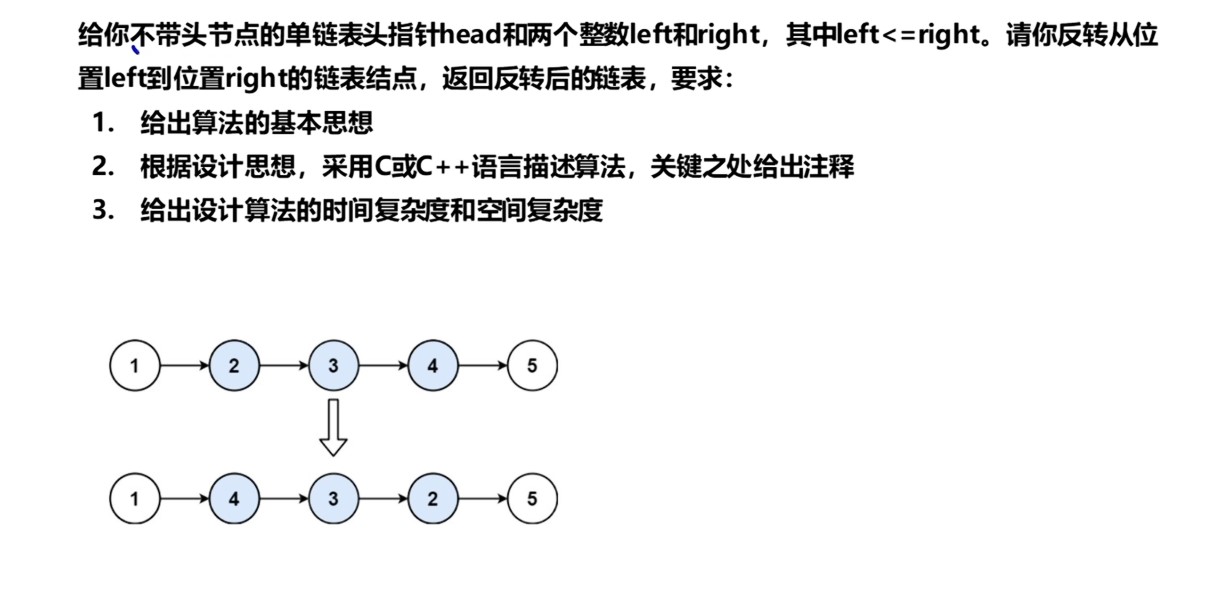
1 | |
1 | |
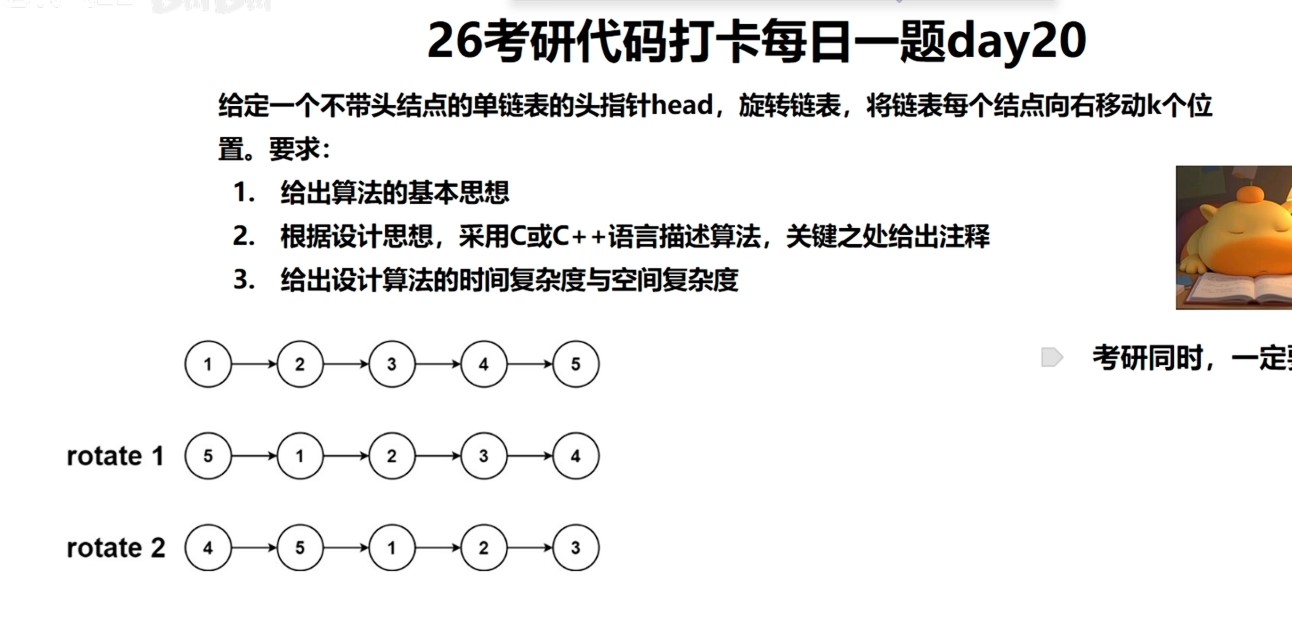
Day20
1 | |
1 | |
Day21

1 | |
1 | |
Day22

1 | |
1 | |
Day23

1 | |
1 | |
Day24
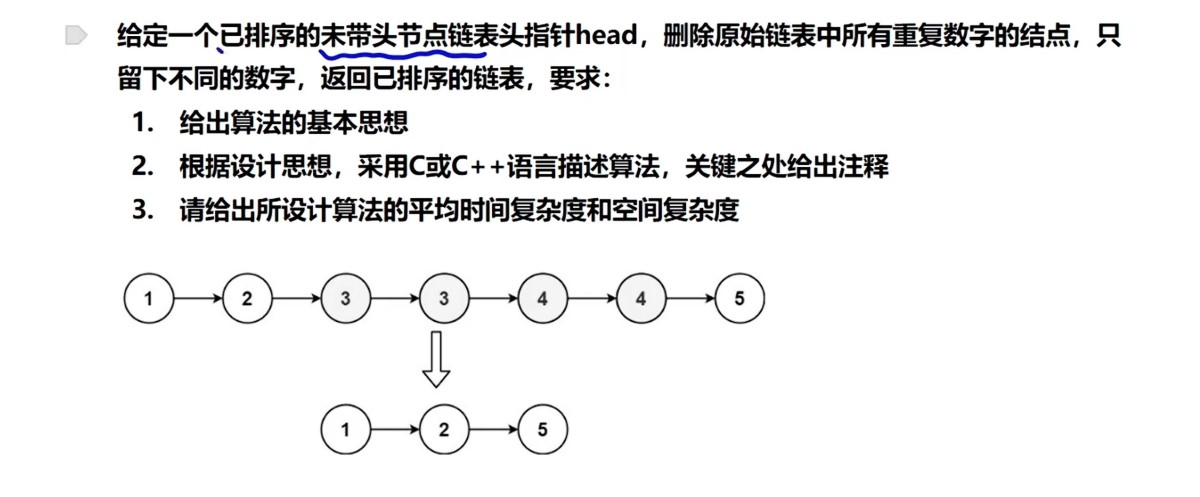
1 | |
1 | |
Day25

1 | |
1 | |
Day26

1 | |
1 | |
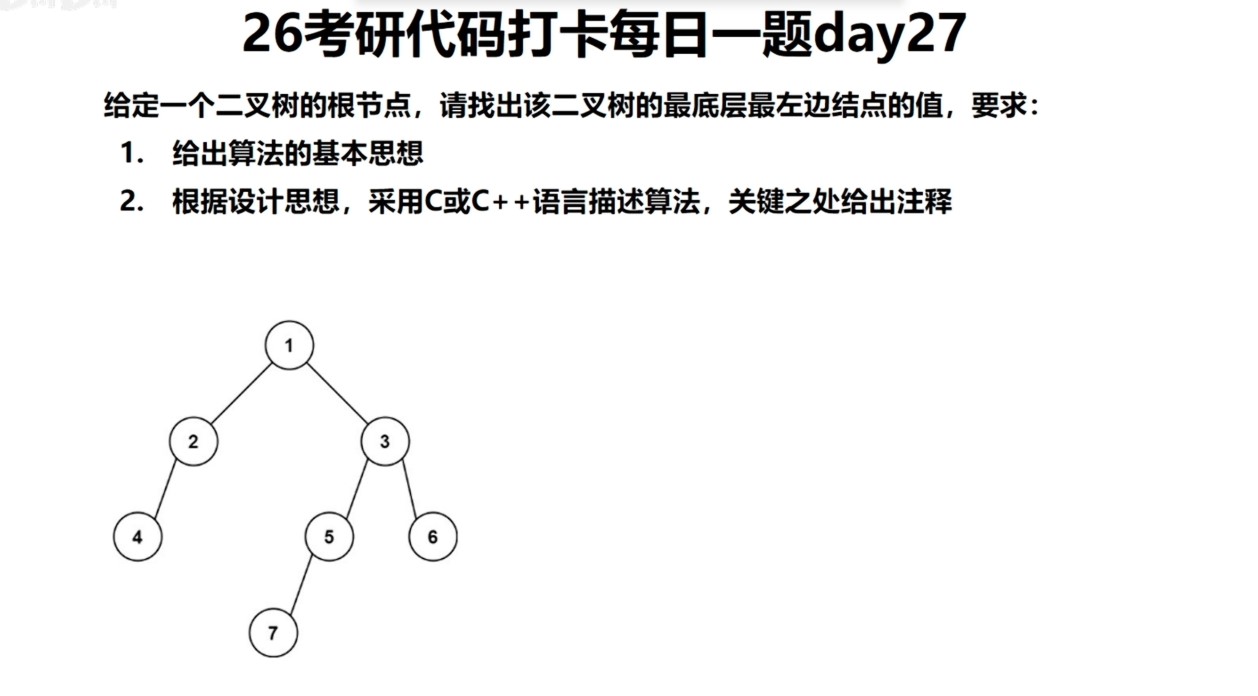
Day27
1 | |
1 | |
Day28

1 | |
1 | |
Day29

1 | |
1 | |
Day30

1 | |
1 | |
Day31

1 | |
1 | |
Day32 统计回溯

1 | |
1 | |
Day33
1 | |
1 | |
Day34
1 | |
1 | |
Day35
1 | |
1 | |
Day36
1 | |
1 | |
Day37
1 | |
1 | |
Day38
1 | |
1 | |
Day39
1 | |
1 | |