语法基础课
1.变量、输入输出、表达式和顺序语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
2.判断语句
3.循环语句
4.数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
5.字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
6.函数
一个典型的函数定义包括:返回类型、函数名字、由0或多个形参组成的列表以及函数体
注:每一个变量都要声明类型
编写函数
1 2 3 4 5 6 int foo (int n) int res=1 ;for (int i =1 ;i<=n;i++)return res;
函数返回值的类型:
变量类型
void
参数也可以是空参数
函数声明
静态变量在函数内只会被创建一次,调用不管多少次用的都是一个变量,只在第一次调用被初始化,相当于在函数内部开了一个仅供函数的全局变量,静态变量不赋值的时候为0,开在堆里面,特别大的数组开在栈里面可能会爆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int output () static int cnt= 0 ;"call :" <<cnt<<"times" ;int main () output ();output ();output ();output ();output ();
函数内部修改不影响函数外部修改
传引用参数
当函数的形参为引用类型时,对形参的修改会影响实参的值。使用引用的作用:避免拷贝、让函数返回额外信息
1 2 3 4 5 6 7 8 9 10 11 12 int max (int &x,int &y ) 10 ,y=20 ;if (x>y )return x;return y;int main () int a,b;max (a,b)<<endl;return 0 ;
二维数组第一维数量可以去掉,第二维不可以去掉
由于数组是传引用函数,函数内形参的修改会影响函数外数组即实参的值
参数可以是默认参数:
默认值必须是后面的参数不能只是第一个参数,但可以都是默认值。
inline
不是调用函数而是相当于直接复制粘贴内部代码到主函数,只适合短小且调用次数不是很多的函数。
没有返回值的函数,return后可以为空。
只有先声明才能用函数
递归
函数自己调用自己
1 2 3 4 int fact (int a) if (a==1 )return 1 ;return n*fact (n-1 )
递归一定要有结束条件不然容易死循环
7.类、结构体、指针和引用
类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> using namespace std;class person {private :int age,height;double money;1000 ];public :void say () "I am" <<name <<endl;int get_age () return age;void add_money (double x) money + =x;int main () "kugeln" ;add_money (10000 );
类里面未定义的变量默认private,结构里面未定义的变量默认public
短简单结构,复杂长类
结构体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> using namespace std;struct person {int age,height;double money;person (){}person (int _age,int _height,double _money)person (int _age,int _height,double _money) : age (_age),height (_height),money (_money){}int main () person p (18 ,180 ,100 ) ;return 0 ;
指针
引用
指针指向存放变量的值的地址
nullptr,是c++中空指针类型的关键字,是在C++11中引入的。用来表示空指针类型。
1 2 3 4 5 6 7 8 9 10 #include <iostream> using namespace std;char a,b;int main () int a =10 ;int * p =&a;return 0 ;
数组名是一种特殊的指针。指针可以做运算。数组的地址是开头的地址,连续排布
指针运算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> using namespace std;int main () int a[5 ] = {1 , 2 , 3 , 4 , 5 };for (int i = 0 ; i < 5 ; i ++ )int * p = &a;int & p = a;return 0 ;
链表
在链表中,如果头结点可能被删掉,则需要一个虚拟头结点,最后返回虚拟节点->next
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> using namespace std;struct Node {int val;int main () for (int i = 1 ;i<=5 ;i++)new Node ();for (Node *p = head;p;p=p->next)' ' ;return 0 ;int main () Node (1 );new Node (1 );auto p =new Node (1 );auto q =new Node (2 );auto o =new Node (3 );
如何遍历链表
单链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> using namespace std;struct Node {int val;Node (int _val) :val (_val),next (NULL ){}int main () auto p =new Node (1 );auto q =new Node (2 );auto o =new Node (3 );for (Node* i = head;i;i = i->next)
链表操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> using namespace std;struct Node {int val;Node (int _val) :val (_val),next (NULL ){}int main () auto p =new Node (1 );auto q =new Node (2 );auto o =new Node (3 );new Node (4 );new Node (4 );new Node (-1 );for (Node* i = head;i;i = i->next)
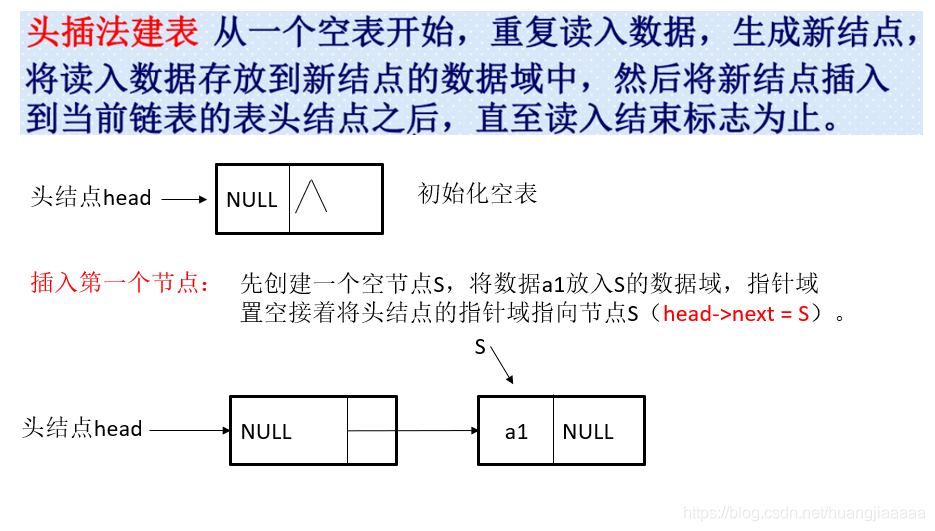
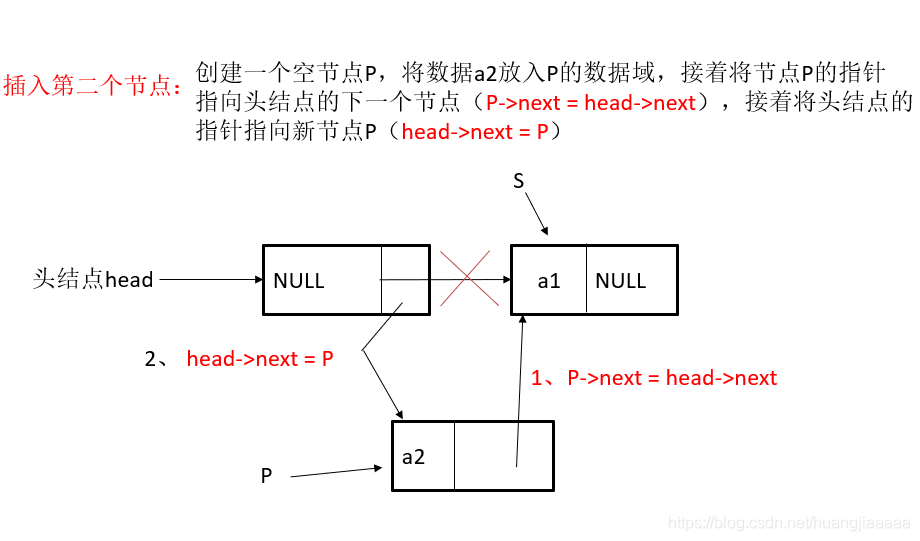
头插法图示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> using namespace std;struct node {int val;node (int _val):val (_val),next (NULL ){}int main () auto a = new node (1 );auto b = new node (2 );for (node* i = head;i;i=i->next)' ' ; for (node* i = head;i;i=i->next)' ' ;system ("pause" );return 0 ;
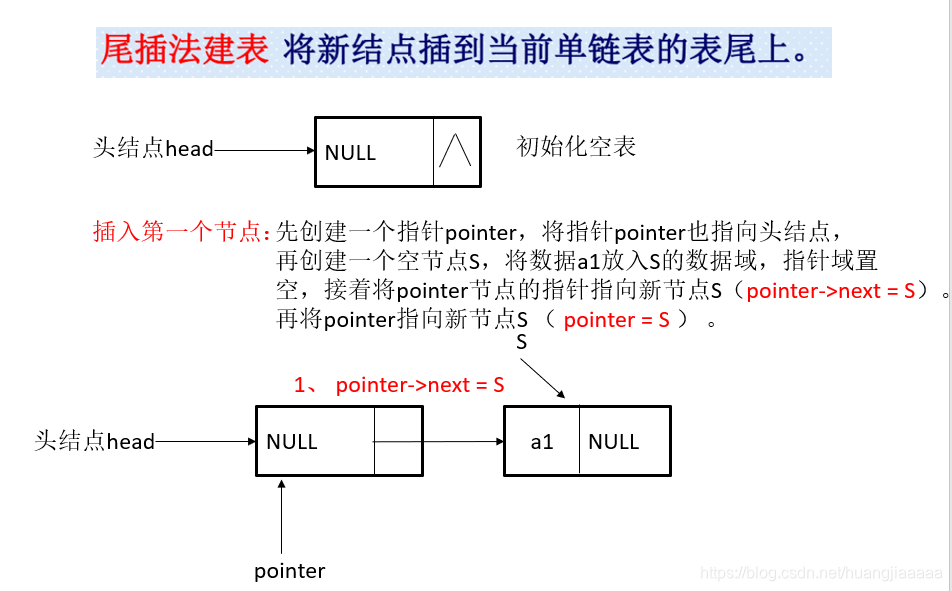
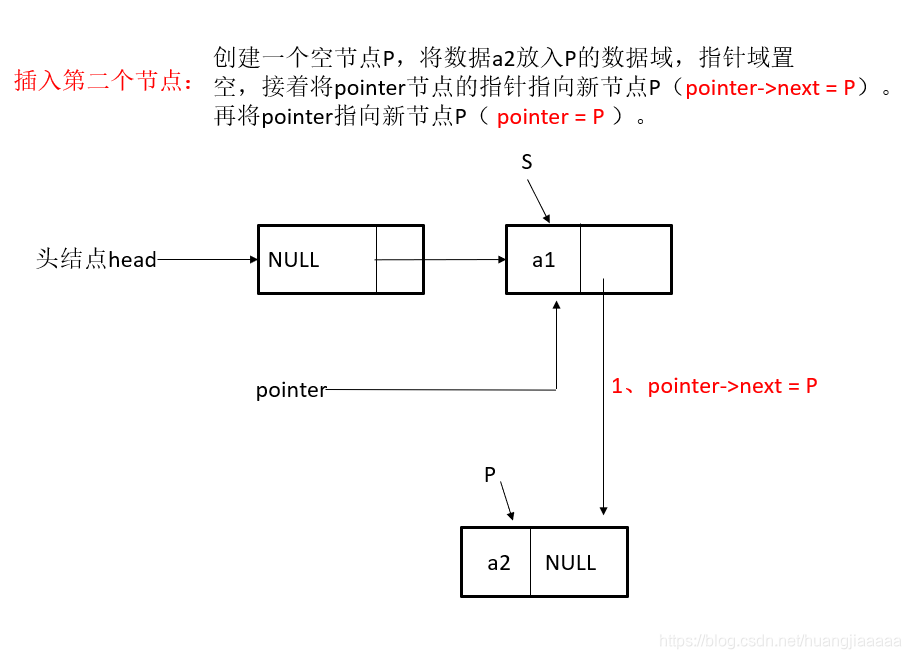
尾插法图示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> using namespace std;struct node {int val;node (int _val):val (_val),next (NULL ){}int main () auto a = new node (1 );auto b = new node (2 );NULL ; for (node* i = head;i;i=i->next)' ' ;system ("pause" );return 0 ;
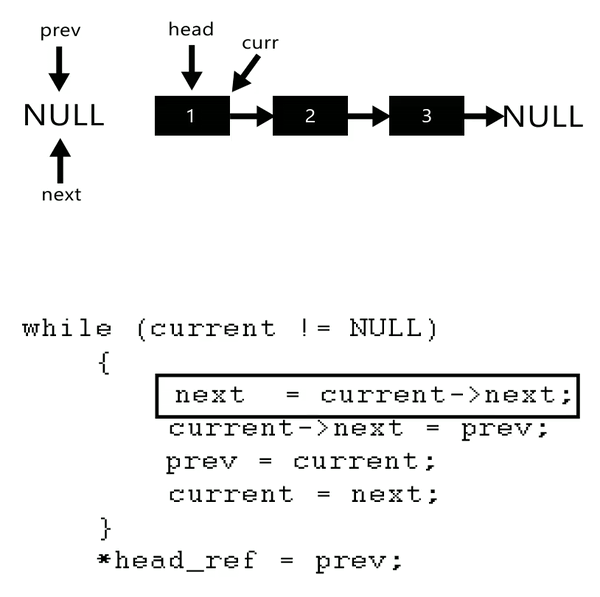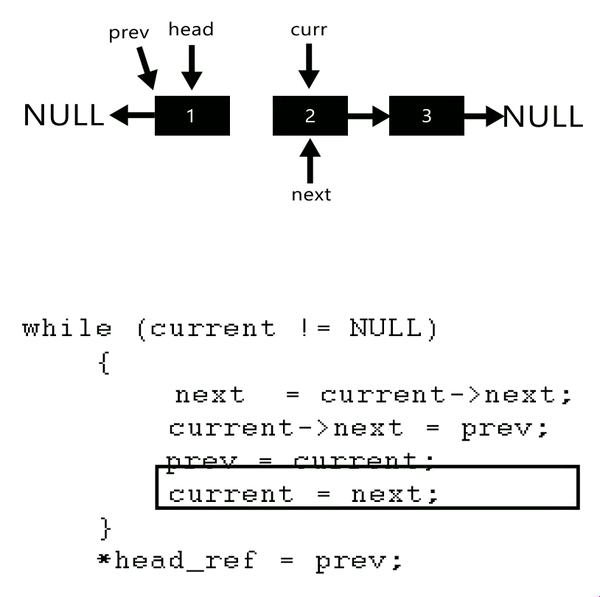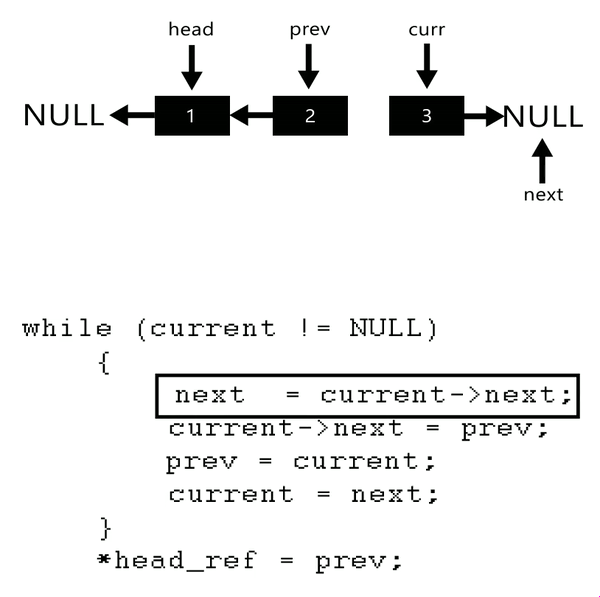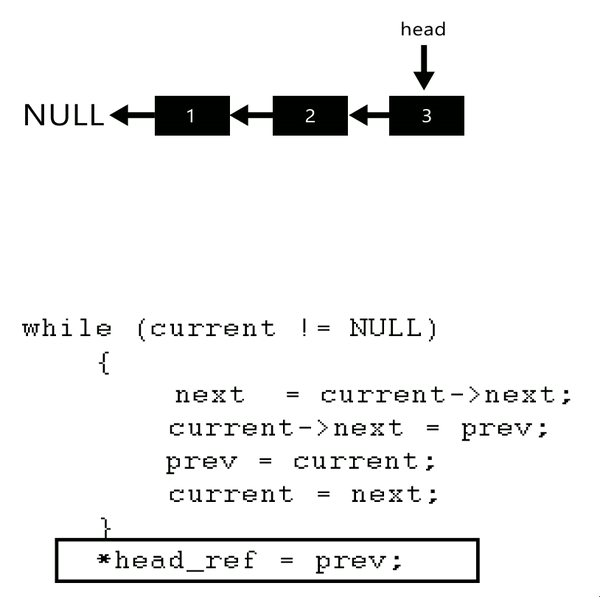
链表反转
1 2 3 4 5 6 7 8 9 10 11 12 13 ListNode* reverseList (ListNode* head) {nullptr ;auto cur = head;while (cur)auto next = cur->next;return pre;
两个链表的第一个公共结点
题解
用两个指针 p1,p2 分别指向两个链表 headA,headB 的头结点,同时向后遍历。
当指针到达链表末尾时,重新定位到另一个链表的头结点。
当它们相遇时,所指向的结点就是第一个公共结点。
解释
A链表总长度为LA + C,B链表总长度为LB + C。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public :ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) {while (p1 != p2) {if (p1 != NULL )else if (p2 != NULL )else return p1;
链表排序合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public :ListNode* merge (ListNode* l1, ListNode* l2) {auto dummy = new ListNode (-1 ), tail = dummy;while (l1 && l2)if (l1->val < l2->val)else if (l1) tail->next = l1;if (l2) tail->next = l2;return dummy->next;
8.STL
vector
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <iostream> #include <vector> using namespace std;int main () int > a;int > b[123 ];struct Rec int x,y;
函数
1 2 3 4 5 6 7 8 9 10 11 12 13 a.size ();empty ();clear ();begin ();begin ();end ();front ();back ();push_back (4 );pop_back ();
迭代器
1 2 3 4 5 6 vector<int >::iterator it = a.begin ();2 ;
遍历迭代器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> #include <vector> using namespace std;int main () int <> a ({1 ,2 ,3 });0 ]<<' ' <<a*.begin ()<<endl;for (int i = 0 ;i<a.size ();i++)for (vector<int >::iterator i = a.begin ();i !=a.end ();i++) ' ' ; for (auto i = a.begin ();i !=a.end ();i++) ' ' ;for (int x : a) cout<<x<<' ' ;
队列
主要包括循环队列queue和优先队列priority_queue两个容器
队列特性先进先出
优先队列优先弹出所有数的最大值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> #include <queue> using namespace std;int main () int > q;double > a;struct Rec {int a,x,y;int >q;int ,vector<int >,greater<int >> b;struct Rec {int a,b;bool operator <(const Rec& t) const {return a<t.a;struct Rec {int a,b;bool operator >(const Rec& t) const {return a>t.a;push (1 );pop ();front ();back ();push (1 );pop ();top ();queue <int > ();
栈
先进后出
1 2 3 4 5 6 7 8 9 #include <iostream> #include <stack> using namespace std;int main () int > stk;push (1 );top ();pop ();
双端队列
既可以队头队尾插入也可以队头队尾弹出,在头部增删元素仅需要O(1)的时间,支持向数组一样随机访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> #include <deque> using namespace std;int main () int > a;begin (),a.end ();front (),a.back ();push_back (1 ),a.push_front (2 );0 ];pop_back ();pop_front ();clear ();return 0 ;
set
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> #include <map> using namespace std;int main () int > a;int > b;int >::iterator it = a.begin ();end ();end ();begin ();insert (x);find (x);if (a.find ()==a.end ()) struct rec {int x,y;bool operator < (const rec&t)const {return x<t.x;size ();empty ();clear ();lower_bound (x);upper_bound (x);erase (it);erase (x);erase (pos,n); erase (position);erase (first,last);count (x);
map
map容器是一个键值对key-value的映射,其内部实现是一棵以key为关键码的红黑树。Map的key和value可以是任意类型,其中key必须定义小于号运算符。
map<key_type, value_type> name;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> #include <map> using namespace std;int main () int ,int >a;1 ] =2 ;10000 ]=3 ;1 ]<<endl;int > a;"kugeln" ]=2 ;"kugeln" ]<<endl;int >>a;"kugeln" ]=vector <int >();"kugeln" ].size ()<<endl;int >>a;"kugeln" ]=vector <int >({1 ,2 ,3 ,4 });、"kugeln" ][2 ]<<endl;insert ({"a" ,{}});find (x);#include <unordered_set> int >a;#include <unordered_multiset> int >b;#include <unordered_map> int ,int >c;
bitset
1 2 3 4 5 6 #include <bitset> 0 ]=1 ;set (3 );reset (3 );
pair
pair 定义在头文件 utility 中,一个pair保存两个数据成员 , 分别命名为 first 、second ,成对出现的数据,可以利用对组来返回这两个数据。与其他标准库类型不同,pair数据成员是 public 的。
pair的基本操作
pair<T1, T2> p:创建一个空的pair对象
pair<T1, T2> p(v1, v2):用v1、v2来初始化pair对象
pair<T1, T2> p={v1, v2}:用v1、v2来初始化pair对象
make_pair(v1, v2):返回一个由v1、v2初始化pair组,其类型根据v1、v2的值来进行推测
p.first:返回p的第一个元素
p.second:返回p的第二个元素
p1==p2:当两个对象的first和second成员都相等时,两个pair对象才相等。
1 2 3 4 pair<int ,string> a;3 ,"kugeln" };' ' <<a.second<<endl;
9.位运算
符号
运算
&
与
|
或
~
非
^
异或
>>
右移
<<
左移
异或可以看成不进位加法
a>>k 相当于a/2^k
a<<k 相当于a*2^k
10.常用库函数
1 2 3 4 5 6 7 8 9 #include <algorithm> vector<int > a ({1 ,2 ,3 ,4 ,5 }) ;reverse (a.begin (),a.end ());for (int x : a)cout<<x<<' ' ;int a[]={1 ,2 ,3 ,4 ,5 };reverse (a,a+5 );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <algorithm> int a[]={1 ,1 ,2 ,2 ,3 ,3 ,4 };int m = unique (a,a+7 )-a;for (int i = 0 ;i<m;i++)cout<<a[i]<<' ' ;vector<int > a ({1 ,1 ,2 ,2 ,3 ,3 ,4 }) ;int m = unique (a.begin (), a.end ()) – a.begin ();int m = unique (a + 1 , a + n + 1 ) – (a + 1 );erase (unique (a.begin (),a.end ()),a.end ());
1 2 3 4 5 6 7 8 9 10 11 12 13 vector<int > a ({1 ,1 ,2 ,2 ,3 ,3 ,4 }) ;random_shuffle (a.begin (),a.end ());for (int x :a)cout<<x<<' ' ;#include <algorithm> #include <ctime> vector<int > a ({1 ,1 ,2 ,2 ,3 ,3 ,4 }) ;srand (time (0 ));random_shuffle (a.begin (),a.end ());for (int x :a)cout<<x<<' ' ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 sort (a.begin (),a.end ());sort (a.begin (),a.end (),greater <int >());bool cmp (int a,int b) return a<b;sort (a.begin (),a.end (),cmp);bool cmp (rec a,rec b) return a.x<b.x;struct rec {int x;int y;5 ];for (int i = 0 ;i<5 ;i++){sort (a,a+5 ,cmp);struct rec {int x;int y;bool operator <(const rec&t)const {return x<t.x;5 ];5 ];for (int i = 0 ;i<5 ;i++){sort (a,a+5 );
1 2 3 4 5 6 7 8 9 10 11 lower_bound (a.begin (),a.end (),x);int i = lower_bound (a + 1 , a + 1 + n, x) - a;int > a{1 ,2 ,3 ,4 ,5 ,6 };int t = upper_bound (a.begin (),a.end (),6 )-a.begin ();int y = *--upper_bound (a.begin (), a.end (), x);
1 2 3 4 5 6 7 8 9 10 #include <algorithm> next_permutation (起始位置,末尾位置+1 );next_permutation (a,a+n);next_permutation (a.begin (),a.end ());next_permutation (起始位置,末尾位置,自定义排序)do {while (next_permutation (a.begin (),a.end ()))
重要的头文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
重要的数学知识
STL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28